4.3. Computing Combination Coefficient Vector
is defined as the computation rate region corresponding to the channel coefficient vector
and correspondent
. According to the work in [
7],
is achievable for any large enough
n and for the existing encoders and decoders such that the receiver can recover the desired codeword combination with
with the average probability of error
if the maximum coding rate of all sources, i.e.,
R for this paper, satisfies the condition:
In this paper,
is determined by applying the method proposed by U. Fincke and M. Pohst [
25] as in the work of [
26] to obtain the highest
. By considering the hardware specification of sensor nodes, this paper exploits Condition (7) to reduce the computational overhead by reducing the number of candidates of
in searching, for which
can provide the highest
. In addition, Condition (7) is also used to filter codeword combination for forwarding to the destination at each relay. Since
, the higher value
q results in a high message loss rate. In this paper, only a small value of
q is considered. Reducing the number of candidates of
, i.e., reducing the bounds of the value of the elements of
, can be done as in the works of [
26,
27] by replacing the condition
with
.
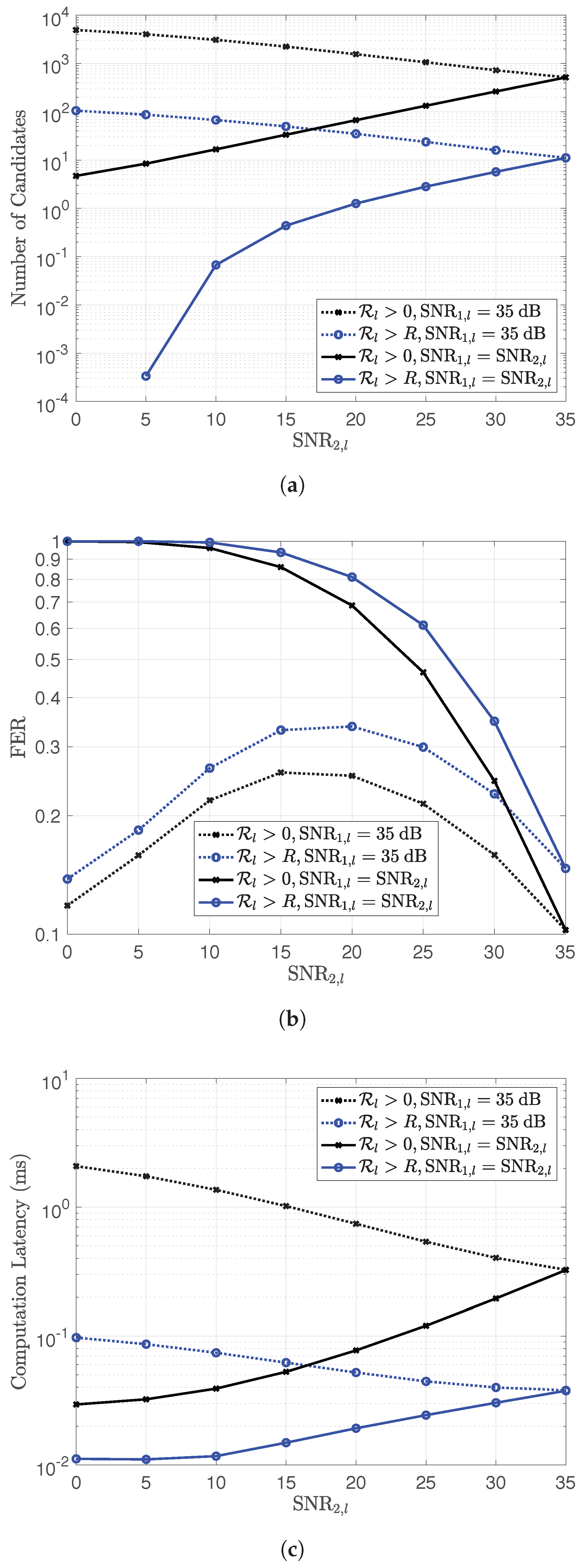
However, this modification causes some decrease in performance in the block error rate or frame error rate (FER) because codeword combination might be correctly received without satisfying Condition (7). By comparing with the case that applies condition
, the number of candidates, FER and computational latency are shown in
Figure 2. The specification of the employed platform is shown in
Table 1. The lattice code
is used for NLC in this comparison, where
, and
is a well-known
lattice.
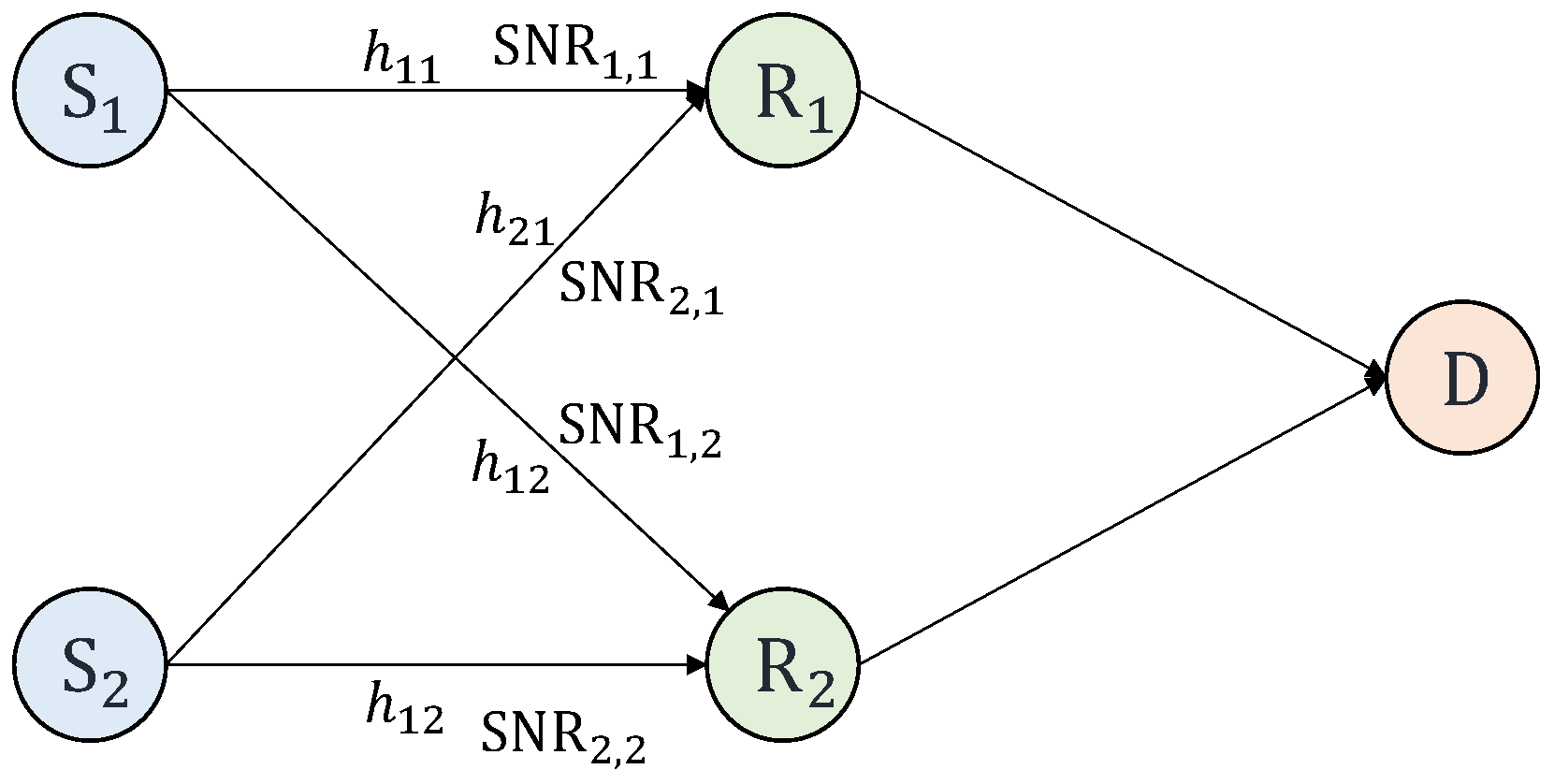
The result is obtained by considering the codeword combinations of two sources at relay
l and taking
and
with two cases:
and
. The FER for condition
was obtained by comparing the codeword combination with the combination of the original codewords. For the case with Condition (7), the codeword combination is filtered with Condition (7) first before comparing with the combination of the original codewords. From
Figure 2, this setting performs the trade-off between the computational latency and the FER performance.
4.4. Encoding and Computing
A big file message is divided into small blocks, and blocks are selected to group into chunks or batches. For source
k where
, the
i-th chunk consists of
blocks and is expressed by
.
and
denote
and
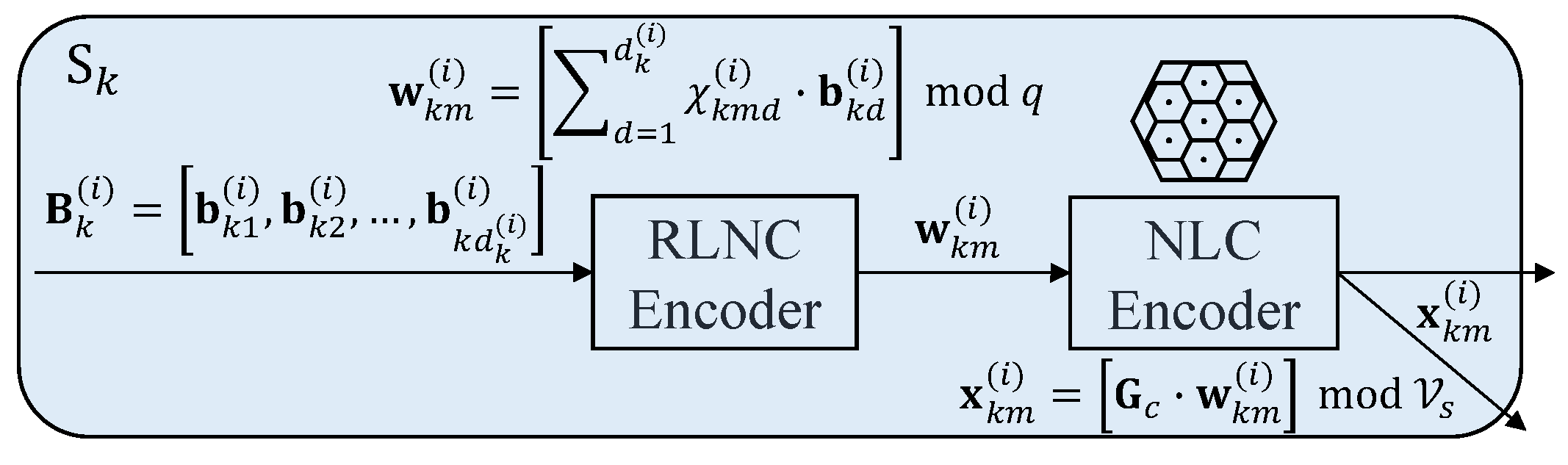
, respectively. RLNC is applied among chunks to generate
M coded blocks,
. The
m-th coded block,
, is obtained by:
where
is randomly drawn from
. It is the coding vector of coded block
. Superscript
is sometimes omitted here for convenience. The computational complexity of the encoding process depends on chunk size
.
The coded blocks of each chunk are then NLC encoded before transmitting to generate
M NLC codewords,
, as shown in
Figure 3. All sources transmit these
M codewords for each chunk simultaneously to the relays.
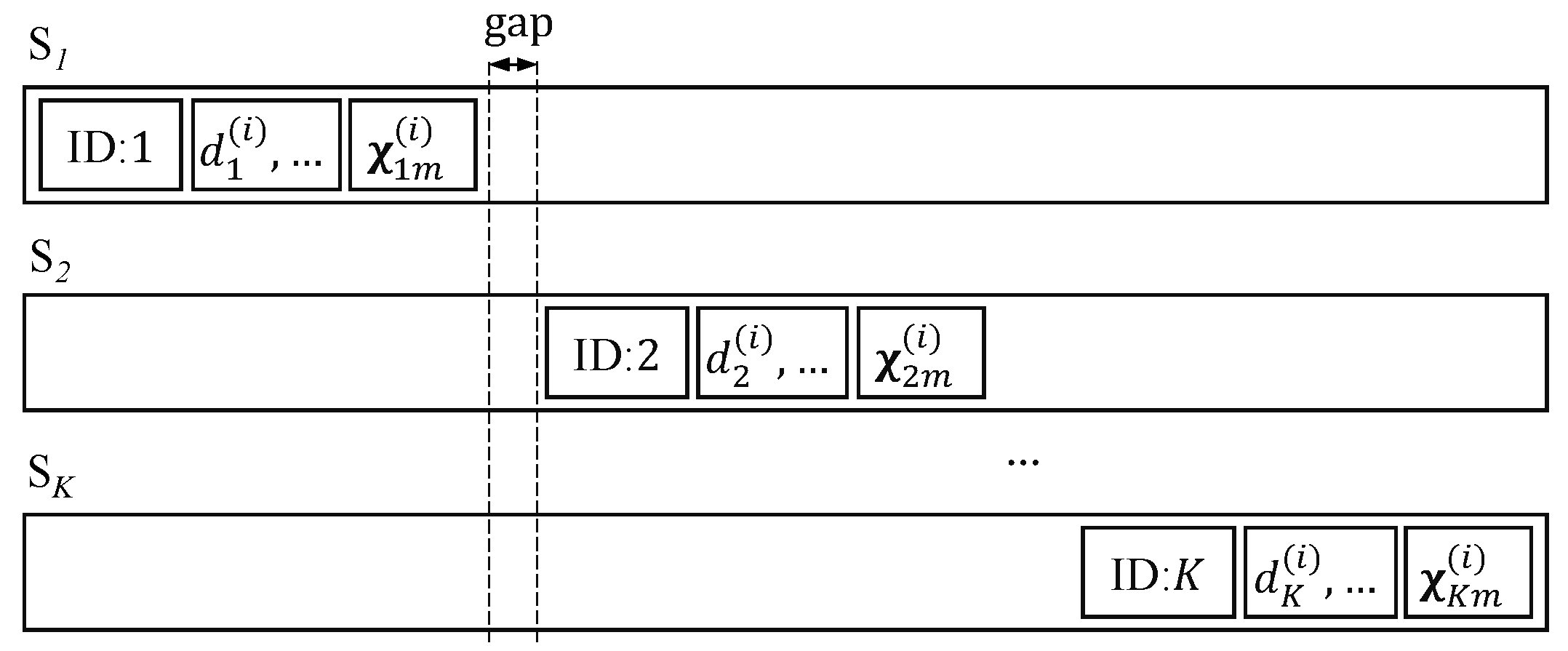
The coding vector
and the information of chunk
i for source
k, such as source ID (
k),
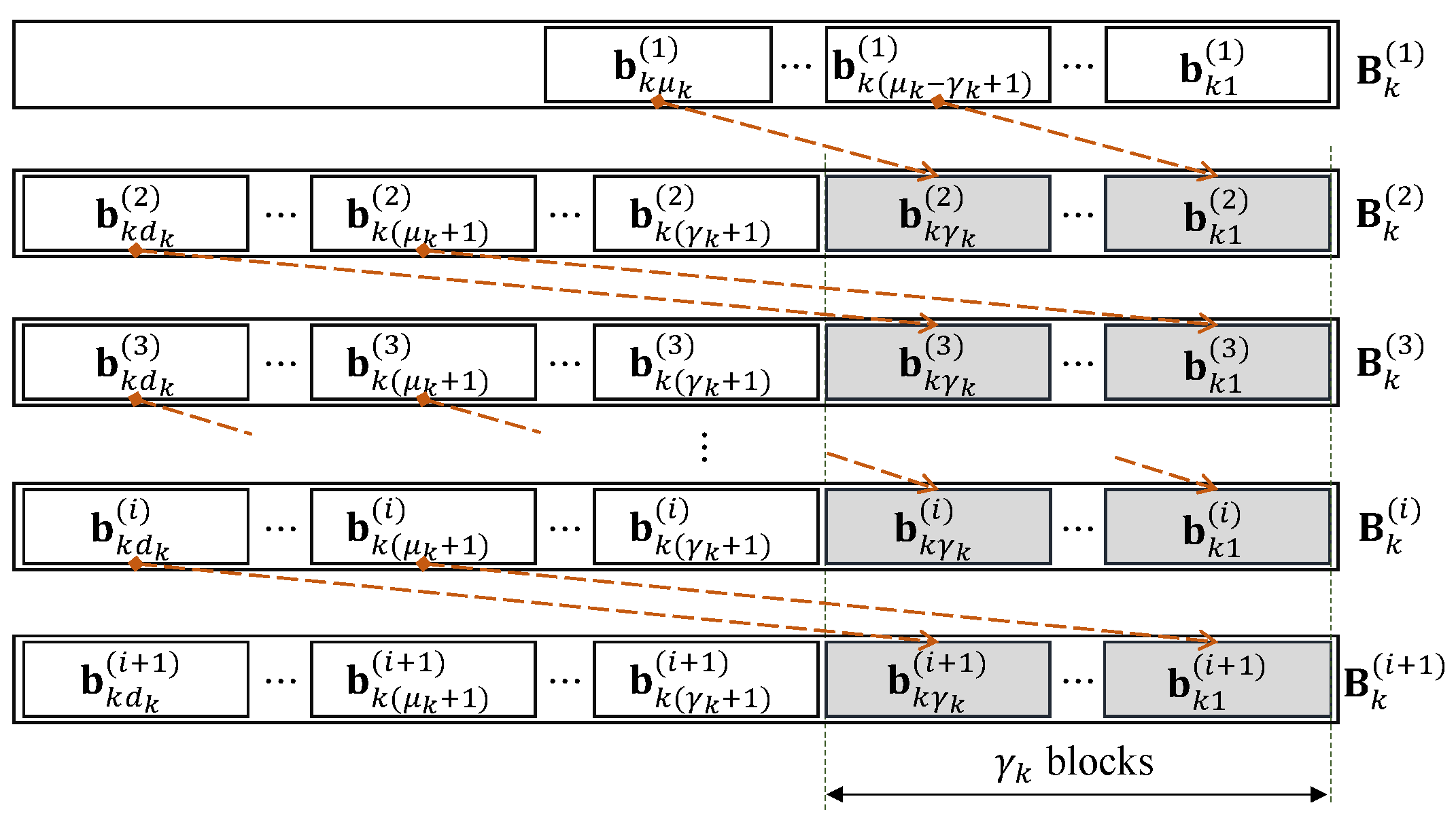
, etc., can be attached to the transmitting data, e.g., at the header of the frame. However, the location of the attached information for a source should not overlap with those of the other sources, as shown in
Figure 4. Hence, the small chunk size is preferred for the header with a limited length. This paper assumes that the length of the attached information is negligible compared with the length of the sending block. Alternatively, this information can be known by the receivers (relays or destination) by broadcasting from each source, for example. This paper assumes that the content of this information is correctly received.
Relay
l for
computes the superposition of
K codewords
to obtain their linear combination
to forward to the destination, which is:
where
s the combination coefficient vector computed at relay
l for the
m-th blocks of all sources for chunk
i. Then, the combined coding coefficient vector of
, is:
4.5. Empirical Probability Distributions
Since lossless transmissions from the relays to the destination are assumed, the total number of linearly independent codeword combinations at the relays for each chunk is the same at the destination. (r for any chunk) denotes the number of linearly independent codeword combinations correctly received at the relays (destination) for chunk i. Hence, is the rank of matrix , which is a set of linearly independent vectors taken from vectors .
The original blocks of all sources for chunk
i are recoverable if there are
linearly independent received codeword combinations for chunk
i, i.e.,
. If the channel state is stable, i.e.,
is constant for all
i, all chunks can be decoded with a suitable value of
M without the need for feedback from the destination. However, with the unstable channel state,
varies with different chunks. Hence, without the aid of feedback, there are some chunks that are undecodable. As in the works of [
17,
28], in this paper,
denotes the empirical probability distribution of
r, for
, where
.
On the other hand, in this paper, ( for any chunk) denotes the rank of the part of the matrix from row to row . is defined as the participation factor of source k in , i.e., in the forwarded codeword combinations of chunk i. In addition, denotes the empirical probability distribution of , for .
In practical applications,
and
can be collected by employing a feedback-based transmission scheme only for the chunks without feedback loss, as in the work of [
29], for example. The overhead caused by the linear dependence between coded blocks and between codeword combinations, i.e., due to the small value of finite field size
q, is taken into account in the data collections of
and
. In addition, exploiting the probability distributions for the design of OCC/CF enables OCC/CF to be applicable to the other channel distributions, ensuring its robustness.
4.6. Decodability
In order to analyze the decodability, in this paper, and denote the probabilities that chunk i is decodable, i.e., and , respectively, when employing an OCC, which is designed by using and , respectively, in single-transmission flow, i.e., transmission from a source to a relay via an orthogonal channel. The overlapping fashions of OCCs corresponding to and are the same.
This paper considers the case that , , and source k generates M coded blocks by the RLNC encoder with linearly independent coded blocks for chunk i and all k, i.e., would be pseudorandom to ensure the linear independence between coded blocks. When employing OCC/CF, the codeword combinations of chunk i are recoverable at the destination if there are received linearly independent codeword combinations, i.e., . To determine the probability that a chunk is decodable, this paper studies two cases as below:
Case I: is a unit vector, i.e., only an element of is equal to one, and the others are zero;
Case II: does not have zero elements; there are only M linearly independent codeword combinations, and they are only forwarded by a relay.
For Case I, can be written as . Hence, the decodability of each chunk only depends on the OCC design using for all k. In this case, the original blocks of each source can be recovered independently since every received codeword combination corresponds to the coded blocks from only one source. By assuming that chunk i for all sources is decodable, i.e., , if the chunks of all sources are decodable, thus the probability that a chunk for all sources is decodable, , can be written as , which is independent of or .
For Case II, since and there are linearly independent coded blocks from source k for chunk i, hence for chunk i. This case assumes that chunk i is not decodable and there are blocks inside chunk i for source k with , which also belong to the other chunks. If these blocks have been already recovered with the decoded chunks, then there are still to recover for chunk i. From another point of view, it is equivalent to the case that matrix has eliminated rows, which are between row and row , and becomes a matrix, . Since is randomly drawn from for , hence can be approximately also drawn from . In addition, can be approximately obtained by eliminating rows from a matrix, which is randomly drawn from . It looks like blocks are back-substituted into a chunk i when employing OCC in single-flow transmission. Then, the decodability of each chunk when employing OCC/CF is the same as when employing OCC designed using in single-flow transmission. Hence, in this case, . With Case II, the feature is that already recovered blocks can be back-substituted into chunk i without waste.
In contrast, for the other case, by taking
and
for example, these recovered blocks can successfully increase the number of linearly independent received coded blocks in chunk
i if they are linearly independent of the existing received coded blocks in chunk
i. In addition, the value of
should be appropriately selected by using
or
for all chunks. From the point of view of
, an example taking
,
,
,
,
(according to the OCC design using
) and
is shown in
Figure 5. In
Figure 5a,b,
,
and
are given. By taking
and
, then there are five linearly independent blocks in chunk
i after back-substitution, i.e., chunk
i is decodable, with four out of six chances. On the other hand, if taking
,
as in
Figure 5b, then chunk
i is decodable with all three possibilities. Therefore, a suitable selection of
and
can provide better performance for OCC/CF. Hence, the OCC design using
for all
k is needed. In
Figure 5c,
,
and
are given. By taking any two different recovered blocks, chunk
i is decodable with nine of ten chances. The undecodable outcome should be caused by the selection of
, i.e., the OCC design using
.
Figure 5c represents Case II where
,
.
For the general case, by combining the two cases above, the effective probability that each chunk is decodable when OCC/CF is applied, denoted by
, can be approximately obtained by:
On the other hand, for the case that , the values of M and for should be selected appropriately such that any chunk i can be decoded by itself, i.e., . For example, if taking for all i, then should be chosen as a multiple of L, and to ensure that there is at most codeword combinations to recover original blocks. For the case that , M can be taken by for any value of , .
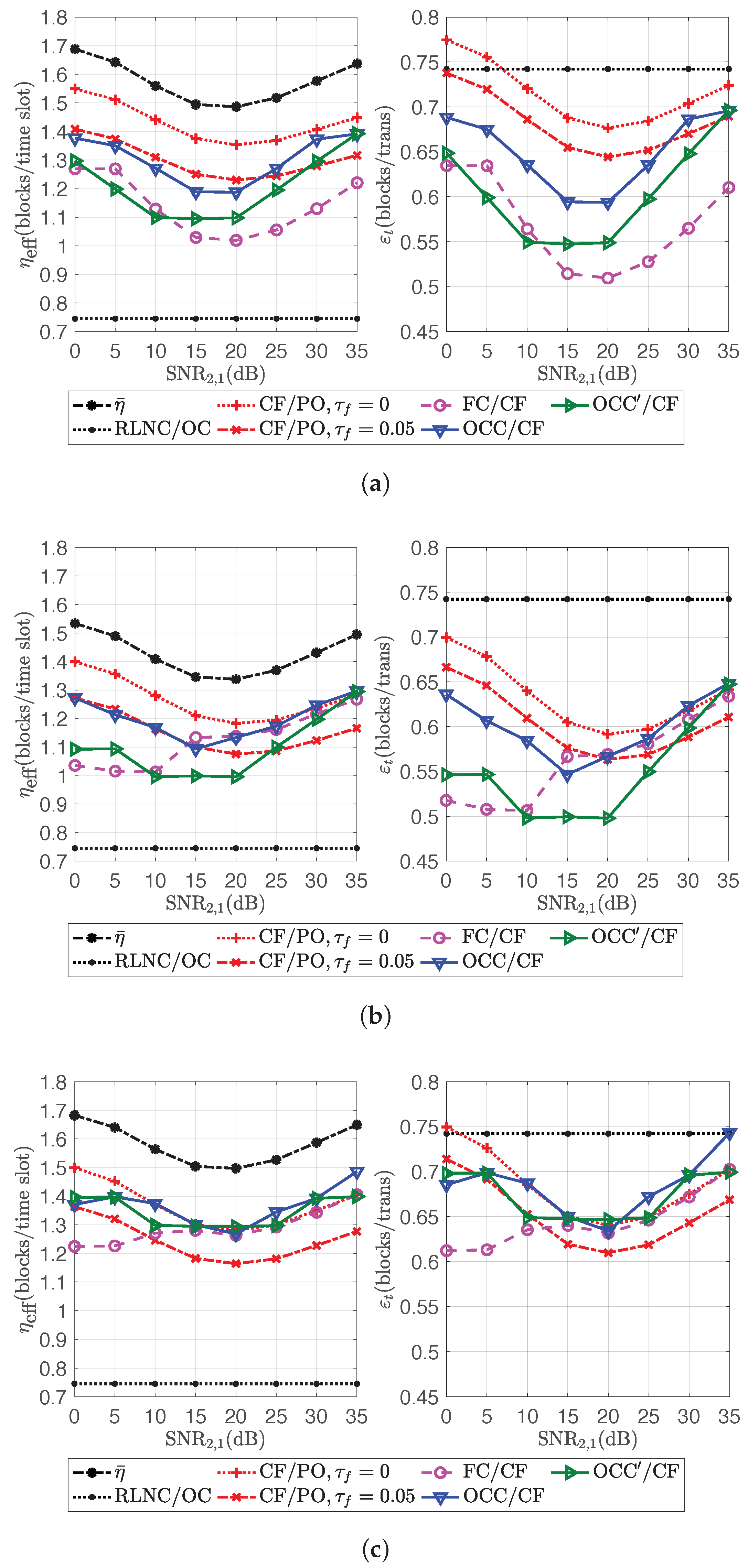
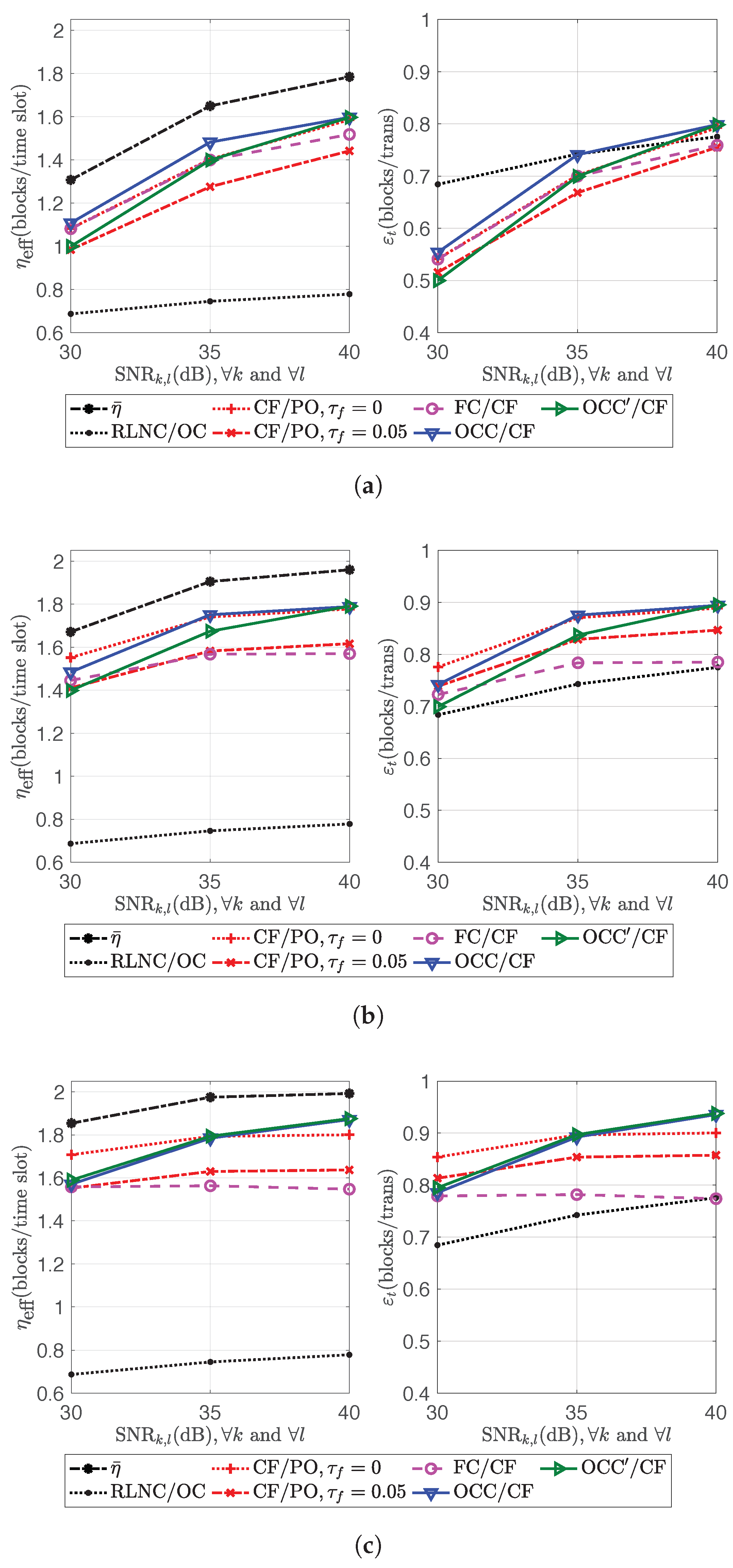
4.7. Channel Efficiency
In this paper, channel efficiency is defined as the ratio of the total number of decoded blocks from all sources to the total transmission time (the total number of time slots for OCC/CF or for the transmission schemes without the need for feedback from the relays) taken from the sources to the relays. and denote the channel efficiencies corresponding to and , respectively.
For a K-source L-relay network, the ideal value of channel efficiency, which is obtained with lossless transmission and without linear dependence between codeword combinations, is . Thus, for , the channel efficiency would be like in the case of single flow transmission via an orthogonal channel. Hence, applying an orthogonal channel might be a better option. This paper only considers the case that .
On the other hand, denotes , and denotes . is called channel capacity in this paper, i.e., the upper bound of . Many OCC designs in single-flow transmission try to obtain close to . In this paper, the (design) overhead is defined as the gap between and .
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}