On-Device Deep Learning Inference for Efficient Activity Data Collection

Abstract
1. Introduction
- We introduce a system design of integrating on-device deep learning inference and activity recognition. We describe on-device deep learning inference using an LSTM-based method which can be used for efficient activity data collection, where estimated activities are used as feedback through notifications on a smartphone.
- We present the proposed method where we provide estimated activities using on-device inference through notifications and the traditional method where we provide simple sentences without estimated activities through notifications. Our proposed method can be applied not only to LSTM but also other models for on-device inference. To evaluate in a realistic setting, we train the model used for on-device deep learning with the open dataset, implement a system and deploy the system to a laboratory, conduct the experiments, review and use the dataset obtained for evaluations.
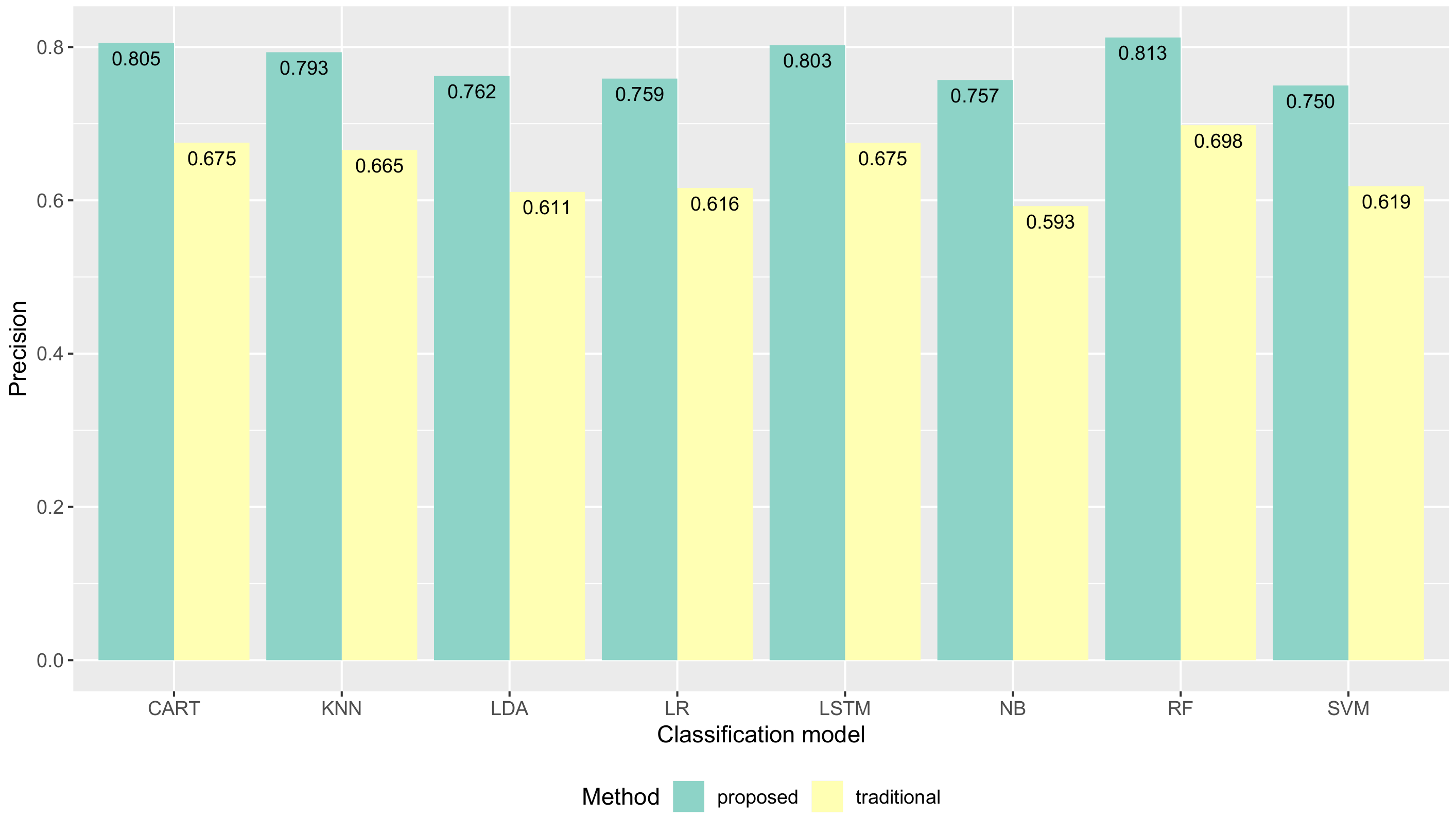
- We evaluate the quality of the proposed method using a standard activity recognition chain by comparing the performance results of several machine learning algorithms as well as a deep learning algorithm with the traditional method. We show that when estimated activities using on-device inference are provided to users as feedback, we can improve the quality of data collection (e.g., the accuracy of several machine learning algorithms has improvements with the proposed method). We also compare the quantity of data collected between the proposed method and the traditional method by showing that the amount of data collected has increased with the proposed method.
- We discuss the results, limitations, challenges, and implications for on-device deep learning inference that support activity data collection and spark future studies.
- We also publish the preliminary dataset openly as Supplementary Information in this paper, which might be useful for activity recognition and the research community.
2. Related Works
3. Methods
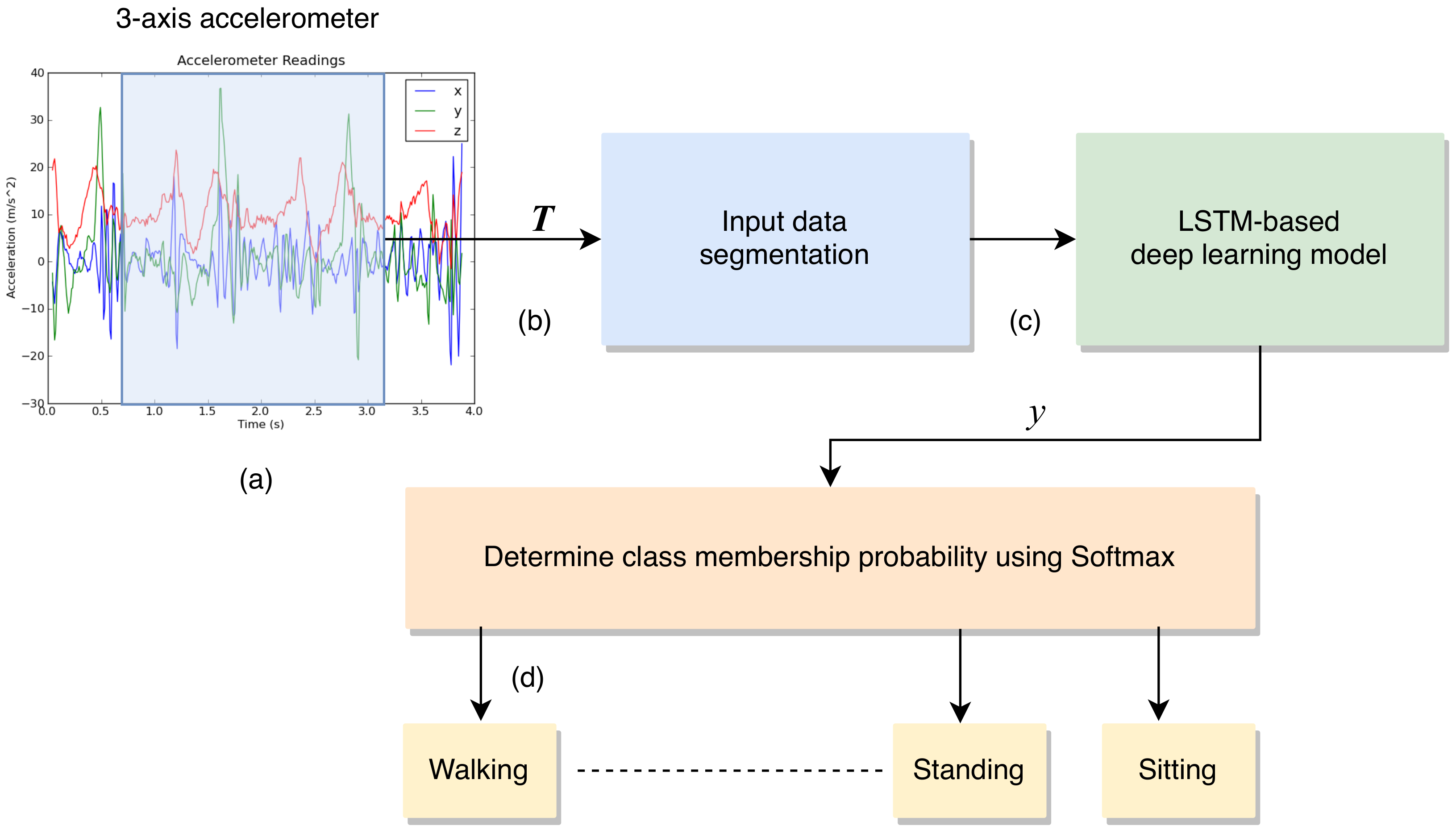
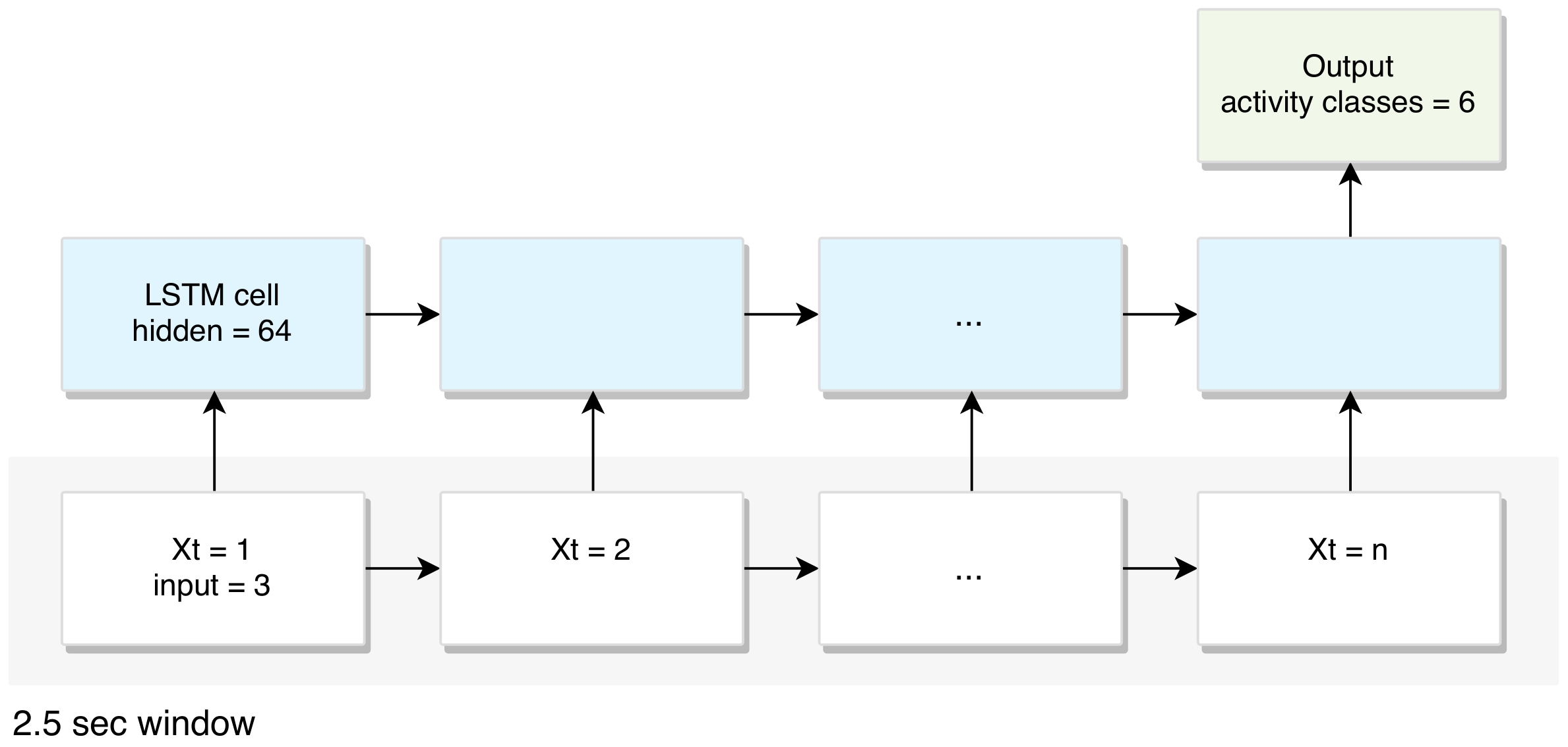
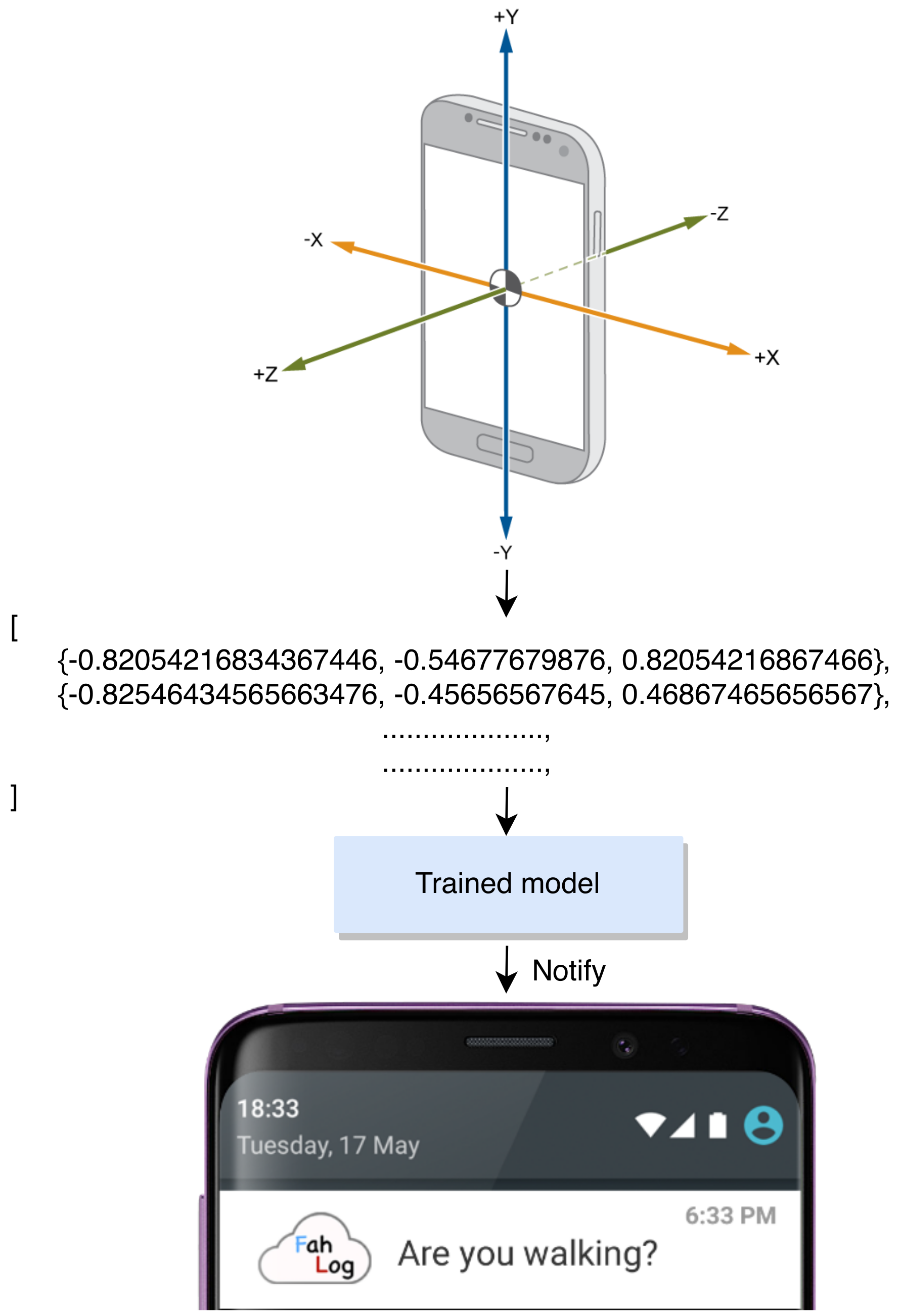
3.1. To Build an LSTM Model Used for On-Device Inference
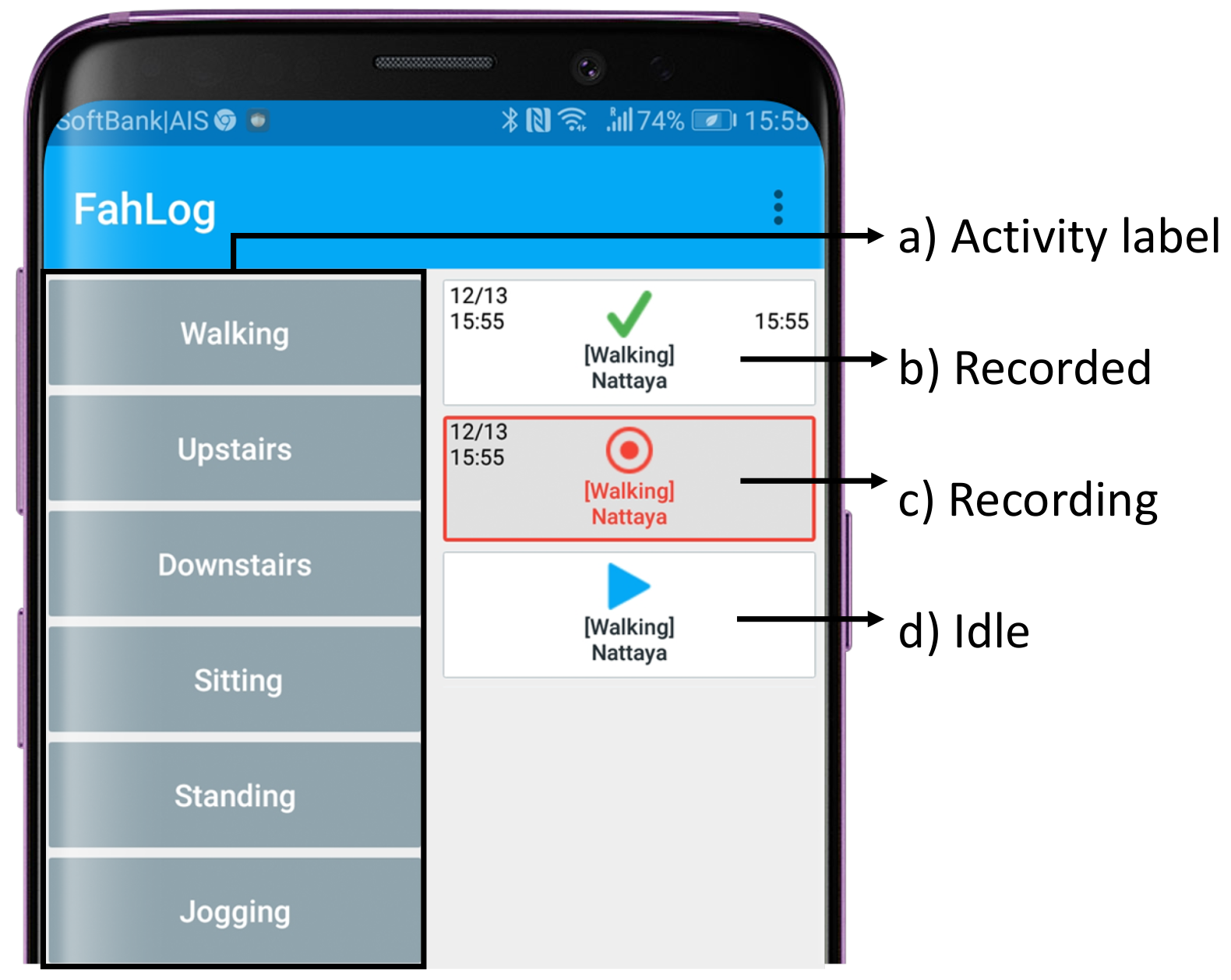
3.2. To Collect Accelerometer Sensor Data and Activity Labels Efficiently
3.3. To Provide Estimated Activities as Feedback through Smartphone Notifications
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Data Description
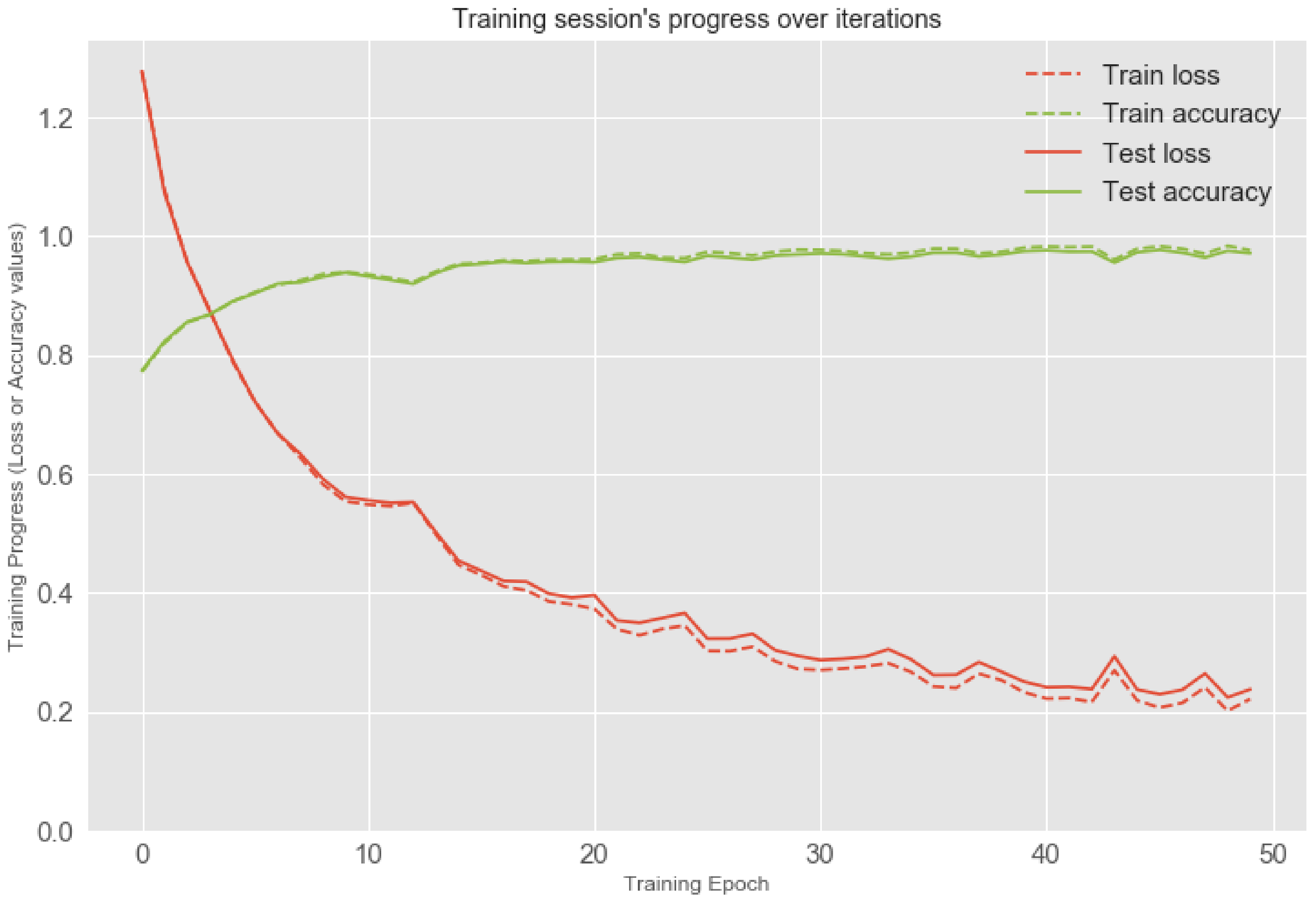
4.3. Activity Recognition Using Smartphone Sensors
4.3.1. Data Preprocessing
4.3.2. Evaluation Method
- L is the set of labels
- is the true label
- y is the predicted label
- is all the true labels that have the label l
- is the number of true labels that have the label l
- computes the precision or recall for the true and predicted labels that have the label l. To compute precision, let . To compute recall, let .
5. Results
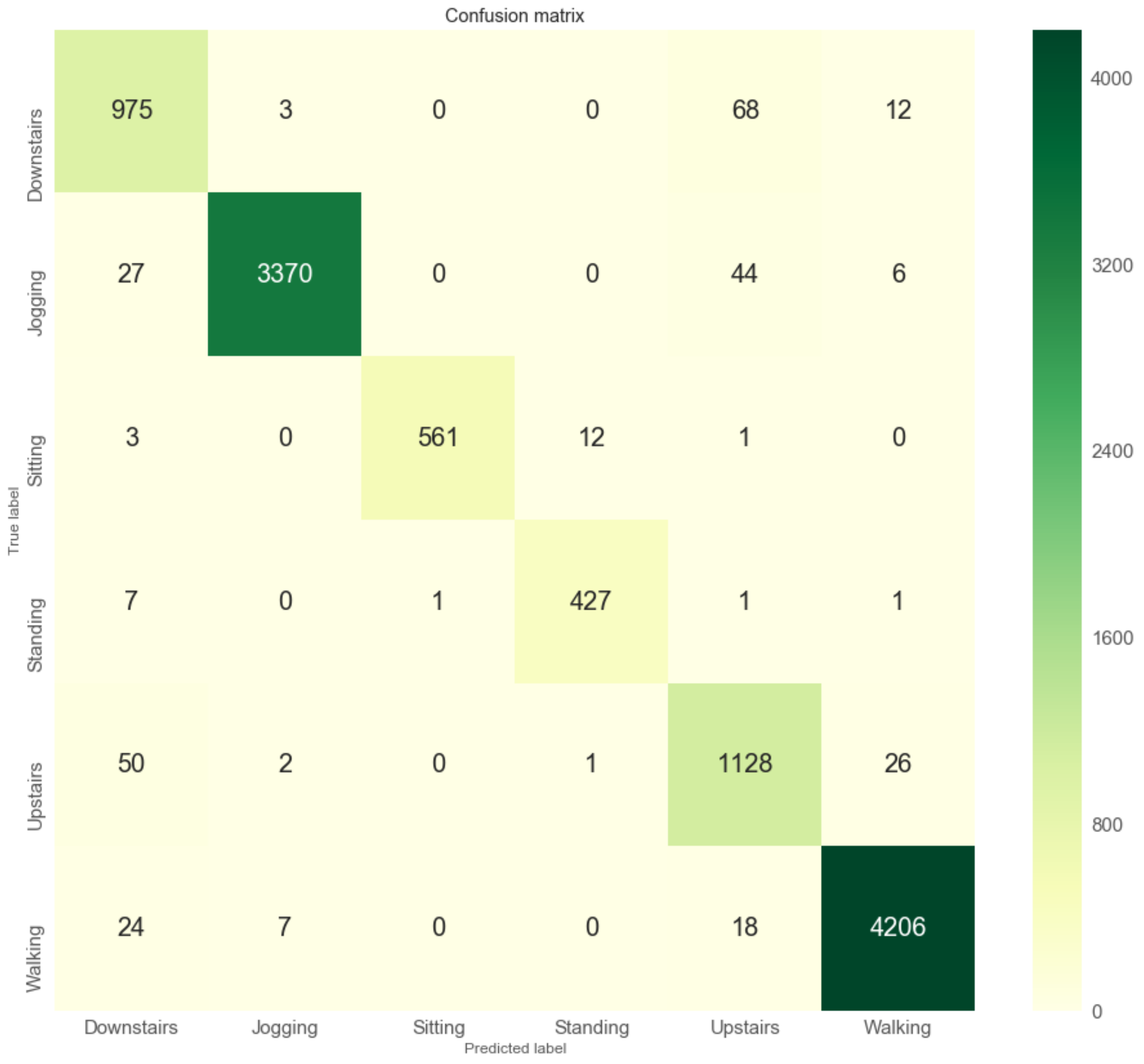
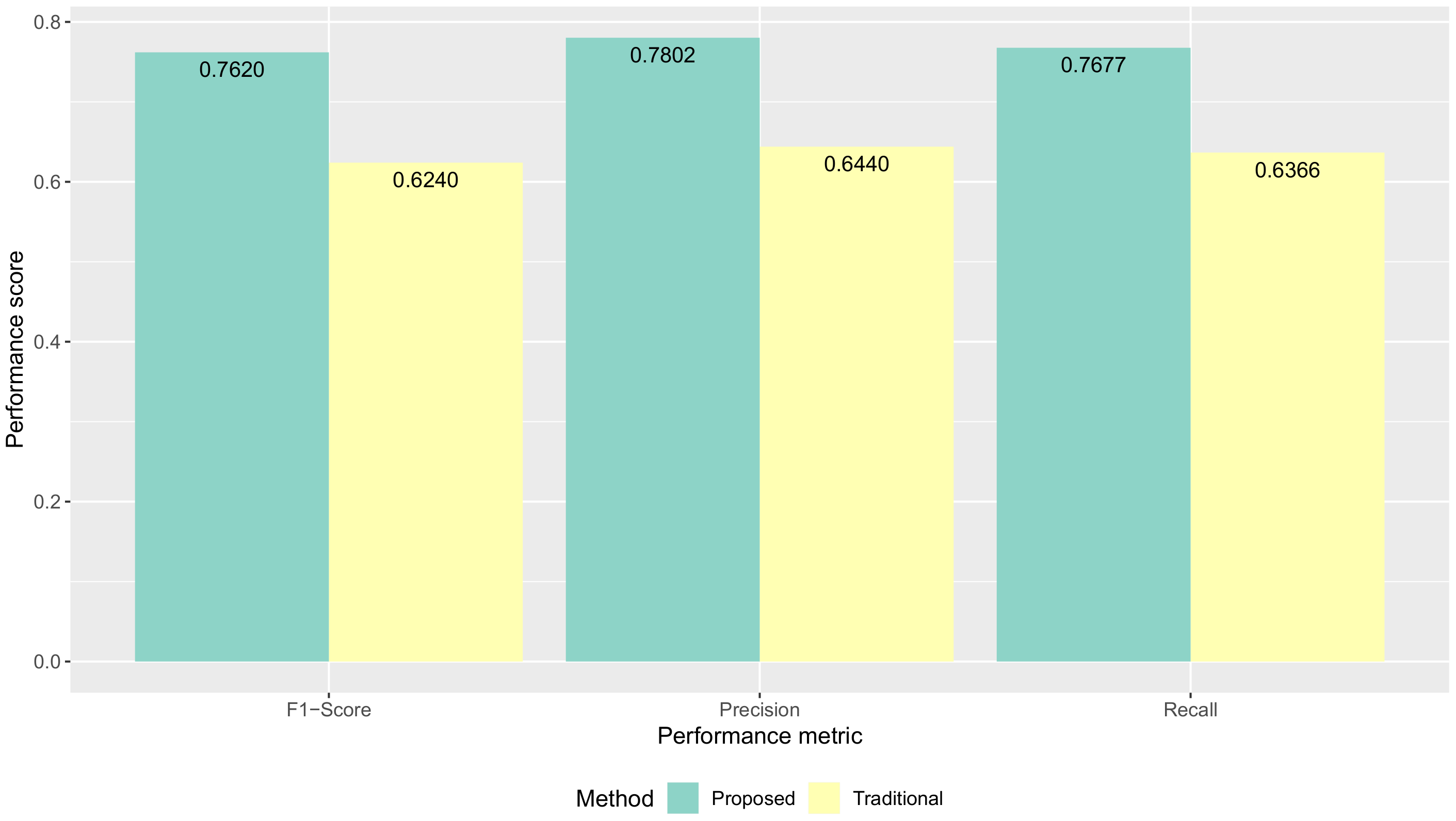
5.1. Quality of Collected Activity Data
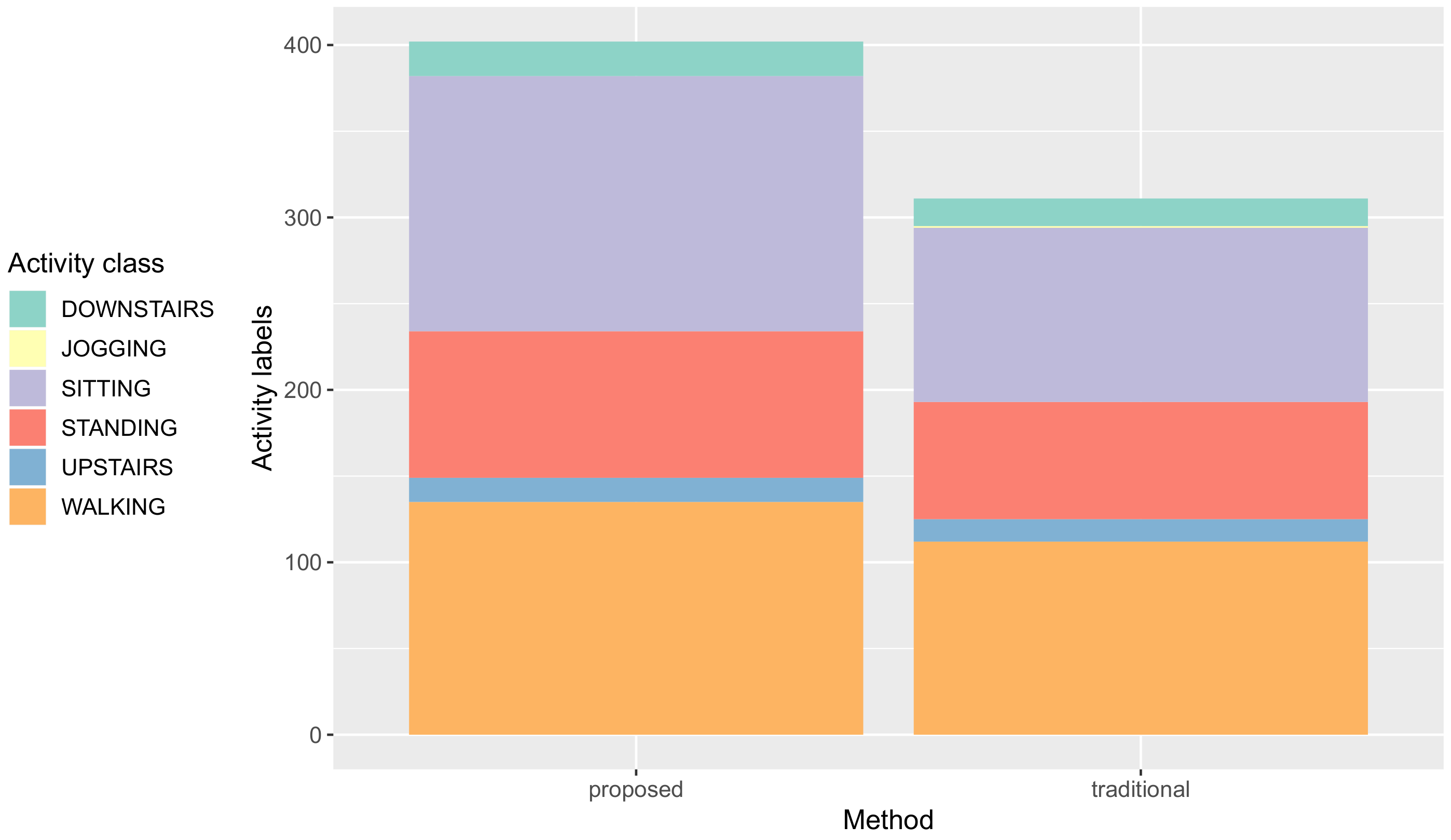
5.2. Quantity of Collected Activity Data
6. Discussion and Future Directions
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long short-term memory |
| RNN | Recurrent neural network |
| SMOTE | Synthetic minority over-sampling technique |
| LR | Logistic regression |
| LDA | Linear discriminant analysis |
| KNN | k-nearest neighbors |
| CART | Decision tree |
| NB | Naive Bayes |
| SVM | Support-vector machine |
| RF | Random forest |
| ReLU | Rectified linear unit |
| IoT | Internet of things |
References
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 33. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Linz/Vienna, Austria, 21–23 April 2004; pp. 1–17. [Google Scholar]
- Mairittha, N.; Inoue, S. Gamification for High-Quality Dataset in Mobile Activity Recognition. In Proceedings of the International Conference on Mobile Computing, Applications, and Services, Osaka, Japan, 28 February–2 March 2018; pp. 216–222. [Google Scholar]
- Rawassizadeh, R.; Momeni, E.; Dobbins, C.; Gharibshah, J.; Pazzani, M. Scalable daily human behavioral pattern mining from multivariate temporal data. IEEE Trans. Knowl. Data Eng. 2016, 28, 3098–3112. [Google Scholar] [CrossRef]
- Guan, T.; He, Y.; Gao, J.; Yang, J.; Yu, J. On-device mobile visual location recognition by integrating vision and inertial sensors. IEEE Trans. Multimed. 2013, 15, 1688–1699. [Google Scholar] [CrossRef]
- Föckler, P.; Zeidler, T.; Brombach, B.; Bruns, E.; Bimber, O. PhoneGuide: Museum guidance supported by on-device object recognition on mobile phones. In Proceedings of the 4th International Conference on Mobile and Ubiquitous Multimedia, Christchurch, New Zealand, 8–10 December 2005; pp. 3–10. [Google Scholar]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the Internet of Things with edge computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Deep Learning for Consumer Devices and Services: Pushing the limits for machine learning, artificial intelligence, and computer vision. IEEE Consum. Electron. Mag. 2017, 6, 48–56. [Google Scholar] [CrossRef]
- Lite, T. Available online: https://www.tensorflow.org/lite (accessed on 2 August 2019).
- Ordóñez, F.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef]
- Ermes, M.; Pärkkä, J.; Mäntyjärvi, J.; Korhonen, I. Detection of daily activities and sports with wearable sensors in controlled and uncontrolled conditions. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 20–26. [Google Scholar] [CrossRef]
- Incel, O.D.; Kose, M.; Ersoy, C. A review and taxonomy of activity recognition on mobile phones. BioNanoScience 2013, 3, 145–171. [Google Scholar] [CrossRef]
- Inoue, S.; Ueda, N.; Nohara, Y.; Nakashima, N. Mobile activity recognition for a whole day: Recognizing real nursing activities with big dataset. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 1269–1280. [Google Scholar]
- Ke, S.R.; Thuc, H.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Cruciani, F.; Cleland, I.; Nugent, C.; McCullagh, P.; Synnes, K.; Hallberg, J. Automatic annotation for human activity recognition in free living using a smartphone. Sensors 2018, 18, 2203. [Google Scholar] [CrossRef] [PubMed]
- Yordanova, K.; Krüger, F. Creating and Exploring Semantic Annotation for Behaviour Analysis. Sensors 2018, 18, 2778. [Google Scholar] [CrossRef] [PubMed]
- Yordanova, K.; Paiement, A.; Schröder, M.; Tonkin, E.; Woznowski, P.; Olsson, C.M.; Rafferty, J.; Sztyler, T. Challenges in annotation of useR data for UbiquitOUs systems: Results from the 1st ARDUOUS workshop. arXiv 2018, arXiv:1803.05843. [Google Scholar]
- Rawassizadeh, R.; Pierson, T.J.; Peterson, R.; Kotz, D. NoCloud: Exploring network disconnection through on-device data analysis. IEEE Pervasive Comput. 2018, 17, 64–74. [Google Scholar] [CrossRef]
- Kumar, K.; Liu, J.; Lu, Y.H.; Bhargava, B. A survey of computation offloading for mobile systems. Mob. Netw. Appl. 2013, 18, 129–140. [Google Scholar] [CrossRef]
- Cuervo, E.; Balasubramanian, A.; Cho, D.K.; Wolman, A.; Saroiu, S.; Chandra, R.; Bahl, P. MAUI: Making smartphones last longer with code offload. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010; pp. 49–62. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Okita, T.; Inoue, S. Activity Recognition: Translation across Sensor Modalities Using Deep Learning. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 1462–1471. [Google Scholar]
- Chen, Y.; Zhong, K.; Zhang, J.; Sun, Q.; Zhao, X. Lstm networks for mobile human activity recognition. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications, Bangkok, Thailand, 24–25 January 2016. [Google Scholar]
- Okita, T.; Inoue, S. Recognition of multiple overlapping activities using compositional CNN-LSTM model. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 165–168. [Google Scholar]
- Alzantot, M.; Wang, Y.; Ren, Z.; Srivastava, M.B. Rstensorflow: Gpu enabled tensorflow for deep learning on commodity android devices. In Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications, Niagara Falls, NY, USA, 23 June 2017; pp. 7–12. [Google Scholar]
- Cao, Q.; Balasubramanian, N.; Balasubramanian, A. MobiRNN: Efficient recurrent neural network execution on mobile GPU. In Proceedings of the 1st International Workshop on Deep Learning for Mobile Systems and Applications, Niagara Falls, NY, USA, 23 June 2017; pp. 1–6. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mairittha, N.; Mairittha, T.; Inoue, S. A Mobile App for Nursing Activity Recognition. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 400–403. [Google Scholar]
- Mairittha, N.; Inoue, S. Crowdsourcing System Management for Activity Data with Mobile Sensors. In Proceedings of the International Conference on Activity and Behavior Computing, Spokane, WA, USA, 30 May–2 June 2019. [Google Scholar]
- Inoue, S.; Mairittha, N.; Mairittha, T.; Hossain, T. Integrating Activity Recognition and Nursing Care Records: The System, Experiment, and the Dataset. In Proceedings of the International Conference on Activity and Behavior Computing, Spokane, WA, USA, 30 May–2 June 2019. [Google Scholar]
- Mairittha, N.; Inoue, S.; Mairittha, T. FahLog: A Manual Activity Annotation App; Fukuoka, Japan. 2019. Available online: https://play.google.com/store/apps/details?id=jp.sozolab.fahlog&hl=en (accessed on 2 August 2019).
- Fah Sozolab. Fahact: An Activity Recognition System. 2019. Available online: https://fahact.sozolab.jp (accessed on 2 August 2019).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Lachenbruch, P.A.; Goldstein, M. Discriminant analysis. Biometrics 1979, 35, 69–85. [Google Scholar] [CrossRef]
- Keller, J.M.; Gray, M.R.; Givens, J.A. A fuzzy k-nearest neighbor algorithm. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 580–585. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, St. John’s, NL, Canada, 4–6 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Çürükoğlu, N.; Özyildirim, B.M. Deep Learning on Mobile Systems. In Proceedings of the 2018 Innovations in Intelligent Systems and Applications Conference (ASYU), Adana, Turkey, 4–6 October 2018; pp. 1–4. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Conditional Detail |
|---|---|
| Proposed | Receive notifications of estimated activities using on-device deep learning inference |
| Traditional | Receive notifications with messages “What are you doing?” without estimated activities. |
| Parameter | Value |
|---|---|
| LSTM layer | 2 fully-connected |
| epochs | 50 |
| hidden layer units | 64 |
| output classes | 6 |
| input features per timestep | 3 () |
| timesteps per series | 200 |
| learning rate | 0.0025 |
| batch size | 1024 |
| Activity Class | # labels |
|---|---|
| Walking | 247 |
| Jogging | 1 |
| Sitting | 249 |
| Standing | 153 |
| Downstairs | 36 |
| Upstairs | 27 |
| Total | 713 |
| Feature | Value |
|---|---|
| num −0.82054216867469876 … | |
| num −0.622 … | |
| num −1.207 … | |
| num 0.085123482931909022 … | |
| num 1.3659708029197057 … | |
| num 5.468 … | |
| num −4.118 … | |
| num 1.1740472194146572 … | |
| num 9.819719626168224 … | |
| num 9.909 … | |
| num 9.742 … | |
| num 0.894526836753883 … |
| User | Method | F1-Score | Recall | Precision |
|---|---|---|---|---|
| 98 | proposed | 0.7778 | 0.7756 | 0.7973 |
| 98 | traditional | 0.7127 | 0.7139 | 0.7391 |
| 98 | Improvement | +0.0651 | +0.0616 | +0.0582 |
| 99 | proposed | 0.7009 | 0.7119 | 0.7156 |
| 99 | traditional | 0.4442 | 0.4830 | 0.4605 |
| 99 | Improvement | +0.2567 | +0.2289 | +0.2551 |
| 101 | proposed | 0.8700 | 0.8774 | 0.8727 |
| 101 | traditional | 0.6449 | 0.6619 | 0.6701 |
| 101 | Improvement | +0.225 | +0.215 | +0.203 |
| 103 | proposed | 0.7693 | 0.7663 | 0.7950 |
| 103 | traditional | 0.6490 | 0.6685 | 0.6584 |
| 103 | Improvement | +0.120 | +0.098 | +0.137 |
| 104 | proposed | 0.7881 | 0.7954 | 0.8120 |
| 104 | traditional | 0.6333 | 0.6223 | 0.6705 |
| 104 | Improvement | +0.155 | +0.173 | +0.142 |
| 105 | proposed | 0.6658 | 0.6794 | 0.6888 |
| 105 | traditional | 0.6600 | 0.6702 | 0.6654 |
| 105 | Improvement | +0.006 | +0.01 | +0.023 |
| Activity Class | Proposed | Traditional | Improvement |
|---|---|---|---|
| Walking | 135 | 112 | +23 |
| Upstairs | 14 | 13 | +1 |
| Standing | 85 | 68 | +17 |
| Sitting | 148 | 101 | +47 |
| Downstairs | 20 | 16 | +4 |
| Jogging | 0 | 1 | −1 |
| Total | 402 | 311 | +91 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mairittha, N.; Mairittha, T.; Inoue, S. On-Device Deep Learning Inference for Efficient Activity Data Collection. Sensors 2019, 19, 3434. https://doi.org/10.3390/s19153434
Mairittha N, Mairittha T, Inoue S. On-Device Deep Learning Inference for Efficient Activity Data Collection. Sensors. 2019; 19(15):3434. https://doi.org/10.3390/s19153434
Chicago/Turabian StyleMairittha, Nattaya, Tittaya Mairittha, and Sozo Inoue. 2019. "On-Device Deep Learning Inference for Efficient Activity Data Collection" Sensors 19, no. 15: 3434. https://doi.org/10.3390/s19153434
APA StyleMairittha, N., Mairittha, T., & Inoue, S. (2019). On-Device Deep Learning Inference for Efficient Activity Data Collection. Sensors, 19(15), 3434. https://doi.org/10.3390/s19153434