Cloud-Based Behavioral Monitoring in Smart Homes



Abstract
1. Introduction
2. Materials and Methods
2.1. System Architecture and Components
- Passive infrared (PIR) sensors for motion detection, suitable for tracing room occupancy. A picture of a fully-assembled Wi-Fi PIR is reported in Figure 1;
- Magnetic contact sensors, useful for monitoring open/close states of different objects. For example, interactions with doors, drawers and medical cabinets can be easily detected with such sensors;
- Bed occupancy sensor, useful in tracing sleeping patterns;
- Chair occupancy sensor, to gather information on how much time and when a user sits on a chair/armchair/sofa;
- Toilet presence sensor, specifically developed to keep track of daily toilet use;
- Fridge sensor, to detect openings of the fridge door; and
- Power meter, to monitor home appliances use, such as TV, microwave oven, air conditioning, etc.
- high-bandwidth handling of incoming messages, originating from multiple IoT devices;
- ability to perform operations on streaming data, possibly being automatically triggered at the arrival of specific messages;
- scalability, allowing future massive deployment of pilots; and
- high service availability, in order to reliably collect and store data.
- Detection of the sensor’s low-battery status and triggering of related alarms on the user interface;
- Monitoring sensor connectivity: sensors (even when inactive) send keep-alive messages at a given frequency (e.g., 60 min intervals). Sensor-specific rules can be created to trigger alarms or countermeasures if a fails to communicate; and
- Detection of inconsistent or grossly abnormal values, and triggering of countermeasures, based on simple rules, e.g., a front door kept open for a long period, or prolonged bed occupancy may trigger caregiver notifications.
2.2. Data Analysis
- Behavior explanatory models (BEM), augmented with outlier detection techniques, are useful for precisely assessing the presence of longitudinal trends in a given time series of interest, e.g., nightly bathroom visits. This can be carried out at multiple time resolutions (e.g., n weeks, n = {2,4,6, …}) and exploiting rolling windows, to detect temporary phenomena.
- Sensor profiles (SP) are useful to compare patterns of single sensors from two different periods. Exploiting a statistical hypothesis testing framework, it is possible to objectively assess whether changes in patterns took place or differences between them are just measurement noise.
- Multivariate habits clusters (MHC) are useful to find recurrent patterns in user data, possibly involving more sensors simultaneously, and give insights on users’ habits by relaxing the assumption of population comparison as per the direct sensor profile comparison.
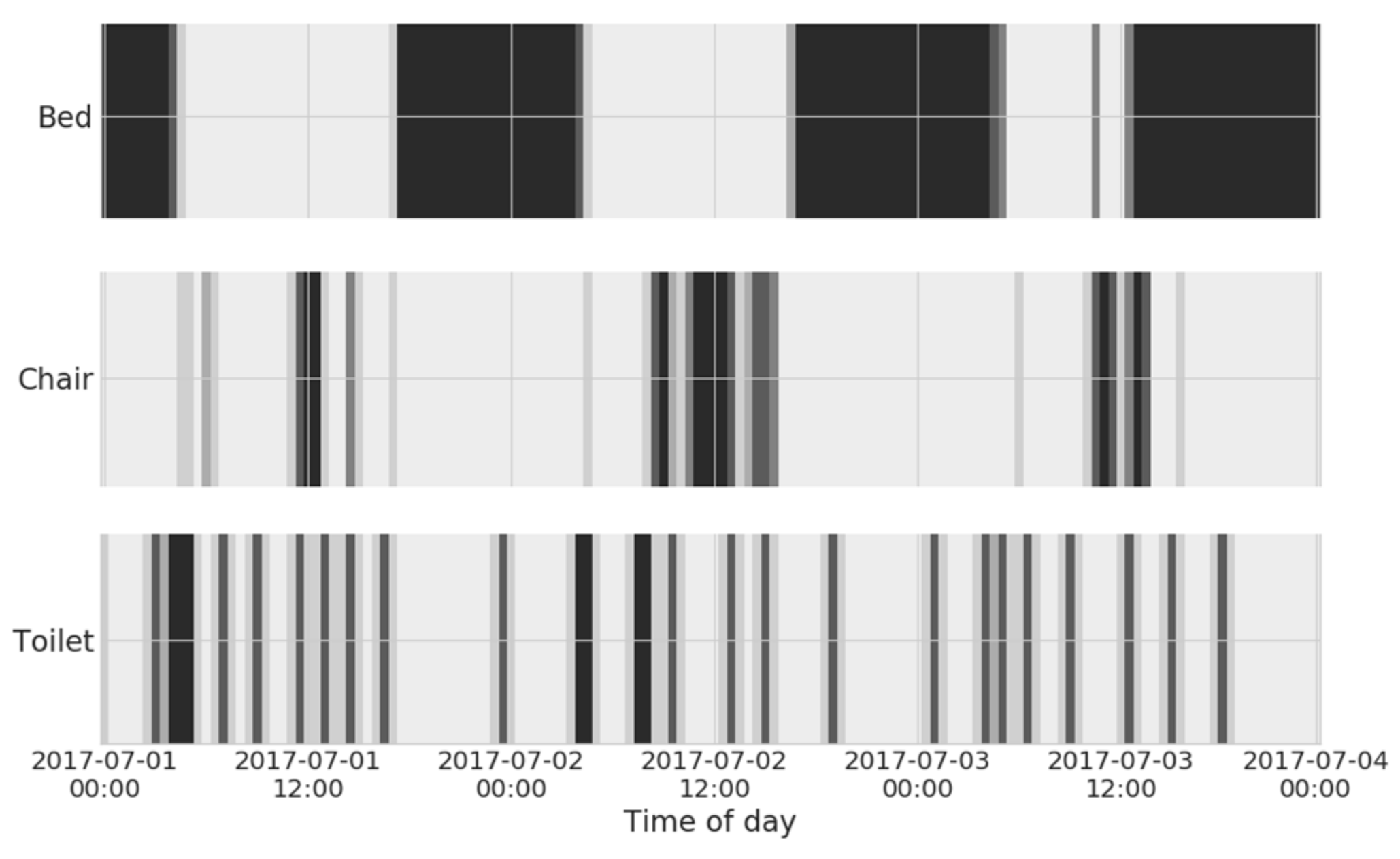
2.2.1. Sensor Data Description and Pre-Processing
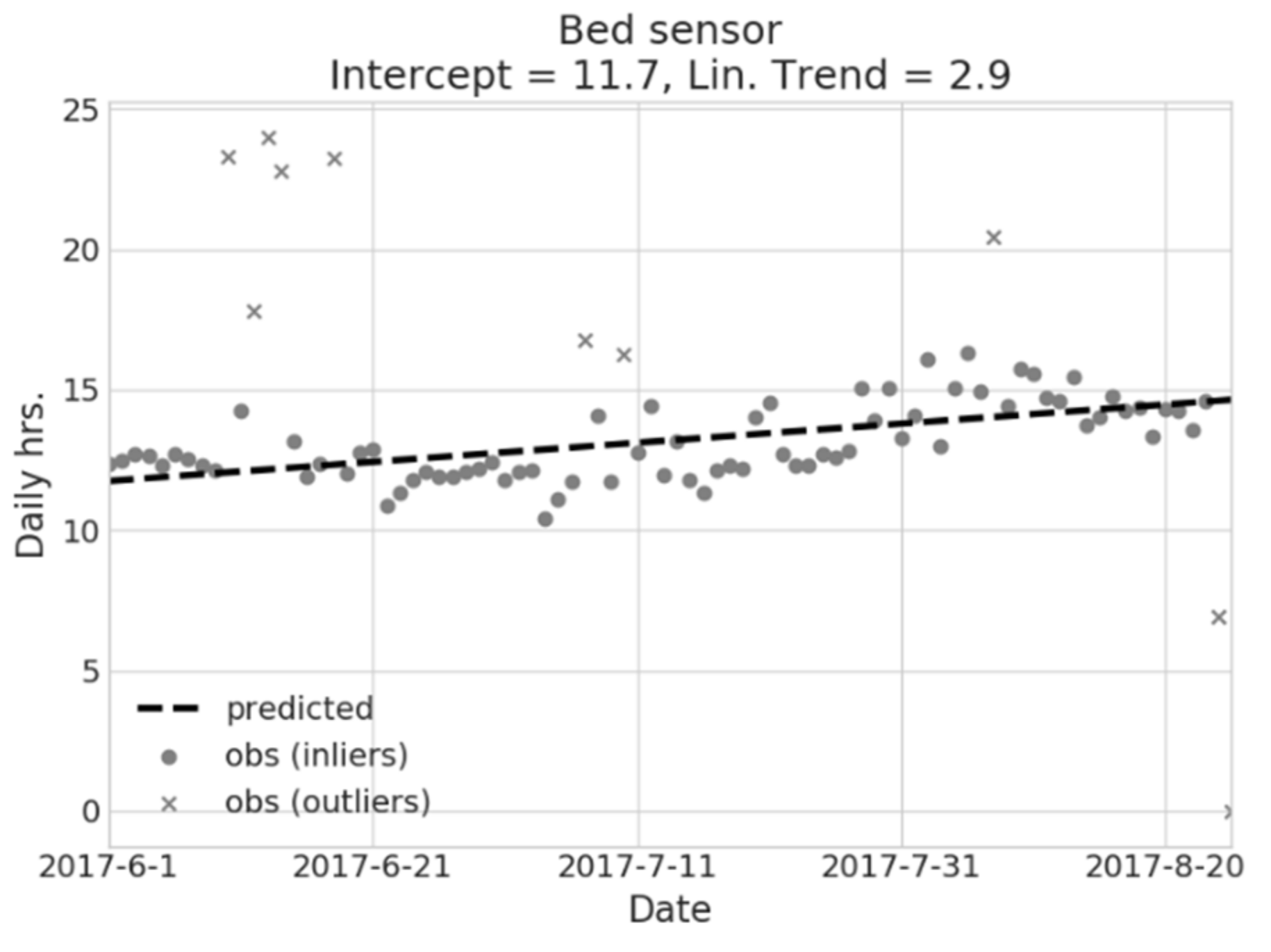
2.2.2. Behavior Explanatory Models (BEM)
- Real-valued regressions. This operation may be conducted by exploiting different frameworks, such as ordinary least squares (OLS), ridge regression, lasso, Bayesian regression, and many others. This kind includes, for example, the amount of time a person spends sitting, lying in bed, watching TV, and so on.
- Discrete-valued regressions. This kind includes, for example, the number of toilet visits during night or the whole day, the number of awakenings from bed, and so on. These quantities are better modeled as discrete random variables, therefore suggesting the application of Poisson/negative binomial regression frameworks.
- bias term: the average event count or measure;
- linear trend term: a linearly-varying feature trying to detect longitudinal increments (or decreases); and
- weekend day: a binary feature, which is false during weekdays and true for weekends. This allows capturing differences between those two categories.
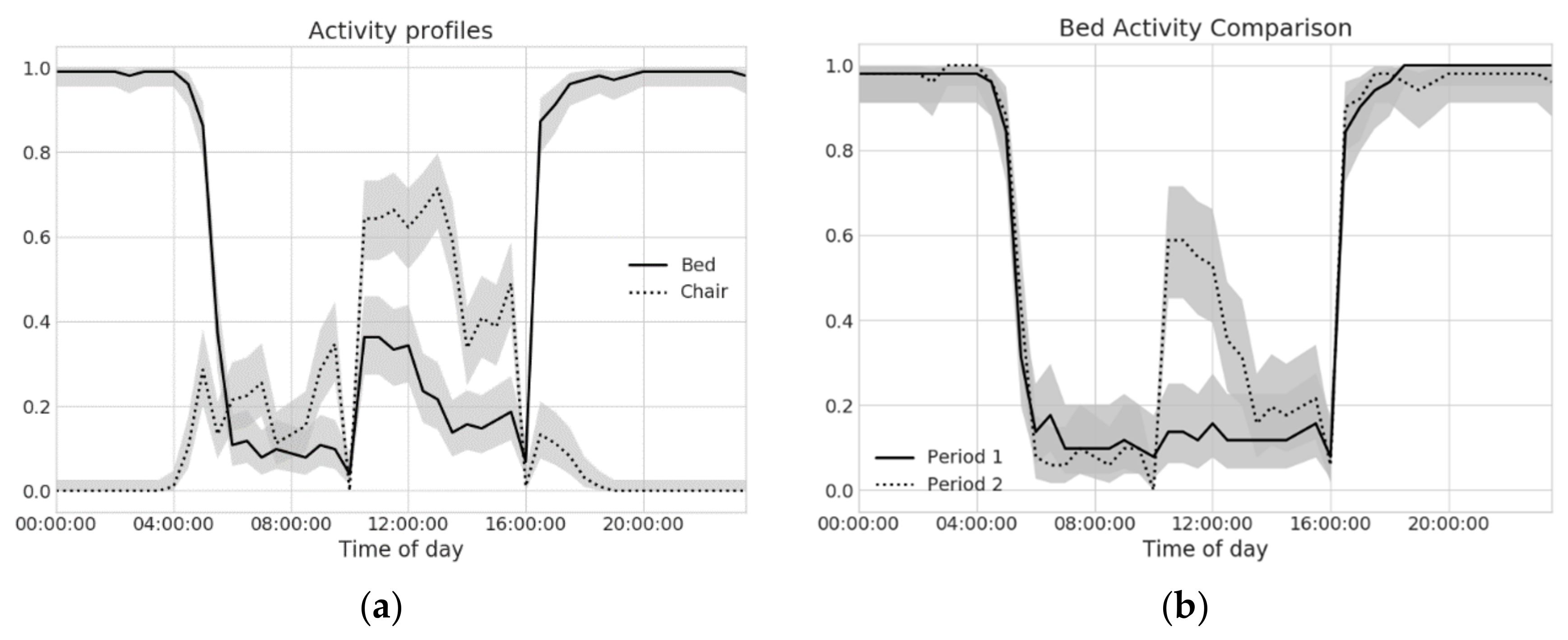
2.2.3. Sensor Profile (SP) Comparison
- For real-valued data, we estimate the expected percentage of time a sensor is seen as active within a given time bin; and
- For discrete-valued data, the expected probability of seeing an activation within a given time bin is estimated, instead. This is particularly useful for more “impulsive” (i.e., sparsely-activated) data, such as fridge/drawer opening or toilet visits.
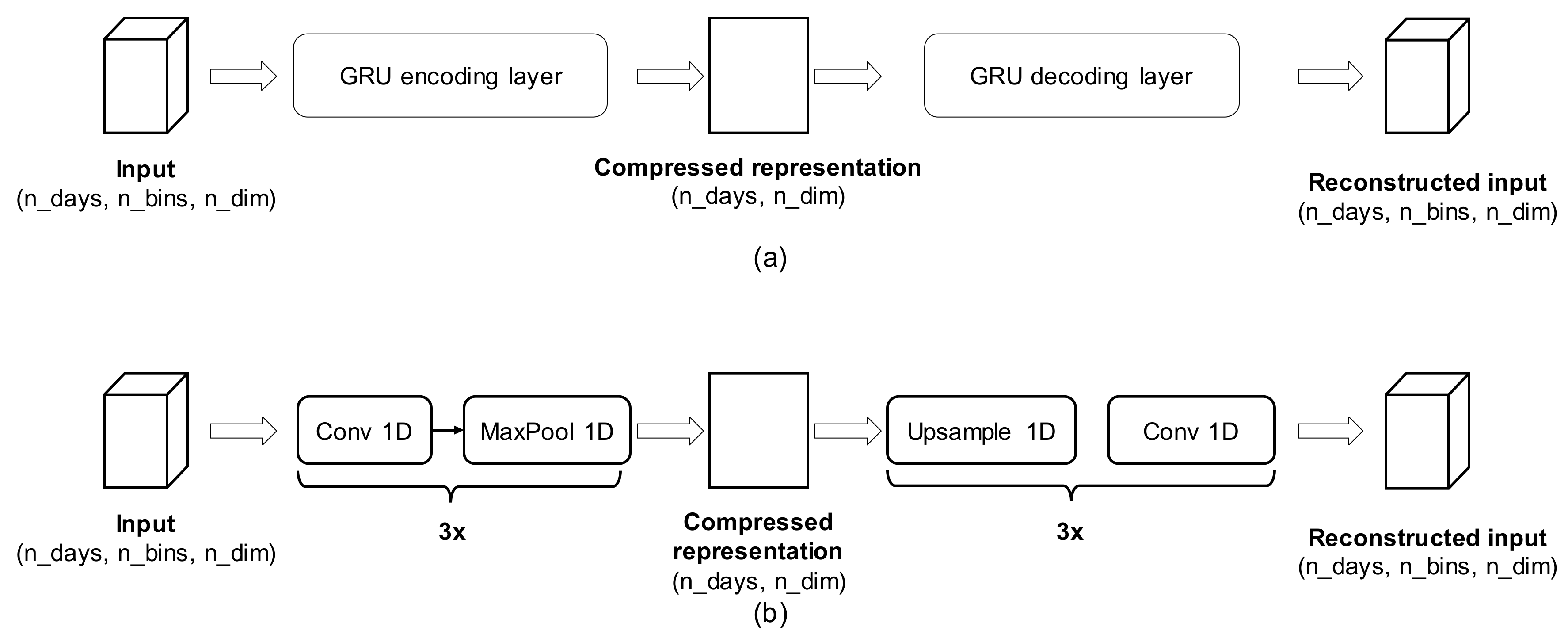
2.2.4. Multivariate Habits Clustering (MHC)
- Recurrent Neural Networks (RNN), among which LSTM (Long-Short Term Memory) [24] and GRU (Gated Recurrent Units) [25] have proven great potential in extracting relevant features, being capable of capturing both fine grained and long term time dependencies in the data. They are commonly exploited in sequence to sequence prediction problems, including machine translation and time series forecasting. A GRU cell can be described as being composed of a memory cell, an update gate and a reset gate. The cell is responsible for remembering values over arbitrary time intervals, whereas the gates control the flow of information from input data, previous output data and the cell state itself. Mathematically, a GRU can be described by the following equations:where the operator ° denotes the Hadamard product (entry-wise product), subscript t and t − 1 refer to current and previous time-step, respectively, xt is the input vector to the GRU unit, zt the update gate’s vector, rt the reset gate’s vector, ht the output vector of the GRU unit, σg is the sigmoid activation function, σh is the hyperbolic tangent activation function, and matrices Wk, Uk, bk, k = {z, r, h} are weight and bias terms that need to be learned from data.
- 1D Convolutional Neural Network (CNN). CNN have largely become popular in machine vision tasks for their ability to find scale-invariant features, when coupled with max-pooling techniques. By performing convolutions only along the temporal axis (Conv1D nets) [26], it is possible to extract relevant features for time series prediction. In general, a convolutional layer operates as follows:where xi and yj are the i-th/j-th input/output map, kij is the convolution kernel (whose size is also called the receptive field) between the i-th input map and the j-th output map, * is the convolution operator, and f the activation function. In our case, activation is ReLU [27]:Max pooling is defined as taking the maximum value over a given receptive field, for example a kxk patch in 2D or a kx1 patch in 1D. Each convolutional layer is characterized by a parameter, i.e., the number of filters, which expresses how many features representations will be learned by it.
3. Results
3.1. Behavioral Explanatory Models
- Overall bed presence (real-valued, unit: hours);
- Nightly (7 p.m.–9 a.m.) bed presence (real-valued, unit: hours);
- Overall chair presence (real-valued, unit: hours);
- Electric appliance use (real-valued, unit: hours);
- Toilet sensor (distinct event counts); and
- Door sensor (distinct event counts).
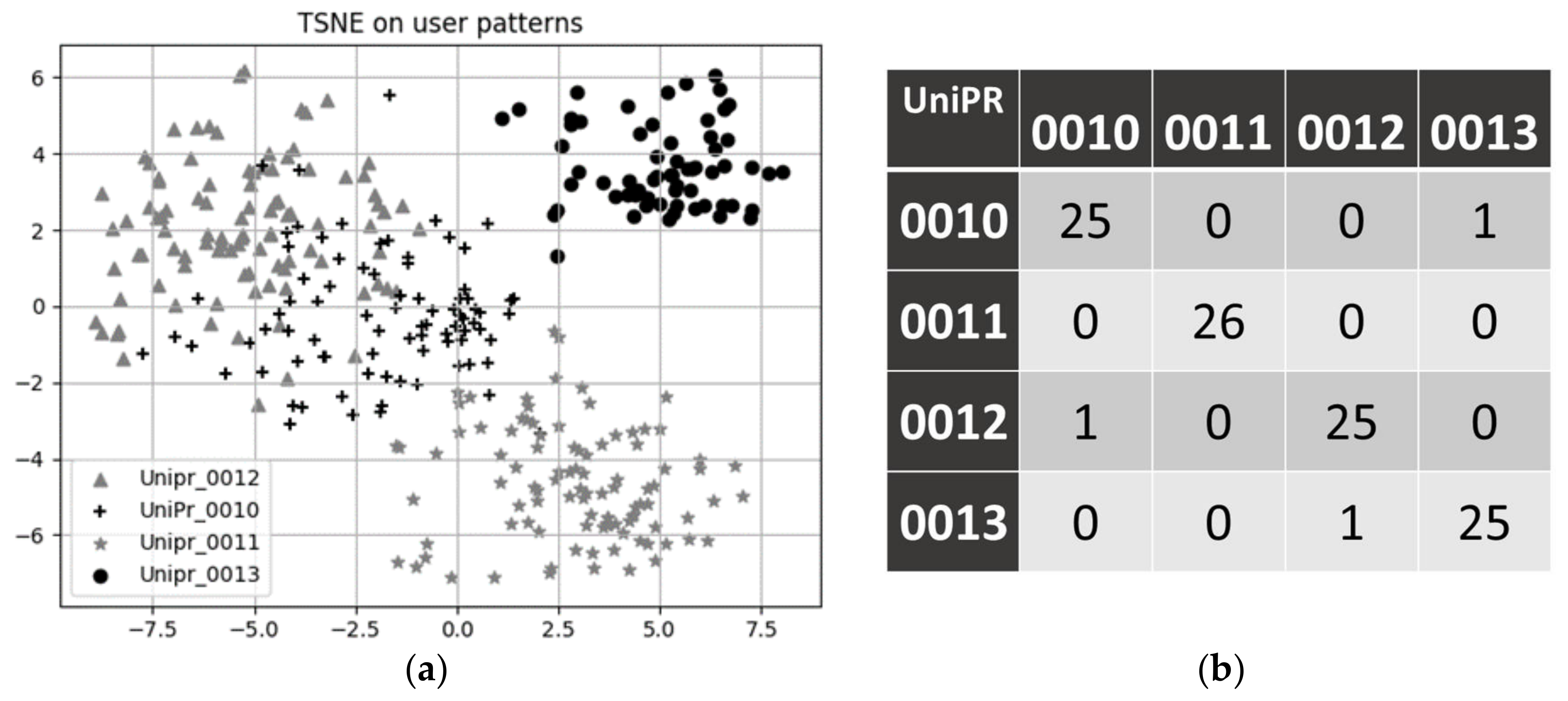
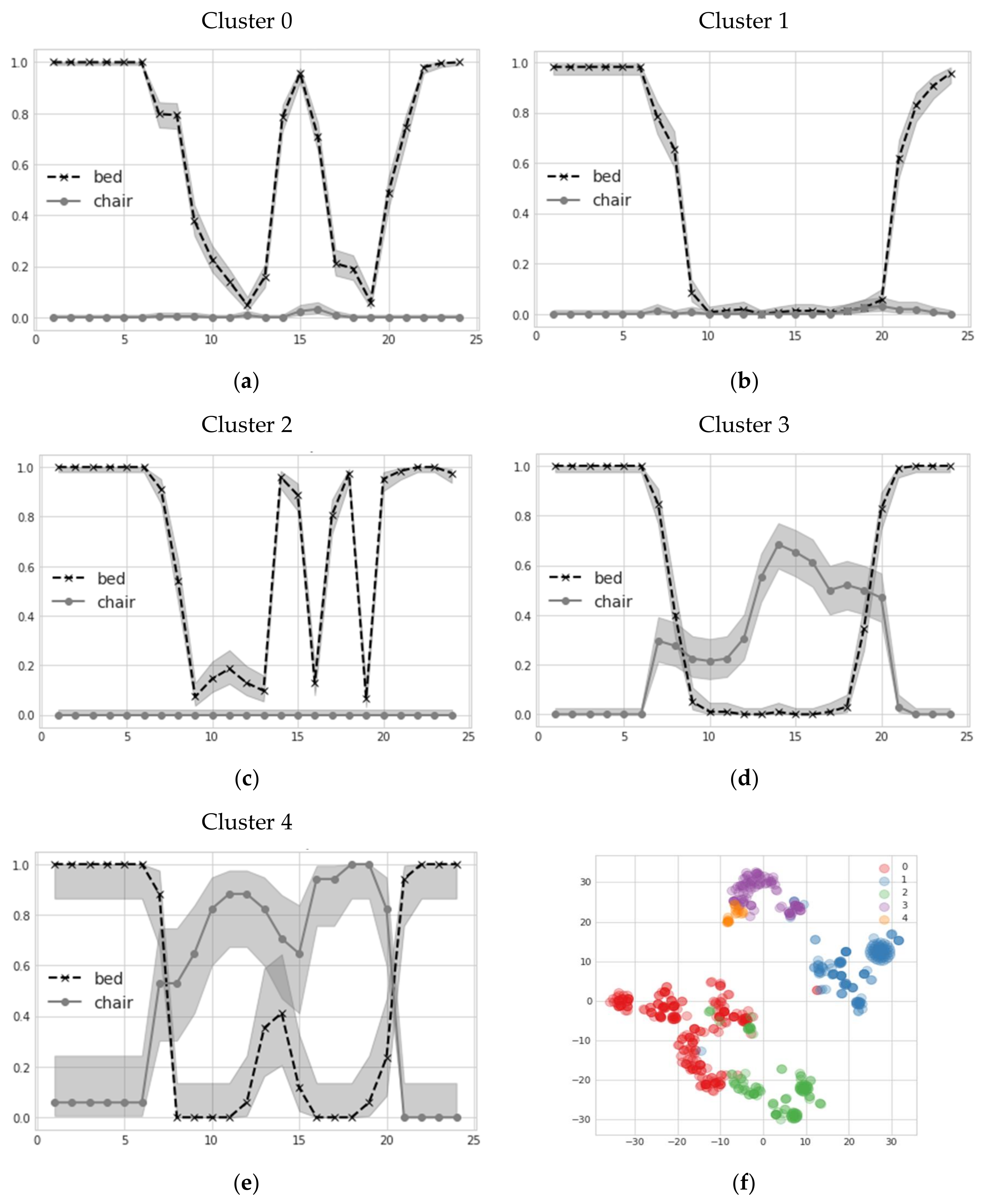
3.2. Sensor Profile Comparison and Multivariate Habit Clustering
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Bloom, D.E.; Boersch-Supan, A.; McGee, P.; Seike, A. Population aging: Facts, challenges, and responses. Benefits Compens. Int. 2011, 41, 22. [Google Scholar]
- Dobre, C.; Mavromoustakis, C.X.; Garcia, N.M.; Mastorakis, G.; Goleva, R.I. Introduction to the AAL and ELE Systems. In Ambient Assisted Living and Enhanced Living Environments, Principles, Technologies and Control; Elsevier: New York, NY, USA, 2017; pp. 1–16. [Google Scholar]
- Losardo, A.; Bianchi, V.; Grossi, F.; Matrella, G.; de Munari, I.; Ciampolini, P. Web-enabled home assistive tools. In Assistive Technology Research Series; IOS Press: Amsterdam, The Netherlands, 2011; Volume 29, pp. 448–455. [Google Scholar]
- Whitten, P.S.; Mair, F.S.; Haycox, A.; May, C.R.; Williams, T.L.; Hellmich, S. Systematic review of cost effectiveness studies of telemedicine interventions. BMJ 2002, 324, 1434–1437. [Google Scholar] [CrossRef] [PubMed]
- Ni, Q.; Hernando, A.G.; de la Cruz, I. The Elderly’s Independent Living in Smart Homes: A Characterization of Activities and Sensing Infrastructure Survey to Facilitate Services Development. Sensors 2015, 15, 11312–11362. [Google Scholar] [CrossRef] [PubMed]
- Ghayvat, H.; Mukhopadhyay, S.; Gui, X.; Suryadevara, N. WSN- and IOT-Based Smart Homes and Their Extension to Smart Buildings. Sensors 2015, 15, 10350–10379. [Google Scholar] [CrossRef] [PubMed]
- Zoha, A.; Gluhak, A.; Imran, M.; Rajasegarar, S. WSN- and IOT-Based Smart Homes and Their Extension to Smart Buildings. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A Smart Home in a Box. Computer 2013, 46, 62–69. [Google Scholar] [CrossRef] [PubMed]
- Lühr, S.; West, G.; Venkatesh, S. Recognition of emergent human behaviour in a smart home: A data mining approach. Pervasive Mob. Comput. 2007, 3, 95–116. [Google Scholar] [CrossRef]
- Gayathri, K.S.; Elias, S.; Shivashankar, S. An Ontology and Pattern Clustering Approach for Activity Recognition in Smart Environments. In Proceedings of the Third International Conference on Soft Computing for Problem Solving; Springer: New Delhi, India, 2014; Volume 1, pp. 833–843. [Google Scholar] [CrossRef]
- Choi, S.; Kim, E.; Oh, S. Human behavior prediction for smart homes using deep learning. In Proceedings of the 2013 IEEE RO-MAN, Gyeongju, Korea, 26–29 August 2013; pp. 173–179. [Google Scholar] [CrossRef]
- Lundström, J.; Järpe, E.; Verikas, A. Detecting and exploring deviating behaviour of smart home residents. Expert Syst. Appl. 2016, 55, 429–440. [Google Scholar] [CrossRef]
- Sprint, G.; Cook, D.J.; Fritz, R.; Schmitter-Edgecombe, M. Using Smart Homes to Detect and Analyze Health Events. Computer 2016, 49, 29–37. [Google Scholar] [CrossRef]
- Sprint, G.; Cook, D.J.; Schmitter-Edgecombe, M. Unsupervised detection and analysis of changes in everyday physical activity data. J. Biomed. Inform. 2016, 63, 54–65. [Google Scholar] [CrossRef] [PubMed]
- Dawadi, P.N.; Cook, D.J.; Schmitter-Edgecombe, M. Automated Cognitive Health Assessment from Smart Home-Based Behavior Data. IEEE J. Biomed. Health Inform. 2016, 20, 1188–1194. [Google Scholar] [CrossRef] [PubMed]
- Suryadevara, N.K.; Mukhopadhyay, S.C.; Wang, R.; Rayudu, R.K. Forecasting the behavior of an elderly using wireless sensors data in a smart home. Eng. Appl. Artif. Intell. 2013, 26, 2641–2652. [Google Scholar] [CrossRef]
- Guerra, C.; Bianchi, V.; Grossi, F.; Mora, N.; Losardo, A.; Matrella, G.; de Munari, I.; Ciampolini, P. The HELICOPTER Project: A Heterogeneous Sensor Network Suitable for Behavioral Monitoring. In Ambient Assisted Living. ICT-Based Solutions in Real Life Situations: 7th International Work-Conference; Springer: Cham, Switzerland, 2015; pp. 152–163. [Google Scholar]
- Mora, N.; Losardo, A.; de Munari, I.; Ciampolini, P. Self-tuning behavioral analysis in AAL ‘FOOD’ project pilot environments. Stud. Health Technol. Inform. 2015, 217, 295–299. [Google Scholar] [PubMed]
- Available online: http://www.aal-europe.eu/projects/noah/ (accessed on 15 March 2018).
- Available online: http://www.activageproject.eu/ (accessed on 15 March 2018).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer New York Inc.: New York, NY, USA, 2016; ISBN 0387848576. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2016, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2009, 12, 2451–2471. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Maas, A.; Hannun, A.; Ng, A. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Ma-chine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Van der Maaten, L.J.P.; Hinton, G.E. Visualizing High-Dimensional Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Song, J.; Takakura, H.; Okabe, Y.; Kwon, Y. Unsupervised anomaly detection based on clustering and multiple one-class SVM. IEICE Trans. Commun. 2009, E92, 1981–1990. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 IEEE International Conference on Data Mining, ICDM, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Description |
|---|---|
| Gtw_id | Gateway unique identifier |
| Obj_id | Sensor unique identifier (within the same Gtw_id domain) |
| Variable_id | Identifier of the variable (e.g., sensor status, battery level etc.) |
| Int_value | Value of the variable, integer |
| Float_value | Value of the variable, floating point |
| String_value | Value of the variable, string |
| Flags | Internal use |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mora, N.; Matrella, G.; Ciampolini, P. Cloud-Based Behavioral Monitoring in Smart Homes. Sensors 2018, 18, 1951. https://doi.org/10.3390/s18061951
Mora N, Matrella G, Ciampolini P. Cloud-Based Behavioral Monitoring in Smart Homes. Sensors. 2018; 18(6):1951. https://doi.org/10.3390/s18061951
Chicago/Turabian StyleMora, Niccolò, Guido Matrella, and Paolo Ciampolini. 2018. "Cloud-Based Behavioral Monitoring in Smart Homes" Sensors 18, no. 6: 1951. https://doi.org/10.3390/s18061951
APA StyleMora, N., Matrella, G., & Ciampolini, P. (2018). Cloud-Based Behavioral Monitoring in Smart Homes. Sensors, 18(6), 1951. https://doi.org/10.3390/s18061951