IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors

 ,
, 
 and
and
Abstract
1. Introduction
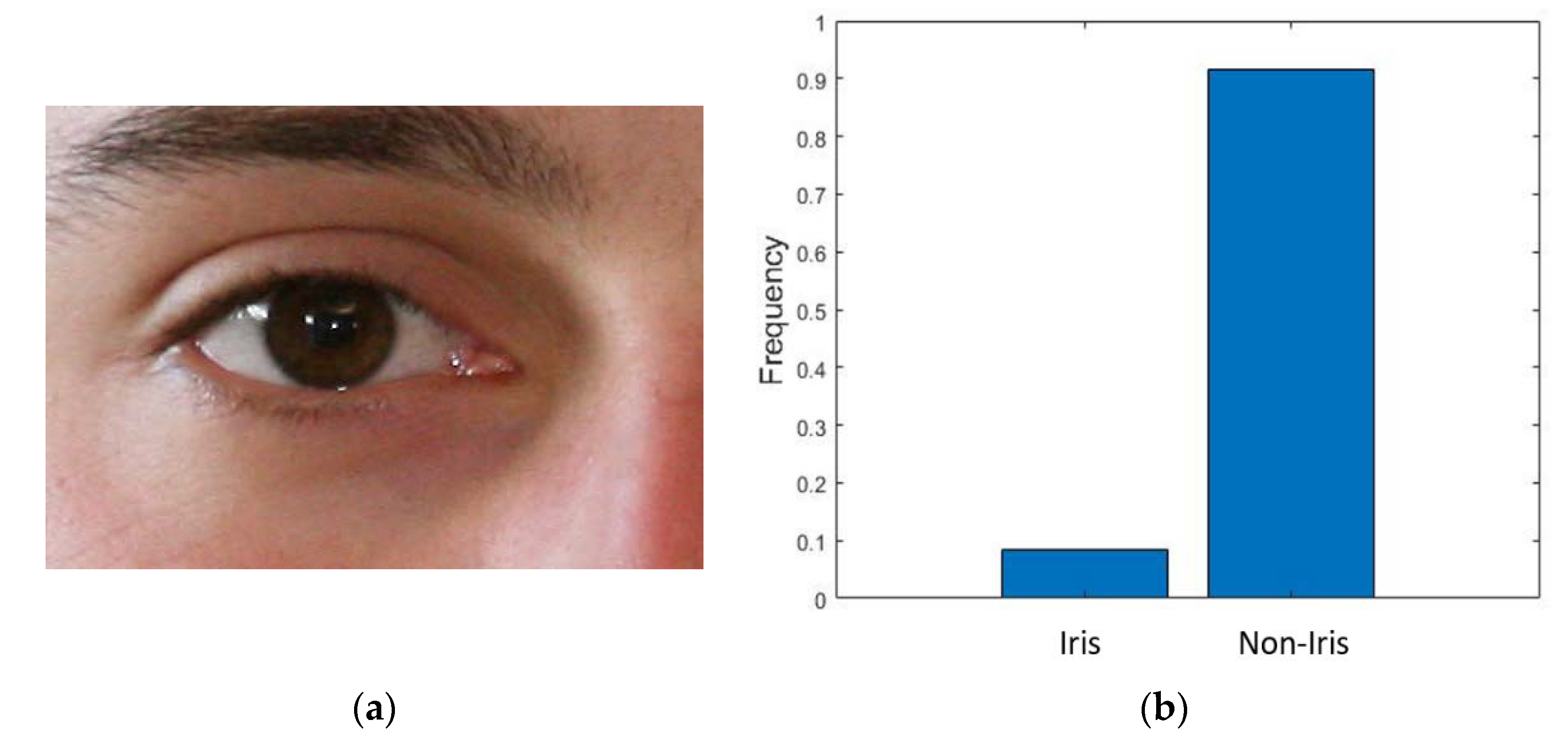
Why Is Iris Segmentation Important?
2. Related Work
2.1. Iris Circular Boundary Detection without Eyelid and Eyelash Detection
2.2. Iris Circular Boundary Detection with Eyelid and Eyelash Detection
2.3. Active Contours for Iris Segmentation
2.4. Region Growing/Watershed-Based Iris Segmentation Methods
2.5. CNN for Iris Segmentation
3. Contribution
- -
- IrisDenseNet is an end-to-end segmentation network that uses the complete image without prior pre-processing or other conventional image processing techniques with the best information gradient flow, which prevents the network from overfitting and vanishing gradient problem.
- -
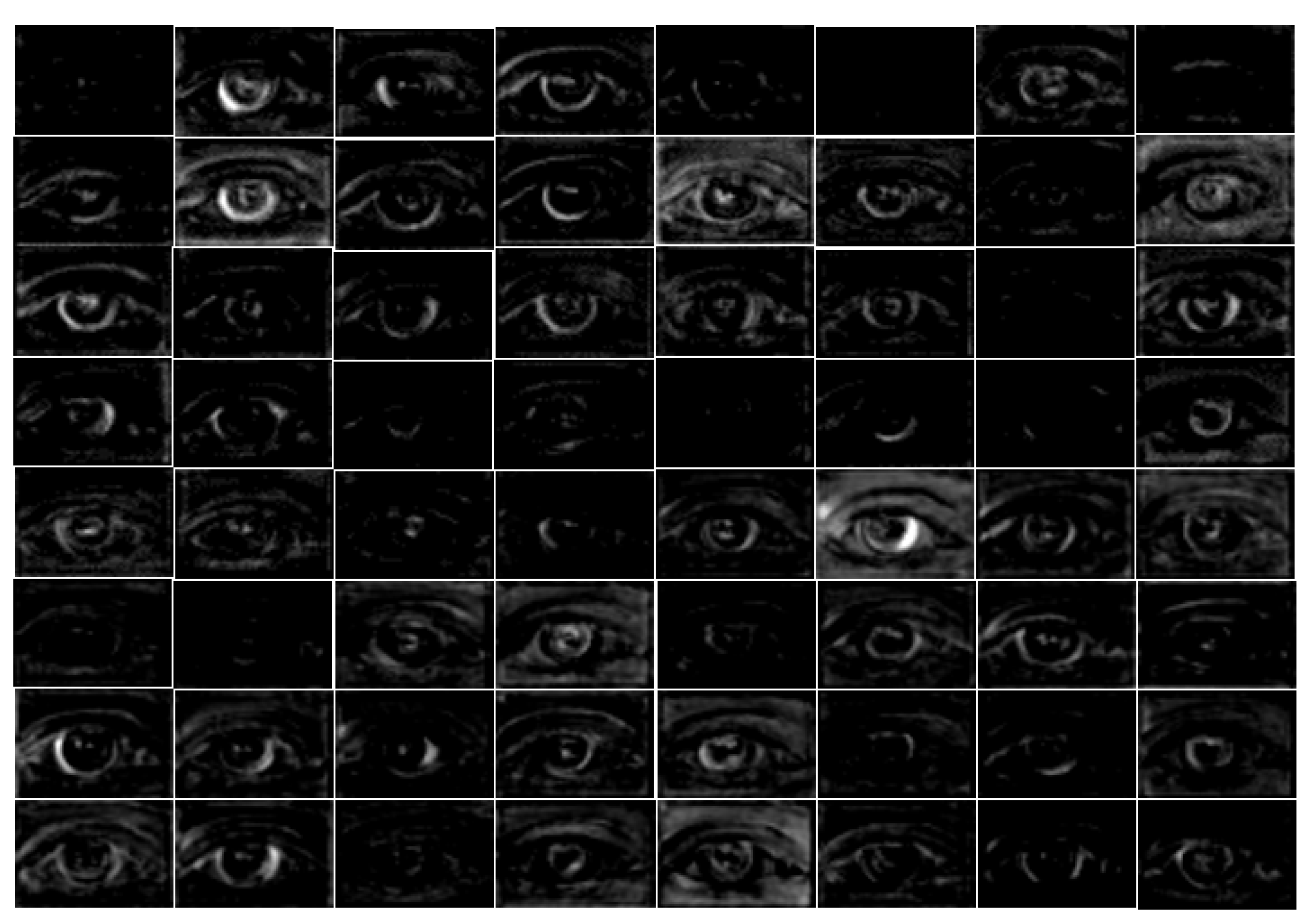
- This study clarifies the power of dense connectivity with a visual difference between the output feature maps from the convolutional layers for dense connectivity and normal connectivity.
- -
- IrisDenseNet is tested with noisy iris challenge evaluation part-II (NICE-II) and various other datasets, which include both visible light and NIR light environments of both color and greyscale images.
- -
- IrisDenseNet is more robust for accurately segmenting the high-frequency areas such as the eyelashes and ghost region present in the iris area.
- -
- To achieve fair comparisons with other studies, our trained IrisDenseNet models with the algorithms are made publicly available through [47].
4. Proposed Method
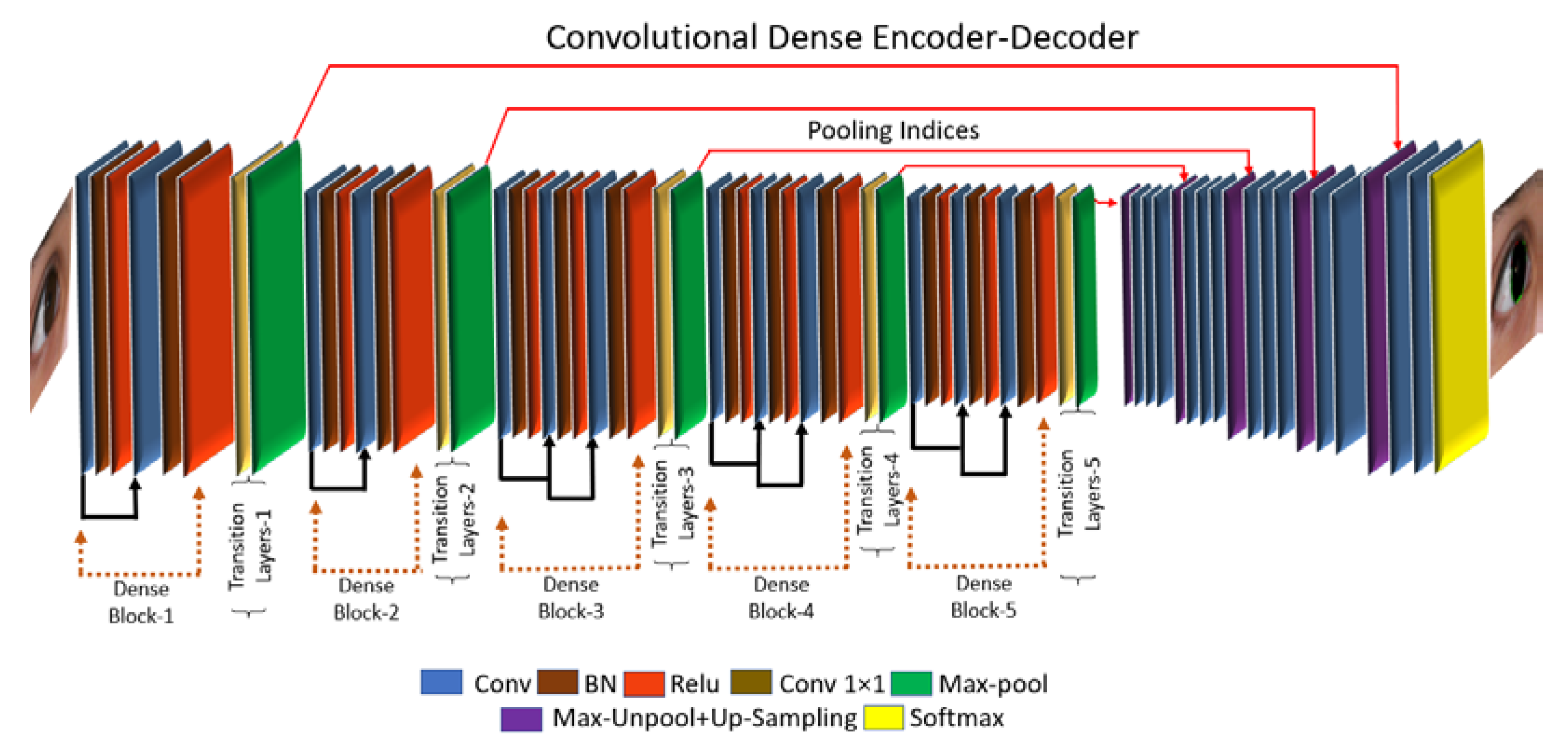
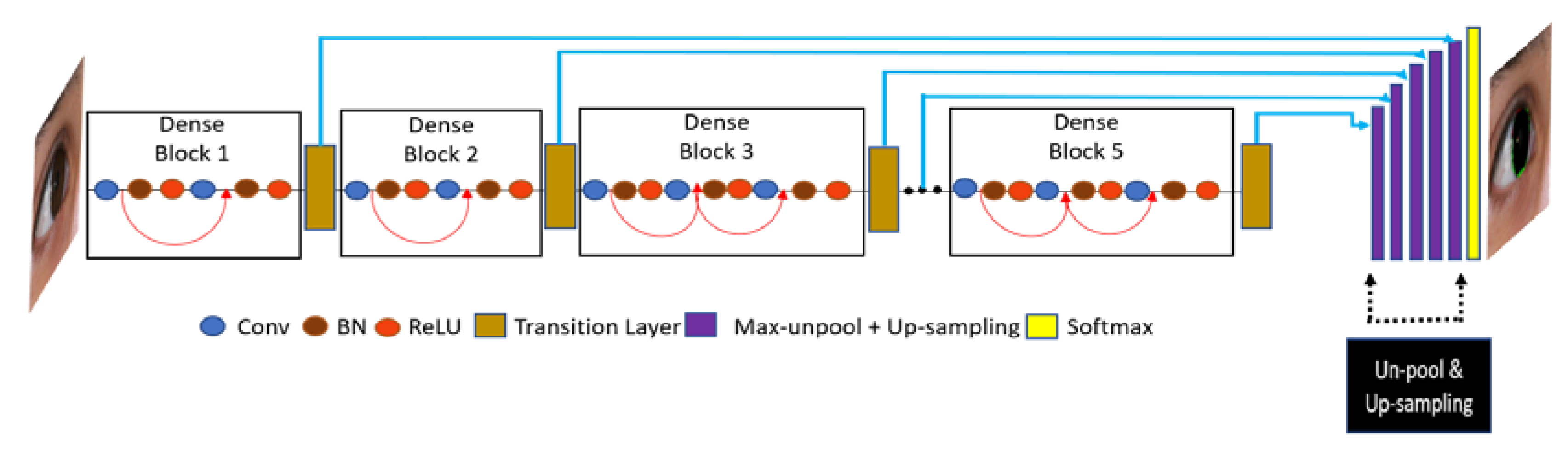
4.1. Overview of the Proposed Architecture
4.2. Iris Segmentation Using IrisDenseNet
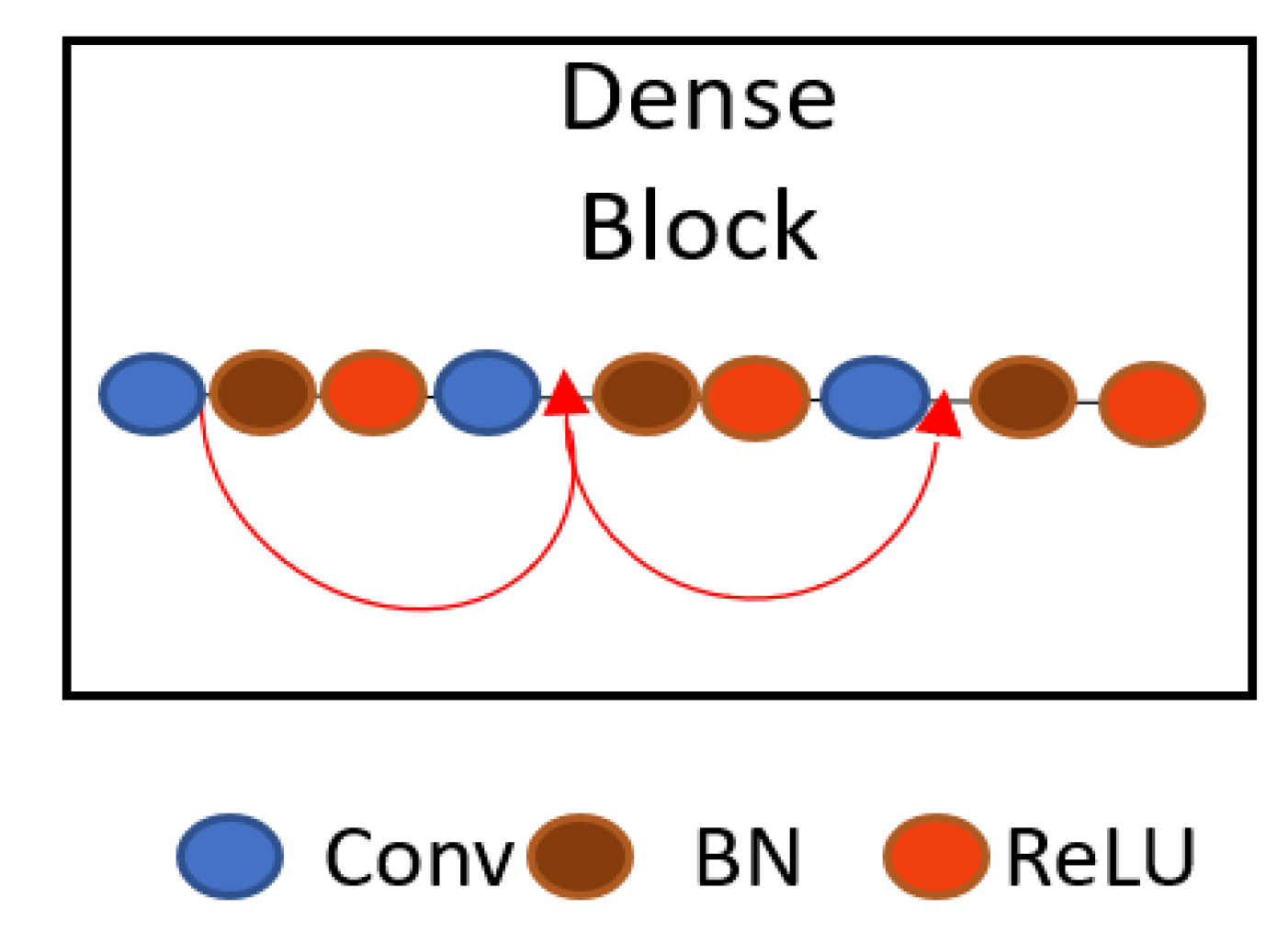
4.2.1. IrisDenseNet Dense Encoder
- -
- DenseNet is using 3 dense blocks for CIFAR and SVHN datasets and 4 dense blocks for ImageNet classification whereas IrisDenseNet uses 5 dense blocks for each dataset.
- -
- In DenseNet, all dense blocks have four convolutional layers [56], whereas IrisDenseNet has two convolutional layers in the first two dense blocks and 3 convolutional layers for the remaining dense blocks.
- -
- In IrisDenseNet, the pooling indices after each dense block are directly fed to the respective decoder block for the reverse operation of sampling.
- -
- In DenseNet, fully connected layers are used for classification purpose, but in order to make the IrisDenseNet fully convolutional, the fully connected layers are not used.
- -
- In DenseNet, the global average pooling is used in the end of the network whereas in IrisDenseNet, global average pooling is not used to maintain the feature map for decoder operation.
- -
- It substantially reduces the vanishing gradient problem in CNNs, which increases the network stability.
- -
- Dense connectivity in the encoder strengthens the features flowing through the network.
- -
- It encourages the feature to be reused due to direct connectivity, so the learned features are much stronger than those of normal connectivity.
4.2.2. IrisDenseNet Decoder
5. Experimental Results
5.1. Experimental Data and Environment
5.2. Data Augmentation
- -
- Cropping and resizing with interpolation
- -
- Flipping the images only in horizontal direction
- -
- Horizontal translation
- -
- Vertical translation
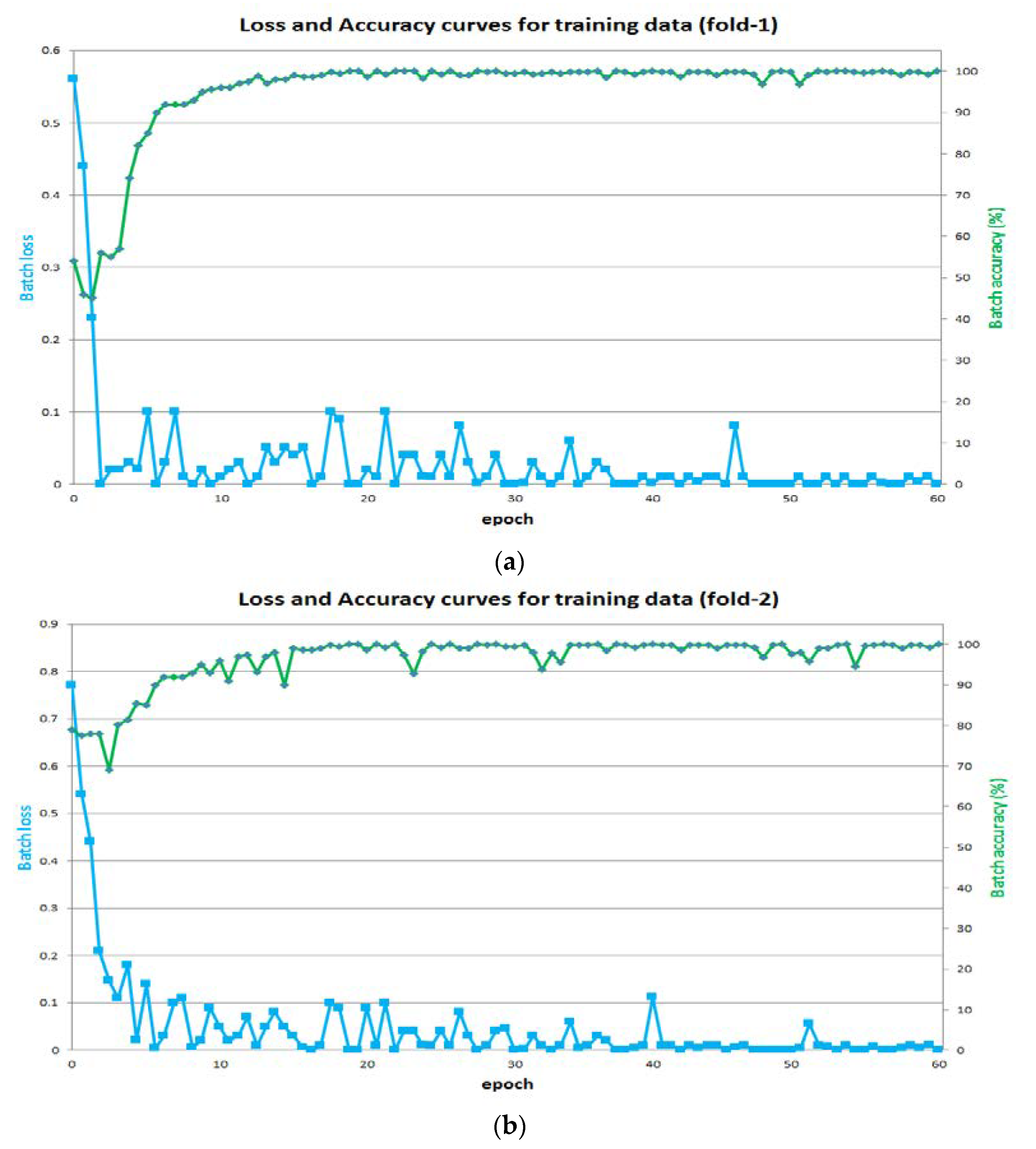
5.3. IrisDenseNet Training
5.4. Testing of IrisDenseNet for Iris Segmentation
5.4.1. Result of Excessive Data Augmentation
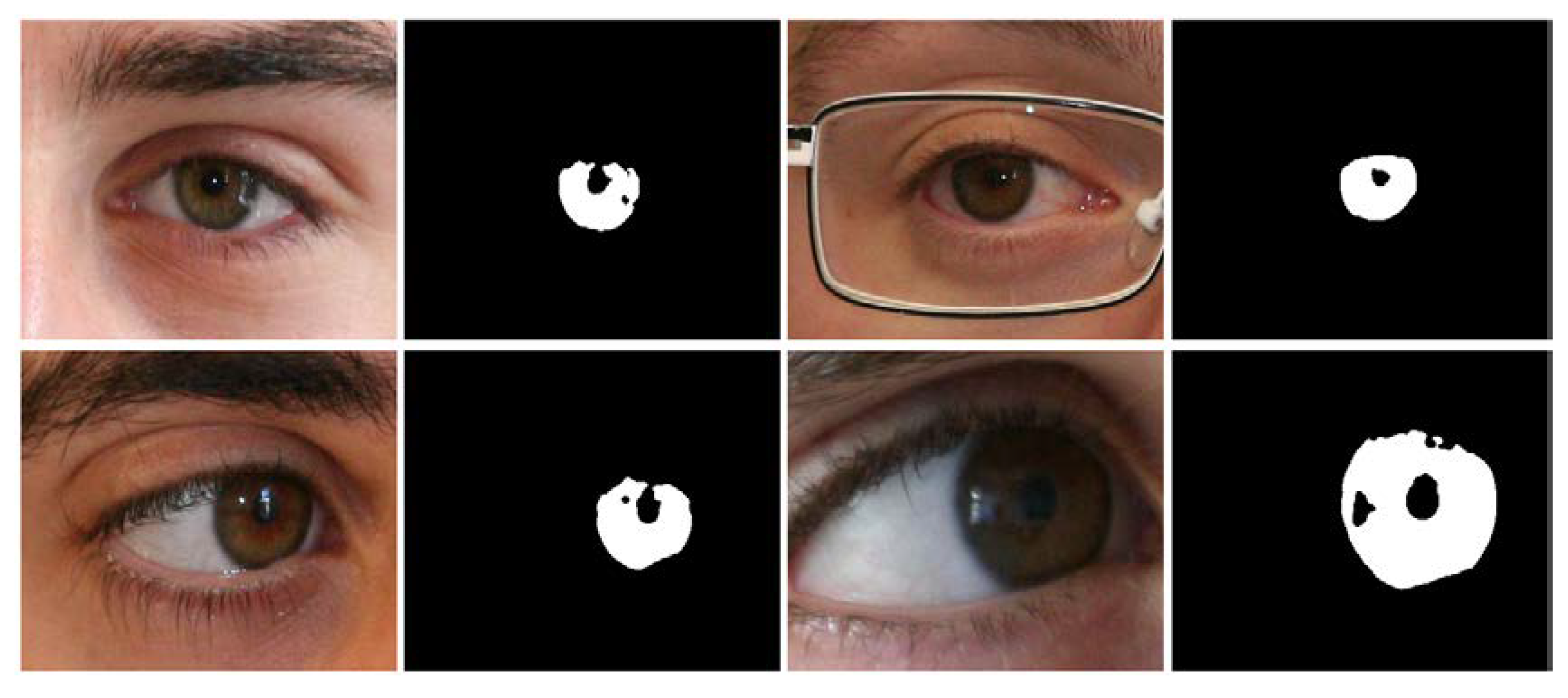
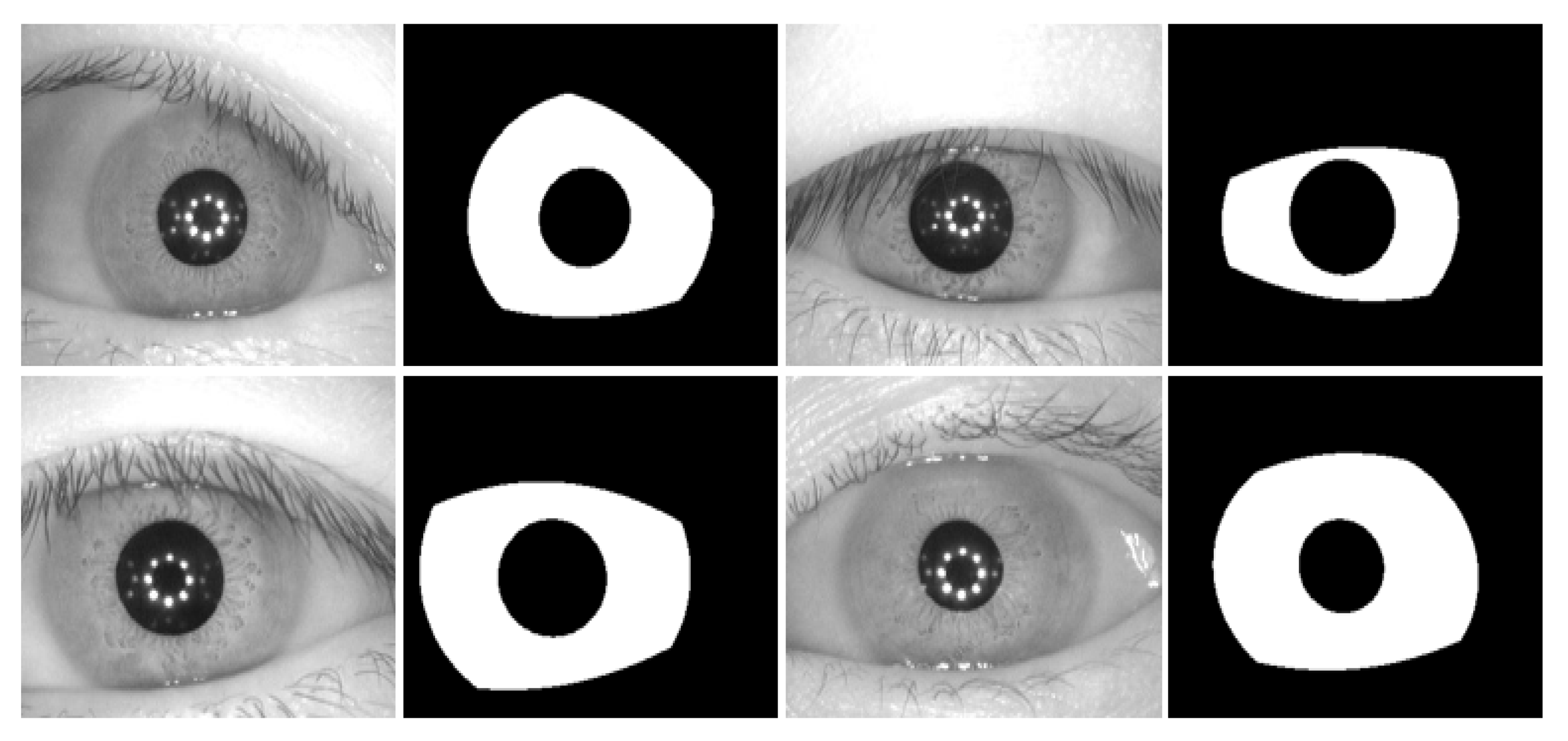
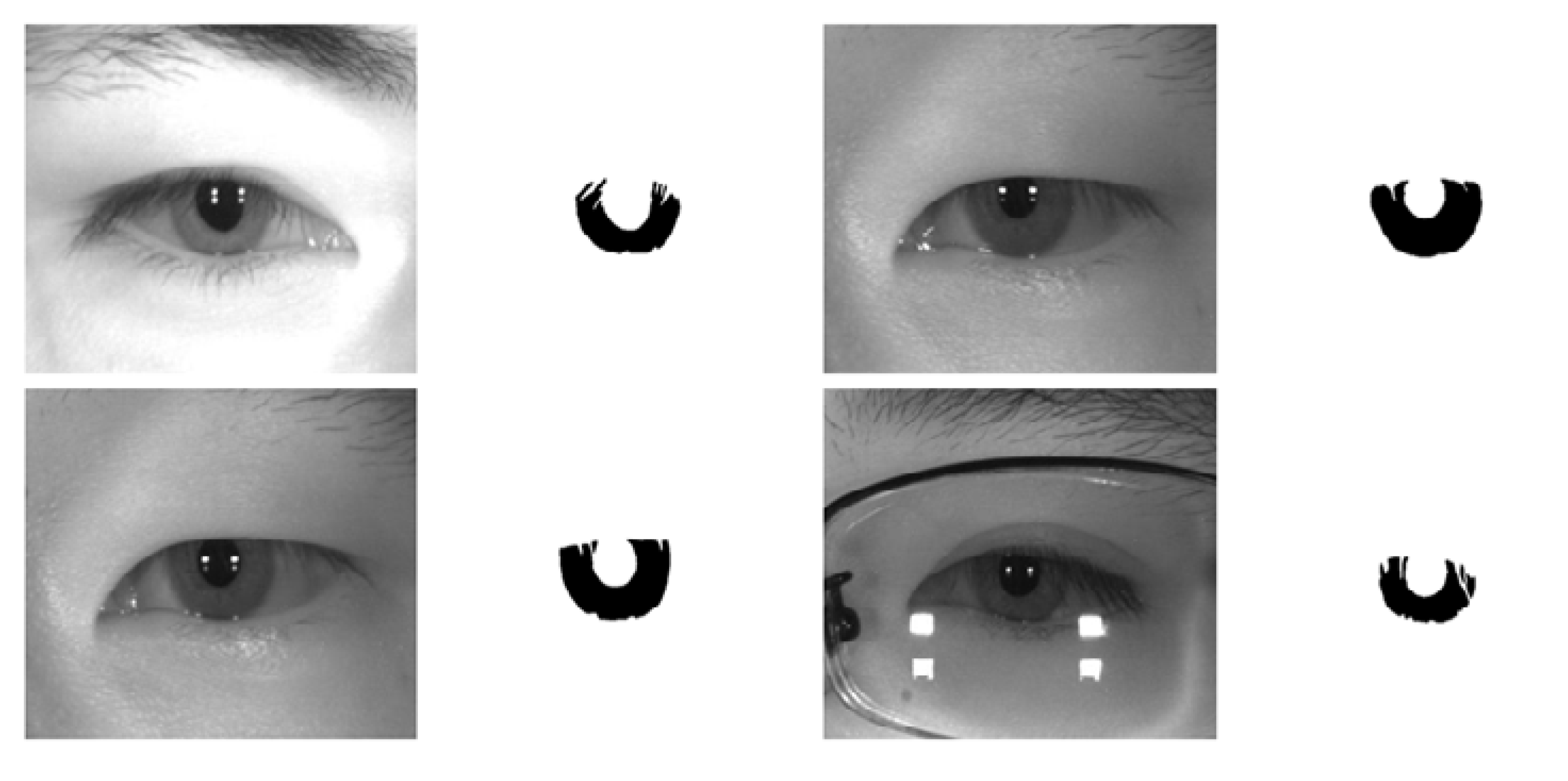
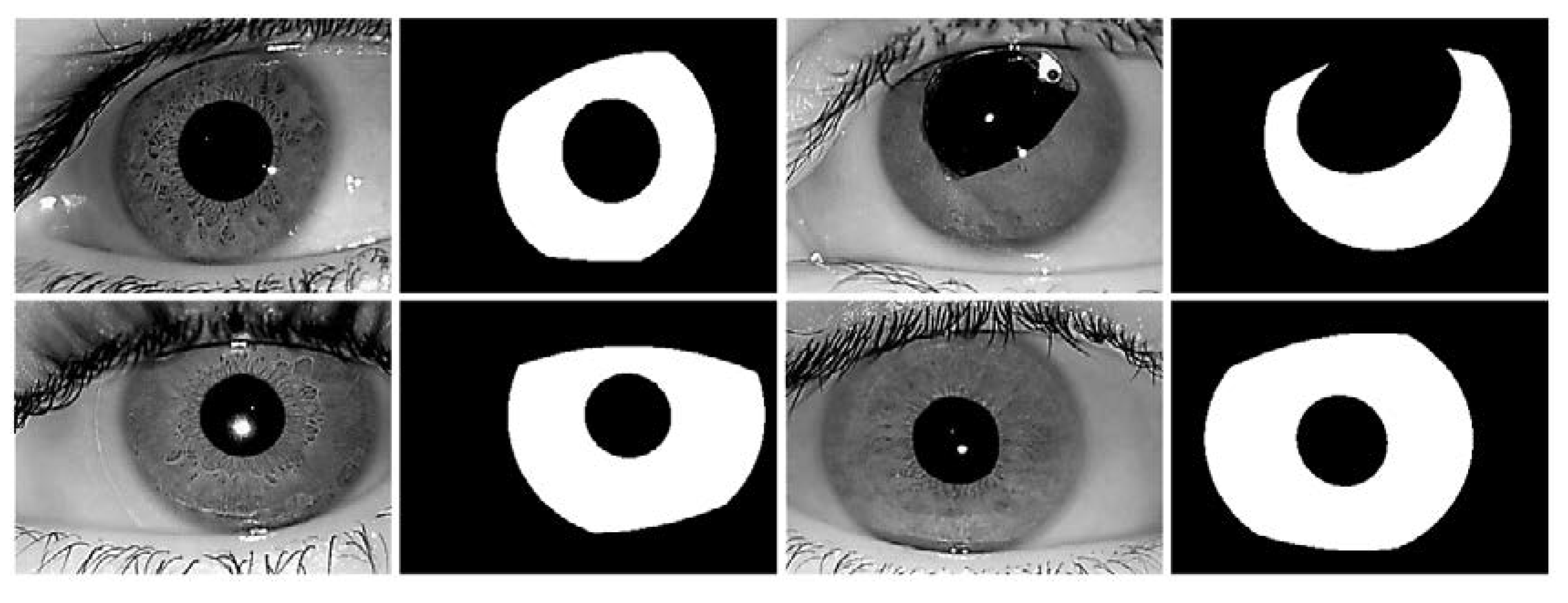
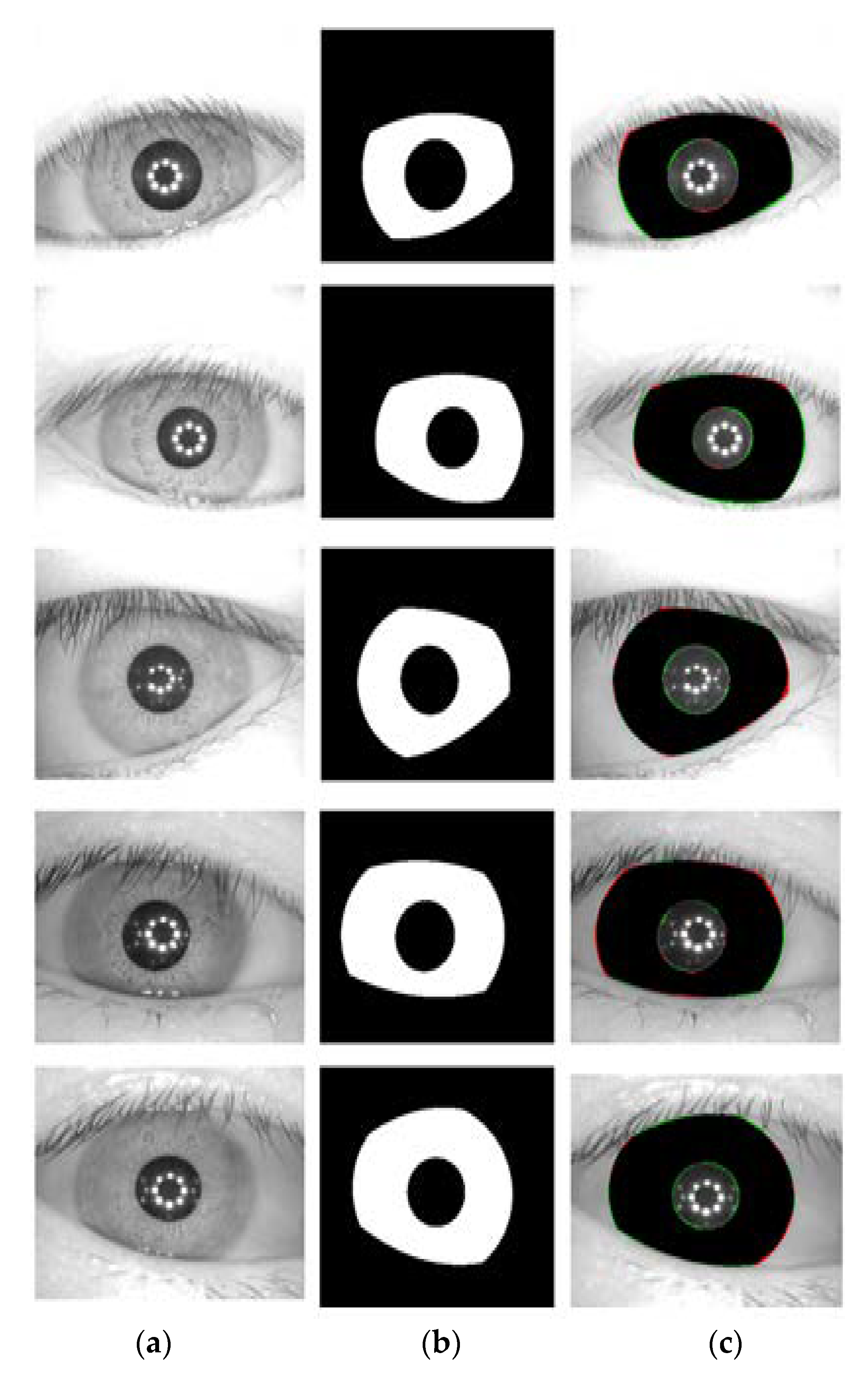
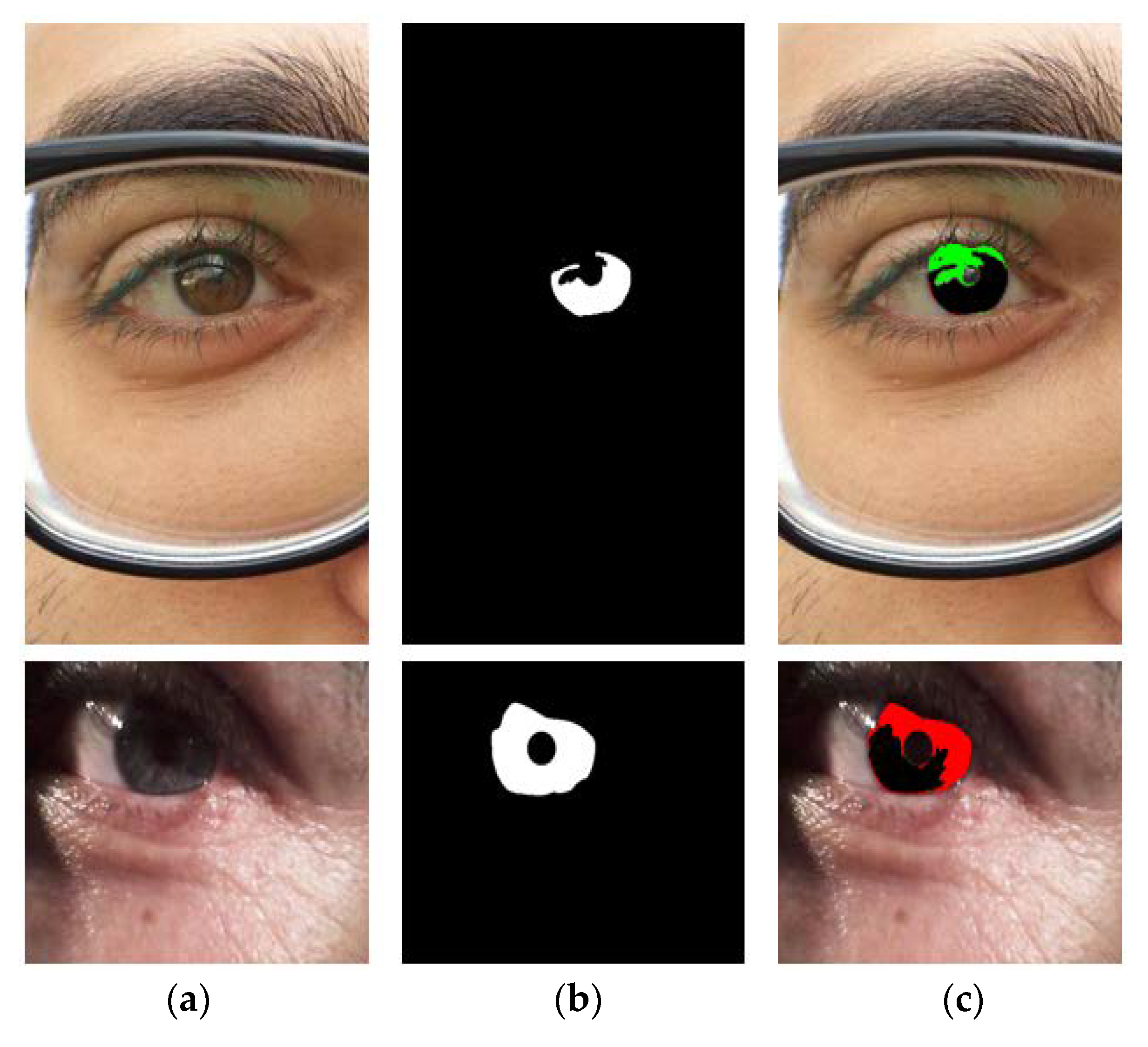
5.4.2. Iris Segmentation Results Obtained by the Proposed Method
5.4.3. Comparison of the Proposed Method with Previous Methods
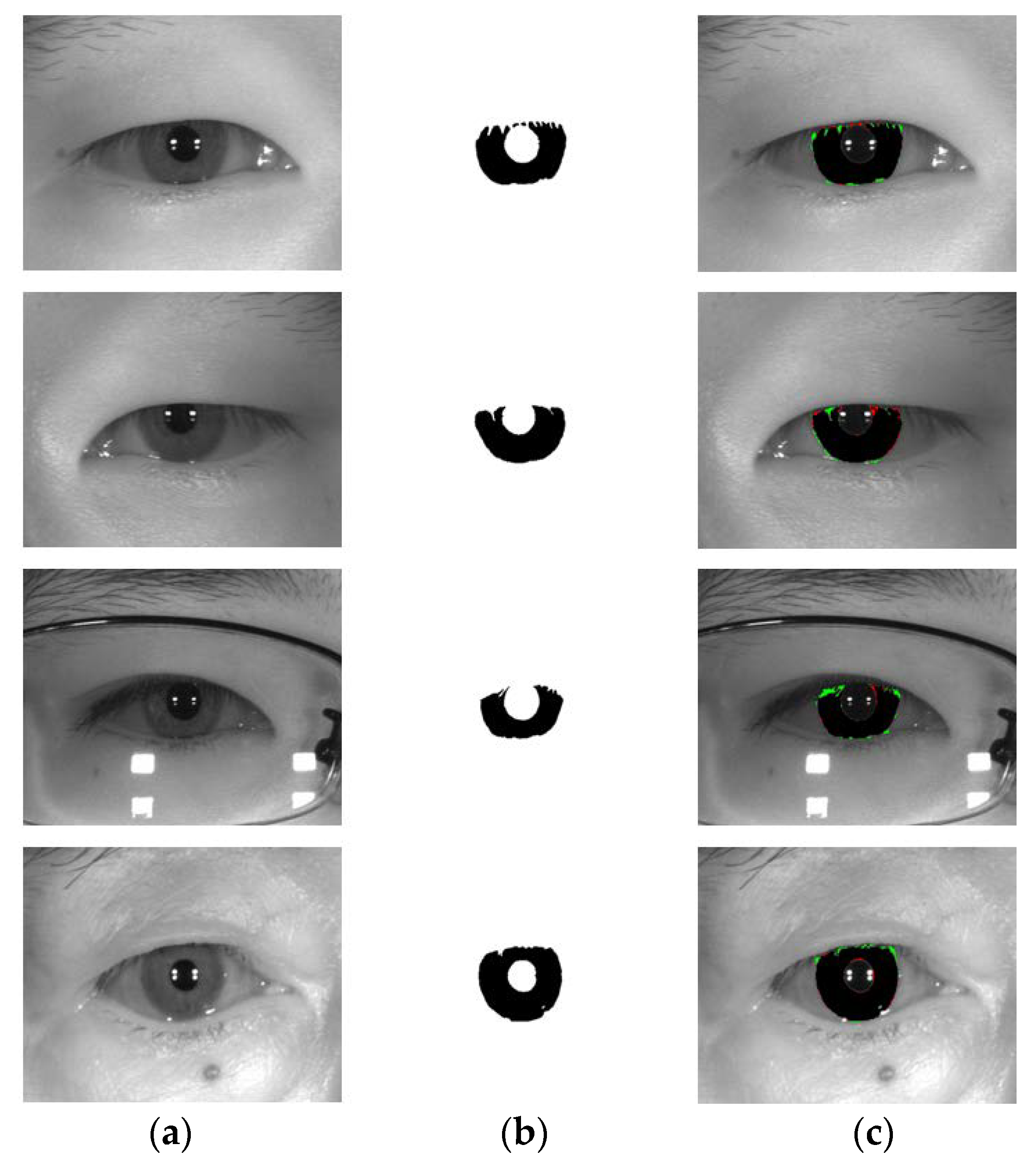
5.4.4. Iris Segmentation Error with Other Open Databases
6. Discussion and Analysis
6.1. Power of Dense Connectivity
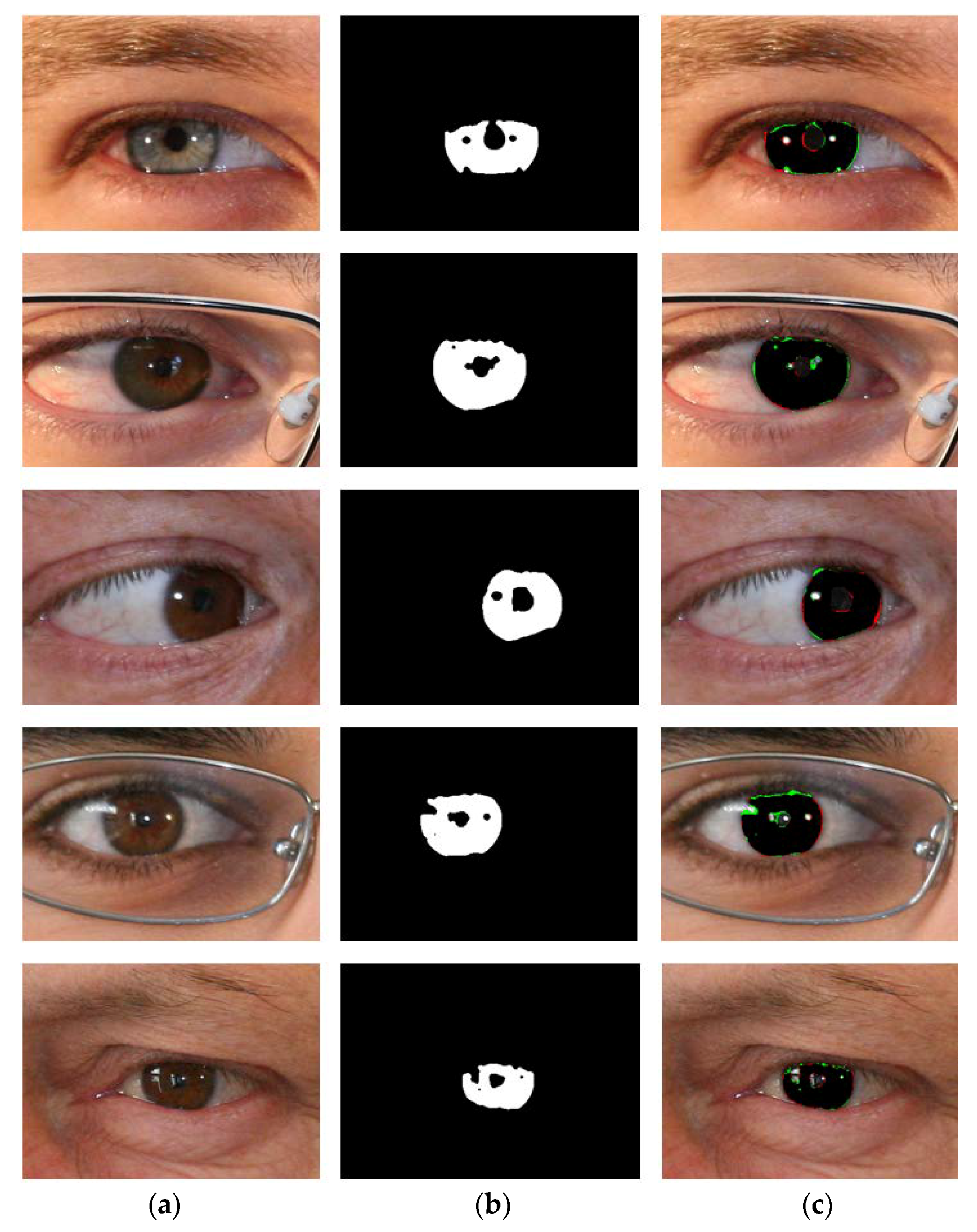
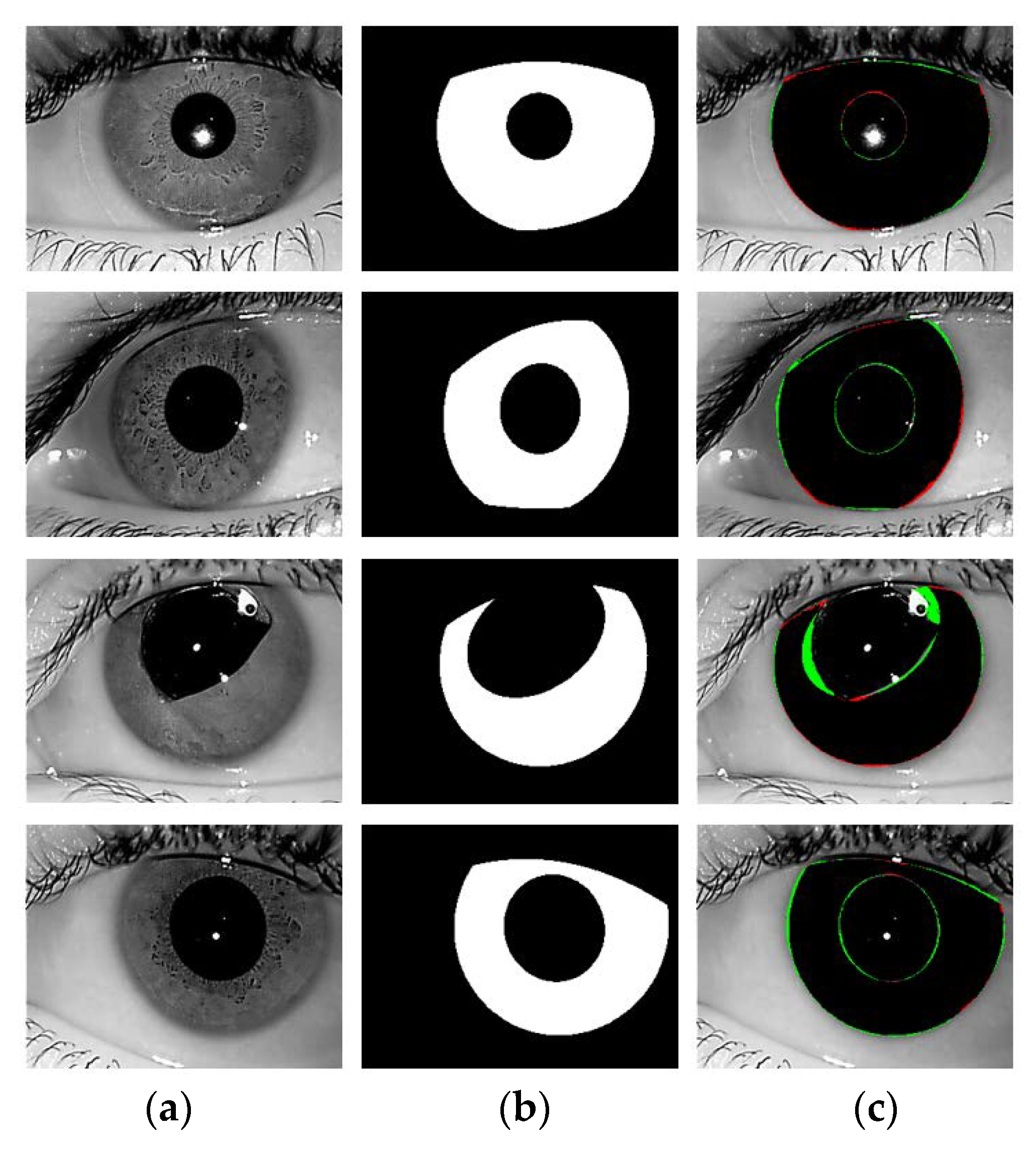
6.2. Comparison of Segmentation Results (IrisDenseNet vs. SegNet)
- -
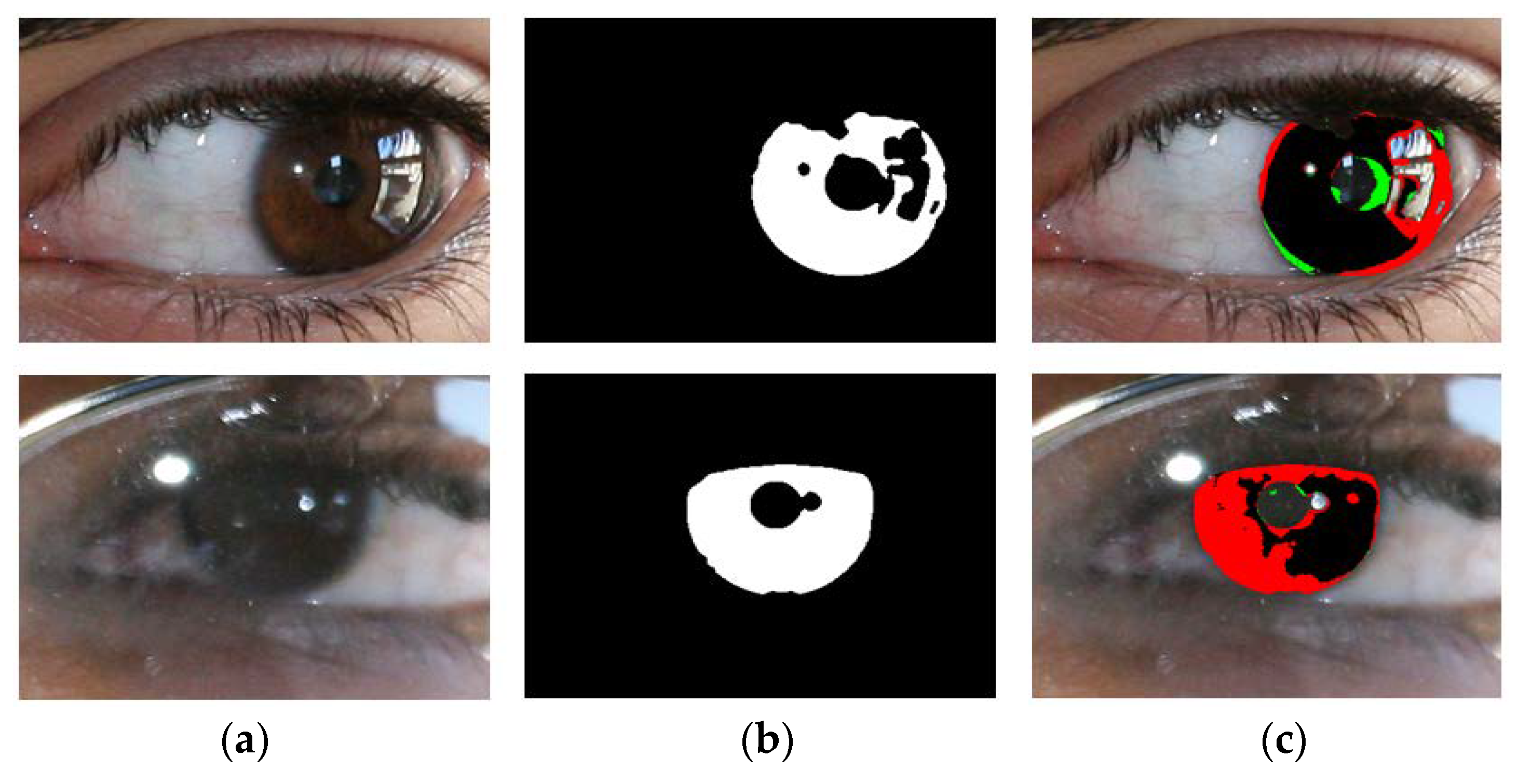
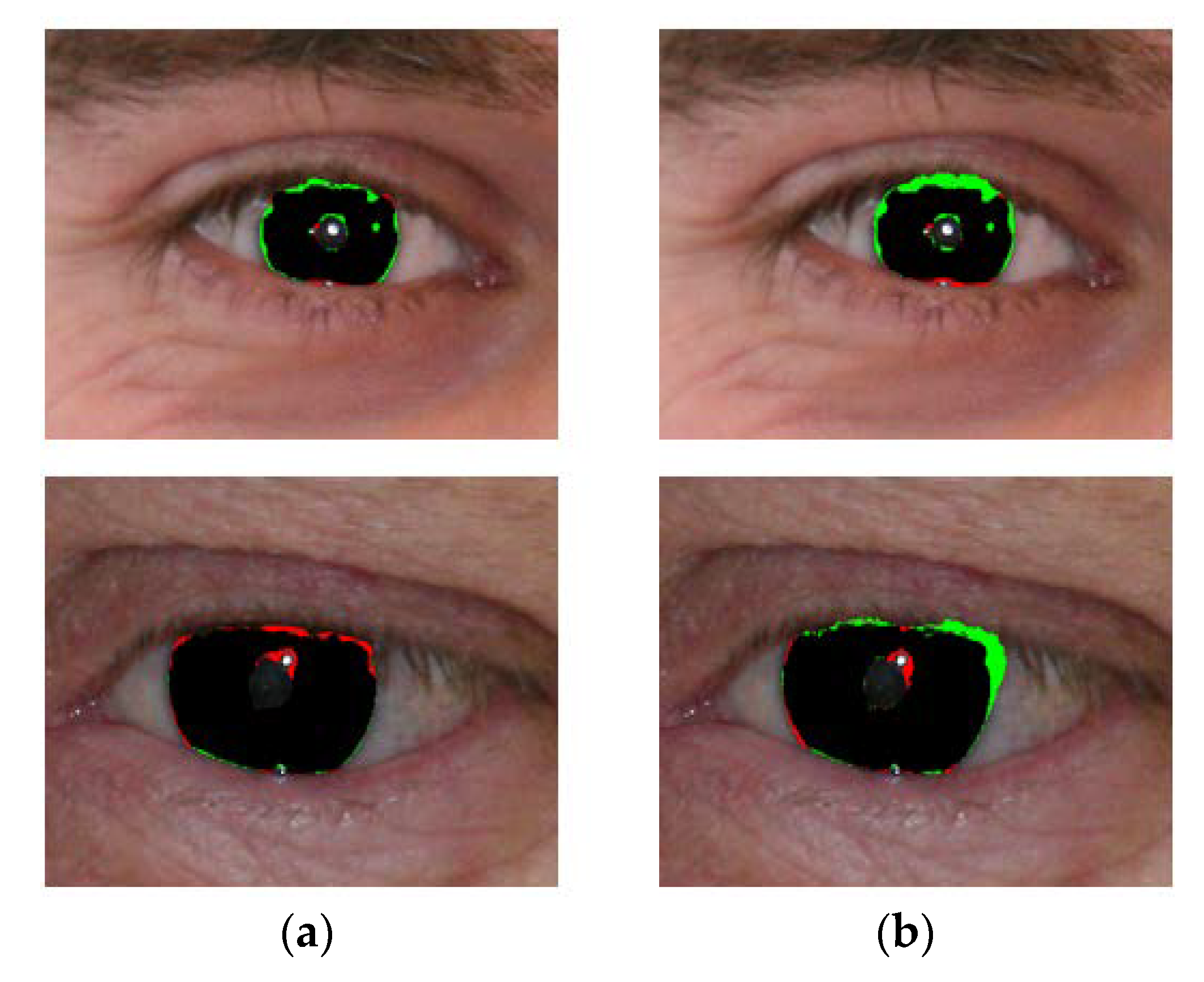
- The segmentation results obtained by IrisDenseNet dense features show a thinner and finer iris boundary as compared to SegNet, which substantially reduces the error rate for the proposed method, as shown in Figure 21a,b.
- -
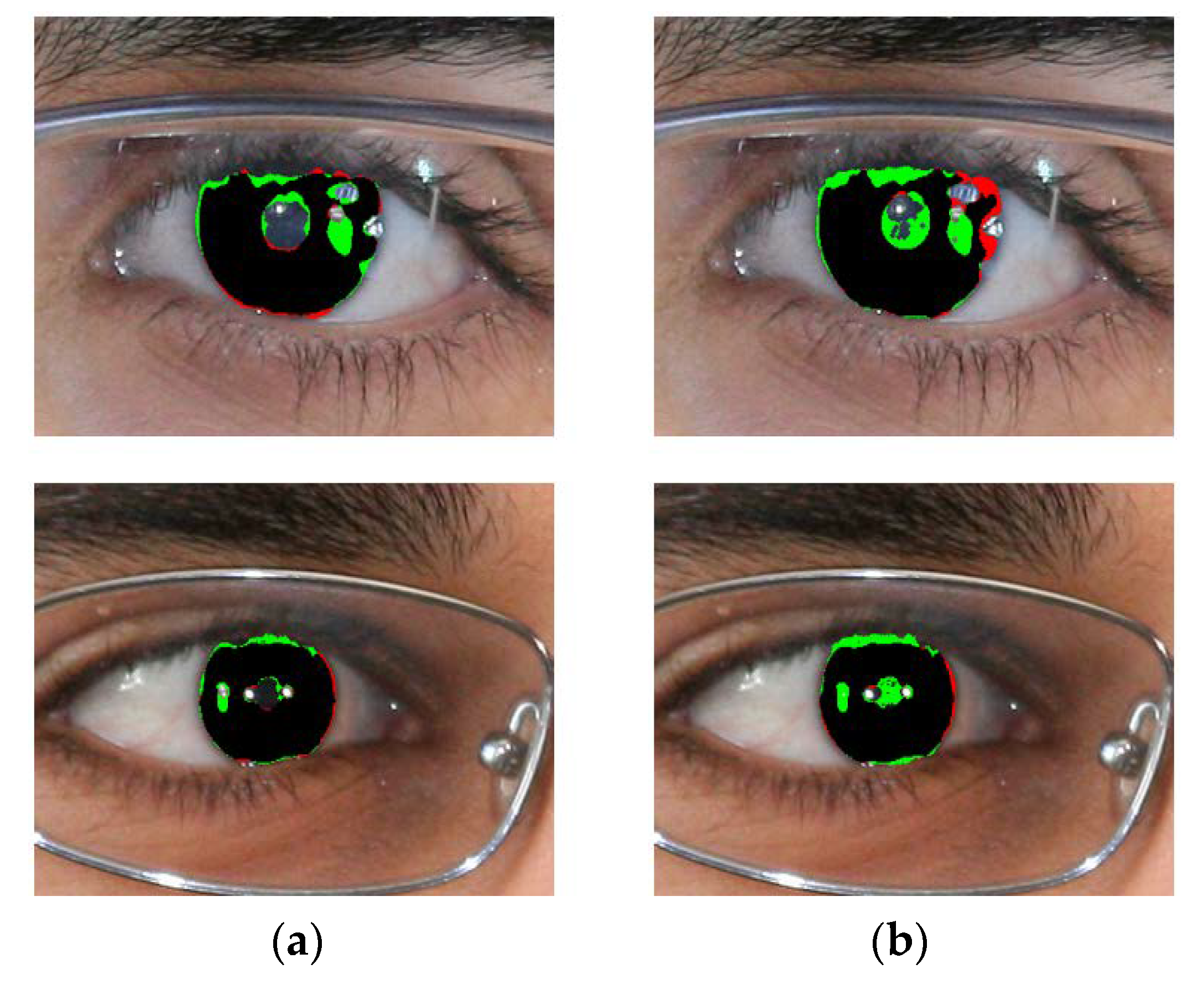
- IrisDenseNet is more robust for the detection of the pupil boundary as compared to SegNet, as shown in Figure 22a,b.
- -
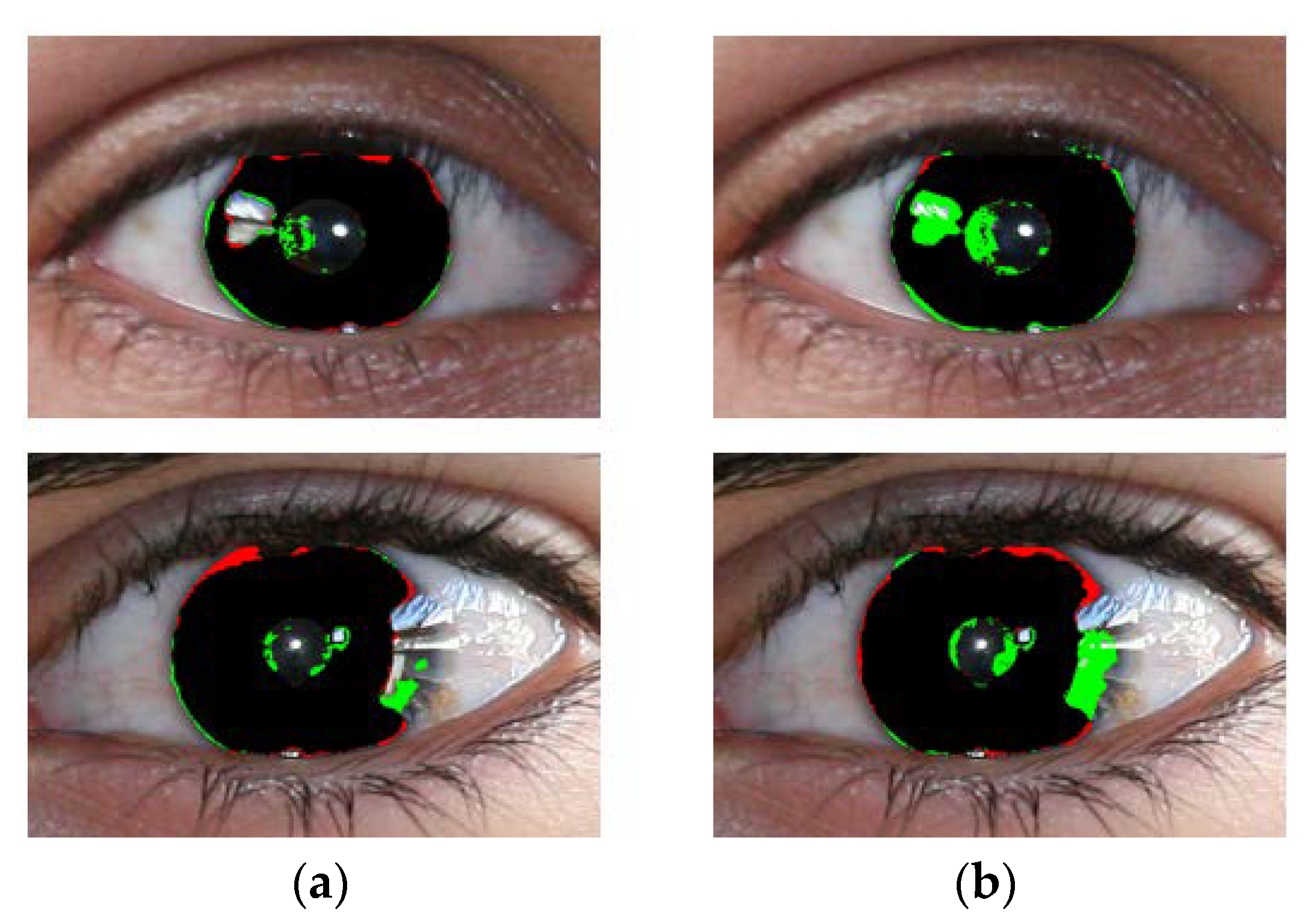
- IrisDenseNet is more robust for the ghost region in the iris area as compared to SegNet, as shown in Figure 23a,b.
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Bowyer, K.W.; Hollingsworth, K.P.; Flynn, P.J. A survey of iris biometrics research: 2008–2010. In Handbook of Iris Recognition; Advances in Computer Vision and Pattern Recognition; Springer: London, UK, 2016; pp. 23–61. [Google Scholar]
- Jain, A.K.; Arora, S.S.; Cao, K.; Best-Rowden, L.; Bhatnagar, A. Fingerprint recognition of young children. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1501–1514. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional neural network-based finger-vein recognition Using NIR Image Sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [PubMed]
- Bonnen, K.; Klare, B.F.; Jain, A.K. Component-based representation in automated face recognition. IEEE Trans. Inf. Forensics Secur. 2013, 8, 239–253. [Google Scholar] [CrossRef]
- Viriri, S.; Tapamo, J.R. Integrating iris and signature traits for personal authentication using user-specific weighting. Sensors 2012, 12, 4324–4338. [Google Scholar] [CrossRef] [PubMed]
- Meraoumia, A.; Chitroub, S.; Bouridane, A. Palmprint and finger-knuckle-print for efficient person recognition based on Log-Gabor filter response. Analog Integr. Circuits Signal Process. 2011, 69, 17–27. [Google Scholar] [CrossRef]
- Alqahtani, A. Evaluation of the reliability of iris recognition biometric authentication systems. In Proceedings of the International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 15–17 December 2016; pp. 781–785. [Google Scholar]
- Bowyer, K.W.; Hollingsworth, K.; Flynn, P.J. Image understanding for iris biometrics: A survey. Comput. Vis. Image Underst. 2008, 110, 281–307. [Google Scholar] [CrossRef]
- Schnabel, B.; Behringer, M. Biometric protection for mobile devices is now more reliable. Opt. Photonik 2016, 11, 16–19. [Google Scholar] [CrossRef]
- Kang, J.-S. Mobile iris recognition systems: An emerging biometric technology. Procedia Comput. Sci. 2012, 1, 475–484. [Google Scholar] [CrossRef]
- Barra, S.; Casanova, A.; Narducci, F.; Ricciardi, S. Ubiquitous iris recognition by means of mobile devices. Pattern Recognit. Lett. 2015, 57, 66–73. [Google Scholar] [CrossRef]
- Albadarneh, A.; Albadarneh, I.; Alqatawna, J. Iris recognition system for secure authentication based on texture and shape features. In Proceedings of the IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies, The Dead Sea, Jordan, 3–5 November 2015; pp. 1–6. [Google Scholar]
- Hajari, K.; Bhoyar, K. A review of issues and challenges in designing iris recognition systems for noisy imaging environment. In Proceedings of the International Conference on Pervasive Computing, Pune, India, 8–10 January 2015; pp. 1–6. [Google Scholar]
- Sahmoud, S.A.; Abuhaiba, I.S. Efficient iris segmentation method in unconstrained environments. Pattern Recognit. 2013, 46, 3174–3185. [Google Scholar] [CrossRef]
- Hofbauer, H.; Alonso-Fernandez, F.; Bigun, J.; Uhl, A. Experimental analysis regarding the influence of iris segmentation on the recognition rate. IET Biom. 2016, 5, 200–211. [Google Scholar] [CrossRef][Green Version]
- Proença, H.; Alexandre, L.A. Iris recognition: Analysis of the error rates regarding the accuracy of the segmentation stage. Image Vis. Comput. 2010, 28, 202–206. [Google Scholar] [CrossRef]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef]
- Roy, D.A.; Soni, U.S. IRIS segmentation using Daughman’s method. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, India, 3–5 March 2016; pp. 2668–2676. [Google Scholar]
- Khan, T.M.; Aurangzeb Khan, M.; Malik, S.A.; Khan, S.A.; Bashir, T.; Dar, A.H. Automatic localization of pupil using eccentricity and iris using gradient based method. Opt. Lasers Eng. 2011, 49, 177–187. [Google Scholar] [CrossRef]
- Ibrahim, M.T.; Khan, T.M.; Khan, S.A.; Aurangzeb Khan, M.; Guan, L. Iris localization using local histogram and other image statistics. Opt. Lasers Eng. 2012, 50, 645–654. [Google Scholar] [CrossRef]
- Huang, J.; You, X.; Tang, Y.Y.; Du, L.; Yuan, Y. A novel iris segmentation using radial-suppression edge detection. Signal Process. 2009, 89, 2630–2643. [Google Scholar] [CrossRef]
- Jan, F.; Usman, I.; Agha, S. Iris localization in frontal eye images for less constrained iris recognition systems. Digit. Signal Process. 2012, 22, 971–986. [Google Scholar] [CrossRef]
- Ibrahim, M.T.; Mehmood, T.; Aurangzeb Khan, M.; Guan, L. A novel and efficient feedback method for pupil and iris localization. In Proceedings of the 8th International Conference on Image Analysis and Recognition, Burnaby, BC, Canada, 22–24 June 2011; pp. 79–88. [Google Scholar]
- Umer, S.; Dhara, B.C. A fast iris localization using inversion transform and restricted circular Hough transform. In Proceedings of the 8th International Conference on Advances in Pattern Recognition, Kolkata, India, 4–7 January 2015; pp. 1–6. [Google Scholar]
- Daugman, J. How iris recognition works. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 21–30. [Google Scholar] [CrossRef]
- Jeong, D.S.; Hwang, J.W.; Kang, B.J.; Park, K.R.; Won, C.S.; Park, D.-K.; Kim, J. A new iris segmentation method for non-ideal iris images. Image Vis. Comput. 2010, 28, 254–260. [Google Scholar] [CrossRef]
- Parikh, Y.; Chaskar, U.; Khakole, H. Effective approach for iris localization in nonideal imaging conditions. In Proceedings of the IEEE Students’ Technology Symposium, Kharagpur, India, 28 February–2 March 2014; pp. 239–246. [Google Scholar]
- Pundlik, S.J.; Woodard, D.L.; Birchfield, S.T. Non-ideal iris segmentation using graph cuts. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–6. [Google Scholar]
- Zuo, J.; Schmid, N.A. On a methodology for robust segmentation of nonideal iris images. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 703–718. [Google Scholar]
- Hu, Y.; Sirlantzis, K.; Howells, G. Improving colour iris segmentation using a model selection technique. Pattern Recognit. Lett. 2015, 57, 24–32. [Google Scholar] [CrossRef]
- Shah, S.; Ross, A. Iris segmentation using geodesic active contours. IEEE Trans. Inf. Forensics Secur. 2009, 4, 824–836. [Google Scholar] [CrossRef]
- Koh, J.; Govindaraju, V.; Chaudhary, V. A robust iris localization method using an active contour model and Hough transform. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2852–2856. [Google Scholar]
- Abdullah, M.A.M.; Dlay, S.S.; Woo, W.L. Fast and accurate method for complete iris segmentation with active contour and morphology. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques, Santorini, Greece, 14–17 October 2014; pp. 123–128. [Google Scholar]
- Abdullah, M.A.M.; Dlay, S.S.; Woo, W.L.; Chambers, J.A. Robust iris segmentation method based on a new active contour force with a noncircular normalization. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 3128–3141. [Google Scholar] [CrossRef]
- Tan, T.; He, Z.; Sun, Z. Efficient and robust segmentation of noisy iris images for non-cooperative iris recognition. Image Vis. Comput. 2010, 28, 223–230. [Google Scholar] [CrossRef]
- Patel, H.; Modi, C.K.; Paunwala, M.C.; Patnaik, S. Human identification by partial iris segmentation using pupil circle growing based on binary integrated edge intensity curve. In Proceedings of the International Conference on Communication Systems and Network Technologies, Katra, India, 3–5 June 2011; pp. 333–338. [Google Scholar]
- Abate, A.F.; Frucci, M.; Galdi, C.; Riccio, D. BIRD: Watershed based iris detection for mobile devices. Pattern Recognit. Lett. 2015, 57, 41–49. [Google Scholar] [CrossRef]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain tumor segmentation using convolutional neural networks in MRI images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef] [PubMed]
- Ahuja, K.; Islam, R.; Barbhuiya, F.A.; Dey, K. A preliminary study of CNNs for iris and periocular verification in the visible spectrum. In Proceedings of the 23rd International Conference on Pattern Recognition, Cancún, Mexico, 4–8 December 2016; pp. 181–186. [Google Scholar]
- Zhao, Z.; Kumar, A. Accurate periocular recognition under less constrained environment using semantics-assisted convolutional neural network. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1017–1030. [Google Scholar] [CrossRef]
- Al-Waisy, A.S.; Qahwaji, R.; Ipson, S.; Al-Fahdawi, S.; Nagem, T.A.M. A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal. Appl. 2017, 20, 1–20. [Google Scholar] [CrossRef]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar]
- Lee, M.B.; Hong, H.G.; Park, K.R. Noisy ocular recognition based on three convolutional neural networks. Sensors 2017, 17, 2933. [Google Scholar]
- Liu, N.; Li, H.; Zhang, M.; Liu, J.; Sun, Z.; Tan, T. Accurate iris segmentation in non-cooperative environments using fully convolutional networks. In Proceedings of the IEEE International Conference on Biometrics, Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Arsalan, M.; Hong, H.G.; Naqvi, R.A.; Lee, M.B.; Kim, M.C.; Kim, D.S.; Kim, C.S.; Park, K.R. Deep learning-based iris segmentation for iris recognition in visible light environment. Symmetry 2017, 9, 263. [Google Scholar] [CrossRef]
- Jalilian, E.; Uhl, A.; Kwitt, R. Domain adaptation for CNN based iris segmentation. In Proceedings of the IEEE International Conference on the Biometrics Special Interest Group, Darmstadt, Germany, 20–22 September 2017; pp. 51–60. [Google Scholar]
- Dongguk IrisDenseNet CNN Model (DI-CNN) with Algorithm. Available online: http://dm.dgu.edu/link.html (accessed on 18 February 2018).
- Kim, J.H.; Hong, H.G.; Park, K.R. Convolutional neural network-based human detection in nighttime images using visible light camera sensors. Sensors 2017, 17, 1065. [Google Scholar]
- Kim, K.W.; Hong, H.G.; Nam, G.P.; Park, K.R. A study of deep CNN-based classification of open and closed eyes using a visible light camera sensor. Sensors 2017, 17, 1534. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.T.; Kim, K.W.; Hong, H.G.; Koo, J.H.; Kim, M.C.; Park, K.R. Gender recognition from human-body images using visible-light and thermal camera videos based on a convolutional neural network for image feature extraction. Sensors 2017, 17, 637. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.K.; Hong, H.G.; Park, K.R. Pedestrian detection based on adaptive selection of visible light or far-infrared light camera image by fuzzy inference system and convolutional neural network-based verification. Sensors 2017, 17, 1598. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.D.; Lee, D.E.; Park, K.R. Multi-national banknote classification based on visible-light line sensor and convolutional neural network. Sensors 2017, 17, 1595. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Deep learning for consumer devices and services: Pushing the limits for machine learning, artificial intelligence, and computer vision. IEEE Consum. Electron. Mag. 2017, 6, 48–56. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, S.; van der Maaten, L.; Weinberger, K.Q. CondenseNet: An efficient DenseNet using learned group convolutions. arXiv, 2017; arXiv:1711.09224. [Google Scholar]
- NICE.II. Noisy Iris Challenge Evaluation-Part II. Available online: http://nice2.di.ubi.pt/index.html (accessed on 28 December 2017).
- Geforce GTX 1070. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1070/ (accessed on 12 January 2018).
- Matlab R2017b. Available online: https://ch.mathworks.com/help/matlab/release-notes.html (accessed on 12 January 2018).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Zhang, T. Solving large scale linear prediction problems using stochastic gradient descent algorithms. In Proceedings of the 21st International Conference on Machine Learning, Banff, Canada, 4–8 July 2004; pp. 919–926. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- NICE.I. Noisy Iris Challenge Evaluation-Part I. Available online: http://nice1.di.ubi.pt/ (accessed on 4 January 2018).
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Luengo-Oroz, M.A.; Faure, E.; Angulo, J. Robust iris segmentation on uncalibrated noisy images using mathematical morphology. Image Vis. Comput. 2010, 28, 278–284. [Google Scholar] [CrossRef]
- Labati, R.D.; Scotti, F. Noisy iris segmentation with boundary regularization and reflections removal. Image Vis. Comput. 2010, 28, 270–277. [Google Scholar] [CrossRef]
- Chen, Y.; Adjouadi, M.; Han, C.; Wang, J.; Barreto, A.; Rishe, N.; Andrian, J. A highly accurate and computationally efficient approach for unconstrained iris segmentation. Image Vis. Comput. 2010, 28, 261–269. [Google Scholar] [CrossRef]
- Li, P.; Liu, X.; Xiao, L.; Song, Q. Robust and accurate iris segmentation in very noisy iris images. Image Vis. Comput. 2010, 28, 246–253. [Google Scholar] [CrossRef]
- Tan, C.-W.; Kumar, A. Unified framework for automated iris segmentation using distantly acquired face images. IEEE Trans. Image Process. 2012, 21, 4068–4079. [Google Scholar] [CrossRef] [PubMed]
- Proenca, H. Iris recognition: On the segmentation of degraded images acquired in the visible wavelength. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1502–1516. [Google Scholar] [CrossRef] [PubMed]
- De Almeida, P. A knowledge-based approach to the iris segmentation problem. Image Vis. Comput. 2010, 28, 238–245. [Google Scholar] [CrossRef]
- Tan, C.-W.; Kumar, A. Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans. Image Process. 2013, 22, 3751–3765. [Google Scholar] [PubMed]
- Sankowski, W.; Grabowski, K.; Napieralska, M.; Zubert, M.; Napieralski, A. Reliable algorithm for iris segmentation in eye image. Image Vis. Comput. 2010, 28, 231–237. [Google Scholar] [CrossRef]
- Haindl, M.; Krupička, M. Unsupervised detection of non-iris occlusions. Pattern Recognit. Lett. 2015, 57, 60–65. [Google Scholar] [CrossRef]
- Zhao, Z.; Kumar, A. An accurate iris segmentation framework under relaxed imaging constraints using total variation model. In Proceedings of the IEEE Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3828–3836. [Google Scholar]
- De Marsico, M.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile iris challenge evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- CASIA-Iris-Interval Database. Available online: http://biometrics.idealtest.org/dbDetailForUser.do?id=4 (accessed on 28 December 2017).
- IIT Delhi Iris Database. Available online: http://www4.comp.polyu.edu.hk/~csajaykr/IITD/Database_Iris.htm (accessed on 28 December 2017).
- Hofbauer, H.; Alonso-Fernandez, F.; Wild, P.; Bigun, J.; Uhl, A. A ground truth for iris segmentation. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 527–532. [Google Scholar]
- Gangwar, A.; Joshi, A.; Singh, A.; Alonso-Fernandez, F.; Bigun, J. IrisSeg: A fast and robust iris segmentation framework for non-ideal iris images. In Proceedings of the International Conference on Biometrics, Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Alonso-Fernandez, F.; Bigun, J. Iris boundaries segmentation using the generalized structure tensor. A study on the effects of image degradation. In Proceedings of the 5th International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 23–27 September 2012; pp. 426–431. [Google Scholar]
- Petrovska, D.; Mayoue, A. Description and documentation of the BioSecure software library. In Technical Report, Proj. No IST-2002-507634-BioSecure Deliv; BioSecure: Paris, France, 2007. [Google Scholar]
- Uhl, A.; Wild, P. Weighted adaptive hough and ellipsopolar transforms for real-time iris segmentation. In Proceedings of the 5th IEEE International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012; pp. 283–290. [Google Scholar]
- Uhl, A.; Wild, P. Multi-stage visible wavelength and near infrared iris segmentation framework. In Proceedings of the 9th International Conference on Image Analysis and Recognition, Aveiro, Portugal, 25–27 June 2012; pp. 1–10. [Google Scholar]
- Rathgeb, C.; Uhl, A.; Wild, P. Iris biometrics: From segmentation to template security. In Advances in Information Security; Springer: New York, NY, USA, 2013. [Google Scholar]
- Masek, L.; Kovesi, P. MATLAB Source Code for a Biometric Identification System Based on Iris Patterns; The School of Computer Science and Software Engineering, The University of Western Australia: Perth, Australia, 2003. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Methods | Strength | Weakness |
|---|---|---|---|
| Iris circular boundary detection without eyelid and eyelash detection | Iris localization by circular HT [17,22,24] | These methods show a good estimation of the iris region in ideal cases | These types of methods are not very accurate for non-ideal cases or visible light environments |
| Integro-differential operator [18] | |||
| Iris localization by gradient on iris-sclera boundary points [19] | A new idea to use a gradient to locate iris boundary | The gradient is affected by eyelashes and true iris boundary is not found | |
| The two-stage method with circular moving window [20] | Pupil based on dark color approximated simply by probability | Calculating gradient in a search way is time-consuming | |
| Radial suppression-based edge detection and thresholding [21] | Radial suppression makes the case simpler for the iris edges | In non-ideal cases, the edges are not fine to estimate the boundaries | |
| Adaptive thresholding and first derivative-based iris localization [23] | Simple way to obtain the boundary based on the gray level in ideal cases | One threshold cannot guarantee good results in all cases | |
| Iris circular boundary detection with eyelid and eyelash detection | Two-circular edge detector assisted with AdaBoost eye detector [26] | Closed eye, eyelash and eyelid detection is executed to reduce error | The method is affected by pupil/eyelid detection error |
| Curve fitting and color clustering [27] | Upper and lower eyelid detections are performed to reduce the error | The empirical threshold is set for eyelid and eyelash detection, and still true boundary is not found | |
| Graph-cut-based approach for iris segmentation [28] | Eyelashes are removed using Markov random field to reduce error | A separate method for each eyelash, pupil, iris detection is time-consuming | |
| Rotated ellipse fitting method combined with occlusion detection [29] | Ellipse fitting gives a good approximation for the iris with reduced error | Still, the iris and other boundaries are considered as circular | |
| Three model fusion-based method assisted with Daugman’s method [30] | Simple integral derivative as a base for iris boundaries is a quite simple way | High-score fitting is sensitive in ideal cases, and can be disturbed by similar RGB pixels in the image | |
| Active contour-based methods | Geodesic active contours, Chan–Vese and new pressure force active contours [31,32,33,34] | These methods iteratively approximate the true boundaries in non-ideal situations | In these methods, many iterations are required for accuracy, which takes much processing time |
| Region growing and watershed methods | Region growing with integro-differential constellation [35] | Both iris and non-iris regions are identified along with reflection removal to reduce error | The rough boundary is found first and then a boundary refinement process is performed separately |
| Region growing with binary integrated intensity curve-based method [36] | Eyelash and eyelid detection is performed along with iris segmentation | The region growing process starts with the pupil circle, so the case of visible light images where the pupil is not clear can cause errors | |
| Watershed BIRD with seed selection [37] | Limbus boundary detection is performed to separate sclera, eyelashes, and eyelid pixels from iris | Watershed transform shares the disadvantage of over-segmentation, so circle fitting is used further | |
| Deep-learning-based methods | HCNNs and MFCNs [44] | This approach shows the lower error than existing methods for non-ideal cases | The similar parts to iris regions can be incorrectly detected as iris points |
| Two-stage iris segmentation method using deep learning and modified HT [45] | Better accuracy due to CNN, which is just applied inside the ROI defined in the first stage | Millions of 21 × 21 images are needed for CNN training and pre-processing required to improve the image | |
| IrisDenseNet for iris segmentation (Proposed Method) | Accurately find the iris boundaries without pre-processing with better information gradient flow. With robustness for high-frequency areas such as eyelashes and ghost regions | Due to dense connectivity, the mini-batch size should be kept low owing to more time required for training |
| Block | Name/Size | No. of Filters | Output Feature Map Size (Width × Height × Number of Channel) |
|---|---|---|---|
| Dense Block-1 | Conv-1_1*/3 × 3 × 3 | 64 | 300 × 400 × 64 |
| Conv-1_2*/3 × 3 × 64 | 64 | ||
| Cat-1 | - | 300 × 400 × 128 | |
| Transition layer-1 | B-Conv-1/1 × 1 | 64 | 300 × 400 × 64 |
| Pool-1/2 × 2 | - | 150 × 200 × 64 | |
| Dense Block-2 | Conv-2_1*/3 × 3 × 64 | 128 | 150 × 200 × 128 |
| Conv-2_2*/3 × 3 × 128 | 128 | ||
| Cat-2 | - | 150 × 200 × 256 | |
| Transition layer-2 | B-Conv-2/1 × 1 | 128 | 150 × 200 × 128 |
| Pool-2/2 × 2 | - | 75 × 100 × 128 | |
| Dense Block-3 | Conv-3_1*/3 × 3 × 128 | 256 | 75 × 100 × 256 |
| Conv-3_2*/3 × 3 × 256 | 256 | ||
| Cat-3 | - | 75 × 100 × 512 | |
| Conv-3_3*/3 × 3 × 256 | 256 | 75 × 100 × 256 | |
| Cat-4 | - | 75 × 100 × 768 | |
| Transition layer-3 | B-Conv-3/1 × 1 | 256 | 75 × 100 × 256 |
| Pool-3/2 × 2 | - | 37 ×50 × 256 | |
| Dense Block-4 | Conv-4_1*/3 × 3 × 256 | 512 | 37 ×50 × 512 |
| Conv-4_2*/3 × 3 × 512 | 512 | ||
| Cat-5 | - | 37 ×50 × 1024 | |
| Conv-4_3*/3 × 3 × 512 | 512 | 37 ×50 × 512 | |
| Cat-6 | - | 37 ×50 × 1536 | |
| Transition layer-4 | B-Conv-4/1 × 1 | 512 | 37 ×50 × 512 |
| Pool-4/2 × 2 | - | 18 × 25 × 512 | |
| Dense Block-5 | Conv-5_1*/3 × 3 × 512 | 512 | 18 × 25 × 512 |
| Conv-5_2*/3 × 3 × 512 | 512 | ||
| Cat-7 | - | 18 × 25 × 1024 | |
| Conv-5_3*/3 × 3 × 512 | 512 | 18 × 25 × 512 | |
| Cat-8 | - | 18 × 25 × 1536 | |
| Transition layer-5 | B-Conv-5/1 × 1 | 512 | 18 × 25 × 512 |
| Pool-5/2 × 2 | - | 9 × 12 × 512 |
| Method | |
|---|---|
| Excessive data augmentation | 0.00729 |
| Data augmentation by changing the contrast and brightness of iris image | 0.00761 |
| Proposed data augmentation in Section 5.2 | 0.00695 |
| Method | |
|---|---|
| Luengo-Oroz et al. [69] | 0.0305 |
| Labati et al. [70] | 0.0301 |
| Chen et al. [71] | 0.029 |
| Jeong et al. [26] | 0.028 |
| Li et al. [72] | 0.022 |
| Tan et al. [73] | 0.019 |
| Proença et al. [74] | 0.0187 |
| de Almeida [75] | 0.0180 |
| Tan et al. [76] | 0.0172 |
| Sankowski et al. [77] | 0.016 |
| Tan et al. [35] | 0.0131 |
| Haindl et al. [78] | 0.0124 |
| Zhao et al. [79] | 0.0121 |
| Arsalan et al. [45] | 0.0082 |
| SegNet-Basic [57] | 0.00784 |
| Proposed IrisDenseNet | 0.00695 |
| Method | ||
|---|---|---|
| Hu et al. [30] | Sub-dataset by iPhone5 | 0.0193 |
| Sub-dataset by Galaxy S4 | 0.0192 | |
| Arsalan et al. [45] | Sub-dataset by iPhone5 | 0.00368 |
| Sub-dataset by Galaxy S4 | 0.00297 | |
| Sub-dataset by Galaxy Tab2 | 0.00352 | |
| SegNet-Basic [57] | Sub-dataset by iPhone5 | 0.0025 |
| Sub-dataset by Galaxy S4 | 0.0027 | |
| Sub-dataset by Galaxy Tab2 | 0.0029 | |
| Proposed IrisDenseNet | Sub-dataset by iPhone5 | 0.0020 |
| Sub-dataset by Galaxy S4 | 0.0022 | |
| Sub-dataset by Galaxy Tab2 | 0.0021 | |
| Method | |
|---|---|
| Tan et al. [73] | 0.0113 |
| Liu et al. [44] (HCNNs) | 0.0108 |
| Tan et al. [76] | 0.0081 |
| Zhao et al. [79] | 0.0068 |
| Liu et al. [44] (MFCNs) | 0.0059 |
| SegNet-Basic [57] | 0.0044 |
| Proposed IrisDenseNet | 0.0034 |
| DB | Method | R | P | F | |||
|---|---|---|---|---|---|---|---|
| CASIA V4.0 Interval | GST [85] | 85.19 | 18 | 89.91 | 7.37 | 86.16 | 11.53 |
| Osiris [86] | 97.32 | 7.93 | 93.03 | 4.95 | 89.85 | 5.47 | |
| WAHET [87] | 94.72 | 9.01 | 85.44 | 9.67 | 89.13 | 8.39 | |
| IFFP [88] | 91.74 | 14.74 | 83.5 | 14.26 | 86.86 | 13.27 | |
| CAHT [89] | 97.68 | 4.56 | 82.89 | 9.95 | 89.27 | 6.67 | |
| Masek [90] | 88.46 | 11.52 | 89 | 6.31 | 88.3 | 7.99 | |
| IDO [25] | 71.34 | 22.86 | 61.62 | 18.71 | 65.61 | 19.96 | |
| IrisSeg [84] | 94.26 | 4.18 | 92.15 | 3.34 | 93.1 | 2.65 | |
| SegNet-Basic [57] | 99.60 | 0.66 | 91.86 | 2.65 | 95.55 | 1.40 | |
| Proposed Method | 97.10 | 2.12 | 98.10 | 1.07 | 97.58 | 0.99 | |
| IITD | GST [85] | 90.06 | 16.65 | 85.86 | 10.46 | 86.6 | 11.87 |
| Osiris [86] | 94.06 | 6.43 | 91.01 | 7.61 | 92.23 | 5.8 | |
| WAHET [87] | 97.43 | 8.12 | 79.42 | 12.41 | 87.02 | 9.72 | |
| IFFP [88] | 93.92 | 10.62 | 79.76 | 11.42 | 85.83 | 9.54 | |
| CAHT [89] | 96.8 | 11.2 | 78.87 | 13.25 | 86.28 | 11.39 | |
| Masek [90] | 82.23 | 18.74 | 90.45 | 11 .85 | 85.3 | 15.39 | |
| IDO [25] | 51.91 | 15.32 | 52.23 | 14.85 | 51.17 | 13.26 | |
| IrisSeg [84] | 95.33 | 4.58 | 93.70 | 5.33 | 94.37 | 3.88 | |
| SegNet-Basic [57] | 99.68 | 0.51 | 92.53 | 2.05 | 95.96 | 1.04 | |
| Proposed Method | 98.0 | 1.56 | 97.16 | 1.40 | 97.56 | 0.84 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors 2018, 18, 1501. https://doi.org/10.3390/s18051501
Arsalan M, Naqvi RA, Kim DS, Nguyen PH, Owais M, Park KR. IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors. 2018; 18(5):1501. https://doi.org/10.3390/s18051501
Chicago/Turabian StyleArsalan, Muhammad, Rizwan Ali Naqvi, Dong Seop Kim, Phong Ha Nguyen, Muhammad Owais, and Kang Ryoung Park. 2018. "IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors" Sensors 18, no. 5: 1501. https://doi.org/10.3390/s18051501
APA StyleArsalan, M., Naqvi, R. A., Kim, D. S., Nguyen, P. H., Owais, M., & Park, K. R. (2018). IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors, 18(5), 1501. https://doi.org/10.3390/s18051501