Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera

Abstract

1. Introduction
2. Literature Review
2.1. SfM
2.2. MVS
2.3. SLAM
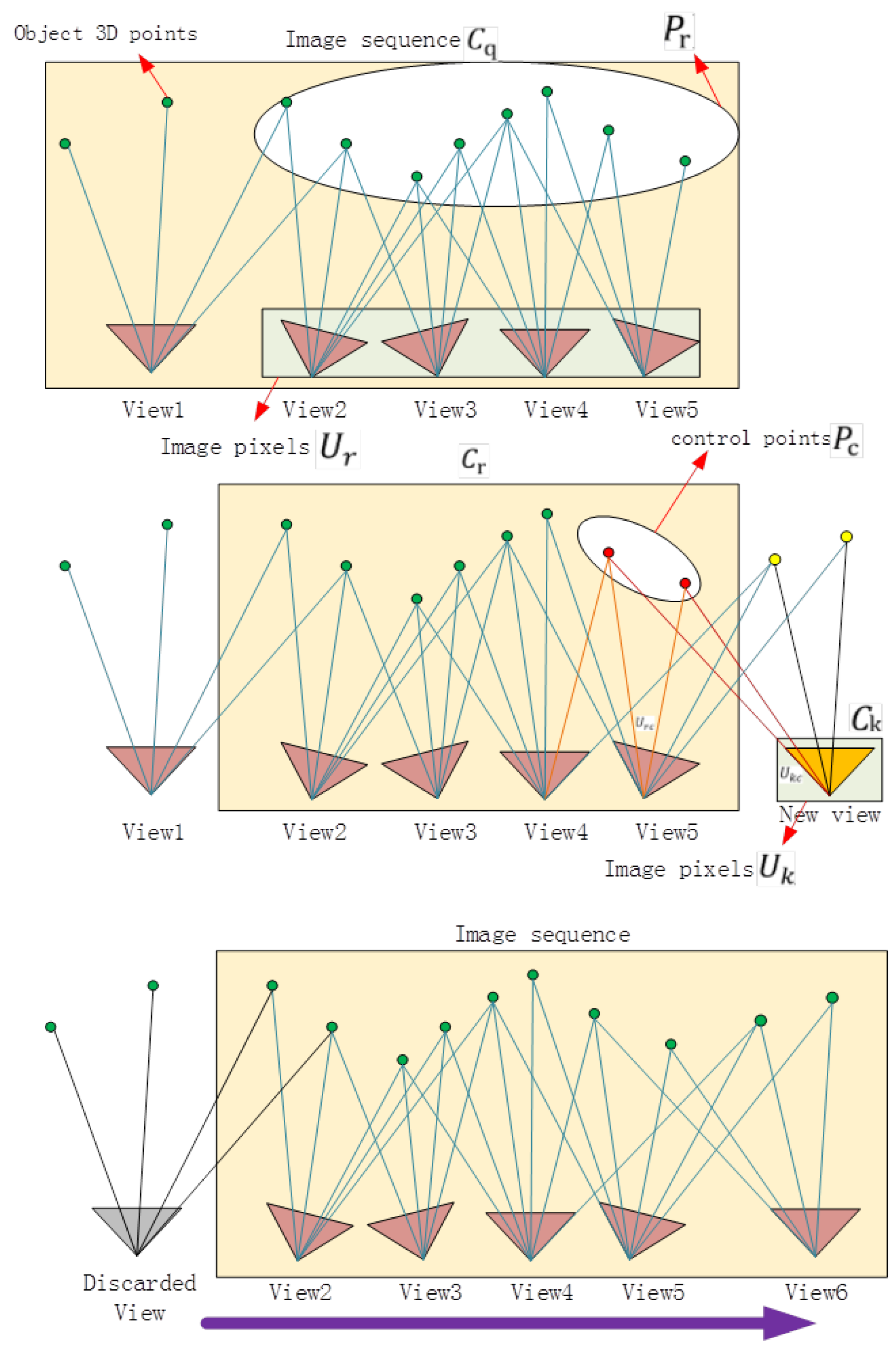
3. Method
3.1. Algorithm Principles
3.2. Selecting Key Images
3.3. Image Queue SfM
3.3.1. SfM Calculation for the Images in the Queue
- Two images are selected from the queue as the initial image pair using the method proposed in [21]. The fundamental matrix of the two images is obtained by the random sample consensus (RANSAC) method [22], and the essential matrix between the two images is then calculated when the intrinsic matrix (obtained by the calibration method proposed in [23]) is known. The first two terms of radial and tangential distortion parameters are also obtained and used for image rectification. After remapping the pixels onto new locations on the image based on distortion model, the image distortion caused by lens could be eliminated. Then, the positions and orientations of the images can be obtained by decomposing the essential matrix according to [24].
- According to the correspondence of the feature points in different images, the 3D coordinates of the feature points are obtained by triangulation (the feature points are denoted as ).
- The structure of the initial image pair is calculated, and one of the coordinate systems of the cameras taking the image pair is set as the global coordinate system. The image of the queue that has completed the structure calculation is placed into the set ().
- The new image () is placed into the set (), and the structural calculation is performed. The new image must meet the following two conditions. First, there should be at least one image in that has common feature points with . Second, at least six of these common feature points must be in (in order to improve the stability of the algorithm, this study requires at least 15 common feature points). Finally, all of the parameters from the structure calculation are optimized by bundle adjustment.
- Repeat step 6 until the structure of all of the images inside the queue is calculated ( = ).
3.3.2. Updating the Image Queue
3.3.3. Weighted Bundle Adjustment
3.3.4. MVS
4. Experiments
4.1. Data Sets
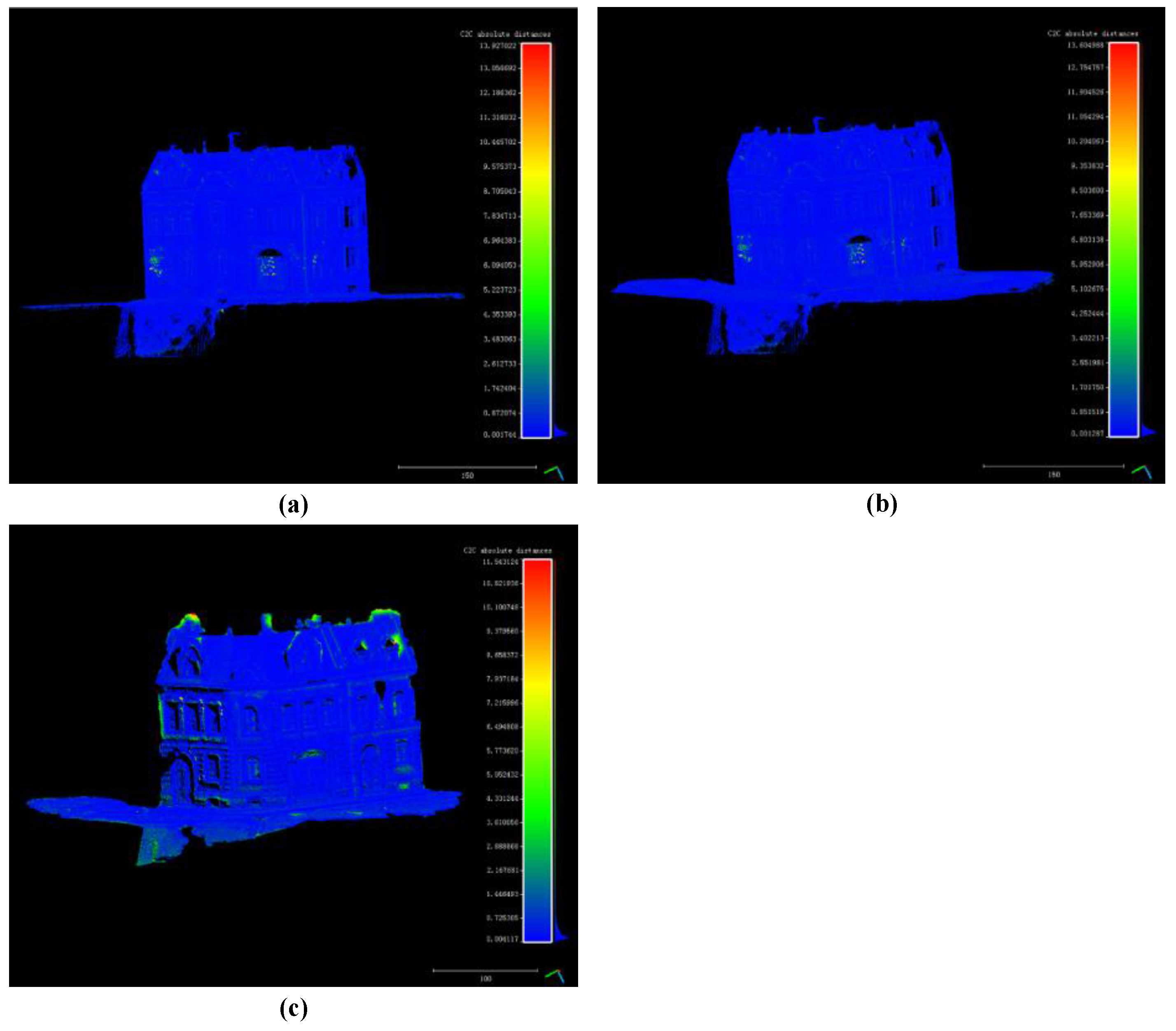
4.2. Precision Evaluation
4.3. Speed Evaluation
4.4. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Polok, L.; Ila, V.; Solony, M.; Smrz, P.; Zemcik, P. Incremental Block Cholesky Factorization for Nonlinear Least Squares in Robotics. Robot. Sci. Syst. 2013, 46, 172–178. [Google Scholar]
- Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and mapping using the Bayes tree. Int. J. Robot. Res. 2012, 31, 216–235. [Google Scholar] [CrossRef]
- Liu, M.; Huang, S.; Dissanayake, G.; Wang, H. A convex optimization based approach for pose SLAM problems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1898–1903. [Google Scholar]
- Beardsley, P.A.; Torr, P.H.S.; Zisserman, A. 3D model acquisition from extended image sequences. In Proceedings of the European Conference on Computer Vision, Cambridge, UK, 14–18 April 1996; pp. 683–695. [Google Scholar]
- Mohr, R.; Veillon, F.; Quan, L. Relative 3-D reconstruction using multiple uncalibrated images. Int. J. Robot. Res. 1995, 14, 619–632. [Google Scholar] [CrossRef]
- Dellaert, F.; Seitz, S.M.; Thorpe, C.E.; Thrun, S. Structure from motion without correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 15 June 2000; Volume 552, pp. 557–564. [Google Scholar]
- Moulon, P.; Monasse, P.; Marlet, R. Adaptive structure from motion with a contrario model estimation. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 257–270. [Google Scholar]
- Wu, C. Towards linear-time incremental structure from motion. In Proceedings of the International Conference on 3DTV-Conference, Aberdeen, UK, 29 June–1 July 2013; pp. 127–134. [Google Scholar]
- Gherardi, R.; Farenzena, M.; Fusiello, A. Improving the efficiency of hierarchical structure-and-motion. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1594–1600. [Google Scholar]
- Moulon, P.; Monasse, P.; Marlet, R. Global fusion of relative motions for robust, accurate and scalable structure from motion. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 3248–3255. [Google Scholar]
- Crandall, D.J.; Owens, A.; Snavely, N.; Huttenlocher, D.P. SfM with MRFs: Discrete-continuous optimization for large-scale structure from motion. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2841–2853. [Google Scholar] [CrossRef] [PubMed]
- Sweeney, C.; Sattler, T.; Höllerer, T.; Turk, M. Optimizing the viewing graph for structure-from-motion. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 801–809. [Google Scholar]
- Snavely, N.; Simon, I.; Goesele, M.; Szeliski, R.; Seitz, S.M. Scene reconstruction and visualization from community photo collections. Proc. IEEE 2010, 98, 1370–1390. [Google Scholar] [CrossRef]
- Wu, C.; Agarwal, S.; Curless, B.; Seitz, S.M. Multicore bundle adjustment. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3057–3064. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Shen, S. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Li, E.; Chen, Y.; Xu, L. Bundled depth-map merging for multi-view stereo. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2769–2776. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise View Selection for Unstructured Multi-View Stereo; Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Moulon, P.; Monasse, P. Unordered feature tracking made fast and easy. In Proceedings of the European Conference on Visual Media Production, London, UK, 5–6 December 2012. [Google Scholar]
- Moisan, L.; Moulon, P.; Monasse, P. Automatic homographic registration of a pair of images, with a contrario elimination of outliers. Image Process. Line 2012, 2, 329–352. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Read. Comput. Vis. 1987, 24, 726–740. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Triggs, B.; Mclauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In Proceedings of the International Workshop on Vision Algorithms: Theory and Practice, Corfu, Greece, 21–22 September 1999; pp. 298–372. [Google Scholar]
- Ceres Solver. Available online: http://ceres-solver.org (accessed on 14 January 2018).
- Sølund, T.; Buch, A.G.; Krüger, N.; Aanæs, H. A large-scale 3D object recognition dataset. In Proceedings of the Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 73–82. Available online: http://roboimagedata.compute.dtu.dk (accessed on 14 January 2018).
- Jensen, R.; Dahl, A.; Vogiatzis, G.; Tola, E. Large scale multi-view stereopsis evaluation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 406–413. [Google Scholar]
- Pierrot Deseilligny, M.; Clery, I. Apero, an Open Source Bundle Adjusment Software for Automatic Calibration and Orientation of Set of Images. In Proceedings of the ISPRS—International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XXXVIII-5/W16, Trento, Italy, 2–4 March 2012; pp. 269–276. [Google Scholar]
- Galland, O.; Bertelsen, H.S.; Guldstrand, F.; Girod, L.; Johannessen, R.F.; Bjugger, F.; Burchardt, S.; Mair, K. Application of open-source photogrammetric software MicMac for monitoring surface deformation in laboratory models. J. Geophys. Res. Solid Earth 2016, 121, 2852–2872. [Google Scholar] [CrossRef]
- Rupnik, E.; Daakir, M.; Deseilligny, M.P. MicMac—A free, open-source solution for photogrammetry. Open Geosp. Data Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Cloud Compare. Available online: http://www.cloudcompare.org (accessed on 14 January 2018).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Image | Resolution | (m, k) | ||
|---|---|---|---|---|---|
| Garden | 126 | 1920 × 1080 | (15, 6)(20, 7)(40, 15) | 25 | 150 |
| Village | 145 | 1920 × 1080 | (15, 6)(20, 7)(40, 15) | 25 | 150 |
| Building | 149 | 1280 × 720 | (15, 6)(20, 7)(40, 15) | 20 | 150 |
| Botanical Garden | 42 | 1920 × 1080 | (15, 6)(20, 7)(40, 15) | 25 | 150 |
| Factory Land | 170 | 1280 × 720 | (15, 6)(20, 7)(40, 15) | 20 | 150 |
| Academic Building | 128 | 1920 × 1080 | (15, 6)(20, 7)(40, 15) | 25 | 150 |
| Pot | 49 | 1600 × 1200 | (8, 3)(10, 4)(15, 6) | 20 | 200 |
| House | 49 | 1600 × 1200 | (8, 3)(10, 4)(15, 6) | 20 | 200 |
| Name | Images | Resolution | Our Method Time (s) | OpenMVG Time (s) | MicMac Time(s) | ||
|---|---|---|---|---|---|---|---|
| m = 15, k = 6 | m = 20, k = 7 | m = 40, k = 15 | |||||
| Garden | 126 | 1920 × 1080 | 284.0 | 291.0 | 336.0 | 1140.0 | 3072.0 |
| Village | 145 | 1920 × 1080 | 169.0 | 209.0 | 319.0 | 857.0 | 2545.0 |
| Building | 149 | 1280 × 720 | 171.0 | 164.0 | 268.0 | 651.0 | 2198.0 |
| Botanical Garden | 42 | 1920 × 1080 | 77.0 | 82.0 | 99.0 | 93.0 | 243.0 |
| Factory Land | 170 | 1280 × 720 | 170.0 | 207.0 | 343.0 | 1019.0 | 3524.0 |
| Academic building | 128 | 1920 × 1080 | 124.0 | 182.0 | 277.0 | 551.0 | 4597.0 |
| m = 15, k = 6 | m = 10, k = 4 | m = 8, k = 3 | |||||
| Pot | 49 | 1600 × 1200 | 35.0 | 39.0 | 47.0 | 56.0 | 351.0 |
| House | 49 | 1600 × 1200 | 59.0 | 53.0 | 54.0 | 74.0 | 467.0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, Y.; Huang, J.; Zhang, X. Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera. Sensors 2018, 18, 225. https://doi.org/10.3390/s18010225
Qu Y, Huang J, Zhang X. Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera. Sensors. 2018; 18(1):225. https://doi.org/10.3390/s18010225
Chicago/Turabian StyleQu, Yufu, Jianyu Huang, and Xuan Zhang. 2018. "Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera" Sensors 18, no. 1: 225. https://doi.org/10.3390/s18010225
APA StyleQu, Y., Huang, J., & Zhang, X. (2018). Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera. Sensors, 18(1), 225. https://doi.org/10.3390/s18010225