1. Introduction
In recent decades, neural network (NN) methods for localization have been studied intensively, with radial basis function (RBF) networks [
1,
2,
3,
4] and multilayer perceptron (MLP) networks [
5,
6,
7,
8] applied for localization. For real-time direction-of-arrival (DOA) estimation problems, a minimal resource allocation network (MRAN) for DOA estimation under array sensor failure in a noisy environment has been developed [
9]. Results indicate the superior performance of MRAN-based DOA estimation in the presence of different antenna effects, failure conditions, and noise levels. A modular NN for the DOA estimation of two coherent sources has also been proposed [
10]. A modified neural multiple-source tracking algorithm (MN-MUST) [
11] was developed for real-time multiple-source tracking problems, wherein a spatial filtering stage was inserted to considerably improve the performance of the system. For wireless sensor networks (WSNs), a flexible MLP-based model for the accurate localization of sensors has been reported [
12], with simulation experiments showing that the location accuracy can be enhanced by increasing the grid sensor density. A new artificial neural network (ANN) approach [
13] has been developed to moderate the effect of miscellaneous noise sources and harsh factory conditions on the localization of wireless sensors. In terms of wireless communication systems, a novel ANN algorithm that utilizes time-of-arrival (TOA) and angle-of-arrival (AOA) measurements to locate mobile stations in non-line-of-sight environments has been proposed [
14]. Additionally, a fingerprint-based localization methodology was applied in an experimental indoor environment, and the processing received signal strength indicator (RSSI) information for determining the position was used to train the NN [
15]. Similarly, an MLP-NN has been applied to wireless local area networks [
16], where a flexible mapping was built between the raw received signal strength (RSS) measurements and the position of the mobile terminal.
Clearly, the above localization methods are conventional two-step techniques that firstly estimate positioning parameters (such as AOA, TOA, and RSS) and then use these parameters to determine the source positions. It has been verified that conventional two-step localization methods are suboptimal, because these positioning parameters are estimated at each base station separately, without using the constraint that all parameters must correspond to the same transmitter. Weiss and Amar proposed the direct position determination (DPD) method [
17,
18,
19,
20,
21], which directly localizes transmitters from sensor outputs. Compared with conventional two-step localization, DPD avoids the measurement-source association problem in the estimation of positioning parameters for multiple-source scenarios, leading to higher positioning accuracy. However, existing DPD methods, whether maximum likelihood (ML)-based algorithms [
17] or multiple signal classification (MUSIC)-based algorithms [
18], are computationally expensive, which makes it difficult to implement them in real time. To reduce the computation time without loss of localization performance, we present an NN method for DPD. To the best of our knowledge, no previous studies have applied the NN method to DPD. The difficulties in applying NNs to DPD include the high-dimensional input space caused by the large amount of raw data from multiple observers and the need for a large training set to cover different combinations of the multiple source locations, signal-to-noise ratios (SNRs), and signal power ratios (SPRs).
To solve the above problems, we propose a modular NN scheme for multiple-source DPD. The proposed method combines RBF and MLP NNs. In our scheme, the area of interest is divided into multiple sub-areas, and RBF-NNs are trained as source location estimators for each sub-area while MLP-NNs are trained to perform detection and filtering, which effectively reduces the size of the training set. The preprocessing operations of dimension reduction and normalization greatly reduce the dimension of the input space. Compared with conventional DPD methods such as ML-based and MUSIC-based algorithms, the main advantage of the proposed method is that it avoids the need for a peak search and the iteration process, which have high computational complexity, and can implement DPD almost instantaneously. In addition, the proposed method can achieve adaptive learning and has excellent generalization performance for samples outside the training set.
The remainder of this paper is organized as follows. The data model is described in
Section 2.
Section 3 introduces a modular NN with an MLP-MLP-RBF structure for DPD. The performance of the proposed method is studied and simulation results are presented in
Section 4.
Section 5 gives the conclusions and future work of the article. The main notation used in this paper is listed in
Table 1.
2. Data Model
Our study aims at line-of-sight passive location scenario of ultra-short-wavelength signals, for the purpose of reconnaissance. Consider an outdoor scenario with
observer arrays, each consisting of
sensors. Assume that there are
stationary transmitters radiating narrowband signals in the far field of the arrays and that the signals are uncorrelated. We presume
and that the signals received by the
-th array can be expressed as
where
is the position of the
-th source;
is the steering vector of the
-th source for the
-th array; and
denotes the complex envelope of the
-th source reaching the
-th array at time
, which has a circular complex Gaussian distribution
, where the variance
is unknown.
is the background noise of the
-th array, which has a zero mean complex Gaussian distribution with covariance matrix
, where
is assumed to be known because it can be estimated or measured in practical applications [
22]. The noise and signals are assumed to be mutually independent.
Equation (1) can be written in matrix form as
where
is the array manifold matrix of the
-th array, which has dimensions of
, and
.
The covariance matrix of the signals at the output of the
-th array is
where
is the covariance matrix of the signals’ complex envelope.
Assuming that the number of snapshots is
, the covariance matrix of the signals received by the
-th array can be estimated as
The SNR and SPR are defined as
On the basis of (1)–(4), for each array, we obtain a mapping relationship : → ( denotes the dimension of position space; generally, ) from the space of the source position to the space of the antenna element output . By combining information from the arrays, a new mapping relationship : → can be obtained from the space of the source position to the space of all antenna element outputs .
3. A Modular NN for DPD
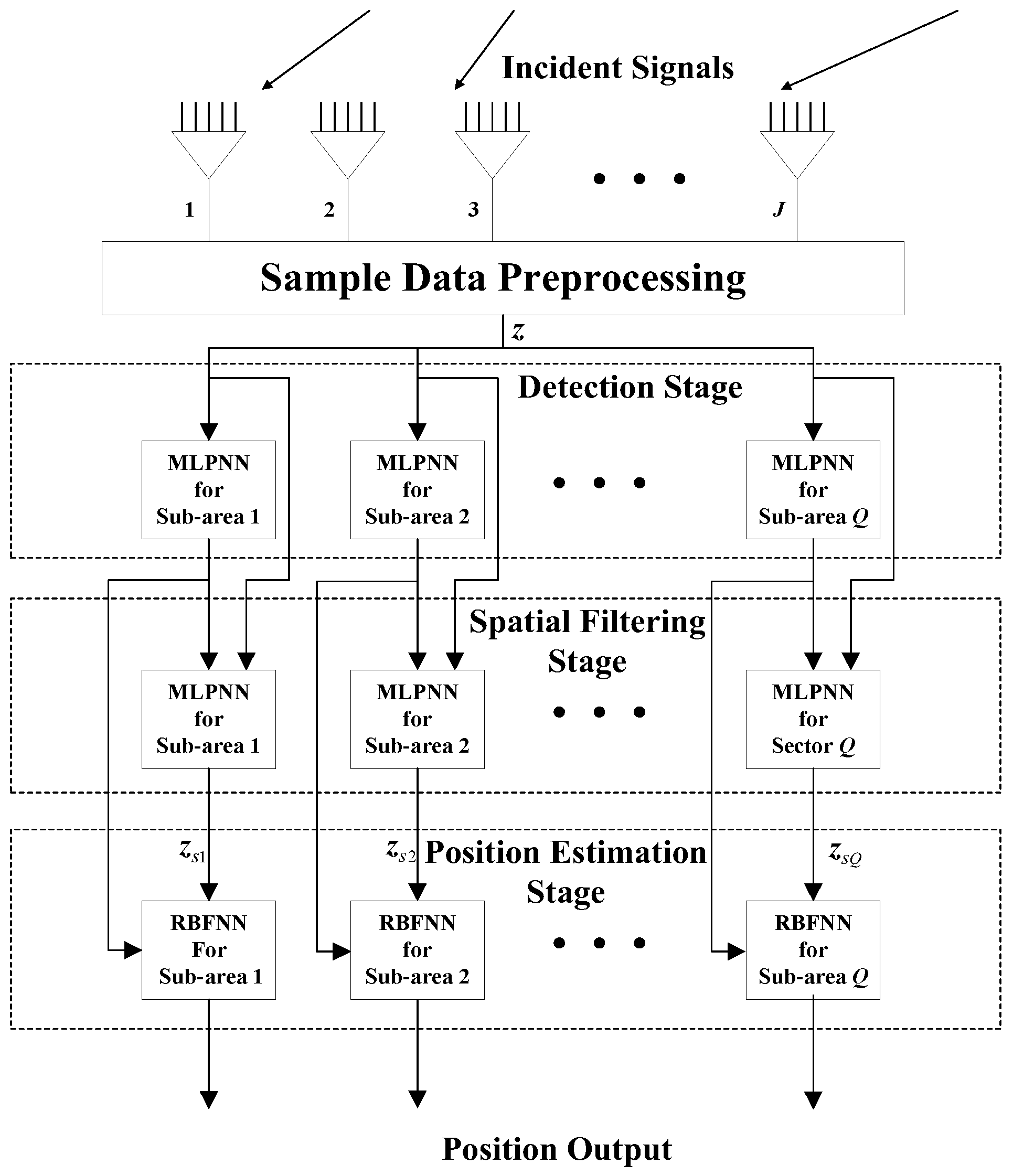
In this section, we propose a modular NN (
Figure 1) combining two MLP-NN modules and one RBF-NN module for DPD. This MLP-MLP-RBF network consists of four parts: sample data preprocessing, detection, spatial filtering, and position estimation. In the sample data preprocessing phase, we calculate the covariance matrix
and perform a dimension reduction for each observer. A joint dimension-reduced structure
(
Section 3.1) is input into the detection and spatial filtering stage. We choose the covariance matrix as the NN input because it contains enough statistical information about the position of the signal. The area of interest is divided into a number of sub-areas. For each specific sub-area, one MLP-NN is trained to detect the presence of a signal, one MLP-NN is trained to filter out signals outside that sub-area, and another RBF-NN is trained to produce an estimation of the source position. When the NN in the detection stage detects a source in a certain sub-area, the NNs in the corresponding spatial filtering stage and the position estimation stage are activated to complete the spatial filtering and the target position estimation.
This subdivision of region can greatly reduce the size of the training set. Assuming that there are training samples in a single source scenario, the number of training samples increases to in the presence of sources. If subdivision of region is not implemented, the size of the training set is enormous, because it grows exponentially with the number of sources. However, there is also a trade-off between memory resources and positioning accuracy. A smaller sub-area will result in a greater number of NNs, but the accuracy will be improved. In practice, the number of NNs for the proposed MLP-MLP-RBF method depends on the available memory resources.
In addition to the huge reduction for the size of the training set, there are two reasons why we use multistage processing:
- (1)
For multiple-source localization scenarios, a single-stage network has the problem that the same input data corresponds to different outputs, which leads to the failure of convergence in the network training process. For example, we consider the case of two sources located at and . The output vectors and correspond to the same input data, which will result in the confusion and make the network unable to converge in the training process, and this situation gets worse as the number of sources increases. This paper overcomes this problem using the subdivision of region and spatial filtering.
- (2)
The NN with a single stage requires to know exactly the number of sources to determine the number of network output units, otherwise the localization will fail. In our study, this assumption is not necessary due to the existence of the detection stage.
It is the ingenious combination of multiple stages (detection, filtering, and position estimation) that enables NN-based multiple-source DPD. Moreover, the detection stage is only responsible for the target detection, which will not affect the final localization performance. The filtering stage may cause performance loss, but the loss is insignificant with effective training. As can be seen from simulation results in
Section 4, performance of the proposed method is generally better than that of the MUSIC-DPD algorithm at low SNRs and can approach the ML accuracy at high SNRs.
NN training takes a long time; however, the characteristics of offline and parallel learning mean that real-time positioning will not be affected. Compared to the traditional MUSIC-based DPD algorithm, the proposed method avoids the need for eigenvalue decomposition and peak search processes, which have high computational complexity. The proposed algorithm only needs to complete a series of addition and multiplication operations to estimate the source position, a procedure that is more suitable for real-time applications. In addition, experimental results show that the positioning accuracy of the MLP-MLP-RBF is comparable to that of the traditional MUSIC-based DPD algorithm.
To reduce the size of the dataset required for the training process, the MLP-NNs in the detection stage are trained with fewer sample data as they only classify the input vectors. More refined data are used to train RBF-NNs in the position estimation stage, as these achieve the high-resolution DPD.
Remark 1. In practical applications, the sources may be located anywhere in space, but generally we can obtain a priori knowledge about the approximate area where the sources are located before localization. We can subdivide the corresponding region based on this prior knowledge, thus avoiding the subdivision of the whole space. Even if this prior knowledge cannot be obtained, we can use an AOA-based two-step processing estimator [23], including AOA estimation using the MUSIC algorithm and the pseudo-linear weighted least-square (PLWLS) location method using the AOA estimates, to obtain the initial estimate of the source positions, and then subdivide the corresponding region according to this initial estimate. Remark 2. If a source is located in the frontier of a sub-area, false or missed detections for this source may occur, which may result in the failure of the final localization, although it is unlikely to happen. To overcome this problem, we can adjust the centers of sub-areas when the output of a certain NN in the detection stage is around 0.5.
Remark 3. The resolution capability of the proposed technique is affected by the size of the sub-area. In practice, we can improve the resolution of the proposed method by further subdividing the sub-areas, of course at the cost of more memory resources. This phenomenon also reflects a trade-off between memory resources and resolution capability.
3.1. Sample Data Preprocessing
In the sample data preprocessing phase, we conduct the following tasks: (1) eliminate the dependency of the covariance matrix on SNR; (2) eliminate the dependency of the covariance matrix on
by dimension reduction and normalization. We first compute the covariance matrix for each array and denote the elements of this matrix by
Exploiting the estimated noise power
,
is calculated as
Using all of the elements in (6) as input will result in a high-dimensional input space. To reduce the dimension of the training samples without loss of information, we make full use of the Hermitian feature of
, and can therefore consider only the elements of the upper triangular part of (6). Furthermore, if it is a uniform linear array, then when the sources are uncorrelated, all entries of the covariance matrix starting from the second row are linear combinations of the entries in the first row [
9]. Eventually, the first row of the covariance matrix is sufficient to represent the entire covariance matrix.
Collecting the elements from the first row of the covariance matrix [
10] together, we have
As the NN does not deal directly with complex numbers, we need to extract the real and imaginary parts of each element in
to reconstruct a
-dimensional vector:
is normalized as
All elements from [
13] for all of the arrays are then collected in the
vector:
Next, is fed into the NN as the input vector.
According to (3), it can easily be obtained that
Therefore, we eliminate the dependence of the covariance matrix on the signal power after normalization.
After our preprocessing scheme, the number of input neurons in the input layer is reduced from to . The proposed preprocessing scheme removes a large number of redundant or irrelevant information and reduces the dimension of the signal parameter space. Hence, the network can be trained more effectively.
3.2. Detection Stage
The “detection stage” uses MLP-NNs with two hidden layers. MLP-NNs are known to be powerful classifiers that can provide superior performance to other classifiers [
24]. The MLP-NNs give a global approximation of a nonlinear mapping, so they may require a long training time. In the particular case, the training convergence speed of this network type is slower, but more accurate than that of the RBF-NN, which is the main reason we apply MLP-NNs in the detection stage. As a classifier, the output of an MLP network is 0 when the sources are outside the observed sub-area and 1 when the source is inside the associated sub-area. The number of neurons in the input and output layers is
and 1, respectively. In addition, we can use fewer training samples because of the binary nature of the output. Note that the “tan-sigmoid” activation functions are used for all neurons in the hidden layer. The output of
-th neuron in the hidden layer can be expressed as
where
represents the input of NN and
and
represent the weight vector and the bias, respectively, with respect to the
-th neuron in the hidden layer. The “purelin” activation functions are used for neurons in the output layer.
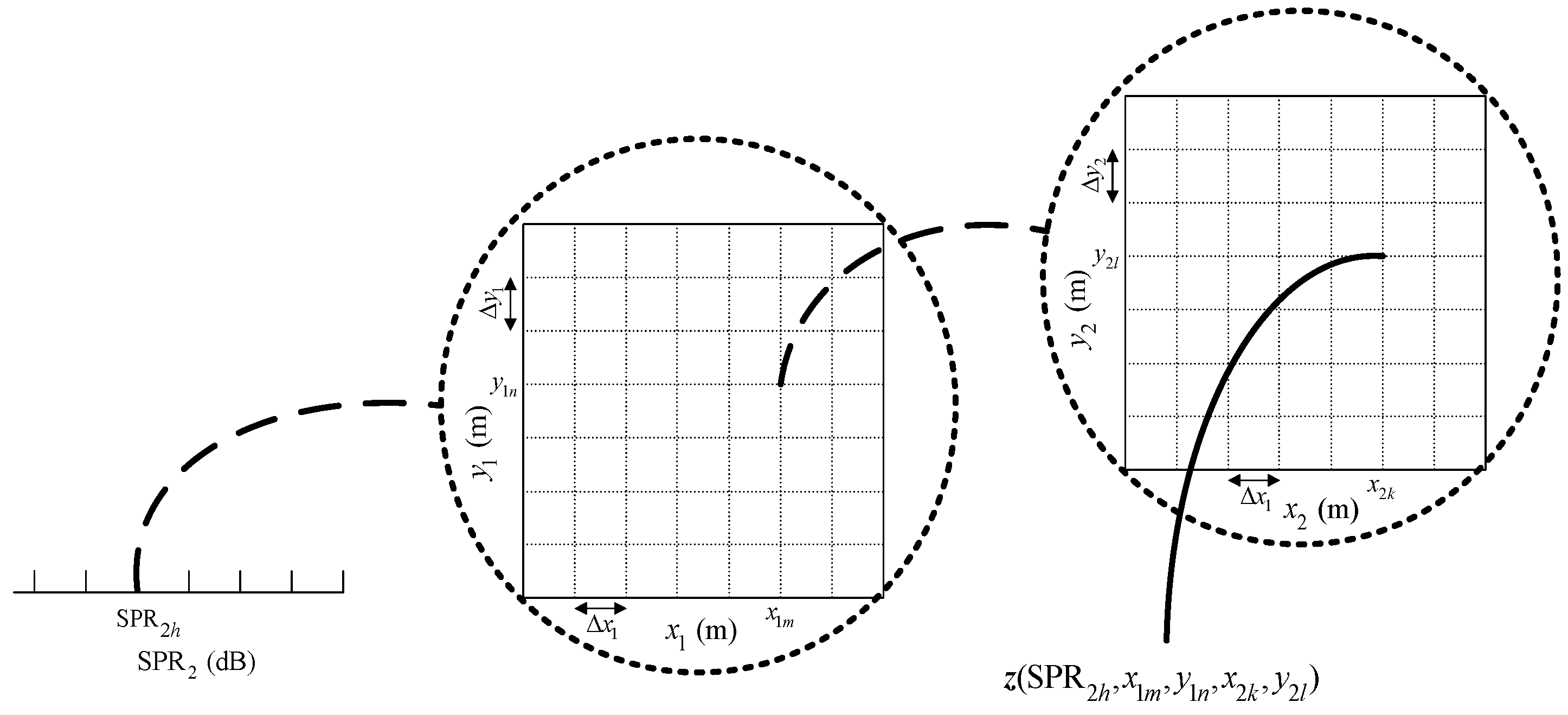
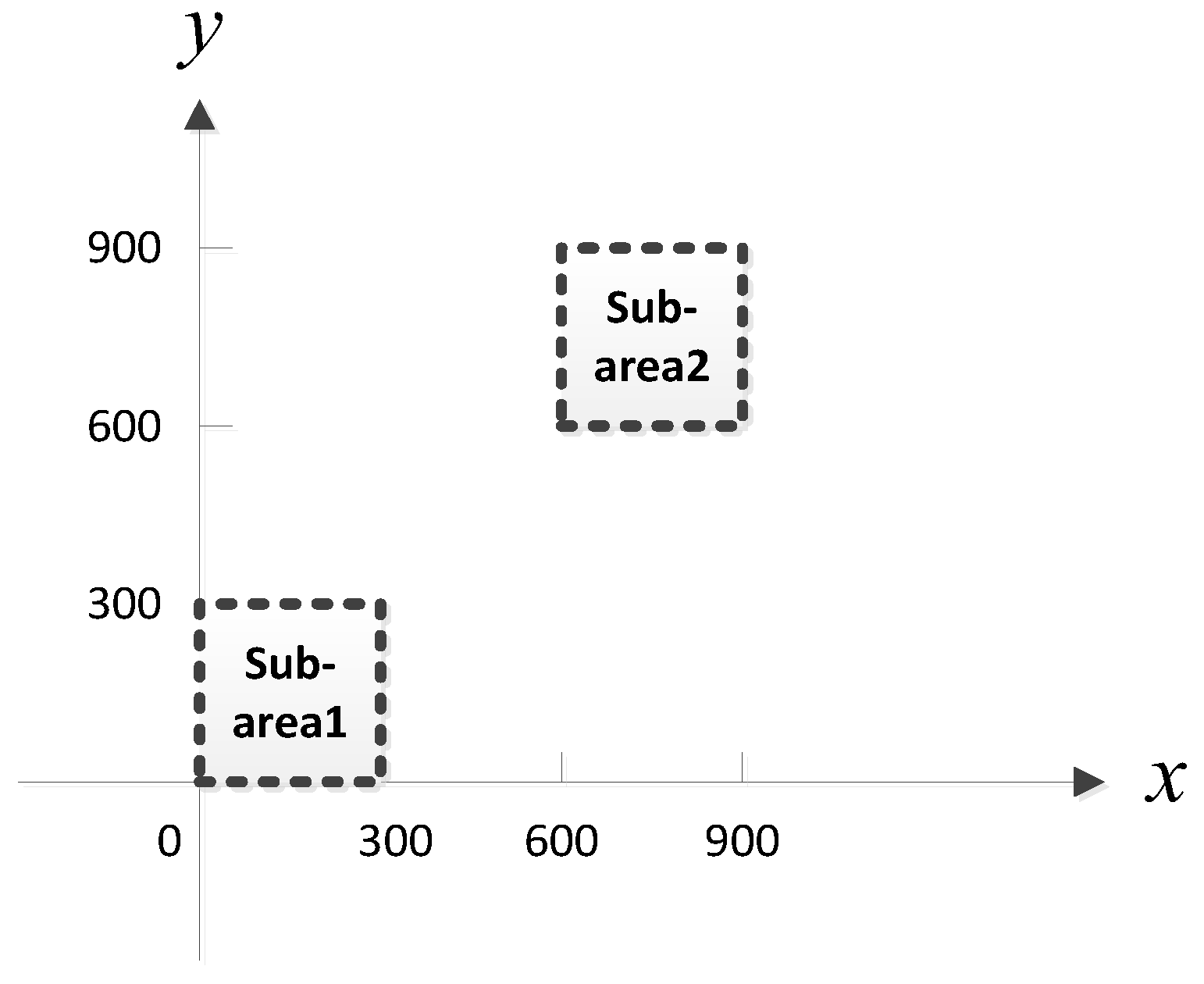
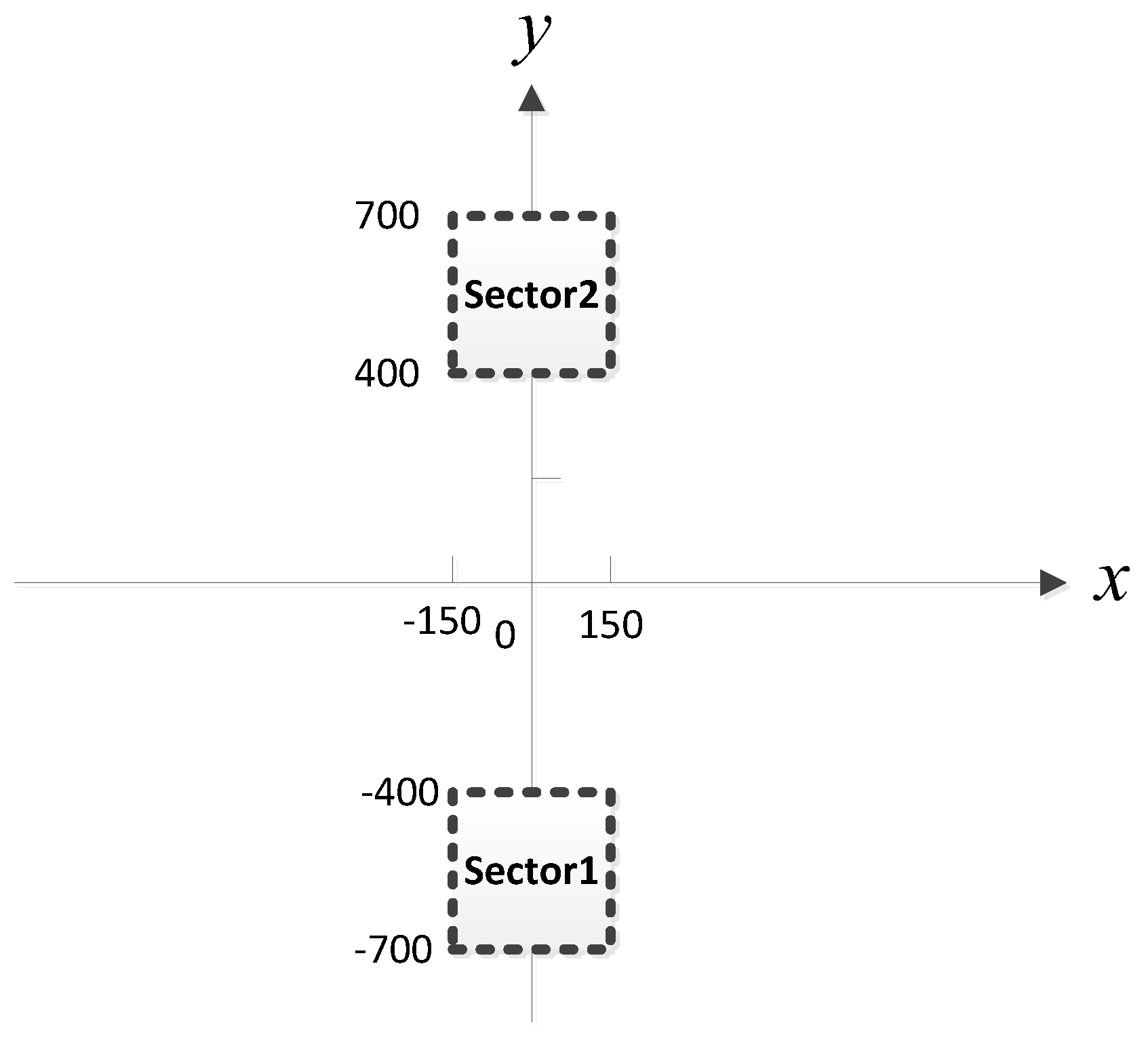
For each MLP-NN in this stage, the specific training steps are as follows (we consider the case of two sub-areas, as illustrated in
Figure 2, and do not permit two sources in one sub-area).
Step 1. Construct the training set for the grid format.
- (1)
Predefine a training step (or resolution) denoted by , , , and , and calculate using (10).
- (2)
Form a training set of observations, in which 1 represents the existence of the source and 0 indicates no signals within the corresponding sub-area. Here, is the input in the training process, and 0 (or 1) is the expected output, i.e., the supervision signal.
Step 2. Construct and train the MLP-NNs properly.
- (1)
Construct the appropriate network structure (specific construction process is described in
Section 4.1).
- (2)
Feed the samples from the training set into the MLP-NN successively, and use Bayesian regularization (BR) [
25] to train the NN (the BR algorithm is widely used because of its excellent generalization performance and prevention of overfitting).
Step 3. Generate a validation set to test the generalization performance of the trained network. The verification set is generated in a similar way to Step 1, but with an offset based on the training step in Step 1.
Remark 4. In Step 1, it is not necessary to set variations of the SNR in the training set, because the input to the NNs (the vector ) eliminates the dependency on the SNR.
3.3. Spatial Filtering Stage
The purpose of the spatial filtering stage is to eliminate signals from outside the corresponding sub-area. The MLP-NNs are still used, but unlike in
Section 3.2, they now act as filters. The number of neurons in both the input and output layers is
. When the output of the NN in the detection stage is 1, the NN of the corresponding sub-area in this stage is activated.
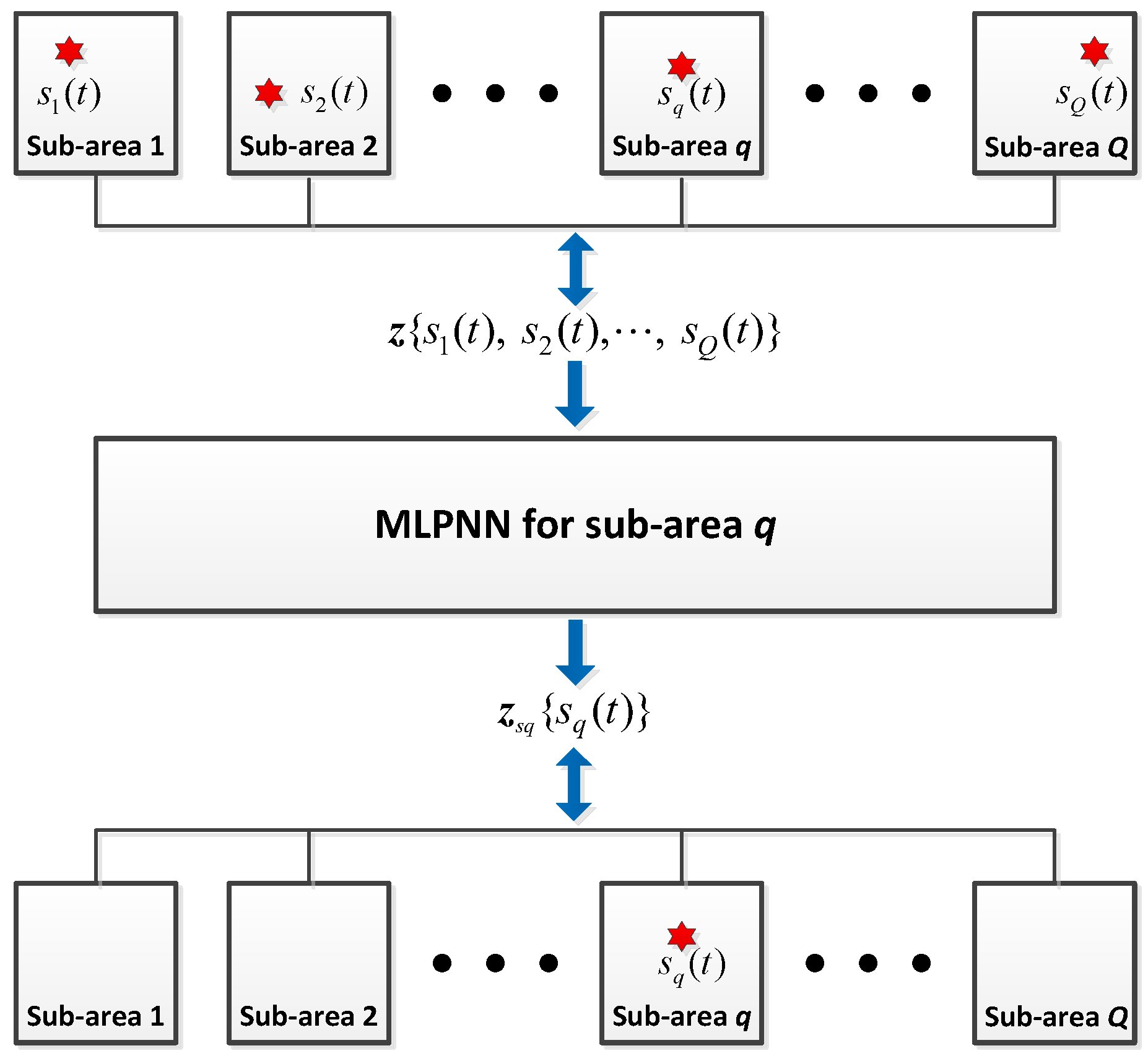
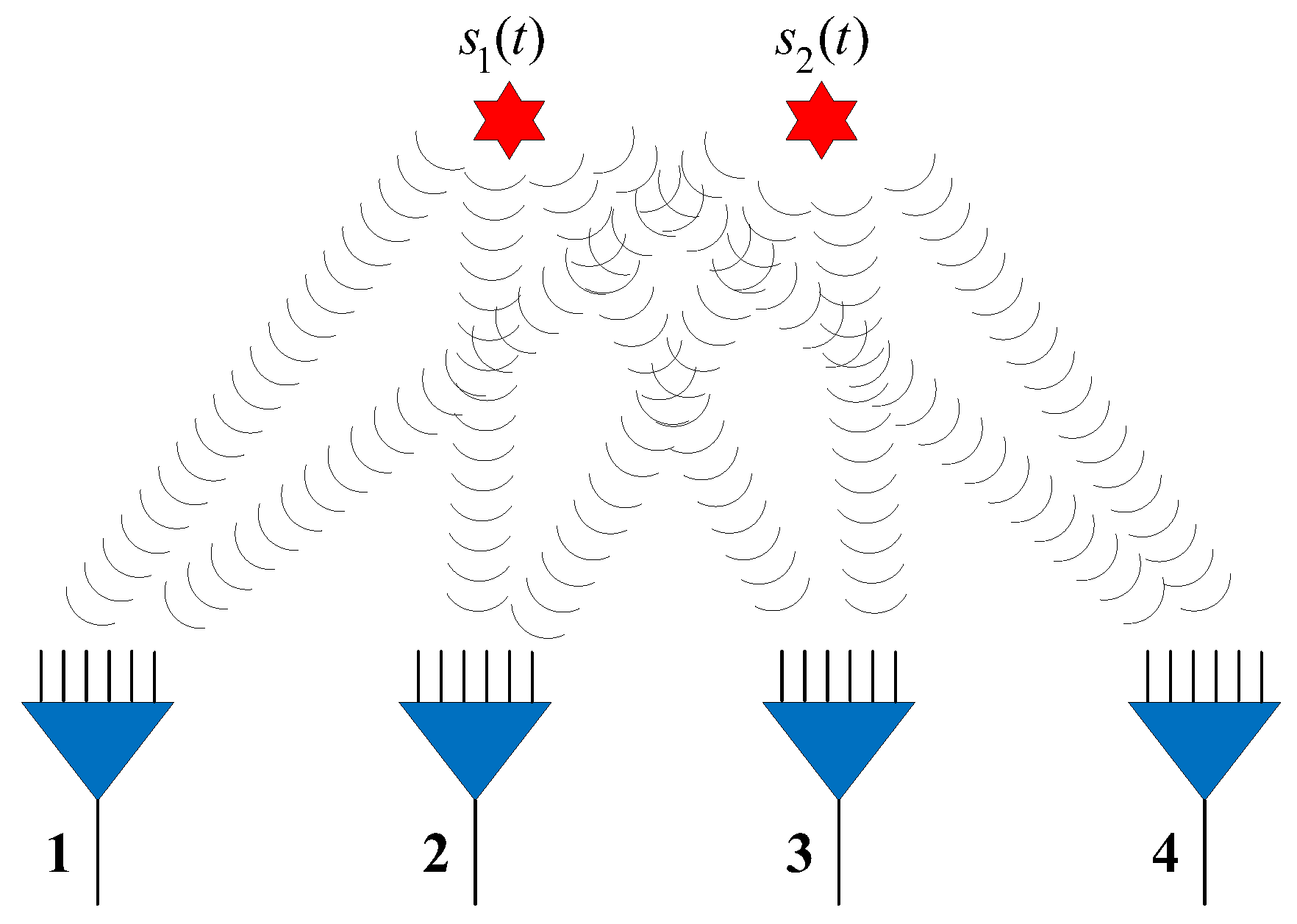
The inputs to the spatial filtering network are the vectors
, as for the detection stage. The output of the spatial filter network for sub-area
is
, which does not include the signals from other sub-areas. For instance, there are
incident sources
, and only source
is in sub-area
. This procedure can be illustrated in
Figure 3, where the red star represents the source. The input to the NN,
, is computed through Equation (10) using signals
, and the output
is computed through Equation (10) again, but the signal is now
. Through the training process, the MLP-NNs learn and generalize this mapping
. In the testing phase, an accurate filtering result can be obtained for samples from outside the training set. The training process is similar to that described in
Section 3.2 and is not repeated here.
3.4. Position Estimation Stage
The NNs in this stage are trained to estimate the source position. When the output of the NNs in the detection stage is 1, the NN of the corresponding sub-area in this stage is activated. The number of neurons in the input and output layers is and (the dimension of position space), respectively.
This stage uses an RBF-NN, which is characterized by a radial basis function as the transmission function for hidden layer neurons. The most commonly used radial basis function is the Gaussian function:
where
represents the
-th hidden layer neuron and
and
represent the center and the width of the Gaussian activation function, respectively. A three-layer RBF-NN is a local approximation of a nonlinear mapping and can approximate any nonlinear function. It has a faster learning convergence rate than MLP-NN, which is why we apply RBF-NNs in the position estimation stage.
The parameters that must be trained in the RBF-NN are the appropriate number of hidden layers , the center and width , and the weight between layers . To select reasonable values for these parameters, the training process is as follows:
In the next section, we illustrate our proposed NN approach via a series of numerical simulations.
4. Simulation Results
In this section, we study the performance of the NNs in the detection, filtering, and position estimation stages. The performance of the proposed network (
Section 3) is then evaluated for different SNRs, SPRs, and source location parameters
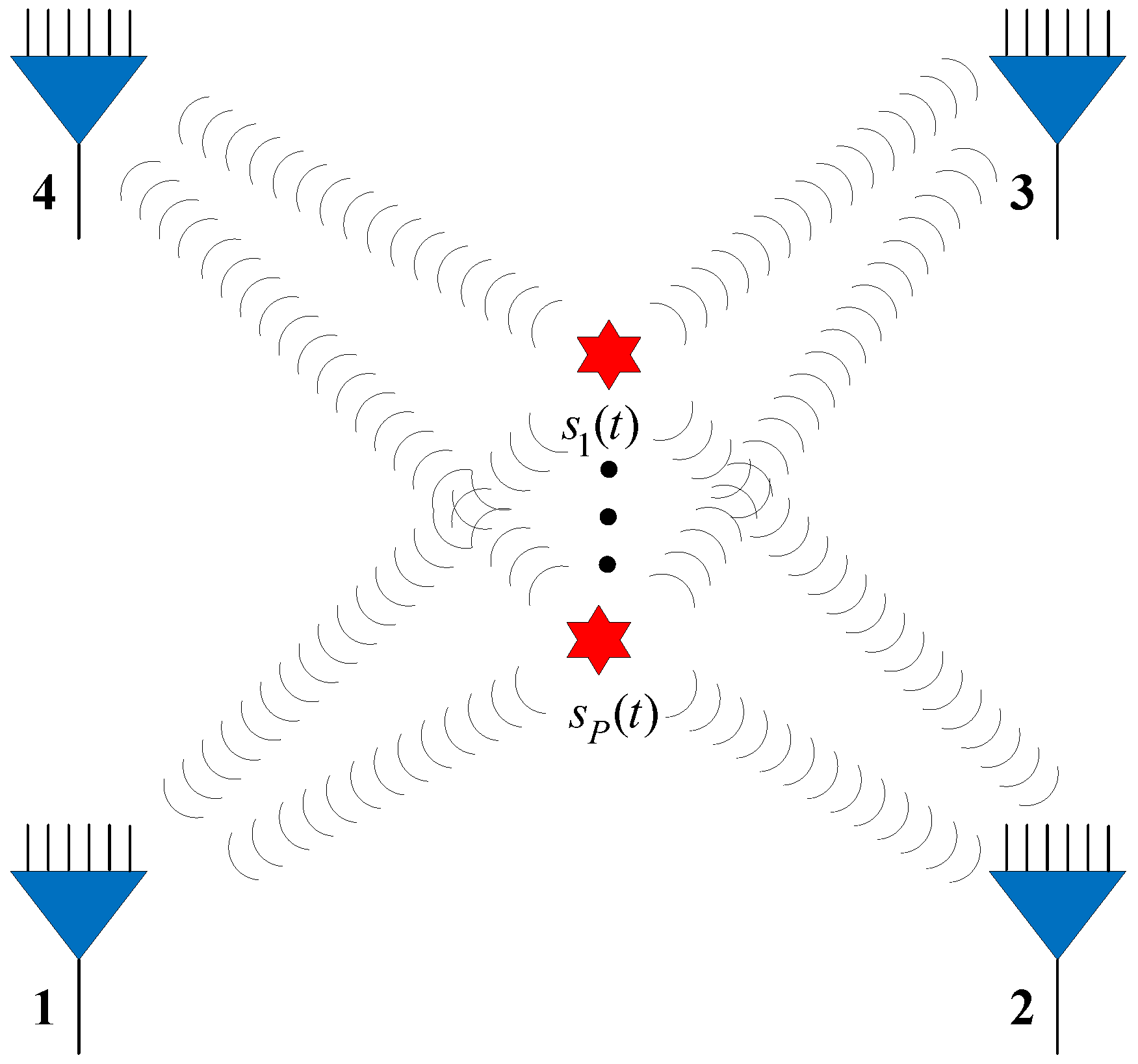
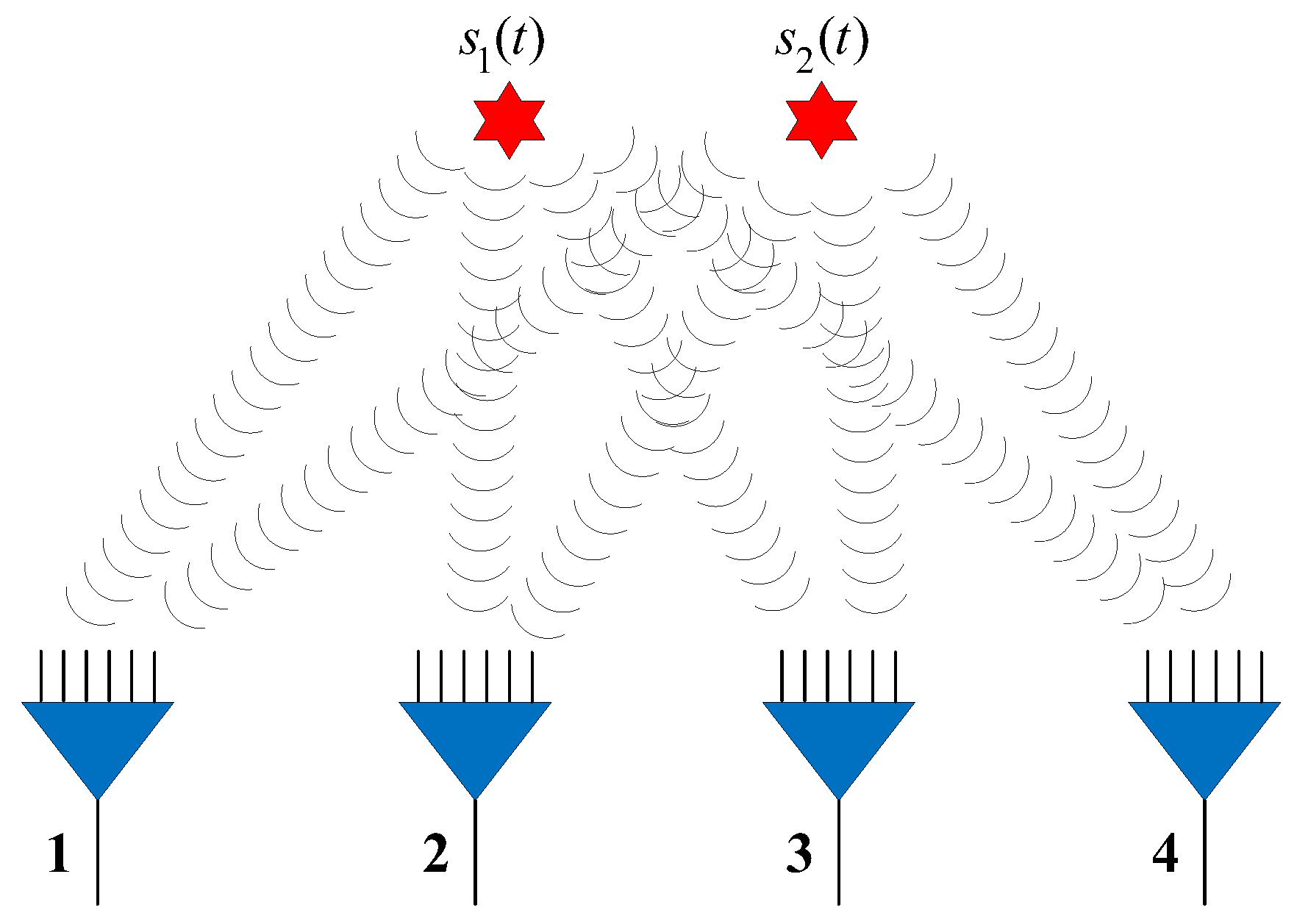
. In the experiments, we assume there are four available observer arrays, as presented in
Figure 4 (the red star and blue triangle represent the source and observer array, respectively), which can receive and locate the radiated source signals. The positions of the observers are listed in
Table 2. Each observer array is equipped with a six-element uniform linear array (ULA).
The number of snapshots is set to . To avoid spatial aliasing, the distance between adjacent elements in the ULA was set to half a wavelength, that is, .
Considering that MUSIC-based and ML-based methods have better performance than the classical beamforming-based method for small AOA separation, in the simulation, we compare the proposed MLP-MLP-RBF method with MUSIC-based and ML-based DPD methods [
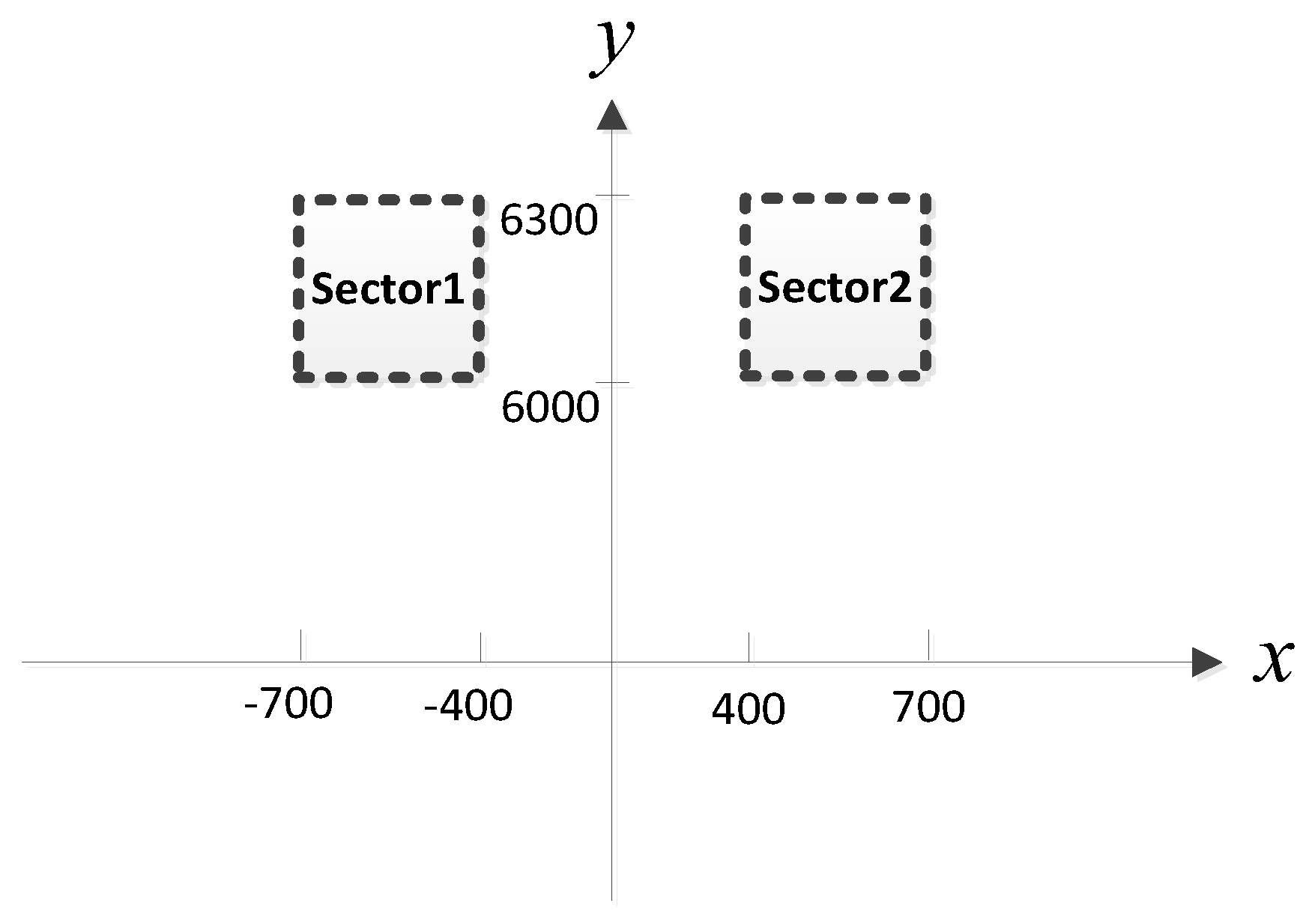
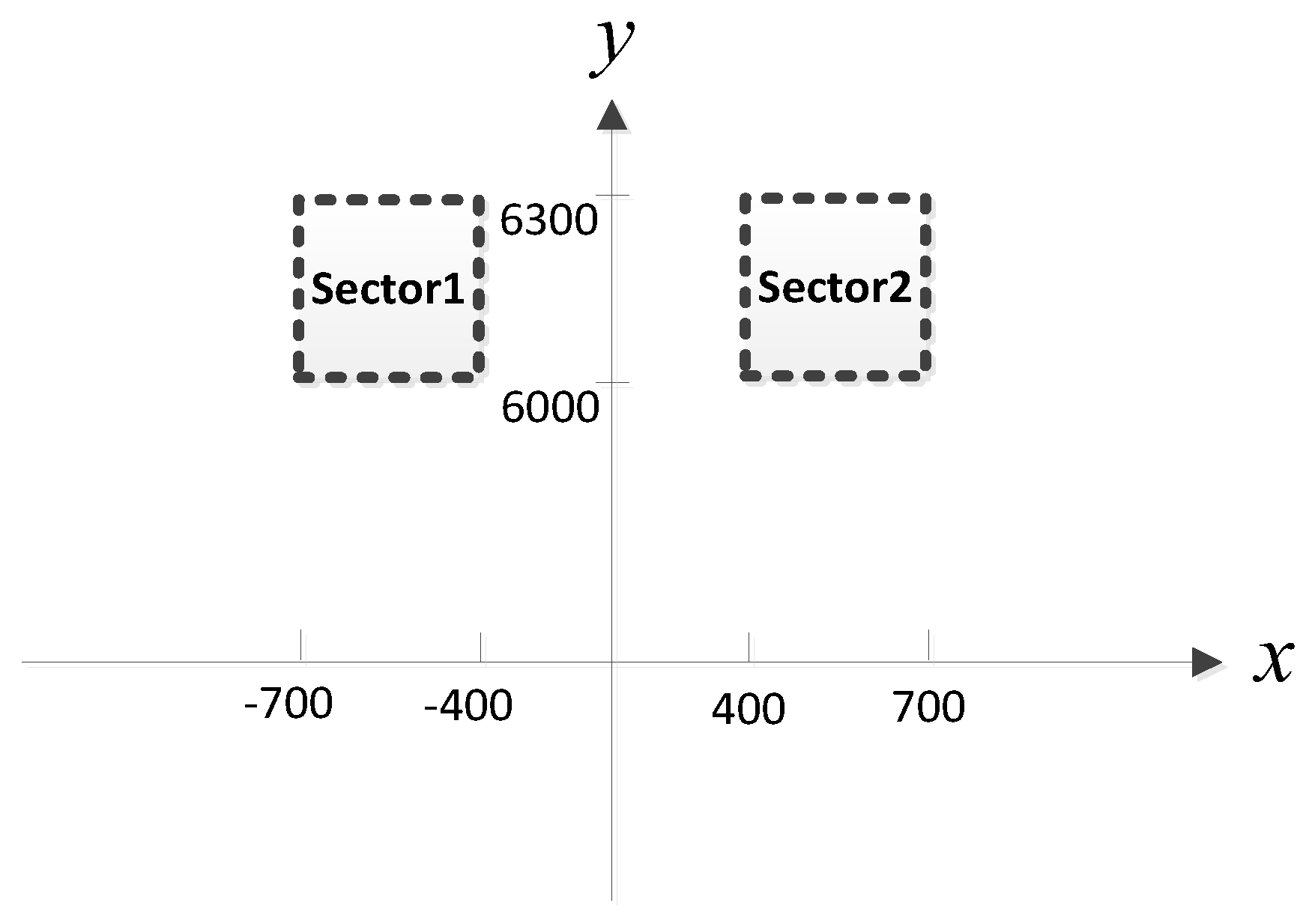
14] to show the superiority of our method. To reduce the computational burden of MUSIC-DPD and facilitate the analysis, we study a special case of two sub-areas, as shown in
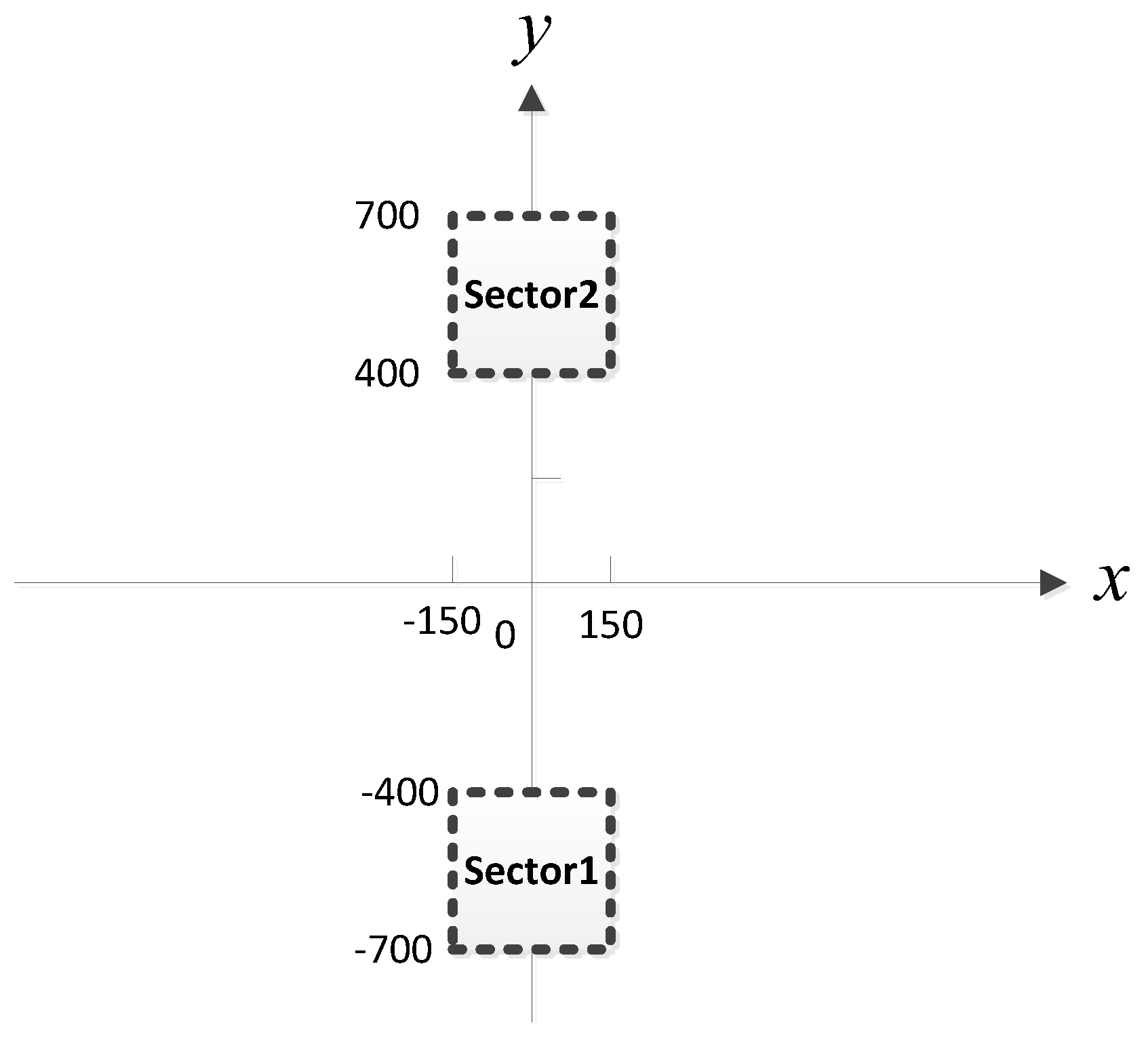
Figure 5. We assume that there is at most one source in each sub-area. In addition, the MUSIC-DPD search strategy uses 20 m coarse search steps and 1 m fine search steps to reduce the computational complexity.
In the training patterns, the training step (or grid resolution) is set to
(
Section 3.2,
Figure 2) and an offset of
is used for the validation patterns.
The MLP-NN with 12 neurons in both hidden layers is applied in the detection stage, and the MLP-NN with two hidden layers of 24 neurons each is applied in the spatial filtering stage (The reasons for this structural configuration are discussed in
Section 4.1). We set
and
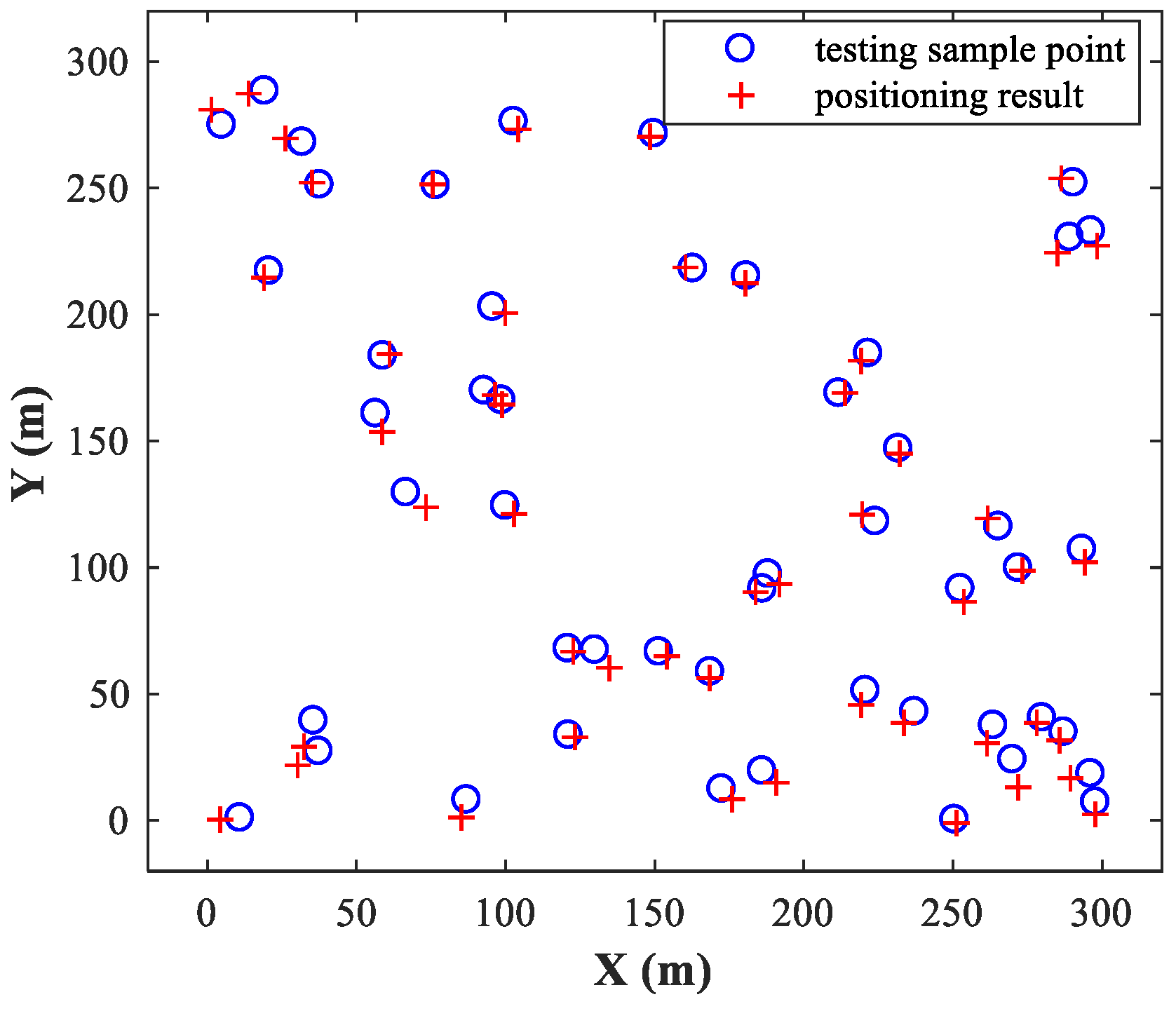
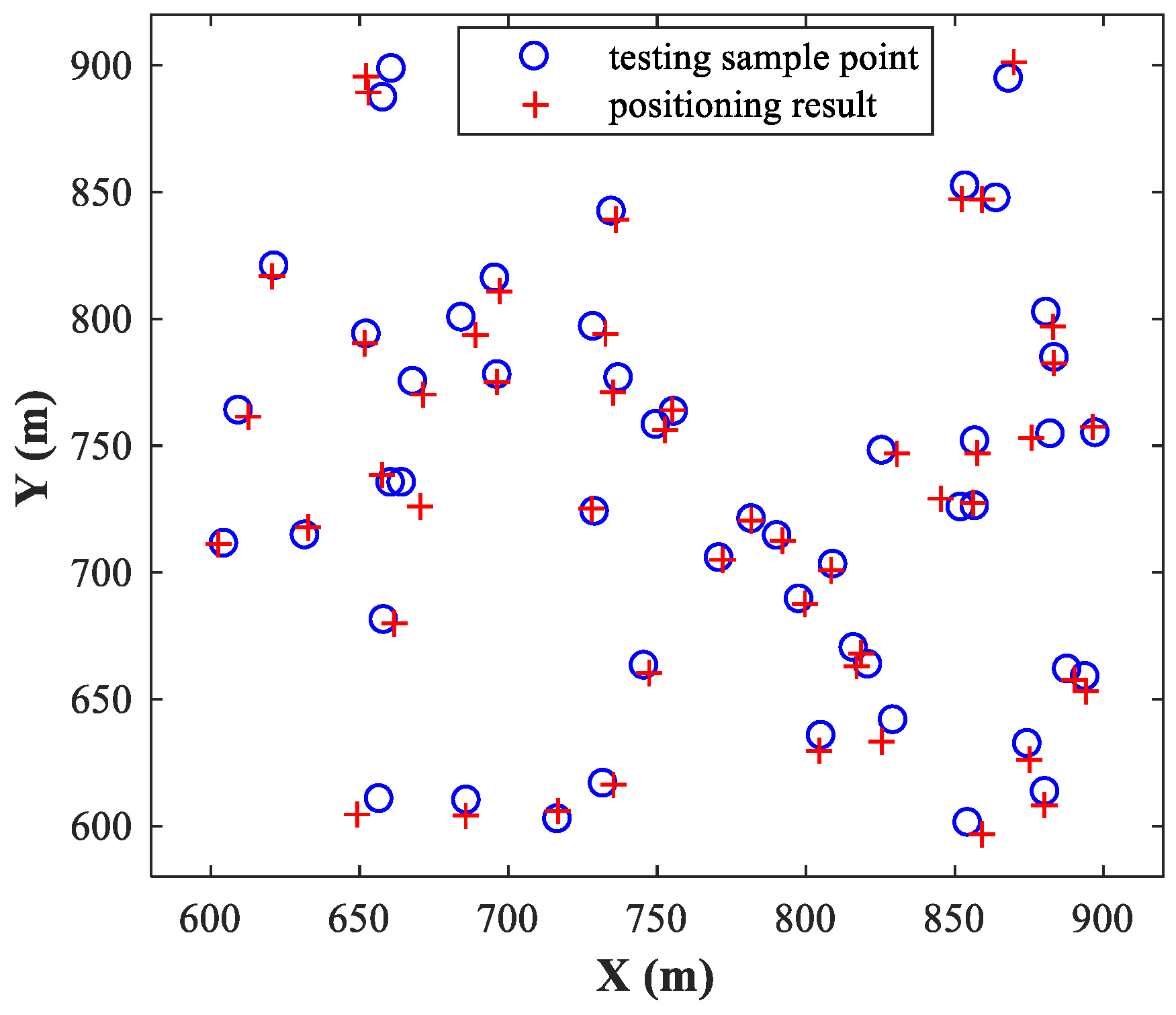
, and then randomly select 50 pairs of test samples within the two sub-areas and locate them using the trained MLP-MLP-RBF network.
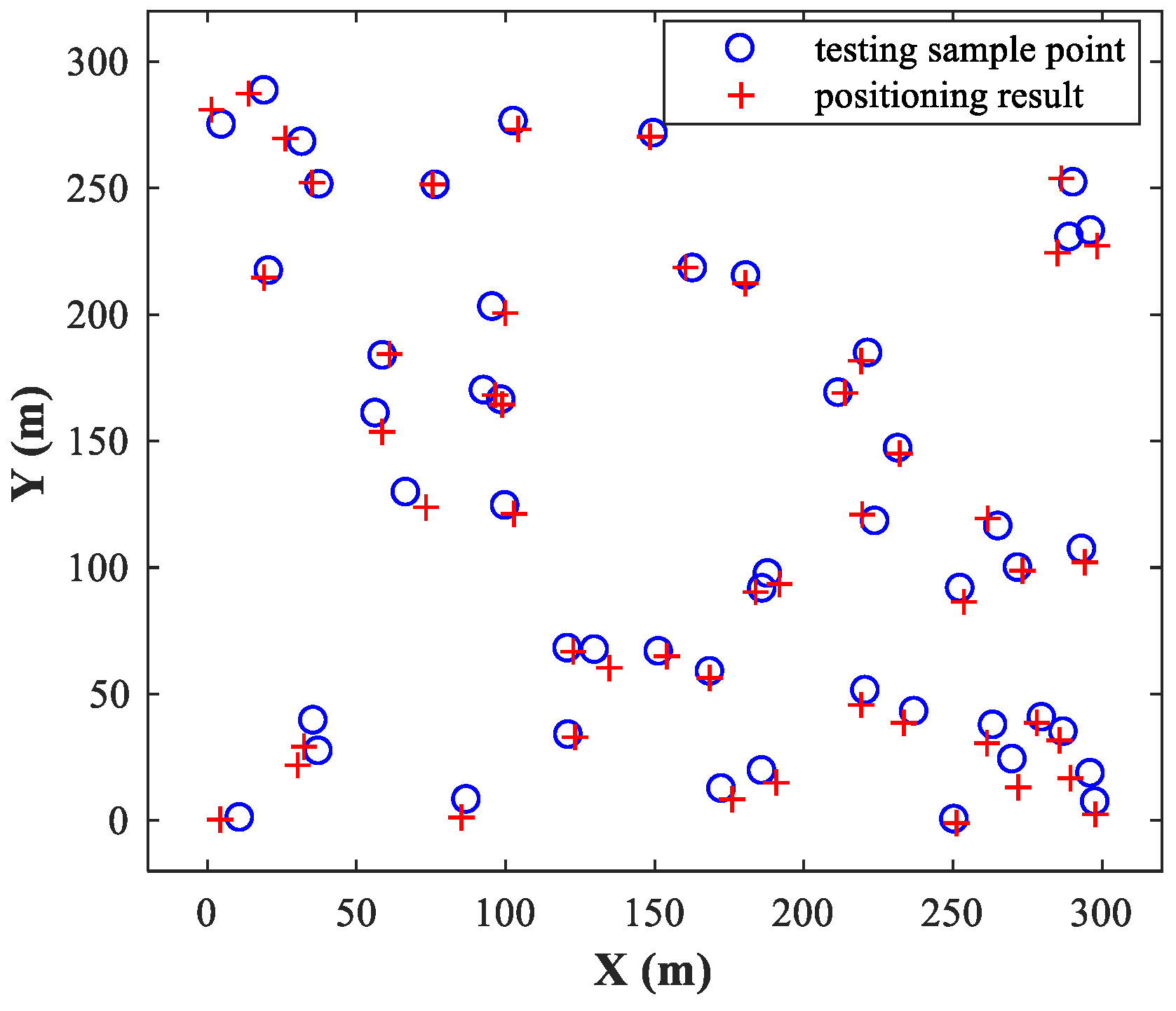
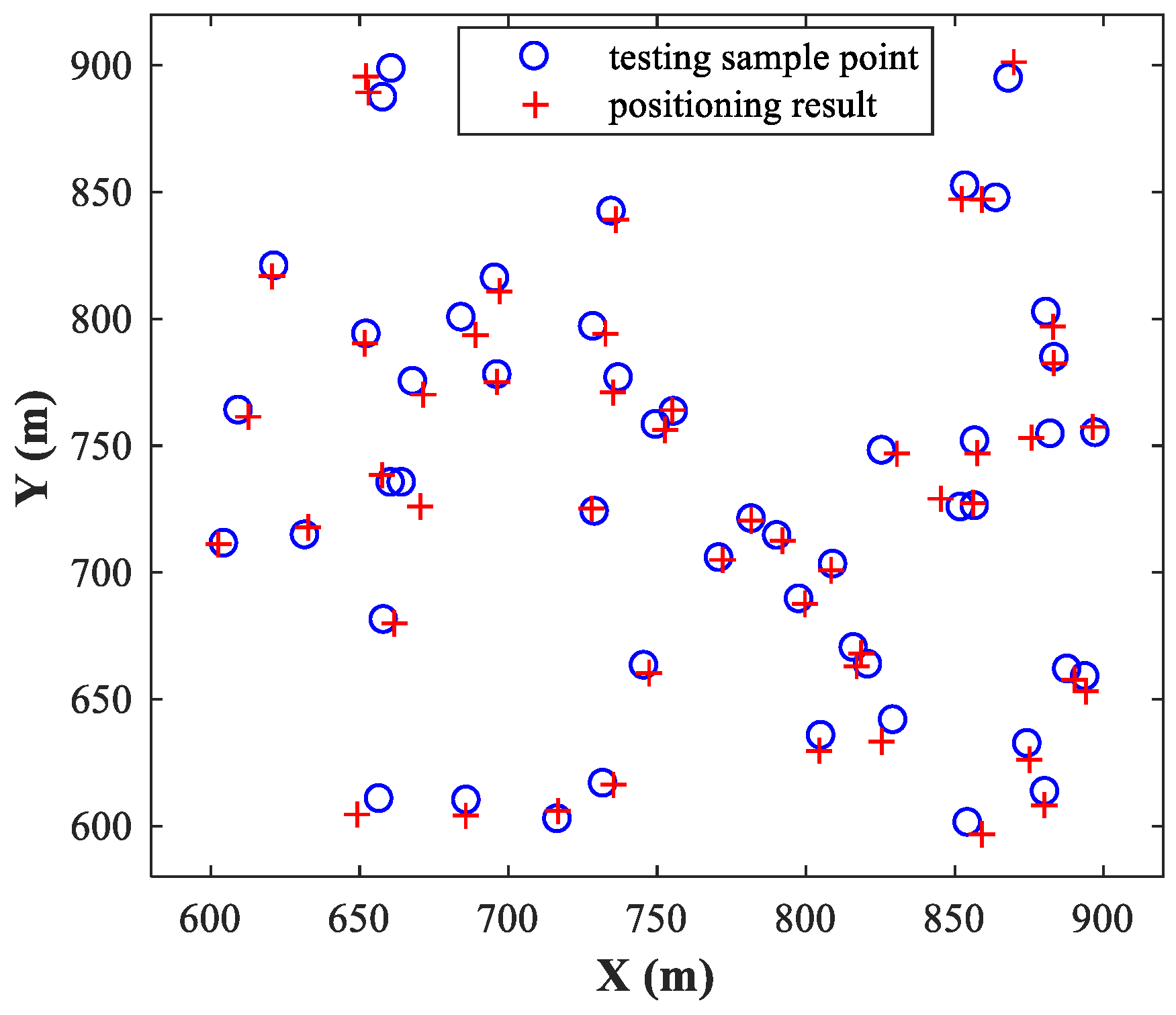
Figure 6 and
Figure 7 show the simulation results for sub-area 1 and sub-area 2, respectively, where the actual and estimated locations are represented by the circle and crisscross symbols, respectively. The simulation results verify the feasibility of the proposed MLP-MLP-RBF method for DPD and demonstrate the high positioning accuracy of our approach.
In the following subsections, the positioning performance of the proposed MLP-MLP-RBF method is evaluated in detail. We conduct
Monte Carlo (MC) experiments and evaluate the estimation accuracy in terms of the
, where
and
are the network responses for the
-th MC experiment. Similarly, the mean relative error
is used to evaluate the performance of the filtering network. On this basis, the following figures show boxplots of RMSE or MRE values calculated for different combinations of
. In other words, in the following simulations, we conduct
MC experiments for each different combination of
. The boxplots [
28] show the minimum, lower quartile, median, upper quartile, and maximum to visually represent the statistical characteristics of the data. The whiskers extending from each end of the box to the maximum and minimum show the extent of the remaining values. The values beyond the ends of the whiskers are treated as outliers. The whisker length is set to 1.5 times the interquartile range. The purpose of applying boxplots in this paper is to illustrate the RMSE and MRE for different combinations of source positions on the same coordinates, which results in a more effective visualization of the positioning performance of the proposed method.
Three basic assumptions are made in the simulations: (1) The array manifold is known exactly; (2) there is at most one source in each sub-area; (3) all radiated signals can be received by each observer.
Note that the proposed method makes no assumptions about the array structure: as long as the array manifold is known, it can be applied directly to the nonuniform array scenario (at this point, is composed of the elements of the upper triangular part of (8)). Furthermore, the transmitters must radiate steady-state signals, otherwise the performance of the proposed method will deteriorate.
Remark 5. The simulation data used in this study is computer-generated. The generated two source signals both follow zero mean circular complex Gaussian distribution with different signal powersand. The signals received at the sensors are contaminated with statistically independent complex Gaussian white noise of power. The signals and noise are mutually independent. The received signal power is inversely proportional to the square of the distance between the source and observer array.
4.1. Study of the MLP-NN Performance in the Detection Stage
In this subsection, we mainly study the performance of the MLP-NN in the detection stage. The number of hidden layers and neurons in each hidden layer in the MLP-NN is not usually known beforehand, and the optimum value is generally found through an investigation. Following [
29], an iterative process is applied to dynamically adjust the network configuration. Finally, an MLP-NN with good statistical properties is obtained. In the simulations described in this subsection, we use the MLP-NNs with two hidden layers each containing 12 neurons. Moreover, according to the analysis in
Section 3.2, the number of neurons in input and output layers is
and 1, respectively. The network is trained for 200 epochs.
As mentioned in
Section 3.2, we can use a training set containing fewer training samples to train the NNs because of the binary nature of the output. Compared with the spatial filtering and position estimation stages, we set a larger training step,
, and hold both SNR and SPR constant. The testing step is set to
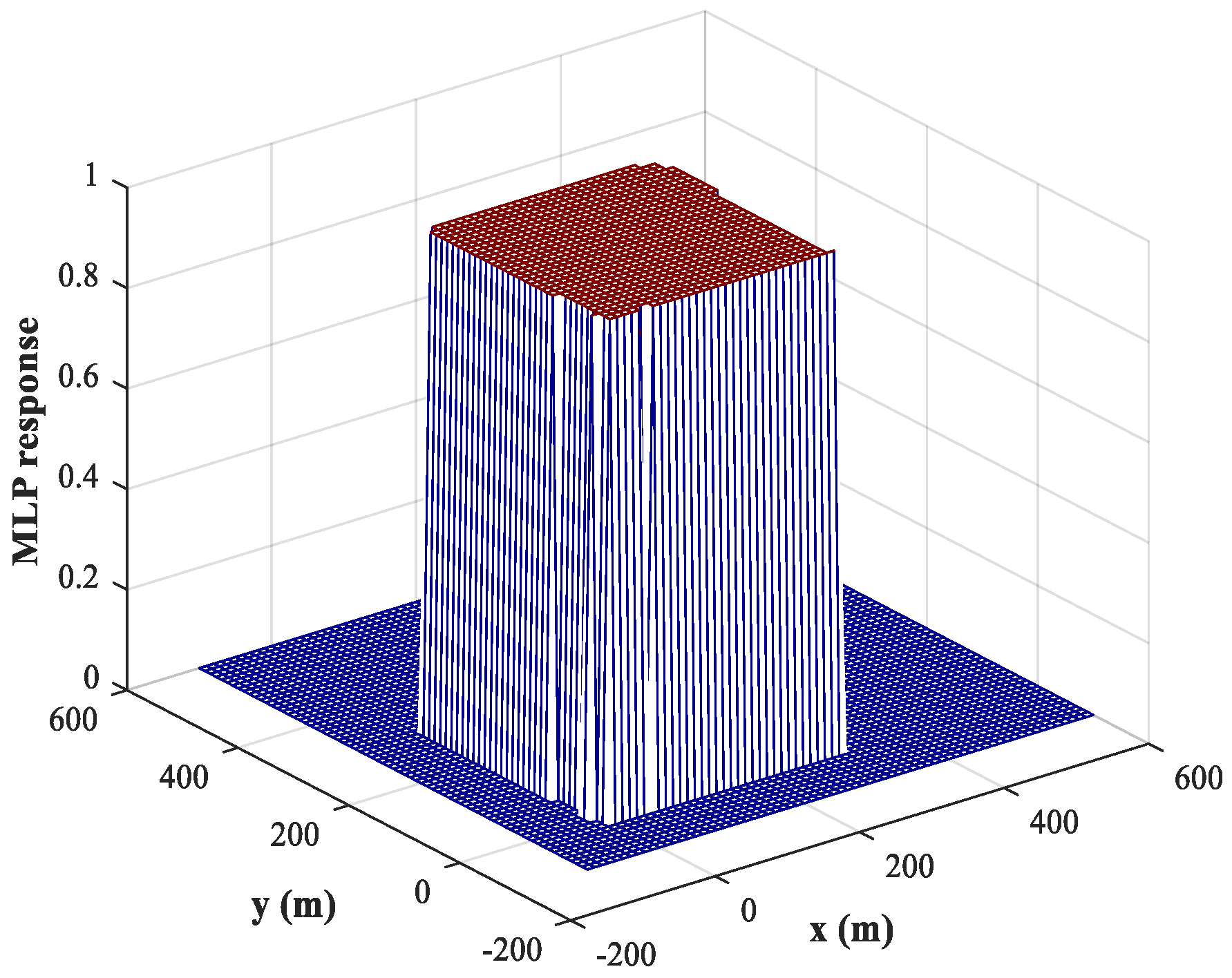
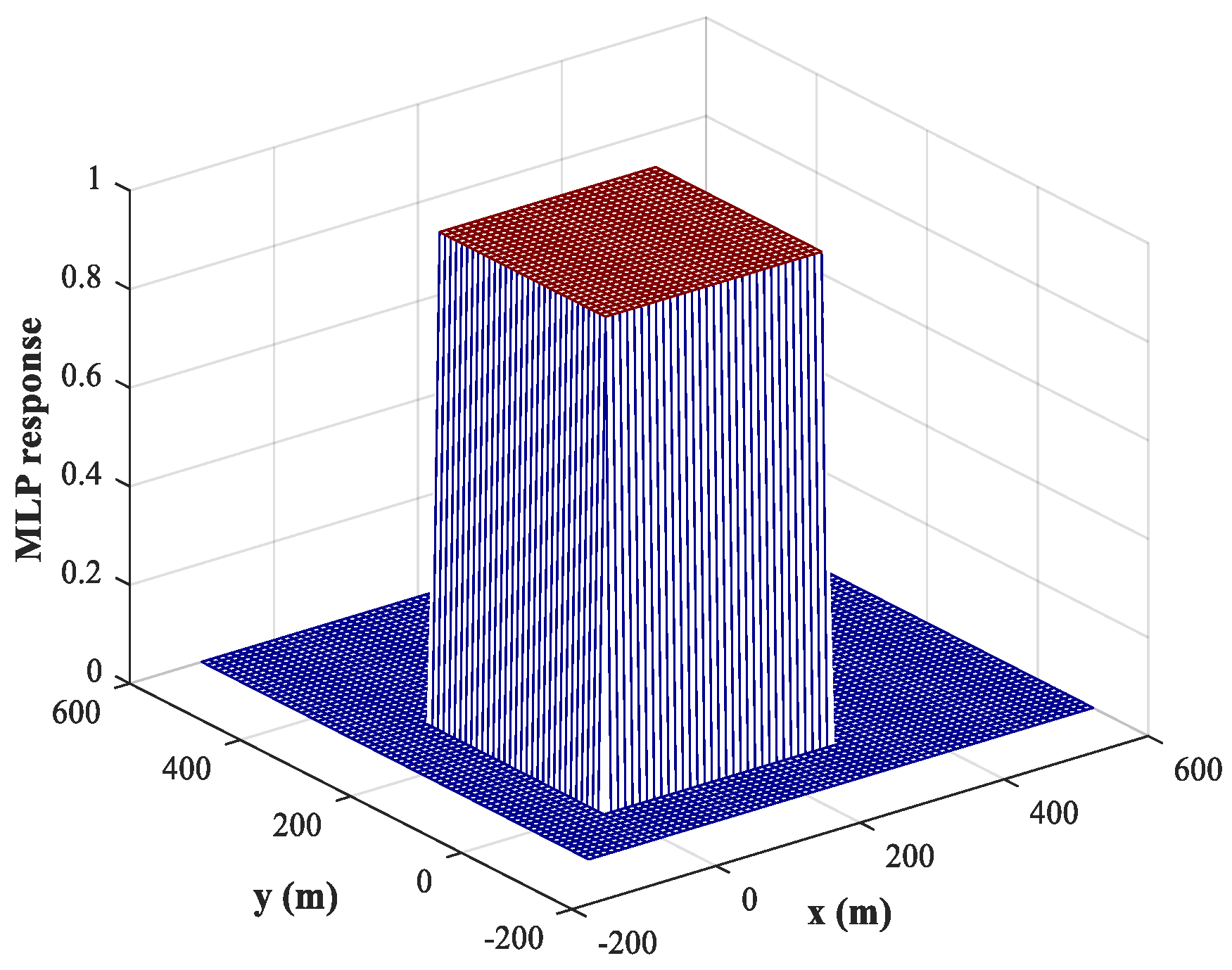
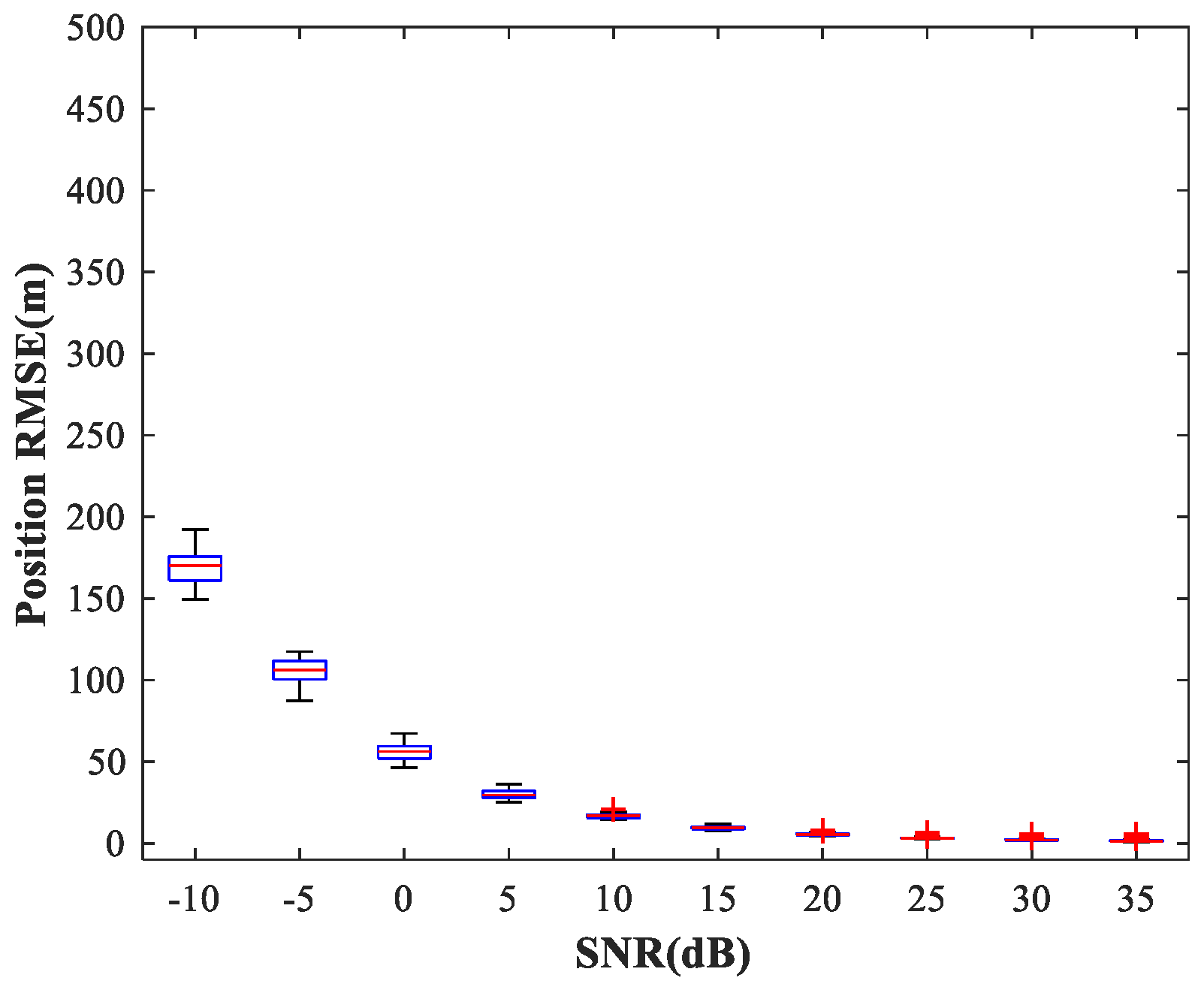
. The corresponding response of the MLP-NN for sub-area 1 is shown in
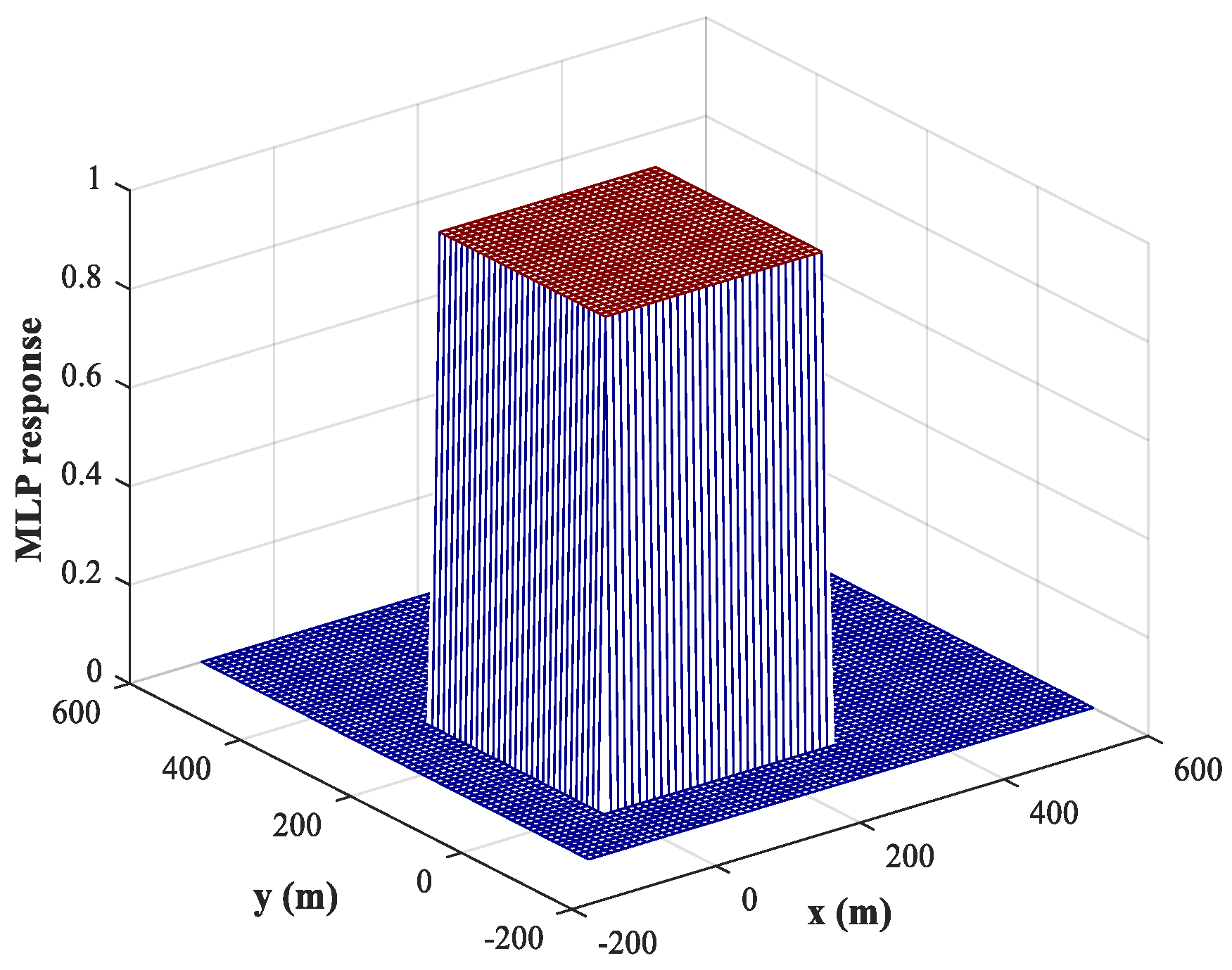
Figure 8 (similar results are obtained for sub-area 2), from which we can conclude that the trained MLP-NN offers good generalization performance and can also carry out accurate detections for most samples outside the training set. The detection accuracy reaches 98.1%. Moreover, the detection errors tend to occur at the edges of the sub-area. To solve this problem, we train the network using variable training steps. We set a smaller training step of
within 50 m of the sub-area boundary and keep the training step in other regions constant. The corresponding response of the MLP-NN trained with variable training steps for sub-area 1 is shown in
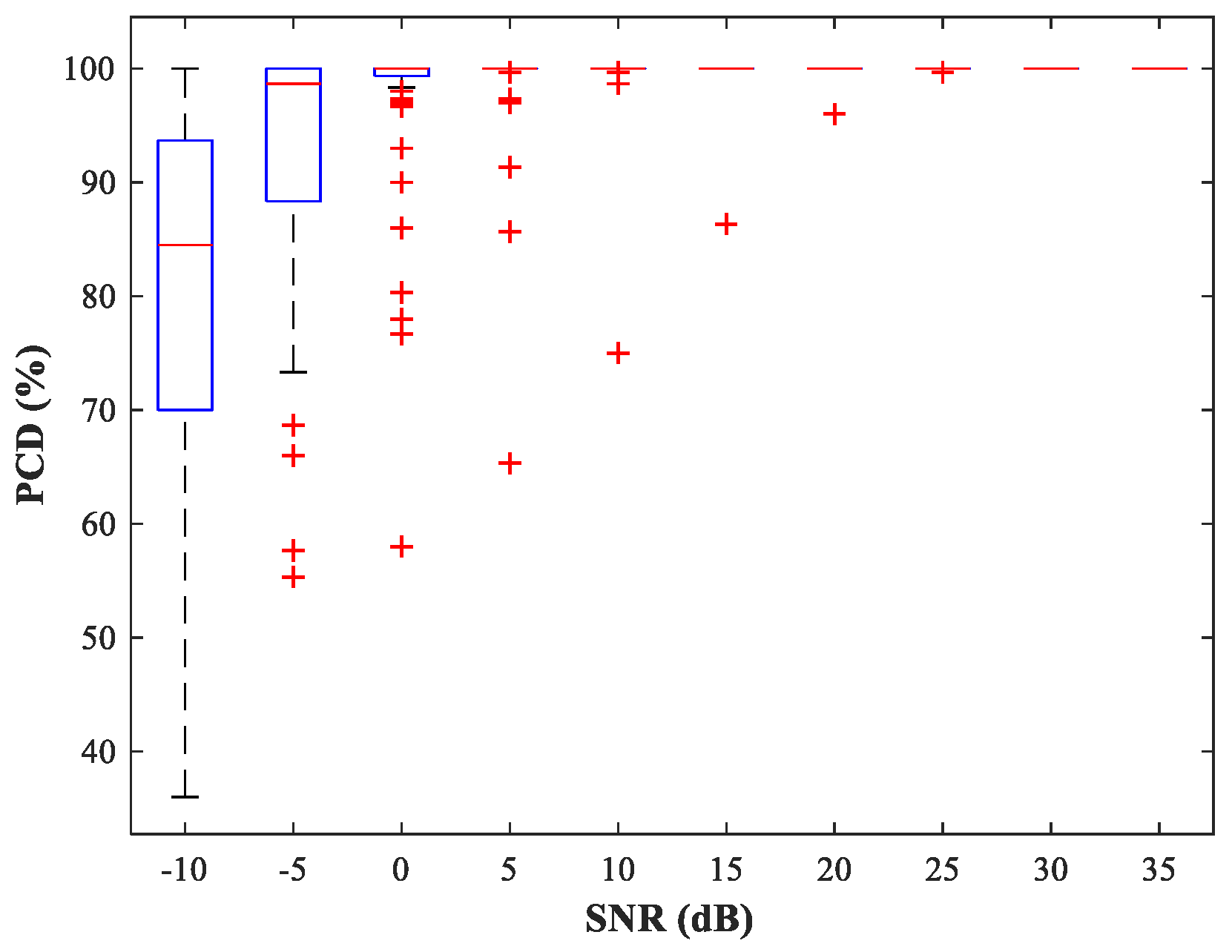
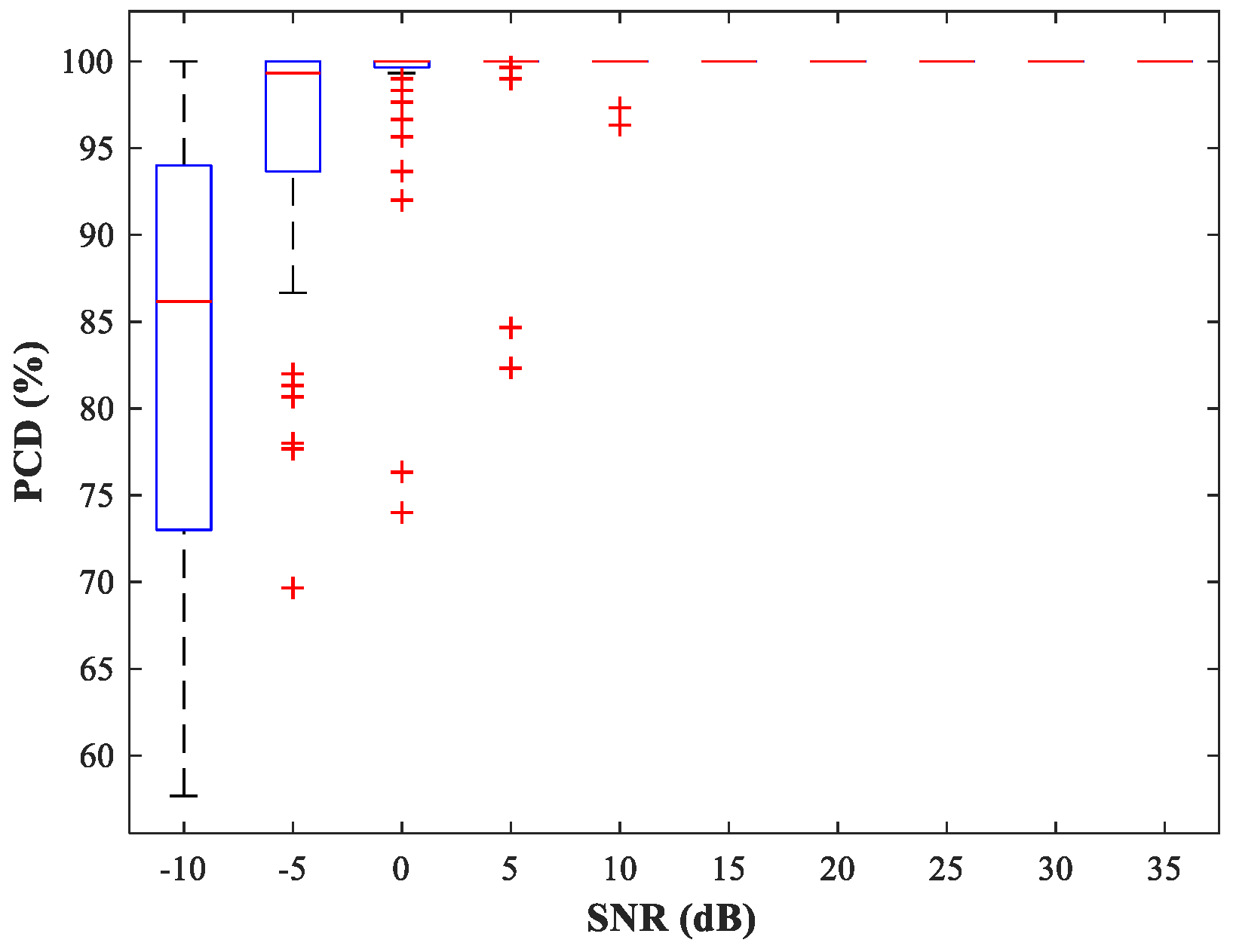
Figure 9, from which we can observe that the detection errors at the edges of the sub-area are significantly reduced and the detection accuracy has increased to 99.8%. Of course, the improvement in detection accuracy is acquired at the cost of computational resources.
Next, we fix
and select the source location
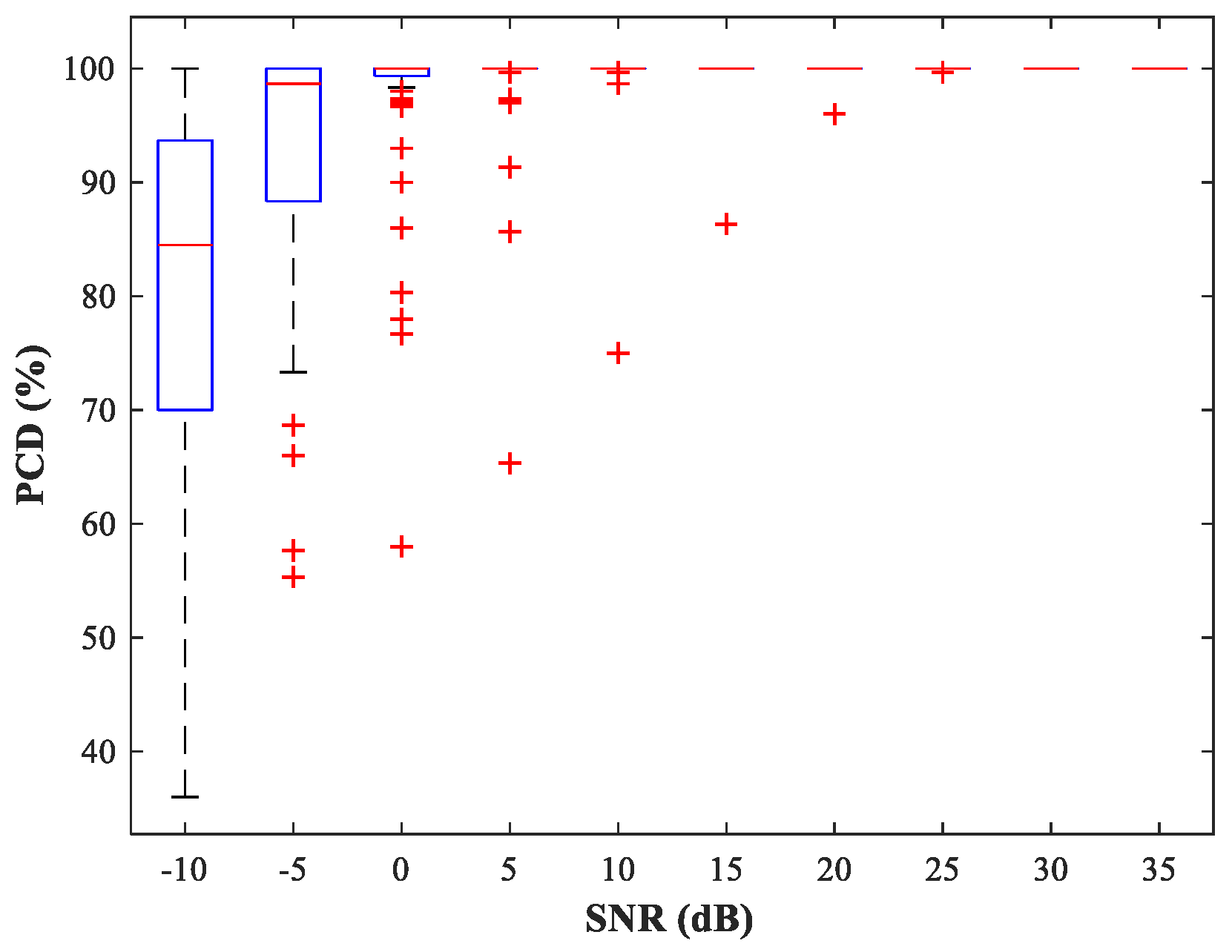
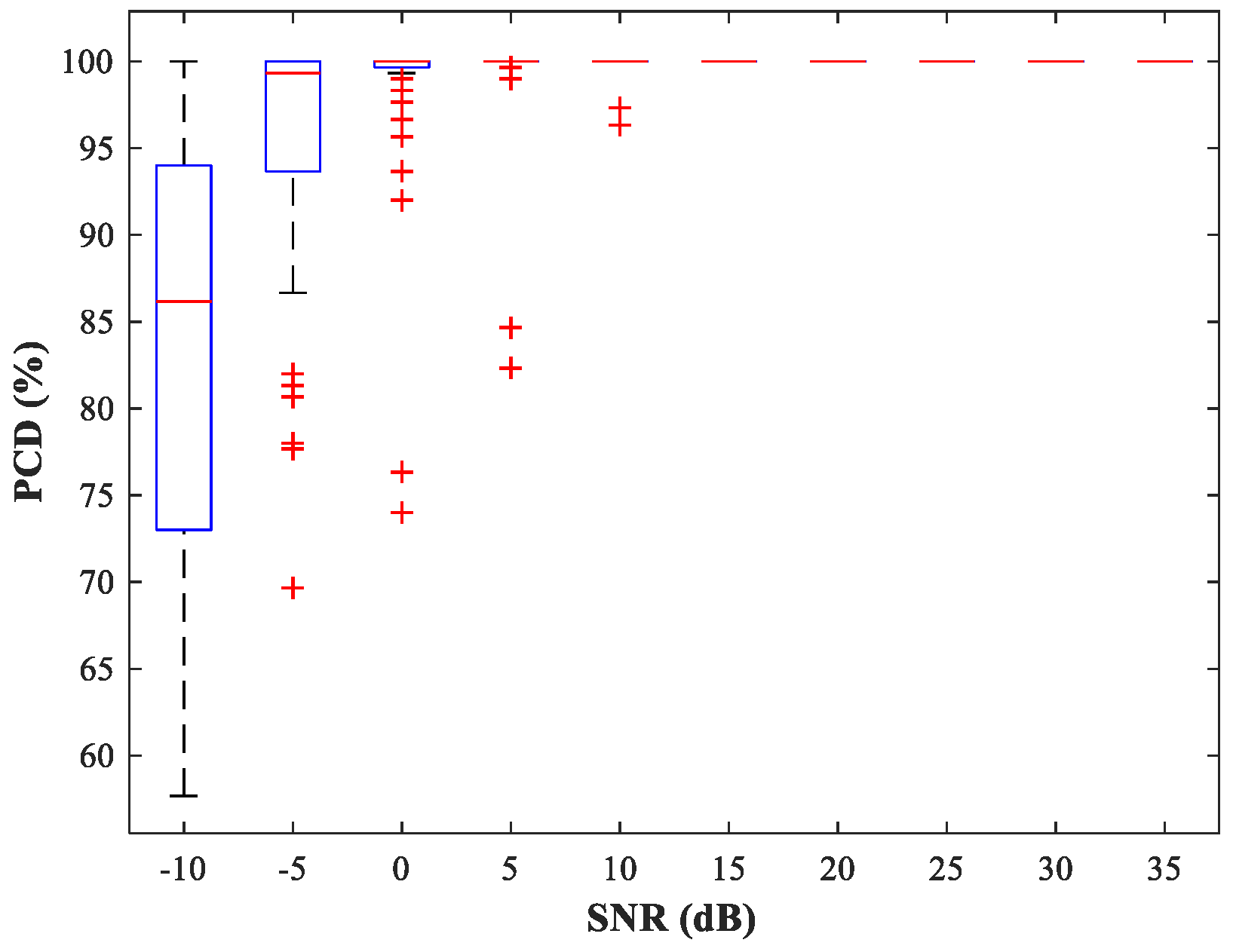
at random. The performance of the detection network is then evaluated by the probability of correct detection (PCD), which is the ratio of the number of correct detections to the total number of detections. In
Figure 10 and
Figure 11, we show boxplots of PCD values calculated for 50 different
and 500 MC experiments under different SNR conditions. Compared with the network trained with uniform steps, the network trained using variable steps has fewer outliers and the detection performance of the latter has improved.
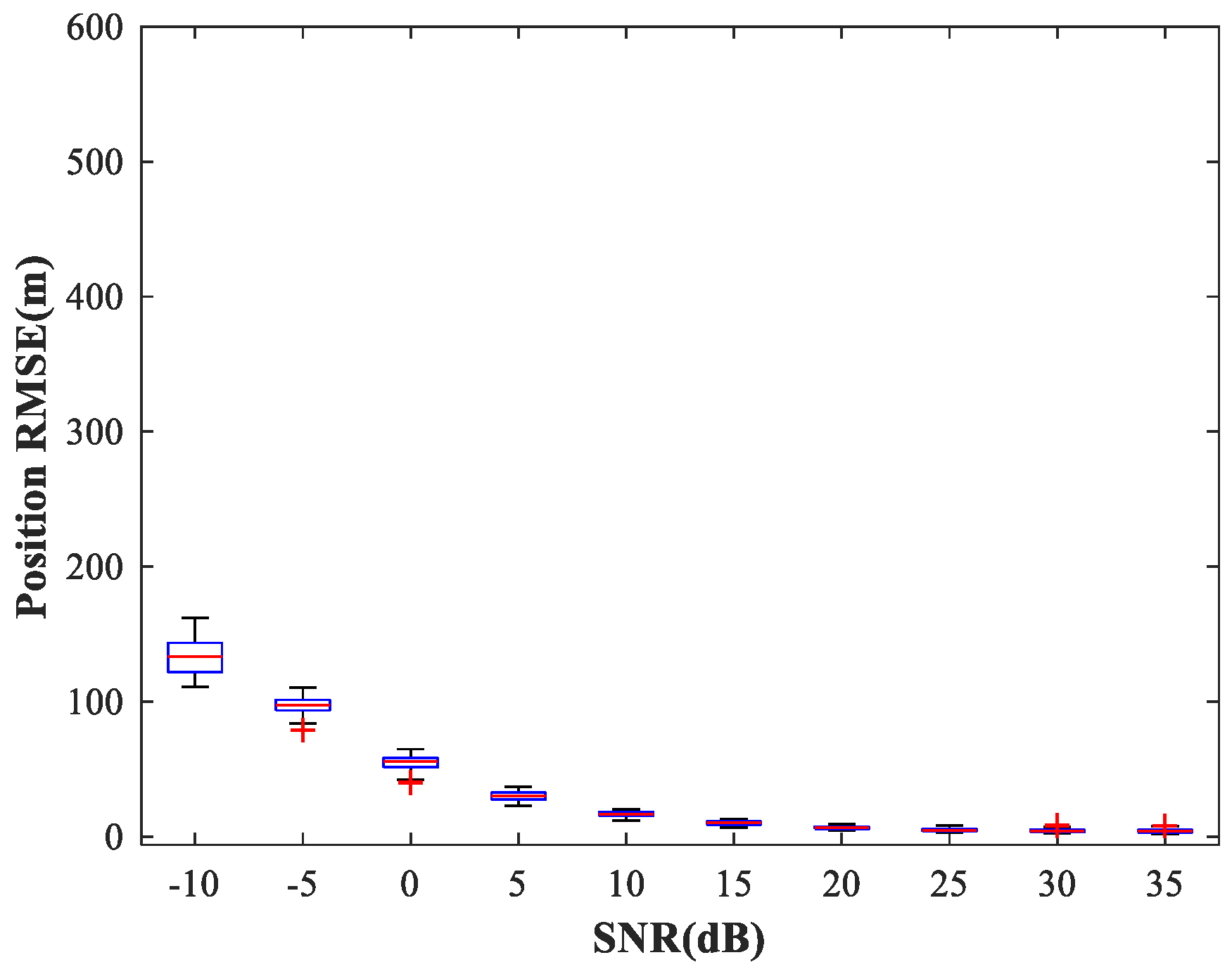
4.2. Study of the MLP-NN Performance in the Spatial Filtering Stage
According to the analysis in
Section 3.3, the number of input neurons is equal to the number of output neurons in this stage; both are set to
under this simulation scenario. The number of hidden layers and the number of neurons in the hidden layer are determined in the same manner described in
Section 4.1. The MLP-NNs with two hidden layers each containing 24 neurons are employed, and the number of neurons in both the input and output layers is
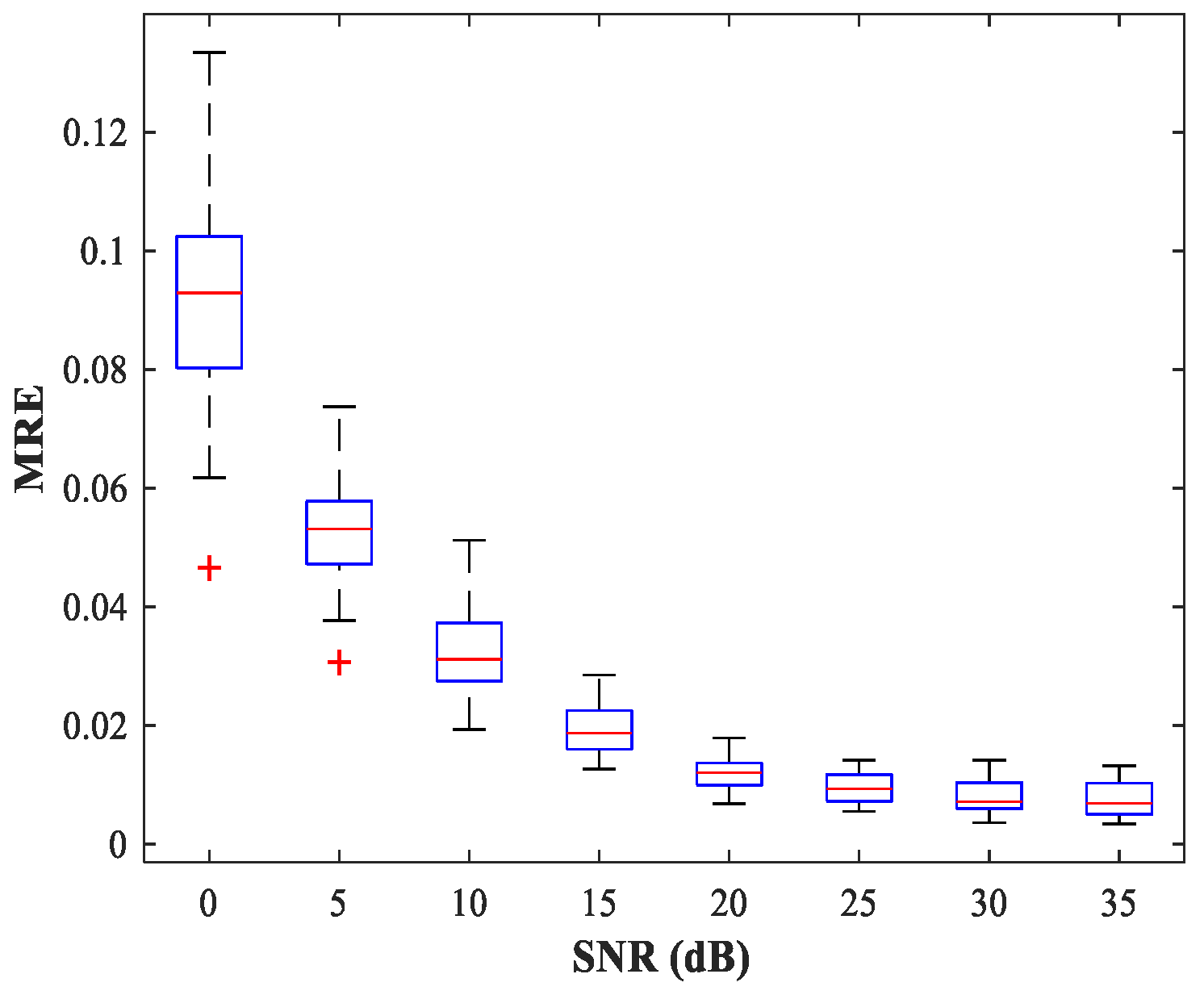
. The network is trained for 200 epochs. For constant simulation conditions,
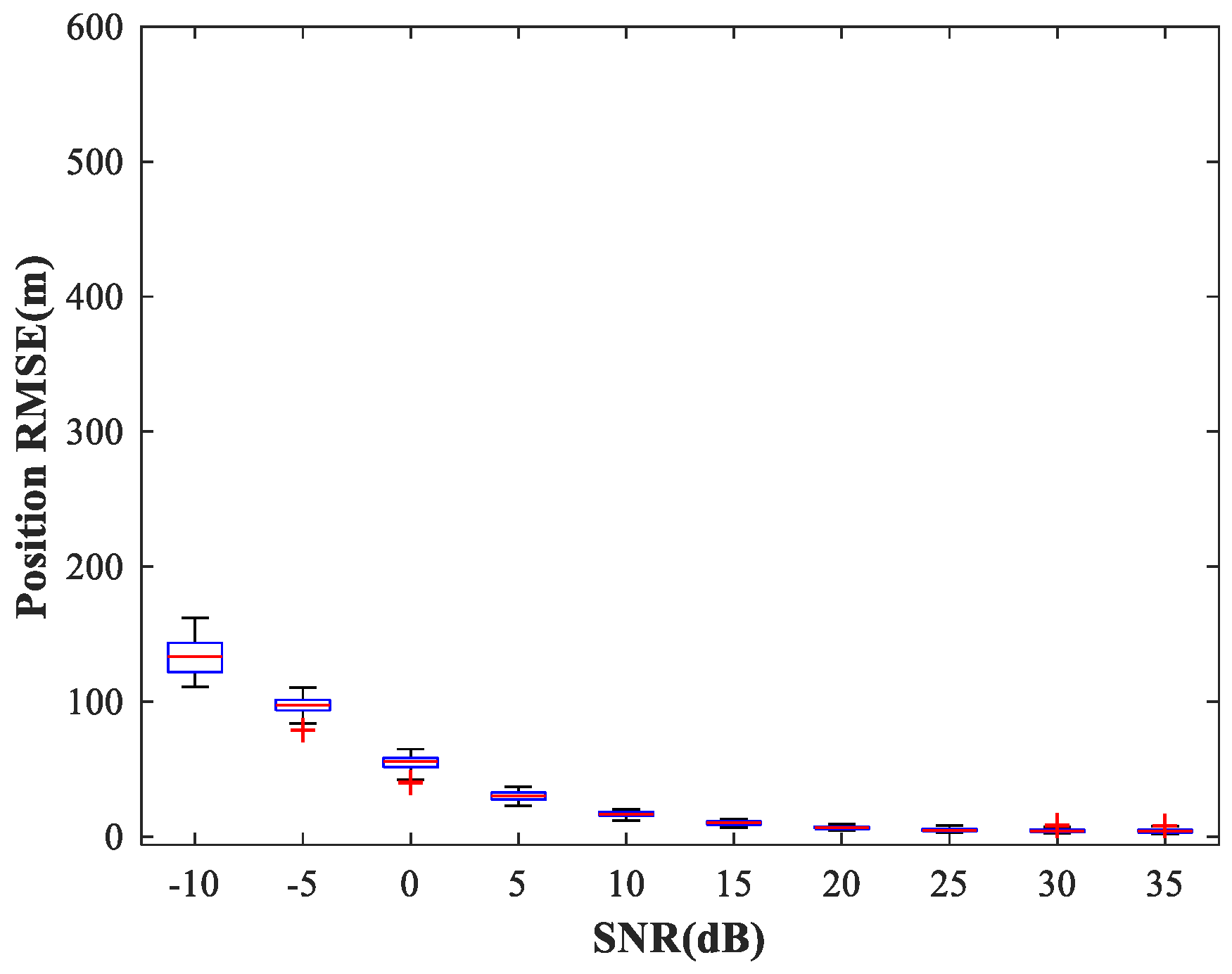
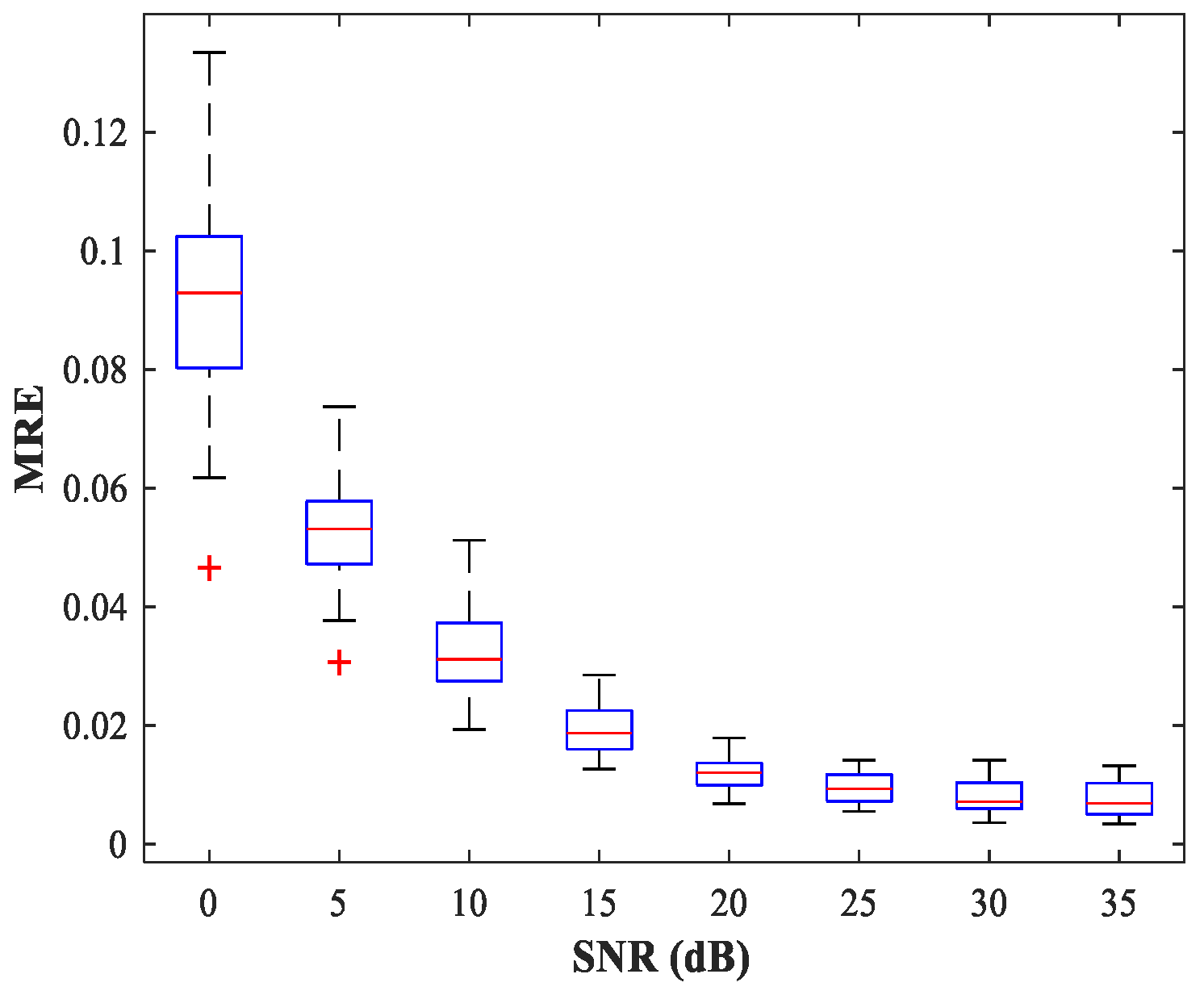
Figure 12 shows the curve of MRE versus SNR. The testing set includes 50 random combinations of
, covering the whole region of the two sub-areas, for SNR values from 0–35 (dB) in steps of 5 (dB). For each combination of SNR,
, and
, we conduct 500 MC experiments.
As can be seen from
Figure 12, the trained MLP-NN displays excellent spatial filtering performance, especially under high SNR conditions.
4.3. Study of the RBF-NN Performance in the Position Estimation Stage
The existence of a spatial filtering network means that the RBF-NN need only respond to one source in the corresponding sub-area, thus greatly reducing the size of the training set. Following [
5], the number of hidden neurons in the RBF-NN is determined by the minimal resource allocation strategy. Finally, the number of neurons in input, hidden, and output layers is
, 40, and
, respectively. The maximum number of neurons, spread of RBFs, and mean squared error goal are set to 500, 1, and
, respectively (For the specific training process, see
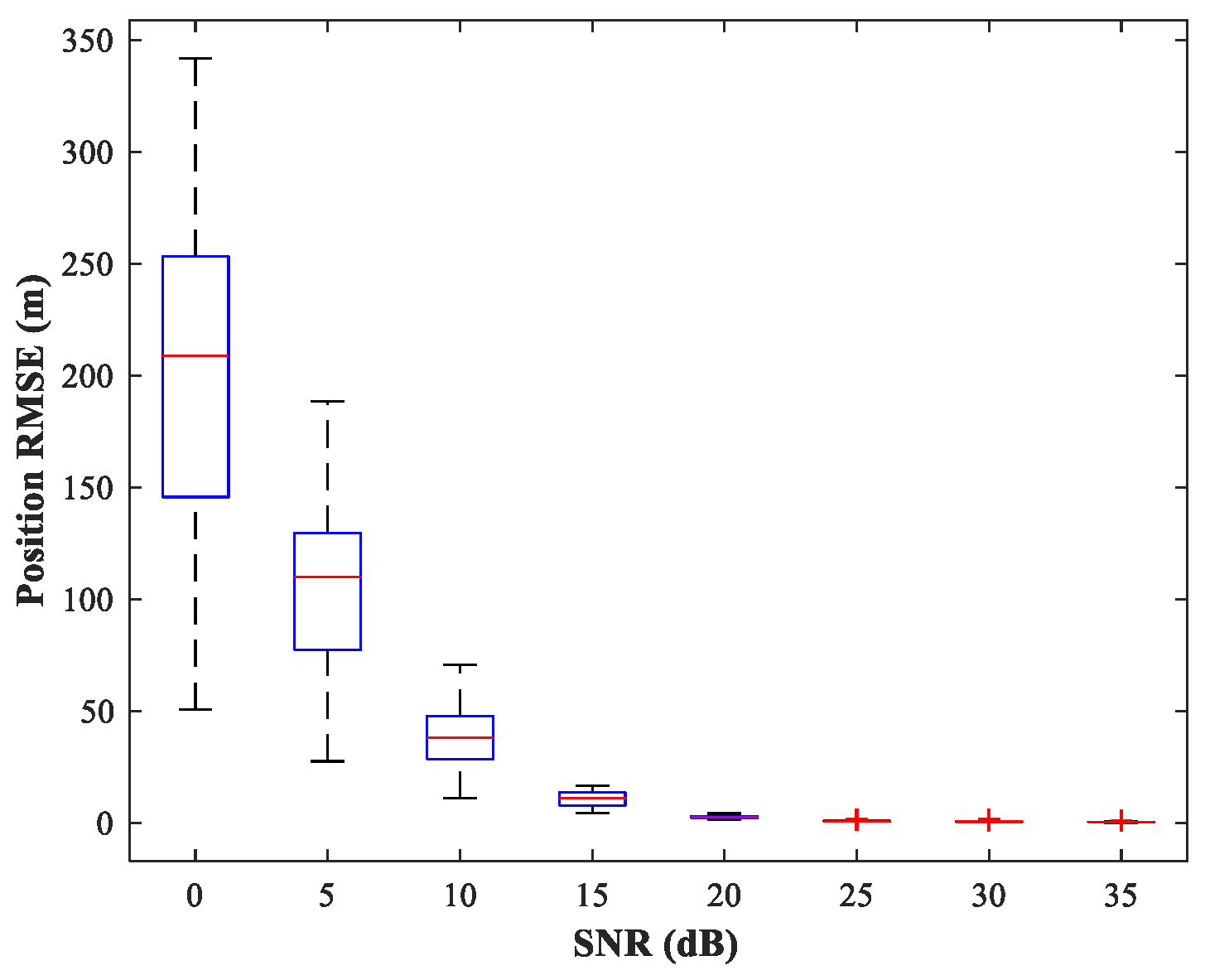
Section 3.4). We consider the same simulation conditions as described in
Section 4.2. The simulation results are shown in
Figure 13. We can see that the trained RBF-NN offers high localization accuracy and small variance in the high SNR situation (
).
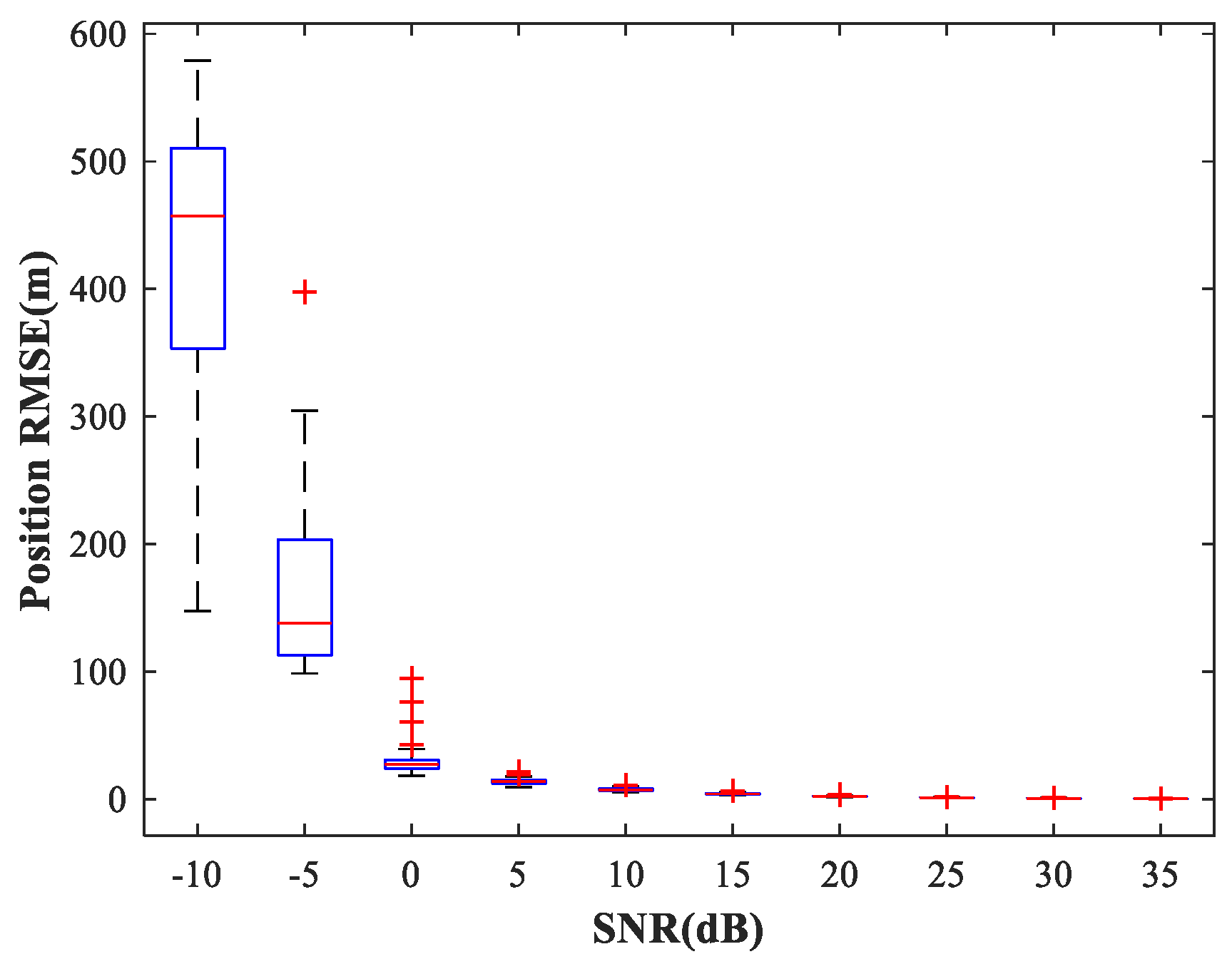
4.4. Study of the Network Generalization for Different SNRs
In the following subsections, we combine the previously trained NNs in the manner of
Figure 1 and study the performance of the complete MLP-MLP-RBF network. The test set comprises 50 random combinations of
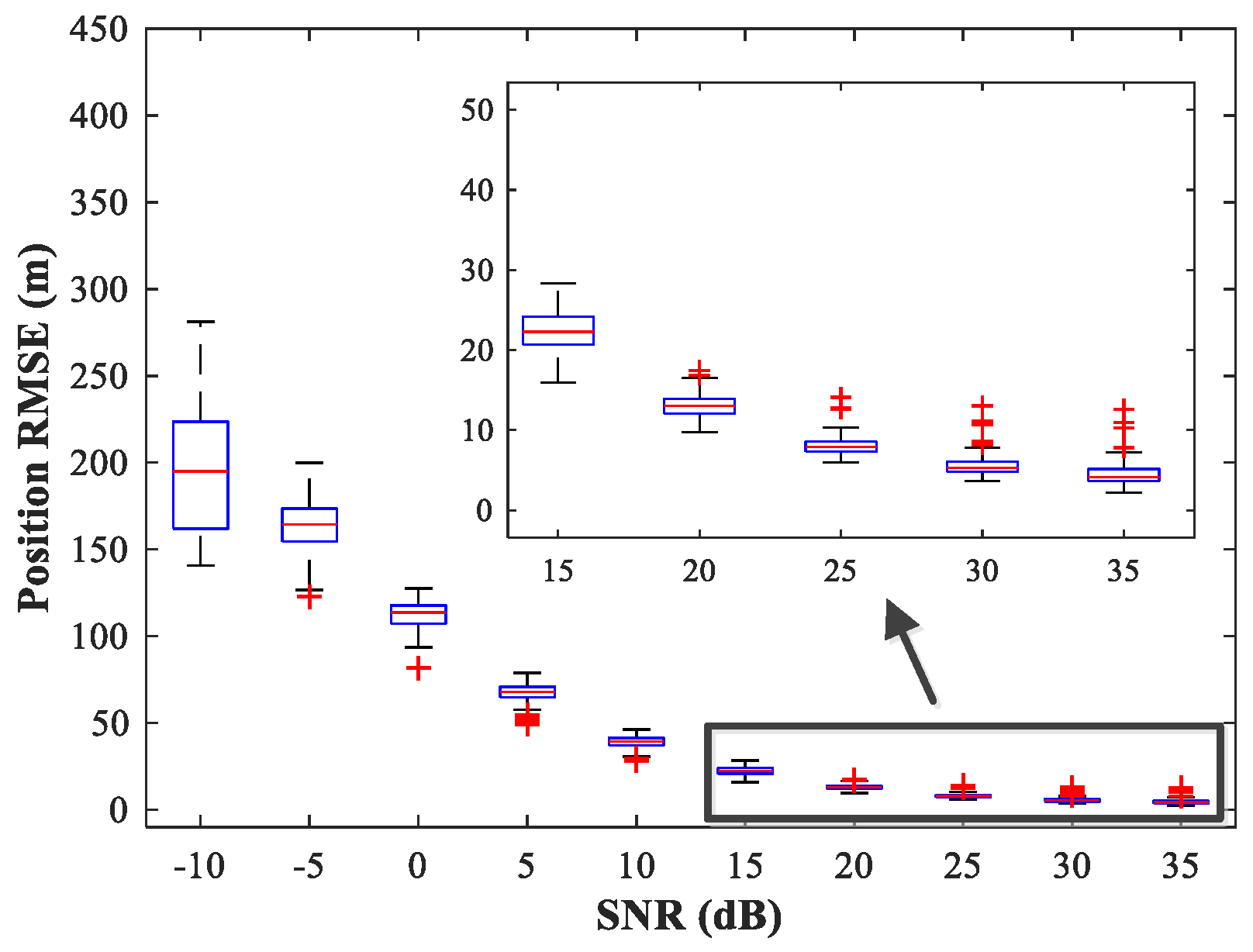
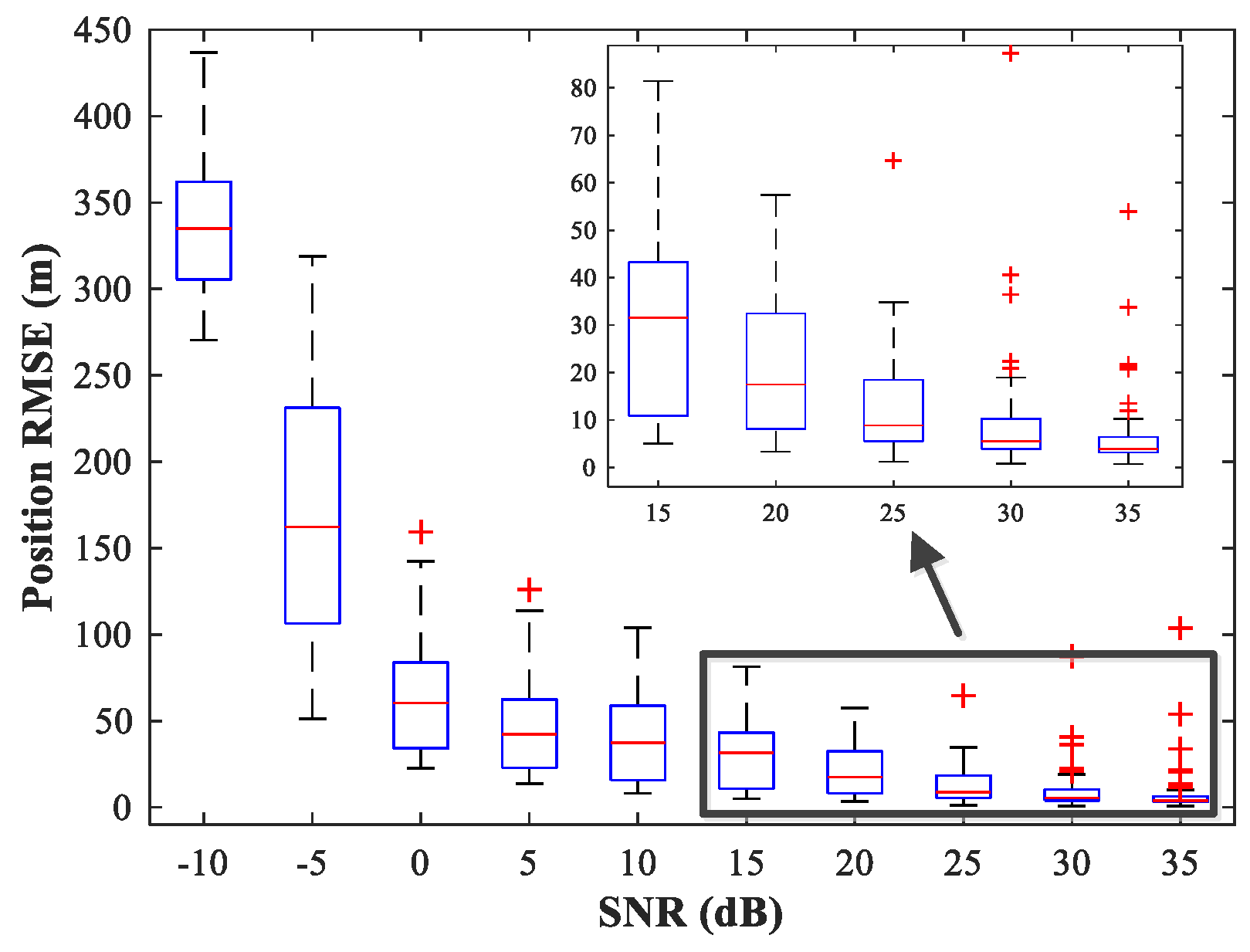
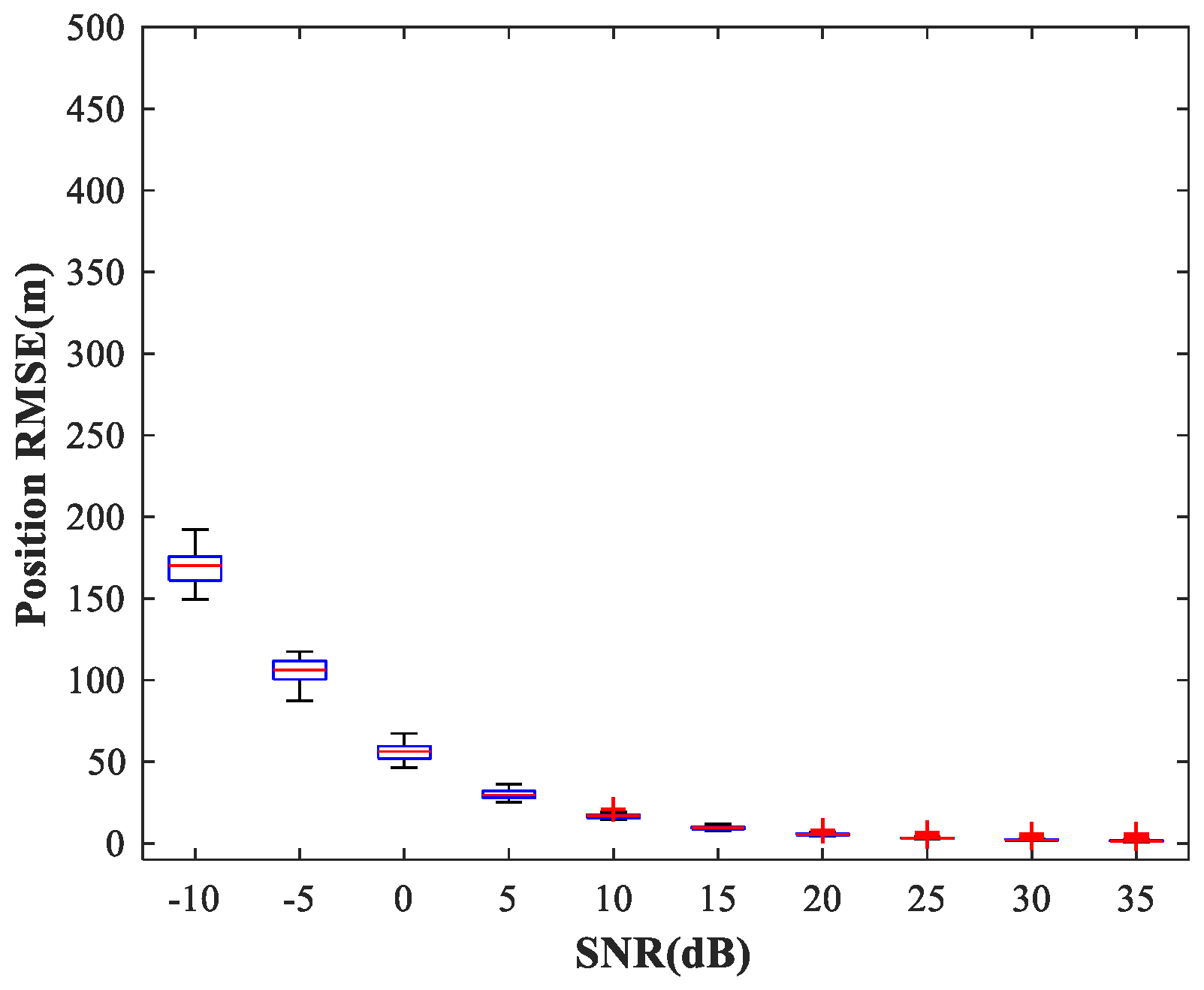
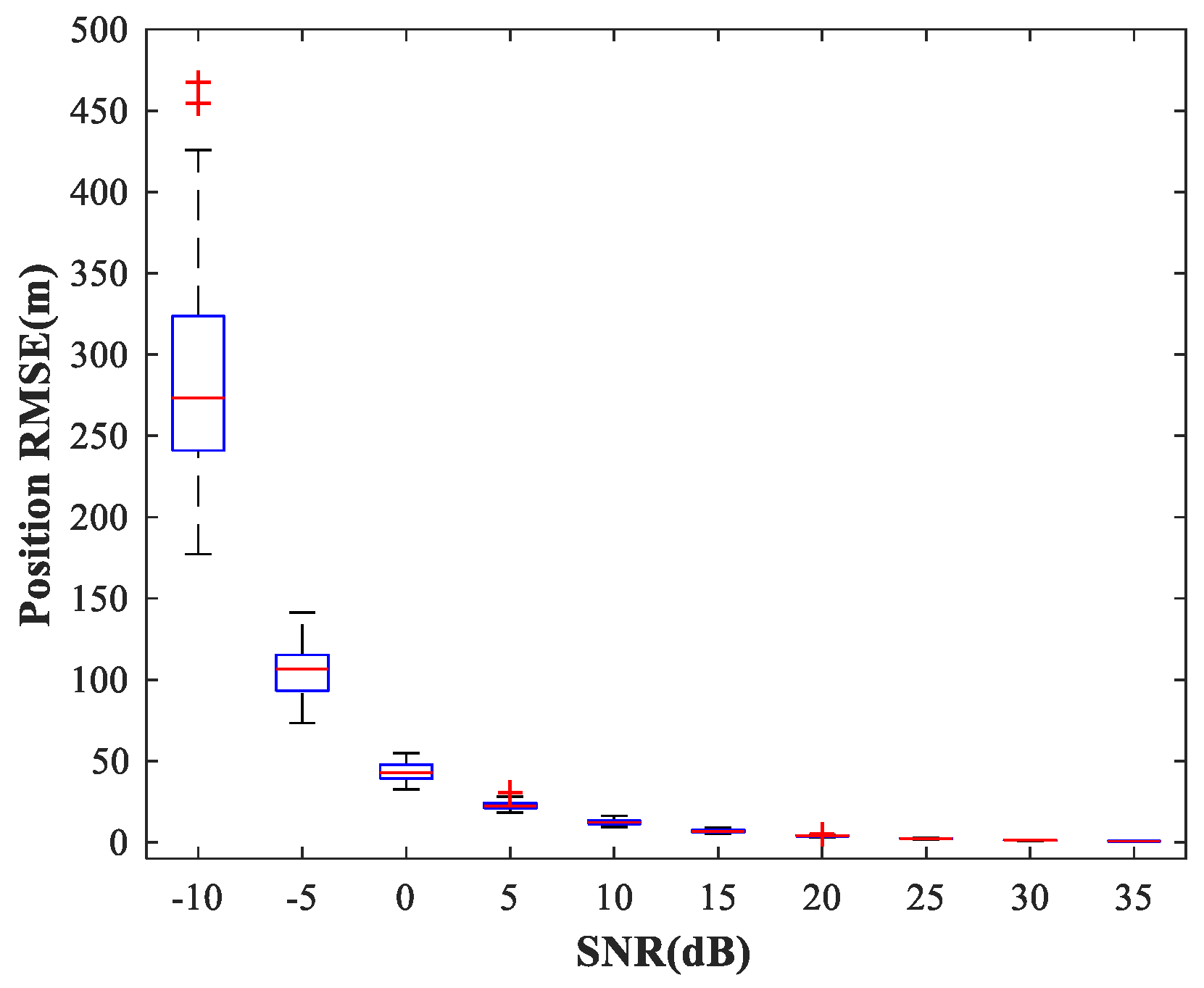
, covering the whole region of the two sub-areas. We fix SPR = 0 dB and vary the SNR in the range −10–35 dB in steps of 5 dB.
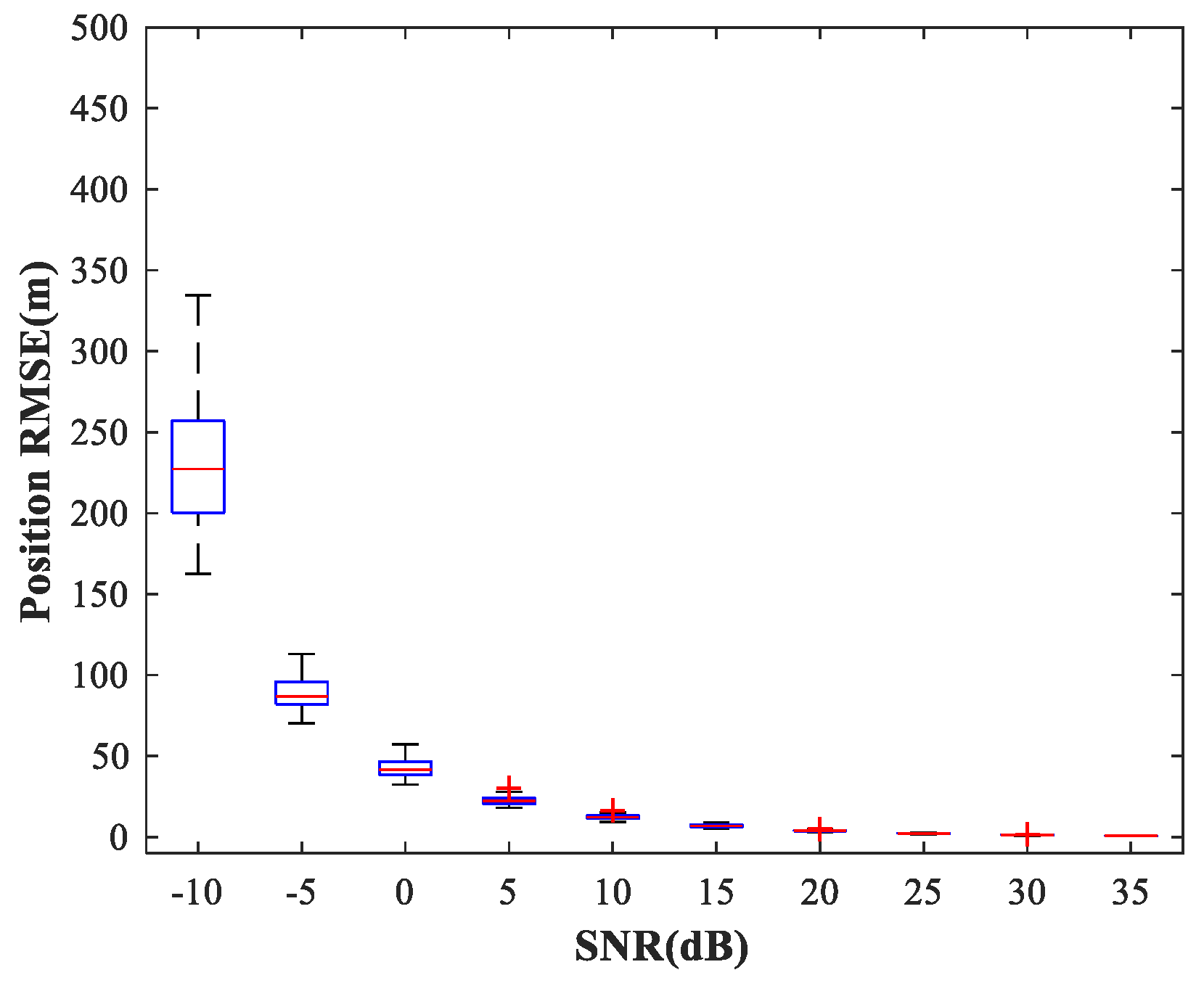
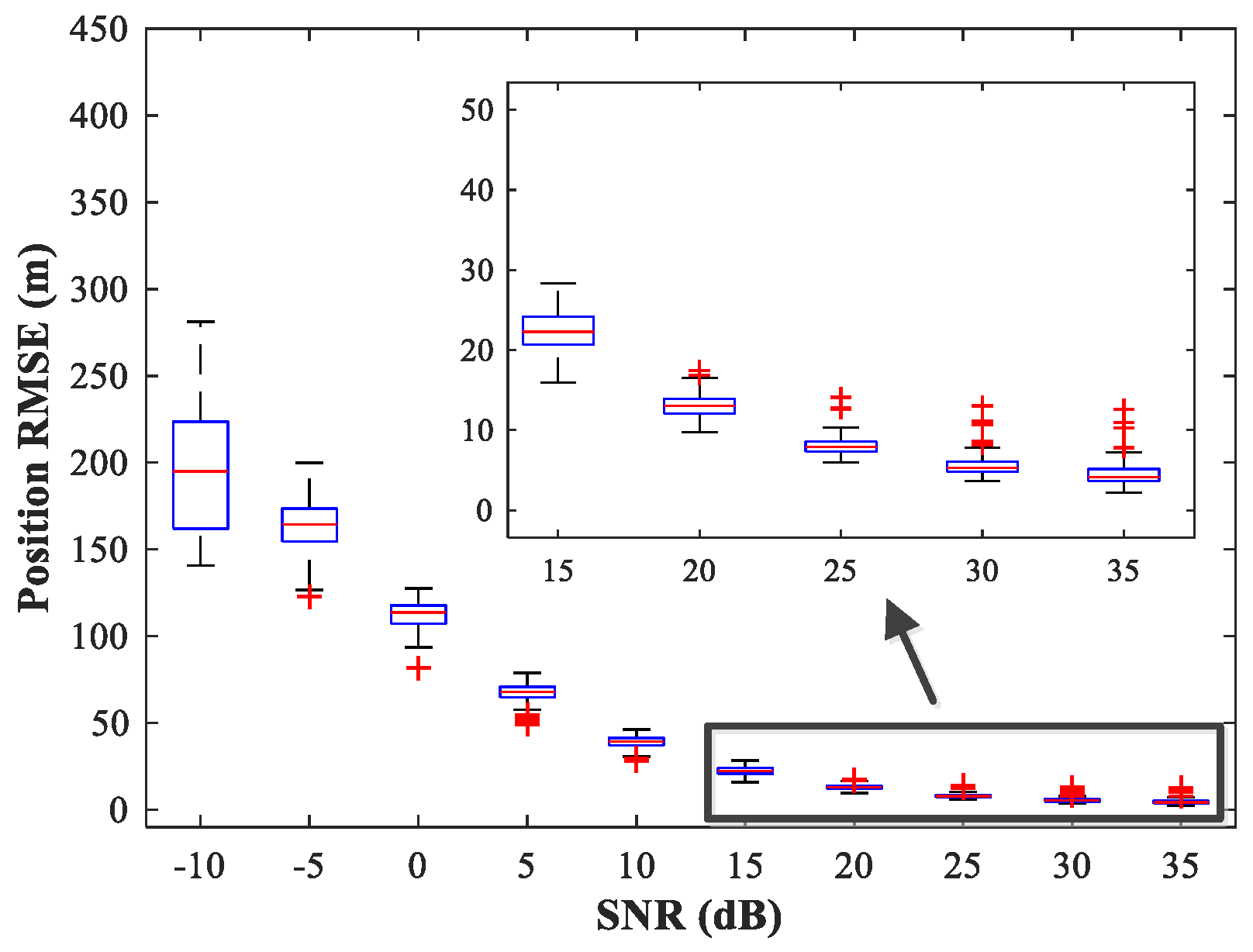
Figure 14,
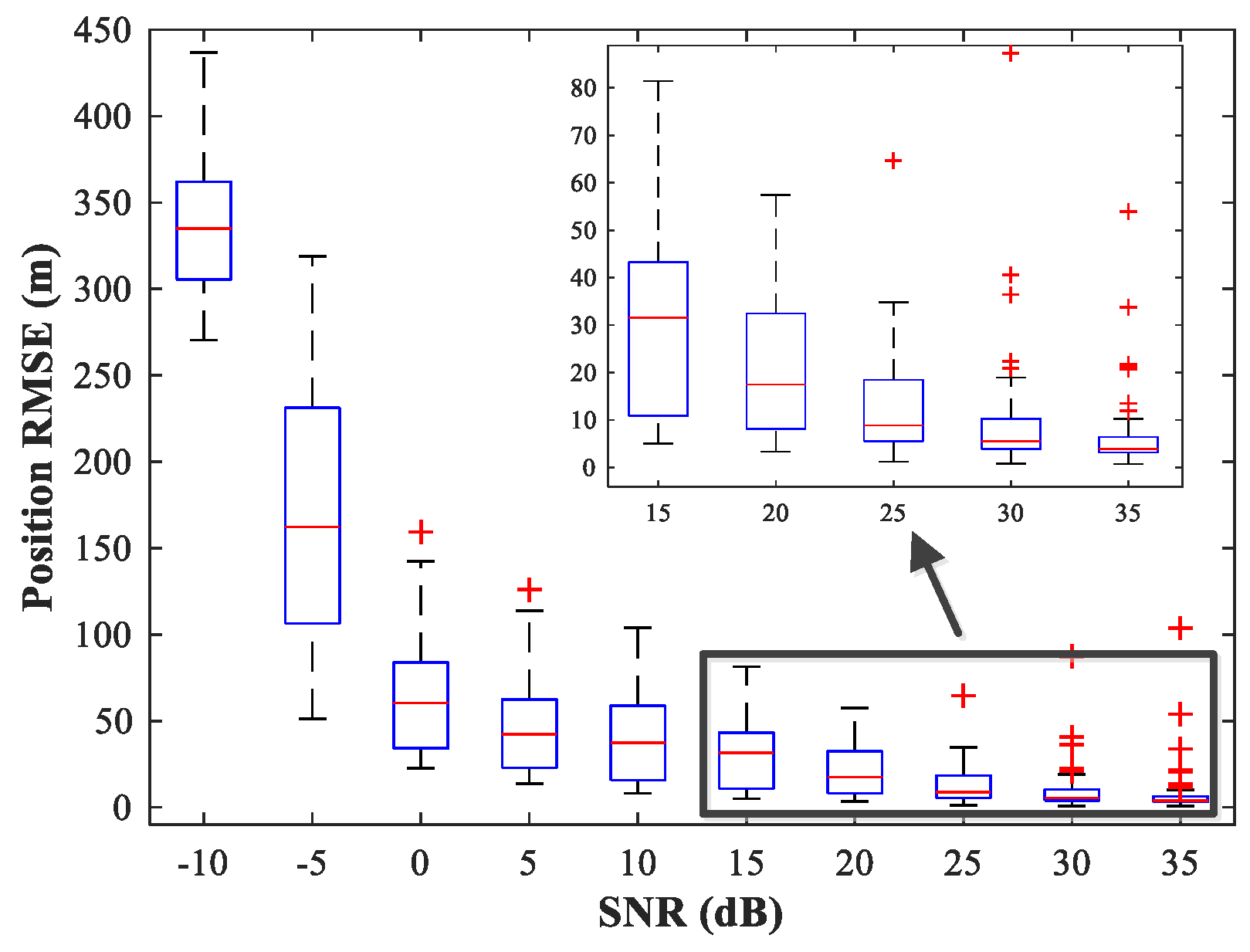
Figure 15 and
Figure 16 show
of the proposed MLP-MLP-RBF method, the MUSIC-DPD algorithm, and the ML-DPD algorithm, respectively.
As expected, compared with the MUSIC-DPD algorithm, the proposed MLP-MLP-RBF method has a lower RMSE value at high SNRs () and smaller variance. Furthermore, we find that the proposed method exhibits better localization performance than the MUSIC-DPD algorithm in the case of low SNRs (). This can be interpreted as the MUSIC-DPD algorithm suffering from the thresholding effect, whereas the MLP-MLP-RBF method is more robust at high noise levels. On the other hand, the proposed MLP-MLP-RBF method can attain the ML accuracy at high SNRs.
4.5. Study of the Network Generalization for Different SPRs
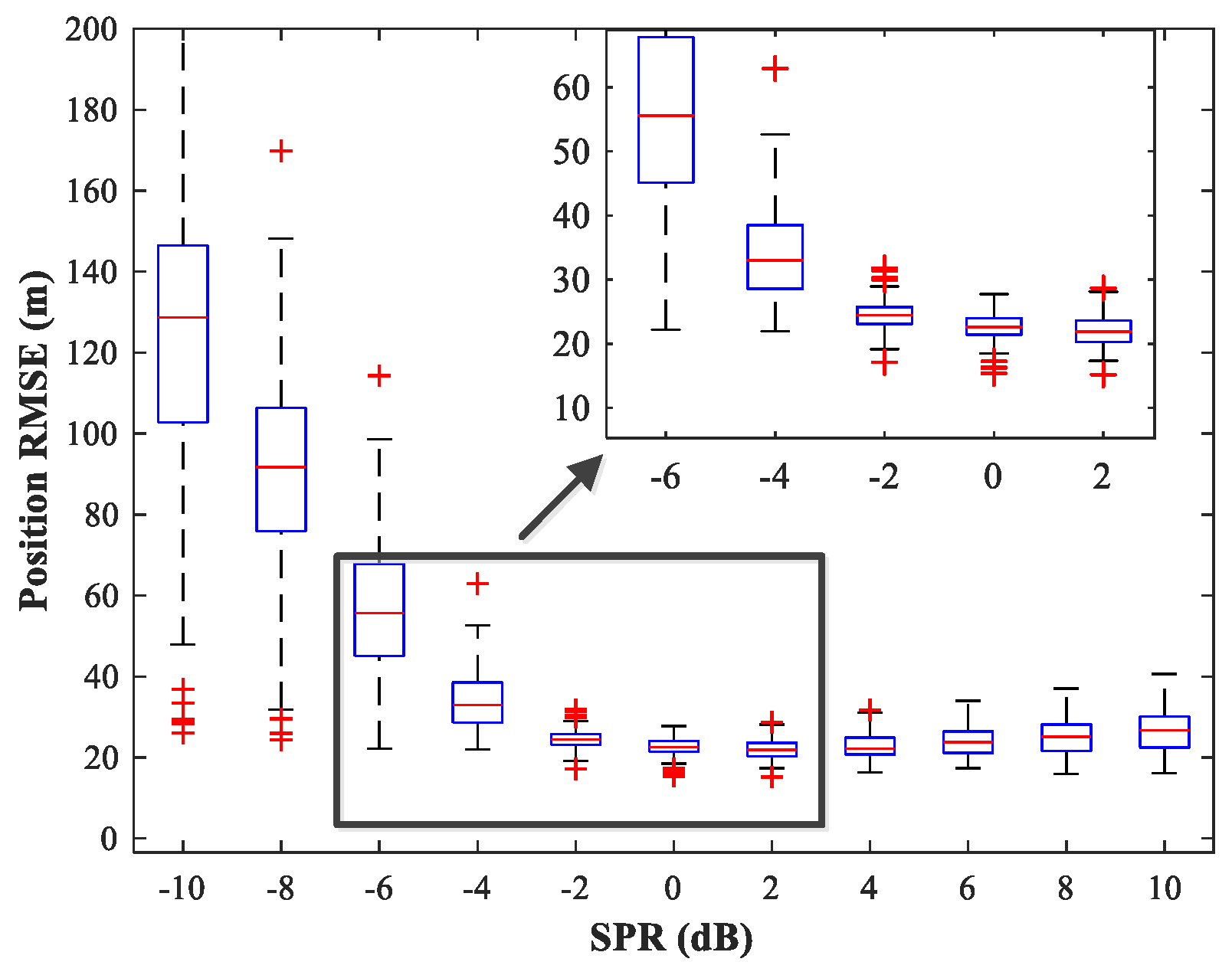
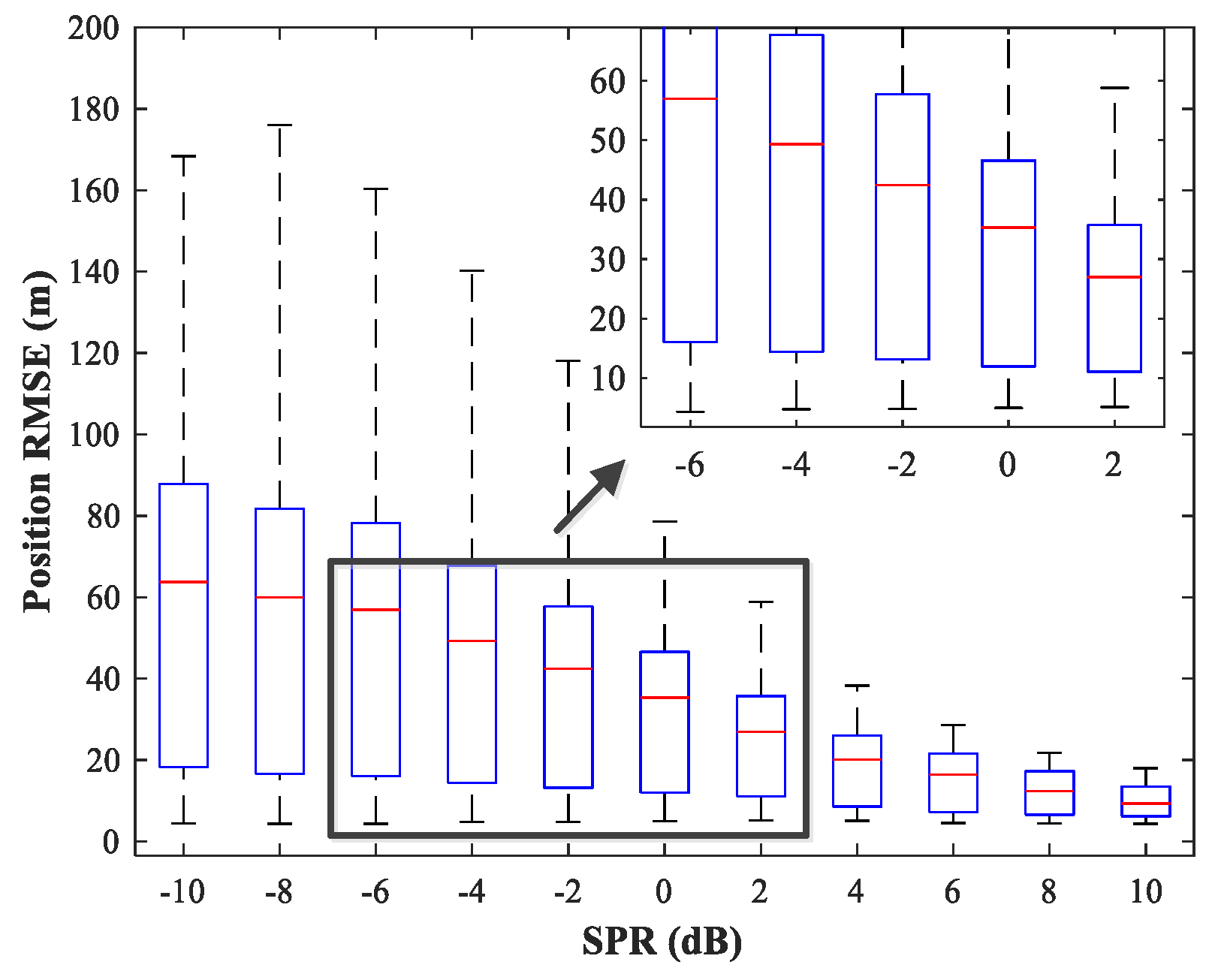
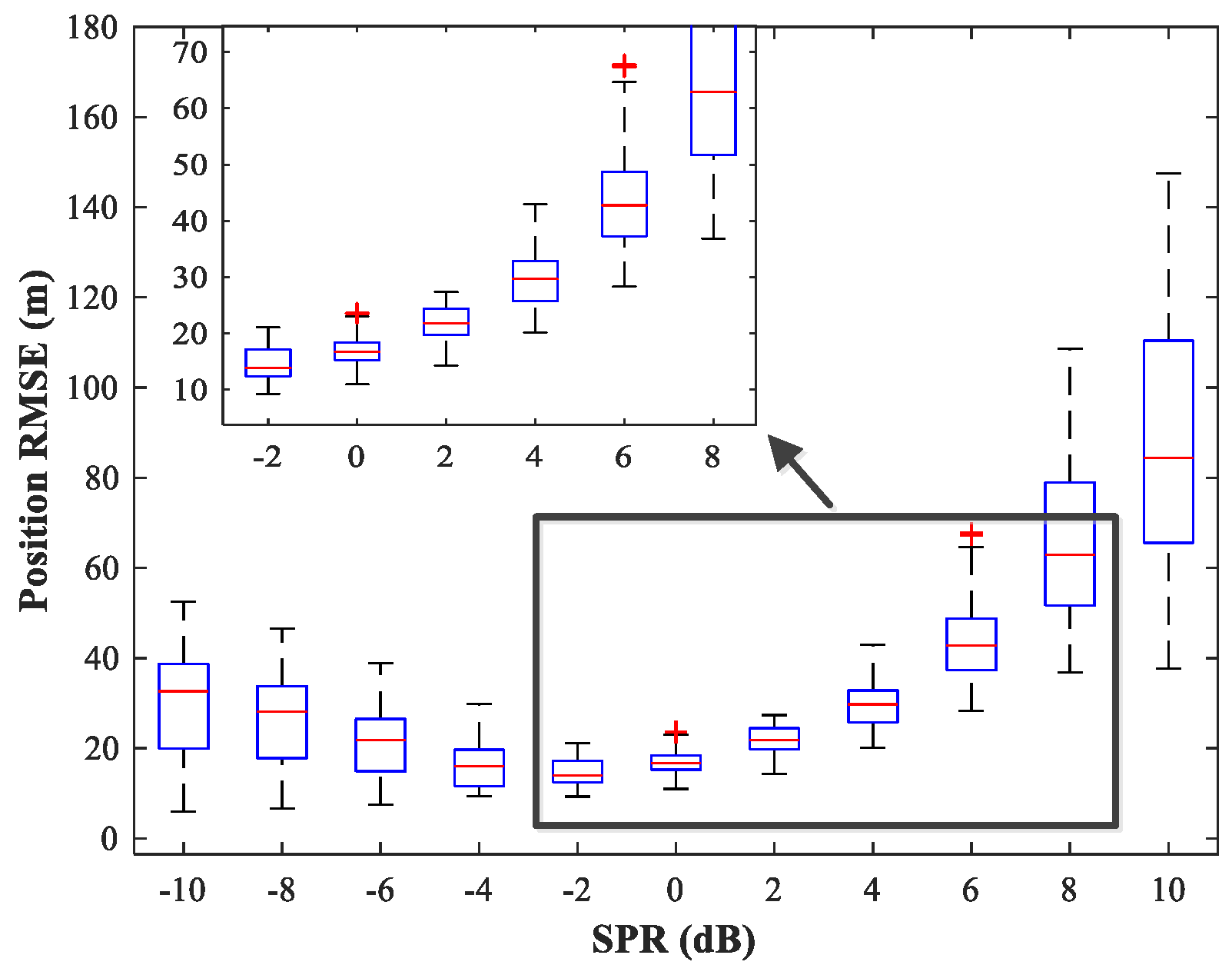
The effect of variations in SPR on the position estimation performance is now studied. The simulation conditions are as previously described. We fix SNR = 15 dB and vary SPR from −10–10 dB in steps of 2 dB. Note that our MLP-MLP-RBF network is trained with SPR = 0 dB, and the goal here is to evaluate the performance of the network with SPR values for which the network is not trained. The simulation results are shown in
Figure 17,
Figure 18,
Figure 19 and
Figure 20. As expected, the sources in sub-areas 1 and 2 have high positioning accuracy under high and low SPR conditions, respectively. This can be explained by the fact that with an increase in SPR, the power of the first source becomes higher than that of the second source. From these figures, we can observe that compared with the MUSIC-DPD algorithm, the proposed network offers higher localization accuracy in the range
for sub-area 1 and
for sub-area 2.
From the above simulation results, we can conclude that the proposed MLP-MLP-RBF method performs similarly to the MUSIC-DPD algorithm. The results show that the MLP-MLP-RBF network offers good generalization performance for SNRs and SPRs that do not appear in the training set.
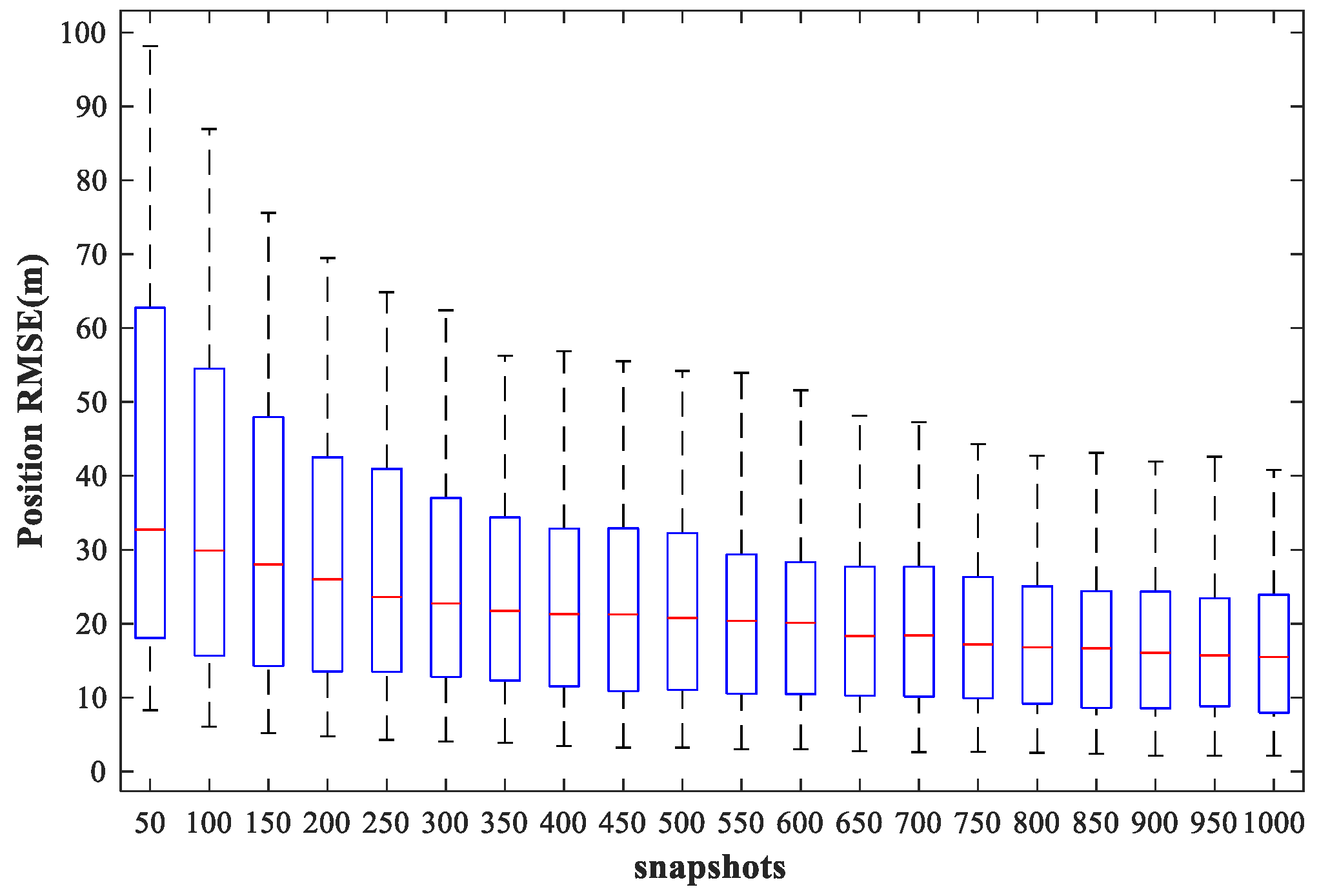
4.6. Study of the Network Performance for Different Snapshots
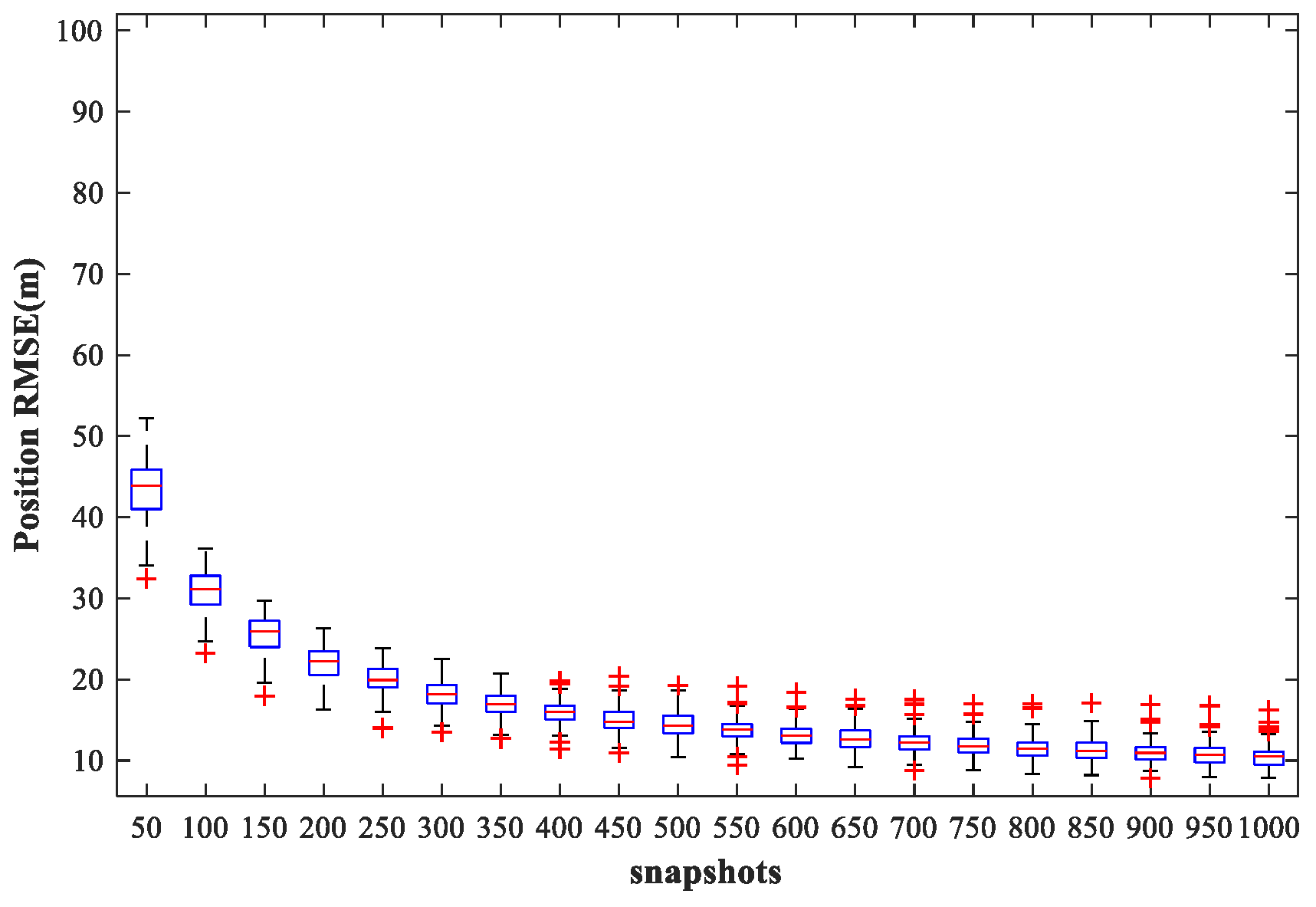
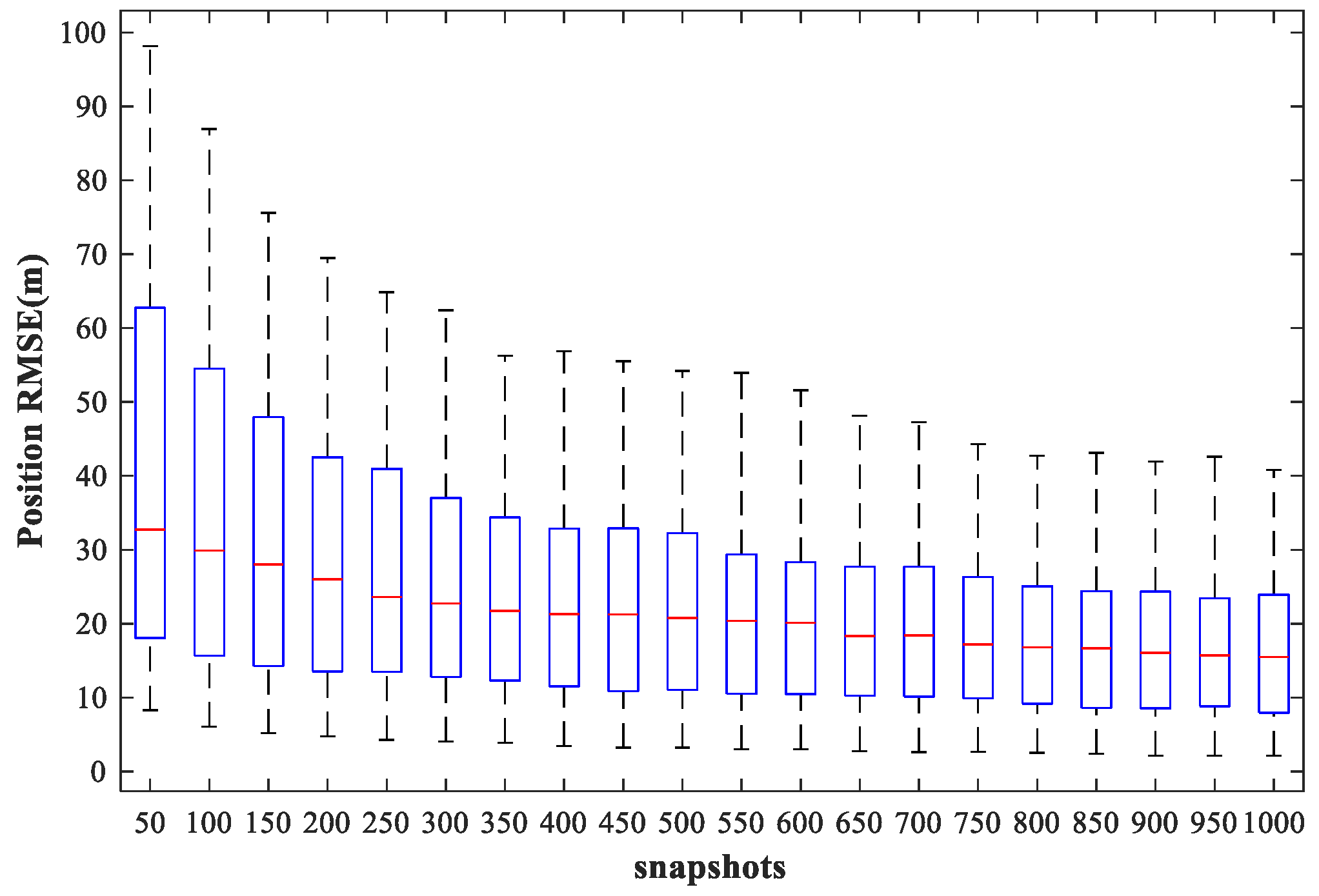
In this subsection, we examine the localization performance of the proposed method for different snapshots. We fix SPR = 0 dB, SNR = 30 dB, and vary the number of snapshots from 50 to 1000 times in steps of 50 times. Other simulation conditions are as described above.
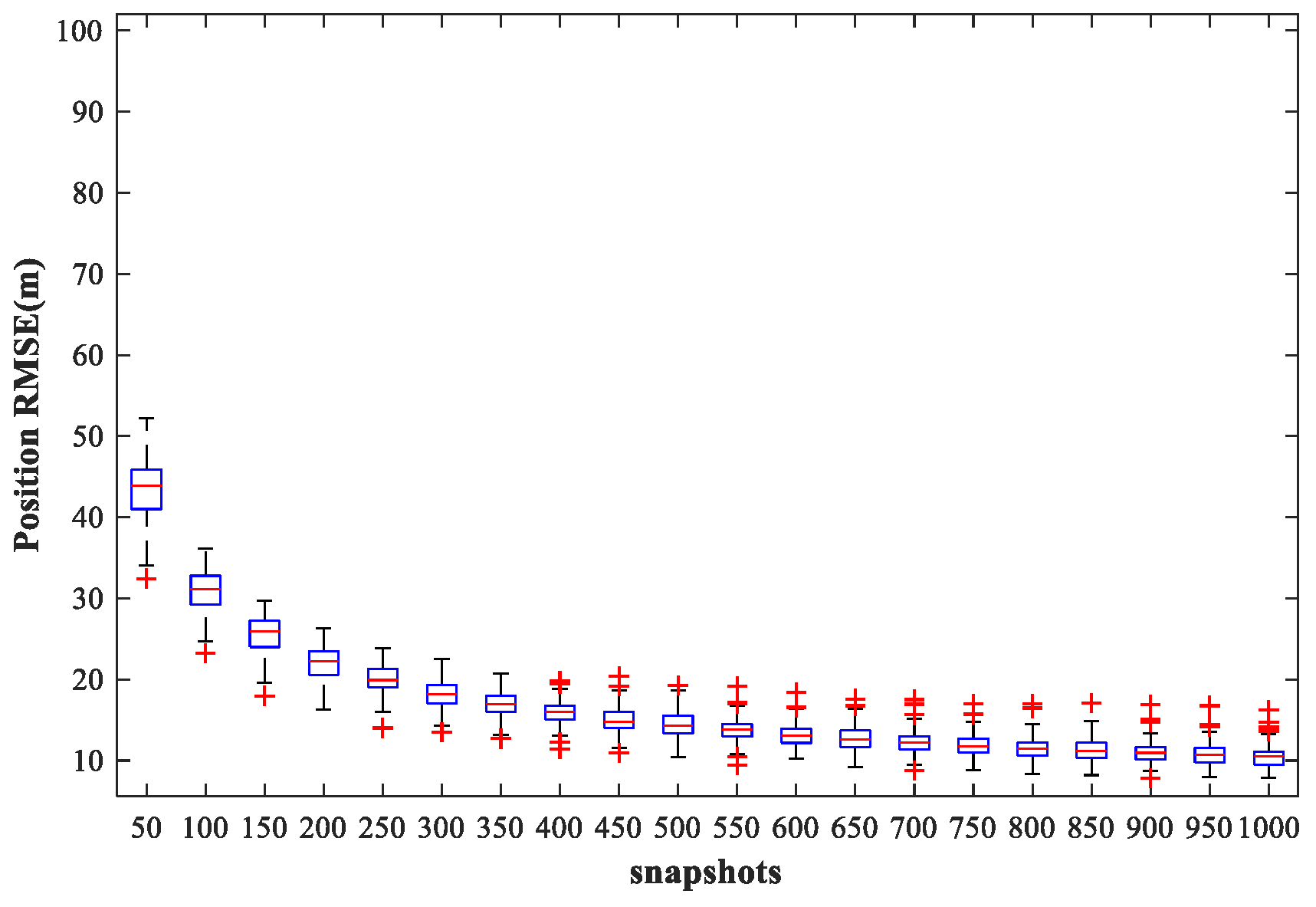
Figure 21 and
Figure 22 show the
of the proposed MLP-MLP-RBF method and the MUSIC-DPD algorithm, respectively, with respect to the number of snapshots.
From the simulation results, we can see that the localization accuracy of both the proposed method and the MUSIC-DPD algorithm increases with the number of snapshots. However, as the number of snapshots continues to increase, the improvement in accuracy slows considerably. Moreover, under these simulation conditions, 200 snapshots are sufficient to meet the required localization accuracy; this is why 200 snapshots were used in the previous simulations.
4.7. Comparison of the Processing Time
To highlight the superiority of our MLP-MLP-RBF network, we now compare the processing time of the proposed method with that of the MUSIC-DPD and ML-DPD algorithms. Note that the MUSIC-DPD algorithm uses a search strategy with a 20 m coarse search step and 1 m fine search step. The computations are executed in Matlab R2017a on a PC with Intel Core i7-3520 CPU.
The simulation conditions are set to
,
,
, and
, and all other conditions are the same as previously described. The simulations are based on 500 MC runs. The average processing times in each stage and the total runtimes of the two methods are shown in
Table 3. Our MLP-MLP-RBF network requires only about 0.04 s to perform position estimation, which is much faster than the MUSIC-DPD and ML-DPD algorithms. The simulation results also indicate that the proposed MLP-MLP-RBF method can effectively solve the real-time multisource localization problem.
4.8. Study of the Network Performance for Nonuniform Arrays
The purpose of this subsection is to verify the feasibility of the proposed method for nonuniform arrays. The positions of the observers are listed in
Table 4. Each observer array is equipped with a six-element nonuniform linear array. For simplicity, the distance between adjacent elements in each array was set to
,
,
,
, and
, respectively. Assume that two sources are located in the two sub-areas of
Figure 23. The other simulation conditions and the network configuration are as described above.
The test set comprises 50 random combinations of
, covering the whole region of the two sub-areas. We fix SPR = 0 dB and vary the SNR in the range −10–35 dB in steps of 5 dB. The simulation results given by the three algorithms are shown in
Figure 24,
Figure 25 and
Figure 26. As expected, the proposed MLP-MLP-RBF method can be applied to nonuniform arrays directly. Moreover, we can obtain a conclusion similar to that for the uniform array scenario; that is, the proposed method has a higher localization accuracy than the MUSIC-DPD algorithm at low SNRs (
) and can attain the ML accuracy at high SNRs.
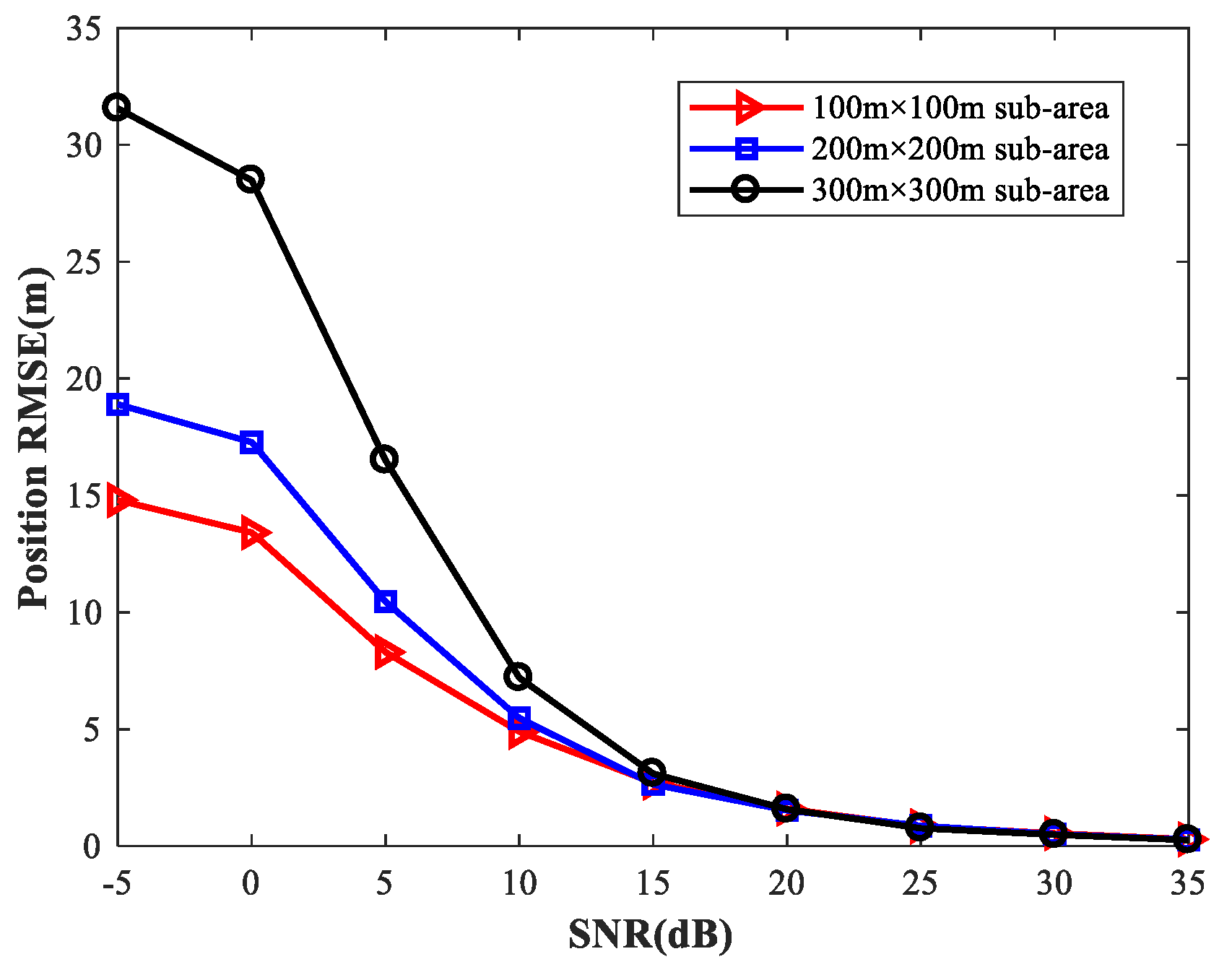
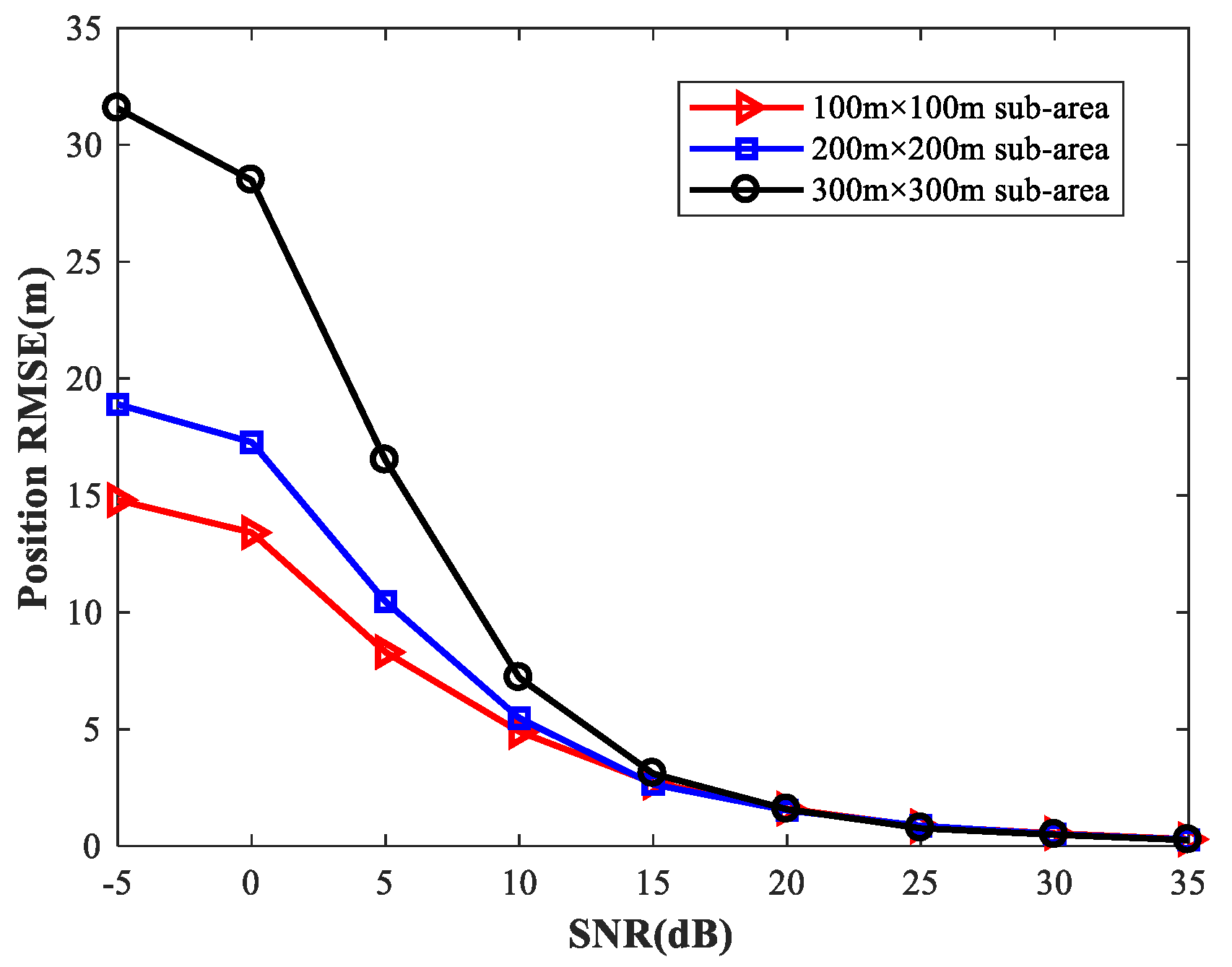
4.9. Study of the Network Performance for Different Sizes of Sub-Area
To provide a general guideline for how to balance memory resources with positioning accuracy, we study the localization performance of the proposed method for different sizes of sub-area with various numbers of observers and antennas. We first set the simulation conditions as previously described. We consider four observers at the positions listed in
Table 2. Each observer array is equipped with a six-element uniform linear array. We fix SPR = 0 (dB),
, and select the source location
at random.
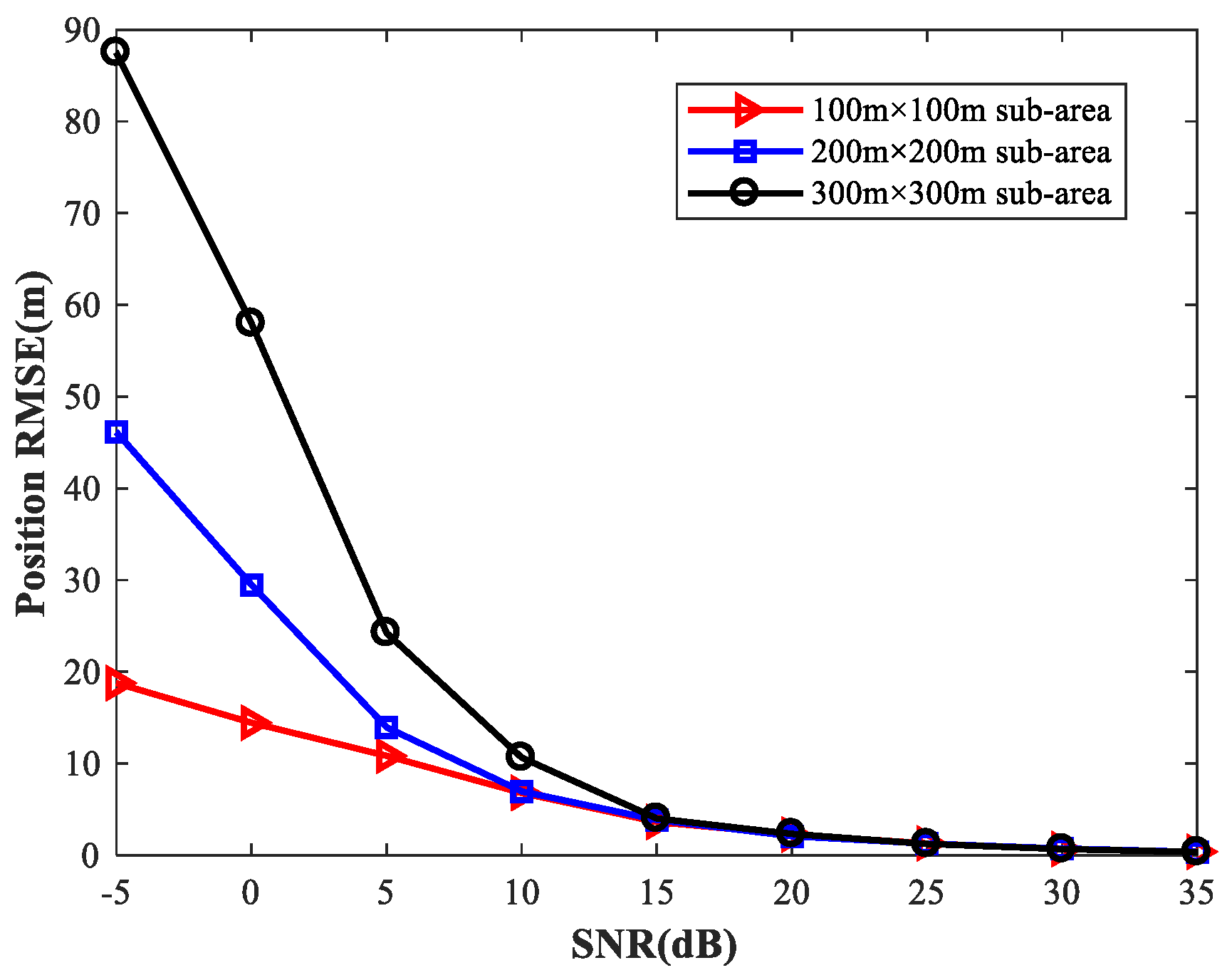
Figure 27 shows the
of the proposed MLP-MLP-RBF method with respect to SNR for different sizes of sub-area (100 m × 100 m, 200 m × 200 m, and 300 m × 300 m). Next, we consider two observers with six antennas and four observers with four antennas, respectively, and the other simulation conditions are as described above. The simulation results are shown in
Figure 28 and
Figure 29.
From these figures, we can see that a smaller sub-area will result in a higher localization accuracy. Moreover, these simulation results also indicate that the positioning accuracy improves with the number of observers and antennas. Based on this, when there are enough observers and antennas available (the reachable positioning accuracy is high), we can reduce the number of sub-areas and achieve a certain positioning accuracy with less computational resources. If the observers and antennas are relatively scarce, we need to further subdivide the sub-areas to achieve the desired positioning accuracy at the cost of more memory resources.
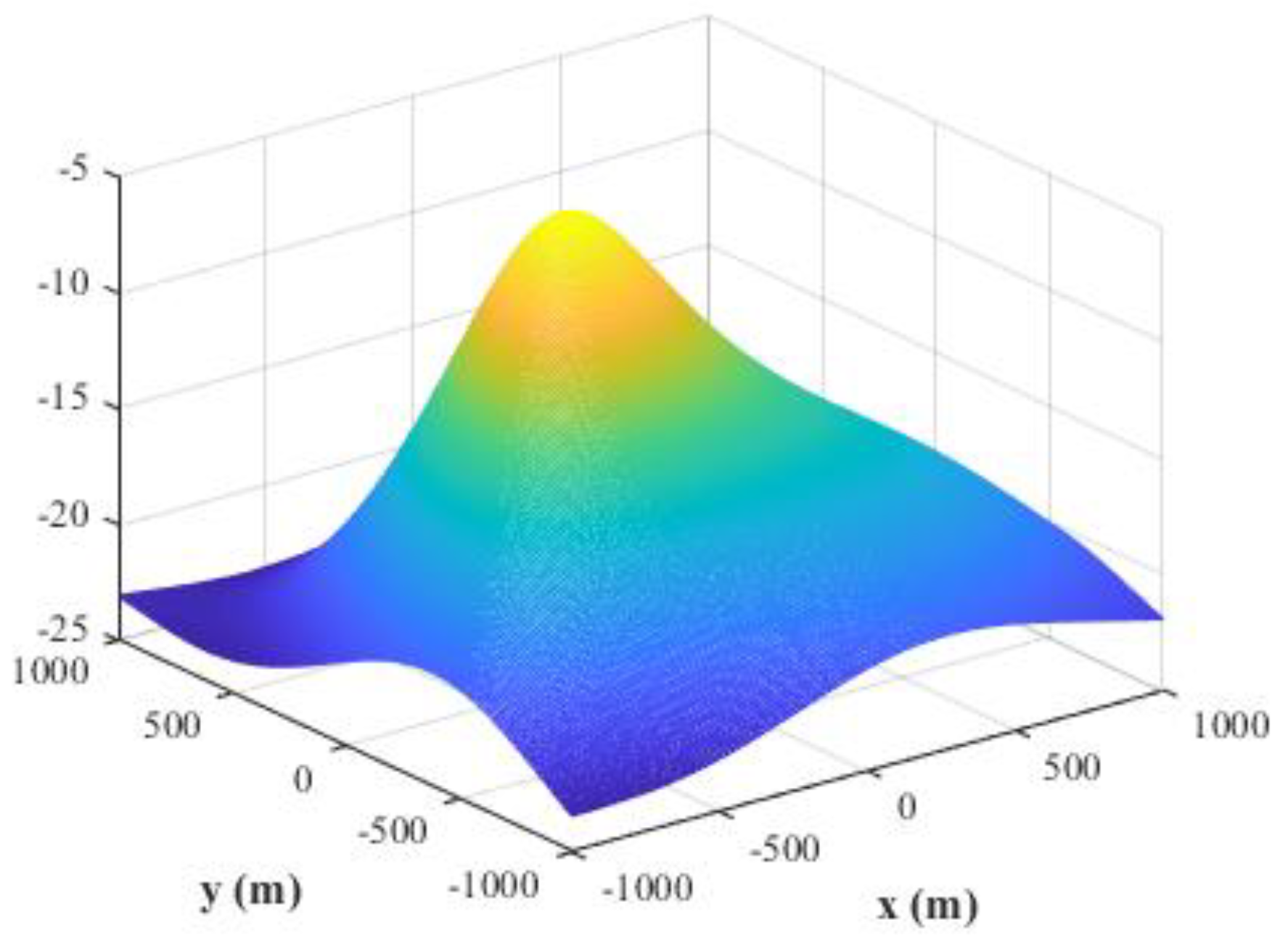
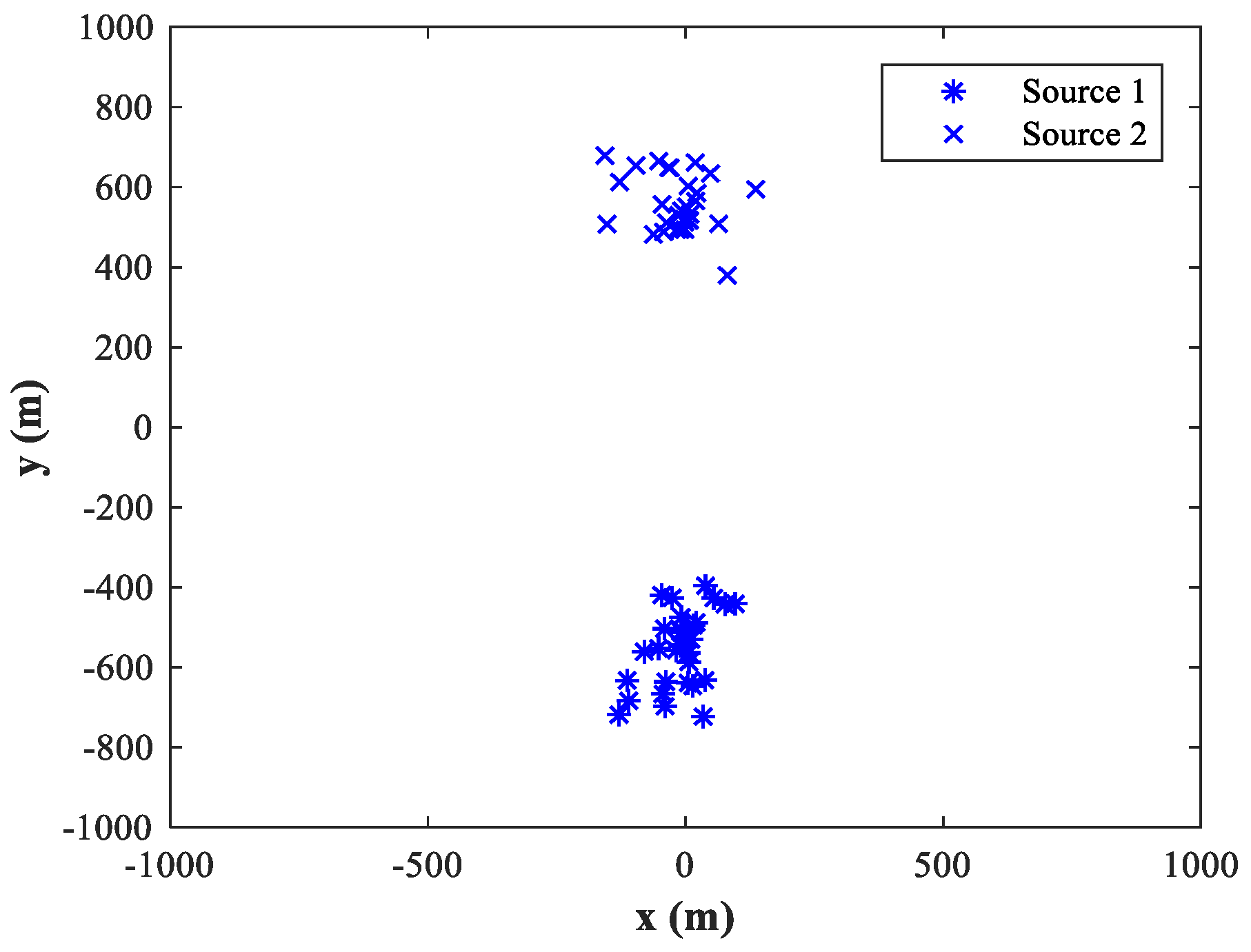
4.10. Comparison of the Resolution Capability for the Proposed Method and MUSIC-DPD Algorithm
The main advantage of MUSIC algorithm is its high resolution. In this subsection, we attempt to compare the resolution capability of the proposed MLP-MLP-RBF network with that of MUSIC-DPD method. Since the proposed technique is based on NN computation, it has no spectrum; so, it is difficult to compare their resolution capability under the standard definition of resolution. Next, we design and conduct a set of simulation experiments to reveal that the proposed method has better resolution capability than MUSIC under low SNR conditions. We fix SPR = 0 dB, SNR = −10 dB,
, and
, and the other simulation conditions are the same as described in
Section 4.8.
Figure 30 and
Figure 31 show the spectrum of the MUSIC-DPD algorithm and simulation results of the proposed method for 30 MC experiments, respectively.
From
Figure 30 and
Figure 31, we can conclude that when MUSIC-DPD algorithm fails due to the overlap of two original spectral peaks at a low SNR, the proposed MLP-MLP-RBF network can distinguish two sources clearly. The simulation shows the resolution capability of the proposed technique from a certain aspect. As can be seen from Remark 3, the resolution capability of the proposed method depends on the size of the sub-area; however, in practice, we can improve the resolution by further subdividing the sub-areas.
4.11. Study of the Network Performance for Other Arrangement of Observer Positions
In this subsection, we examine the localization performance of the proposed method for other observer position arrangement. We consider four observers at the positions listed in
Table 5. Without loss of generality, each observer array is equipped with a six-element nonuniform linear array. The simulation environment is shown in
Figure 32. Assume that two sources are located in the two sub-areas of
Figure 33. The other simulation conditions are the same as described in
Section 4.8.
We fix SPR = 0 dB and vary the SNR in the range −10–35 dB in steps of 5 dB. The simulation results for three algorithms mentioned above are shown in
Figure 34,
Figure 35 and
Figure 36. As expected, the proposed MLP-MLP-RBF method can be well-generalized to other observer position arrangements. Furthermore, we can get the same conclusion as that in
Section 4.4 and
Section 4.8, thus it is not repeated here.
5. Conclusions and Future Work
In this paper, we have proposed a new NN-based DPD algorithm (MLP–MLP–RBF) for multiple sources. The MLP-MLP-RBF network performs the DPD through data preprocessing, detection, spatial filtering, and position estimation stages. The originalities of the proposed MLP-MLP-RBF network are the dimension reduction and normalization for all array sample covariance matrixes, the implementation of the spatial filtering network that effectively filters out the sources beyond the relevant sub-area, and the subdivision of region that greatly reduces the amount of training data required. These novel developments enable multiple-source DPD. We have also elaborated on the construction and training processes of two types of NNs in various stages.
Finally, several simulation experiments are conducted to verify the superiority of the new algorithm and the validity of the theoretical derivation. The performance of the NNs in the detection, filtering, and position estimation stages is verified. The proposed MLP-MLP-RBF network shows good generalization performance for a wide range of SNR and SPR values, and its performance is generally better than that of the MUSIC-DPD algorithm at low SNRs and can attain the ML accuracy at high SNRs. Furthermore, a key advantage of this approach over the MUSIC-DPD and ML-DPD algorithms is its ability to provide the DPD almost instantaneously, making it suitable for real-time implementation.
Currently, the proposed method only uses the angle information of the radiated signals in the two-dimensional positioning scene. In future work, we will extend the method to overcome the following issues:
Multiple target localization combining angle and delay information.
Location estimation in three dimensions.
Extending the detection stage to estimate the number of sources for a sub-area.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}