Computer Vision Classification of Barley Flour Based on Spatial Pyramid Partition Ensemble


 ,
, 
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
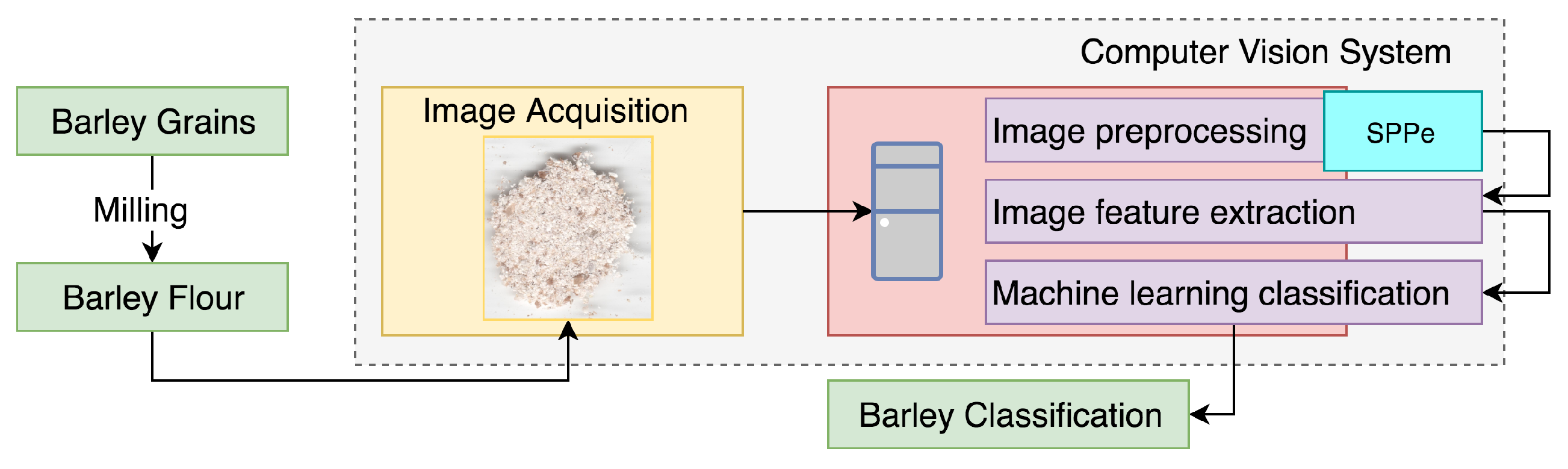
3.1. Computer Vision System
Image Acquisition and Preprocessing
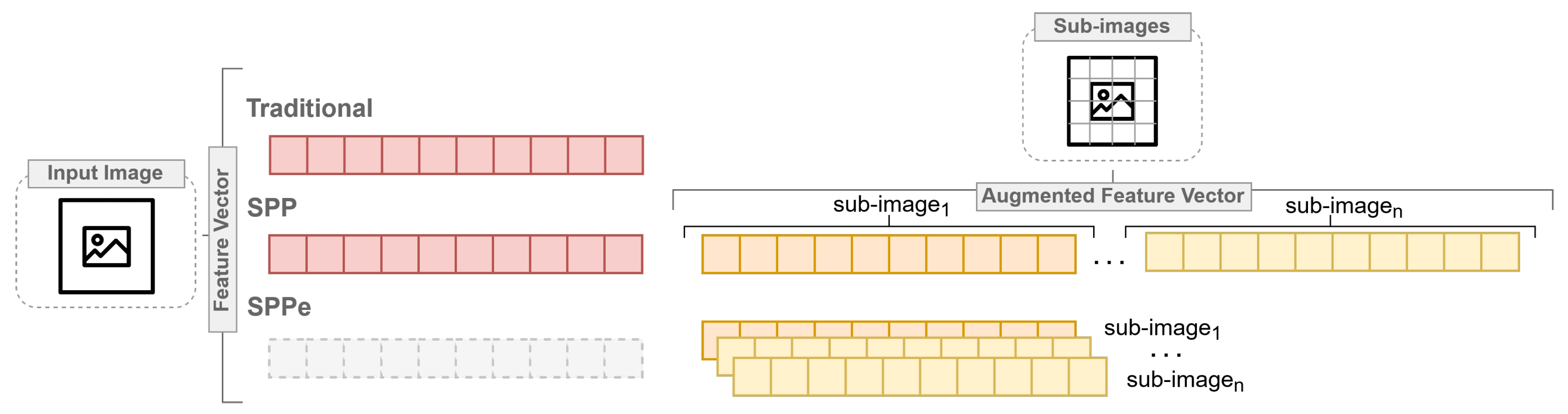
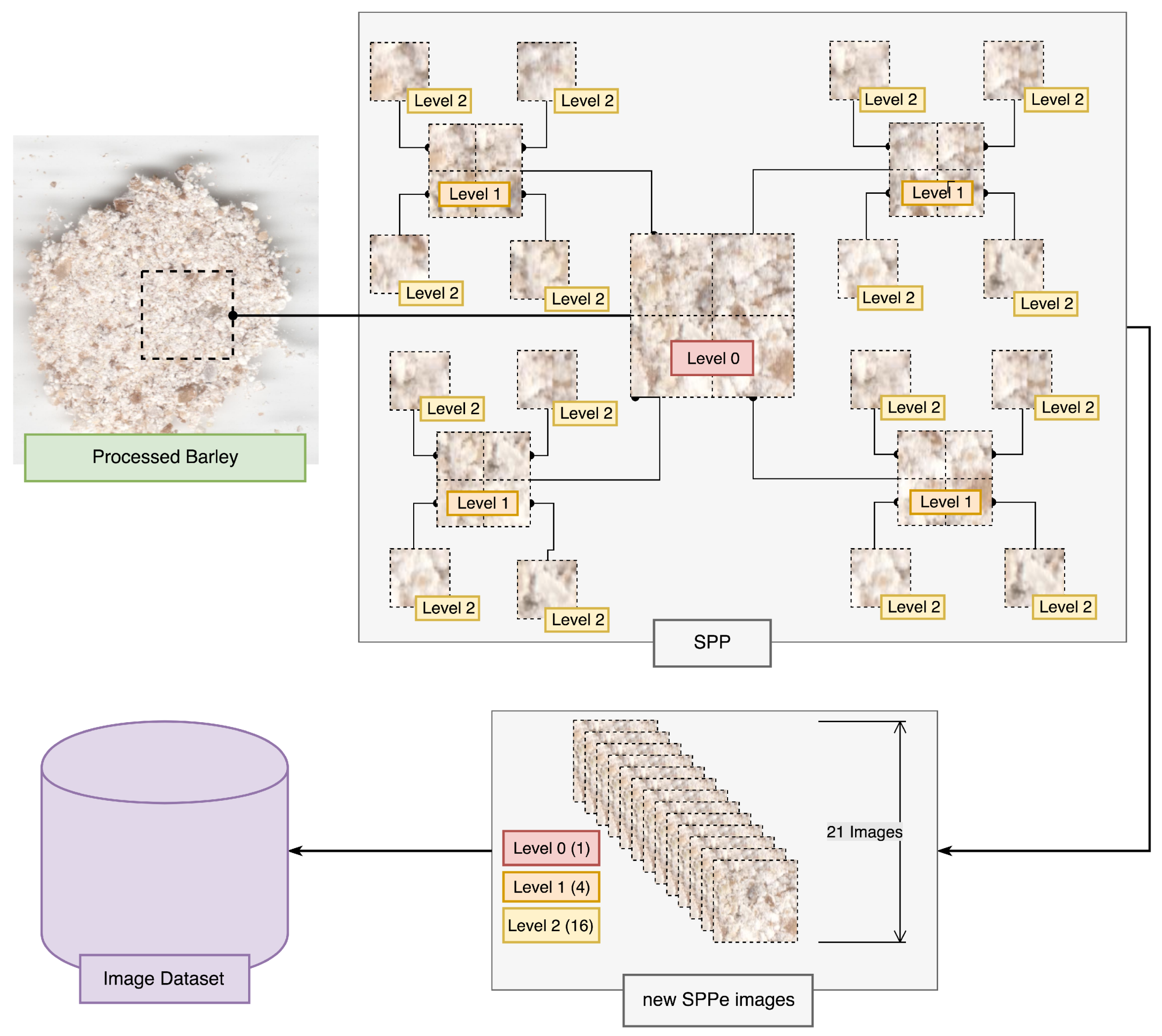
3.2. Spatial Pyramid Partition Ensemble
3.2.1. Image Analysis and Feature Extraction
3.2.2. Machine Learning
3.3. Evaluation Metrics
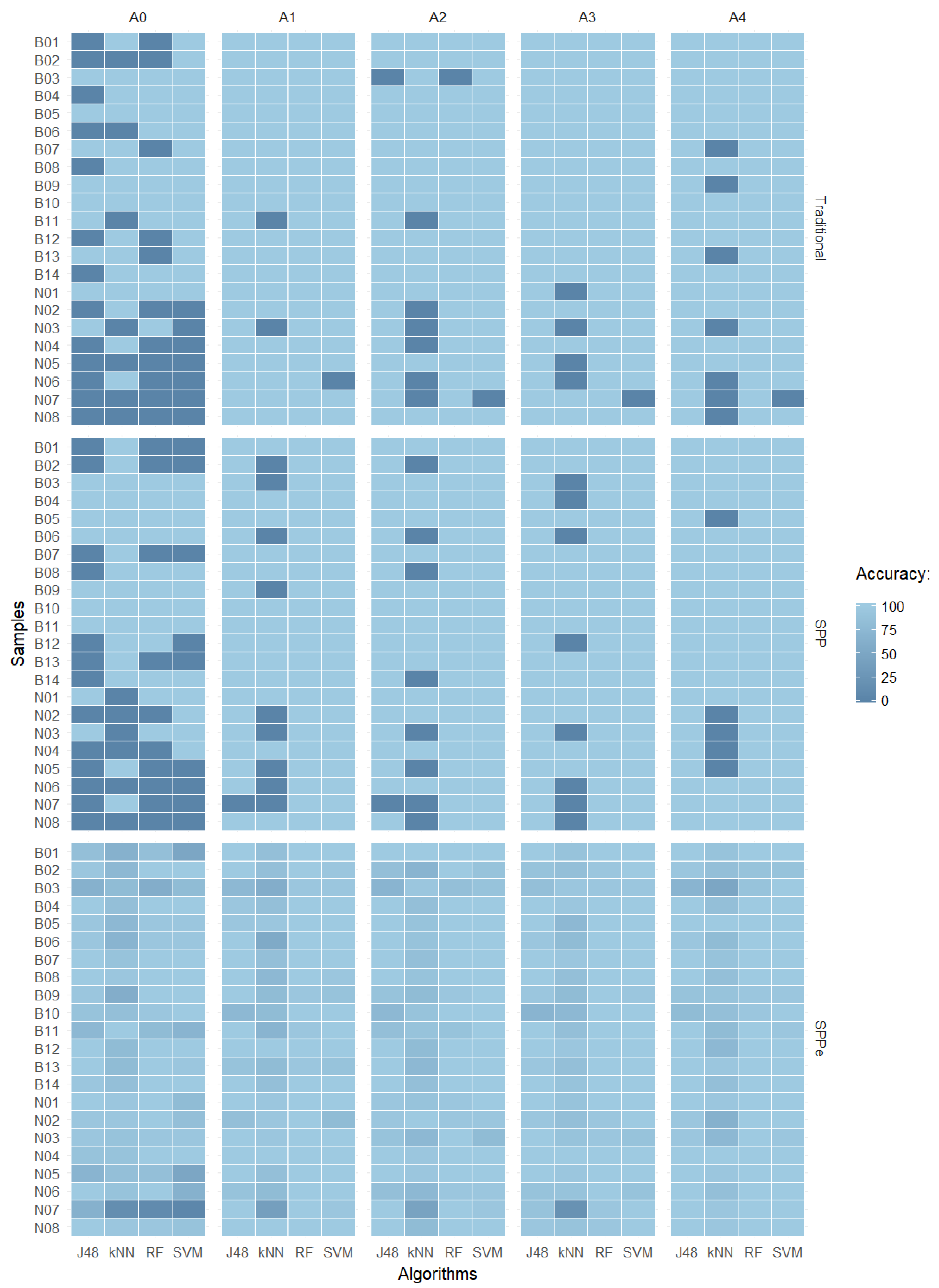
4. Results and Discussion
4.1. Algorithms and Image Processing Methods
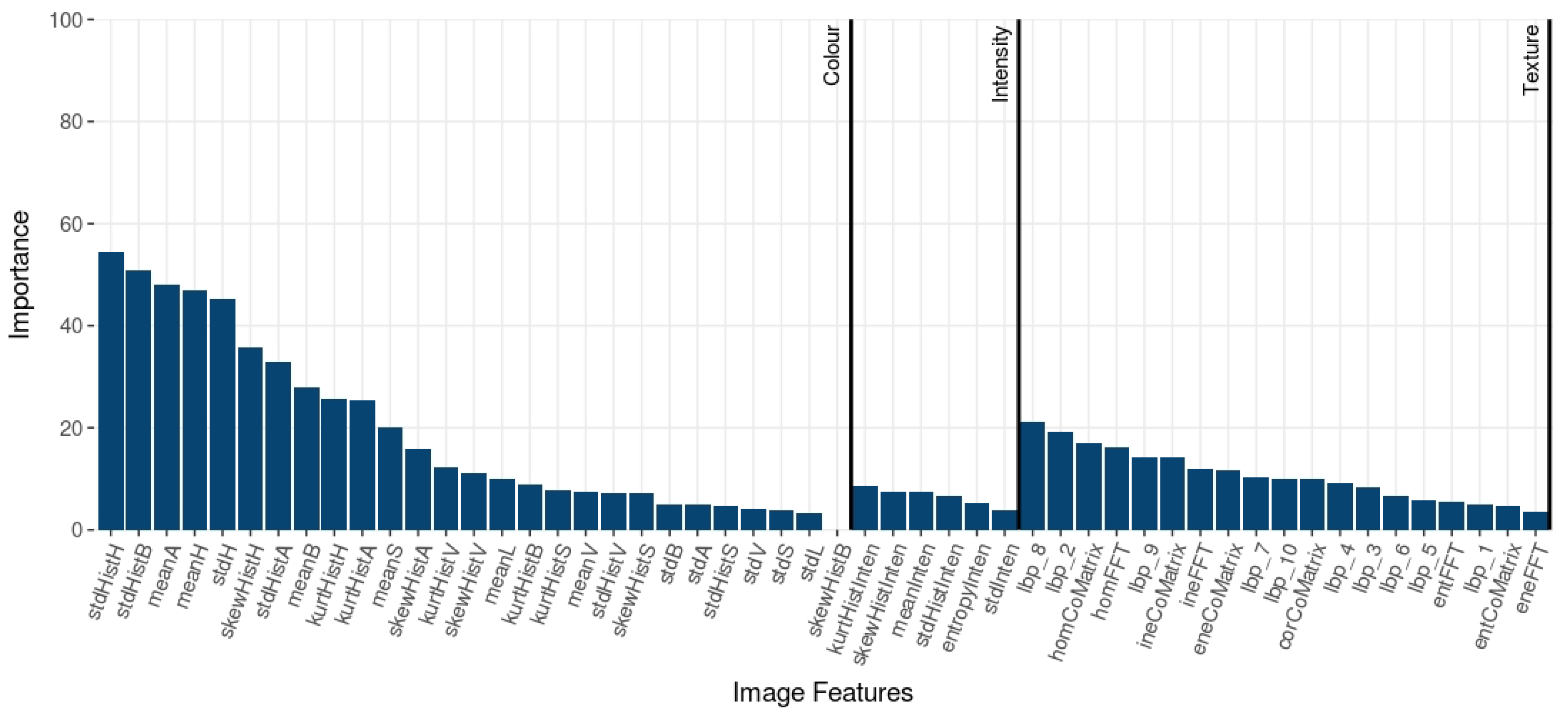
4.2. Evaluation of Image Features
4.3. SPPe in the Industry
- The input image (acquisition) being extracted from the camera. Images are acquired by a camera placed at the scene under inspection.
- The scene has to be appropriately illuminated and arranged, which promotes suitable reception of the image properties that are necessary for image processing (feature extraction and classification).
- The processing system stage consists of a computer employed for processing the acquired images, resulting in classifying as naked or malting barley flour.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Idehen, E.; Tang, Y.; Sang, S. Bioactive phytochemicals in barley. J. Food Drug Anal. 2017, 25, 148–161. [Google Scholar] [CrossRef]
- Bhatty, R. β-Glucan content and viscosities of barleys and their roller-milled flour and bran products. Cereal Chem. 1992, 69, 469–471. [Google Scholar]
- Taketa, S.; Kikuchi, S.; Awayama, T.; Yamamoto, S.; Ichii, M.; Kawasaki, S. Monophyletic origin of naked barley inferred from molecular analyses of a marker closely linked to the naked caryopsis gene (nud). Theor. Appl. Genet. 2004, 108, 1236–1242. [Google Scholar] [CrossRef]
- Edney, M.J.; O’Donovan, J.T.; Turkington, T.K.; Clayton, G.W.; McKenzie, R.; Juskiw, P.; Lafond, G.P. Effects of seeding rate, nitrogen rate and cultivar on barley malt quality. Sci. Food Agric. 2015, 92, 2672–2678. [Google Scholar] [CrossRef]
- Shewry, P.R.; Ullrich, S.E. Barley: Chemistry and Technology; AACCI Press: St. Paul, MN, USA, 2014; Volume 2. [Google Scholar]
- Paredes, P.; Rodrigues, G.C.; do Rosário Cameira, M.; Torres, M.O.; Pereira, L.S. Assessing yield, water productivity and farm economic returns of malt barley as influenced by the sowing dates and supplemental irrigation. Agric. Water Manag. 2017, 179, 132–143. [Google Scholar] [CrossRef]
- Lim, J.; Kim, G.; Mo, C.; Oh, K.; Kim, G.; Ham, H.; Kim, S.; Kim, M. Application of near infrared reflectance spectroscopy for rapid and non-destructive discrimination of hulled barley, naked barley, and wheat contaminated with Fusarium. Sensors 2018, 18, 113. [Google Scholar] [CrossRef]
- Newman, C.W.; Newman, R.K. A brief history of barley foods. Cereal Foods World 2006, 51, 4–7. [Google Scholar] [CrossRef]
- Szczypinski, P.M.; Klepaczko, A.; Zapotoczny, P. Identifying barley varieties by computer vision. Comput. Electron. Agric. 2015, 110, 1–8. [Google Scholar] [CrossRef]
- Du, C.J.; Sun, D.W. Learning techniques used in computer vision for food quality evaluation: A review. J. Food Eng. 2006, 72, 39–55. [Google Scholar] [CrossRef]
- Kurtulmuş, F.; Gürbüz, O.; Değirmencioğlu, N. Discriminating drying method of tarhana using computer vision. J. Food Process Eng. 2014, 37, 362–374. [Google Scholar] [CrossRef]
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef]
- Sabanci, K.; Kayabasi, A.; Toktas, A. Computer vision-based method for classification of wheat grains using artificial neural network. Sci. Food Agric. 2016, 97, 2588–2593. [Google Scholar] [CrossRef]
- Aslan, M.F.; Sabanci, K.; Yiğit, E.; Kayabaşi, A.; Toktaş, A.; Duysak, H. A Comparative Classification of Wheat Grains for Artificial Neural Network and Extreme Learning Machine. Uluslararası Çevresel Eğilimler Derg. 2017, 1, 14–21. [Google Scholar]
- Mittal, G.S. Computerized Control Systems in the Food Industry; Marcel Dekker, Inc.: New York, NY, USA, 1996. [Google Scholar]
- Zhao, X.; Wang, W.; Ni, X.; Chu, X.; Li, Y.F.; Sun, C. Evaluation of Near-infrared hyperspectral imaging for detection of peanut and walnut powders in whole wheat flour. Appl. Sci. 2018, 8, 1076. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, H.; Kim, M.S.; Qin, J.; Kandpal, L.M.; Bae, H.; Rahman, A.; Cho, B.K. Calibration and testing of a Raman hyperspectral imaging system to reveal powdered food adulteration. PLoS ONE 2018, 13, e0195253. [Google Scholar] [CrossRef]
- Foca, G.; Masino, F.; Antonelli, A.; Ulrici, A. Prediction of compositional and sensory characteristics using RGB digital images and multivariate calibration techniques. Anal. Chim. Acta 2011, 706, 238–245. [Google Scholar] [CrossRef]
- Su, W.H.; Sun, D.W. Fourier transform infrared and Raman and hyperspectral imaging techniques for quality determinations of powdery foods: A review. Compr. Rev. Food Sci. Food Saf. 2018, 17, 104–122. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, X.; Wang, T.; Lu, F. Discriminative Spatial Tree for Image Classification. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 283–288. [Google Scholar]
- Sharma, G.; Jurie, F.; Schmid, C. Discriminative spatial saliency for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3506–3513. [Google Scholar]
- Pereira, L.F.S.; Barbon, S.; Valous, N.A.; Barbin, D.F. Predicting the ripening of papaya fruit with digital imaging and random forests. Comput. Electron. Agric. 2018, 145, 76–82. [Google Scholar] [CrossRef]
- Da Costa Barbon, A.P.A.; Barbon, S., Jr.; Campos, G.F.C.; Seixas, J.L.S., Jr.; Peres, L.M.; Mastelini, S.M.; Andreo, N.; Ulrici, A.; Bridi, A.M. Development of a flexible Computer Vision System for marbling classification. Comput. Electron. Agric. 2017, 142, 536–544. [Google Scholar] [CrossRef]
- Kurtulmuş, F.; Ünal, H. Discriminating rapeseed varieties using computer vision and machine learning. Expert Syst. Appl. 2015, 42, 1880–1891. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Liu, T.; Liu, Y. Prediction of total viable counts on chilled pork using an electronic nose combined with support vector machine. Meat Sci. 2012, 90, 373–377. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Wang, M.; Wang, J.; Li, D. Comparison of random forest, support vector machine and back propagation neural network for electronic tongue data classification: Application to the recognition of orange beverage and Chinese vinegar. Sens. Actuators B Chem. 2013, 177, 970–980. [Google Scholar] [CrossRef]
- Papadopoulou, O.S.; Panagou, E.Z.; Mohareb, F.R.; Nychas, G.J.E. Sensory and microbiological quality assessment of beef fillets using a portable electronic nose in tandem with support vector machine analysis. Food Res. Int. 2013, 50, 241–249. [Google Scholar] [CrossRef]
- Prevolnik, M.; Andronikov, D.; Žlender, B.; Font-i Furnols, M.; Novič, M.; Škorjanc, D.; Čandek-Potokar, M. Classification of dry-cured hams according to the maturation time using near infrared spectra and artificial neural networks. Meat Sci. 2014, 96, 14–20. [Google Scholar] [CrossRef] [PubMed]
- Ai, F.F.; Bin, J.; Zhang, Z.M.; Huang, J.H.; Wang, J.B.; Liang, Y.Z.; Yu, L.; Yang, Z.Y. Application of random forests to select premium quality vegetable oils by their fatty acid composition. Food Chem. 2014, 143, 472–478. [Google Scholar] [CrossRef]
- Granitto, P.M.; Gasperi, F.; Biasioli, F.; Trainotti, E.; Furlanello, C. Modern data mining tools in descriptive sensory analysis: A case study with a Random forest approach. Food Qual. Prefer. 2007, 18, 681–689. [Google Scholar] [CrossRef]
- Barbon, A.P.A.; Barbon, S.; Mantovani, R.G.; Fuzyi, E.M.; Peres, L.M.; Bridi, A.M. Storage time prediction of pork by Computational Intelligence. Comput. Electron. Agric. 2016, 127, 368–375. [Google Scholar] [CrossRef]
- Liakos, K.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag Inc.: New York, NY, USA, 1995. [Google Scholar]
- Brighton, H.; Mellish, C. Advances in Instance Selection for Instance-Based Learning Algorithms. Data Min. Knowl. Discov. 2002, 6, 153–172. [Google Scholar] [CrossRef]
- Hornik, K.; Karatzoglou, D.M.; Zeileis, A.; Hornik, M.K. The Rweka Package. 2007. Available online: ftp://ftp.uni-bayreuth.de/pub/math/statlib/R/CRAN/doc/packages/RWeka.pdf (accessed on 15 May 2019).
- Muñoz, I.; Rubio-Celorio, M.; Garcia-Gil, N.; Guàrdia, M.D.; Fulladosa, E. Computer image analysis as a tool for classifying marbling: A case study in dry-cured ham. J. Food Eng. 2015, 166, 148–155. [Google Scholar] [CrossRef]
- Saberioon, M.; Císař, P.; Labbé, L.; Souček, P.; Pelissier, P.; Kerneis, T. Comparative Performance Analysis of Support Vector Machine, Random Forest, Logistic Regression and k-Nearest Neighbours in Rainbow Trout (Oncorhynchus Mykiss) Classification Using Image-Based Features. Sensors 2018, 18, 1027. [Google Scholar] [CrossRef] [PubMed]
- Nowakowski, K.; Boniecki, P.; Tomczak, R.J.; Kujawa, S.; Raba, B. Identification of malting barley varieties using computer image analysis and artificial neural networks. In Proceedings of the Fourth International Conference on Digital Image Processing (ICDIP 2012), Kuala Lumpur, Malaysia, 7–8 April 2012; International Society for Optics and Photonics: San Diego, CA, USA, 2012; Volume 8334, p. 833425. [Google Scholar]
- Kociołek, M.; Szczypiński, P.M.; Klepaczko, A. Preprocessing of barley grain images for defect identification. In Proceedings of the 2017 IEEE Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 20–22 September 2017; pp. 365–370. [Google Scholar]
- Pazoki, A.; Pazoki, Z.; Sorkhilalehloo, B. Rain Fed Barley Seed Cultivars Identification Using Neural Network and Different Neurons Number. World Appl. Sci. J. 2013, 5, 755–762. [Google Scholar]
- Ciesielski, V.; Lam, B.; Nguyen, M.L. Comparison of evolutionary and conventional feature extraction methods for malt classification. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation (CEC), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Li, D.; Li, N.; Wang, J.; Zhu, T. Pornographic images recognition based on spatial pyramid partition and multi-instance ensemble learning. Knowl.-Based Syst. 2015, 84, 214–223. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, S.; Huang, Q.; Liu, J.; Liang, C.; Tian, Q. Image classification using spatial pyramid robust sparse coding. Pattern Recognit. Lett. 2013, 34, 1046–1052. [Google Scholar] [CrossRef]
- Saez, Y.; Baldominos, A.; Isasi, P. A Comparison Sudy of Classifier Algorithms for Cross-Person Physical Activity Recognition. Sensors 2017, 17, 66. [Google Scholar] [CrossRef]
- Campos, G.F.; Barbon, S.; Mantovani, R.G. A meta-learning approach for recommendation of image segmentation algorithms. In Proceedings of the 2016 29th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Sao Paulo, Brazil, 4–7 October 2016; pp. 370–377. [Google Scholar]
- Kapur, J.; Sahoo, P.; Wong, A. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Nixon, M.; Aguado, A.S. Feature Extraction and Image Processing for Computer Vision; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Shen, H.K.; Chen, P.H.; Chang, L.M. Automated steel bridge coating rust defect recognition method based on color and texture feature. Autom. Constr. 2013, 31, 338–356. [Google Scholar] [CrossRef]
- Hiremath, P.; Shivashankar, S. Wavelet based co-occurrence histogram features for texture classification with an application to script identification in a document image. Pattern Recognit. Lett. 2008, 29, 1182–1189. [Google Scholar] [CrossRef]
- Chaudhuri, B.B.; Sarkar, N. Texture segmentation using fractal dimension. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 72–77. [Google Scholar] [CrossRef]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers. Mult. Classif. Syst. 2007, 34, 1–17. [Google Scholar]
- Quinlan, J. C4.5 Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1992. [Google Scholar]
- Sharma, T.C.; Jain, M. WEKA approach for comparative study of classification algorithm. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 1925–1931. [Google Scholar]
- Scornet, E.; Biau, G.; Vert, J.P. Consistency of random forests. Ann. Stat. 2015, 43, 1716–1741. [Google Scholar] [CrossRef]
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 2005; Volume 177. [Google Scholar]
- Kennard, R.W.; Stone, L.A. Computer aided design of experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Kroth, M.A.; Ramella, M.S.; Tagliari, C.; Francisco, A.D.; Arisi, A.C.M. Genetic Similarity of Brazilian Hull-Less and Malting Barley Varieties Evaluated by Rapd Markers. Agric. Sci. 2005, 62, 36–39. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample ID | Cultivar | Type |
|---|---|---|
| B01 | BRS Aliensa | Malting |
| B02 | BRS Itanema | Malting |
| B03 | BRS Brau | Malting |
| B04 | MN 6021 | Malting |
| B05 | BRS Sampa | Malting |
| B06 | BRS Korbel | Malting |
| B07 | MN 6021 | Malting |
| B08 | BRS Elis | Malting |
| B09 | BRS Korbel | Malting |
| B10 | BRS Elis | Malting |
| B11 | BRS Mandurí | Malting |
| B12 | BRS Brau | Malting |
| B13 | BRS Cauê | Malting |
| B14 | BRS Cauê | Malting |
| N01 | 149852 | Naked |
| N02 | 149853 | Naked |
| N03 | 149857 | Naked |
| N04 | 149846 | Naked |
| N05 | 149858 | Naked |
| N06 | 149841 | Naked |
| N07 | 149855 | Naked |
| N08 | 149859 | Naked |
| No. | Type | Name | Description |
|---|---|---|---|
| 1 | Color | meanH | Mean value of the H channel |
| 2 | Color | StdH | Standard deviation of the H channel |
| 3 | Color | meanS | Mean value of the S channel |
| 4 | Color | stdS | Standard deviation of the S channel |
| 5 | Color | MeanV | Mean value of the V channel |
| 6 | Color | stdV | Standard deviation of the V channel |
| 7 | Color | stdHistH | Standard deviation of H channel histogram |
| 8 | Color | kurtHistH | Kurtosis of H channel histogram |
| 9 | Color | skewHistH | Skewness of H channel histogram |
| 10 | Color | stdHistS | Standard deviation of S channel histogram |
| 11 | Color | kurtHistS | Kurtosis of S channel histogram |
| 12 | Color | skewHistS | Skewness of S channel histogram |
| 13 | Color | stdHistV | Standard deviation of V channel histogram |
| 14 | Color | kurtHistV | Kurtosis of V channel histogram |
| 15 | Color | skewHistV | Skewness of V channel histogram |
| 16 | Color | meanL | Mean value of the L channel |
| 17 | Color | stdL | Standard deviation of the L channel |
| 18 | Color | meanA | Mean value of the A channel |
| 19 | Color | stdA | Standard deviation of the A channel |
| 20 | Color | meanB | Mean value of the B channel |
| 21 | Color | stdB | Standard deviation of the B channel |
| 22 | Color | stdHistL | Standard deviation of L channel histogram |
| 23 | Color | kurtHistL | Kurtosis of L channel histogram |
| 24 | Color | skewHistL | Skewness of L channel histogram |
| 25 | Color | stdHistA | Standard deviation of A channel histogram |
| 26 | Color | kurtHistA | Kurtosis of A channel histogram |
| 27 | Color | skewHistA | Skewness of A channel histogram |
| 28 | Color | stdHistB | Standard deviation of B channel histogram |
| 29 | Color | kurtHistB | Kurtosis of B channel histogram |
| 30 | Color | skewHistB | Skewness of B channel histogram |
| 31 | Intensity | meanInten | Mean value of intensity image |
| 32 | Intensity | StdInten | Standard deviation of Intensity image |
| 33 | Intensity | entropyInten | Entropy of intensity image |
| 34 | Intensity | stdHistInten | Standard deviation of Intensity image histogram |
| 35 | Intensity | kurtHistInten | Kurtosis of intensity image histogram |
| 36 | Intensity | skewHistInten | Skewness of intensity image histogram |
| 37–46 | Texture | - | Vector of Local Binary Patterns (LBP) rotationally invariant features |
| 47 | Texture | entCoMatrix | Entropy of grey-level co-occurrence matrix |
| 48 | Texture | ineCoMatrix | Inertia of grey-level co-occurrence matrix |
| 49 | Texture | eneCoMatrix | Energy of grey-level co-occurrence matrix |
| 50 | Texture | corCoMatrix | Correlation of grey-level co-occurrence matrix |
| 51 | Texture | homCoMatrix | Homogeneity of grey-level co-occurrence matrix |
| 52 | Texture | eneFFT | FFT Energy |
| 53 | Texture | entFFT | FFT Entropy |
| 54 | Texture | ineFFT | FFT Inertia |
| 55 | Texture | homFFT | FFT Homogeneity |
| Algorithm | Description | R Package | Hyperparameters |
| K-Nearest Neighbor (k-NN) | A non-parametric lazy learning algorithm; the training data are not used for any generalization [55]. | RWeka | Euclidean distance; k= 5 |
| Decision Tree (J48) | A decision tree widely applied to represent series of rules that lead to a class or value [56,57]. | RWeka | C = 0.25; threshold = 0.25; with pruning |
| Random Forest (RF) | A combination of decision tree models that provides more accurate prediction [33,58]. | RandomForest | ntree = 100; mtry = 7 |
| Support Vector Machine (SVM) | A statistical learning algorithm, used for supervised ML and food quality solutions [34,59]. | e1071 | kernel = polynomial; , degree = 3 |
| Algorithm | Metric | Cross-Validation | Prediction | ||||
|---|---|---|---|---|---|---|---|
| Traditional | SPP | SPPe | Traditional | SPP | SPPe | ||
| RF | Accuracy | 90.00 | 91.00 | 100.00 | 90.00 | 95.00 | 95.00 |
| Precision | 71.88 | 71.88 | 100.00 | 86.67 | 96.88 | 96.88 | |
| Recall | 68.93 | 69.43 | 100.00 | 86.67 | 90.00 | 90.00 | |
| Time (s) | 65.35 () | 281.63 (±1.09) | 217.11 (±0.40) | 62.53 (±0.12) | 268.71 (±0.39) | 207.07 (±0.34) | |
| k-NN | Accuracy | 77.56 | 70.56 | 95.56 | 80.00 | 60.00 | 75.00 |
| Precision | 60.79 | 57.25 | 95.85 | 74.51 | 52.75 | 65.63 | |
| Recall | 58.79 | 53.88 | 94.81 | 66.67 | 53.33 | 63.33 | |
| Time (s) | 64.50 (±0.10) | 279.34 (±0.94) | 209.49 (±0.36) | 62.44 (±0.15) | 268.51 (±0.36) | 206.11 (±0.29) | |
| J48 | Accuracy | 89.00 | 88.00 | 100.00 | 85.00 | 85.00 | 100.00 |
| Precision | 71.88 | 71.88 | 100.00 | 79.77 | 91.67 | 100.00 | |
| Recall | 68.43 | 67.93 | 100.00 | 83.33 | 70.00 | 100.00 | |
| Time (s) | 70.14 (±0.26) | 353.37 (±2.31) | 210.79 (±0.37) | 62.61 (±0.10) | 270.71 (±0.38) | 206.32 (±0.33) | |
| SVM | Accuracy | 93.00 | 92.00 | 98.89 | 80.00 | 95.00 | 95.00 |
| Precision | 70.42 | 72.50 | 99.11 | 89.47 | 96.88 | 96.88 | |
| Recall | 70.00 | 70.36 | 98.57 | 60.00 | 90.00 | 90.00 | |
| Time (s) | 64.62 (±0.15) | 280.57 (±0.95) | 213.40 (±0.43) | 62.83 (±0.12) | 268.66 (±0.37) | 206.75 (±0.37) | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopes, J.F.; Ludwig, L.; Barbin, D.F.; Grossmann, M.V.E.; Barbon, S., Jr. Computer Vision Classification of Barley Flour Based on Spatial Pyramid Partition Ensemble. Sensors 2019, 19, 2953. https://doi.org/10.3390/s19132953
Lopes JF, Ludwig L, Barbin DF, Grossmann MVE, Barbon S Jr. Computer Vision Classification of Barley Flour Based on Spatial Pyramid Partition Ensemble. Sensors. 2019; 19(13):2953. https://doi.org/10.3390/s19132953
Chicago/Turabian StyleLopes, Jessica Fernandes, Leniza Ludwig, Douglas Fernandes Barbin, Maria Victória Eiras Grossmann, and Sylvio Barbon, Jr. 2019. "Computer Vision Classification of Barley Flour Based on Spatial Pyramid Partition Ensemble" Sensors 19, no. 13: 2953. https://doi.org/10.3390/s19132953
APA StyleLopes, J. F., Ludwig, L., Barbin, D. F., Grossmann, M. V. E., & Barbon, S., Jr. (2019). Computer Vision Classification of Barley Flour Based on Spatial Pyramid Partition Ensemble. Sensors, 19(13), 2953. https://doi.org/10.3390/s19132953