Sensing Urban Transportation Events from Multi-Channel Social Signals with the Word2vec Fusion Model



Abstract
1. Introduction
2. Related Work
2.1. Social Media Based Transportation Research
2.2. Topic Modeling
2.3. Cross-Platform Event Detection
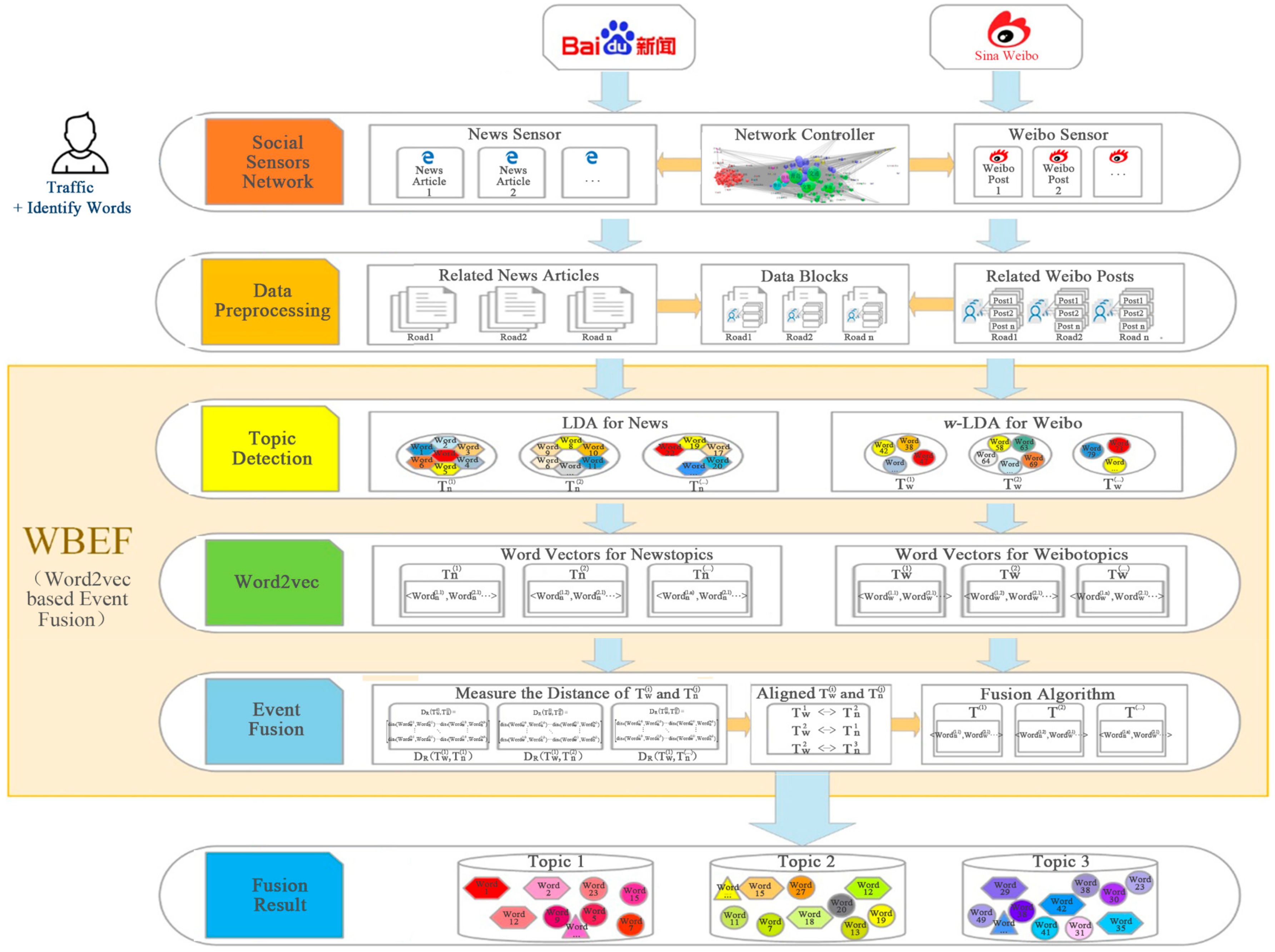
3. Methodology
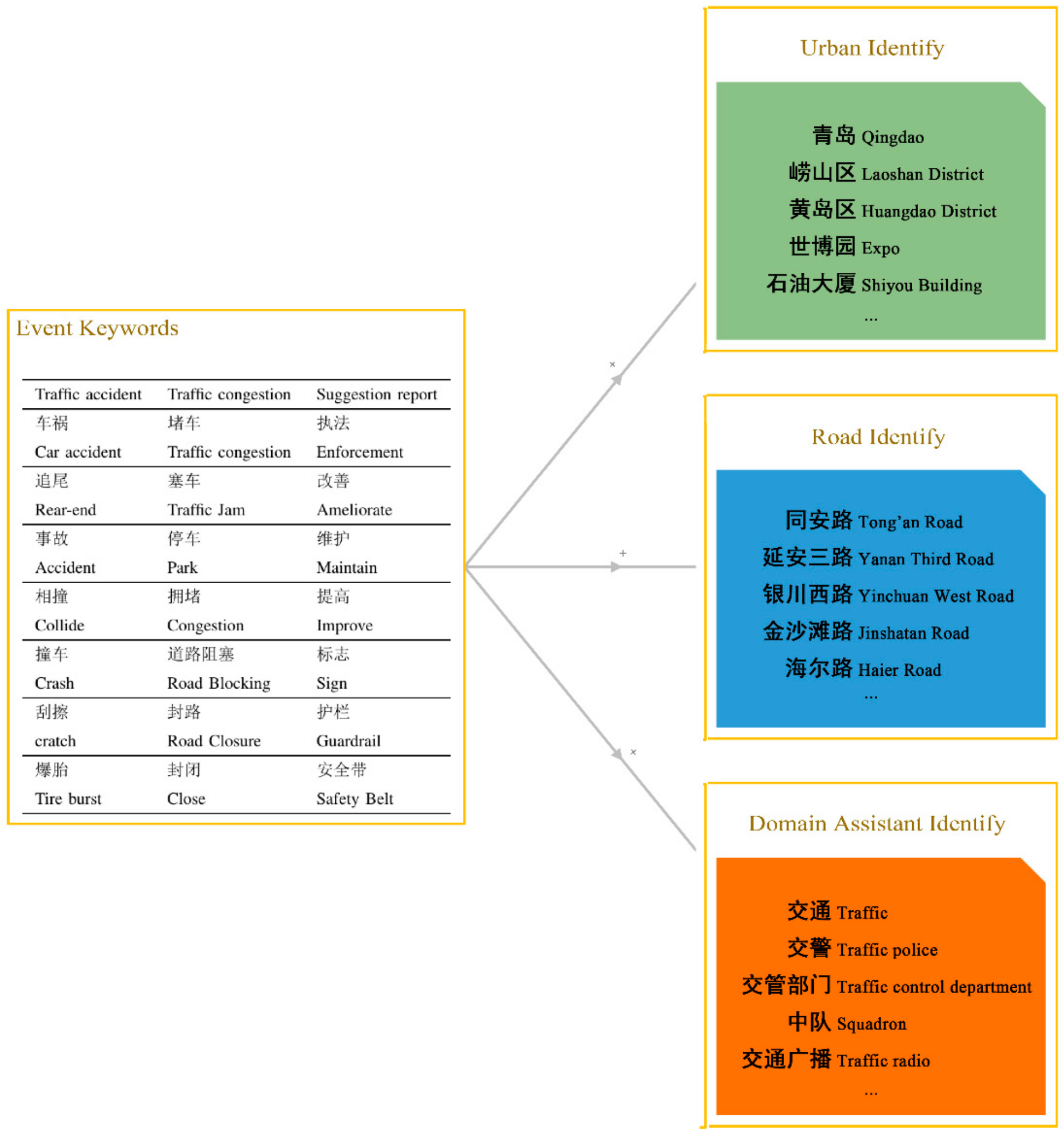
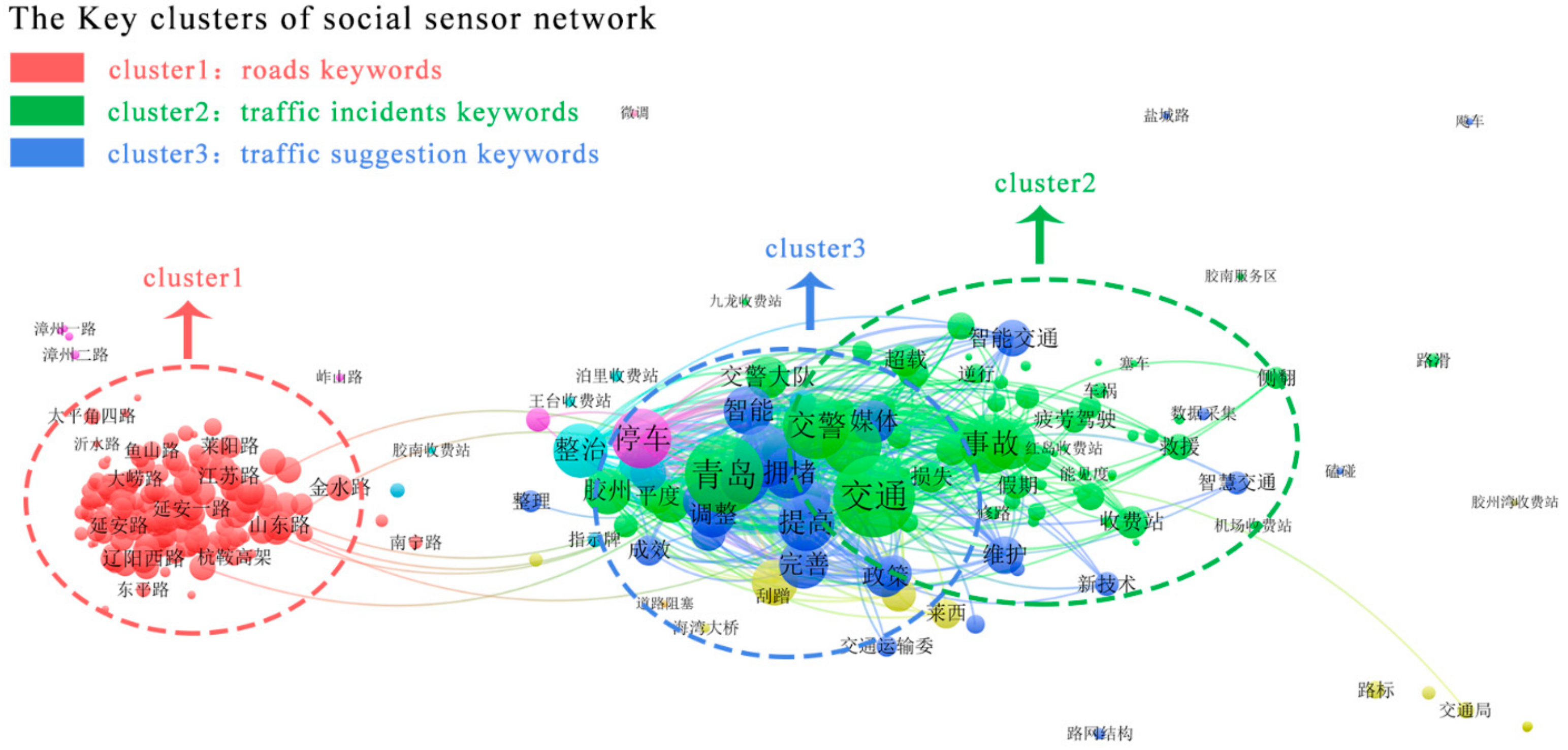
3.1. Social Sensors Network
3.2. Data Preprocessing
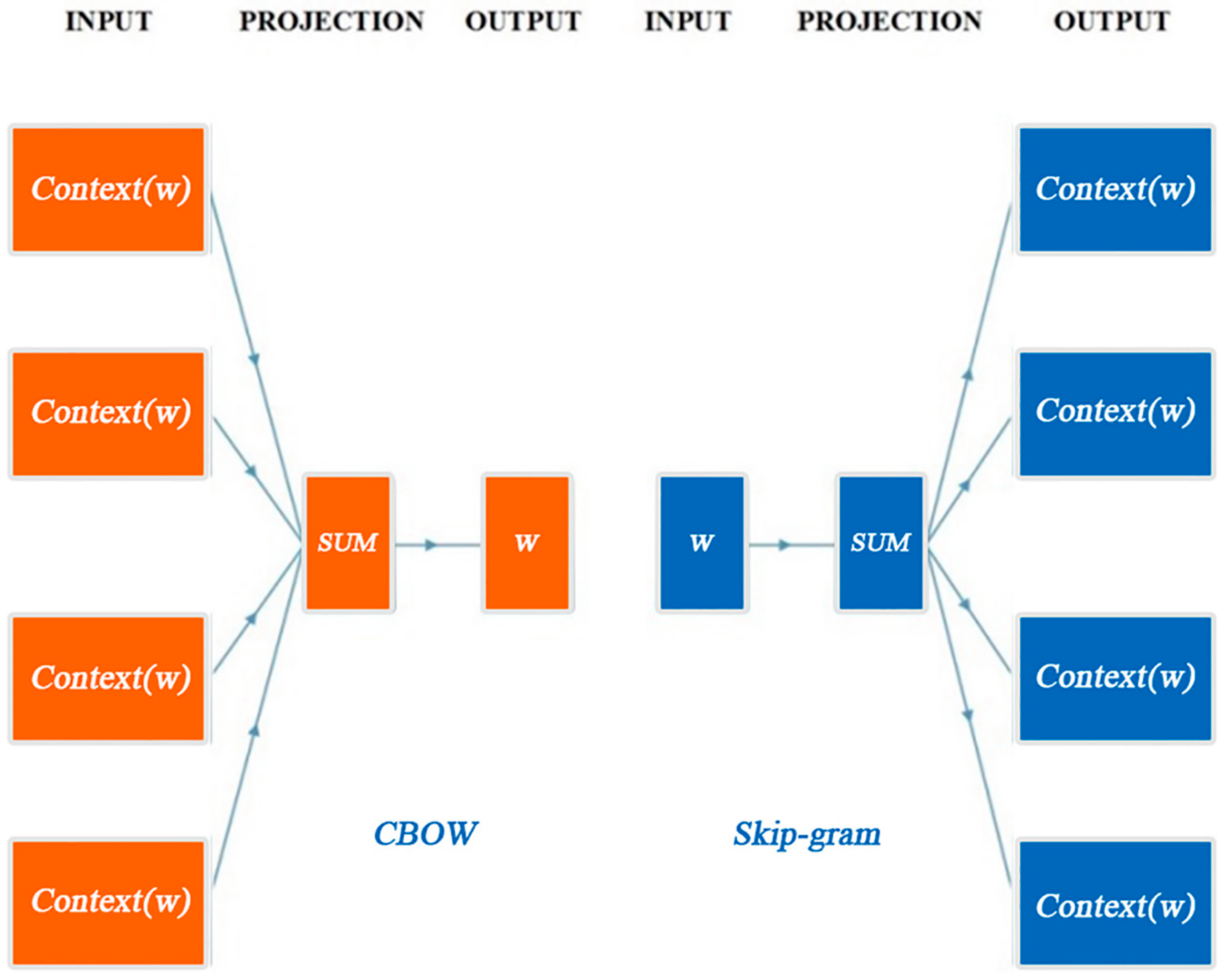
3.3. Word2vec Based Event Fusion Model
3.3.1. Transportation Events Detection from News and Weibo
- a)
- Combine all training messages generated by the same user into user profiles;
- b)
- Train the w-LDA model with training user profiles;
- c)
- Aggregate all testing messages generated by the same user into testing user profiles;
- d)
- Use the trained w-LDA model to infer a topic mixture.
| Algorithm 1. w-LDA Generation Process |
| Input:K, U, T, |
| Output:, , uProfileSet |
| //Step 1: User profiles data generation |
| For each author u = 1…U |
| Traverse all the Weibo posts t = 1…T; |
| Aggregate the posts generated by author u into users’ profile s uProfileSet(p) |
| Return uProfileSet |
| //Step 2: Topics generation |
| For each topic z = 1…K |
| Draw ~ Dirichlet ()// sample mix components for topic-word |
| //Step 3: Topic words generation |
| For each user profile p = 1…P |
| Draw ~ Dirichlet ()// sample mix components for user profile-topic |
| For each word in generated user profile p, i = 1…Np |
| Draw ~ Multinomial () // Sample topic for user profile p |
| Draw ~ Multinomial () //Sample word for topic |
| Return and |
3.3.2. Transportation Events Representation
3.3.3. Transportation Events Fusion
- Events similarity measure:
- Events alignment:
- Events fusion:
| Algorithm 2. Transportation Events Alignment and Fusion |
| Input:,,, |
| Output: AlignedTopicsList, FusionEventMatrix |
| //Step 1: aligning the topic clusters inand, return AlignedTopicsList |
| For each in |
| WeiboIndex = i |
| For each in |
| If |
| NewsAlignedIndex = j |
| End for // Find the closest topic cluster |
| Append (WeiboIndex, NewsAlignedIndex) to AlignedTopicsList |
| End for // couple closet the topic clusters into pairs |
| //Step 2: fusing the words in the cross-paired topics, return FusionEventMatrix |
| For each index pair in AlignedTopicsList |
| i = WeiboIndex; |
| j = NewsAlignedIndex |
| LBn = |
| UBw = + // calculate the low boundary and up boundary for news words |
| LBw = − |
| UBw = + // calculate the low boundary and up boundary for weibo words |
| For each in |
| For each in |
| If |
| minWordDis = |
| minWordIndex = n |
| End for // Find the shortest word embedding distance in coupled clusters |
| If LBw < minWordDis < UBw // remove anomaly word in Weibo cluster |
| If LBn < minWordDis < UBn |
| Append to FusionEventList // append words in News cluster |
| Else |
| Append to FusionEventList // append words in Weibo cluster |
| End for |
| Append FusionEventList to FusionEventMatrix |
| End for |
4. Experiments
4.1. Data Description
4.2. WBEF Model Verification
4.2.1. Transportation Word Embedding
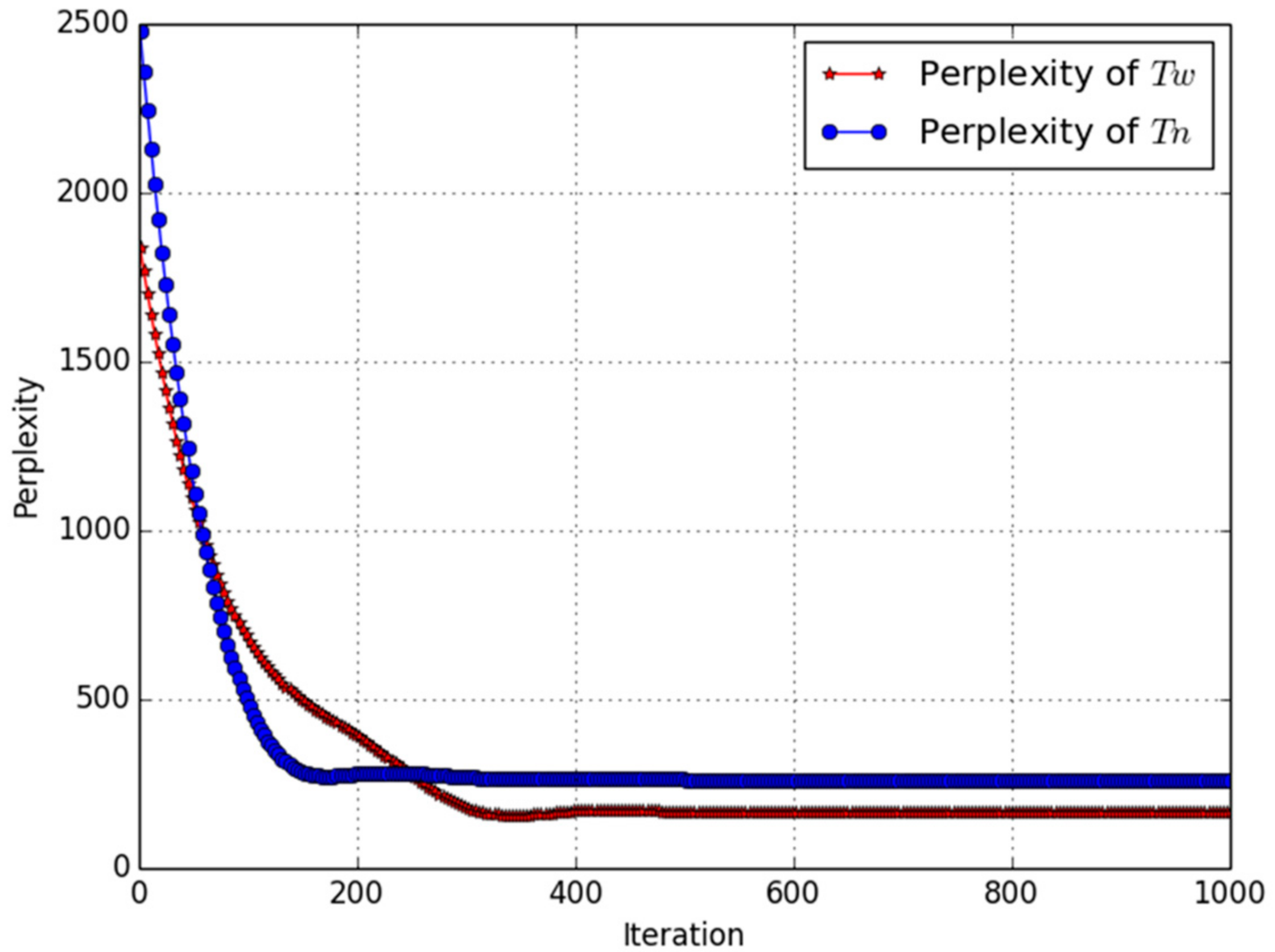
4.2.2. Transportation Event Detection
4.2.3. Distance Metrics for Transportation Events Fusion
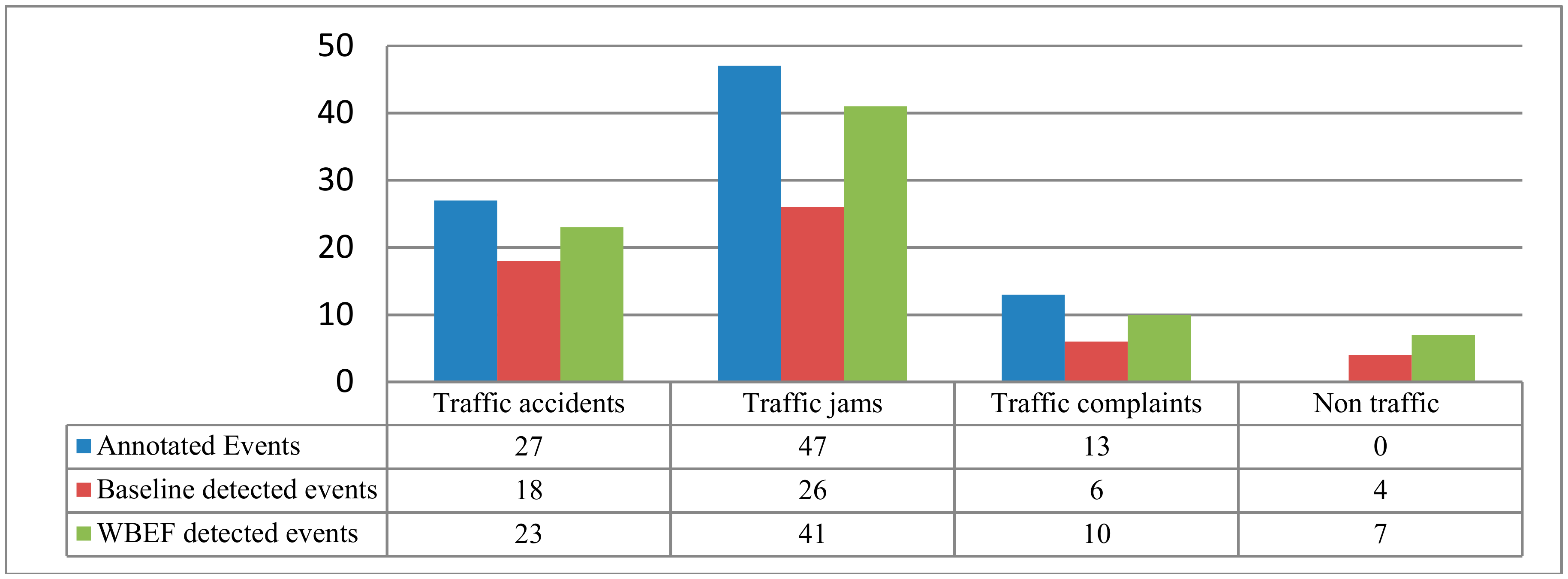
4.3. Overall Performance
5. Case Study in Application Scenario
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Table of Variables
| Symbol | Description | Data Structure | Supporting Process |
| T | Number of Weibo posts | Int T | w-LDA |
| U | Number of Weibo users | Int U | |
| K | Number of topics | Int K | |
| V | Number of words in the vocabulary | Int V | |
| V | Number of uers profiles | Int V | |
| Np | Number of words in p-th user profile | Int N[P] | |
| K-dimensional prior weight vectors of topics in a document, | Float a[K] | ||
| V-dimensional vector prior weight of words in a topic | Float b[V] | ||
| V-dimensional vector of probabilities, represents distribution of words in topic z | Double phi [Z][V] | ||
| K-dimensional vector of probabilities, represents distribution of topics in user profile p | Double theta [P][K] | ||
| Identity of current topic of word in user profile | Int 1…K | ||
| Identity of current word in user profile | Int 1…V | ||
| Identity of current user profiles | Int 1…P | ||
| Document-Topic matrix, the number of times topic j has been assigned to words in user profile . | int npt [P][K] | ||
| Topic-Word matrix, Number of times that word has been assigned to topic j | int ntw [K][V] | ||
| Wi | Identity of current word vector (200 dimensions) trained by traffic word2vec | Double [200] | Similarity measure |
| Identity of current topic word cluster detected from Weibo | Double tw[K] | ||
| Identity of current topic word cluster detected from News | Double tn[K] | ||
| Word embedding- cluster tensor, identity of the current word embedding in i-th cluster detected from Weibo | Double cew[K] [Wi] | ||
| Word embedding- cluster tensor, identity of the current word embedding in i-th cluster detected from News | Double cen [K] [Wi] | ||
| Words similarity, measure the similarity between word embedding and | Double wd | ||
| Topic similarity matrix, measure the distances between each words in the given topic cluster and | Double td[K][K] | Event fusion | |
| Average shortest distance between and | Double atd | ||
| Normalized average shortest distance between and | Double natd | ||
| The standard deviation of normalized topic distances | Double sd |
References
- Cheng, S.-T.; Li, J.-P.; Horng, G.-J.; Wang, K.-C. The Adaptive Road Routing Recommendation for Traffic Congestion Avoidance in Smart City. Wirel. Pers. Commun. 2014, 77, 225–246. [Google Scholar] [CrossRef]
- Lecue, F.; Tallevi-Diotallevi, S.; Hayes, J.; Tucker, R.; Bicer, V.; Sbodio, M.; Tommasi, P. Smart traffic analytics in the semantic web with STAR-CITY: Scenarios, system and lessons learned in Dublin City. J. Web Semant. 2014, 27–28, 26–33. [Google Scholar] [CrossRef]
- Papageorgiou, M.; Diakaki, C.; Dinopoulou, V.; Kotsialos, A.; Wang, Y.B. Review of road traffic control strategies. Proc. IEEE 2003, 91, 2043–2067. [Google Scholar] [CrossRef]
- El Faouzi, N.E.; Leung, H.; Kurian, A. Data fusion in intelligent transportation systems: Progress and challenges—A survey. Inf. Fusion 2011, 12, 4–10. [Google Scholar] [CrossRef]
- Morgul, E.F.; Yang, H.; Kurkcu, A.; Ozbay, K.; Bartin, B.; Kamga, C.; Salloum, R. Virtual Sensors Web-Based Real-Time Data Collection Methodology for Transportation Operation Performance Analysis. Transp. Res. Rec. 2014, 2442, 106–116. [Google Scholar] [CrossRef]
- Zheng, X.H.; Chen, W.; Wang, P.; Shen, D.Y.; Chen, S.H.; Wang, X.; Zhang, Q.; Yang, L. Big Data for Social Transportation. IEEE Trans. Intell. Transp. Syst. 2016, 17, 620–630. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, X.H.; Zhang, Q.P.; Wang, T.; Shen, D.Y. Crowdsourcing in ITS: The State of the Work and the Networking. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1596–1605. [Google Scholar] [CrossRef]
- Xiong, G.; Zhu, F.; Liu, X.; Dong, X.; Huang, W.; Chen, S.; Zhao, K. Cyber-physical-social system in intelligent transportation. IEEE J. Autom. Sin. 2015, 2, 320–333. [Google Scholar]
- Wang, F.Y. The Emergence of Intelligent Enterprises: From CPS to CPSS. IEEE Intell. Syst. 2010, 25, 85–88. [Google Scholar] [CrossRef]
- Wang, F.Y. Parallel Control and Management for Intelligent Transportation Systems: Concepts, Architectures, and Applications. IEEE Trans. Intell. Transp. Syst. 2010, 11, 630–638. [Google Scholar] [CrossRef]
- Zeng, K.; Liu, W.L.; Wang, X.; Chen, S.H. Traffic Congestion and Social Media in China. IEEE Intell. Syst. 2013, 28, 72–77. [Google Scholar] [CrossRef]
- Mo, H.; Hao, X.X.; Zheng, H.B.; Liu, Z.Z.; Wen, D. Linguistic Dynamic Analysis of Traffic Flow Based on Social Media-A Case Study. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2668–2676. [Google Scholar] [CrossRef]
- D’Andrea, E.; Ducange, P.; Lazzerini, B.; Marcelloni, F. Real-Time Detection of Traffic From Twitter Stream Analysis. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2269–2283. [Google Scholar] [CrossRef]
- Cao, J.; Zeng, K.; Wang, H.; Cheng, J.; Qiao, F.; Wen, D.; Gao, Y. Web-Based Traffic Sentiment Analysis: Methods and Applications. IEEE Trans. Intell. Transp. Syst. 2014, 15, 844–853. [Google Scholar]
- Nguyen, H.; Liu, W.; Rivera, P.; Chen, F. TrafficWatch: Real-Time Traffic Incident Detection and Monitoring Using Social Media. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Auckland, New Zealand, 19–22 April 2016. [Google Scholar]
- Ni, M.; He, Q.; Gao, J. Forecasting the Subway Passenger Flow Under Event Occurrences with Social Media. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1623–1632. [Google Scholar] [CrossRef]
- Maghrebi, M.; Abbasi, A.; Waller, S.T. Transportation Application of Social Media: Travel Mode Extraction. In Proceedings of the 19th International Conference on Intelligent Transportation Systems, Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar]
- Abidin, A.F.; Kolberg, M.; Hussain, A. Integrating Twitter Traffic Information with Kalman Filter Models for Public Transportation Vehicle Arrival Time Prediction. Big-Data Anal. Cloud Comput. 2015. [Google Scholar] [CrossRef]
- Chaniotakis, E.; Antoniou, C. Use of Geotagged Social Media in Urban Settings: Empirical Evidence on Its Potential from Twitter. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas, Spain, 15–18 September 2015. [Google Scholar]
- Xiong, G.; Zhu, F.; Dong, X.; Fan, H.; Hu, B.; Kong, Q.; Kang, W.; Teng, T. A Kind of Novel ITS Based on Space-Air-Ground Big-Data. IEEE Intell. Transp. Syst. Mag. 2016, 8, 10–22. [Google Scholar] [CrossRef]
- Zhou, T.; Gao, L.; Ni, D. Road traffic prediction by incorporating online information. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Zhu, F.; Li, Z.; Chen, S.; Xiong, G. Parallel Transportation Management and Control System and Its Applications in Building Smart Cities. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1576–1585. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, F.Y.; Wang, K.; Lin, W.H.; Xu, X.; Chen, C. Data-Driven Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1624–1639. [Google Scholar] [CrossRef]
- Lv, Y.; Chen, Y.; Zhang, X.; Duan, Y.; Li, N.L. Social media based transportation research: The state of the work and the networking. IEEE J. Autom. Sin. 2017, 4, 19–26. [Google Scholar] [CrossRef]
- Chaniotakis, E.; Antoniou, C.; Pereira, F. Mapping Social Media for Transportation Studies. IEEE Intell. Syst. 2016, 31, 64–70. [Google Scholar] [CrossRef]
- Ahmed, M.S.; Cook, A.R. Analysis of Freeway Traffic Time-series Data by Using Box-jenkins Techniques. Transp. Res. Board 1979, 773, 1–9. [Google Scholar]
- He, J.; Shen, W.; Divakaruni, P.; Wynter, L.; Lawrence, R.D. Improving traffic prediction with tweet semantics. In Proceedings of the Proceedings of the 23th International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Gu, Y.; Qian, Z.; Chen, F. From Twitter to detector: Real-time traffic incident detection using social media data. Transp. Res. Part C Emerg. Technol. 2016, 67, 321–342. [Google Scholar] [CrossRef]
- Fu, K.; Lu, C.T.; Nune, R.; Tao, J.X. Steds: Social Media Based Transportation Event Detection with Text Summarization. Available online: http://europa.nvc.cs.vt.edu/~ctlu/Publication/2015/IEEE-ITSC-Proceedings-STEDS-2015.pdf (accessed on 20 November 2018).
- Gutiérrez, C.; Figuerias, P.; Oliveira, P.; Costa, R.; Jardim-Goncalves, R. Twitter mining for traffic events detection. In Proceedings of the 2015 Science and Information Conference (SAI), London, UK, 28–30 July 2015. [Google Scholar]
- Lu, H.; Zhu, Y.; Shi, K.; Lv, Y.; Shi, P.; Niu, Z. Using Adverse Weather Data in Social Media to Assist with City-Level Traffic Situation Awareness and Alerting. Appl. Sci. 2018, 8, 1193. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Zhai, K.; Boyd-Graber, J. Online latent Dirichlet Allocation with Infinite Vocabulary. Available online: http://proceedings.mlr.press/v28/zhai13.pdf (accessed on 20 November 2018).
- Paisley, J.; Wang, C.; Blei, D.M.; Jordan, M.I. Nested Hierarchical Dirichlet Processes. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 256–270. [Google Scholar] [CrossRef] [PubMed]
- Quan, X.; Kit, C.; Ge, Y.; Pan, S.J. Short and sparse text topic modeling via self-aggregation. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Ramage, D.; Dumais, S.T.; Liebling, D.J. Characterizing Microblogs with Topic Models. In Proceedings of the Fourth International Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.-P.; Yan, H.; Li, X. Comparing twitter and traditional media using topic models. In Proceedings of the 33rd European conference on Advances in information retrieval, Dublin, Ireland, 18–21 April 2011. [Google Scholar]
- Hou, L.; Li, J.; Li, X.-L.; Su, Y. Measuring the Influence from User-Generated Content to News via Cross-dependence Topic Modeling. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hanoi, Vietnam, 20–23 April 2015. [Google Scholar]
- Oghina, A.; Breuss, M.; Tsagkias, M.; De Rijke, M. Predicting IMDB Movie Ratings Using Social Media. In Proceedings of the European Conference on Information Retrieval, Barcelona, Spain, 1–5 April 2012. [Google Scholar]
- Bao, B.-K.; Xu, C.; Min, W.; Hossain, M.S. Cross-Platform Emerging Topic Detection and Elaboration from Multimedia Streams. ACM Trans. Multimed. Comput. Commun. Appl. 2015, 11, 1–21. [Google Scholar] [CrossRef]
- Koike, D.; Takahashi, Y.; Utsuro, T.; Yoshioka, M.; Kando, N. Time Series Topic Modeling and Bursty Topic Detection of Correlated News and Twitter. Available online: http://www.aclweb.org/anthology/I13-1118 (accessed on 20 November 2018).
- Qian, S.; Zhang, T.; Xu, C. A Generic Framework for Social Event Analysis. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017. [Google Scholar]
- Li, M.; Wang, J.; Tong, W.; Yu, H.; Ma, X.; Chen, Y.; Cai, H.; Han, J. EKNOT: Event knowledge from news and opinions in Twitter. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, J.; Tong, W.; Yu, H.; Li, M.; Ma, X.; Cai, H.; Hanratty, T.; Han, J. Mining Multi-aspect Reflection of News Events in Twitter: Discovery, Linking and Presentation. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015. [Google Scholar]
- Wang, F.Y. A framework for social signal processing and analysis: from social sensing networks to computational dialectical analytics. Sci. Sin. Inf. 2013, 43, 1598–1611. [Google Scholar]
- Liu, T.; Che, W.; Zhenghua, L.I. Language Technology Platform. J. Chin. Inf. Process. 2011, 2, 13–16. [Google Scholar]
- Kim, E.H.J.; Jeong, Y.K.; Kim, Y.Y.; Kang, K.Y.; Song, M. Topic-based content and sentiment analysis of Ebola virus on Twitter and in the news. J. Inf. Sci. 2016, 42, 763–781. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: real-time event detection by social sensors. In Proceedings of the 19th international conference on World wide web, Raleigh, CA, USA, 26–30 April 2010. [Google Scholar]
- Hong, L.; Davison, B.D. Empirical study of topic modeling in Twitter. In Proceedings of the SIGKDD Workshop on Social Media Analytics, Washington, DC, USA, 25 June 2010. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. Available online: http://www.aclweb.org/anthology/D14-1162 (accessed on 20 November 2018).
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to Generate a Good Word Embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. Available online: https://arxiv.org/abs/1301.3781 (accessed on 20 November 2018).
- Socher, R.; Bauer, J.; Manning, C.D.; Y, N.A. Parsing with Compositional Vector Grammars. Available online: http://www.aclweb.org/anthology/P13-1045 (accessed on 20 November 2018).
- Zhou, G.; He, T.; Zhao, J.; Hu, P. Learning Continuous Word Embedding with Metadata for Question Retrieval in Community Question Answering. Available online: http://www.aclweb.org/anthology/P15-1025 (accessed on 20 November 2018).
- Rekabsaz, N. Enhancing Information Retrieval with Adapted Word Embedding. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016. [Google Scholar]
- Musto, C.; Semeraro, G.; De Gemmis, M.; Lops, P. Learning Word Embeddings from Wikipedia for Content-Based Recommender Systems. In Proceedings of the European Conference on Information Retrieval, Padua, Italy, 20–23 March 2016. [Google Scholar]
- Lin, Q.; Niu, Y.; Zhu, Y.; Lu, H.; Shi, K.; Keith, Z.; Niu, Z. Heterogeneous Knowledge-Based Attentive Neural Networks for Short-Term Music Recommendations. IEEE Access. 2018, 6, 58990–59000. [Google Scholar] [CrossRef]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Ghosh, S.; Korlam, G.; Ganguly, N. Spammers’ networks within online social networks: A case-study on Twitter. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Yang, C.; Harkreader, R.; Gu, G. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Hayati, P.; Chai, K.; Potdar, V.; Talevski, A. HoneySpam 2.0: Profiling Web Spambot Behaviour. In Proceedings of the 12th International Conference on Principles of Practice in Multi-Agent Systems, Nagoya, Japan, 14–16 December 2009. [Google Scholar]
- Chen, C.; Wu, K.; Srinivasan, V.; Zhang, X. Battling the internet water army: detection of hidden paid posters. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013. [Google Scholar]
- Tarus, J.K.; Niu, Z.; Yousif, A. A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Gener. Comput. Syst. 2017, 72, 37–48. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R= | Formula |
|---|---|
| Euclidean Distance | |
| Cosine Distance | |
| Manhattan Distance | |
| Chebyshev Distance | |
| Standardized Euclidean Distance | where s[l] is standard deviation |
| Training Dataset (about 2 Years) | Testing Dataset (7 Days) | Case Study Dataset (1 Day) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Text | Authors | Roads | Text | Authors | Roads | Text | Authors | Roads | |
| News Articles | 301,684 | - | 132 | 2369 | - | 37 | 334 | - | 12 |
| Weibo Posts | 839,587 | 271,260 | 147 | 4072 | 2600 | 49 | 581 | 428 | 25 |
| Traffic Words | Similar Words | Similarity | Traffic Words | Similar Words | Similarity |
|---|---|---|---|---|---|
| 交通拥堵 Traffic congestion | 交通拥挤 Heavy traffic | 83.47% | 交通事故 Traffic accident | 交通事件 Traffic incident | 82.19% |
| 交通阻塞 Traffic jam | 83.46% | 车祸 Car accident | 69.77% | ||
| 堵车 Caught in traffic | 75.28% | 伤亡事故 Fatality accident | 62.43% | ||
| 塞车 Stuck in traffic | 60.27% | 碰撞 Traffic crash | 60.86% | ||
| 滞留 Traffic blocking | 59.45% | 重大事故 Major accident | 59.33% |
| Road | Type | ||
|---|---|---|---|
| 抚顺路 Fushun Road | 抚顺路 施工现场 堵车 交叉路口 缓慢… Fushun Road, construction site, traffic jams, intersection, slow moving… | 交通广播 抚顺路 一动不动 堵死 附近 高峰时段 疏通 水泄不通… Traffic broadcast, Fushun Road, blocked, slow moving, nearby, peak hours, dispersion, crowd and jam… | 拥堵 Traffic Jam |
| 银川西路 Yinchuan WestRoad | 银川西路 会场 一段路 规划 答复 拥堵… Yinchuan WestRoad, theater, road section, city planning, response, traffic jams… | 信号灯 失灵十字路口 怎么回事 东向西 吐槽 为何… Traffic signals, not work, crossroads, what happened, east to west, complain, reason… | 投诉 Traffic Complaint |
| 人民路 RenMin Road | 人民路 交警 民警 男子 驾驶 撞墙 双腿 受伤… RenMin Road, traffic police, police officer, man, car driving, hit the wall, legs, injured… | 人民路 救援 现场 不慎 情况危急 求助 车底… RenMin Road, rescue, accident scene, critical situation, help, car bottom… | 事故 Traffic Accident |
| Distance Measure (R=) | Average and Standard Deviation | 人民路 RenMin Road | 伊春路 YiChun Road | 山东路 ShanDong Road | 延吉路 JiYan Road | 延安三路Yan’ An San Road | 抚顺路 FuShun Road | 敦化路 AnHua Road | 登州路 DengZhou Road | 银川西路 YinChuan Xi Road | 鞍山路 AnShan Road |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Euclidean | 0.896 | 1.088 | 1.03 | 1.09 | 0.973 | 0.986 | 1.101 | 0.96 | 1.083 | 0.916 | |
| 0.07278 | |||||||||||
| Cosine | 0.0031 | 0.0041 | 0.0033 | 0.0036 | 0.0029 | 0.0032 | 0.0071 | 0.0034 | 0.0036 | 0.0029 | |
| 0.00117 | |||||||||||
| Manhattan | 10.15 | 12.33 | 11.31 | 12.28 | 10.97 | 11.12 | 12.36 | 10.81 | 12.21 | 10.32 | |
| 0.8176 | |||||||||||
| Chebyshev | 0.169 | 0.206 | 0.191 | 0.207 | 0.185 | 0.189 | 0.207 | 0.181 | 0.208 | 0.174 | |
| 0.01386 | |||||||||||
| Weighted Euclidean | 19.78 | 19.99 | 19.68 | 19.54 | 19.91 | 19.6 | 19.54 | 20 | 19.91 | 20 | |
| 0.17455 | |||||||||||
| Hits | Miss | False Alarm | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|
| Baseline Model | 50 | 37 | 4 | 92.6% | 57.4% | 70.9% |
| The Proposed Model | 74 | 13 | 7 | 91.4% | 85.1% | 88.1% |
| Target Road | Relevant Locations | Traffic Words | Traffic Causal Words | Other Words |
|---|---|---|---|---|
| 金沙滩路 Gold Beach Road | 黄岛区 啤酒城 隧道 Huangdao District, Beer Square, Cross-sea Tunnel. | 缓慢 交通拥堵 高峰 客流 车流量 停车 交警 Slow, traffic jam, rush hour, passenger flow, traffic flow, parking, traffic polices | 啤酒节 开幕式 开园 Beer festival, opening ceremony, park opening | 黄晓明 明星 直播 Xiaoming Huang, Superstar, live show |
| 同安路 Tong An Road | 国信体育场 银川东路 劲松七路 海尔路 Guoxin Stadium, Yin Chuan Xi Road, Jin Song Qi Road, Hai Er Road | 绕行 高峰 慢行 管制 拥堵 停车 调流 交通广播 预案 Passing round, rush hour, slow, traffic control, traffic jam, parking, traffic flow regulation, traffic broadcast, Traffic plan. | 五月天 演唱会 Mayday singer group, concert | 门票 五迷 提示 Tickets, fans, notice |
| 延安三路 Yan An San Road | 石油大厦 Petroleum Building | 交通拥堵 交警 交通广播 道路封锁 车辆疏导 疏散 Traffic jam, traffic policies, traffic broadcast, road closed, traffic dispersion, evacuation | 火情 火警 起火 扑灭 Fire situation, fire alarm, catch fire, Fire extinguished | 伤亡 电梯井 Casualties, elevator hoist way |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Shi, K.; Zhu, Y.; Lv, Y.; Niu, Z. Sensing Urban Transportation Events from Multi-Channel Social Signals with the Word2vec Fusion Model. Sensors 2018, 18, 4093. https://doi.org/10.3390/s18124093
Lu H, Shi K, Zhu Y, Lv Y, Niu Z. Sensing Urban Transportation Events from Multi-Channel Social Signals with the Word2vec Fusion Model. Sensors. 2018; 18(12):4093. https://doi.org/10.3390/s18124093
Chicago/Turabian StyleLu, Hao, Kaize Shi, Yifan Zhu, Yisheng Lv, and Zhendong Niu. 2018. "Sensing Urban Transportation Events from Multi-Channel Social Signals with the Word2vec Fusion Model" Sensors 18, no. 12: 4093. https://doi.org/10.3390/s18124093
APA StyleLu, H., Shi, K., Zhu, Y., Lv, Y., & Niu, Z. (2018). Sensing Urban Transportation Events from Multi-Channel Social Signals with the Word2vec Fusion Model. Sensors, 18(12), 4093. https://doi.org/10.3390/s18124093