A Robust Diffusion Minimum Kernel Risk-Sensitive Loss Algorithm over Multitask Sensor Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Multitask Diffusion Estimation
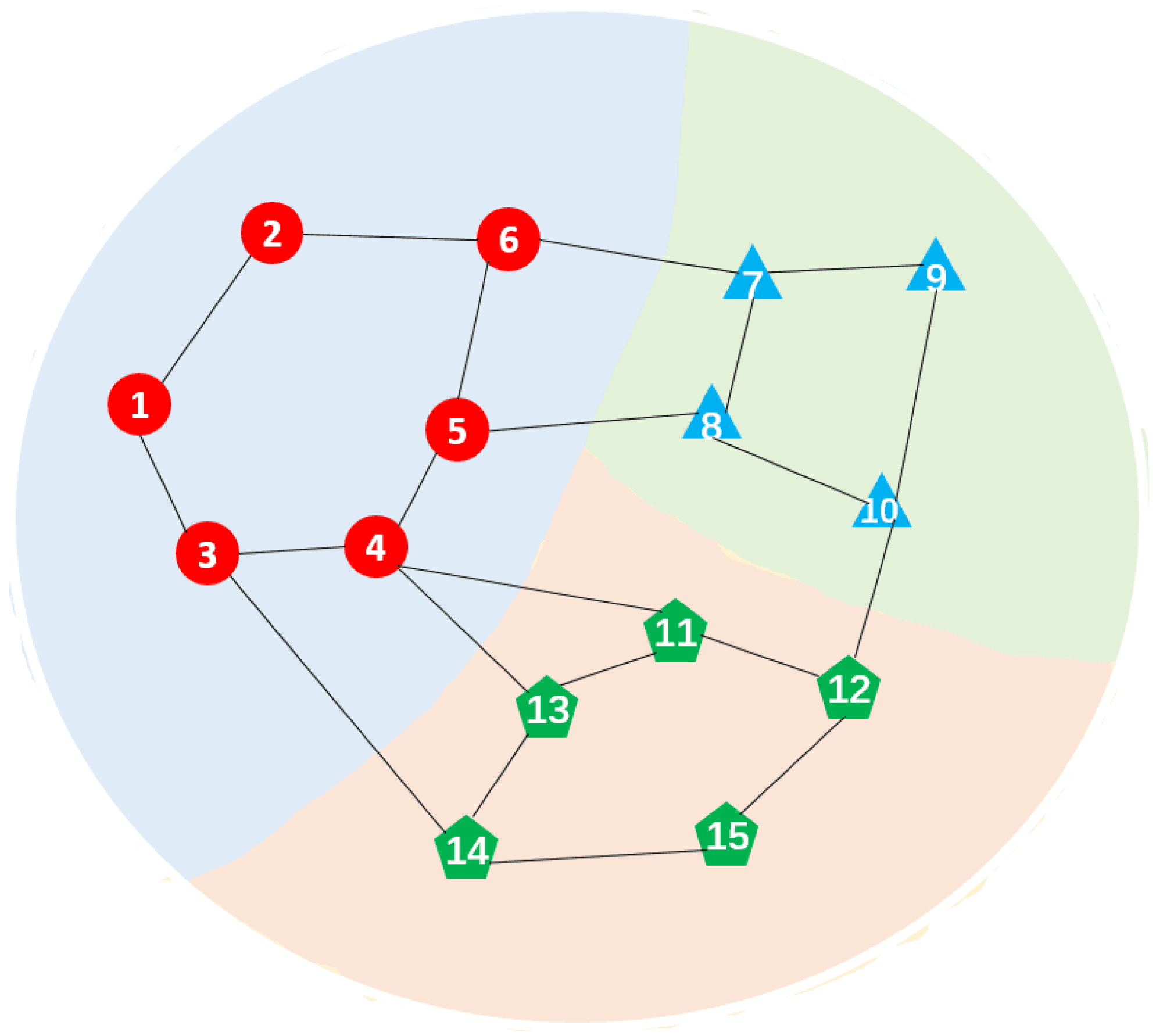
2.1. Data Model
2.2. Diffusion MKRSL Algorithm
| Algorithm 1: Multitask Diffusion MKRSL Algorithm |
| Input: , , , , and satisfying (10) Initialization: Start with for all l. for for each node k: Adaptation Communication Transmit the intermediate to all neighbors in Combination end for |
3. Performance Analysis
3.1. Mean Performance
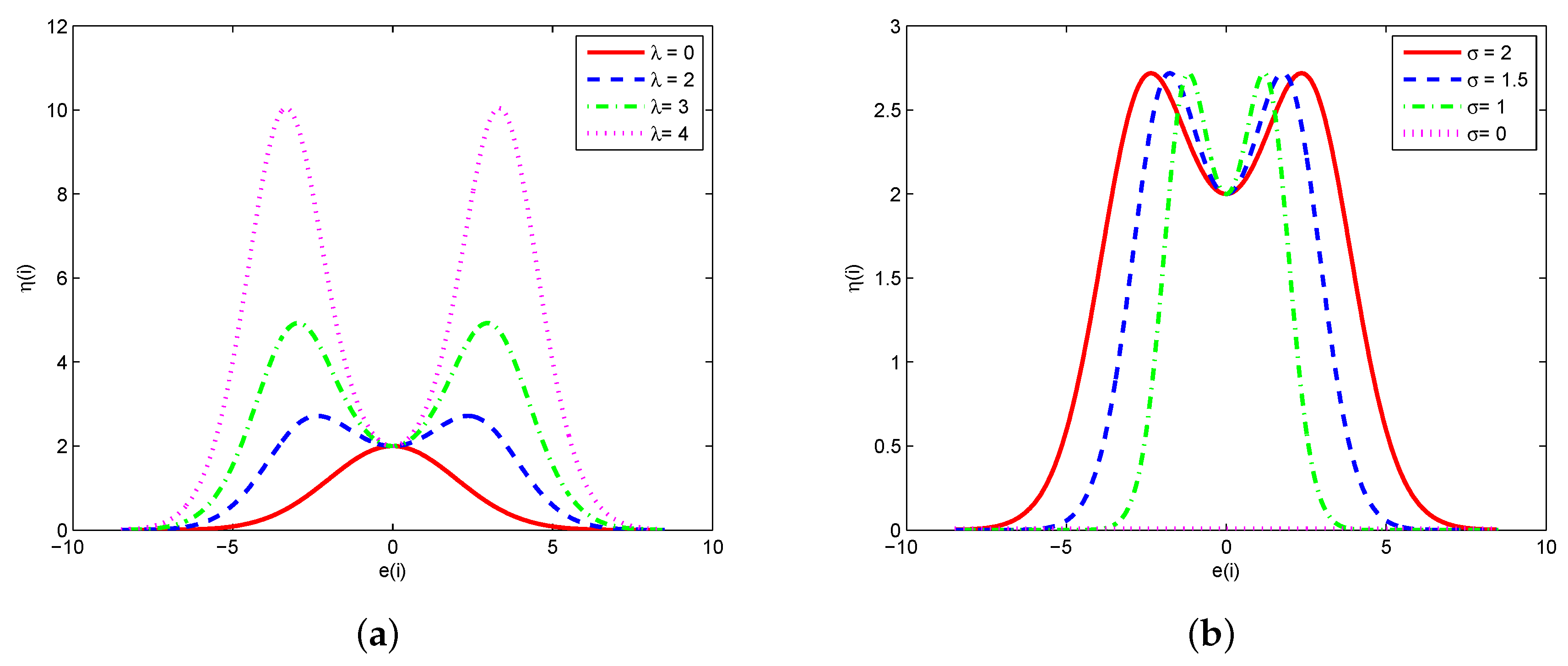
3.2. Mean-Square Performance
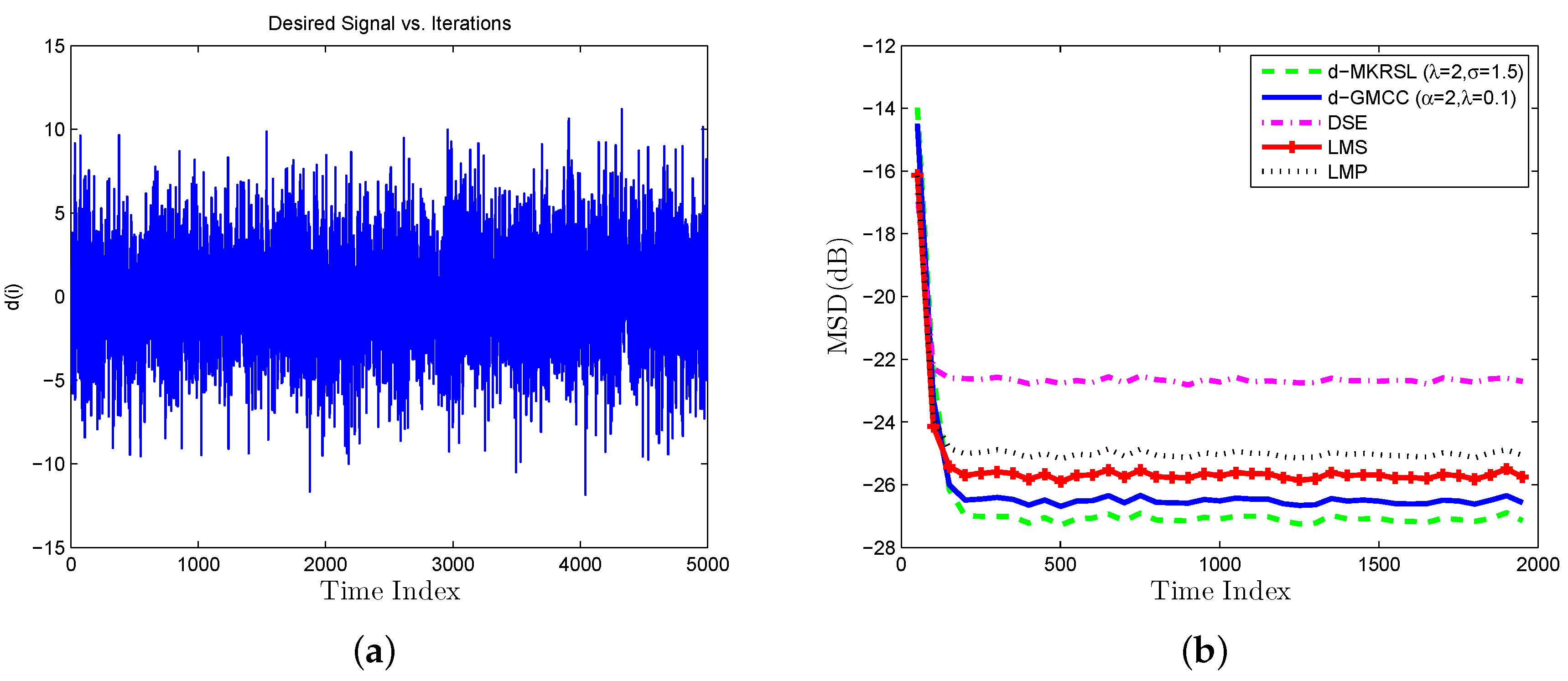
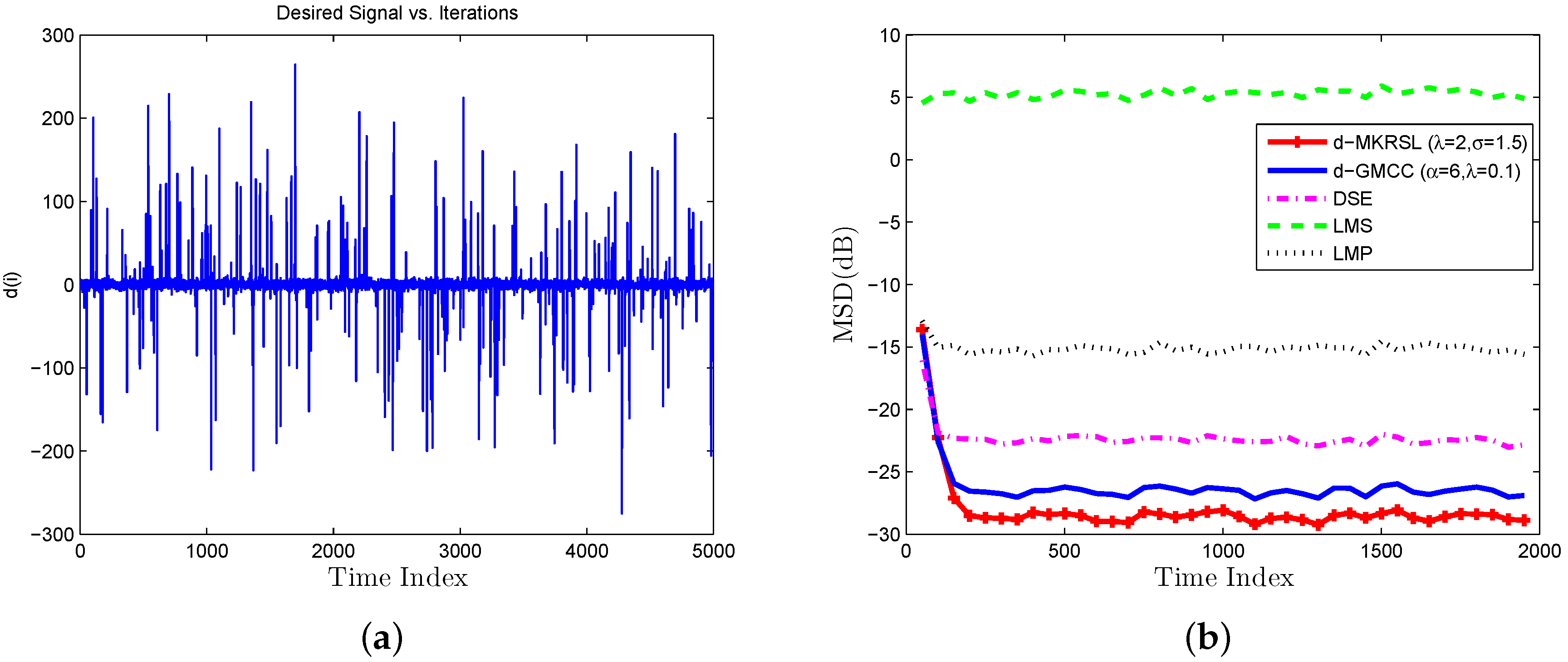
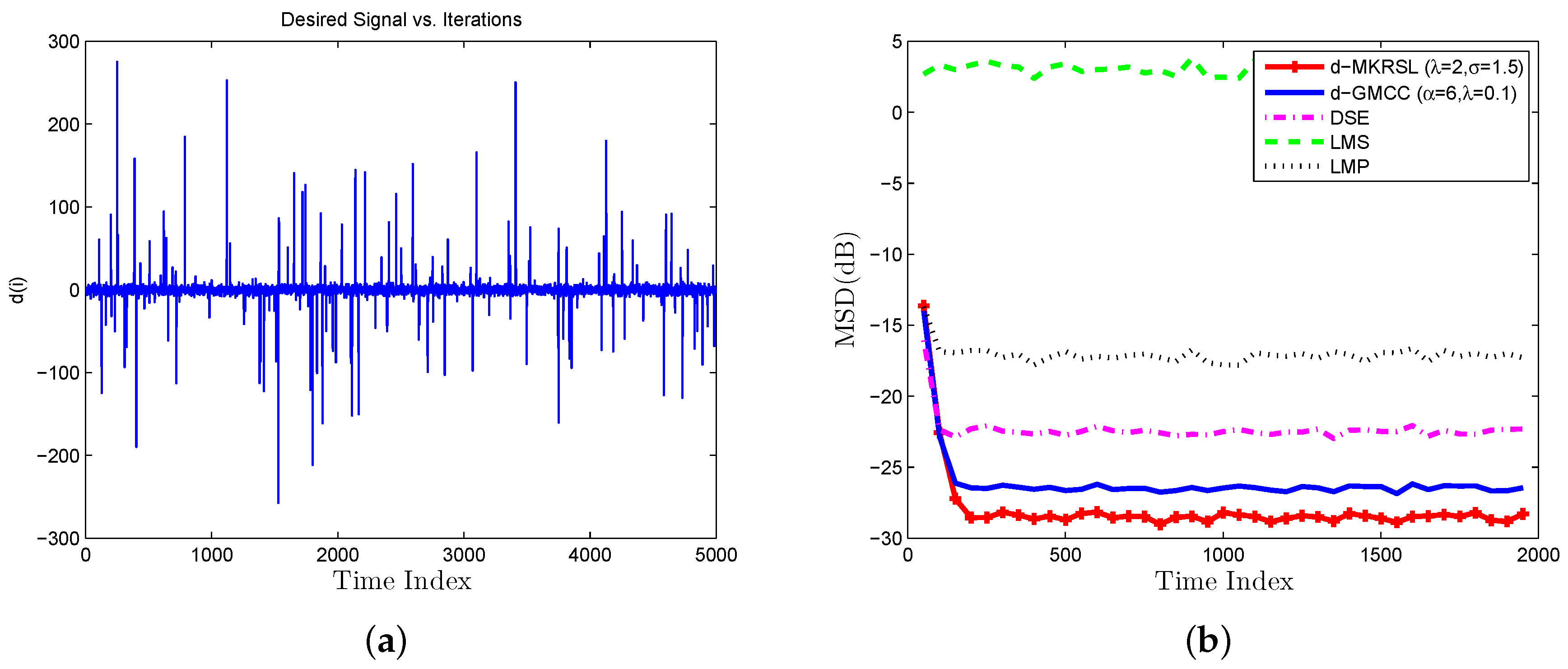
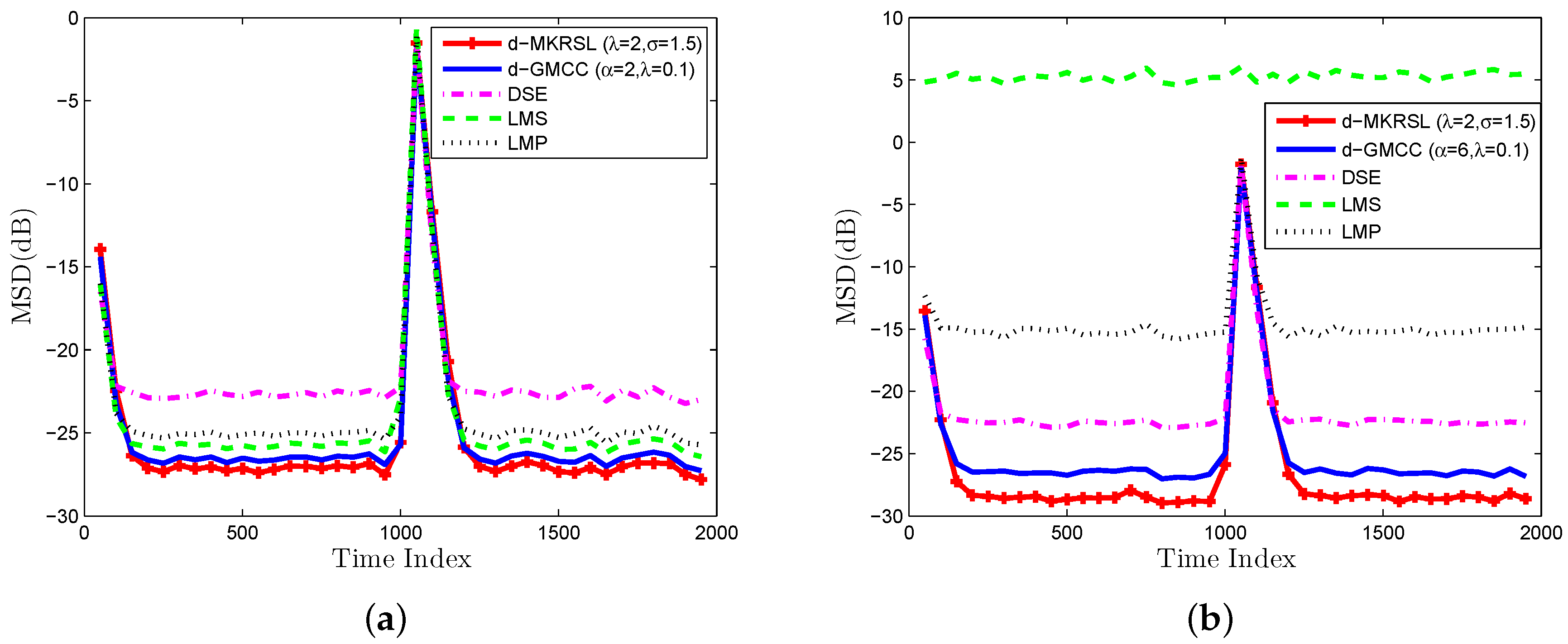
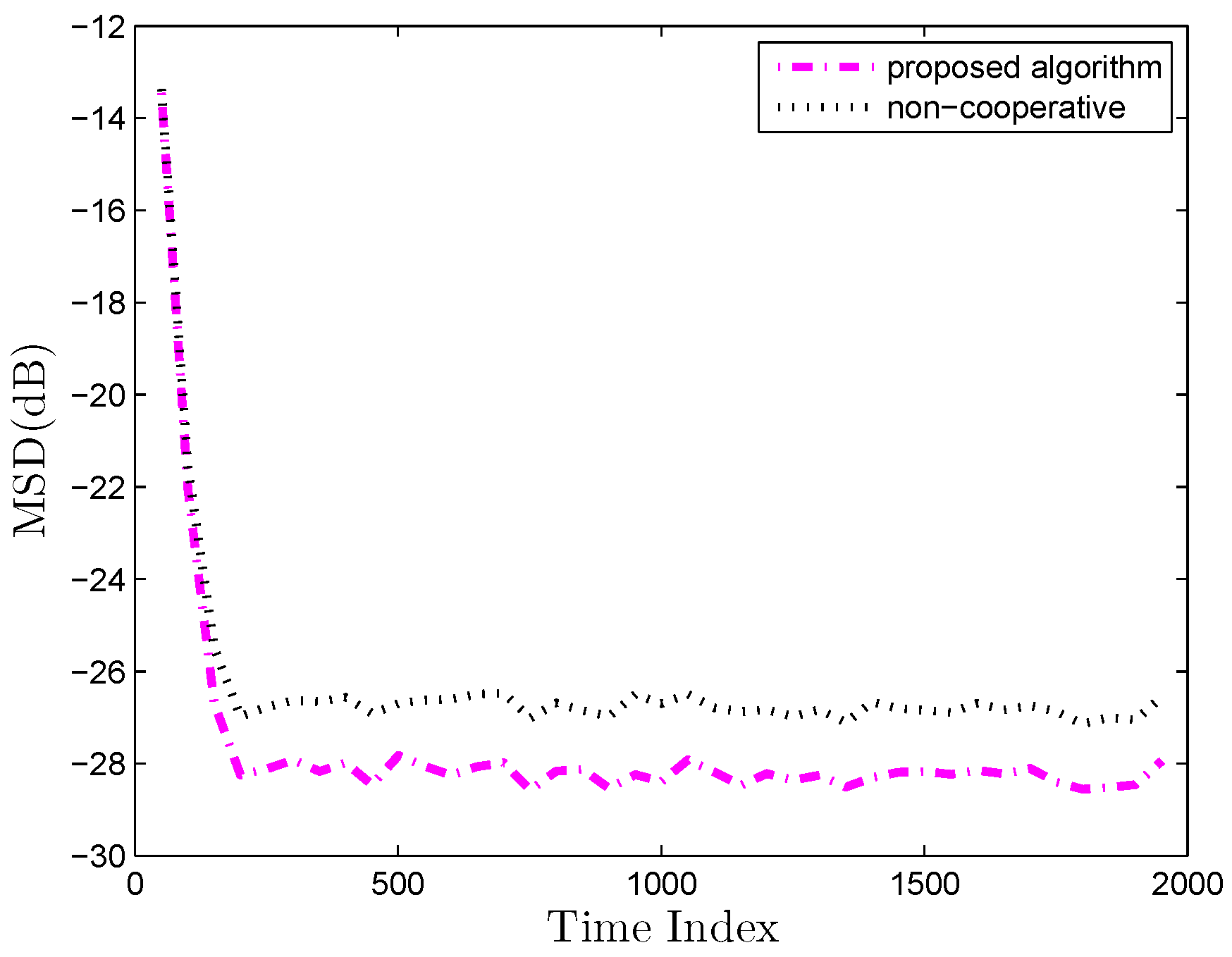
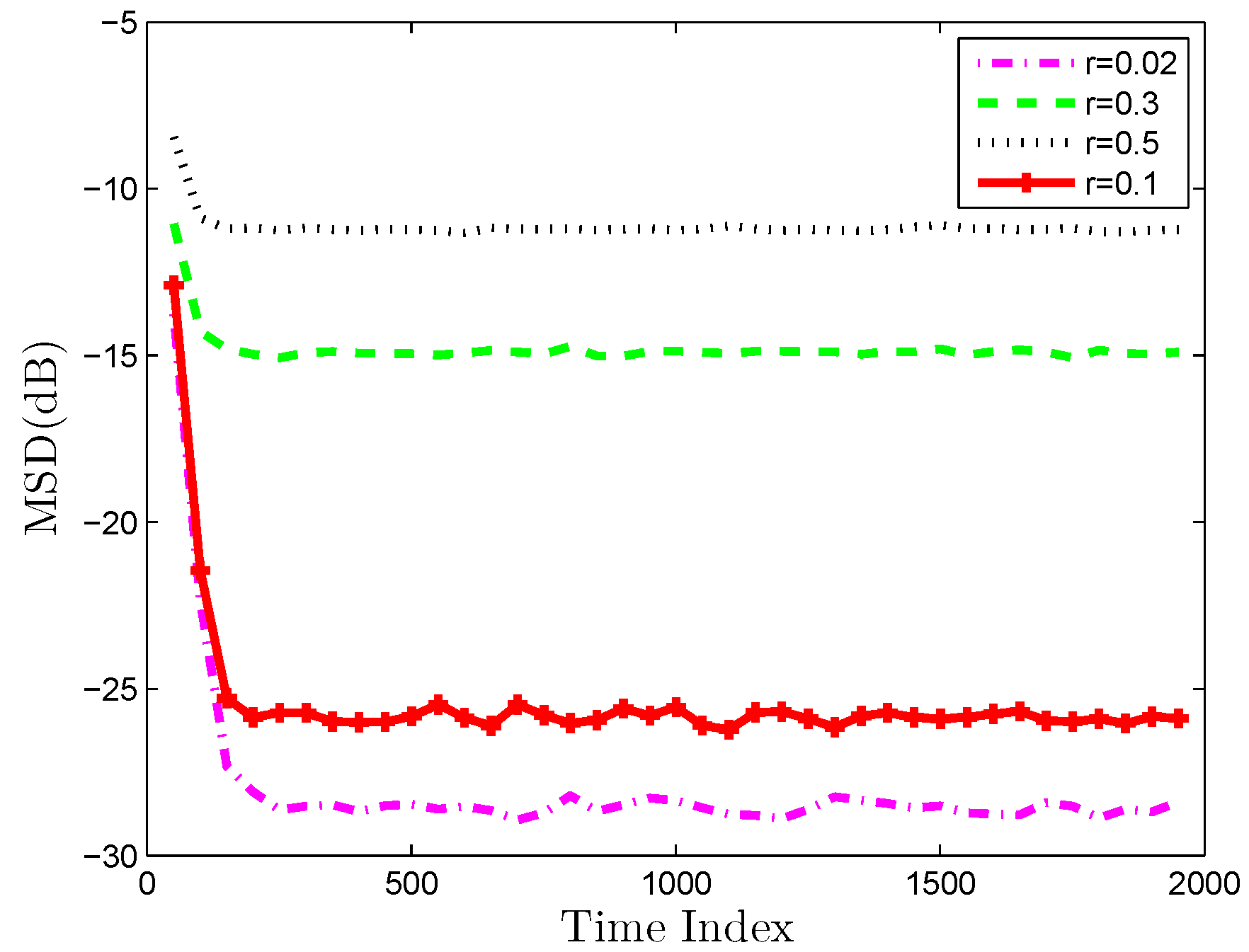
4. Simulation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sayed, A.H. Adaptation, learning, and optimization over networks. Found. Trends Mach. Learn. 2014, 7, 311–801. [Google Scholar] [CrossRef]
- Lorenzo, P.D.; Barbarossa, S.; Sayed, A.H. Bio-inspired swarming for dynamic radio access based on diffusion adaptation. In Proceedings of the 2011 19th European Signal Processing Conference (EUSIPCO), Barcelona, Spain, 29 August–2 September 2011; pp. 402–406. [Google Scholar]
- Chen, J.; Cao, X.; Cheng, P.; Xiao, Y.; Sun, Y. Distributed collaborative control for industrial automation with wireless sensor and actuator networks. IEEE Trans. Ind. Electron. 2010, 57, 4219–4230. [Google Scholar] [CrossRef]
- Sayed, A.H.; Tu, S.; Chen, J.; Zhao, X.; Towfic, Z.J. Diffusion strategies for adaptation and learning over networks. IEEE Signal Process. Mag. 2013, 30, 155–171. [Google Scholar] [CrossRef]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Kar, S.; Moura, J.M.F. Distributed consensus algorithms in sensor networks: Link failures and channel noise. IEEE Trans. Signal Process. 2009, 57, 355–369. [Google Scholar] [CrossRef]
- Wang, J.; Peng, D.; Jing, Z.; Chen, J. Consensus-Based Filter for Distributed Sensor Networks with Colored Measurement Noise. Sensors 2018, 18, 3678. [Google Scholar] [CrossRef] [PubMed]
- Nedic, A.; Ozdaglar, A. Distributed subgradient methods for multiagent optimization. IEEE Trans. Autom. Control 2009, 54, 48–61. [Google Scholar] [CrossRef]
- Nedic, A.; Bertsekas, D.P. Incremental subgradient methods for nondifferentiable optimization. SIAM J. Optim. 2001, 12, 109–138. [Google Scholar] [CrossRef]
- Rabbat, M.G.; Nowak, R.D. Quantized incremental algorithms for distributed optimization. IEEE J. Sel. Areas Commun. 2005, 23, 798–808. [Google Scholar] [CrossRef]
- Lopes, C.G.; Sayed, A.H. Incremental adaptive strategies over distributed networks. IEEE Trans. Signal Process. 2007, 48, 223–229. [Google Scholar] [CrossRef]
- Chen, J.; Sayed, A.H. Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Trans. Signal Process. 2012, 60, 4289–4305. [Google Scholar] [CrossRef]
- Cattivelli, F.S.; Sayed, A.H. Diffusion LMS strategies for distributed estimation. IEEE Trans. Signal Process. 2010, 58, 1035–1048. [Google Scholar] [CrossRef]
- Zhao, X.; Sayed, A.H. Performance limits for distributed estimation over LMS adaptive networks. IEEE Trans. Signal Process. 2012, 60, 5107–5124. [Google Scholar] [CrossRef]
- Tu, S.Y.; Sayed, A.H. Diffusion strategies outperform consensus strategies for distributed estimation over adaptive networks. IEEE Trans. Signal Process. 2012, 60, 6217–6234. [Google Scholar] [CrossRef]
- Chen, F.; Li, X.; Duan, S.; Wang, L.; Wu, J. Diffusion generalized maximum correntropy criterion algorithm for distributed estimation over multitask network. Digit. Signal Process. 2018, 81, 16–25. [Google Scholar] [CrossRef]
- Liu, Y.; Li, C.; Tang, W.K.S.; Zhang, Z. Distributed estimation over complex networks. Inf. Sci. 2012, 197, 91–104. [Google Scholar] [CrossRef]
- Chen, F.; Shao, X. Broken-motifs diffusion LMS algorithm for reducing communication load. Signal Process. 2017, 197, 91–104. [Google Scholar] [CrossRef]
- Chen, F.; Shao, X. Complementary performance analysis of general complex-valued diffusion LMS for noncircular signals. Signal Process. 2019, 160, 237–246. [Google Scholar]
- Cattivelli, F.S.; Lopes, C.G.; Sayed, A.H. A diffusion RLS scheme for distributed estimation over adaptive networks. In Proceedings of the 2007 IEEE 8th Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Helsinki, Finland, 17–20 June 2007; pp. 1–5. [Google Scholar]
- Cattivelli, F.S.; Lopes, C.G.; Sayed, A.H. Diffusion recursive leasts-quares for distributed estimation over adaptive networks. IEEE Trans. Signal Process. 2008, 56, 1865–1877. [Google Scholar] [CrossRef]
- Gao, W.; Chen, J. Kernel Least Mean p-Power algorithm. IEEE Signal Process. Lett. 2017, 24, 996–1000. [Google Scholar] [CrossRef]
- Shao, X.; Chen, F.; Ye, Q.; Duan, S. A Robust Diffusion Estimation Algorithm with Self-Adjusting Step-Size in WSNs. Sensors 2017, 17, 824. [Google Scholar] [CrossRef] [PubMed]
- Wen, F. Diffusion least-mean P-power algorithms for distributed estimation in alpha-stable noise environments. Electron. Lett. 2013, 49, 1355–1356. [Google Scholar] [CrossRef]
- Ni, J.; Chen, J.; Chen, X. Diffusion sign-error LMS algorithm: formulation and stochastic behavior analysis. Signal Process. 2016, 128, 142–149. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zhao, H.; Principe, J.C. Maximum correntropy Kalman filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Zhao, H.; Zheng, N.; Principe, J.C. Generalized correntropy for robust adaptive filtering. IEEE Trans. Signal Process. 2016, 64, 3376–3387. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Zheng, N.; Principe, J.C. Kernel Risk-Sensitive Loss: Definition, Properties and Application to Robust Adaptive Filtering. IEEE Trans. Signal Process. 2017, 65, 2888–2901. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Sayed, A.H. Diffusion LMS over multitask networks. IEEE Trans. Signal Process. 2015, 63, 2733–2748. [Google Scholar] [CrossRef]
- Chen, J.; Sayed, A.H. Distributed Pareto optimization via diffusion strategies. IEEE J. Sel. Top. Signal Process. 2013, 7, 205–220. [Google Scholar] [CrossRef]
- Zhao, X.; Sayed, A.H. Clustering via diffusion adaptation over networks. In Proceedings of the 2012 3rd International Workshop on Cognitive Information Processing (CIP), Parador de Baiona, Spain, 28–30 May 2012; pp. 1–6. [Google Scholar]
- Zhao, X.; Sayed, A.H. Distributed clustering and learning over networks. IEEE Trans. Signal Process. 2015, 63, 3285–3300. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Hero, A.O.; Sayed, A.H. Diffusion LMS for mu1titask problems with overlapping hypothesis subspaces. In Proceedings of the 2014 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Reims, France, 21–24 September 2014; pp. 1–6. [Google Scholar]
- Bogdanovic, N.; Plata-Chaves, J.; Berberidis, K. Distributed diffusion-based LMS for node-specific parameter estimation over adaptive networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7223–7227. [Google Scholar]
- Chen, J.; Richard, C.; Sayed, A.H. Multitask diffusion adaptation over networks. IEEE Trans. Signal Process. 2014, 62, 4129–4144. [Google Scholar] [CrossRef]
- Nassif, R.; Richard, C.; Ferrari, A. Proximal multitask learning over networks with sparsity-inducing coregularization. IEEE Trans. Signal Process. 2016, 64, 6329–6344. [Google Scholar] [CrossRef]
- Ma, W.; Chen, B.; Duan, J.; Zhao, H. Diffusion maximum correntropy criterion algorithms for robust distributed estimation. Digit. Signal Process. 2016, 58, 10–19. [Google Scholar] [CrossRef]
- Sayed, A.H. Adaptive Filters; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Haykin, S. Adaptive Filter Theory; Prentice-Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Kelley, C.T. Iterative Methods for Optimization; SIAM: Philadelphia, PA, USA, 1999. [Google Scholar]
- Abadir, K.M.; Magnus, J.R. Matrix Algebra; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Chan, S.C.; Zou, Y.X. A recursive least M-estimate algorithm for robust adaptive filtering in impulsive noise: fast algorithm and convergence performance analysis. IEEE Trans. Signal Process. 2004, 52, 975–991. [Google Scholar] [CrossRef]
- Sayed, A.S.; Zoubir, A.M.; Sayed, A.H. Robust adaptation in impulsive noise. IEEE Trans. Signal Process. 2016, 64, 2851–2865. [Google Scholar] [CrossRef]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Shi, Q.; Xiao, S.; Duan, S.; Chen, F. A Robust Diffusion Minimum Kernel Risk-Sensitive Loss Algorithm over Multitask Sensor Networks. Sensors 2019, 19, 2339. https://doi.org/10.3390/s19102339
Li X, Shi Q, Xiao S, Duan S, Chen F. A Robust Diffusion Minimum Kernel Risk-Sensitive Loss Algorithm over Multitask Sensor Networks. Sensors. 2019; 19(10):2339. https://doi.org/10.3390/s19102339
Chicago/Turabian StyleLi, Xinyu, Qing Shi, Shuangyi Xiao, Shukai Duan, and Feng Chen. 2019. "A Robust Diffusion Minimum Kernel Risk-Sensitive Loss Algorithm over Multitask Sensor Networks" Sensors 19, no. 10: 2339. https://doi.org/10.3390/s19102339
APA StyleLi, X., Shi, Q., Xiao, S., Duan, S., & Chen, F. (2019). A Robust Diffusion Minimum Kernel Risk-Sensitive Loss Algorithm over Multitask Sensor Networks. Sensors, 19(10), 2339. https://doi.org/10.3390/s19102339