LSTM-Guided Coaching Assistant for Table Tennis Practice

Abstract
1. Introduction
2. Methods
2.1. Data Collection
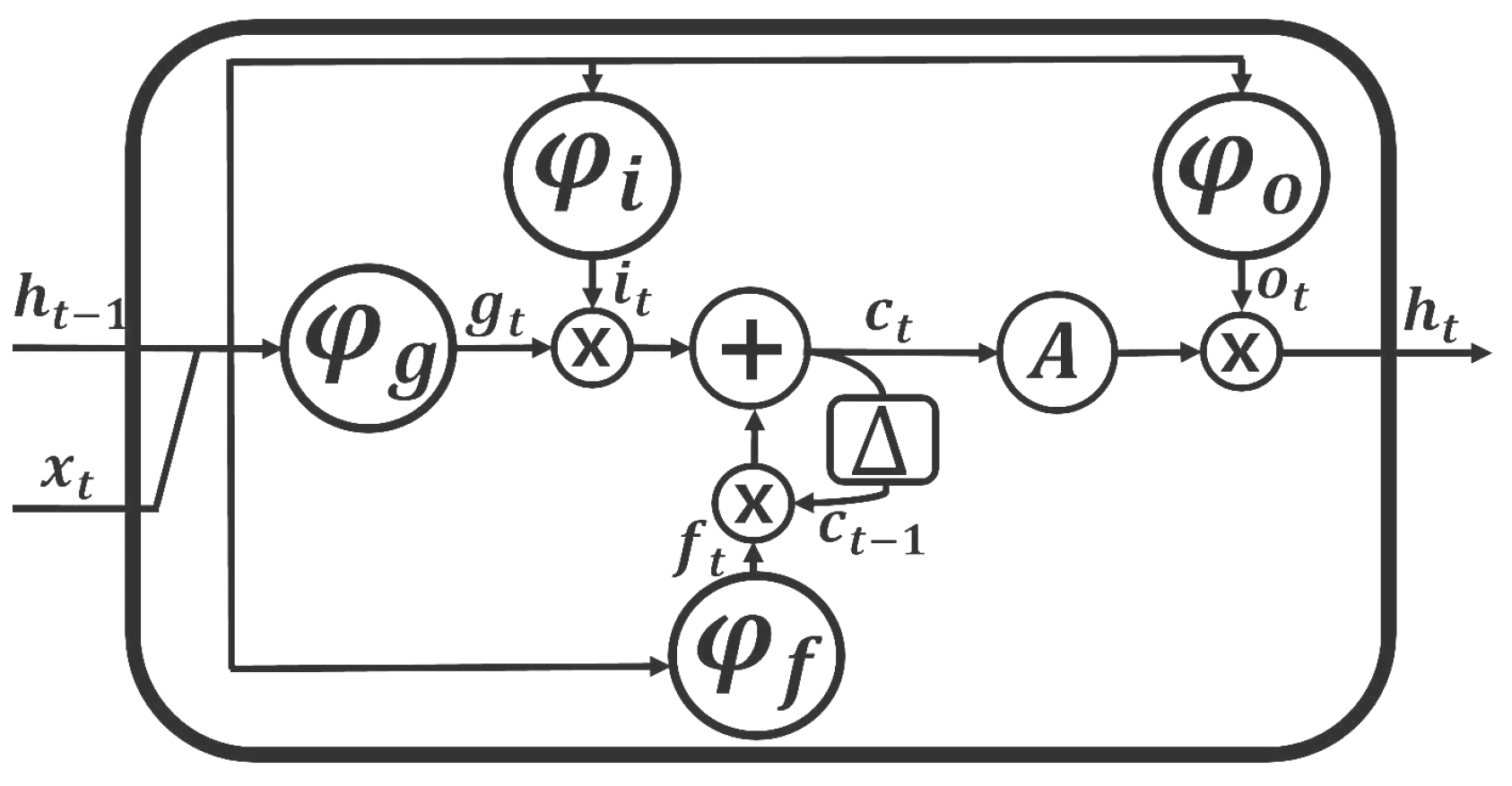
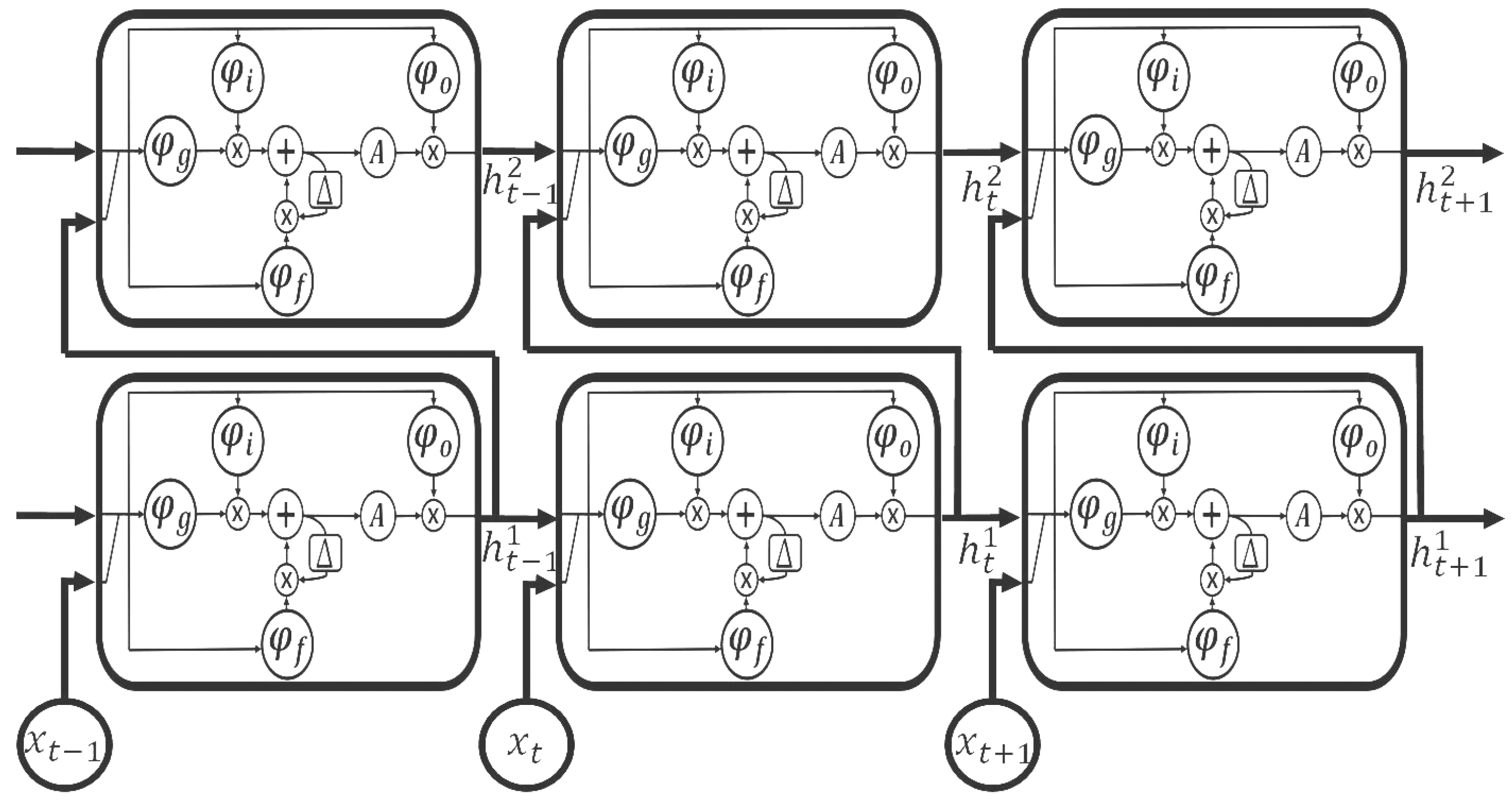
2.2. Unidirectional LSTM RNN
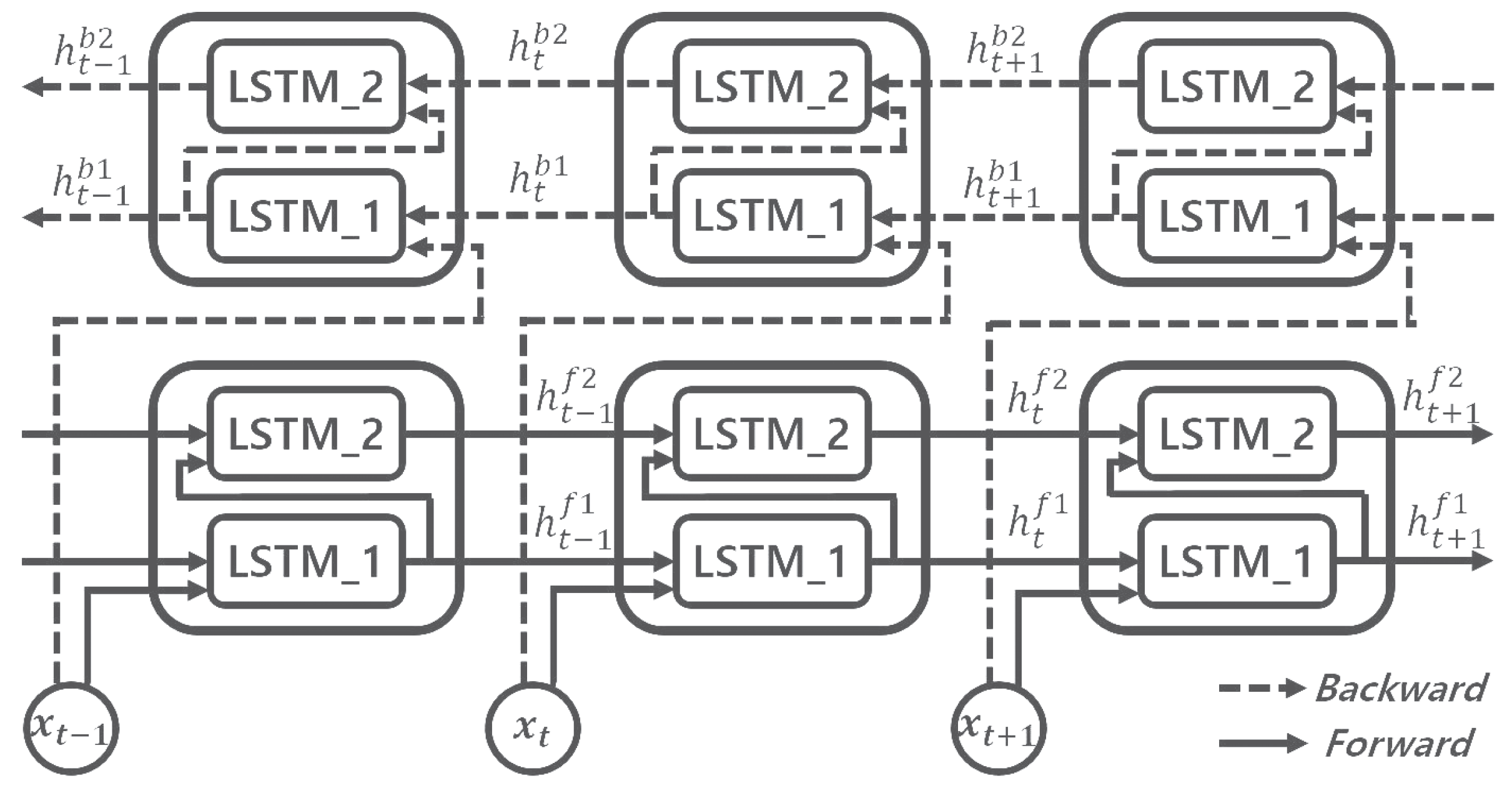
2.3. Bidirectional LSTM RNN
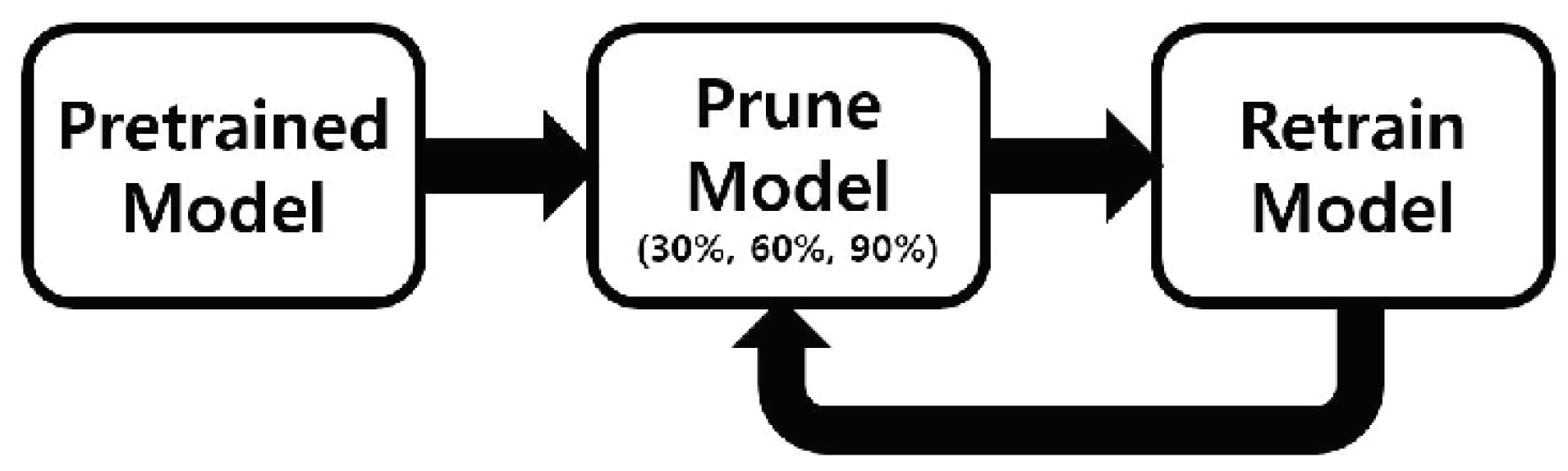
2.4. Pruning Networks
2.5. Training for Classification
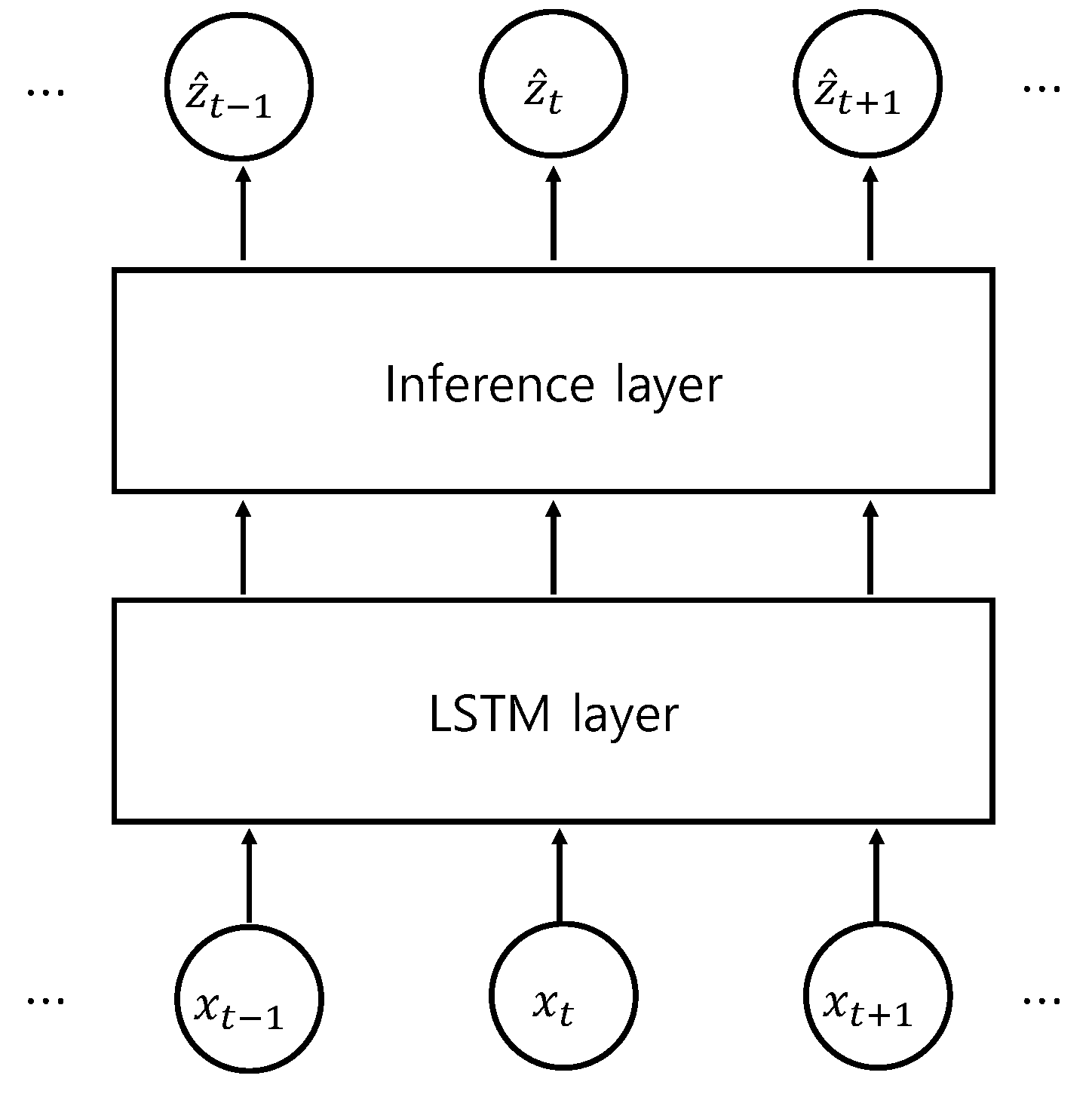
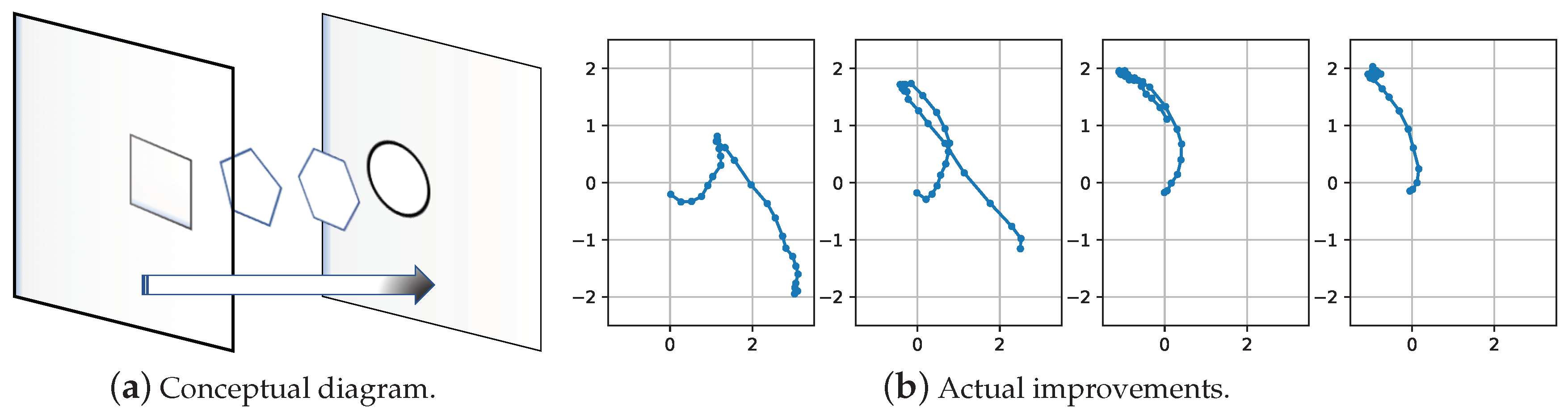
2.6. Network Augmentation for Coaching Information
- The features used for performing the classification tasks should be also used in the augmented network.
- The augmented network should provide some low-dimensional latent representations, which can identify dynamic characteristics of the sensor data and enable visual interactions and/or evaluative feedback between the coach and the beginner concerning skill performance accuracy.
- It should be able to function as a coaching assistant when used in a closed loop with the beginner as the user.
3. Experimental Results
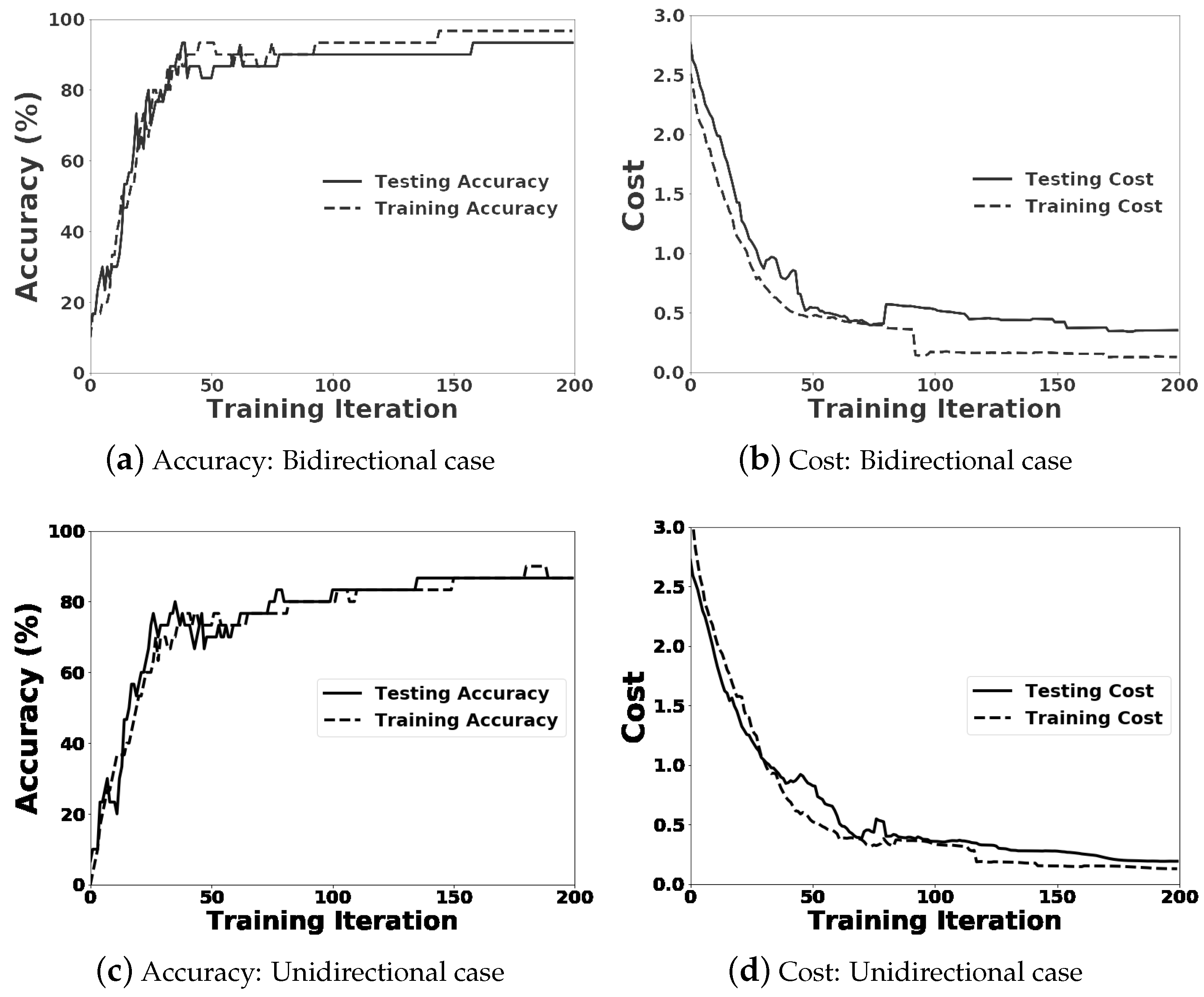
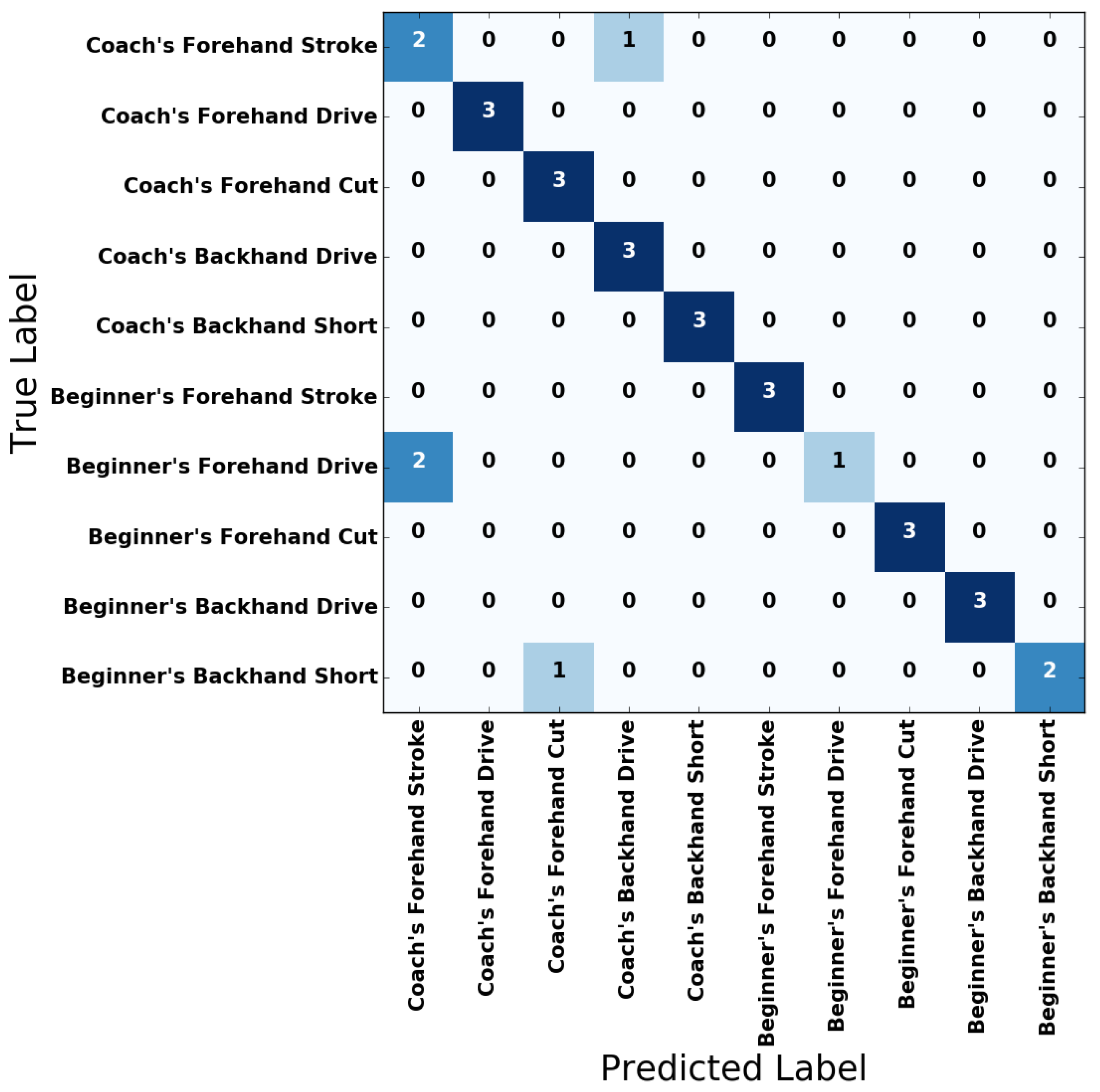
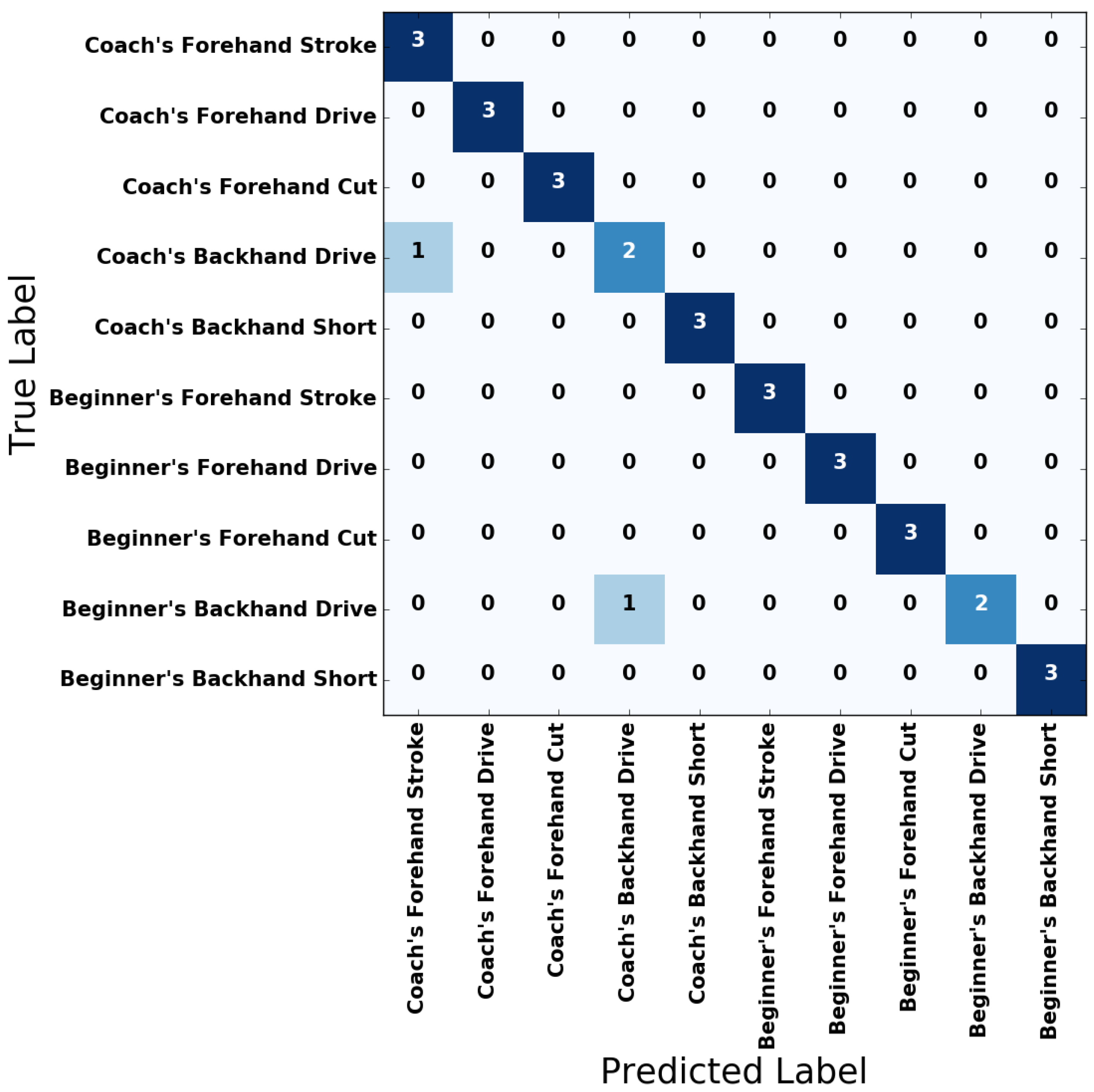
3.1. Classifying by LSTM RNNs
3.2. Pruning
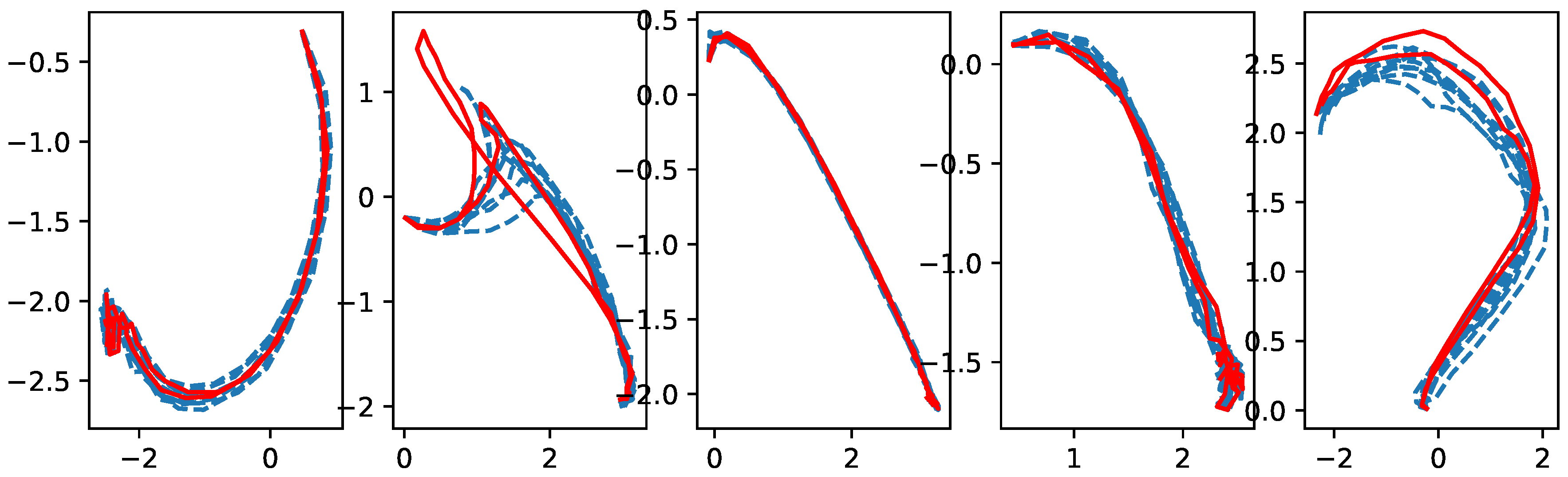
3.3. Identifying Latent Patterns
4. Discussion and Conclusions
4.1. Discussion
4.2. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, T.; Park, J.; Heo, S.; Sung, K.; Park, J. Characterizing Dynamic Walking Patterns and Detecting Falls with Wearable Sensors Using Gaussian Process Methods. Sensors 2017, 17, 1172. [Google Scholar] [CrossRef] [PubMed]
- Kranz, M.; Möller, A.; Hammerla, N.; Diewald, S.; Plötz, T.; Olivier, P.; Roalter, L. The mobile fitness coach: Towards individualized skill assessment using personalized mobile devices. Pervasice Mob. Comput. 2013, 9, 203–215. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.-Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed]
- Bayo-Monton, J.L.; Martinez-Millana, A.; Han, W.; Fernandez-Llatas, C.; Sun, Y.; Traver, V. Wearable Sensors Integrated with Internet of Things for Advancing eHealth Care. Sensors 2018, 18, 1851. [Google Scholar] [CrossRef] [PubMed]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for Human Activity Recognition using Mobile Sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, China, 9–12 October 2015. [Google Scholar]
- Hessen, H.-O.; Tessem, A.J. Human Activity Recognition with Two Body-Worn Accelerometer Sensors. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 203–215. [Google Scholar] [CrossRef] [PubMed]
- Zen, H.; Sak, H. Unidirectional Long Short-term Memory Recurrent Neural Network with Recurrent Output Layer for Low-latency Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Brisbane, Australia, 19–24 April 2015; pp. 4470–4474. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning. J. Korean Soc. Civ. Eng. 2006, 60, 78. [Google Scholar]
- Huang, L.; Sun, J.; Xu, J.; Yang, Y. An Improved Residual LSTM Architecture for Acoustic Modeling. In Proceedings of the IEEE International Conference on Computer and Communication Systems, Krakow, Poland, 11–14 July 2017; pp. 101–105. [Google Scholar]
- Zhu, M.; Gupta, S. To prune, or not to prune: Exploring the efficacy of pruning for model compression. Mach. Learn. 2017, arXiv:1710.01878. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Scikit-Learn: Machine Learning in Python. Available online: http://scikit-learn.org/stable/ (accessed on 11 June 2018).
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. Mach. Learn. 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. Mach. Learn. 2014, arXiv:1401.4082. [Google Scholar]
- Raschka, S. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Krishnan, R.G.; Shalit, U.; Sontag, D. Structured Inference Networks for Nonlinear State Space Models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 2101–2109. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Table Tennis Terminology. Available online: http://lucioping.altervista.org/English/basicinfo/TT%20terminology.htm (accessed on 12 June 2018).
- Table Tennis Terminology. Available online: https://www.allabouttabletennis.com/table-tennis-terminology.html (accessed on 12 June 2018).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Stacks | Type | Initial Design | After Pruning (30%) | After Pruning (60%) |
|---|---|---|---|---|
| 1 | Unidirectional | 9.26 × 103 | 6.48 × 103 | 3.70 × 103 |
| 1 | Bidirectional | 17.90 × 103 | 12.53 × 103 | 7.16 × 103 |
| 2 | Unidirectional | 17.58 × 103 | 12.30 × 103 | 7.03 × 103 |
| 2 | Bidirectional | 34.54 × 103 | 24.18 × 103 | 13.82 × 103 |
| Type | Performance |
|---|---|
| Overall Accuracy (Uni) | 86.7% |
| Average Precision (Uni) | 87.5% |
| Average Recall (Uni) | 86.7% |
| F1 Score (Uni) | 86.3% |
| Overall Accuracy (Bi) | 93.3% |
| Average Precision (Bi) | 95.0% |
| Average Recall (Bi) | 93.3% |
| F1 Score (Bi) | 93.1% |
| Type | Initial Design | After Pruning (30%) | After Pruning (60%) | After Pruning (90%) |
|---|---|---|---|---|
| Overall Accuracy (Uni) | 86.7% | 86.7% | 86.7% | 83.3% |
| Average Precision (Uni) | 87.5% | 87.5% | 87.5% | 84.2% |
| Average Recall (Uni) | 86.7% | 86.7% | 86.7% | 83.3% |
| F1 Score (Uni) | 86.3% | 86.3% | 86.3% | 82.4% |
| Overall Accuracy (Bi) | 93.3% | 93.3% | 93.3% | 93.3% |
| Average Precision (Bi) | 95.0% | 95.0% | 94.2% | 95.0% |
| Average Recall (Bi) | 93.3% | 93.3% | 93.3% | 93.3% |
| F1 Score (Bi) | 93.1% | 93.1% | 93.3% | 93.1% |
| Type | Initial Design | After Pruning (30%) | After Pruning (60%) | After Pruning (90%) |
|---|---|---|---|---|
| Unidirectional | 0.23 s | 0.21 s | 0.19 s | 0.15 s |
| Bidirectional | 0.26 s | 0.24 s | 0.22 s | 0.19 s |
| 1: Obtain sets of training data for each class of skills, and for each subject (coach or beginner). |
| 2: Obtain sets of test data for each class of skills, and for each subject (coach or beginner). |
| 3: Train the LSTM RNN with the training data for classification purposes, and fix the classifier network. |
| 4: Compose the augmented network by combining the embedding of the LSTM RNN classifiers with inference network, and compute latent trajectories with the training data for each class of skills and each subject (coach or beginner). |
| 5: Check the validity of the obtained latent trajectories via cross-validation using the test dataset. If not satisfactory, repeat the above until satisfactory. |
| 6: Plot the latent trajectories for the coach’s skills. |
| 7: In the beginner’s practice with the IMU sensors, compute and plot the latent trajectories for skills. When the resultant latent trajectories are not close to the coach’s, explore other motion skills and follow the motion yielding more similar latent trajectories. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, S.-M.; Oh, H.-C.; Kim, J.; Lee, J.; Park, J. LSTM-Guided Coaching Assistant for Table Tennis Practice. Sensors 2018, 18, 4112. https://doi.org/10.3390/s18124112
Lim S-M, Oh H-C, Kim J, Lee J, Park J. LSTM-Guided Coaching Assistant for Table Tennis Practice. Sensors. 2018; 18(12):4112. https://doi.org/10.3390/s18124112
Chicago/Turabian StyleLim, Se-Min, Hyeong-Cheol Oh, Jaein Kim, Juwon Lee, and Jooyoung Park. 2018. "LSTM-Guided Coaching Assistant for Table Tennis Practice" Sensors 18, no. 12: 4112. https://doi.org/10.3390/s18124112
APA StyleLim, S.-M., Oh, H.-C., Kim, J., Lee, J., & Park, J. (2018). LSTM-Guided Coaching Assistant for Table Tennis Practice. Sensors, 18(12), 4112. https://doi.org/10.3390/s18124112