Using Sleep Time Data from Wearable Sensors for Early Detection of Migraine Attacks



Abstract
1. Introduction
- Is it possible to recognize a migraine attack beforehand using wearable sensors?
- Should the recognition be based on personal or user-independent prediction models?
2. Related Work
3. Data Set and Feature Extraction
3.1. Collected Data Set
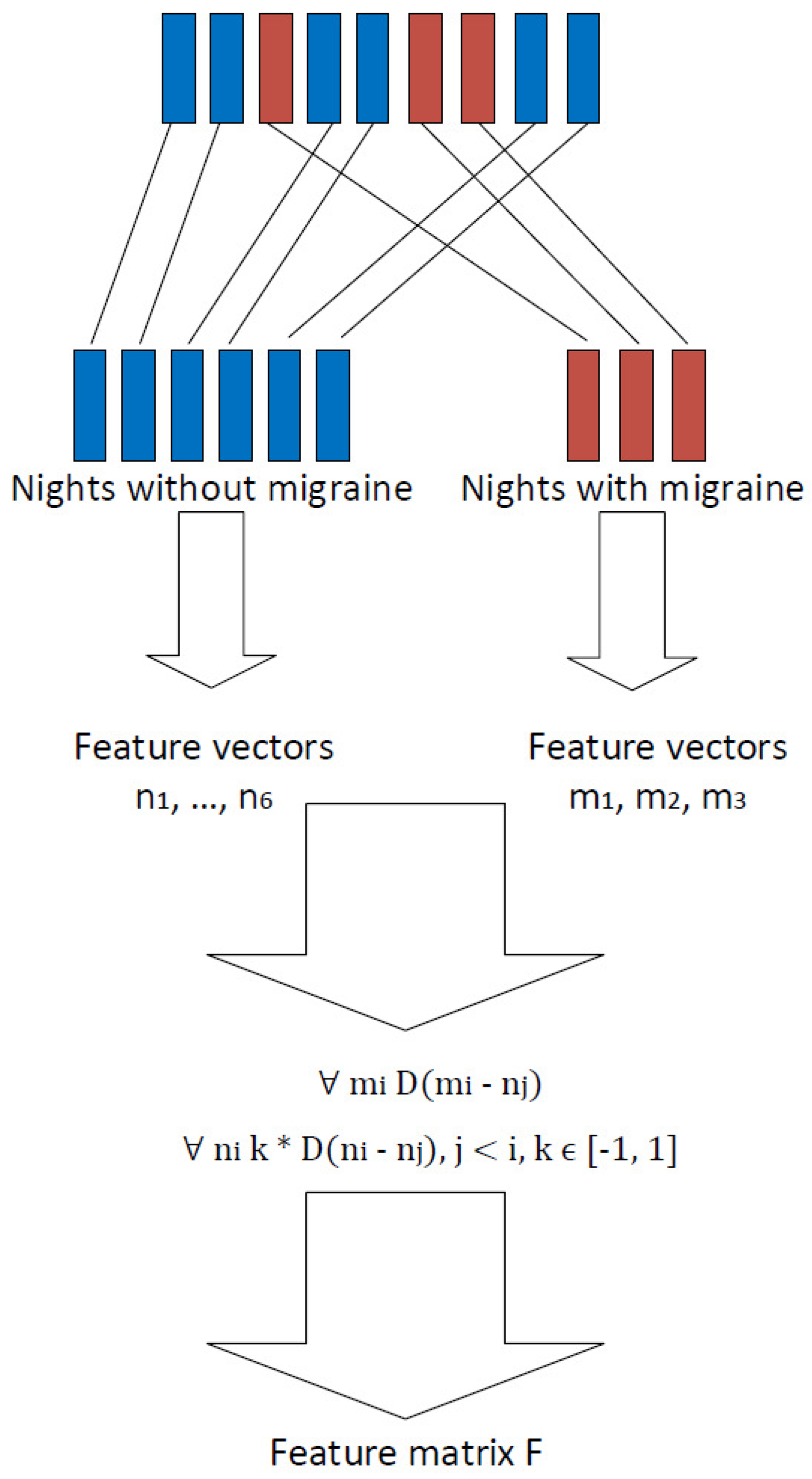
3.2. Studying Sleep Time Data and Increasing the Number of Data Points
| Algorithm 1: Algorithm to calculate night comparison features. Feature vectors are extracted from nights before a non-migraine day and vectors from nights before a migraine day. |
| input: Feature vectors output: Night comparison feature matrix F, labels L counter = 1;  return feature matrix F, labels L; |
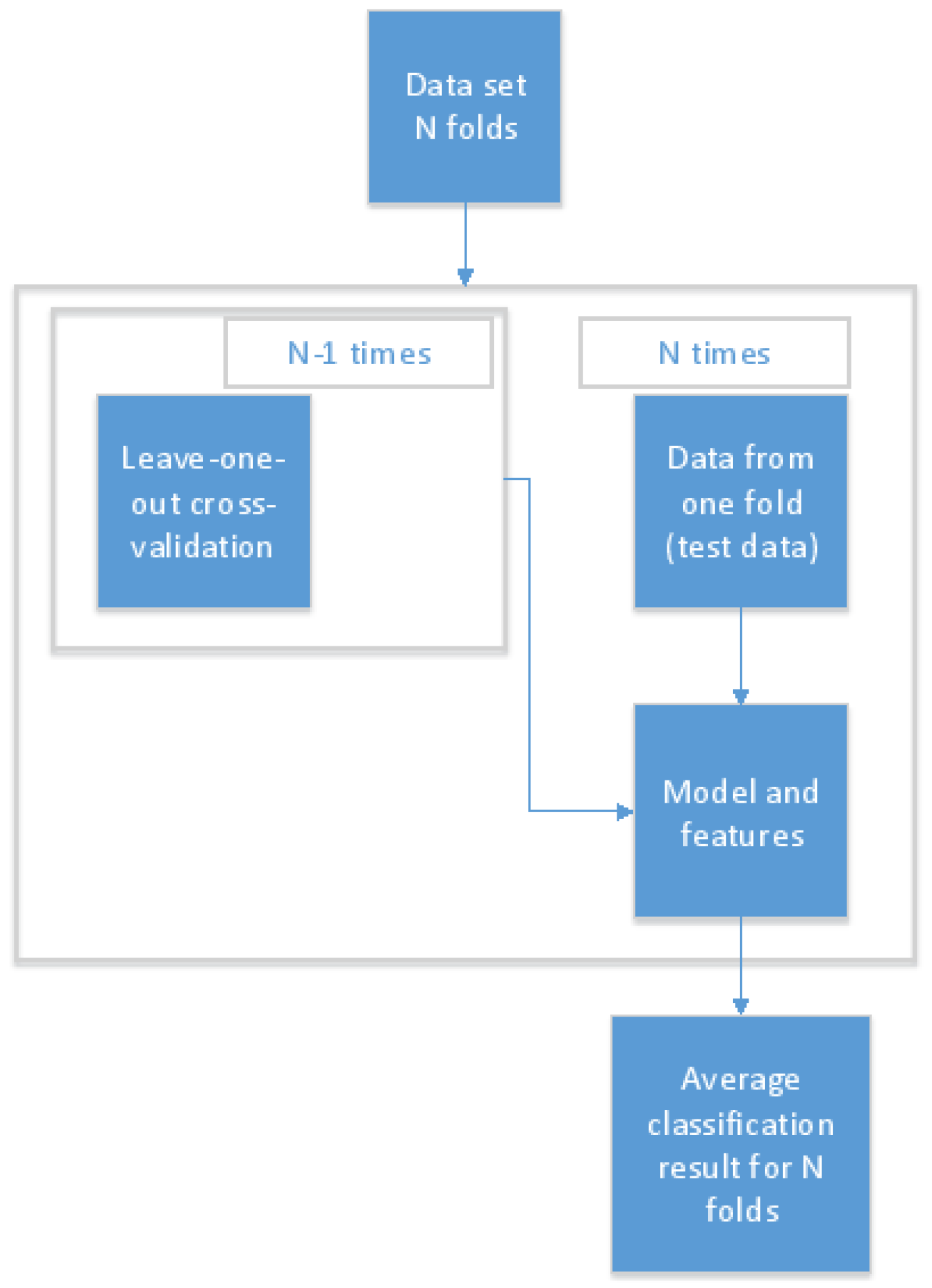
4. Early Recognition of Migraine Attacks Using Biosignals
5. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goadsby, P.J.; Lipton, R.B.; Ferrari, M.D. Migraine—Current understanding and treatment. N. Engl. J. Med. 2002, 346, 257–270. [Google Scholar] [CrossRef] [PubMed]
- Olesen, J.; Tfelt-Hansen, P.; Welch, K. The Headaches; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2000. [Google Scholar]
- Headache Classification Committee of the International Headache Society. Classification and diagnostic criteria for headache disorders, cranial neuralgias and facial pain. Cephalalgia 1998, 8, 1–96. [Google Scholar]
- Steiner, T.J.; Stovner, L.J.; Vos, T.; Jensen, R.; Katsarava, Z. Migraine is first cause of disability in under 50 s: Will health politicians now take notice? J. Headache Pain 2018, 19. [Google Scholar] [CrossRef] [PubMed]
- Stovner, L.; Zwart, J.A.; Hagen, K.; Terwindt, G.; Pascual, J. Epidemiology of headache in Europe. Eur. J. Neurol. 2006, 13, 333–345. [Google Scholar] [CrossRef] [PubMed]
- Linde, M.; Gustavsson, A.; Stovner, L.J.; Steiner, T.J.; Barré, J.; Katsarava, Z.; Lainez, J.M.; Lampl, C.; Lantéri-Minet, M.; Rastenyte, D.; et al. The cost of headache disorders in Europe: the Eurolight project. Eur. J. Neurol. 2012, 19, 703–711. [Google Scholar] [CrossRef] [PubMed]
- Blau, J.N. Migraine: Theories of pathogenesis. Lancet Neurol. 1992, 339, 1202–1207. [Google Scholar] [CrossRef]
- Headache Classification Committee of the International Headache Society. The international classification of headache disorders, (beta version). Cephalalgia 2013, 33, 629–808. [Google Scholar]
- Usai, S.; Grazzi, L.; Andrasik, F.; Bussone, G. An innovative approach for migraine prevention in young age: A preliminary study. Neurol. Sci. 2010, 31, 181–183. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Huttunen, H.L.; Halonen, R.; Koskimäki, H. Exploring Use of Wearable Sensors to Identify Early Symptoms of Migraine Attack. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 500–505. [Google Scholar]
- Borazio, M.; Van Laerhoven, K. Combining Wearable and Environmental Sensing into an Unobtrusive Tool for Long-term Sleep Studies. In Proceedings of the 2Nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 71–80. [Google Scholar]
- Reimer, U.; Emmenegger, S.; Maier, E.; Zhang, Z.; Khatami, R. Recognizing Sleep Stages with Wearable Sensors in Everyday Settings. In Proceedings of the 3rd International Conference on Information and Communication Technologies for Ageing Well and e-Health, Porto, Portugal, 28–29 April 2017; pp. 172–179. [Google Scholar]
- Jennum, P.; Jensen, R. Sleep and headache. Sleep Med. Rev. 2002, 6, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Fujiwara, K.; Miyajima, M.; Yamakawa, T.; Abe, E.; Suzuki, Y.; Sawada, Y.; Kano, M.; Maehara, T.; Ohta, K.; Sasai-Sakuma, T.; et al. Epileptic Seizure Prediction Based on Multivariate Statistical Process Control of Heart Rate Variability Features. IEEE Trans. Biomed. Eng. 2016, 63, 1321–1332. [Google Scholar] [CrossRef] [PubMed]
- Kropp, P.; Gerber, W.D. Prediction of migraine attacks using a slow cortical potential, the contingent negative variation. Neurosci. Lett. 1998, 257, 73–76. [Google Scholar] [CrossRef]
- Cao, Z.H.; Ko, L.W.; Lai, K.L.; Huang, S.B.; Wang, S.J.; Lin, C.T. Classification of Migraine Stages based on Resting-State EEG Power. In Proceedings of the IJCNN International Joint Conference on Neural Networks, Killarney, UK, 12–17 July 2015; Volume 4, pp. 973–980. [Google Scholar]
- Pagán, J.; Orbe, D.; Irene, M.; Gago, A.; Sobrado, M.; Risco-Martín, J.L.; Ayala, J.L. Robust and Accurate Modeling Approaches for Migraine Per-Patient Prediction from Ambulatory Data. Sensors 2015, 15, 15419–15442. [Google Scholar] [CrossRef] [PubMed]
- Pagán, J.; Risco-Martín, J.L.; Moya, J.M.; Ayala, J.L. Grammatical Evolutionary Techniques for Prompt Migraine Prediction. In Proceedings of the 2016 on Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; pp. 973–980. [Google Scholar]
- Empatica E4. Available online: https://www.empatica.com/research/e4/ (accessed on 3 December 2017).
- Mönttinen, H.; Koskimäki, H.; Siirtola, P.; Röning, J. Electrodermal activity asymmetry in sleep-a case study for migraine detection. In EMBEC & NBC 2017; Springer: Singapore, 2017. [Google Scholar]
- Empatica. What Should I Know to Use the PPG/IBI Data in my Experiment? Available online: https://support.empatica.com/hc/en-us/articles/203621335-What-should-I-know-to-use-the-PPG-IBI-data-in-my- experiment- (accessed on 6 September 2017).
- Koskimäki, H.; Mönttinen, H.; Siirtola, P.; Huttunen, H.L.; Halonen, R.; Röning, J. Early Detection of Migraine Attacks Based on Wearable Sensors: Experiences of Data Collection Using Empatica E4. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; pp. 506–511. [Google Scholar]
- Camm, A.J.; Malik, M.; Bigger, J.; Breithardt, G.; Cerutti, S.; Cohen, R.J.; Coumel, P.; Fallen, E.L.; Kennedy, H.L.; Kleiger, R.; et al. Heart rate variability. Standards of measurement, physiological interpretation, and clinical use. Eur. Heart J. 1996, 17, 354–381. [Google Scholar]
- Hand, D.J.; Mannila, H.; Smyth, P. Principles of Data Mining; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Siirtola, P.; Koskimäki, H.; Röning, J. Personal models for eHealth—Improving user-dependent human activity recognition models using noise injection. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar]
- Devijver, P.A.; Kittler, J. Pattern Recognition: A Statistical Approach; Prentice Hall: London, UK, 1982. [Google Scholar]
- Koskimäki, H. Avoiding Bias in Classification Accuracy—A Case Study for Activity Recognition. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015; pp. 301–306. [Google Scholar]



{kind=link}
{kind=link}
| Study Subject | Age | Gender | BMI | Aura Symptoms | Type of Medication |
|---|---|---|---|---|---|
| 1 | 30 | male | 21.7 | yes | preventive |
| 2 | 60 | female | 22.0 | no | acute |
| 3 | 32 | female | 39.1 | no | preventive |
| 4 | 47 | female | 22.4 | no | acute |
| 5 | 46 | female | 23.7 | no | acute |
| 6 | 47 | male | 23.6 | yes | acute |
| 7 | 48 | female | 29.0 | no | acute |
| Study Subject | Trial Duration (Days) | Migraine Days | Number of Observations |
|---|---|---|---|
| 1 | 29 | 17 | 270 |
| 2 | 32 | 5 | 455 |
| 3 | 24 | 7 | 223 |
| 4 | 25 | 8 | 248 |
| 5 | 27 | 6 | 310 |
| 6 | 28 | 10 | 255 |
| 7 | 35 | 14 | 504 |
| Total | 200 | 67 | 2265 |
| Feature | Signal | Number of Features |
|---|---|---|
| Standard deviation | acc, bvp, temp, hr, eda, hrv | 6 |
| Mean | acc, bvp, temp, hr, eda, hrv | 6 |
| Minimum | acc, bvp, temp, hr | 4 |
| Maximum | acc, bvp, temp, hr, eda | 5 |
| Median | acc, bvp, temp, hr, eda | 5 |
| 5th percentile | acc, bvp, temp, hr, eda | 5 |
| 25th percentile | acc, bvp, temp, hr, eda | 5 |
| 75th percentile | acc, bvp, temp, hr, eda | 5 |
| 95th percentile | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: standard deviation | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: mean | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: maximum | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: minimum | acc, bvp, temp, hr, eda | 4 |
| Comparing first and last hours of sleep: median | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: 5th percentile | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: 25th percentile | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: 75th percentile | acc, bvp, temp, hr, eda | 5 |
| Comparing first and last hours of sleep: 95th percentile | acc, bvp, temp, hr, eda | 5 |
| Correlation between signals | acc, bvp, temp, hr, eda | 14 |
| Root mean square of time difference of adjacent heart beats | hrv | 1 |
| Mean of time difference of adjacent heart beats | hrv | 1 |
| Standard deviation of time difference of adjacent heart beats | hrv | 1 |
| Number of measured heart beats | hrv | 1 |
| The number of pairs of adjacent heart beats whose difference is more than 50 ms | hrv | 1 |
| Total power | hrv | 1 |
| Study Subject | Personal Model (QDA) | User-Independent Model (QDA) | Personal Model (LDA) | User-Independent Model (LDA) |
|---|---|---|---|---|
| 1 | 91.2% (8.1) | 52.6% (2.3) | 75.7% (10.4) | 52.8% (3.1) |
| 2 | 60.4% (13.5) | 48.0% (0.6) | 62.0% (7.4) | 52.5% (4.7) |
| 3 | 95.2% (4.7) | 47.9% (5.5) | 70.3% (7.4) | 43.6% (5.5) |
| 4 | 94.9% (6.9) | 48.5% (5.3) | 70.8% (12.5) | 41.2% (5.4) |
| 5 | 69.6% (15.1) | 36.0% (6.6) | 69.1% (9.0) | 49.1% (2.8) |
| 6 | 95.2% (5.0) | 52.1% (6.2) | 70.3% (8.7) | 55.6% (6.6) |
| 7 | 82.0% (12.6) | 49.9% (2.6) | 74.4% (7.6) | 47.1% (4.7) |
| Mean | 84.1% (15.3) | 47.4% (7.5) | 70.2% (9.8) | 49.1% (7.7) |
| Study Subject | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| 1 | 91.2% (8.1) | 99.6% (2.0) | 90.0% (20.5) |
| 2 | 60.4% (13.5) | 98.1% (2.4) | 30.0% (34.0) |
| 3 | 95.2% (4.7) | 100.0% (0.0) | 85.0% (38.9) |
| 4 | 94.9% (6.9) | 100.0% (0.0) | 95.0% (15.4) |
| 5 | 69.6% (15.1) | 100.0% (0.0) | 42.5% (33.5) |
| 6 | 95.2% (5.0) | 99.5% (2.2) | 85.0% (28.6) |
| 7 | 82.0% (12.6) | 97.8% (3.6) | 73.5% (25.7) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siirtola, P.; Koskimäki, H.; Mönttinen, H.; Röning, J. Using Sleep Time Data from Wearable Sensors for Early Detection of Migraine Attacks. Sensors 2018, 18, 1374. https://doi.org/10.3390/s18051374
Siirtola P, Koskimäki H, Mönttinen H, Röning J. Using Sleep Time Data from Wearable Sensors for Early Detection of Migraine Attacks. Sensors. 2018; 18(5):1374. https://doi.org/10.3390/s18051374
Chicago/Turabian StyleSiirtola, Pekka, Heli Koskimäki, Henna Mönttinen, and Juha Röning. 2018. "Using Sleep Time Data from Wearable Sensors for Early Detection of Migraine Attacks" Sensors 18, no. 5: 1374. https://doi.org/10.3390/s18051374
APA StyleSiirtola, P., Koskimäki, H., Mönttinen, H., & Röning, J. (2018). Using Sleep Time Data from Wearable Sensors for Early Detection of Migraine Attacks. Sensors, 18(5), 1374. https://doi.org/10.3390/s18051374