Full-Duplex Multi-Hop Wireless Networks Optimization with Successive Interference Cancellation

Abstract
:1. Introduction
2. The Mathematical Model for FD-SIC Multi-Hop Wireless Networks
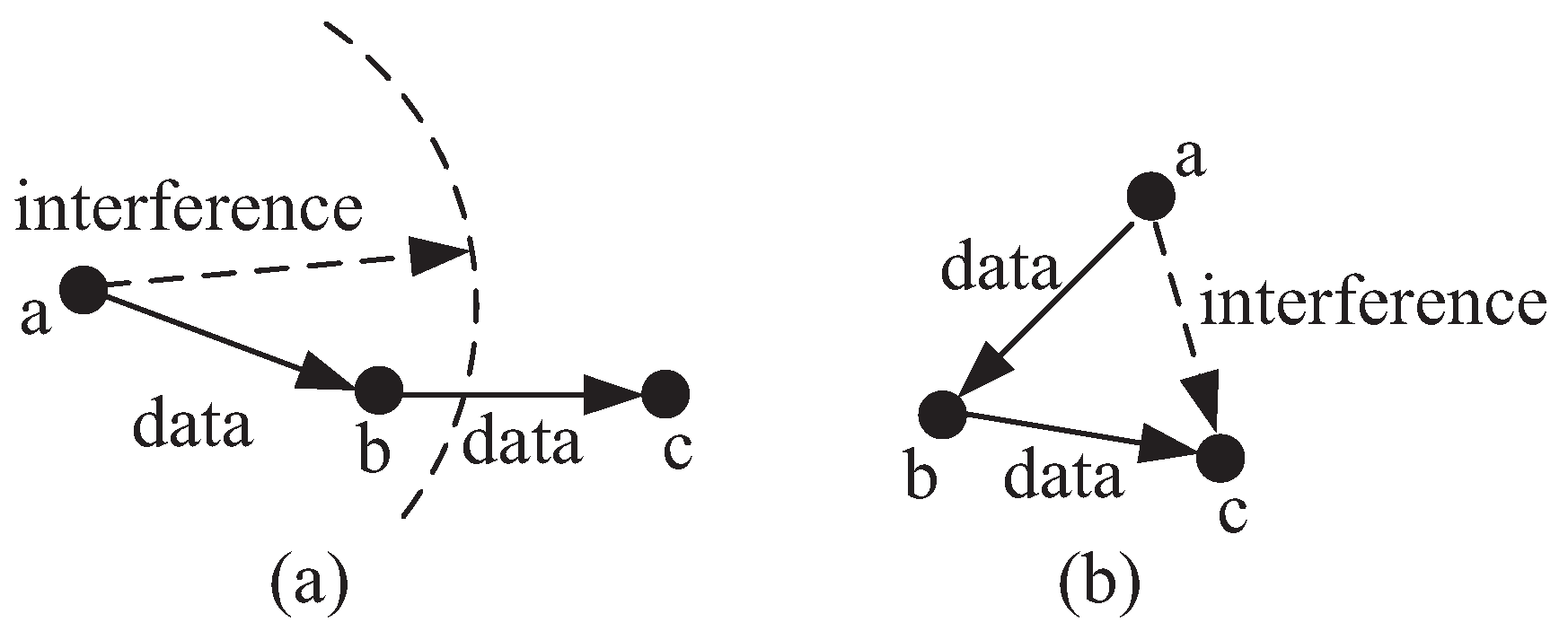
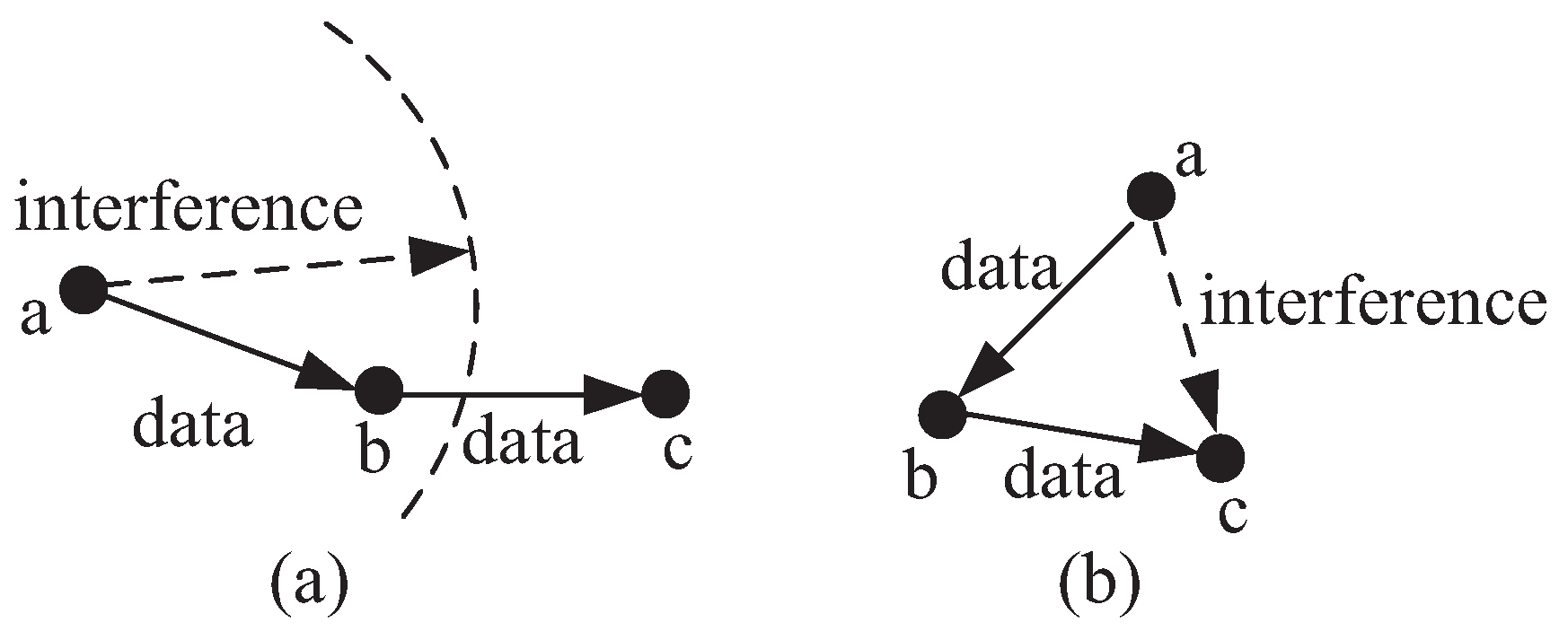
2.1. Physical Layer and Link Layer Model
2.2. Network Layer Model and Problem Formulation
3. Optimization for FD-SIC Multi-Hop Wireless Networks
3.1. Main Idea
- I
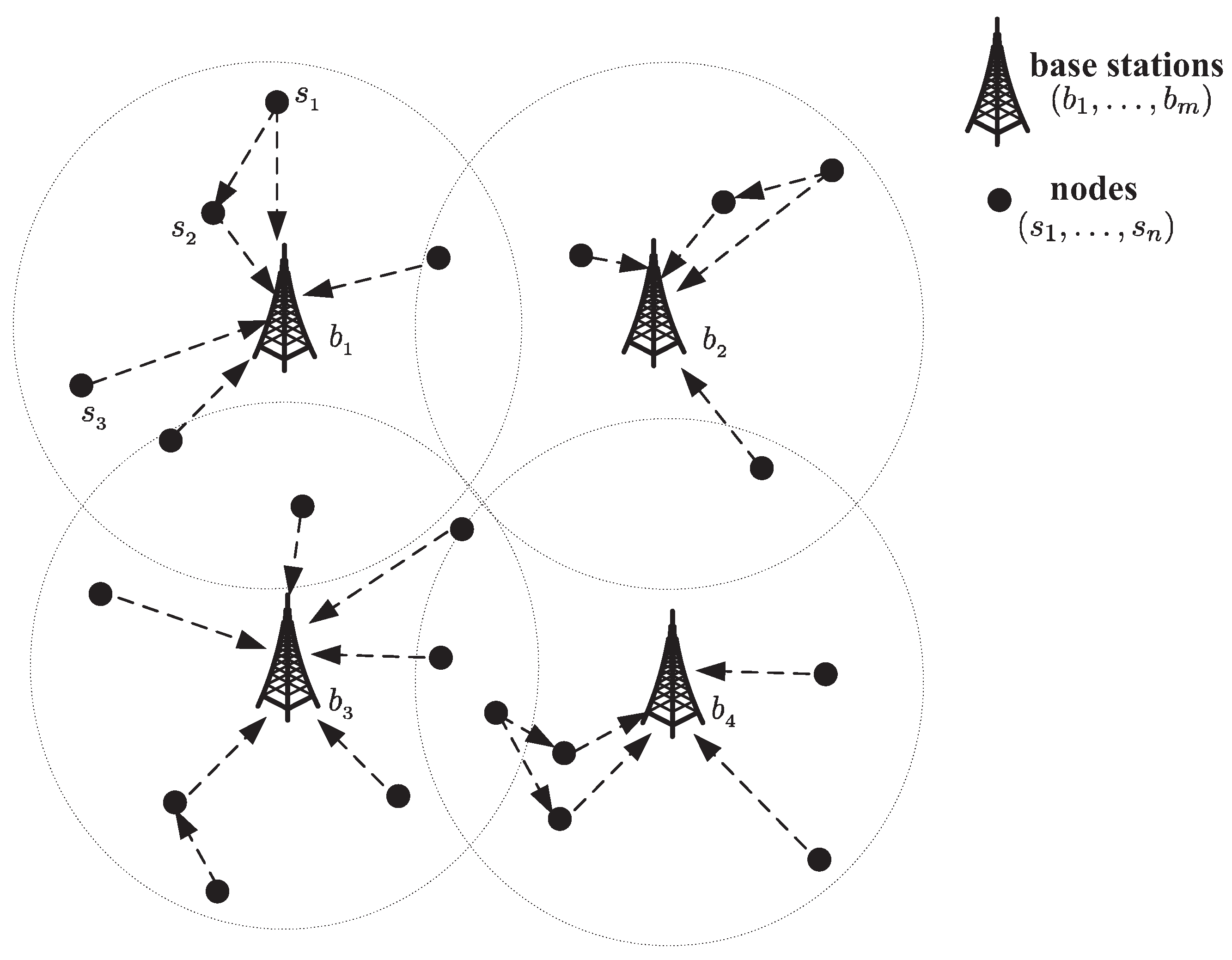
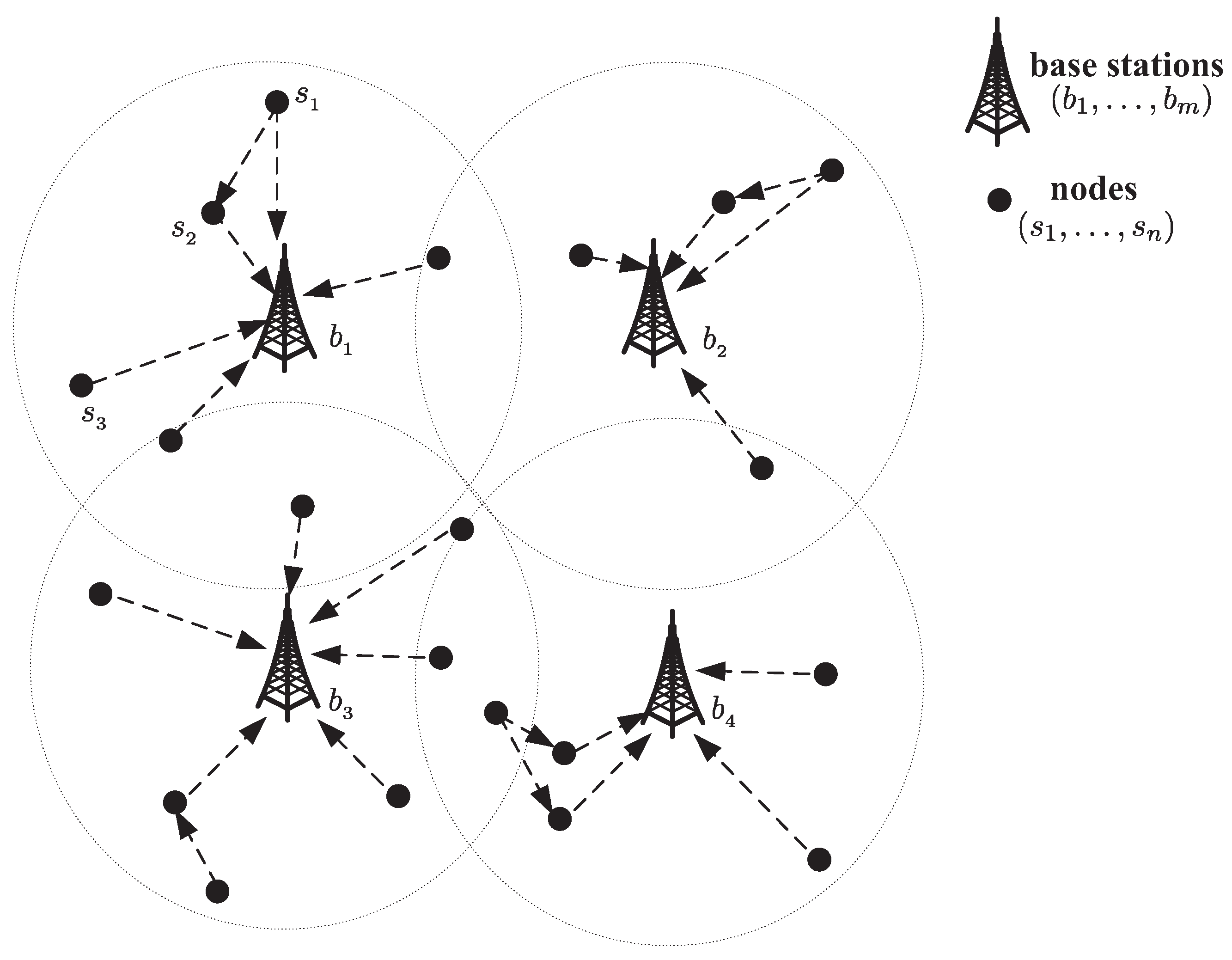
- Divide the whole area into several regions. Each region includes one base station and many sensor nodes. Each sensor node will only communicate with the base station in the same region, and base stations can communicate with each other.
- II.
- III.
- Under current and values, calculate K, all and values by Equation (10).
- IV.
- Try to improve the current scheduling solution ( and values), thus K may be increased. If we can find a way to increase K, then go back to Step III, else our algorithm terminates.
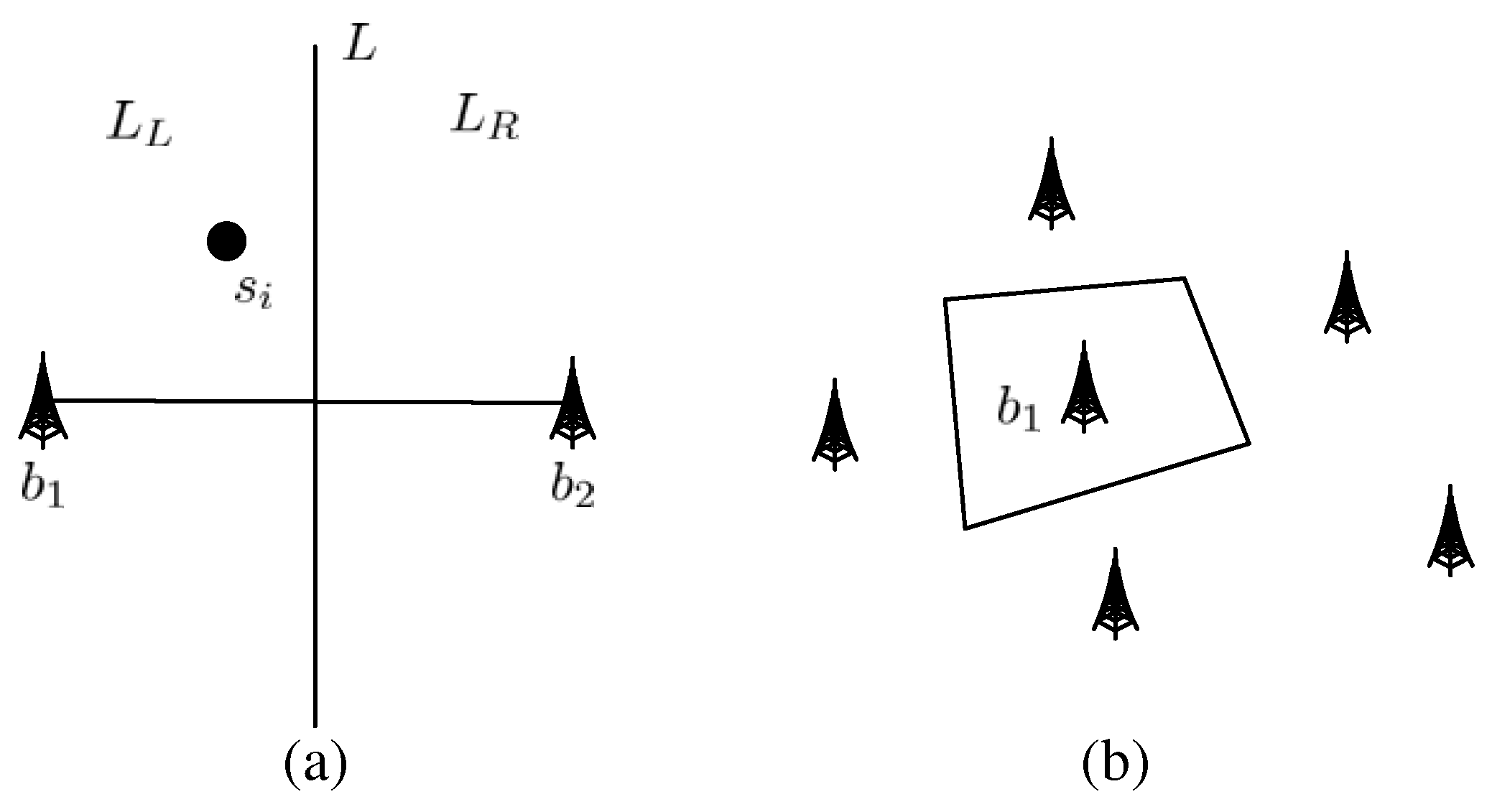
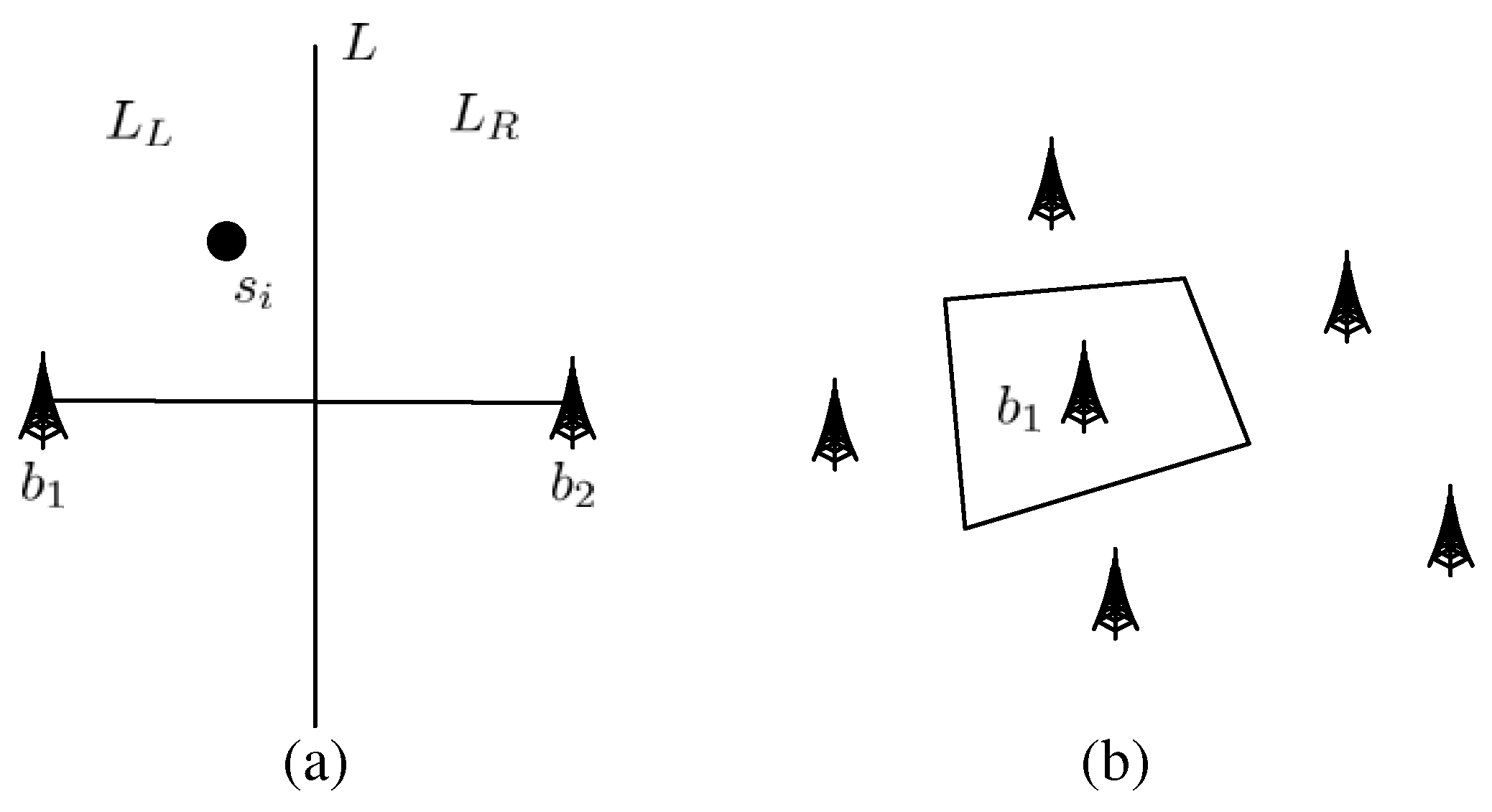
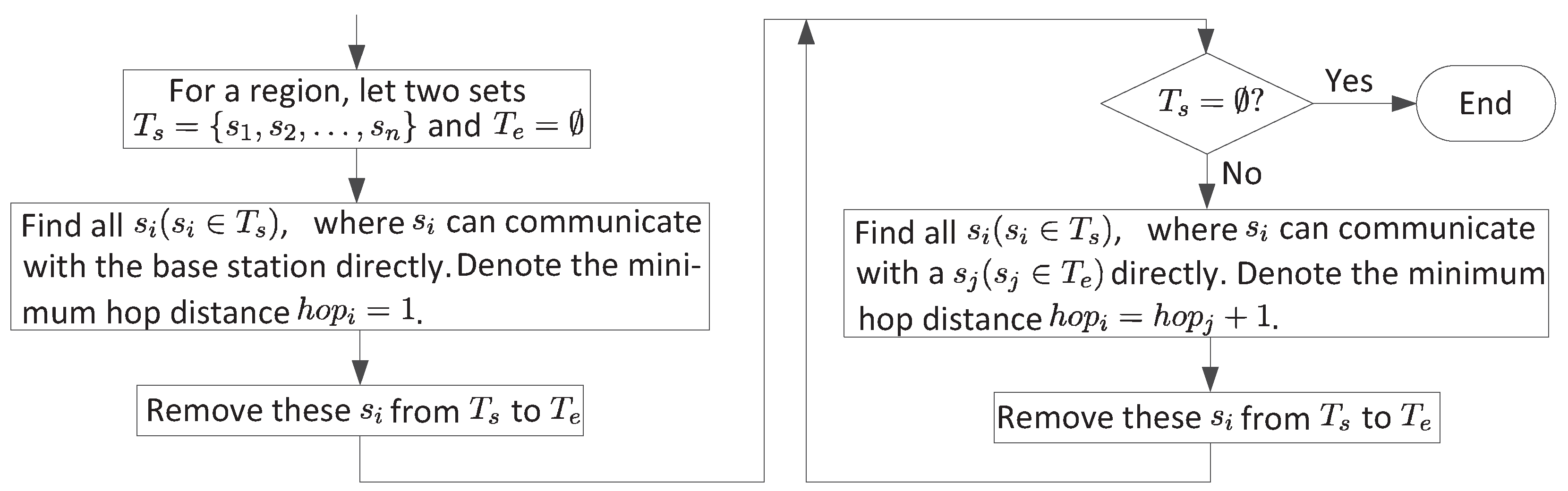
3.2. Base Station Selection
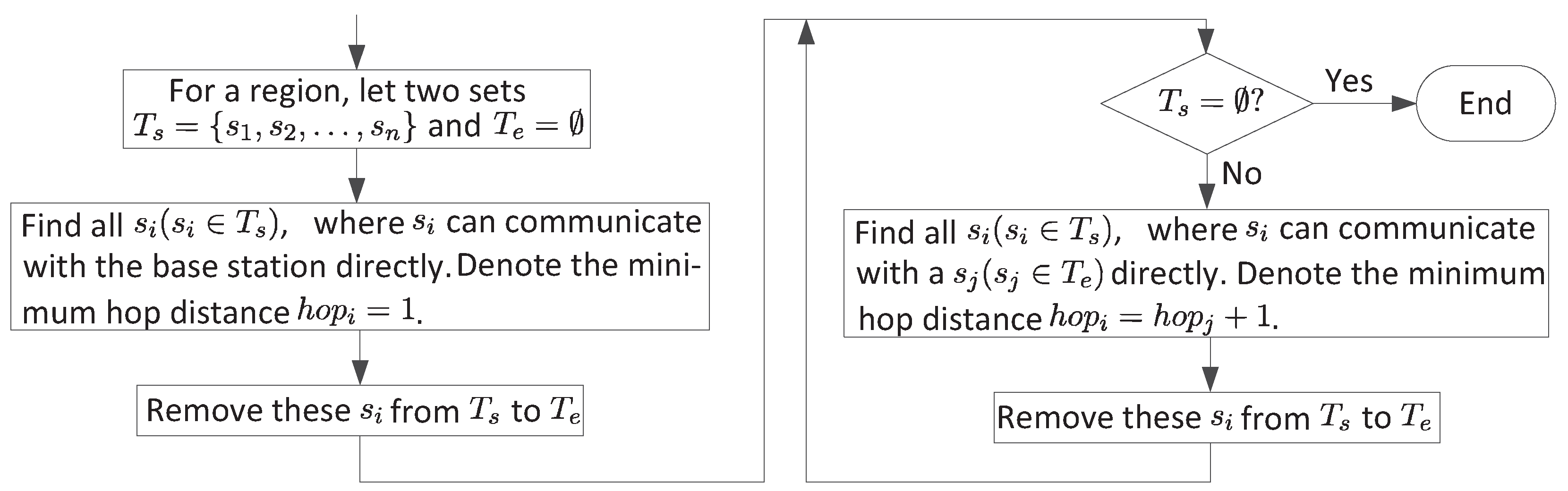
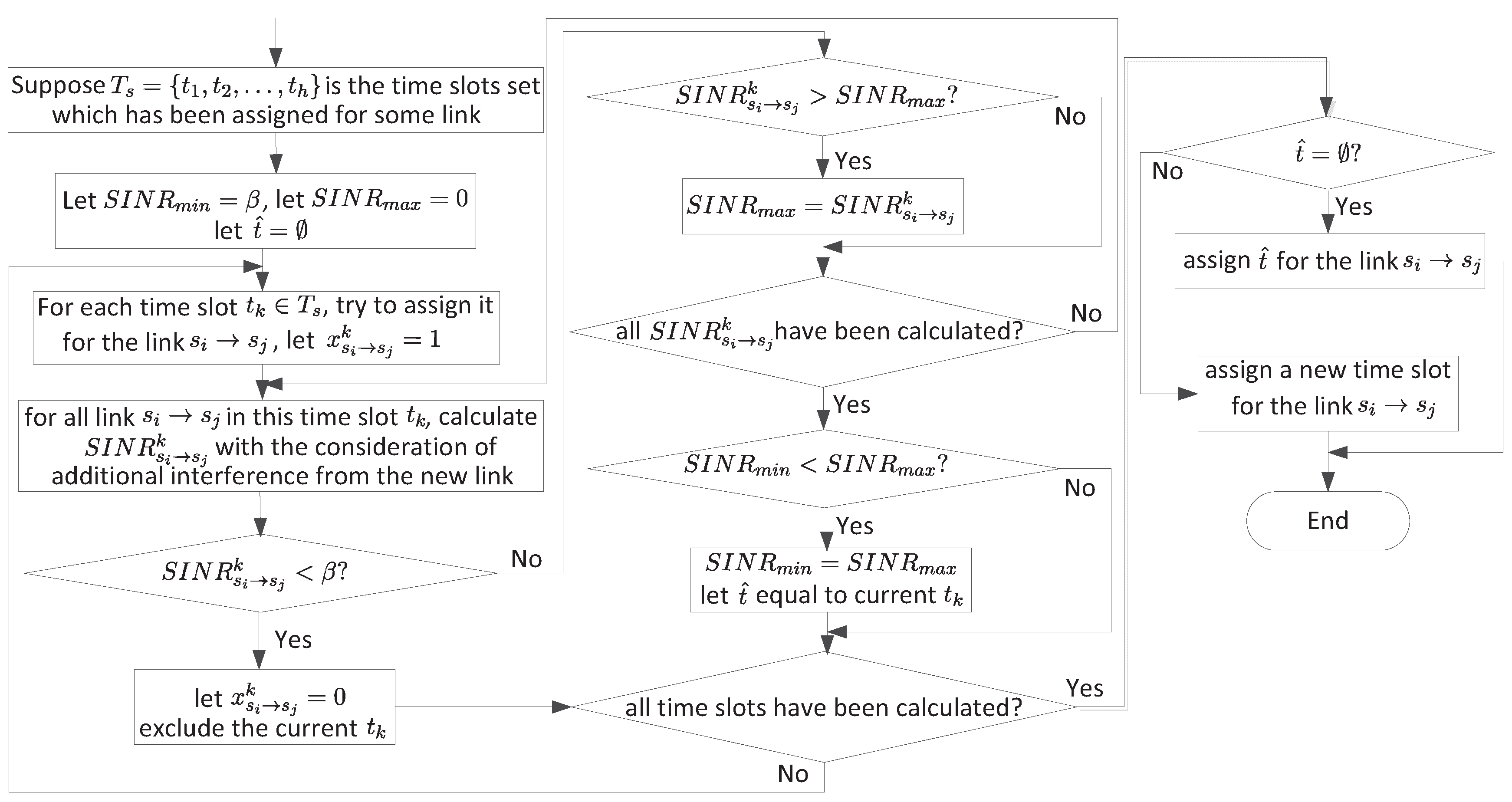
3.3. Establish the First Routing Paths
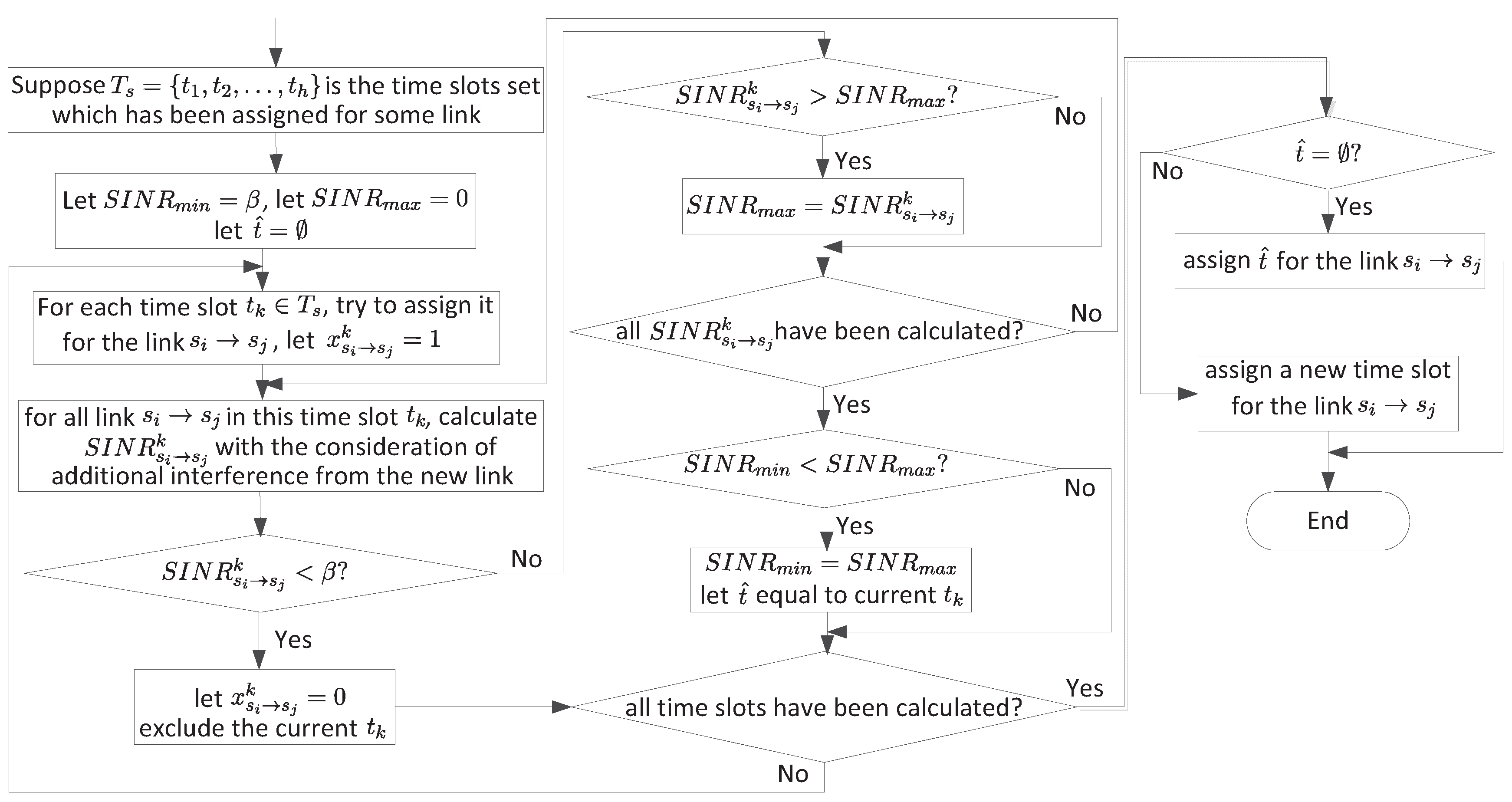
- When a link is created, we first try to assign a time slot already used by some other link. If this time slot cannot be used (i.e., the assignment makes some existing links or the new link with ), then we should consider another existing time slot. If no existing time slots can be used, we assign a new time slot. Otherwise, an available time slot is found.
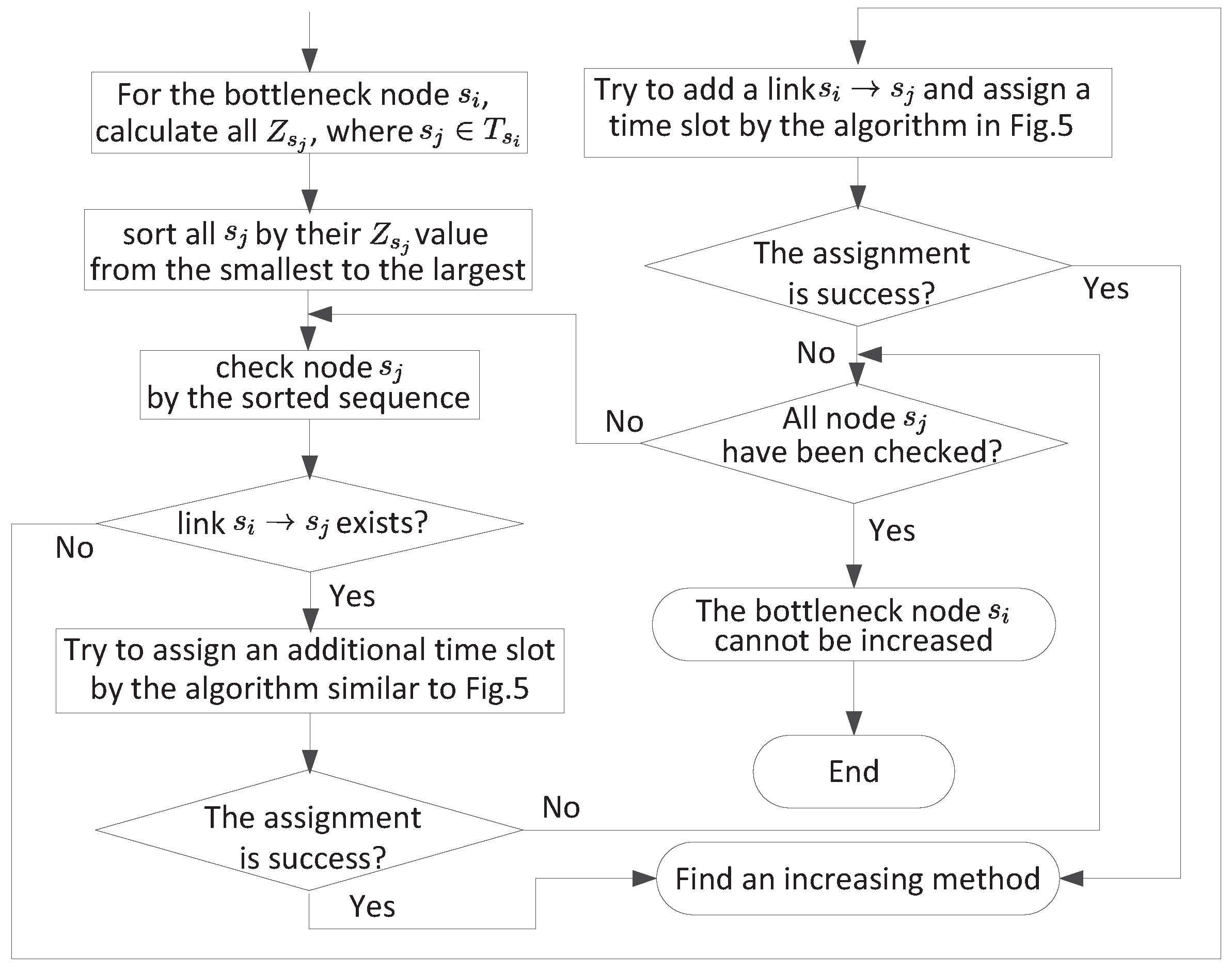
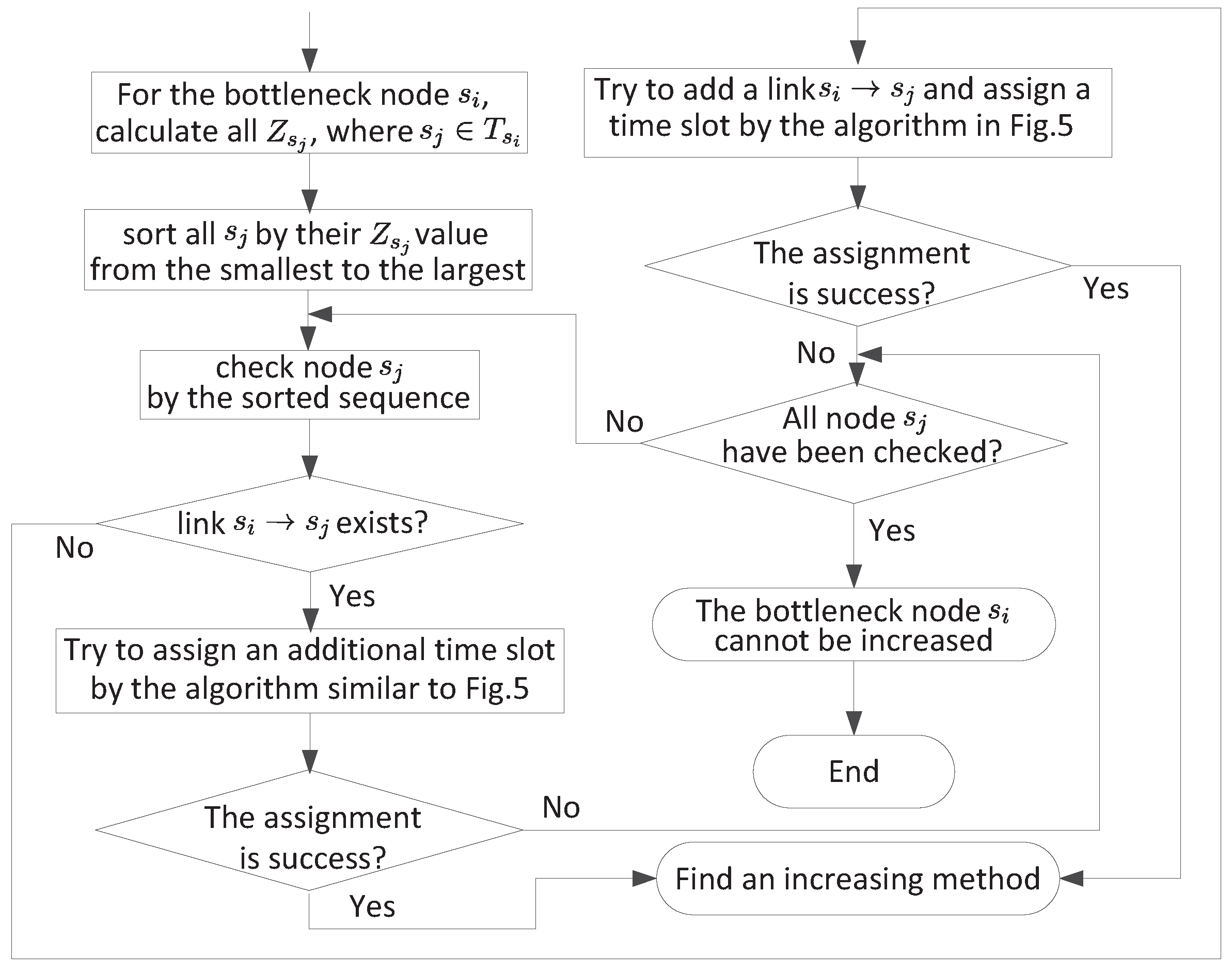
3.4. Improve the Current Scheduling Solution
- Possible improvement by a new time slot. For each out-going link , we can revise the algorithm in Figure 5 to determine a suitable time slot. That is, instead of considering all time slots, we only consider time slots not used by link . Once a new time slot is found, possible improvement on link is while possible improvement from node to the base station is . Thus, possible improvement is . Note that, for the link , possible improvement is .
- Possible improvement by a new link. For a new link, we can apply the algorithm in Figure 5 to determine a suitable time slot. Once a new time slot is found, possible improvement is again for the link , or for the link .
3.5. Complexity
- To identify hop distance for all nodes, we need to visit all neighboring nodes of each node. The complexity is , where E is the number of all possible links.
- The complexity to select a next hop node for each node is .
- The complexity to assign a time slot to the first link is . To analyze the complexity to assign a time slot for the th link, we assume that previous e links use time slots. When we consider a used time slot for the th link, we need to check up to SINR values, where is the number of links in this time slot. In the worst case, we may check up to SINR values and then decide to assign a new time slot. The complexity is . Thus, the total complexity for time slot assignment is at most .
- The complexity to identify bottleneck node is .
- To calculate possible improvement for a neighboring node, we need to solve a maximum flow problem. Some algorithms (e.g., Push-relabel algorithm with FIFO vertex selection rule) for the maximum flow problem have complexity . The total complexity for a node ’s neighbors is .
- Sorting neighbors has a complexity .
- To analyze the complexity of assigning an additional time slot for an existing link, we assume that other links use time slots. We need to check up to e SINR values. In the worst case, we may find that time slots are not available and then assign a new time slot. The complexity is .To analyze the complexity of assigning a time slot for a new link, we assume that previous e links use time slots. When we consider a used time slot, we need to check up to SINR values. In the worst case, we may find that time slots are not available and then assign a new time slot. The complexity is .Thus, the total complexity to assign a new time slot or add a new link is .
- The complexity of solving an LP in Equation (10) is again .
4. Simulation Results
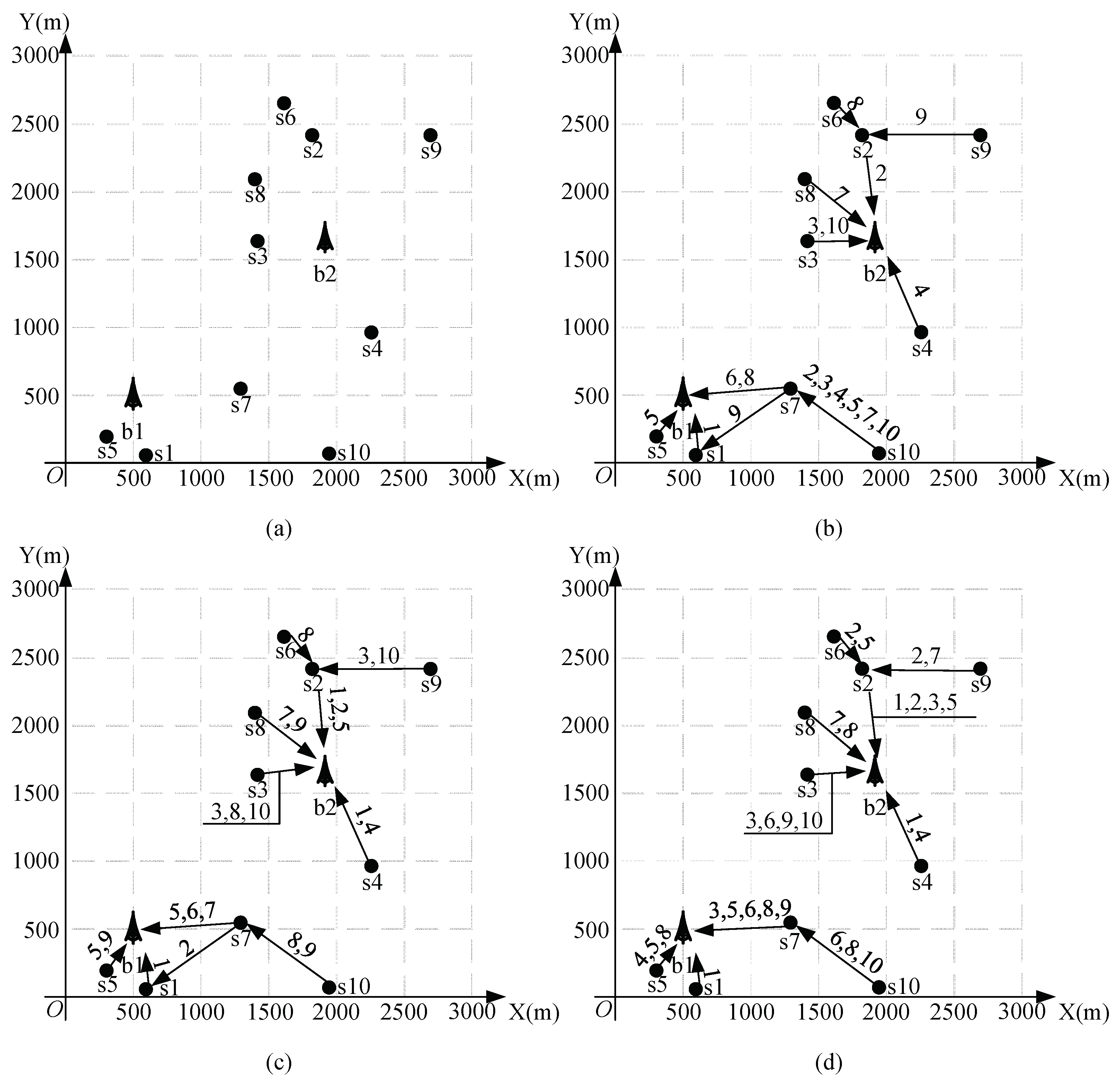
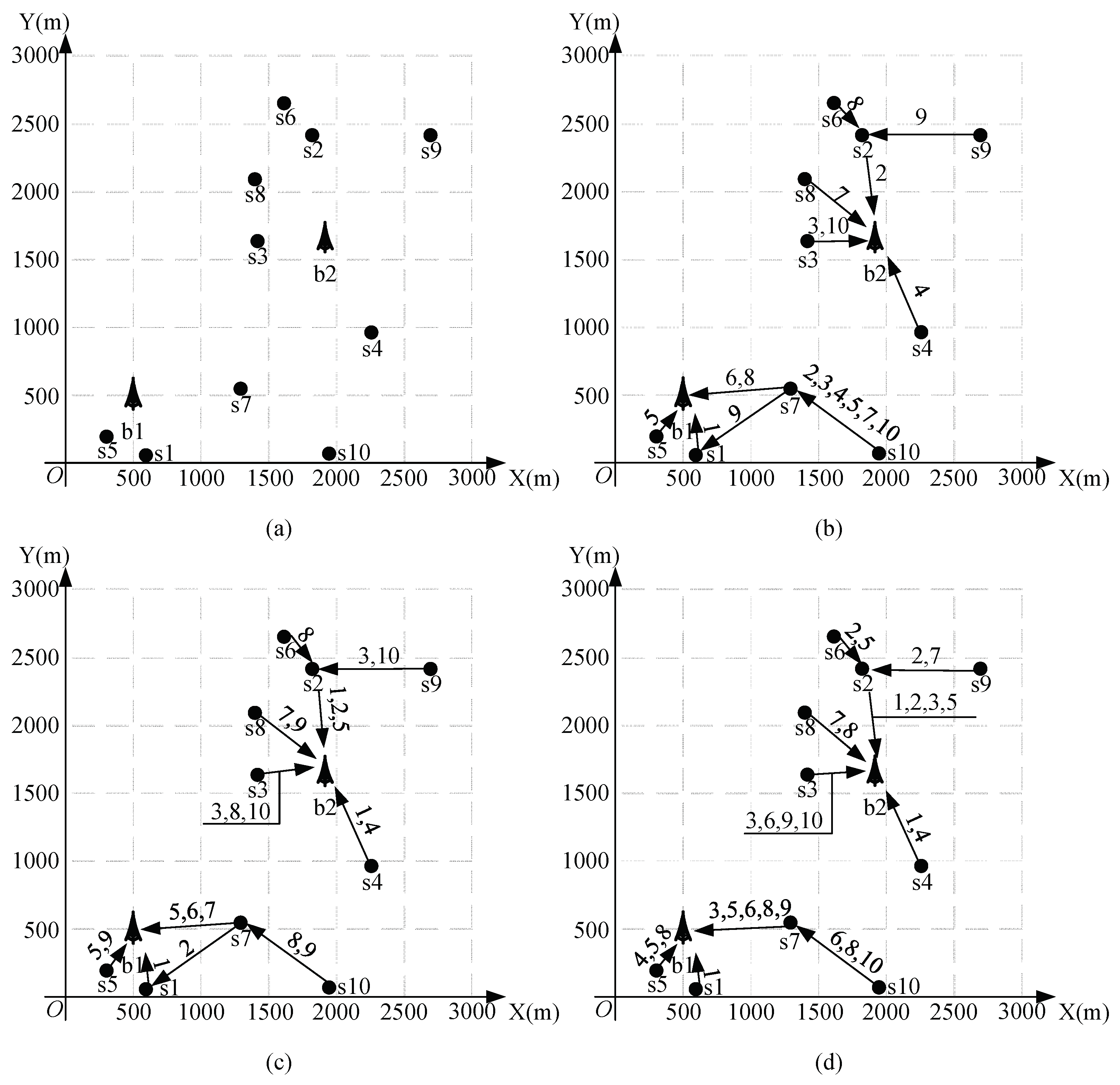
4.1. Results for a Multi-Hop Network with 10 Nodes and 2 Base Stations
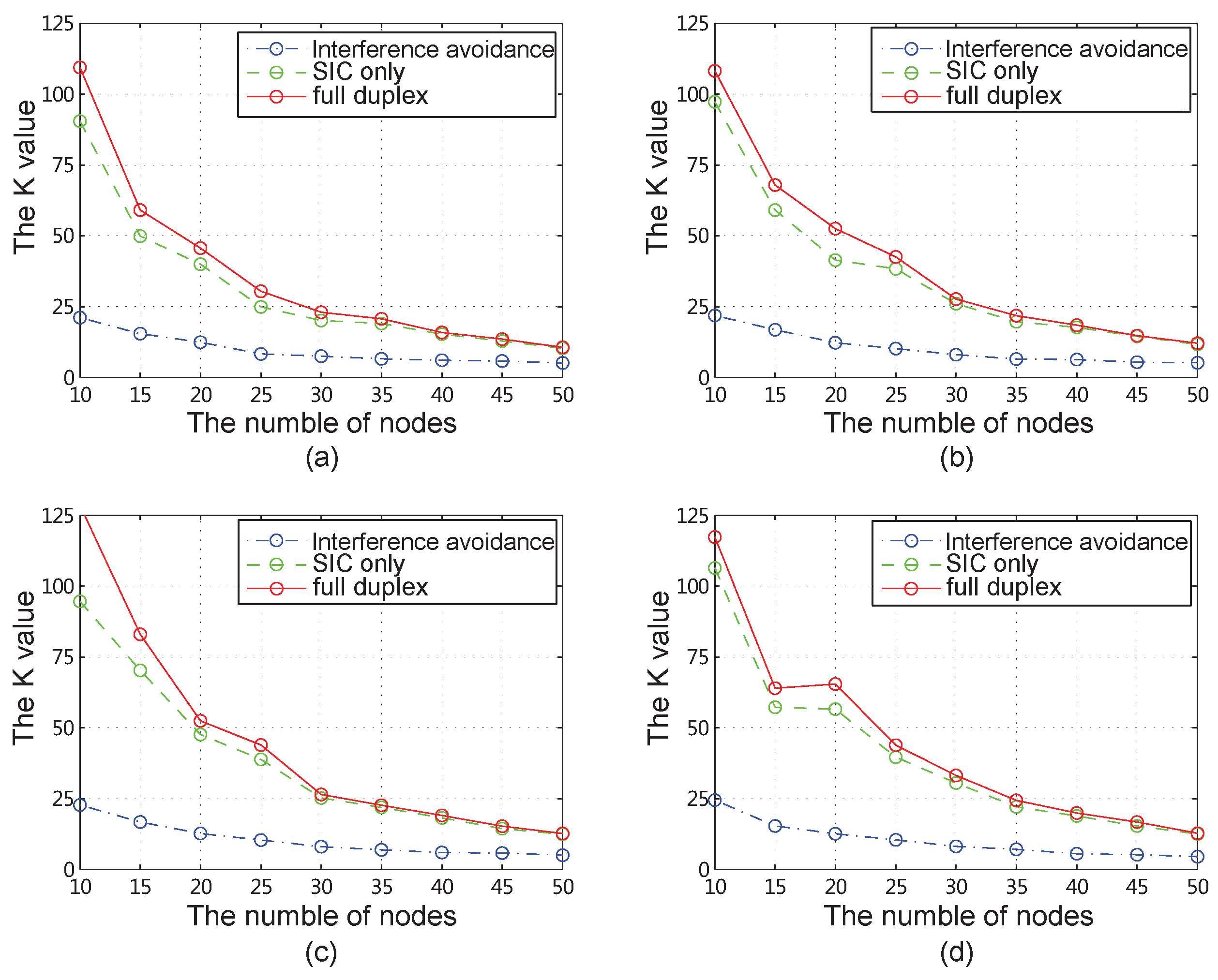
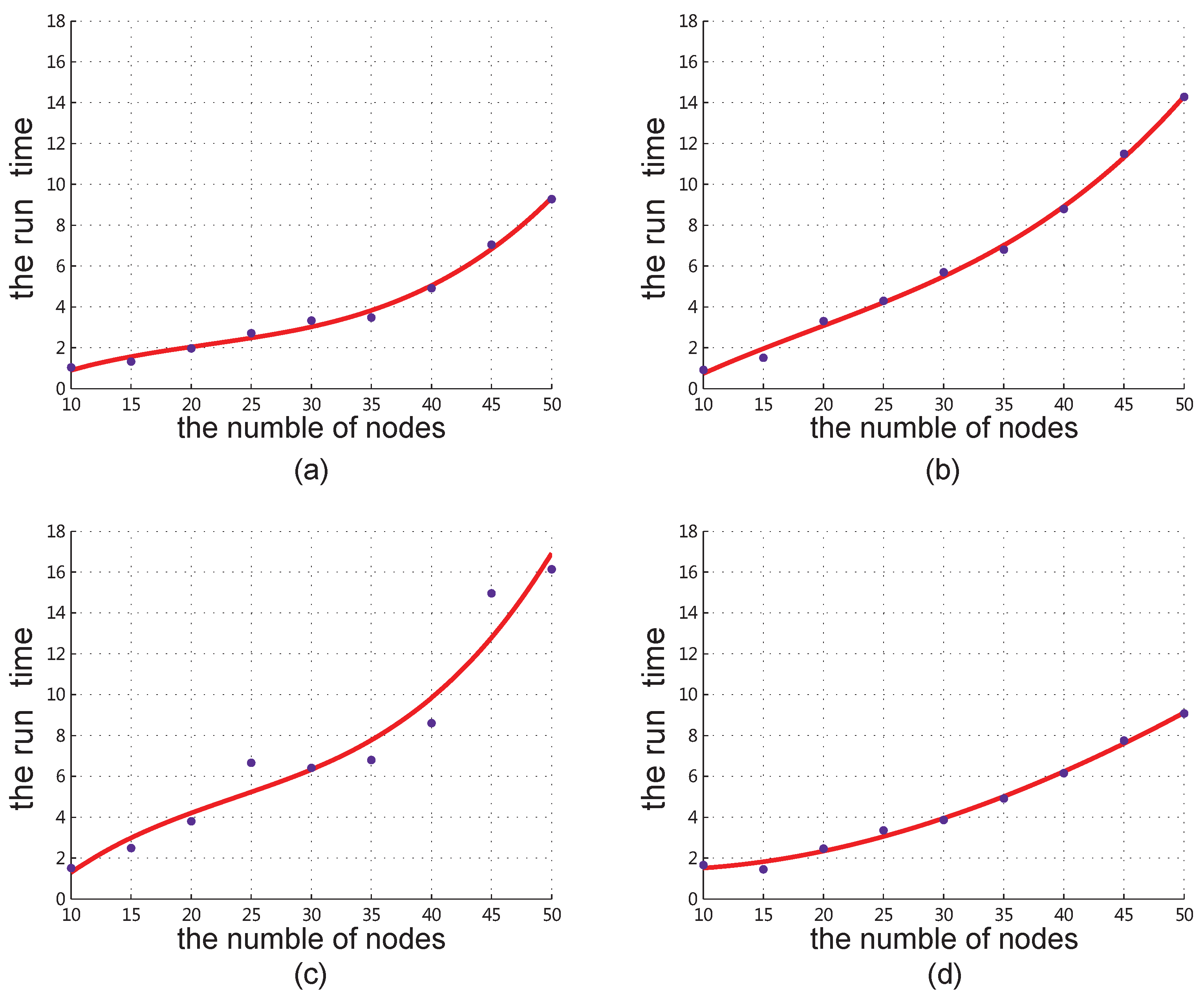
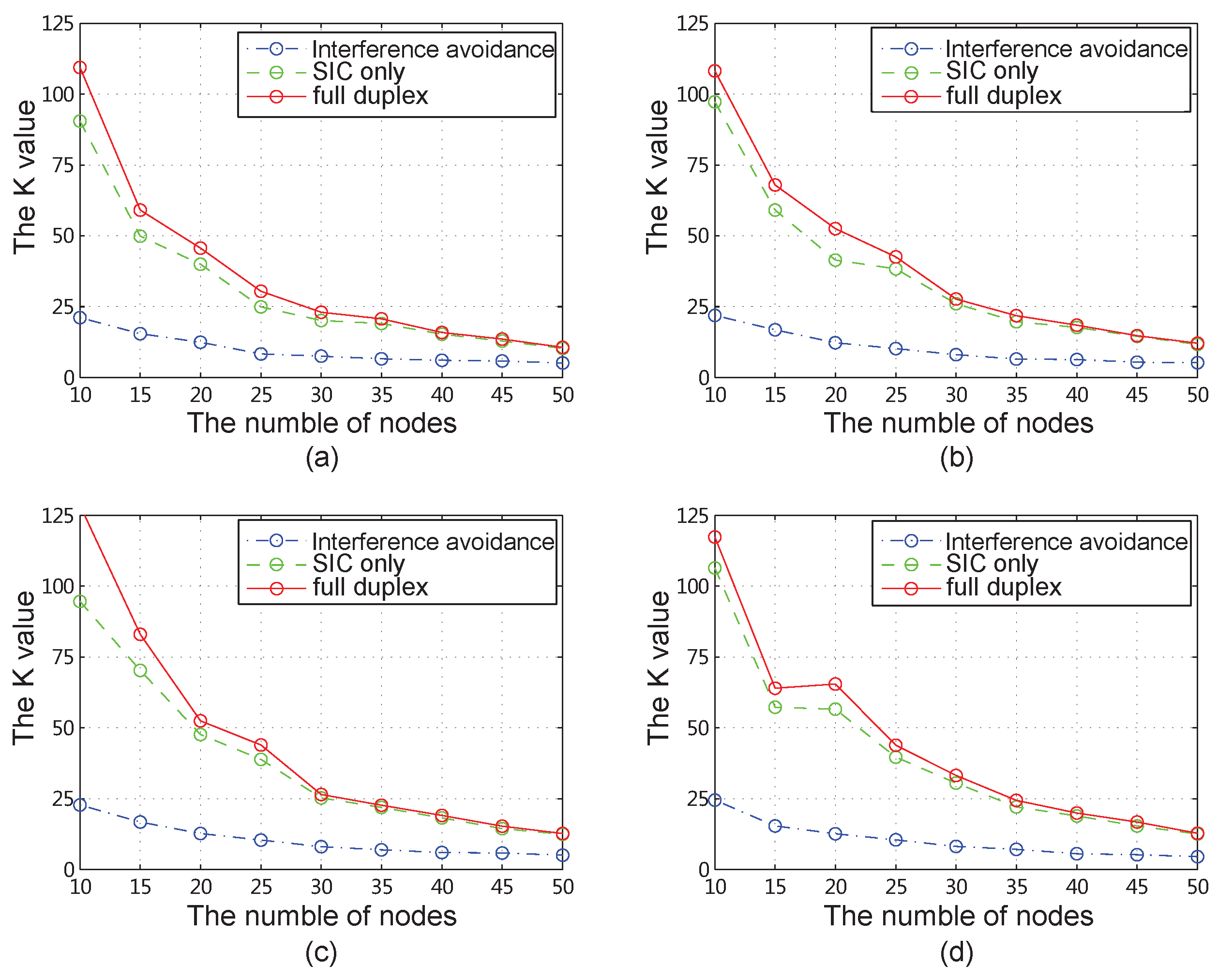
4.2. Results for All Network Instances
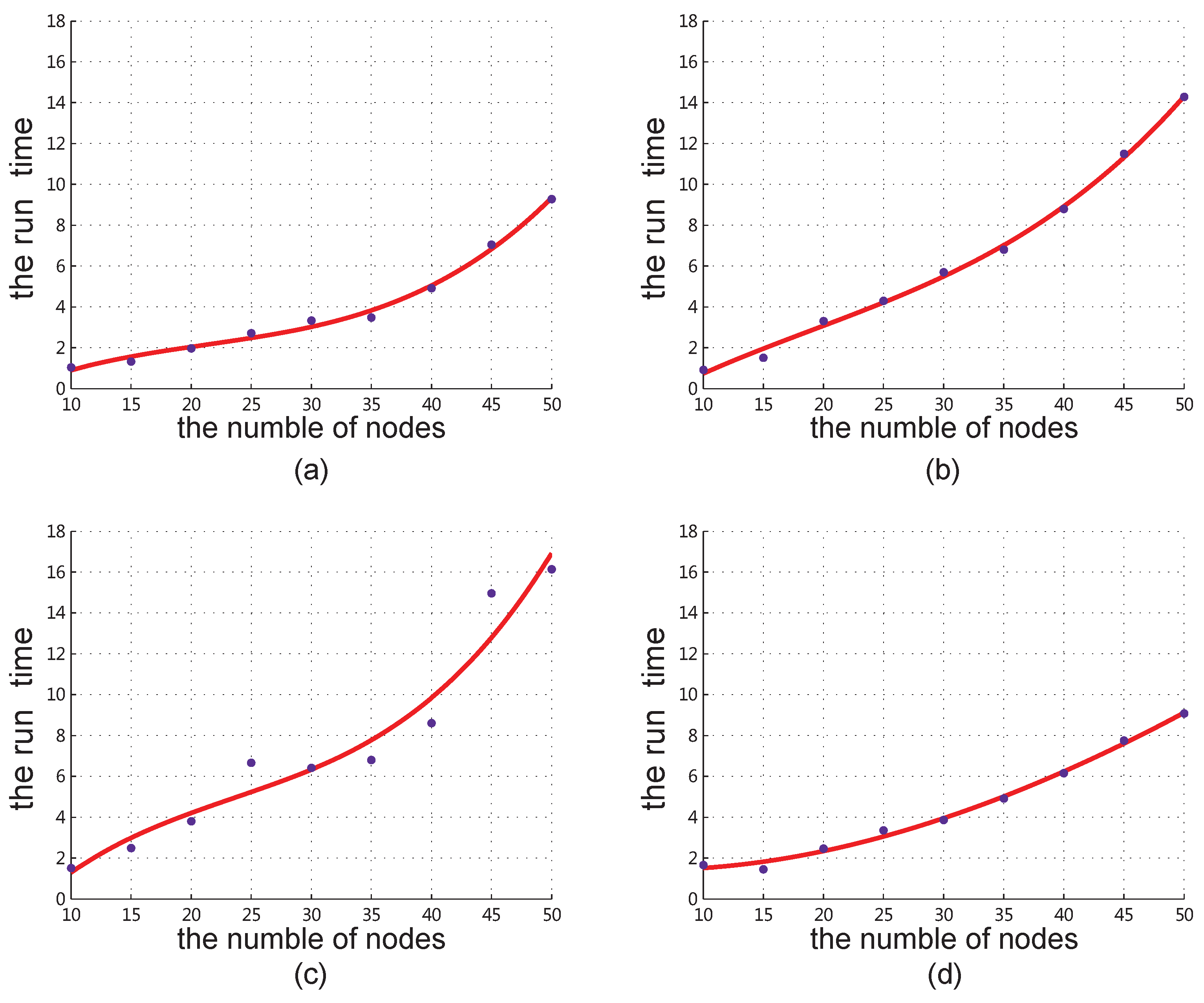
4.3. Complexity from Simulation Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goldsmith, A. Wireless Communications; Cambridge University Press: New York, NY, USA, 2005; pp. 32–58. ISBN 978-0521837163. [Google Scholar]
- Zhang, Z.; Chai, X.; Long, K.; Vasilakos, A.V.; Hanzo, L. Full Duplex Techniques for 5G Networks: Self-interference Cancellation, Protocol Design, and Relay Selection. IEEE Commun. Mag. 2015, 5, 128–137. [Google Scholar] [CrossRef]
- Rashtchi, R.; Gohary, R.H.; Yanikomeroglu, H. Generalized Cross-Layer Designs for Generic Half-Duplex Multicarrier Wireless Networks with Frequency-Reuse. IEEE Trans. Wirel. Commun. 2015, 1, 458–471. [Google Scholar] [CrossRef]
- Zhou, J.; Reiskarimian, N.; Diakonikolas, J.; Dinc, T.; Chen, T.; Zussman, G.; Krishnaswamy, H. Integrated Full Duplex Radios. IEEE Commun. Mag. 2017, 4, 142–151. [Google Scholar] [CrossRef]
- Li, R.; Chen, Y.; Li, G.; Liu, G. Full-Duplex Cellular Networks. IEEE Commun. Mag. 2017, 4, 184–191. [Google Scholar] [CrossRef]
- Kim, D.; Lee, H.; Hong, D. A Survey of In-Band Full-Duplex Transmission: From the Perspective of PHY and MAC Layers. IEEE Commun. Surv. Tutor. 2015, 4, 2017–2046. [Google Scholar] [CrossRef]
- Sabharwal, A.; Schniter, P.; Guo, D.; Bliss, D.W.; Rangarajan, S.; Wichman, R. In-Band Full-Duplex Wireless: Challenges and Opportunities. IEEE J. Sel. Areas Commun. 2014, 9, 1637–1652. [Google Scholar] [CrossRef]
- Choi, J.I.; Jain, M.; Srinivasan, K. Achieving Single Channel, Full Duplex Wireless Communication. In Proceedings of the International Conference on Mobile Computing and Networking, MOBICOM, Chicago, IL, USA; 2010; Volume 9, pp. 1–12. [Google Scholar] [CrossRef]
- Bharadia, D.; McMilin, E.; Katti, S. Full Duplex Radios. Proc. ACM SIGCOMM 2013, 8, 375–386. [Google Scholar] [CrossRef]
- Duarte, M.; Sabharwal, A. Full-duplex Wireless Communications Using Off-the-shelf Radios: Feasibility and First Results. IEEE Trans. Signals Syst. Comput. 2010, 2, 1558–1562. [Google Scholar] [CrossRef]
- Mohan, M.V.A.; Anilkumar, C.D. Theoretical Analysis of Antenna Cancellation Technique in Full-Duplex Communication System. In Proceedings of the International Conference on Innovations in information Embedded and Communication Systems, Coimbatore, India, 17–18 March 2017; Volume 5, pp. 1–5. [Google Scholar] [CrossRef]
- Ahmed, E.; Eltawil, A.M. All-Digital Self-Interference Cancellation Technique for Full-Duplex Systems. IEEE Trans. Wirel. Commun. 2015, 7, 3519–3532. [Google Scholar] [CrossRef]
- Riihonen, T.; Werner, S.; Wichman, R. Mitigation of Loopback Self-interference in Full-duplex MIMO Relays. IEEE Trans. Signals Process. 2011, 12, 5983–5993. [Google Scholar] [CrossRef]
- Liu, G.; Yu, F.R.; Ji, H.; Leung, V.C.M.; Li, X. In-Band Full-Duplex Relaying: A Survey, Research Issues and Challenges. IEEE Commun. Surv. Tutor. 2015, 2, 500–524. [Google Scholar] [CrossRef]
- Zhang, Z.; Long, K.; Vasilakos, A.V.; Hanzo, L. Full-Duplex Wireless Communications: Challenges, Solutions, and Future Research Directions. Proc. IEEE 2016, 7, 1369–1409. [Google Scholar] [CrossRef]
- Afifi, W.; Abdel-Rahman, M.J.; Krunz, M.; MacKenzie, A.B. Full-duplex or Half-duplex: A Bayesian Game for Wireless Networks with Heterogeneous Self-interference Cancellation Capabilities. IEEE Trans. Mob. Comput. 2018, 5, 1076–1089. [Google Scholar] [CrossRef]
- Noura, M.; Nordin, R. A Survey on Interference Management for Device-to-device (D2D) Communication and Its Challenges in 5G Networks. J. Netw. Comput. Appl. 2016, C, 130–150. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, S.; Li, H.; Zhao, N.; Leung, V.C.M. Interference-Alignment and Soft-space-reuse based Cooperative Transmission for Multi-cell Massive MIMO Networks. IEEE Trans. Wirel. Commun. 2018, 3, 1907–1922. [Google Scholar] [CrossRef]
- Gupta, V.K.; Nambiar, A.; Kasbekar, G.S. Complexity Analysis, Potential Game Characterization and Algorithms for the Inter Cell Interference Coordination with Fixed Transmit Power Problem. IEEE Trans. Veh. Technol. 2018, 4, 3054–3068. [Google Scholar] [CrossRef]
- Weber, S.P.; Andrews, J.G.; Yang, X.; Veciana, G.D. Transmission Capacity of Wireless Ad Hoc Networks with Successive Interference Cancellation. IEEE Trans. Inf. Theory 2007, 8, 2799–2814. [Google Scholar] [CrossRef]
- Jiang, C.; Shi, Y.; Qin, X.; Yuan, X.; Hou, Y.T.; Lou, W.; Kompella, S.; Midkiff, S.F. Cross-Layer Optimization for Multi-Hop Wireless Networks with Successive Interference Cancellation. IEEE Trans. Wirel. Commun. 2016, 8, 5819–5831. [Google Scholar] [CrossRef]
- Liu, R.; Shi, Y.; Lui, K.S.; Shen, M.; Wang, Y.; Li, Y. Bandwidth-aware High-throughput Routing with Successive Interference Cancelation in Multihop Wireless Networks. IEEE Trans. Veh. Technol. 2015, 12, 5866–5877. [Google Scholar] [CrossRef]
- Ma, C.; Wu, W.; Cui, Y.; Wang, X. On the performance of successive interference cancellation in D2D-enabled cellular networks. Proc. IEEE Conf. Comput. Commun. 2015, 8, 37–45. [Google Scholar] [CrossRef]
- Lin, C.T.; Tseng, F.S.; Wu, W.R.; Jheng, F.J. Joint Precoders Design for Full-Duplex MIMO Relay Systems with QR-SIC Detector. IEEE Glob. Commun. Conf. 2015, 7, 1–6. [Google Scholar] [CrossRef]
- Shi, L.; Shi, Y.; Ye, Y.; Wei, Z.; Han, J. An Efficient Interference Management Framework for Multi-hop Wireless Networks. IEEE Wirel. Commun. Netw. Conf. 2013, 4, 1129–1134. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, J.; Shi, Y.; Ding, X.; Wei, Z. Optimal Base Station Placement for Wireless Sensor Networks with Successive Interference Cancellation. Sensors 2015, 1, 1676–1690. [Google Scholar] [CrossRef]
- Shi, L.; Gao, Y.; Wei, Z.; Ding, X.; Shi, Y. The Mine Locomotive Wireless Network Strategy based on Successive Interference Cancellation with Dynamic Power Control. Int. J. Distrib. Sens. Netw. 2017, 5, 1–11. [Google Scholar] [CrossRef]
- Shi, Y.; Hou, Y.T. A Distributed Optimization Algorithm for Multi-hop Cognitive Radio Networks. IEEE Int. Conf. Comput. Commun. 2008, 1966–1974. [Google Scholar] [CrossRef]
- Shi, Y.; Hou, Y.T.; Liu, J.; Kompella, S. Bridging the Gap between Protocol and Physical Models for Wireless Networks. IEEE Trans. Mob. Comput. 2013, 7, 1404–1416. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman: New York, NY, USA, 1983; pp. 32–58. ISBN 9780716710455. [Google Scholar]
- Gupta, P.; Kumar, P.R. The Capacity of Wireless Networks. IEEE Trans. Inf. Theory 2000, 2, 388–404. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| i | Coordinates | i | Coordinates | ||
|---|---|---|---|---|---|
| 1 | (425, 462) | 837.26 | 6 | (293, 638) | 302.43 |
| 2 | (402, 638) | 449.89 | 7 | (617, 425) | 550.01 |
| 3 | (687, 711) | 619.55 | 8 | (474, 772) | 578.13 |
| 4 | (713, 984) | 204.02 | 9 | (995, 1017) | 189.43 |
| 5 | (801, 903) | 112.95 | 10 | (301, 469) | 167.50 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, L.; Li, Z.; Bi, X.; Liao, L.; Xu, J. Full-Duplex Multi-Hop Wireless Networks Optimization with Successive Interference Cancellation. Sensors 2018, 18, 4301. https://doi.org/10.3390/s18124301
Shi L, Li Z, Bi X, Liao L, Xu J. Full-Duplex Multi-Hop Wireless Networks Optimization with Successive Interference Cancellation. Sensors. 2018; 18(12):4301. https://doi.org/10.3390/s18124301
Chicago/Turabian StyleShi, Lei, Zhehao Li, Xiang Bi, Lulu Liao, and Juan Xu. 2018. "Full-Duplex Multi-Hop Wireless Networks Optimization with Successive Interference Cancellation" Sensors 18, no. 12: 4301. https://doi.org/10.3390/s18124301
APA StyleShi, L., Li, Z., Bi, X., Liao, L., & Xu, J. (2018). Full-Duplex Multi-Hop Wireless Networks Optimization with Successive Interference Cancellation. Sensors, 18(12), 4301. https://doi.org/10.3390/s18124301