1. Introduction
Activity recognition has drawn significant attention from the machine learning research community due to its growing demand from many potential applications such as security and surveillance (e.g., detecting suspicious activities in airports), industrial applications (e.g., monitoring of activities performed by workers on assembly lines), healthcare (e.g., monitoring patient’s disease progression), and sports (e.g., monitoring the quality of execution), amongst others.
One application of activity recognition that supports people in their daily activities is the smart home. The smart home has gained popularity due to its role in supporting the inhabitants, typically older adults who are living alone. Low-powered, unobtrusive sensors such as state-change sensors, motion sensors, pressure mats, etc. are commonly used to capture information about the inhabitant. These sensors are attached to the household objects in the home (e.g., a television, cupboard, etc.) and are activated when the inhabitant performs their daily activities. For example, turning on or off the bathroom light would activate the sensor attached to it. Sensor data collected from the smart home is used by the activity recognition system to learn and monitor the inhabitant’s daily activities.
Many supervised and unsupervised methods have been proposed for activity recognition [
1,
2,
3]. These methods attempt to learn from as many sensors as possible with the aim that the classifier acquires a good representation of the inhabitant’s activities. Unfortunately, training on a bank of sensors not only requires more training data but also has an effect on recognition performance. The challenge, however, is to identify which sensors are useful and how many sensors are required to effectively recognise the activities of the inhabitant.
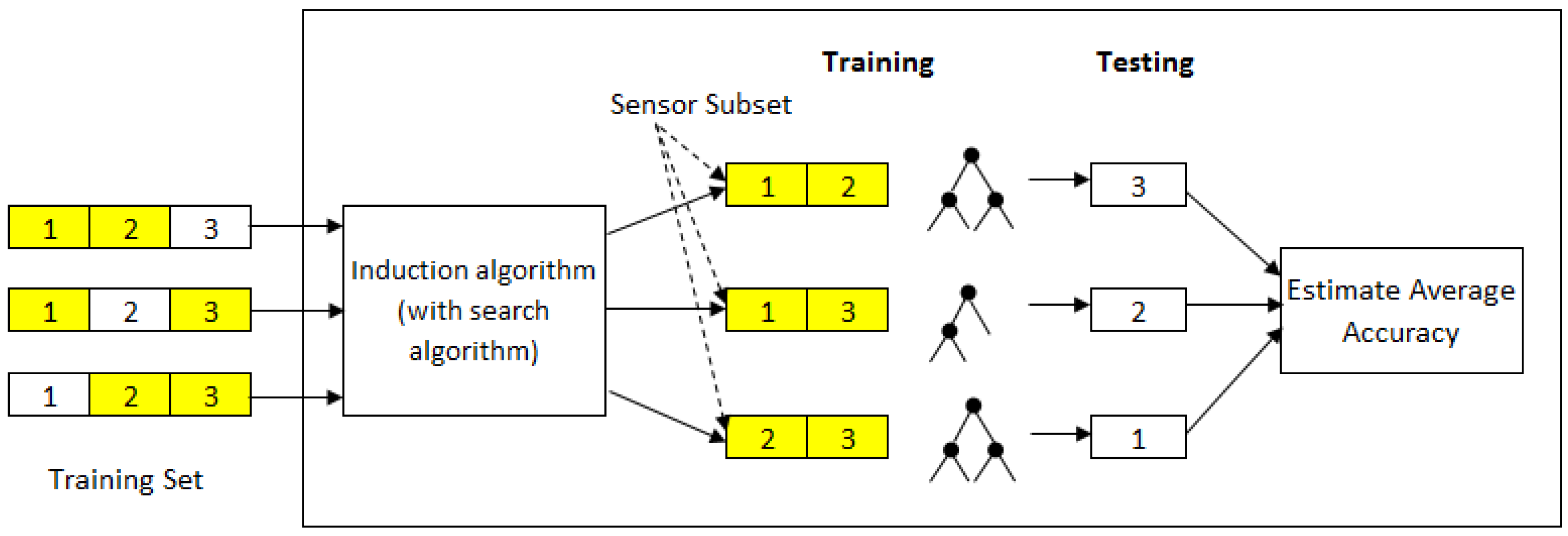
The wrapper method is one of the commonly used methods for sensor selection. It uses an induction algorithm (e.g., a decision tree) as an evaluation function to score the sensors based on their predictive performance. It aims to find a subset of sensors in such a way that when an induction algorithm is trained on this reduced set of sensors, it will produce a classifier with better recognition accuracy. A greedy sequential search algorithm is often applied to search through the space of possible sensors. Depending on the search, it can begin with either an empty set of sensors or a full set of sensors. The former is called forward selection, while the latter is called backward elimination. To reduce variability resulting from the data, multiple rounds of cross-validation are performed using different partitions of the training set. The validation results are then averaged over the rounds. This means that for each sensor subset that is evaluated, an induction algorithm is invoked
k-times in a
k-fold cross-validation. Such an approach, however, is computationally expensive as a new classifier has to be trained for each subset evaluation.
Figure 1 shows an example of wrapper-based sensor selection using 3-fold cross-validation.
A search algorithm that is dependent on accuracy estimates may choose a sensor subset with high accuracy but poor predictive power [
4]. Such a method, which is guided by accuracy estimates, may result in overfitting at the expense of generalisation to a previously unseen sensor subset. This motivates us to look into methods to address the sensor selection problem without the need to rely on any search algorithm and accuracy estimates. In this paper, we take a different approach to sensor selection. Rather than sequentially evaluate each sensor subset, we train the decision tree directly on each partition of the training set and then address the sensor generalisation through tree alignment. We demonstrate our approach on two public datasets obtained in two distinct smart home environments.
The paper is organised as follows.
Section 2 discusses related works on sensor selection. A discussion of our proposed method is presented in
Section 3.
Section 4 details the real world data used and the evaluation method.
Section 5 discusses the experimental results.
Section 6 presents the discussion regarding the improvement of our method over previous work. Finally, we summarise the work presented in this paper.
2. Related Work
Both filter-based and wrapper-based methods are widely used to select informative sensors for activity recognition. The filter-based approach relies on some heuristics to evaluate the characteristic of the sensors. In the works of both Chahuara et al. [
5], and Chua and Foo [
6], information gain criterion were used to select the set of informative sensors. Classifiers were trained on sensors with non-zero information gain. Cook and Holder [
7] used the mutual information criterion to measure dependency between sensors and activities. Sensors with high mutual information are considered as informative since they can best discriminate between activities. Similar work was also seen in Dobrucali and Barshan [
8], where they used mutual information criterion on wearable motion sensors to select the set of informative sensors based on sensor types, measurement axes, and sensor locations. The filter-based approach for sensor selection may not necessarily reduce the number of sensors. These sensors are usually ranked based on the their importance and there is a need to rely on prior knowledge to define a suitable cut-off point in order to determine the number of sensors needed in the final subset.
The wrapper-based approach uses an induction algorithm to score sensors based on their predictive performance. Bourobou et al. [
2] used the decision tree as a learning algorithm for sensor selection. Attal et al. [
9] applied the random forest as a wrapper method to identify the set of informative sensors for recognising human physical activities, such as sitting, lying, standing, etc. Saputri, Khan, and Lee [
10] used a three-stage process based on a genetic algorithm for finding common sensors of physical activity for each subject. Mafrur et al. [
11] used the support vector machine with sequential floating forward selection to reduce both loading and prediction time for activity recognition on mobile phones. However, the wrapper-based approach is more computationally expensive than the filter-based approach and may run the risk of overfitting [
4,
12].
Some methods attempt to reduce overfitting by using an early-stopping strategy, i.e., to stop the search before overfitting occurs. Verachtert et al. [
13] applied a dynamic stopping condition into naïve Bayes. They used support and accuracy criteria to dynamically determine the stopping point. These criteria are estimated from a validation set, which means that the validation set needs to acquire a good data representation in order to accurately determine a suitable threshold. The work by Loughrey and Cunnigham [
14] proposed a genetic algorithm with an early-stopping mechanism through the use of nested cross-validation. Inner cross-validation is used to tune the parameters, while outer cross-validation evaluates the accuracy of the training and validation sets. However, the parameters of the genetic algorithm are dependent on the dataset being used.
3. Our Proposed Method
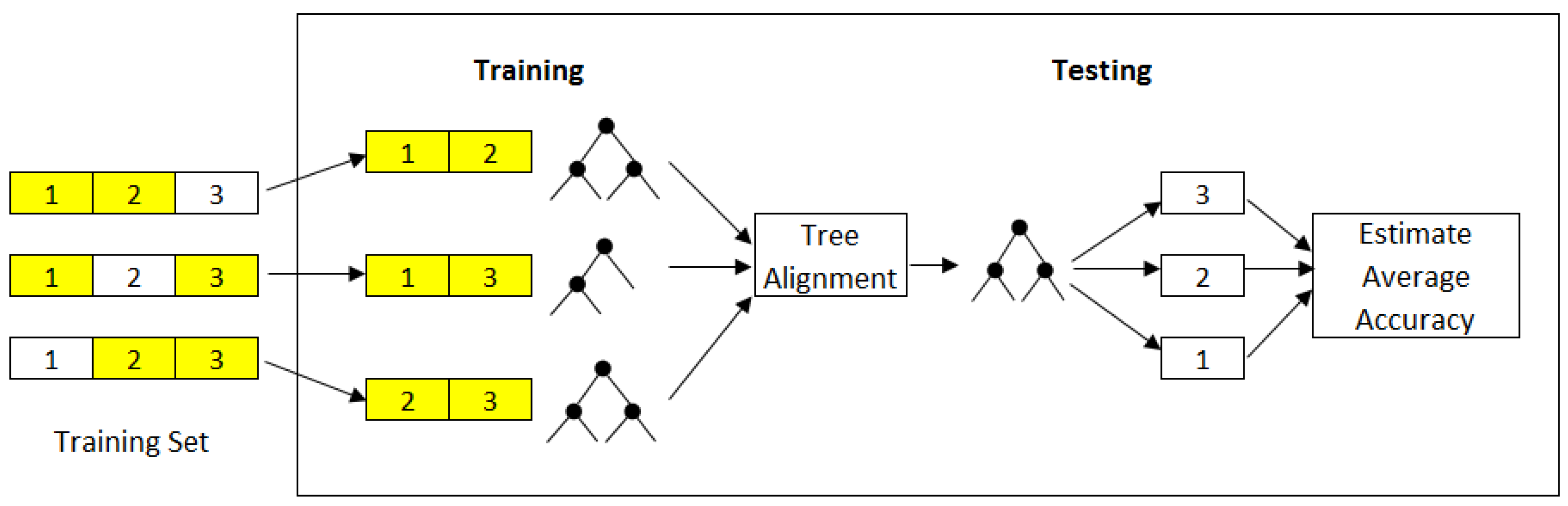
Our approach to the sensor selection problem is to train a decision tree directly on each partition of the training set. Tree alignment is then performed on the trained trees to find a tree where the similarity between this tree and all given trees is maximal. Tree alignment is a way of arranging the sequences in trees to identify regions of similarity among them.
Figure 2 shows our proposed method based on tree alignment for sensor selection, which contrasts to prior works given it eliminates the need for testing the decision tree models for each subset evaluation. To measure the similarity between pairs of trees, we used the Needleman-Wunsch algorithm [
15].
Needleman-Wunsch Algorithm
The Needleman-Wunsch algorithm [
15] is commonly used as a global alignment technique in bio-informatics to align protein or nucleotide sequences. The algorithm uses a scoring system by giving a value for each match, mismatch, and indel (gap). If a match is
, mismatch
, and gap
, the alignment score for two sequences,
‘ACTGA’ and
‘ACAA’ is 1. The alignment for sequences
x and
y is as follows:
Sequences may have different lengths (seen in the case of the sequences x and y), which is the reason why letters are paired up with dashes in the other sequence, to signify either insertions or deletions in the sequences.
The Needleman-Wunsch algorithm uses a two-dimensional matrix (size (
)×(
), where
and
are the lengths of the sequences
x and
y) to keep track of the alignment score. The algorithm first initialises the first column and first row as 0 and subsequently adds the gap score for the first column, i.e., having values
and, similarly, for the first row, to have values
. The score for each remaining cell is computed using the following Equation (
1):
where
is the element of the
ith row and
jth column in the
M matrix,
is the substitution score (i.e.,
if the letter at position
i is the same as the letter at position
j, and
if there is a mismatch), and
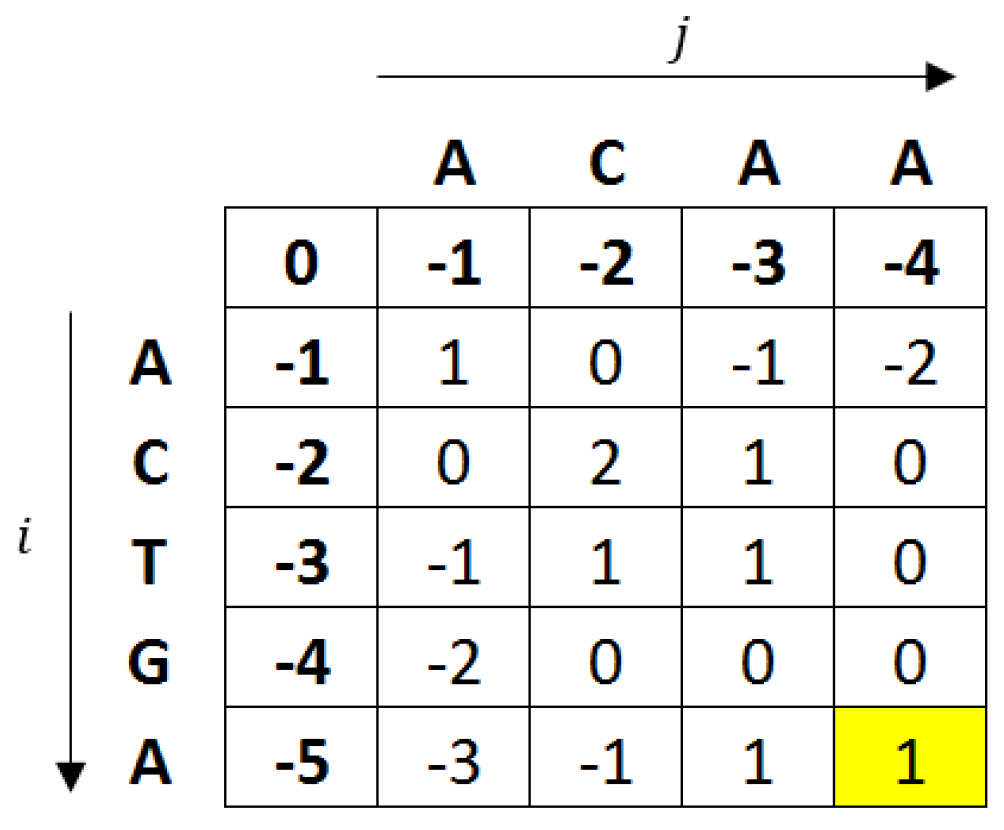
g is the gap penalty. The value on the last row and column in the matrix (shaded in
Figure 3) represents the alignment score.
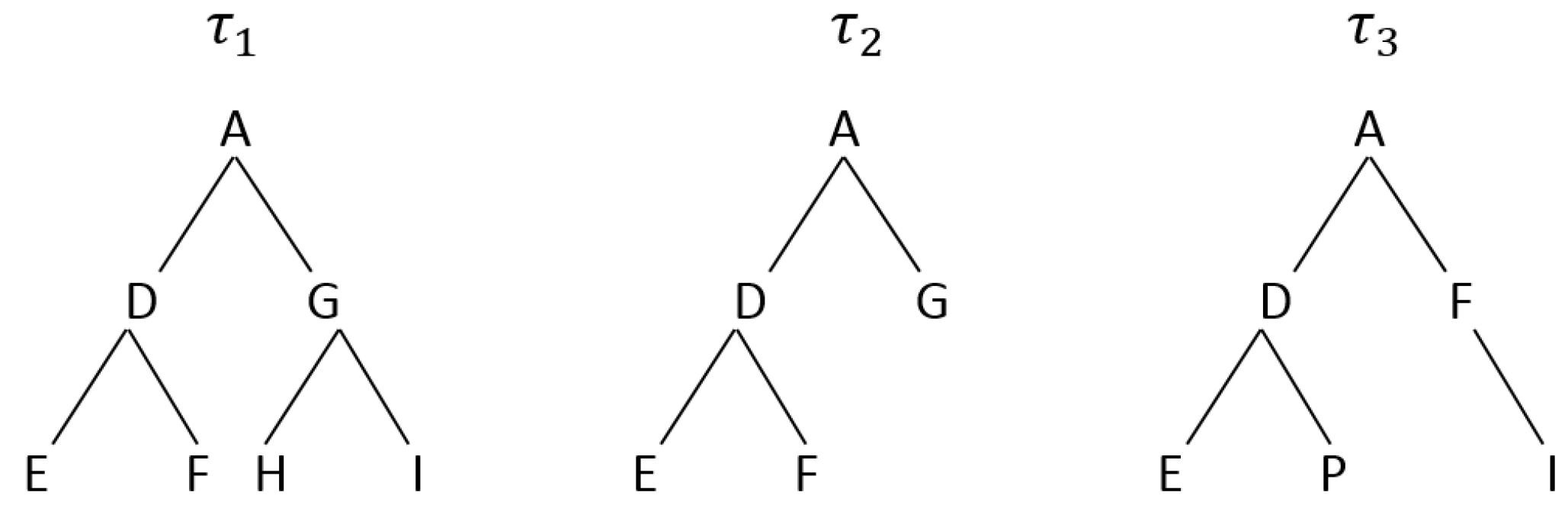
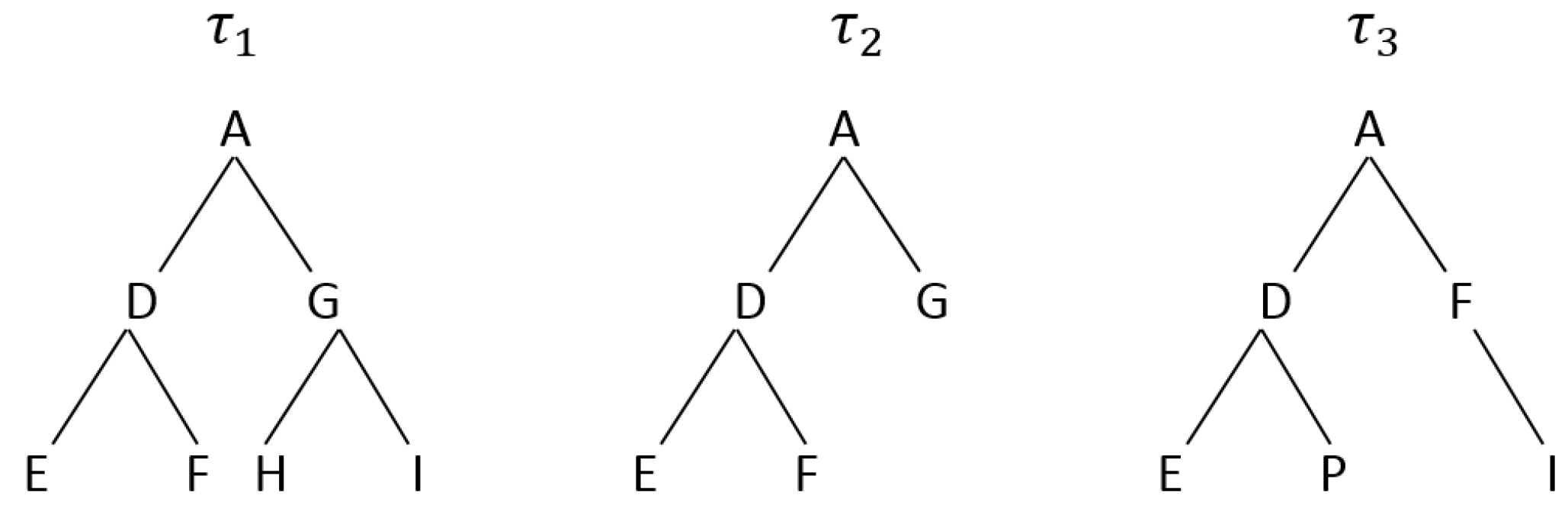
Based on the Needleman-Wunsch algorithm, similarity between a pair of trees can be computed. A high alignment score indicates that two trees are similar. To show this, we use the example of the trees
,
, and
, shown in
Figure 4. A pre-order tree traversal is first performed on the trees. This generates a sequence of ‘ADEFGHI’ for
, ‘ADEFG’ for
, and ‘ADEPFI’ for
. A tree alignment is then performed on the generated sequences using the Needleman-Wunsch algorithm. The alignment score of
and
is 3 while
and
have a score of 2, which clearly shows that
is more similar to
than
. This process is repeated for every pair of trees. The tree
, with the highest average similarity score, is chosen as the ‘best’ tree whereby all the sensors in that tree are considered as informative.
Algorithm 1 shows the steps of using Needleman-Wunsch algorithm for tree alignment. The output is a matrix containing the alignment score for every pair of trees. This matrix is then used to calculate the average similarity score.
| Algorithm 1 Tree Alignment Using Needleman-Wunsch Algorithm |
Require: a set of trees
Ensure:
Ensure: Perform pre-order tree traversal on
while not end of k do
for do
if then
Perform pre-order tree traversal on
Using Equation (1), calculate similarity between and
end if
end for
end while
Select tree with max of average similarity score of matrix |
Finding similarity in tree data structures has been used extensively in XML documents [
16,
17]. The Levenshtein edit distance [
18] is commonly used as a measure of similarity to transform one tree into another by applying edit operations such as insertion, deletion, and substitution. The main difference between the Needleman-Wunsch algorithm and the Levenshtein distance algorithm is that the Levenshtein distance algorithm used a static penalty cost to any mismatched letters whilst the Needleman-Wunsch algorithm gives weights to matches and mismatches differently.
5. Experiments and Results
We conducted three experiments. In the first experiment, we trained on the sensors selected through the tree alignment by applying the Needleman-Wunch algorithm. We then compared the result to the full set of baseline sensors to see how effective the proposed method is. In the second experiment, we compared our method with two baseline methods, while in the third we looked at the computational performance.
5.1. Experiment 1: Sensor Selection Based on Tree Alignment
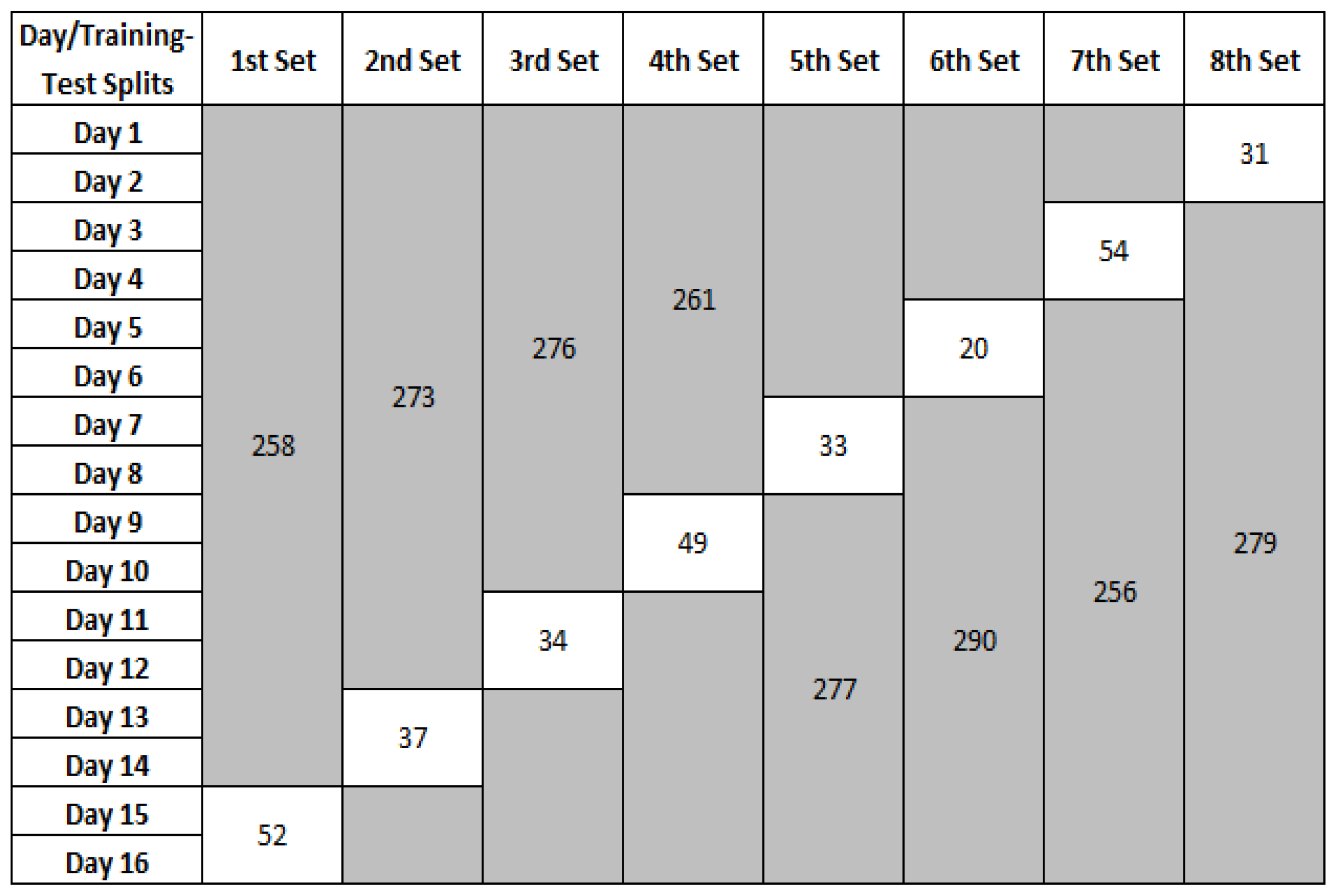
In this experiment, we first trained the decision tree on each training set of the MIT PlaceLab dataset (discussed in
Section 4). This results in a total of eight trees. From these trained trees, we performed tree alignment using the Needleman-Wunch algorithm. In our work, we used
for a gap,
for an unmatched, and
for a matched. The reason for setting a higher gap penalty is to reduce the overall score caused by insertions or deletions in sequences. These values, however, are determined empirically.
Table 2 shows the results.
Referring to the table,
has the highest average similarity score. This means that
is more similar to all the other trees. Thus, all sensors in this tree are considered as informative. There are a total of 13 sensors in
. To test how well this set of 13 sensors recognises the activities of the inhabitant, we removed the other 11 sensors from the training and test sets respectively. The rationale of removing these sensors is as though they were removed physically from the home [
7]. We then trained the four classifiers on the 13 sensors.
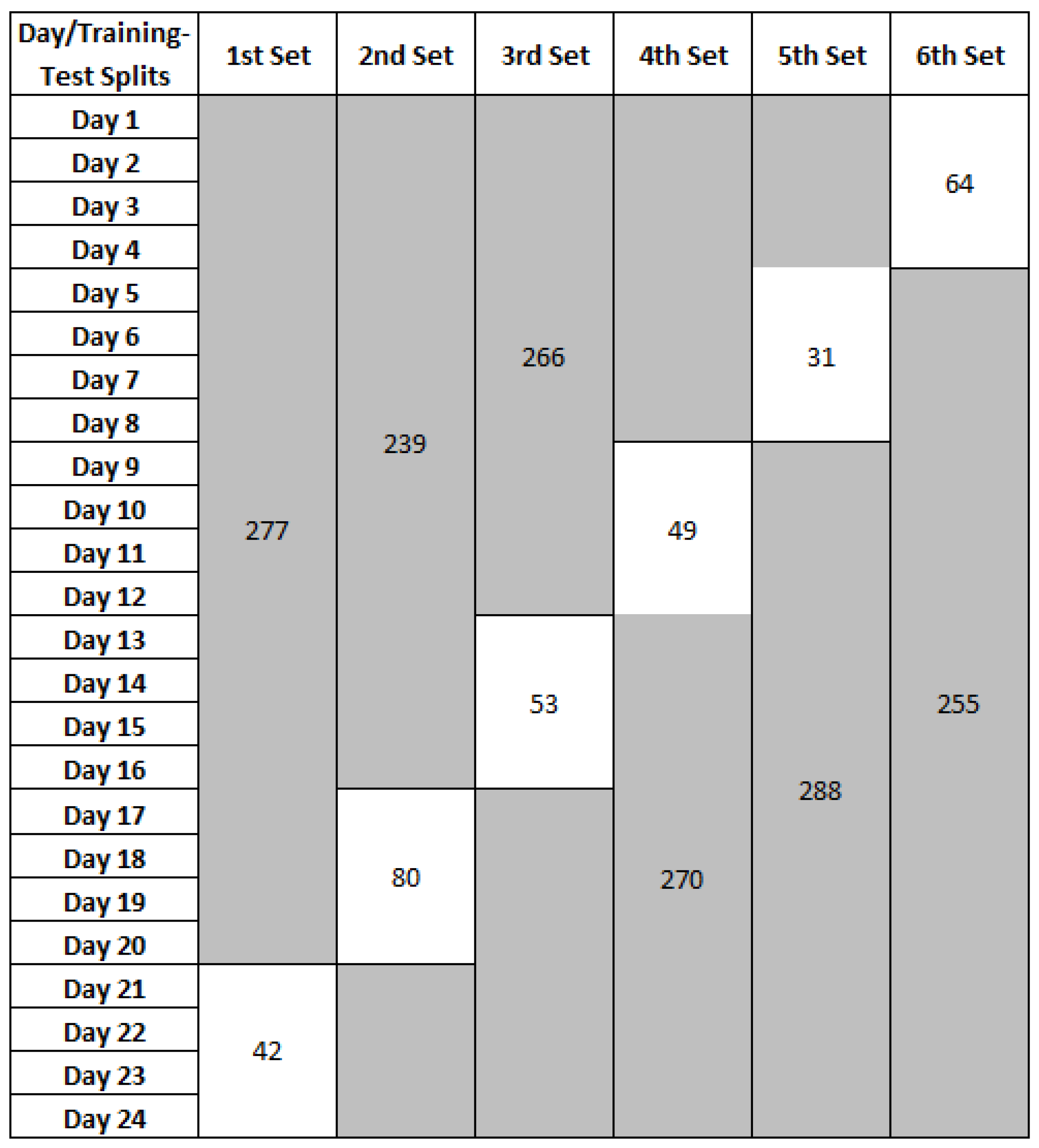
We repeated the same procedure on the van Kasteren dataset. In this dataset, , and each have the same similarity score. Further investigations showed that these trees have identified the same set of six sensors. It was observed that there are less activity variations in this dataset (compared to MIT PlaceLab), which resulted in tree resemblance. The classifiers are trained on all the six informative sensors (the other eight sensors were removed from the training and test sets, respectively).
We also compared the set of informative sensors identified with the full set of baseline sensors to see how effective the proposed method is. For the MIT PlaceLab, we trained the four classifiers on the full set of 24 sensors and 14 sensors on the van Kasteren datasets. The results are shown in
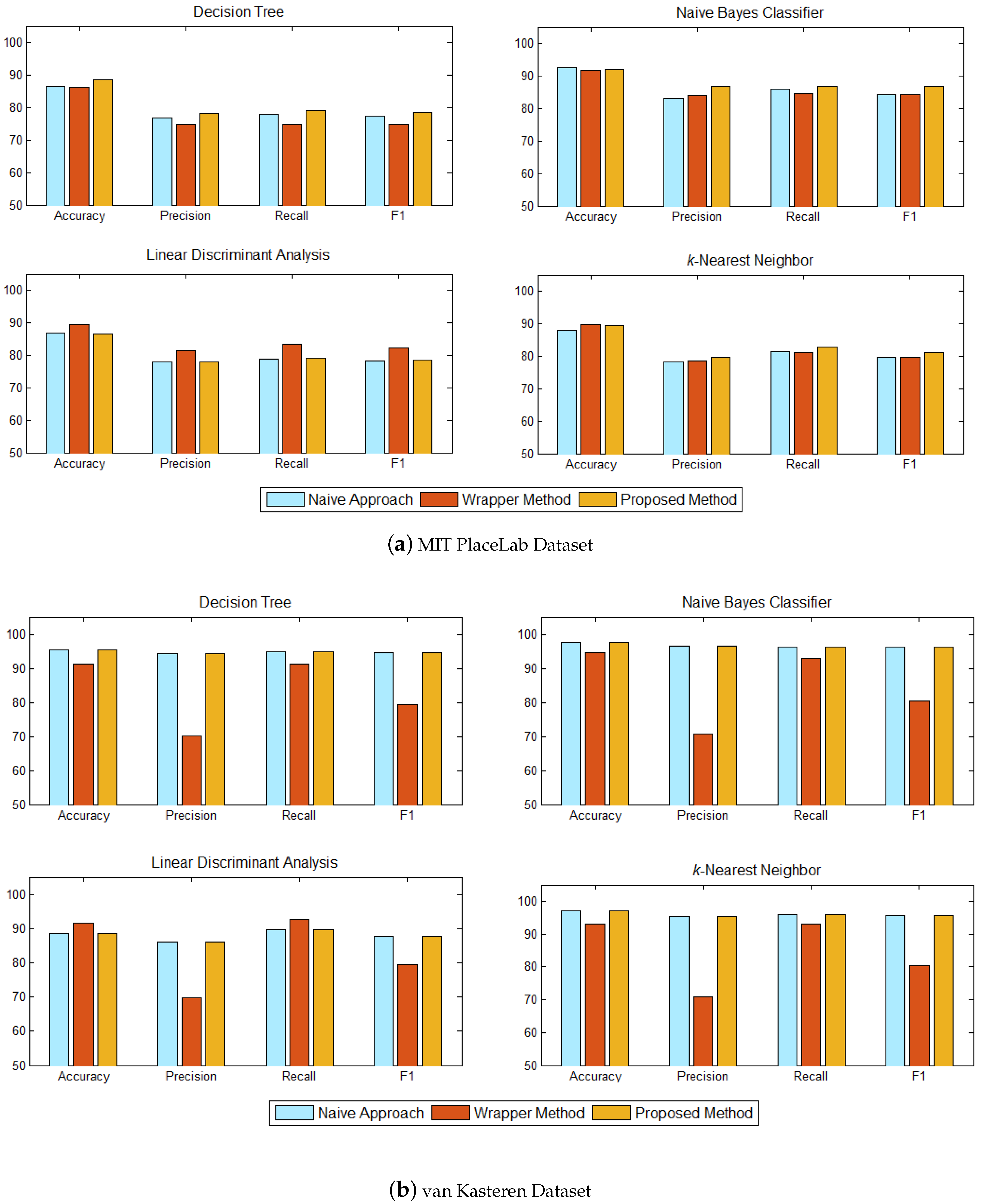
Figure 7.
In comparison to the full set of 24 sensors on MIT PlaceLab dataset (
Figure 7a), our proposed method, which was based on 13 informative sensors, performed better on the decision tree but not as good in the linear discriminant analysis. However, the differences in both cases are not significant. The accuracies of our method obtained on naïve Bayes and
k-nearest neighbor are comparable to the full set of 24 sensors.
As for the van Kasteren dataset (
Figure 7b), our method, which trained on six informative sensors achieved almost the same accuracy with the full set of 14 sensors across all the classifiers. The encouraging results on both datasets have shown that the proposed method works effectively to identify the set of informative sensors for activity recognition.
5.2. Experiment 2: Comparison with the Baseline Methods
In this experiment, we compared our proposed method with two baseline methods—a naive approach and a wrapper method with sequential forward selection.
5.2.1. A Naive Approach for Sensor Selection
The first baseline method is to select a tree that best classifies the activities by cross-validation. This is indeed a naive approach with the assumption that the tree that best classifies the activities consists of sensors that are informative. In this experiment, we first trained the decision tree on each training set and then tested the performance of the learned tree on the test sets. The tree with the highest average recognition accuracy is selected as the best classification tree.
Table 3 shows the results on both datasets.
Referring to
Table 3a,
has the highest average recognition accuracy and thus identified as the ‘best’ tree for the MIT PlaceLab dataset. In this tree, there is a total of 16 informative sensors. As for the van Kasteren dataset (
Table 3b),
and
achieved the same recognition accuracy. Further investigations on these trees showed that they have identified the same set of sensors. From the full set of 14 sensors, these trees have identified six sensors as informative.
Once the ‘best’ classification tree had been identified, we then trained the four classifiers on the set of informative sensors, i.e., 16 sensors on the MIT PlaceLab dataset and six sensors on the van Kasteren dataset. The results are shown in
Figure 8.
5.2.2. Wrapper with Sequential Forward Selection
For the second baseline method, we used the sequential forward selection method and linear discriminant analysis as the learning algorithm. Sequential forward selection is a greedy search algorithm that sequentially select sensors that best predict activities until there is no improvement in prediction.
For the MIT PlaceLab dataset, 20 out of 24 sensors were selected as informative while seven out of 14 sensors were selected from the van Kasteren dataset. We then trained the classifiers on the set of selected informative sensors.
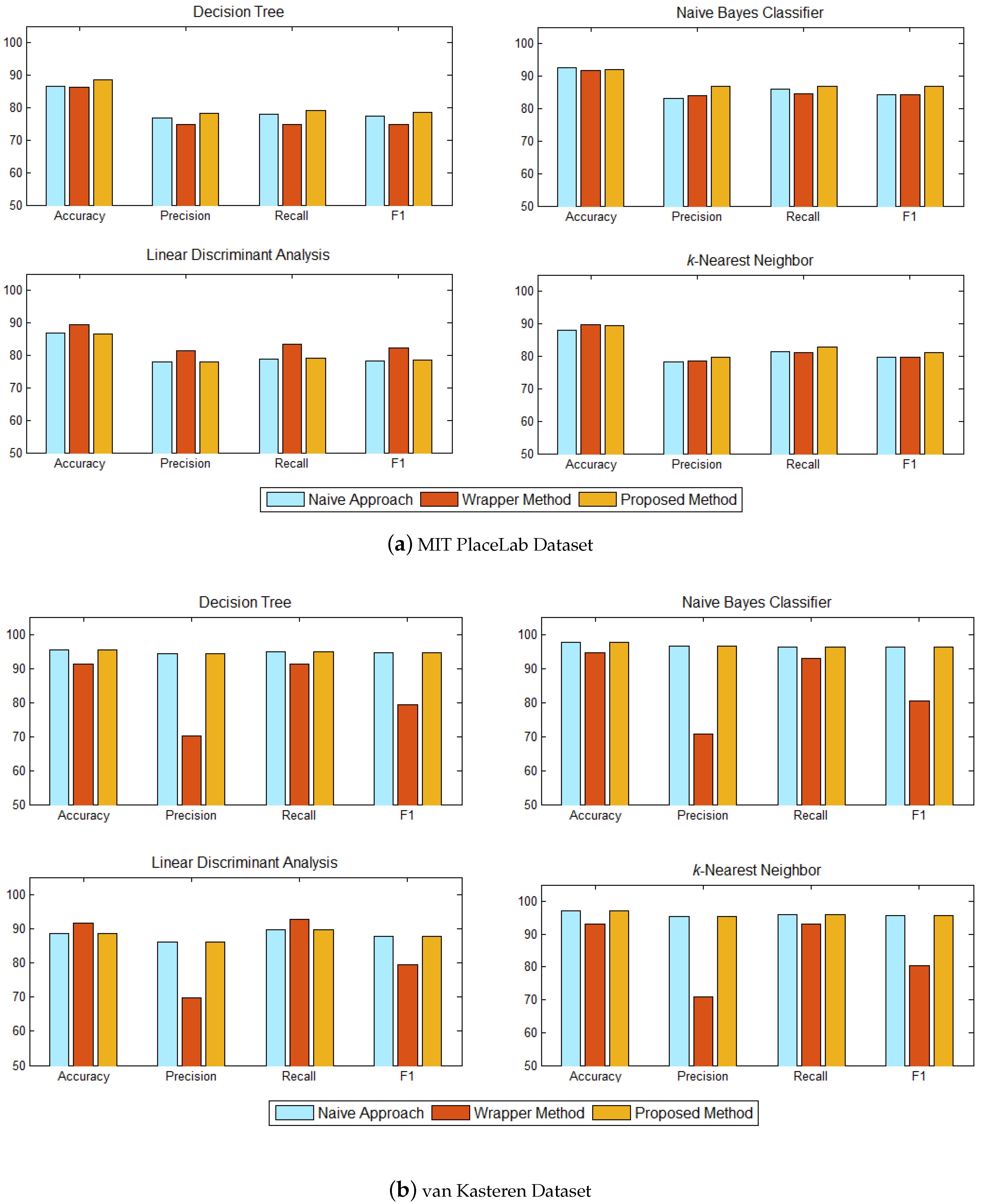
The recognition performance between our proposed method and the baseline methods are shown in
Figure 8. Each subplot shows the performance of each classifier—decision tree, naïve Bayes classifier, linear discriminant analysis, and
k-nearest neighbor. For the MIT PlaceLab, our method achieved almost the same accuracies as the baseline wrapper method across all the classifiers, did slightly better in decision tree and not as good in the linear discriminant analysis. The baseline wrapper method has the lowest precision and F1 across all the classifiers on the van Kasteran dataset. This method also has a lower accuracy and recall in the decision tree, naïve Bayes classifier, and
k-nearest neighbor.
5.3. Experiment 3: Computational Performance
In this experiment, we looked at the computational performance between our method and baseline methods. To evaluate the overall computational performance, 30 runs on each test set were carried out on both datasets.
Table 4 shows the average computation time (in sec) between our method and the baseline methods on each test set.
Our method has a lower running time compared to the two baseline methods on the van Kasteran dataset. There is no difference in running time between our method and the naive approach on the MIT dataset but the baseline wrapper method takes a longer time to run.
6. Discussion
Table 5 shows the total number of informative sensors identified for each method. Our method identified a smaller subset of informative sensors compared to the baseline methods for both datasets. As for the van Kasteren dataset, both our method and the baseline naive approach identified the same set of sensors.
For the MIT PlaceLab dataset (
Figure 8a), our method achieved an accuracy comparable to the two baseline methods across all the classifiers. Although our proposed method does not appear to be significantly better, it used only 13 informative sensors to recognise the inhabitant’s activities, while the baseline naive method used 16 sensors and the baseline wrapper method used 20 sensors. In comparison with the baseline naive method, our method has a higher precision, recall, and F1 across all the classifiers, which shows that our method is able to identify the set of informative sensors that is better suited for activity recognition. Among all the classifiers, the baseline wrapper method has a higher recognition performance when trained on the linear discriminant analysis. This is expected as we used the linear discriminant analysis as the learning algorithm to select sensors for the baseline wrapper method.
As for the van Kasteren dataset (
Figure 8b), as both of our method and the baseline naive method identified the same set of sensors, they achieved the same recognition performance across all the classifiers and significantly better than the baseline wrapper method. In terms of accuracy and recall, the baseline wrapper method had a better recognition for the linear discriminant analysis since the learning algorithm used for the wrapper method is trained using the linear discriminant analysis. However, the baseline wrapper method has the lowest precision and F1 across all the classifiers, which means that many activities have been incorrectly classified. The performance of our method achieved a consistent performance in accuracy, precision, recall, and F1 across all the classifiers, which makes our method suitable for sensor selection.
In terms of computational performance (see
Table 4), the baseline wrapper method has a longer running and evaluation time since such a method requires a new classifier to be trained on each sensor subset evaluation. Although the difference is not significant in magnitude, the baseline wrapper method takes at least 50 folds longer (2.53 s as compared to the 0.05 s of our method) to run on the first set of the MIT PlaceLab dataset. When the number of sensors for evaluation increased from 14 (van Kasteren) to 24 (MIT PlaceLab), the computational time, on average, increased by 40%. This is expected as when the number of sensors for evaluation increases, a larger sensor space needs to be examined and thus takes a longer time to evaluate. The additional computational cost for the wrapper method is definitely non-trivial if we are performing sensor selection on a larger dataset.
The wrapper method in general uses cross-validation to guide the search through the use of validation sets to assess the predictive ability of the learning algorithm over the sensor subset. Such a method, which is guided by accuracy estimates, may result in overfitting. As can be seen from
Figure 8, the wrapper method, overall, achieved better recognition accuracy but lower precision, recall, and F1 across decision tree, naïve Bayes classifier, and
k-nearest neighbour, on both datasets. Since our method does not rely on a search algorithm nor does it depend on any accuracy estimates, it can help to reduce overfitting and have a better ability to generalise. Referring to
Figure 8, our method has better precision, recall, and F1 on both datasets, which shows that our method is able to identify the set of sensors that is well suited for activity recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}