Design Methodology of Microservices to Support Predictive Analytics for IoT Applications


Abstract
:1. Introduction
- We present a design methodology based on microservices to support predictive analytics for IoT applications. We identify the major features of the predictive analytics and then, develop and deploy them into microservices. In the outcome, each autonomous microservice handles an analytic functionality where it is composed and orchestrated with other microservices in the containerized environment to achieve service objectives.
- The proposed design combines both the data-driven and knowledge-based approaches to process and analyze IoT data. In this view, IoT data processing mechanisms based on machine learning and semantic web technologies have been considered.
- We demonstrate a way to combine semantic technologies in machine learning pipeline with respect to feature creation from semantically linked annotated data.
- We have designed an ontology for the semantic representation of streaming data. Semantic web technologies are used to represent multi-source IoT data. We also present virtual objects and composite virtual objects to create virtual counterparts for physical devices in our implementation.
- We demonstrate a use case scenario and a prototype implementation where the components have been developed to realize the feasibility of the design.
2. Background and Related Work
2.1. IoT Analytics
2.2. Microservices
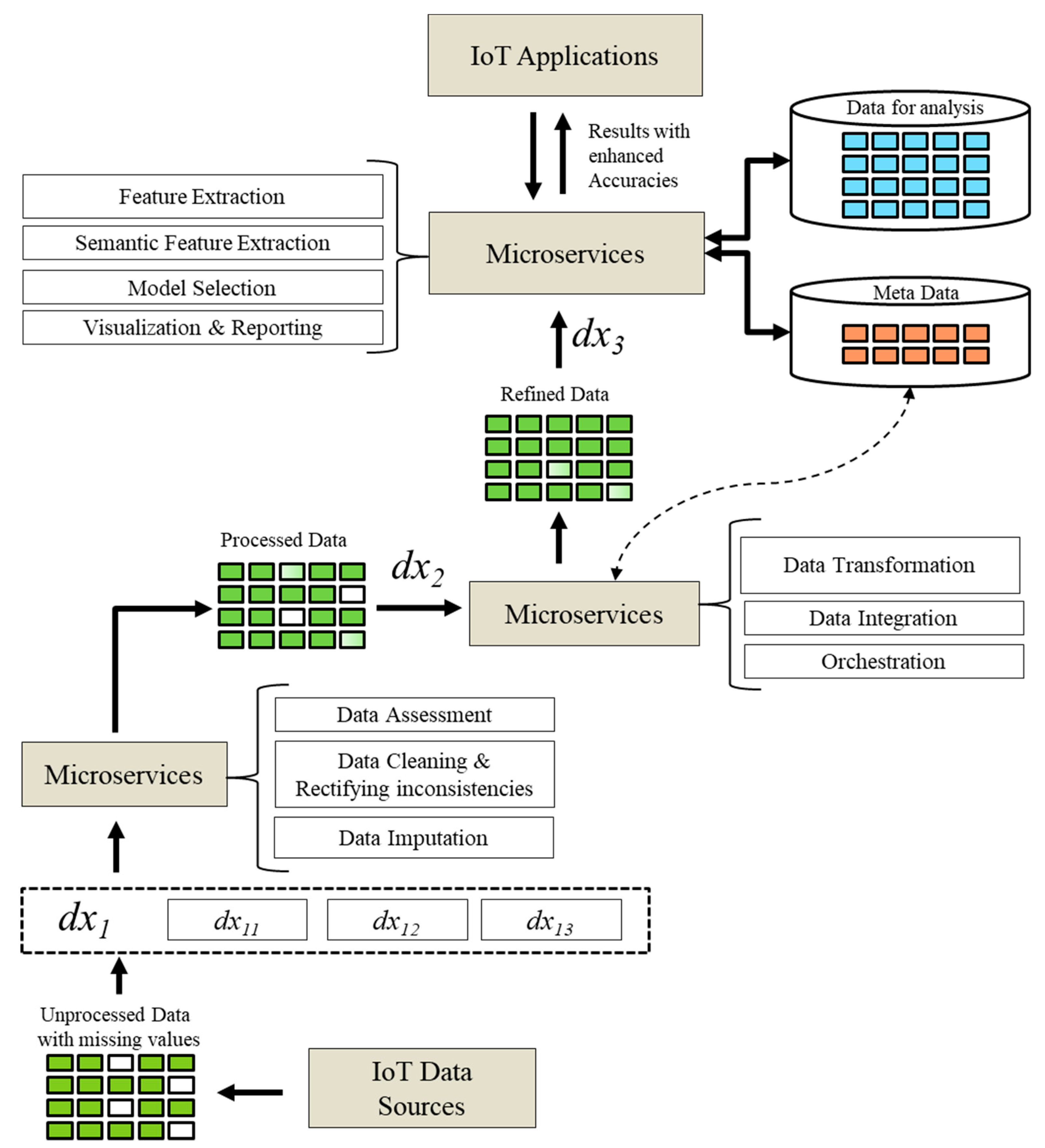
3. Proposed Design Methodology
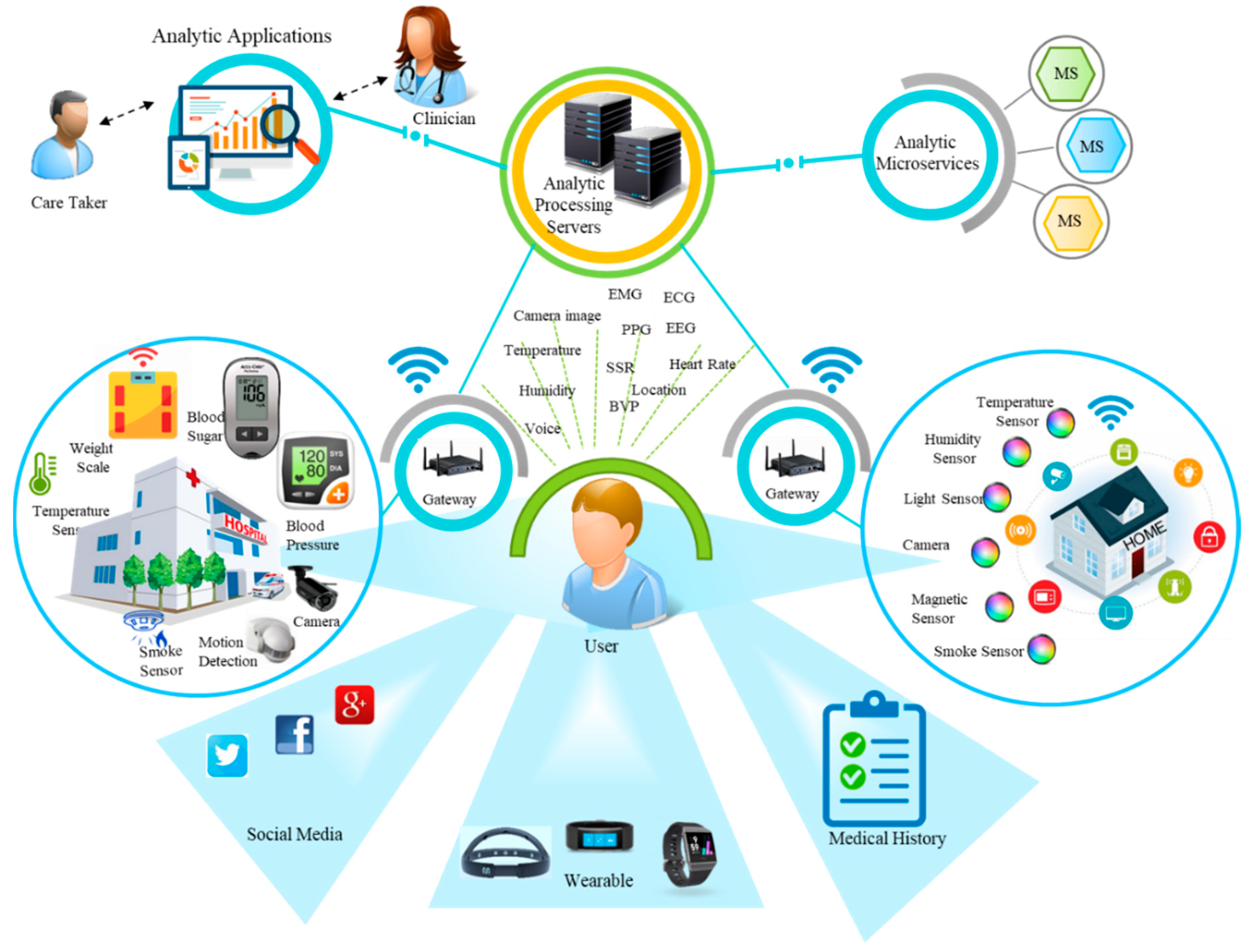
3.1. Web of Objects (WoO) Reference Architecture for IoT Services
3.2. Details on the Proposed Design Methodology
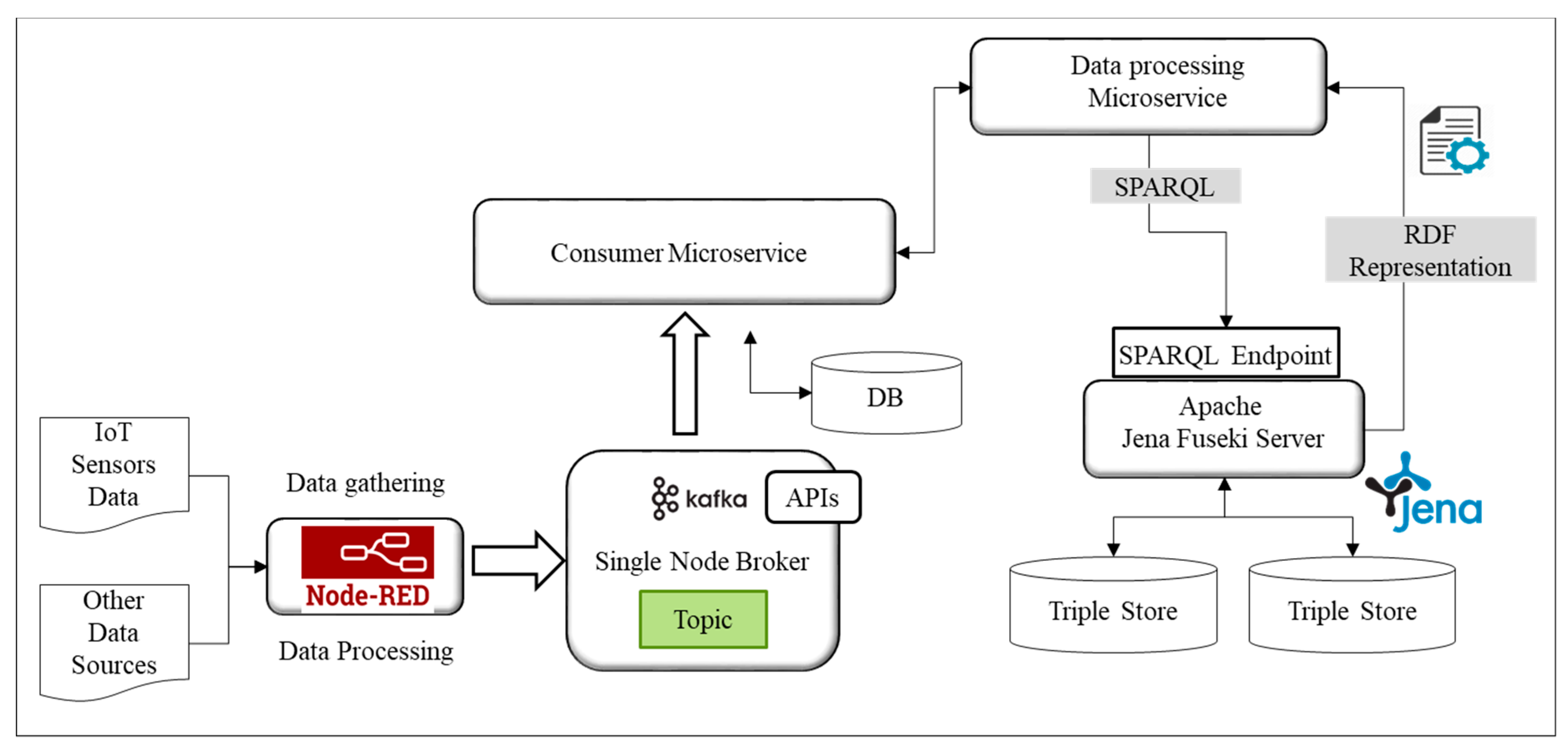
3.2.1. Data Preprocessing and Transformation
3.2.2. Virtualization
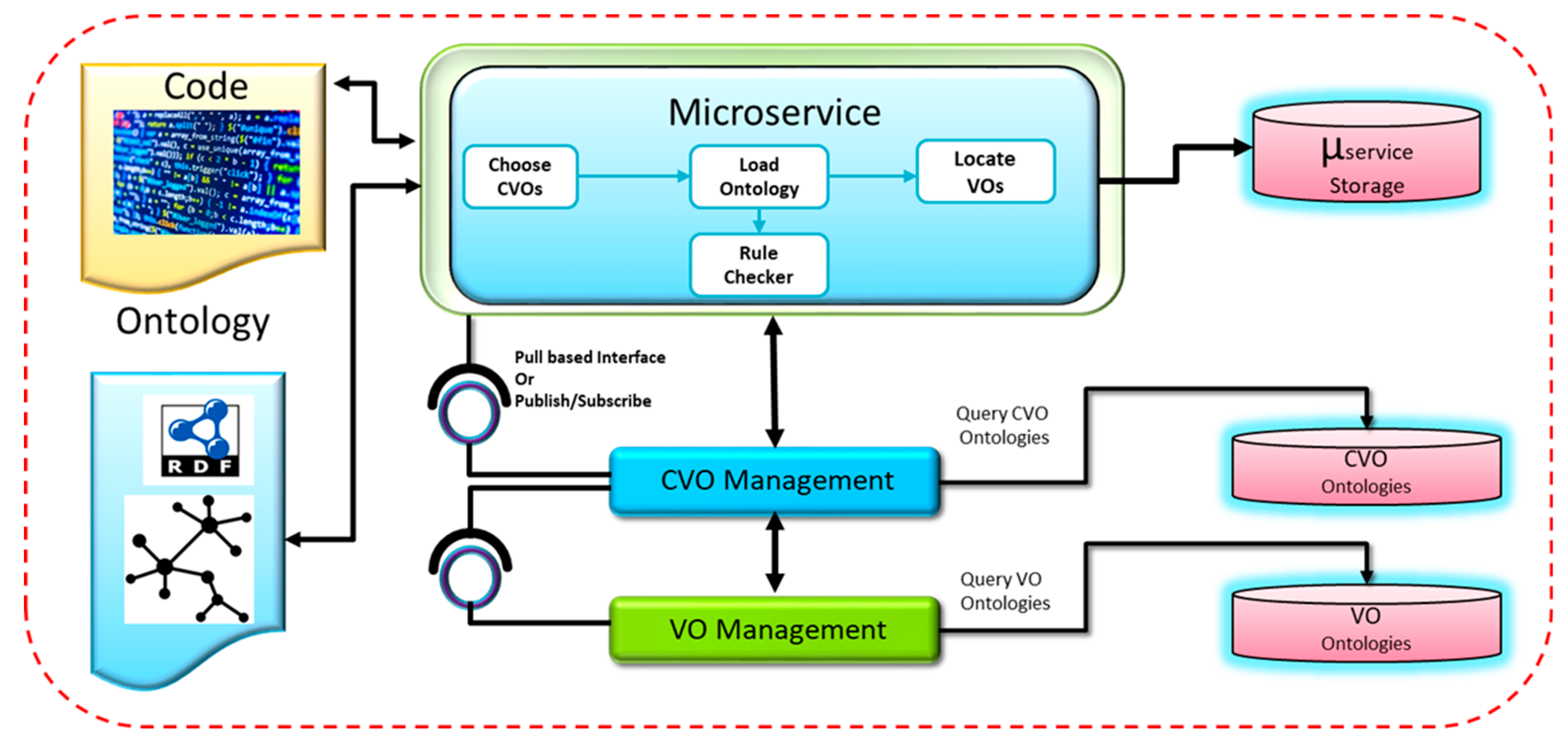
3.2.3. Service Support Functions for Microservices
3.2.4. Predictive Analytics in Microservices
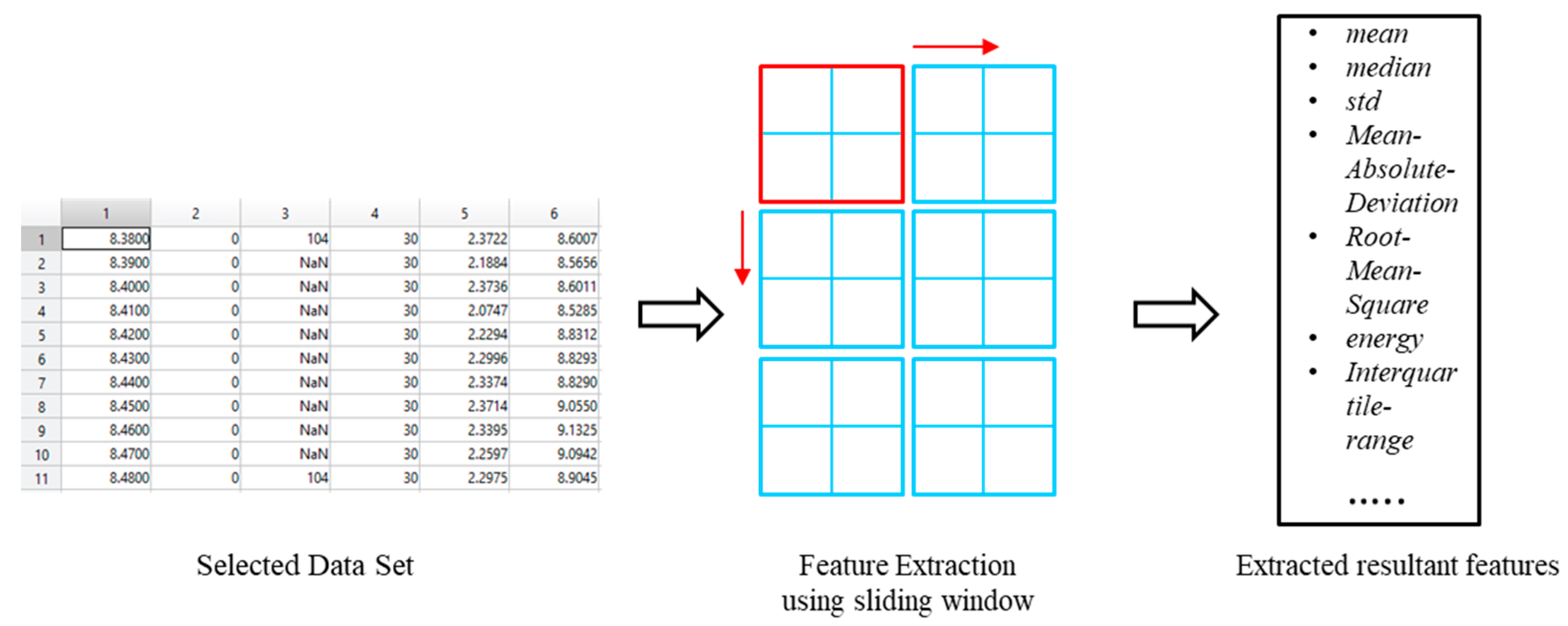
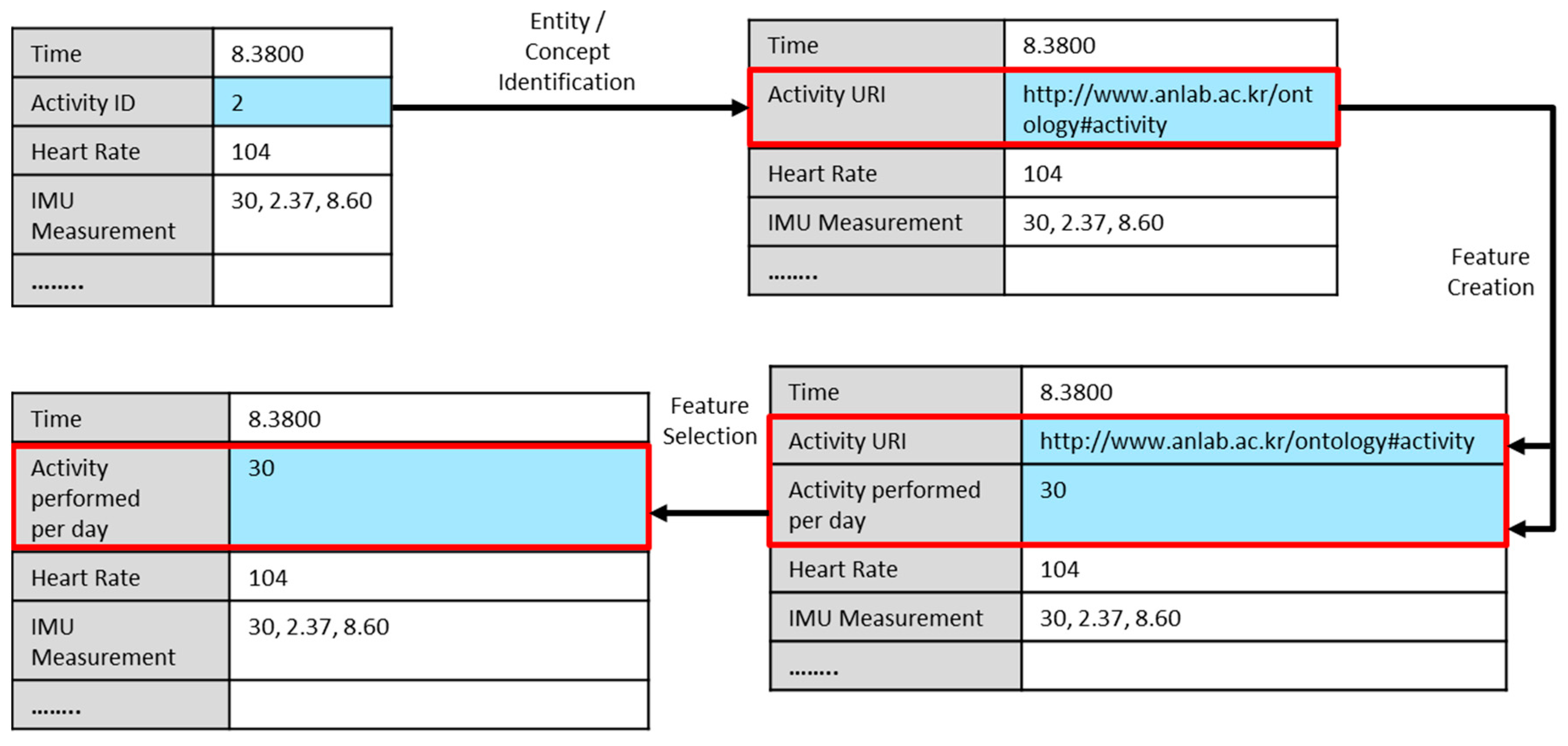
3.2.5. Analytic Processes Pipeline
Data Set
Data Preprocessing
Feature Extraction
Creating and Selecting New Features from VO Data
Semantic Annotation of Data
3.2.6. Analytic Processes Flow
3.2.7. Microservices Composition
| Algorithm 1: Composition of Microservices |
| Require: A set of microservices (⅀ф) and the pointer to entries in the registry (ℝe) |
| Output: Microservices Composition Graph (ℂ) |
| 1: ⅀Mμ ← Load list Microservices extracted from the registry in the model |
| 2: ⅀Mo ← Load list of Objects (CVOs, VOs) in the model |
| 3: μ₸ ← performQueryOnServiceModel (⅀Mμ, qr) |
| 4: Ώ ← performQueryOnObjModel (⅀Mo, qr’) |
| 5: for All do |
| 6: for All do |
| 7: if ins Ώ in Ώ then |
| 8: add to ℿmatched |
| 9: persist ℿmatched into selected composition graph |
| 10: end if |
| 11: end for |
| 12: for All μ ℿmatched do |
| 13: if //Check the microservice availability matric |
| 14: if in ℿmatched then |
| 15: Ɵ ← Evaluate_Ranking (Rank assignment for microservice) |
| 16: add to ℿMRanked |
| 17: store ℿMRanked |
| 18: end if |
| 19: end for |
| 20: for All ℿMRanked do |
| 21: if then |
| 22: include to Wf |
| 23: Ƥ ← Wf//Add Workflow to Priority Queue |
| 24: Validate_Queue (Ƥ) |
| 25: Store Wf to the List of Wf_Compositions |
| 26: end if |
| 27: end for |
3.2.8. Microservices Design with Web Objects
4. Discussion on the Use Case and Prototype Implementation
4.1. Use Case Scenario Details
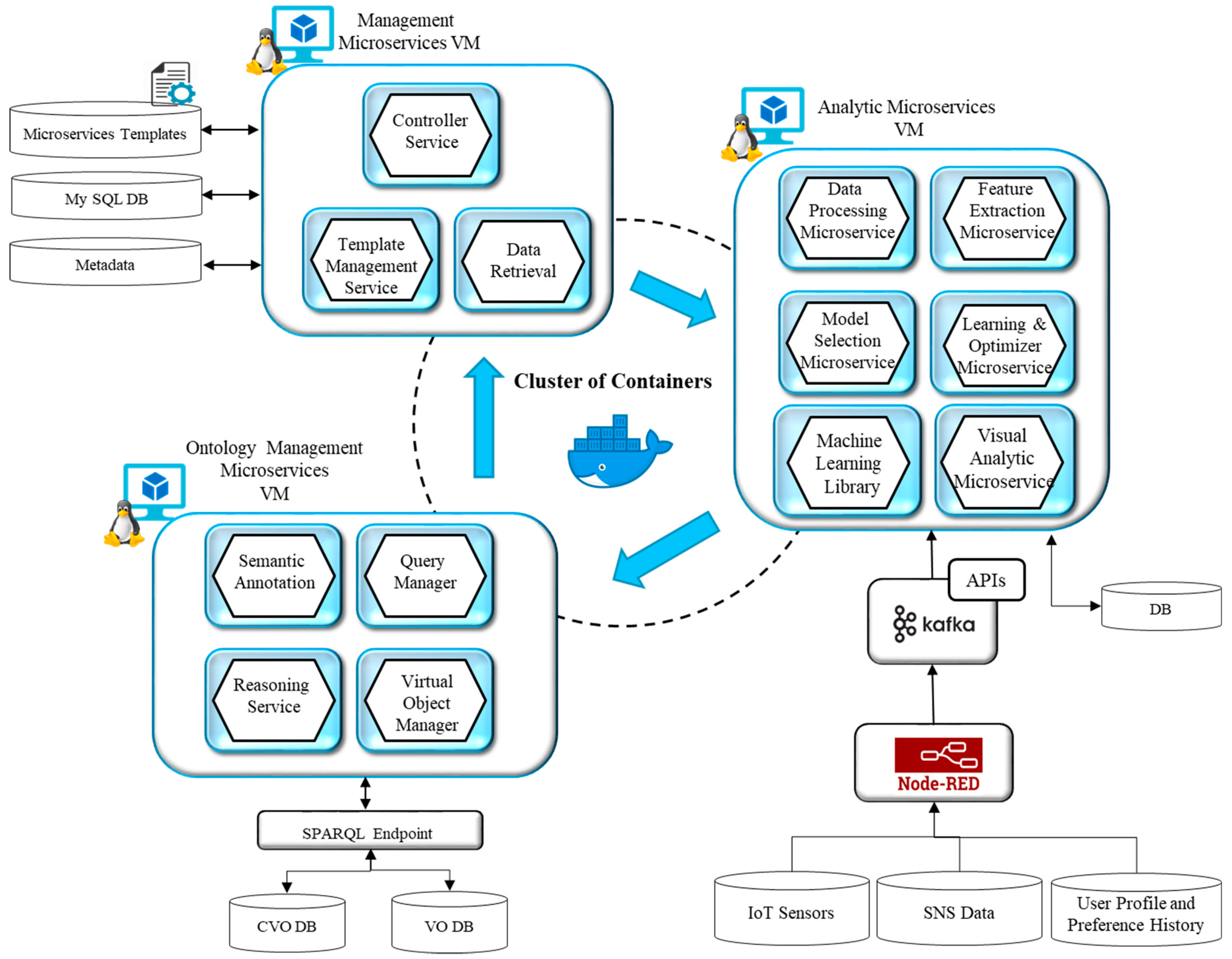
4.2. Prototype Implementation Details
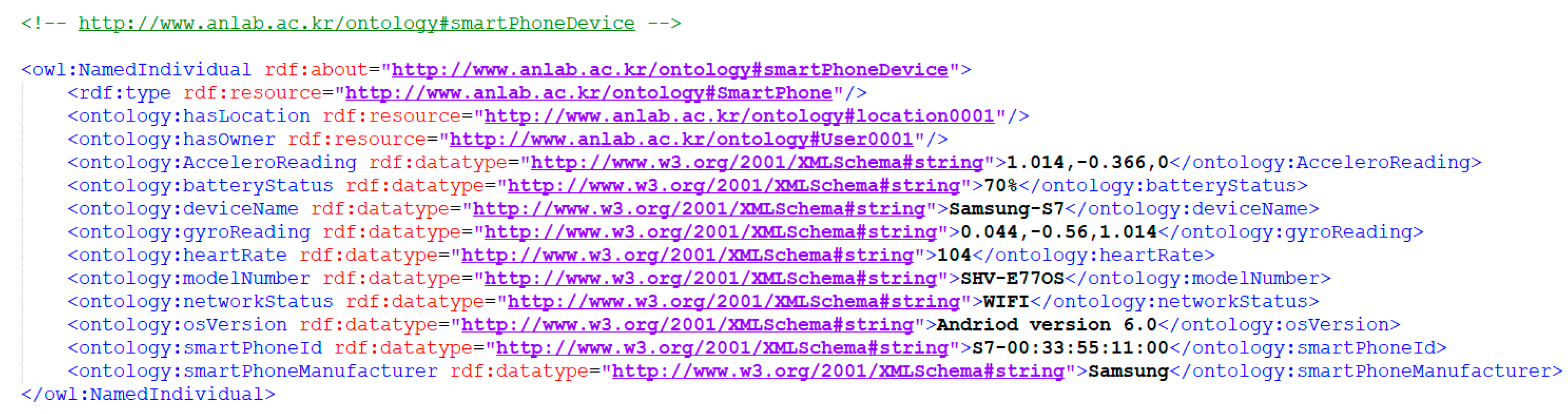
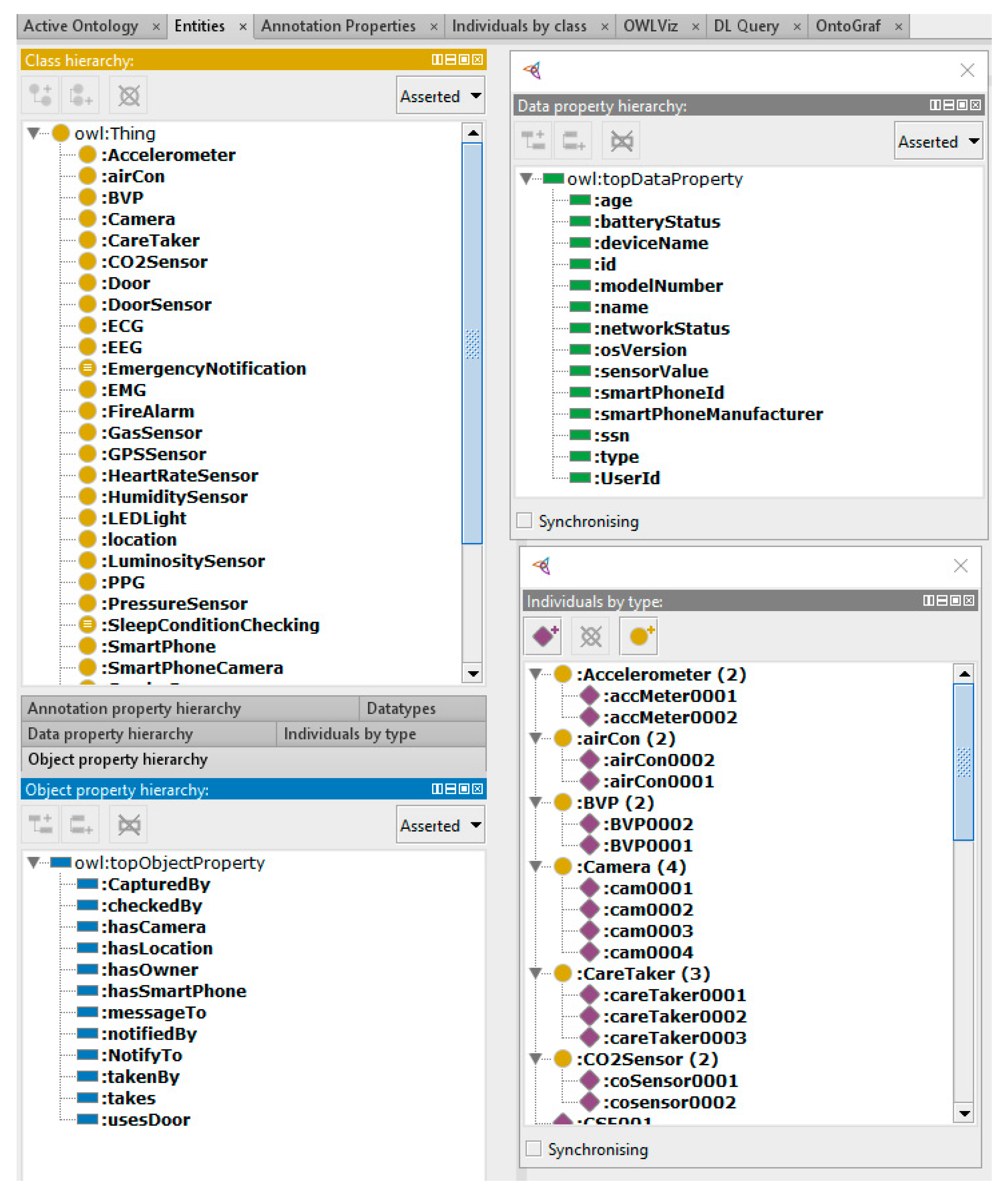
Semantic Ontology
4.3. Results and Discussion
4.3.1. Analytic Results with Datasets
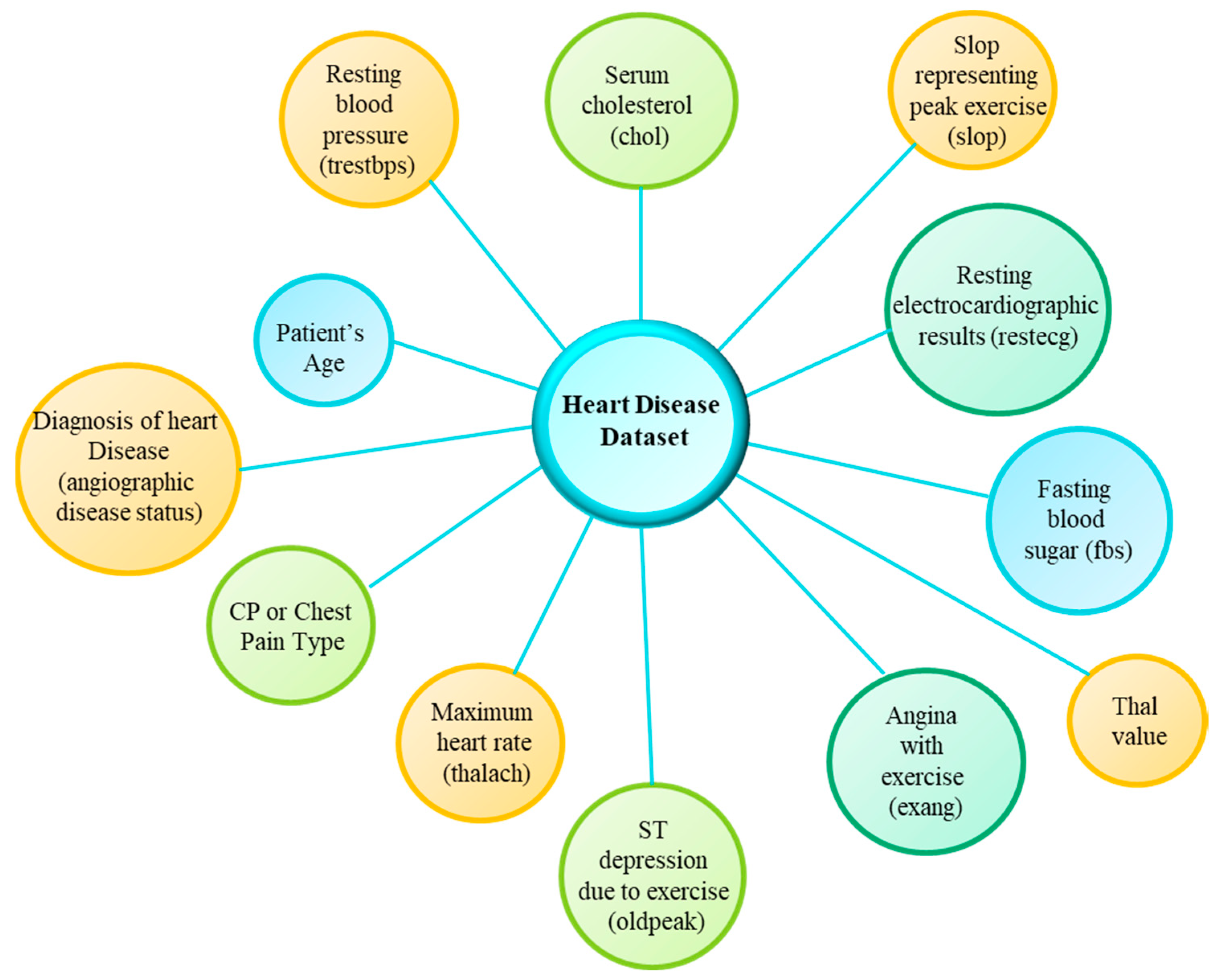
Analysis with Cleveland Heart Disease Dataset
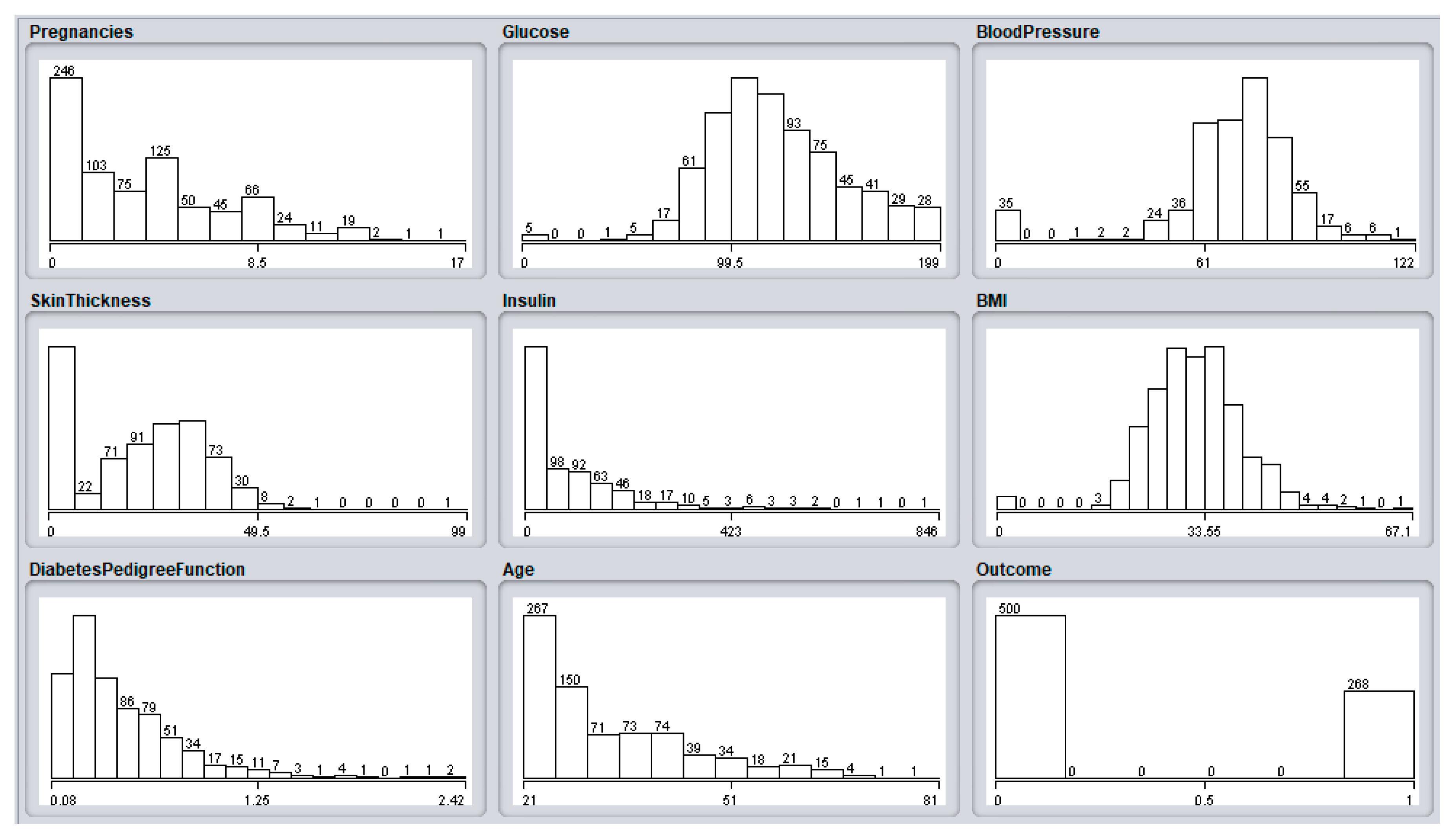
Analysis with Diabetes Dataset
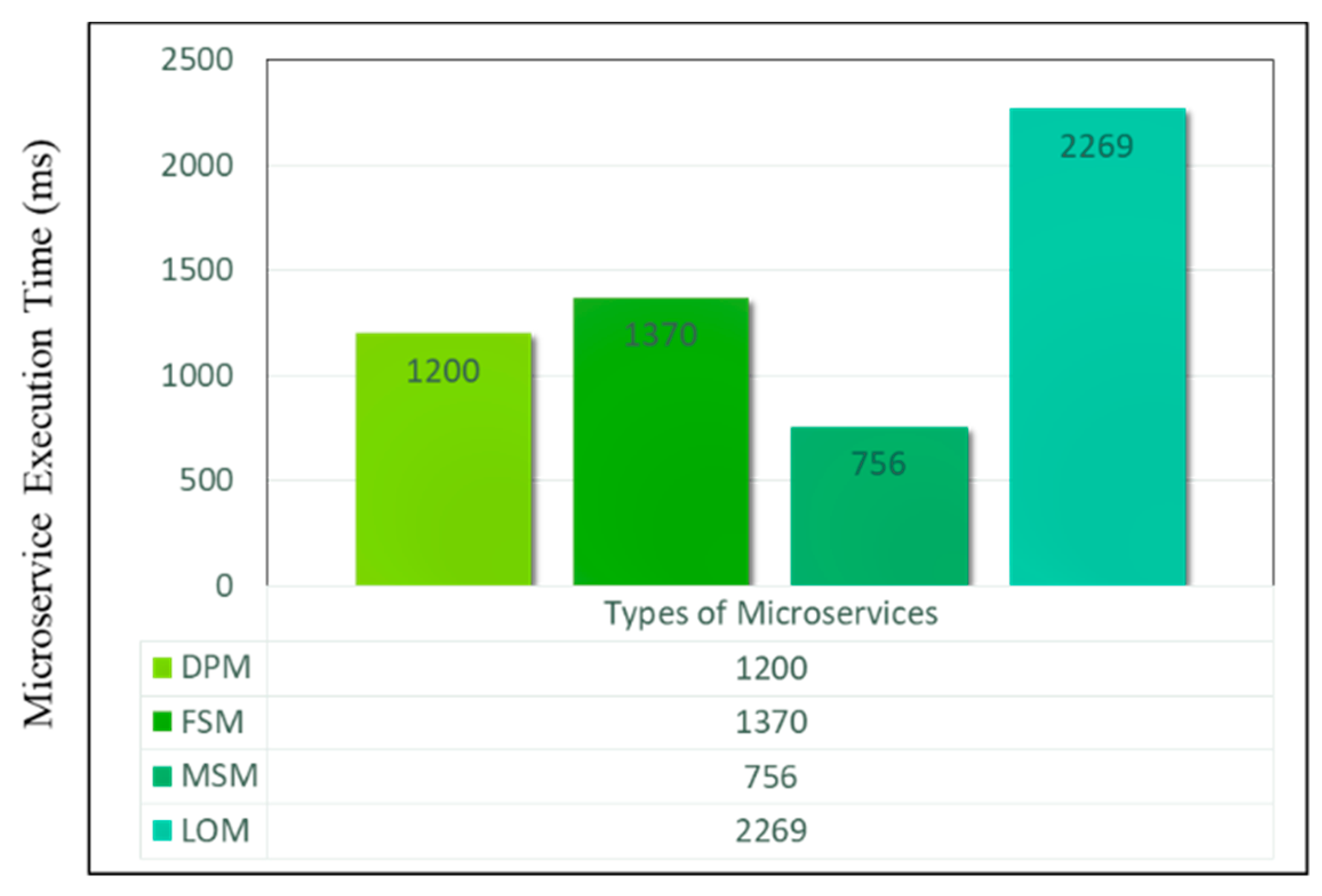
4.3.2. Performance Analysis of Service Functions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Sensing as a service model for smart cities supported by Internet of Things. Trans. Emerg. Telecommun. Technol. 2014, 25, 81–93. [Google Scholar] [CrossRef]
- Cao, Y.; Chen, S.; Hou, P.; Brown, D. FAST: A fog computing assisted distributed analytics system to monitor fall for stroke mitigation. In Proceedings of the 2015 IEEE International Conference on Networking, Architecture and Storage (NAS), Boston, MA, USA, 6–7 August 2015; pp. 2–11. [Google Scholar]
- Suryadevara, N.K.; Mukhopadhyay, S.C.; Wang, R.; Rayudu, R.K. Forecasting the behavior of an elderly using wireless sensors data in a smart home. Eng. Appl. Artif. Intell. 2013, 26, 2641–2652. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, Y.; Xuan, J.; Chen, H.; Mei, L. Crowdsourcing based social media data analysis of urban emergency events. Multimed. Tools Appl. 2017, 76, 11567–11584. [Google Scholar] [CrossRef]
- Mannini, A.; Sabatini, A.M. Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers. Sensors 2010, 10, 1154–1175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef] [Green Version]
- Ozay, M.; Esnaola, I.; Vural, F.T.Y.; Kulkarni, S.R.; Poor, H.V. Machine Learning Methods for Attack Detection in the Smart Grid. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1773–1786. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the OSDI 2016, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Landset, S.; Khoshgoftaar, T.M.; Richter, A.N.; Hasanin, T. A survey of open source tools for machine learning with big data in the Hadoop ecosystem. J. Big Data 2015, 2, 24. [Google Scholar] [CrossRef]
- iCore: Internet Connected Objects for Reconfigurable Ecosystems, European FP7 Project. Available online: http://cordis.europa.eu/project/rcn/100873_en.html (accessed on 5 May 2018).
- Kelaidonis, D.; Somov, A.; Foteinos, V.; Poulios, G.; Stavroulaki, V.; Vlacheas, P.; Demestichas, P.; Baranov, A.; Biswas, A.R.; Giaffreda, R. Virtualization and Cognitive Management of Real World Objects in the Internet of Things. In Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besancon, France, 20–23 November 2012; pp. 187–194. [Google Scholar]
- Sasidharan, S.; Somov, A.; Biswas, A.R.; Giaffreda, R. Cognitive management framework for Internet of Things:—A prototype implementation. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Korea, 6–8 March 2014; pp. 538–543. [Google Scholar]
- Foteinos, V.; Kelaidonis, D.; Poulios, G.; Stavroulaki, V.; Vlacheas, P.; Demestichas, P.; Giaffreda, R.; Biswas, A.R.; Menoret, S.; Nguengang, G.; et al. A Cognitive Management Framework for Empowering the Internet of Things; Springer: Berlin/Heidelberg, Germany, 2013; pp. 187–199. [Google Scholar]
- Nitti, M.; Pilloni, V.; Colistra, G.; Atzori, L. The Virtual Object as a Major Element of the Internet of Things: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1228–1240. [Google Scholar] [CrossRef]
- Y.4452: Functional Framework of Web of Objects. Available online: http://www.itu.int/rec/T-REC-Y.4452-201609-P (accessed on 24 January 2017).
- Lan, M.; Samy, L.; Alshurafa, N.; Suh, M.K.; Ghasemzadeh, H.; Macabasco-O’Connell, A.; Sarrafzadeh, M. WANDA. In Proceedings of the conference on Wireless Health—WH ’12, San Diego, CA, USA, 23–25 October 2012; pp. 1–8. [Google Scholar]
- Bazzani, M.; Conzon, D.; Scalera, A.; Spirito, M.A.; Trainito, C.I. Enabling the IoT Paradigm in E-health Solutions through the VIRTUS Middleware. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 1954–1959. [Google Scholar]
- Vargheese, R.; Dahir, H. An IoT/IoE enabled architecture framework for precision on shelf availability: Enhancing proactive shopper experience. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 21–26. [Google Scholar]
- Huang, Z.; Lin, K.-J.; Tsai, B.-L.; Yan, S.; Shih, C.-S. Building edge intelligence for online activity recognition in service-oriented IoT systems. Future Gener. Comput. Syst. 2018, 87, 557–567. [Google Scholar] [CrossRef]
- Patel, P.; Ali, M.I.; Sheth, A. On Using the Intelligent Edge for IoT Analytics. IEEE Intell. Syst. 2017, 32, 64–69. [Google Scholar] [CrossRef]
- Chang, H.-T.; Mishra, N.; Lin, C.-C. IoT Big-Data Centred Knowledge Granule Analytic and Cluster Framework for BI Applications: A Case Base Analysis. PLoS ONE 2015, 10, e0141980. [Google Scholar] [CrossRef] [PubMed]
- Mishra, N.; Chang, H.-T.; Lin, C.-C. An IoT Knowledge Reengineering Framework for Semantic Knowledge Analytics for BI-Services. Math. Probl. Eng. 2015, 2015, 759428. [Google Scholar] [CrossRef]
- Newman, S. Building Microservices: Designing Fine-Grained Systems; O’Reilly Media, Inc.: Newton, MA, USA, 2015. [Google Scholar]
- Krause, L. Microservices: Patterns and Applications: Designing Fine-Grained Services by Applying Patterns; Lucas Krause: Minneapolis, MN, USA, 2015. [Google Scholar]
- Viktor, F. The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Namiot, D.; Sneps-Sneppe, M. On microservices Architecture. Int. J. Open Inf. Technol. 2014, 2, 9. [Google Scholar]
- Krylovskiy, A.; Jahn, M.; Patti, E. Designing a Smart City Internet of Things Platform with Microservice Architecture. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015; pp. 25–30. [Google Scholar]
- Bonino, D.; Alizo, M.T.; Alapetite, A.; Gilbert, T.; Axling, M.; Udsen, H.; Soto, J.A.; Spirito, M. ALMANAC: Internet of Things for Smart Cities. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015; pp. 309–316. [Google Scholar]
- Developing Microservices for PaaS with Spring and Cloud Foundry. Available online: https://www.infoq.com/presentations/microservices-pass-spring-cloud-foundry (accessed on 20 March 2017).
- Microservices in Action, Part 2: Containers and Microservices—A Perfect Pair. Available online: https://www.ibm.com/developerworks/cloud/library/cl-bluemix-microservices-in-action-part-2-trs/index.html (accessed on 9 February 2017).
- Jarwar, M.A.; Ali, S.; Kibria, M.G.; Kumar, S.; Chong, I. Exploiting interoperable microservices in web objects enabled Internet of Things. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks (ICUFN), Milan, Italy, 4–7 July 2017; pp. 49–54. [Google Scholar]
- Jarwar, M.; Kibria, M.; Ali, S.; Chong, I. Microservices in Web Objects Enabled IoT Environment for Enhancing Reusability. Sensors 2018, 18, 352. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Kibria, M.G.; Jarwar, M.A.; Lee, H.K.; Chong, I. A Model of Socially Connected Web Objects for IoT Applications. Wirel. Commun. Mob. Comput. 2018, 2018, 6309509. [Google Scholar] [CrossRef]
- Kibria, M.; Ali, S.; Jarwar, M.; Kumar, S.; Chong, I. Logistic Model to Support Service Modularity for the Promotion of Reusability in a Web Objects-Enabled IoT Environment. Sensors 2017, 17, 2180. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Kibria, M.G.; Chong, I. WoO enabled IoT service provisioning based on learning user preferences and situation. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 474–476. [Google Scholar]
- Ali, S.; Kim, H.-S.; Chong, I. Implementation model of WoO based smart assisted living IoT service. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 19–21 October 2016; pp. 816–818. [Google Scholar]
- Kumar, S.; Kibria, M.G.; Ali, S.; Jarwar, M.A.; Chong, I. Smart spaces recommending service provisioning in WoO platform. In Proceedings of the 2017 International Conference on Information and Communications (ICIC), Hanoi, Vietnam, 26–28 June 2017; pp. 311–313. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Junger, W.L.; de Leon, A.P. Imputation of missing data in time series for air pollutants. Atmos. Environ. 2015, 102, 96–104. [Google Scholar] [CrossRef]
- Grzegorowski, M.; Stawicki, S. Window-Based Feature Extraction Framework for Multi-Sensor Data: A Posture Recognition Case Study. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; pp. 397–405. [Google Scholar]
- Reiss, A.; Hendeby, G.; Stricker, D. Towards Robust Activity Recognition for Everyday Life: Methods and Evaluation. In Proceedings of the ICTs for improving Patients Rehabilitation Research Techniques, Venice, Italy, 5–8 May 2013; pp. 25–32. [Google Scholar]
- Paulheim, H. Exploiting linked open data as background knowledge in data mining. In Proceedings of the 2013 International Conference on Data Mining on Linked Data, Prague, Czech Republic, 1 January 2013; Volume 1082, pp. 1–10. [Google Scholar]
- Paulheim, H.; Fümkranz, J. Unsupervised generation of data mining features from linked open data. In Proceedings of the 2nd International Conference on Web Intelligence, Mining and Semantics—WIMS ’12, Craiova, Romania, 13–15 June 2012; p. 1. [Google Scholar]
- Vyas, O.P.; Narasimha, V.; Kappara, P.; Ichise, R. LiDDM: A Data Mining System for Linked Data. In Proceedings of the Workshop on Linked Data on the Web, CEUR Workshop Proceedings, Hyderabad, India, 29 March 2011. [Google Scholar]
- Ristoski, P.; Paulheim, H. Semantic Web in data mining and knowledge discovery: A comprehensive survey. Web Semant. Sci. Serv. Agents World Wide Web 2016, 36, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I. Feature Extraction: Foundations and Applications; Springer-Verlag: Berlin, Germany, 2006. [Google Scholar]
- Ali, S.; Kibria, M.G.; Jarwar, M.A.; Kumar, S.; Chong, I. Microservices model in WoO based IoT platform for depressive disorder assistance. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 18–20 October 2017; pp. 864–866. [Google Scholar]
- Docker Documentation | Docker Documentation. Available online: https://docs.docker.com/ (accessed on 12 March 2018).
- Node-RED: A Programming Tool for Wiring Together Hardware Devices, APIs and Online Services. Available online: https://nodered.org/ (accessed on 5 February 2018).
- Apache Kafka: A Distributed Streaming Plateform. Available online: https://kafka.apache.org/ (accessed on 20 March 2018).
- Protégé. A free, open-source ontology editor and framework for building intelligent systems. Available online: https://protege.stanford.edu/ (accessed on 9 February 2018).
- Apache Jena—Apache Jena Fuseki. Available online: https://jena.apache.org/documentation/fuseki2/ (accessed on 27 February 2018).
- Scikit-Learn: Machine Learning in Python. Available online: http://scikit-learn.org/stable/ (accessed on 4 March 2018).
- UCI Machine Learning Repository: Heart Disease Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Heart+Disease (accessed on 22 December 2017).
- Pima Indians Diabetes Database | Kaggle. Available online: https://www.kaggle.com/uciml/pima-indians-diabetes-database (accessed on 4 February 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Description | Attribute ID | Attribute Description | Attribute ID |
|---|---|---|---|
| Time stamp | 1 | Chest IMU 3-D Acc (ms−2) ± 6 g | 25–27 |
| ID for the Activity | 2 | Chest IMU 3-D Gyr (rad/s) | 28–30 |
| Heart rate (beats per minute) | 3 | Chest IMU 3-D Mag (μT) | 31–33 |
| Temperature (Celsius) for IMU hand | 4 | Chest IMU 4-D orientation | 34–37 |
| Hand IMU 3-D Acc (ms−2) ± 16 g | 5–7 | Ankle Temperature (Celsius) | 38 |
| Hand IMU 3-D Acc (ms−2) ± 6 g | 8–10 | Ankle IMU 3-D Acc (ms−2) ± 16 g | 39–41 |
| Hand IMU 3-D Gyr (rad/s) | 11–13 | Ankle IMU 3-D Acc (ms−2) ± 6 g | 42–44 |
| Hand IMU 3-D Mag (μT) | 14–16 | Ankle IMU 3-D Gyr (rad/s) | 45–47 |
| Hand IMU 4-D orientation | 17–20 | Ankle IMU 3-D Mag (μT) | 48–50 |
| Chest IMU Temperature (Celsius) | 21 | Ankle IMU 4-D orientation | 51–54 |
| Chest IMU 3-D Acc (ms−2) ± 16 g | 22–24 |
| Notation | Description |
|---|---|
| ⅀ф | Services objects where ф is a replacement for Mμ to denote microservices, Mo to denote virtual objects (CVOs and VOs). |
| μ₸ | Represents all service objects returned in response to the query request. |
| μ | Represents the single instance iterated from the collection of Microservices. |
| M | Represents data model based on the specified ontology. Where ⅀Ms represents service data model, ⅀Mc represents context data model and user profile model is represented as ⅀Mu |
| qr | Q is the query to retrieve the available service templates. |
| qr’ | Q’ is the query to retrieve the associated objects. |
| ℝe | Entries of microservices in the registry. |
| Ώ | Set of objects’ that belong to the microservices category |
| ins Ώ | An instance of Ώ |
| Iteration item of the list of microservice objects | |
| An instance of iteration items in the list of microservice objects | |
| ℿmatched | List of all matched service items |
| An instance of iteration items in the list of matched microservice items | |
| ℿMRanked | List of all matched ranking |
| Ɵ | Ranking value assigned to a service object |
| Iterator item for the ranking list | |
| Threshold to rank a service object | |
| Wf | Workflow for the composition of service objects |
| Ƥ | Priority queue to store ranked object instances. |
| Rth | Assigned Ranking |
| Attribute Information for the Cleveland Heart Disease Dataset | ||
|---|---|---|
| 1 | Patient’s Age | Age of the patient in years |
| 2 | Sex | 1 = Male; 0 = female |
| 3 | CP or Chest Pain Type | 1 = typical angina; 2 = atypical angina; 3 = non-anginal pain; 4 = asymptomatic |
| 4 | Resting blood pressure (trestbps) | The resting blood pressure measured in mm Hg on admission to hospital |
| 5 | Serum cholestoral (chol) | Patient’s serum cholestoral level measured in mg/dL |
| 6 | Fasting blood sugar (fbs) | Fasting blood sugar level if >120 mg/dL then 1 = true and 0 = no |
| 7 | Resting electrocardiographic results (restecg) | The Resting electrocardiographic results. It is 0 = normal; 1 = ST-T wave abnormality; 2 = left ventricular hypertrophy by the criteria of Estes. |
| 8 | Maximum heart rate (thalach) | The maximum heart rate achieved |
| 9 | Angina with exercise (exang) | The exercise caused due to angina where 1 = yes and 0 = no |
| 10 | ST depression due to exercise (oldpeak) | The ST depression induced by exercise relative to the rest condition |
| 11 | Slop representing peak exercise (slop) | The slope for peak exercise ST segment where 1 = upsloping; 2 = flat; 3 = down sloping |
| 12 | Number of major vessels (ca) | The number of major vessel from 0 to 3 that are flourosopy colored |
| 13 | Thal value | The thal value is 3 = normal; 6 = fixed defect; 7 = reversable defect. |
| 14 | Diagnosis of heart disease (angiographic disease status) | This is the predicted attribute where value 0 = (<50 percent narrowing diameter) and value 1 = (>50 percent narrowing diameter) |
| Attribute Information for the Diabetes Database | ||
|---|---|---|
| 1 | Pregnancies | Pregnancy with respect to the number of times |
| 2 | Glucose Level | The Plasma glucose concentration a 2 h in an oral glucose tolerance test |
| 3 | Blood Pressure Measure | The diastolic blood pressure in (mm Hg) |
| 4 | Skin Thickness | The triceps skinfold thickness (mm) |
| 5 | Insulin measure | Two-hour serum insulin (mu U/mL) |
| 6 | BMI | The body mass index (weight /height) kg/m |
| 7 | Diabetes Pedigree Function | The diabetes pedigree function |
| 8 | Age | Age of patient in years |
| 9 | Class | The class category variable in 0 or 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, S.; Jarwar, M.A.; Chong, I. Design Methodology of Microservices to Support Predictive Analytics for IoT Applications. Sensors 2018, 18, 4226. https://doi.org/10.3390/s18124226
Ali S, Jarwar MA, Chong I. Design Methodology of Microservices to Support Predictive Analytics for IoT Applications. Sensors. 2018; 18(12):4226. https://doi.org/10.3390/s18124226
Chicago/Turabian StyleAli, Sajjad, Muhammad Aslam Jarwar, and Ilyoung Chong. 2018. "Design Methodology of Microservices to Support Predictive Analytics for IoT Applications" Sensors 18, no. 12: 4226. https://doi.org/10.3390/s18124226