Accurate Fall Detection in a Top View Privacy Preserving Configuration




Abstract
:1. Introduction
- Wearable sensors: usually represented by accelerometers [3] positioned on human body parts, equipped with a battery and a wireless communication interface. The use of this technology requires the collaboration of the subjects wearing the device and recharging the battery, with the assumption that subjects affected by neurological problems could find it difficult to carry out these procedures.
- Ambient sensors: magnetic sensors for doors and windows, or bed and armchair sensors, which provide information on the interaction of the monitored subject with the objects. In contrast to the wearable sensors, this technology does not require subject collaboration, but the provided information is used for some specific application [4,5,6].
- Video cameras: the classic technology [7] for monitoring domestic and non-domestic environments. The use of this type of sensor for fall detection could generate problems in some situations. Firstly, because the video captured by the cameras depends on environmental lighting, sometimes strong variations in brightness make it difficult to capture images or videos of sufficient quality. In addition, the installation of the cameras in rooms such as bathrooms or bedrooms can generate problems with privacy preservation. The advantage of the cameras is to have a wider field of view than the depth sensors, but this drawback could be solved by installing multiple depth devices to cover a larger area. Moreover, depth sensors [8,9] allow privacy preservation, since it is not possible to recognize faces or other personal details from depth images.
2. Related Works
3. Method Details
3.1. Dataset and Protocol
- facility to detect falls in which the person ends lying on the ground;
- ability to detect falls in which the person finishes sitting on the ground;
- ability to detect falls in which the person falls on the ground finishing on the knees, possibly interacting with objects in the environment;
- ability to track the person’s recovery, and discriminate the fall in which the subject remains on the ground with respect to the one in which the person is able to get up (recovery).
- 1.
- he/she falls from standing position and then remains on the ground;
- 2.
- he/she falls from standing position and then recovers;
- 3.
- he/she falls during walking and then remains on the ground;
- 4.
- he/she falls during walking and then recovers.
- 1.
- at the beginning from walking and, after the task, walking again;
- 2.
- at the beginning from a standing position and, after the task, standing up again.
- depth: depth frame in 320 × 240 format, captured at 30 fps ;
- RGB: RGB frame in the 640 × 480 format, captured at 30 fps;
3.2. Parameters Setting and Algorithm Specifics
- SensorHeight = 3000 mm; height at which the Kinect sensor is installed with respect to the floor.
- FloorDistance = 600 mm; threshold height from the floor.
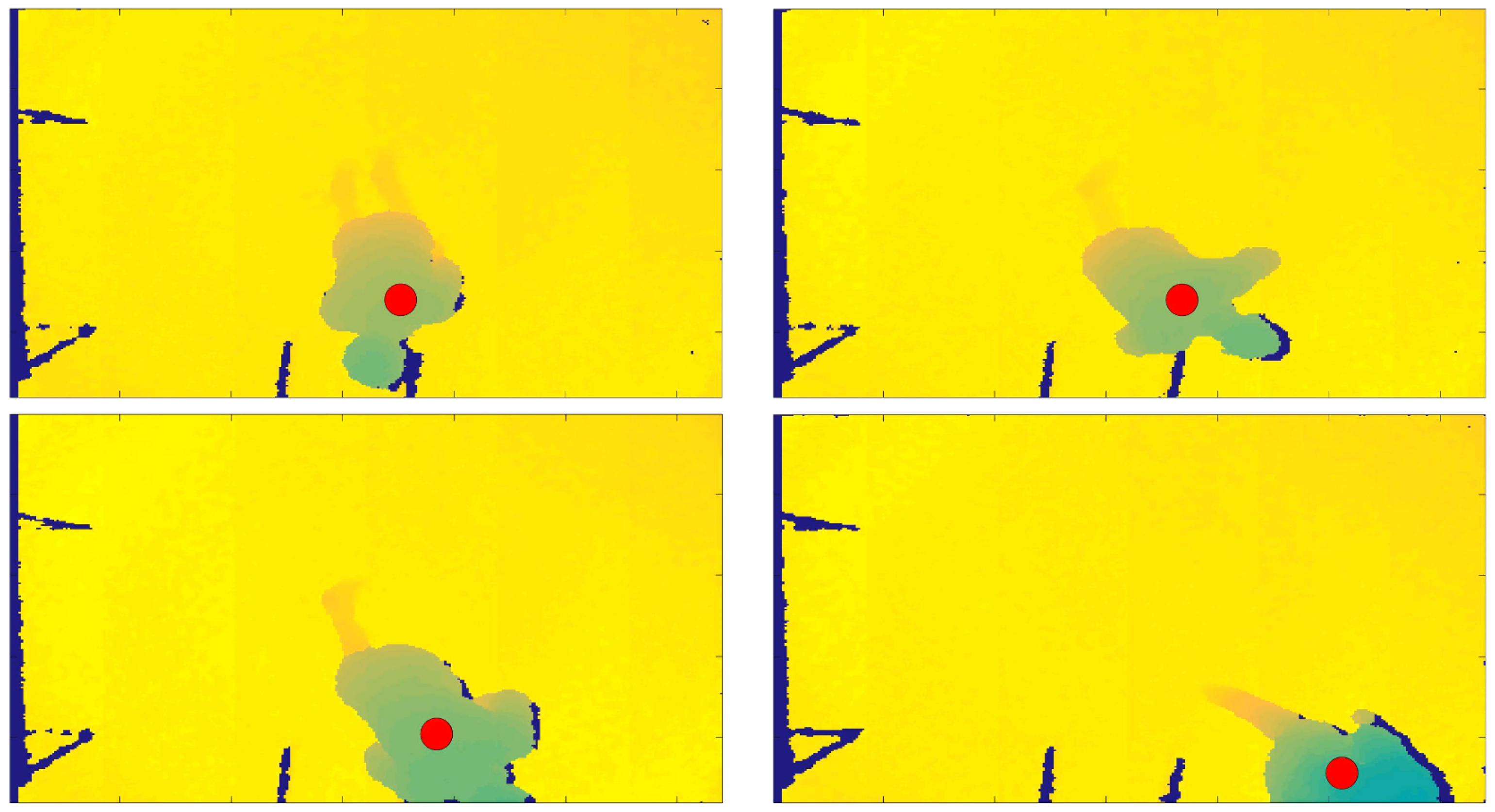
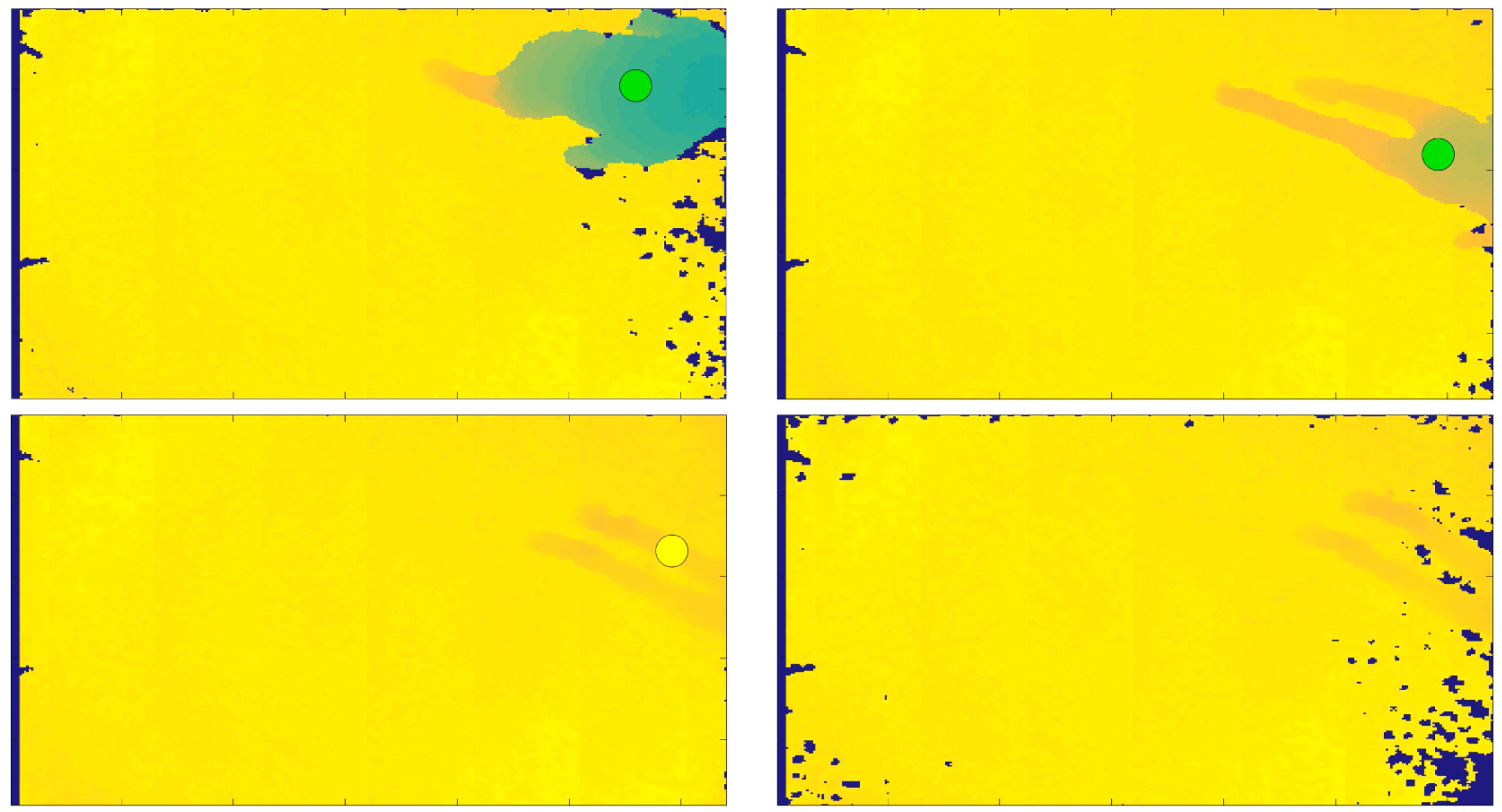
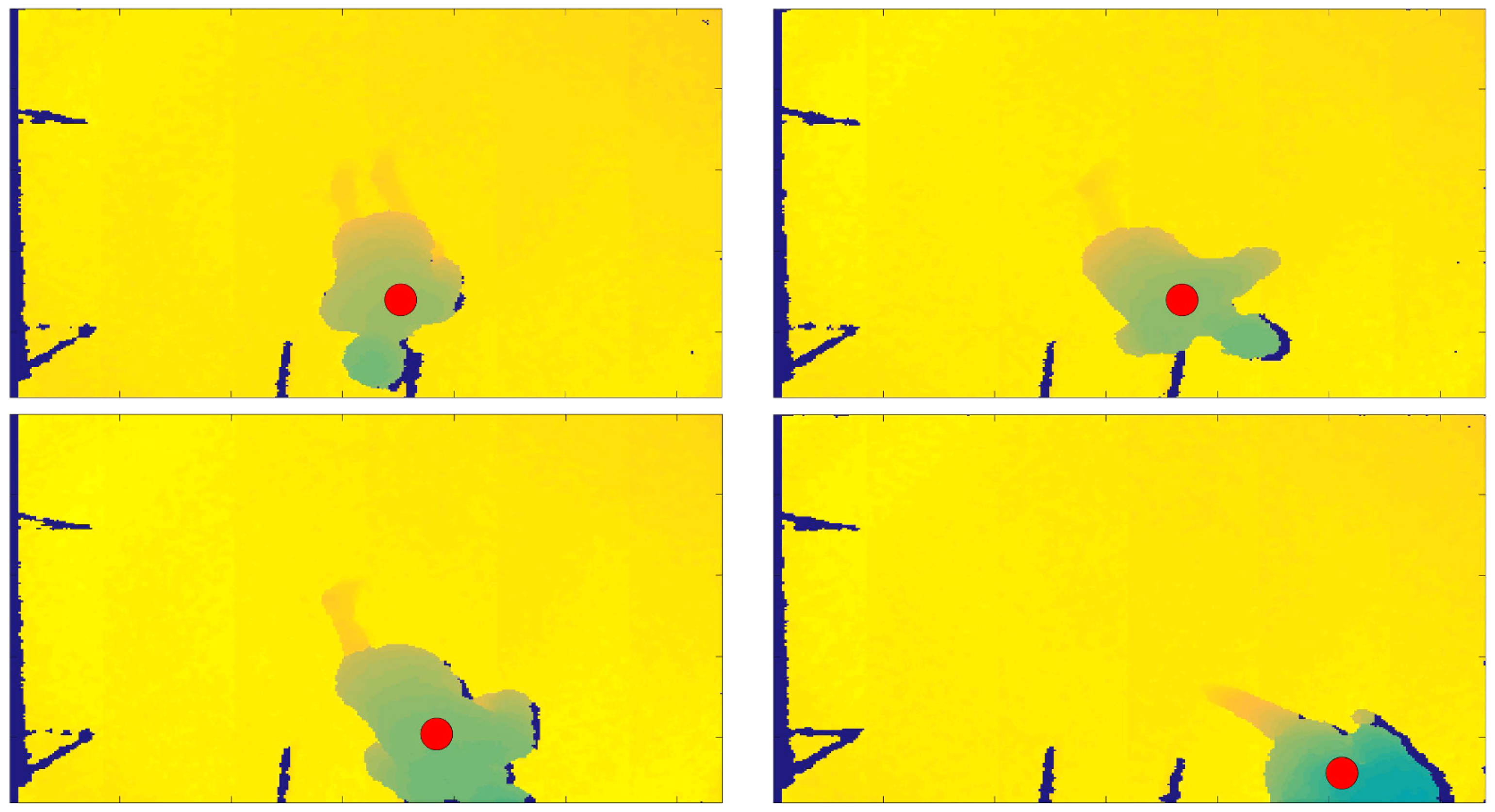
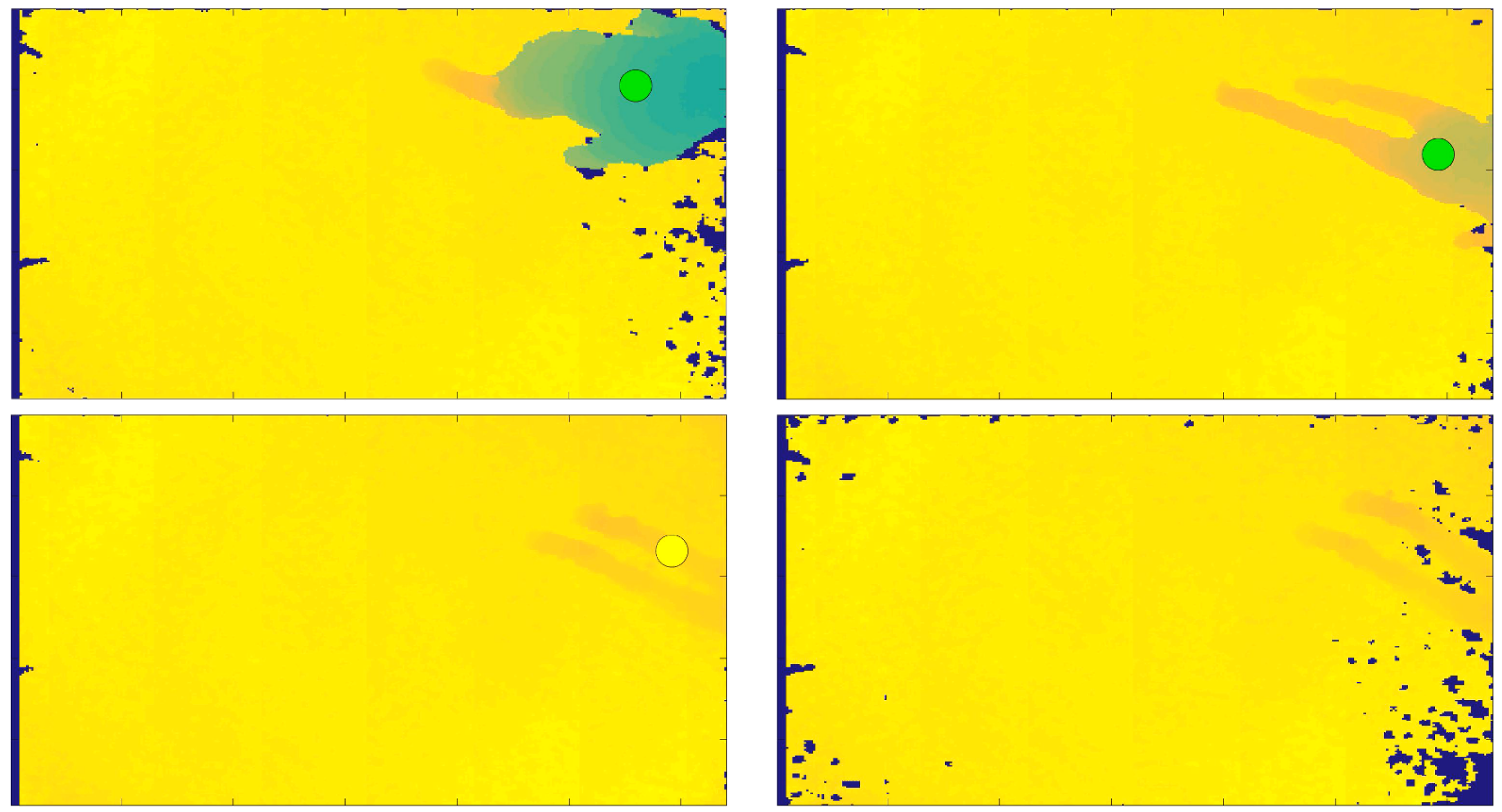
- thresholdFall = SensorHeight − FloorDistance; if the person’s distance from the sensor, in the current frame, exceeds this quantity defined thresholdFall, then the person is considered as near the floor, and therefore a fall or warning can be notified. Figure 2 shows the person’s distance from the sensor in the frame in which the person is standing, on the left, and in the current processed frame, on the right.
- wind_time = 3 s; time chosen to evaluate the presence of a fall or warning.
- recovery_time = 2 s; maximum time for which the subject can be detected on the ground without the identification of falls.
- warning_time = 1 s; maximum time for which the subject can be detected on the ground without warning notification.
- sit_time = 3 s; time duration of the sequence over which the features are extracted from the depth frames.
- shift_time = 1 s; portion of the buffer to be removed before extracting the features from the depth frames.
- wait_time = 1 s; waiting time after an ADL identification through SVM before restarting the evaluation.
- features type = Depth Values Histogram, DVH; type of features to be calculated from the depth data to use the SVM classifier. The DVH features are represented by the histograms calculated on the distance values of the depth frame normalized with respect to the distance from the floor.
- numBins = 256; number of bins to consider for the histograms computation in the DVH features.
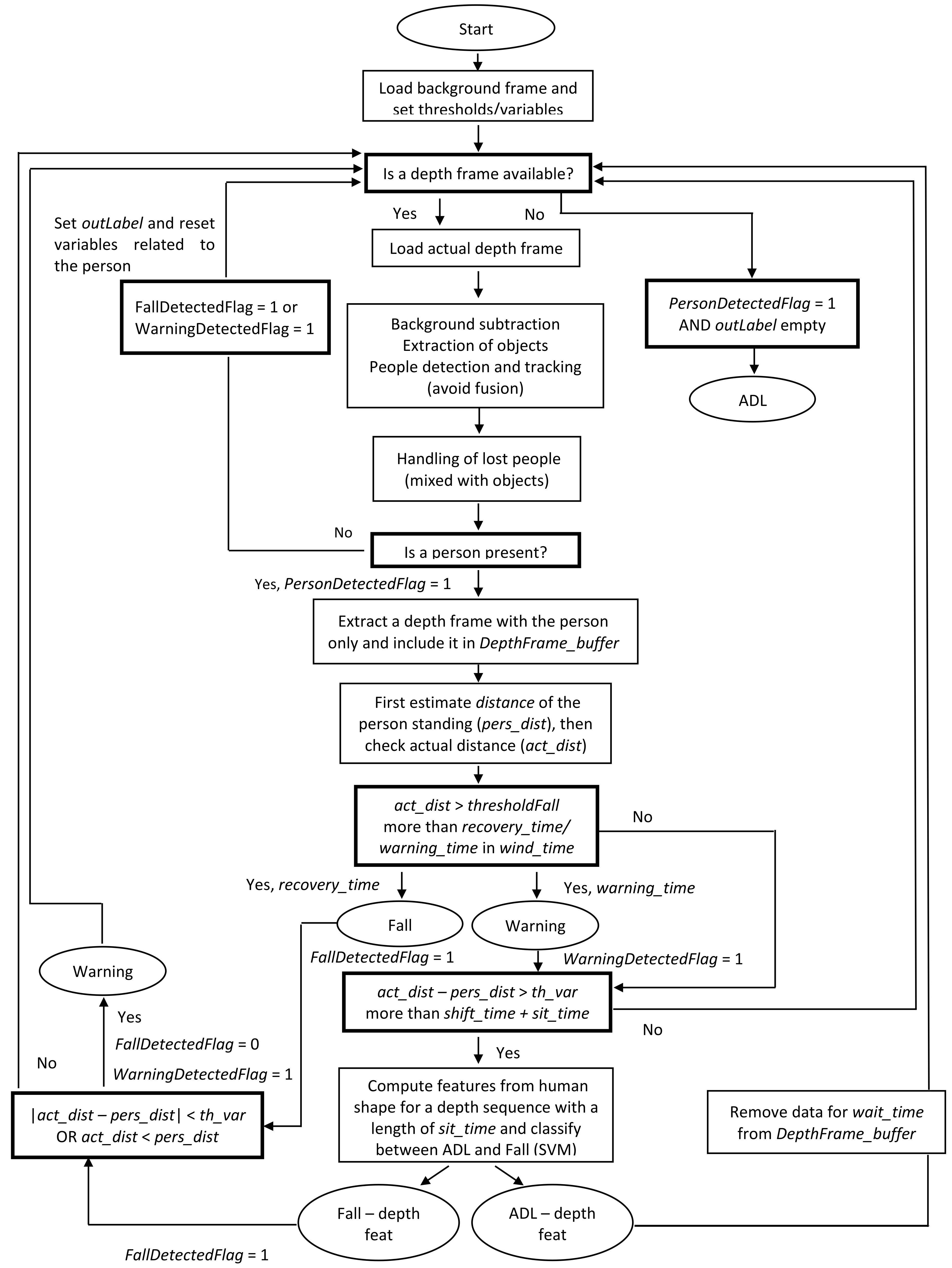
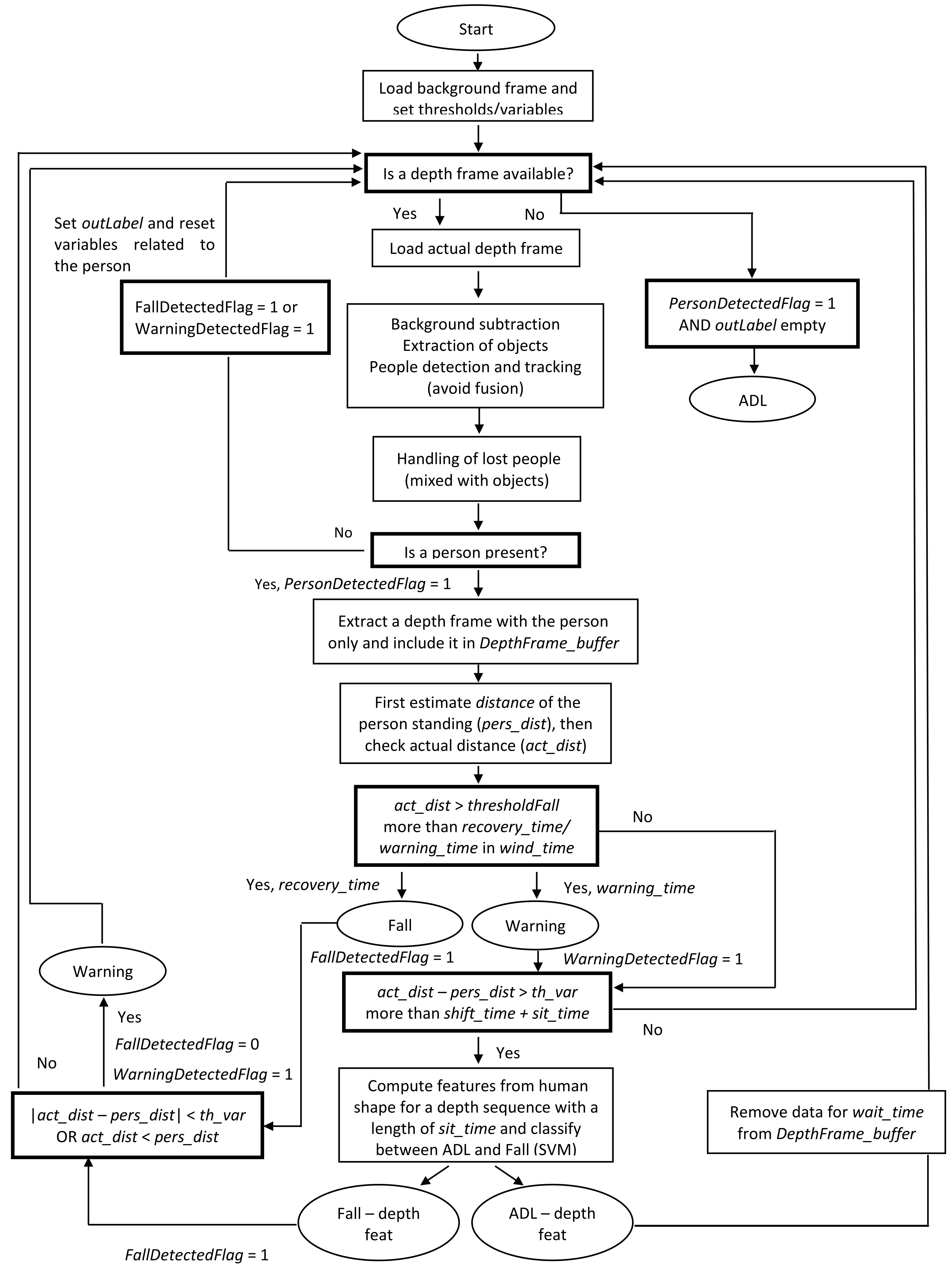
3.3. Fall Detection Algorithm
- construction of a matrix that contains a sequence of depth frames from the sensor that has to be processed (row pixels × column pixels × number of f rames);
- creation of a structure relative to the feature type computed on depth data output;
- creation of a matrix with features computed from the sequence of data (number of features × number of frames).
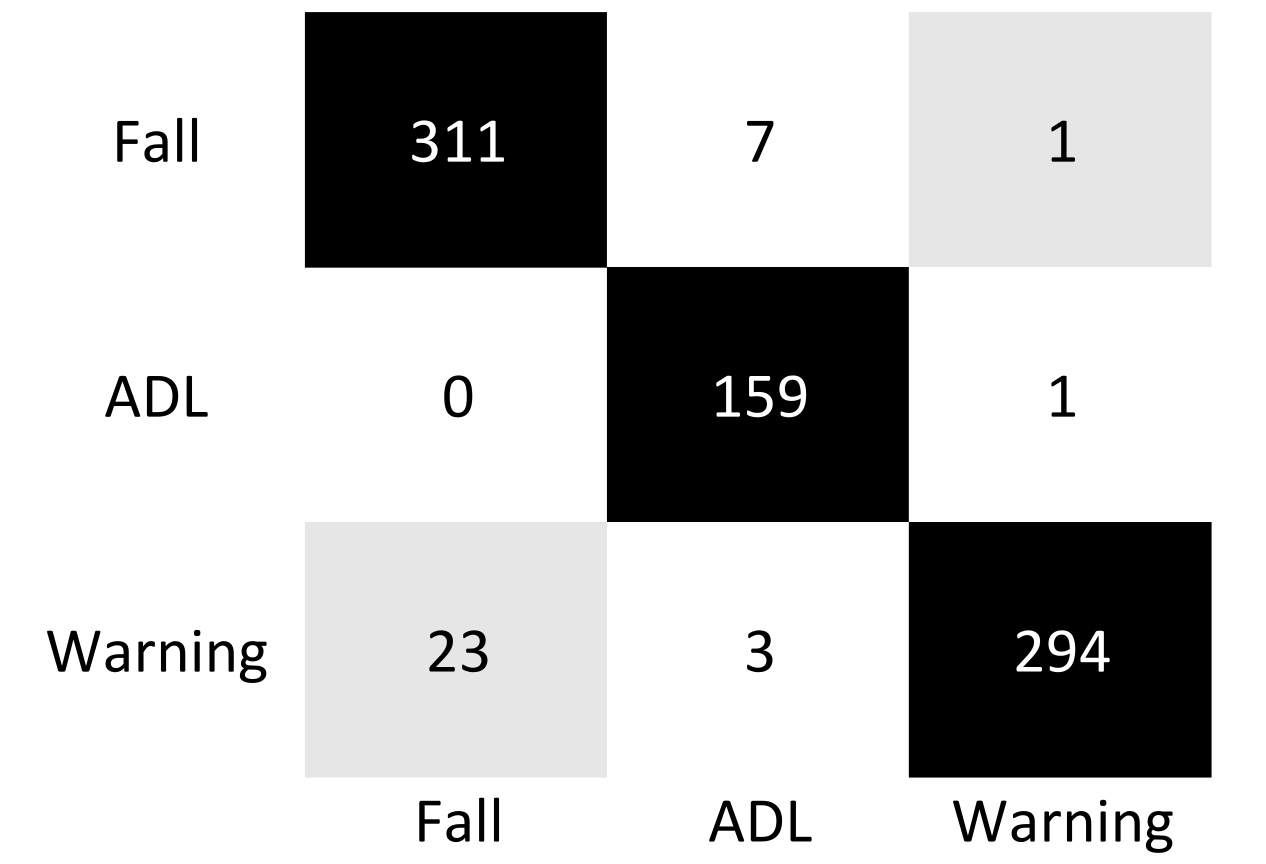
4. Results and System Performance
5. Conclusions and Future Works
Author Contributions
Acknowledgments
Conflicts of Interest
Ethical Statements
Abbreviations
| AAL | Ambient Assisted Living |
| ADL | Activity of Daily Living |
| k-NN | K-Nearest Neighbors |
| INME | Integrated Normalized Motion Energy |
| SVM | Support Vector Machine |
| RGB-D | Red, Green, Blue-Depth |
References
- Drummond, M.F.; Sculpher, M.J.; Claxton, K.; Stoddart, G.L.; Torrance, G.W. Methods for the Economic Evaluation of Health Care Programmes; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Chatterji, S.; Byles, J.; Cutler, D.; Seeman, T.; Verdes, E. Health, functioning, and disability in older adults—Present status and future implications. Lancet 2015, 385, 563–575. [Google Scholar] [CrossRef]
- Mao, A.; Ma, X.; He, Y.; Luo, J. Highly Portable, Sensor-Based System for Human Fall Monitoring. Sensors 2017, 17, 2096. [Google Scholar] [CrossRef] [PubMed]
- Rosales, L.; Su, B.Y.; Skubic, M.; Ho, K.C. Heart rate monitoring using hydraulic bed sensor ballistocardiogram. J. Ambient Intell. Smart Environ. 2017, 9, 193–207. [Google Scholar] [CrossRef]
- Kethman, W.; Harris, B.; Wang, F.; Murphy, T. Monitoring System for Assessing Control of a Disease State. US Patent US15/010,488, 29 January 2016. [Google Scholar]
- Tan, T.H.; Gochoo, M.; Jean, F.R.; Huang, S.C.; Kuo, S.Y. Front-Door Event Classification Algorithm for Elderly People Living Alone in Smart House Using Wireless Binary Sensors. IEEE Access 2017, 5, 10734–10743. [Google Scholar] [CrossRef]
- Nakamura, J. Image Sensors and Signal Processing for Digital Still Cameras; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Mazurek, P.; Wagner, J.; Morawski, R.Z. Acquisition and preprocessing of data from infrared depth sensors to be applied for patients monitoring. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), 2015, Warsaw, Poland, 24–26 September 2015; Volume 2, pp. 705–710. [Google Scholar] [CrossRef]
- Pittaluga, F.; Koppal, S.J. Privacy Preserving Optics for Miniature Vision Sensors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Gasparrini, S.; Cippitelli, E.; Spinsante, S.; Gambi, E. A Depth-Based Fall Detection System Using a Kinect® Sensor. Sensors 2014, 14, 2756–2775. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Sorokin, A. Human activity recognition with metric learning. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin, Germany, 2008; pp. 548–561. [Google Scholar]
- Shrivakshan, G.; Chandrasekar, C. A comparison of various edge detection techniques used in image processing. IJCSI Int. J. Comput. Sci. Issues 2012, 9, 272–276. [Google Scholar]
- Stone, E.E.; Skubic, M. Fall detection in homes of older adults using the Microsoft Kinect. IEEE J. Biomed. Health Inf. 2015, 19, 290–301. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Wang, N.; Lv, C.; Cui, J. Human body fall detection based on the Kinect sensor. In Proceedings of the 2015 8th International Congress on Image and Signal Processing (CISP), Shenyang, China, 14–16 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 367–371. [Google Scholar]
- Pham, H.H.; Le, T.L.; Vuillerme, N. Real-time obstacle detection system in indoor environment for the visually impaired using microsoft kinect sensor. J. Sens. 2016, 2016. [Google Scholar] [CrossRef]
- Amini, A.; Banitsas, K.; Cosmas, J. A comparison between heuristic and machine learning techniques in fall detection using Kinect v2. In Proceedings of the 2016 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Benevento, Italy, 15–18 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Kepski, M.; Kwolek, B. Fall detection using ceiling-mounted 3D depth camera. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 Janurary 2014; IEEE: Piscataway, NJ, USA, 2014; Volume 2, pp. 640–647. [Google Scholar]
- Feng, W.; Liu, R.; Zhu, M. Fall detection for elderly person care in a vision-based home surveillance environment using a monocular camera. Signal Image Video Process. 2014, 8, 1129–1138. [Google Scholar] [CrossRef]
- Kasturi, S.; Jo, K.H. Classification of human fall in top Viewed kinect depth images using binary support vector machine. In Proceedings of the 2017 10th International Conference on Human System Interactions (HSI), Ulsan, Korea, 17–19 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 144–147. [Google Scholar]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef] [PubMed]
- Aziz, O.; Klenk, J.; Schwickert, L.; Chiari, L.; Becker, C.; Park, E.J.; Mori, G.; Robinovitch, S.N. Validation of accuracy of SVM-based fall detection system using real-world fall and non-fall datasets. PLoS ONE 2017, 12, e0180318. [Google Scholar] [CrossRef] [PubMed]
- Nizam, Y.; Jamil, M.M.A.; Mohd, M.N. A depth image approach to classify daily activities of human life for fall detection based on height and velocity of the subject. In 3rd International Conference on Movement, Health and Exercise; Springer: Singapore, Singapore, 2016; pp. 63–68. [Google Scholar]
- De Quadros, T.; Lazzaretti, A.E.; Schneider, F.K. A Movement Decomposition and Machine Learning-based Fall Detection System Using Wrist Wearable Device. IEEE Sens. J. 2018, 18. [Google Scholar] [CrossRef]
- Montanini, L.; Del Campo, A.; Perla, D.; Spinsante, S.; Gambi, E. A footwear-based methodology for fall detection. IEEE Sens. J. 2017, 18. [Google Scholar] [CrossRef]
- Bian, Z.P.; Hou, J.; Chau, L.P.; Magnenat-Thalmann, N. Fall detection based on body part tracking using a depth camera. IEEE J. Biomed. Health Inf. 2015, 19, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Zhang, L.; Dong, H.; Alelaiwi, A.; Saddik, A.E. Evaluating and Improving the Depth Accuracy of Kinect for Windows v2. IEEE Sens. J. 2015, 15, 4275–4285. [Google Scholar] [CrossRef]
- Landau, M.J.; Choo, B.Y.; Beling, P.A. Simulating Kinect Infrared and Depth Images. IEEE Trans. Cybern. 2016, 46, 3018–3031. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Prefix Name | Suffix Name | Description |
|---|---|---|---|
| Backward fall, finishing lying | FBELFR | ST | Subject is standing, falls backwards, and remains on the ground. |
| FBELFR | STRC | Subject is standing, falls backwards, stays on the ground | |
| for a while, and then gets up again. | |||
| FBELFR | WK | Subject walks, falls backward, and remains on the ground. | |
| FBELFR | WKRC | Subject walks, falls backward, stays on the ground | |
| for a while, and then gets up again. | |||
| Backward fall, finishing sitting | FBESFR | ST | Subject is standing, falls backwards, and remains on the ground. |
| FBESFR | STRC | Subject is standing, falls backwards, stays on the ground | |
| for a while, and then gets up again. | |||
| FBESFR | WK | Subject walks, falls backward, and remains on the ground. | |
| FBESFR | WKRC | Subject walks, falls backward, stays on the ground | |
| for a while, and then gets up again. | |||
| Forward fall, finishing lying | FFELFR | ST | Subject is standing, falls forwards, and remains on the ground. |
| FFELFR | STRC | Subject is standing, falls forwards, stays on the ground | |
| for a while, and then gets up again. | |||
| FFELFR | WK | Subject walks, falls forwards, and remains on the ground. | |
| FFELFR | WKRC | Subject walks, falls forwards, stays on the ground | |
| for a while, and then gets up again | |||
| Forward fall on the knees grabbing the chair | FFOKCH | ST | Subject is standing, falls forwards, and remains on the ground, |
| grabbing the chair. | |||
| FFOKCH | STRC | Subject is standing, falls forwards, stays on the ground | |
| grabbing the chair for a while, and then gets up again. | |||
| FFOKCH | WK | Subject walks, falls backward, and remains on the ground, | |
| grabbing the chair. | |||
| FFOKCH | WKRC | Subject walks, falls backward, stays on the ground | |
| grabbing the chair for a while, and then gets up again. | |||
| Forward fall on the knees | FFOKFR | ST | Subject is standing, falls forwards, and remains on the ground. |
| FFOKFR | STRC | Subject is standing, falls forwards, stays on the ground | |
| for a while, and then gets up again. | |||
| FFOKFR | WK | Subject walks, falls forwards, and remains on the ground. | |
| FFOKFR | WKRC | Subject walks, falls forwards, stays on the ground | |
| for a while, and then gets up again. | |||
| Forward fall on the knees grabbing the sofa | FFOKSO | ST | Subject is standing, falls forwards, and remains on the ground, |
| grabbing the sofa. | |||
| FFOKSO | STRC | Subject is standing, falls forwards, stays on the ground | |
| grabbing the sofa for a while, and then gets up again. | |||
| FFOKSO | WK | Subject walks, falls forwards, and remains on the ground, | |
| grabbing the sofa. | |||
| FFOKSO | WKRC | Subject walks, falls forwards, and stays on ground | |
| grabbing the sofa for a while, and then gets up again. | |||
| Left side fall | FSLEFR | ST | Subject is standing, falls on their left side, and remains on the ground. |
| FSLEFR | STRC | Subject is standing, falls on their left side, stays on the ground | |
| for a while, and then gets up again. | |||
| FSLEFR | WK | Subject walks, falls on their left side, and remains on the ground. | |
| FSLEFR | WKRC | Subject walks, falls on their left side, stays on the ground | |
| for a while, and then gets up again. | |||
| Right side fall | FSRIFR | ST | Subject is standing, falls on their right side, and remains on the ground. |
| FSRIFR | STRC | Subject is standing, falls on their right side, stays on the ground | |
| for a while, and then gets up again. | |||
| FSRIFR | WK | Subject walks, falls on their right side, and remains on the ground. | |
| FSRIFR | WKRC | Subject walks, falls on their right side, stays on the ground | |
| for a while, and then gets up again. | |||
| Pick up object from floor with bending | APBE | ST | Subject is standing, bends, picks up an object on the floor, and then stands up again. |
| APBE | WK | Subject walks, bends, picks up an object on the floor, and then stands up again. | |
| Pick up object from floor with squatting | APSQ | ST | Subject is standing, squats, picks up an object on the floor, and then stands up again. |
| APSQ | WK | Subject walks, squats, picks up an object on the floor, and then stands up again. | |
| Sit and get up from the chair | ASCH | ST | Subject is standing, sits on a chair, and then stands up again. |
| ASCH | WK | Subject walks, sits on a chair, and then stands up again. | |
| Sit and get up from the couch | ASSO | ST | Subject is standing, sits on a couch, and then stands up again. |
| ASSO | WK | Subject walks, sits on a couch, and then stands up again. |
| Subject | Sex | Age | Weight (kg) | Height (cm) |
|---|---|---|---|---|
| ES01 | M | 28 | 65 | 177 |
| ES02 | F | 40 | 60 | 163 |
| ES03 | F | 35 | 63 | 161 |
| ES04 | F | 29 | 74 | 170 |
| ES05 | F | 25 | 52 | 160 |
| ES06 | F | 26 | 55 | 165 |
| ES07 | M | 30 | 65 | 176 |
| ES08 | M | 55 | 80 | 173 |
| ES09 | M | 21 | 58 | 169 |
| ES10 | M | 21 | 70 | 178 |
| ES11 | M | 23 | 59 | 175 |
| ES12 | M | 28 | 74 | 178 |
| ES13 | M | 28 | 76 | 160 |
| ES14 | M | 26 | 73 | 182 |
| ES15 | M | 40 | 87 | 187 |
| ES16 | M | 21 | 80 | 189 |
| ES17 | M | 22 | 64 | 167 |
| ES18 | M | 22 | 72 | 170 |
| ES19 | M | 21 | 78 | 188 |
| ES20 | M | 21 | 78 | 177 |
| Performances | Results |
|---|---|
| True Positives (TPs) | 629 |
| True Negatives (TNs) | 159 |
| False Positives (FPs) | 1 |
| False Negatives (FNs) | 10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ricciuti, M.; Spinsante, S.; Gambi, E. Accurate Fall Detection in a Top View Privacy Preserving Configuration. Sensors 2018, 18, 1754. https://doi.org/10.3390/s18061754
Ricciuti M, Spinsante S, Gambi E. Accurate Fall Detection in a Top View Privacy Preserving Configuration. Sensors. 2018; 18(6):1754. https://doi.org/10.3390/s18061754
Chicago/Turabian StyleRicciuti, Manola, Susanna Spinsante, and Ennio Gambi. 2018. "Accurate Fall Detection in a Top View Privacy Preserving Configuration" Sensors 18, no. 6: 1754. https://doi.org/10.3390/s18061754
APA StyleRicciuti, M., Spinsante, S., & Gambi, E. (2018). Accurate Fall Detection in a Top View Privacy Preserving Configuration. Sensors, 18(6), 1754. https://doi.org/10.3390/s18061754