
Road Traffic Anomaly Detection via Collaborative Path Inference from GPS Snippets

Abstract
:1. Introduction
- Collaborative path inference. CPI model performs collaborative path inference incorporating both static and dynamic feature into a Conditional Random Field (CRF), and then reconstructs sparse GPS snippets to fine-grained trajectories;
- Dynamic feature learning. We aim to collaboratively learn dynamic context features hidden in data via tensor decomposition [10] technique. To tackle the data sparsity problem in the GPS snippets dataset, we exploit two normalization terms, which are robust and can avert over-fitting;
- Road anomaly detection. We calculate the anomalous degree for each road segment from counting the volumes of fine-grained trajectories in given time intervals. Two kinds of road anomalies are defined in this paper and we devise an algorithm to detect them effectively;
- Real evaluation. We evaluate our solution using a real world dataset including a large number of taxi traces. Experimental results show that our solutions are effective in path inference and road anomaly detection especially under low sampling rate between GPS locations.
2. Related Work
2.1. Path Inference
2.2. Road Anomaly Detection
3. Background
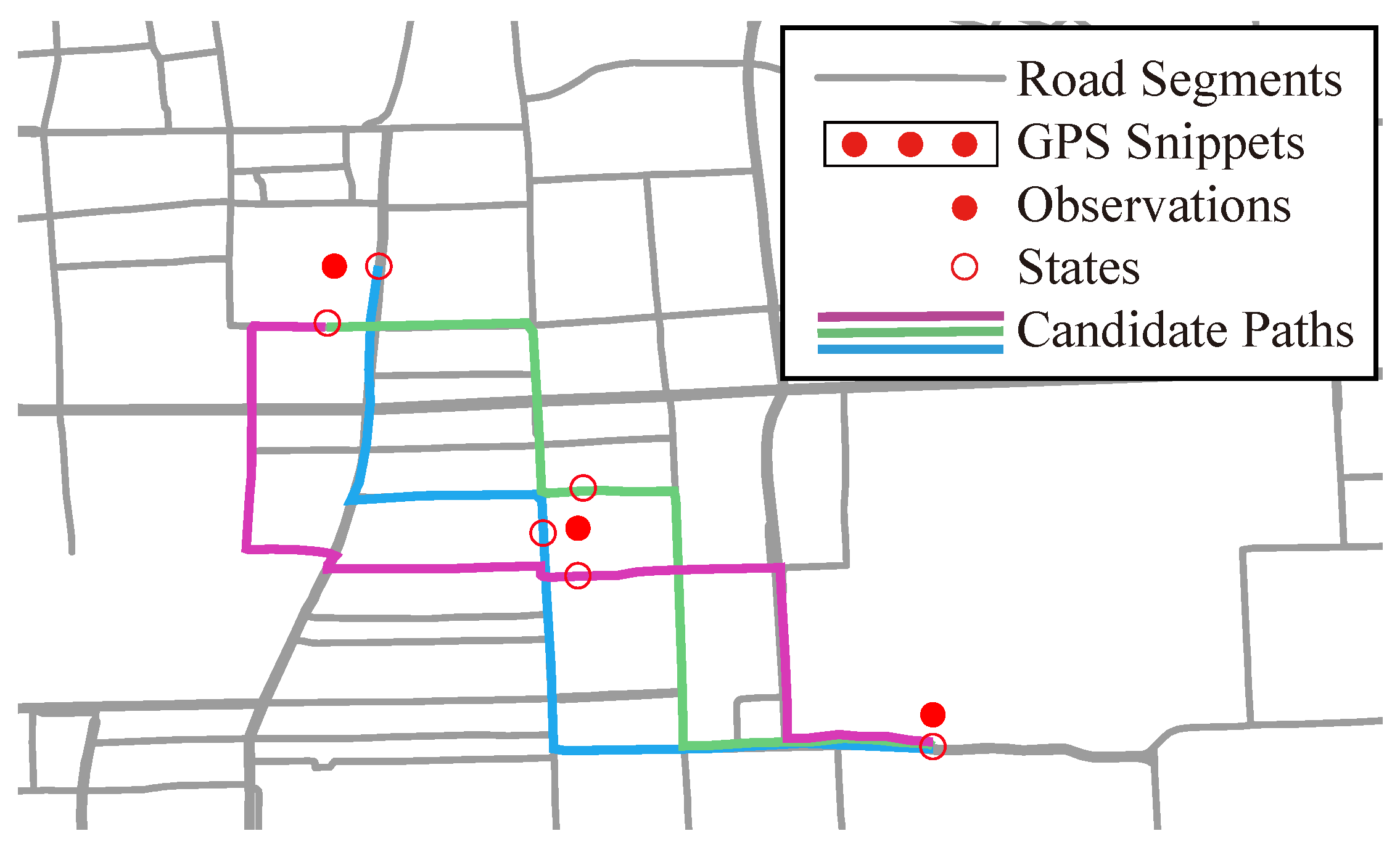
3.1. Path Inference
3.2. Road Anomaly Detection
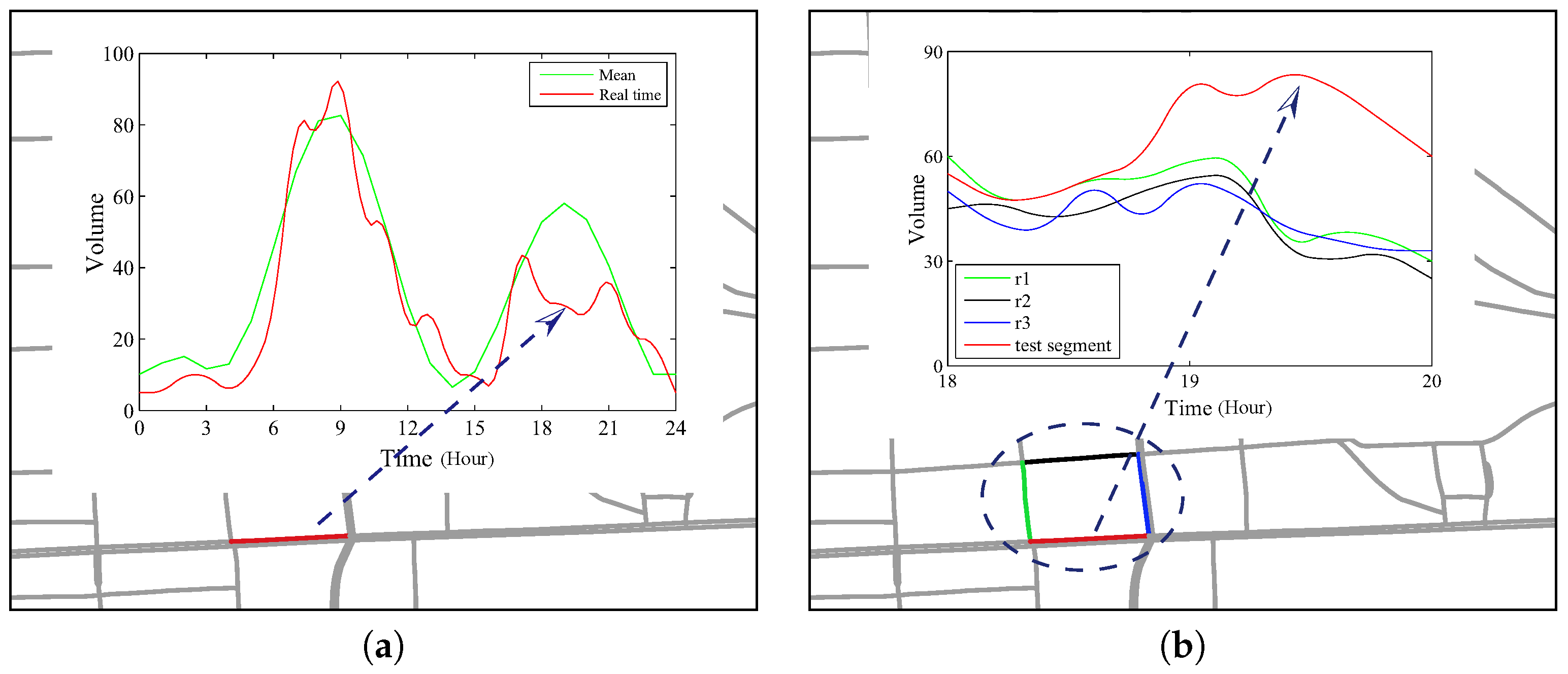
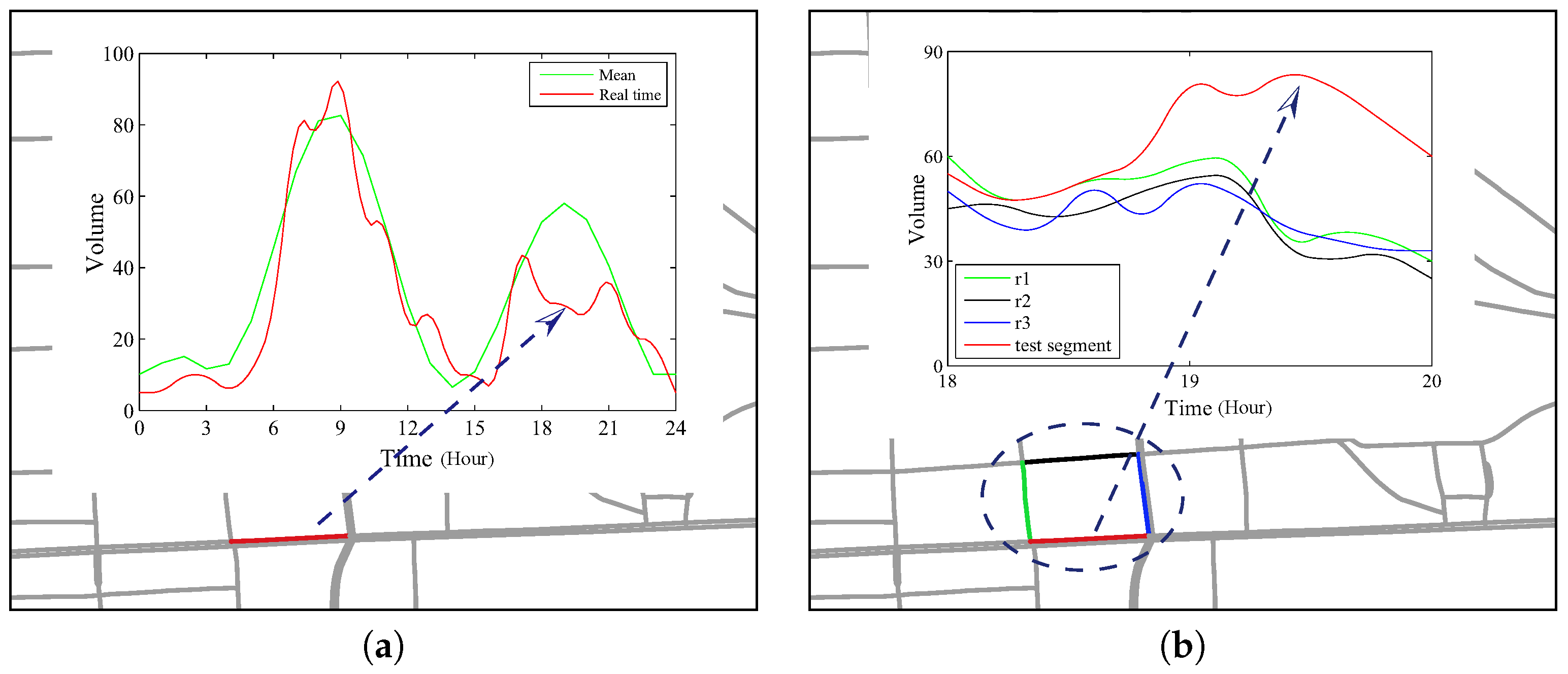
- Self-Evolving Anomaly (SEA). Given time interval , assume all road segments have the same type of expected volume distribution. A Self-Evolving Anomaly is a road segment , such that in time interval the values of associated volume set deviate from the expected distribution according to its historical values.
- Context-Evolving Anomaly (CEA). A Context-Evolving Anomaly is a road segment , such that in time interval the values of associated volume set deviate from the values of its connected neighbors in a region. Note that since we focus on road segments within local area, even two remote road segments could behave similarly but we leave this out of scope.
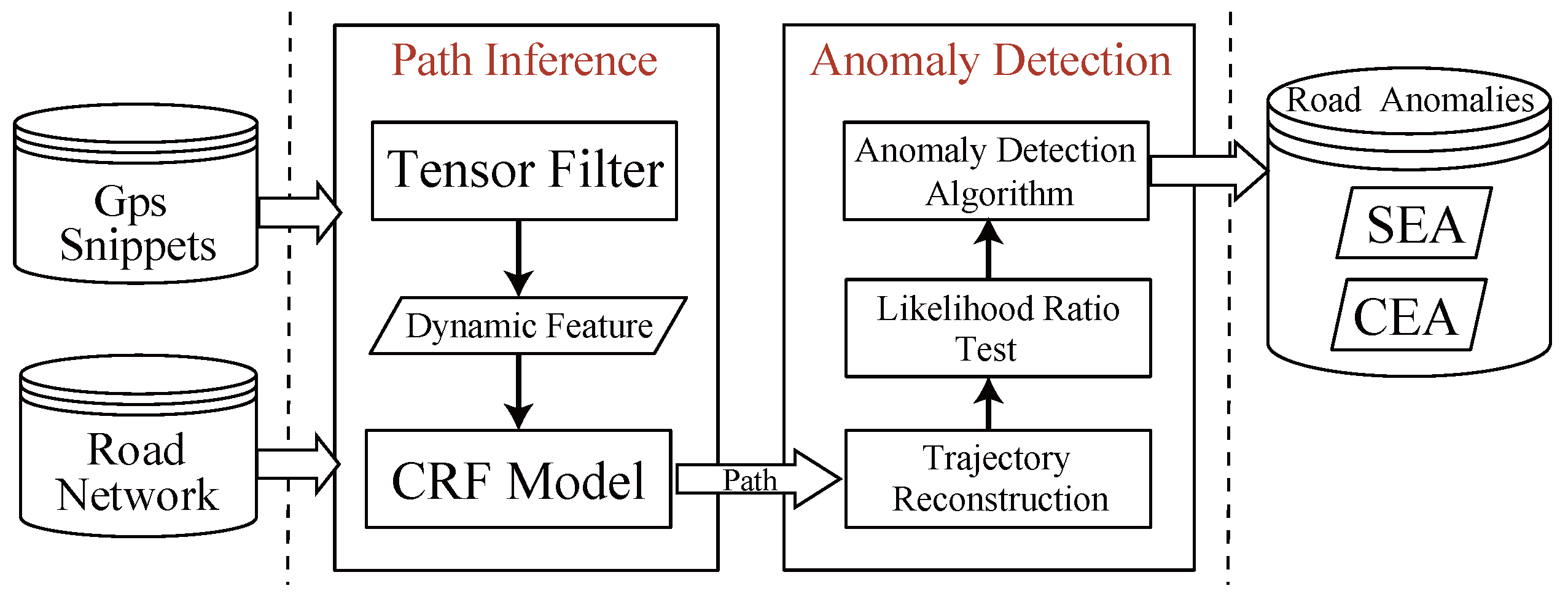
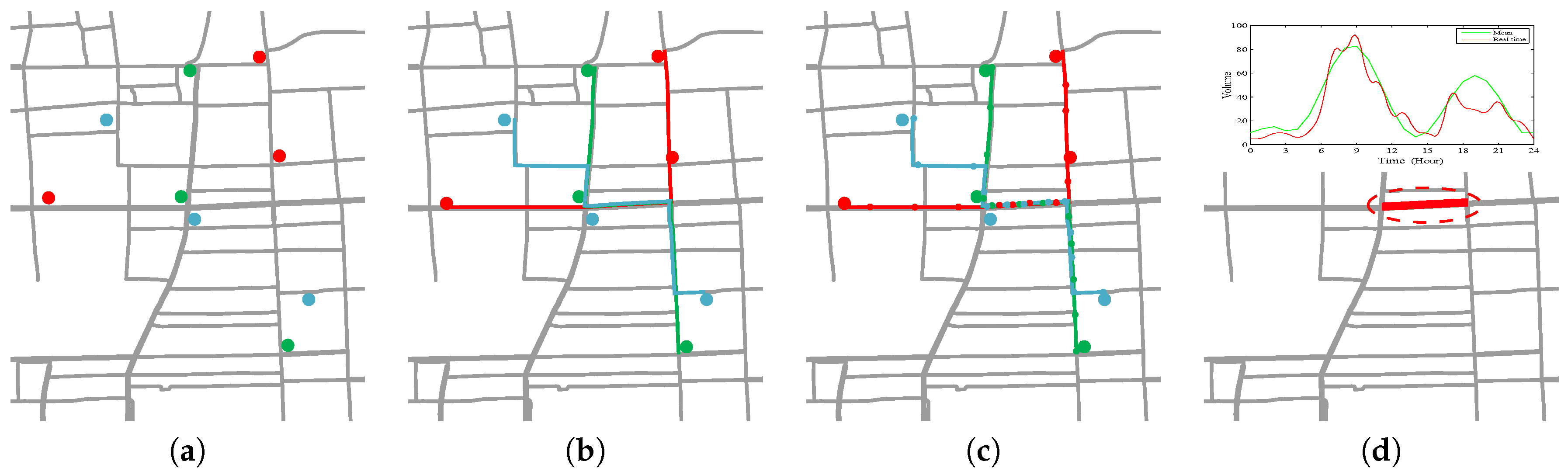
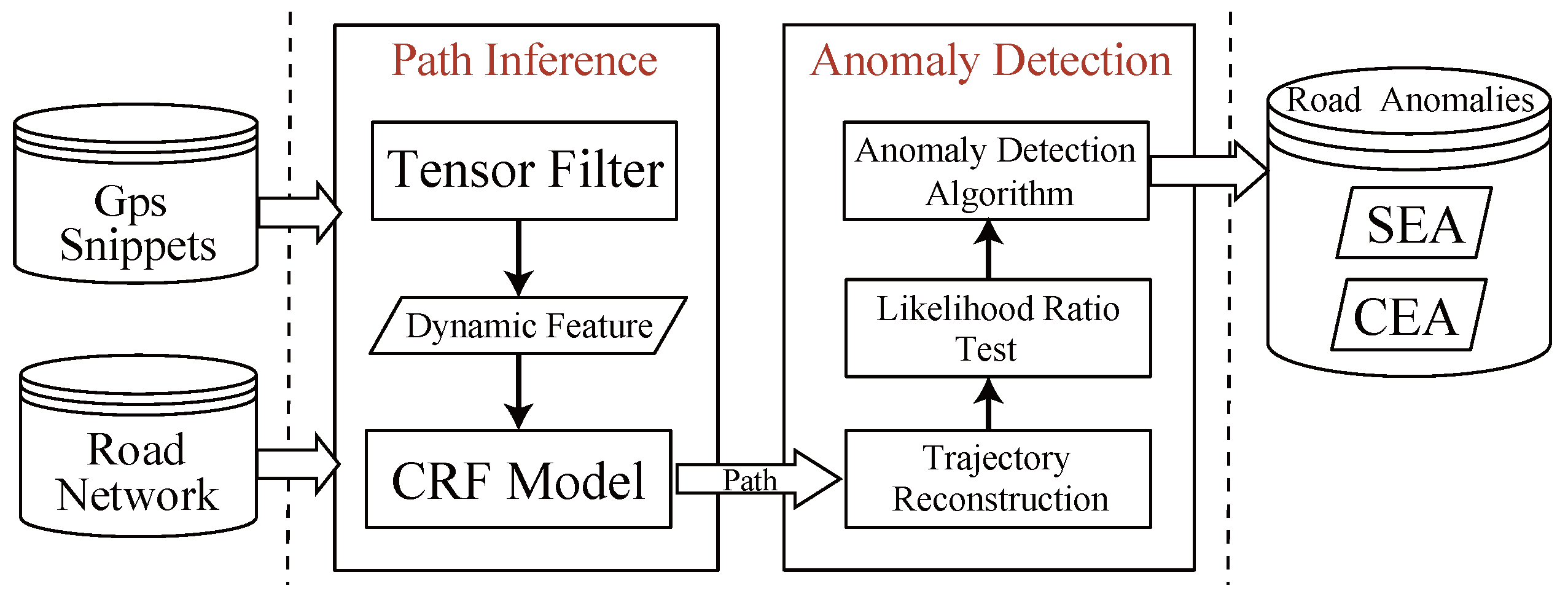
3.3. System Framework
4. Path Inference
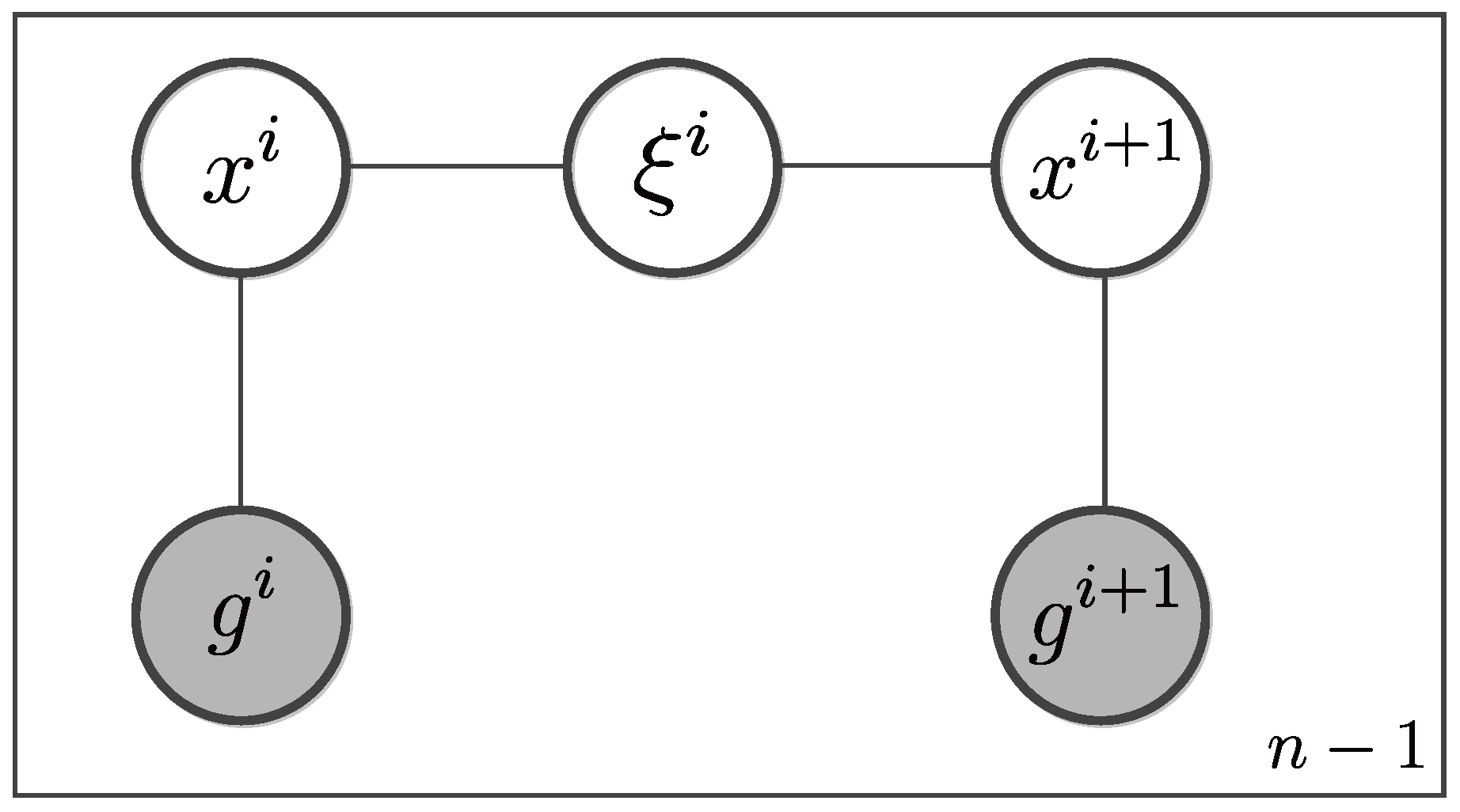
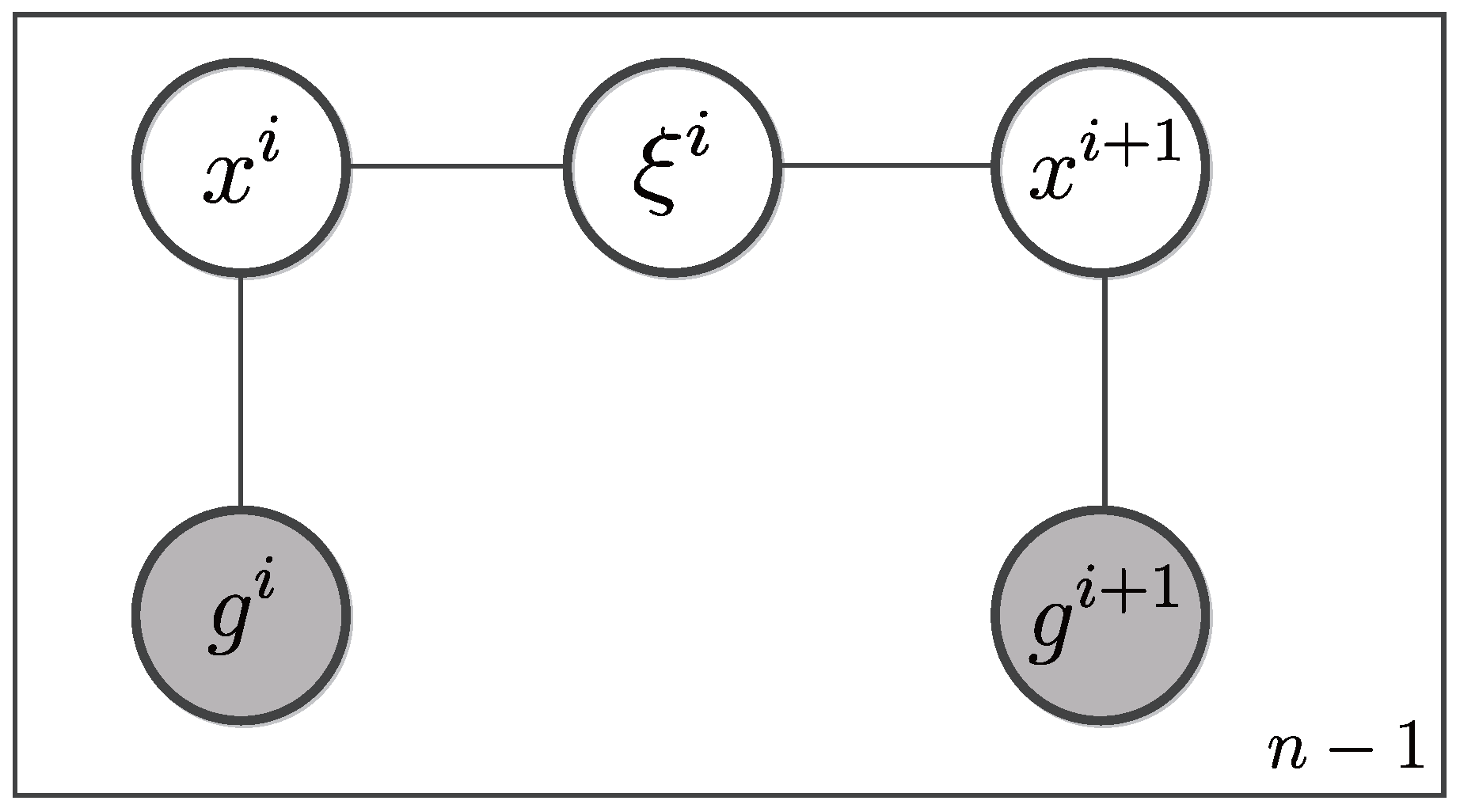
4.1. CRF model
4.1.1. Model Specification
4.1.2. Model Inference
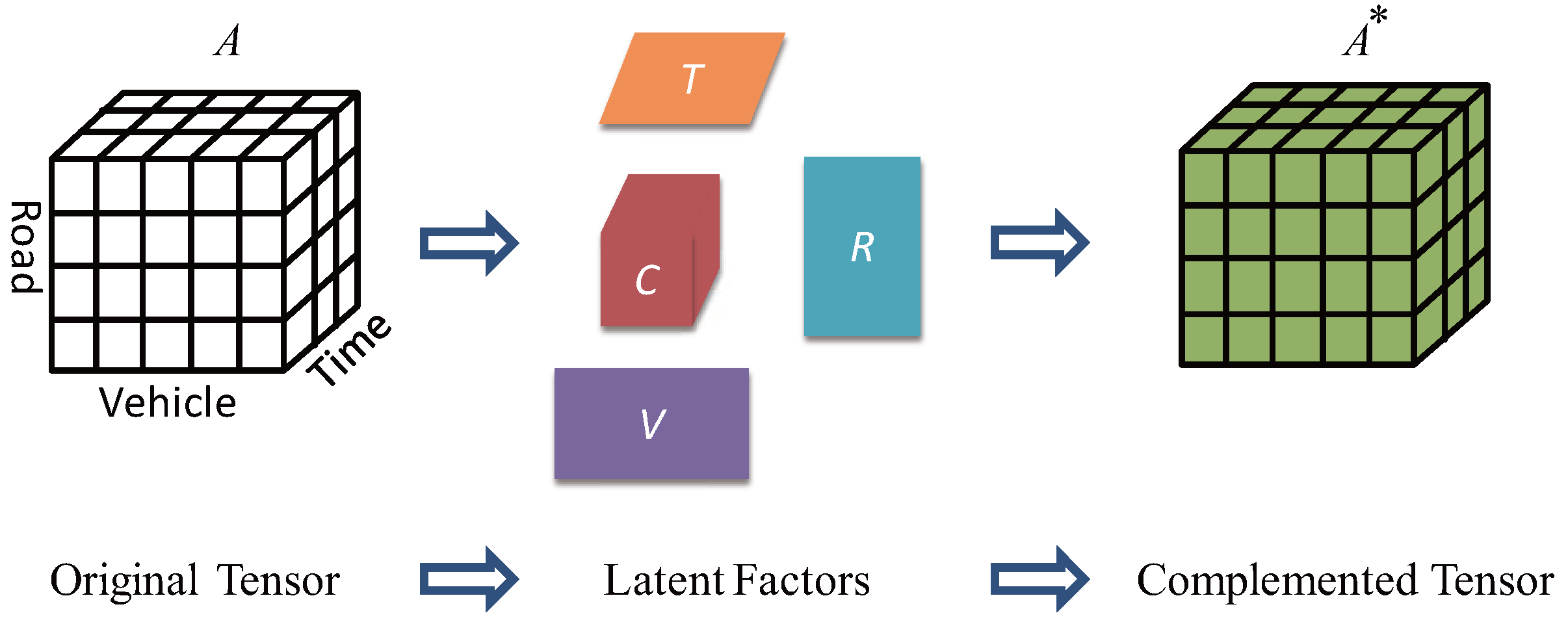
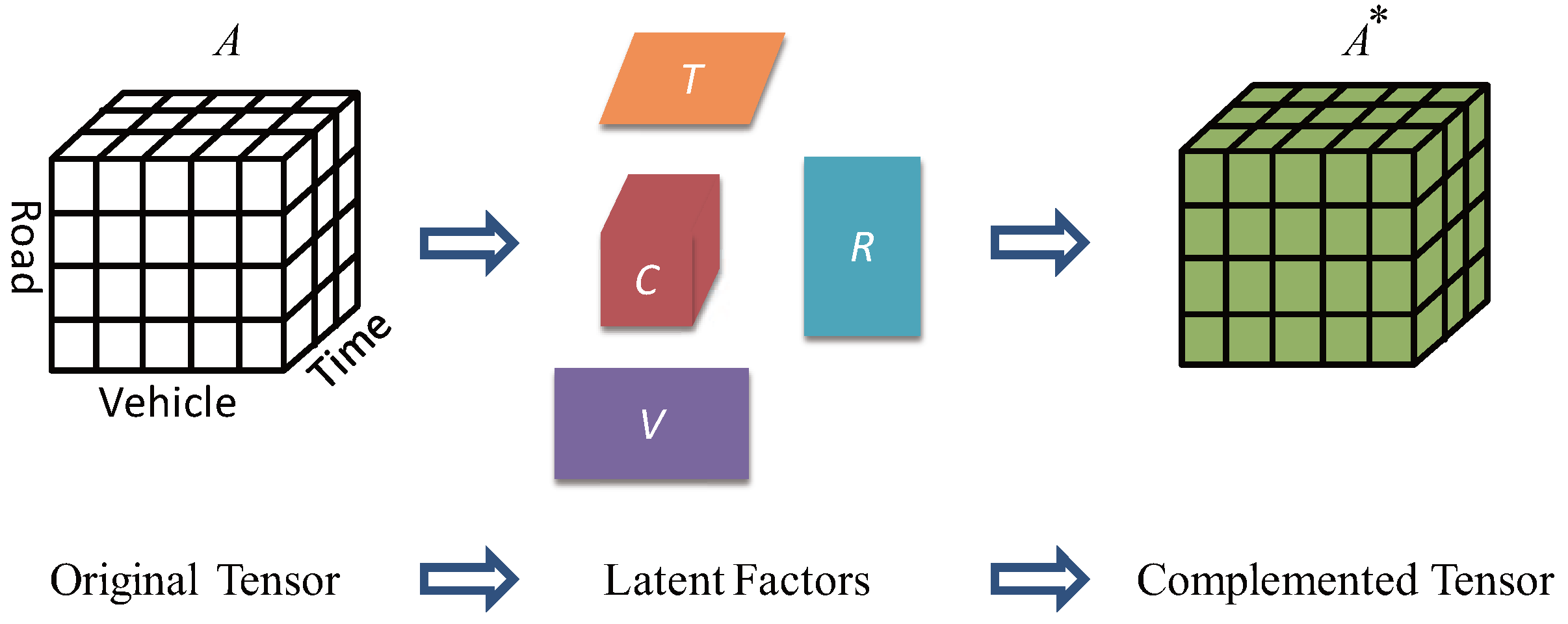
4.2. Collaborative Tensor Filter
4.2.1. Tensor Construction
4.2.2. Tensor Decomposition with Regularization
| Algorithm 1: Tensor Decomposition Procedure |
| Input: tensor and an error threshold ϵ Output: core tensor C, latent factor matrices V,R,T  |
4.2.3. Dynamic Feature Extraction
5. Road Traffic Anomaly Detection
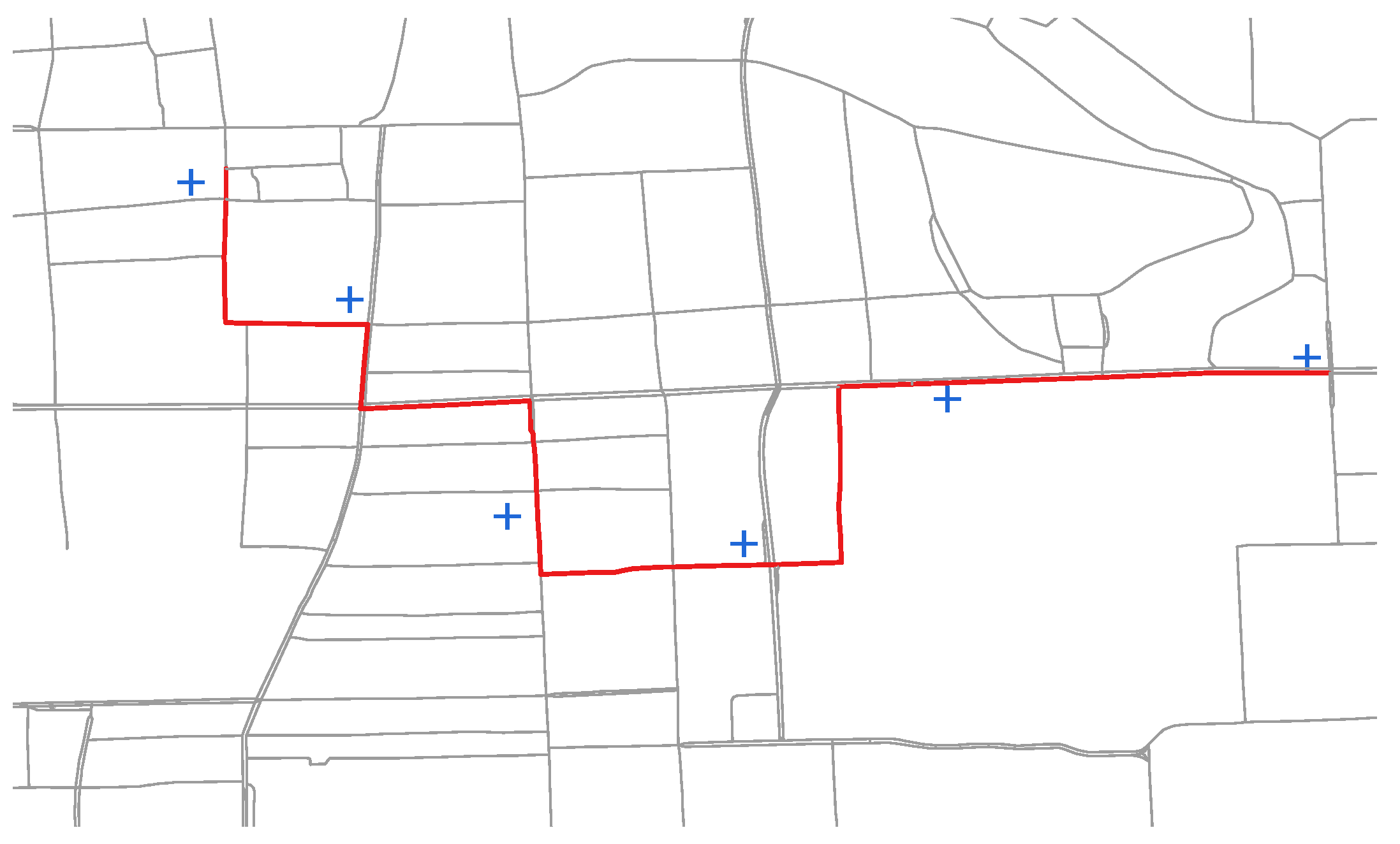
5.1. Trajectory Reconstruction
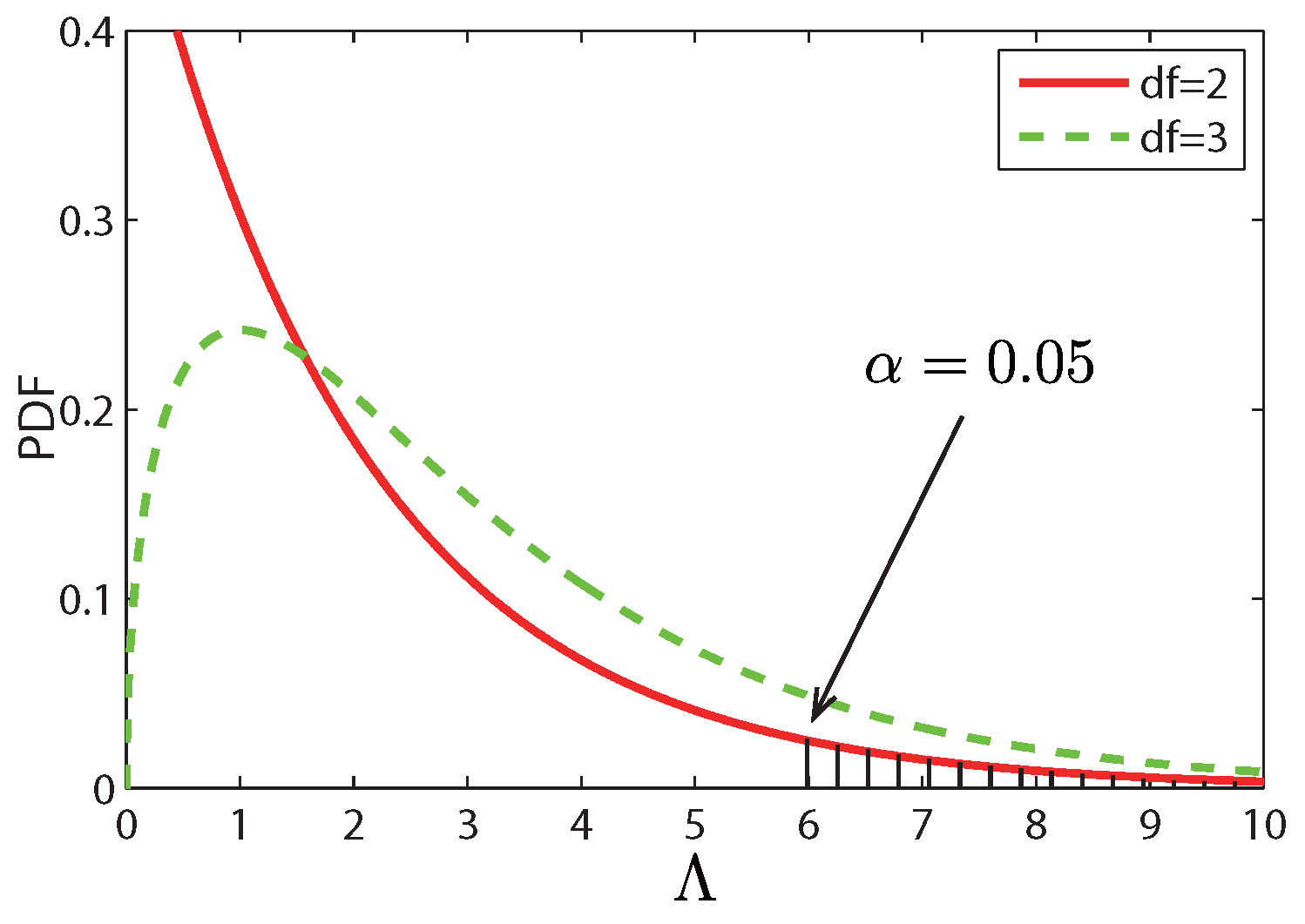
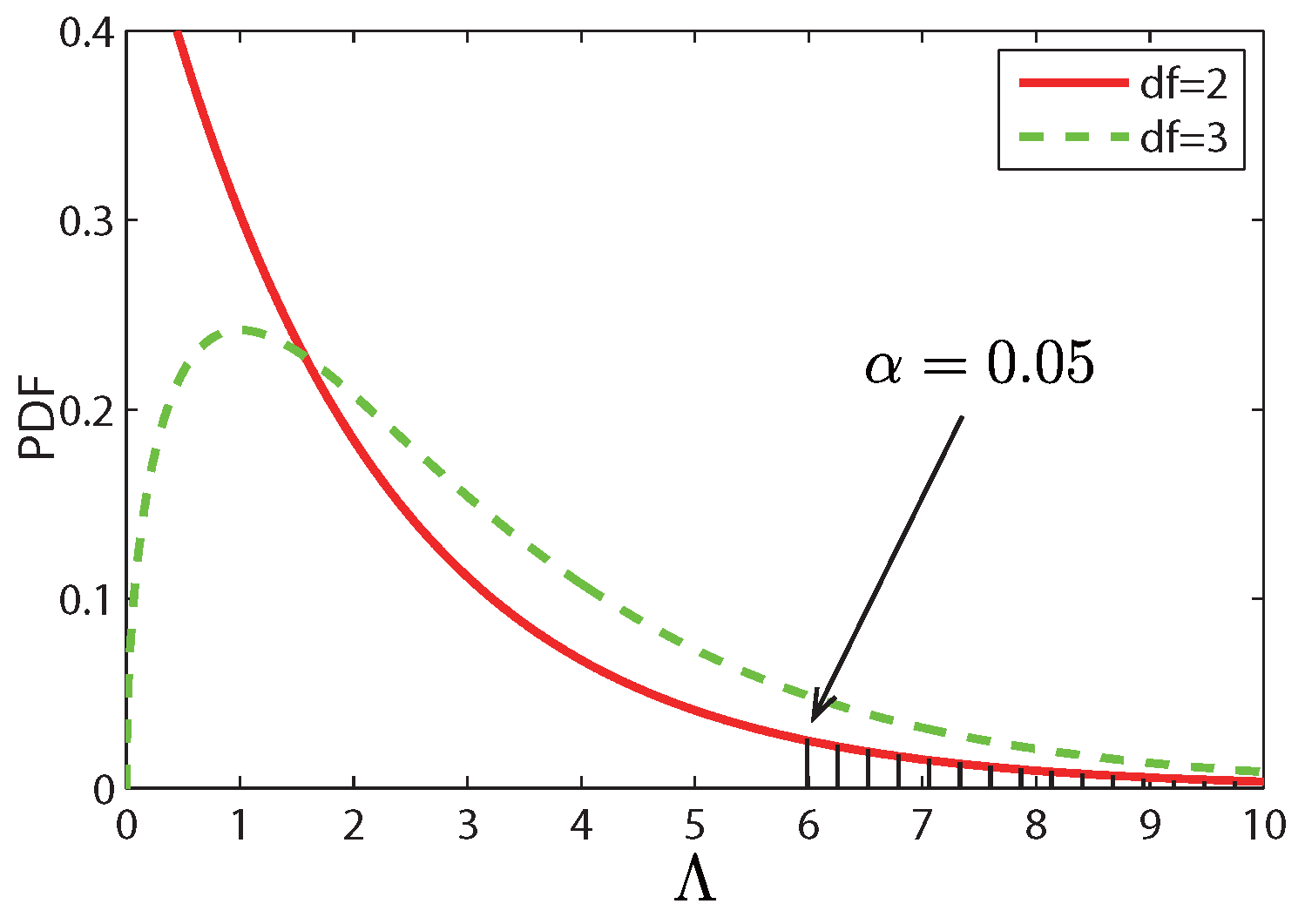
5.2. Likelihood Ratio Test
5.2.1. Self-Evolving Anomaly Detection
- (a)
- The likelihood of null model:
- (b)
- Estimate the parameter for the alternative model:
- (c)
- The likelihood of alternative model:
- (d)
- Calculate and d:
5.2.2. Context-Evolving Anomaly Detection
- (a)
- Estimate the MLE parameter from for the null model;
- (b)
- Calculate the likelihood of null model given ;
- (c)
- Estimate the MLE parameter from the neighbors volume data sets of , ;
- (d)
- Calculate the likelihood of alternative model given ;
- (e)
- Calculate test statistic , anomaly degree d, and give judgement.
| Algorithm 2: RN-Scan (Road Traffic Anomaly Detection) |
| Input: Inferred vehicle path set, Road Network Output: SEA set A, CEA set C  |
6. Experiments
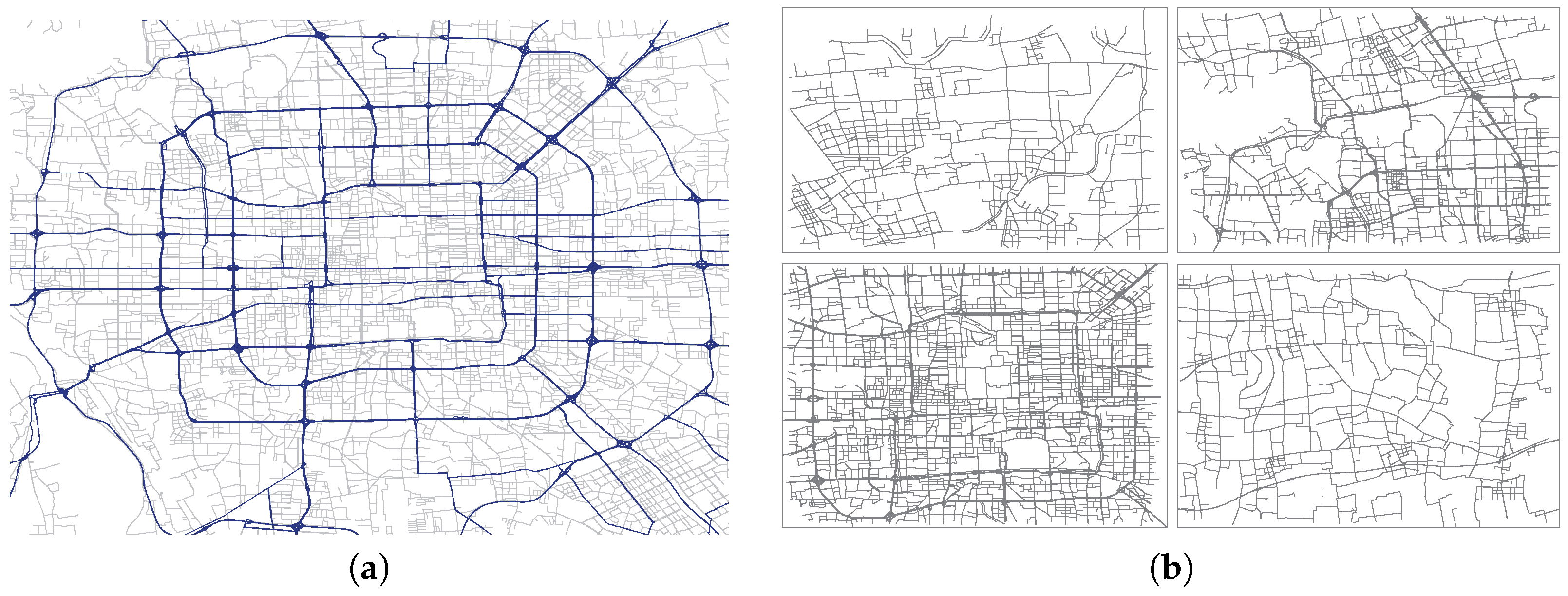
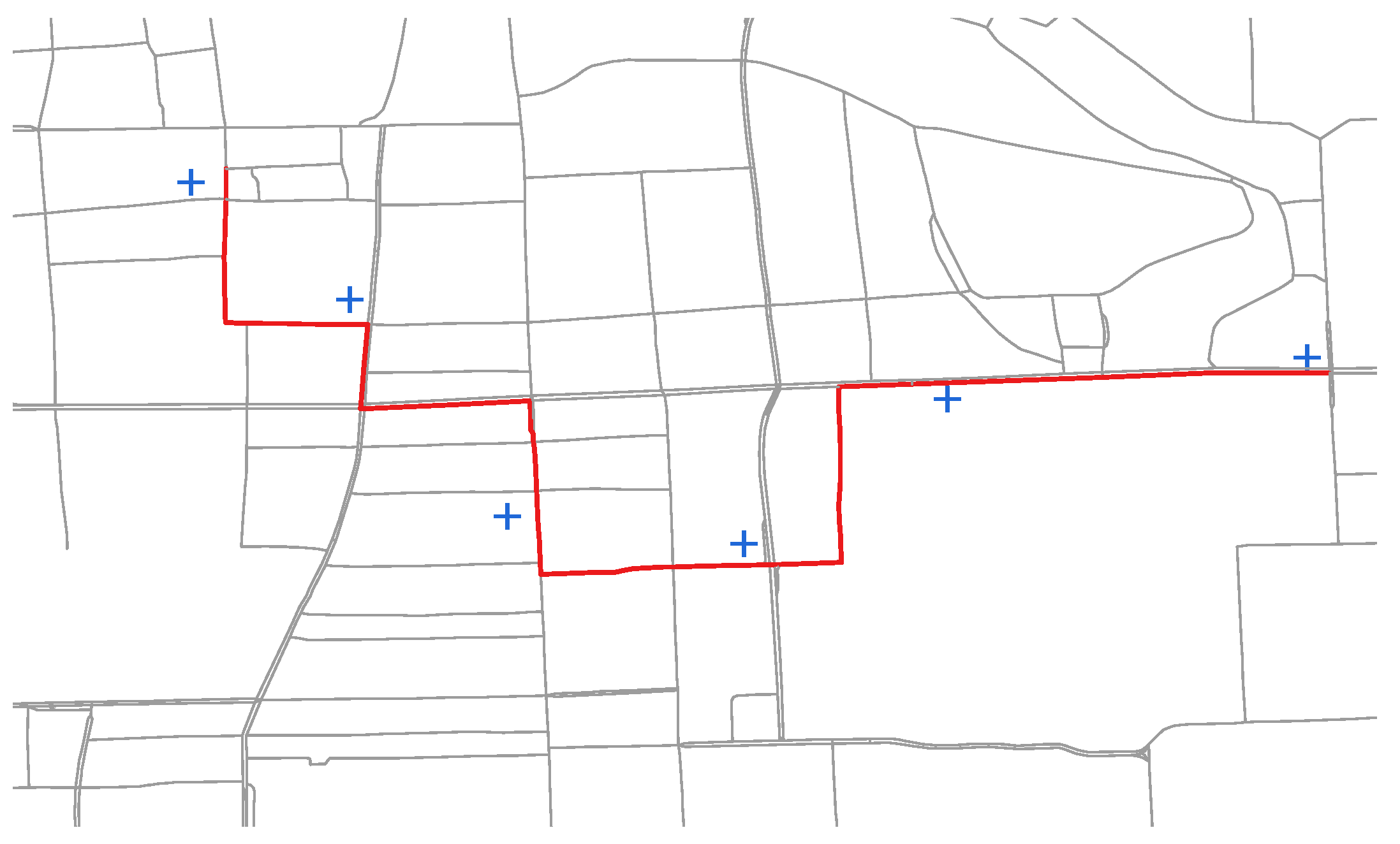
6.1. Dataset
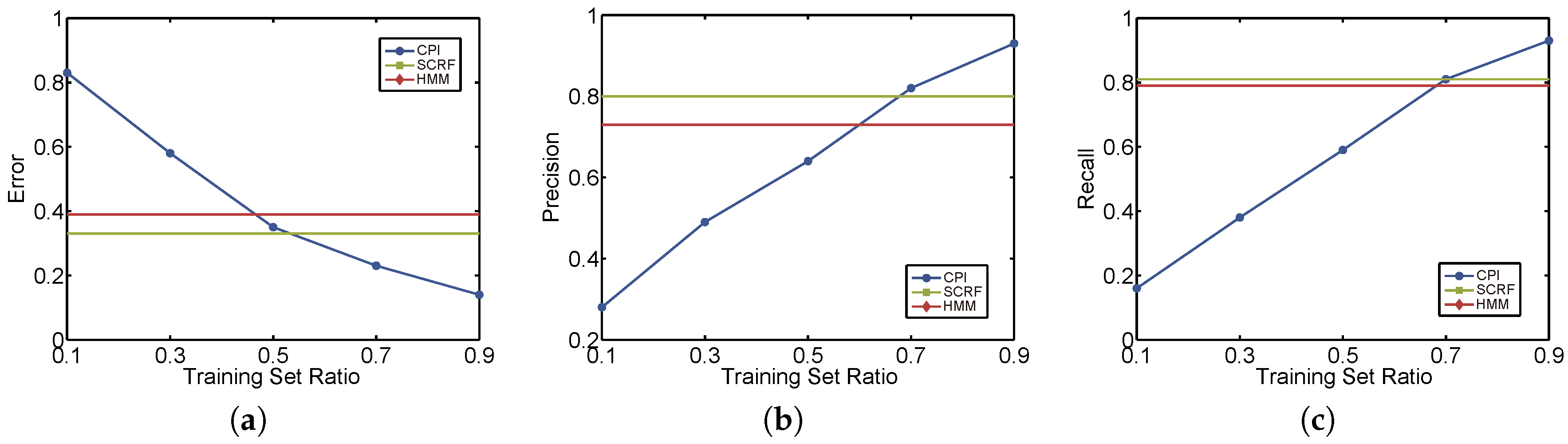
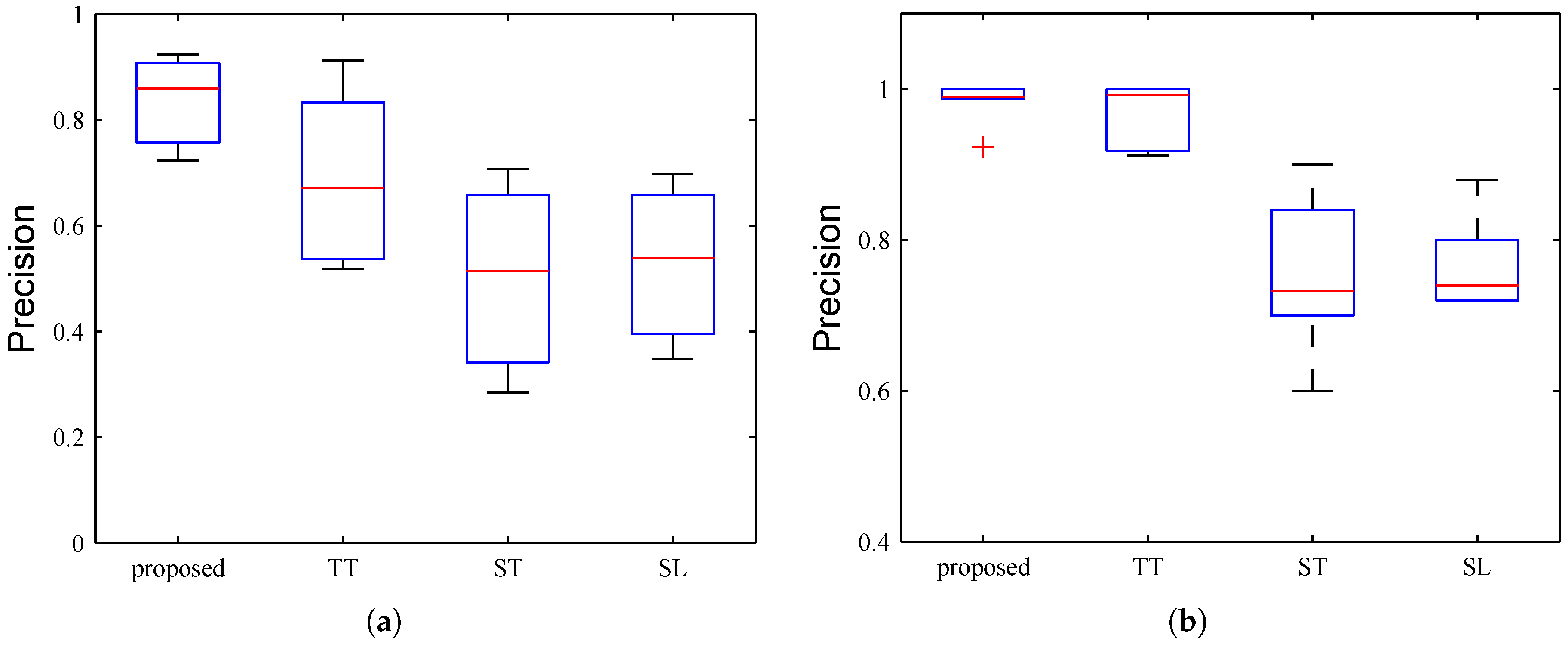
6.2. Evaluation on Path Inference
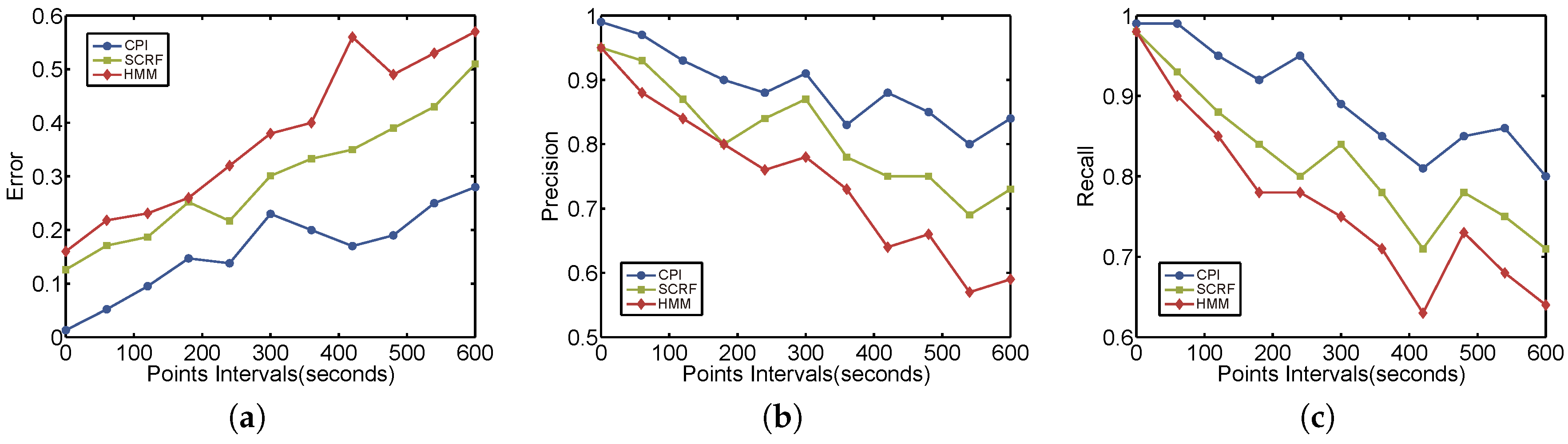
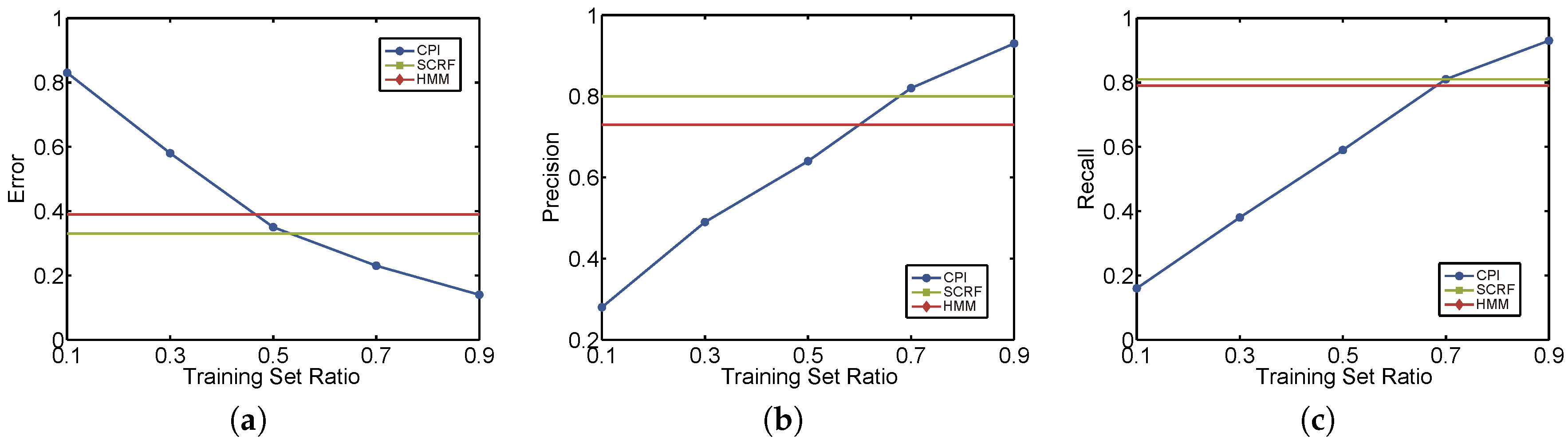
6.2.1. Evaluation Approach
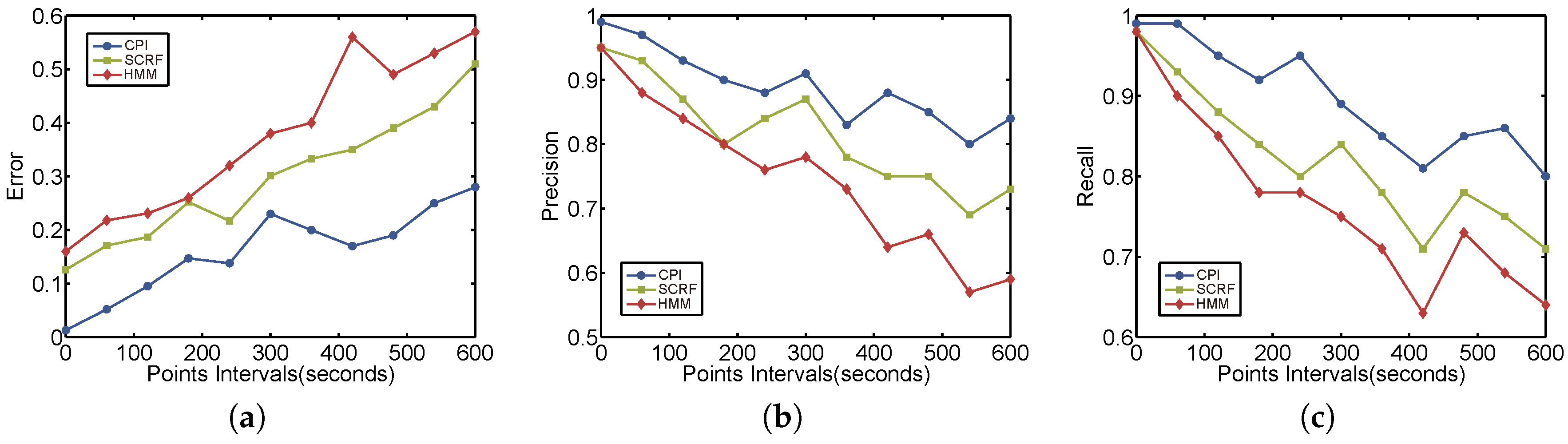
6.2.2. Results
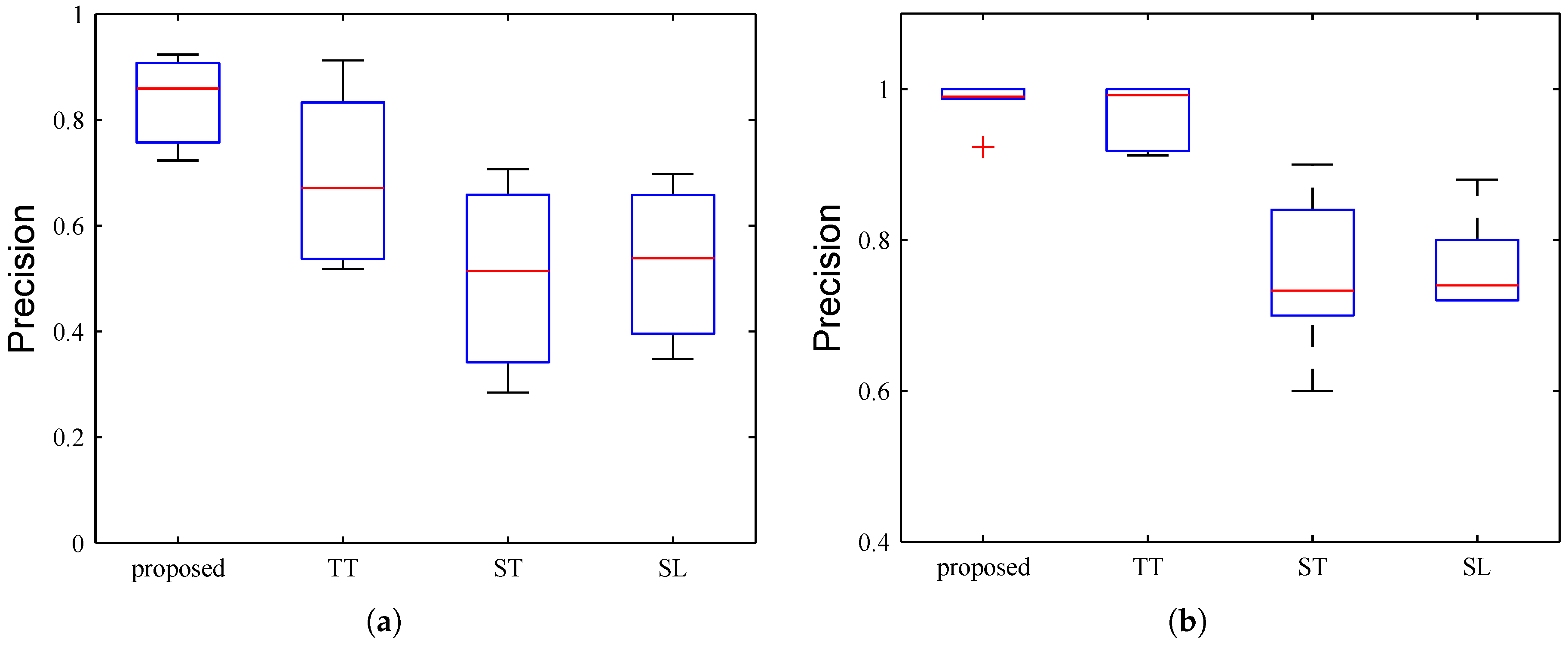
6.3. Evaluation on Anomaly Detection
6.3.1. Settings
6.3.2. Evaluation for SEA
6.3.3. Evaluation for CEA
6.4. Efficiency
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. ACM Trans. Intell. Syst. Technol. 2014, 5, 38:1–38:55. [Google Scholar] [CrossRef]
- Guan, X.; Huang, Y.; Cai, Z.; Ohtsuki, T. Intersection-based forwarding protocol for vehicular ad hoc networks. Telecommun. Syst. 2016, 62, 67–76. [Google Scholar] [CrossRef]
- Huang, Y.; Guan, X.; Cai, Z.; Ohtsuki, T. Multicast capacity analysis for social-proximity urban bus-assisted VANETs. In Proceedings of the IEEE International Conference on Communications, ICC 2013, Budapest, Hungary, 9–13 June 2013; pp. 6138–6142.
- Wen, H.; Ge, S.; Chen, S.; Wang, H.; Sun, L. Abnormal event detection via adaptive cascade dictionary learning. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 847–851.
- Khan, F.; Akhtar, N.; Qadeer, M.A. RFID Enhancement in Road Traffic Analysis by Augmenting Reciever with TelegraphCQ. In Proceedings of the Second International Workshop on Knowledge Discovery and Data Mining, WKDD 2009, Moscow, Russia, 23–25 January 2009; pp. 331–334.
- Li, M.; Ahmed, A.; Smola, A.J. Inferring Movement Trajectories from GPS Snippets. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM), Shanghai, China, 2–6 February 2015.
- Yin, H.; Wolfson, O. A Weight-based Map Matching Method in Moving Objects Databases. In Proceedings of the 16th International Conference on Scientific and Statistical Database Management (SSDBM), Santorini Island, Greece, 21–23 June 2004; pp. 437–438.
- Hunter, T.; Abbeel, P.; Bayen, A. The Path Inference Filter: Model-Based Low-Latency Map Matching of Probe Vehicle Data. IEEE Trans. Intell. Transp. Syst. 2014, 15, 507–529. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Amatriain, X.; Baltrunas, L.; Oliver, N. Multiverse recommendation: N-dimensional tensor factorization for context-aware collaborative filtering. In Proceedings of the 2010 ACM Conference on Recommender Systems (RecSys), Barcelona, Spain, 26–30 September 2010; pp. 79–86.
- Huang, Y.; Chen, M.; Cai, Z.; Guan, X.; Ohtsuki, T.; Zhang, Y. Graph Theory Based Capacity Analysis for Vehicular Ad Hoc Networks. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–5.
- White, C.E.; Bernstein, D.; Kornhauser, A.L. Some map matching algorithms for personal navigation assistants. Transp. Res. Part C Emerg. Technol. 2000, 8, 91–108. [Google Scholar] [CrossRef]
- Greenfeld, J.S. Matching GPS observations to locations on a digital map. In Proceedings of the Transportation Research Board 81st Annual Meeting, Washington, DC, USA, 13–17 January 2002.
- Brakatsoulas, S.; Pfoser, D.; Salas, R.; Wenk, C. On Map-Matching Vehicle Tracking Data. In Proceedings of the 31st International Conference on Very Large Data Bases (VLDB), Trento, Italy, 4–6 October 2005.
- Gustafsson, F.; Gunnarsson, F.; Bergman, N.; Forssell, U.; Jansson, J.; Karlsson, R.; Nordlund, P. Particle filters for positioning, navigation, and tracking. IEEE Trans. Signal Process. 2002, 50, 425–437. [Google Scholar] [CrossRef]
- Najjar, M.E.E.; Bonnifait, P. A Road-Matching Method for Precise Vehicle Localization Using Belief Theory and Kalman Filtering. Auton. Robots 2005, 19, 173–191. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, X.; Sun, G. An Interactive-Voting Based Map Matching Algorithm. In Proceedings of the Eleventh International Conference on Mobile Data Management (MDM), Kansas City, MO, USA, 23–26 May 2010.
- Newson, P.; Krumm, J. Hidden Markov map matching through noise and sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems (ACM-GIS), Seattle, WA, USA, 4–6 November 2009; pp. 336–343.
- Osogami, T.; Raymond, R. Map Matching with Inverse Reinforcement Learning. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI), Beijing, China, 3–9 August 2013.
- Wang, Y.; Zheng, Y.; Xue, Y. Travel time estimation of a path using sparse trajectories. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), New York, NY, USA, 24–27 August 2014.
- Zhong, Y.; Yuan, N.J.; Zhong, W.; Zhang, F.; Xie, X. You Are Where You Go: Inferring Demographic Attributes from Location Check-ins. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM), Shanghai, China, 2–6 February 2015; pp. 295–304.
- Cai, Z.; He, Z.; Guan, X.; Li, Y. Collective Data-Sanitization for Preventing Sensitive Information Inference Attacks in Social Networks. IEEE Trans. Dependable Secur. Comput. 2016, PP, 1. [Google Scholar] [CrossRef]
- Gao, S.; Denoyer, L.; Gallinari, P. Link Pattern Prediction with tensor decomposition in multi-relational networks. In Proceedings of the IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 333–340.
- Wang, X.; Guo, L.; Ai, C.; Li, J.; Cai, Z. An Urban Area-Oriented Traffic Information Query Strategy in VANETs. In Proceedings of the 8th International Conference on Wireless Algorithms, Systems, and Applications (WASA), Zhangjiajie, China, 7–10 August 2013; pp. 313–324.
- Zheng, X.; Cai, Z.; Li, J.; Gao, H. An Application-Aware Scheduling Policy for Real-Time Traffic. In Proceedings of the 35th IEEE International Conference on Distributed Computing Systems (ICDCS), Columbus, OH, USA, 29 June–2 July 2015; pp. 421–430.
- Zheng, X.; Cai, Z.; Li, J.; Gao, H. A Study on Application-aware Scheduling in Wireless Networks. IEEE Trans. Mob. Comput. 2016, PP, 1. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, H.; Liao, Y.; Sun, L. Vehicle Anomaly Detection Based on Trajectory Data of ANPR System. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6.
- Pang, L.X.; Chawla, S.; Liu, W.; Zheng, Y. On detection of emerging anomalous traffic patterns using GPS data. Data Knowl. Eng. 2013, 87, 357–373. [Google Scholar] [CrossRef]
- Chawla, S.; Zheng, Y.; Hu, J. Inferring the Root Cause in Road Traffic Anomalies. In Proceedings of the 12th IEEE International Conference on Data Mining (ICDM), Brussels, Belgium, 10–13 December 2012; pp. 141–150.
- Liu, W.; Zheng, Y.; Chawla, S.; Yuan, J.; Xing, X. Discovering spatio-temporal causal interactions in traffic data streams. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1010–1018.
- Karnstedt, M.; Klan, D.; Pölitz, C.; Sattler, K.; Franke, C. Adaptive burst detection in a stream engine. In Proceedings of the 2009 ACM Symposium on Applied Computing (SAC), Honolulu, HI, USA, 9–12 March 2009; pp. 1511–1515.
- Liu, S.; Chen, L.; Ni, L.M. Anomaly Detection from Incomplete Data. Trans. Knowl. Discov. Data 2014, 9, 11:1–11:22. [Google Scholar] [CrossRef]
- Wu, M.; Song, X.; Jermaine, C.; Ranka, S.; Gums, J. A LRT framework for fast spatial anomaly detection. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 887–896.
- Bader, B.W.; Kolda, T.G. Efficient MATLAB computations with sparse and factored tensors. SIAM J. Sci. Comput. 2007, 30, 205–231. [Google Scholar] [CrossRef]
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd sensing of traffic anomalies based on human mobility and social media. In Proceedings of the 21st International Conference on Advances in Geographic Information Systems (SIGSPATIAL), Orlando, FL, USA, 5–8 November 2013; pp. 334–343.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 8–10 | 11–13 | 14–16 | 17–19 | 20–22 | |
|---|---|---|---|---|---|
| proposed | 7 | 6 | 4 | 5 | 5 |
| Snippet-LRT method | 3 | 3 | 4 | 1 | 3 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Wen, H.; Yi, F.; Zhu, H.; Sun, L. Road Traffic Anomaly Detection via Collaborative Path Inference from GPS Snippets. Sensors 2017, 17, 550. https://doi.org/10.3390/s17030550
Wang H, Wen H, Yi F, Zhu H, Sun L. Road Traffic Anomaly Detection via Collaborative Path Inference from GPS Snippets. Sensors. 2017; 17(3):550. https://doi.org/10.3390/s17030550
Chicago/Turabian StyleWang, Hongtao, Hui Wen, Feng Yi, Hongsong Zhu, and Limin Sun. 2017. "Road Traffic Anomaly Detection via Collaborative Path Inference from GPS Snippets" Sensors 17, no. 3: 550. https://doi.org/10.3390/s17030550
APA StyleWang, H., Wen, H., Yi, F., Zhu, H., & Sun, L. (2017). Road Traffic Anomaly Detection via Collaborative Path Inference from GPS Snippets. Sensors, 17(3), 550. https://doi.org/10.3390/s17030550