Content-Aware Focal Plane Selection and Proposals for Object Tracking on Plenoptic Image Sequences

Abstract
1. Introduction
- We propose a novel focus index selection algorithm, content-aware focal plane selection, that identifies the maximally focused and visually consistent focal plane. While the prior techniques [2,3] have only used the focus measure, our selection method additionally consider whether the target object is clearly appeared in the image plane (Section 4).
- We propose a novel bounding box proposal scheme based on the optimal focus index computed by our content-aware focal plane selection algorithm. Since the focus index is directly related to the distance between the camera and object, we use the change of the focus index to accurately estimate the scale of the object in the image plane. We also design an algorithm to propose the location of candidate bounding boxes by modeling of the trajectory of the object. We generate several candidate bounding boxes based on the both scale and motion factors and select the best one among them according to the visual similarity to the target object (Section 5).
2. Related Work
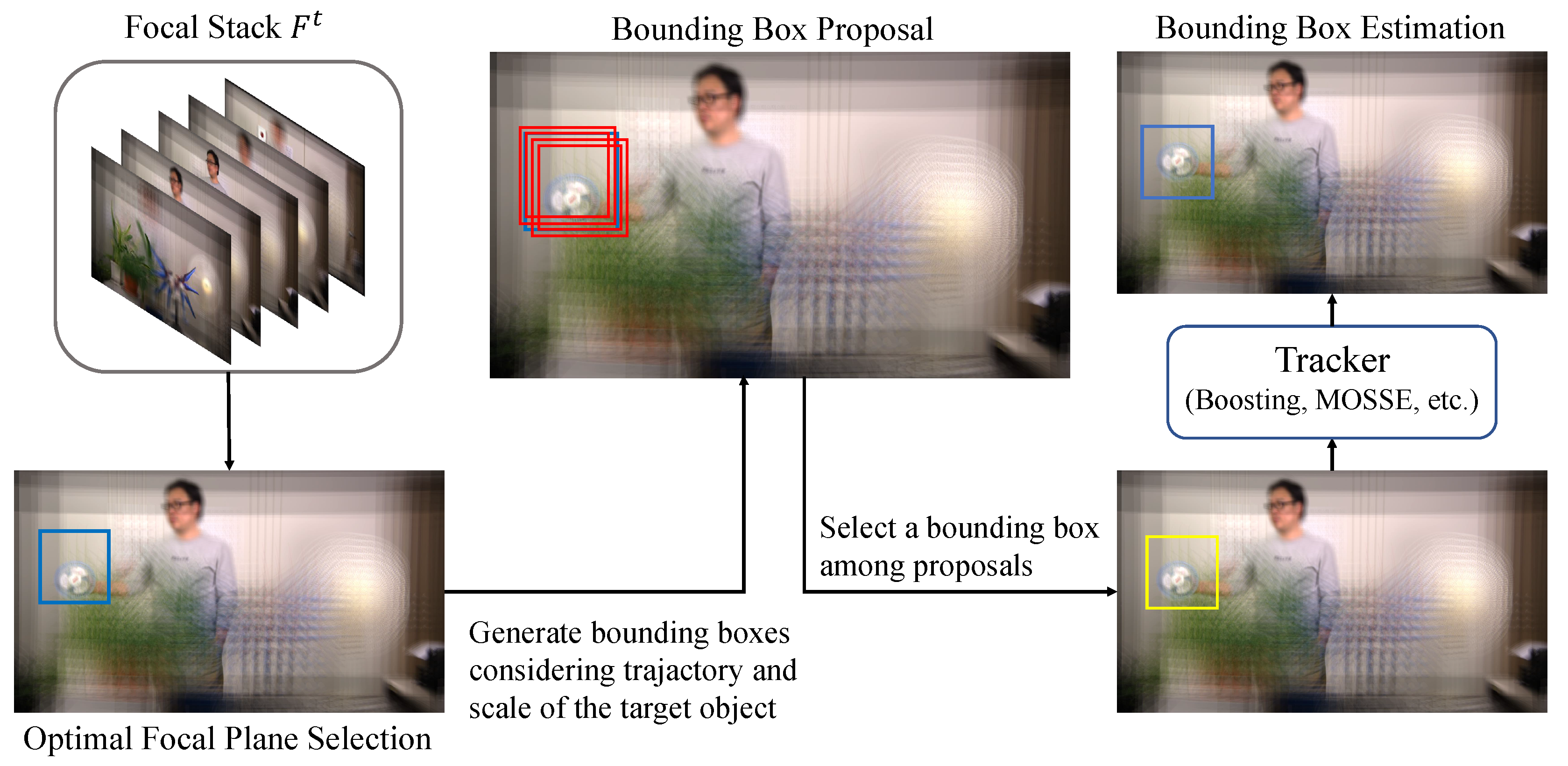
3. Problem Formulation and Overview
3.1. Problem Formulation
3.2. Overview
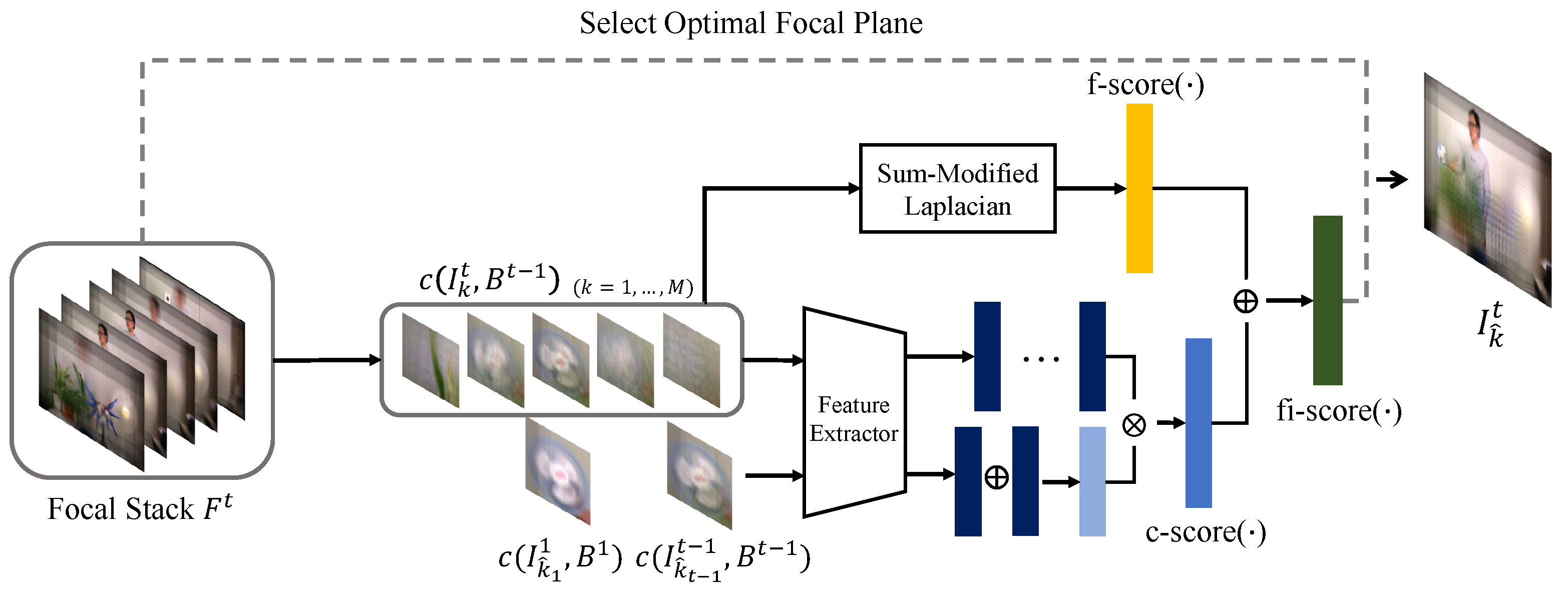
4. Focus Index Selection
4.1. Focus Measure Based Focus Index Selection
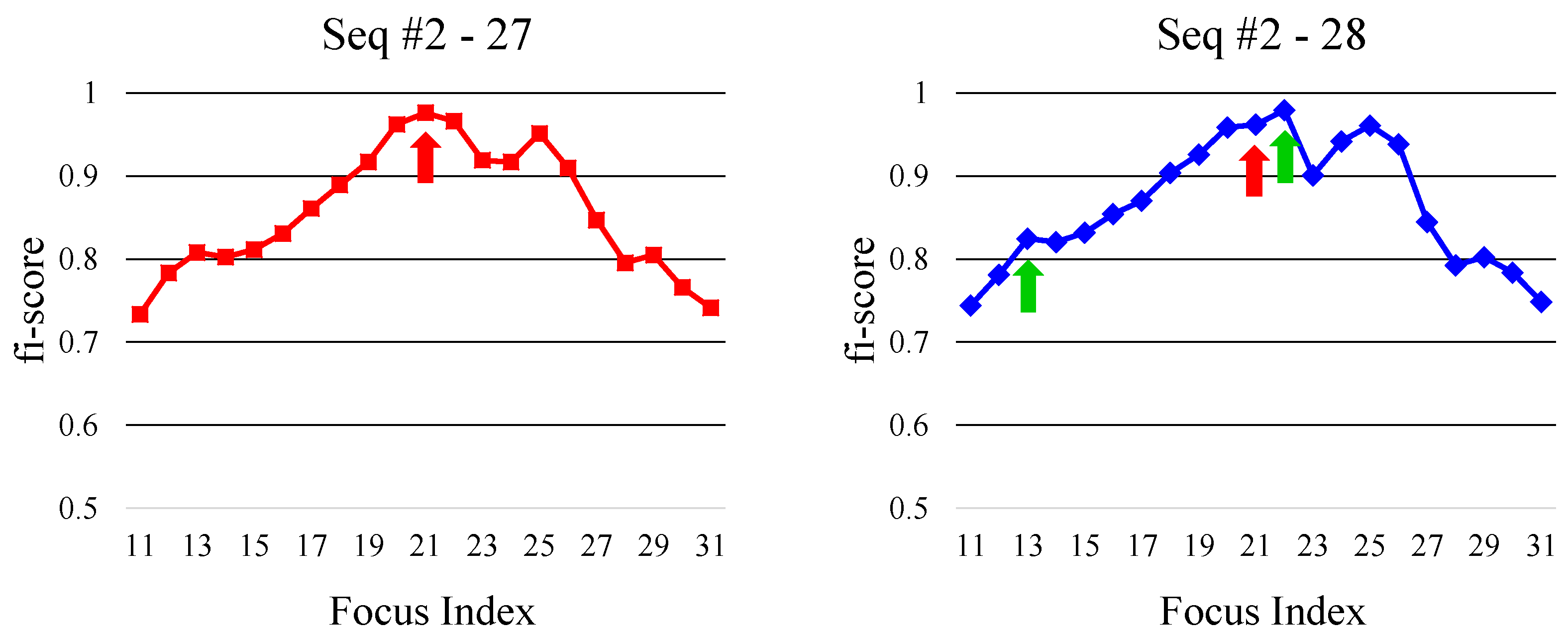
4.2. Content-Based Score for Focus Index Selection
4.3. Combined Score and Focus Index Selection
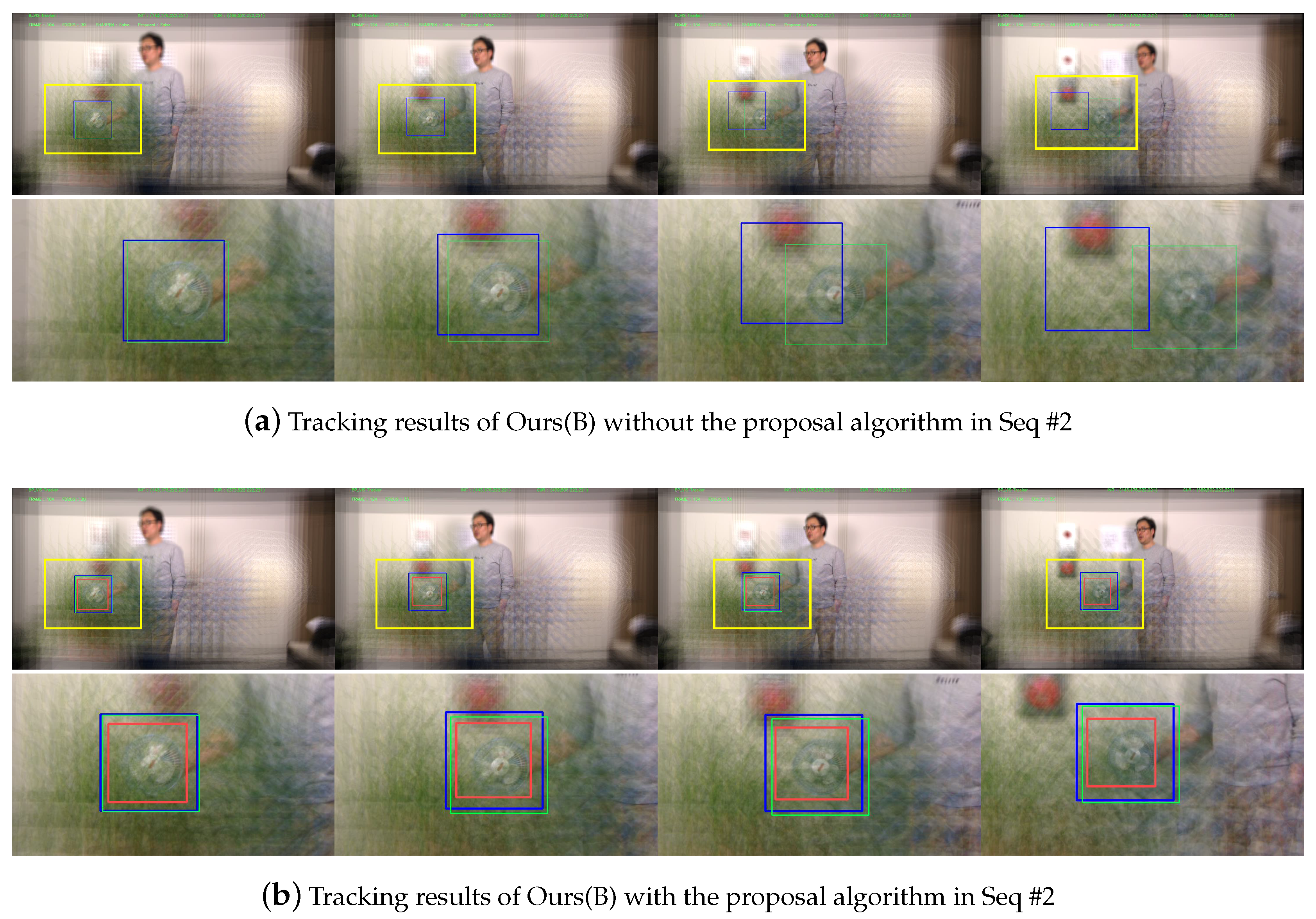
5. Bounding Box Proposal Based on Focus Index
5.1. Scaling Factors
5.2. Motion Factors
6. Evaluation
6.1. Benchmarks
- Seq #1: The simplest one among three benchmarks. The target object is simply moving horizontally in the image plane and partially occluded. This sequence consists of 150 frames and the size of the focal stack is 14.
- Seq #2: The target object is moving far from the camera, so its size in the image is getting smaller. The occlusion is more serious than Seq #1. The number of frames and the size of the focal stack are 220 and 40, respectively.
- Seq #3: Contrary to Seq #2, the target object is approaching to the camera, so its size is getting larger. This sequence has 230 frames and the size of the focal stack is the same with Seq #2. The occlusion is the most serious among three sequences.
6.2. Evaluation Protocol
6.3. Experimental Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cho, M.; Javidi, B. Three-dimensional tracking of occluded objects using integral imaging. Opt. Lett. 2008, 33, 2737–2739. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.W.; Bae, S.J.; Park, S.; Kim, D.H. Object tracking using plenoptic image sequences. In Proceedings of the Three-Dimensional Imaging, Visualization, and Display, Anaheim, CA, USA, 9–13 April 2017; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10219, p. 1021909. [Google Scholar]
- Bae, D.H.; Kim, J.W.; Noh, H.C.; Kim, D.H.; Heo, J.P. Plenoptic imaging techniques to improve accuracy and robustness of 3D object tracking. In Proceedings of the Three-Dimensional Imaging, Visualization, and Display, Orlando, FL, USA, 15–19 April 2018; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10666, p. 106660H. [Google Scholar]
- Pertuz, S.; Puig, D.; Garcia, M.A. Analysis of focus measure operators for shape-from-focus. Pattern Recognit. 2013, 46, 1415–1432. [Google Scholar] [CrossRef]
- Grabner, H.; Grabner, M.; Bischof, H. Real-time tracking via on-line boosting. In Proceedings of the British Machine Vision Conference; BMVA Press: Blue Mountains, ON, USA, 2006; Volume 1, pp. 47–56. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional features for correlation filter based visual tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 58–66. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intel. 2014, 36, 1442–1468. [Google Scholar]
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. Man Cybern. Part C 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Yilmaz, A.; Javed, O.; Shah, M. Object Tracking: A Survey. ACM Comput. Surv. 2006, 38. [Google Scholar] [CrossRef]
- Adam, A.; Rivlin, E.; Shimshoni, I. Robust fragments-based tracking using the integral histogram. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 798–805. [Google Scholar]
- Liu, B.; Huang, J.; Yang, L.; Kulikowsk, C. Robust tracking using local sparse appearance model and k-selection. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1313–1320. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Fast compressive tracking. IEEE Trans. Pattern Anal. Mach. Intel. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Grabner, H.; Matas, J.; Van Gool, L.; Cattin, P. Tracking the invisible: Learning where the object might be. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1285–1292. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intel. 2011, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Wen, L.; Lei, Z.; Vasconcelos, N.; Li, S.Z. Robust deformable and occluded object tracking with dynamic graph. IEEE Trans. Image Process. 2014, 23, 5497–5509. [Google Scholar] [CrossRef] [PubMed]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Cehovin, L.; Fernandez, G.; Vojir, T.; Hager, G.; Nebehay, G.; Pflugfelder, R. The visual object tracking vot2015 challenge results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 1–23. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intel. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Shahbaz Khan, F.; Felsberg, M.; van de Weijer, J. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Lukezic, A.; Vojir, T.; Zajc, L.C.; Matas, J.; Kristan, M. Discriminative Correlation Filter with Channel and Spatial Reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 6, p. 8. [Google Scholar]
- Shi, G.; Xu, T.; Guo, J.; Luo, J.; Li, Y. Consistently Sampled Correlation Filters with Space Anisotropic Regularization for Visual Tracking. Sensors 2017, 17, 2889. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Zhang, S.; Qiao, X. Scene-Aware Adaptive Updating for Visual Tracking via Correlation Filters. Sensors 2017, 17, 2626. [Google Scholar] [CrossRef] [PubMed]
- Xue, X.; Li, Y.; Shen, Q. Unmanned Aerial Vehicle Object Tracking by Correlation Filter with Adaptive Appearance Model. Sensors 2018, 18, 2751. [Google Scholar] [CrossRef] [PubMed]
- Nayar, S.K.; Nakagawa, Y. Shape from Focus. IEEE Trans. Pattern Anal. Mach. Intel. 1994, 16, 824–831. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; Volume 4, p. 12. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Montreal, Canada, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Lake Tahoe, Nevada, 2013; pp. 809–817. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In European Conference on Computer Vision; Springer: Cham, Switaerland, 2016; pp. 749–765. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 Jun 2013. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural codes for image retrieval. In European Conference on Computer Vision; Springer: Cham, Switaerland, 2014; pp. 584–599. [Google Scholar]
- Babenko, A.; Lempitsky, V. Aggregating local deep features for image retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv0, 2016; arXiv:1602.0736. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq #1 | Seq #2 | Seq #3 | |
|---|---|---|---|
| −0.9 | −6.8 | −6.7 | |
| −0.2 | 0.8 | 0.9 | |
| 0.05 | 0.2 | 0.2 | |
| Focal Stack Size M | 14 | 40 | 40 |
| Frames | 150 | 220 | 230 |
| Seq #1 | Seq #2 | Seq #3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Focus | Proposal | Tracker | D | O | D | O | D | O |
| Baseline #1 [2] | f-score | × | Boosting | 44.502 | 0.852 | 59.997 | 0.712 | 142.796 | 0.576 |
| Baseline #2 [3] | f-score | Fixed ratio | Boosting | 39.293 | 0.867 | 55.916 | 0.735 | 41.101 | 0.822 |
| Ours(B) | fi-score | Ours | Boosting | 28.256 | 0.904 | 34.980 | 0.825 | 15.014 | 0.858 |
| Ours(M) | fi-score | Ours | MOSSE | 8.400 | 0.959 | 26.584 | 0.882 | 11.394 | 0.889 |
| Ours(MC) | fi-score | Ours | MOSSE+CNN | 11.978 | 0.946 | 27.469 | 0.879 | 9.148 | 0.915 |
| Boosting | MOSSE | MOSSE+CNN | |
|---|---|---|---|
| f-score | 28.665/0.853 | 31.630/0.829 | 13.601/0.873 |
| fi-score | 19.984/0.842 | 11.534/0.888 | 9.807/0.909 |
| Seq #1 | Seq #2 | Seq #3 | ||||
|---|---|---|---|---|---|---|
| Distance | Overlap | Distance | Overlap | Distance | Overlap | |
| Ours(M) w/o Proposal | 8.789 | 0.957 | 43.868 | 0.807 | 11.534 | 0.888 |
| Ours(M) | 8.400 | 0.959 | 26.584 | 0.882 | 11.394 | 0.889 |
| Ours(MC) w/o Proposal | 14.523 | 0.936 | 43.683 | 0.810 | 9.807 | 0.909 |
| Ours(MC) | 11.978 | 0.946 | 27.469 | 0.879 | 9.148 | 0.915 |
| Seq #1 | Seq #2 | Seq #3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| VGG | SQZ | IncRes | VGG | SQZ | IncRes | VGG | SQZ | IncRes | |
| Ours(M) w/o P | 8.789 | 8.624 | 8.627 | 43.868 | 4.957 | 15.967 | 11.534 | 11.509 | 23.347 |
| Ours(M) | 8.400 | 8.322 | 8.271 | 26.584 | 4.653 | 15.954 | 11.394 | 11.358 | 12.485 |
| Ours(MC) w/o P | 14.523 | 85.041 | 44.089 | 43.683 | 23.516 | 34.385 | 9.807 | 11.956 | 15.021 |
| Ours(MC) | 11.978 | 18.765 | 13.939 | 27.469 | 18.566 | 11.685 | 9.148 | 11.828 | 9.450 |
| Time(s)/Frame | |||
|---|---|---|---|
| VGG | SQZ | IncRes | |
| Ours(M) w/o Proposal | 0.275 | 0.085 | 0.281 |
| Ours(M) | 0.319 | 0.155 | 0.322 |
| Ours(MC) w/o Proposal | 0.658 | 0.565 | 1.111 |
| Ours(MC) | 0.706 | 0.633 | 1.186 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, D.H.; Kim, J.W.; Heo, J.-P. Content-Aware Focal Plane Selection and Proposals for Object Tracking on Plenoptic Image Sequences. Sensors 2019, 19, 48. https://doi.org/10.3390/s19010048
Bae DH, Kim JW, Heo J-P. Content-Aware Focal Plane Selection and Proposals for Object Tracking on Plenoptic Image Sequences. Sensors. 2019; 19(1):48. https://doi.org/10.3390/s19010048
Chicago/Turabian StyleBae, Dae Hyun, Jae Woo Kim, and Jae-Pil Heo. 2019. "Content-Aware Focal Plane Selection and Proposals for Object Tracking on Plenoptic Image Sequences" Sensors 19, no. 1: 48. https://doi.org/10.3390/s19010048
APA StyleBae, D. H., Kim, J. W., & Heo, J.-P. (2019). Content-Aware Focal Plane Selection and Proposals for Object Tracking on Plenoptic Image Sequences. Sensors, 19(1), 48. https://doi.org/10.3390/s19010048