1. Introduction
Hyperspectral image (HSI) classification deals with the problem of pixel-wise labeling of the hyperspectral spectrum, which has historically been a heavily studied, but not yet perfectly solved problem in remote sensing. With the recent development of hyperspectral remote capturing sensors, HSIs normally contain millions of pixels with hundreds of spectral wavelengths (channels). The HSI classification is intrinsically challenging. While more and more high-dimensional HSIs accumulate and are made public available, ground truth labels remain scarce, due to the immense manual efforts required to collect them. In addition, the generalization ability of neural networks is unsatisfactory if they are trained with insufficient labeled data, due to the curse of dimensionality [
1].
In the early days, conventional feature extraction and classifier design was popular among HSI classification practitioners. Favuel et al. [
2] provide a detailed review of recent advances in this area. Many varieties of conventional features have been applied, including raw spectral pixels, spectral pixel patches and their dimension reduced versions by methods such as principal component analysis [
3], manifold learning [
4], sparse coding [
5] and latent space methods [
6,
7,
8,
9]. Likewise, various conventional classifiers have been applied, such as support vector machines [
10], Markov random fields [
11], decision trees [
12], etc. In particular, some early approaches have already tried the incorporation of spatial information by extracting large homogeneous regions using majority voting [
13], watershed [
14] or hierarchical segmentation [
15]. Those two-stage (Stage 1: feature extraction; Stage 2: classification.) or multistage (in addition to the feature extraction stage and classification stage, there could be additional pre-/post-processing stages) methods suffer from some limitations. Firstly, it is highly time consuming to choose the optimal variant of conventional features and optimal parameter values for different HSI datasets, due to their wildly different physical properties (such as the number of channels/wavelengths) and visual appearances. Secondly, conventional classifiers have recently been outperformed by deep neural networks, particularly the convolutional neural network (CNN)-based ones.
In the past few years, deep learning methods have become popular for image classification and labeling problems [
16,
17,
18], as an end-to-end solution that simultaneously extracts features and classifies. Unlike image capturing with regular cameras with only red, green and blue channels, HSIs are generated by the accumulation of many spectrum bands [
19,
20,
21], with each pixel typically containing hundreds of narrow bands/channels. Many deep learning-based methods have been adapted to address the HSI classification problem, such as CNN variants [
22,
23,
24,
25], autoencoders [
26,
27,
28,
29] and deep belief networks (DBN) [
30,
31]. Despite their promising performance, the scarcity of training labels remains a great challenge.
Recently, Li et al. [
32] proposed the pixel pair features (PPF) to mitigate the problem of training label shortage. Unlike conventional spectral pixel-based or patch-based methods, the PPF is purely based on combined pairs of pixels from the entire training set. This pixel-pairing process is used both in the training and testing (label prediction for the target dataset) stages. During the training process, two pixels are randomly chosen from the entire labeled training set, and the label of each PPF pair is deduced by a subtle rule based on the existing labels of both pixels. For pairs with pixels of the same labeled class, the pair label is trivially assigned as the shared pixel label. The interesting case arises when two pixels in a pair are of different labeled classes (which is especially likely for multi-class problems; the likelihood increases as the number of classes increases): the pair is labeled as “extra”, an auxiliary class artificially introduced. This random combination of pixels significantly increases the number of labeled training instances (within a total of
labeled pixels of class
c in the training set, there could be
randomly sampled PPF pairs for the class
c), alleviating the training sample shortage.
Despite its success, the PPF implementation [
32] includes randomly sampled pairs across the entire training set, which incurs very larger intra-class variances and changes the overall training set statistical distribution. Due to the intrinsic properties of HSI imaging, pixels with the same ground truth class labels could appear differently and statistically distribute differently across channels/wavelengths, especially for pixels geographically far apart from each other. Additionally, the PPF implementation [
32] includes a pair label prediction rule inconsistent with its training pair labeling rule. At the testing (label prediction) stage, the “extra” class is deliberately removed, forcing the classifier (a Softmax layer) to pick an essentially wrong label for such PPF pairs.
Inspired by [
32], a revamped version of the HSI classification feature is proposed in this paper, which is termed the “spatial pixel pair feature” (SPPF). The core differences of the proposed SPPF and the prior PPF are the geographically co-located pixel selection rule and the pair label assignment rule. For each location of interest, SPPF always selects the central pixel (at the location of interest) and one from its immediate eight-neighbor, at both the training and testing stage. In addition, an SPPF pixel pair is always labeled with the central pixel label, regardless of the other neighboring pixel.
Although the smaller neighborhood size yields fewer folds of training sample increase (the proposed SPPF offers up to eight-folds of training sample increase), the small neighborhood substantially decreases the intra-class variances. Statistically speaking, geographically co-located SPPF pixels are much more likely to share similar channel/wavelength measurement distributions than their PPF counterparts. Furthermore, the simple SPPF pair label assignment rule eliminates the complicated and possibly erroneous handling of “extra” class labels.
Alongside the shortage of training samples, the deep neural network structural design for the classifier is another challenge, especially for high dimensional HSI data. In this paper, we further propose a flexible multi-stream CNN-based classification framework that is compatible with multiple in-stream sub-networks. This framework is composed of a series of sub-networks/streams, each of which independently process one SPPF pixel pair. The outputs from these sub-networks are fused (in the “late fusion” fashion) with one average pooling layer that leverages the class variance and a few-fully connected (FC) layers for final predictions.
The remainder of this paper is structured as follows.
Section 2 provides a brief overview of related work on HSI classification with deep neural networks.
Section 3 presents the new SPPF feature and the new classification framework. Subsequently,
Section 4 provides detailed experimental settings and results, with some discussions on potential future work. Finally, conclusions are drawn in
Section 5.
2. Related Work
HSI classification has long been a popular research topic in the field of remote sensing, and the primary challenge is the highly-limited training labels. Recent breakthroughs were primarily achieved by deep learning methods, especially CNN-based ones [
22,
32].
Hu et al. [
22] propose a CNN that directly processes each single HSI pixel (i.e., raw HSI pixel as the feature) and exploits the spatial information by embedding spectrum bands in lower dimensions. For notational simplicity, this method name is abbreviated to “Pixel-
” in this paper (no official abbreviation is provided in [
22]), as it is based on individual HSI pixels, and the CNN inputs are all the channels/wavelengths from one pixel (hence the subscript 1). The Pixel-
method outperforms many previous conventional methods without resorting to any prior knowledge or feature engineering. However, noise remains an open issue and heavily affects the prediction quality. Largely due to the lack of spatial information, the discontinuity artifacts (especially the ‘salt-and-pepper’ noise patterns) are widespread.
More recent efforts [
33,
34,
35] have been made to incorporate spatial consistency in HSI classification. Qian et al. [
36] especially claim that spatial information is often more critical than spectral information in the HSI classification task. Slavkovikj et al. [
37] incorporate both spatial and spectral information by proposing a CNN that process a HSI pixel patch, which is abbreviated as Patch-
in this paper (in [
37], a patch typically covers
pixels, i.e., the inputs of CNN covers nine pixels, hence the 9 subscript). The Patch-
method learns structured spatial-spectral information directly from the HSI data, while CNN extracts a hierarchy of increasingly spatial features [
38]. Later, Yu et al. [
39] proposed a similar approach with carefully crafted network structures to process three-dimensional training data. Meanwhile, Shi et al. [
40] further enhanced the spatial consistency by adopting a 3D recurrent neural network (RNN) following the CNN processing. Recently, Zhang et al. [
41] proposed a dual stream CNN, with one CNN stream extracting the spectral feature (similar to Pixel-
[
22]) and the other extracting the spatial-spectral feature (similar to Patch-
[
37]). Subsequently, both features are flattened and concatenated, before feeding into a prediction module.
Despite the success of the aforementioned approaches, the shortage of available training samples remains a vital challenge, especially when neural networks go deeper and wider [
42], due to more parameters in a larger scale network model. To alleviate this problem, many efforts have been made. The first natural effort is better data augmentation. Slavkovikj et al. [
37] introduce additional artificial noises based on the HSI class-specific spectral distributions. Granted that there is the risk of migrating the original spectral distribution, a reasonable amount of additive noise could lead to better generalization performance. Another way of augmenting training samples is proposed in [
32], where randomly sampled pixel pairs (i.e., the PPF feature) from the entire training dataset are used. The PPF feature exploits the similarity between pixels of the same labeled class and ensures enough labeled PPF training pairs for its classifier.
Another group of work addresses the limited training labels challenge by exploiting the statistical characters in HSI channels/wavelengths. Methods like multi-scale feature extraction [
23] extract multi-scale features using autoencoders followed by classifiers training. However, these methods are based on a lower dimensional spectral subspace, which may omit valuable information. Alternatively, some efforts have been made to combine HSI classification with auxiliary tasks such as super-pixel segmentation [
43]. The super-pixel segmentation provides strong local consistency for labels and can also serve as a post-processing procedure. Romero et al. [
44] present a greedy layer-wise unsupervised pre-training for CNNs, which leads to both performance gains and improved computational efficiency.
Additionally, the vast variations in the statistical distributions of channels/wavelengths also draw much research attention. Slavkovikj et al. [
45] propose an unsupervised sub-feature learning method in the spectral domain. This dictionary learning-based method greatly enhanced the hyperspectral feature representations. Zabalza et al. [
46] extract features from a segmented spectral space with autoencoders. The slicing of the original features greatly reduces the complexity of network design and improves the efficiency of data abstraction. Very recently, Ran et al. [
47] propose the band-sensitive network (BsNet) for feature extraction from correlated band groups, with each band group earning a respective classification confidence. The BsNet label prediction is based on all available band group classification confidences.
3. SPPF and Proposed Classification Framework
In this section, the classification problem of HSI data is first formulated mathematically, followed by the introductions of early HSI features (raw spectral pixel feature and spectral pixel patch feature). Subsequently, the new SPPF feature is proposed and compared against the prior PPF feature. Finally, a new multi-stream CNN-based classification framework is introduced.
Let
be an HSI dataset, with
W,
H,
D being the width (i.e., the total number of longitude resolution), height (i.e., the total number of latitude resolution) and dimension (i.e., spectral channels/wavelengths), respectively. Suppose among the total number of
pixels,
N of them are labeled ones in the training set
:
is a
D-dimensional real-valued spectral pixel measurement;
is its corresponding integer valued label;
is the set of labeled classes, with
K being the total number of classes.
The goal of HSI classification is to find a prediction function for unlabeled pixels , given the training set .
For methods with incorporated spatial information (e.g., [
37]), the prediction function
f involves more inputs than
itself. Additionally, a set of neighboring pixels
is also
f’s inputs. Therefore, the predicted label
is,
For notational simplicity, define
as a set containing both the query pixel
and its neighboring pixels
,
and let
represent the label of set
. With different choices of neighborhoods
, both
and
change accordingly. In the following sections, a bracketed number in the superscript of
and
is used to distinguish such variations.
3.1. Raw Spectral Pixel Feature
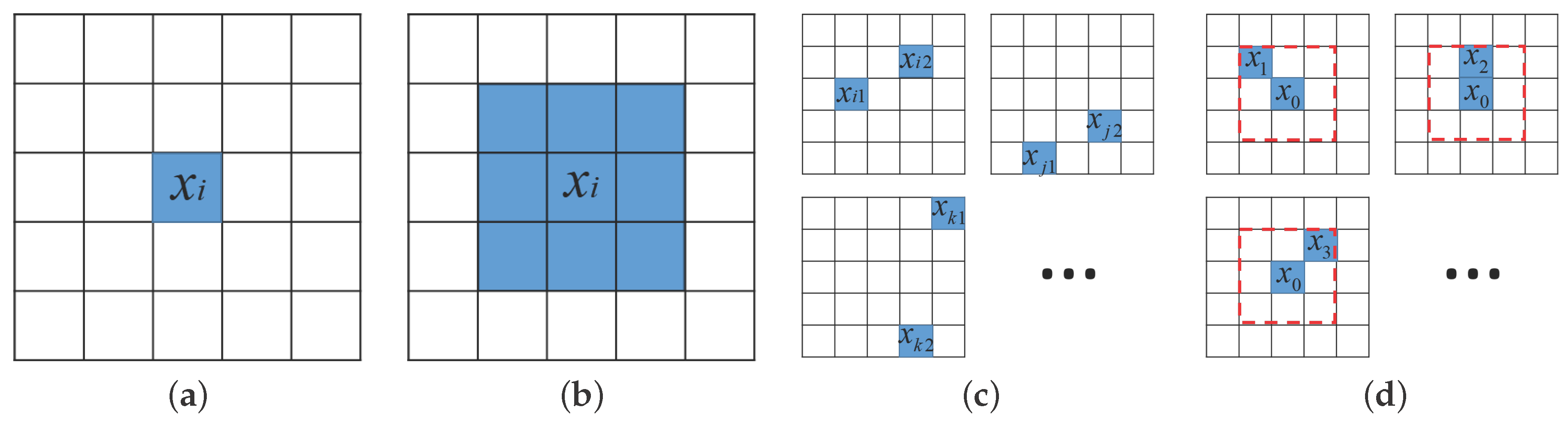
As shown in
Figure 1a, a spectral pixel is a basic component of HSI. The raw spectral pixel feature is used in early CNN-based work, such as Pixel-
[
22]. With such a feature, the label prediction task is:
During
’s training process, labeling of
is straightforward,
where
is the label associated with
.
Despite its simplicity, the lack of spatial consistency information often leads to erroneous predicted labels, especially within class boundaries.
3.2. Spectral Pixel Patch Feature
Proposed in [
37], the spectral pixel patch feature uses the entire neighboring patch as basis for classification, as shown in
Figure 1b,
where
denotes all eight pixels in
’s eight-neighbor.
During
’s training process, labeling of
is completely based on the label
of the central pixel
,
In contrast to the raw spectral pixel feature, the spectral pixel patch feature provides spatial information and promotes local consistency in labeling, leading to smoother class regions. The introduction of spatial information in significantly improves the prediction accuracy and contextual consistency.
3.3. PPF
The PPF feature [
32] is illustrated in
Figure 1c. Pairs of labeled pixels are randomly chosen across the entire training set
, and the label prediction is carried out by:
During
’s training process, labeling of
is based on the following rule,
where
and
are the associated labels of
and
from pixel pair
, respectively.
is a newly introduced class label, denoting an “auxiliary” class not in the original
. In this paper, we set it as
.
Comparing Equation (
8) and Equation (
9), it is evident that the spans of
and
are different. The element
in Equation (
9) is outside the range of
. Therefore, there is a mismatch between the training labels and prediction labels, which could leads to suboptimal classification performance.
Additionally, there are no spatial constraints imposed on the choice of
and
while generating training samples
according to Equation (
9). Therefore,
and
could be far apart from each other geographically. As Qian et al. argued in [
36], spatial information could be more critical than its spectral counterpart, so such a pair generation scheme in Equation (
8) could lead to high intra-class variances in training data
and possibly confuses classifier
.
Practically, during the label prediction process in Equation (
8), multiple
’s are normally chosen from the reference pixel
’s neighborhood
,
where
denotes the total number of testing pixel pairs assembled for
. “Card” in Equation (
10) represents the cardinality of a set. A series of
’s are constructed as:
and their respective predictions are:
The final predicted label is determined by a majority voting,
where “mode” in Equation (
13) denotes statistical mode (i.e., the value that appears most often).
3.4. Proposed SPPF
To address the lack of spatial constraints while selecting
and eliminating the extra
label in Equation (
9), the new SPPF feature is proposed and illustrated in
Figure 1d. The label prediction is carried out by
,
The SPPF prediction function always processes exactly eight sets of SPPF pairs , and these pairs holistically contribute to the prediction without resorting to majority voting.
During
’s training process, only pixels from the reference pixel
’s eight neighbors are used for constructing
. In addition, labeling of
is purely based on the central reference pixel
’s label
, eliminating any auxiliary class labels.
The SPPF training set with pixel pairs and labels is:
where
,
.
3.5. Proposed Classification Framework with SPPF
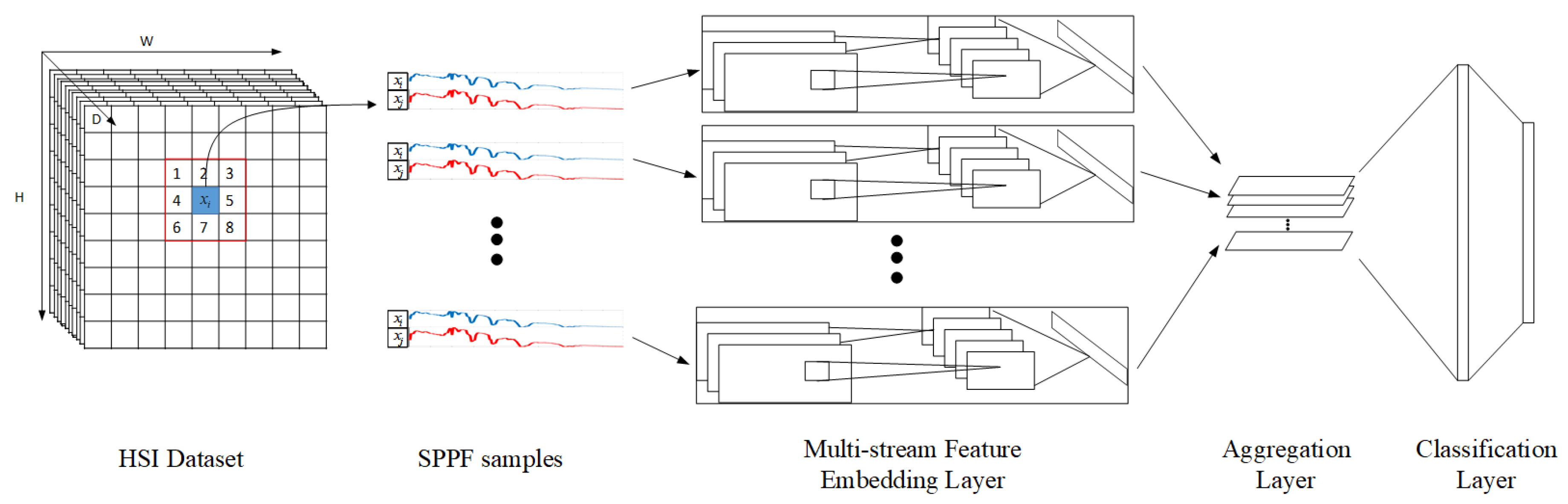
On top of the proposed SPPF feature, a multi-stream CNN architecture is proposed for classification, as shown in
Figure 2. Overall, there are three major component layers: firstly, the multi-stream feature embedding layers; secondly, an aggregation layer; and finally, a classification layer.
The multi-stream feature embedding layers are designed to extract discriminative features from SPPFs. These layers are grouped into eight streams/sub-networks, each of which processes a single
, where
. A major advantage of this design is the flexibility of incorporating various nets as streams/sub-networks. We have adopted both classical CNN implementations, as well as alternatives such as [
47]. All sub-networks have their input layers slightly adjusted to fit the pixel pair inputs; and last scoring layers (i.e., SoftMax layers) are removed. After passing the multi-stream feature embedding layers, HSI data are transformed into eight streams of
K-dimensional feature vectors, ready to be fed to the next aggregation layer.
Empirically, the overall classification performance is insensitive to different choices of sub-networks, given a reasonable sub-network scale. In fact, due to the limited amount of training data, slightly shallower/simpler networks enjoy a marginal performance advantage.
The aggregation layer is one average pooling layer, which additively combines information from all streams together, leading to its robustness against noises and invariance from local rotations. The output of the prior multi-stream embedded layer is of dimension
;
are first concatenated to form
:
Subsequently, an average pooling layer process outputs a vector . Even if there are noise contaminations in some streams/sub-networks, is less susceptible to them, thanks to the averaging effect. Lastly, two fully-connected (FC) layers and a SoftMax layer serve as the classification layers, providing confidence scores and prediction labels.
4. Experimental Results and Discussion
In this section, we give the detailed configuration description of the datasets we use and the models we build for analyzing the new SPPF and the proposed classification framework. For HSI classification measurement, we choose the overall accuracy (OA) and average class accuracy (AA) as the evaluation strategy (the overall accuracy is defined as the ratio of correctly labeled samples to all test samples, and the average accuracy is calculated by simply averaging the accuracies for each class.).
4.1. Dataset Description
India Pines dataset: The NASA Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) Indian Pines image was captured over the agricultural Indian Pine test site located in the northwest of Indiana. The spectral image has a spatial resolution of and a range of 220 spectral bands from 0.38–2.5 m. Prior to commencing the experiments, the water absorption bands were removed. Hence, we are dealing with a 200-band length spectrum. What is more, the labeled classes are highly unbalanced. We choose nine out of 16 classes, which consists of more than 400 samples. In total, 9234 samples are left for further analysis.
University of Pavia dataset: The University of Pavia image (PaviaU) was acquired by the ROSIS-03 sensor over the University of Pavia, Italy. The image measures with a spatial resolution of 1.3 m per pixel. There are 115 channels whose coverage ranges from 0.43–0.86 m, and 12 absorption bands were discarded for noise concern. There are nine different classes in the PaviaU reference map and 42,776 labeled samples used in this paper.
Salinas scene dataset: This scene is also collected by the 224-band AVIRIS sensor over Salinas Valley, California, and is characterized by high spatial resolution ( 3.7-m pixels). As with Indian Pines scene, we discarded the 20 water absorption bands, in this case bands with the numbers: [108–112], [154–167], 224. This image was available only as at-sensor radiance data. It includes vegetables, bare soils and vineyard fields. The Salinas ground-truth contains 16 classes and 54,129 samples.
4.2. Model Setup and Training
For efficiency demonstration of the proposed method, we first have some classical shallow classification methods built in the comparison experiment, for example SVM [
10] and ELM [
48]. We use the LIBSVM [
49] and ELM (
http://www.ntu.edu.sg/home/egbhuang/elm_codes.html) development toolkit for building those two models separately. For the SVM model, we use the polynomial kernel function, with
equal to one and the rest of the hyper-parameters set as the default. For the ELM model, we set the number of hidden neurons as 7000 and choose the Sine function as the activation function. Predictions are given by each model regarding raw input spectrum pixels.
As for CNN-based deep models, we have reproduced three works, CNN from [
37], BsNet [
47] and PPF [
32]. To distinguish, we have adjusted the model’s name in different case. For example, we have
and
to present the model in [
37] working on the spectrum pixel (one pixel) and spatial patch (nine pixels), respectively.
is for the model in [
37] when it is embedded into the proposed framework working on a pixel pair (two pixels). We further simplified the
subnetwork, which we quote as
-lite in this paper, with the number of neurons in the fully-connected layers set to 400 and 200, respectively. In this way, the total parameters have greatly dropped from 4,650,697 down to 2,100,297 for one single subnetwork. Meanwhile, the chance of overfitting is greatly decreased. In
Table 1, we have listed out the different configurations for better clarification.
For the PPF framework [
32], we have adjusted the voting size during the testing stage to be three (the default value is five), which matches the size with other spatial spectral methods (
) in our paper.
When building the proposed framework in
Figure 2, we choose
,
-lite and BsNet as the subnetworks, which we refer to as SPPF framework (
), SPPF framework (
-lite), and SPPF framework (BsNet) respectively. The subnetworks are initialized with default configurations and further fine-tuned for advantageous performance during the training stage of the whole framework. The rest of the parameters are set to be the default.
The proposed and comparative CNN models are all developed using the Torch7 deep learning package [
50], which makes many efforts to improve the performance and efficacy of benchmark deep learning methods. The training procedures for all models are run on an Intel Core-i7 3.4-GHz PC with an Nvidia Titan X GPU. For the proposed framework, we use the tricks in efficient backprop [
51] for initialization and the adaptive subgradient online learning (Adagrad) strategy [
52] for optimization, which allows us to derive strong regret guarantees. Further details and analysis of the performance of the network configurations are given in the following subsection of the experimental classification results.
4.3. Configuration Tests
For establishing a stable architecture, we have tested several configurations and verifications on different datasets. The major configurations are kept in the same, except parameters to be verified.
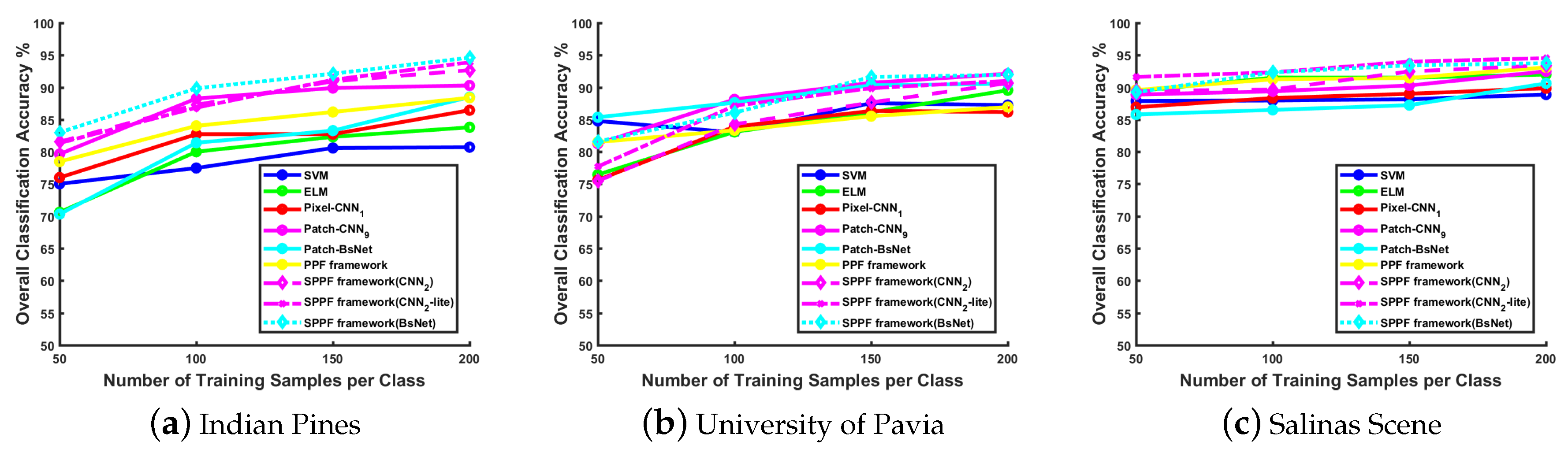
Effect of training samples:
Figure 3 illustrates the classification performance with various numbers of training samples on different datasets. Generally, when the training size increases, the performance of all methods has a noticeable improvement. In the following experiments, we choose 200 samples from each class, which gives a relatively larger number of training samples against the overfitting problem. The remaining instances of each class are grouped into the testing set. The detailed dataset class description and configuration are presented in
Table 2. All those samples are normalized to a new range with zero mean and unit variance before they are fed into different models.
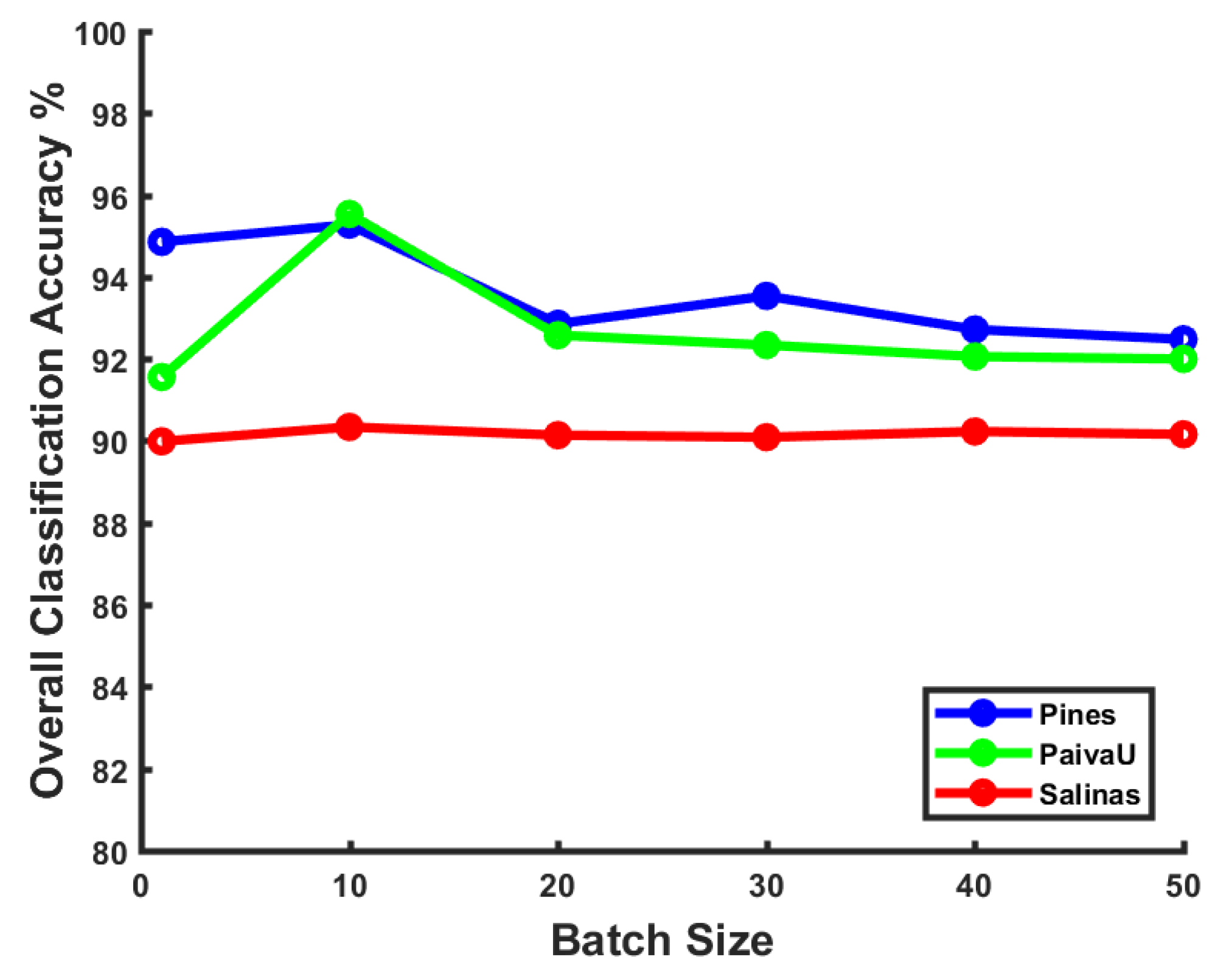
Effect of batch size: The size of sample batches during the training stage can also have some impact on the model performance, especially for optimization methods like stochastic gradient decent. We have tested various batch size values ranging from 1–50 on three datasets. The results are shown in
Figure 4. We can figure out that a larger batch size does not necessarily always help the model obtain better performance. Although the mini-batch training trick has the strength of faster convergence maintenance, a larger batch size with limited samples disturbs the convergence stability occasionally. In the following experiments, we choose a batch of 10 samples for training, which gets the top classification precision in our framework.
Effect of the average pooling layer: The average pooling layer is designed to introduce the framework with noise and variance stability, which also shares a similar property as the voting stage in the PPF framework. As can be seen from
Table 3, the precision improved with about 0.8% for the Pines and Salinas datasets. For the PaviaU dataset, the influence is not that obvious. As the spectrum in PaviaU is much shorter (103 bands in fact), noises may not be that essential as the remaining two dataset with over 200 bands. With no harm to the final precision, we would keep the averaging layer in the following experiments for all datasets.
Effect of FC layers: There is no doubt that the capacity of fully-connected layers can directly influence the final classification accuracy. While a larger size of FC layers increases the classifier capacity, models with smaller ones are easier to train and suit problems with limited training samples better. During the framework design, we have tried to use two and three fully-connected layers alternatively. As shown in
Table 4, the model with
-lite as subnetworks working on different datasets shows various performance results. Take the Pines dataset as an example: when we change from two FC layers to three FC layers, the precision obtains about a 2% decrease. Meanwhile, we have a slight drop on the PaviaU dataset and about 0.5% improvement on the Salinas dataset. One reason might be that the higher capacity of a fully-connected classification module is needed when we have a superior number of classes in the dataset. In the remaining experiments, to make one unified framework, we choose two FC layers as the prediction module.
4.4. Classification Results
In this subsection, we give the detailed results from the proposed model, as well as comparative ones on three datasets.
Table 8,
Table 9 and
Table 10 list out the details of OA and AA for the Pines, PaviaU and Salinas datasets, respectively.
One obvious observation would be that CNN-based deep models (Columns 4–10) show boosting performance over shallow models like SVM (Column 2) and ELM (Column 3). That reflects the booming development of deep learning methods in recent years with competing accuracy.
Spatial consistency reserves a strong constraint for HSI classification. For spatial spectral-based CNN models (Column 5), there is about a 4% improvement compared to spectral alone (Column 4). The introduction of neighbor pixels not only gives models more information during prediction, but also maintains contextual consistency.
For SPPF-based models, it is verified that the performance of conventional deep learning solutions for HSI classification can be further boosted by the proposed SPPF-based framework. When comparing Column 5 with Column 7 and Column 6 with Column 10, we can observe that both CNN [
37] and BsNet get better performance when embedded in the proposed framework. This confirms that the proposed framework works efficiently without any increasing of training samples. Besides, the SPPF framework with
-lite (Column 9) shows even better results than
(Column 8), which contains much more parameters than the previous one. Hence, the framework also shows an advantage in controlling the model size on the same task. Moreover, we do not need that many parameters to maintain a good performance if the problem has limited samples. To be concise, by simply changing from conventional CNN models to the SPPF framework, we can greatly shrink the model size and meanwhile relieve the over-fitting chance.
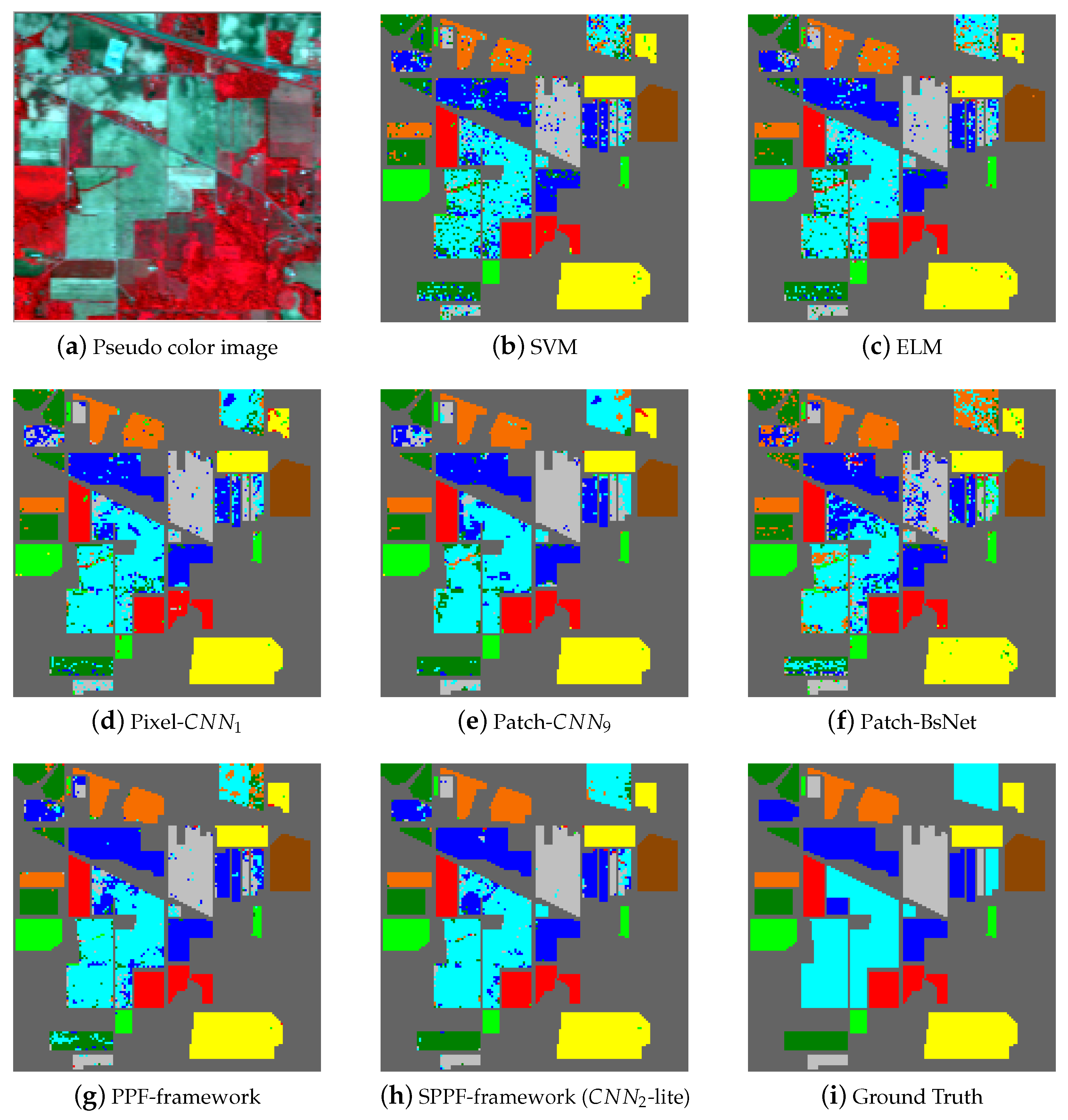
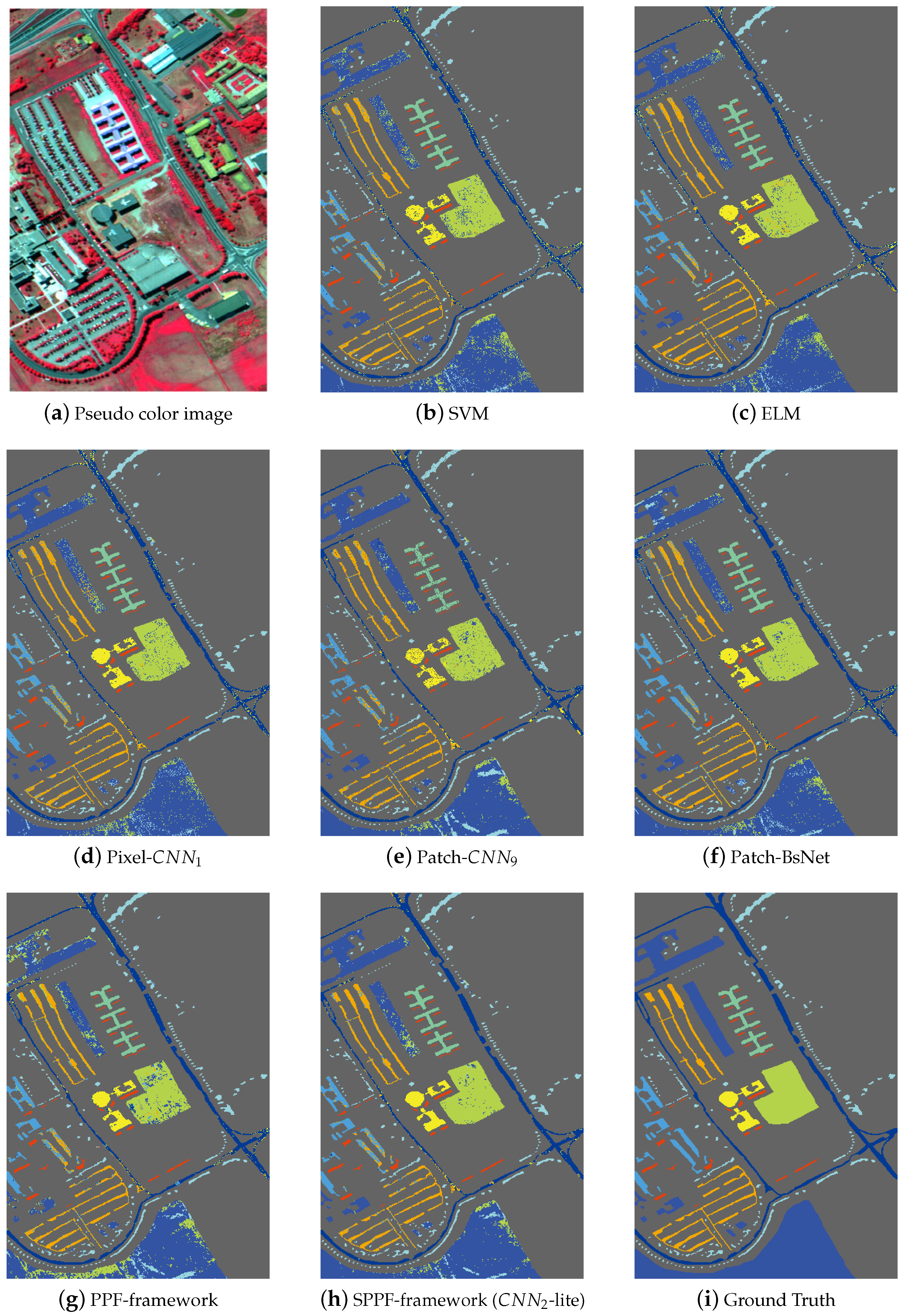
Figure 5,
Figure 6 and
Figure 7 shows the thematic maps accompanying the results from
Table 8,
Table 9 and
Table 10 separately. In
Figure 5a, we give one pseudo color image of the Indian Pines dataset for a better illustration of the natural scene and also for the declaration of why spatial consistency holds.
Figure 5b–g shows the classification results from SVM, ELM, Pixel-
, Patch-
, BsNet and the PPF framework,
Figure 5h shows the result from the SPPF framework (
-lite), which is the best one of the SPPF models. Lastly,
Figure 5i gives the ground truth map. Similar results are also shown in
Figure 6 and
Figure 7 for the remaining two datasets. It is straightforward to tell that the results from SPPF show superior performance to the previous methods, where less noisy labels are given and the spatial consistency is improved.
The statistical differences of SPPF over competitive models with the standardized McNemar test are given in
Table 5. According to the definition in [
53], the value
Z from McNemar’s test reflects that one method is significantly statistically different from another when its absolute value is larger than
. The larger value of Z shows better accuracy improvement. In the table, all the values show that the proposed SPPF outperforms previous CNN-based solutions.
Table 6 gives the total time consumption of training models and the average time cost of testing one sample. All the experiments are fulfilled with the Torch7 package using the same PC described in
Section 4.2. It is worth mentioning that as we have set the early-stopping criterion when training error stops dropping or validation accuracy starts decreasing, the training time does not necessarily reflect each model’s complexity. The testing time, on the other hand, is more suitable as a reflection of the model complexity. It is reasonable for the PPF model to take a much longer training time, as it is dealing with many more samples. Besides, the relatively high testing consumption of PPF relies on the fact that the model should be run eight times before the voting stage. Meanwhile, the voting stage, which is not a part of the model, also requires extra time. When conventional CNN models are embedded into the SPPF framework, their time consumptions increase accordingly. However, the testing time difference of BsNet when embedded is not that obvious. That is because most of the time consumption comes from the grouping stage, which shows no difference in those cases. Besides, the input channels are decreased, which also helps with time saving.
4.5. Discussion
Based on the comparison tests in
Section 4.3 and the classification results in
Section 4.4, a brief performance analysis is included in this section.
The primary comparative advantage of the proposed SPPF framework is the incorporation of contextual information, which has significantly boosted the spatial consistency. Unlike conventional CNN-based HSI classification methods (e.g.,
,
), the discontinuity artifact (such mislabeled pixels distribute randomly and sparsely and form a salt-and-pepper noise pattern in
Figure 5,
Figure 6 and
Figure 7) has greatly attenuated. In addition, the proposed spatial information preserving pixel pair selection scheme in
Section 3.4 are also evidently proven to be superior to the original PPF in
Table 8,
Table 9 and
Table 10.
The advantages of the subnetwork-based multi-stream framework are also verified. Firstly, this particular design offers a scalable network structure template without requiring the formidable manual selection process to determine a suitable sub-network configuration. According to the last three columns in
Table 8,
Table 9 and
Table 10, this multi-stream framework is robust to different selections of subnetworks: both
and BsNet provide decent performances, only marginally inferior to the optimal
-lite. Incidentally, from the comparison between
and
-lite in the SPPF framework, it appears that more parameters (in
) do not necessarily guarantee improved classification accuracy.
For future work, the incorporation of pixel-group features with three or more pixel-combinations shows great potential. Being a natural extension to the pixel pair feature, the triplet pixel feature is introduced and briefly tested bellow, with initial performance already better than the original pixel pair feature. Further analysis of the choices of adjacent pixels and label assignment strategy is going to be included in our future work.
Effect of spatial triplet pixel features: Since we have designed the framework to adopt multiple pixel-pairs as input rather than the normal patch, it is interesting to explore if more pixels as features can work better. In this subsection, we use triplet pixels as an input feature for subnetworks. Comparing with pixel-pairs, triplet pixels show the subnetworks more information and also greater potential of better classification capacity. For achieving this experiment, the first convolutional layer in subnetwork is changed to three input channels, slightly different from the two input channels for SPPF framework, which we present as
-lite. The remainder of the whole framework is kept the same. For sample formatting, we have instance
, with
being the query central pixel,
. The label prediction for one triplet pixel is carried out by
,
where
. The training label for this spatial triplet pixel features is defined as:
Since the combination of triplets are various for a
-neighbor, in practice, we randomly choose eight triplets to fit into the framework presented previously. The final prediction results are shown in
Table 7. The precision shows noticeable increase on all datasets. This observation embraces our proposal that using spatial consistency can greatly improve the models’ capacity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}