homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring





Abstract
:1. Introduction
- A detailed state-of-the-art review of existing AAL techniques based on audio processing and high performance computing platforms.
- The design and deployment of a low-cost distributed architecture at home to collect and process audio data from several sources based on a low-cost GPU embedded platform.
- The implementation of a data-mining based system able to detect and classify acoustic events related to AAL in real-time.
2. Related Work
2.1. AAL Research Projects
2.2. WASNs for Tele-Care
2.3. Embedded Audio Applications Using Low-Cost Graphical Processing Units
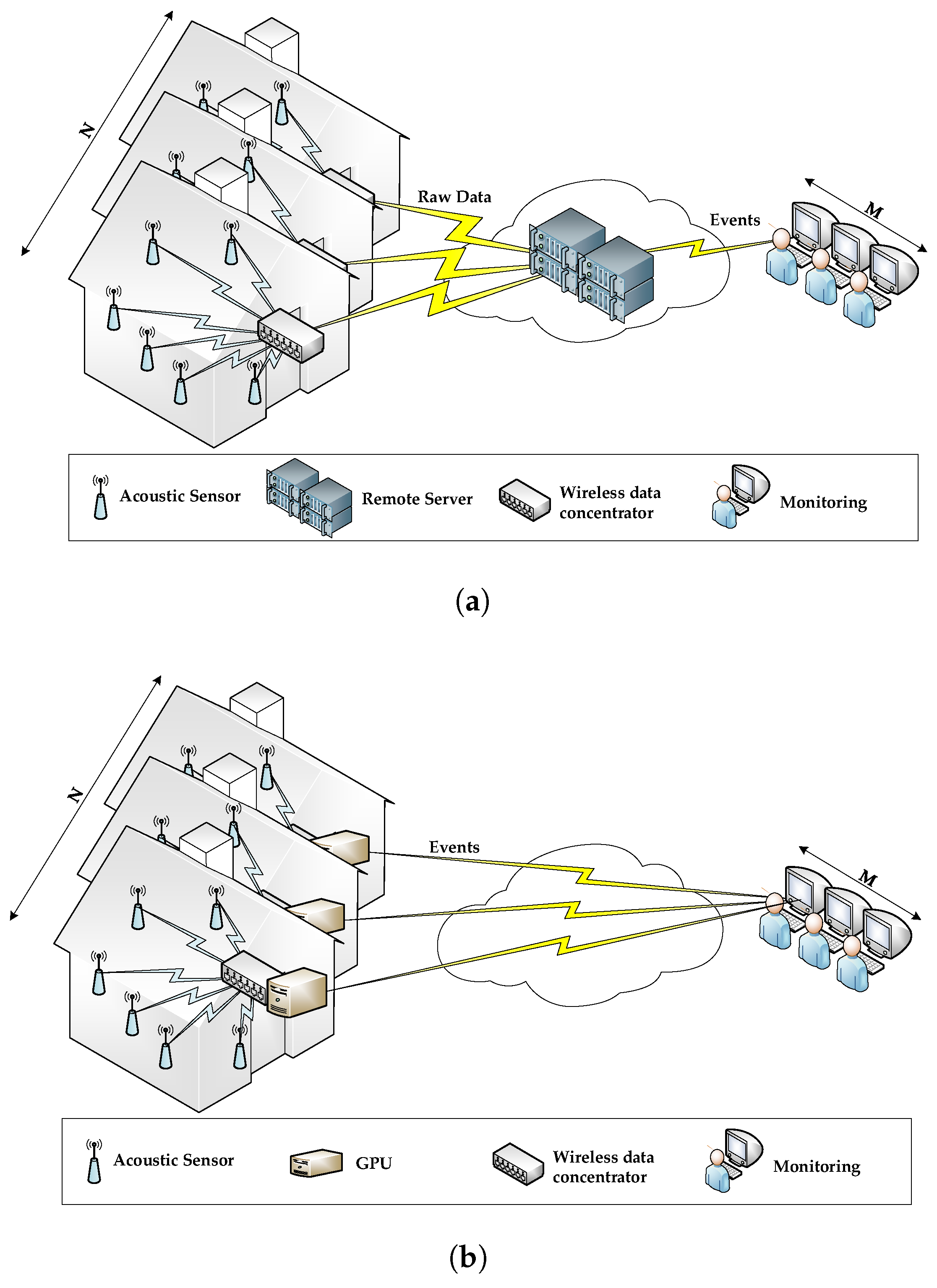
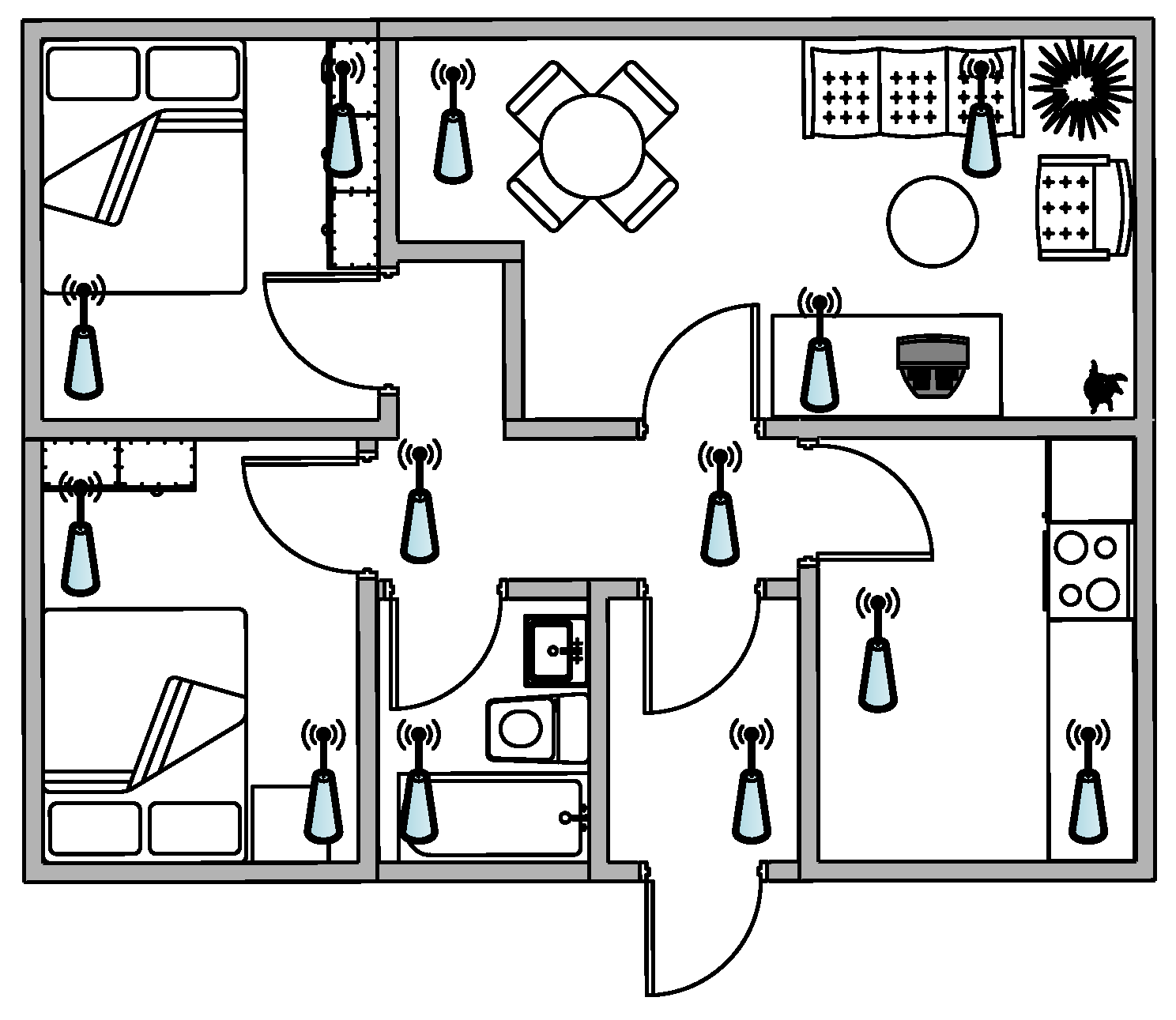
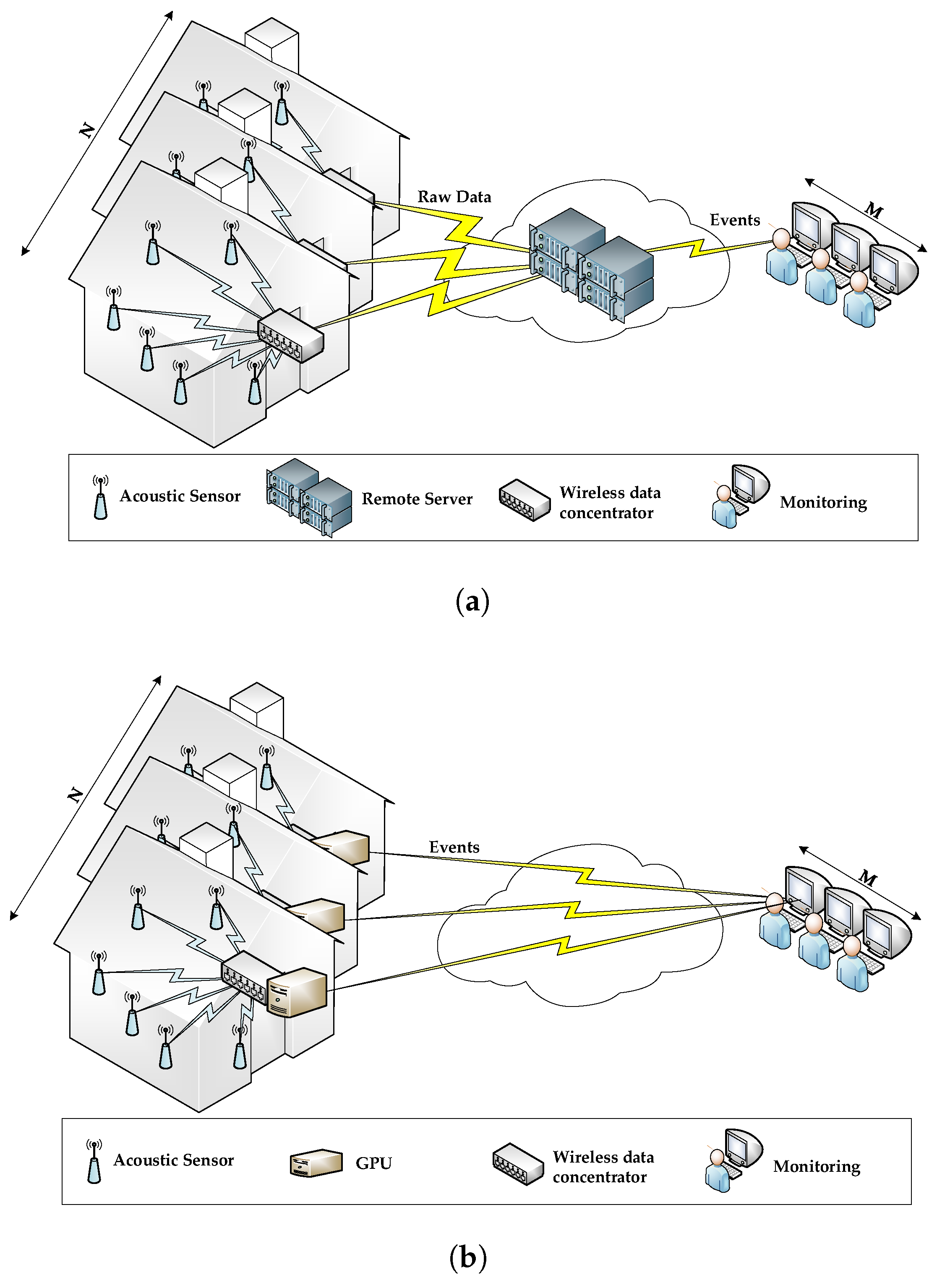
3. WASN for Surveillance and Behavioural Monitoring
3.1. System Architecture
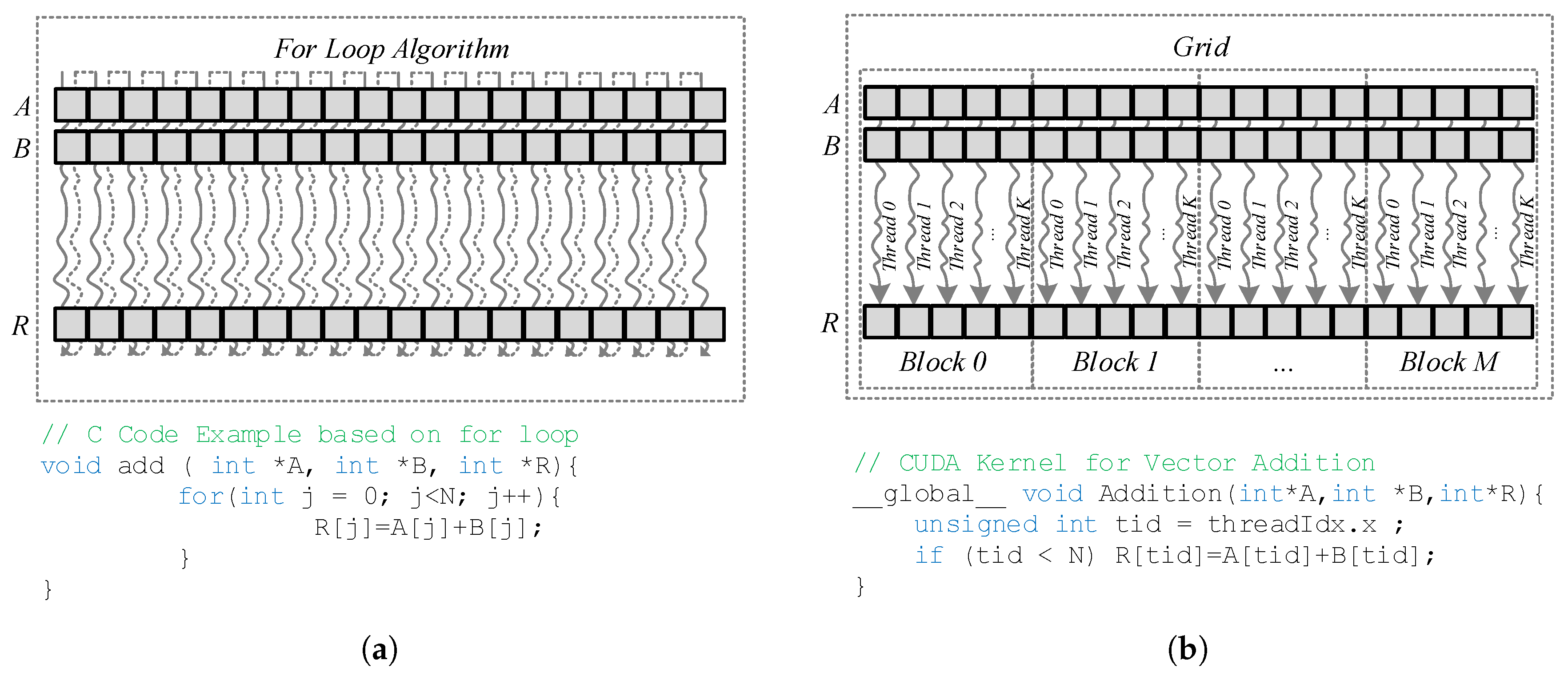
3.2. GPU for Acoustic Signal Processing
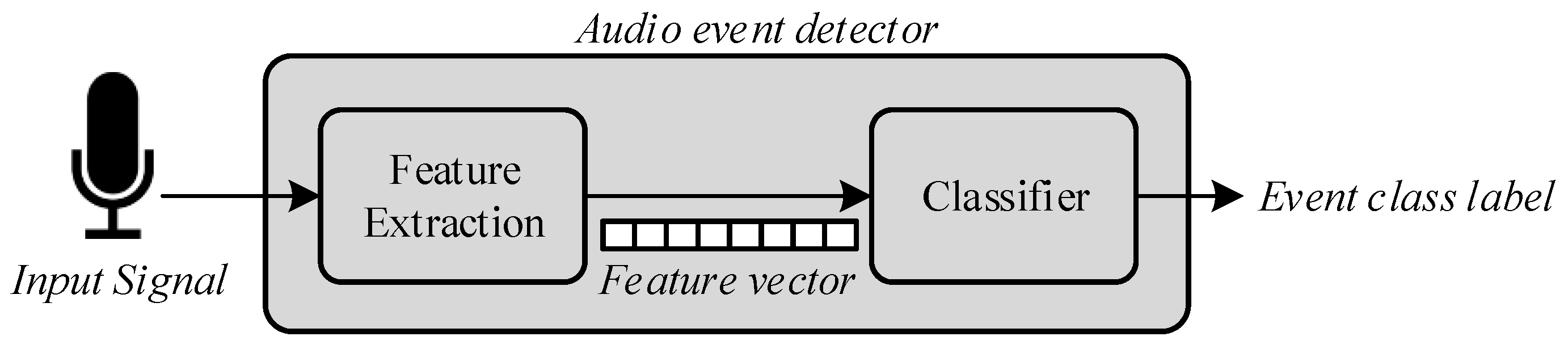
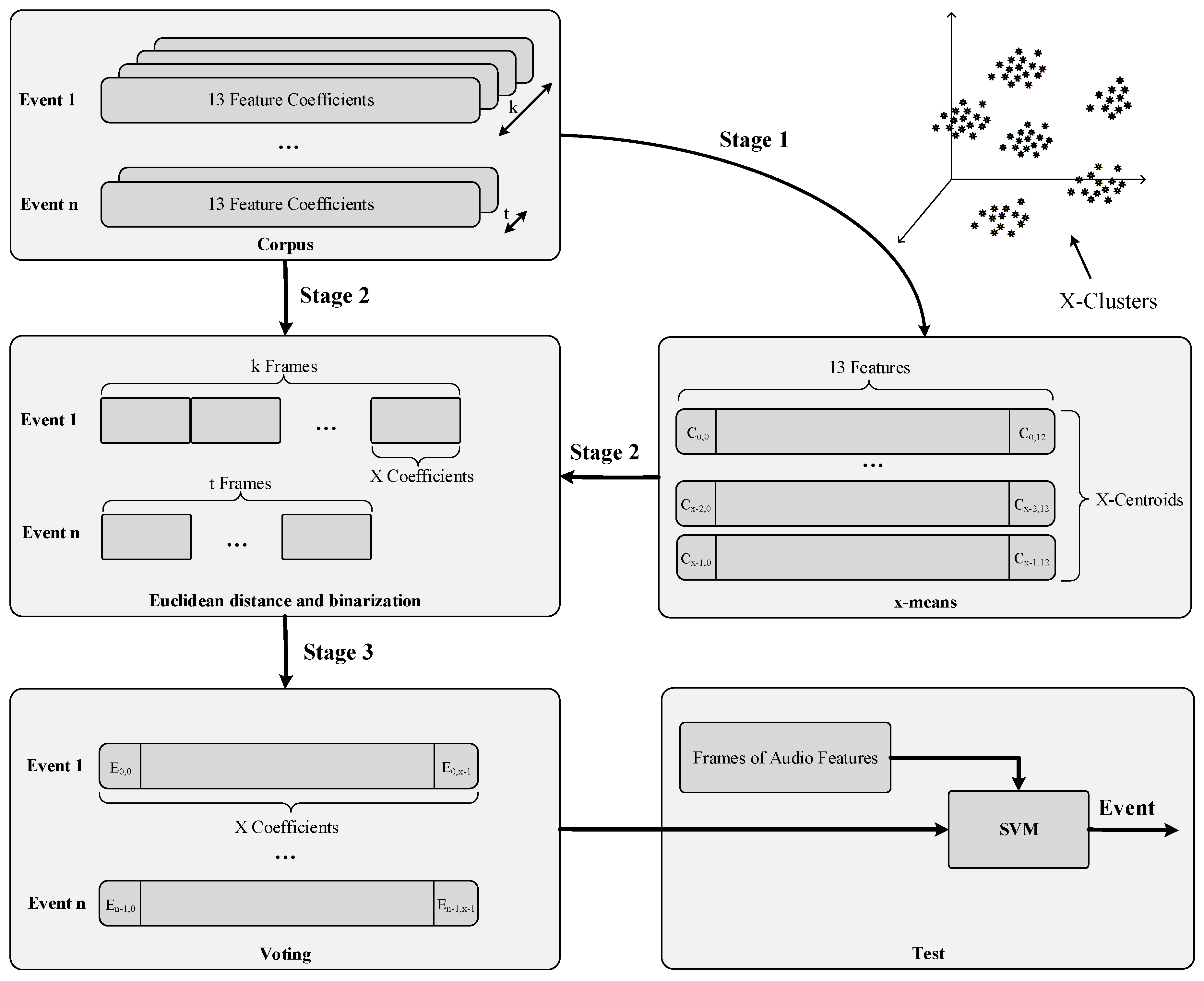
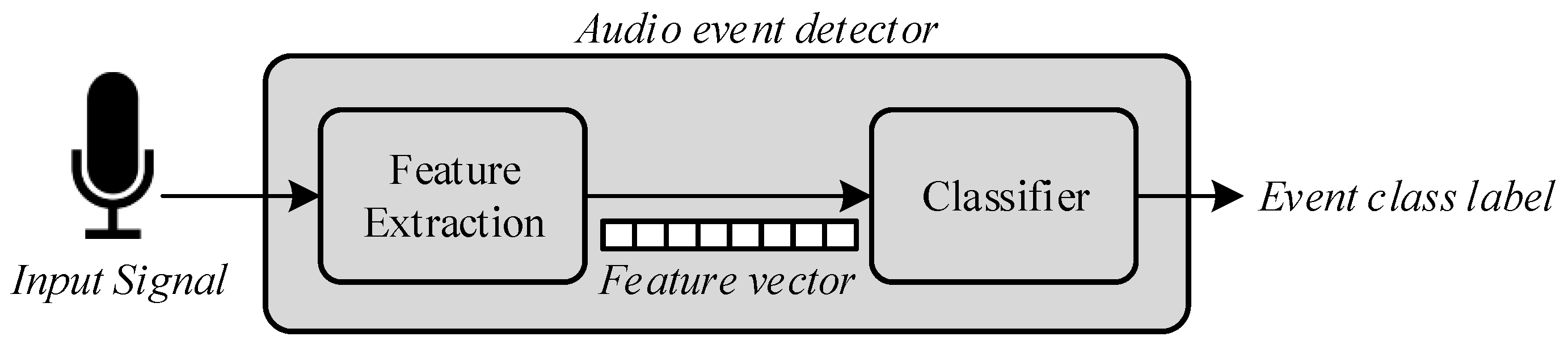
4. Audio Event Detection Algorithm
4.1. Feature Extraction
4.2. Automatic Audio Event Classification
- Class overlapping [70]. Splitting acoustic events in quasi-stationary short frames enriches the characterization of events but drives to a situation where two 30 ms samples from different events might share several similarities in terms of their spectrum and, hence, the derived MFCC values.
- Samples coherence. The same audio event can be defined by different combinations of a fixed set of 30 ms frames. That is, a glass breaking can be characterized by the sequence of 30 ms frames A-B-C-D, A-C-B-D, etc. Unfortunately, artificially building a data set with all possible combinations as suggested in [69], is not feasible due to the huge amount of samples to combine. This is very different from other audio domains such as speech recognition where the system has to identify fixed audio sequences, which follow a phonetically-based temporal evolution [65]. Therefore, existing approaches based on Hidden Markov Models (HMM) [69] do not fit well the problem at hand [71].
- Class imbalance [70,72]. The length (i.e., number of vectors) of each audio event is different (e.g., someone falling lasts longer than a dog barking). Existing solutions that aim to sub-sample or over-sample the original data cannot be applied to the audio domain because the semantics variation of the derived MFCC would affect the classification performance negatively.
5. Test and Results
5.1. Analysis of the Algorithm Operations on the GP-GPU
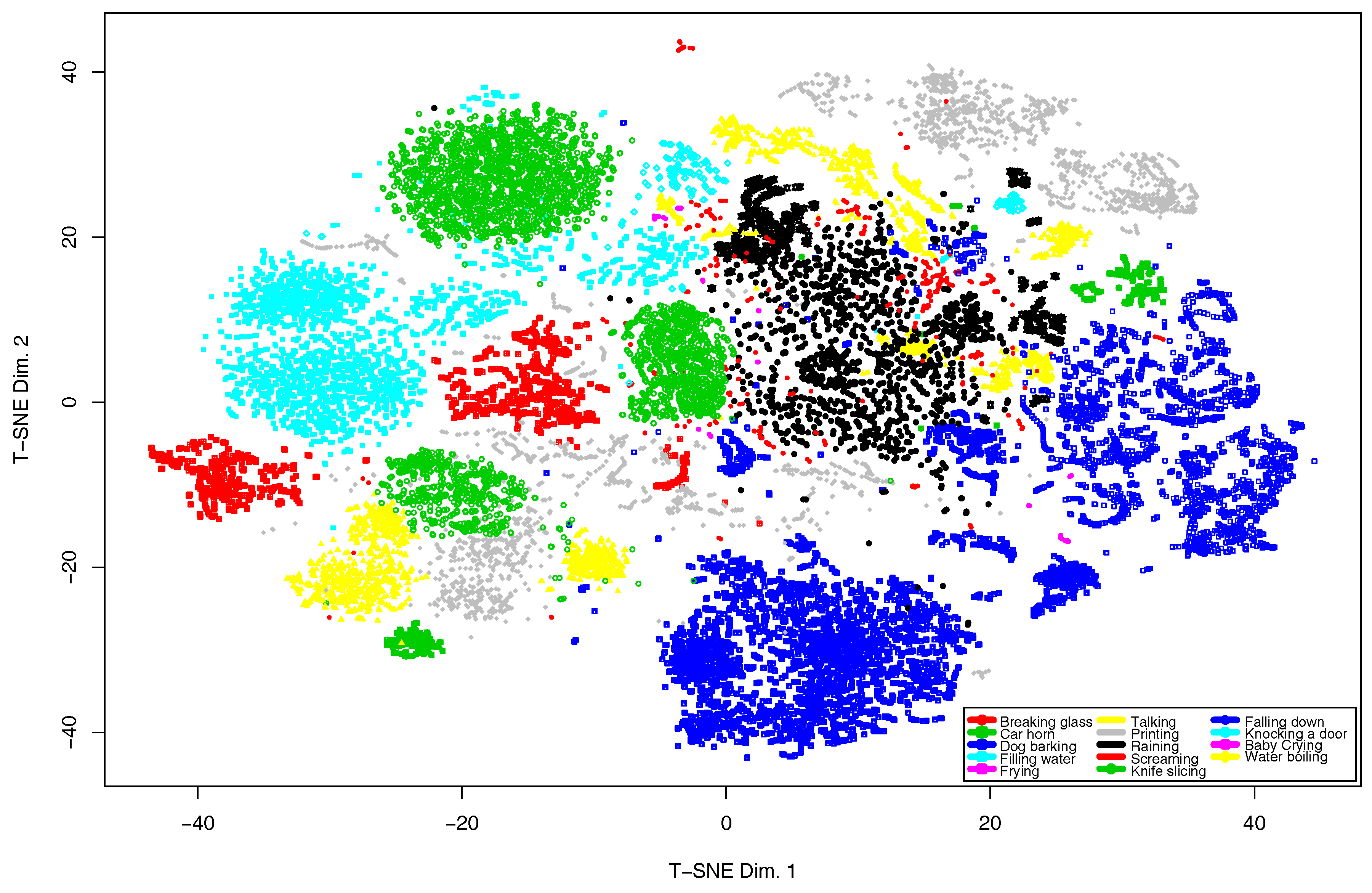
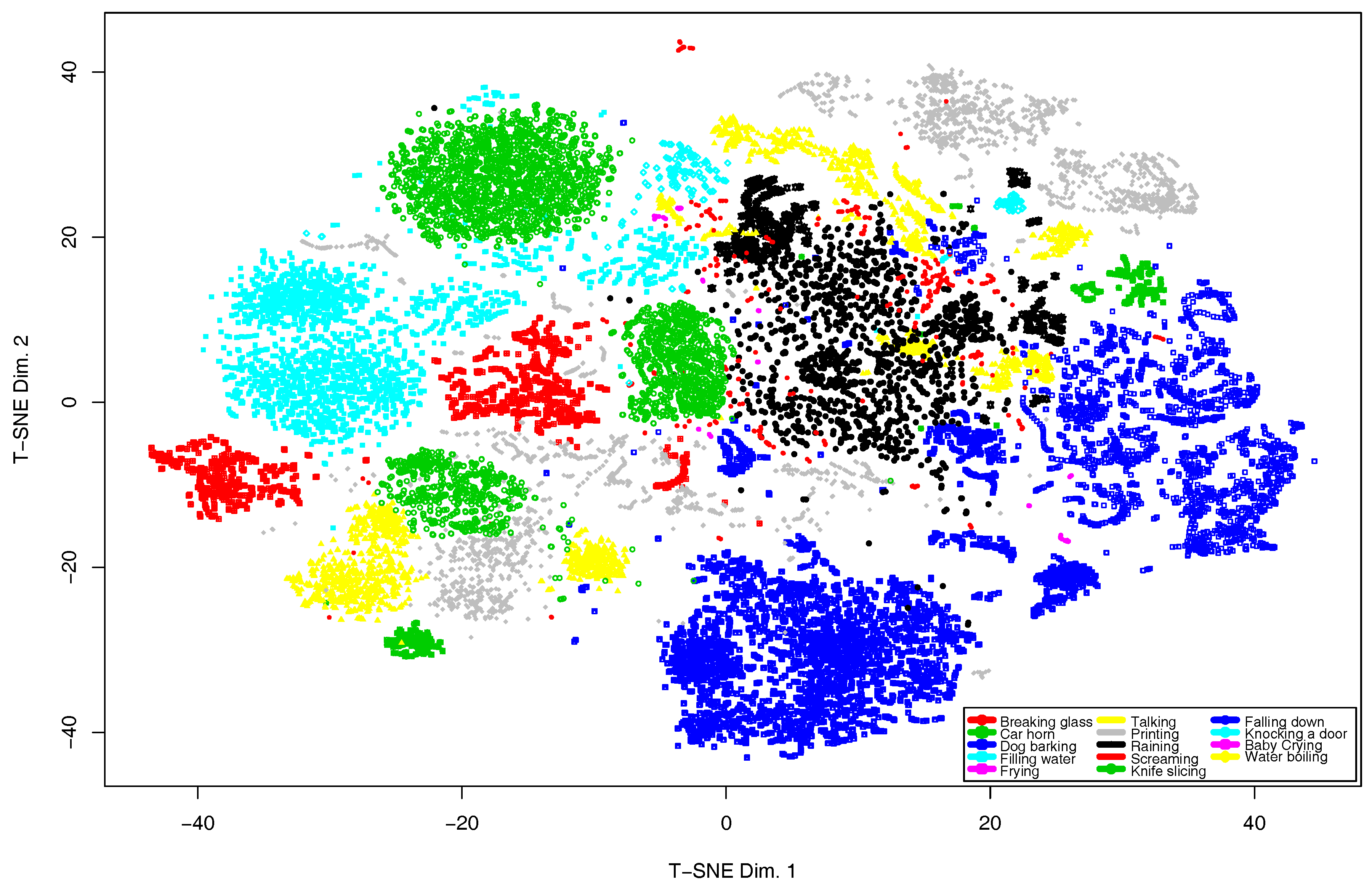
5.2. Analysis of the Algorithm Performance in terms of Audio Event Detection Accuracy
6. Discussion
6.1. Robustness of the Real-Time Audio Events Classification
6.1.1. Event Overlapping in Groups of Classes
6.1.2. Audio Events Mixture
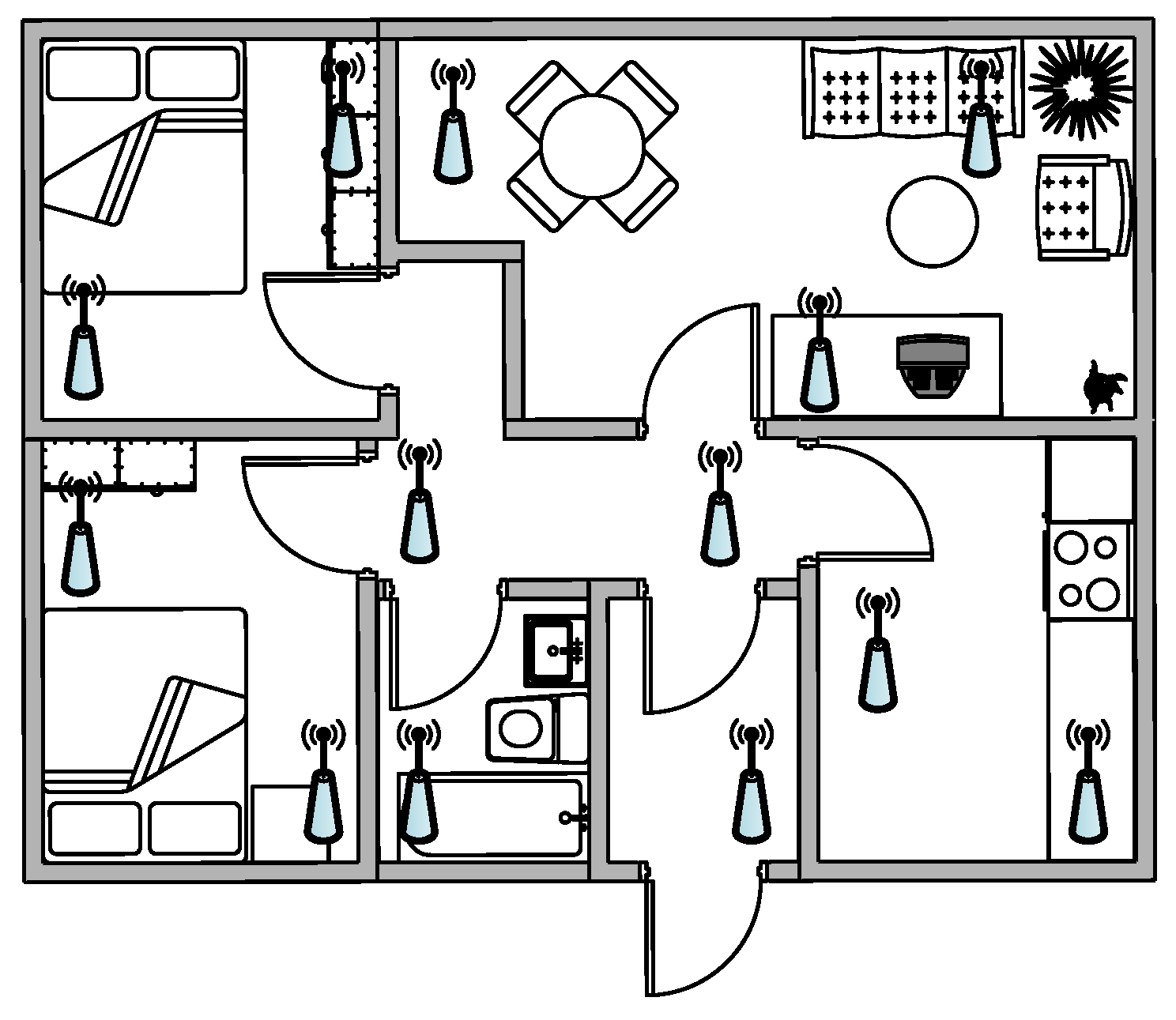
6.2. Acoustic Nodes Placement
6.3. GP-GPU Platform Proposal
6.4. Implications of the Proof-of-Concept
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AAD | Acoustic Activity Detection |
| AAL | Ambient Assisted Living |
| ADC | Analog to Digital Converter |
| ADL | Activities Daily Living |
| ARM | Advanced RISC Machines |
| BSP | Board Support Package |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| DCT | Discrete Cosine Transform |
| DFT | Discrete Fourier Transform |
| DNN | Deep Neural Networks |
| DTW | Dynamic Time Warping |
| HPC | High Performance Computing |
| FFT | Fast Fourier Transform |
| FPGA | Field Programmable Gate Array |
| GFLOP | Giga-Floating Point Operations |
| GMM | Gaussian Mixture Models |
| GPU | Graphic Processing Unit |
| GP-GPU | General Purpose Graphics Processing Unit |
| GRITS | Grup de Recerca en Internet Technologies & Storage |
| GTM | Grup de Recerca en Tecnologies Mèdia |
| HMM | Hidden Markov Model |
| IoT | Internet of Thing |
| MEC | Mobile Edge Computing |
| MFCC | Mel Frequency Cepstral Coefficient |
| RFID | Radio Frequency Identification |
| SIMT | Single Instruction Multiple Thread |
| SoC | System on Chip |
| SNR | Signal to Noise Ratio |
| SVM | Support Vector Machine |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
| WASN | Wireless Acoustic Sensor Network |
| WFS | Wave Field Synthesis |
| WSN | Wireless Sensor Network |
References
- Suzman, R.; Beard, J. Global Health and Aging—Living Longer; National Institute on Aging: Bethesda, MD, USA, 2015.
- United Nations. World Population Ageing: 2015; United Nations Department of Economic and Social Affairs (Population Division): New York, NY, USA, 2015. [Google Scholar]
- National Institute on Aging. Growing Older in America: The Health and Retirement Study; U.S. Department of Health and Human Services: Washington, DC, USA, 2007.
- Chatterji, S.; Kowal, P.; Mathers, C.; Naidoo, N.; Verdes, E.; Smith, J.P.; Suzman, R. The health of aging populations in China and India. Health Aff. 2008, 27, 1052–1063. [Google Scholar] [CrossRef] [PubMed]
- Lafortune, G.; Balestat, G. Trends in Severe Disability among Elderly People. Assessing the Evidence in 12 OECD Countries and the Future Implications; OECD Health Working Papers 26; Organization for Economic Cooperation and Development: Paris, France, 2007. [Google Scholar]
- Rashidi, P.; Mihailidis, A. A survey on Ambient-Assisted Living tools for older adults. IEEE J. Biomed. Health Inform. 2013, 17, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Vacher, M.; Portet, F.; Fleury, A.; Noury, N. Challenges in the Processing of Audio Channels for Ambient Assisted Living. In Proceedings of the 12th IEEE International Conference on e-Health Networking Applications and Services (Healthcom), Lyon, France, 1–3 July 2010; pp. 330–337. [Google Scholar]
- Guyot, P.; Valero, X.; Pinquier, J.; Alías, F. Two-Step Detection of Water Sound Events for the Diagnostic and Monitoring of Dementia. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013. [Google Scholar]
- Valero, X.; Alías, F.; Guyot, P.; Pinquier, J. Assisting Doctors in the Diagnostic and Follow-up of Dementia Using the Sound Information from Wearable Sensors. In Proceedings of the 4th R+D+i Workshop on ICT & Health, Girona, Spain, 22 May 2013. [Google Scholar]
- Jaschinski, C.; Allouch, S.B. An extended view on benefits and barriers of Ambient Assisted Living solutions. Int. J. Adv. Life Sci. 2015, 7, 2. [Google Scholar]
- Goetze, S.; Moritz, N.; Apell, J.E.; Meis, M.; Bartsch, C.; Bitzer, J. Acoustic user interfaces for ambient assisted living technologies. Inform. Health Soc. Care 2010, 34, 161–179. [Google Scholar] [CrossRef] [PubMed]
- Cobos, M.; Perez-Solano, J.J.; Berger, L.T. Acoustic-Based Technologies for Ambient Assisted Living. In Introduction to Smart eHealth and eCare Technologies; Taylor & Francis Group: Boca Raton, FL, USA, 2016; pp. 159–180. [Google Scholar]
- Selga, J.M.; Zaballos, A.; Navarro, J. Solutions to the Computer Networking Challenges of the Distribution Smart Grid. IEEE Commun. Lett. 2013, 17, 588–591. [Google Scholar] [CrossRef]
- Sánchez, J.; Corral, G.; Martín de Pozuelo, R.; Zaballos, A. Security issues and threats that may affect the hybrid cloud of FINESCE. Netw. Protoc. Algorithms 2016, 8, 26–57. [Google Scholar] [CrossRef]
- Caire, P.; Moawad, A.; Efthymiou, V.; Bikakis, A.; Le Traon, Y. Privacy Challenges in Ambient Intelligence Systems. Lessons Learned, Gaps and Perspectives from the AAL Domain and Applications. J. Ambient Intell. Smart Environ. 2016, 8, 619–644. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. Mobile Edge Computing: Survey and Research Outlook. IEEE Commun. Surv. Tutor. 2017; arXiv:1701.01090. [Google Scholar]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017. [Google Scholar] [CrossRef]
- Alsina-Pagès, R.M.; Navarro, J.; Casals, E. Automated Audio Data Monitoring for a Social Robot in Ambient Assisted Living Environments. New Friends. In Proceedings of the 2nd International Conference on Social Robots in Therapy and Education, Barcelona, Spain, 2–4 November 2016. [Google Scholar]
- Hervás, M.; Alsina-Pagès, R.M.; Navarro, J. homeSound: A High Performance Platform for Massive Data Acquisition and Processing in Ambient Assisted Living Environments. In Proceedings of the 6th International Conference on Sensor Networks, SENSORNETS 2017, Oporto, Portugal, 19–21 February 2017. [Google Scholar]
- What Is Smart Home—Basic Idea. Available online: http://cctvinstitute.co.uk (accessed on 29 October 2016).
- Chan, M.; Estève, D.; Escriba, C.; Campo, E. A review of smart homes–Present state and future challenges. Comput. Methods Programs Biomed. 2008, 91, 55–81. [Google Scholar] [CrossRef] [PubMed]
- Erden, F.; Velipasalar, S.; Alkar, A.Z.; Cetin, A.E. Sensors in Assisted Living: A survey of signal and image processing methods. IEEE Signal Process. Mag. 2016, 33, 36–44. [Google Scholar] [CrossRef]
- EU Comission. Active and Assisted Living Programme. ICT for Ageing Well. Available online: http://www.aal-europe.eu/ (accessed on 21 February 2017).
- Abowd, G.; Mynatt, E. Smart Environments: Technology, Protocols, and Applications. In Designing for the Human Experience in Smart Environments; Wiley: Hoboken, NJ, USA, 2004; pp. 153–174. [Google Scholar]
- Chen, T.L.; King, C.H.; Thomaz, A.L.; Kemp, C.C. Touched by a Robot: An Investigation of Subjective Responses to Robot Initiated Touch. In Proceedings of the 2011 6th ACM/IEEE International Conference on Human Robot Interaction, Lausanne, Switzerland, 8–11 March 2011; pp. 457–464. [Google Scholar]
- Yamazaki, T. The Ubiquitous Home. Int. J. Smart Home 2007, 1, 17–22. [Google Scholar]
- Rashidi, P.; Cook, D.J. Keeping the Resident in the Loop: Adapting the Smart Home to the User. IEEE Trans. Syst. Man Cibern. J. 2009, 39, 949–959. [Google Scholar] [CrossRef]
- Adlam, T.; Faulkner, R.; Orpwood, R.; Jones, K.; Macijauskiene, J.; Budraitiene, A. The installation and support of internationally distributed equipment for people with dementia. IEEE Trans. Inf. Technol. Biomed. 2004, 8, 253–257. [Google Scholar] [CrossRef] [PubMed]
- Bouchard, B.; Giroux, S.; Bouzouane, A. A Keyhole Plan Recognition Model for Alzheimer Patients: First results. Appl. Artif. Intell. 2007, 21, 623–658. [Google Scholar] [CrossRef]
- Mégret, R.; Dovgalecs, V.; Wannous, H.; Karaman, S.; Benois-Pineau, J.; El Khoury, E.; Pinquier, J.; Joly, P.; André-Obrecht, R.; Gaëstel, R.; et al. The IMMED Project: Wearable Video Monitoring of People with Age Dementia. In Proceedings of the 18th ACM international conference on Multimedia, New York, NY, USA, 2010; pp. 1299–1302. [Google Scholar]
- Adami, A.; Pavel, M.; Hayes, T.; Singer, C. Detection of movement in bed using unobtrusive load cell sensors. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 481–490. [Google Scholar] [CrossRef] [PubMed]
- Tapia, E.; Intille, S.; Larson, K. Activity Recognition in the Home Using Simple and Ubiquitous Sensors. In Proceedings of the International Conference on Pervasive Computing, Linz and Vienna, Austria, 21–23 April 2004; Volume 3001, pp. 158–175. [Google Scholar]
- LeBellego, G.; Noury, N.; Virone, G.; Mousseau, M.; Demongeot, J. A Model for the Measurement of Patient Activity in a Hospital Suite. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 1. [Google Scholar] [CrossRef]
- Barnes, N.; Edwards, N.; Rose, D.; Garner, P. Lifestyle monitoring-technology for supported independence. Comput. Control Eng. 1998, 9, 169–174. [Google Scholar] [CrossRef]
- Tamura, T.; Kawarada, A.; Nambu, M.; Tsukada, A.; Sasaki, K.; Yamakoshi, K.I. E-healthcare at an experimental welfare techno house in Japan. Open Med. Inform. 2007, 1, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Rantz, M.; Skubic, M.; Koopman, R.; Phillips, L.; Alexander, G.; Miller, S.; Guevara, R. Using Sensor Networks to Detect Urinary Tract Infections in Older Adults. In Proceedings of the International Conference on e-Health Networking Applications and Services, Columbia, MO, USA, 13–15 June 2011; pp. 142–149. [Google Scholar]
- Sertatıl, C.; Altınkaya, A.; Raoof, K. A novel acoustic indoor localization system employing CDMA. Digital Signal Process. 2012, 22, 506–517. [Google Scholar] [CrossRef]
- Kivimaki, T. Technologies for Ambient Assisted Living: Ambient Communication and Indoor Positioning. Ph.D. Thesis, Tampere University of Technology Tampere, Tampere, Finland, 2015. [Google Scholar]
- Temko, A. Acoustic Event Detection and Classification. Ph.D. Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2007. [Google Scholar]
- Vuegen, L.; Van Den Broeck, B.; Karsmakers, P.; Van hamme, H.; Vanrumste, B. Automatic Monitoring of Activities of Daily Living Based on Real-Life Acoustic Sensor Data: A Preliminary Study. In Proceedings of the 4th Workshop on Speech and Language Processing for Assistive Technologies, Grenoble, France, 21–22 August 2013; pp. 113–118. [Google Scholar]
- Kraft, F.; Malkin, R.; Schaaf, R.; Waibel, A. Temporal ICA for Classification of Acoustic Events in a Kitchen Environment. In Proceedings of the European Conference on Speech Communication and Technology (INTERSPEECH), International Speech Communication Association (ISCA), Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Chahuara, P.; Fleury, A.; Portet, F.; Vacher, M. On-line Human Activity Recognition from Audio and Home Automation Sensors: comparison of sequential and nonsequential models in realistic Smart Homes. J. Ambient Intell. Smart Environ. 2016, 8, 399–422. [Google Scholar] [CrossRef]
- Ellis, D. Detecting Alarm Sounds. In Proceedings of the Workshop on Consistent and Reliable Acoustic Cues (CRAC-2001), CRAC, Aalborg, Denmark, 3–7 September 2001. [Google Scholar]
- Popescu, M.; Mahnot, A. Acoustic Fall Detection Using One-Class Classifiers. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 3505–3508. [Google Scholar]
- Doukas, C.N.; Maglogiannis, I. Emergency Fall Incidents Detection in Assisted Living Environments Utilizing Motion, Sound, and Visual Perceptual Components. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 277–289. [Google Scholar] [CrossRef] [PubMed]
- Bouakaz, S.; Vacher, M.; Bobillier Chaumon, M.E.; Aman, F.; Bekkadja, S.; Portet, F.; Guillou, E.; Rossato, S.; Desseree, E.; Traineau, P.; et al. CIRDO: Smart Companion for Helping Elderly to live at home for longer. IRBM 2014, 35, 101–108. [Google Scholar] [CrossRef]
- Jaalinoja, J. Requirements Implementation in Embedded Software Development; VTT Publications: Espoo, Finland, 2004. [Google Scholar]
- Nvidia, JETSON TK1. Unlock the Power of the GPU for Embedded Systems Applications. Available online: http://www.nvidia.com/object/jetson-tk1-embedded-dev-kit.html (accessed on 21 February 2017).
- Whitepaper, NVIDIA Tegra K1, A New Era in Mobile Computing. Available online: http://www.nvidia.com/content/PDF/tegra_white_papers/Tegra_K1_whitepaper_v1.0.pdf (accessed on 10 February 2017).
- Theodoropoulos, D.; Kuzmanov, G.; Gaydadjiev, G. A Minimalistic Architecture for Reconfigurable WFS-Based Immersive-Audio. In Proceedings of the 2010 International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 30 November–2 December 2010; pp. 1–6. [Google Scholar]
- Theodoropoulos, D.; Kuzmanov, G.; Gaydadjiev, G. Multi-core platforms for beamforming and wave field synthesis. IEEE Trans. Multimed. 2011, 13, 235–245. [Google Scholar] [CrossRef]
- Ranjan, R.; Gan, W.S. Fast and Efficient Real-Time GPU Based Implementation of Wave Field Synthesis. In Proceedings of the IEEE International Conference on Acoustics Speech Signal Processing, Florence, Italy, 4–9 May 2014; pp. 7550–7554. [Google Scholar]
- Belloch, J.A.; Gonzalez, A.; Quintana-Orti, E.S.; Ferrer, M.; Valimaki, V. GPU-Based Dynamic Wave Field Synthesis Using Fractional Delay Filters and Room Compensation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 25, 435–447. [Google Scholar] [CrossRef]
- Alonso, P.; Cortina, R.; Rodríguez-Serrano, F.J.; Vera-Candeas, P.; Alonso-González, M.; Ranilla, J. Parallel online time warping for real-time audio-to-score alignment in multi-core systems. J. Supercomput. 2016, 73, 126–138. [Google Scholar] [CrossRef]
- Sigtia, S.; Stark, A.M.; Krstulović, S.; Plumbley, M.D. Automatic environmental sound recognition: Performance versus computational cost. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2096–2107. [Google Scholar] [CrossRef]
- Satria, M.T.; Gurumani, S.; Zheng, W.; Tee, K.P.; Koh, A.; Yu, P.; Rupnow, K.; Chen, D. Real-Time System-Level Implementation of a Telepresence Robot Using an Embedded GPU Platform. In Proceedings of the Design, Automation Test in Europe Conference Exhibition, Dresden, Germany, 14–18 March 2016; pp. 1445–1448. [Google Scholar]
- Oro, D.; Fernández, C.; Martorell, X.; Hernando, J. Work-Efficient Parallel Non-Maximum Suppression for Embedded GPU Architectures. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1026–1030. [Google Scholar]
- Ulusel, O.; Picardo, C.; Harris, C.B.; Reda, S.; Bahar, R.I. Hardware Acceleration of Feature Detection and Description Algorithms on Low-Power Embedded Platforms. In Proceedings of the 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–9. [Google Scholar]
- Houzet, D.; Fung, J. Session 4: Signal and Image Processing on GPU. In Proceedings of the 2011 Conference on Design and Architectures for Signal and Image Processing (DASIP), Tampere, Finland, 2–4 November 2011. [Google Scholar]
- CUI Inc. CMA-4544PF-W. 2013. Available online: http://www.cui.com/product/resource/pdf/cma-4544pf-w.pdf (accessed on 10 December 2016).
- Sutter, H.; Larus, J. Software and the concurrency revolution. Queue 2005, 3, 54–62. [Google Scholar] [CrossRef]
- Hwu, W.W.; Keutzer, K.; Mattson, T. The concurrency challenge. IEEE Des. Test Comput. 2008, 25, 312–320. [Google Scholar] [CrossRef]
- Kirk, D.B.; Wen-Mei, W.H. Programming Massively Parallel Processors: A Hands-on Approach; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- NVIDIA Corp. NVIDIA’s Next Generation Cuda Compute Architecture: Kepler TM GK110/210. 2014. Available online: http://international.download.nvidia.com/pdf/kepler/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf (accessed on 21 February 2017).
- Alías, F.; Socoró, J.C.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Mermelstein, P. Distance Measures for Speech Recognition–Psychological and Instrumental. In Pattern Recognition and Artificial Intelligence; Academic Press, Inc: New York, NY, USA, 1976; pp. 374–388. [Google Scholar]
- Liang, S.; Fan, X. Audio content classification method research based on two-step strategy. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2014, 5, 57–62. [Google Scholar] [CrossRef]
- Siegler, M.A.; Jain, U.; Raj, B.; Stern, R.M. Automatic Segmentation, Classification and Clustering of Broadcast News Audio. In Proceedings of the DARPA Speech Recognition Workshop, Chantilly, VA, USA, 2–5 February 1997. [Google Scholar]
- Scaringella, N.; Zoia, G.; Mlynek, D. Automatic genre classification of music content: a survey. IEEE Signal Process. Mag. 2006, 23, 133–141. [Google Scholar] [CrossRef]
- Prati, R.C.; Batista, G.E.; Monard, M.C. Class Imbalances Versus Class Overlapping: An Analysis of a Learning System Behavior. In Mexican International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 312–321. [Google Scholar]
- Wang, J.C.; Wang, J.F.; He, K.W.; Hsu, C.S. Environmental Sound Classification Using Hybrid SVM/KNN Classifier and MPEG-7 Audio Low-Level Descriptor. In Proceedings of the International Joint Conference on Neural Networks, IJCNN’06, Vancouver, BC, Canada, 16–21 July 2006; pp. 1731–1735. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar]
- Pelleg, D.; Moore, A.W. X-means: Extending K-means with Efficient Estimation of the Number of Clusters. ICML 2000, 1, 727–734. [Google Scholar]
- Joachims, T. Training linear SVMs in Linear Time. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’06, Philadelphia, PA, USA, 20–23 August 2006; pp. 217–226. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A Comparison of Methods for Multiclass Support Vector Machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Van der Maaten, L.J.P.; Hinton, G.E. Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Mesaros, A.; Heittola, T.; Eronen, A.; Virtanen, T. Acoustic Event Detection in Real Life Recordings. In Proceedings of the 2010 18th European Signal Processing Conference, Aalborg, Denmark, 23–27 August 2010; IEEE: New York, NY, USA, 2010; pp. 1267–1271. [Google Scholar]
- Alías, F.; Socoró, J.C. Description of anomalous noise events for reliable dynamic traffic noise mapping in real-life urban and suburban soundscapes. Appl. Sci. (Sect. Appl. Acoust.) 2017, 7, 146. [Google Scholar] [CrossRef]
- Creixell, E.; Haddad, K.; Song, W.; Chauhan, S.; Valero, X. A Method for Recognition of Coexisting Environmental Sound Sources Based on the Fisher’s Linear Discriminant Classifier. In Proceedings of the INTERNOISE, Innsbruck, Austria, 15–18 September 2013. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Computational Cost | Floating Point Operations |
|---|---|---|
| Hamming Windowing | M | |
| FFT | ||
| Filter Bank | ||
| Logarithm | R | 48 |
| DCT | 624 | |
| Subspace transformation | 273 | |
| SVM | 1840 |
| Falling down | Knife Slicing | Screaming | Raining | Printing | Talking | Frying | Filling Water | Knocking a Door | Dog Barking | Car Horn | Breaking Glass | Baby Crying | Water Boiling | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Falling down | 62.07 | 2.87 | 1.72 | 7.47 | 6.32 | 2.23 | 0.00 | 4.02 | 6.90 | 1.15 | 3.85 | 0.17 | 0.00 | 1.23 |
| Knife slicing | 3.67 | 67.46 | 1.04 | 7.29 | 0.00 | 3.15 | 2.18 | 1.04 | 4.68 | 4.78 | 0.00 | 0.15 | 1.43 | 3.03 |
| Screaming | 2.42 | 2.08 | 91.72 | 0.00 | 1.29 | 0.11 | 0.18 | 1.33 | 0.13 | 0.48 | 0.13 | 0.00 | 0.00 | 0.13 |
| Raining | 1.11 | 0.05 | 0.12 | 96.33 | 0.79 | 0.19 | 0.23 | 0.17 | 0.23 | 0.10 | 0.04 | 0.03 | 0.17 | 0.45 |
| Printing | 9.61 | 0.00 | 0.67 | 0.00 | 84.67 | 0.22 | 0.16 | 0.64 | 1.33 | 0.10 | 0.95 | 0.77 | 0.13 | 0.75 |
| Talking | 2.97 | 3.12 | 1.91 | 1.51 | 2.14 | 78.14 | 0.92 | 1.16 | 2.79 | 0.62 | 2.63 | 1.65 | 0.11 | 0.33 |
| Frying | 3.89 | 4.08 | 2.76 | 1.97 | 0.18 | 0.12 | 83.19 | 0.03 | 0.74 | 0.48 | 0.91 | 0.61 | 0.86 | 0.18 |
| Filling water | 2.08 | 0.94 | 2.86 | 0.00 | 1.96 | 0.84 | 0.39 | 73.73 | 0.00 | 2.6 | 1.96 | 0.41 | 5.52 | 6.71 |
| Knocking a door | 1.41 | 0.75 | 1.96 | 2.71 | 0.96 | 0.93 | 0.06 | 0.00 | 88.63 | 0.04 | 0.00 | 0.16 | 0.44 | 1.96 |
| Dog barking | 2.19 | 0.82 | 3.19 | 0.16 | 2.92 | 1.79 | 0.52 | 0.14 | 0.64 | 87.15 | 0.08 | 0.13 | 0.17 | 0.10 |
| Car horn | 1.11 | 5.95 | 1.33 | 0.00 | 0.47 | 0.00 | 0.29 | 1.19 | 1.19 | 0.07 | 79.05 | 0.31 | 0.71 | 8.33 |
| Breaking glass | 0.21 | 1.74 | 0.91 | 1.67 | 0.91 | 0.74 | 0.18 | 0.32 | 0.15 | 0.13 | 0.09 | 92.17 | 0.67 | 0.11 |
| Baby crying | 3.08 | 0.00 | 4.14 | 1.29 | 3.80 | 1.83 | 2.48 | 0.11 | 0.06 | 0.34 | 0.02 | 0.19 | 82.54 | 0.12 |
| Water boiling | 1.08 | 2.15 | 0.69 | 0.00 | 2.08 | 0.38 | 1.71 | 0.33 | 1.39 | 1.86 | 2.08 | 3.25 | 1.83 | 81.17 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsina-Pagès, R.M.; Navarro, J.; Alías, F.; Hervás, M. homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors 2017, 17, 854. https://doi.org/10.3390/s17040854
Alsina-Pagès RM, Navarro J, Alías F, Hervás M. homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors. 2017; 17(4):854. https://doi.org/10.3390/s17040854
Chicago/Turabian StyleAlsina-Pagès, Rosa Ma, Joan Navarro, Francesc Alías, and Marcos Hervás. 2017. "homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring" Sensors 17, no. 4: 854. https://doi.org/10.3390/s17040854
APA StyleAlsina-Pagès, R. M., Navarro, J., Alías, F., & Hervás, M. (2017). homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors, 17(4), 854. https://doi.org/10.3390/s17040854