Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration



Abstract
:1. Introduction
2. Related Work
2.1. Local Registration
2.2. Global Registration
2.3. Local Descriptors Registration
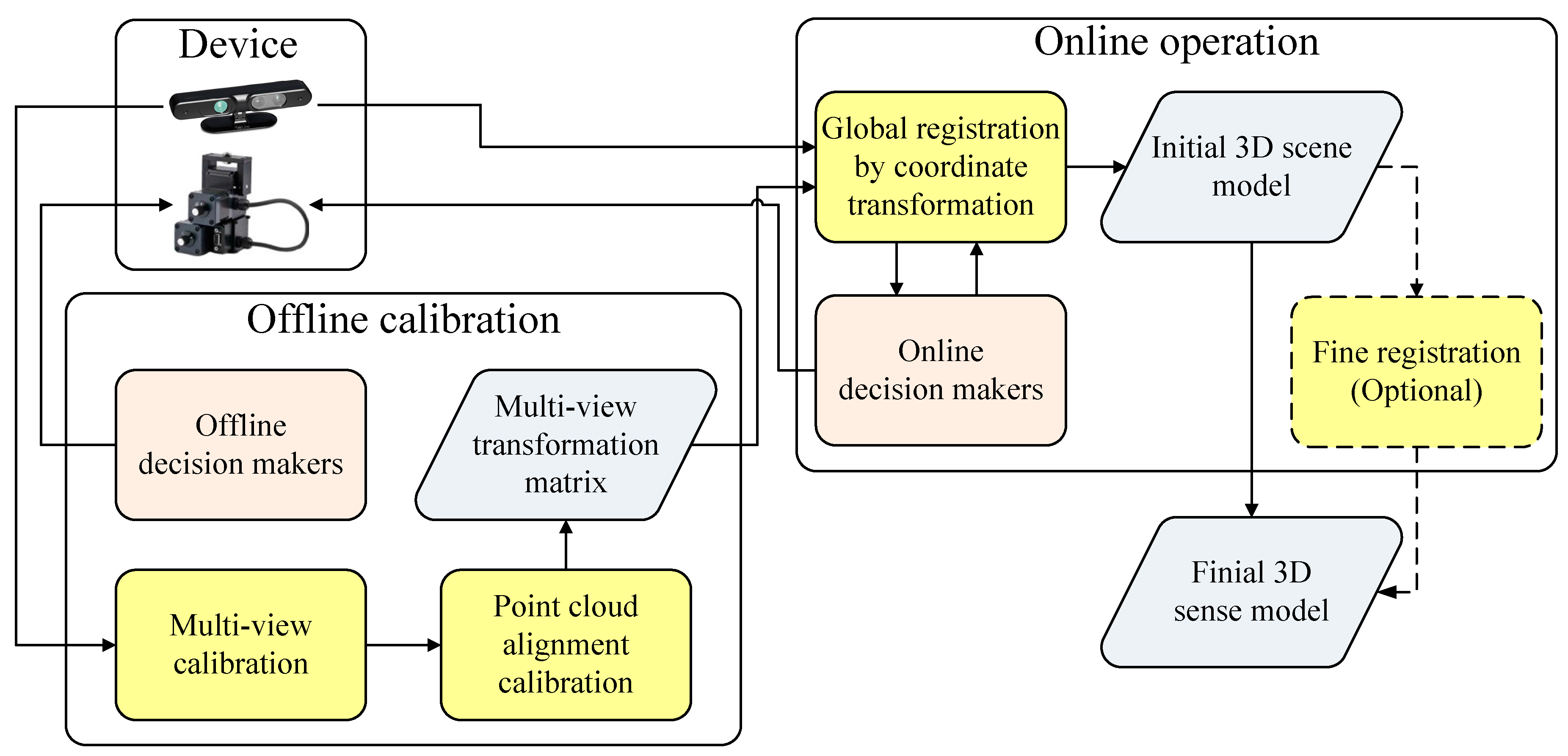
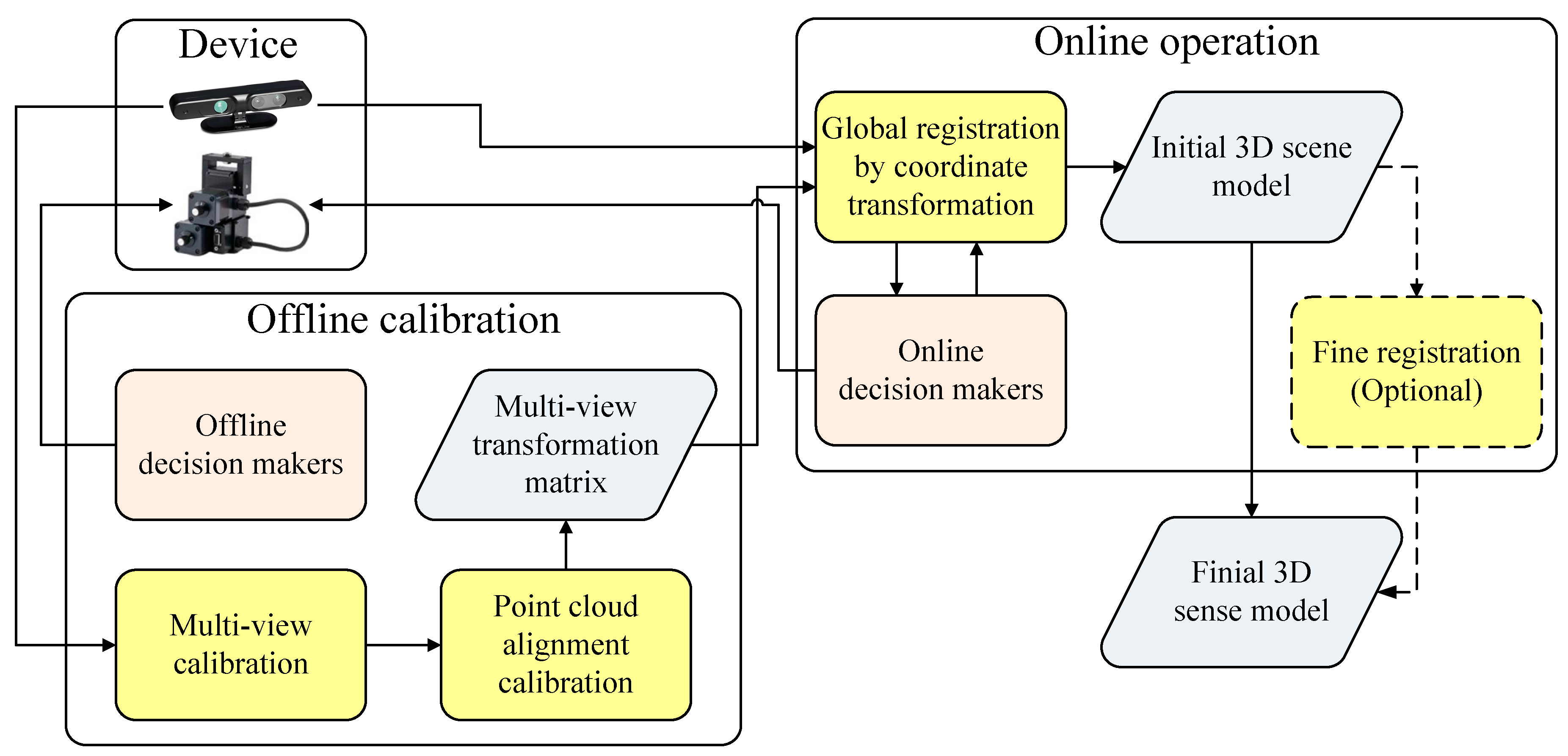
3. System Architecture
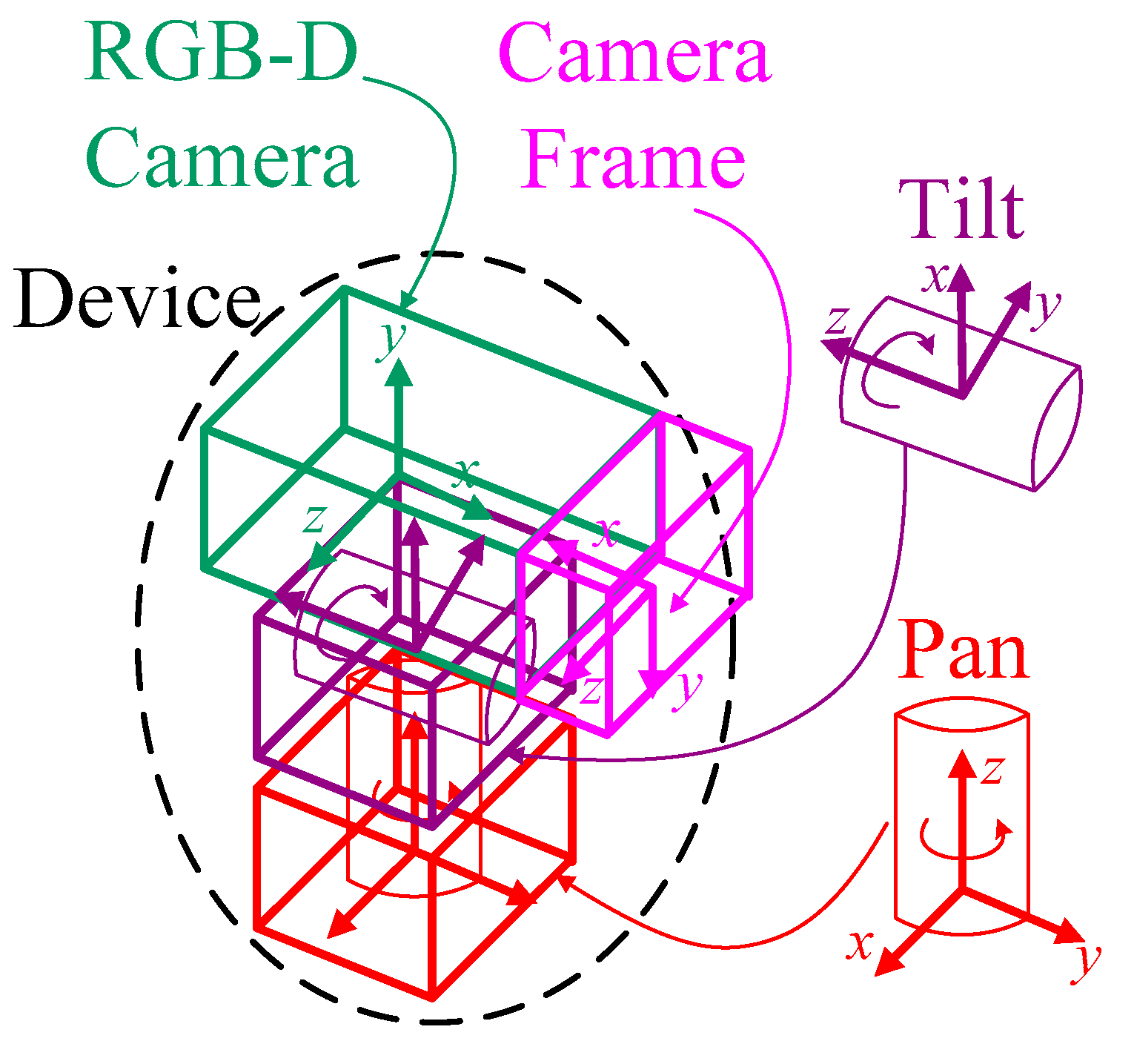
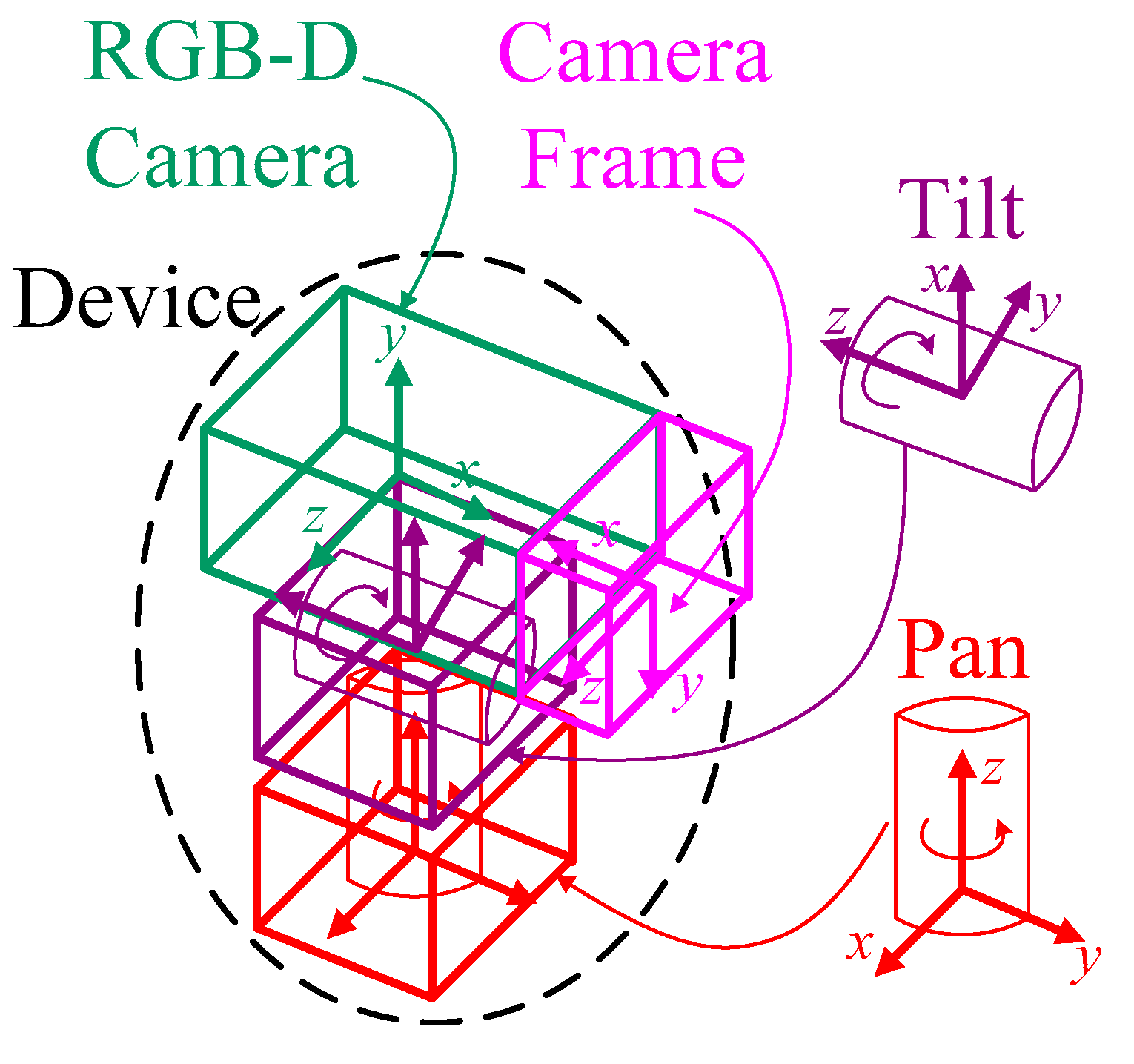
3.1. Forward Kinematics Approach
3.2. Camera Calibration Approach
- Start to capture the initial frame F0, and define its coordinate as a world coordinate W.
- Conduct multi-view calibration to obtain the extrinsic parameter matrix for the initial world coordinate.
- Control the motor and allow it to rotate to the next point.
- Capture the frame Fi, and conduct multi-view calibration to obtain the extrinsic parameter matrix.
- Generate point cloud Pi, and conduct point cloud alignment calibration to obtain the transformation matrix.
- If completed, store all the transformation matrices; otherwise, go back to Step 3 to make a decision.
- Start to capture the initial frame F0 and generate point cloud P0, and define the coordinate of the point cloud P0 as the world coordinate W.
- Control the motor and allow it to rotate to the next point, wait until the motor rotates to the fixed point, and then haul back the motor to complete the command.
- Capture the frame Fi and generate a point cloud Pi.
- Transform the point cloud Pi to Pi0 using the corresponding transformation matrix Ti0 estimated in the offline calibration.
- If completed, generate the initial 3D scene reconstruction model; otherwise, go back to Step 3 to make a decision of aligning the next point cloud.
- If the fine registration step is enabled, then use one of the existing ICP methods to refine the initial 3D scene reconstruction model; otherwise, use the initial 3D scene reconstruction model as the final result.
- Generate the final 3D scene reconstruction model.
4. The Proposed Method
4.1. Offline Calibration
4.2. Online Operation
5. Experimental Results
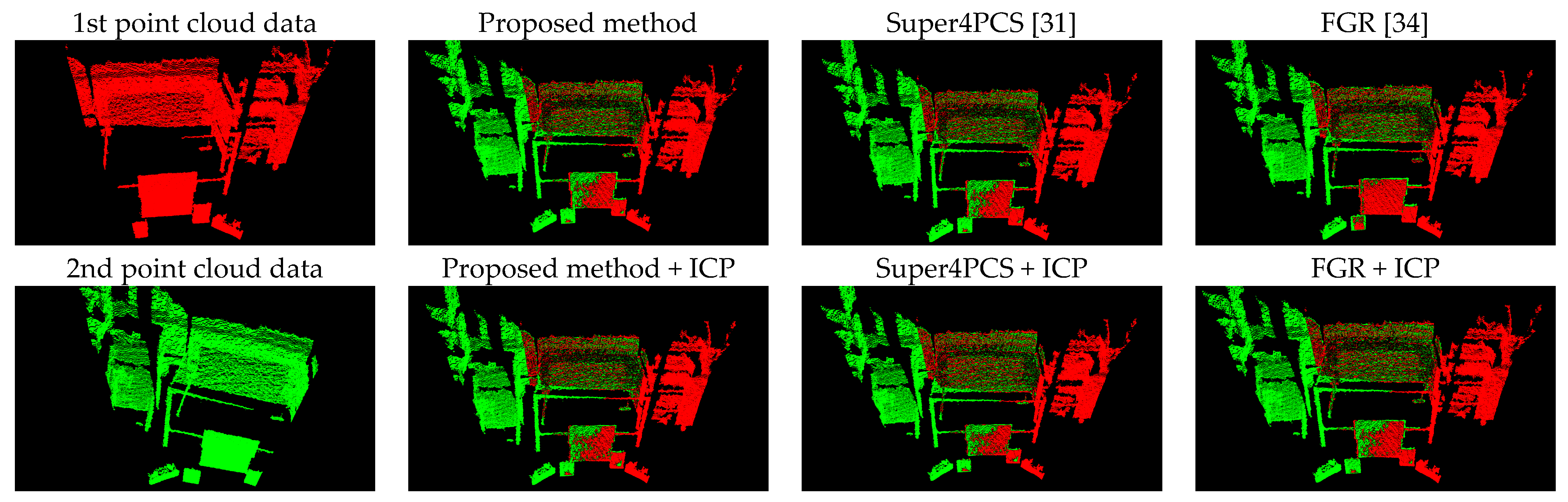
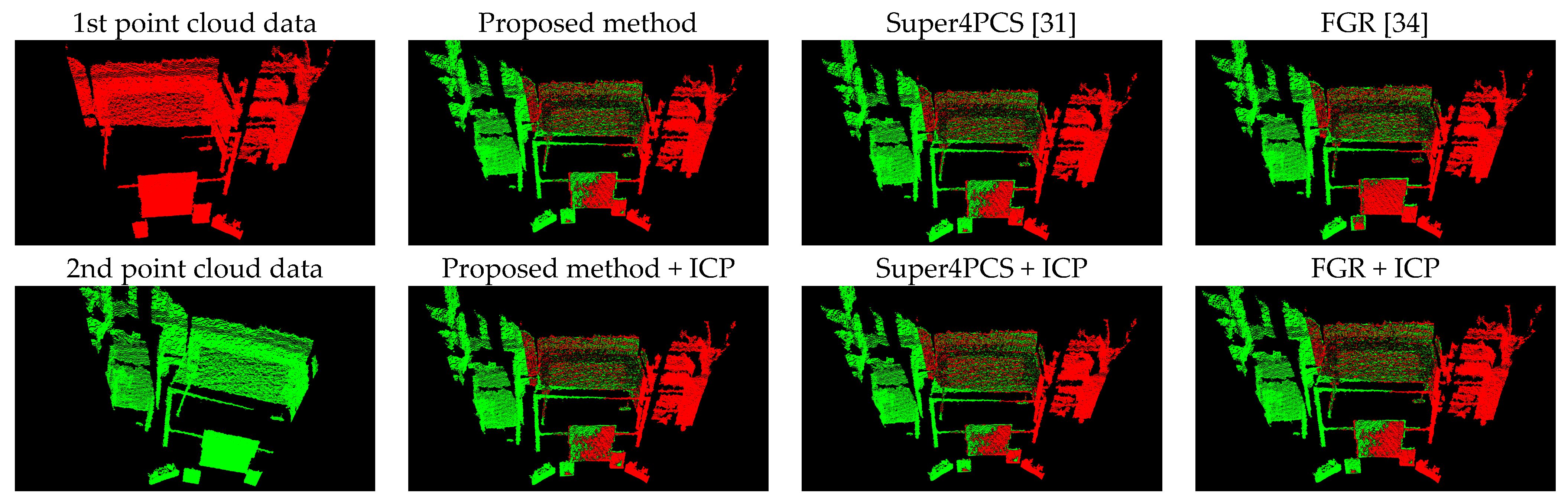
5.1. Point Cloud Registration Results
5.2. Quantitative Evaluation
5.3. Computational Efficiency
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Souza, A.A.S.; Maia, R.; Goncalves, L.M.G. 3D Probabilistic Occupancy Grid to Robotic Mapping with Stereo Vision. In Current Advancements in Stereo; Bhatti, A., Ed.; InTech Open Access: Rijeka, Croatia, 2012; ISBN 978-953-51-0660-9. [Google Scholar]
- Saxena, A.; Chung, S.H.; Ng, A.Y. 3-D Depth Reconstruction from a Single Still Image. Int. J. Comput. Vis. 2008, 76, 53–69. [Google Scholar] [CrossRef]
- Kahn, A. Reducing the Gap between Augmented Reality and 3D Modeling with Real-Time Depth Imaging. Int. J. Comput. Vis. 2013, 17, 111–123. [Google Scholar] [CrossRef]
- Yang, S.; Maturana, D.; Scherer, S. Real-time 3D Scene Layout from a Single Image Using Convolutional Neural Networks. In Proceedings of the Robotics and Automation of the Conference, Stockholm, Sweden, 16–21 May 2016; pp. 2183–2189. [Google Scholar]
- Choi, C.; Trevor, A.J.B.; Christensen, H.I. RGB-D Edge Detection and Edge-based Registration. In Proceedings of the Intelligent Robots and Systems of the Conference, Tokyo, Japan, 3–7 November 2013; pp. 1568–1575. [Google Scholar]
- Liu, F.; Lv, Q.; Lin, H.; Zhang, Y.; Qi, K. An Image Registration Algorithm Based on FREAK-FAST for Visual SLAM. In Proceedings of the Chinese Control of the Conference, Chengdu, China, 27–29 July 2016. [Google Scholar]
- Zanuttigh, P.; Marin, G.; Mutto, C.D.; Dominio, F.; Minto, L.; Cortelazzo, G.M. Operating Principles of Structured Light Depth Cameras. In Time-of-Flight and Structured Light Depth Cameras; Pietro, Z., Giulio, M., Carlo, D.M., Fabio, D., Ludovico, M., Guido, M.C., Eds.; Springer International Publishing: Heidelberg, Germany, 2016; pp. 43–79. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate Camera Calibration from Multi-View Stereo and Bundle Adjustment. Int. J. Comput. Vis. 2009, 84, 257–268. [Google Scholar] [CrossRef]
- Puwein, J.; Ziegler, R.; Vogel, J.; Pollefeys, M. Robust Multi-View Camera Calibration for Wide-Baseline Camera Networks. In Proceedings of the Applications of Compute Vision of the Workshop, Kona, HI, USA, 5–7 January 2011. [Google Scholar]
- Li, B.; Heng, L.; Koser, K.; Pollefeys, M. A Multiple-Camera System Calibration Toolbox Using a Feature Descriptor-Based Calibration Pattern. In Proceedings of the Intelligent Robots and Systems of the Conference, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Holz, D.; Ichim, A.E.; Tombari, F.; Rusu, R.B.; Behnke, S. Registration with the Point Cloud Library: A Modular Framework for Aligning in 3-D. IEEE Robot. Autom. Mag. 2015, 22, 110–124. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Matabosch, C.; Salvi, J.; Fofi, D.; Meriaudeau, F. Range Image Registration for Industrial Inspection. In Proceedings of the SPIE of the Conference, San Jose, CA, USA, 17 January 2005; pp. 216–227. [Google Scholar]
- Salvi, J.; Matabosch, C.; Fofi, D.; Forest, J. A Review of Recent Range Image Registration Methods with Accuracy Evaluation. Image Vis. Comput. 2007, 25, 578–596. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object Modeling by Registration of Multiple Range Images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Pulli, K. Multiview Registration for Large Data Sets. In Proceedings of the 3-D Digital Imaging and Modeling of the Conference, Ottawa, ON, Canada, 8 October 1999. [Google Scholar]
- Masuda, T. Object Shape Modeling from Multiple Range Images by Matching Signed Distance Fields. In Proceedings of the 3D Data Processing Visualization and Transmission of the Symposium, Padova, Italy, 19–21 June 2002. [Google Scholar]
- Silva, L.; Bellon, O.R.P.; Boyer, K.L. Enhanced, Robust Genetic Algorithms for Multiview Range Image Registration. In Proceedings of the 3-D Digital Imaging and Modeling of the Conference, Banff, AB, Canada, 6–10 October 2003. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient Variants of the ICP Algorithm. In Proceedings of the 3-D Digital Imaging and Modeling of the Conference, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Low, K.-L. Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration; Technical Report TR04-004; Department of Computer Science University, North Carolina at Chapel Hill: Orange, NC, USA, 2004. [Google Scholar]
- Serafin, J.; Grisetti, G. NICP: Dense Normal Based Point Cloud Registration. In Proceedings of the Intelligent Robots and Systems of the Conference, Hamburg, Germany, 28 September–2 October 2015; pp. 742–749. [Google Scholar]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera. In Proceedings of the User Interface Software and Technology of the Conference, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Learning Informative Point Classes for Acquisition of Object Model Maps. In Proceedings of the Control, Automation, Robotics and Vision of the Conference, Hanoi, Vietnam, 17–20 December 2008. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetx, M. Aligning Point Cloud Views using Persistent Feature Histograms. In Proceedings of the Intelligent Robots and Systems of the Conference, Nice, France, 22–26 September 2008. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D Registration. In Proceedings of the Robotics and Automation of the Conference, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Tombari, F.; Salti, S.; Stefano, L.D. Unique Signatures of Histograms for Local Surface Description. In Proceedings of the Computer Vision of the European Conference, Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar]
- Nascimento, E.R.; Schwartz, W.R.; Oliveira, G.L.; Veira, A.W.; Campos, M.F.M.; Mesquita, D.B. Appearance Geometry Fusion for Enhanced Dense 3D Alignment. In Proceedings of the Graphics, Patterns and Images of the Conference, Ouro Preto, Brazil, 22–25 August 2012. [Google Scholar]
- Schmiedel, T.; Einhorn, E.; Gross, H.-M. IRON: A Fast Interest Point Descriptor for Robust NDT-Map Matching and Its Application to Robot Localization. In Proceedings of the Intelligent Robots and Systems of the Conference, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Song, W.; Yun, S.; Jung, S.-W.; Won, C.S. Rotated Top-Bottom Dual-Kinect for Improved Field of View. Multimed. Tools Appl. 2016, 75, 8569–8593. [Google Scholar] [CrossRef]
- Li, H.; Liu, H.; Cao, N.; Peng, Y.; Xie, S.; Luo, J.; Sun, Y. Real-Time RGB-D Image Stitching Using Multiple Kinects for Improved Field of View. Int. J. Adv. Robot. Syst. 2017, 14, 1–8. [Google Scholar] [CrossRef]
- Mellado, N.; Mitra, N.; Aiger, D. SUPER 4PCS Fast Global Pointcloud Registration via Smart Indexing. In Proceedings of the Computer Graphics of the European Association Conference, Strasbourg, France, 7–11 April 2014. [Google Scholar]
- Segal, A.V.; Haehnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics Science and Systems of the Conference, Seattle, WA, USA, 29 June–1 July 2009. [Google Scholar]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4-Points Congruent Sets for Robust Pairwise Surface Registration. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef]
- Zhou, Q.-Y.; Park, J.; Koltun, V. Fast Global Registration. In Proceedings of the Computer Vision of the European Conference, Amsterdam, The Netherlands, 8–16 October 2016; pp. 766–782. [Google Scholar]
- Murray, R.M.; Li, Z.; Sastry, S.S. A Mathematical Introduction to Robotic Manipulation. In Forward Kinematics; CRC Press: Boca Raton, FL, USA, 1994; pp. 83–95. [Google Scholar]
- Spong, M.W.; Hutchinson, S.; Vidyasagar, M. Forward Kinematics: the Denavit-hartenberg Convention. In Robot Dynamics and Control, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2004; pp. 57–82. ISBN 978-0-471-61243-8. [Google Scholar]
- Matkan, A.A.; Hajeb, M.; Mirbagheri, B.; Sadeghian, S.; Ahmadi, M. Spatial Analysis for Outlier Removal from LiDAR Data. In Proceedings of the Geospatial Information Research of the European Conference, Tehran, Iran, 15–17 November 2014. [Google Scholar]
- Wolff, K.; Kim, C.; Zimmer, H.; Schroers, C.; Botsch, M.; Sorkine-Hornung, O.; Sorkine-Hornung, A. Point Cloud Noise and Outlier Removal for Image-Based 3D Reconstruction. In Proceedings of the 3D Vision of the Conference, Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- ASUS Xtion Pro. Available online: https://www.asus.com/3D-Sensor/Xtion_PRO/ (accessed on 12 August 2017).
- E46-17 Pan-tilt Platform. Available online: http://www.flir.com/mcs/view/?id=63554 (accessed on 12 August 2017).
- Automatic Registration of Ground-Based LiDAR Point Clouds of Forested Areas. Available online: http://www.cis.rit.edu/DocumentLibrary/admin/uploads/CIS000133.pdf (accessed on 12 August 2017).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | αk (deg) | ak (mm) | dk (mm) | θk (deg) |
|---|---|---|---|---|
| 1 | 90 | 0 | 45 | θp |
| 2 | 90 | 74.466 | 0 | θt + 90 |
| 3 | 0 | 23 | 0 | −90 |
| 4 | 0 | 0 | 0 | 180 |
| Rated Payload | Maximum Speed | Position Resolution | Tilt Range | Pan Range |
|---|---|---|---|---|
| 2.72 Kg | 300°/s | 0.013° | −47° to +31° | −159° to +159° |
| Average RMS | Online Registration Methods | ||
|---|---|---|---|
| Test Dataset | Forward Kinematics Equation (4) | Camera Calibration Equation (8) | Proposed Method Equation (11) |
| Room 1 | 18.7566 | 21.1770 | 18.4981 |
| Room 2 | 26.6134 | 30.5964 | 26.3199 |
| Room 3 | 19.5648 | 25.5299 | 18.3148 |
| Test Dataset | Proposed Method | Super4PCS | FGR | Proposed Method + ICP | Super4PCS+ ICP | FGR + ICP |
|---|---|---|---|---|---|---|
| 1 m dataset | 19.6716 | 22.1680 | 19.7152 | 19.5366 | 20.3303 | 19.2841 |
| 3 m dataset | 19.9090 | 30.2470 | 20.1706 | 19.6401 | 29.2774 | 19.0025 |
| 5 m dataset | 32.0353 | 43.1703 | 33.9440 | 31.5003 | 40.6470 | 31.2734 |
| Room 1 | 18.4981 | 27.0479 | 18.8040 | 18.3856 | 24.4929 | 18.4195 |
| Room 2 | 26.3199 | 29.0571 | 29.5579 | 25.7527 | 25.6207 | 25.7157 |
| Room 3 | 18.3148 | 20.9321 | 18.7524 | 18.2912 | 18.3036 | 18.2979 |
| Test Dataset | Proposed Method | Super4PCS | FGR | Proposed Method + ICP | Super4PCS + ICP | FGR + ICP |
|---|---|---|---|---|---|---|
| 1 m dataset | 4.11 | 553,958.70 | 12,077.14 | 27,378.52 | 599,331.00 | 70,038.29 |
| 3 m dataset | 3.14 | 528,159.80 | 30,508.29 | 17,385.10 | 574,146.00 | 119,717.10 |
| 5 m dataset | 4.18 | 100,250.80 | 48,501.62 | 32,572.52 | 237,221.20 | 65,188.71 |
| Room 1 | 3.77 | 636,178.79 | 10,902.57 | 40,000.84 | 732,519.07 | 60,492.71 |
| Room 2 | 4.24 | 135,305.92 | 57,163.71 | 52,331.24 | 261,104.14 | 160,310.5 |
| Room 3 | 3.90 | 582,703.07 | 25,278.57 | 46,932.69 | 671,707.43 | 53,883.57 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-Y.; Huang, C.-H. Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration. Sensors 2017, 17, 1874. https://doi.org/10.3390/s17081874
Tsai C-Y, Huang C-H. Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration. Sensors. 2017; 17(8):1874. https://doi.org/10.3390/s17081874
Chicago/Turabian StyleTsai, Chi-Yi, and Chih-Hung Huang. 2017. "Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration" Sensors 17, no. 8: 1874. https://doi.org/10.3390/s17081874
APA StyleTsai, C.-Y., & Huang, C.-H. (2017). Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration. Sensors, 17(8), 1874. https://doi.org/10.3390/s17081874