The AM4I Architecture and Framework for Multimodal Interaction and Its Application to Smart Environments





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (a)
- exploit the different ways of communication between the environment and the user through seamless integration of user and building (interactive) devices;
- (b)
- consider additional environment information to contextualize interaction (e.g., comfort related measures);
- (c)
- evolve, through time, to encompass novel technologies and interaction designs;
- (d)
- generically support system instantiations complying with different cultures.
- (a)
- overall support to develop and deploy multimodal interaction;
- (b)
- simple integration of user and environment devices and sensors and their dynamic (i.e., changeable over time) management;
- (c)
- integrated exploration of several ways to communicate—the so-called modalities—in both directions between users and the environment;
- (d)
- consideration of multi-device environments as seamless interaction ecosystems; and
- (e)
- provide off-the-shelf modalities, which can be readily available to developers, avoiding the need to master their supporting technologies and complexity including, for instance, speech interaction and multilanguage support.
2. Background & Related Work
2.1. Multimodal Interaction
2.2. Multidevice
2.3. Sensors and Actuators
2.4. Main Challenges
- How to enable and support simple development of truly MMI applications, considering, for instance, the amount of technologies and complexity involved in deploying interaction modalities;
- In line with the previous point, how to simplify the exploration of fusion and integrate fusion engines in MMI frameworks, enabling full exploration of the multiple interaction modalities available;
- How to handle not only the devices deployed in the smart environment, but also those devices carried by users, which are natural candidates for interacting with the environment, and can become a common aspect when traveling between environments;
- How to provide a custom, user-adapted experience of the smart environment, addressing preferences and needs and, particularly, those aspects that might have a strong impact on the naturalness of the interaction, such as the user’s language;
- How to make multi-device interaction part of our everyday life, wherever we go and whichever devices are involved, in the sense that it should become an inherent feature of any application, and its implementation should be transparent to the developer.
- How to handle, in a unified, simple and coherent way, the different types and communication technologies of sensors and actuators for the smart environments, to enable a seamless interaction with the environment as a whole, and not a set of interactive isolated artifacts.
3. The AM4I Architecture
3.1. Main Requirements
- (1)
- modular design, and fully decoupled components.
- (2)
- future extensibility, such as the creation of new modalities and components by adopting, whenever possible, standard formats, languages and approaches.
- (3)
- easy to use and deploy, for multiple platforms, provide components and modules off-the-shelf, and be scalable.
- (4)
- support multi-device interaction, both with devices installed in the smart environment, but also personal devices, such as smartphones, with a more transient existence, in the ecosystem;
- (5)
- provide different ways of interaction and consider approaches to provide developers with high-level methods as an entry point to define and explore fusion of modalities (redundancy and complementary);
- (6)
- user and context awareness to provide applications with the information relevant to adapt their features and those of the environment to particular user needs, preferences and mood;
- (7)
- assuming speech interaction as a key aspect to contribute to a more natural interaction with the environment, and recognizing that, nowadays, multilanguage environments are quite common, support multilingual interfaces, both in visual and speech modalities.
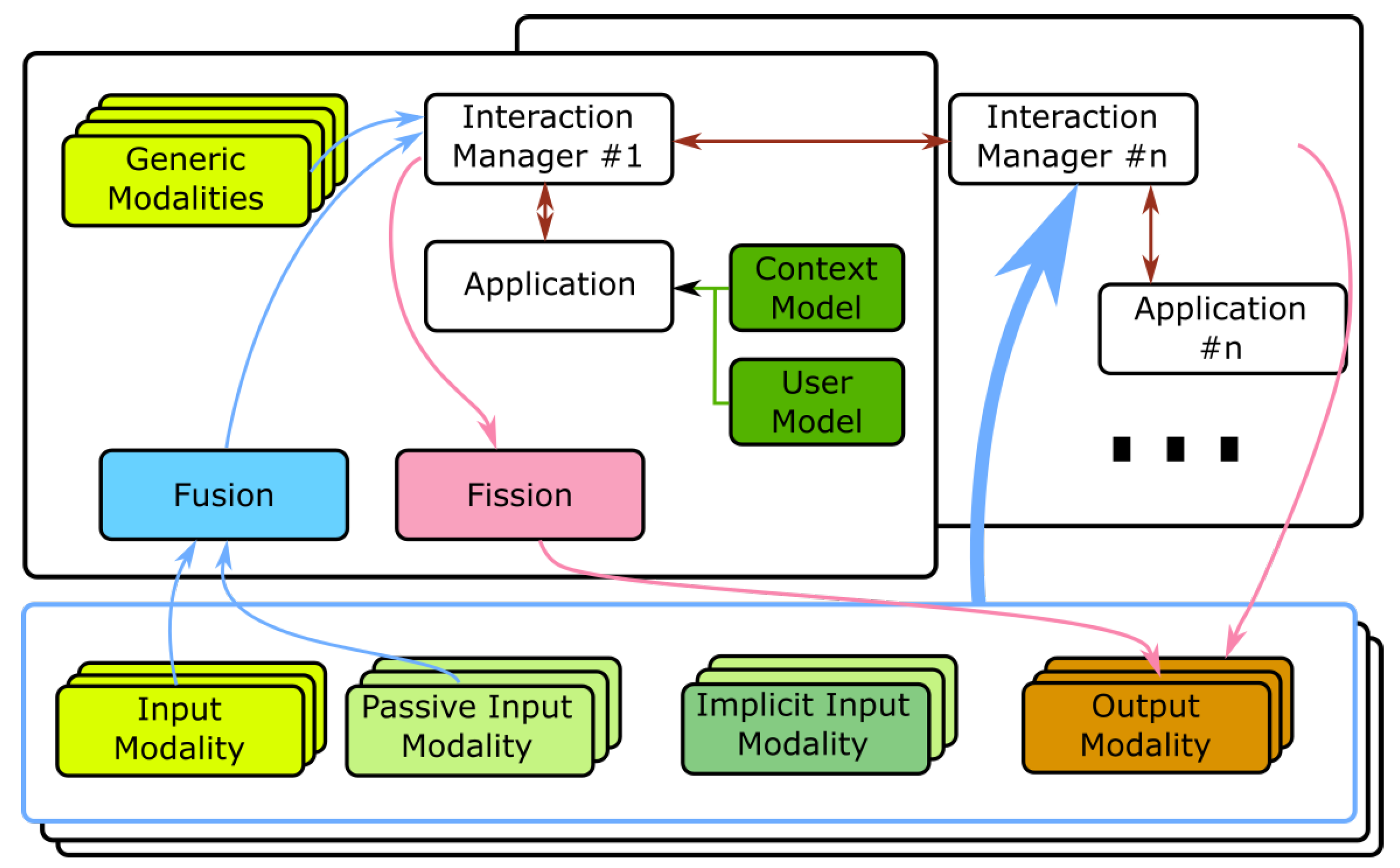
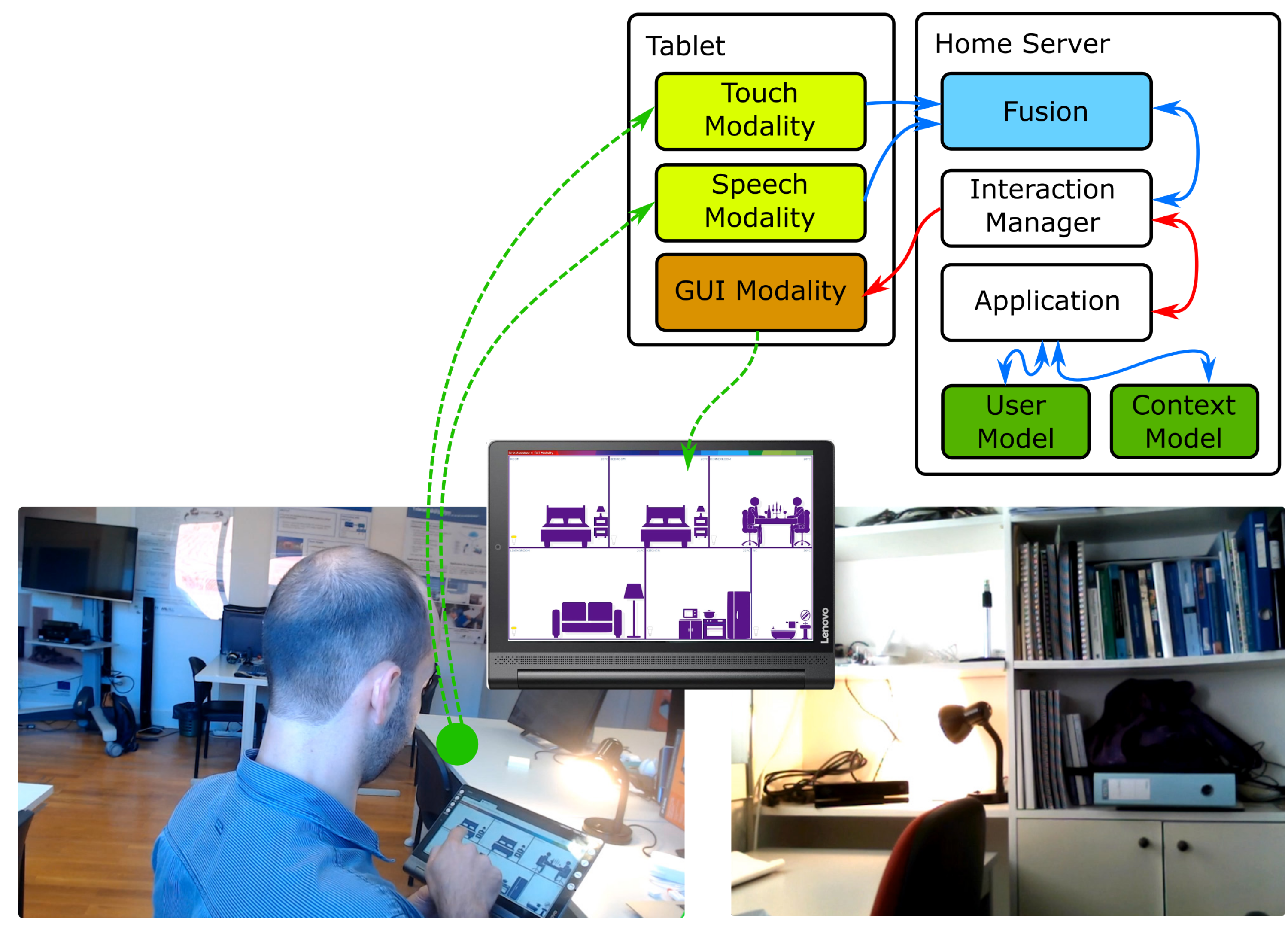
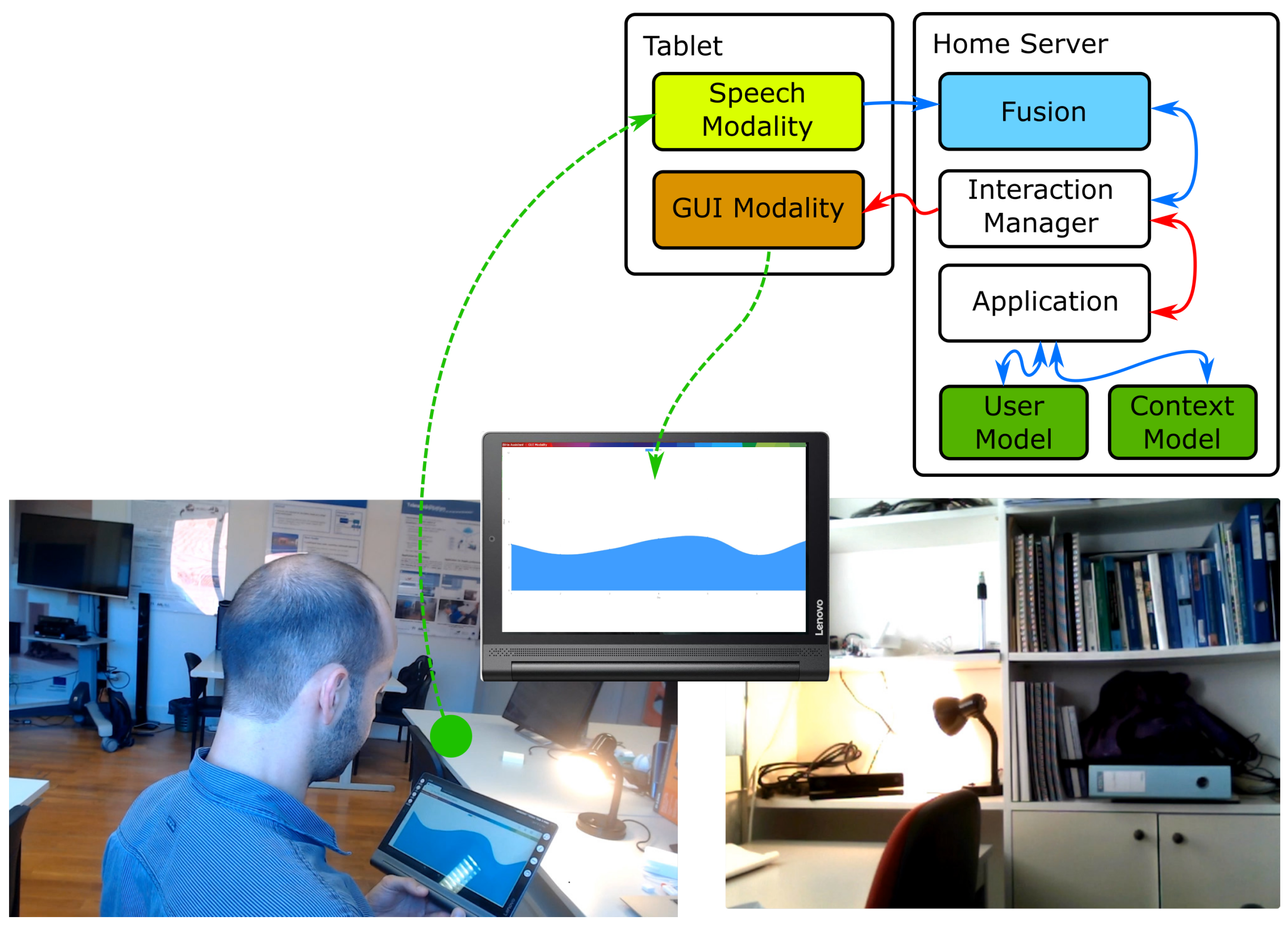
3.2. Overview of Architecture
- Modalities are the components that support the communication (interaction) to and from the building. To comply with the modularity requirement, modalities are separate, decoupled processes. There are several types of modalities:
- Input: responsible for listening to the user’s commands (e.g., touch, speech, gaze) and generating events, coded with the MMI life cycle event markup as described in the W3C standard [13];
- Output: providing ways for the system to communicate with the user, transmitting any desired information and feedback (e.g., graphics, speech messages, text, sound);
- Mixed: gathering, in the same module, both input and output capabilities;
- Passive or Implicit: providing relevant interaction information to the system without an explicit action from the user and very important sources of information to feed context and user models (e.g., temperature, user’s location, affective state, comfort levels). Implicit modalities provide information regarding the user while passive provide information from the environment;
- Generic: enabling a complex interaction option, of-the-shelf, highly configurable, encapsulating a set of diverse technologies, and reusable in any application adopting the architecture (e.g., multilingual speech interaction, multimodal affective context)
The modalities can run locally (e.g., on the occupant’s laptop) or in a hybrid setup, relying on support Services to perform more complex processing or enable their easier update (e.g., automatic speech recognition and natural language understanding [48], emotion identification). Legacy technologies can be integrated into the architecture, as modalities, by creating portals, as proposed in [49].An (input) modality can give feedback to the user without intervention of the application (and Interaction Manager) if it has the capabilities to do it. Since the architecture adopts the definition of modalities as proposed by the W3C, a speech modality, for instance, integrating input and output can directly provide feedback to the user by synthetic speech. If the modality does not integrate the needed output capabilities, it needs to generate an event requesting that the application delivers the feedback to the user through other means.The modalities should abide to a common semantics of events (e.g., say “left” or a “swipe left” gesture can have the common outcome of LEFT), adopting the ideas of Dialog Acts [50,51]. This way, as long as the semantics is kept, an application can seamlessly profit from modalities developed and/or integrated after its release, a very important feature for the building scenario with a longer timespan than technology. - Interaction Managers are core modules in the architecture since they are responsible for receiving the events generated by the input modalities and producing new messages to be delivered to the output modalities. They can run locally (e.g., in the device held by the user), in the building servers or in the cloud. Multiple Interaction Managers can be used, by an application, and different applications can share the same Interaction Manager and, if needed, share modalities. It is also through the Interaction Manager that a single application can be transparently controlled by multiple devices, at the same time.
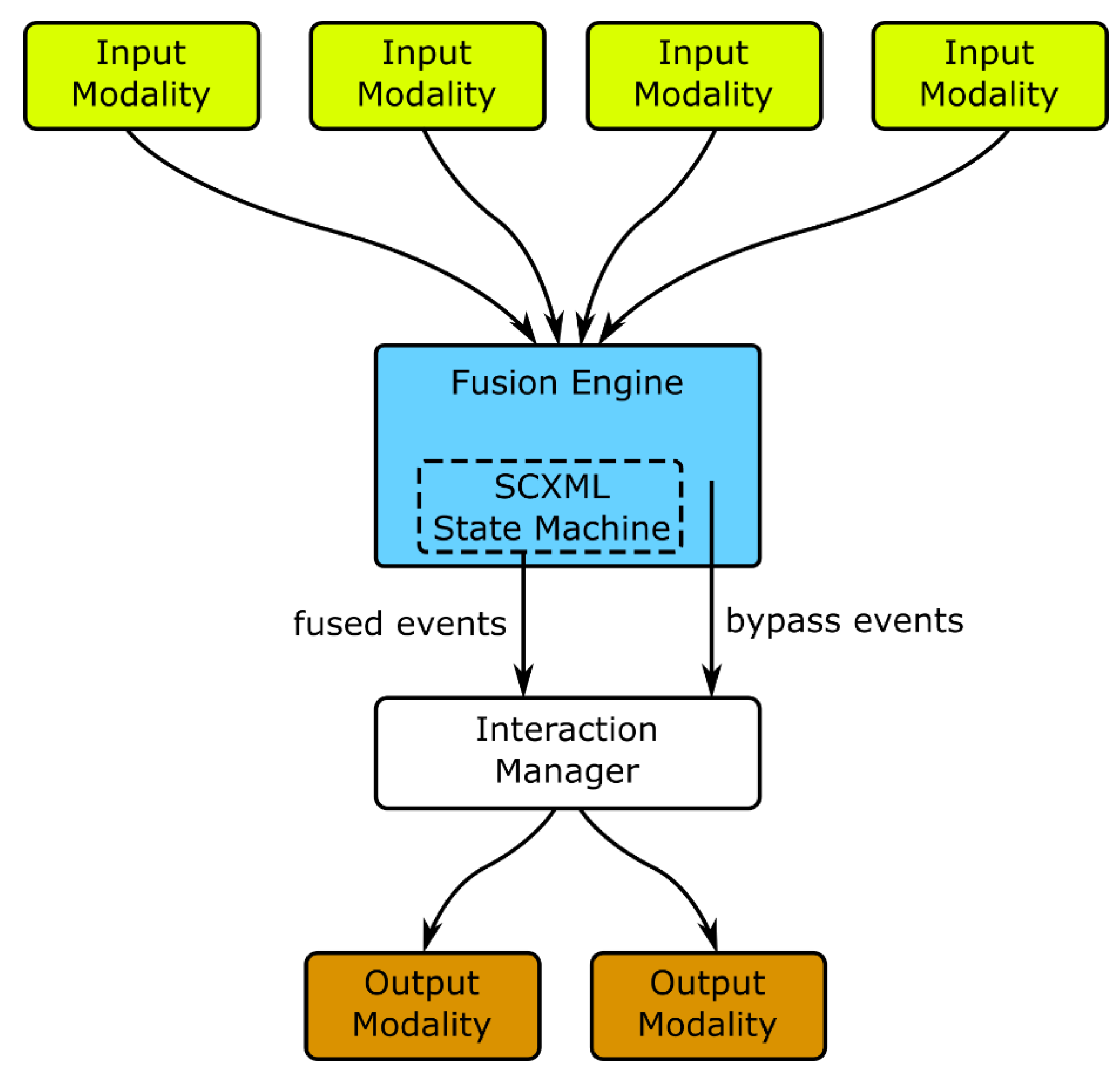
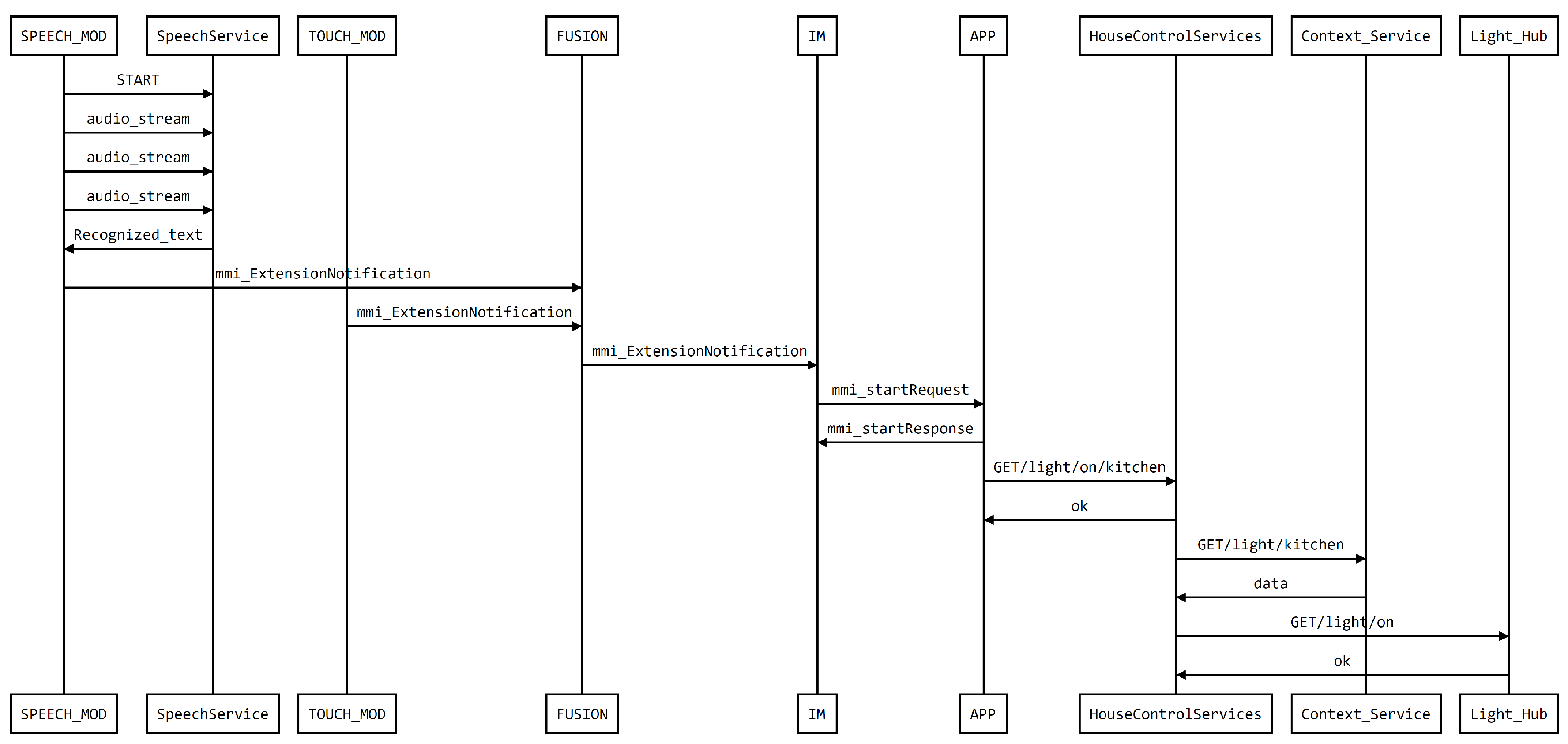
- Fusion is an important feature, since it allows multiple interaction events, coming from different modalities, to be combined into new single events aggregating all the information (e.g, point to a lamp—gesture identifying the target—and say “turn this on”—voice identifying the action). Fusion, in the AM4I architecture, is separated from the Interaction Manager, to allow the exchange of the module by other fusion modules and is actually where all modalities send their events for an early processing before the fused event is sent to the Interaction Manager. A common event semantics, among modalities is also important to simplify the specification of fusion rules.
- Fission consists in selecting one or more output modalities to deliver a message or content to the user [52] and is an important module for an increased adaptation to the occupant. Typically, in a multimodal environment, a set of output modalities is available and the system can choose from one or more modalities to render the message. The selection can be based on the type of message (e.g., text, numbers, warnings), availability of modalities (e.g., graphical display, speech output) or user context (e.g., alone, in the building lobby, in a meeting).
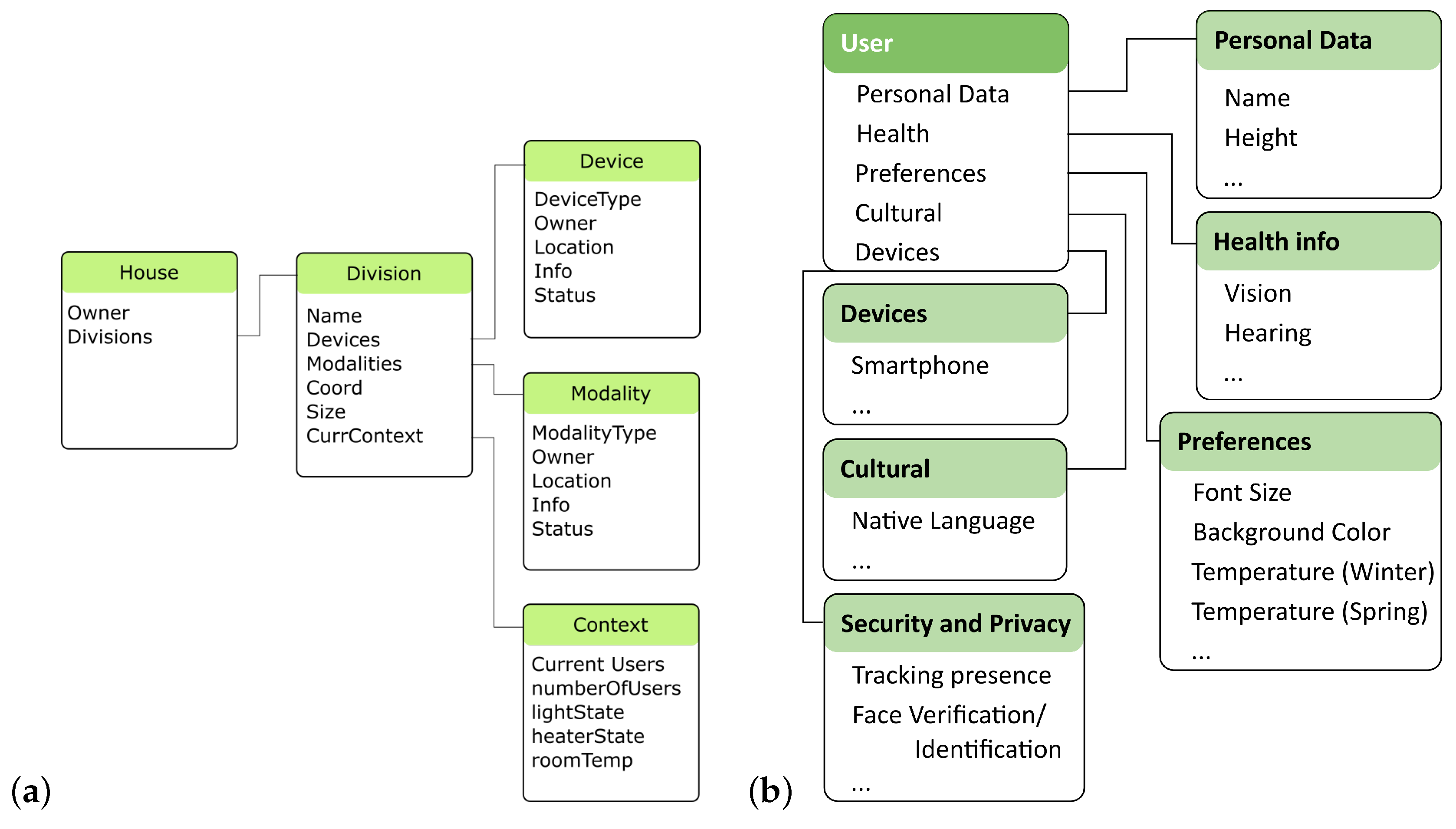
- Context and User models are essential for improving the level of adaptation provided by the system and can be available at building servers and/or the Cloud. They are available for use by multiple applications and this does not mean that only one monolithic general model is available. If needed, an application can have its own models, possibly obtaining part of the information from those pertaining a wider scope, and populating its own with more specific information. They must adopt standard representations to enable access by the applications without compromising privacy and security issues. The existence of user and context models does not mean that the occupants need (or will be forced) to disclose any of that information (e.g., location, affective state, facial features) to interact with the building and experience some base level of adaptation. Context and User models are there to complement and improve adaptation.
- Communication, Standards, and Interoperability, considering the required decoupling among architectural components, should rely on widely disseminated practices. The definition of the event transport layer, the communication protocol and markup languages for the communication between the Interaction Manager and the modalities inherit from the decoupled nature of the W3C multimodal interaction architecture specification and our proposal adopts markup languages (e.g., the Extensible MultiModal Annotation markup language—EMMA) used to transport notifications between components [13,53,54].
- The applications receive and process the events from input modalities; implement all the functional requirements; use and update context and user models to adapt; control services (e.g., central heating system) and actuators; and generate the output information to be conveyed to users using output modalities. They are executable programs that handle mainly the application logic, context and user awareness. User only interacts with the modalities, implemented as separate processes. The Applications can be single-device, one application running in multiple devices [19,55], server/cloud-based applications supporting features for (parts of) the building, or complex services consisting of different collaborative applications running at different locations.
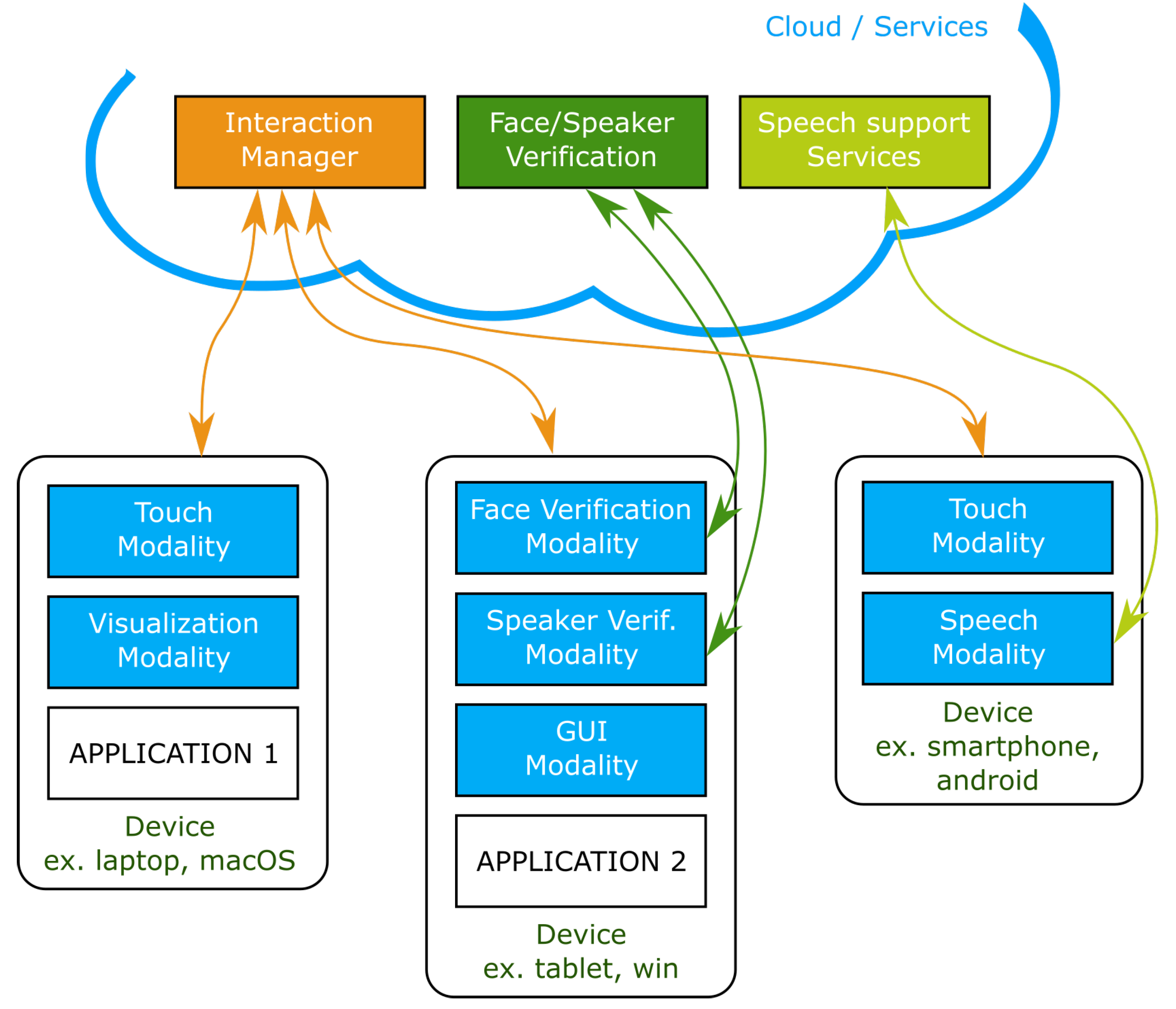
- Multimodal Interaction—The architecture supports a variable and dynamic number of input and output modalities by adopting an Interaction Manager assisted by Fusion and Fission services. These modules, together, can be seen as a macro Interaction Manager capable of receiving events from input (and passive) modalities, combining them (considering, for instance, a CARE model [5,56]) and sending information to output modalities.In the first approach, each device runs an instance of the Interaction Manager while, in the second approach, a single cloud based Interaction Manager runs remotely and each device connects to it.
- Multidevice—The proposal encompasses Interaction Managers, which are continuously running at building servers or the cloud, and all the interaction modalities know their location and communicate with them [15,17]. Complex devices, such as smartphones, integrate in the architecture manifold: as platforms to run applications, as (several) passive modalities, and providing multiple input and output modalities.
- Multiplatform—One important characteristic of the architecture, originating from its decoupled, distributed nature, is the ability to encompass multiple platforms. The Interaction Managers, Fusion and Fission modules are generic and available as services allowing applications to run in any platform, such as iOS, Windows, Android, or Linux variants, as long as they abide to the communication protocols.It is also possible to develop modules that run, without changes, in different platforms, and browsers are strong candidates to support these applications, since they run in almost every platform by, for instance, adopting an approach based on HTML5 (https://www.w3.org/TR/html5/)/Javascript applications.
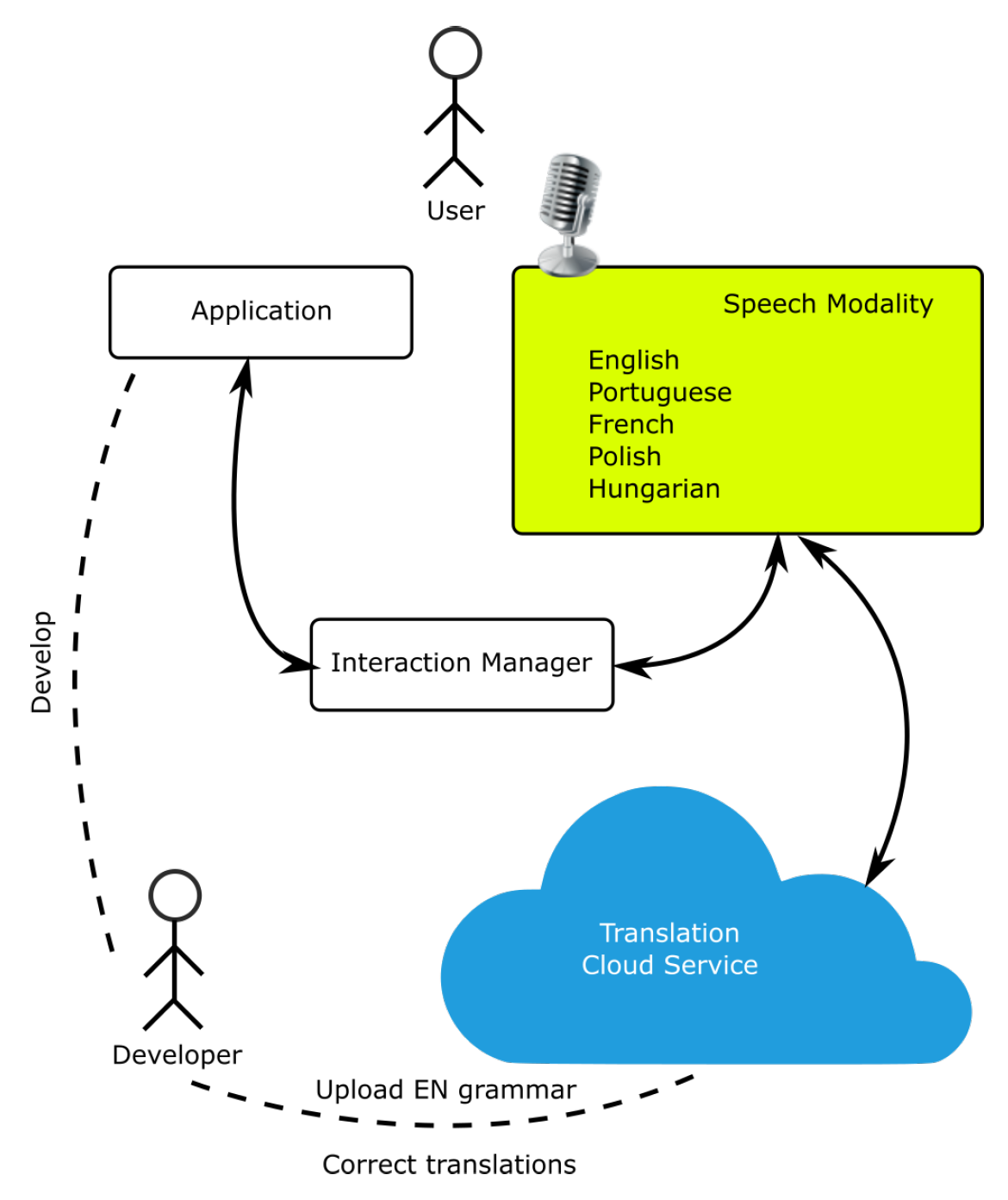
- Multilingual—As a first approach, generic modalities are the architecture components contributing to support interaction adapted to users culture. An important example is the included generic speech input modality supporting spoken commands in different languages, taking the user profile into account, as proposed in [17,57].Other parts of the architecture contributing to multiculturalism are the user models and passive modalities providing information on cultural aspects, such as, for example, the languages spoken and understood by an occupant. A passive modality considering, for example, information on the most commonly used dictionary in a smartphone, might help selecting the language for speech input and/or output.
- Adaptive—To support adaptation, the architecture provides:(1) models and services for users and contexts, that can be considered to adapt the interaction with the applications. (2) integration and gathering of contextual information, including information from different sensing technologies and building installed systems (e.g., security cameras can support the determination of user location); (3) output adaptation considering user and context. Passing information to the user is very important and must make the best possible use of the available modalities taking into consideration context and user. The architecture handles this by adding adaptability to output modalities and a dynamic registry of available output modalities taking into account the context and user, as proposed for AdaptO [6].
4. The AM4I Framework
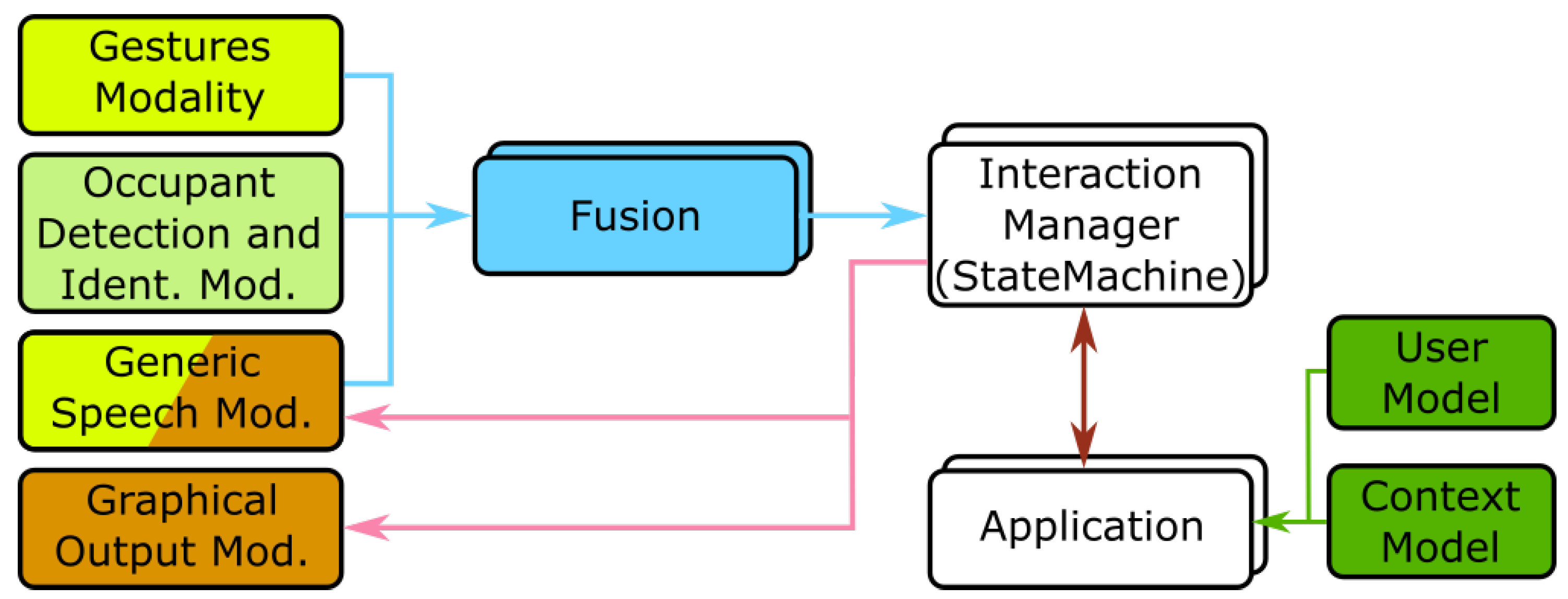
4.1. Modalities
4.1.1. Generic Speech Modality
Speech Input
Speech Output
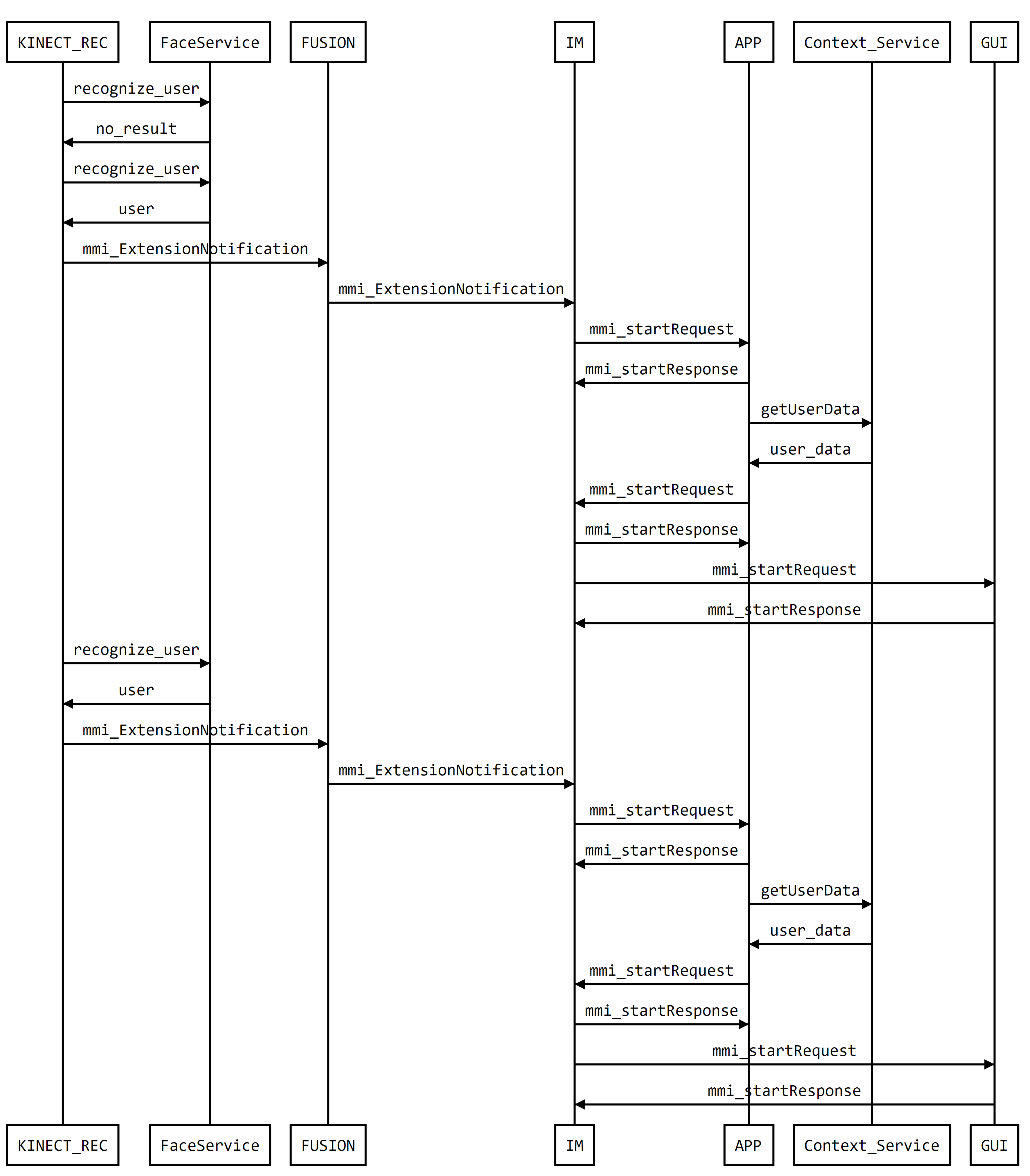
4.1.2. Modality for Occupants Detection and Identification
4.1.3. Graphical Output Modality
4.1.4. Gestures Modality
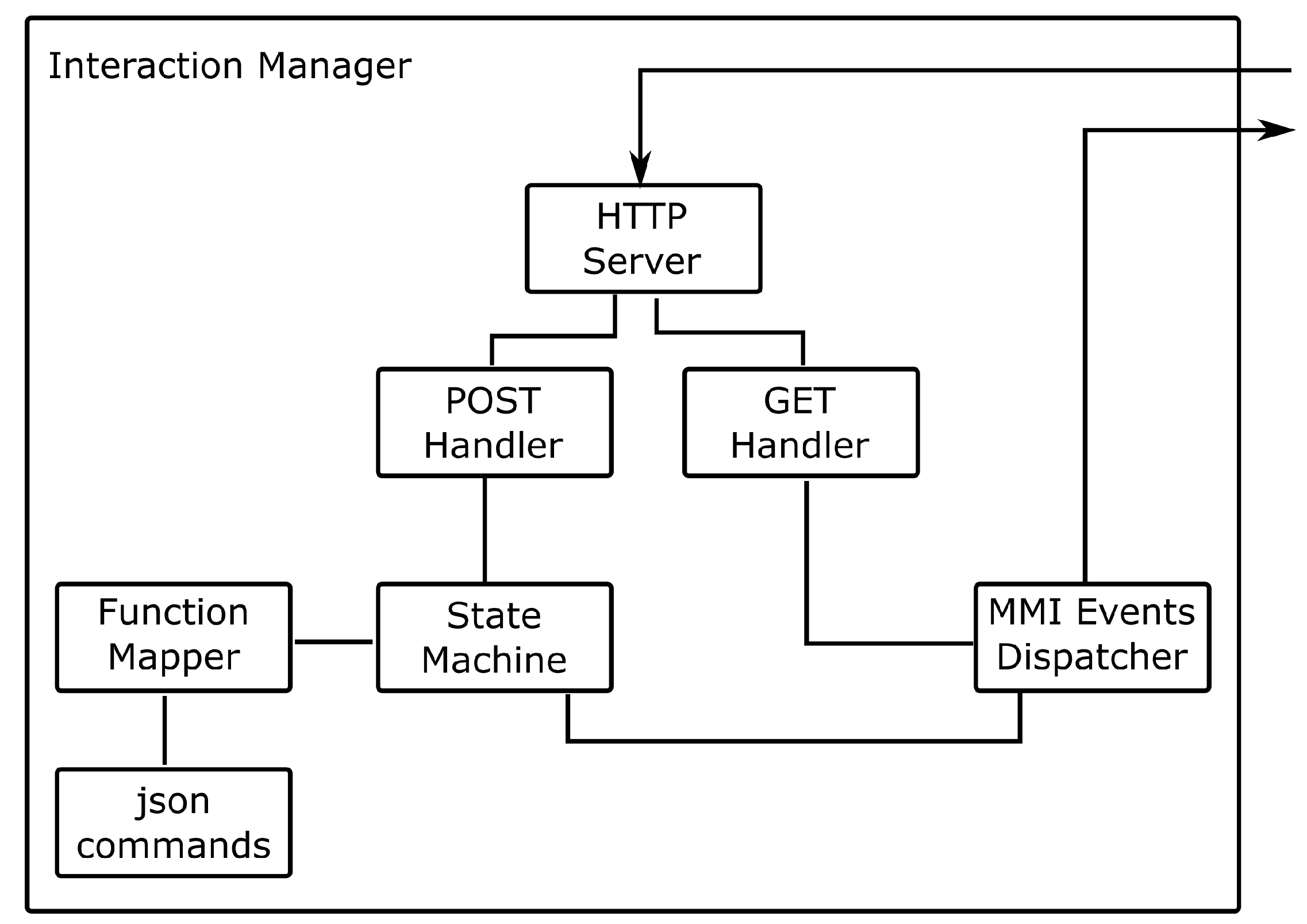
4.2. Interaction Managers
4.3. Fusion
4.4. User and Context Services
5. Deploying AM4I in Smart Environments: First Results
5.1. Non-Residential Smart Building
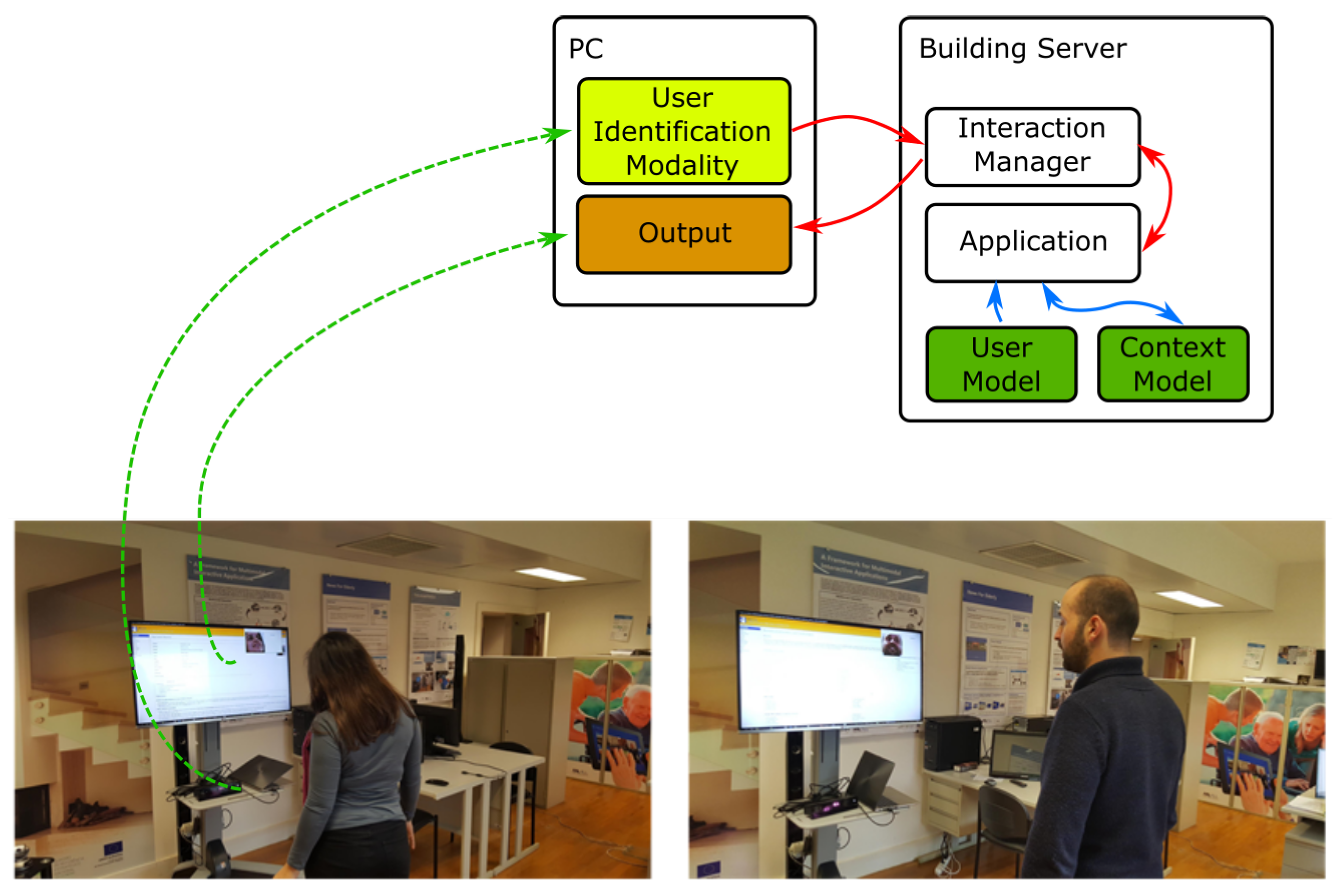
5.1.1. Proof-of-Concept 1—User-Adapted Content
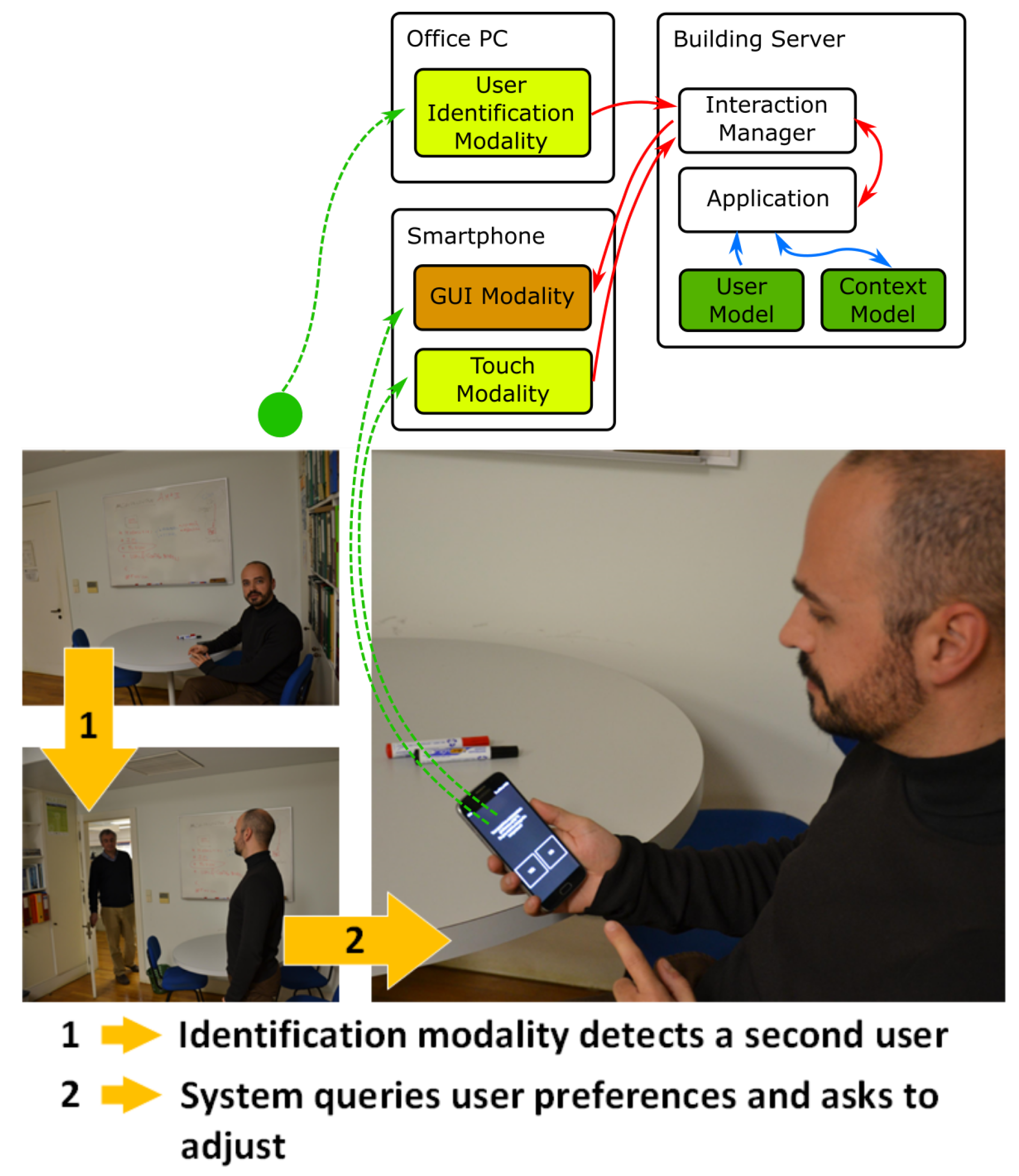
5.1.2. Proof-of-Concept 2—Meeting
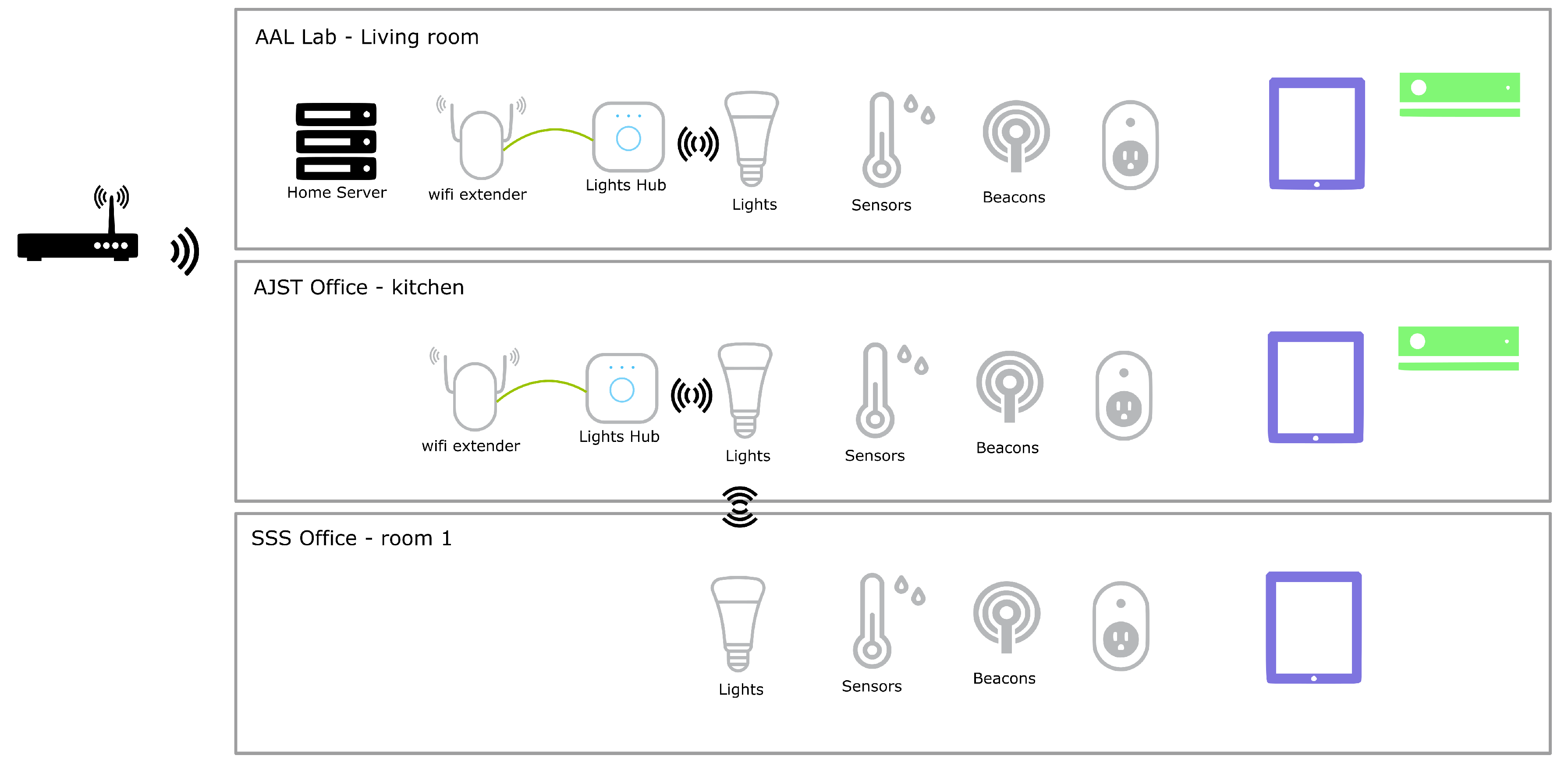
5.2. Smart Home Context
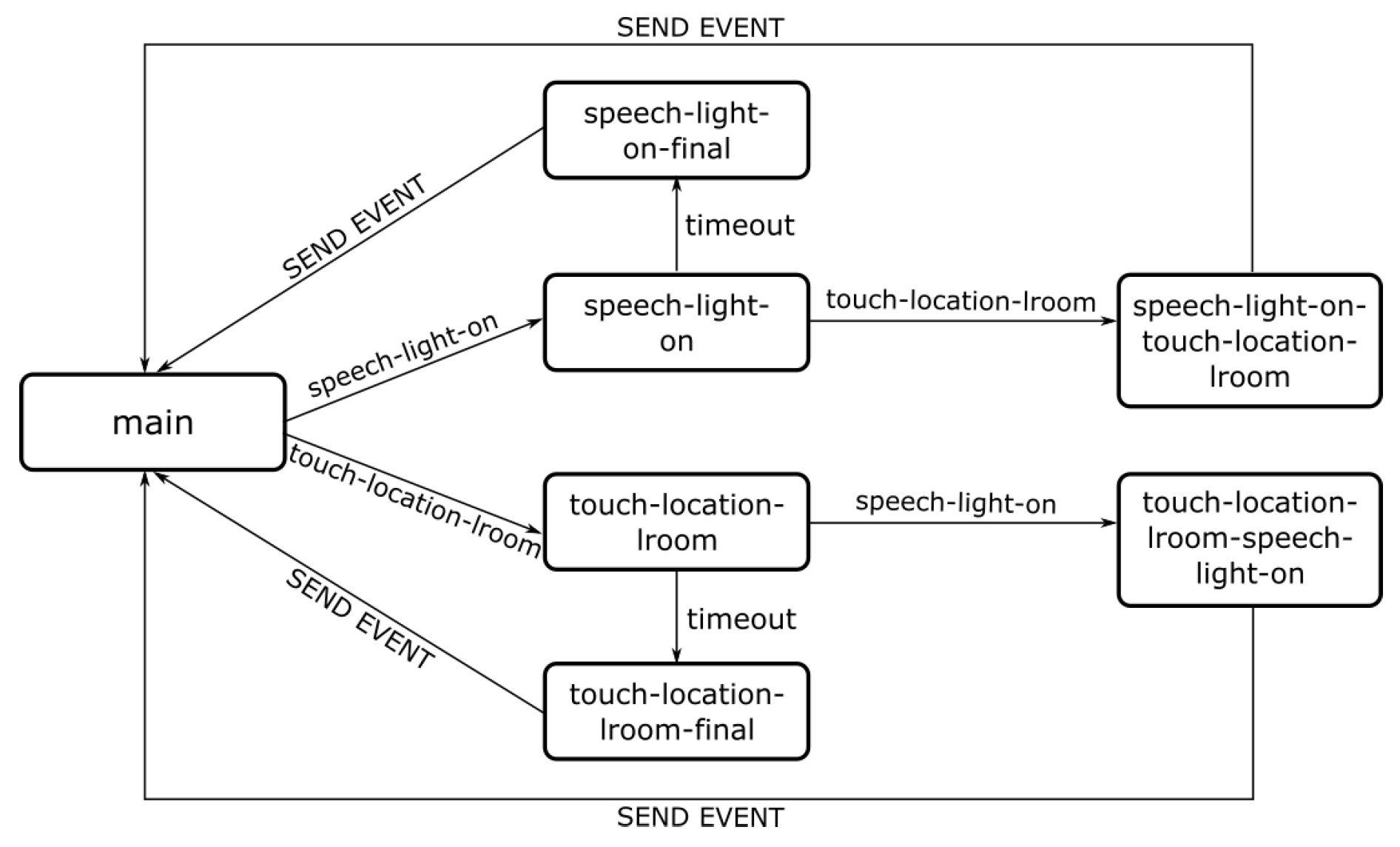
5.2.1. Proof-of-Concept #1: Controlling the Lights in Any Division
5.2.2. Proof-of-Concept #2: Accessing House Information
6. Conclusions
Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AAL | Ambient Assisted Living |
| AM4I | Adaptive Multiplatform Multidevice Multilingual Multimodal Interaction |
| API | Application Programming Interfaces |
| ASR | Automatic Speech Recognition |
| BLE | Bluetooth Low Energy |
| CARE | Complementarity, Assignment, Redundancy and Equivalence |
| EMMA | Extensible MultiModal Annotation markup language |
| HBI | Human Building Interaction |
| HCI | Human Computer Interaction |
| HTML5 | HyperText Markup Language5 |
| HTTP | Hypertext Transfer Protocol |
| IDE | Integrated Development Environment |
| IM | Interaction Manager |
| JSON | JavaScript Object Notation |
| MMI | MultiModal Interaction |
| SCXML | State Chart XML |
| SGH | Smart Green Homes |
| SLU | Spoken Language Understanding |
| SOCA | Smart Open Campus |
| SSML | Speech Synthesis Markup Language |
| W3C | World Wide Web Consortium |
References
- DiSalvo, C.; Jenkins, T. Fruit Are Heavy: A Prototype Public IoT System to Support Urban Foraging. In Proceedings of the 2017 Conference on Designing Interactive Systems, Edinburgh, UK, 10–14 June 2017; pp. 541–553. [Google Scholar] [CrossRef]
- Crabtree, A.; Tolmie, P. A Day in the Life of Things in the Home. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, San Francisco, CA, USA, 27 February–2 March 2016; pp. 1738–1750. [Google Scholar]
- Hargreaves, T.; Wilson, C. Smart Homes and Their Users; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Turk, M. Multimodal interaction: A review. Pattern Recognit. Lett. 2014, 36, 189–195. [Google Scholar] [CrossRef]
- Dumas, B.; Lalanne, D.; Ingold, R. HephaisTK: A toolkit for rapid prototyping of multimodal interfaces. In Proceedings of the International Conference on Multimodal Interfaces—ICMI-MLMI ’09, Cambridge, MA, USA, 2–4 November 2009; pp. 231–232. [Google Scholar] [CrossRef]
- Teixeira, A.; Pereira, C.; Oliveira e Silva, M.; Pacheco, O.; Neves, A.; Casimiro, J. AdaptO—Adaptive Multimodal Output. In Proceedings of the 1st International Conference on Pervasive and Embedded Computing and Communication Systems, Vilamoura, Algarve, Portugal, 5–7 March 2011; pp. 91–100. [Google Scholar]
- Bouchet, J.; Nigay, L. ICARE: A component-based approach for the design and development of multimodal interfaces. In Proceedings of the Extended Abstracts of the 2004 Conference on Human Factors and Computing Systems—CHI ’04, Vienna, Austria, 24–29 April 2004; p. 1325. [Google Scholar] [CrossRef]
- Serrano, M.; Nigay, L.; Lawson, J.Y.L.; Ramsay, A.; Murray-Smith, R.; Denef, S. The openinterface framework: A tool for multimodal interaction. In Proceedings of the Twenty-Sixth Annual CHI Conference Extended Abstracts on Human Factors in Computing Systems—CHI ’08, Florence, Italy, 5–10 April 2008; p. 3501. [Google Scholar] [CrossRef]
- Hoste, L.; Dumas, B.; Signer, B. Mudra: A unified multimodal interaction framework. In Proceedings of the 13th International Conference on Multimodal Interfaces—ICMI ’11, Alicante, Spain, 14–18 November 2011; p. 97. [Google Scholar] [CrossRef]
- Sonntag, D.; Engel, R.; Herzog, G.; Pfalzgraf, A.; Pfleger, N.; Romanelli, M.; Reithinger, N. SmartWeb Handheld—Multimodal Interaction with Ontological Knowledge Bases and Semantic Web Services. In Artifical Intelligence for Human Computing; Springer: Berlin/Heidelberg, Germany, 2007; pp. 272–295. [Google Scholar] [CrossRef]
- Niklfeld, G.; Finan, R.; Pucher, M. Architecture for adaptive multimodal dialog systems based on voiceXML. In Proceedings of the 7th European Conference on Speech Communication and Technology, 2nd INTERSPEECH Event, Aalborg, Denmark, 3–7 November 2001; pp. 2341–2344. [Google Scholar]
- Lawson, J.Y.L.; Al-Akkad, A.A.; Vanderdonckt, J.; Macq, B. An open source workbench for prototyping multimodal interactions based on off-the-shelf heterogeneous components. In Proceedings of the 1st ACM SIGCHI Symposium on Engineering Interactive Computing Systems—EICS ’09, Pittsburgh, PA, USA, 15–17 July 2009; pp. 245–254. [Google Scholar] [CrossRef]
- Bodell, M.; Dahl, D.A.; Kliche, I.; Larson, J.; Porter, B. Multimodal Architecture and Interfaces, W3C. 2012. Available online: https://www.w3.org/TR/mmi-arch/ (accessed on 4 March 2019).
- Dahl, D.A. The W3C multimodal architecture and interfaces standard. J. Multimodal User Interfaces 2013, 7, 171–182. [Google Scholar] [CrossRef]
- Teixeira, A.; Almeida, N.; Pereira, C.; Oliveira e Silva, M.; Vieira, D.; Silva, S. Applications of the Multimodal Interaction Architecture in Ambient Assisted Living. In Multimodal Interaction with W3C Standards: Towards Natural User Interfaces to Everything; Dahl, D.A., Ed.; Springer: New York, NY, USA, 2017; pp. 271–291. [Google Scholar]
- Teixeira, A.; Almeida, N.; Pereira, C.; Oliveira e Silva, M. W3C MMI Architecture as a Basis for Enhanced Interaction for Ambient Assisted Living. In Proceedings of the Get Smart: Smart Homes, Cars, Devices and the Web, W3C Workshop on Rich Multimodal Application Development, New York, NY, USA, 22–23 July 2013. [Google Scholar]
- Almeida, N. Multimodal Interaction—Contributions to Simplify Application Development. Ph.D. Thesis, Universidade de Aveiro, Aveiro, Portugal, 2017. [Google Scholar]
- Dumas, B.; Ingold, R.; Lalanne, D. Benchmarking fusion engines of multimodal interactive systems. In Proceedings of the 2009 International Conference on Multimodal Interfaces—ICMI-MLMI ’09, Cambridge, MA, USA, 2–4 November 2009; pp. 169–176. [Google Scholar] [CrossRef]
- Almeida, N.; Silva, S.; Santos, B.S.; Teixeira, A. Interactive, Multi-Device Visualization Supported by a Multimodal Interaction Framework: Proof of Concept. In Human Aspects of IT for the Aged Population, Design for Aging; Zhou, J., Salvendy, G., Eds.; Springer: Cham, Switzerland, 2016; pp. 279–289. [Google Scholar]
- Schnelle-Walka, D.; Duarte, C.; Radomski, S. Multimodal Fusion and Fission within the W3C MMI Architectural Pattern. In Multimodal Interaction with W3C Standards: Toward Natural User Interfaces to Everything; Dahl, D.A., Ed.; Springer: Cham, Switzerland, 2017; pp. 393–415. [Google Scholar] [CrossRef]
- Rousseau, C.; Bellik, Y.; Vernier, F. Multimodal Output Specification/Simulation Platform. In Proceedings of the 7th International Conference on Multimodal Interfaces, Torento, Italy, 4–6 October 2005; pp. 84–91. [Google Scholar] [CrossRef]
- Rousseau, C.; Bellik, Y.; Vernier, F.; Bazalgette, D. Architecture Framework For Output Multimodal Systems Design. In Proceedings of the Supporting Community Interaction: Possibilities and Challenges, OZCHI 2004, Wollongong, Australia, 22–24 November 2004. [Google Scholar]
- Rousseau, C.; Bellik, Y.; Vernier, F. WWHT: Un Modèle Conceptuel Pour La Prèsentation Multimodale D’Information. In Proceedings of the 17th Conference on L’Interaction Homme-Machine, Toulouse, France, 27–30 September 2005; pp. 59–66. [Google Scholar] [CrossRef]
- Coetzee, L.; Viviers, I.; Barnard, E. Model based estimation for multi-modal user interface component selection. In Proceedings of the 20th Annual Symposium of the Pattern Recognition Association of South Africa (PRASA 2009), Stellenbosch, South Africa, 30 November–1 December 2009. [Google Scholar]
- Houben, S.; Marquardt, N.; Vermeulen, J.; Klokmose, C.; Schöning, J.; Reiterer, H.; Holz, C. Opportunities and Challenges for Cross-device Interactions in the Wild. Interactions 2017, 24, 58–63. [Google Scholar] [CrossRef]
- Dong, T.; Churchill, E.F.; Nichols, J. Understanding the Challenges of Designing and Developing Multi-Device Experiences. In Proceedings of the 2016 ACM Conference on Designing Interactive Systems, Brisbane, Australia, 4–6 June 2016; pp. 62–72. [Google Scholar] [CrossRef]
- Neate, T.; Jones, M.; Evans, M. Cross-device media: A review of second screening and multi-device television. Pers. Ubiquitous Comput. 2017, 21, 391–405. [Google Scholar] [CrossRef]
- Shen, C.; Esenther, A.; Forlines, C.; Ryall, K. Three modes of multisurface interaction and visualization. In Proceedings of the Information Visualization and Interaction Techniques for Collaboration across Multiple Displays Workshop associated with CHI, Montreal, QC, Canada, 22–23 April 2006; Volume 6. [Google Scholar]
- Woźniak, P.; Lischke, L.; Schmidt, B.; Zhao, S.; Fjeld, M. Thaddeus: A Dual Device Interaction Space for Exploring Information Visualisation. In Proceedings of the 8th Nordic Conference on Human-Computer Interaction Fun, Fast, Foundational—NordiCHI ’14, Helsinki, Finland, 26–30 October 2014; pp. 41–50. [Google Scholar] [CrossRef]
- Kernchen, R.; Meissner, S.; Moessner, K.; Cesar, P.; Vaishnavi, I.; Boussard, M.; Hesselman, C. Intelligent Multimedia Presentation in Ubiquitous Multidevice Scenarios. IEEE Multimed. 2010, 17, 52–63. [Google Scholar] [CrossRef]
- Houben, S.; Marquardt, N. WATCHCONNECT: A Toolkit for Prototyping Smartwatch-Centric Cross-Device Applications. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 1247–1256. [Google Scholar]
- Weibel, N.; Satyanarayan, A.; Lazar, A.; Oda, R.; Yamaoka, S.; Doerr, K.U.; Kuester, F.; Griswold, W.G.; Hollan, J.D. Hiperface: A multichannel architecture to explore multimodal interactions with ultra-scale wall displays. In Proceedings of the 33rd International Conference on Software Engineering, ICSE’11, Honolulu, HI, USA, 21–28 May 2011. [Google Scholar]
- Badam, S.K.; Elmqvist, N. PolyChrome: A Cross-Device Framework for Collaborative Web Visualization. In Proceedings of the Ninth ACM International Conference on Interactive Tabletops and Surfaces—ITS ’14, Dresden, Germany, 16–19 November 2014; pp. 109–118. [Google Scholar] [CrossRef]
- Heikkinen, T.; Goncalves, J.; Kostakos, V.; Elhart, I.; Ojala, T. Tandem Browsing Toolkit: Distributed Multi-Display Interfaces with Web Technologies. In Proceedings of the International Symposium on Pervasive Displays, Copenhagen, Denmark, 3–4 June 2014. [Google Scholar]
- Hamilton, P.; Wigdor, D.J. Conductor: Enabling and understanding cross-device interaction. In Proceedings of the 32nd Annual ACM Conference on Human Factors in Computing Systems—CHI ’14, Toronto, ON, Canada, 26 April–1 May 2014; pp. 2773–2782. [Google Scholar] [CrossRef]
- Chung, H.; North, C.; Self, J.Z.; Chu, S.; Quek, F. VisPorter: Facilitating information sharing for collaborative sensemaking on multiple displays. Pers. Ubiquitous Comput. 2014, 18, 1169–1186. [Google Scholar] [CrossRef]
- Blumendorf, M.; Roscher, D.; Albayrak, S. Dynamic user interface distribution for flexible multimodal interaction. In Proceedings of the International Conference on Multimodal Interfaces and the Workshop on Machine Learning for Multimodal Interaction on—ICMI-MLMI ’10, Beijing, China, 8–10 November 2010; p. 1. [Google Scholar] [CrossRef]
- Chen, Y.; Liang, X.; Hong, T.; Luo, X. Simulation and visualization of energy-related occupant behavior in office buildings. Build. Simul. 2017, 10, 785–798. [Google Scholar] [CrossRef]
- Ghiani, G.; Manca, M.; Paternò, F. Authoring context-dependent cross-device user interfaces based on trigger/action rules. In Proceedings of the 14th International Conference on Mobile and Ubiquitous Multimedia, Linz, Austria, 30 November–2 December 2015; pp. 313–322. [Google Scholar]
- Di Mauro, D.; Augusto, J.C.; Origlia, A.; Cutugno, F. A framework for distributed interaction in intelligent environments. In Proceedings of the European Conference on Ambient Intelligence, Malaga, Spain, 26–28 April 2017; Springer: Berlin, Germany, 2017; pp. 136–151. [Google Scholar]
- Nebeling, M.; Kubitza, T.; Paternò, F.; Dong, T.; Li, Y.; Nichols, J. End-user development of cross-device user interfaces. In Proceedings of the 8th ACM SIGCHI Symposium on Engineering Interactive Computing Systems, Brussels, Belgium, 21–24 July 2016; pp. 299–300. [Google Scholar]
- Almeida, N.; Silva, S.; Teixeira, A.; Vieira, D. Multi-Device Applications Using the Multimodal Architecture. In Multimodal Interaction with W3C Standards: Toward Natural User Interfaces to Everything; Dahl, D.A., Ed.; Springer: Cham, Switzerland, 2017; pp. 367–383. [Google Scholar] [CrossRef]
- Seyed, A. Examining User Experience in Multi-Display Environments. Ph.D. Thesis, University of Calgary, Calgary, AB, Canada, 2013. [Google Scholar]
- Paternò, F. Design and Adaptation for Cross-Device, Context-Dependent User Interfaces. In Proceedings of the 33rd Annual ACM Conference Extended Abstracts on Human Factors in Computing Systems—CHI EA ’15, Seoul, Korea, 18–23 April 2015; pp. 2451–2452. [Google Scholar] [CrossRef]
- Rowland, C.; Goodman, E.; Charlier, M.; Light, A.; Lui, A. Designing Connected Products: UX for the Consumer Internet of Things; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Risteska Stojkoska, B.L.; Trivodaliev, K.V. A review of Internet of Things for smart home: Challenges and solutions. J. Clean. Prod. 2017, 140, 1454–1464. [Google Scholar] [CrossRef]
- Shahzad, K.; Oelmann, B. A comparative study of in-sensor processing vs. raw data transmission using ZigBee, BLE and Wi-Fi for data intensive monitoring applications. In Proceedings of the 2014 11th International Symposium on Wireless Communications Systems (ISWCS), Barcelona, Spain, 26–29 August 2014; pp. 519–524. [Google Scholar] [CrossRef]
- Williams, J.D.; Kamal, E.; Ashour, M.; Amr, H.; Miller, J.; Zweig, G. Fast and easy language understanding for dialog systems with Microsoft Language Understanding Intelligent Service (LUIS). In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 159–161. [Google Scholar]
- Dahl, D.A. Standard Portals for Intelligent Services. In Multimodal Interaction with W3C Standards; Springer: Cham, Switzerland, 2017; pp. 257–269. [Google Scholar] [CrossRef]
- Young, S. CUED Standard Dialogue Acts; Technical Report; Cambridge University Engineering Depqrtment: Cambridge, UK, 2009. [Google Scholar]
- Bunt, H.; Alexandersson, J.; Carletta, J.; Choe, J.W.; Fang, A.C.; Hasida, K.; Lee, K.; Petukhova, V.; Popescu-Belis, A.; Romary, L.; et al. Towards an ISO Standard for Dialogue Act Annotation. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), European Language Resources Association (ELRA), Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Bui, T. Multimodal Dialogue Management-State of the Art. (CTIT Technical Report Series; No. 06-01); Centre for Telematics and Information Technology (CTIT), University of Twente: Enschede, The Netherlands, 2006. [Google Scholar]
- Dahl, D.A. (Ed.) Multimodal Interaction with W3C Standards; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Baggia, P.; Burnett, D.C.; Carter, J.; Dahl, D.A.; McCobb, G.; Raggett, D. EMMA: Extensible MultiModal Annotation Markup Language. 2009. Available online: https://www.w3.org/TR/emma/ (accessed on 4 March 2019).
- Almeida, N.; Silva, S.; Teixeira, A. Multimodal Multi-Device Application Supported by an SCXML State Chart Machine. In Proceedings of the Workshop on Engineering Interactive Systems with SCXML, The Sixth ACM SIGCHI Symposium on Computing Systems, Rome, Italy, 17–20 June 2014. [Google Scholar]
- Coutaz, J.; Nigay, L.; Salber, D.; Blandford, A.; May, J.; Young, R.M. Four Easy Pieces for Assessing the Usability of Multimodal Interaction: The Care Properties. In Human–Computer Interaction; Nordby, K., Helmersen, P., Gilmore, D.J., Arnesen, S.A., Eds.; Springer: Boston, MA, USA, 1995; Chapter Four Easy; pp. 115–120. [Google Scholar] [CrossRef]
- Almeida, N.; Silva, S.; Teixeira, A. Design and Development of Speech Interaction: A Methodology. Proceedings of Human-Computer Interaction International Conference, HCI International 2014, Crete, Greece, 22–27 June 2014. [Google Scholar]
- Teixeira, A.; Braga, D.; Coelho, L.; Fonseca, J.; Alvarelhão, J.; Martín, I.; Alexandra, Q.; Rocha, N.; Calado, A.; Dias, M. Speech as the Basic Interface for Assistive Technology. In Proceedings of the DSAI—Software Development for Enhancing Accessibility and Fighting Info-exclusion, Lisbon, Portugal, 3–5 June 2009. [Google Scholar]
- Teixeira, A.; Francisco, P.; Almeida, N.; Pereira, C.; Silva, S. Services to Support Use and Development of Speech Input for Multilingual Multimodal Applications for Mobile Scenarios. In Proceedings of the Ninth International Conference on Internet and Web Applications and Services (ICIW 2014), Track WSSA—Web Services-based Systems and Applications, Paris, France, 20–24 July 2014. [Google Scholar]
- Teixeira, A.; Francisco, P.; Almeida, N.; Pereira, C.; Silva, S. Services to Support Use and Development of Multilingual Speech Input. Int. J. Adv. Internet Technol. 2015, 8, 1–12. [Google Scholar]
- Ward, W. Understanding spontaneous speech: The Phoenix system. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, ICASSP 91, Toronto, ON, Canada, 14–17 May 1991; Volume 1, pp. 365–367. [Google Scholar] [CrossRef]
- Almeida, N.; Teixeira, A.; Rosa, A.F.; Braga, D.; Freitas, J.; Dias, M.S.; Silva, S.; Avelar, J.; Chesi, C.; Saldanha, N. Giving Voices to Multimodal Applications. In Human Aspects of IT for the Aged Population. Design for Aging; Kurosu, M., Ed.; Springer: Berlin, Germany, 2015; pp. 273–283. [Google Scholar]
- Sole, A.D. Microsoft Computer Vision APIs Distilled: Getting Started with Cognitive Services; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Barnett, J. Introduction to SCXML. In Multimodal Interaction with W3C Standards; Springer: Cham, Switzerland, 2017; pp. 81–107. [Google Scholar]
- Commons, A. SCXML-Commons SCXML. 2005. Available online: http://commons.apache.org/scxml/ (accessed on 7 January 2018).
- Almeida, N.; Teixeira, A.; Silva, S.; Freitas, J. Fusion of Speech with other modalities in a W3C based Multimodal Interaction Framework. In Proceedings of the IberSpeech, Lisbon, Portugal, 23–25 November 2016; pp. 291–300. [Google Scholar]
- Vieira, D. Enhanced Multimodal Interaction Framework and Applications. Master’s Thesis, Universidade de Aveiro, Aveiro, Portugal, 2015. [Google Scholar]
- Hämäläinen, A.; Teixeira, A.; Almeida, N.; Meinedo, H.; Fegyó, T.; Dias, M.S. Multilingual speech recognition for the elderly: The AALFred personal life assistant. Procedia Comput. Sci. 2015, 67, 283–292. [Google Scholar] [CrossRef][Green Version]
- Saldanha, N.; Avelar, J.; Dias, M.; Teixeira, A.; Gonçalves, D.; Bonnet, E.; Lan, K.; Géza, N.; Csobanka, P.; Kolesinski, A. A Personal Life Assistant for “natural” interaction: The PaeLife project. In Proceedings of the AAL Forum 2013 Forum, Norrköping, Sweden, 24–26 September 2013. [Google Scholar]
- Bartashevich, D.; Oliveira, L.; Teixeira, A.; Silva, S. Hands Free Presentations: Multimodal Interaction with PowerPoint. In Proceedings of the INForum 2018, Coimbra, Portugal, 3–4 September 2018. [Google Scholar]
- Rogers, Y.; Sharp, H.; Preece, J. Interaction Design: Beyond Human-Computer Interaction; John Wiley & Sons: West Sussex, UK, 2011. [Google Scholar]
- Nabil, S.; Kirk, D.; Ploetz, T.; Wright, P. Designing Future Ubiquitous Homes with OUI Interiors: Possibilities and Challenges. Interact. Des. Archit. 2017, 32, 28–37. [Google Scholar]
- Cooper, A.; Reimann, R.; Cronin, D. About Face 3.0: The Essentials of Interaction Design; John Wiley & Sons Inc.: Indianapolis, IN, USA, 2007. [Google Scholar]
- Day, J.K.; O’Brien, W. Oh behave! Survey stories and lessons learned from building occupants in high-performance buildings. Energy Res. Soc. Sci. 2017, 31, 11–20. [Google Scholar] [CrossRef]
- Moezzi, M.; Janda, K.B.; Rotmann, S. Using stories, narratives, and storytelling in energy and climate change research. Energy Res. Soc. Sci. 2017, 31, 1–10. [Google Scholar] [CrossRef]
- Leal, A.; Teixeira, A.; Silva, S. On the creation of a Persona to support the development of technologies for children with Autism Spectrum Disorder. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Toronto, ON, Canada, 17–22 July 2016; pp. 213–223. [Google Scholar]
- Silva, S.; Teixeira, A. Design and Development for Individuals with ASD: Fostering Multidisciplinary Approaches through Personas. J. Autism Dev. Disorders 2019, 49, 2156–2172. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, A.; Vitor, N.; Freitas, J.; Silva, S. Silent Speech Interaction for Ambient Assisted Living Scenarios. In Human Aspects of IT for the Aged Population. Aging, Design and User Experience; Zhou, J., Salvendy, G., Eds.; Springer: Cham, Switzerland, 2017; pp. 369–387. [Google Scholar]
- Freitas, J.; Teixeira, A.; Dias, M.S.; Silva, S. An Introduction to Silent Speech Interfaces; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Silva, S.; Teixeira, A. An Anthropomorphic Perspective for Audiovisual Speech Synthesis. In Proceedings of the 10th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2017), Porto, Portugal, 21–23 February 2017; pp. 163–172. [Google Scholar] [CrossRef]
- Henriques, T.; Silva, S.; Brás, S.; Soares, S.C.; Almeida, N.; Teixeira, A. Emotionally-Aware Multimodal Interfaces: Preliminary Work on a Generic Affective Modality. In Proceedings of the 8th International Conference on Software Development and Technologies for Enhancing Accessibility and Fighting Info-Exclusion, DSAI 2018, Thessaloniki, Greece, 20–22 June 2018. [Google Scholar]
- Rodríguez, B.H.; Moissinac, J.C. Discovery and Registration: Finding and Integrating Components into Dynamic Systems. In Multimodal Interaction with W3C Standards: Toward Natural User Interfaces to Everything; Dahl, D.A., Ed.; Springer: Cham, Switzerland, 2017; pp. 325–349. [Google Scholar] [CrossRef]
- Goodhew, J.; Pahl, S.; Goodhew, S.; Boomsma, C. Mental models: Exploring how people think about heat flows in the home. Energy Res. Soc. Sci. 2017, 31, 145–157. [Google Scholar] [CrossRef]
- D’Oca, S.; Chen, C.F.; Hong, T.; Belafi, Z. Synthesizing building physics with social psychology: An interdisciplinary framework for context and occupant behavior in office buildings. Energy Res. Soc. Sci. 2017, 34, 240–251. [Google Scholar] [CrossRef]
- Kharrufa, A.; Ploetz, T.; Olivier, P. A Unified Model for User Identification on Multi-Touch Surfaces: A Survey and Meta-Analysis. ACM Trans. Comput. Hum. Interact. 2018, 24, 39:1–39:2. [Google Scholar] [CrossRef]
- Pereira, C. Dynamic Evaluation for Reactive Scenarios. Ph.D. Thesis, Universidade de Aveiro, Aveiro, Portugal, 2016. [Google Scholar]
- Pereira, C.; Almeida, N.; Martins, A.I.; Silva, S.; Rosa, A.F.; Silva, M.O.E.; Teixeira, A. Evaluation of Complex Distributed Multimodal Applications Evaluating a TeleRehabilitation System When It Really Matters. In Proceedings of the Human Aspects of IT for the Aged Population, Design for Everyday Life, Los Angeles, CA, USA, 2–7 August 2015. [Google Scholar]















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almeida, N.; Teixeira, A.; Silva, S.; Ketsmur, M. The AM4I Architecture and Framework for Multimodal Interaction and Its Application to Smart Environments. Sensors 2019, 19, 2587. https://doi.org/10.3390/s19112587
Almeida N, Teixeira A, Silva S, Ketsmur M. The AM4I Architecture and Framework for Multimodal Interaction and Its Application to Smart Environments. Sensors. 2019; 19(11):2587. https://doi.org/10.3390/s19112587
Chicago/Turabian StyleAlmeida, Nuno, António Teixeira, Samuel Silva, and Maksym Ketsmur. 2019. "The AM4I Architecture and Framework for Multimodal Interaction and Its Application to Smart Environments" Sensors 19, no. 11: 2587. https://doi.org/10.3390/s19112587
APA StyleAlmeida, N., Teixeira, A., Silva, S., & Ketsmur, M. (2019). The AM4I Architecture and Framework for Multimodal Interaction and Its Application to Smart Environments. Sensors, 19(11), 2587. https://doi.org/10.3390/s19112587