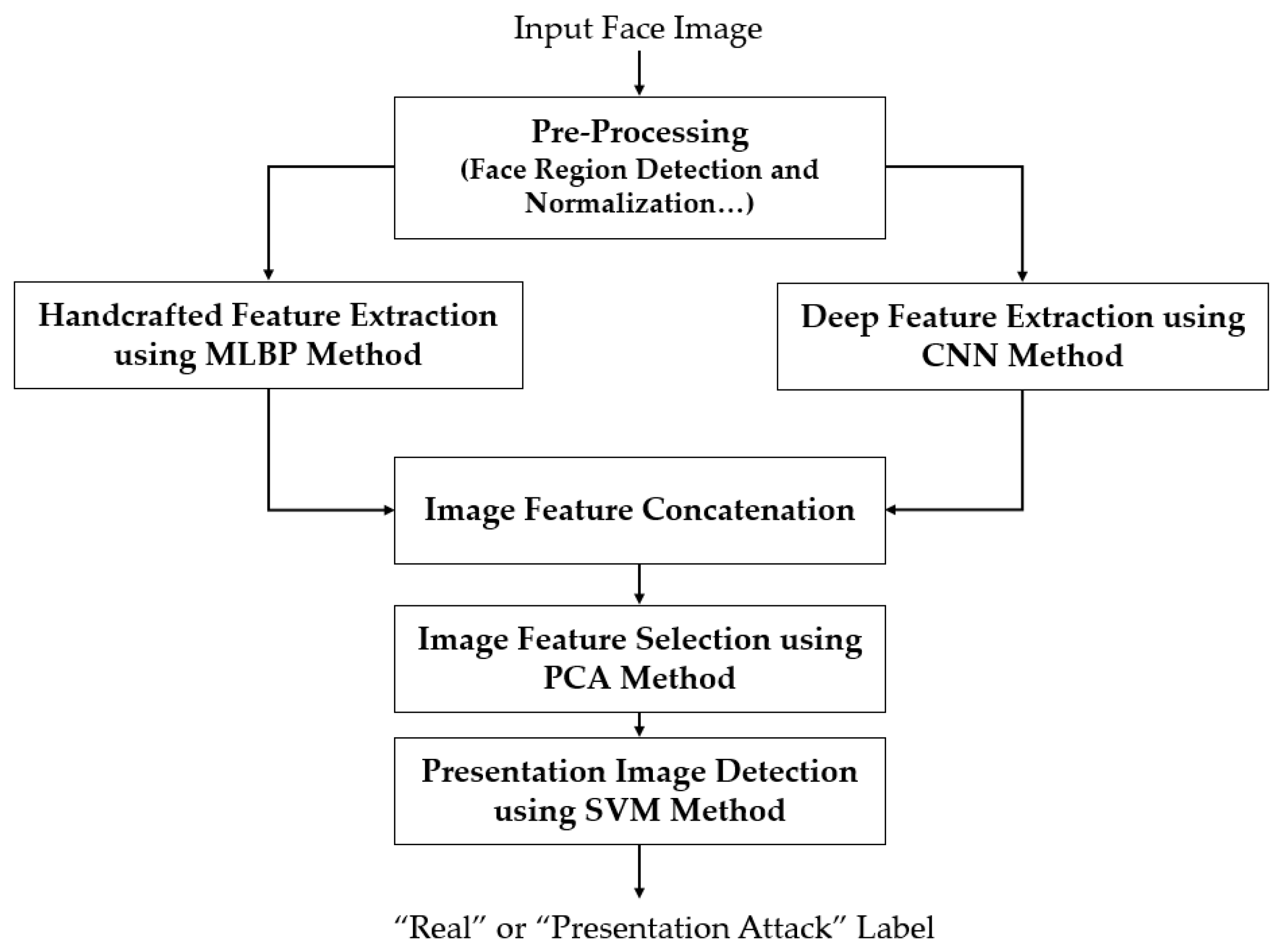
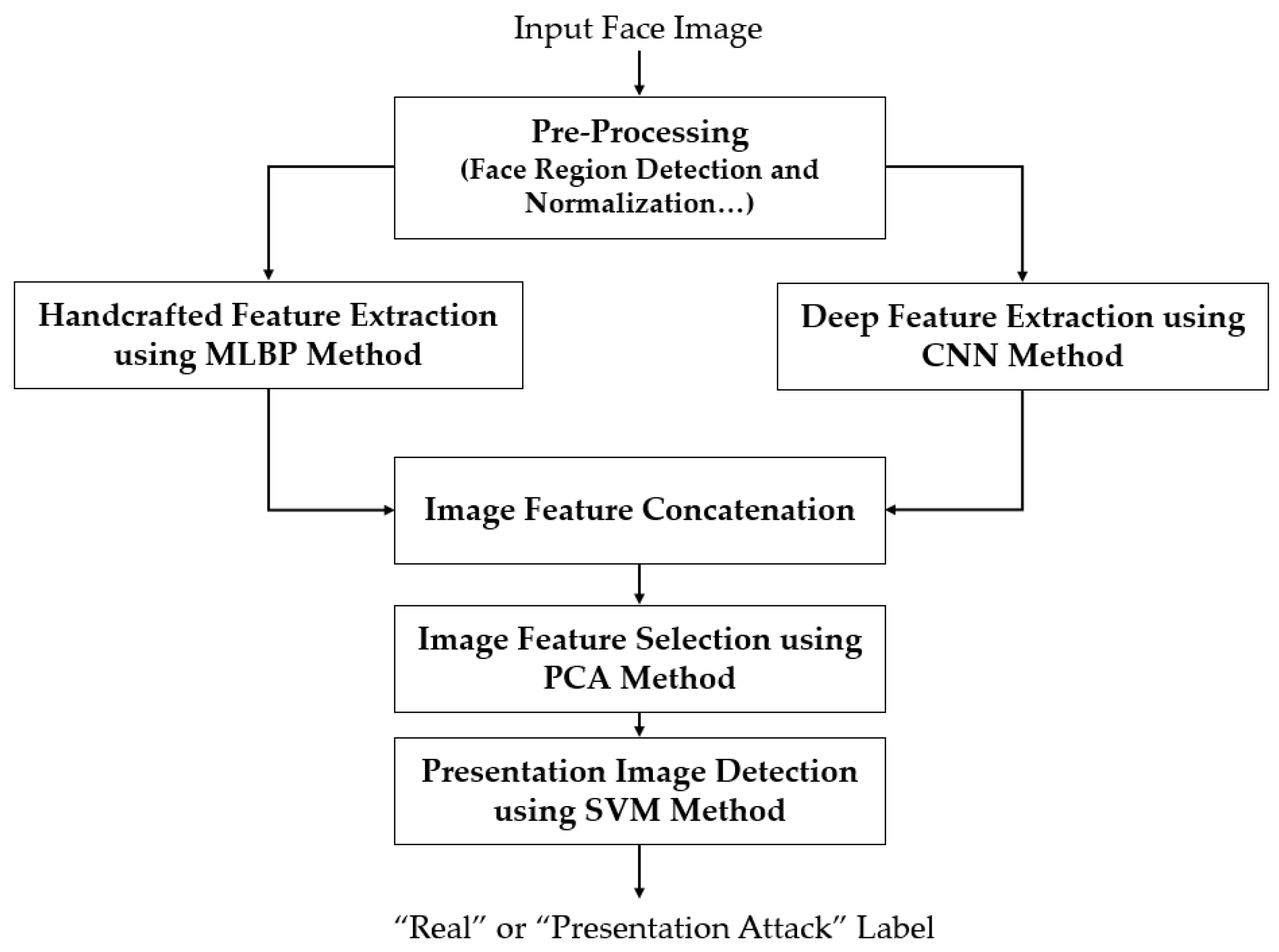
Figure 1.
Flowchart of our proposed PAD method for a face recognition system.
Figure 1.
Flowchart of our proposed PAD method for a face recognition system.
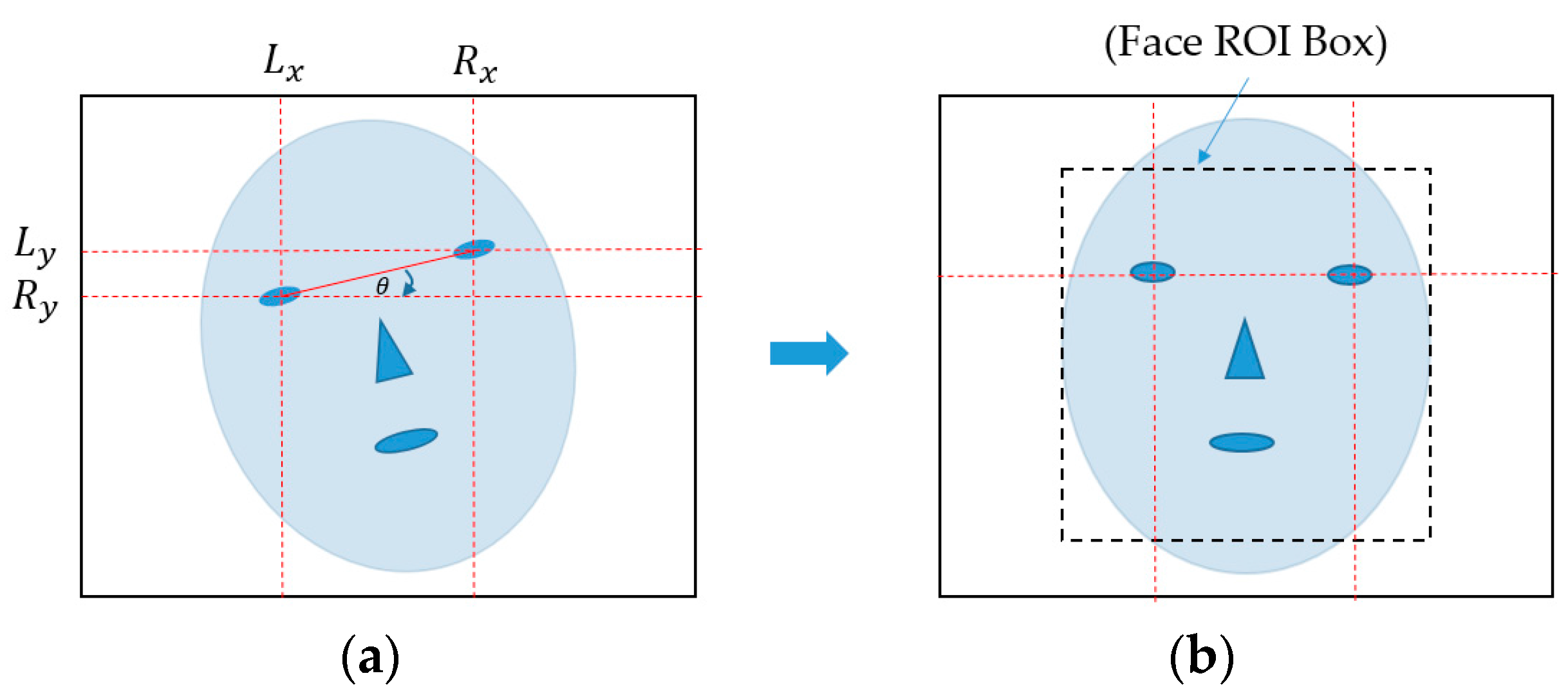
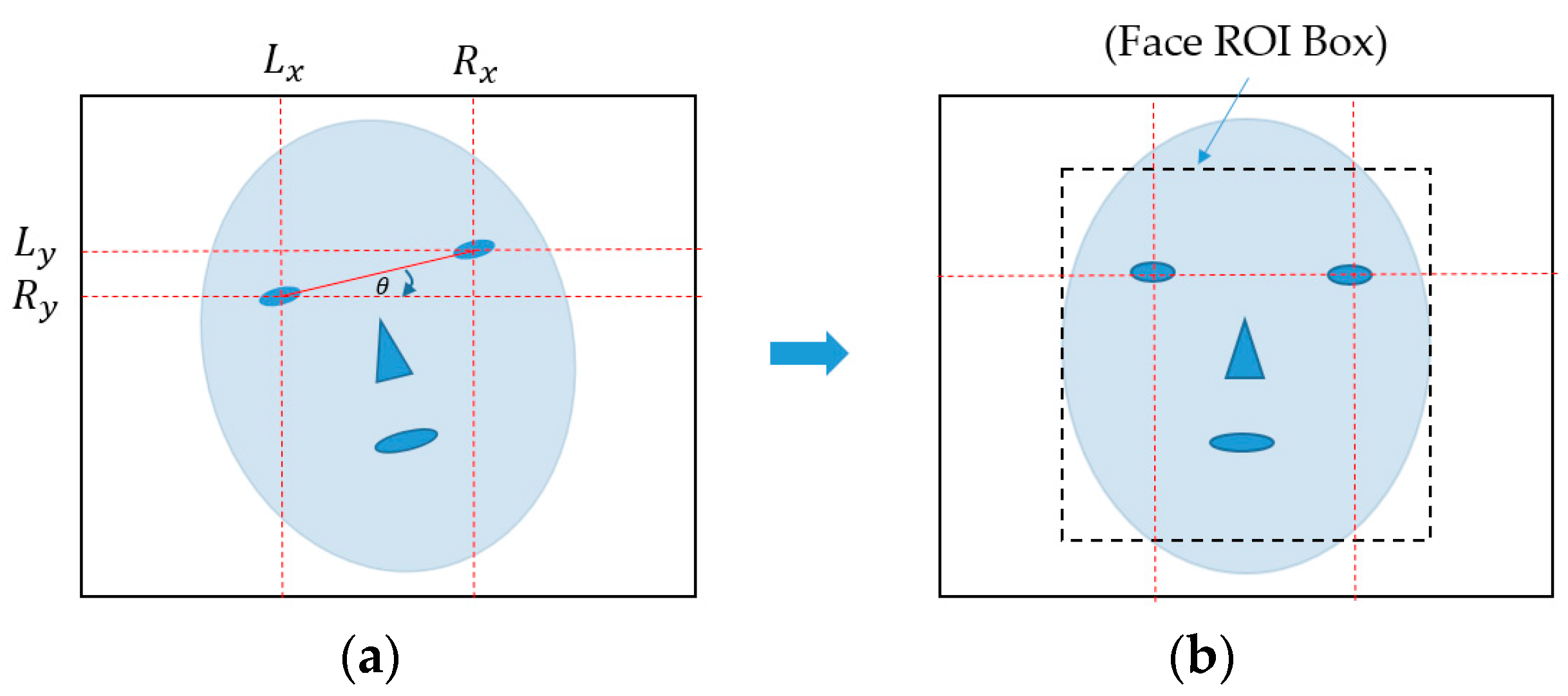
Figure 2.
Description of in-plane rotation compensation and face region localization in our research: (a) input face image with in-plane rotation phenomenon and (b) resultant image of in-plane rotation compensation with localized face region box.
Figure 2.
Description of in-plane rotation compensation and face region localization in our research: (a) input face image with in-plane rotation phenomenon and (b) resultant image of in-plane rotation compensation with localized face region box.
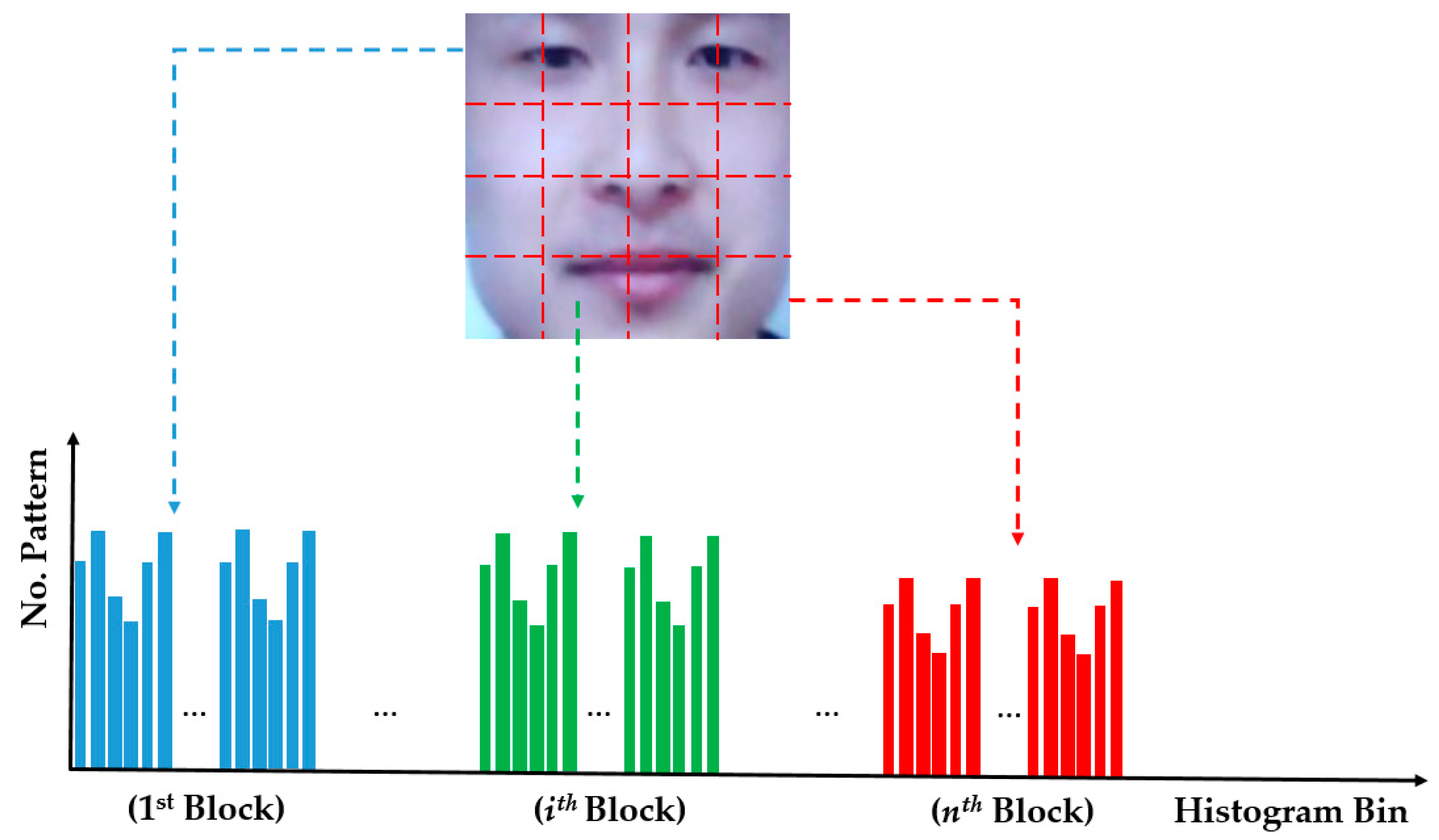
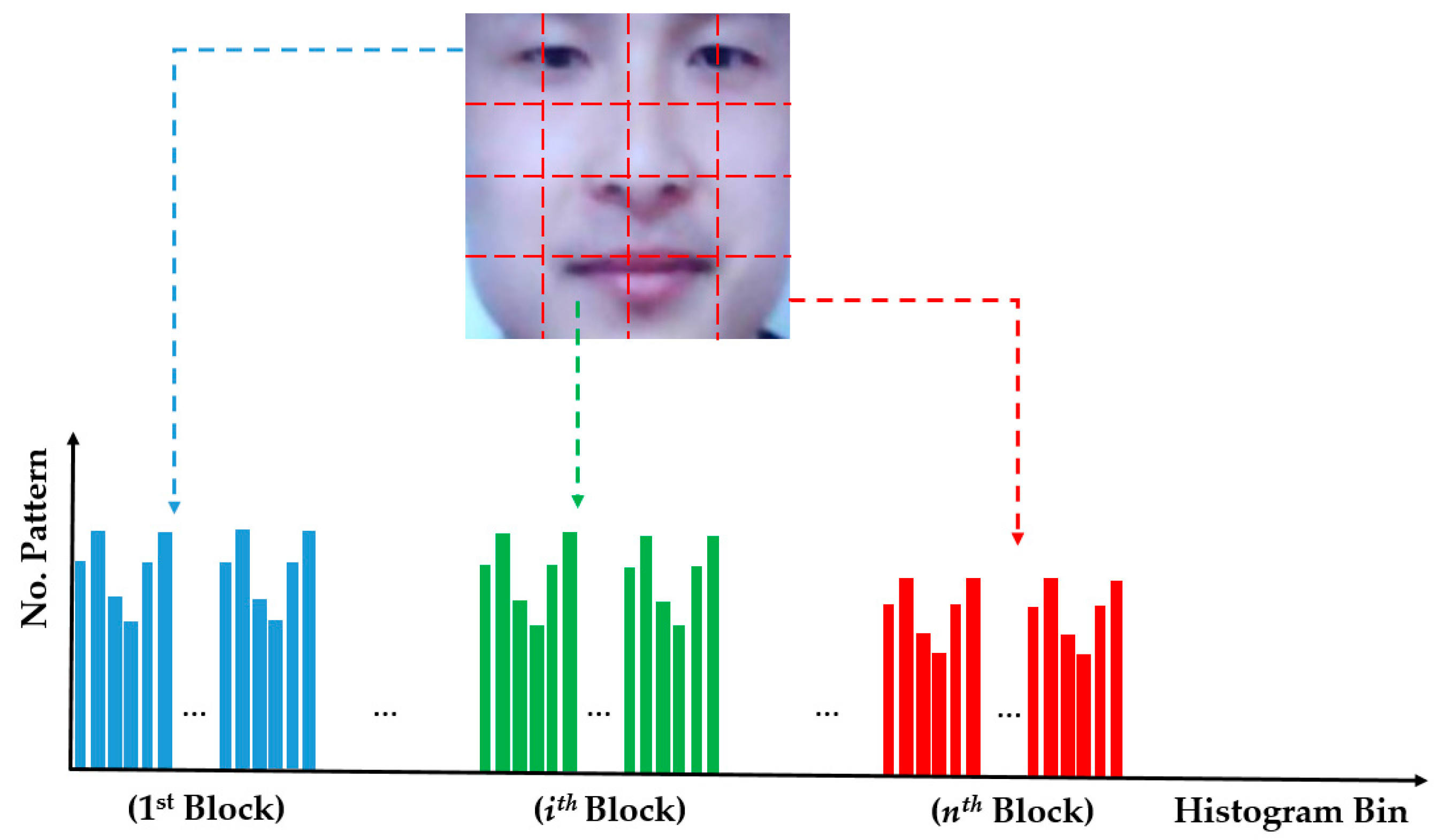
Figure 3.
Description of image feature extraction using the MLBP method.
Figure 3.
Description of image feature extraction using the MLBP method.
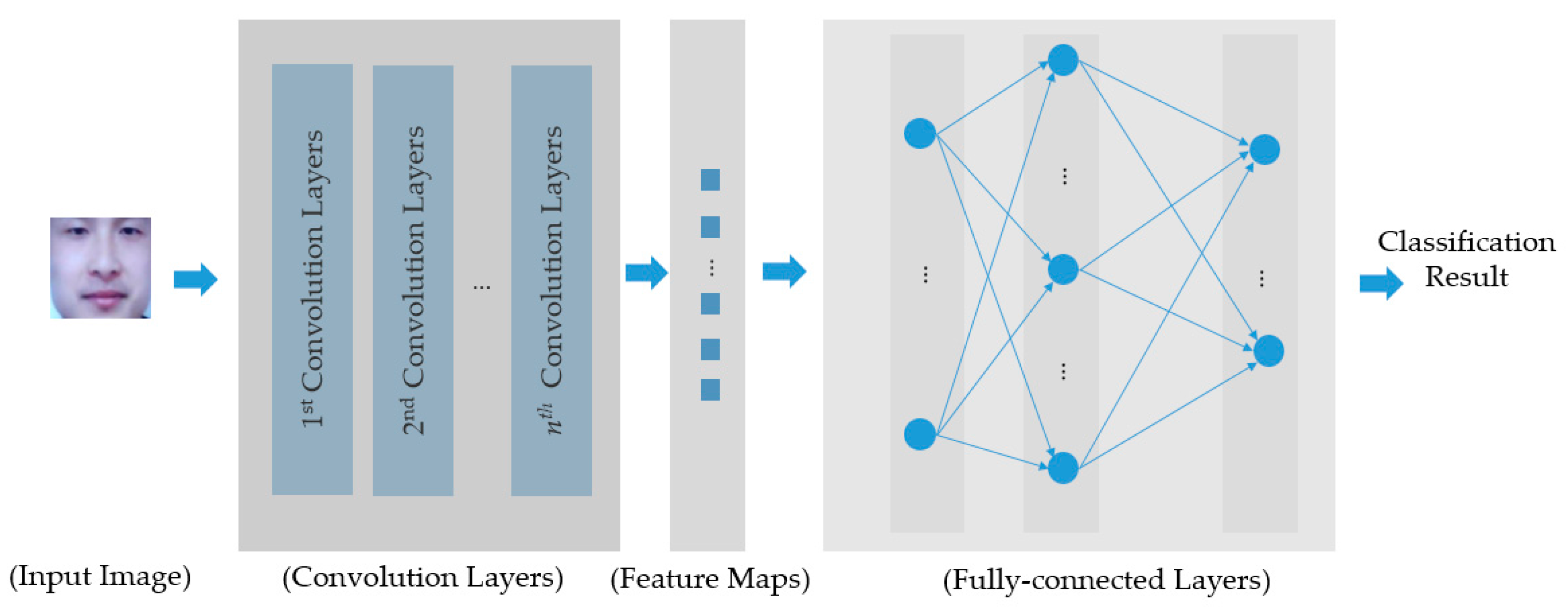
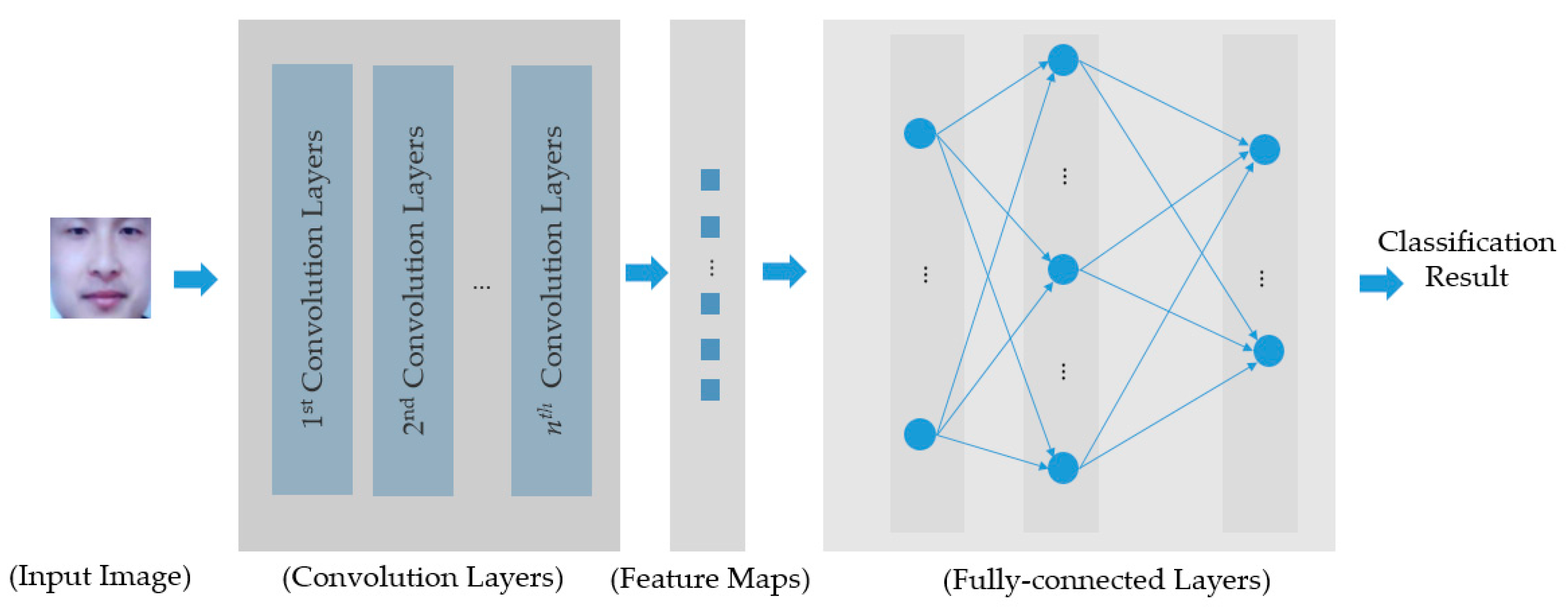
Figure 4.
Description of general structure of a CNN.
Figure 4.
Description of general structure of a CNN.
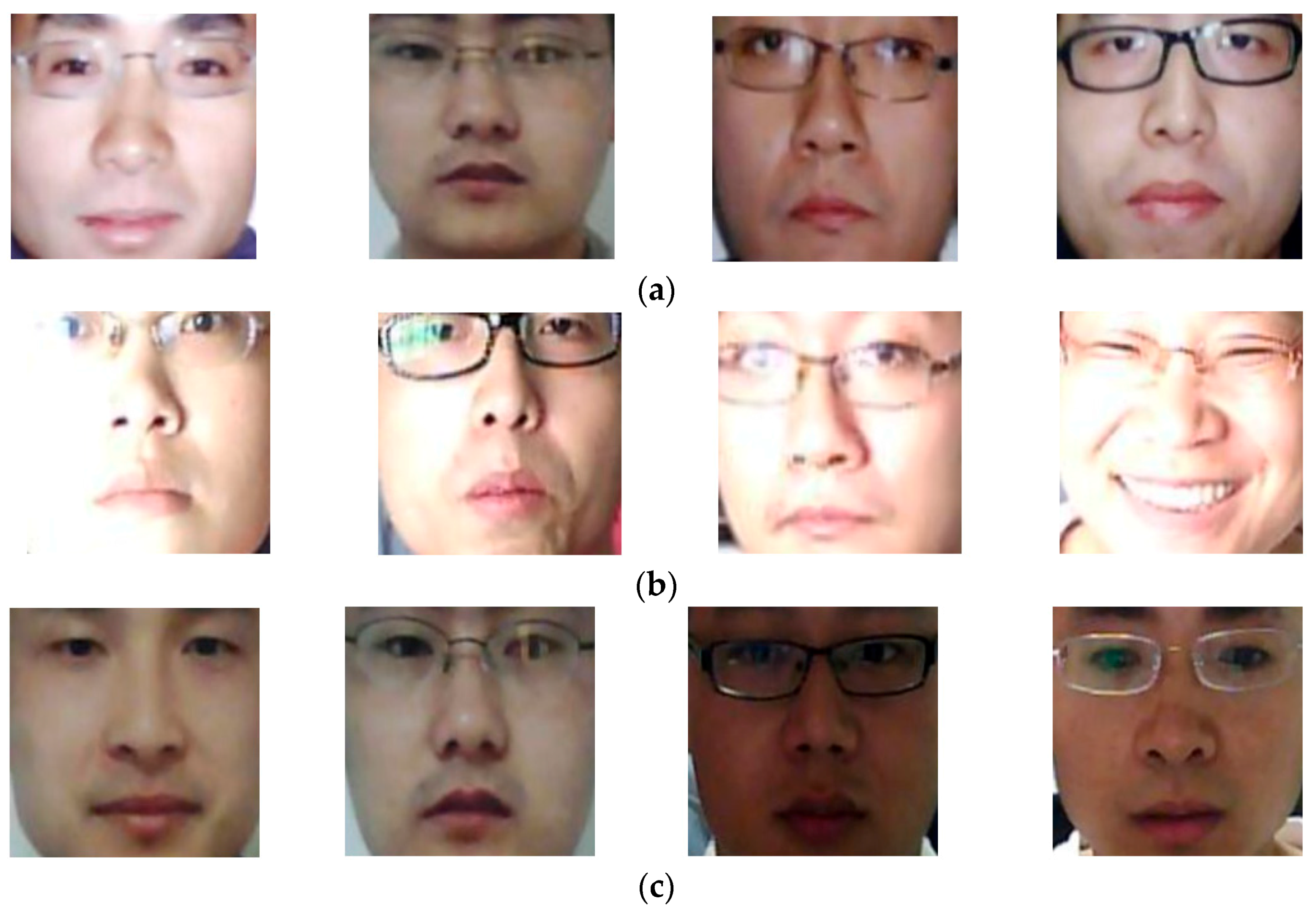
Figure 5.
Example face region images in NUAA database: (a) real images and (b) presentation attack images.
Figure 5.
Example face region images in NUAA database: (a) real images and (b) presentation attack images.
Figure 6.
Example face region images from CASIA database: (a) real access images, (b) presentation attack images using video display, (c) presentation attack images using wrap photo, and (d) presentation attack images using cut photo.
Figure 6.
Example face region images from CASIA database: (a) real access images, (b) presentation attack images using video display, (c) presentation attack images using wrap photo, and (d) presentation attack images using cut photo.
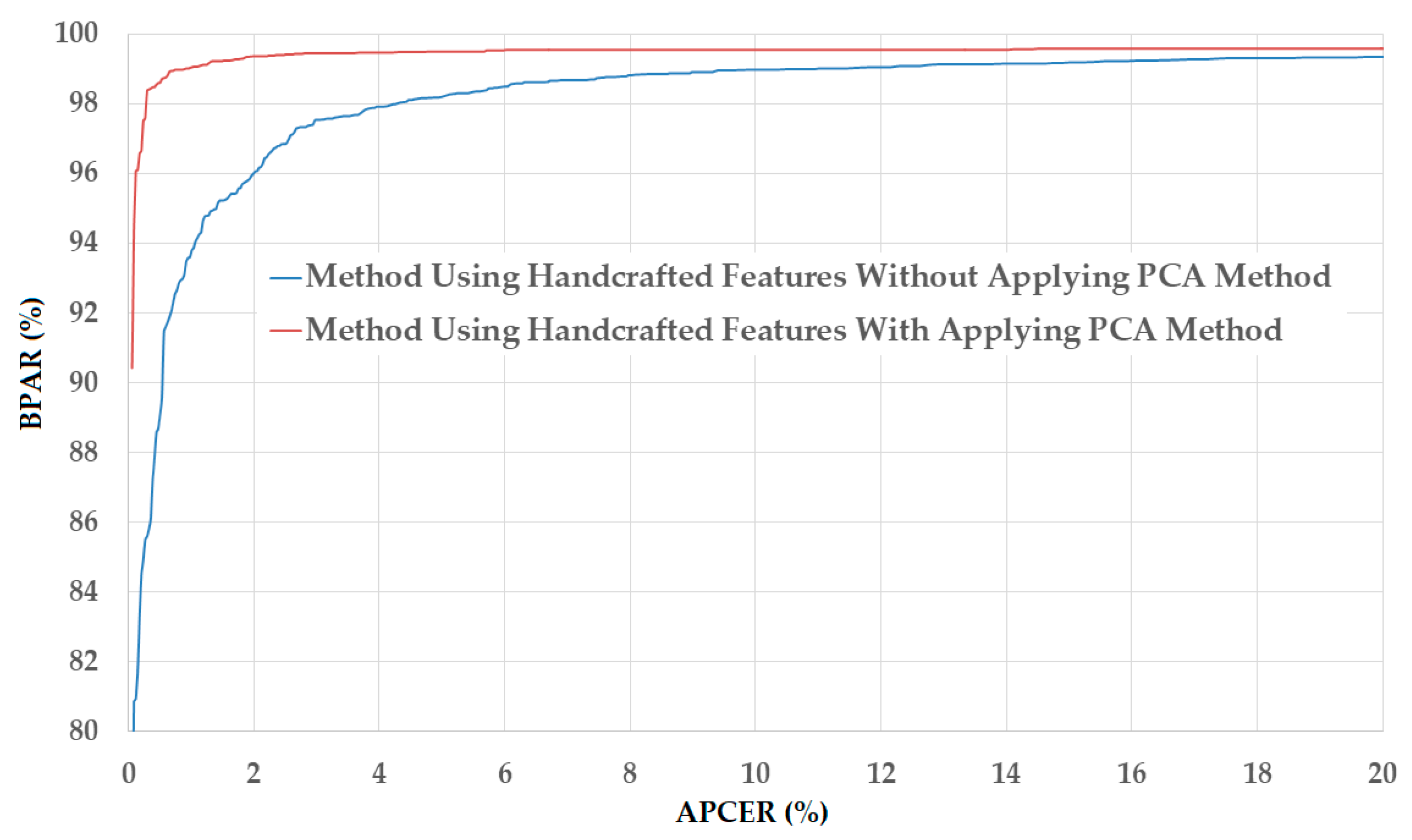
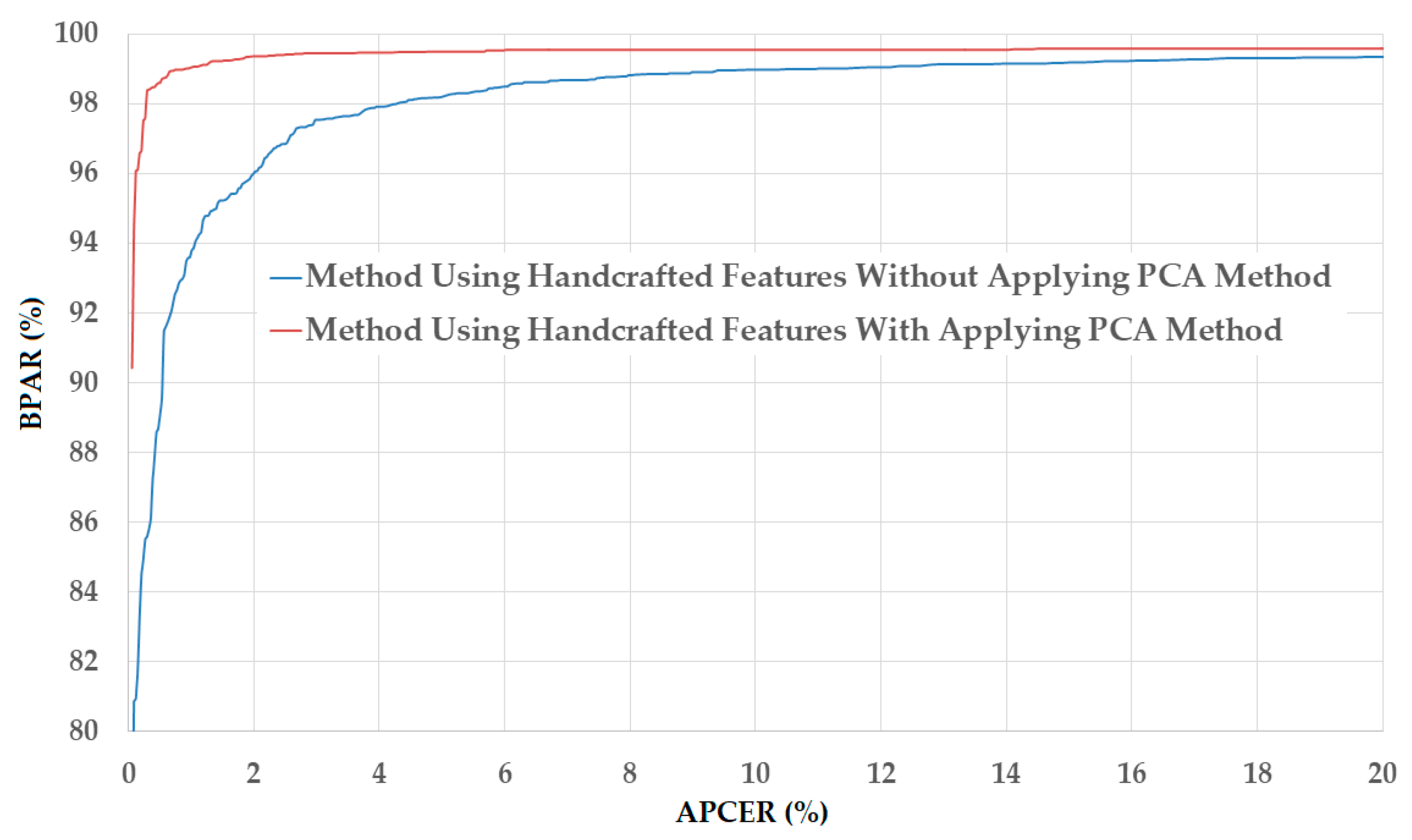
Figure 7.
DET curves of the detection system that uses only handcrafted image features on NUAA database with and without applying PCA method.
Figure 7.
DET curves of the detection system that uses only handcrafted image features on NUAA database with and without applying PCA method.
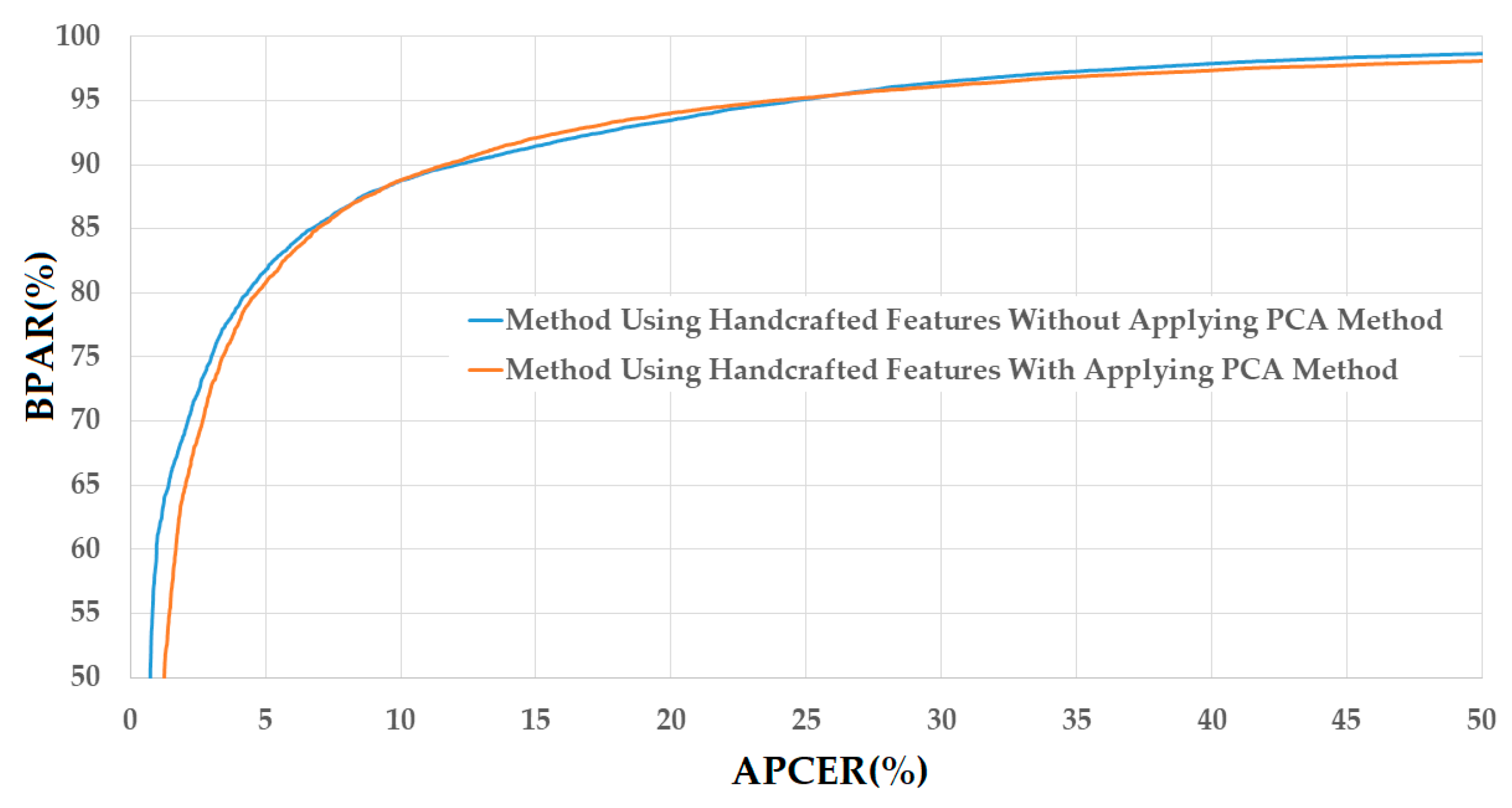
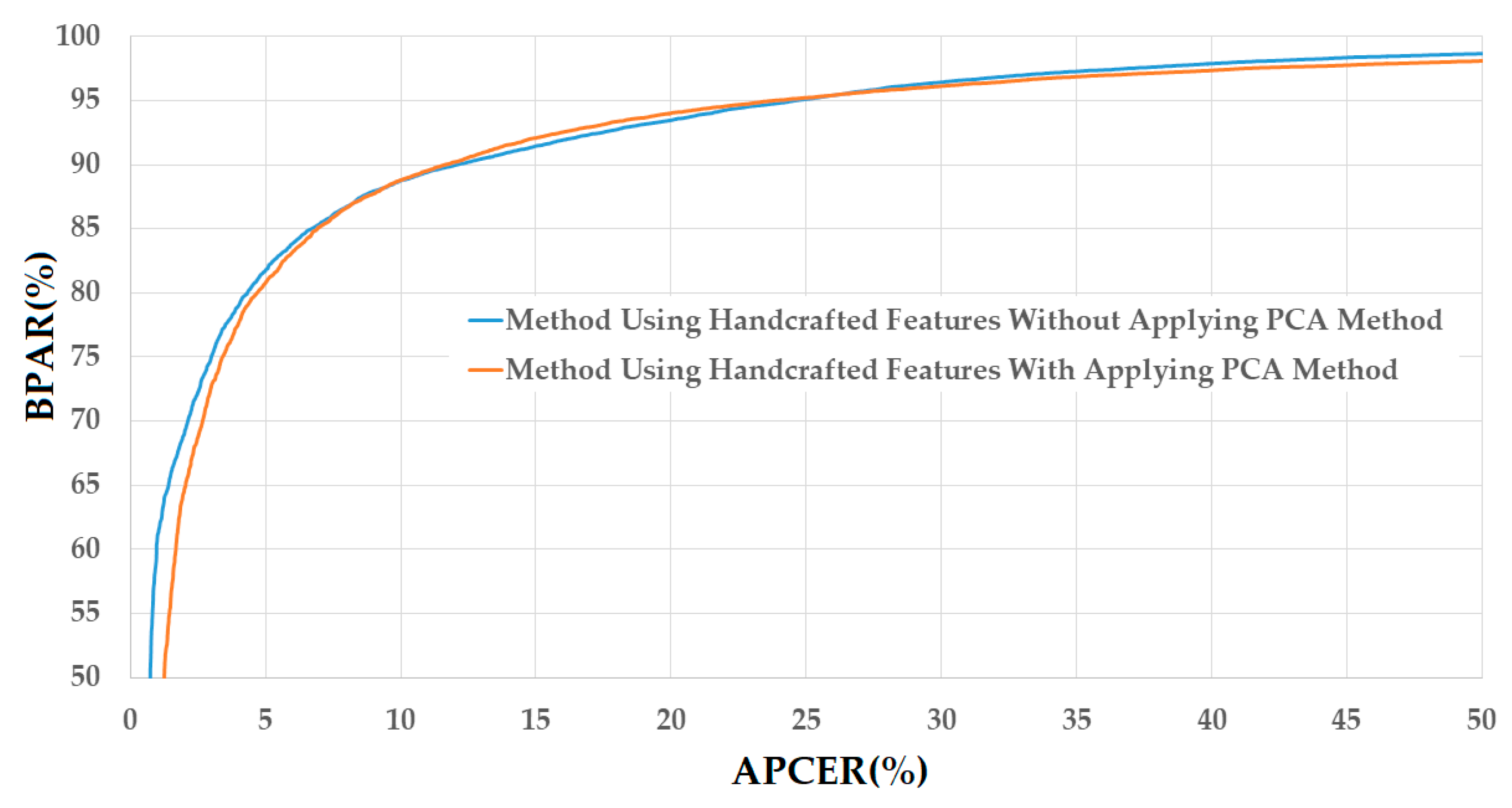
Figure 8.
DET curves of the detection system that uses only handcrafted image features on CASIA database with and without PCA applying method.
Figure 8.
DET curves of the detection system that uses only handcrafted image features on CASIA database with and without PCA applying method.
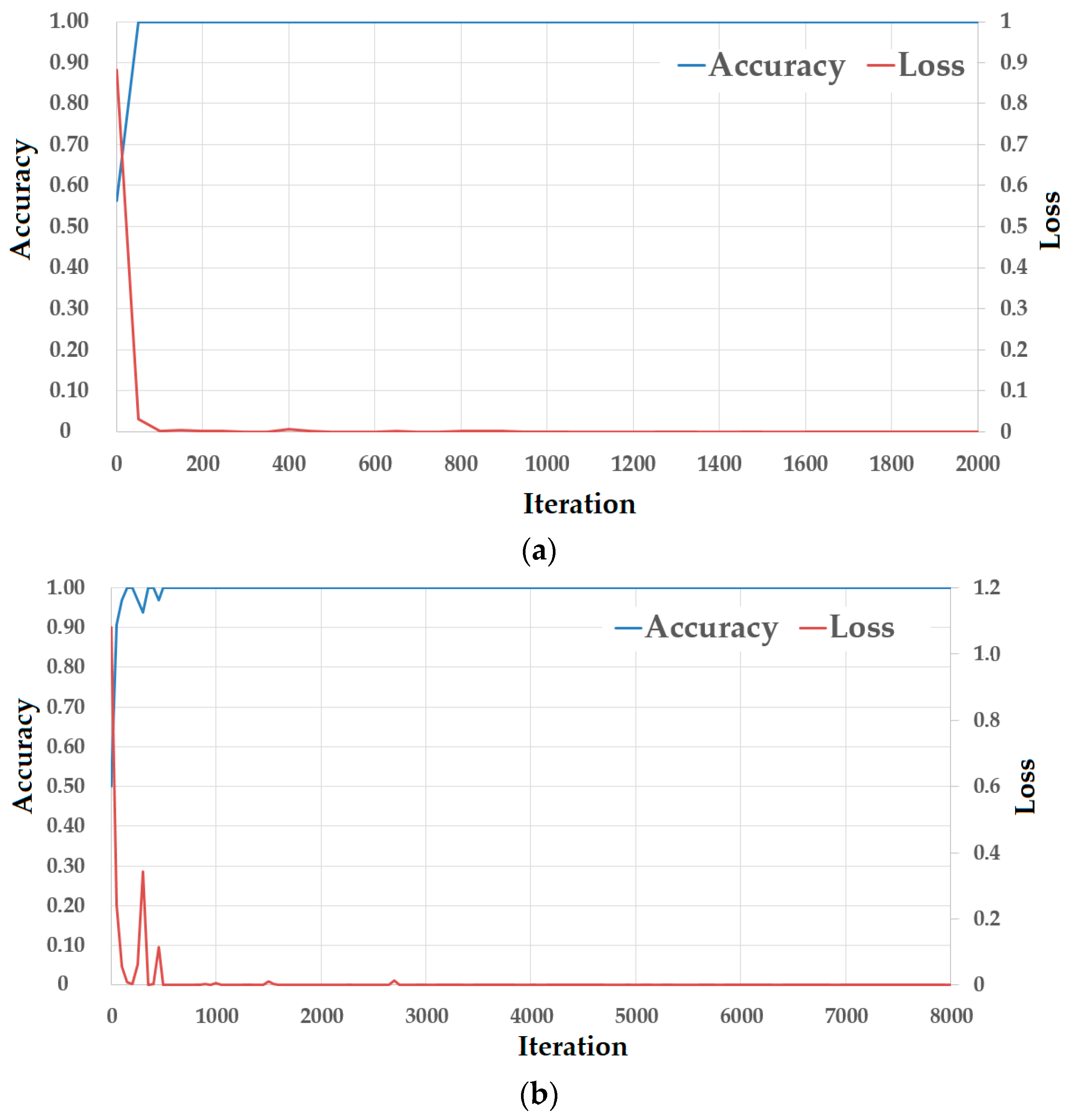
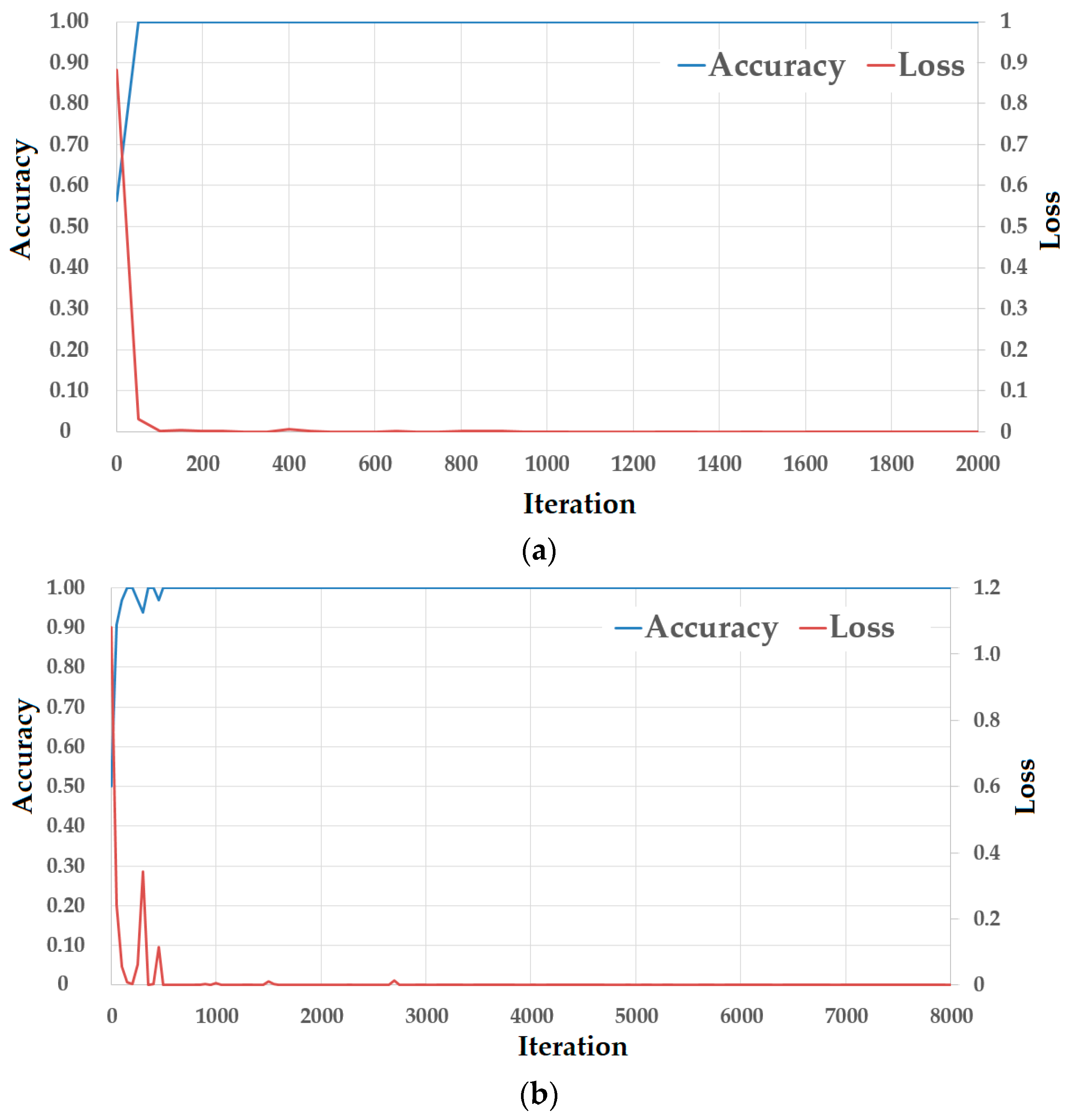
Figure 9.
Loss curves of training procedures using (a) NUAA database, and (b) CASIA database.
Figure 9.
Loss curves of training procedures using (a) NUAA database, and (b) CASIA database.
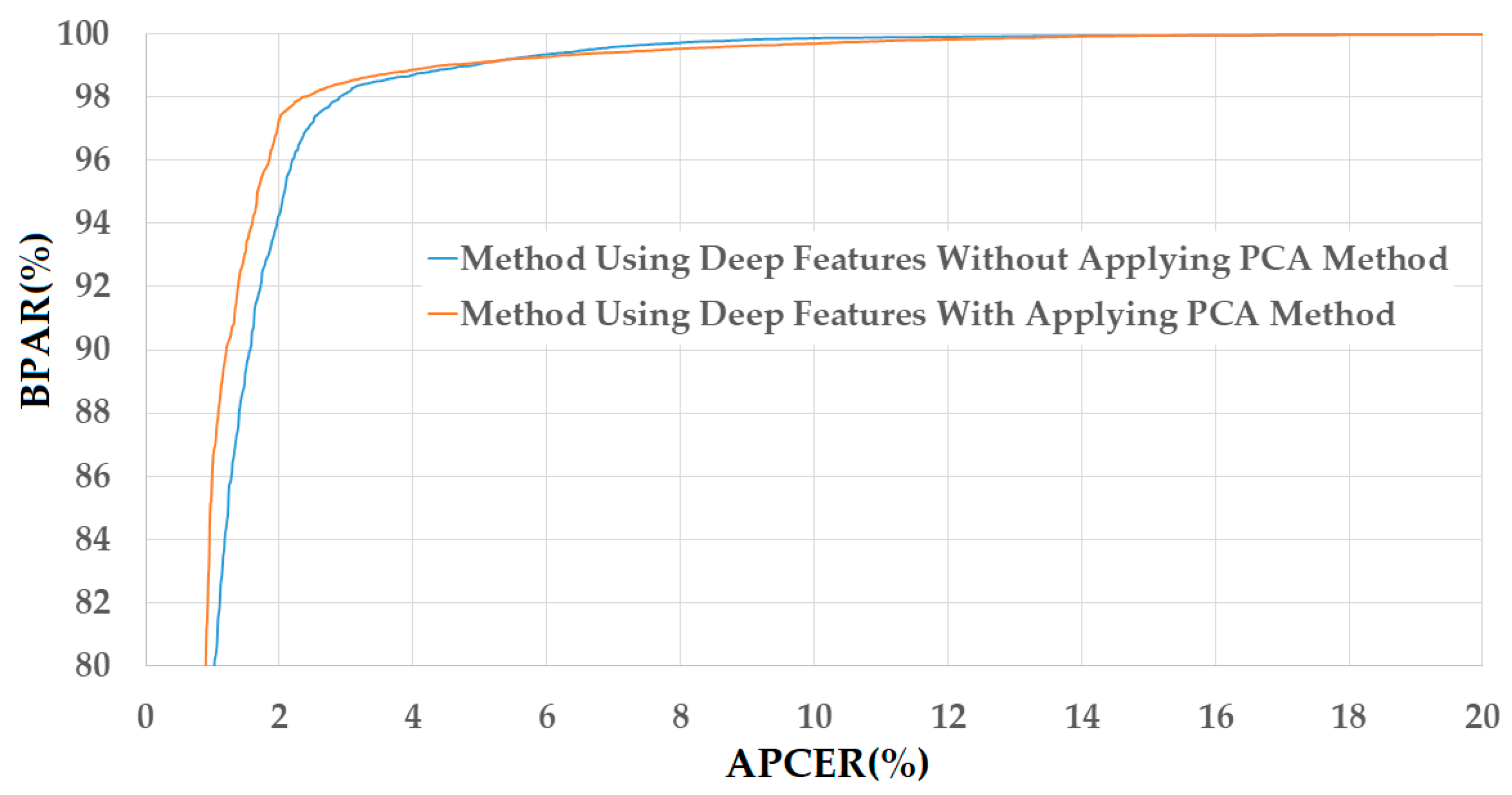
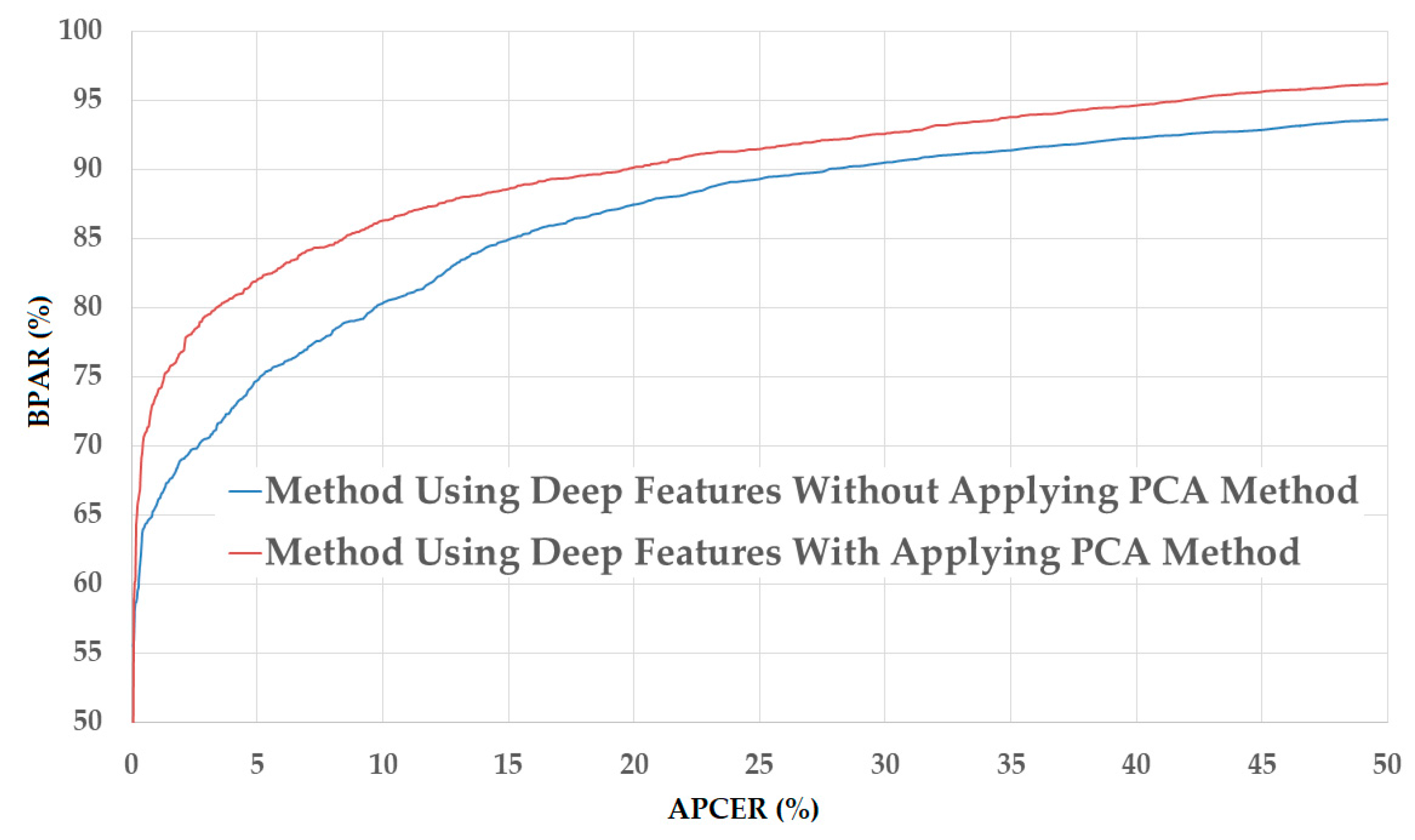
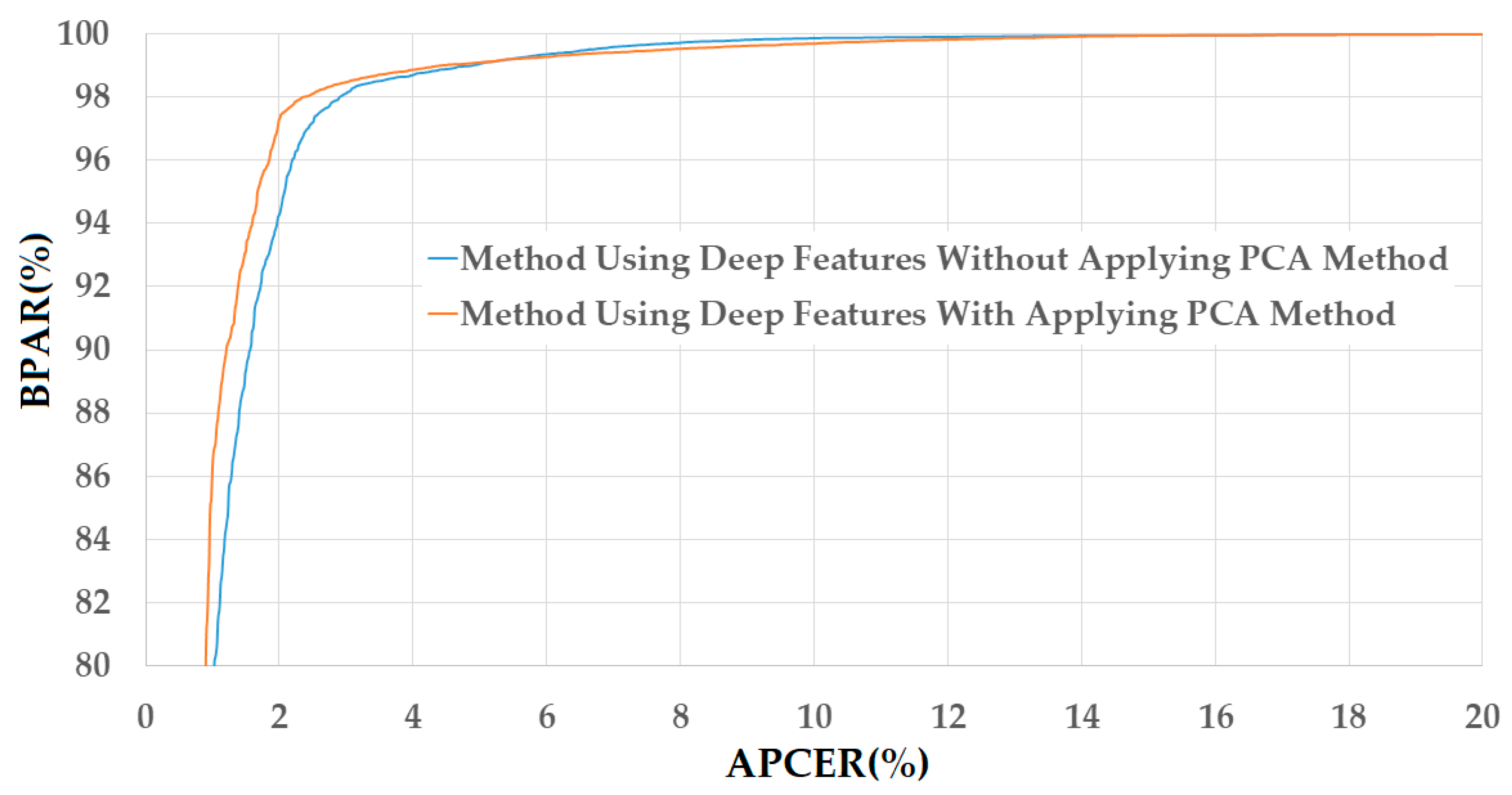
Figure 10.
DET curves of the detection system that uses only deep image features on NUAA database with and without applying PCA method.
Figure 10.
DET curves of the detection system that uses only deep image features on NUAA database with and without applying PCA method.
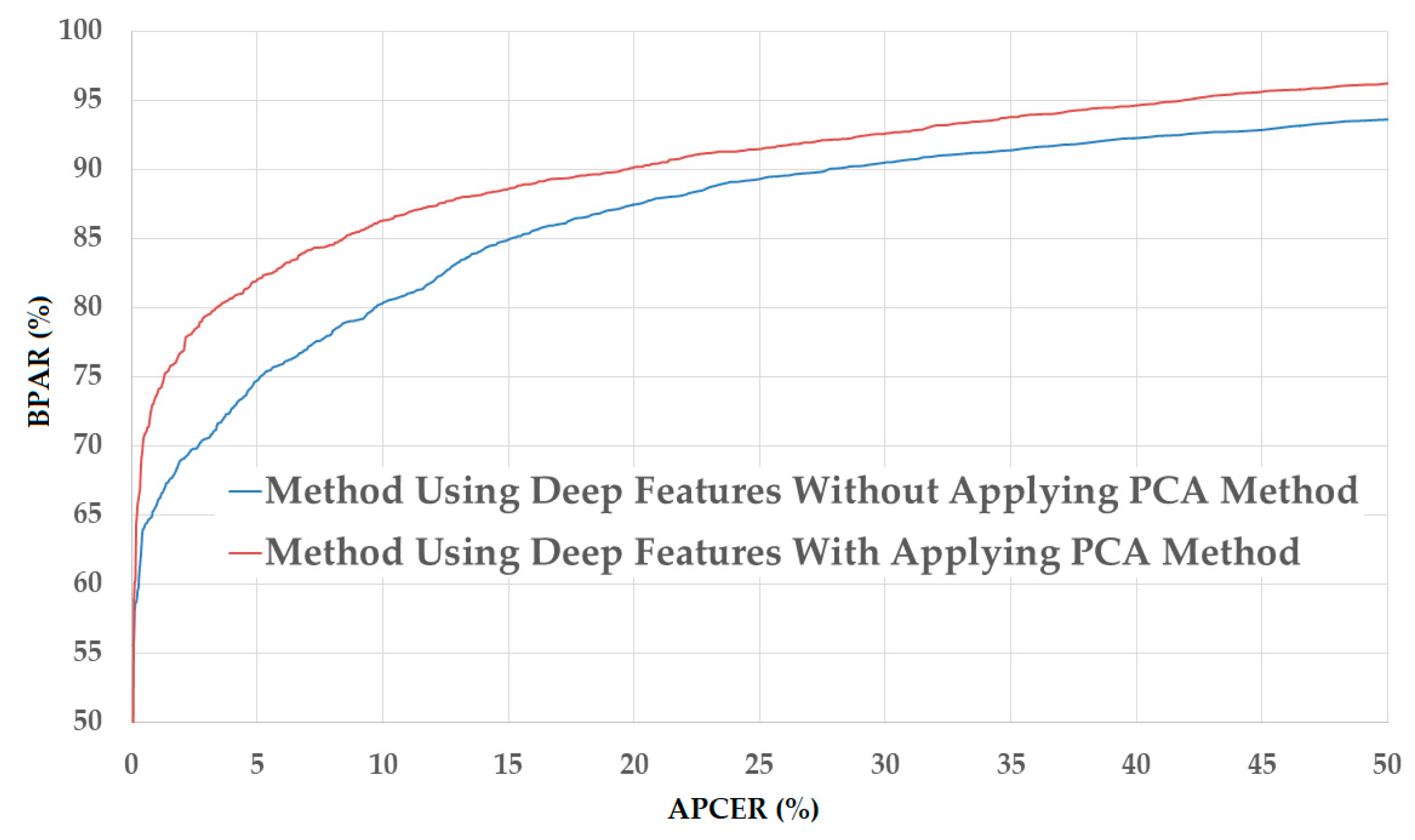
Figure 11.
DET curves of the detection system that uses only deep image features on CASIA database with and without applying PCA method.
Figure 11.
DET curves of the detection system that uses only deep image features on CASIA database with and without applying PCA method.
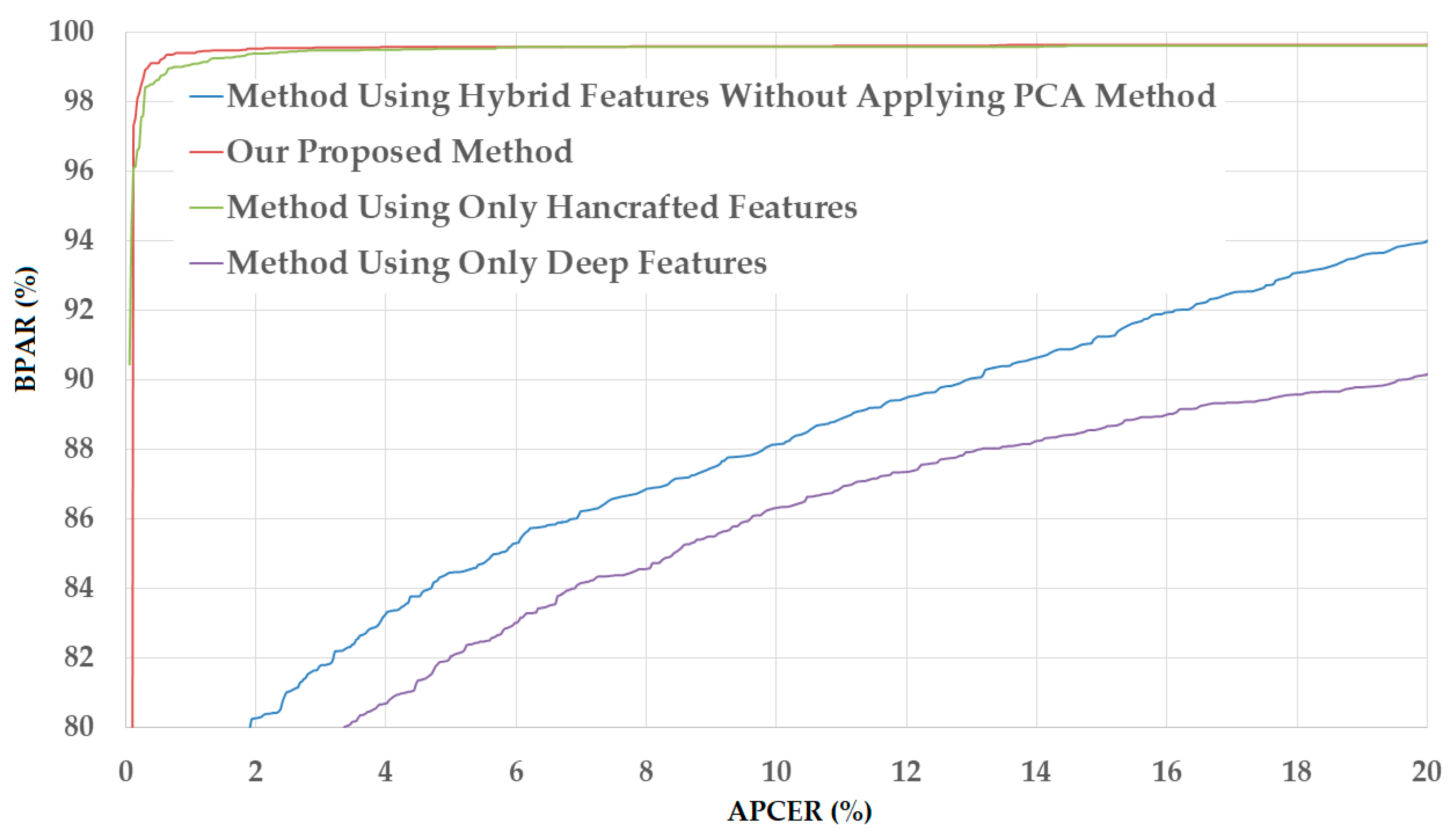
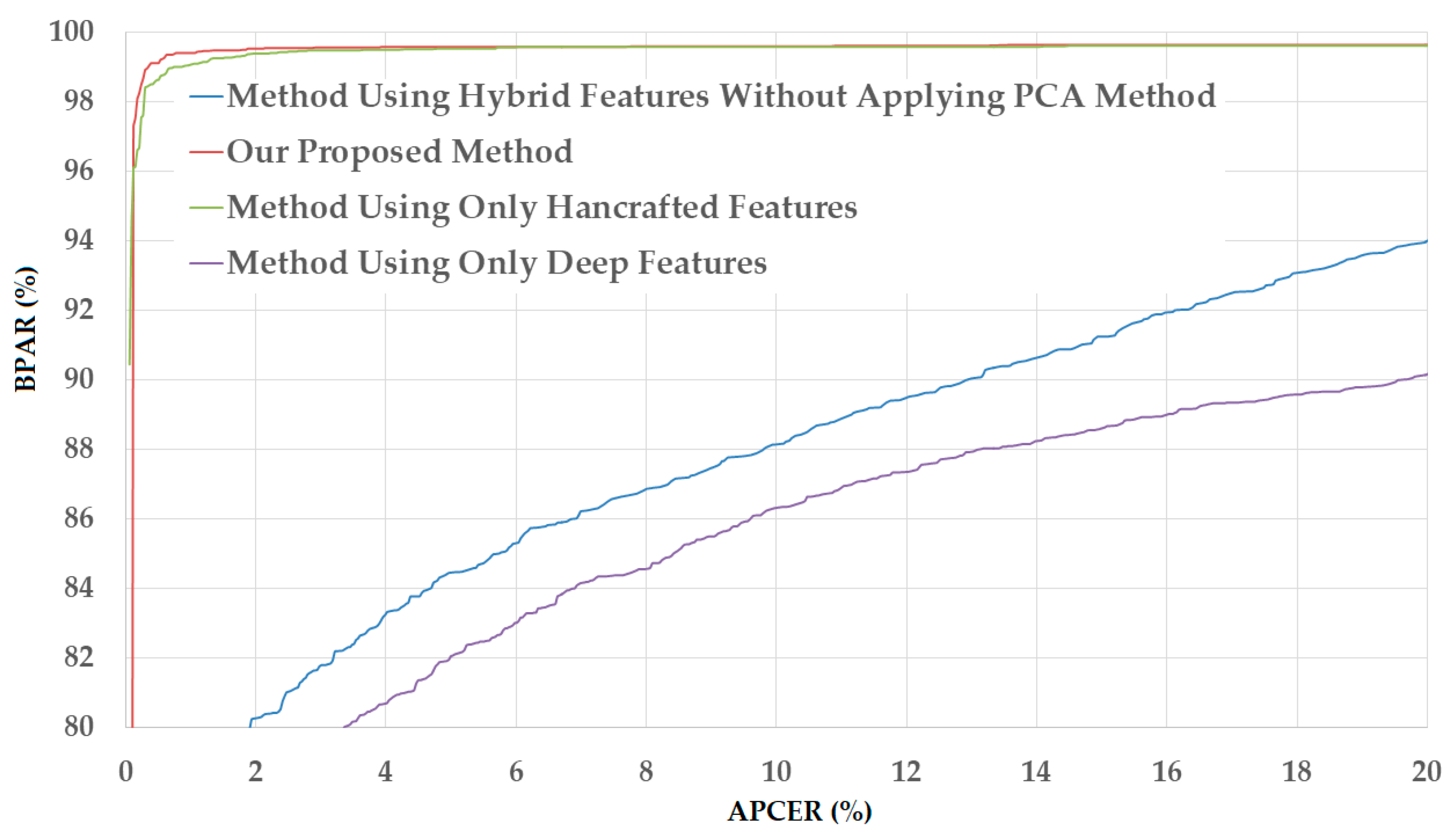
Figure 12.
DET curves of our proposed PAD method in comparison with other methods on NUAA database.
Figure 12.
DET curves of our proposed PAD method in comparison with other methods on NUAA database.
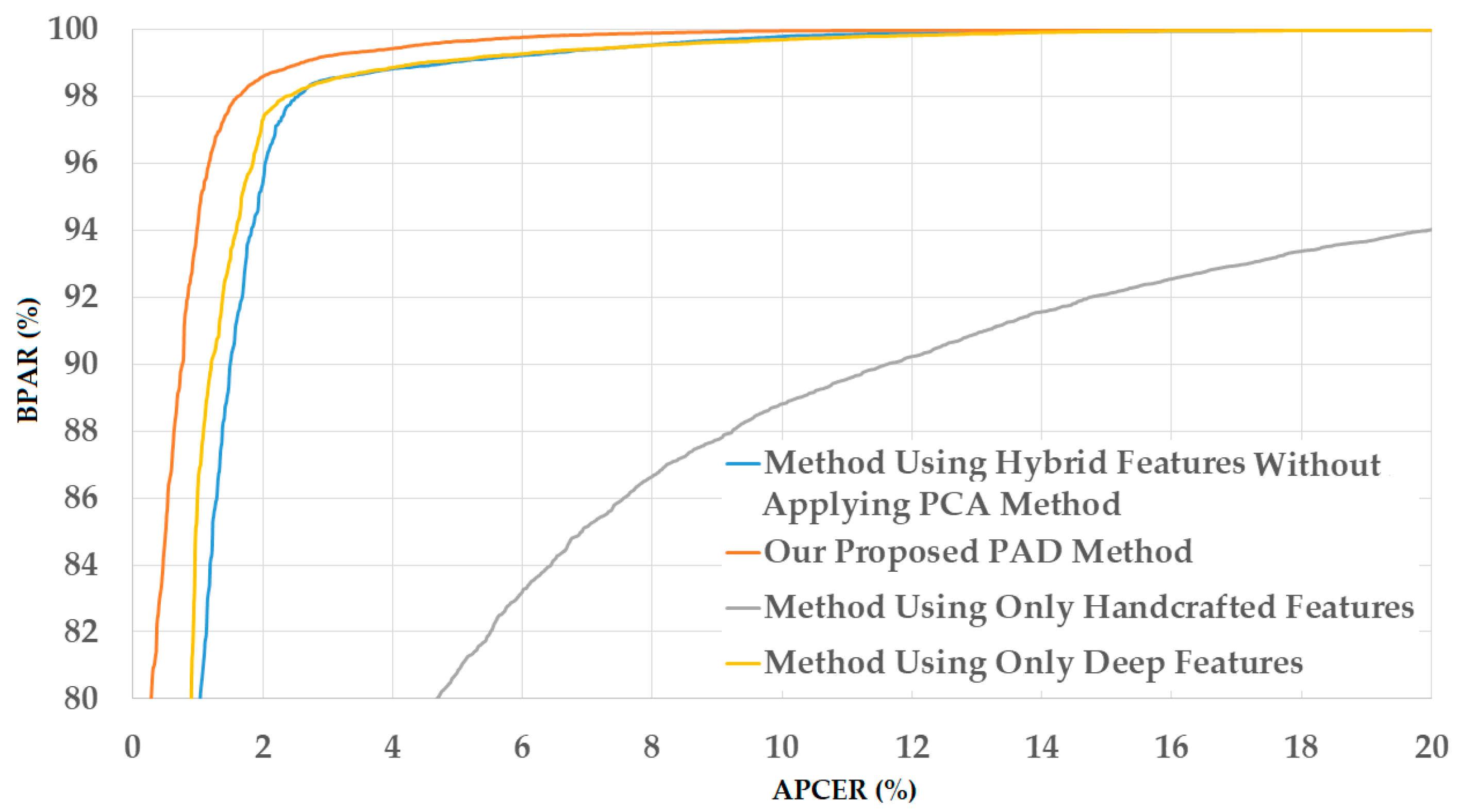
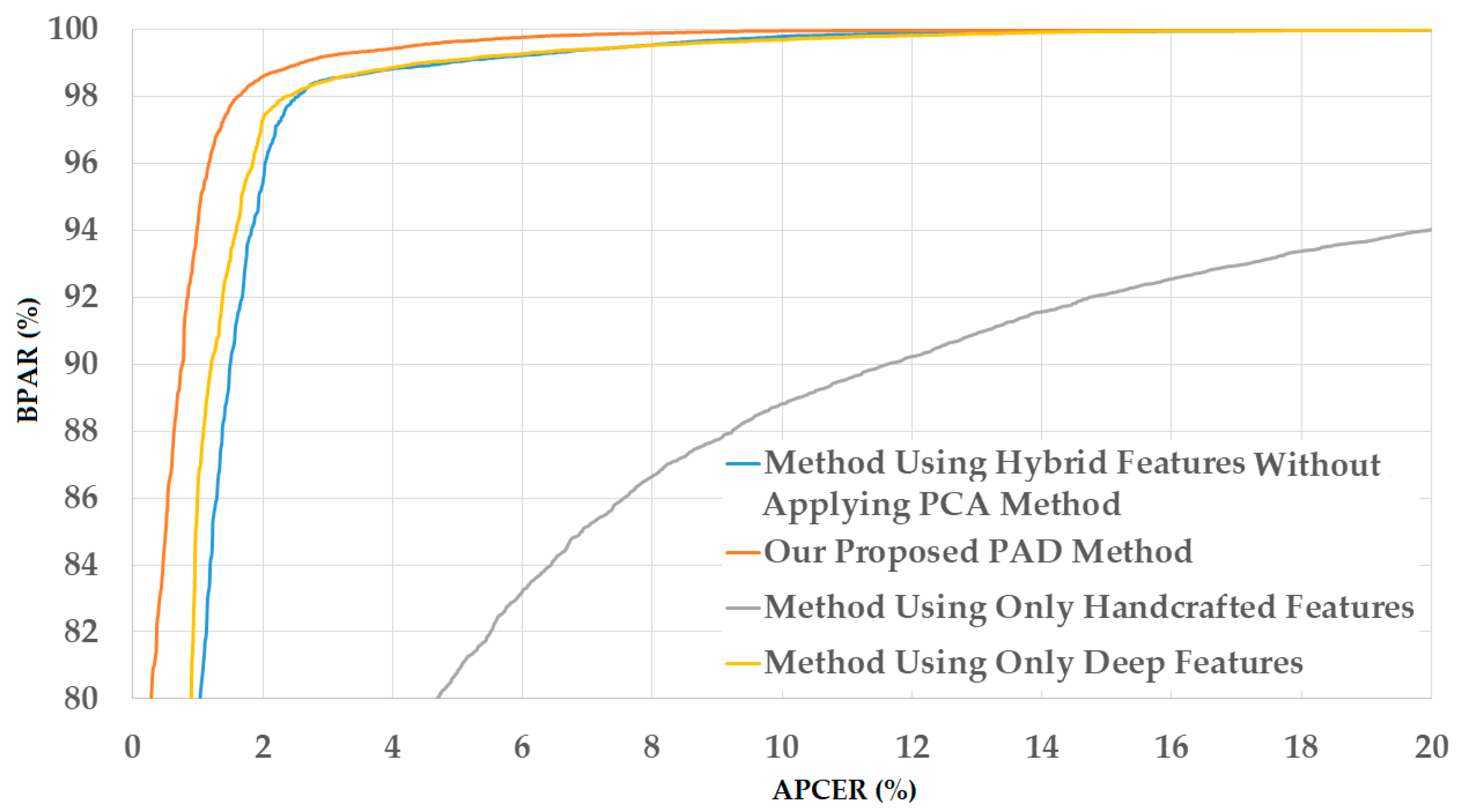
Figure 13.
DET curves of our proposed PAD method in comparison with other methods on CASIA database.
Figure 13.
DET curves of our proposed PAD method in comparison with other methods on CASIA database.
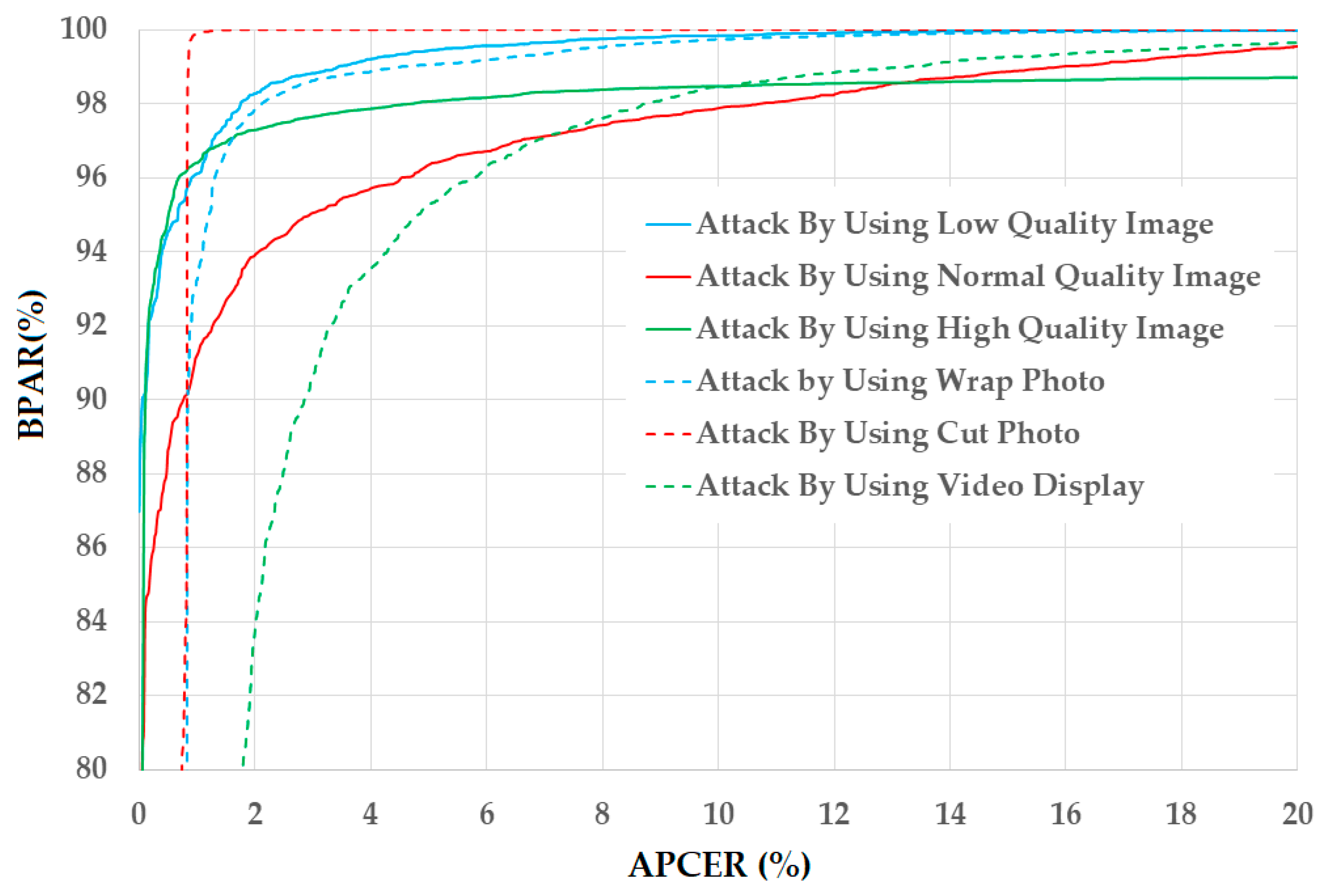
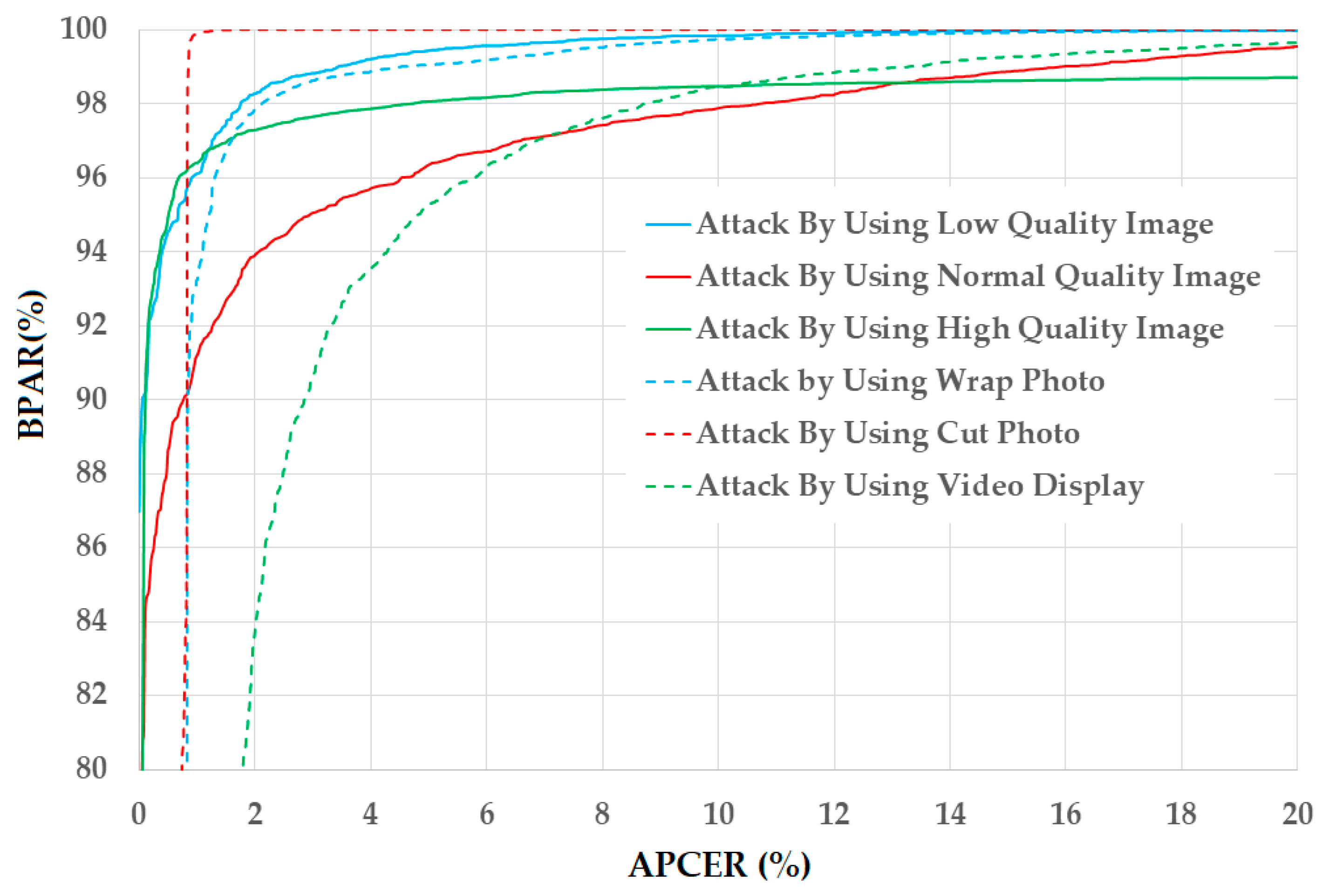
Figure 14.
DET curves of the detection system using our proposed PAD method on six sub-databases of CASIA database according to image quality (low, normal, and high quality) and attacking methods (using wrap photo, cut photo, and video display).
Figure 14.
DET curves of the detection system using our proposed PAD method on six sub-databases of CASIA database according to image quality (low, normal, and high quality) and attacking methods (using wrap photo, cut photo, and video display).
Figure 15.
Examples of detection result images by PAD method that uses only MLBP features for detection problem on NUAA database: (a) “presentation attack to real” error cases; (b) “real to presentation attack” error cases; and (c) correct detection cases.
Figure 15.
Examples of detection result images by PAD method that uses only MLBP features for detection problem on NUAA database: (a) “presentation attack to real” error cases; (b) “real to presentation attack” error cases; and (c) correct detection cases.
Figure 16.
Examples of detection result images of the PAD method that uses only deep features on NUAA database: (a) “real to presentation attack” error cases, (b) “presentation to real” error cases, and (c) correct detection cases.
Figure 16.
Examples of detection result images of the PAD method that uses only deep features on NUAA database: (a) “real to presentation attack” error cases, (b) “presentation to real” error cases, and (c) correct detection cases.
Figure 17.
Examples of detection result images by our proposed PAD method on NUAA database: (a) images detected incorrectly by the PAD method that uses only MLBP features, but correctly detected by our proposed PAD method, and (b) images detected incorrectly by the PAD method that uses only deep features, but correctly detected by our proposed PAD method.
Figure 17.
Examples of detection result images by our proposed PAD method on NUAA database: (a) images detected incorrectly by the PAD method that uses only MLBP features, but correctly detected by our proposed PAD method, and (b) images detected incorrectly by the PAD method that uses only deep features, but correctly detected by our proposed PAD method.
Table 1.
Comparison of previous research on PAD problem for a face recognition system and our proposed method.
Table 1.
Comparison of previous research on PAD problem for a face recognition system and our proposed method.
| Category | Method | Strength | Weakness |
|---|
| Non-training-based feature extraction methods | - -
Using sparse low-rank bilinear discriminative model [ 14]; Gabor filtering, LBP features, and LPQ features [ 15, 20]; Color texture information based on LBP method [ 17]; and DLTP features [ 21]. - -
Using image quality assessment [ 19]
| - -
Easy to implement - -
Suitable for detecting low-quality presentation attack images
| - -
Detection accuracy is fair - -
Detection accuracy may vary according to the image database
|
| Training-based feature extraction methods | - -
Using CNN method with structure and parameter optimization [ 10] - -
Using handcrafted features and multiple pre-trained CNN models for feature extraction, and SVM method classification [ 34]. - -
Using multiple pre-trained CNN models for deep feature extraction; Combining deep and handcrafted image features using score-level fusion method [ 35]
| - -
Learn the features for discriminating the real and presentation attack images automatically using a large number of training images [ 10] - -
Extract deep image features easily using pre-trained CNN models which were trained for other problems with handcrafted features [ 34] - -
Combines the strength of handcrafted and deep features for the detection problem; high detection accuracy [ 35]
| - -
Requires time-consuming and powerful hardware for training a CNN model; Requires a large number of training images [ 10] - -
Requires multiple CNN and SVM models for extracting image features, and classification [ 34] - -
More complex than conventional methods; requires long processing time because of the use of multiple CNN and SVM models.
|
- -
Using single CNN model; fine-tunes CNN model using a large number of images to train deep feature extractor; combines deep and handcrafted image features using score-level fusion and feature-level fusion methods.
(Proposed method) | - -
More simple than previous deep learning-based methods by the use of single CNN model - -
Combines the strength of handcrafted and deep features for the detection problem - -
Archives better detection accuracy than single method (handcrafted or deep method)
| - -
Complex and requires considerable processing power as compared to single handcrafted method or CNN method - -
Requires a large number of training images
|
Table 2.
Description of the CNN architecture (based on VGG Net-19 network architecture) used in our study for PAD for a face recognition system.
Table 2.
Description of the CNN architecture (based on VGG Net-19 network architecture) used in our study for PAD for a face recognition system.
| Layer Name | Number of Filters | Filter Size | Stride Size | Padding Size | Dropout Value | Output Size |
|---|
| Input Layer | n/a | n/a | n/a | n/a | n/a | 224 × 224 × 3 |
| Convolution Layer (conv1_1) | 64 | 3 × 3 × 3 | 1 × 1 | 1 × 1 | 224 × 224 × 64 |
| ReLU (relu1_1) | n/a | n/a | n/a | n/a | 224 × 224 × 64 |
| Convolution Layer (conv1_2) | 64 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | 224 × 224 × 64 |
| ReLU (relu1_2) | n/a | n/a | n/a | n/a | 224 × 224 × 64 |
| MAX Pooling Layer (pool1) | 1 | 2 × 2 | 2 × 2 | 0 | 112 × 112 × 64 |
| Convolution Layer (conv2-1) | 128 | 3 × 3 × 64 | 1 × 1 | 1 × 1 | 112 × 112 × 128 |
| ReLU (relu2_1) | n/a | n/a | n/a | n/a | 112 × 112 × 128 |
| Convolution Layer (conv2_2) | 128 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | 112 × 112 × 128 |
| ReLU (relu2_2) | n/a | n/a | n/a | n/a | 112 × 112 × 128 |
| MAX Pooling Layer (pool2) | 1 | 2 × 2 | 2 × 2 | 0 | 56 × 56 × 128 |
| Convolution Layer (conv3_1) | 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 | 56 × 56 × 256 |
| ReLU (relu3_1) | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| Convolution Layer (conv3_2) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | 56 × 56 × 256 |
| ReLU (relu3_2) | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| Convolution Layer (conv3_3) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | 56 × 56 × 256 |
| ReLU (relu3_3) | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| Convolution Layer (conv3_4) | 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | 56 × 56 × 256 |
| ReLU (relu3_4) | n/a | n/a | n/a | n/a | 56 × 56 × 256 |
| MAX Pooling Layer (pool3) | 1 | 2 × 2 | 2 × 2 | 0 | 28 × 28 × 256 |
| Convolution Layer (conv4_1) | 512 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | 28 × 28 × 512 |
| ReLU (relu4_1) | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| Convolution Layer (conv4_2) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 28 × 28 × 512 |
| ReLU (relu4_2) | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| Convolution Layer (conv4_3) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 28 × 28 × 512 |
| ReLU (relu4_3) | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| Convolution Layer (conv4_4) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 28 × 28 × 512 |
| ReLU (relu4_4) | n/a | n/a | n/a | n/a | 28 × 28 × 512 |
| MAX Pooling Layer (pool4) | 1 | 2 × 2 | 2 × 2 | 0 | 14 × 14 × 512 |
| Convolution Layer (conv5_1) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 14 × 14 × 512 |
| ReLU (relu5_1) | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_2) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 14 × 14 × 512 |
| ReLU (relu5_2) | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_3) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 14 × 14 × 512 |
| ReLU (relu5_3) | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| Convolution Layer (conv5_4) | 512 | 3 × 3 × 512 | 1 × 1 | 1 × 1 | 14 × 14 × 512 |
| ReLU (relu5_4) | n/a | n/a | n/a | n/a | 14 × 14 × 512 |
| MAX Pooling Layer (pool5) | 1 | 2 × 2 | 2 × 2 | 0 | 7 × 7 × 512 |
| Fully Connected Layer (fc6) | n/a | n/a | n/a | n/a | 4096 |
| ReLU (relu6) | 4096 |
| Dropout Layer (drop6) | 0.50 | 4096 |
| Fully Connected Layer (fc7) | n/a | 4096 |
| ReLU (relu7) | 4096 |
| Dropout Layer (drop7) | 0.50 | 4096 |
| Output Layer (fc8) | n/a | 2 |
| Softmax Layer (prob.) | 2 |
| Classification Layer (output) | 2 |
Table 3.
Description of the NUAA database and its augmented databases used in our study.
Table 3.
Description of the NUAA database and its augmented databases used in our study.
| Database | Training Database | Testing Database | Total (Training/Testing) |
|---|
| Real Access | Presentation Attack | Real Access | Presentation Attack |
|---|
| Original NUAA Database | 1743 | 1748 | 3362 | 5761 | (3491/9123) |
| Augmented NUAA Database | 43,575
(1743 × 25) | 43,700
(1748 × 25) | 3362 | 5761 | (87,275/9123) |
Table 4.
Description of CASIA database and its augmented databases used in our study.
Table 4.
Description of CASIA database and its augmented databases used in our study.
| Database | Training Database | Testing Database | Total
(Training/Testing) |
|---|
| Real Access | Presentation Attack | Real Access | Presentation Attack |
|---|
| Original CASIA Database | 10,914 | 34,138 | 15,910 | 49,712 | 45,052/65,622 |
| Augmented CASIA Database | 21,828
(10,914 2) | 68,276
(34,138 2) | 15,910 | 49,712 | 90,104/65,622 |
Table 5.
Detection accuracy (in terms of APCER, BPCER, and ACER) of the PAD method that uses only handcrafted features on the NUAA and CASIA databases (unit: %).
Table 5.
Detection accuracy (in terms of APCER, BPCER, and ACER) of the PAD method that uses only handcrafted features on the NUAA and CASIA databases (unit: %).
| Database | SVM Kernel | Without PCA | With PCA | |
|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER | No. PC |
|---|
| NUAA Database | Linear Kernel | 2.604 | 2.380 | 2.492 | 0.972 | 3.183 | 2.077 | 90 |
| RBF Kernel | 1.597 | 31.440 | 16.518 | 0.712 | 1.220 | 0.966 | 310 |
| Polynomial Kernel | 1.840 | 31.916 | 16.878 | 0.590 | 0.744 | 0.667 | 310 |
| CASIA Database | Linear Kernel | 11.904 | 13.53 | 12.717 | 12.294 | 11.717 | 12.006 | 590 |
| RBF Kernel | 8.8309 | 12.176 | 10.504 | 8.862 | 12.450 | 10.656 | 550 |
| Polynomial Kernel | 8.5355 | 12.838 | 10.687 | 9.610 | 11.522 | 10.566 | 530 |
Table 6.
Parameters of SGD method for training CNN model in our experiments using transfer learning technique.
Table 6.
Parameters of SGD method for training CNN model in our experiments using transfer learning technique.
| Mini-Batch Size | Initial Learning Rate | Learning Rate Drop Factor | Learning Rate Drop Period (Epochs) | Training Size (Epochs) | Momentum |
|---|
| 32 | 0.001 | 0.1 | 2 | 6 | 0.9 |
Table 7.
Detection accuracy (in terms of APCER, BPCER, and ACER) of the PAD method that uses only deep features on NUAA and CASIA databases (unit: %).
Table 7.
Detection accuracy (in terms of APCER, BPCER, and ACER) of the PAD method that uses only deep features on NUAA and CASIA databases (unit: %).
| Database | SVM Kernel | Without PCA | With PCA | |
|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER | No. PC |
|---|
| NUAA Database | Linear Kernel | 7.915 | 22.219 | 15.067 | 6.909 | 15.586 | 11.247 | 40 |
| RBF Kernel | 9.130 | 20.583 | 14.857 | 5.034 | 20.226 | 12.630 | 20 |
| Polynomial Kernel | 8.367 | 20.851 | 14.609 | 7.412 | 23.587 | 15.500 | 30 |
| CASIA Database | Linear Kernel | 3.143 | 1.645 | 2.398 | 2.652 | 1.770 | 2.211 | 80 |
| RBF Kernel | 3.067 | 1.756 | 2.412 | 3.369 | 2.183 | 2.776 | 70 |
| Polynomial Kernel | 3.218 | 1.881 | 2.550 | 3.344 | 2.004 | 2.174 | 240 |
Table 8.
Detection accuracy (in terms of APCER, BPCER, and ACER) of our proposed PAD method on NUAA and CASIA databases using feature-level fusion method (unit: %).
Table 8.
Detection accuracy (in terms of APCER, BPCER, and ACER) of our proposed PAD method on NUAA and CASIA databases using feature-level fusion method (unit: %).
| Database | SVM Kernel | Without PCA | With PCA | |
|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER | No. PC |
|---|
| NUAA Database | Linear Kernel | 6.145 | 14.010 | 10.077 | 1.788 | 1.755 | 1.771 | 150 |
| RBF Kernel | 3.888 | 25.937 | 14.913 | 0.174 | 42.683 | 21.428 | 10 |
| Polynomial Kernel | 6.665 | 15.021 | 10.843 | 0.555 | 0.357 | 0.456 | 460 |
| CASIA Database | Linear Kernel | 2.784 | 1.629 | 2.207 | 2.037 | 1.356 | 1.696 | 120 |
| RBF Kernel | 2.766 | 1.613 | 2.189 | 1.879 | 1.710 | 1.795 | 110 |
| Polynomial Kernel | 2.753 | 1.647 | 2.200 | 2.037 | 1.513 | 1.775 | 210 |
Table 9.
Detection accuracy (in terms of APCER, BPCER, and ACER) of our proposed PAD method on NUAA and CASIA databases using score-level fusion method (unit: %).
Table 9.
Detection accuracy (in terms of APCER, BPCER, and ACER) of our proposed PAD method on NUAA and CASIA databases using score-level fusion method (unit: %).
| Database | SVM Kernel | Without PCA | With PCA |
|---|
| APCER | BPCER | ACER | APCER | BPCER | ACER |
|---|
| NUAA Database | Linear Kernel | 2.500 | 2.282 | 2.391 | 2.202 | 1.951 | 2.077 |
| RBF Kernel | 6.131 | 22.631 | 14.381 | 0.565 | 1.185 | 0.875 |
| Polynomial Kernel | 5.417 | 20.784 | 13.100 | 0.476 | 0.784 | 0.630 |
| CASIA Database | Linear Kernel | 3.124 | 1.332 | 2.228 | 3.180 | 1.181 | 2.181 |
| RBF Kernel | 3.080 | 1.487 | 2.283 | 2.665 | 1.973 | 2.319 |
| Polynomial Kernel | 3.344 | 1.229 | 2.286 | 2.407 | 1.177 | 1.792 |
Table 10.
Comparison of detection error (ACER) of our proposed PAD method with various previous methods using NUAA database (unit: %).
Table 10.
Comparison of detection error (ACER) of our proposed PAD method with various previous methods using NUAA database (unit: %).
| Baseline Method [14] | Gabor [15] | LPQ [15] | DLTP [21] | LBP [15] | LBP + Fisher Score + SVM [20] | Score-Fusion of Deep and Handcrafted Features [34,35] | Proposed Method |
|---|
| 9.500 | 9.500 | 4.600 | 3.500 | 2.900 | 1.000 | 0.630 | 0.456 |
Table 11.
Comparison of detection errors (ACERs) of our proposed PAD method with various previous methods using CASIA database (unit: %).
Table 11.
Comparison of detection errors (ACERs) of our proposed PAD method with various previous methods using CASIA database (unit: %).
| Baseline Method [16] | Combination of LBP, Fisher Score, and SVM [20] | Color Texture based on LBP Method [17] | DLTP [21] | Patch-Based Classification Method [23] | Score-Fusion of Deep and Handcrafted Features [34,35] | Proposed Method |
|---|
| 17.000 | 13.100 | 6.200 | 5.400 | 5.07 | 1.792 | 1.696 |
Table 12.
The processing time of our proposed method (unit: ms).
Table 12.
The processing time of our proposed method (unit: ms).
| Face Detection and Normalization | Feature Extraction by MLBP Method | Feature Extraction by CNN Method | Feature Selection by PCA Method | Classification by SVM Method | Total Processing Time |
|---|
| 16.956 | 12.915 | 19.519 | 0.792 | 0.320 | 50.502 |
Table 13.
Description of the three sub-databases of CASIA database according to quality of face region and their augmented database used in our study.
Table 13.
Description of the three sub-databases of CASIA database according to quality of face region and their augmented database used in our study.
| Database According to Quality of Face Regions | Training Database | Testing Database | Total
(Training/Testing) |
|---|
| Real Access | Presentation Access | Real Access | Presentation Access |
|---|
| Low Quality Database | Original Database | 3140 | 11,019 | 5298 | 16,174 | 14,159/21,472 |
| Augmented Database | 12,560 | 44,076 | 5298 | 16,174 | 56,636/21,472 |
| Normal Quality Database | Original Database | 3197 | 11,276 | 4830 | 16,157 | 14,473/20,987 |
| Augmented Database | 12,788 | 45,104 | 4830 | 16,157 | 57,892/20,987 |
| High Quality Database | Original Database | 4577 | 11,843 | 5782 | 17,381 | 16,420/23,163 |
| Augmented Database | 18,308 | 47,372 | 5782 | 17,381 | 65,680/23,163 |
Table 14.
Detection accuracies of our proposed PAD method on sub-databases of CASIA database according to the image quality (unit: %).
Table 14.
Detection accuracies of our proposed PAD method on sub-databases of CASIA database according to the image quality (unit: %).
| Database | SVM Kernel | APCER | BPCER | ACER |
|---|
| Low Quality Database | Linear Kernel | 3.718 | 0.742 | 2.230 |
| RBF Kernel | 3.114 | 0.643 | 1.879 |
| Polynomial Kernel | 1.906 | 1.762 | 1.834 |
| Normal Quality Database | Linear Kernel | 4.472 | 4.209 | 4.340 |
| RBF Kernel | 2.836 | 5.063 | 3.950 |
| Polynomial Kernel | 4.576 | 4.444 | 4.510 |
| High Quality Database | Linear Kernel | 0.882 | 3.958 | 2.420 |
| RBF Kernel | 1.211 | 3.210 | 2.210 |
| Polynomial Kernel | 0.796 | 4.102 | 2.449 |
Table 15.
Description of the three sub-databases of CASIA database according to attacking methods (wrap photo, cut photo, and video display) and their augmented database used in our study.
Table 15.
Description of the three sub-databases of CASIA database according to attacking methods (wrap photo, cut photo, and video display) and their augmented database used in our study.
| Database According to Attack Method | Training Database | Testing Database | Total
(Training/Testing) |
|---|
| Real Access | Presentation Access | Real Access | Presentation Access |
|---|
| Wrap Photo Database | Original Database | 10,914 | 12,860 | 15,910 | 19,250 | 23,774/35,160 |
| Augmented Database | 43,656 | 51,440 | 15,910 | 19,250 | 95,096/35,160 |
| Cut Photo Database | Original Database | 10,914 | 9,499 | 15,910 | 14,801 | 20,413/30,711 |
| Augmented Database | 43,656 | 37,996 | 15,910 | 14,801 | 81,652/30,711 |
| Video Display Database | Original Database | 10,914 | 11,779 | 15,910 | 15,661 | 22,693/31,571 |
| Augmented Database | 43,656 | 47,116 | 15,910 | 15,661 | 90,772/31,571 |
Table 16.
Detection accuracies of our proposed PAD method on sub-databases of CASIA database according to the attacking methods (unit: %).
Table 16.
Detection accuracies of our proposed PAD method on sub-databases of CASIA database according to the attacking methods (unit: %).
| Database | SVM Kernel | APCER | BPCER | ACER |
|---|
| Wrap Photo Database | Linear Kernel | 2.244 | 2.888 | 2.566 |
| RBF Kernel | 2.206 | 1.901 | 2.054 |
| Polynomial Kernel | 2.520 | 2.390 | 2.455 |
| Cut Photo Database | Linear Kernel | 1.113 | 0.203 | 0.658 |
| RBF Kernel | 0.905 | 0.263 | 0.584 |
| Polynomial Kernel | 0.949 | 0.142 | 0.545 |
| Video Access Database | Linear Kernel | 5.506 | 4.163 | 4.835 |
| RBF Kernel | 5.0409 | 5.491 | 5.266 |
| Polynomial Kernel | 4.6574 | 5.159 | 4.908 |
Table 17.
Comparison of detection errors (ACERs) of our proposed PAD method with previous methods using CASIA sub-databases according to image quality and attacking methods (unit: %).
Table 17.
Comparison of detection errors (ACERs) of our proposed PAD method with previous methods using CASIA sub-databases according to image quality and attacking methods (unit: %).
| Detection Method | Low Quality Database | Normal Quality Database | High Quality Database | Wrap Photo Database | Cut Photo Database | Video Access Database |
|---|
| Baseline Method [16] | 13.0 | 13.0 | 26.0 | 16.0 | 6.0 | 24.0 |
| LBP-TOP [22] | 10.0 | 12.0 | 13.0 | 6.0 | 12.0 | 10.0 |
| IQA [23] | 31.7 | 22.2 | 5.6 | 26.1 | 18.3 | 34.4 |
| Combination of LBP, Fisher Score, and SVM [20] | 7.2 | 8.8 | 14.4 | 12.0 | 10.0 | 14.7 |
| Patch-based Classification Method [23] | 5.26 | 6.00 | 5.30 | 5.78 | 5.49 | 5.02 |
| Color Texture based on LBP method [17] | 7.8 | 10.1 | 6.4 | 7.5 | 5.4 | 8.4 |
| Proposed Method | 1.834 | 3.950 | 2.210 | 2.054 | 0.545 | 4.835 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}