A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3


Abstract
:1. Introduction
- A method for automatic generation of the lane label images is presented. The lane is automatically labeled on the image of a simple scenario using the color information. The generated label dataset can be used for the CNN model training.
- A lane detection model based on the YOLO v3 is proposed. By designing a two-stage network that can learn the lane features automatically and adaptively under the complex traffic scenarios, and finally a detection model that can detect lane fast and accurate is obtained.
- As the lanes detected by the network model based on the YOLO v3 is relatively independent, the RANSAC algorithm is adopted to fit the final required curve.
2. Lane Detection Algorithm
2.1. Automatic Generation of Label Images
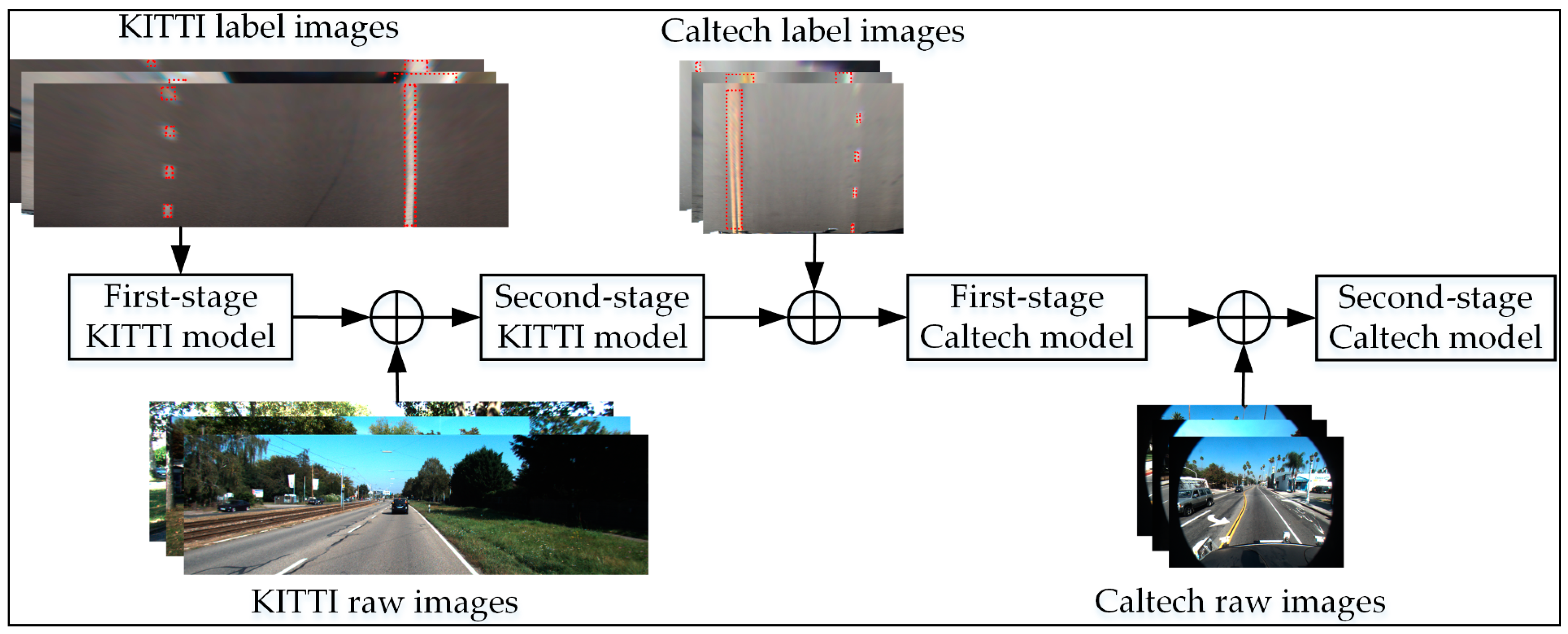
2.2. Construction of Detection Models
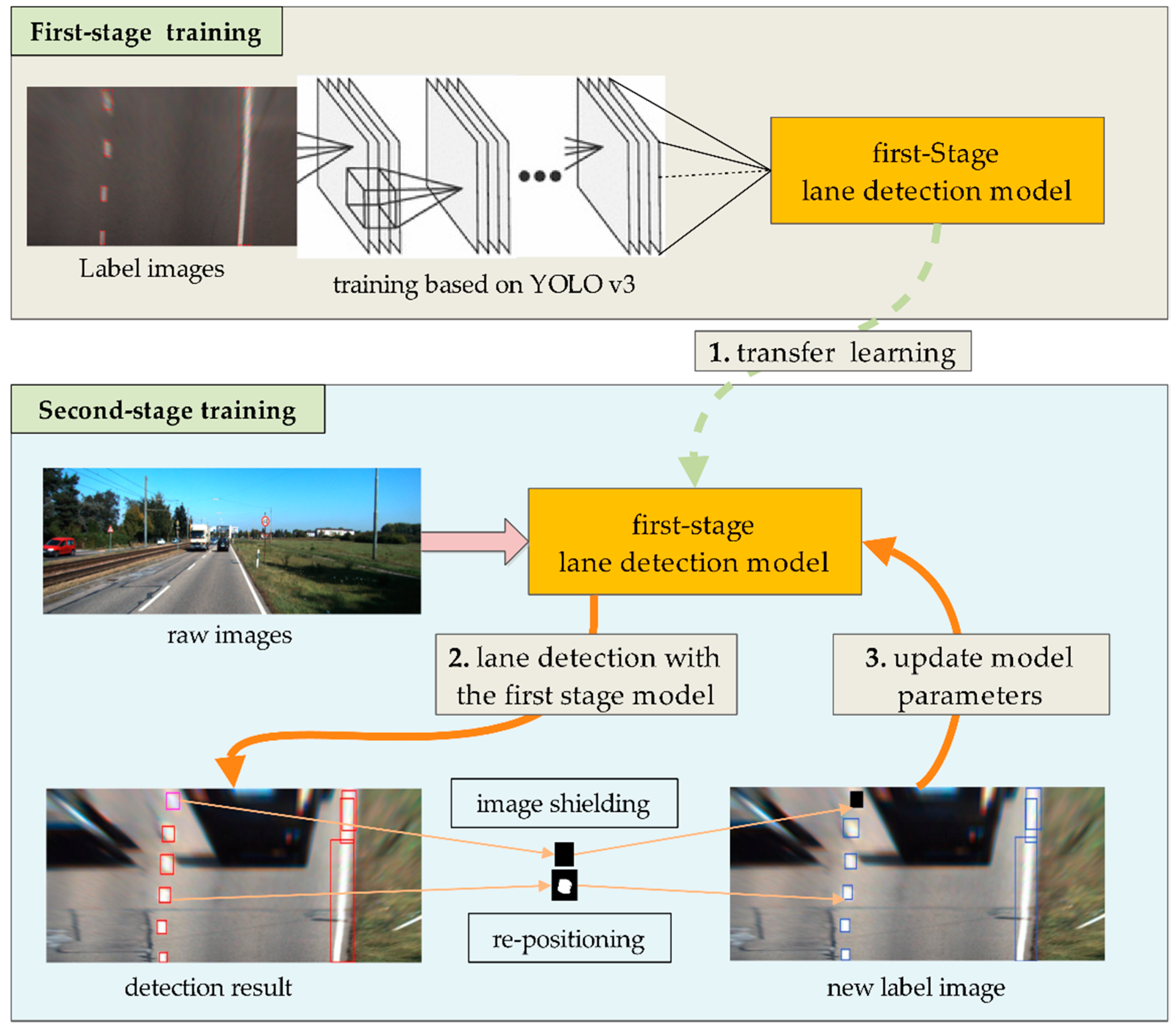
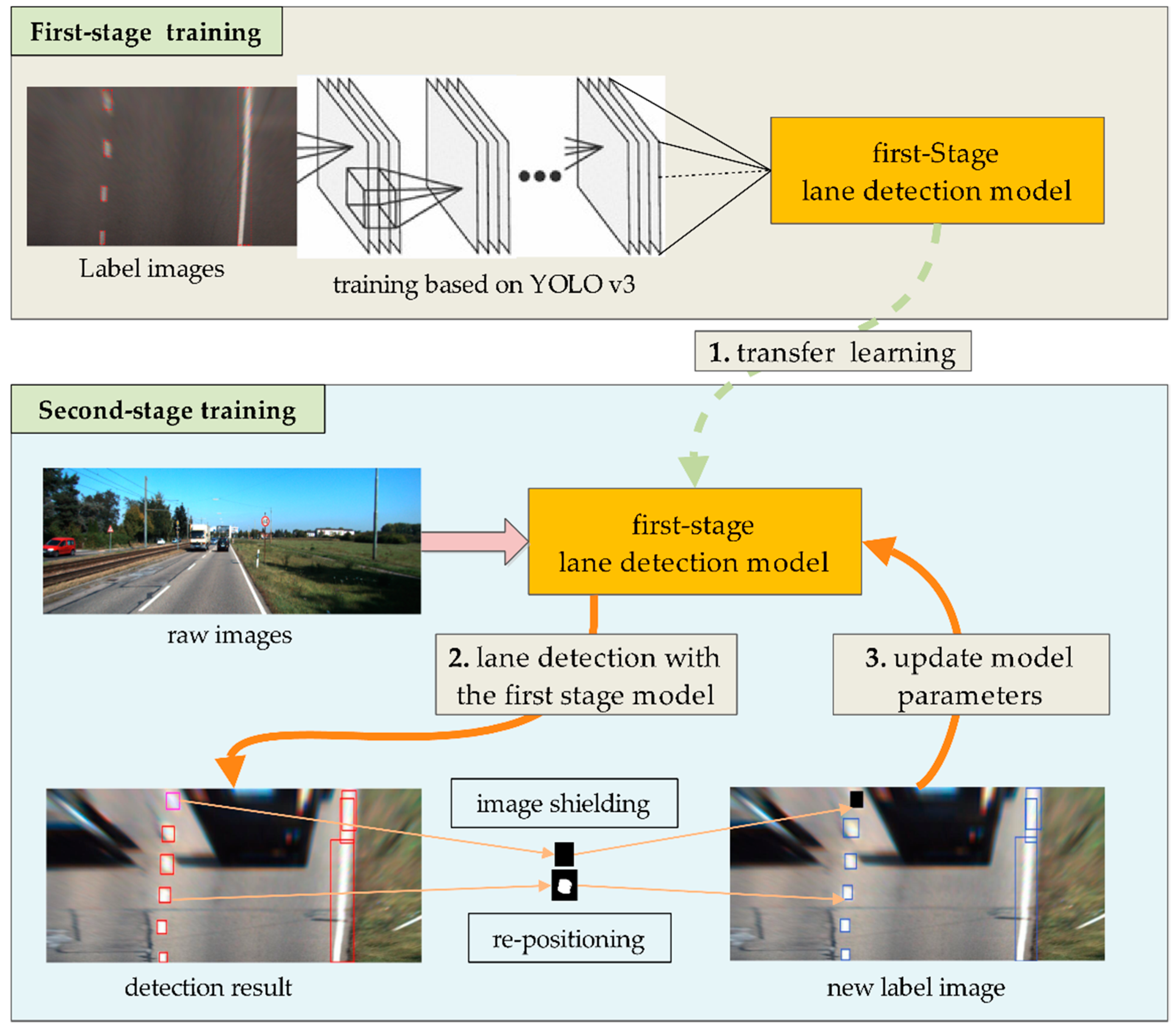
2.3. Adaptive Learning of Lane Features
| Algorithm 1 The second-stage model fine-training algorithm |
| Initialization: |
| 1. Collect the image sets under various scenarios; 2. First-stage model training hlane_1; |
| 3. Set the confidence threshold T; 4. Set the threshold growth factor ζ; |
| 5. Divide images into multiple sets M, of which each contains the batch size number of images |
| Training process: |
| For batch in M: |
| for Xi in batch: |
| 1. Obtain the coordinates, width, and height (x, y, w, h), and confidence ξ using the model hlane_1 |
| if T ≤ ξi: |
| (1) Set a new area of the bounding box as (x, y, w + 2δ, h + 2δ) |
| (2) Determine the lane edge using the adaptive threshold detection algorithm based on the Canny |
| (3) Binarize the area and determine the connected domain of the lane |
| (4) Determine a new bounding box (x’, y’, w’, h’) of the lane |
| else if T/4 ≤ ξi < T: |
| (1) Set a new area of the bounding box as (x, y, w + 2δ, h + 2δ) |
| (2) Set the pixel value in the new area to 0 |
| end |
| end |
| 2. Obtain the processed image sets |
| 3. Make T = T + ζ, retrain hlane_1 |
| end |
2.4. Lane Fitting
3. Experimental and Discussion
3.1. Model Training
3.1.1. Evaluation of Label Image Generation Algorithm
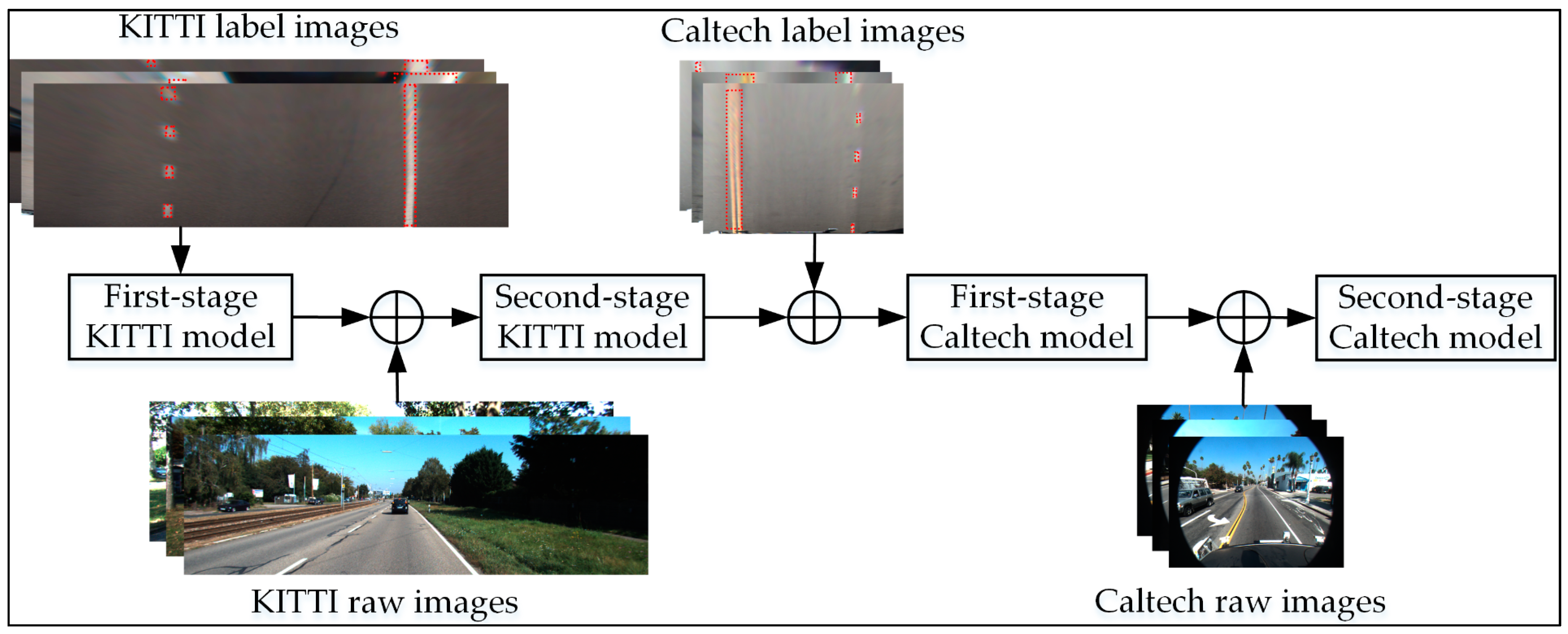
3.1.2. Model Training on KITTI Data Sets
3.1.3. Training of the Second-Stage Model
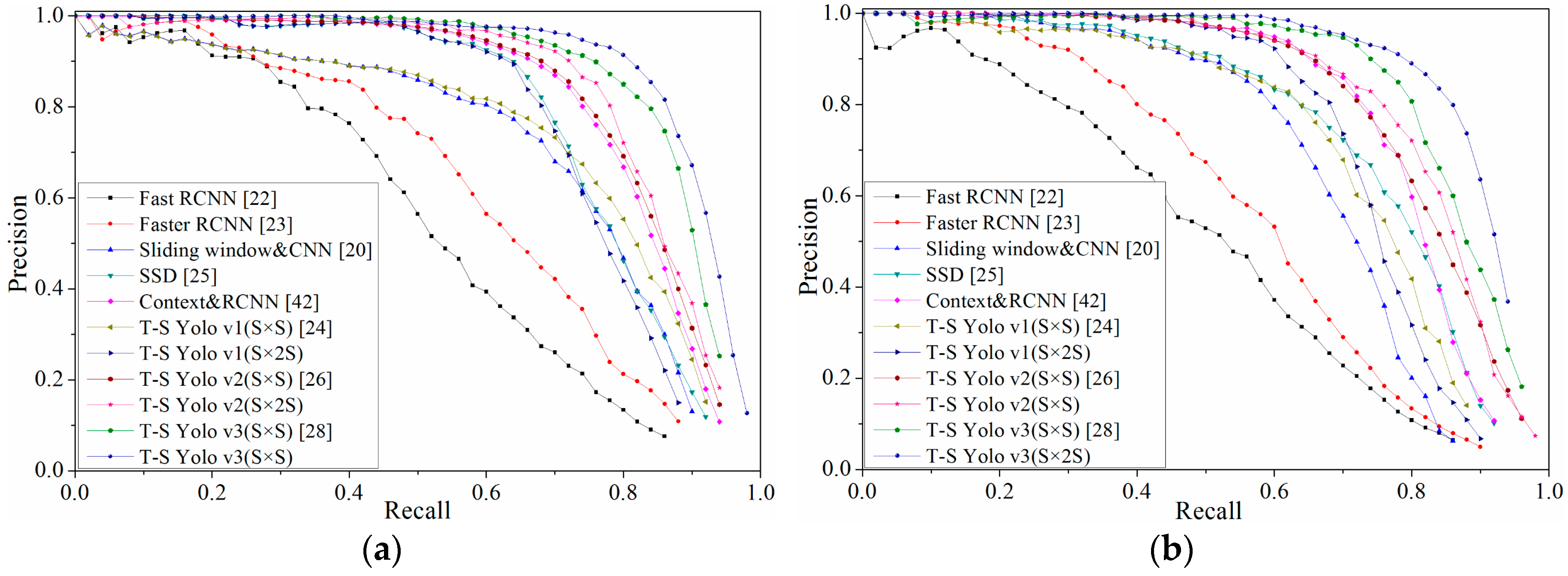
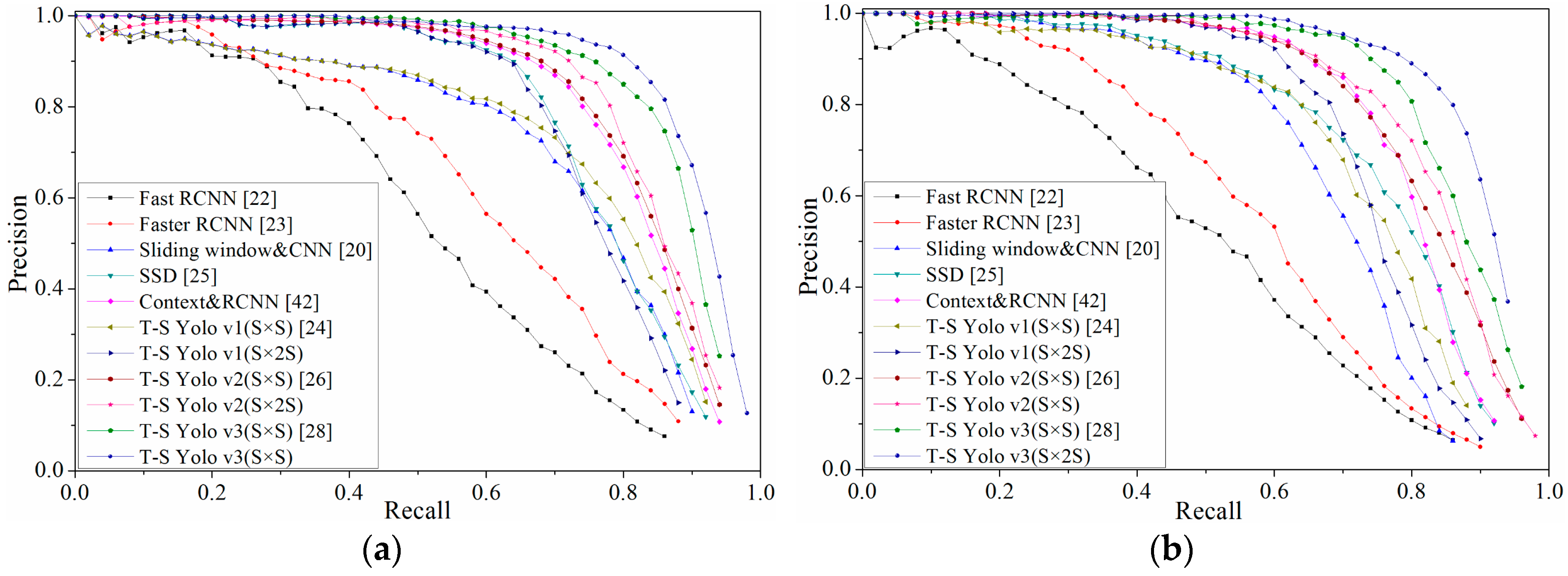
3.2. Evaluation of the Effectiveness of Detection Algorithm
3.3. Lane Line Fitting Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sivaraman, S.; Trivedi, M.M. Integrated lane and vehicle detection, localization, and tracking: A synergistic approach. IEEE Trans. Intell. Transp. Syst. 2013, 14, 906–917. [Google Scholar] [CrossRef]
- Xiang, Z.; Wei, Y.; XiaoLin, T.; Yun, W. An Improved Algorithm for Recognition of Lateral Distance from the Lane to Vehicle Based on Convolutional Neural Network. Available online: http://digital-library.theiet.org/content/journals/10.1049/iet-its.2017.0431 (accessed on 9 April 2018).
- Low, C.Y.; Zamzuri, H.; Mazlan, S.A. Simple robust road lane detection algorithm. In Proceedings of the 2014 5th IEEE Intelligent and Advanced Systems (ICIAS), Kuala Lumpur, Malaysia, 3–5 June 2014; pp. 1–4. [Google Scholar]
- Bounini, F.; Gingras, D.; Lapointe, V.; Pollart, H. Autonomous vehicle and real time road lanes detection and tracking. In Proceedings of the 2015 IEEE Vehicle Power and Propulsion Conference (VPPC), Montreal, QC, Canada, 19–22 October 2015; pp. 1–6. [Google Scholar]
- Ding, D.; Lee, C.; Lee, K.Y. An adaptive road ROI determination algorithm for lane detection. In Proceedings of the 2013 IEEE Region 10 Conference, Xi’an, China, 22–25 October 2013; pp. 1–4. [Google Scholar]
- El Hajjouji, I.; El Mourabit, A.; Asrih, Z.; Mars, S.; Bernoussi, B. FPGA based real-time lane detection and tracking implementation. In Proceedings of the IEEE International Conference on Electrical and Information Technologies (ICEIT) 2016, Tangiers, Morocco, 4–7 May 2016; pp. 186–190. [Google Scholar]
- Shin, J.; Lee, E.; Kwon, K.; Lee, S. Lane detection algorithm based on top-view image using random sample consensus algorithm and curve road model. In Proceedings of the 2014 6th IEEE International Conference on Ubiquitous and Future Networks (ICUFN), Shanghai, China, 8–11 July 2014; pp. 1–2. [Google Scholar]
- Tang, X.; Zou, L.; Yang, W.; Huang, Y.; Wang, H. Novel mathematical modelling methods of comprehensive mesh stiffness for spur and helical gears. Appl. Math. Model. 2018, 64, 524–540. [Google Scholar] [CrossRef]
- De Paula, M.B.; Jung, C.R. Automatic detection and classification of road lane markings using onboard vehicular cameras. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3160–3169. [Google Scholar] [CrossRef]
- Chi, F.H.; Huo, C.L.; Yu, Y.H.; Sun, T.Y. Forward vehicle detection system based on lane-marking tracking with fuzzy adjustable vanishing point mechanism. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2012, Brisbane, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Revilloud, M.; Gruyer, D.; Rahal, M.C. A lane marker estimation method for improving lane detection. In Proceedings of the 2016 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 289–295. [Google Scholar]
- Tang, X.; Hu, X.; Yang, W.; Yu, H. Novel torsional vibration modeling and assessment of a power-split hybrid electric vehicle equipped with a dual-mass flywheel. IEEE Trans. Veh. Technol. 2018, 67, 1990–2000. [Google Scholar] [CrossRef]
- Shin, S.; Shim, I.; Kweon, I.S. Combinatorial approach for lane detection using image and LiDAR reflectance. In Proceedings of the 2015 19th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang, Korea, 28–30 October 2015; pp. 485–487. [Google Scholar]
- Rose, C.; Britt, J.; Allen, J.; Bevly, D. An integrated vehicle navigation system utilizing lane-detection and lateral position estimation systems in difficult environments for GPS. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2615–2629. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Brust, C.A.; Sickert, S.; Simon, M.; Rodner, E.; Denzler, J. Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding. Available online: https://arxiv.org/abs/1502.06344 (accessed on 23 February 2015).
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as Deep: Spatial CNN for Traffic Scene Understanding. 2017. Available online: https://arxiv.org/abs/1712.06080 (accessed on 17 December 2017).
- Satzoda, R.K.; Trivedi, M.M. Efficient lane and vehicle detection with integrated synergies (ELVIS). In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 708–713. [Google Scholar]
- Kim, J.; Lee, M. Robust lane detection based on convolutional neural network and random sample consensus. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 454–461. [Google Scholar]
- Borkar, A.; Hayes, M.; Smith, M.T. Robust lane detection and tracking with RANSAC and Kalman filter. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP) 2009, Cairo, Egypt, 7–10 November 2009; pp. 3261–3264. [Google Scholar]
- Li, J.; Mei, X.; Prokhorov, D.; Tao, D. Deep neural network for structural prediction and lane detection in traffic scene. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 690–703. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Wang, Z.; Xiang, C.; Dong, M.; Hu, C.; Wang, R. A novel global sensitivity analysis on the observation accuracy of the coupled vehicle model. Veh. Syst. Dyn. 2018, 1–22. [Google Scholar] [CrossRef]
- Ahmed, E.; Clark, A.; Mohay, G. A novel sliding window based change detection algorithm for asymmetric traffic. In Proceedings of the 2008 IFIP International Conference on Network and Parallel Computing (NPC) 2008, Shanghai, China, 8–21 October 2008; pp. 168–175. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 6, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. Available online: https://arxiv.org/abs/1612.08242 (accessed on 9 April 2018).
- Tang, X.; Yang, W.; Hu, X.; Zhang, D. A novel simplified model for torsional vibration analysis of a series-parallel hybrid electric vehicle. Mech. Syst. Signal Process. 2017, 85, 329–338. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Vial, R.; Zhu, H.; Tian, Y.; Lu, S. Search video action proposal with recurrent and static YOLO. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2035–2039. [Google Scholar]
- Alvar, S.R.; Bajić, I.V. MV-YOLO: Motion Vector-Aided Tracking by Semantic Object Detection. Available online: https://arxiv.org/abs/1805.00107 (accessed on 15 June 2018).
- Nugraha, B.T.; Su, S.F. Towards self-driving car using convolutional neural network and road lane detector. In Proceedings of the 2nd International Conference on Automation, Cognitive Science, Optics, Micro Electro-Mechanical System, and Information Technology (ICACOMIT 2017), Jakarta, Indonesia, 23–24 October 2017; pp. 65–69. [Google Scholar]
- Ning, G.; Zhang, Z.; Huang, C.; Ren, X.; Wang, H.; Cai, C.; He, Z. Spatially supervised recurrent convolutional neural networks for visual object tracking. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Borkar, A.; Hayes, M.; Smith, M.T. A novel lane detection system with efficient ground truth generation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 365–374. [Google Scholar] [CrossRef]
- Duong, T.T.; Pham, C.C.; Tran, T.H.P.; Nguyen, T.P.; Jeon, J.W. Near real-time ego-lane detection in highway and urban streets. In Proceedings of the IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia 2016), Seoul, Korea, 26–28 October 2016; pp. 1–4. [Google Scholar]
- López-Rubio, F.J.; Domínguez, E.; Palomo, E.J.; López-Rubio, E.; Luque-Baena, R.M. Selecting the color space for self-organizing map based foreground detection in video. Neural Process Lett. 2016, 43, 345–361. [Google Scholar] [CrossRef]
- Liang, P.; Blasch, E.; Ling, H. Encoding color information for visual tracking: Algorithms and benchmark. IEEE Trans. Image Process. 2015, 24, 5630–5644. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, L.; Huang, H.; Li, X.; Xu, W.; Zheng, L.; Huang, J. Nighttime lane markings recognition based on Canny detection and Hough transform. In Proceedings of the IEEE International Conference on Real-time Computing and Robotics (RCAR 2016), Angkor Wat, Cambodia, 6–10 June 2016; pp. 411–415. [Google Scholar]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Zhang, X.; Zhuang, Y.; Wang, W.; Pedrycz, W. Online Feature Transformation Learning for Cross-Domain Object Category Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2857–2871. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Sayrol, E.; Giro-I-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 598–606. [Google Scholar]
- Ying, Z.; Li, G.; Tan, G. An illumination-robust approach for feature-based road detection. In Proceedings of the 2015 IEEE International Symposium on Multimedia (ISM), Miami, FL, USA, 14–16 December 2015; pp. 278–281. [Google Scholar]
- Tian, Y.; Gelernter, J.; Wang, X.; Chen, W.; Gao, J.; Zhang, Y.; Li, X. Lane marking detection via deep convolutional neural network. Neurocomputing 2018, 280, 46–55. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | KITTI | Caltech | ||
|---|---|---|---|---|
| mAP (%) | Speed (ms) | mAP (%) | Speed (ms) | |
| Fast RCNN [25] | 49.87 | 2271 | 53.13 | 2140 |
| Faster RCNN [26] | 58.78 | 122 | 61.73 | 149 |
| Sliding window & CNN [23] | 68.98 | 79,000 | 71.26 | 42,000 |
| SSD [28] | 75.73 | 29.3 | 77.39 | 25.6 |
| Context & RCNN [45] | 79.26 | 197 | 81.75 | 136 |
| Yolo v1 (S × S) [27] | 72.21 | 44.7 | 73.92 | 45.2 |
| T-S Yolo v1 (S × 2S) | 74.67 | 45.1 | 75.69 | 45.4 |
| Yolo v2 (S × S) [29] | 81.64 | 59.1 | 82.81 | 58.5 |
| T-S Yolo v2 (S × 2S) | 83.16 | 59.6 | 84.07 | 59.2 |
| Yolo v3 (S × S) [31] | 87.42 | 24.8 | 88.44 | 24.3 |
| T-S Yolo v3 (S × 2S) | 88.39 | 25.2 | 89.32 | 24.7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yang, W.; Tang, X.; Liu, J. A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3. Sensors 2018, 18, 4308. https://doi.org/10.3390/s18124308
Zhang X, Yang W, Tang X, Liu J. A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3. Sensors. 2018; 18(12):4308. https://doi.org/10.3390/s18124308
Chicago/Turabian StyleZhang, Xiang, Wei Yang, Xiaolin Tang, and Jie Liu. 2018. "A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3" Sensors 18, no. 12: 4308. https://doi.org/10.3390/s18124308
APA StyleZhang, X., Yang, W., Tang, X., & Liu, J. (2018). A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3. Sensors, 18(12), 4308. https://doi.org/10.3390/s18124308