1. Introduction
With the proliferation of social media and the pervasiveness of sensor-embedded portable devices, the boundaries between real life and the virtual world have vanished. Most of these devices are connected to the Internet and are capable of capturing and delivering various types of media that report on a wide range of topics. Every day, hundreds of millions of registered users are generating and sharing massive amounts of data on social networks and interacting with each other regardless of time and location. The shared data describe people’s interests, daily activities, opinions, and what is happening in their surrounding environment. Consequently, users on social media are acting as social sensors, providing large-scale data about their social and living environments that would be impossible to obtain from other sources [
1,
2]. Krishnamurthy and Poor in [
3] defined a social sensor as "an agent that provides information on social networks about their environment after interaction with others". Social sensory data that are available on social media impact the decisions and choices of individuals and communities. Opinions and reviews of restaurants or hotels on TripAdvisor, Yelp, and Foursquare influence the choices of other people. On Twitter and Facebook, people post short messages about their feelings, opinions, and social events. Due to the real-time nature of posts on some social media platforms, people and authorities can find a large number of texts, photos, videos, or a combination of these media reporting real-world events and news. These events are not limited to social events, such as concerts, sports, and elections; they can also include information on emergencies and disasters such as earthquakes, storms, and traffic jams [
4]. These examples demonstrate the merge that is occurring between the real world and social media. Notably, people are moving away from storing their photos and memories in physical albums and are now using social photo-sharing sites, such as Flickr and Instagram, where they become involved with a larger community. These social media services offer users features to store and organize their media, share it with other users, and document their memories via text-free descriptions and annotations. The mining of social sensory data contributes to the analysis of people’s opinions and behaviors and, in turn, can provide better services to the users and their environment through informed decision making, crisis management, product recommendations, and future trend predictions. Social data, however, are difficult to measure and process with physical sensors [
3]. Although users’ opinions about products and their movie preferences are readily available, they cannot be measured using physical or hardware sensors. Moreover, the popularity of a product, an image or a video cannot be detected or predicted by traditional sensors.
Evidently, social data have created opportunities to understand the behavior of users and provide better services, yet they also present new challenges, especially from the data analysis perspective. Social data have unique characteristics that differentiate them from traditional data. This type of data is defined as huge amounts of diverse and noisy data with variations in quality, posted on social networks by users with different backgrounds combined with various types of metadata [
5,
6]. Additionally, social media data are interconnected, which is highly correlated with the social behavior that captures the perspective of communities or individuals in regards to the shared media [
5]. This social behavior can be expressed explicitly by either liking, commenting or marking as a favorite or implicitly by simply viewing the item without taking any explicit action. Sharing content and interacting with others on social media is motivated by social presence and popularity [
7]. Thus, users maintain a list of contacts or friends and subscribe to multiple self-organized groups to connect with people who share their interests. In addition, users on social media utilize the features provided by the service providers, such as hashtags, and text-free annotations, to boost the visibility of their content to other users. These unique characteristics of social data influence the social interactions and data propagation, which results in a nonstandard pattern of information flow [
3]. Thus, understanding the dynamic of social data flow [
3] and user social behavior helps build systems that are able to analyze and interpret social data to provide services that enhance the user’s living environment explicitly or implicitly. As an illustration of enhanced living environment examples, data collected from social media increase awareness during crises such as floods and fires [
8]. Updates on construction and traffic jams help users navigate a route and avoid congestion. This is an explicit impact of social media on the physical world. Implicitly, providing users with more accurate and satisfying results to their inquiries on search engines saves them time and effort. Moreover, social data contribute in building systems that detect objects and faces in images, which can be used in authentication and security systems. In addition, the availability of images with rich textual information and geo-location data on social media sites, such as Flickr, are used to recommend places and attractive destinations to travelers.
The above-mentioned examples demonstrate the importance of social interactions in social media data mining and analysis. In this paper, we take the opportunity to explore the factors that could impact the social interactions of social sensors “users” on social media which lead to content popularity. With the growth of social media, only a limited number of users and their content attract a great deal of attention from users; whereas, many others go unnoticed. When we consider images in social photo-sharing sites, we witness a variation in their number of views or “social popularity”, regardless of their visual appeal. This motivates us to answer the question: which factors impact the popularity of social content? Understanding the social behavior and the underlying structure of social photo-sharing sites will contribute to designing better prediction algorithms. We examine Flickr, a photo-sharing social network, in order to study the social interactions between users and images. Since Flickr has large amounts of publicly available photos and provides a comprehensive API, it allows us to collect information about images and users with their social context. Moreover, Flickr has various features that allow users to make their photographs accessible and visible to a large number of online users. In addition to sharing images with friends and group members, users on Flickr are encouraged to annotate their images with text-free tags so that they can be accessible via keyword searches. As depicted in
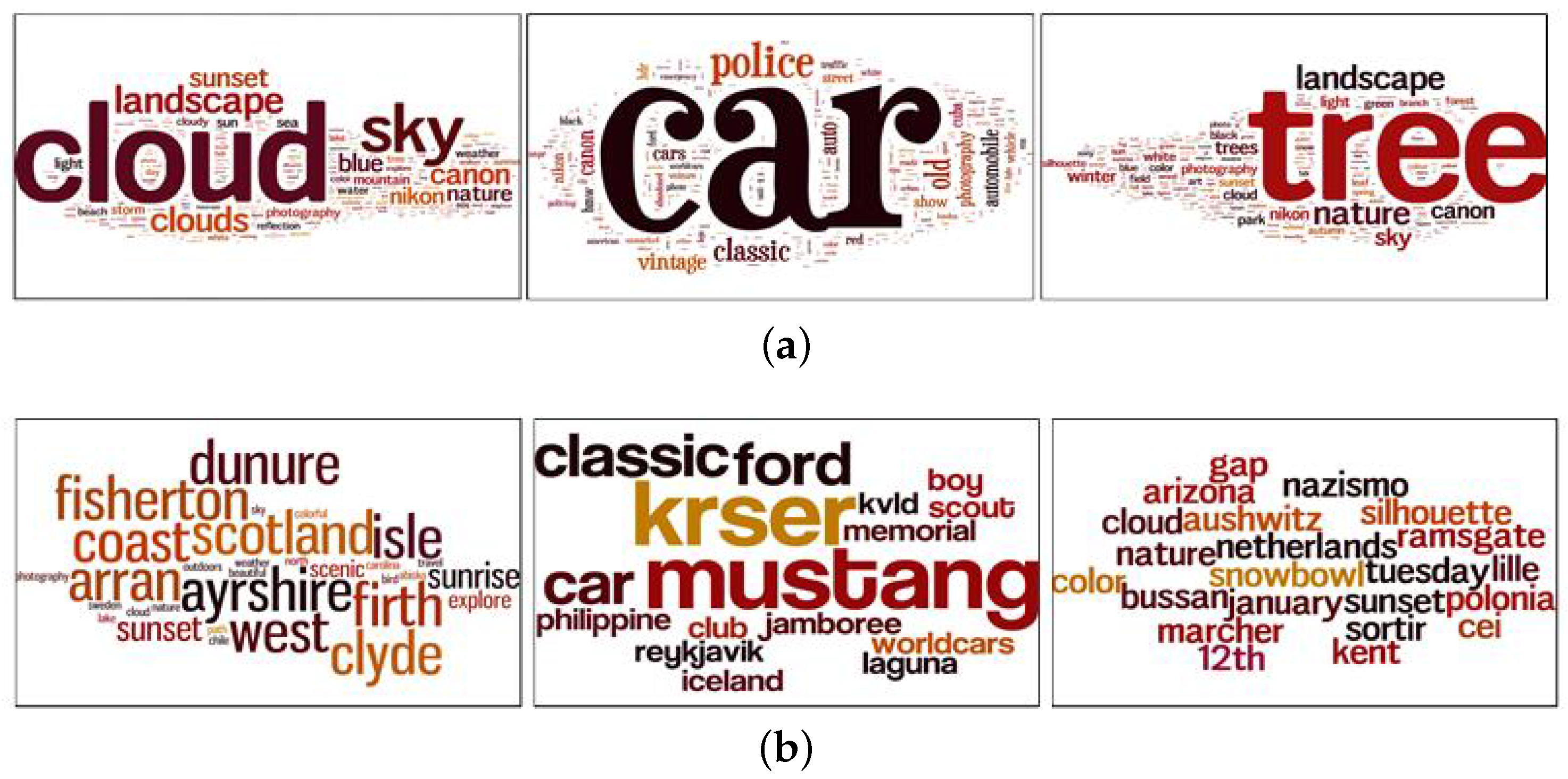
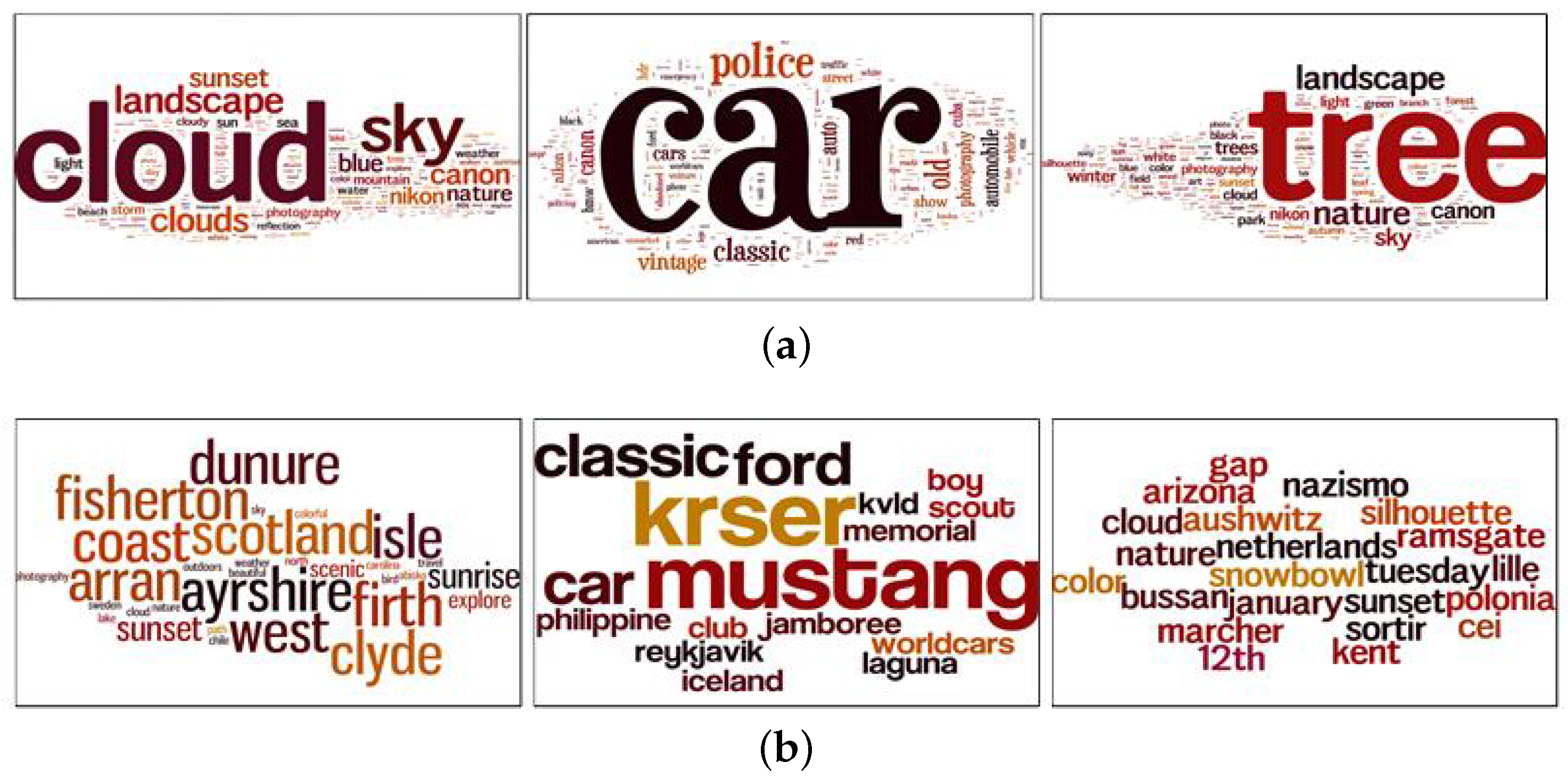
Figure 1a–c are examples of images uploaded by the same user. In
Figure 1a,b, the images share the same visual content; whereas in
Figure 1c, the image represents a different visual concept. The three images in
Figure 1 received different amounts of social interactions, even though the images had a similar visual appearance. This variation in the number of social interactions between the images is impacted by factors other than visual content.
Figure 1 shows the differences between the images in terms of surrounding text represented by tags and the number of groups that an image is joining, which affect the number of social interactions. Attaching descriptive tags to the images and sharing them with suitable groups help in making them popular. Thus we study the relationship between social context, visual content, and textual information and social interactions. While the image’s visual semantic, sentiment and Aesthetic exhibit an impact on the social interactions, the user and the image social contexts play a significant role in the image’s popularity. Examples of such social context are the user’s contacts and the image’s groups. The effect of the textual information cannot be neglected when predicting an image’s popularity. Once the analysis is complete, we apply our findings to implement a social image popularity prediction algorithm. This work is an initial step that can guide users to boost their image’s popularity on photo-sharing social networks by showing the factors that will affect their social interactions as well as the topics that are more attractive to their contacts.
Prior studies attempted to address the topic of predicting an image’s popularity with content and/or social factors [
9,
10,
11] by utilizing basic features. In [
12], the authors combined social context with low level and deep learning features to determine what makes an image popular, while [
13] only considered an image’s visual content using deep learning features to distinguish between popular and unpopular scenes that affect an image’s popularity. In [
14], the authors addressed the visual sentiments that impact an image’s popularity. In our work, we address the problem by first scrutinizing the social behavior in Flickr to determine how users browse social photo-sharing sites and then analyzing the correlation between users and an image’s social factors with regard to social popularity. In addition, we investigate the role of associated text in an image’s popularity. We conclude that three factors, social behavior, visual content, and surrounding text, absolutely influence the photos visibility to other users and subsequently its popularity.
In this paper, we are targeting Flickr as our main platform in studying a social image popularity problem. First, we define the image popularity as the number of views or the number of comments and favorites. Then, we analyze the social and textual contexts that are available on Flickr and that may impact the image popularity in
Section 3. Lastly, we propose a system to predict images popularity by implementing a prediction algorithm based on multi-modality features in
Section 4. In the prediction system, we use content-based features, the social context of users and images, and textual features to predict the popularity ranking scores of a given set of images. From our data analysis, we determine that images may be posted in groups where the owners are not even members. These groups accept images by invitation and are considered prestigious groups in Flickr. Thus, we use image groups as one of the image’s social factors. Unlike prior works, we examine the effect of different levels of visual features that represent the semantic and sentiment concepts that appear in the image. Moreover, we consider investigating the influence of an image’s beauty on its popularity, especially when images are similar in visual content and social factors. Our experiments demonstrate the capability of visual, social, and textual features to predict an image’s popularity within different sets of images. In addition, we validate the benefit of combining multi-modal features in order to improve the performance of the prediction algorithm. Our prediction algorithm is designed for Flickr, and cannot be directly applied to other social networks due to the differences in available social and content features. Yet, the concept of utilizing multi-modal features that propose in our paradigm is applicable to other social networks.
We summarize the contributions of our work as follows:
We provide a comprehensive study that analyze a real data collected from Flickr to explore the factors that could impact the social interactions. We have studied the relationship between the explicit and implicit social interactions and the social context of users and images.
We further investigate the effect of visual content and surrounding text on the interaction analysis, which is defined as popularity prediction in this paper. Various visual features, including low level, middle level, and semantic features, as well as textual information are explored to provide a comprehensive understanding of this issue.
Finally, we consider combining different studied factors and investigate their effect on predicting different levels of interactions. We demonstrate the impact on the algorithm’s performance as it integrates the three modalities of features. Our results show that when combining various types of features which represent different visual aspects, the performance of the algorithm is improved. For example, combining semantic level and low level features can improve the algorithm’s performance over using an individual feature. Moreover, features from different modalities provide enhancement on the prediction algorithm’s performance.
In the remainder of the paper, a review of related work is presented in
Section 2. We then present the data collection and analysis in
Section 3. In
Section 4, we describe our approach in predicting image popularity. The experiments and result analysis are provided in
Section 5. Finally,
Section 6 includes a summary of our findings and a discussion of possible future work.
4. Image Popularity Prediction
The popularity of social images is measured by various social signals, depending on the social interactions supported by the social media sites. For example, on Facebook, the popularity can be measured by the number of likes or comments, whereas on Twitter, it is measured by the number of re-tweets. Previous works addressed popularity prediction as a regression or classification problem. In this work, we target Flickr as the main platform for predicting a social image’s popularity, where the popularity is related to social interaction behaviors. Consequently, we define an image’s popularity based on its received number of explicit or implicit interaction. Explicit interactions are represented by the number of comments and favorites, where users explicitly express their interest in an image. In our work, we refer to these as “interactions”. Implicit social interactions are defined simply as the number of views. At this point, we formalize popularity prediction as learning to rank images on Flickr based on their popularity score in terms of the number of views or the number of comments and favorites. Because our dataset consists of images with dramatic variations in their number of views and interactions, we apply the log function. Images receive social interactions during their time online, so to normalize the effect of the time factor we divide the number of interactions an image has obtained by the number of days since it was first uploaded on Flickr. This is known as a log-normalization approach, which is proposed by [
12], and defined in Equation (
2).
where
is the popularity measure. In the following, we consider two types of popularity measures: (i) “views” is the number of views; (ii) “interaction” is the sum of the number of comments and the number of favorite. Comments and favorite have comparable values and explicitly show the users interests thus we consider them as a measure of popularity.
is the time duration in days since the uploaded date on Flickr.
From our data analysis, we observe that the number of views varies between images within users’ collections and groups.
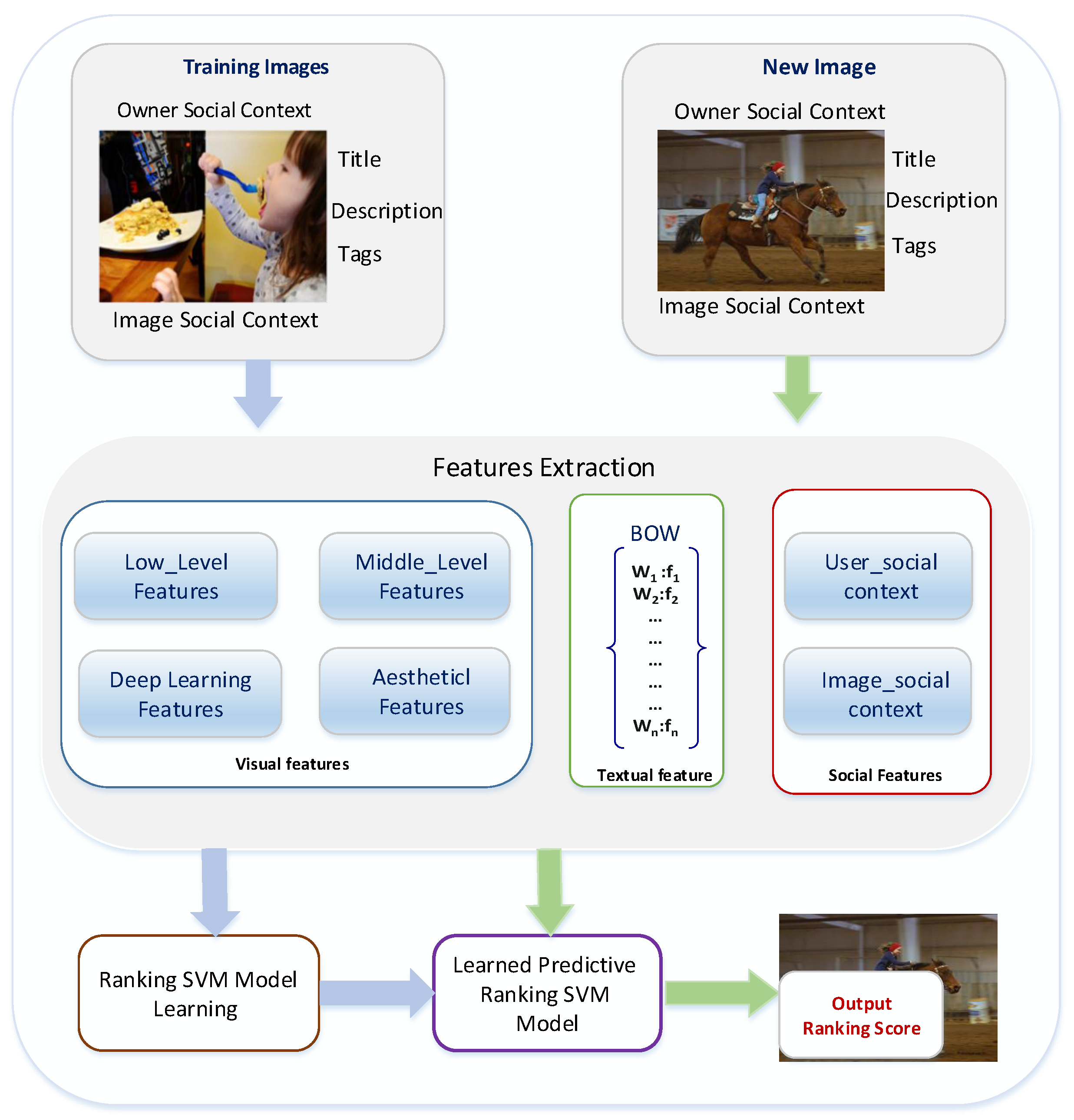
Figure 5 illustrates an example of this inequality in image popularity scores. Thus, we are proposing a popularity prediction algorithm utilizing multi-modal features. We investigate the effect of different visual features that are designed to represent different visual aspects of images, including visual variances and visual semantics. In addition, we consider the impact of an image’s beauty, where we hypothesize that if images are similar in terms of visual content and social cues, then the beauty will play an important role on the popularity of the images. Moreover, we explore the role of contextual and textual factors in predicting an image’s popularity. In our approach, we follow the standard framework for prediction, which consists of two main components: feature extraction and model learning. This framework is depicted in
Figure 6. Given a training set of images, we extract different types of features to represent the images. Then, in the model learning stage, we utilize the Ranking Support Vector Machine (Ranking SVM) [
29] to be trained on our dataset, and the learned model will be used to predict image popularity ranking score for a new set of photos. In the following sections, we briefly introduce the Ranking SVM algorithm and provide the details of the features that are used in our work.
4.1. Ranking SVM
We consider the problem of popularity prediction as a pairwise learning to rank problem. In the pairwise technique, the ranking problem is reduced to a classification problem over a pair of images, where the objective is to learn the preference between the two images. In our experiment, we apply the
regularized
loss function Ranking SVM algorithm to learn the preference between a pair of images with the linear kernel implemented using the LIBLINEAR library [
30].
In Ranking SVM, a set of training images with labels is given as
, where
is a
d-dimensional feature vector of image
i and
is the popularity score of image
i. There exists a preference order for a pair of images such that “
is preferred to
” is denoted as
when
. The objective of a ranking function is to return a score for each data point, an image in our case, where a global ranking over the data is generated. Thus, the ranking function
F outputs a ranking score for images such that
for
, which minimize the given loss function.
F is assumed to be a linear ranking function:
to learn
F, the weight vector
w should be computed for most of the pairs such that:
Now, the relationship between the pair of images
and
is represented by the new vector
. The relationship between any pair of images can therefore be represented by a new feature vector and new labels as follows [
29,
31,
32,
33,
34]:
The problem now becomes a classification problem using SVM that can assign positive or negative label to any vector .
4.2. Image Visual Content Features
To investigate the effect of an image’s content on its popularity, we consider various types of visual features that describe different perspectives of the image. We use Low level computer vision features that efficiently describe the visual appearance of the image, extracted directly from the pixel information. Although low level features perform well when describing the image, they fail to interpret the semantic of the image. Thus, we leverage middle level features that are designed to address the semantic and affective gaps. In addition to these features, we adopt Aesthetic features to represent the beauty of the image, and we extract high level features that detect the appearance of objects in the image using a deep learning technique.
4.2.1. Low level Features
We consider extracting four low level features, described as follows:
Color Histogram: We extract the RGB color channels to represent the color distribution of the image. The three color histograms are concatenated to form one feature vector of 768 dimensions [
35].
Local Binary Pattern (LBP): A famous texture descriptor widely used in computer vision applications. It works by comparing the value of each pixel with its 8 neighbors in a
neighborhood. If the value of the selected pixel is greater than its neighbors’ values, the neighboring pixels are encoded with 1; otherwise, they take on a value of 0. This results in eight binary numbers that are concatenated in a clockwise direction to calculate the corresponding decimal value of the selected pixel [
36,
37]. Ojala et al. [
38] recognized that certain patterns are more informative than others, which resulted in the introduction of the uniform LBP. In our work, we used the uniform LBP descriptor, which resulted in 59-dimensional features.
GIST: A popular descriptor in recognition applications and image retrieval, proposed by [
39]. GIST recognizes the scenes in images based on the formation of spatial representations that summarize the description of the image scenes, such as layout and category, with few objects. We adopt the GIST descriptor, where the image is divided into a
grid, and the orientation of the pixels is computed by a Gabor filter. The use of the GIST algorithm resulted in a 320-dimensional feature vector [
39,
40].
Bag_of_Visual_Word (BoVW): A widely used feature in image classification inspired by the famous Bag_of_Word feature (BoW) used in information retrieval and text mining. Due to the differences between images and discrete words in textual documents, the images are treated as patches of representative samples, where the keypoints are detected by applying the SIFT descriptor. The descriptors are then grouped into clusters, where each cluster represents a quantified visual word. Finally, the images are represented as BoVW vectors based on their vocabulary distribution [
41,
42]. In our work, we follow the same approach presented in [
43] which consider a 2-layer spatial pyramid and max pooling strategy to generate the BoVW. This resulted in feature vectors of 1500 dimensions.
4.2.2. Middle level Features
We have explored middle level features that represent different semantic concepts present in the images. Moreover, we consider features that detect the emotions and sentiments that appear in the visual content. The selected features are the following:
Classemes: A descriptor that is built to detect objects in images. This descriptor is a combination of the outputs of classifiers trained to detect 2659 object categories. These categories consist of visual concepts, including concrete names or abstract nouns, and are suitable for a general_category image search. The category labels are selected from the Large Scale Concept Ontology for Multimedia (LSCOM), which is designed for image retrieval [
44].
Category_Level Attributes: Represents properties shared across categories that can be described using adjectives, such as long and red (in the case of hair), instead of concise object names. In our work, we extracted the attribute features based on the technique introduced in [
45], which resulted in a feature of 2000 dimensions.
SentiBank: Unlike Classemes and Attribute, SentiBank is a middle level feature designed to leverage the affective gap between low level features and the sentiments present in the visual content. SentiBank is designed based on Visual Sentiment Ontology (VSO) and can detect 1200 Adjective_Noun Pairs (ANPs), such as ’peaceful lake’ and ’smiling eyes’, that are shown in images [
43].
4.2.3. Aesthetic Features
In addition to semantic concept detection, we investigate the impact of the image’s beauty on its popularity. We adopt Aesthetic features that are based on psycho-visual statistics rather than those based on art principles, as proposed by Bhattacharya et al. in [
46]. These features are designed for videos, where the features are extracted at the cell, frame, and shot levels. Because we apply the features to images, we only consider cell- and frame-level features. This is a 149-dimensional feature vector.
4.2.4. Deep Learning Features
Deep learning techniques have gained greater popularity in image classification and object recognition due to their promising performance. In our work, we used a Convolution Neural Network (CNN) architecture that is trained to classify 1.3 M images from the ImageNet challenge into one of 1000 object categories [
47]. More specifically, we used the CAFFE [
48] framework of the CNN to extract the following features:
FC7: We extract features from the last fully connected layer (FC7), which is the layer located directly before the classification layer. The output of this layer is a 4096 dimensional features vector and is considered to be a middle level feature.
FC8: High level features that are represented by a 1000-dimensional feature vector representing the output of the classification layer, which can distinguish between 1000 objects.
4.3. Contextual Features
The data analysis provided in
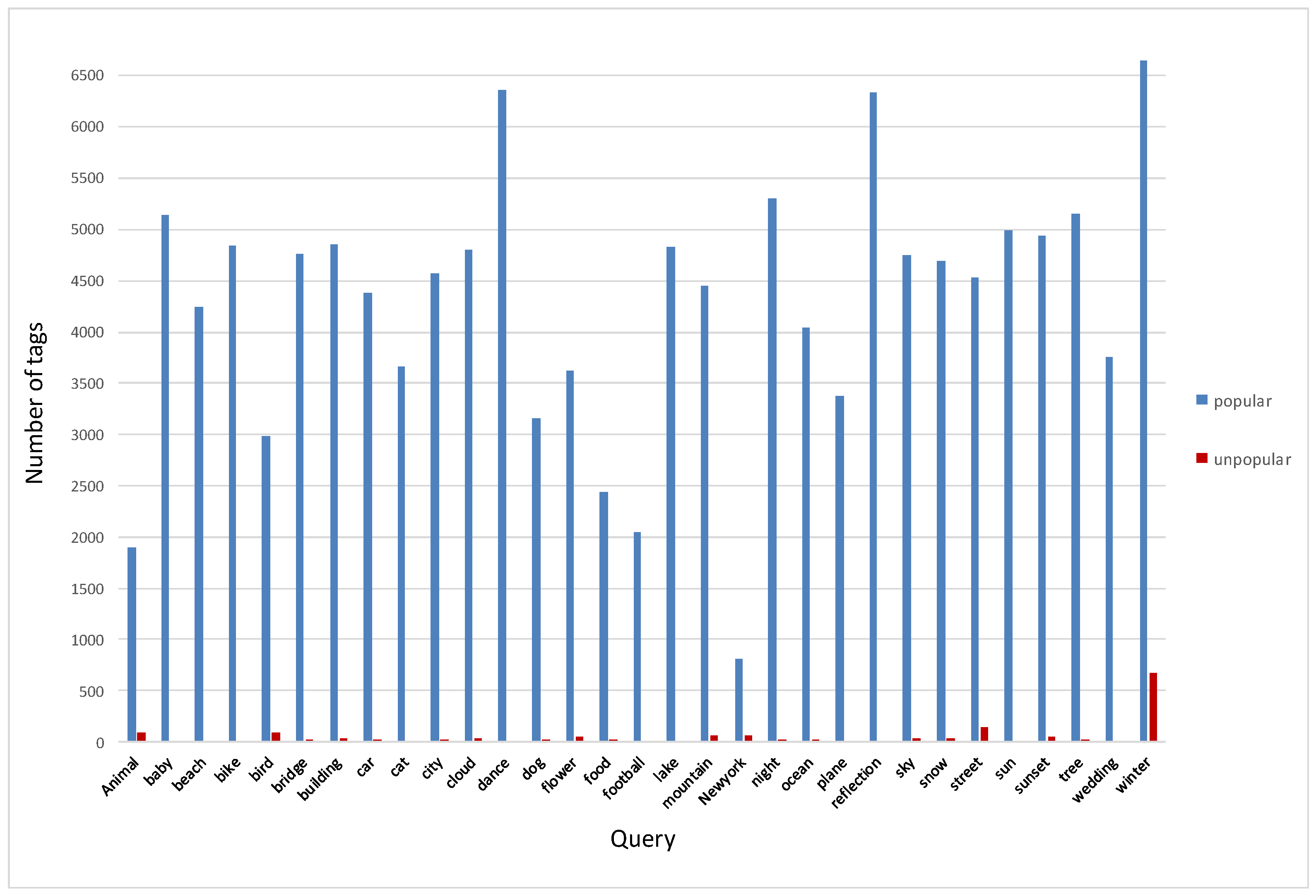
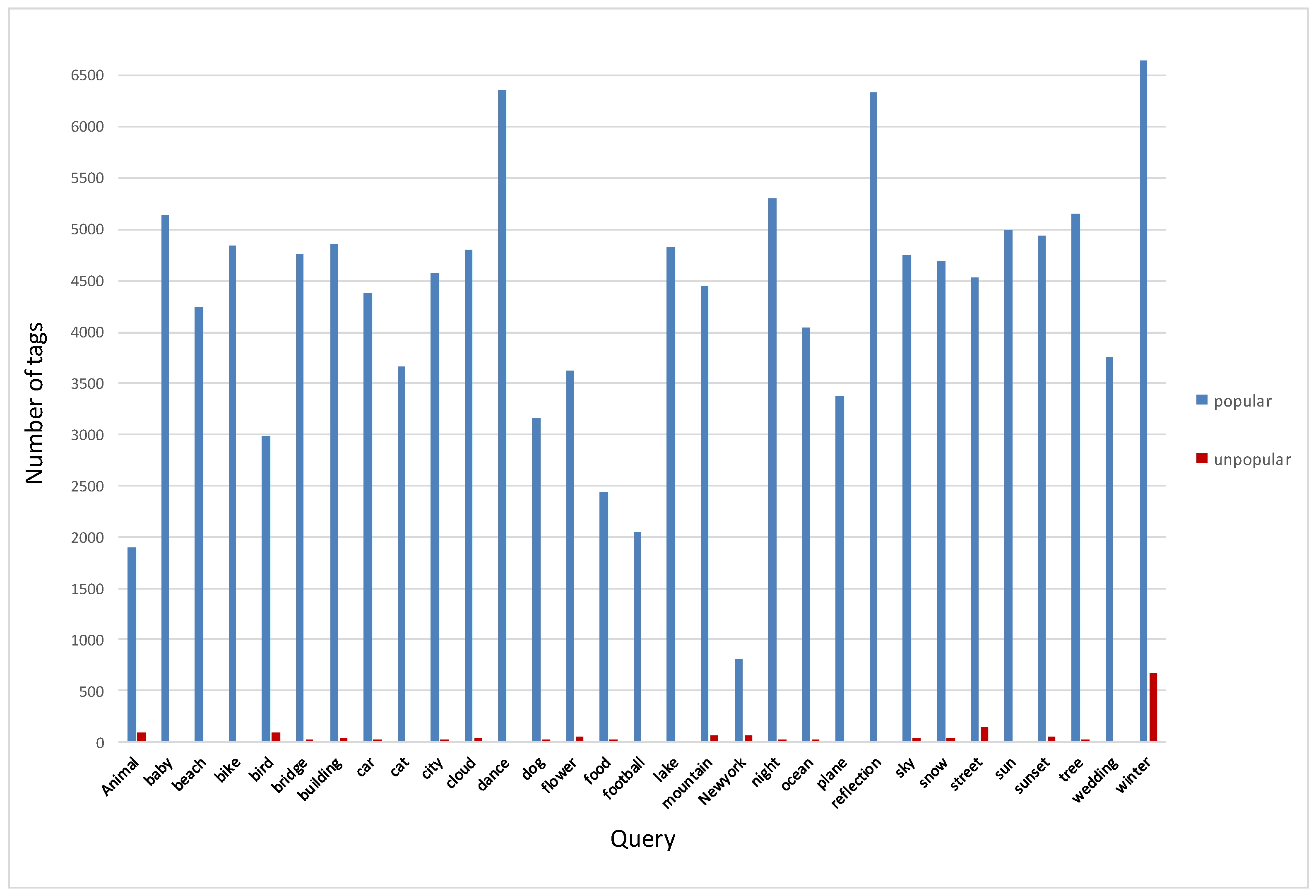
Section 3.2 shows a social image’s popularity is not only dependent on the visual content, but the contextual factors play a primary role on an image’s popularity as well. We define the contextual features as the statistical information about the images and their owners on photo-sharing social networks. Contacts and groups where the images are shared with people interested in similar content show a strong positive influence on the number of views and interaction that the images will receive. Consequently, we must consider different contextual factors that impact the image popularity. We have categorized the contextual features into owners’ features and images’ features. The owner’s contextual factors that are correlated with popularity and considered in our experiments are the number of contacts, total number of uploaded photos, and average number of views of the uploaded images. In addition, we consider the number of groups a user subscribes to, the average number of group members, and the average number of images belonging to the groups. We choose to use the number of group members and the number of images to indicate the popularity and activity level of the groups. Furthermore, we consider the contextual features of images that are provided by the images’ owners: the total number of groups, the average number of members participating in these groups, and the average number of photos shared with the groups. The decision to select image groups as a contextual feature was made based on our observations from the data analysis, where we saw that images could be shared with groups that were not in the owner’s list. In addition, we include the number of tags associated with the image as a context feature of the image. We decided to exploit the number of tags assigned with images because intuition led us to believe that an image with more tags will appear more often in search results. We combined all the social features after applying l_2 normalization to generate one feature vector with 10 dimensions.
4.4. Textual Features
Images are not always given descriptive tags, and the quality of the tags cannot be neglected [
49]. This is clearly demonstrated in our data analysis. Thus, we explore the effect of text attached to the image on its popularity. We have used the basic textual feature Bag_of_Word (BOW), which is heavily used in text mining due to its simplicity and good performance. Each image is represented as a feature vector of length
n where each element is corresponding to a term in a pre-defined vocabulary. This feature vector can be represented as binary or frequency vector. To generate the vocabulary, we consider two schema: Term Frequency (TF) to select the most frequent terms appear in images tags, title, and description, and Term frequency-Inverse Document Frequency (TF-IDF) that reduce the weight assigned to more frequent terms. Before selecting the vocabulary, we applied essential natural language preprocessing steps such as removing the stop words and URLs. Also, we applied the Word-Net Lemmatizer provided in the NLTK [
50]. The vocabulary used to generate the BOW is of size 1000 terms. Thus, we have a feature vector with 1000 dimensions. This setting of the vocabulary size is the best choice for our problem based on experimental results.
4.5. Fusion Techniques
In previous sections, we presented the features that have been selected to individually predict an image’s popularity. In this section, we provide the details of combining multi-modal features, where we aim to boost the performance of the prediction algorithm using fusion techniques. We use the following methods:
To combine the individual features to improve the performance of the prediction algorithm, we perform the sequential strategy to select the features. In this approach, we rank the features based on the achieved performance correlation. Then, starting from the best feature, we add an additional feature to be integrated based on its rank. If the added feature boosts the performance, we add the next feature until there is no improvement in the performance; when such is the case, we discard the feature that did not generate a further improvement. We select this approach of features combination since we have many different features and it has been used successfully in [
56,
57,
58].
6. Conclusions
In this study, we analyzed the social interaction behavior between online users and social images. Our analysis demonstrated that features provided by social networks facilitate the visibility of social images and boost the social interactions. Sharing images with groups and annotating them with descriptive tags help expand their visibility and reach more online users. In addition, evidence shows that, most popular images have a title and description that describe the content and the semantic behind the photographs; whereas, uninteresting images neglect this aspect. Moreover, a user’s popularity influences the popularity of their images, where users with larger social networks and popular images will receive more interactions than inactive users. Notably, a user’s images are not all equal in their popularity score. Thus, we propose to predict an image’s popularity on Flickr by considering three factors: image content, user and image contextual cues and textual features. We conducted extensive experiments on real dataset to evaluate the effectiveness of each individual features as well as their combination. The experimental results show the effectiveness of visual, contextual, and textual features when predicting an image’s popularity. Furthermore, combining multi-modal features boosts the prediction algorithm’s performance. Consequently, our proposed method of utilizing multi-modal approach to predict an image popularity on photo-sharing social networks is more effective than single modal approach.
In our study and as an initial step, we considered the internal factors that can affect the social popularity of images. Our work can be extended by considering the external factors that influence the popularity of media content such as real-world events. In addition, we could customize the popularity prediction to specific geographical regions and predict popular images based on cultural factors. It would be interesting to see how different aspects would affect the popularity of images based on geographical location and cultural background. Understanding these factors that impact image popularity and mining people’s opinions on these popular photos will help us in providing better services to enhance users’ living environments, especially if they are related to real-world issues. Possible future work could include topic popularity and product sales that can be predicted using early uploaded images which have an impact on economic and marketing sectors.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}