Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days


Abstract
:1. Introduction
- (i)
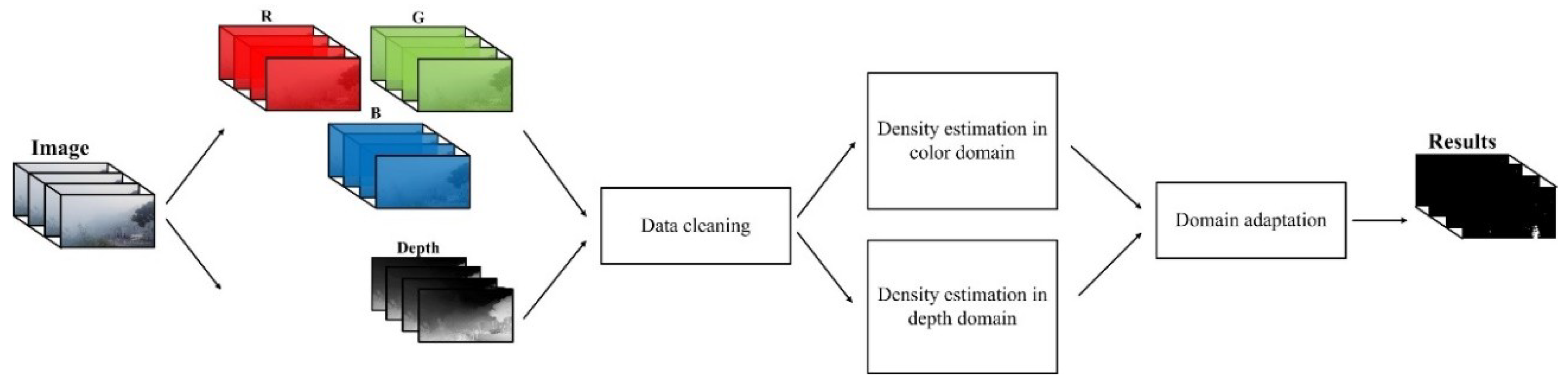
- Depth-information-based object detection on foggy days. Aiming to conquer the challenges posed by foggy days, our method exploits the depth information for object detection.
- (ii)
- Domain-adaptation-learning-based background modeling on foggy days. Our method trains the background models with the color and depth information separately, and they are jointly trained via the domain adaptation learning strategy.
- (iii)
- Exploring depth and color features in images on foggy days. Our method explores the features in both the color and depth domains, and fuses them for object detection on foggy days.
2. Related Works
2.1. Image Processing
2.2. Object Detection
3. Proposed Method
3.1. Depth Estimate and Data Cleaning
3.1.1. Skylight Area Recognition and Removal
- (i)
- Low channel variation. In contrast to other optical components, the channel variation is relatively low for the skylight.
- (ii)
- Distance-dependent intensity. Owing to the light scattering factor in haze environments, in skylight areas, the intensity of any point is related to its distance from the optical collimation.
3.1.2. Dark Channel Prior Model-Based Depth Estimation
3.1.3. Data Cleaning for Depth Information
3.2. Domain Adaptation Learning and Fusion Method
3.2.1. KDE Model
3.2.2. Color–Depth Cross-Source Domain Adaptation
| Algorithm 1. Color–Depth Domain Adaptation Learning |
| Input: color images (source domain), depth maps (target domain) |
| Output: optimal weight parameters and |
| Initialization: weight parameters |
|
4. Experimental Results
4.1. Evaluation Criterion
4.2. Qualitative Evaluation
4.3. Quantitative Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, H.; Shao, Z.; Tan, J. Recognition of car makes and models from a single traffic-camera image. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3182–3192. [Google Scholar] [CrossRef]
- Wu, L.; Du, X.; Fu, X. Security threats to mobile multimedia applications: Camera-based attacks on mobile phones. IEEE Commun. Mag. 2014, 52, 80–87. [Google Scholar] [CrossRef]
- Li, Y.; You, S.; Brown, M.S.; Tan, R.T. Haze visibility enhancement: A survey and quantitative benchmarking. Comput. Vis. Image Underst. 2017, 1, 1–6. [Google Scholar] [CrossRef]
- Wang, X.; Chen, N.; Xu, L. Spatiotemporal difference-of-Gaussians filters for robust infrared small target tracking in various complex scenes. Appl. Opt. 2015, 54, 1573–1586. [Google Scholar] [CrossRef]
- Almaadeed, N.; Asim, M.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. Automatic Detection and Classification of Audio Events for Road Surveillance Applications. Sensors 2018, 18, 1858. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Moon, J.H. Robust Lane Detection and Tracking for Real-Time Applications. IEEE Trans. Intell. Transp. Syst. 2018, 1–6. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, J.B.; He, N.; Zhang, L.L.; Lu, K. Single image dehazing with a physical model and dark channel prior. Neurocomputing 2015, 149, 718–728. [Google Scholar] [CrossRef]
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef]
- Shwartz, S.; Namer, E.; Schechner, Y.Y. Blind haze separation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Ma, T.; Hu, X.; Zhang, L.; Lian, J.; He, X.; Wang, Y.; Xian, Z. An evaluation of skylight polarization patterns for navigation. Sensors 2015, 15, 5895–5913. [Google Scholar] [CrossRef] [PubMed]
- Schechner, Y.Y.; Narasimhan, S.G.; Nayar, S.K. Polarization-based vision through haze. Appl. Opt. 2003, 20, 511–525. [Google Scholar] [CrossRef]
- Liang, J.; Ren, L.; Ju, H.; Zhang, W.; Qu, E. Polarimetric dehazing method for dense haze removal based on distribution analysis of angle of polarization. Opt. Express 2015, 23, 46–57. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Yang, J.; Chen, D.; He, X.; Han, Y.; Zhang, J.; Zhang, Z. Ultra-compact broadband polarization beam splitter with strong expansibility. Photonics Res. 2018, 6, 574–578. [Google Scholar] [CrossRef]
- Kopf, J.; Neubert, B.; Chen, B.; Cohen, M.; Cohen-Or, D.; Deussen, O.; Uyttendaele, M.; Lischinski, D. Deep Photo: Model-Based Photograph Enhancement and Viewing; ACM: New York, NY, USA, 2008. [Google Scholar]
- Nishino, K.; Kratz, L.; Lombardi, S. Bayesian defogging. Int. J. Comput. Vis. 2012, 98, 263–278. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Cai, B.; Xu, X.; Tao, D. Real-time video dehazing based on spatio-temporal mrf. In Proceedings of the Pacific Rim Conference on Multimedia, Xian, China, 15–16 September 2016. [Google Scholar]
- Wang, G.; Ren, G.; Jiang, L.; Quan, T. Single image dehazing algorithm based on sky region segmentation. Inf. Technol. J. 2013, 12, 1168–1175. [Google Scholar] [CrossRef]
- Yu, F.; Qing, C.; Xu, X.; Cai, B. Image and video dehazing using view-based cluster segmentation. In Proceedings of the IEEE International Conference on Visual Communications and Image Processing, Chengdu, China, 27–30 November 2016. [Google Scholar]
- Zhu, Y.; Tang, G.; Zhang, X.; Jiang, J.; Tian, Q. Haze removal method for natural restoration of images with sky. Neurocomputing 2018, 275, 499–510. [Google Scholar] [CrossRef]
- Oreifej, O.; Li, X.; Shah, M. Simultaneous video stabilization and moving object detection in turbulence. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 450–462. [Google Scholar] [CrossRef] [PubMed]
- Gilles, J.; Alvarez, F.; Ferrante, N.; Fortman, M.; Tahir, L.; Tarter, A.; von Seeger, A. Detection of moving objects through turbulent media. Decomposition of Oscillatory vs Non-Oscillatory spatio-temporal vector fields. Image Vis. Comput. 2018, 73, 40–55. [Google Scholar] [CrossRef]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual domain adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Li, W.; Duan, L.; Xu, D.; Tsang, I.W. Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1134–1148. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Lu, Z.; Zhou, Y.; Sun, J.; Xu, Q.; Lao, C.; He, H.; Zhang, G.; Liu, L. Far-field outdoor experimental demonstration of down-looking synthetic aperture ladar. Chin. Opt. Lett. 2017, 15, 082801. [Google Scholar]
- Zhou, W.; Jin, N.; Jia, M.; Yang, H.; Cai, X. Three-dimensional positioning method for moving particles based on defocused imaging using single-lens dual-camera system. Chin. Opt. Lett. 2016, 10, 031201. [Google Scholar] [CrossRef]
- Wang, S.; Wang, J.; Chung, F.L. Kernel density estimation, kernel methods, and fast learning in large data sets. IEEE Trans. Cybern. 2014, 44, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Omid-Zohoor, A.; Young, C.; Ta, D.; Murmann, B. Toward Always-On Mobile Object Detection: Energy Versus Performance Tradeoffs for Embedded HOG Feature Extraction. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1102–1115. [Google Scholar] [CrossRef]
- Foggy Morning with Traffic. Available online: https://www.youtube.com/watch?v=ekh-BaoCLPU (accessed on 17 December 2016).
- Heavy Fog Disrupts Traffic. Available online: https://www.youtube.com/watch?v=jde2I1PSW4Y (accessed on 5 February 2017).
- Traffic Congestion as Heavy Fog. Available online: https://www.youtube.com/watch?v=wwxhlFo_Nqw (accessed on 6 February 2017).
- Static Shot of Street as People Are Walking and Fog Blows Through. Available online: https://www.youtube.com/watch?v=CWNaPcbc1hE (accessed on 30 June 2015).
- Zhang, S.; Yao, H.; Liu, S. Dynamic background modeling and subtraction using spatio-temporal local binary patterns. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A universal background subtraction algorithm for video sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Yang, C.; Yu, W. Moving object detection by detecting contiguous outliers in the low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 597–610. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Ma, Q.; Zhang, L. Spatio-temporal saliency detection using phase spectrum of quaternion fourier transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image analysis using mathematical morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 4, 532–550. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | |||||||
|---|---|---|---|---|---|---|---|
| ST-MoG | 0.4015 | 0.4686 | 0.4826 | 0.5341 | 0.5365 | 0.1062 | 3.8571 |
| Vibe | 0.5951 | 0.7690 | 0.5952 | 0.4298 | 0.6001 | 0.0551 | 4.1294 |
| DECOLOR | 0.5254 | 0.4518 | 0.5719 | 0.5526 | 0.5636 | 0.0687 | 2.7658 |
| PQFT | 0.4217 | 0.5041 | 0.4124 | 0.4217 | 0.4614 | 0.1547 | 6.3871 |
| Our method | 0.6147 | 0.6215 | 0.6754 | 0.5955 | 0.5997 | 0.0425 | 3.9200 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Li, X.; Zheng, H.; Gao, H.; Wang, H. Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days. Sensors 2018, 18, 3286. https://doi.org/10.3390/s18103286
Chen Z, Li X, Zheng H, Gao H, Wang H. Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days. Sensors. 2018; 18(10):3286. https://doi.org/10.3390/s18103286
Chicago/Turabian StyleChen, Zhe, Xiaofang Li, Hao Zheng, Hongmin Gao, and Huibin Wang. 2018. "Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days" Sensors 18, no. 10: 3286. https://doi.org/10.3390/s18103286
APA StyleChen, Z., Li, X., Zheng, H., Gao, H., & Wang, H. (2018). Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days. Sensors, 18(10), 3286. https://doi.org/10.3390/s18103286