Classifying Parkinson’s Disease Based on Acoustic Measures Using Artificial Neural Networks



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection and Preprocessing
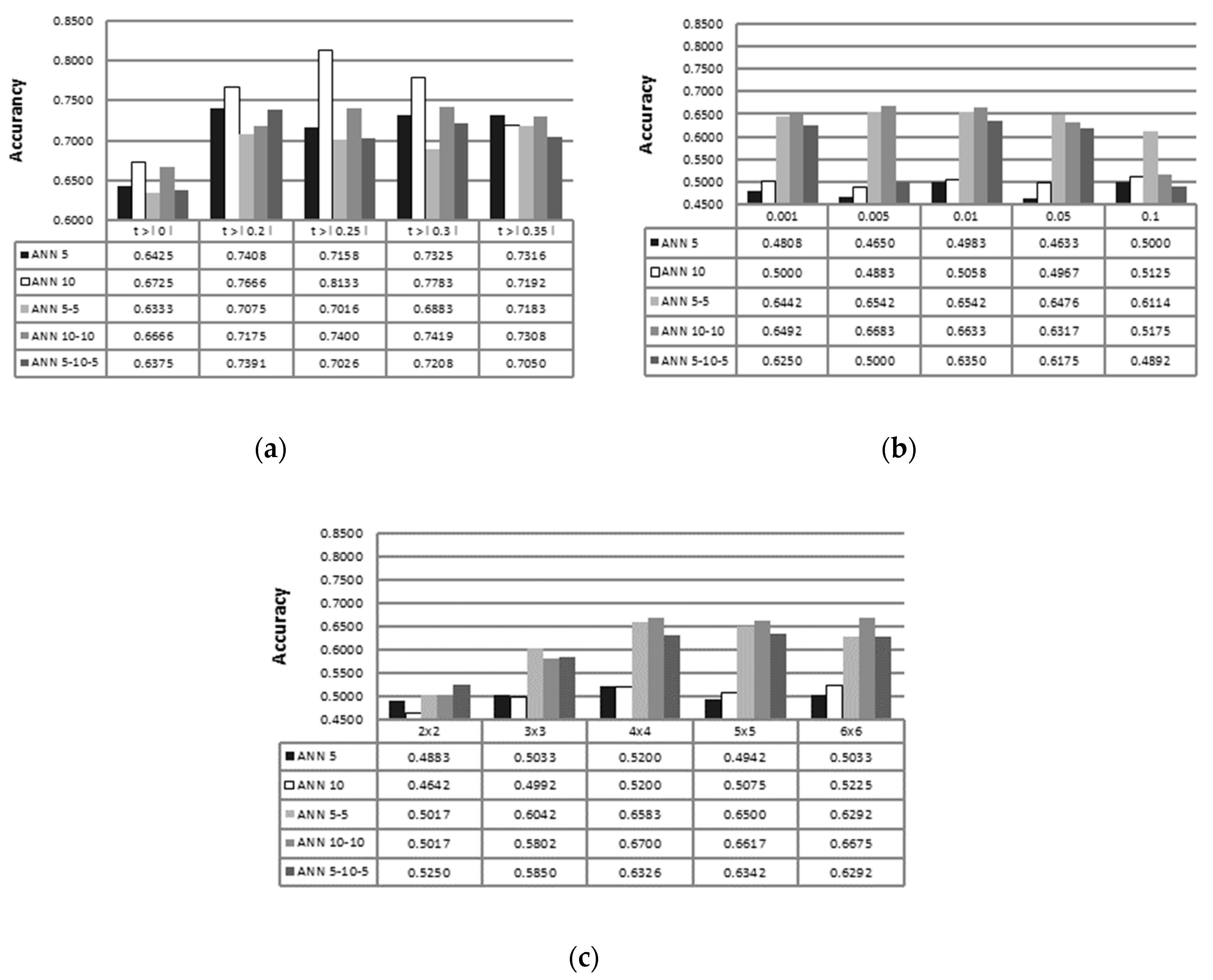
2.2. Feature Selection Using Pearson’s and Kendall’s Correlation Coefficient
2.3. Feature Selection Using Principal Component Analysis (PCA)
2.4. Feature Selection Using Self-Organizing Map (SOM)
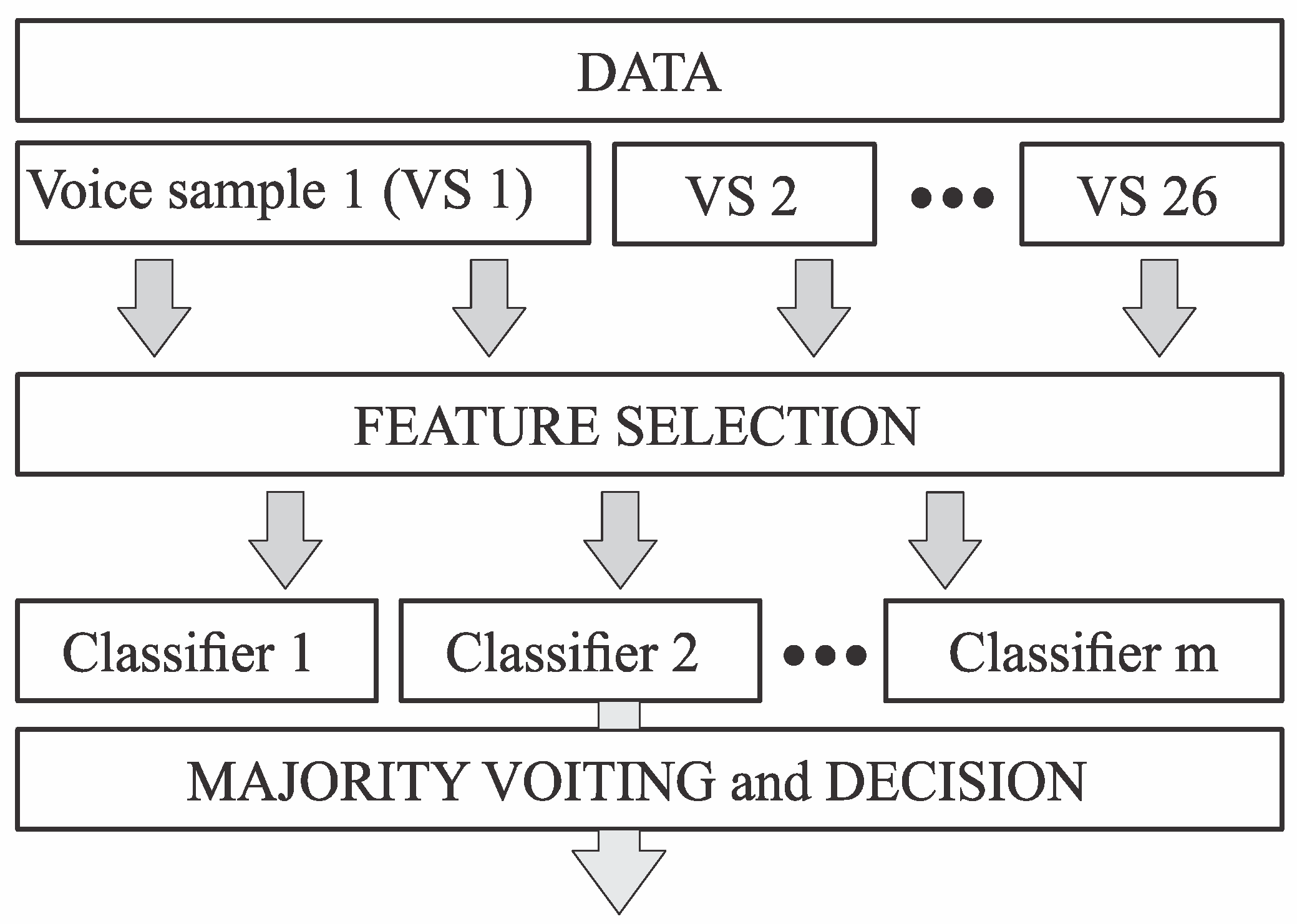
2.5. Artificial Neural Networks (ANNs) and Classification Problems
2.6. Majority Voting
2.7. Generalization to Unseen Data: Leave-One-Individual-Out
2.8. Classifier Evaluation Measures
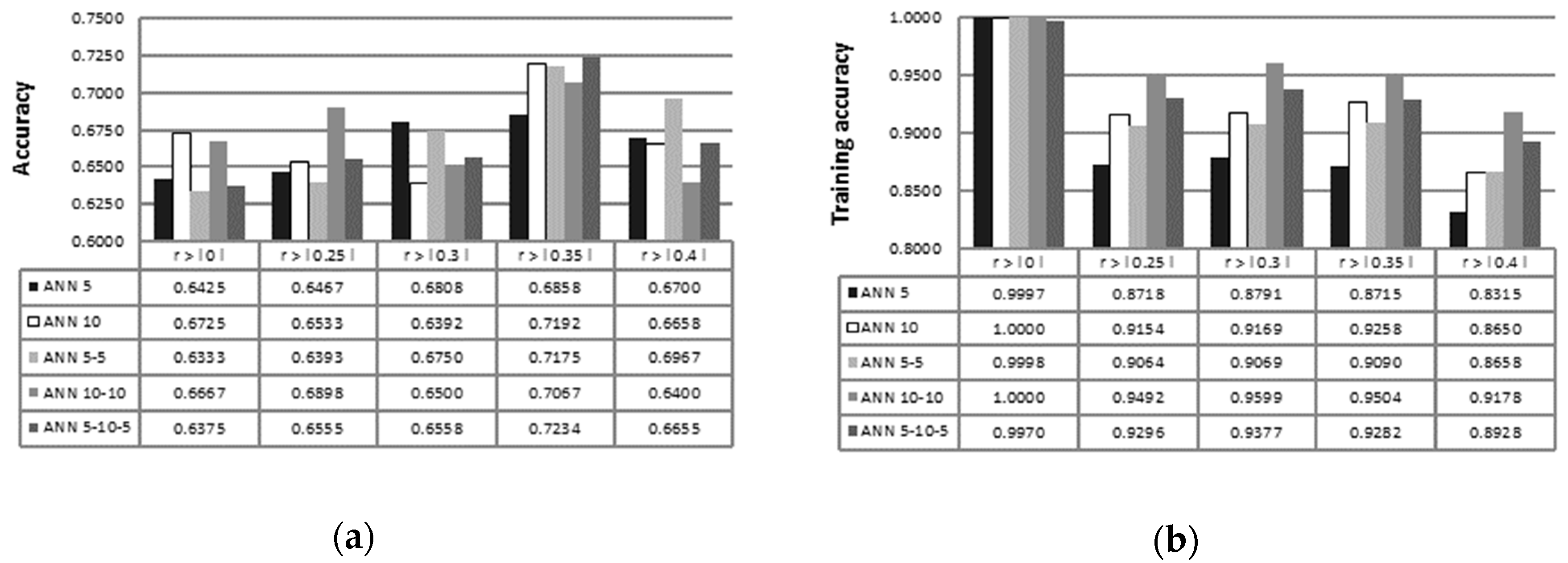
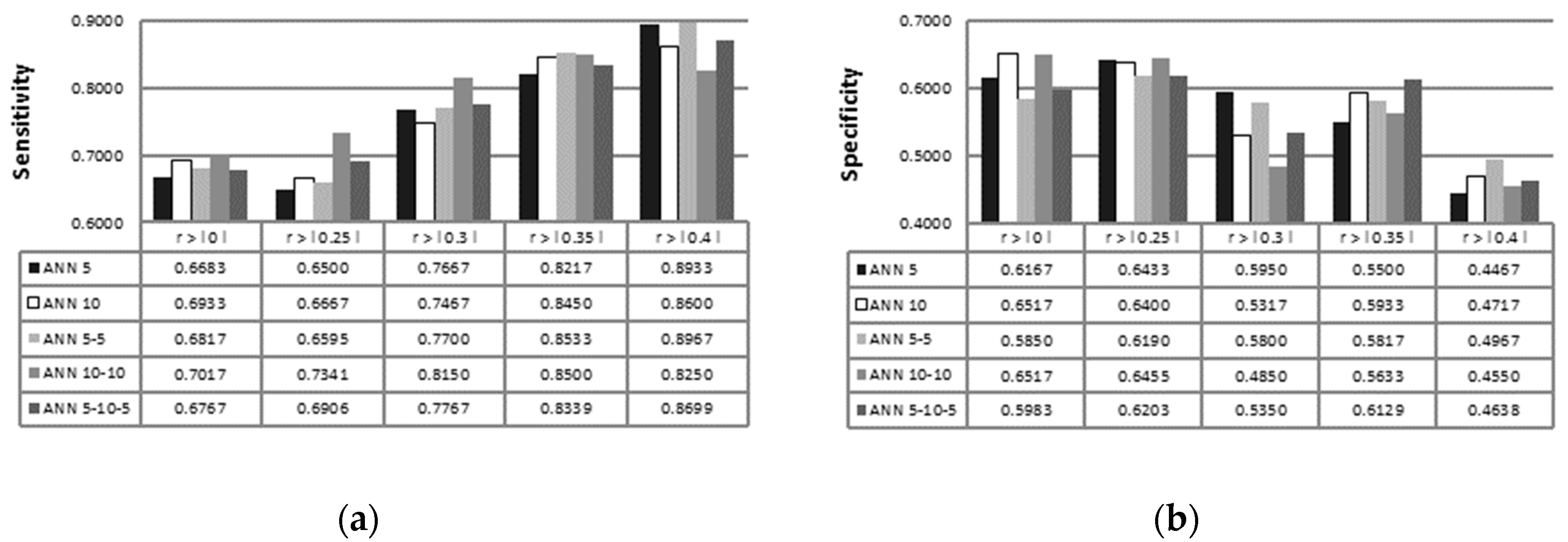
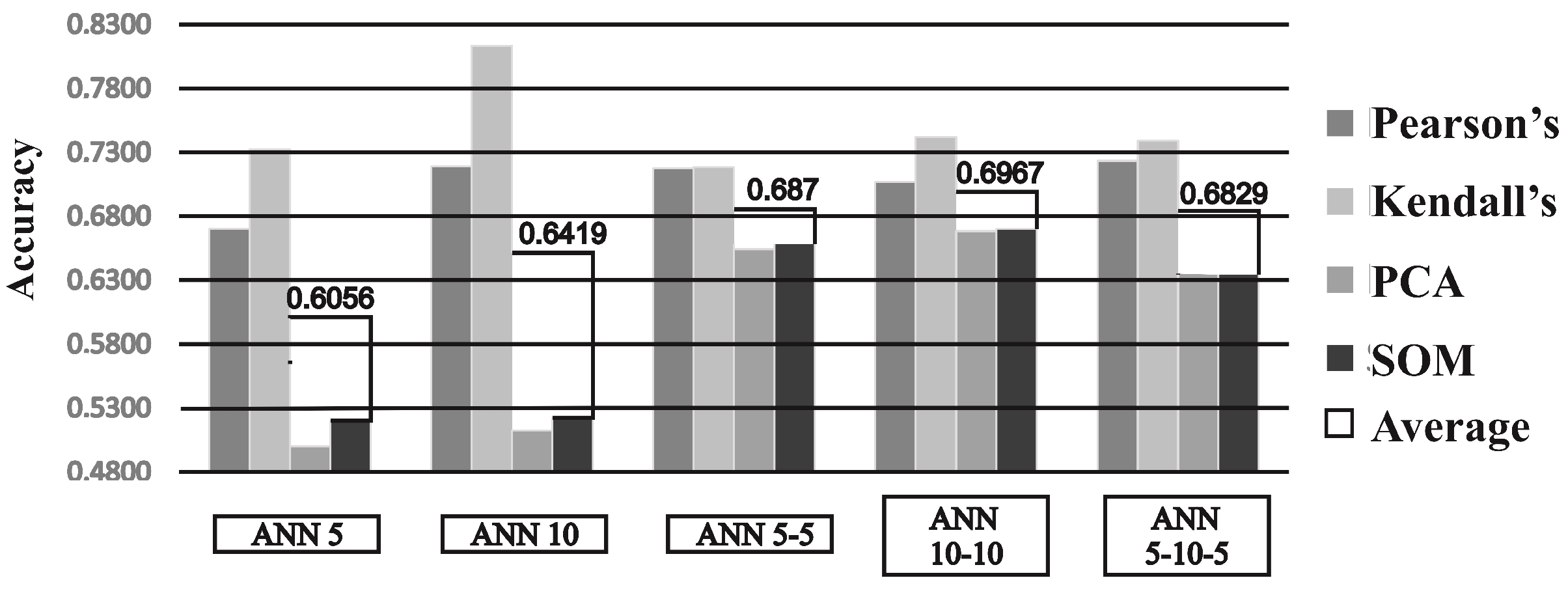
3. Results
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Jankovic, J. Parkinson’s Disease: Clinical Features and Diagnosis. J. Neurol. Neurosurg. Psychiatry 2008, 79, 368–376. [Google Scholar] [CrossRef]
- Uebelacker, L.; Epstein-Lubow, G.; Lewis, T.; Broughton, M.; Friedman, J.H. A Survey of Parkinson’s Disease Patients: Most Bothersome Symptoms and Coping Preferences. J. Parkinsons Dis. 2014, 4, 717–723. [Google Scholar] [CrossRef] [PubMed]
- Skodda, S. Aspects of Speech Rate and Regularity in Parkinson’s Disease. J. Neurol. Sci. 2011, 310, 231–236. [Google Scholar] [CrossRef] [PubMed]
- Bugalho, P.; Viana-Baptista, M. REM Sleep Behavior Disorder and Motor Dysfunction in Parkinson’s Disease—A Longitudinal Study. Parkinsonism Relat. Disord. 2013, 19, 1084–1087. [Google Scholar] [CrossRef] [PubMed]
- Reeve, A.; Simcox, E.; Turnbull, D. Ageing and Parkinson’s Disease: Why Is Advancing Age the Biggest Risk Factor? Ageing Res. Rev. 2014, 14, 19–30. [Google Scholar] [CrossRef] [PubMed]
- Samii, A.; Nutt, J.G.; Ransom, B.R. Parkinson’s Disease. Lancet 2004, 363, 1783–1793. [Google Scholar] [CrossRef]
- Zenon, A.; Olivier, E. Contribution of the Basal Ganglia to Spoken Language: Is Speech Production like the Other Motor Skills? Behav. Brain Sci. 2014, 37, 576. [Google Scholar] [CrossRef] [PubMed]
- Foppa, A.A.; Chemello, C.; Vargas-Pelaez, C.M.; Farias, M.R. Medication Therapy Management Service for Patients with Parkinson’s Disease: A Before-and-After Study. Neurol. Ther. 2016, 5, 85–99. [Google Scholar] [CrossRef] [PubMed]
- Arena, J.; Stoessl, A.J. Optimizing Diagnosis in Parkinson’s Disease: Radionuclide Imaging. Parkinsonism Relat. Disord. 2015, 22, S47–S51. [Google Scholar] [CrossRef]
- Weingarten, C.P.; Sundman, M.H.; Hickey, P.; Chen, N. Neuroimaging of Parkinson’s Disease: Expanding Views. Neurosci. Biobehav. Rev. 2015, 59, 16–52. [Google Scholar] [CrossRef]
- Oliveira, F.P.M.; Faria, D.B.; Costa, D.C.; Castelo-Branco, M.; Tavares, J.M.R.S. Extraction, Selection and Comparison of Features for an Effective Automated Computer-Aided Diagnosis of Parkinson’s Disease Based on [123I]FP-CIT SPECT Images. Eur. J. Nucl. Med. Mol. Imaging 2017, 45, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, F.P.; Castelo-Branco, M. Computer-Aided Diagnosis of Parkinson’s Disease based on [123I]FP-CIT SPECT Binding Potential Images, Using the Voxels-as-Features Approach and Support Vector Machines. J. Neural Eng. 2015, 12, 26008. [Google Scholar] [CrossRef] [PubMed]
- Rizzo, G.; Copetti, M.; Arcuti, S.; Martino, D.; Fontana, A.; Logroscino, G. Accuracy of Clinical Diagnosis of Parkinson Disease. Neurology 2016, 86, 566–576. [Google Scholar] [CrossRef] [PubMed]
- Rusz, J.; Bonnet, C.; Klempíř, J.; Tykalová, T.; Baborová, E.; Novotný, M.; Rulseh, A.; Růžička, E. Speech Disorders Reflect Differing Pathophysiology in Parkinson’s Disease, Progressive Supranuclear Palsy and Multiple System Atrophy. J. Neurol. 2015, 262, 992–1001. [Google Scholar] [CrossRef] [PubMed]
- Saxena, M.; Behari, M.; Kumaran, S.S.; Goyal, V.; Narang, V. Assessing Speech Dysfunction Using BOLD and Acoustic Analysis in Parkinsonism. Parkinsonism Relat. Disord. 2014, 20, 855–861. [Google Scholar] [CrossRef] [PubMed]
- New, A.B.; Robin, D.A.; Parkinson, A.L.; Eickhoff, C.R.; Reetz, K.; Hoffstaedter, F.; Mathys, C.; Sudmeyer, M.; Michely, J.; Caspers, J.; et al. The Intrinsic Resting State Voice Network in Parkinson’s Disease. Hum. Brain Mapp. 2015, 36, 1951–1962. [Google Scholar] [CrossRef] [PubMed]
- Sapir, S. Multiple Factors Are Involved in the Dysarthria Associated with Parkinson’s Disease: A Review With Implications for Clinical Practice and Research. J. Speech Lang. Hear. Res. 2014, 57, 1330–1343. [Google Scholar] [CrossRef]
- Galaz, Z.; Mekyska, J.; Mzourek, Z.; Smekal, Z.; Rektorova, I.; Eliasova, I.; Kostalova, M.; Mrackova, M.; Berankova, D. Prosodic Analysis of Neutral, Stress-Modified and Rhymed Speech in Patients with Parkinson’s Disease. Comput. Methods Programs Biomed. 2016, 127, 301–317. [Google Scholar] [CrossRef]
- Pawlukowska, W.; Gołąb-Janowska, M.; Safranow, K.; Rotter, I.; Amernik, K.; Honczarenko, K.; Nowacki, P. Articulation Disorders and Duration, Severity and L-Dopa Dosage in Idiopathic Parkinson’s Disease. Neurol. Neurochir. Pol. 2015, 49, 302–306. [Google Scholar] [CrossRef]
- Lirani-Silva, C.; Mourão, L.F.; Gobbi, L.T.B. Dysarthria and Quality of Life in Neurologically Healthy Elderly and Patients with Parkinson’s Disease. CoDAS 2015, 27, 248–254. [Google Scholar] [CrossRef]
- Blumin, J.H.; Pcolinsky, D.E.; Atkins, J.P. Laryngeal Findings in Advanced Parkinson’s Disease. Ann. Otol. Rhinol. Laryngol. 2004, 113, 253–258. [Google Scholar] [CrossRef] [PubMed]
- Martens, H.; Nuffelen, G.; Wouters, K.; Bodt, M. Reception of Communicative Functions of Prosody in Hypokinetic Dysarthria Due to Parkinson’s Disease. J. Parkinsons Dis. 2016, 6, 219–229. [Google Scholar] [CrossRef] [PubMed]
- Sachin, S.; Shukla, G.; Goyal, V.; Singh, S.; Aggarwal, V.; Behari, M. Clinical Speech Impairment in Parkinson’s Disease, Progressive Supranuclear Palsy, and Multiple System Atrophy. Neurol. India 2008, 56, 122–126. [Google Scholar] [CrossRef] [PubMed]
- Chenausky, K.; MacAuslan, J.; Goldhor, R. Acoustic Analysis of PD Speech. Parkinsons Dis. 2011, 2011, 435232. [Google Scholar] [CrossRef] [PubMed]
- Hrelja, M.; Klancnik, S.; Irgolic, T.; Paulic, M.; Balic, J.; Brezocnik, M. Turning Parameters Optimization Using Particle Swarm Optimization. In Proceedings of the 24th DAAAM International Symposium on Intelligent Manufacturing Automation, Zadar, Croatia, 23–26 October 2013; Volume 69, pp. 670–677. [Google Scholar] [CrossRef]
- Ficko, M.; Brezovnik, S.; Klancnik, S.; Balic, J.; Brezocnik, M.; Pahole, I. Intelligent Design of an Unconstrained Layout for a Flexible Manufacturing System. Neurocomputing 2010, 73, 639–647. [Google Scholar] [CrossRef]
- Affonso, C.; Rossi, A.; Vieira, F.; de Carvalho, A. Deep Learning for Biological Image Classification. Expert Syst. Appl. 2017, 85, 114–122. [Google Scholar] [CrossRef]
- Liu, C.H.; Xiong, W. Modelling and Simulation of Quality Risk Forecasting in a Supply Chain. Int. J. Simul. Model. 2015, 14, 359–370. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of Dysphonia Measurements for Telemonitoring of Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015–1022. [Google Scholar] [CrossRef]
- Sakar, C.O.; Kursun, O. Telediagnosis of Parkinson’s Disease Using Measurements of Dysphonia. J. Med. Syst. 2010, 34, 591–599. [Google Scholar] [CrossRef]
- Can, M. Neural Networks to Diagnose the Parkinson’s Disease. Southeast Eur. J. Soft Comput. 2013, 2. [Google Scholar] [CrossRef]
- Khemphila, A.; Boonjing, V. Heart Disease Classification Using Neural Network and Feature Selection. In Proceedings of the 2011 21st International Conference on Systems Engineering, Las Vegas, NV, USA, 16–18 August 2011; Volume 64. [Google Scholar] [CrossRef]
- Åström, F.; Koker, R. A Parallel Neural Network Approach to Prediction of Parkinson’s Disease. Expert Syst. Appl. 2011, 38, 12470–12474. [Google Scholar] [CrossRef]
- Ma, C.; Ouyang, J.; Chen, H.; Zhao, X. An Efficient Diagnosis System for Parkinson’s Disease Using Kernel-Based Extreme Learning Machine with Subtractive Clustering Features Weighting Approach. Comput. Math. Methods Med. 2014, 2014, 985789. [Google Scholar] [CrossRef]
- Lahmiri, S. Parkinson’s Disease Detection Based on Dysphonia Measurements. Phys. A Stat. Mech. Its Appl. 2016, 471, 98–105. [Google Scholar] [CrossRef]
- Lahmiri, S.; Dawson, D.; Shmuel, A. Performance of Machine Learning Methods in Diagnosing Parkinson’s Disease Based on Dysphonia Measures. Biomed. Eng. Lett. 2017, 8, 29–39. [Google Scholar] [CrossRef]
- Sakar, B.; Isenkul, M.; Sakar, C.; Sertbaş, A.; Gurgen, F.; Delil, S.; Apaydin, H.; Kursun, O. Collection and Analysis of a Parkinson Speech Dataset with Multiple Types of Sound Recordings. IEEE J. Biomed. Health Inform. 2013, 17, 828–834. [Google Scholar] [CrossRef]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 26 September 2018).
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. Available online: http://www.praat.org/ (accessed on 5 December 2016).
- Omid, M.; Mahmoudi, A.; Omid, M. Development of Pistachio Sorting System Using Principal Component Analysis (PCA) Assisted Artificial Neural Network (ANN) of Impact Acoustics. Expert Syst. Appl. 2010, 37, 7205–7212. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organization and Associative Memory/Teuvo Kohonen; Springer series in information sciences, 8; Springer: Berlin, Germany; New York, NY, USA, 1989; ISBN 978-3-540-51387-2. [Google Scholar]
- Svozil, D.; Kvasnicka, V.; Pospíchal, J. Introduction to Multi-Layer Feed-Forward Neural Networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- López Martínez, E.; Hernández, H.J.; Serna, S.; Campillo, B. Artificial Neural Networks to Estimate the Thermal Properties of an Experimental Micro-Alloyed Steel and Their Application to the Welding Thermal Analysis. J. Mech. Eng. 2015, 61–64, 741–750. [Google Scholar] [CrossRef]
- Xie, H.L.; Liu, Z.B.; Yang, J.Y.; Sheng, Z.Q.; Xu, Z.W. Modelling of Magnetorheological Damper for Intelligent Bionic Leg and Simulation of a Knee Joint Movement Control. Int. J. Simul. Model. 2016, 15, 144–156. [Google Scholar] [CrossRef]
- Klancnik, S.; Ficko, M.; Balic, J.; Pahole, I. Computer Vision-Based Approach to End Mill Tool Monitoring. Int. J. Simul. Model. 2015, 14, 571–583. [Google Scholar] [CrossRef]
- Simeunovic, N.; Kamenko, I.; Bugarski, V.; Jovanovic, M.; Lalic, B. Improving Workforce Scheduling Using Artificial Neural Networks Model. Adv. Prod. Eng. Manag. 2017, 12, 337–352. [Google Scholar] [CrossRef]
- Salih, A.; Abdelrhman, N. Determining the Efficient Structure of Feed-Forward Neural Network to Classify Breast Cancer Dataset. Int. J. Adv. Comput. Sci. Appl. 2014, 5. [Google Scholar] [CrossRef]
- Cheng, B.; Titterington, D.M. Neural Networks: A Review from a Statistical Perspective. Stat. Sci. 1994, 9, 2–30. [Google Scholar] [CrossRef]
- Xiang, C.; Ding, S.Q.; Heng Lee, T. Geometrical Interpretation and Architecture Selection of MLP. IEEE Trans. Neural Netw. 2005, 16, 84–96. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Starzyk, J.A.; Zhu, Z. Optimized Approximation Algorithm in Neural Networks without Overfitting. IEEE Trans. Neural Netw. 2008, 19, 983–995. [Google Scholar] [CrossRef] [PubMed]
- Chandrasekaran, M. Artificial Neural Network Modeling for Surface Roughness Prediction in Cylindrical Grinding of Al-SiCp Metal Matrix Composites and ANOVA Analysis. Adv. Prod. Eng. Manag. 2014, 9, 59–70. [Google Scholar] [CrossRef]
- Shen, Q.; Jiang, J.-H.; Jiao, C.-X.; Lin, W.-Q.; Shen, G.-L.; Yu, R.-Q. Hybridized Particle Swarm Algorithm for Adaptive Structure Training of Multilayer Feed-Forward Neural Network: QSAR Studies of Bioactivity of Organic Compounds. J. Comput. Chem. 2004, 25, 1726–1735. [Google Scholar] [CrossRef]
- Blum, A. Neural Networks in C++: An Object-Oriented Framework for Building Connectionist Systems; Wiley: New York, NY, USA, 1992; ISBN 0-471-53847-7. [Google Scholar]
- Duch, W.; Jankowski, N. Survey of Neural Transfer Functions. Neural Comput. Surv. 1999, 2, 163–212. [Google Scholar]
- Reunanen, J.; Guyon, I.; Elisseeff, A. Overfitting in Making Comparisons Between Variable Selection Methods. J. Mach. Learn. Res. 2003, 3, 1371–1382. [Google Scholar]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Kallel, R.; Cottrell, M.; Vigneron, V. Bootstrap for Neural Model. Selection. Neurocomputing 2002, 48, 175–183. [Google Scholar] [CrossRef]
- Kohavi, R.; Provost, F. Glossary of Terms. Mach. Learn. 1998, 2, 217–274. [Google Scholar] [CrossRef]
- Behroozi, M.; Sami, A. A Multiple-Classifier Framework for Parkinson’s Disease Detection Based on Various Vocal Tests. Int. J. Telemed. Appl. 2016, 2016, 6837498. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Number | Feature | Mean | Stand. Deviation |
|---|---|---|---|
| 1 | Jitter (local) | 2.67952 | 1.76505 |
| 2 | Jitter (local, absolute) | 0.00017 | 0.00011 |
| 3 | Jitter (rap) | 1.24705 | 0.97946 |
| 4 | Jitter (ppq5) | 1.34832 | 1.13874 |
| 5 | Jitter (ddp) | 3.74116 | 2.93844 |
| 6 | Number of pulses | 12.91839 | 5.45220 |
| 7 | Number of periods | 1.19489 | 0.42007 |
| 8 | Mean period | 5.69960 | 3.01518 |
| 9 | Standard dev. of period | 7.98355 | 4.84089 |
| 10 | Shimmer (local) | 12.21535 | 6.01626 |
| 11 | Shimmer (local, dB) | 17.09844 | 9.04554 |
| 12 | Shimmer (apq3) | 0.84601 | 0.08571 |
| 13 | Shimmer (apq5) | 0.23138 | 0.15128 |
| 14 | Shimmer (apq11) | 9.99954 | 4.29130 |
| 15 | Shimmer (dda) | 163.3683 | 56.02168 |
| 16 | Fraction of locally unvoiced frames | 168.7276 | 55.96991 |
| 17 | Number of voice breaks | 27.54763 | 36.67262 |
| 18 | Degree of voice breaks | 134.5381 | 47.05806 |
| 19 | Median pitch | 234.8760 | 121.5412 |
| 20 | Mean pitch | 109.7442 | 150.0277 |
| 21 | Standard deviation | 105.9692 | 149.4171 |
| 22 | Minimum pitch | 0.00655 | 0.00188 |
| 23 | Maximum pitch | 0.00084 | 0.00072 |
| 24 | Autocorrelation | 27.68286 | 20.97529 |
| 25 | Noise-to-harmonic | 1.13462 | 1.16148 |
| 26 | Harmonic-to-noise | 12.37001 | 15.16192 |
| Predicted | ||
|---|---|---|
| Actual | Positive | Negative |
| Positive | TP | FN |
| Negative | FP | TN |
| ID | Voice Sample | Related Features | Related Features | Related Features | Related Features | Related Features |
|---|---|---|---|---|---|---|
| 1 | Vowel “a” | All | 24 | None | None | None |
| 2 | Vowel “o” | All | 19, 24 | 24, 19 | None | None |
| 3 | Vowel “u” | All | 13, 21 | None | None | None |
| 4 | Number 1 | All | 1, 2, 3, 4, 5, 24 | 1, 2, 3, 4, 5, 24 | 1, 2, 4 | 1, 4 |
| 5 | Number 2 | All | 1, 2, 8, 9, 10, 11 | 2, 8, 9, 10, 11 | 10 | None |
| 6 | Number 3 | All | 12, 13, 14, 17, 19, 23, 25, 26 | 17, 19, 23, 25, 26 | 17, 19, 23, 25, 26 | 17, 25 |
| 7 | Number 4 | All | 1, 2, 3, 4, 5, 10, 20, 21 | 1, 2, 3, 4, 5, 10 | 1, 2, 3, 4, 5 | 1, 2, 3, 4, 5 |
| 8 | Number 5 | All | 24 | 24 | 24 | None |
| 9 | Number 6 | All | 10, 23, 26 | None | None | None |
| 10 | Number 7 | All | 17, 19, 24, 26 | None | None | None |
| 11 | Number 8 | All | 9, 10 | 9 | None | None |
| 12 | Number 9 | All | 26 | 26 | None | None |
| 13 | Number 10 | All | 1, 2, 3, 5, 8, 9, 11, 23 | None | None | None |
| 14 | Short sentence 1 | All | None | None | None | None |
| 15 | Short sentence 2 | All | 3, 4, 5, 24, 25, 26 | 25, 26 | 25 | 25 |
| 16 | Short sentence 3 | All | 3, 4, 5, 10, 25, 26 | 4, 10, 25, 26 | 10, 26 | 26 |
| 17 | Short sentence 4 | All | 1, 2, 3, 4, 5, 10, 24, 25, 26 | 1, 2, 3, 4, 5, 10, 26 | 1, 2, 3, 4, 5, 10, 26 | 3, 4, 5, 10 |
| 18 | Word 1 | All | 1, 2, 4, 7 | 1, 2 | None | None |
| 19 | Word 2 | All | 10 | None | None | None |
| 20 | Word 3 | All | 17, 19, 23, 25 | 17, 19, 23, 25 | 17, 19 | 17, 19 |
| 21 | Word 4 | All | 3, 5 | None | None | None |
| 22 | Word 5 | All | 26 | 26 | None | None |
| 23 | Word 6 | All | 2, 10 | None | None | None |
| 24 | Word 7 | All | 17 | None | None | None |
| 25 | Word 8 | All | 1, 2, 3, 4, 5, 10, 17, 19, 23, 24, 25 | 1, 2, 3, 5, 17, 19, 23, 25 | 4, 17, 19 | 17, 19 |
| 26 | Word 9 | All | 2, 24 | 24 | None | None |
| Number of classifiers | 26 | 25 | 16 | 10 | 8 | |
| ID | Voice Sample | Related Features | Related Features | Related Features | Related Features | Related Features |
|---|---|---|---|---|---|---|
| 1 | Vowel “a” | All | 6, 7, 9, 10, 14 | 10 | None | None |
| 2 | Vowel “o” | All | 17, 24 | 24 | 24 | 24 |
| 3 | Vowel “u” | All | 24 | 24 | None | None |
| 4 | Number 1 | All | 1, 2, 3, 4, 5, 6, 7, 9,10, 24 | 1, 2, 3, 4, 5, 6, 24 | 1, 2, 4, 24 | None |
| 5 | Number 2 | All | 1, 2, 3, 4, 5, 6, 8, 9, 10, 11 | 1, 8, 9, 10, 11 | 9 | None |
| 6 | Number 3 | All | 12, 13, 14, 17, 19, 23, 24, 25, 26 | 12, 13, 17, 19, 23, 25, 26 | 17, 23, 25, 26 | 17,25,26 |
| 7 | Number 4 | All | 1, 2, 3, 4, 5, 10, 20, 21 | 1, 2, 3, 4, 5, 10, | 1, 2, 3, 4, 5, | 1,2,3,4,5 |
| 8 | Number 5 | All | 24 | 24 | 24 | None |
| 9 | Number 6 | All | 10, 24, 26 | 10, 26 | None | None |
| 10 | Number 7 | All | 1, 3, 4, 5, 8, 11, 24 | 4, 5 | 4 | None |
| 11 | Number 8 | All | 9 | 9 | 9 | None |
| 12 | Number 9 | All | 2, 3, 4, 5, 21, 26 | 4, 26 | 4 | None |
| 13 | Number 10 | All | 1, 3, 5, 20, 23 | 23 | None | None |
| 14 | Short sentence 1 | All | 25, 26 | None | None | None |
| 15 | Short sentence 2 | All | 3, 4, 5, 8, 10, 11, 17, 25, 26 | 24, 25, 26 | 25 | 25 |
| 16 | Short sentence 3 | All | 1, 2, 3, 4, 5, 10, 17, 24, 25, 26 | 10, 26 | 26 | None |
| 17 | Short sentence 4 | All | 1, 2, 3, 4, 5, 10 | 1, 2, 3, 4, 5, 10 | 1, 3, 4, 5, 10, 25, 26 | 3,5 |
| 18 | Word 1 | All | 1, 2, 3, 4, 5, 7 | 1, 2, 4, 7 | 1, 4 | None |
| 19 | Word 2 | All | None | None | None | None |
| 20 | Word 3 | All | 17, 19, 23, 25 | 17, 19, 25 | 17, 25 | 17 |
| 21 | Word 4 | All | 3, 5 | None | None | None |
| 22 | Word 5 | All | 17, 19, 26 | None | None | None |
| 23 | Word 6 | All | 10, 17 | 10 | None | None |
| 24 | Word 7 | All | 3, 5, 23 | None | None | None |
| 25 | Word 8 | All | 1, 2, 3, 4, 5, 10, 14, 17, 19, 23, 25 | 2, 17, 19, 25 | 17, 19 | 17 |
| 26 | Word 9 | All | 2, 3 4, 5, 24 | 24 | None | None |
| Number of classifiers | 26 | 25 | 21 | 15 | 7 | |
| ID | Voice Sample | Related Features |
|---|---|---|
| 1 | Vowel “a” | None |
| 2 | Vowel “o” | 24 |
| 3 | Vowel “u” | None |
| 4 | Number 1 | 1, 2, 3, 4, 5, 24 |
| 5 | Number 2 | 2, 9, 10 |
| 6 | Number 3 | 17, 19, 23, 25, 26 |
| 7 | Number 4 | 1, 2, 3, 4, 5, 10 |
| 8 | Number 5 | 24 |
| 9 | Number 6 | None |
| 10 | Number 7 | None |
| 11 | Number 8 | 9 |
| 12 | Number 9 | 26 |
| 13 | Number 10 | None |
| 14 | Short sentence 1 | None |
| 15 | Short sentence 2 | 25, 26 |
| 16 | Short sentence 3 | 4, 10, 25, 26 |
| 17 | Short sentence 4 | 1, 2, 3, 4, 5, 10, 26 |
| 18 | Word 1 | 2 |
| 19 | Word 2 | None |
| 20 | Word 3 | 17, 19, 23, 25 |
| 21 | Word 4 | None |
| 22 | Word 5 | None |
| 23 | Word 6 | None |
| 24 | Word 7 | None |
| 25 | Word 8 | 1, 2, 3, 5, 6, 17, 19, 23, 25 |
| 26 | Word 9 | 24 |
| Number of classifiers | 15 | |
| Classifier | Feature Selection | Accuracy (%) | Sensitivity (%) | Specificity (%) | MCC |
|---|---|---|---|---|---|
| k-NN (k = 1) | / [37] | ||||
| A-MCFS [59] | |||||
| k-NN (k = 3) | / [37] | ||||
| A-MCFS [59] | |||||
| k-NN (k = 5) | / [37] | ||||
| A-MCFS [59] | |||||
| k-NN (k = 7) | / [37] | ||||
| A-MCFS [59] | |||||
| SVM (linear kernel) | / [59] | ||||
| A-MCFS [59] | |||||
| SVM (RBF kernel) | / [59] | ||||
| A-MCFS [59] | |||||
| ANN 10 | / | ||||
| ANN 5-10-5 | Pearson’s | ||||
| ANN 10 | Kendall’s | ||||
| ANN 10-10 | PCA | ||||
| ANN 10-10 | SOM | ||||
| ANN (fine-tuned) | A-MCFS |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berus, L.; Klancnik, S.; Brezocnik, M.; Ficko, M. Classifying Parkinson’s Disease Based on Acoustic Measures Using Artificial Neural Networks. Sensors 2019, 19, 16. https://doi.org/10.3390/s19010016
Berus L, Klancnik S, Brezocnik M, Ficko M. Classifying Parkinson’s Disease Based on Acoustic Measures Using Artificial Neural Networks. Sensors. 2019; 19(1):16. https://doi.org/10.3390/s19010016
Chicago/Turabian StyleBerus, Lucijano, Simon Klancnik, Miran Brezocnik, and Mirko Ficko. 2019. "Classifying Parkinson’s Disease Based on Acoustic Measures Using Artificial Neural Networks" Sensors 19, no. 1: 16. https://doi.org/10.3390/s19010016
APA StyleBerus, L., Klancnik, S., Brezocnik, M., & Ficko, M. (2019). Classifying Parkinson’s Disease Based on Acoustic Measures Using Artificial Neural Networks. Sensors, 19(1), 16. https://doi.org/10.3390/s19010016