1. Introduction
Olfactory perception based on Electronic noses (E-noses) [
1] has attracted much attention in research communities in recent years. Although the feasibility of E-noses has been demonstrated with various solutions in a considerable number of cases, the drift problem still hampers its further development. Drift, normally caused by environmental and physicochemical factors, disturbs the compatibility between the gas-sensor responses and the Artificial Intelligence (AI) algorithms in E-nose systems. It is evident that gas-sensor drift would irreversibly mislead the AI models over time. In other words, drift will significantly influence the performance of E-nose systems that make decisions based on AI algorithms.
There are several ways to mitigate the negative effects of gas-sensor drift. The primary option is gas-sensor enhancement, which improves the sensor’s repeatability and stability by employing an advanced structure or film composition. Aiming for more universal and cost-effective methodologies, algorithm-based methods are becoming fashionable. Among these, a number of methods are used for decomposing the drift component from responses of the gas-sensor-array. Accordingly, what remains are the corrected responses after drift correction. In practice, the drift component can be decomposed based on statistical characteristics by means of Principal Component Analysis (PCA), Common PCA (CPCA) [
2], PCA-based Component Correction (PCA-CC) [
3], Independent Component Analysis (ICA) [
4,
5], and wavelet [
6,
7]. Additionally, it is possible to identify components unrelated to the classification as drift signals using Orthogonal Signal Correction (OSC) [
8,
9], Partial Least Squares (PLS) [
10], and Linear Discriminate Analysis (LDA) [
11]. Furthermore, machine-learning approaches can be used to correct the recognition models, instead of the gas-sensor responses. Adaptive classifiers, including Self-Organizing Maps (SOM) [
12,
13] and Adaptive Resonance Theory (ART) [
14,
15], have been adopted as recognition units that train themselves automatically with drifted gas samples. Moreover, some researchers have assumed that current drift is related to previous ones; accordingly, the recognition output of a drifted sample can be expressed as an output-ensemble of several sub-classifiers [
16,
17,
18,
19,
20] that have been trained on drifted gas samples during different periods. Thus, the final output is one that has been corrected based on previous drift tendencies. We should note that sufficient correction samples, full and complete categories, and sufficient correction time are essential prerequisites of all of the above methods. Unfortunately, these requirements may not be fully satisfied in many practical uses, e.g., there may be insufficient time to collect enough samples, or it may be too expensive to obtain the categories of the correction samples.
To extend the possible applications of E-noses, we divided a conventional drifted sample for drift correction into two parts: the instance and the label. Here, “instance” refers to the feature vector abstracted from the gas-sensor-array responses in one experiment, while “label” refers to the category of a “sample”. In real applications, the two parts are not always presented together, and the “label” may be costly to access. Hence, new machine-learning paradigms have been adopted to deal with this challenge. Luo et al. utilized a deep-learning neural network to abstract the drift-independent features for recognition in [
21], eliminating the drift of the features. Zhang et al. focused on the situation in which the labels for the drifted instances are unknown [
11,
22]. Meanwhile, Liu et al. presented a label estimation method with manifold learning and joint kernels to achieve pseudo-labels for drift correction [
23]. Considering online situations in which there are many drifted instances and only a small number of labels are accessible (due to the high cost of labelling), Domain Adaptation Extreme Learning Machines (DAELM) [
24], Standardization Error-based Model Improvement (SEMI) [
25], and Transfer sample-based Coupled Task Learning (TCTL) [
26] have been proposed to maximize the information-usage efficiency of both instances and labels. However, these methodologies designate samples for drift correction randomly or subjectively, making the anti-drift effect unstable or non-convergent. Therefore, Active Learning (AL) was introduced for drift correction, aiming to tag labels to limited instances selectively and intentionally [
27].
According to previous study, AL has already been used to improve the classification precision of E-noses [
28], as well as being employed as a suitable framework for online drift compensation (many drifted instances and limited labels). The core of the AL framework is its “instance-selection strategy”, which filters out the instances needing labelling. At present, stream-based [
29] and pool-based [
30] ALs are popular instance-selection strategies. The stream-based strategy chooses instances based on a fixed threshold that relies on local data information, whereas the pool-based strategy selects appropriate instances based on the global data distribution. Furthermore, the pool-based strategy can be divided into several sub-types. Uncertainty Sampling (US) [
31], Query-By-Committee (QBC) [
32], and Error Reduction (ER) sampling [
33] are typical among pool-based strategies.
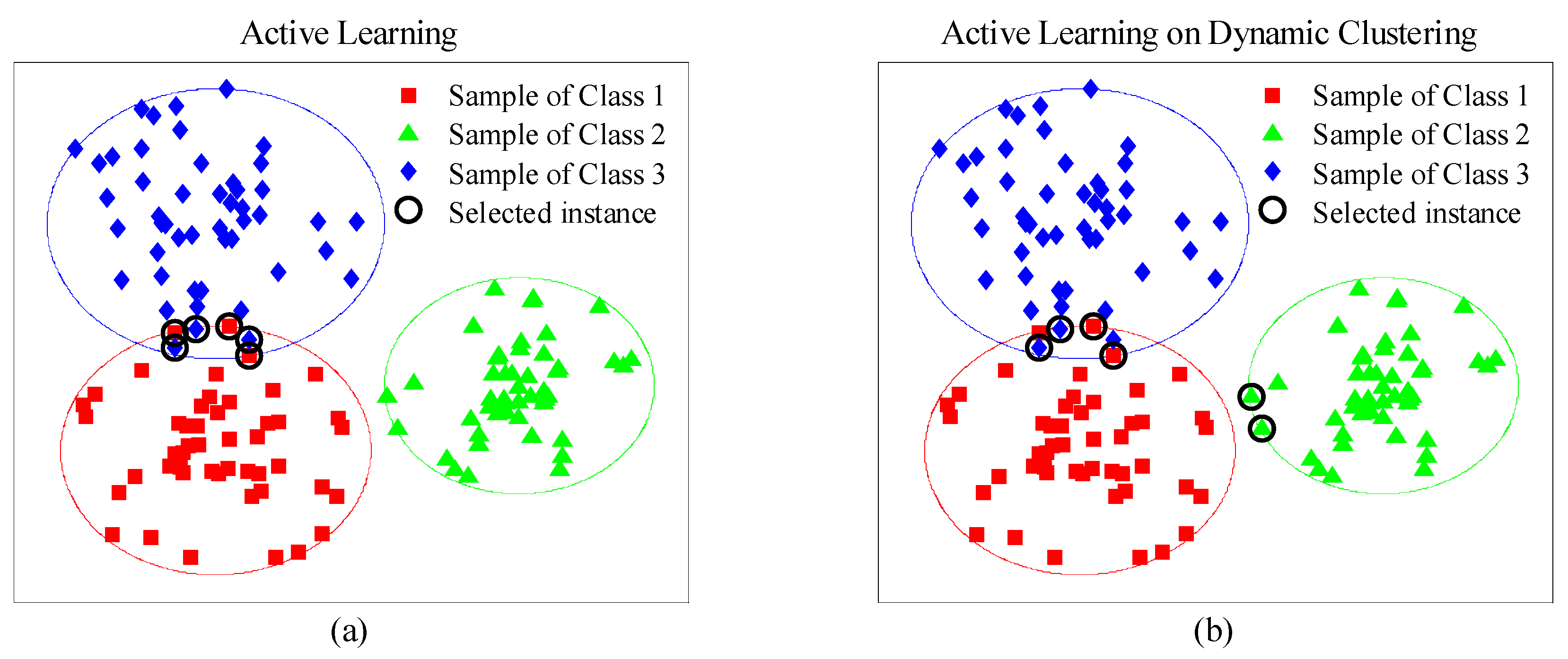
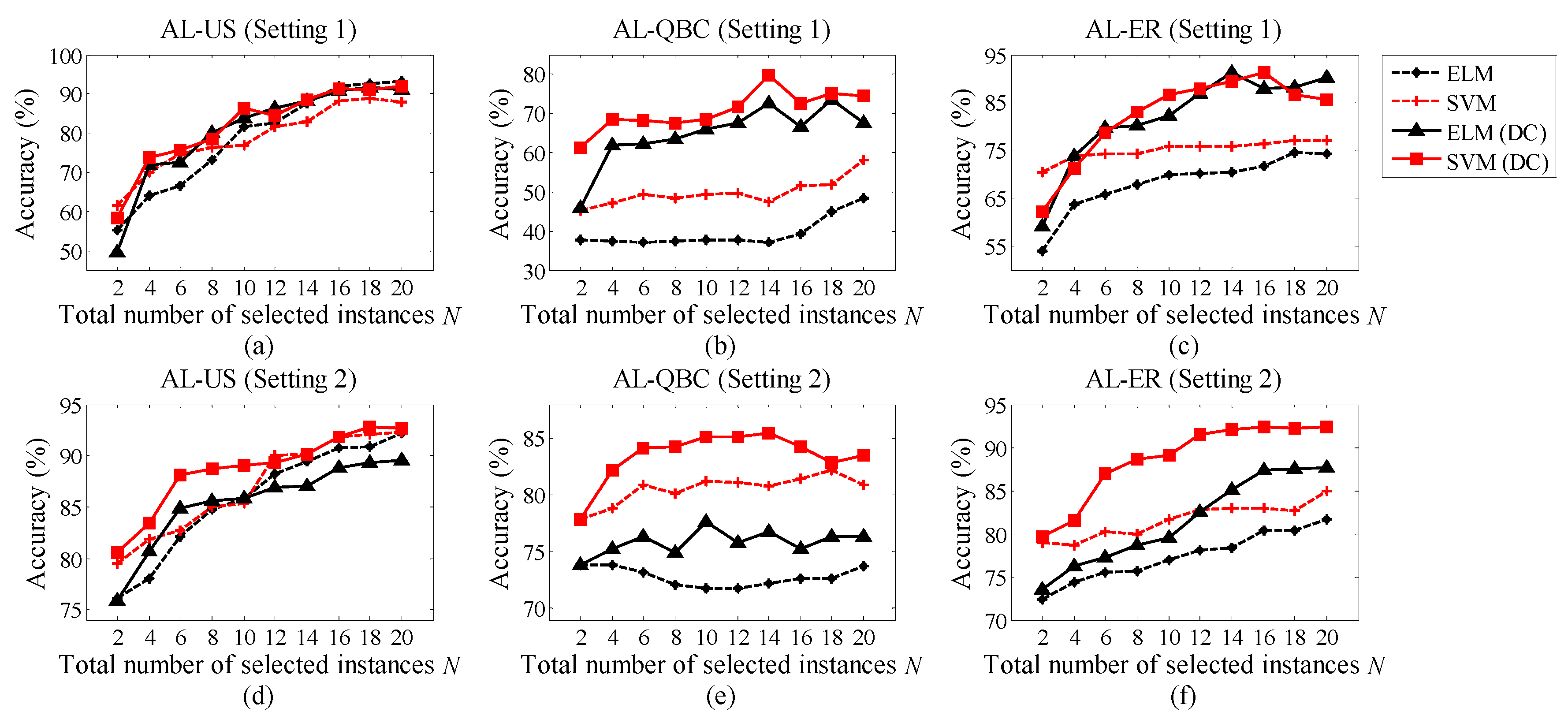
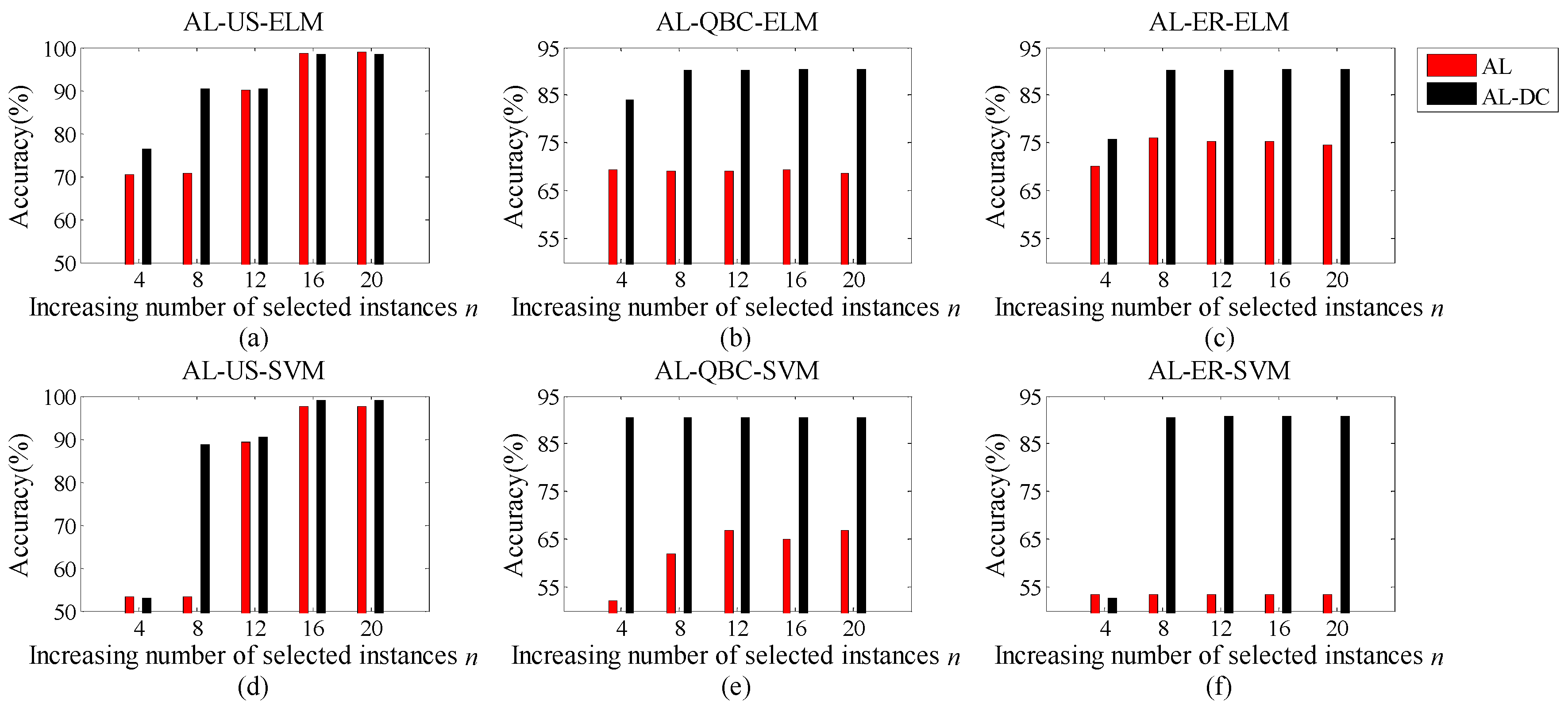
In this paper, we propose an advanced AL methodology for Dynamic Clustering (AL-DC) in order to improve the effect of drift correction under online conditions. For AL-DC, drifted instances are collected together in a data pool and automatically allocated to several non-overlapping clusters. Then, the instance-selection process alternately selects instances from each cluster. In other words, we create an AL mechanism that makes the category ratio of the selected instances as equal as possible. A public database was adopted to verify the effectiveness and robustness of the proposed method. Based on the experimental results, AL-DC achieved higher accuracy than any of the other state-of-the-art methodologies in a practical online scenario. AL-DC also demonstrated faster accuracy convergence than the other AL methods. Additionally, we used the Labelling Efficiency Index (LEI) to comprehensively measure the implementation efficiency and the labelling cost.
The rest of the paper is structured as follows: we detail the traditional AL and the proposed AL-DC methods in
Section 2.
Section 3 describes the E-nose drift database used in both the long-term drift and short-term drift scenarios. In
Section 4, we present and discuss the results achieved using the database. Finally, we summarize our conclusions in
Section 5.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}