1. Introduction
The current state sensing and awareness of flight vehicles relies on traditional sensors and detection devices mounted on different locations of the vehicle, e.g., Pitot tubes installed in front of the nose for airspeed measurement, transducers located on each side of the fuselage for angle of attack detection. Inspired by the unsurpassed flight capabilities of birds, a novel “fly-by-feel” (FBF) concept has been recently proposed for the development of the next generation of intelligent air vehicles that can “feel”, “think”, and “react” [
1,
2]. Such bio-inspired systems will not only be able to sense the environment (temperature, pressure, aerodynamic forces, etc.), but also be able to think in real-time and be aware of their current flight state and structural health condition. Further, such systems will react intelligently under various situations and achieve superior performance and agility. Compared with the traditional approaches, this FBF concept has the following advantages: (1) structural complexity reduction by integrated structures with self-sensing ability, (2) structural health on-line monitoring through embedded multi-functional materials, (3) autonomous flight control and decision-making based on self-awareness [
2]. Towards this end, great challenges have been posed to the current structural design and data processing methods with a departure from the existing technologies.
Recent years have seen the development of different sensing network architectures and simulations [
3,
4,
5,
6], among which, an expandable network made of polymer-based substrates was designed by the Structure and Composites Lab (SACL) at Stanford University. This network contains many micro-nodes which have the potential to integrate micro-sensors, actuators and electronics for different applications [
7]. Based on the development of integration and fabrication techniques [
8,
9,
10], a smart structure with the sensor network monolithically embedded in the layup of a composite UAV wing was successfully fabricated [
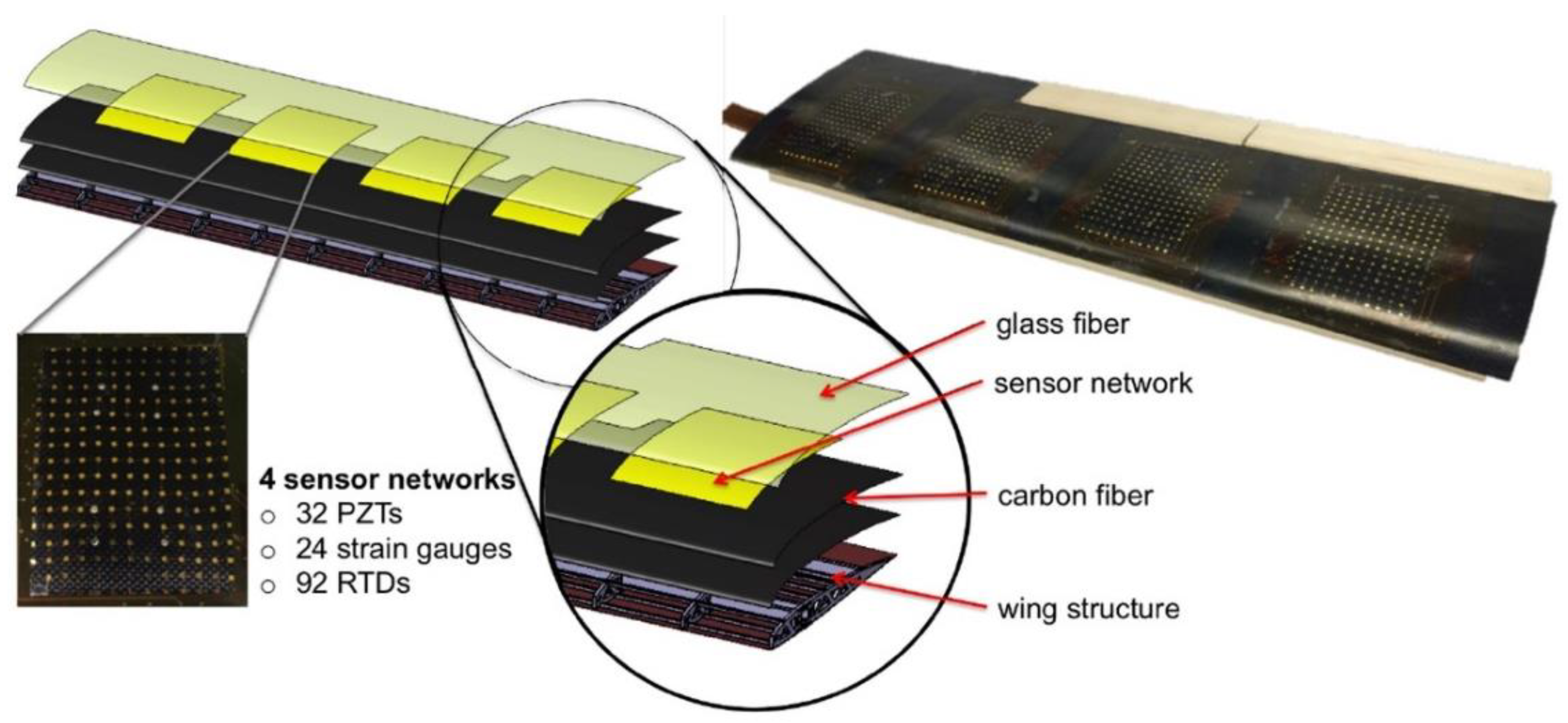
11]. This smart wing consists of four sensor networks and each network is integrated with strain gauges, resistive temperature detectors (RTD) and piezoelectric lead zirconate titanate (PZT) transducers. Specifically, the strain gauge is used to measure the wing strain distribution and identify any potentially dangerous areas. RTD detects the temperature distribution in order to provide the temperature compensation [
12]. PZT transducers can be used for both active and passive measurements. In the active mode, they can be used for damage detection and structural health monitoring while in passive mode, the wing structural vibration during flying can be captured to reflect the air dynamic characteristics [
11]. The wing configuration is shown in
Figure 1.
After realizing sensing ability through multi-functional structures development, the next step is to equip the smart wing with thinking and judging capability, i.e., the structure is expected to be aware of surroundings and identify its current flying state. There have been studies devoted to addressing the related identification problem based on either strain or vibration signals obtained from experiments. Huang et al. studied the active flutter control and closed-loop flutter identification and a fast-recursive subspace method was applied in high-dimensional aero-servo-elastic system. The wind tunnel test showed that the natural frequency and modal damping ratios of the flutter modes can be precisely tracked [
13]. Pang and Cesnik employed non-linear least squares fit and Kalman filtering to obtain wing shape information and rigid body attitude. Results revealed that the Kalman filter has good performance in the presence of sensor noise [
14]. For elastic deformation, Sodja et al. conducted a dynamic aeroelastic wind tunnel experiment under harmonic pitching excitations, experimental data including the bending and torsion deformation were consistent with the elastic analysis model developed by the Delft University of Technology [
15]. For more general flight states, Kopsaftopoulos and Chang established a stochastic global identification method using PZT signals from both time and frequency domain based on developed Vector-dependent Functionally Pooled (VFP) model [
2,
16,
17]. A large range of airspeeds and angles of attack were considered in the VFP-based identification framework and the structural dynamics of the composite wing could be captured and predicted.
Overall, the above data processing approaches mainly belong to state space methods and improved time series analysis. Based on the previous study yet from another perspective, if we can extract distinguished features from the continuous coupled structural aerodynamic behavior, it is possible to identify the flight state directly using the limited features instead of detailed characterization of the structural responses. Machine learning techniques can be employed to establish the mapping relationship from the feature space to the practical state space.
Facing a series of signals generated from the embedded sensor network, one of the main challenges is what kind of features should be extracted and whether these features are useful for classification. A set of features without careful selection and evaluation may lead to poor results whatever superior machine learning models are applied. Feature engineering is such a research field including feature extraction and selection. For a period of time series signals with noise, various statistical features can be calculated such as the mean value, standard deviation, peak value, kurtosis, etc. from both time domain and frequency domain [
18], a feature pool is then created with different number of features depending on the characteristics of the signals [
19,
20,
21]. More features are encouraged to avoid missing important candidates with superior classification performance. The next step is feature selection in which a limited subset is obtained by eliminating less effective features. It reduces model dimension and computational time [
22]. Generally, feature selection can be divided into three categories as filter, wrapper and embedded. Filter methods rank the variables completely separate to the model used for classification. The assignment of feature importance is based on information generated by some statistical algorithms. Filter methods are computationally simple and fast without the interaction with the classifier and feature dependencies [
23]. Embedded solutions select salient features as part of the learning process of the model, which can be linear regression, support vector machine, decision tree, random forest, etc. These methods integrate the subset selection into the model construction but are difficult to adjust for the optimal search [
24]. The third category is wrapper, in which features are selected based on the performance of a given model by searching the possible subsets space and assessing the performance of the given model on each subset, models can be various learning machines [
25]. Although wrapper methods often achieve sound classification performance by considering the feature dependencies, the frequent interactions between feature subset search and the classifier cause high computational costs [
26].
We have demonstrated the effectiveness of establishing the mapping relationship from the feature space to the flight state space through neural networks modelling [
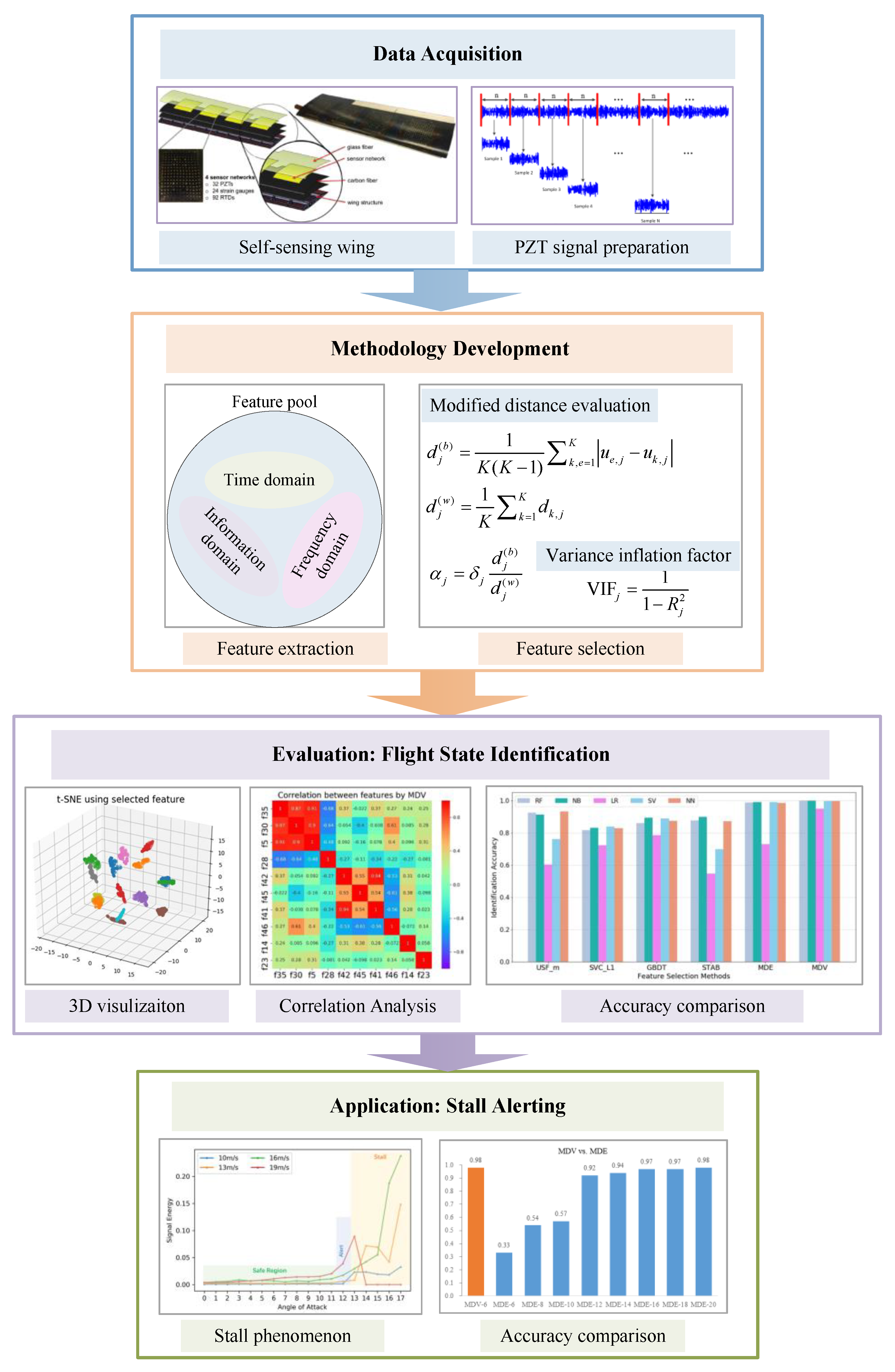
27]. This paper significantly improves the previous work by creating a much larger feature pool and considering the co-linearity among various features. To sum up, the objective of this paper is the introduction and evaluation of a novel feature selection method for accurate flight state identification of a self-sensing wing structure based on experimental vibration data recorded by piezoelectric sensors under multiple flight states. The developed method belongs to the filter family and is capable of obtaining a group of most important features for classification with low mutual dependency. The framework of the data acquisition, methodology development, evaluation and application is shown in
Figure 2.
The rest of the paper is organized as follows:
Section 2 presents the problem statement.
Section 3 focuses on the feature extraction and feature selection in which the novel filter algorithm is introduced. Two case studies including the general flight state identification and the stall detection and alerting are conducted in
Section 4 followed by their results and discussions in
Section 5. Concluding marks are made in the last section.
2. Problem Statement
The problem statement of this work is as follows: based on signals collected from the PZT sensors embedded in the self-sensing wing through a series of experiments under varying flight states, develop a feature selection method that is capable of obtaining limited useful features for flight state identification with high accuracy and low model complexity. Specifically, the coupled aerodynamic-mechanical responses represent different flight states, with each state characterized by a specific angle of attack (AoA) and airspeed and kept constant during the data collection. The first problem is that whether a few salient features can be extracted from a period of vibrational time series (e.g., thousands of data points) as a representation of the corresponding flight state. In this way, we can skip the investigation into the detailed aeroelastic behavior and use the limited features to identify the specific flight state directly instead of using the entire lengthy signal. This would significantly reduce the complexity of the flight state characterization. The second problem is how to guarantee the effectiveness of selected features. If the selected strong features are highly correlated with each other, they will exhibit similar identification ability which are still away from the optimal subset.
The above two problems constitute the motivation of this study and are addressed in the following approaches: firstly, a large number of features is extracted to cover a wide range of descriptions of the flight state. Then, a modified distance evaluation algorithm is conducted to obtain a subset of individually powerful features followed by the combination of a variance inflation factor algorithm to reduce high dependency among features in the subset. Machine learning models are employed to evaluate the above method for multiple flight states identification as well as a specific case of stall detection and alerting.
The main novel aspects of this study include:
- (1)
A large feature pool is created covering up to 47 different features from the time, frequency and information domains.
- (2)
A novel filter feature selection method is developed by combining a modified distance evaluation algorithm and a variance inflation factor.
- (3)
The flight state identification is treated as a classification problem by establishing the mapping relationship from the feature space to the physical space characterized by varying angle of attack and airspeed of the self-sensing wing structure in wind tunnel experiments.
- (4)
The application on stall detection and alerting with high identification accuracy provides new perspectives for autonomous flight control with real-time flight state monitoring.
3. Methodology Development
In this section, a novel filter feature selection method is proposed via the combination of a modified distance evaluation algorithm and a variance inflation factor. In order to obtain sufficient feature candidates, a large feature pool is firstly created by extracting features covering a wide range. The output of this method is a feature subset consisting of most salient features with low correlation, which is able to represent a lengthy time-series signal of the wing structural response under certain flight state.
3.1. Feature Extraction
Feature extraction relies heavily on experts’ knowledge, it is encouraged to extract different kinds of features, as many as possible in case of missing useful ones. In this study, we intend to create a large feature pool from three main sources, namely the time, frequency and information domains.
In time domain, 25 statistical features are calculated including 12 commonly used features such as mean, standard deviation, variance, peak, mean absolute deviation, etc. and 13 un-dimensional features such as crest factor, shape factor and a series of normalized central moments. The expressions of all time domain features are listed in
Table 1. In terms of their physical insights,
t1–
t12 may reflect the vibration amplitude and energy while
t13–
t25 may represent the series distribution of the signal in time domain.
Previous studies employed Fast Fourier Transform (FFT) to convert the time series into frequency spectrum [
19,
20]. However, the signal instances from the wind tunnel experiments are samples of a stochastic process with considerable noise. Welch’s method improves FFT by shortening the signals and averaging, and thus the peaks are smoothed for noise reduction [
28]. Herein, a sample-long Hamming data window with 90% overlap is used for the Welch-based spectral estimation. A series of power spectrum
y(
k) without
log transformation is then used for frequency domain feature extraction. Thirteen statistical features such as mean spectrum, spectrum center, root mean square spectrum, etc. and their mathematical expressions are shown in
Table 2.
f1 may indicate the vibration energy in the frequency domain.
f2–4,
f6,
f10–13 may describe the convergence of the spectrum power.
f5,
f7–9 may show the position change of the main frequency.
In electroencephalograph (EEG) analysis for neural diseases diagnosis and vibration analysis for mechanical defects, fractal dimensions from computational geometry and entropies from information theory have demonstrated effectiveness in early diseases/fault diagnosis [
29,
30]. Inspired by that, a group of complex features are employed and their terminologies are Multi-Scale Entropy, Partial Mean of Multi-Scale Entropy, Petrosian Fractal Dimension, Higuchi Fractal Dimension, Fisher Information, Approximate Entropy, and Hurst Exponent, respectively.
Multi-Scale Entropy (MSE) introduces the scale factor based on the sample entropy to measure the complexity of signal under different scale factors [
31]. It is calculated as:
where
is the scale factor,
m is the embedding dimension and
r is the threshold. Here
m = 2,
r = 0.2
* standard deviation,
.
The first three values are selected due to the relatively high distinction among different classes. Also, an integrated non-linear index called Partial Mean of Multi-Scale Entropy (PMMSE) is used to simultaneously reflect the mean value and variation trend of MSE [
32], which is expressed as:
where
,
MSEa,
MSEb,
MSEc represent mean, median and standard deviation of
.
Fractal dimension characterizes the space filling capacity of a pattern that changes with the scale at which it is measured [
33]. Herein, two approaches are used as Petrosian Fractal Dimension (PFD) and Higuchi Fractal Dimension (HFD). PFD is calculated as:
where
N is the length of the signal and
is the number of sign changes in the signal derivative [
30].
In terms of HFD, firstly
k new series are constructed from the original signal
by
, where
m = 1, 2, …,
k. Secondly the length
for each new series is calculated as:
and the average length
. After
repetitions, a least-squares method is used to obtain the best slope that fits the curve of
versus
, which is defined as the Higuchi Fractal Dimension. For details, please refer to [
34].
Fisher Information (FI) measures the expected value of the observed information [
35]. Its mathematical expression using normalized singular spectrum is:
where
is the normalized value through
, and
M is the number of singular value.
Approximate Entropy (ApEn) quantifies the amount of regularity and the unpredictability of fluctuations of a signal [
36], which is computed in the following procedures:
- (1)
Set the input as .
- (2)
Construct the subsequence for , where m is the subsequence length.
- (3)
Construct a set of subsequences , where is defined in Step (2).
- (4)
For each , , where .
- (5)
Hurst Exponent (HST) measures the long-term memory of a signal. It is used to quantify the relative tendency of the signal either to regress to the mean or to cluster in a direction [
37]. For time series
, its accumulated deviation within range
T is calculated as
, where
,
. Then:
The slope of versus for is defined as the Hurst Exponent.
In summary, abbreviations of the complex features extracted from information domain are listed in
Table 3.
3.2. Feature Selection
Feature extraction guarantees a wide coverage of the object descriptions from various aspects while feature selection ensures that a set of most salient descriptions can be utilized. For large-scale models, feature selection is of utter importance in computation reduction and efficiency improvement.
The distance evaluation technique ranks the feature importance independent of the model used for classification, which belongs to the filter category as mentioned in the Introduction. Salient features result in minimum inner-class distances of the same class while have maximum margins for different classes. It has been widely used in fault diagnosis of rotating machinery [
20,
21,
38]. Suppose a feature set has
K conditions,
, where
is the
jth eigenvalue of the
ith sample under the
kth condition,
is the sample number of the
kth condition, and
J is the feature number of each sample. Totally
features are obtained in the feature set
. Herein, a modified distance evaluation algorithm is presented as follows:
- (1)
Calculate the average distance of the same condition samples:
then obtain the average distance of
K conditions:
- (2)
Calculate the average eigenvalue of all samples under the same condition:
then obtain the average distance between condition samples:
- (3)
Calculate the variance factor of
as:
- (4)
Calculate the compensation factor as:
- (5)
Calculate the ratio
and
considering the compensation factor:
then normalize
and obtaining the feature importance criteria:
A higher
indicates that the corresponding feature
j has greater importance. Features can be ranked in terms of the
values in Equation (15) in descending order. This algorithm is referred to as Modified Distance Evaluation algorithm (MDE). Although the top ranked features have superior discriminative capability, they may suffer from high multi-collinearity, which refers to the non-independence among features [
39]. Herein, the variance inflation factor (VIF) is used to avoid high collinearity. Assuming a training sample set
X with
J features
and class
Y, the VIF of feature
j is calculated as:
where
is the R-squared value of the regression equation
, in which
contains all features except
. An improved algorithm combining MDE and VIF is presented in Algorithm 1 and is abbreviated as MDV (Modified Distance evaluation and variance inflation Factor).
| Algorithm 1: MDV Algorithm. |
- (1)
Set the selected future subset Fsub = , j = 1; - (2)
Rank the J features in terms of the defined in Equation (15) in descending order. Set Fr to represent the index list of the ranked features. Add the first feature in Fr to Fsub, j = j + 1; - (3)
while j < J : calculate the VIFj of the jth feature in Fr with the features in Fsub; if VIFj < 10: add the jth feature in Fr to Fsub; end j = j + 1; end
|
The MDV algorithm describes the feature-subset selection for multi-class classification based on the filter method with the MDE and VIF. The threshold of 10 in MDV is an empirical value. A larger threshold will result in a higher correlation of the selected feature in F
r with the existing features in F
sub [
23].
5. Results and Discussion
5.1. General Flight State Identification
The first data set with a relatively low resolution of 16 flight states is used to evaluate the performance of six feature selection methods, which include Univariate Feature Selection based on mutual information (UFS_m), Support Vector Machine with L1 regularization (SVM_L1), Gradient Boosted Decision Tree (GBDT) and Stability selection (STAB), Modified Distance Evaluation (MDE), and our proposed filter method Modified Distance Evaluation with Variance Inflation Factor (MDV). Feature rankings are obtained and the top 10 features for different methods are listed in
Table 5 and their detailed expressions are listed in
Appendix A.
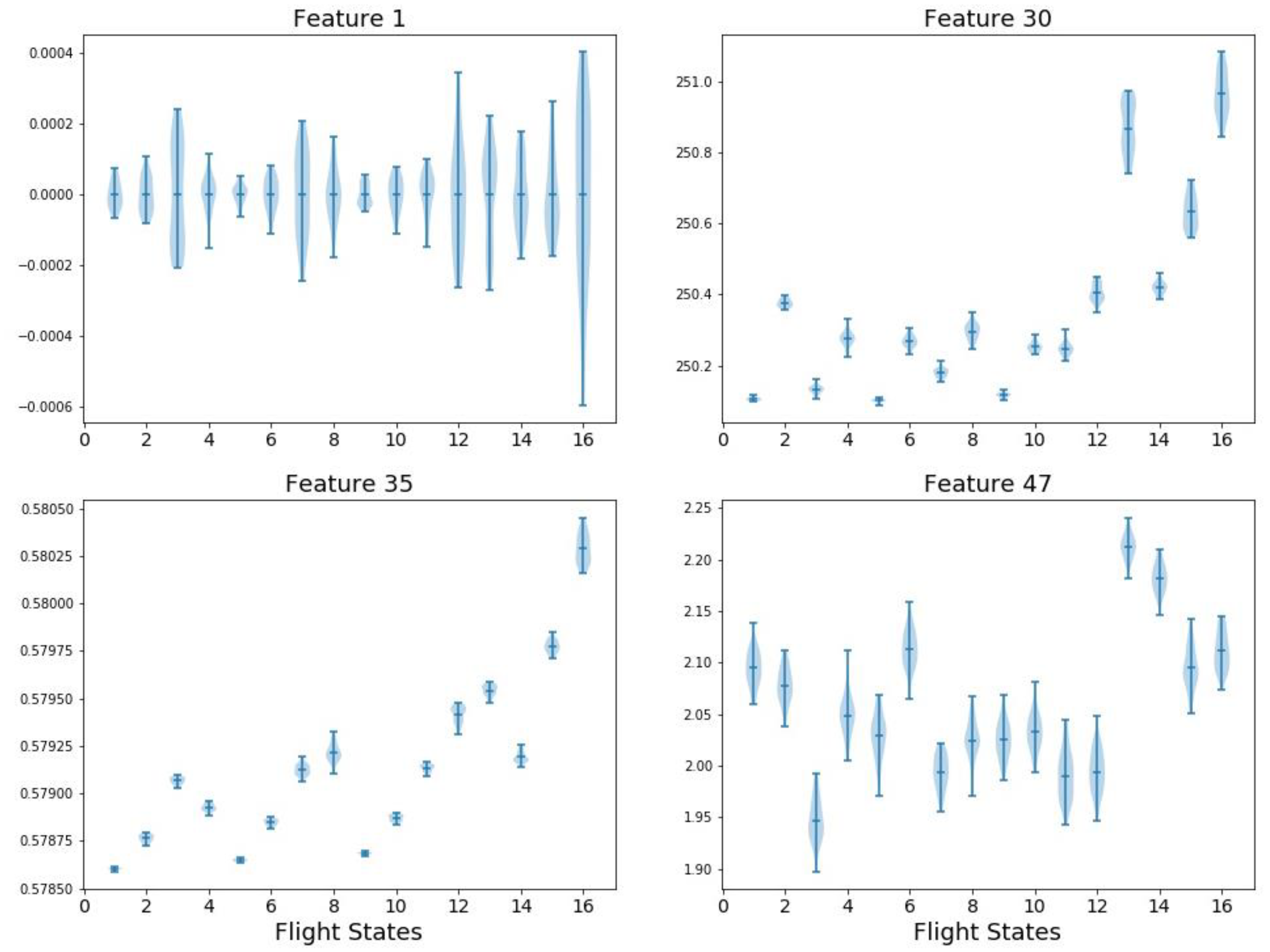
It is observed from the table that the ranking results vary with the different methods. An intuitive evaluation is to simply visualize the features distribution under various flight states. For example, four features are plotted in
Figure 5 including: F1 (mean value in time domain), F29 (spectrum kurtosis in frequency domain), F35 (spectrum power convergence in frequency domain), and F47 (Hurst Exponent in information domain). The
x axis denotes the 16 flight states while the
y axis is the feature value before normalization. The shaded area along each vertical line segment represents the feature distribution in a single flight state and each subplot of
Figure 5 describes a feature distribution on 16 flight states. As mentioned in
Section 3, F1 (mean value) has no effects in classification. Correspondingly, F1 has the highest overlap among flight states. Similarly, F47 has large overlaps which exhibits pool classification capability. Theoretically, the ranking of F1 and F47 should be low but they are ranked high in GBDT and STAB. In comparison, F30 and F35 show smaller overlap and thus have better classification performance. This may provide some physical insights of the effectiveness of different feature selection methods.
The last column MDV in
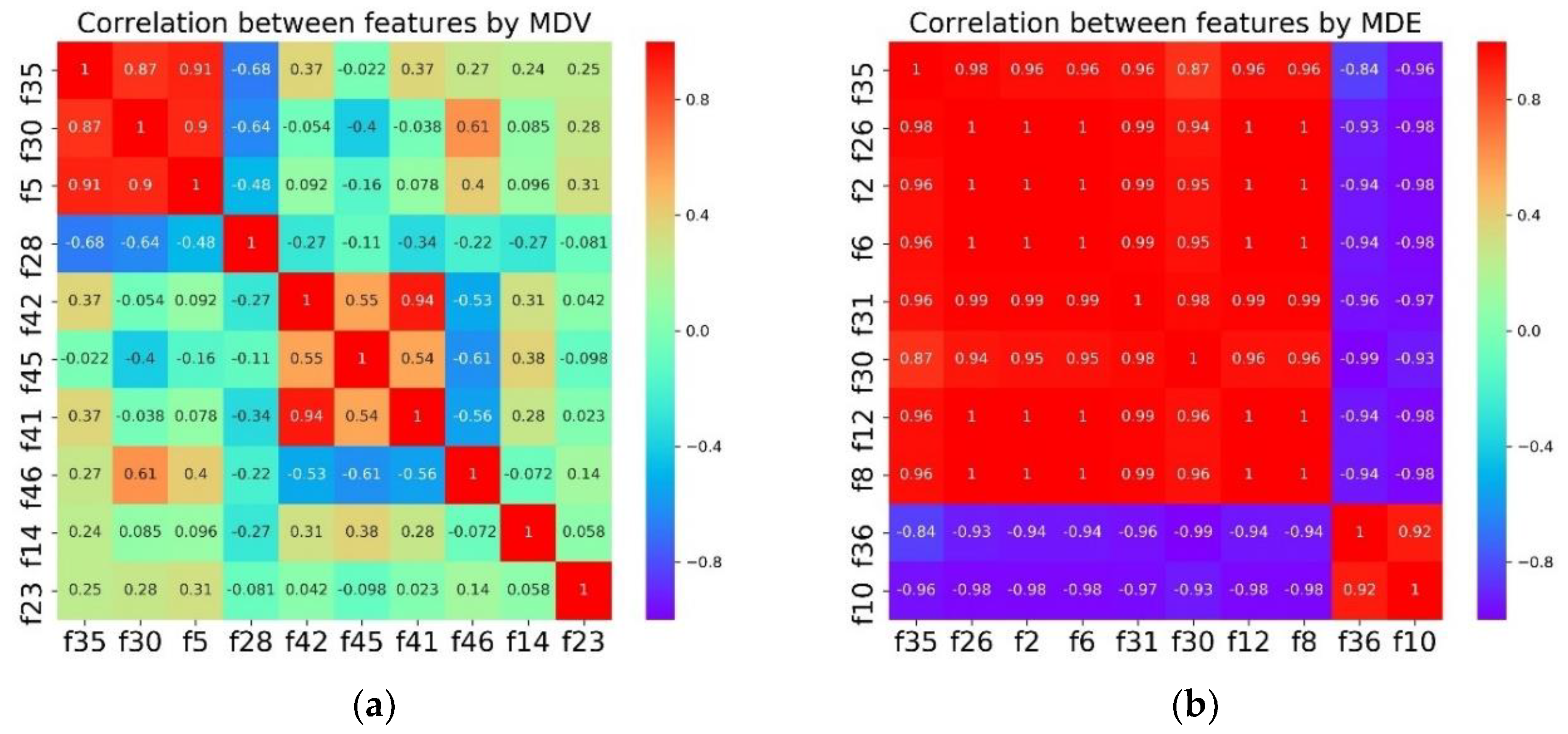
Table 4 is an improvement of MDE for preventing high collinearity. To examine the effects of the proposed algorithm, Correlation analysis is conducted for MDV and MDE as shown in
Figure 6.
It is obvious that the top 10 features selected by MDE are highly correlated with each other. In comparison, the overall collinearity of the features in MDV is much lower except for the small region of the top three.
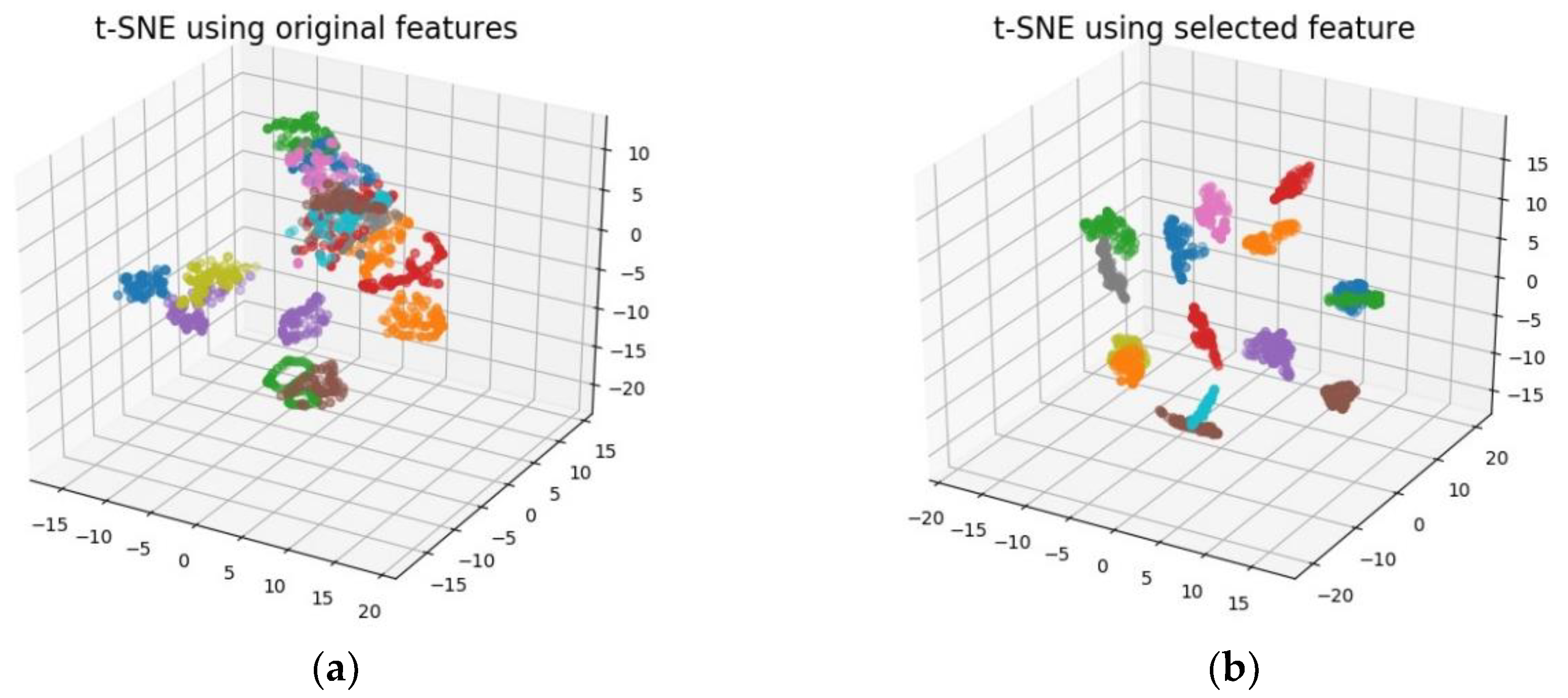
To visualize the feature selection performance by MDV, t-Distributed Stochastic Neighbor Embedding (t-SNE) is employed which is a relatively new method of dimension reduction particularly suitable for non-linear and high-dimensional datasets. It is a kind of manifold learning technique by mapping to probability distributions through affine transformation. For detailed algorithm, please refer to [
45]. The 3D visualization by t-SNE is shown in
Figure 7. The left figure is the visualization using the entire feature pool while the right figure uses only top six features obtained by MDV. It can be seen that the feature subset through MDV selection exhibits better classification effects compared to the entire feature pool.
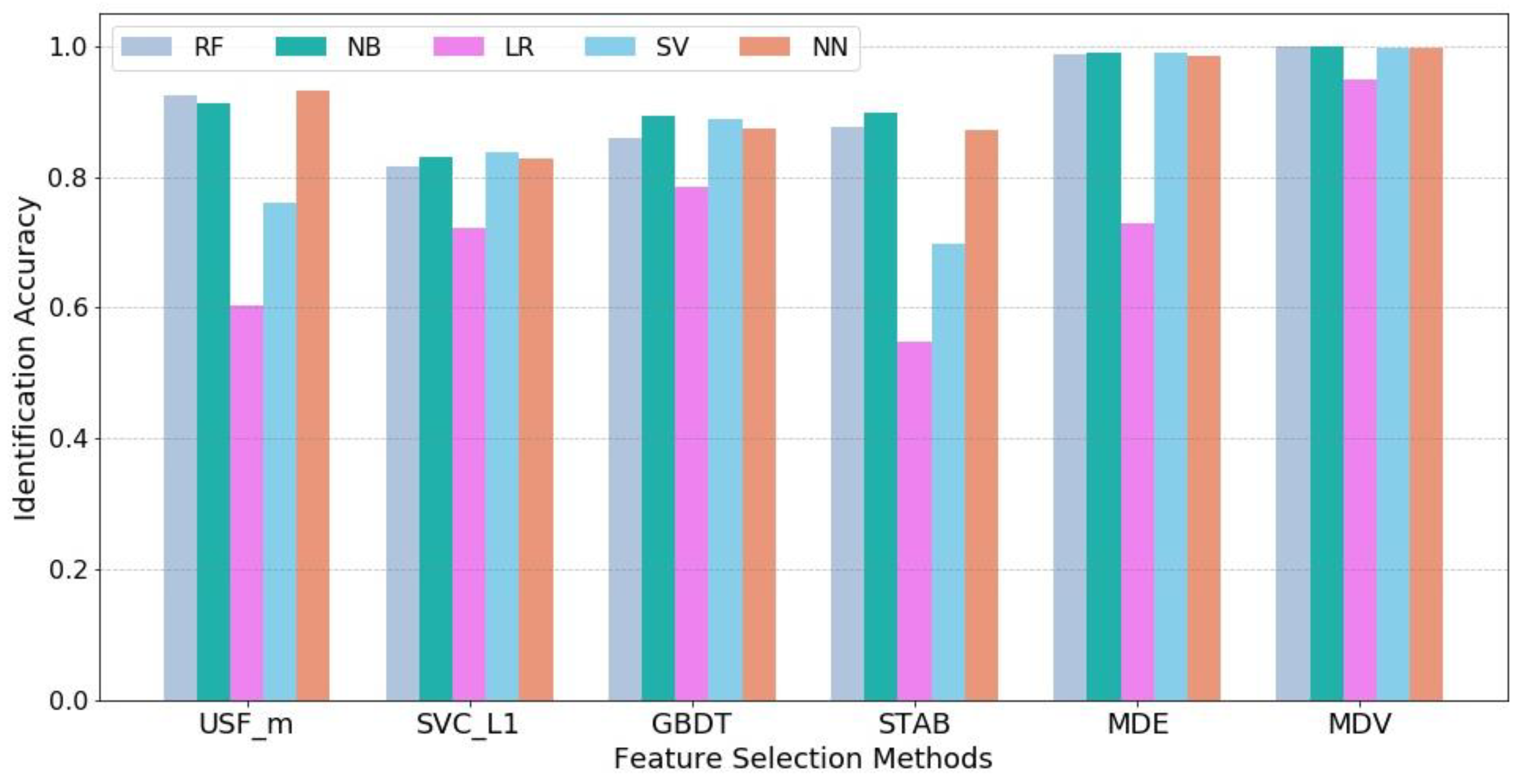
Further, machine learning techniques are used to quantify the flight state identification process. For each feature selection method, the most salient 6 features are obtained as model inputs and the 16 flight states are set as model outputs. Five supervised learning models are employed including Logistic Regression (LR), Support Vector Machine (SVM), Naïve Bayes (NB), Random Forest (RF), and Neural Network (NN). Cross-validation is used in each model and the average accuracy value of five tests is computed to reduce the unbalance influence between training and testing samples. It should be noted that since the objective of the case study is to compare the effects of different feature selection methods instead of obtaining the optimized parameter setting for each machine learning model to achieve the highest accuracy level, default parameter settings in Python scikit-learn package for LR, SVM, NB and RF are used and remain the same for all feature selection methods while for NN, the parameter setting is as follows: {hidden layer size = 20, solver = ‘lbfgs’, activation function = ’relu’, learning rate = 0.001, maximum iteration = 100}. The identification results are shown in
Figure 8.
It can be observed that our proposed method MDV achieves the highest identification accuracy in all five machine learning models and particularly, there is a significant improvement in Logistic Regression. This demonstrates the superior effectiveness of MDV. The comparison between MDV and MDE shows that a group of individually powerful features with low collinearity can lead to better results.
5.2. Stall Detection and Alerting
So far, the developed MDV algorithm has achieved the best performance in feature selection and the final flight state identification accuracy is up to 100%. Herein, the second dataset with higher resolution is used for the application of stall detection and alerting. Similarly, totally 47 features as discussed in
Section 3 are extracted and the most salient 6 features are selected by MDV as model inputs. A neural network is employed with the same parameter settings as the first case. The split rule is 80% samples for training and 20% samples for testing.
The classification report is shown in
Table 6 including three criteria: Precision, Recall and F1-score. Precision is the ratio of correctly predicted positive observations to the total predicted positive observations while Recall is the ratio of correctly predicted positive observations to the all observations in the actual class. F1-Score is the weighted average of Precision and Recall: F1-Score = 2 * (Recall * Precision)/(Recall + Precision) [
46]. Safe, Alert, and Stall regions are divided with corresponding flight states. The overall identification accuracy is 98%.
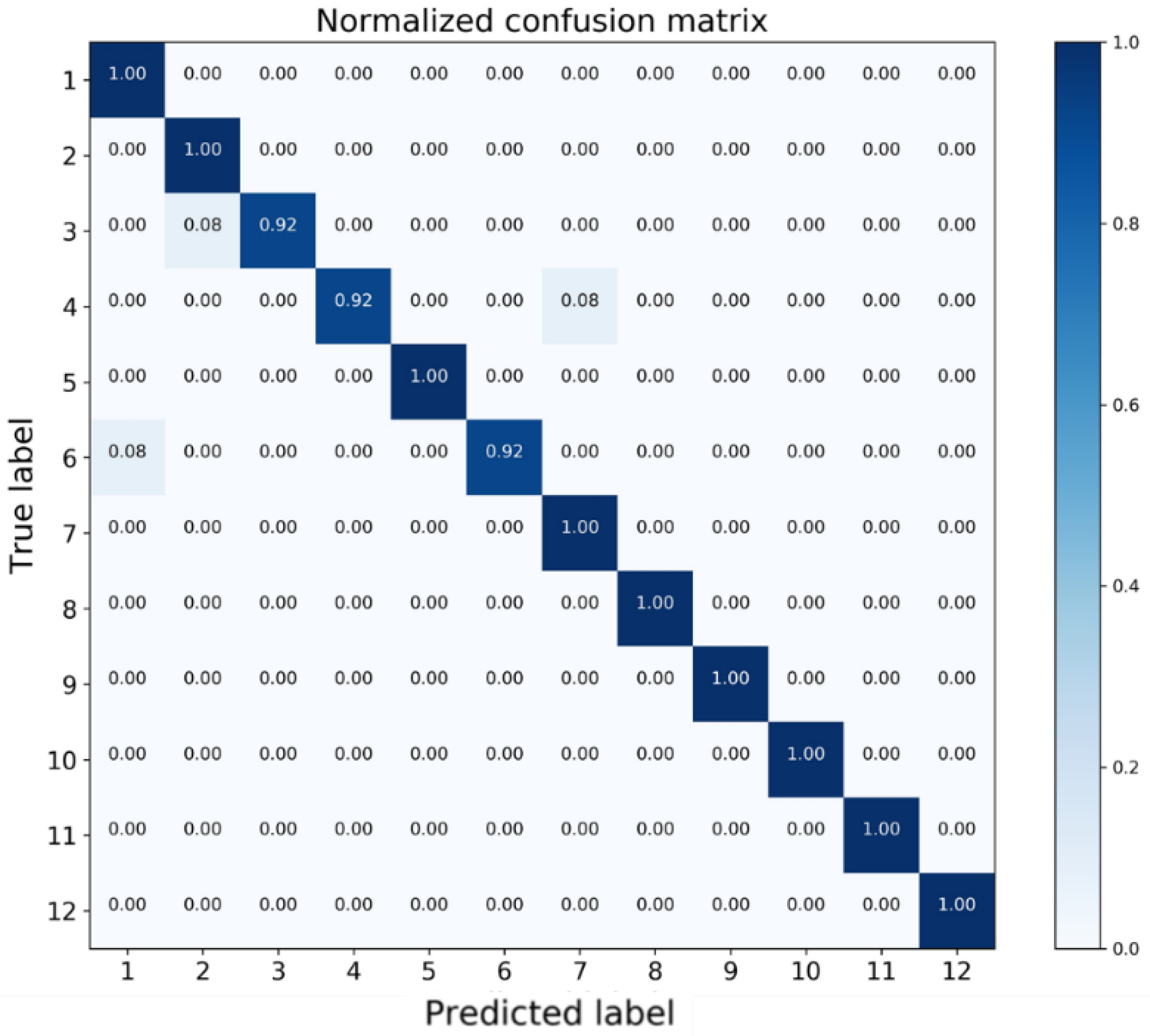
To facilitate detailed analysis, a normalized confusion matrix is presented in
Figure 9. Each row of the matrix represents the test samples in a true class label while each column indicates the samples in a predicted class label [
47]. As can be observed from
Table 6, for stall states (ID: 9, 10, 11, 12), Recall values all equal to 100%, meaning that all the critical states can be successfully identified and there is no safety risk.
In terms of alert states (ID: 5, 6, 7, 8), Recall value of State 6 is 0.92, which means 92% samples in State 6 are correctly predicted. By examining the 6th row in the confusion matrix, the rest 8% samples are misclassified as State 1, which is in the safe region. This situation may lead to dangerous results since the wing is already in the alert states yet there is no warning. From the other perspective, the precision value of State 7 is 0.92, which indicates that among all samples predicted as State 7, there are 8% samples actually belonging to State 4 as shown in the 7th column of the confusion matrix. This value can be interpreted as the false-alarm ratio that the wing flying in the safe region yet receives a false alert.
For safe states (ID: 1, 2, 3, 4), the misclassified samples are for State 3 and State 4, in which 8% samples of State 3 are predicted as State 2 while 8% samples of State 4 are identified as State 7, which is the false alarm.
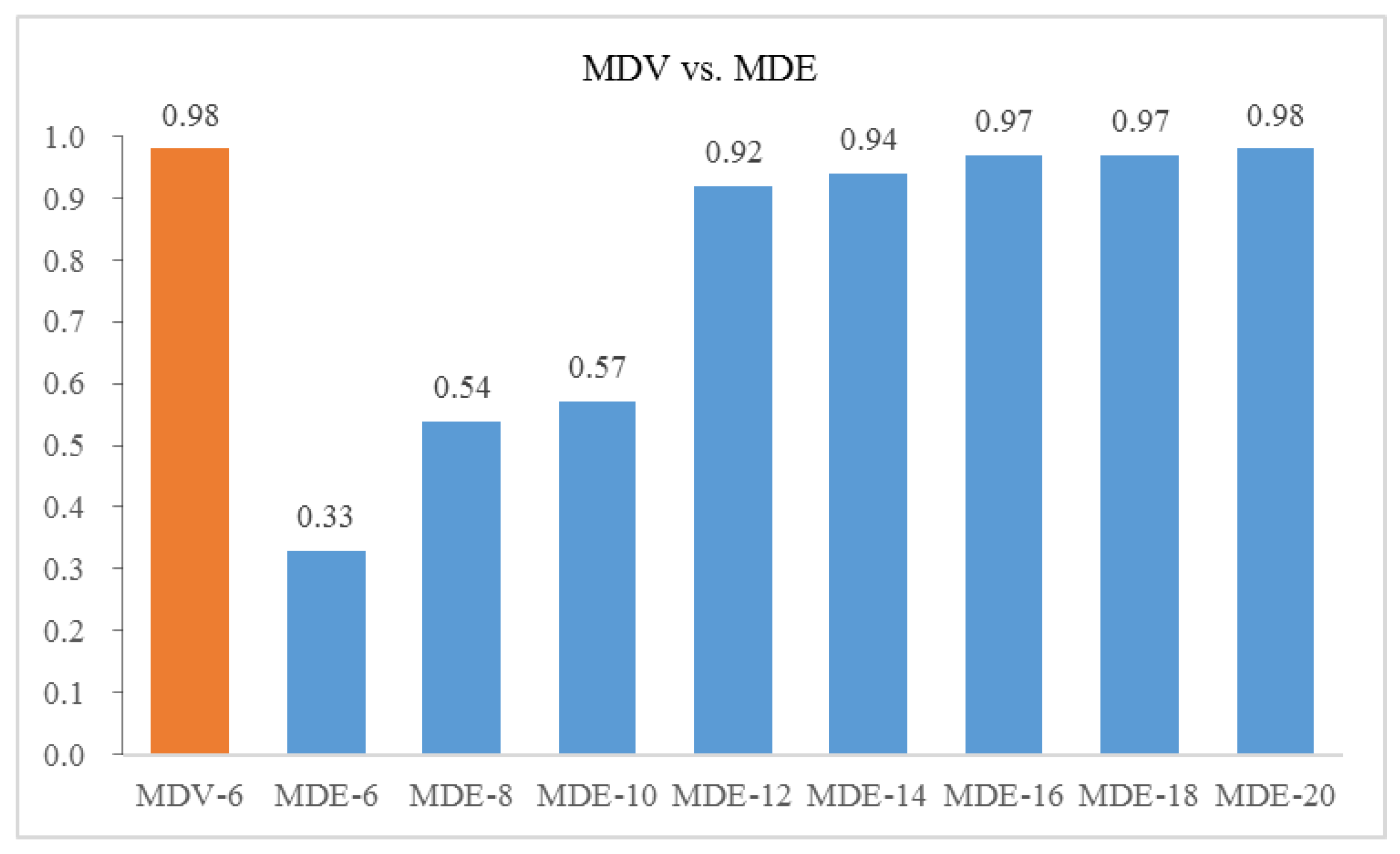
Further, we select the different number of features from the modified distance evaluation (MDE) method and use the same neural network structure for training and testing. The comparison on the overall identification accuracy between MDV and various MDE is shown in
Figure 10. The
x axis denotes number of top ranked features selected.
It can be seen that if we use the same number of input as MDV, features selected by MDE lead to a pool result of 0.33. The identification accuracy reaches the same level as MDV until the number of top ranked features selected from MDE increases to 20. This shows that our proposed method MDV is able to address the collinearity problem and uses fewer features to achieve superior performance with a considerable model complexity reduction.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









