SECOND: Sparsely Embedded Convolutional Detection


Abstract
:1. Introduction
- We apply sparse convolution in LiDAR-based object detection, thereby greatly increasing the speeds of training and inference.
- We propose an improved method of sparse convolution that allows it to run faster.
- We propose a novel angle loss regression approach that demonstrates better orientation regression performance than other methods do.
- We introduce a novel data augmentation method for LiDAR-only learning problems that greatly increases the convergence speed and performance.
2. Related Work
2.1. Front-View- and Image-Based Methods
2.2. Bird’s-Eye-View-Based Methods
2.3. 3D-Based Methods
2.4. Fusion-Based Methods
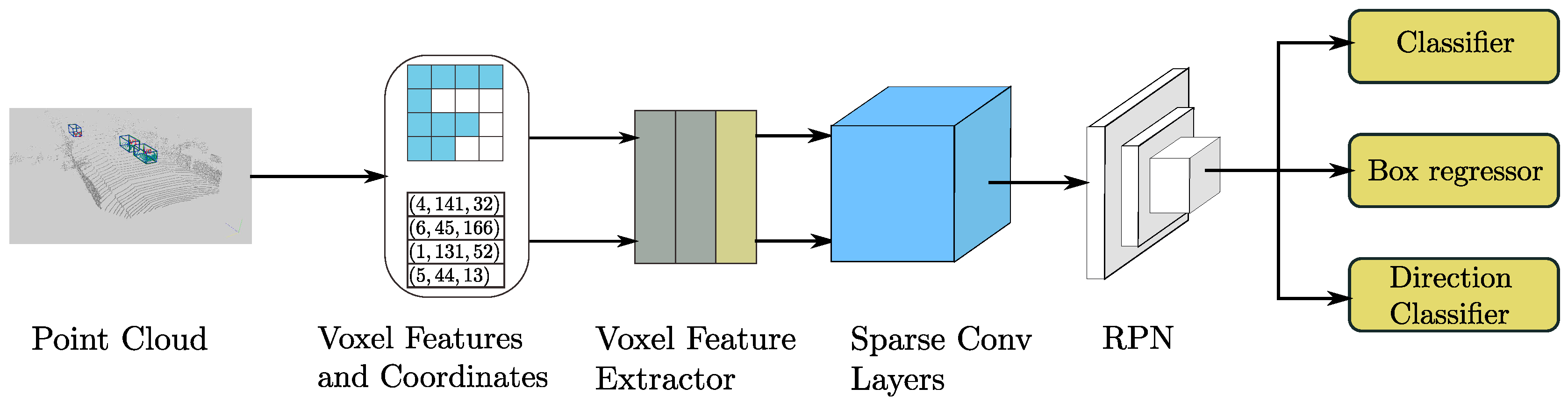
3. SECOND Detector
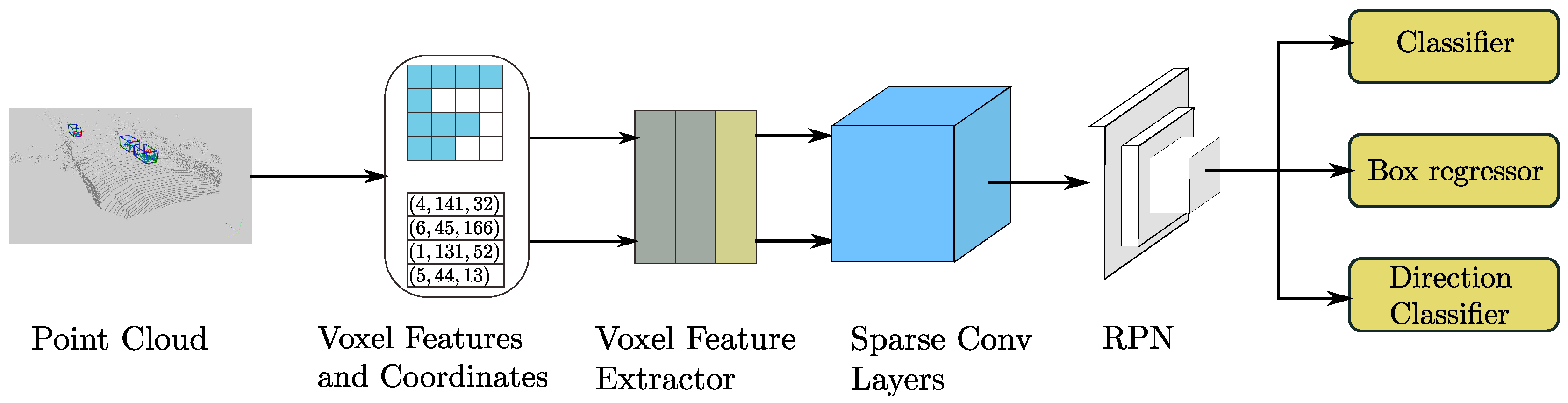
3.1. Network Architecture
3.1.1. Point Cloud Grouping
3.1.2. Voxelwise Feature Extractor
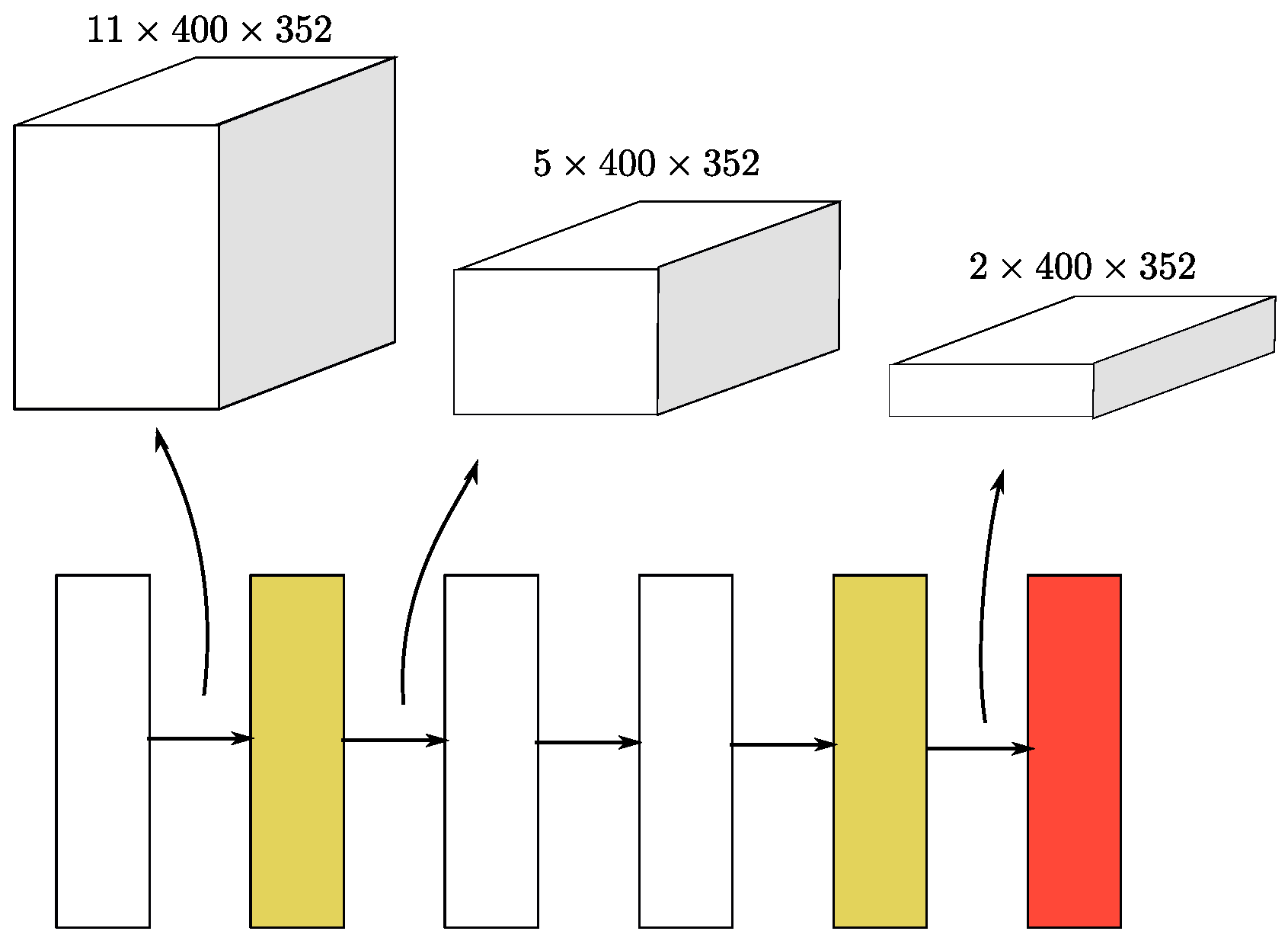
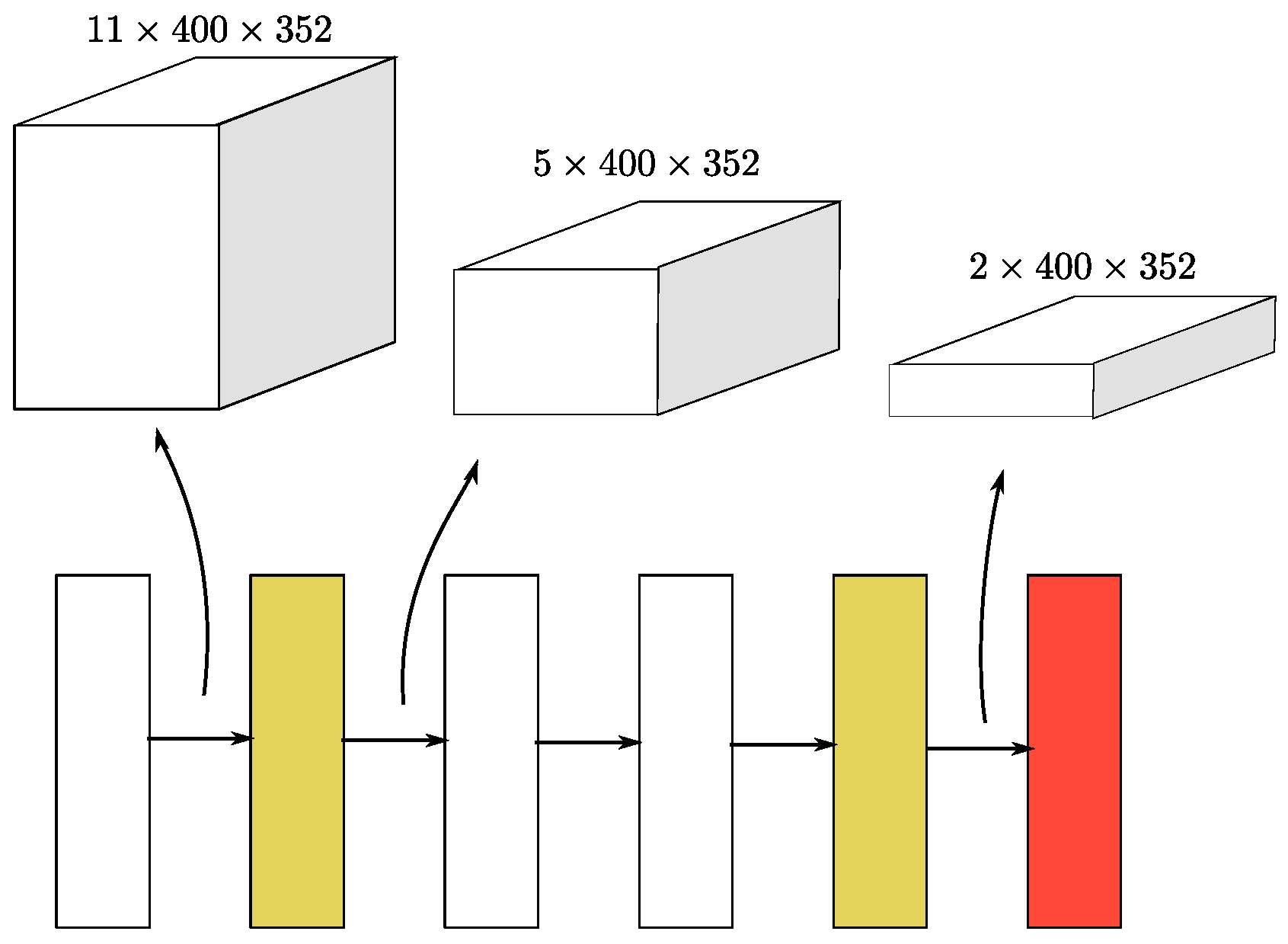
3.1.3. Sparse Convolutional Middle Extractor
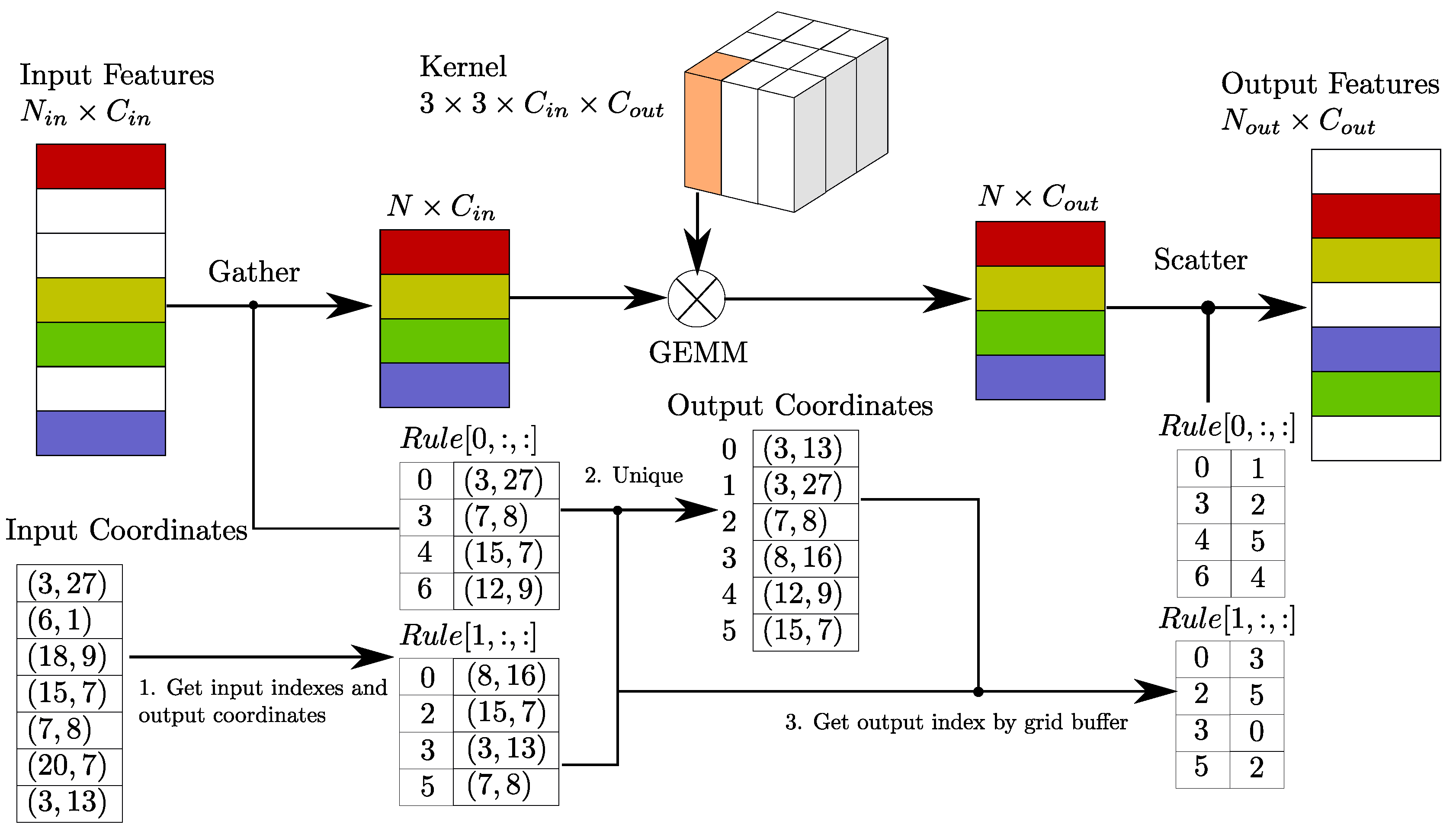
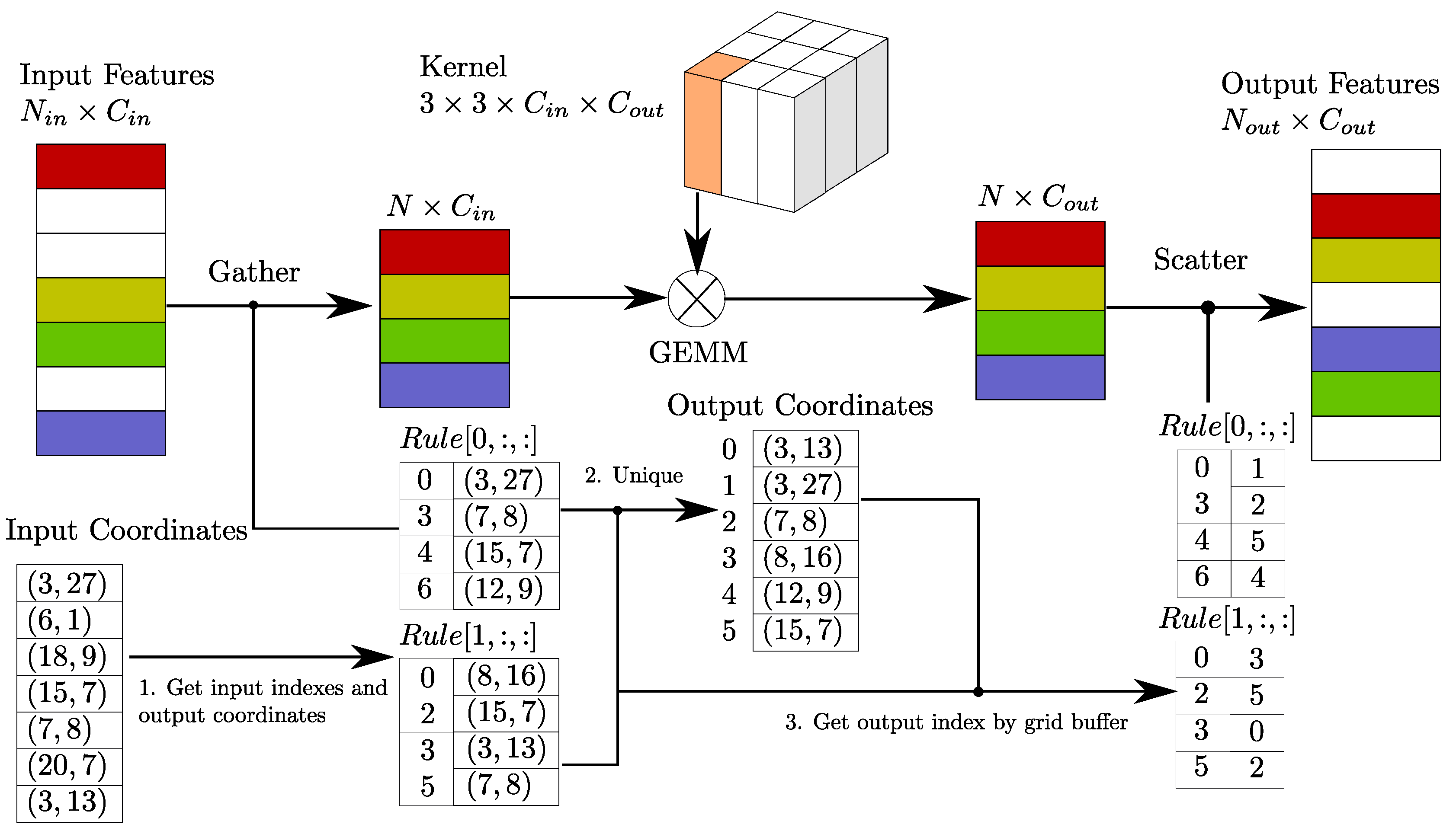
Review of Sparse Convolutional Networks
Sparse Convolution Algorithm
Rule Generation Algorithm
| Algorithm 1: 3D Rule Generation |
 |
Sparse Convolutional Middle Extractor
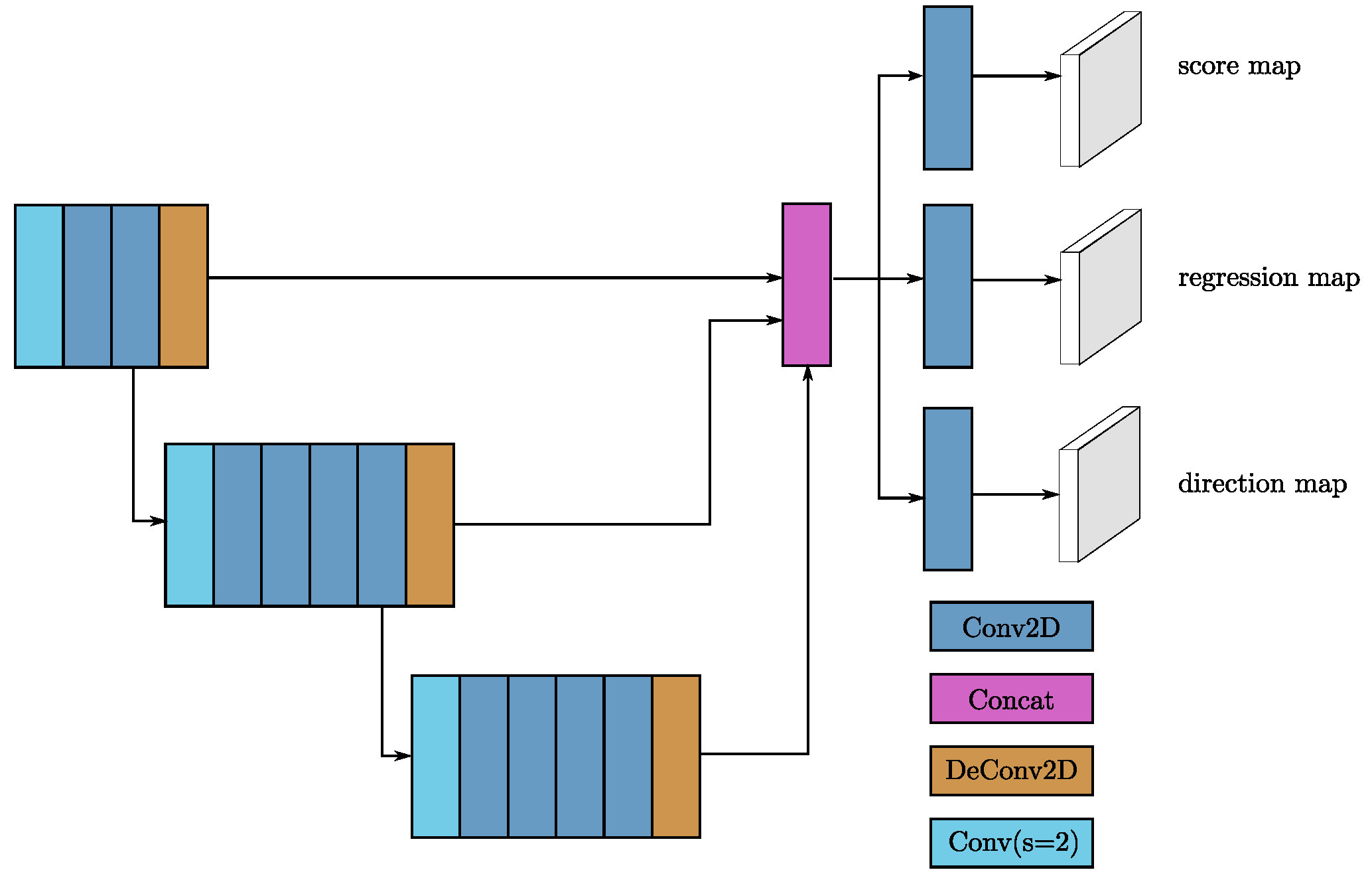
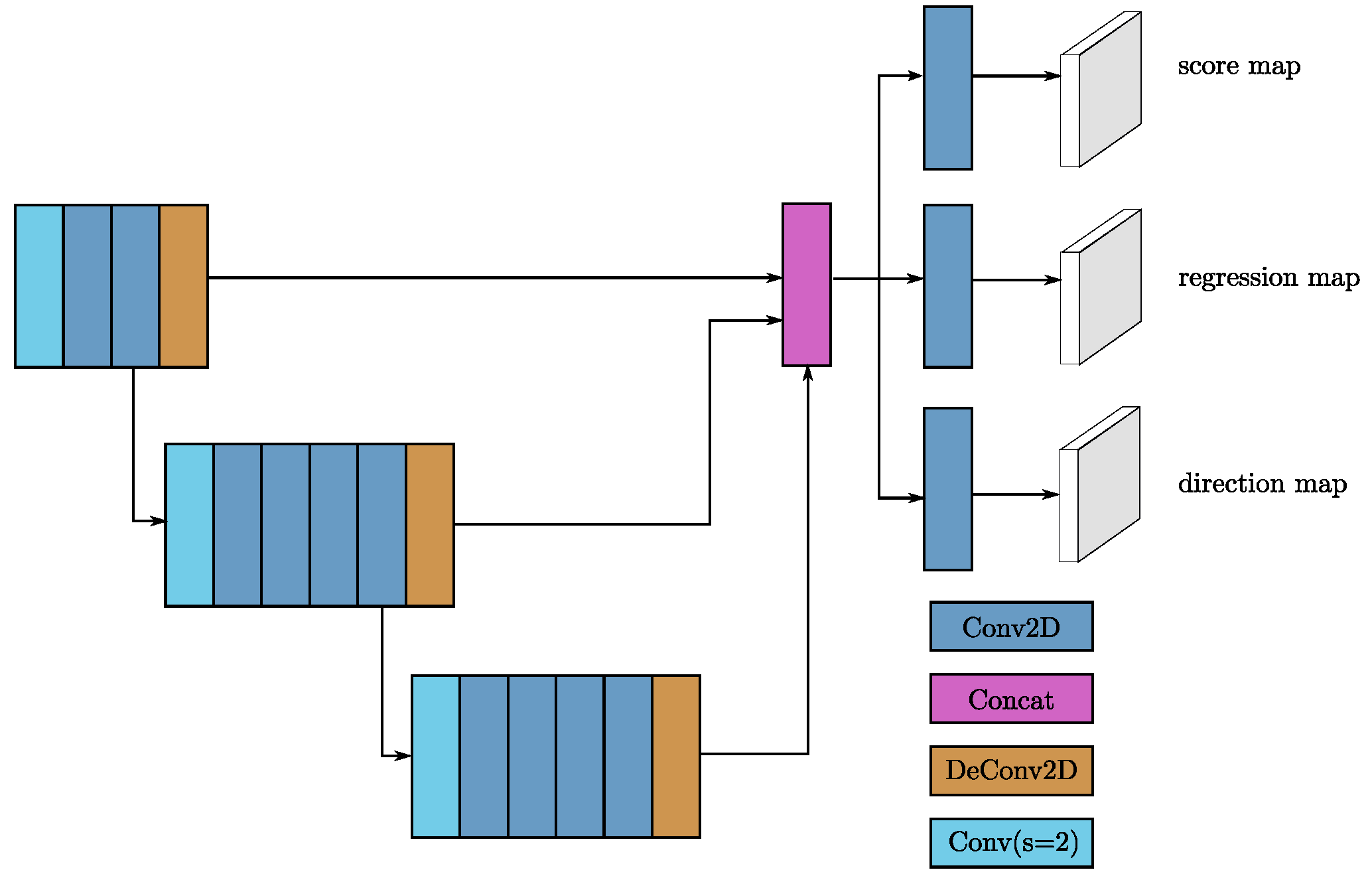
3.1.4. Region Proposal Network
3.1.5. Anchors and Targets
3.2. Training and Inference
3.2.1. Loss
Sine-Error Loss for Angle Regression
Focal Loss for Classification
Total Training Loss
3.2.2. Data Augmentation
Sample Ground Truths from the Database
Object Noise
Global Rotation and Scaling
3.2.3. Optimization
3.2.4. Network Details
4. Experiments
4.1. Evaluation Using the KITTI Test Set
4.2. Evaluation Using the KITTI Validation Set
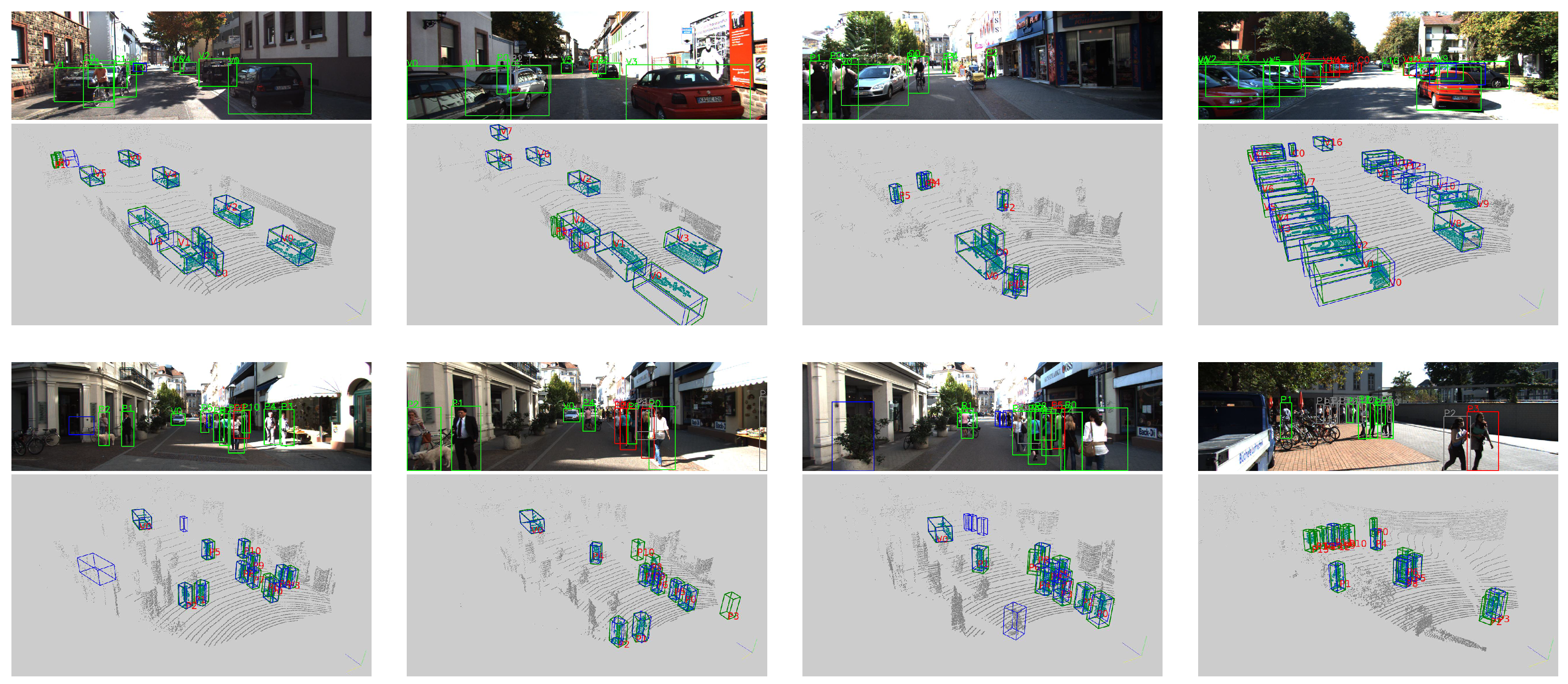
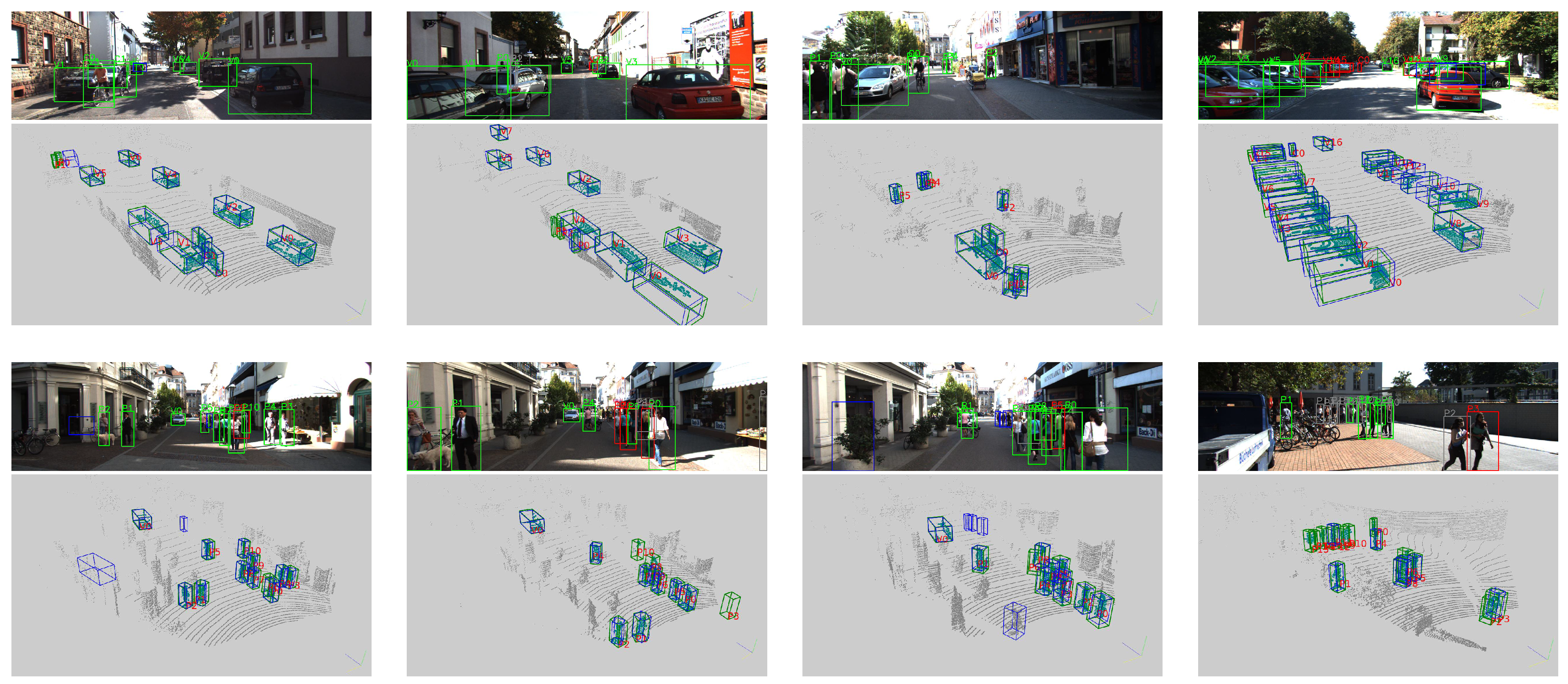
4.3. Analysis of the Detection Results
4.3.1. Car Detection
4.3.2. Pedestrian and Cyclist Detection
4.4. Ablation Studies
4.4.1. Sparse Convolution Performance
4.4.2. Different Angle Encodings
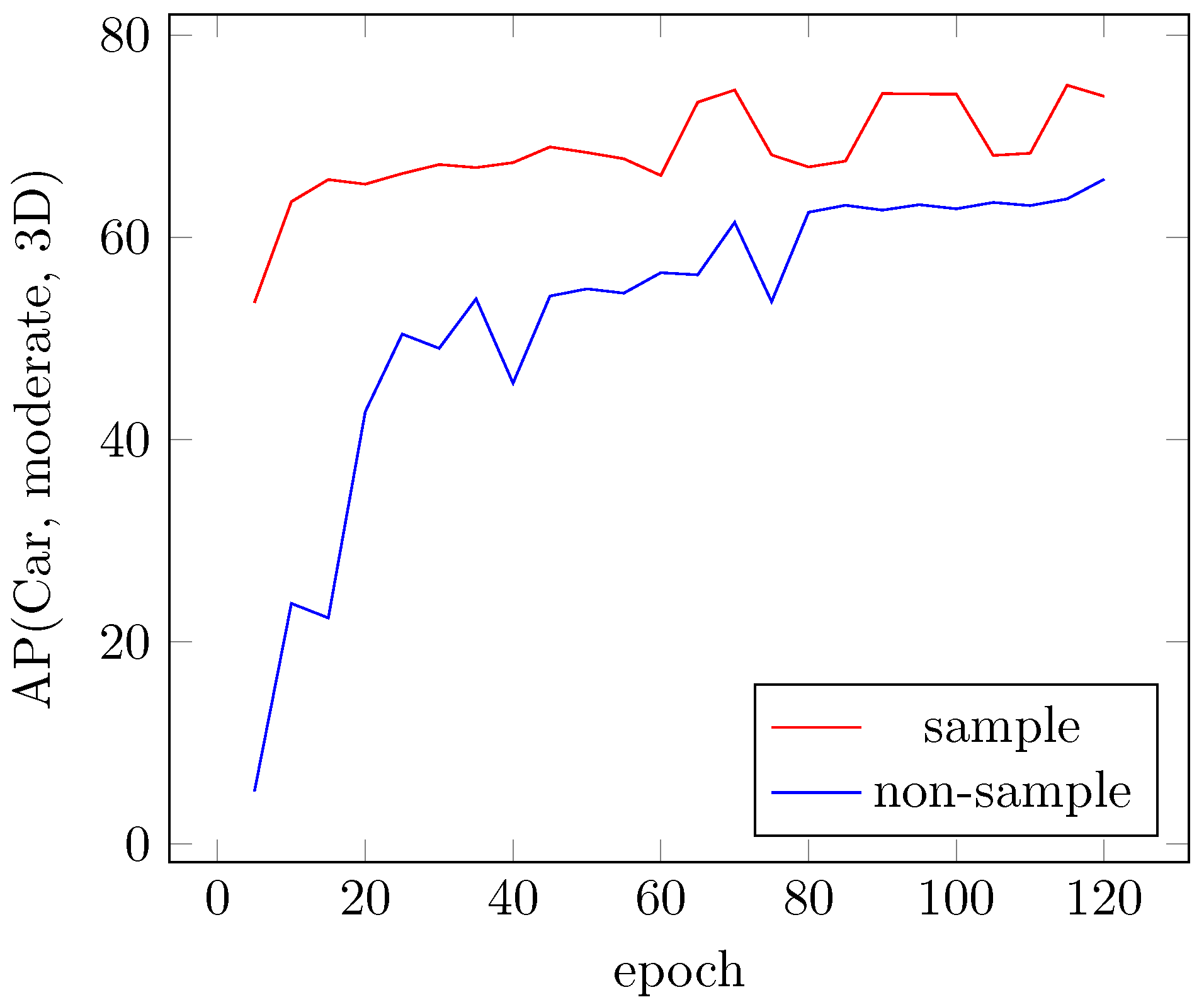
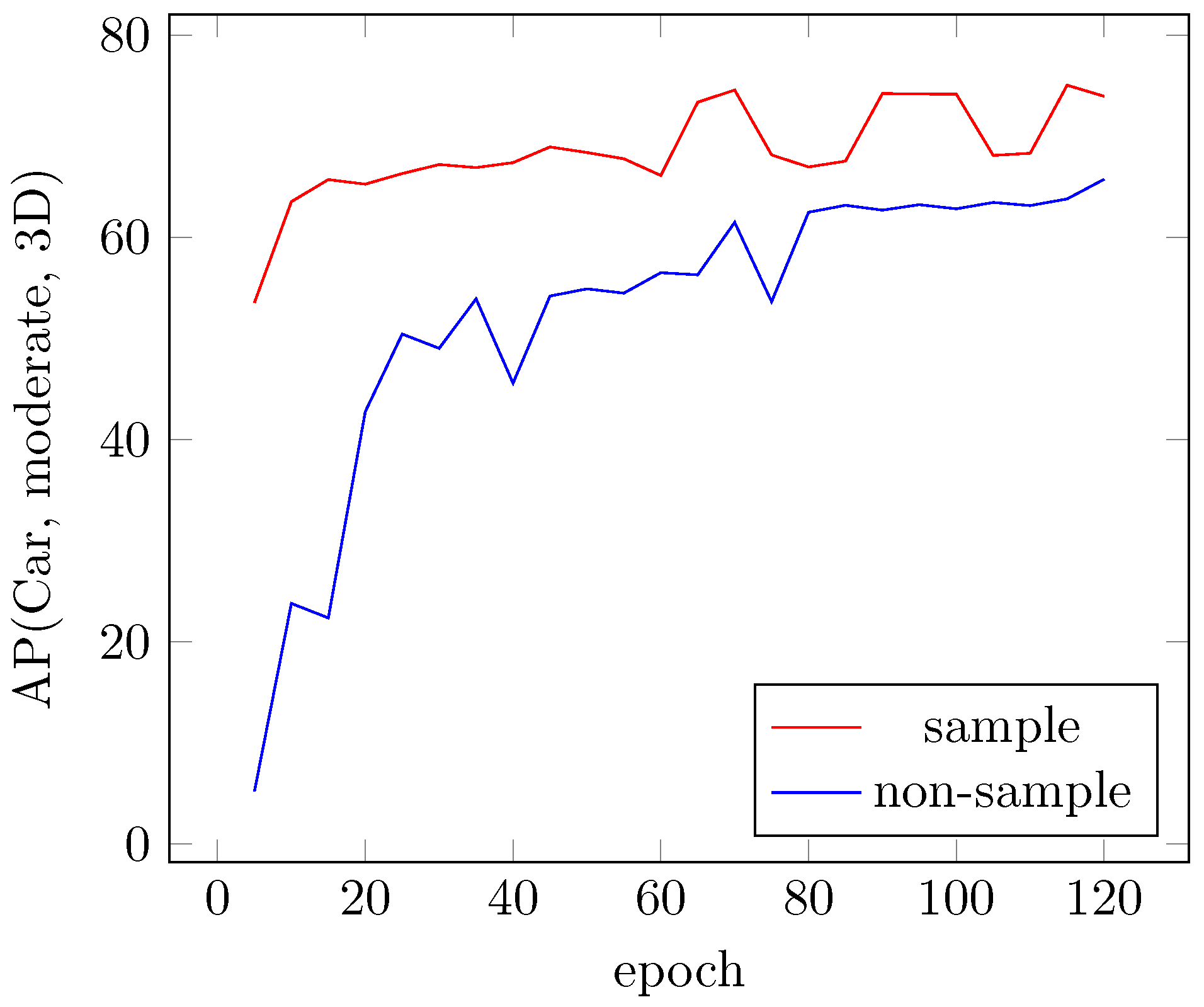
4.4.3. Sampling Ground Truths for Faster Convergence
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. arXiv, 2017; arXiv:1703.06870. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. arXiv, 2017; arXiv:1711.07319. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals using stereo imagery for accurate object class detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed]
- Kitti 3D Object Detection Benchmark Leader Board. Available online: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d (accessed on 28 April 2018).
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S. Joint 3D Proposal Generation and Object Detection from View Aggregation. arXiv, 2017; arXiv:1712.02294. [Google Scholar]
- Du, X.; Ang Jr, M.H.; Karaman, S.; Rus, D. A general pipeline for 3D detection of vehicles. arXiv, 2018; arXiv:1803.00387. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. arXiv, 2017; arXiv:1711.08488. [Google Scholar]
- Wang, D.Z.; Posner, I. Voting for Voting in Online Point Cloud Object Detection. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; Volume 1. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3D point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. arXiv, 2017; arXiv:1711.06396. [Google Scholar]
- Li, B. 3D fully convolutional network for vehicle detection in point cloud. In Proceedings of the IEEE 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2004; pp. 580–587. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Košecká, J. 3D bounding box estimation using deep learning and geometry. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5632–5640. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3D lidar using fully convolutional network. arXiv, 2016; arXiv:1608.07916. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.M. Complex-YOLO: Real-time 3D Object Detection on Point Clouds. arXiv, 2018; arXiv:1803.06199. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection From Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Chen, B. PointCNN. arXiv, 2018; arXiv:1801.07791. [Google Scholar]
- Graham, B. Spatially-sparse convolutional neural networks. arXiv, 2014; arXiv:1409.6070. [Google Scholar]
- Graham, B. Sparse 3D convolutional neural networks. arXiv, 2015; arXiv:1505.02890. [Google Scholar]
- Graham, B.; van der Maaten, L. Submanifold Sparse Convolutional Networks. arXiv, 2017; arXiv:1706.01307. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3D object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Vasudevan, A.; Anderson, A.; Gregg, D. Parallel multi channel convolution using general matrix multiplication. In Proceedings of the 2017 IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), Seattle, WA, USA, 10–12 July 2017; pp. 19–24. [Google Scholar]
- SparseConvNet Project. Available online: https://github.com/facebookresearch/SparseConvNet (accessed on 28 April 2018).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv, 2017; arXiv:1708.02002. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sparse Convolution (1 layer) | |||
| Channels | SECOND | SpConvNet [31] | Dense |
| 8.6 | 21.2 | 567 | |
| 13.8 | 24.8 | 1250 | |
| 25.3 | 37.4 | ||
| 58.7 | 86.0 | ||
| Submanifold Convolution (4 layers) | |||
| Channels | SECOND | SpConvNet [31] | Dense |
| 7.1 | 16.0 | ||
| 11.3 | 21.5 | ||
| 20.4 | 37.0 | ||
| 49.0 | 94.1 | ||
| Method | Time (s) | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| MV3D [8] | 0.36 | 71.09 | 62.35 | 55.12 | N/A | N/A | N/A | N/A | N/A | N/A |
| MV3D (LiDAR) [8] | 0.24 | 66.77 | 52.73 | 51.31 | N/A | N/A | N/A | N/A | N/A | N/A |
| F-PointNet [11] | 0.17 | 81.20 | 70.39 | 62.19 | 51.21 | 44.89 | 40.23 | 71.96 | 56.77 | 50.39 |
| AVOD [9] | 0.08 | 73.59 | 65.78 | 58.38 | 38.28 | 31.51 | 26.98 | 60.11 | 44.90 | 38.80 |
| AVOD-FPN [9] | 0.1 | 81.94 | 71.88 | 66.38 | 46.35 | 39.00 | 36.58 | 59.97 | 46.12 | 42.36 |
| VoxelNet (LiDAR) [14] | 0.23 | 77.47 | 65.11 | 57.73 | 39.48 | 33.69 | 31.51 | 61.22 | 48.36 | 44.37 |
| SECOND | 0.05 | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 |
| Method | Time (s) | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| MV3D [8] | 0.36 | 86.02 | 76.90 | 68.49 | N/A | N/A | N/A | N/A | N/A | N/A |
| MV3D (LiDAR) [8] | 0.24 | 85.82 | 77.00 | 68.94 | N/A | N/A | N/A | N/A | N/A | N/A |
| F-PointNet [11] | 0.17 | 88.70 | 84.00 | 75.33 | 58.09 | 50.22 | 47.20 | 75.38 | 61.96 | 54.68 |
| AVOD [9] | 0.08 | 86.80 | 85.44 | 77.73 | 42.51 | 35.24 | 33.97 | 63.66 | 47.74 | 46.55 |
| AVOD-FPN [9] | 0.1 | 88.53 | 83.79 | 77.90 | 50.66 | 44.75 | 40.83 | 62.39 | 52.02 | 47.87 |
| VoxelNet (LiDAR) [14] | 0.23 | 89.35 | 79.26 | 77.39 | 46.13 | 40.74 | 38.11 | 66.70 | 54.76 | 50.55 |
| SECOND | 0.05 | 88.07 | 79.37 | 77.95 | 55.10 | 46.27 | 44.76 | 73.67 | 56.04 | 48.78 |
| Method | Time (s) | Easy | Moderate | Hard |
|---|---|---|---|---|
| MV3D [8] | 0.36 | 71.29 | 62.68 | 56.56 |
| F-PointNet [11] | 0.17 | 83.76 | 70.92 | 63.65 |
| AVOD-FPN [9] | 0.1 | 84.41 | 74.44 | 68.65 |
| VoxelNet [14] | 0.23 | 81.97 | 65.46 | 62.85 |
| SECOND | 0.05 | 87.43 | 76.48 | 69.10 |
| SECOND (small) | 0.025 | 85.50 | 75.04 | 68.78 |
| Method | Time (s) | Easy | Moderate | Hard |
|---|---|---|---|---|
| MV3D [8] | 0.36 | 86.55 | 78.10 | 76.67 |
| F-PointNet [11] | 0.17 | 88.16 | 84.02 | 76.44 |
| VoxelNet [14] | 0.23 | 89.60 | 84.81 | 78.57 |
| SECOND | 0.05 | 89.96 | 87.07 | 79.66 |
| SECOND (small) | 0.025 | 89.79 | 86.20 | 79.55 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| Vector [9] | 85.99 | 74.79 | 67.82 |
| SECOND | 87.43 | 76.48 | 69.10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. https://doi.org/10.3390/s18103337
Yan Y, Mao Y, Li B. SECOND: Sparsely Embedded Convolutional Detection. Sensors. 2018; 18(10):3337. https://doi.org/10.3390/s18103337
Chicago/Turabian StyleYan, Yan, Yuxing Mao, and Bo Li. 2018. "SECOND: Sparsely Embedded Convolutional Detection" Sensors 18, no. 10: 3337. https://doi.org/10.3390/s18103337
APA StyleYan, Y., Mao, Y., & Li, B. (2018). SECOND: Sparsely Embedded Convolutional Detection. Sensors, 18(10), 3337. https://doi.org/10.3390/s18103337