1. Introduction
Clustering is an important topic in machine learning, which aims to discover similar data and group them into clusters. Various clustering algorithms have been proposed and widely used in different areas such as sensor networks [
1,
2,
3,
4], image processing [
5,
6,
7], data mining [
8,
9,
10], text information processing [
11,
12], etc.
In classical clustering algorithms, the centroid-based methods, density-based methods and connectivity-based methods are the most commonly used in practice (such a categorization is according to the different cluster models employed). The most well-known clustering methods include the
k-means [
13], DBSCAN [
14], CURE (Clustering Using REpresentatives) [
15], etc. They respectively belong to the three aforementioned categories. There are also many recent works focused on improving the performance of the classic clustering schemes [
16,
17,
18,
19], or exploiting novel clustering methods using different closeness measures [
20,
21,
22,
23].
The effectiveness of clustering methods, to a great extent, is determined by the closeness measure between data points or clusters. In most classical methods, only the geometric distance is used to measure the closeness between data points, and the closeness between clusters is based on the closeness between their representative data points.
However, the distance-based metrics only focus on the geometric closeness. Although these metrics are appropriate for clustering tasks where the data points’ distribution conforms to some strong assumptions, e.g., regular shapes and uniform density, they perform not so well in complicated situations. For example, in
k-means and its related methods, partitions are formed based on the distance between each data point and each centroid. Such partitioning rule will bring incorrect results when data points belonging to a given cluster are closer to the centroids of other clusters than to the centroid of the given correct cluster [
24]. In DBSCAN, the clustering performance depends on the two parameters defining the neighborhood size and density threshold, which are based on some geometric distances [
25]. Since the threshold is predefined and fixed, DBSCAN will generate incorrect results, if the densities of the data points in different clusters are varying. In existing agglomerative hierarchical clustering methods [
26], sub-clusters are merged according to the closeness measures such as the single linkage and the complete linkage [
27], where the closeness is determined by the pairwise geometric distances between inter-cluster representative data points. Due to the similar reasons that cause problems in the aforementioned methods, these agglomerative hierarchical algorithms usually work well only for the spherical-shaped or uniformly-distributed clusters [
24].
The limitations of the traditional closeness measures in clustering have attracted much attention, and thus, many approaches using different closeness definitions have been proposed to address the aforementioned problems. One branch of methods uses the clusters’ probability distribution information and its closeness definition. For example, Lin and Chen [
28] proposed the cohesion-based self-merging algorithm, which measures the closeness between two sub-clusters by computing and accumulating the “joinability” value of each data point in the two clusters. Dhillon et al. [
29] used a KL divergence-based [
30] clustering scheme to cluster words in the document categorization. KL-divergence is a measure of “distance” between two probability distributions (it is not a true distance metric because it is not symmetric, and it violates the triangle inequality). In the scheme, a word is assigned to a cluster if the distribution of this word has the smallest “distance” (measured by KL divergence) to the weighted sum of the distributions of the words in that cluster. Similar ideas can be seen in [
31,
32]. Heller et al. [
33] and Teh et al. [
34] used Bayes rule in a hierarchical clustering scheme to guide the merging process, where each pair of the clusters is assigned a posterior probability based on the Bayesian hypothesis test and the two clusters with the highest posterior probability are merged. By incorporating the distribution information, these methods are more robust to outliers and can deal with data with arbitrary shapes. However, users must know the clusters’ probability density functions (pdf) before running the algorithms. Another branch of refined clustering methods are based on the graph theory. Karypis et al. [
24] proposed the algorithm of chameleon, where a graph based on
k-nearest neighbors is constructed and then cut into sub-clusters. The relative inter-connectivity and the relative closeness are used to determine the closeness between sub-clusters, and the algorithm achieves good results in finding clusters with arbitrary shapes. Similarly, we can see in [
35,
36], and more recently in [
37], that Zhang et al. proposed an agglomerative clustering method where a structural descriptor of clusters on the graph is defined and used as clusters’ closeness measure. The properties of graph theory make it very appropriate to describe clustering problems, and the methods based on graph theory perform well in dealing with clusters with arbitrary shapes. However, we find that these methods often fail to adapt to clustering tasks with very different clusters’ densities, although they use new closeness measures. In the two branches of refined clustering methods above, different kinds of closeness measures have been proposed to address the problems caused by the geometric distance-based closeness measures. These new measures do not focus on the geometric closeness alone, and they achieve success in many clustering tasks. However, they still have their own limitations. In particular, as mentioned above, these closeness measures either ignore the density information or need strong a priori information.
Therefore, in this paper, we first focus on designing a more comprehensive closeness measure between data points to substitute the traditional geometric distance-based closeness measures in clustering algorithms. The new measure is called the Closeness Measure based on the Neighborhood Chain (), where the neighborhood chain is a relationship established between two data points through a chain of neighbors. By substituting their original closeness measures with , many simple clustering methods can deal with the complicated clustering tasks with arbitrary clusters shapes and different clusters densities.
Prior to ours, there were some recent works in the literature that also utilized the
k-nearest neighbors relationship in clustering problems. For example, Liu et al. [
38] proposed a clustering algorithm named ADPC-KNN (Adaptive Density Peak Clustering
kNN), where they modified the density peaks’ clustering [
39] by using the distribution information of
k-nearest neighbors of a data point to calculate its local density. Sur et al. [
40] proposed a clustering method that forms a cluster by iteratively adding the cluster’s nearest neighbor into that cluster (a threshold is defined determining whether this nearest neighbor can be added into the cluster). In a series of work proposed in [
41,
42,
43,
44], Qiu et al. used an algorithm called nearest neighbor descent and its several modifications to organize the data points into a fully-connected graph “in-tree”, and the clustering results can be obtained after removing a small number of redundant edges in the graph. In the nearest neighbor descent algorithm, each data point “descends” to (links to) its nearest neighbor in the descending direction of density. Other similar works utilizing the
k-nearest neighbors in clustering can be seen in [
45,
46].
In the above cited works, the neighborhood relationship is used in many ways and resolves different problems in clustering. However, our work presented in this paper is different from the existing methods. In our work, the neighborhood relationship is used to construct a pair-wise closeness measure between two data points, which incorporates not only the connectivity, but also the density information of data points.
The work in this paper is an extension of our previous preliminary work in [
47], where the basic concepts of
were preliminarily proposed. In this paper, we provide more detailed definition and analysis about
. Furthermore, based on
, we also propose a clustering ensemble framework that combines different closeness measures. Due to the involvement of neighborhood relationships, the computational cost of
is relatively high. In the proposed framework, we use different closeness measures (
and Euclidean distance) for different data points and get the unified clustering results. In this way, we are able to limit the use of
to the “least required” number of data points to get the correct clustering results. Therefore, based on the proposed framework, we can get better clustering results and, at the same time, higher efficiency.
The rest of the paper is organized as follows.
Section 2 introduces the basics of the traditional clustering methods and their limitations. In
Section 3, the neighborhood chain is introduced, and
is proposed. The performance of several clustering methods whose closeness measures are substituted with
is provided. The clustering ensemble framework based on different closeness measures is proposed and tested in
Section 4.
Section 5 concludes this paper.
3. Measuring Closeness between Data Points Based on the Neighborhood Chain
As discussed in
Section 2, using the geometric distance alone to measure the closeness might cause problems. The main reason lies in that under the geometric distance metrics, the closeness between data points is fully determined by the positions of the two points being measured in the feature space, and the influence of any other surrounding data points is ignored. However, in many cases, being geometrically close does not necessarily mean that two data points are more likely to belong to the same cluster.
In this section, we propose a Closeness Measure based on the Neighborhood Chain () that quantifies the closeness between data points by measuring the difficulty for one data point attempting to “reach” another through a chain of neighbors. The difficulty is measured by two quantifications called the neighborhood reachability cost and the neighborhood reachability span. Under such a closeness measure, a data point can reach another data point at a low cost as long as they belong to the same cluster, while a data point costs much more to reach another if they belong to different clusters.
Note that the terms “reach” and “reachability” have also appeared in DBSCAN and OPTICS (Ordering Points To Identify the Clustering Structure) [
50], describing whether two data points are density connected based on the geometric distance alone. However, in this paper, the “neighborhood reachability” is defined based on the neighborhood relationship between two data points.
3.1. Neighborhood Chain
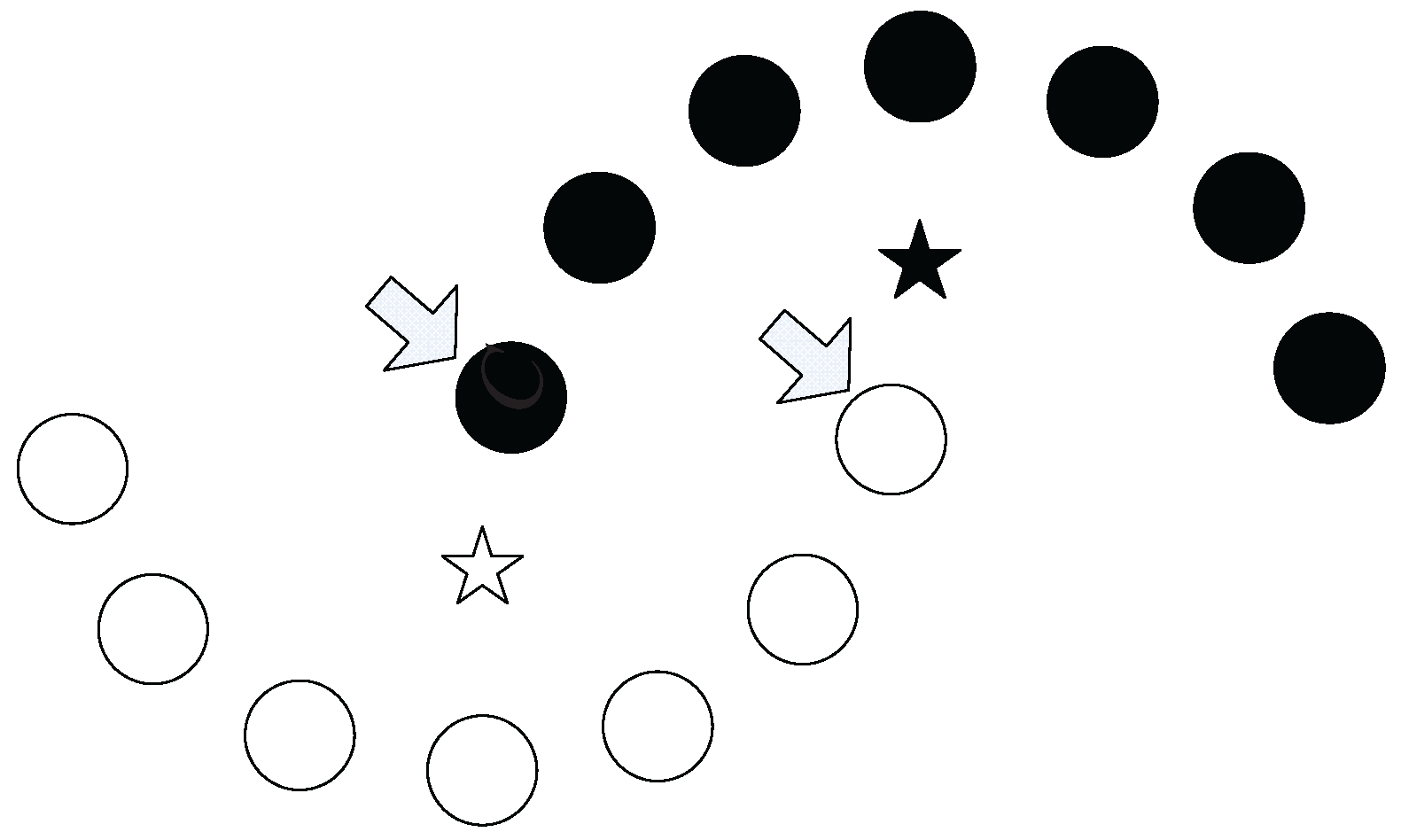
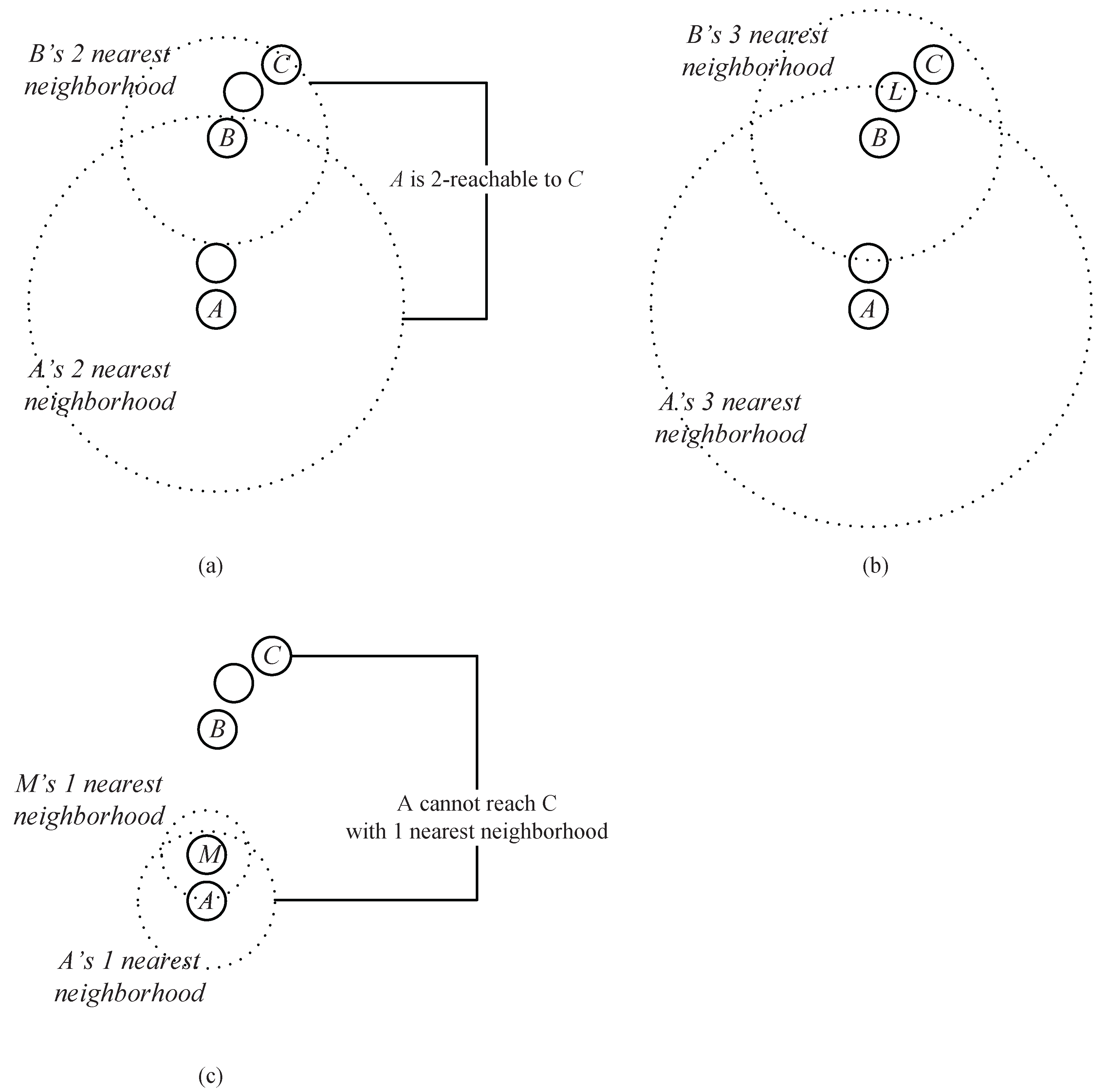
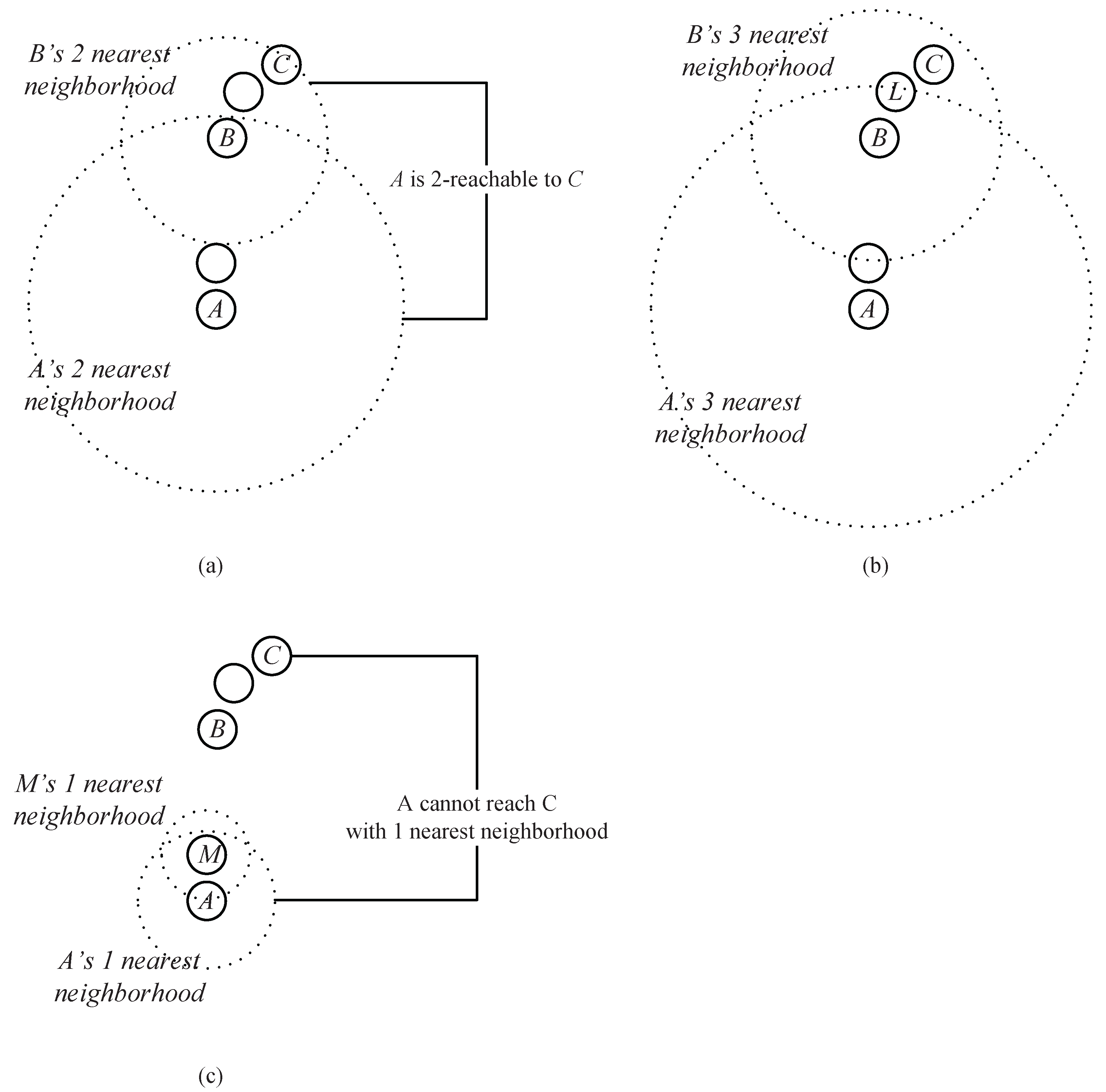
The neighborhood chain contains a series of data points, including a start point and an end point. Each data point in the chain (except the start point) is one of the k nearest neighbors of its precedent data point. Before giving the formal definition of the neighborhood chain, we first use an example to intuitively illustrate how a chain is established.
Example 1. As shown in Figure 4a, assume that A, B and C are the data points in a dataset. Obviously, B is in the two nearest neighbors of A, and C is in the two nearest neighbors of B. Thus, through an intermediate data point B, a chain from A to C based on the two nearest neighbors is established. We say that C can be reached by A via the chain of two nearest neighbors through B. As shown in
Figure 4b,
Bis also in the three (or more) nearest neighbors of
A, and
C at the same time is in the corresponding number of the nearest neighbors of
B, which means that the chain from
A to
C based on three (or more) neighbors can also be established. However, the chain established based on the two neighbors takes a lower cost (which means that the required neighbor’s number is less).
Actually, in
Figure 4, two nearest neighbors comprise the minimum requirement to establish a chain from
A to
C (
Figure 4c shows that the chain from
A to
C cannot be established based on one nearest neighbor). Therefore, we say that
A can reach
C through a neighborhood chain with two nearest neighbors, or
C is two-reachable from
A.
The formal definition of the neighborhood chain is as follows. Assume that
is a dataset and
. Let
be a positive integer that makes a set of data points
in
satisfy:
where
represents the set containing a data point and its
nearest neighbors. If such an integer
exists, we say that the
from
A to
C can be established.
In the given dataset
,
can take different values to establish different chains from data point
A to
C. For example, in Example 1 shown above,
can be 2, 3 or 4 (or even more), which respectively can establish the chain
A-
B-
C,
A-
L-
C, or
A-
C. Therefore, we define:
as the required neighbor’s number to establish the neighborhood chain from
A to
C. In the rest of this paper, the neighborhood chain refers to the chain established based on the required neighbor’s number.
When the required neighbor’s number is determined, the corresponding data points
that satisfy Equation (
1) are called the intermediate point in the chain from
A to
C. In
Figure 4a,
, and
B is an intermediate point from the data point
A to
C.
In practice, the required neighbor’s number and the corresponding intermediate points can be determined through a “trial and error” process. Such a process can be illustrated by
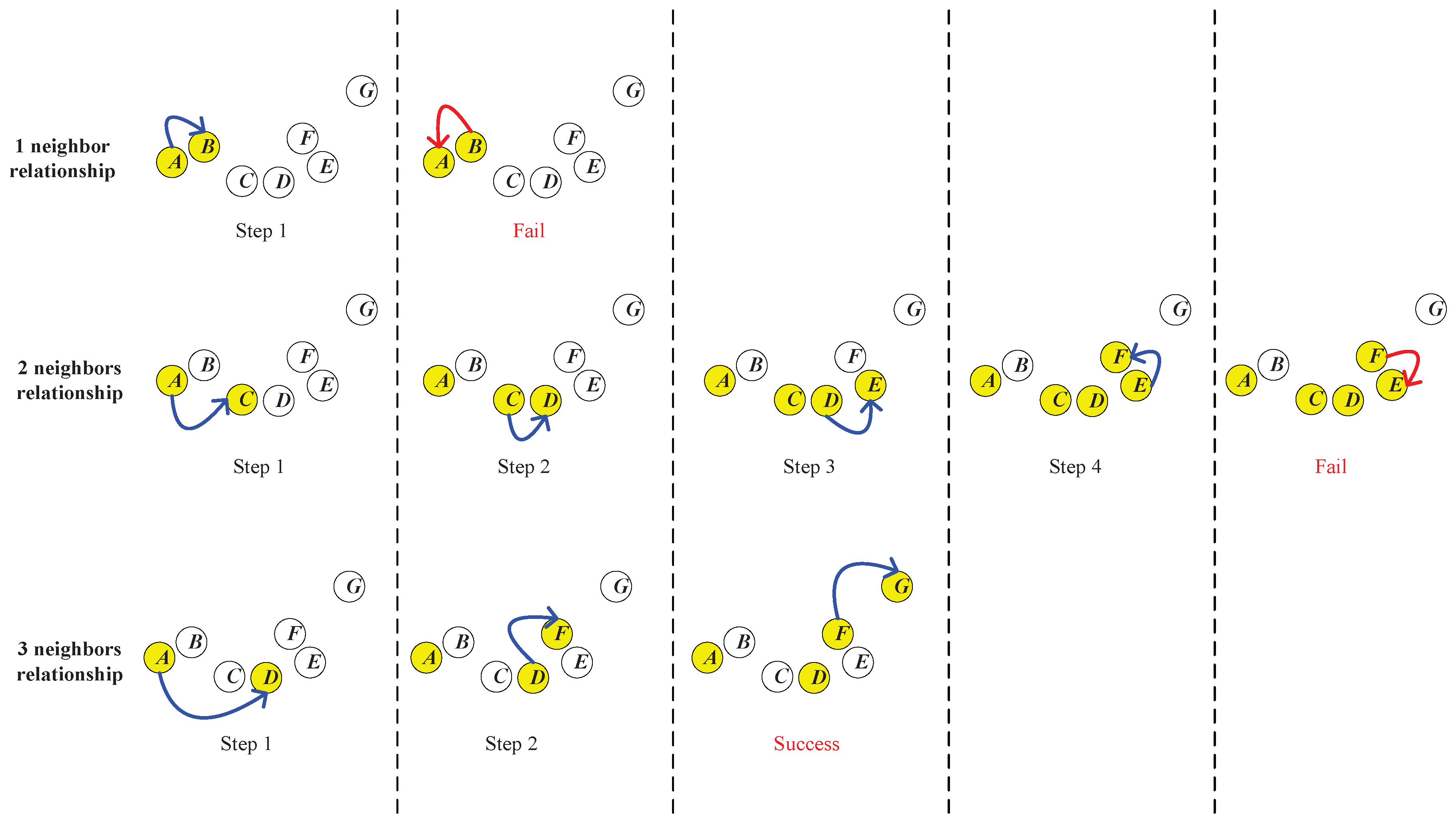
Figure 5.
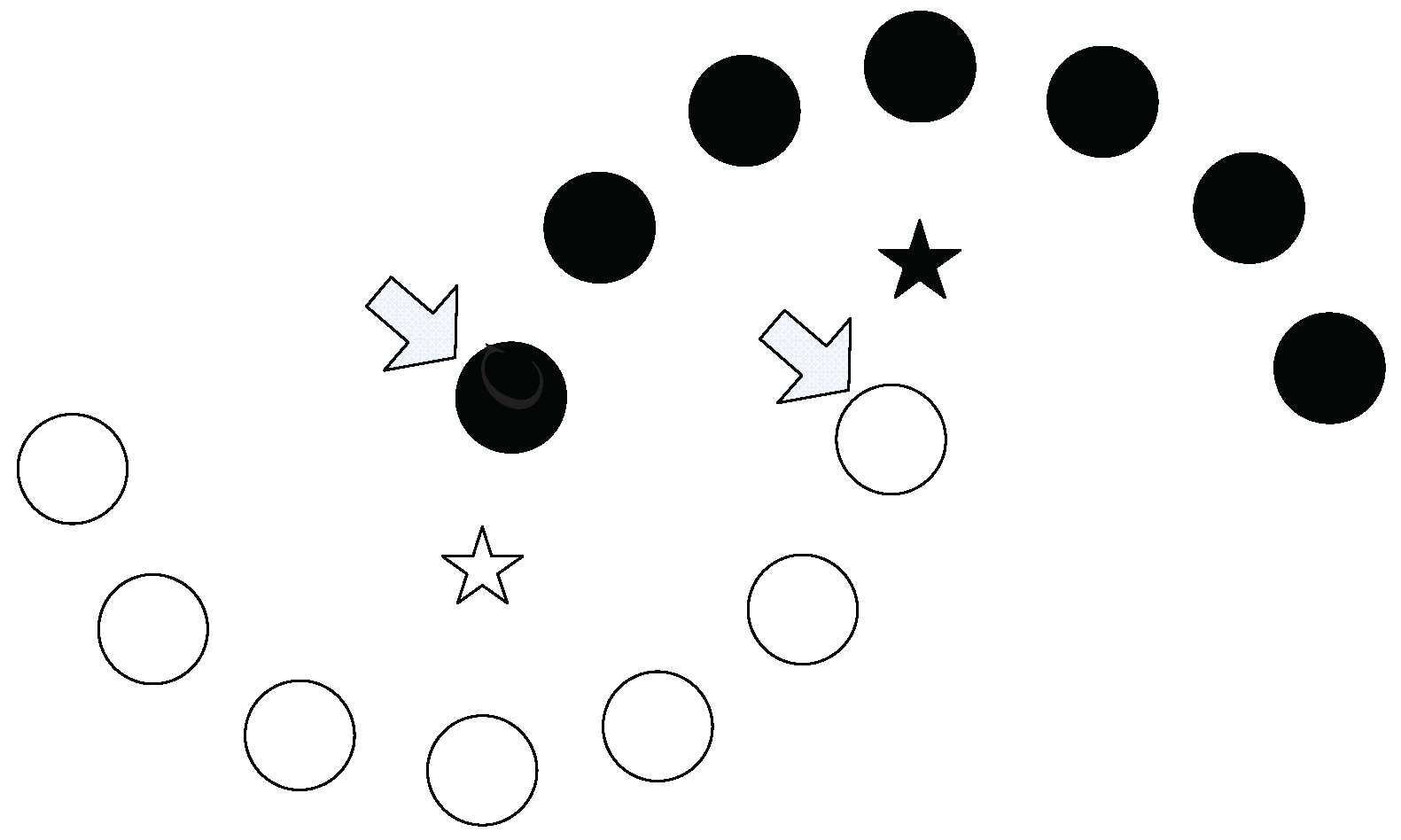
As shown in
Figure 5,
A,
B,...,
G are seven data points in a dataset. Now, we would like to establish a neighborhood chain from
A to
G and determine the required neighbor’s number
. First, we try the one nearest neighbor relationship. As shown in the first row of
Figure 5, in Step 1, we search the nearest neighbor of the start point
A, which is
B, and add it into the chain. In Step 2, we continue to search the nearest neighbor of
B. However, we find that
A is
B’s nearest neighbor, and
A is already in the chain. Therefore, the searching process enters a loop, and the chain from
A to
C cannot be established.
Then, we start over to try the two nearest neighbors’ relationship. As shown in the second row of
Figure 5, in Step 1, we find that
B and
C are both in the two nearest neighbors of the start point
A, and we add
C into the chain, because
C is closer to the destination (the end point
G). In Step 2, we continue to search the two nearest neighbors of
C, which is newly added into the chain, and
B and
D are found. In this step,
D is added into the chain because it is closer to
G. In Steps 3 and 4,
E and
F are added into the chain sequentially. However, in Step 5, when we search the two nearest neighbors of the newly added
F, we only find
E and
D, which are both in the chain already. Therefore, the searching process fails in this step, and the chain from
A to
G cannot be established.
As shown in the third row of
Figure 5, we start over to try the three nearest neighbors’ relationship. In Step 1, we add
D into the chain, because it is the closest to the destination (the end point
G) in the three nearest neighbors of
A. In Step 2, we find
C,
E and
F in the three nearest neighbors of
D, and we add
F into the chain for the same reason. In Step 3, we find the end point
G in the three nearest neighbors of
F, which means that the chain from
A to
G is successfully established. Therefore, the three nearest neighbors comprise the minimum neighbor’s number required to establish the chain, which means that
.
Along with the determination of , the neighborhood chain from A to G is obtained, which is A-D-F-G. {D,F} is the set of intermediate points of the chain from A to G.
In practical applications, in the “trial and error” process to establish the neighborhood chain, we might encounter some situations where several data points in the neighborhood of a point (which is newly added into the chain) have the same distance to the end point we want to reach. In such situations, we just randomly choose one of these points to be added into the chain.
3.2. Quantifying the Difficulty to Establish a Neighborhood Chain
In this part, we define two quantifications of the difficulty in establishing a neighborhood chain, which are the neighborhood reachability cost and neighborhood reachability span.
Neighborhood reachability cost (
): The neighborhood reachability cost is designed based on the required neighbor’s number when establishing a chain from one data point to another. Note that the required neighbor’s number is usually not symmetric, i.e., the required neighbor’s number from a data point
A to another data point
C is usually different from that from
C to
A (as shown in
Figure 6). We define a symmetric quantification:
as the
when establishing a chain between
A and
C, where
can be a function that is monotonically increasing on
. Obviously, the more neighborhood reachability cost needed, the more difficulty in establishing the chain.
In the rest of this paper,
in Equation (
3) is designated as the exponential function, because it can make the
value grow much faster than the
R value grows, which will magnify the difference between the closeness value of two data points from the same cluster and that of two data points from different clusters.
In Equation (
3),
is used to select the bigger one out of
and
to make
a symmetric quantification.
Neighborhood reachability span (
): Although using the geometric distance alone to measure the closeness between data points might cause problems as previously mentioned, it can still be used as a part of the closeness measure to depict in detail the difficulty in establishing a neighborhood chain. The neighborhood reachability span of a neighborhood chain quantifies the maximum span (distance) between the two adjacent intermediate points in a chain.
, if
are the intermediate points in the chain from
A to
C, then there is:
where
is the unidirectional span in the chain from
A to
C, and
is the Euclidean distance between two intermediate points. The
of the chain between two data points
A and
C is defined as:
By selecting the bigger one out of the two unidirectional spans, the is also a symmetric quantification.
3.3. Closeness Measure between Data Points Based on the Neighborhood Chain
The neighborhood reachability cost and the neighborhood reachability span are two parts that jointly quantify the difficulty to establish a neighborhood chain between two data points, and the difficulty in establishing the chain can be used to measure the data points’ closeness. The
between any two data points
A and
C in a dataset is defined as:
A bigger value means that the chain between the two data points can be more easily established, which represents that the two points are closer, while a smaller represents the opposite. Strictly speaking, is not a distance metric since it violates the triangle inequality due to the use of the neighborhood relationship. However, using as a kind of closeness (similarity) measure, we can obtain more intuitive and rational closeness quantifications compared with using traditional closeness metrics based on the geometric distance alone in clustering tasks. The followings are two examples illustrating the computation of .
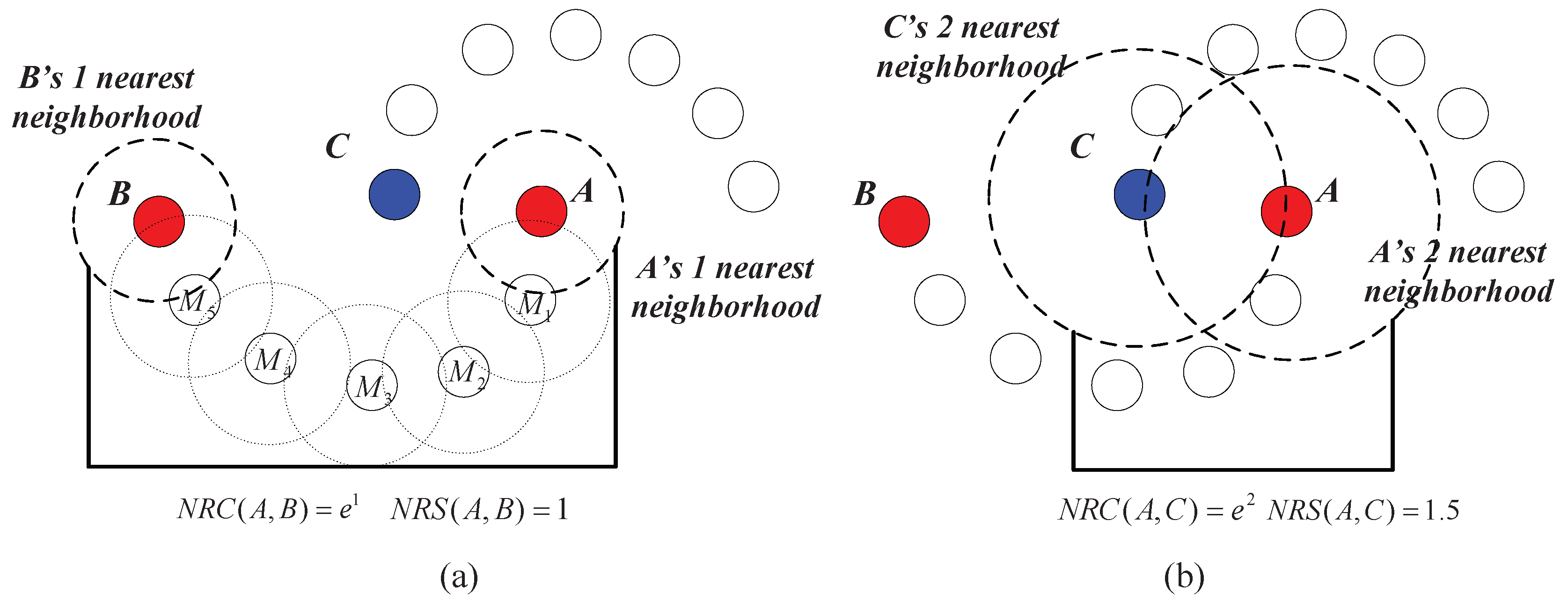
Example 2. As shown in Figure 7a,b, assume that the distance between any two adjacent data points belonging to the same cluster is one (e.g., the distance between and is one) and the distance between the nearest pair of data points that belong to different clusters is 1.5 (i.e., the distance between A and C is 1.5). In
Figure 7a, we calculate the
value between data points
A and
B. Note that
is in the nearest neighborhood of
A;
is in the nearest neighborhood of
; and the relationship spread all the way to B. Therefore,
, and we have
.
to
are the intermediate points in the chain between
A and
B, and the distance between any two adjacent intermediate points is one. Therefore, we have
. Then,
.
In
Figure 7b, we calculate the
value between data points
A and
C. Note that two nearest neighbors are needed to establish a chain between
A and
C, so we have
and
. Therefore,
.
In this example, we see that although the geometric distance between A and B is much longer than that between A and C, A and B is much “closer” than A and C using the measure.
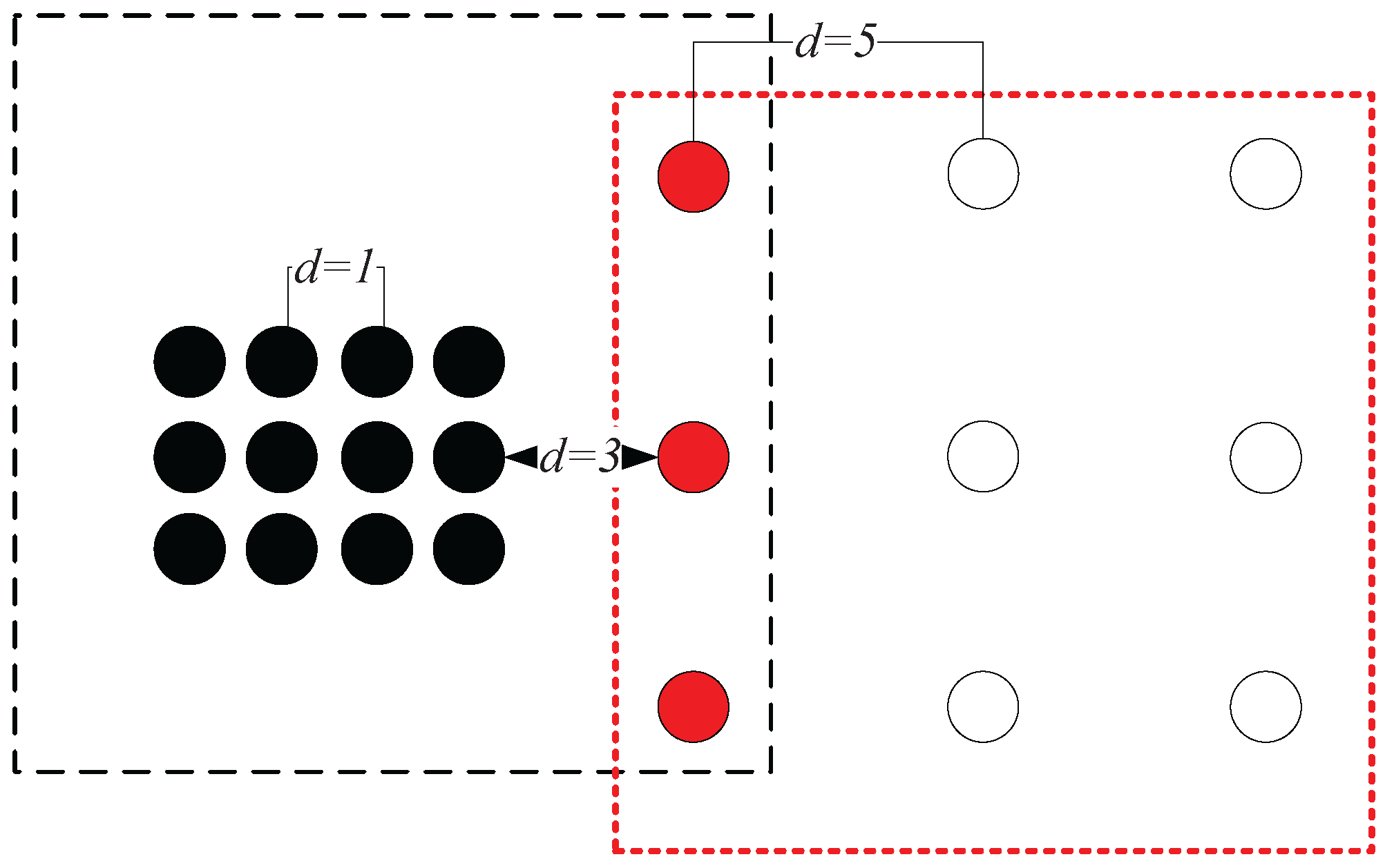
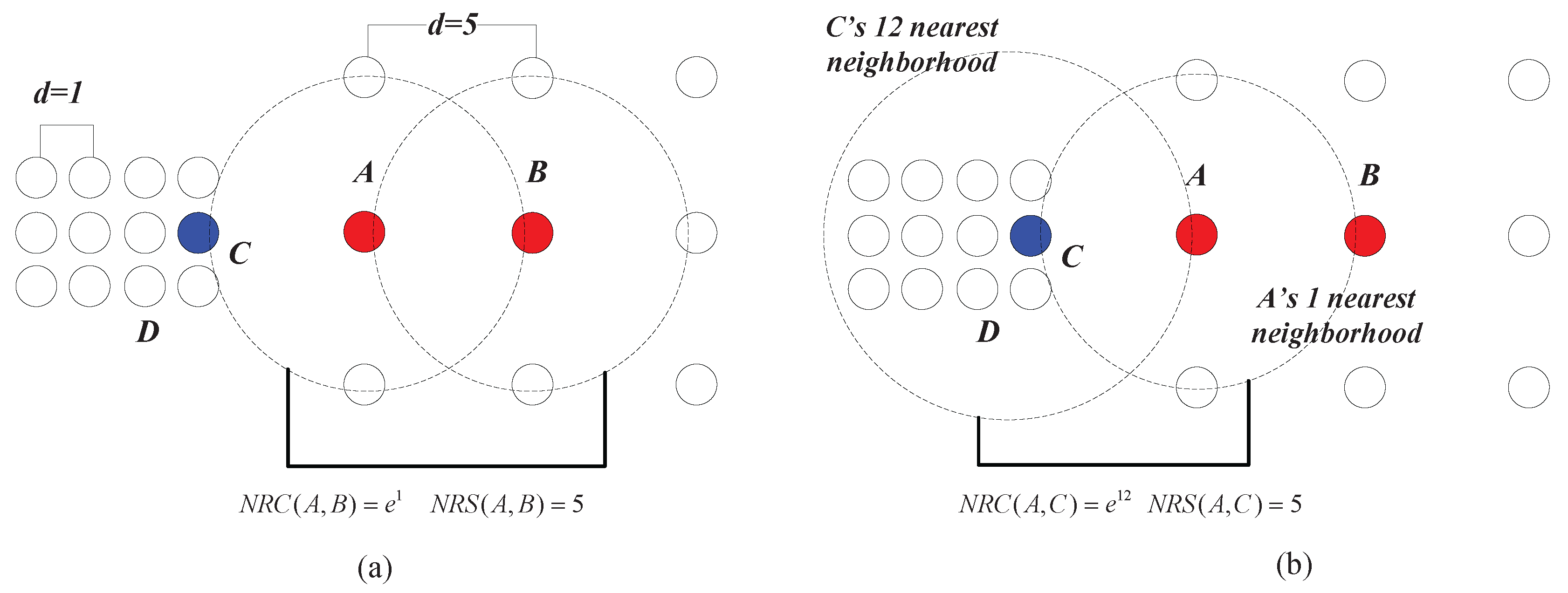
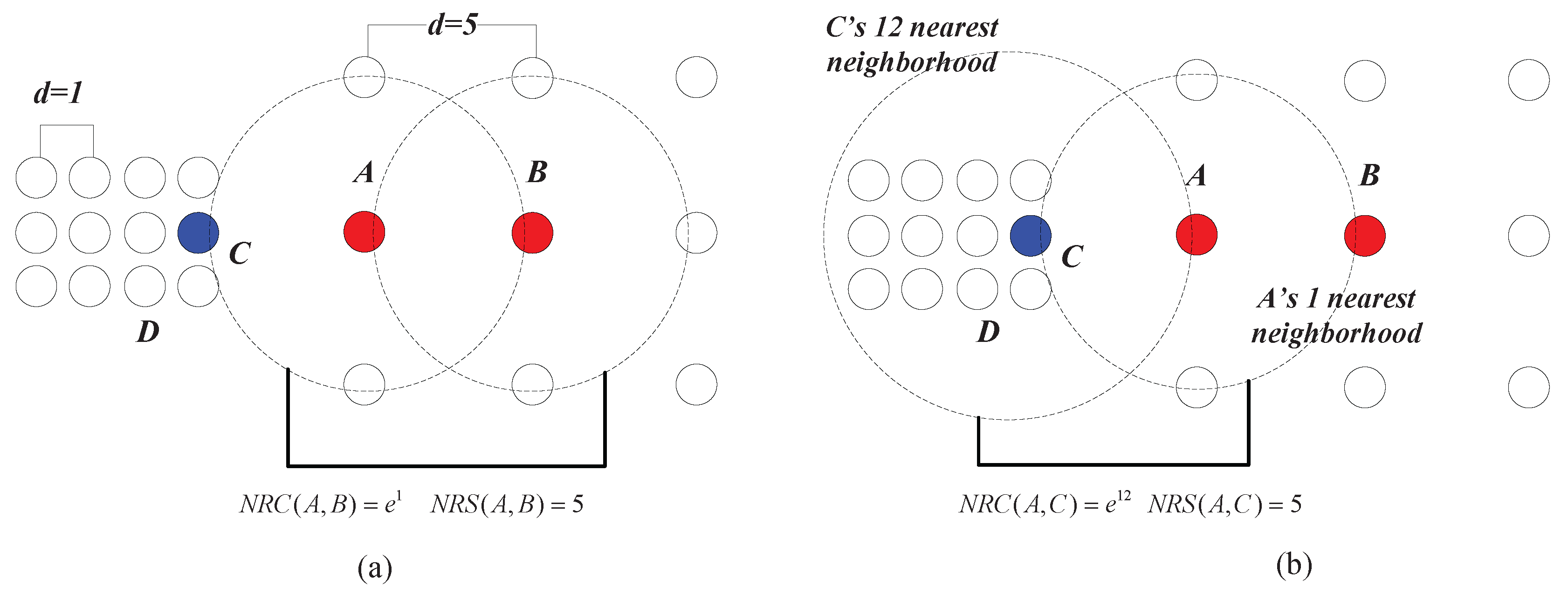
Example 3. As shown in Figure 8a, the chain between A and B can be established with one nearest neighbor, thus and . In Figure 8b, C can be reached by A with one nearest neighbor, and thus, . However, the lowest cost that it takes for A to be reached by C is 12 nearest neighbors, which means that . Therefore, we have . This shows that although the geometric distance between A and C is equal to that between A and B (e.g., the Euclidean distances between A and C and that between A and B are both five in this case), the data points from two different clusters can be clearly separated using the measure ( is much smaller than ). In fact, in the case shown in
Figure 8, the neighborhood reachability cost between any two data points that belong to the same cluster is always
(e.g.,
). This means that although the densities of the two clusters are different from the global point of view, the relationship between data points within each cluster, from the clusters’ local point of view, are very similar. In other words, this means that seeing from the individual cluster they belong to, the closeness between
A and
B is similar to that between
C and
D. In such a situation, the closeness of data points depicted by
can adapt to different clusters’ “local density”, while traditional density-based methods like DBSCAN using geometric distance metrics alone can only deal with the clusters having the same density.
In the last part of this section, we give the algorithm to compute the
value in pseudocode. The Algorithm 1 is as follows:
| Algorithm 1 |
| : , , , =, and the dataset . |
| : the value of . |
| : find ’s k nearest neighbors in , and denote them as . |
| : In , find the point closest to , and denote it as . If multiple points in have the same distance to , choose one randomly, and denote it as . |
| : If ==, GO TO . Otherwise, GO TO . |
| : If is found in , then set = , , k = k + 1, and GO TO . |
| Otherwise, =∪, , and GO TO . |
| : If this is the first time entering , then , and equals the maximum distance between any two adjacent points in . Set , =, , , and GO TO . |
| Otherwise, , and equals the maximum distance between any two adjacent points in . GO TO . |
| : Calculate , , and . |
3.4. Computational Complexity of
In the worst case, the computational cost to calculate could be . In the following, we will illustrate how the expression is obtained.
In order to quantify the computational cost when measuring the closeness between two data points (say A and C) with , we need to examine the computational cost of each component ( and ) of the measure.
Computational cost to calculate
: As shown in Equation (
3), we need first to compute
and
before computing
. As illustrated in
Section 3.1, we use a “trial and error” process to build the neighborhood chain from
A to
C. Assume that we need to try
t times to successfully build the chain from data point
A to
C (which means that the chain is established on the
t-th try, and
), and in each try
i,
, we have added
points into the (unaccomplished) chain before the establishing of the chain fails. In the
t-th try, the chain is established; therefore,
is the number of the intermediate points from
A to
C. Under such assumptions, we actually need to execute
times the nearest neighbor searching algorithm, where the distance between one data point (whose neighbors are to be found) and all other data points in the dataset will be computed. Therefore, the computational cost calculating
can be expressed as
, where
n is the number of data points. Similarly, we assume that
(which means that the chain from
C to
A is established on the
-th try), and in each try to establish the chain from
C to
A,
(
) represents the number of data points added into the chain. The computational cost calculating
can be expressed as
. Therefore, the computational cost calculating
can be obtained by summing the cost of
and
and be expressed as
.
Computational cost to calculate
: As shown in Equations (
4) and (
5), we need to compute the distance between each pair of the adjacent intermediate points in the chain from
A to
C and that from
C to
A. Therefore, under the assumptions in the previous paragraph, the computational cost calculating
can be expressed as
.
The total computational cost to calculate can be obtained by summing the cost of and . In normal situations, and are much less than the data points number n; therefore, the cost of is negligible. The computational cost to calculate can be expressed as .
The expression illustrates that the computational cost to calculate is determined by the total execution times of the nearest neighbor searching algorithm in the establishing of the neighborhood chain from A to C and from C to A. Such an expression of the computational cost depends largely on the inner structures of the given dataset, and the selected start and end points; therefore, we can hardly use it to evaluate the average computational cost to calculate the value between any two data points in a dataset. However, we can still use it to estimate the highest possible cost to calculate in the worst case. In the extreme situation, t and can both reach , and and can also reach . Therefore, in the worst case, the computational cost to calculate could be .
3.5. Substituting Closeness Measures in Traditional Clustering Methods with
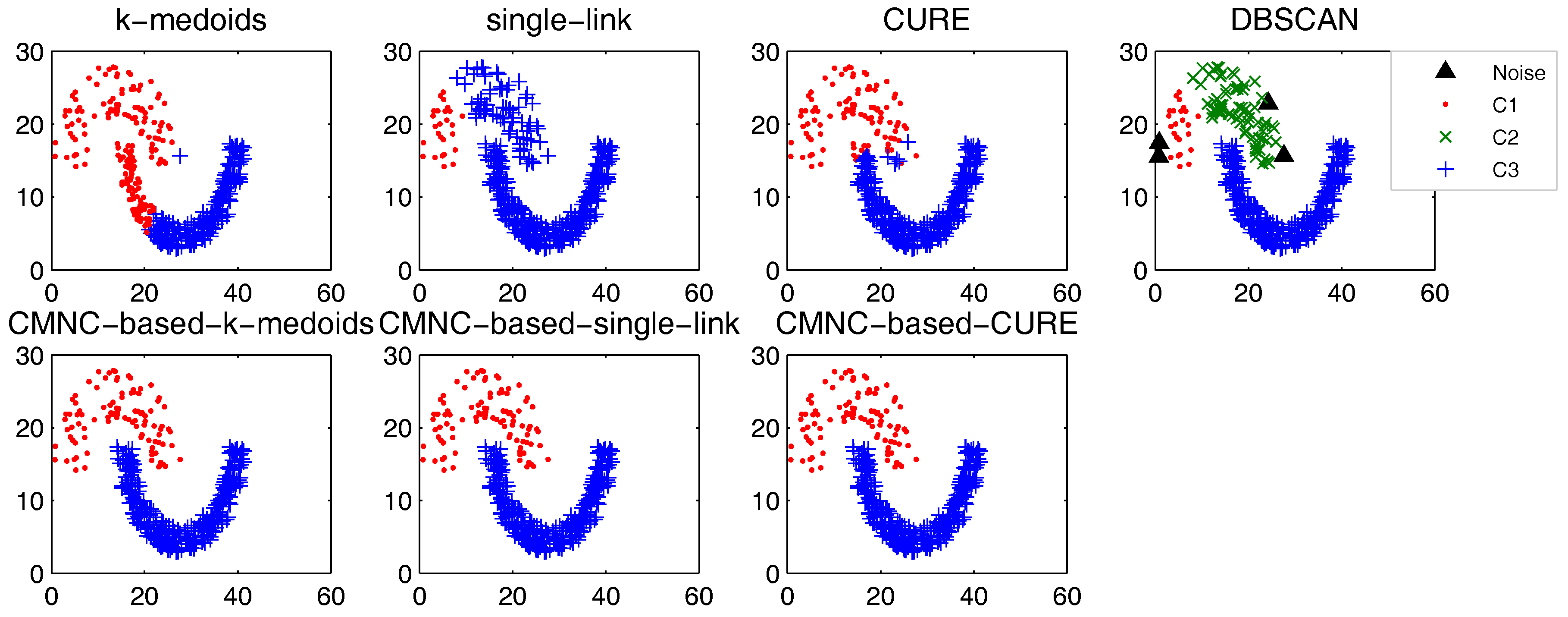
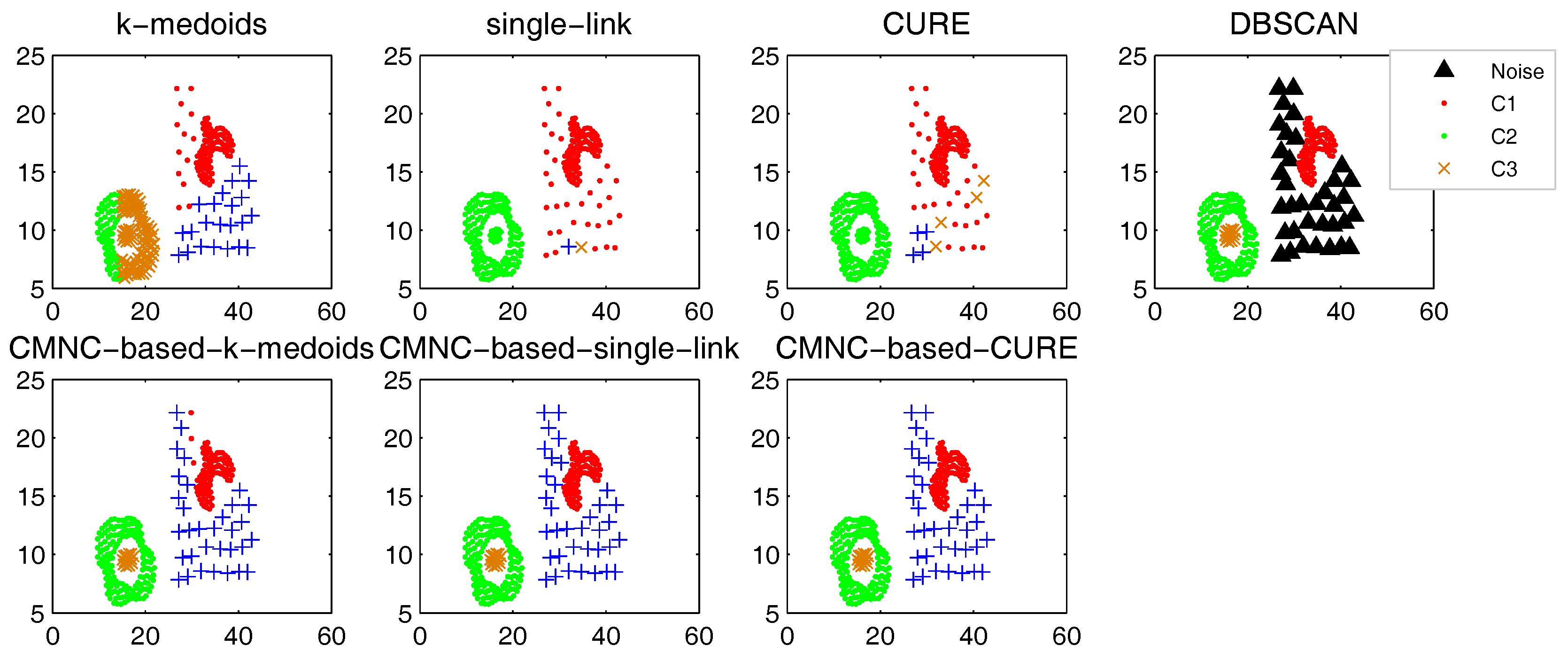
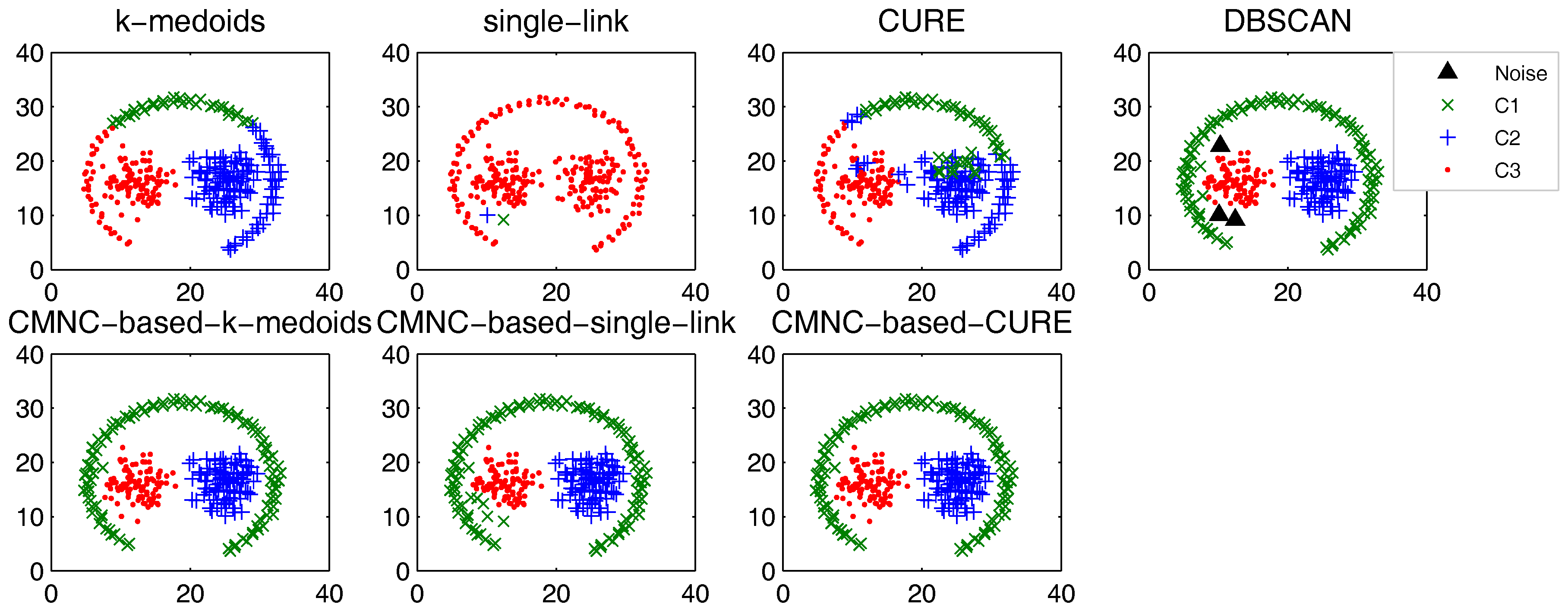
In this part, we test the performance of the proposed closeness measure by substituting the geometric-distance-based closeness measures between data points in some clustering methods with . The methods for testing include the original versions of k-medoids, single-link, CURE and their -based versions (the closeness between the data points or between clusters in these methods is calculated with pairwise-distance-based measures; thus, it is easy to substitute these measures with ). DBSCAN is also tested for comparison.
In the test of all the original version methods, Euclidean distance is used as the closeness measure. In the test of k-medoids and -based k-medoids, to exclude the impact of initial centers selection, we give them the same initial centers, where each center is randomly selected from one natural cluster. In -based k-medoids, the “distance” between data points and the centers is calculated with . In -based single-link method, the similarity of two clusters is represented by the value of their most similar (using measure) pair of data points. In -based CURE method, the clusters with the closest (using measure) pair of representative data points are merged in each iteration. The natural (true) clusters number is assigned to k-medoids, single-link, CURE and their -based versions as the input parameter.
The test results of the aforementioned methods on three datasets [
51,
52,
53] are shown in
Figure 9,
Figure 10 and
Figure 11. For DBSCAN, the shown results are the best results selected by traversing its parameters
and
.
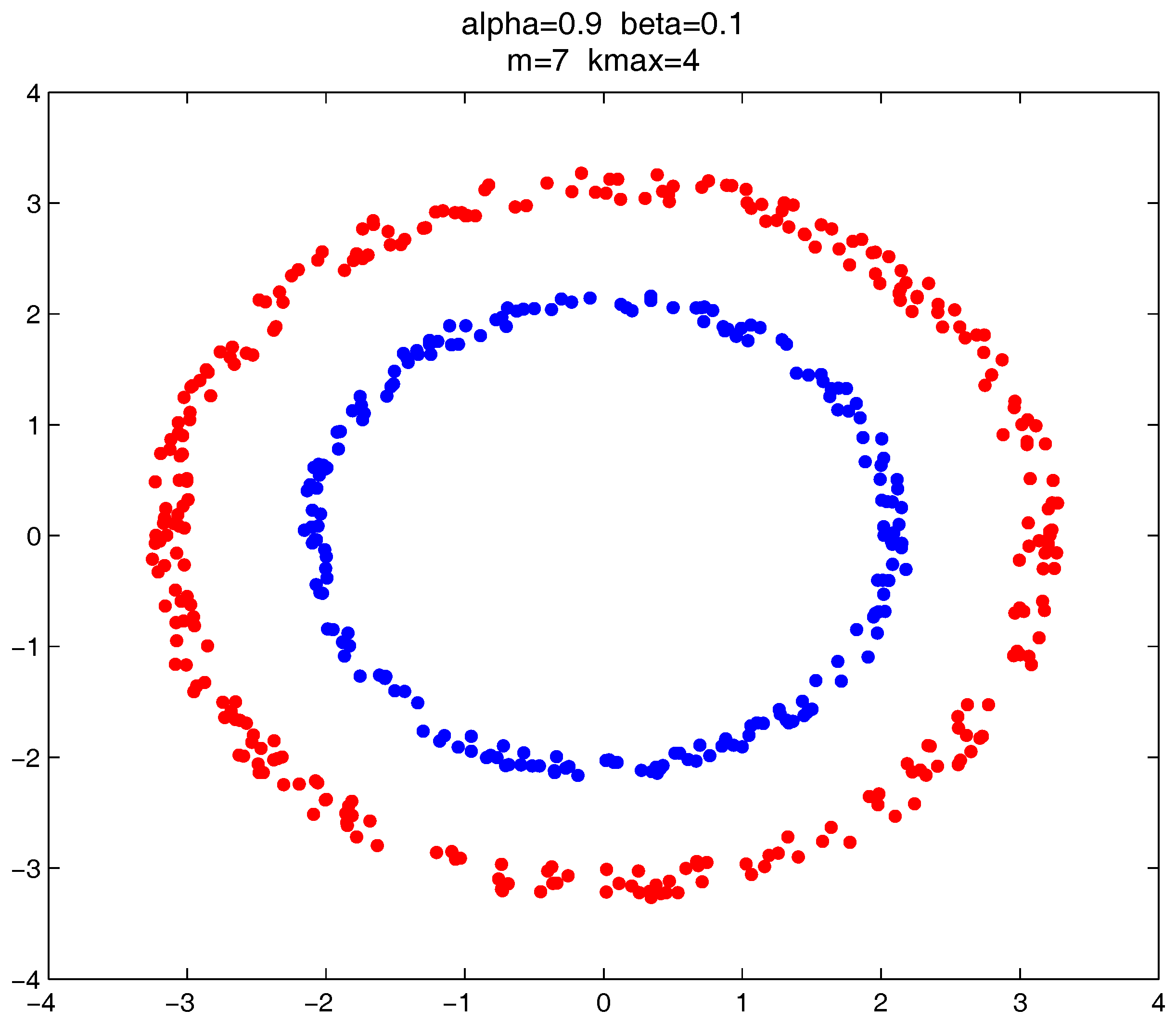
In
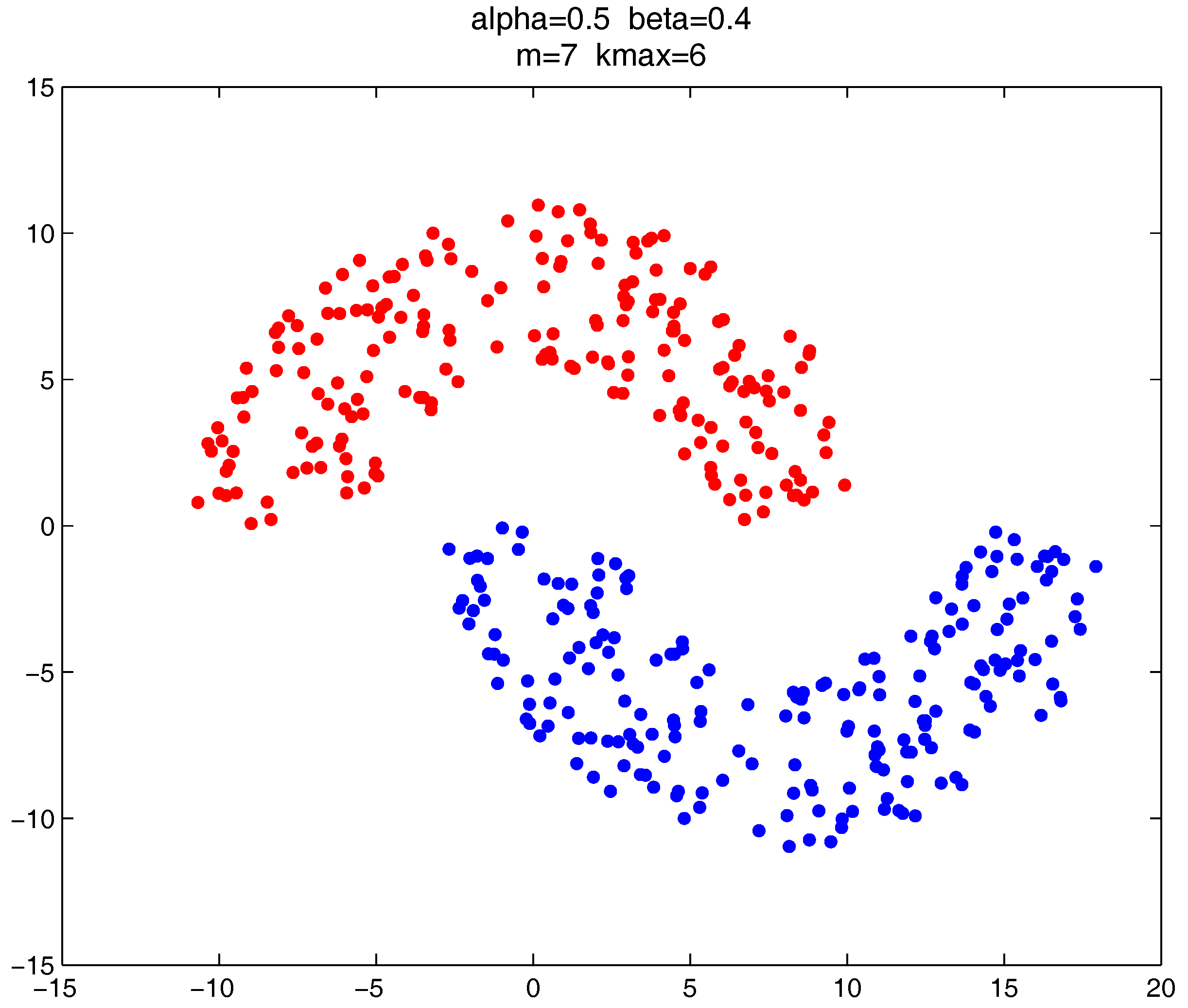
Figure 9, there are two natural clusters, and the two clusters have different densities and twisted shapes. In
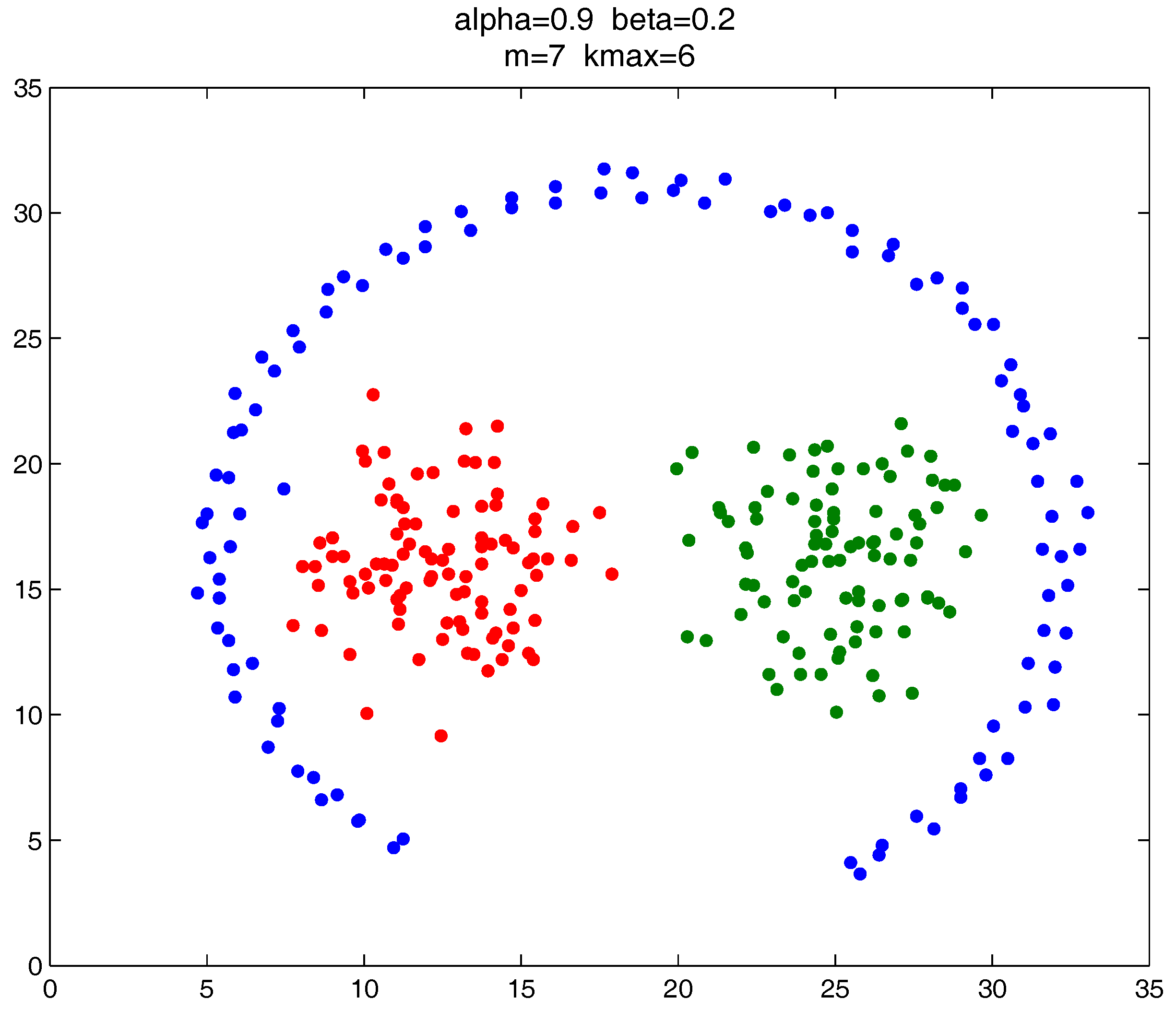
Figure 10, four natural clusters can be found, in which two clusters have the shapes of concentric circles and the other two have very different densities. In
Figure 11, there are three clusters in total, and two of them are spherically distributed. However, the third one that surrounds the two clusters makes the situation more complicated.
These datasets are difficult for the test using traditional clustering methods, and they fail to find all the clusters correctly as shown in
Figure 9,
Figure 10 and
Figure 11. However, by substituting the closeness measures, the
-based methods successfully find the correct clusters in all the tested datasets. In this test, DBSCAN can also handle the non-spherical clusters shapes. However, it cannot deal with the clusters having different densities. For example, in
Figure 10, if a big
is set, the two natural clusters in the upper-right corner will be considered as a whole cluster, while if a small
is set, the data points in the sparsely-distributed cluster will all be considered as the noise.
We have also tested the clustering methods on some UCI datasets [
54]. The Normalized Mutual Information (NMI) [
55] and the Clustering Error (CE) [
56] are used as the quantitative criterion for the performance evaluation of the tested methods.
NMI provides an indication of the shared information between a pair of clusters [
55]. The bigger this NMI value, the better the clustering performance. For CE, obviously, a lower value is preferred. The test results are shown in
Table 1 and
Table 2. For
k-medoids and
-based
k-medoids, the results shown are the average results of 20 runs. For
and
-based
, the results shown are the best results found by traversing the needed parameters.
Note that the
and
results of
k-medoids and
-based
k-medoids methods are obtained by averaging the results of 20 runs, where their initial centers are chosen randomly, so we need further to implement a test of significance to validate that the results of
-based
k-medoids are significantly better than that of the original
k-medoids method. The methodology we use in this paper is the
t-test [
57]. In the test, we assume that the
and
results of each run of
k-medoids and
-based
k-medoids come from two normal distributions that have the same variance. The null hypothesis (
) is that the mean of the
(or
) results of
-based
k-medoids equals that of the original
k-medoids method. On the contrary,
represents that the mean values of the two groups of data are statistically different (under certain significance level). If
holds, we have:
where
and
respectively represent the mean of the
(or
) results obtained by
-based
k-medoids and the original
k-medoids methods,
and
respectively represent the number of instances in
X and
Y and:
where
and
respectively represent the variance (using Bessel’s correction) of the two sets of results.
If the observation of the
t-statistic
falls into the rejection region, which means that
, then
will be rejected, representing that the mean values of the
and
results obtained by
-based
k-medoids are statistically different from those obtained by the original
k-medoids method. The test results are shown in
Table 3 and
Table 4.
The results in
Table 3 and
Table 4 illustrate that we have sufficient reasons to reject the null hypothesis
on all the tested datasets (under significance level
), which means that the results obtained by
-based
k-medoids are statistically better (lower under
index and higher under
index) than those of the original
k-medoids method.
Synthesizing the clustering results shown in
Figure 9,
Figure 10 and
Figure 11 and the test results in
Table 1,
Table 2,
Table 3 and
Table 4, it can be concluded that, on the tested datasets, by substituting the closeness measures with
, the
-based methods can counter-act the drawbacks of the traditional methods and generate correct results in clustering tasks with arbitrary cluster shapes and different cluster scales. The results also show that the
-based methods can work well for the tested real-world data and can achieve better performance (under
and
indexes) than their original versions.
4. Multi-Layer Clustering Ensemble Framework Based on Different Closeness Measures
In previous sections, we proposed
to deal with the problems brought by the closeness measures based on geometric distance and achieved good results in clustering tasks with arbitrary cluster shapes and different cluster densities. However, as shown in
Section 3.4, the computational cost of
is high due to the involvement of neighborhood relationships. Actually, in many simple clustering tasks, or for the “simple part” of some complicated tasks, the geometric distance-based closeness measures can also lead to satisfactory clustering results. They can handle these simple tasks with low computational cost, and they are also easy to implement. Therefore, in this section, we try to incorporate the advantages of
and geometric distance-based closeness measures to deal with complicated clustering tasks with higher clustering accuracy and, at the same time, higher time efficiency.
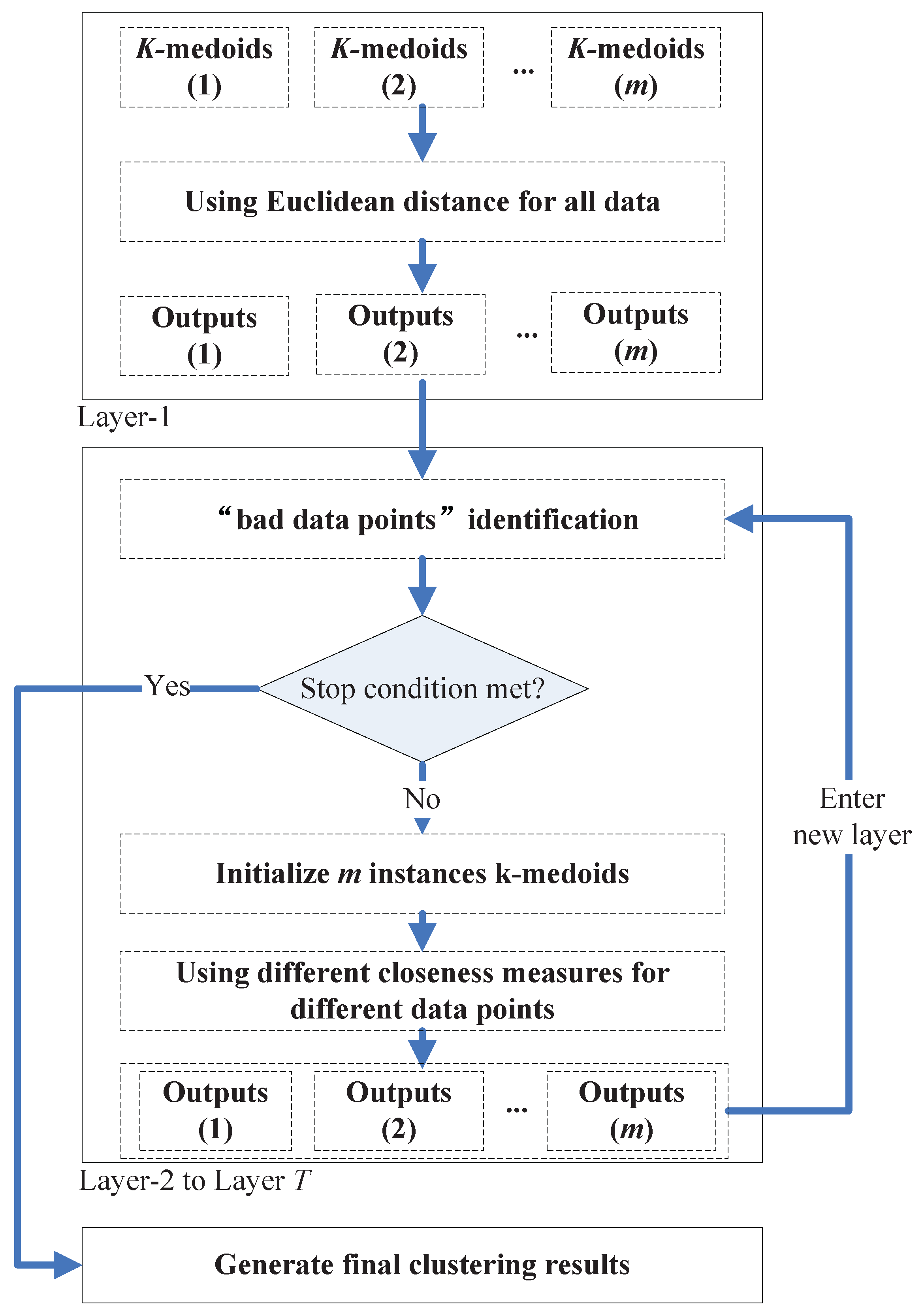
In order to combine the two kinds of closeness measures, we propose a multi-layer clustering ensemble framework. In this framework, the data points that are hard to group into the correct cluster (we call them the “bad data points”, e.g., the data points in the overlapping regions of two non-spherical shaped clusters) can be identified. Thus (in prototype-based clustering schemes), we can apply only to these data points when calculating their closeness to the clusters’ centroids. In this way, the new framework can retain the low computational cost in simple clustering tasks, where only a few “bad data points” need to be dealt with; while in complicated cases, the new framework can achieve much better clustering accuracy than traditional ones and not much computational cost due to the selective application of .
In the framework, a group of
k-medoids algorithms with random
k values (
) and
k initial centroids (in the rest of this paper, we will call them the “member clusterers”) run repeatedly from Layer-1 to Layer-
T. In the first layer, Euclidean distance is used as the closeness measure of all pairs of data points. In the following layers, along with the execution of the “bad data points” identification algorithm on the previous layer’s output, some data points will be identified to be the “bad data points”, and
will be used when calculating the “distance” between these “bad data points” and the clusters’ centroids in the member clusterers. The identification algorithm will be executed once in each new layer based on the outputs of the previous layer, and the iteration ends when no more “bad data points” (compared with the “bad data points” number found in the previous layer) are found in a certain layer, or when the user assigned maximum layer’s iteration number
T is met. One additional
k-medoids (or other clustering methods) will be executed based on the finally found “bad data points” and normal data points to generate the final clustering results.
Figure 12 shows an illustration of the proposed framework.
4.1. Output of One Layer
In the proposed framework, a group of member clusterers runs in each layer. Assume n is the data point’s number in a dataset. Each clusterer will generate a matrix called the Partitioning Matrix (PM), where if the i-th and the j-th data points belong to the same cluster, or zero if otherwise. Assume m is the clusterer’s number. In each layer, we can obtain m instances of PM.
By extracting the value in position from each PM, we can obtain a vector with the length m indicating the m clusterers’ judgments on whether the i-th and the j-th data points belong to the same cluster. We call this vector the Judgment Vector (JV).
Each pair of data points can generate one judgment vector, therefore, the outputs of one layer will be instances of JV (the vectors generated for and are the same, and any data point must be in the same cluster with itself).
4.2. Identification of “Bad Data Points”
The “bad data points” refers to those data points that cannot be easily clustered correctly, e.g., the data points in the overlapping regions of two clusters. One possible pair of “bad data points” can be characterized by one JV that has elements with high discrepancy. It indicates that the clusterers have very different judgments on whether this pair of data points belongs to the same cluster, which means that these two data points might be hard to cluster correctly under the available conditions.
The discrepancy of the elements in one JV can be quantified by Shannon entropy as:
where
is the number of “1” elements in JV.
By calculating the entropy of each JV output from the previous layer, we can obtain an matrix where the element in position indicates the quantified discrepancy of the clusterers’ judgments on data points pair . We call this matrix the Entropy Matrix (EM). Assume W is a data point. In the dataset, there are n different pairs of data points that contains W. In these n pairs of data points, if the number of the pairs that have relatively high discrepancy is relatively large, then there will be a higher possibility that W is a “bad data point”.
Therefore, we define data point
W to be a “bad data point” if:
where
returns the elements’ number in a set,
is a user-defined parameter and
finds the elements in the
w-th row (
w is the order number of data point
W in the
n data points) of EM whose values are bigger than another user-defined parameter
.
In Equation (
10),
and
are two parameters influencing the number of “bad data points” identified in a certain layer. The larger
and
are, the less “bad data points” will be found.
4.3. Output of the Clustering Ensemble Framework
After the “bad data points” are found in the previous layer, the clusterers in a new layer can generate new PMs based on different closeness measures. In this new layer, the clusterers will apply the metric when calculating the “distance” between the clusters’ centroids and the “bad data points”.
After obtaining the new PMs, we can further obtain the new JVs and the new EM. The “bad data points” identification algorithm will run again in this new layer and output the identified “bad data points” to the next new layer. This iteration stops when no more “bad data points” are found in a certain layer, or the user-given maximum iteration number T is met.
One additional instance of clustering methods will be executed using different closeness measures based on the finally found “bad data points” and normal data points to generate the final clustering results.
Following, we give an outline of the proposed clustering ensemble framework (See Algorithm 2).
| Algorithm 2 |
| : n data points, number of clusterers m, max clusters number , max iteration number T, parameters , . |
| : data partitioning |
| : |
| . Initialize m member clusterers (k-medoids) with random k values (constrained to ) and random k clusters centroids. |
| . Calculate to with the m clusterers. If this is not the first time entering , then is applied to the “bad data points”. Otherwise, only Euclidean distance is used. |
| . Extract JV for every pair of data points from to . |
| . Calculate information entropy on each JV, and generate EM. |
| . Identify “bad data points” based on EM. |
| . If no more “bad data points” are identified compared with the last iteration, or the iteration number reaches T, GO TO . Else, enter a new layer and GO TO . |
| . Generate the partitioning on the dataset. Return the clusters found. |
4.4. Experiments
In this section, we will test the proposed clustering ensemble framework.
4.4.1. Influence of Parameter Selection
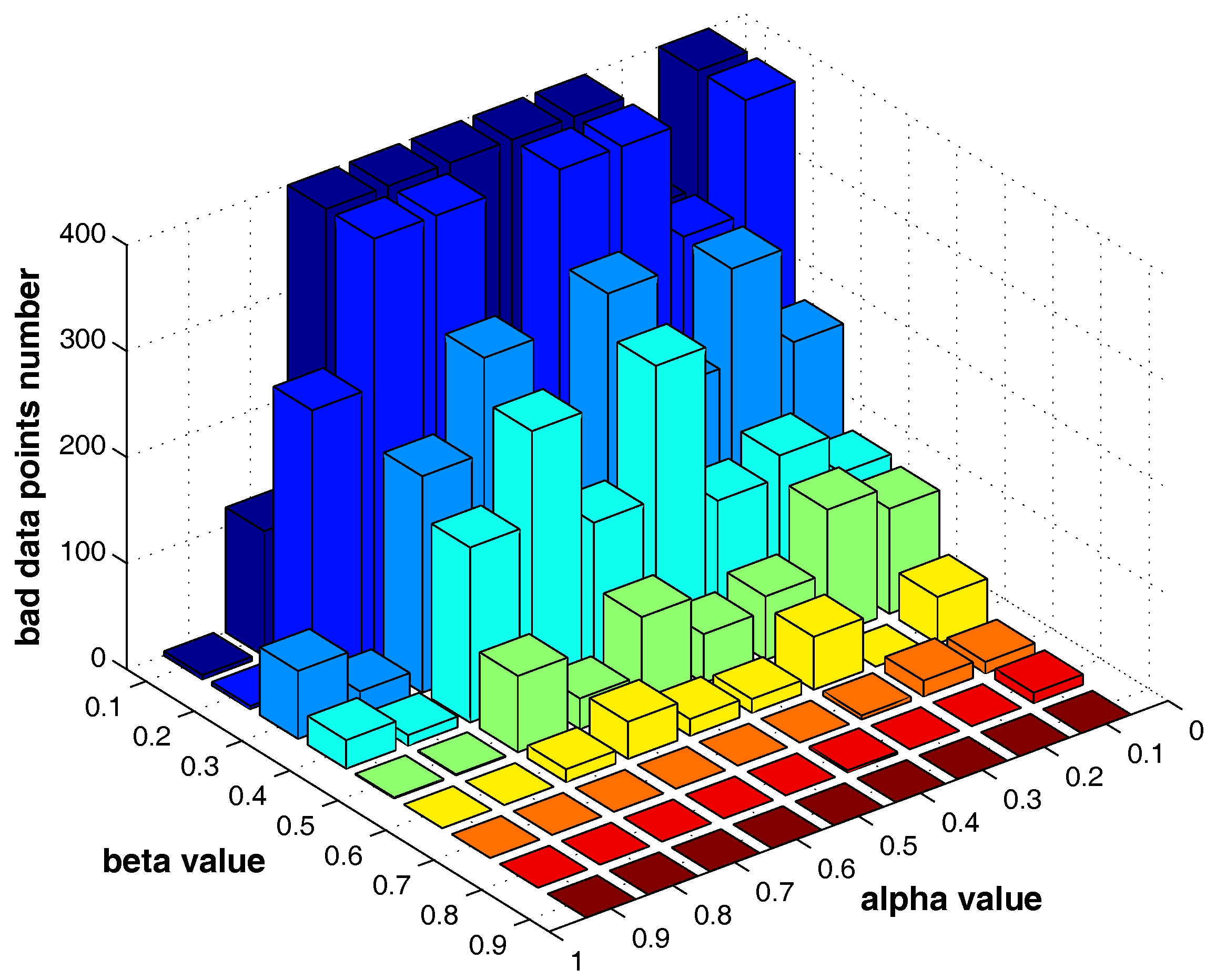
In the proposed framework, parameters that need to be assigned by the user include the number of member clusterers m, the number of max clusters , number of max iterations T and the parameters , .
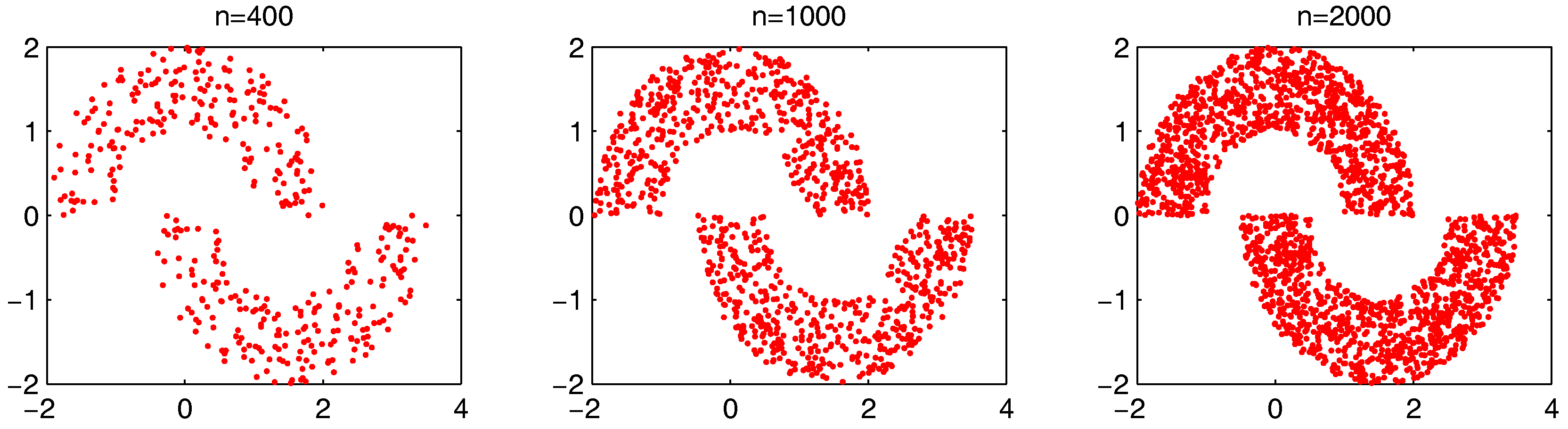
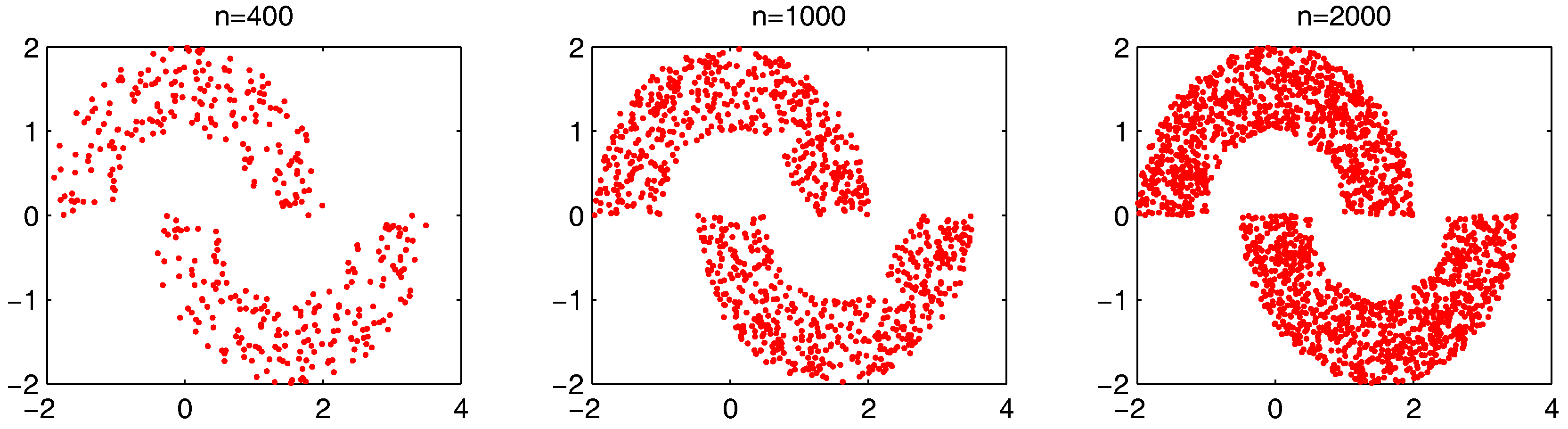
The settings of m, and T do not significantly influence the clustering results, while and are two major parameters that influence the identification of “bad data points”. In the following, we fist examine how the two parameters can influence the “bad data points” detection. The test is run on the “double-moon” dataset, which contains two clusters and 400 data points.
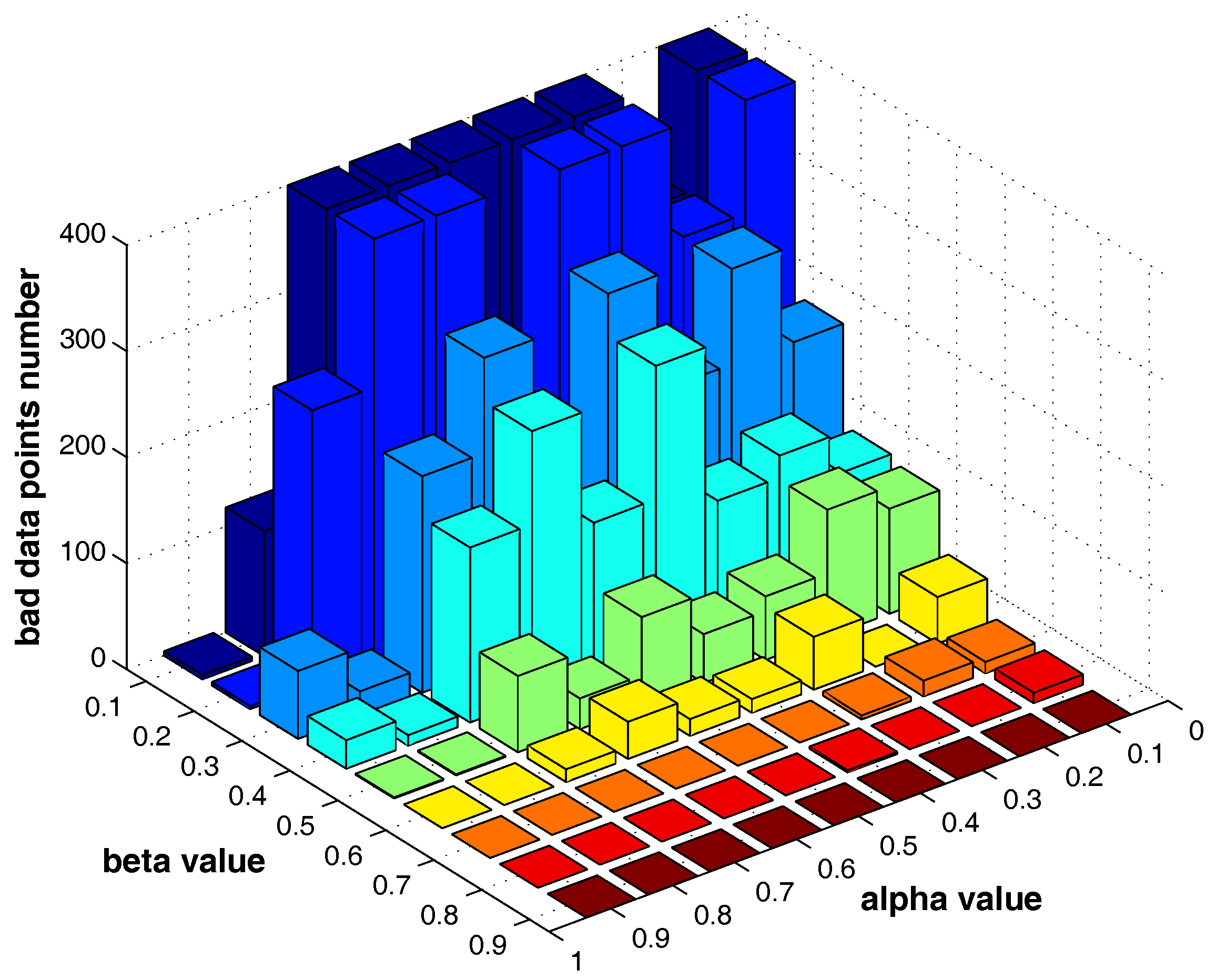
Figure 13 shows the number of the “bad data points” found by the identification algorithm under different
and
combinations.
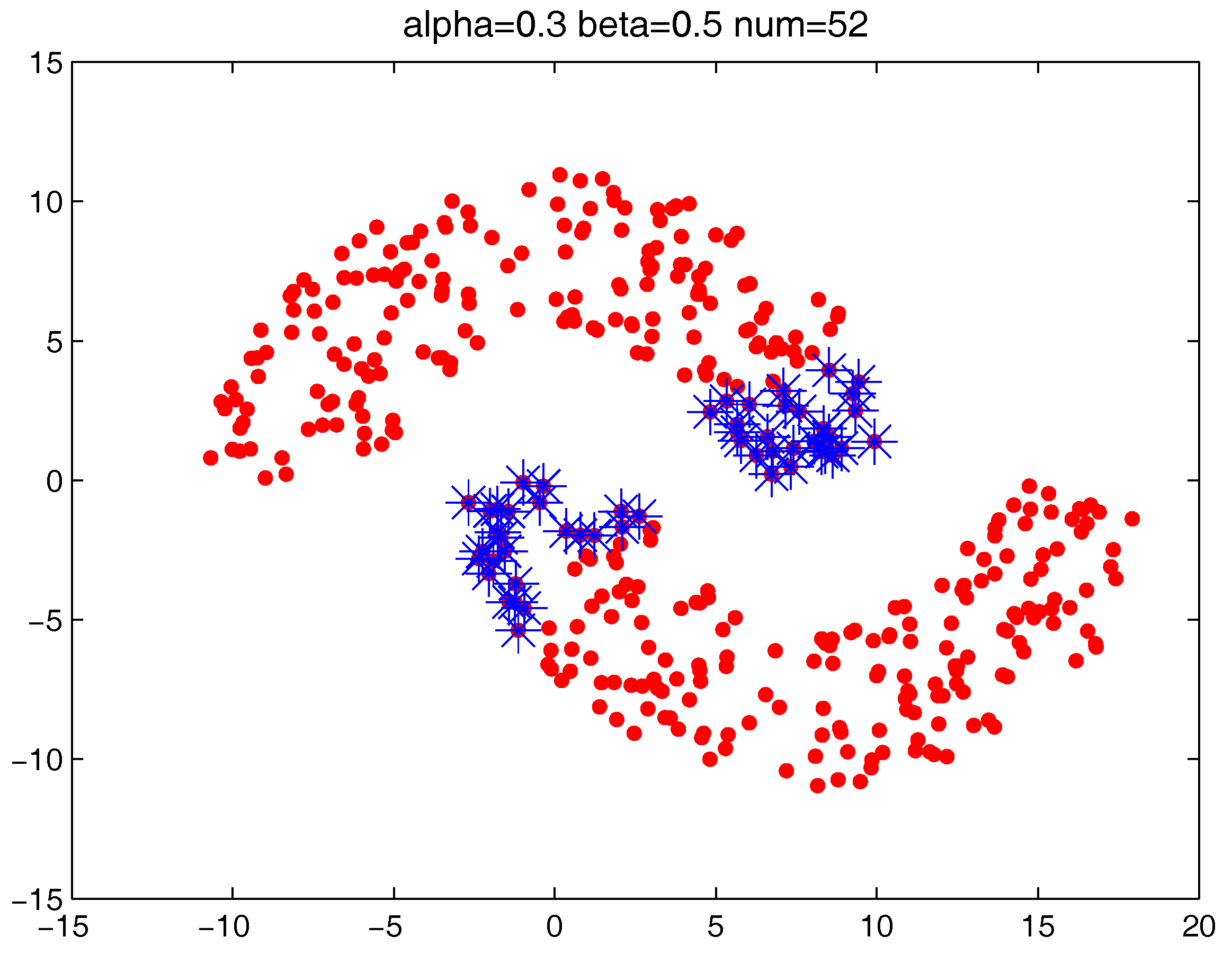
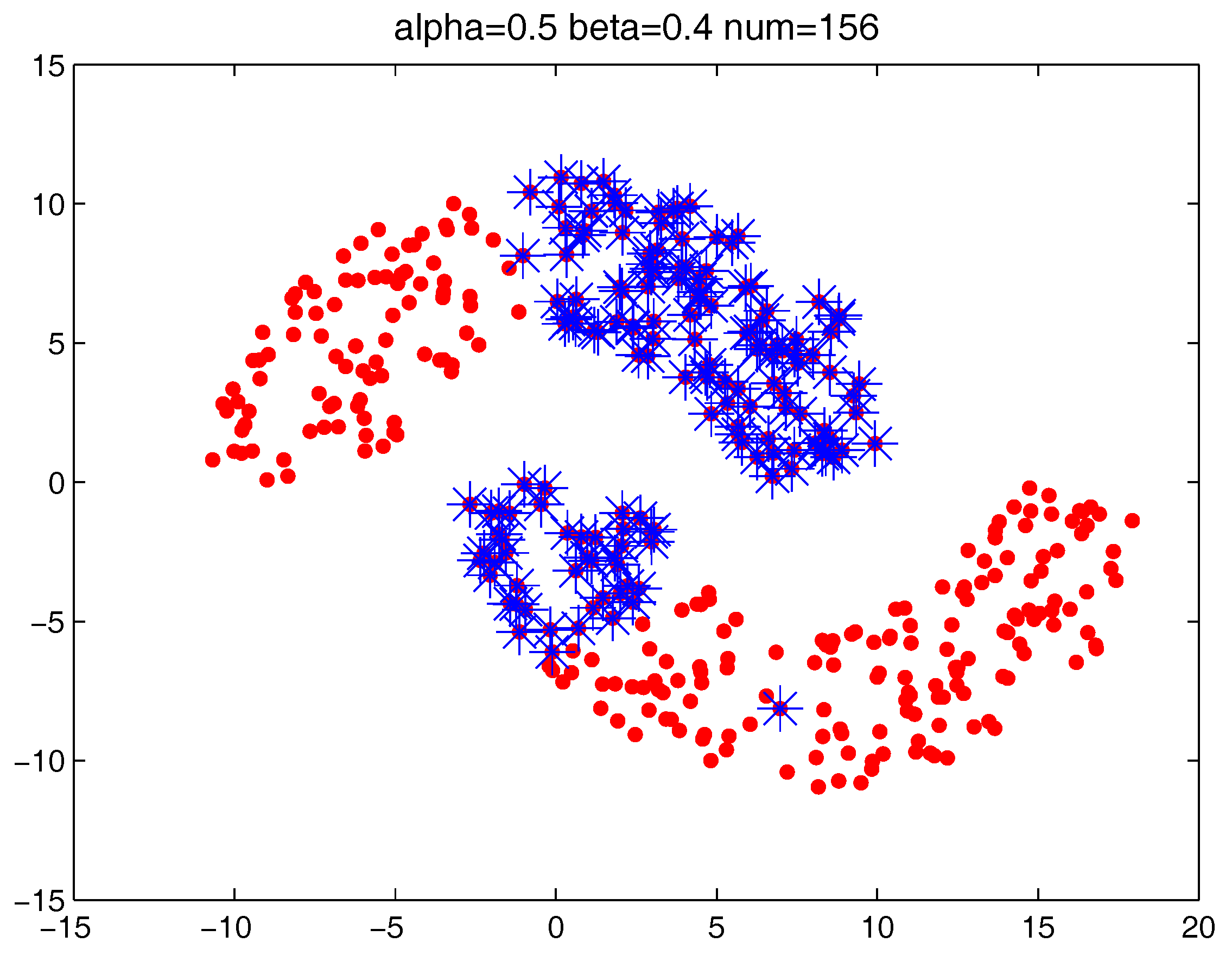
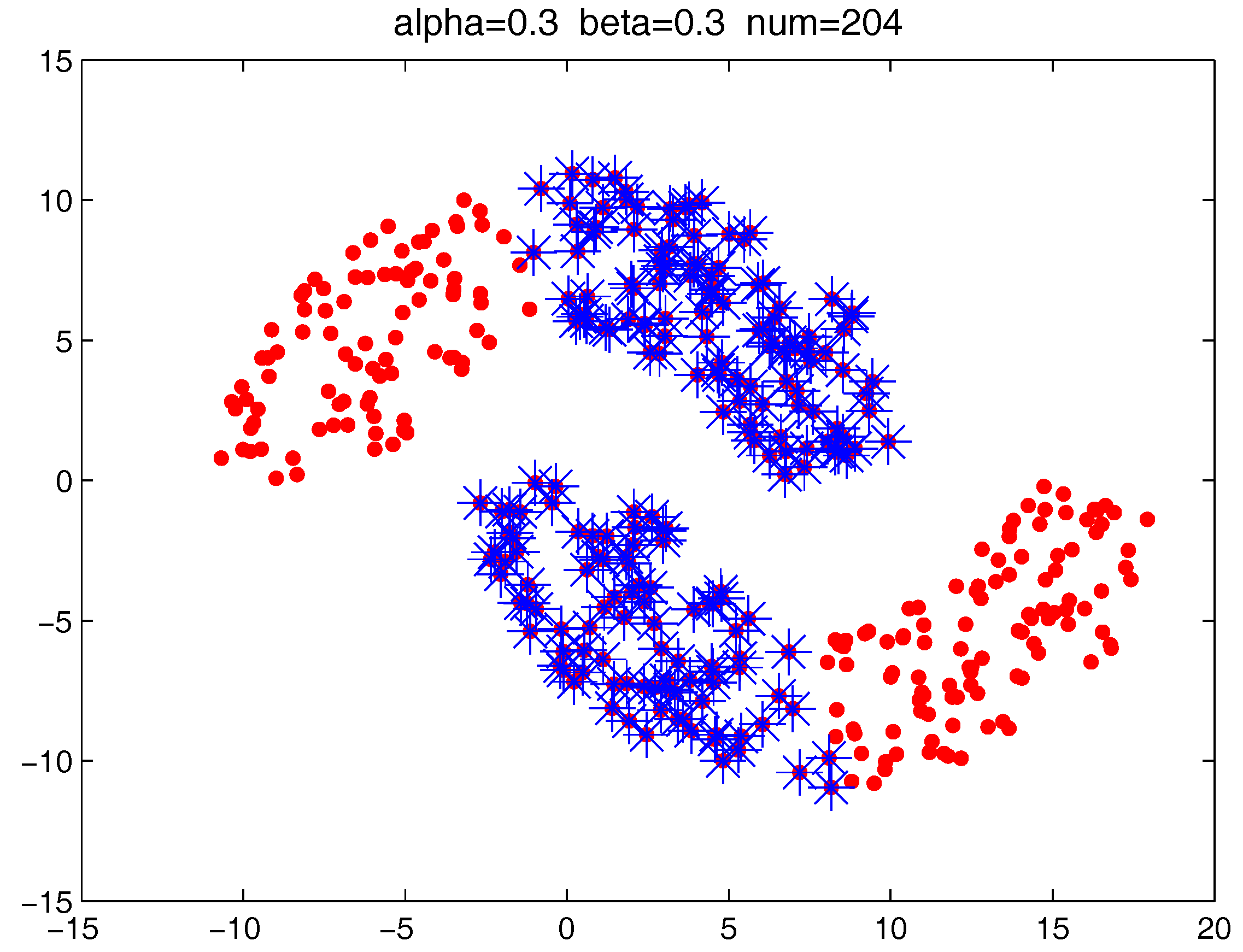
Figure 14,
Figure 15 and
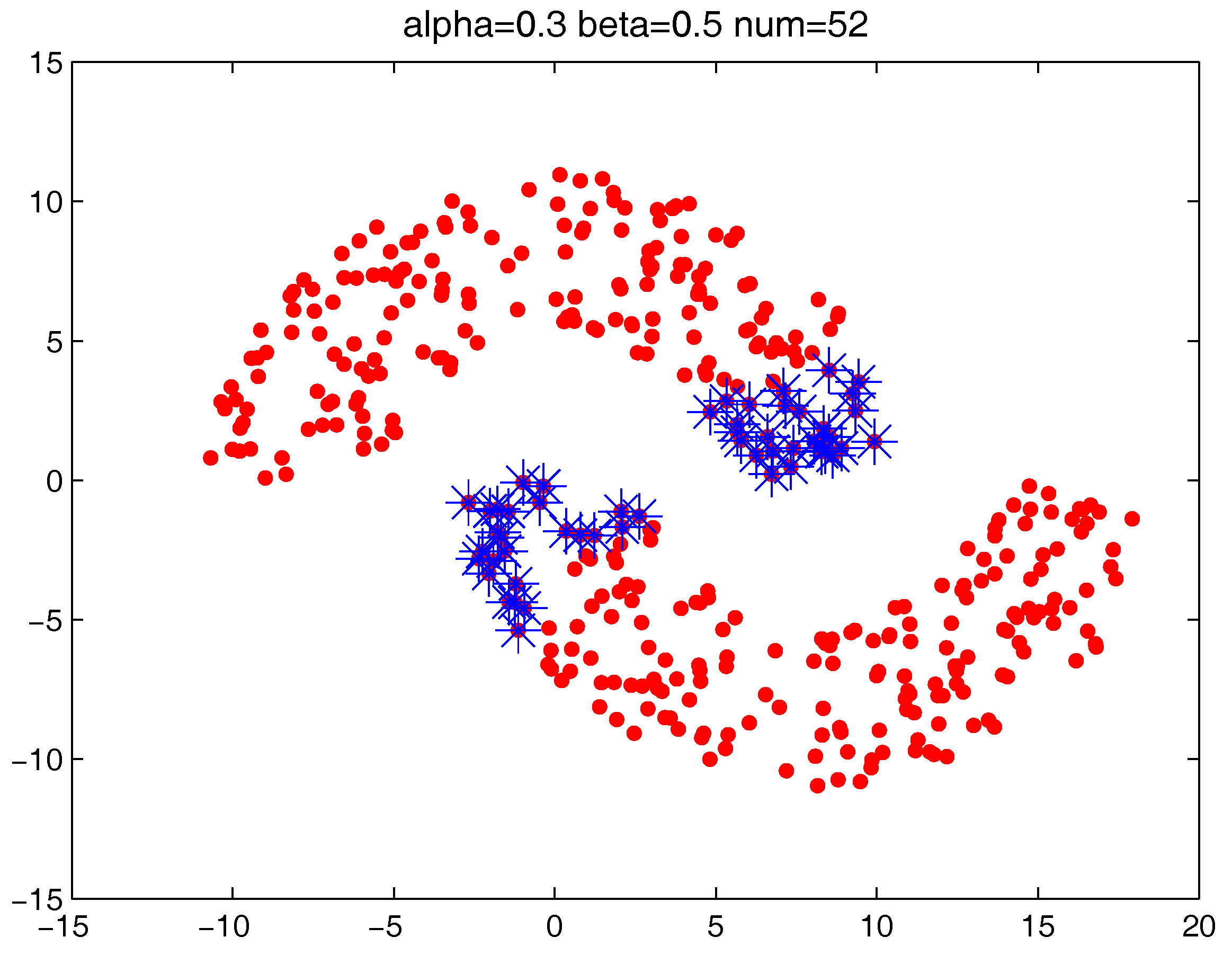
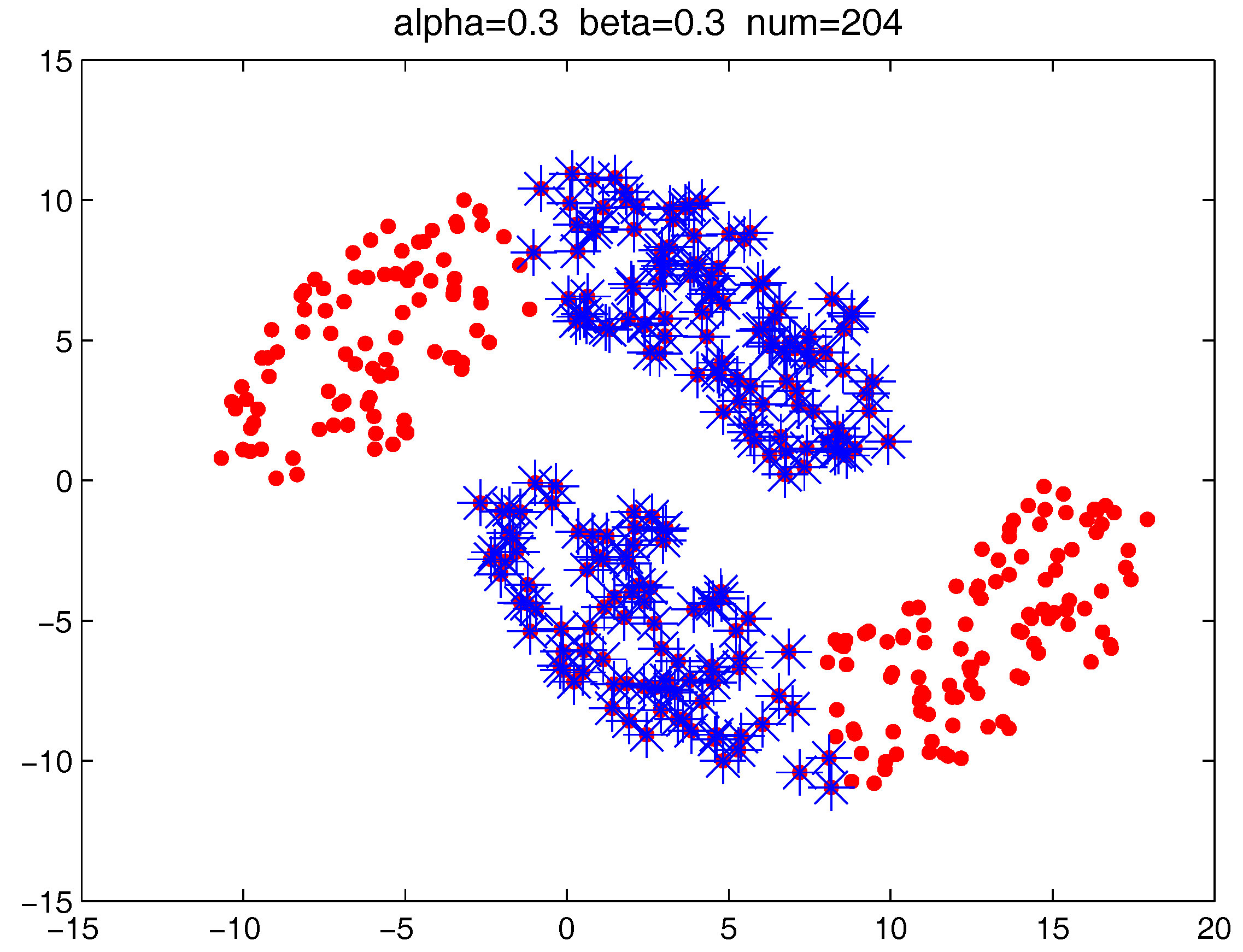
Figure 16 locate the “bad data points” (the blue asterisks) found under three certain parameter combinations. The figures illustrate that along with the increase of the number of “bad data points” found, the remaining data points (the dots) become much more easier to cluster correctly with simple clustering algorithms.
In order to more generally examine the effect of parameters
and
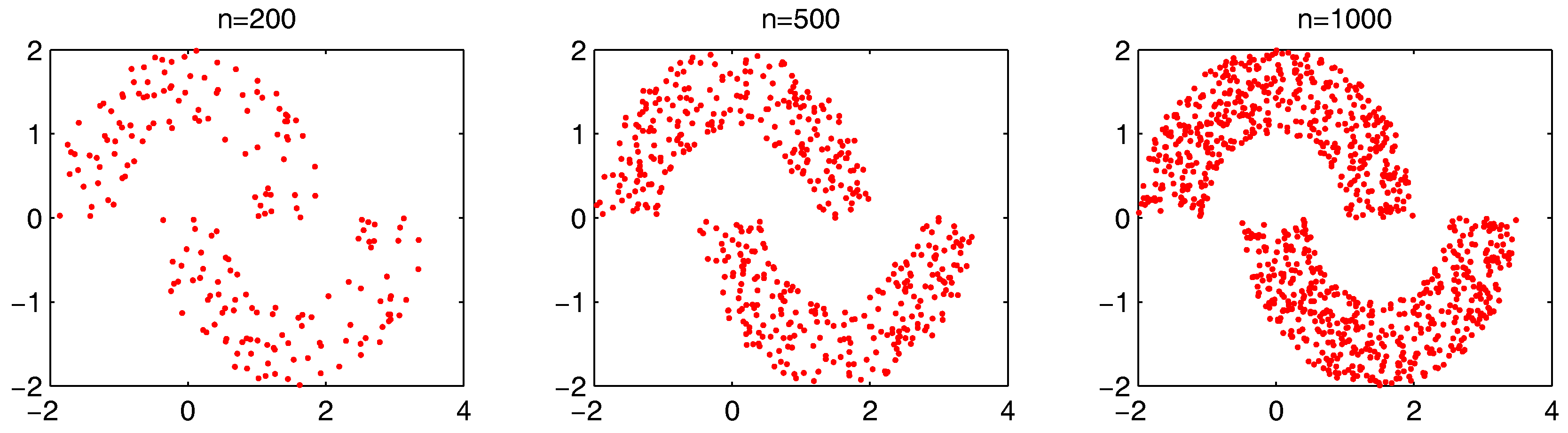
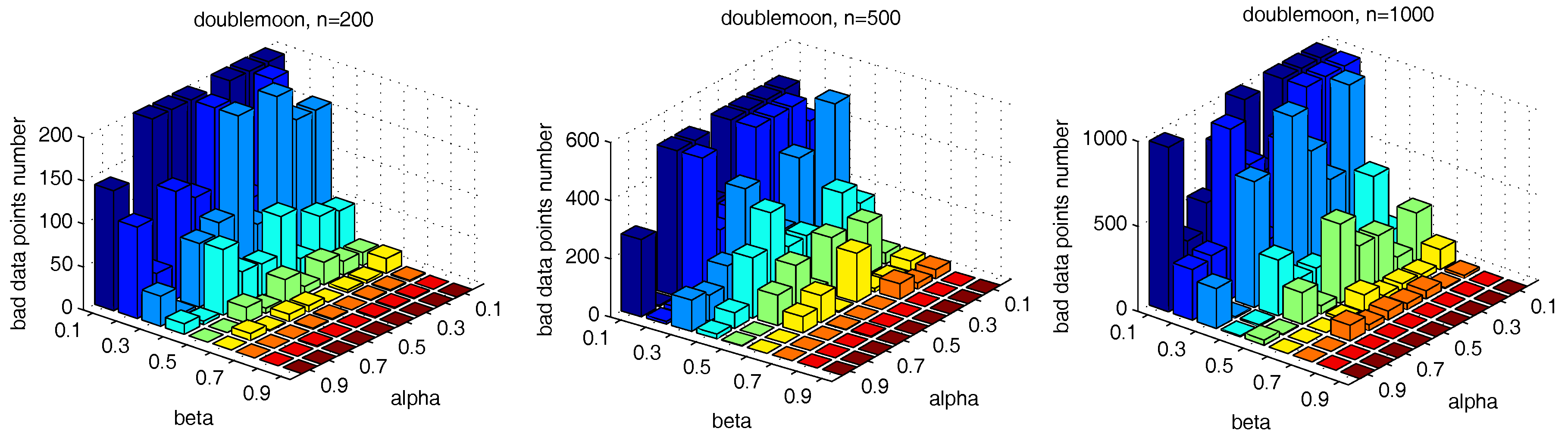
, we further test the parameter combinations on several more datasets. We first change the data point’s number in the “double-moon” dataset, varying from 200–1000, which is shown in
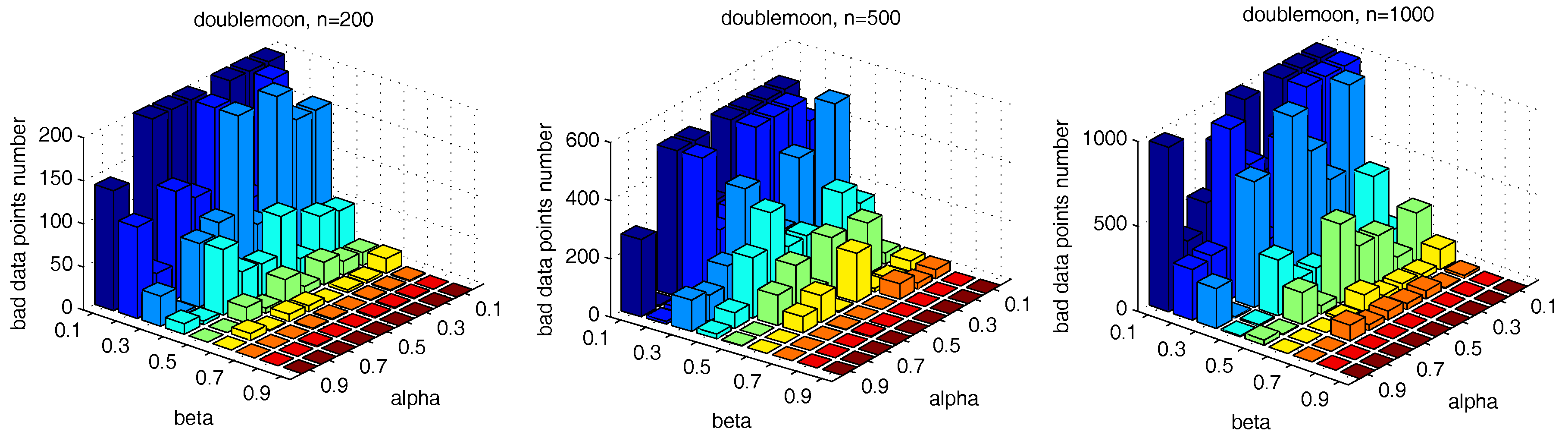
Figure 17. The numbers of the “bad data points” found in these datasets under different
and
combinations are shown in
Figure 18.
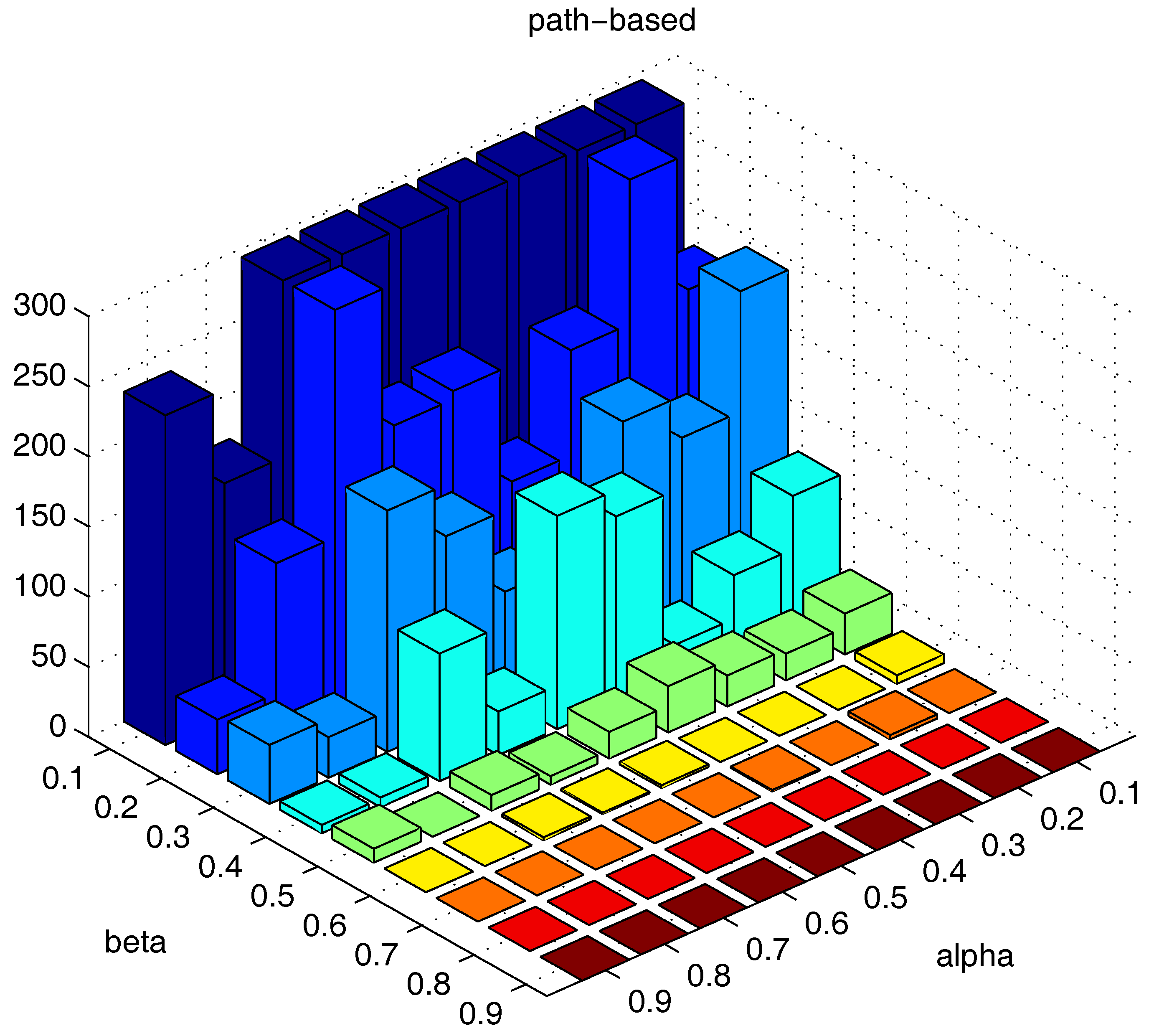
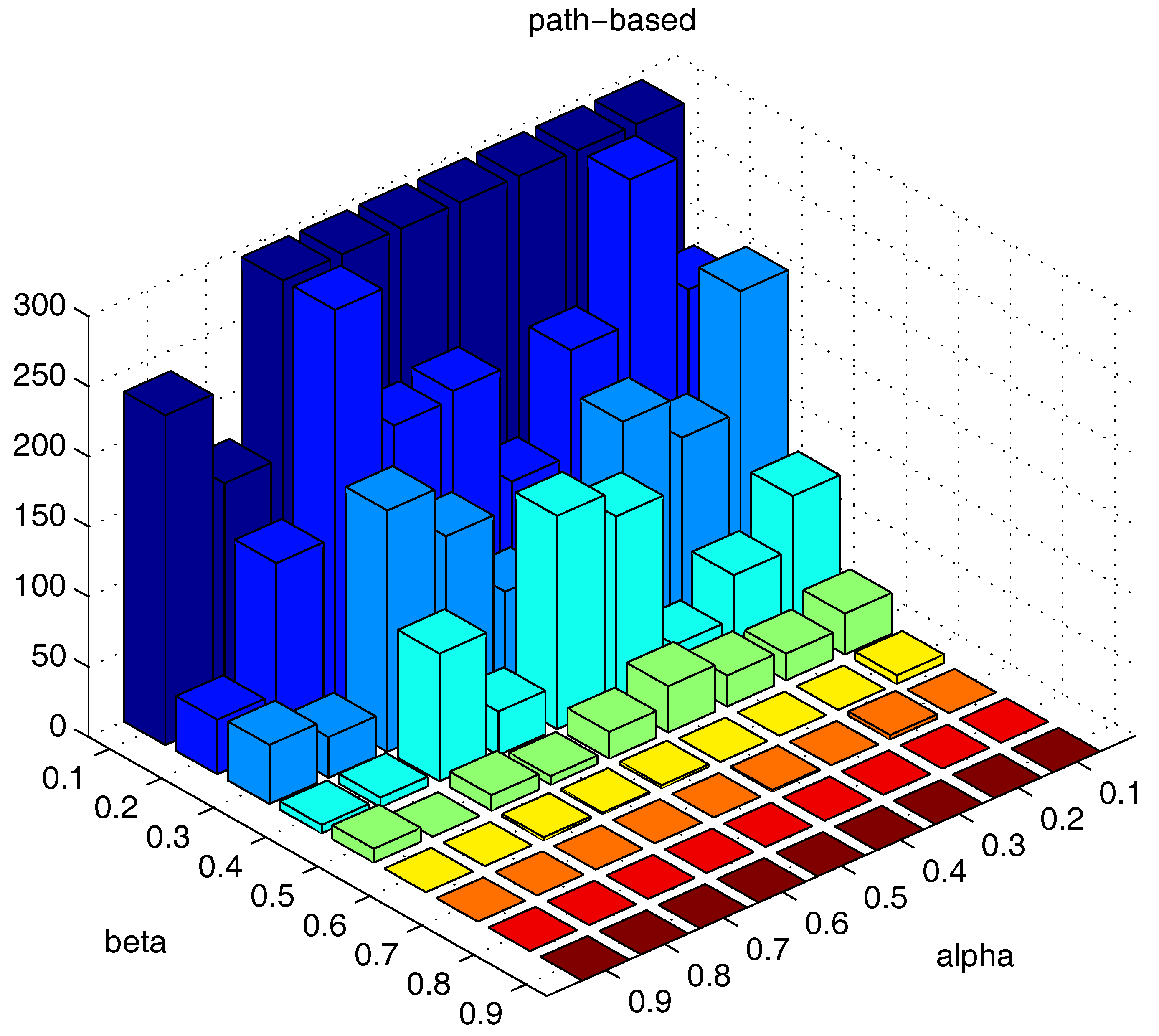
We also test the parameter combinations on another synthetic dataset “path-based” (the dataset is shown in
Figure 11), and the numbers of the “bad data points” found under different parameter combinations are shown in
Figure 19.
The results in
Figure 18 and
Figure 19 show that, in different datasets, parameters
and
influence the number of the “bad data points” in similar ways. Therefore, the changing tendency of the “bad data points” number presented under different parameter combinations illustrated in the figures can be seen as a general guide for the tested datasets when choosing the parameters in practice.
4.4.2. Clustering Results of the Proposed Framework
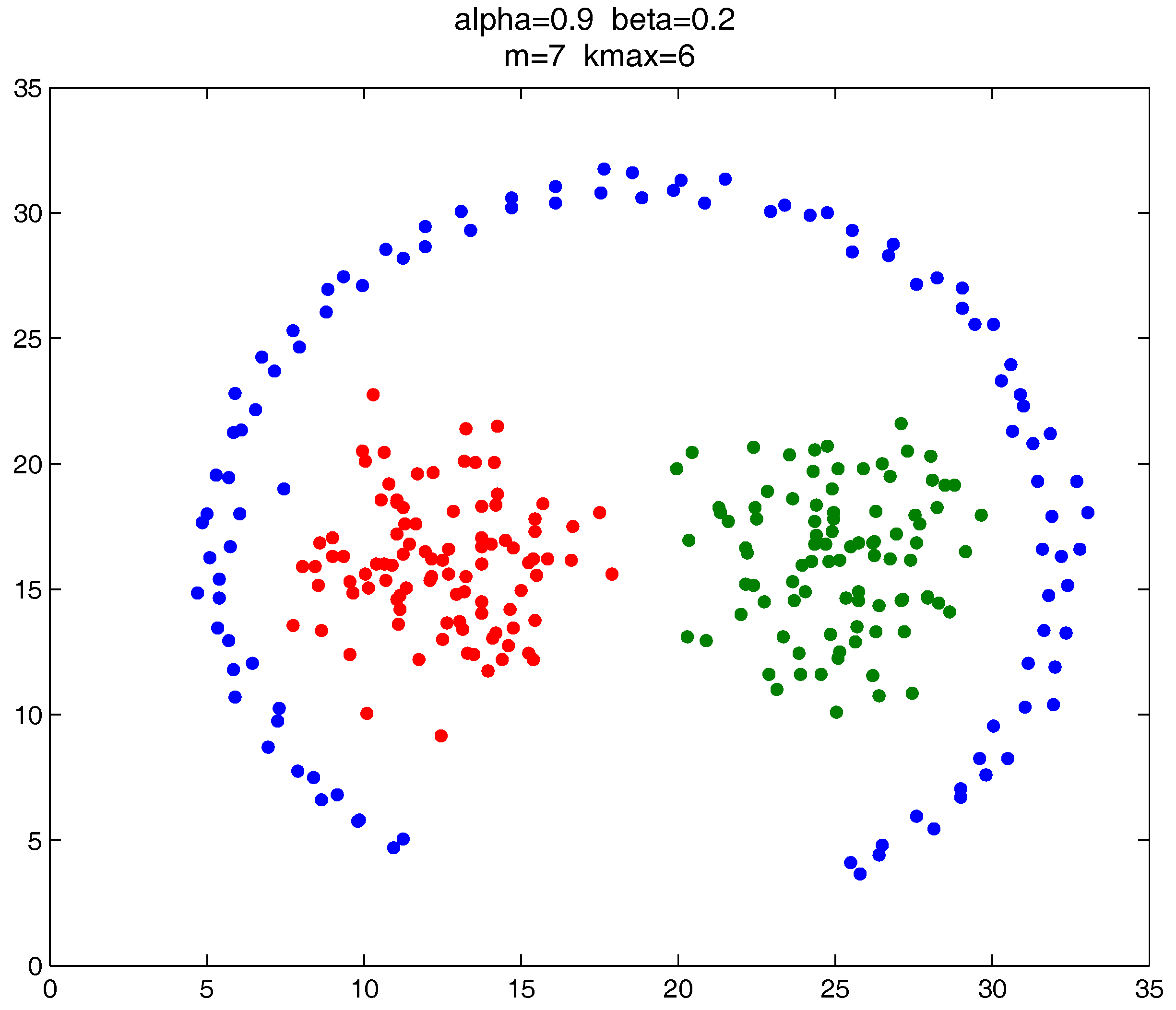
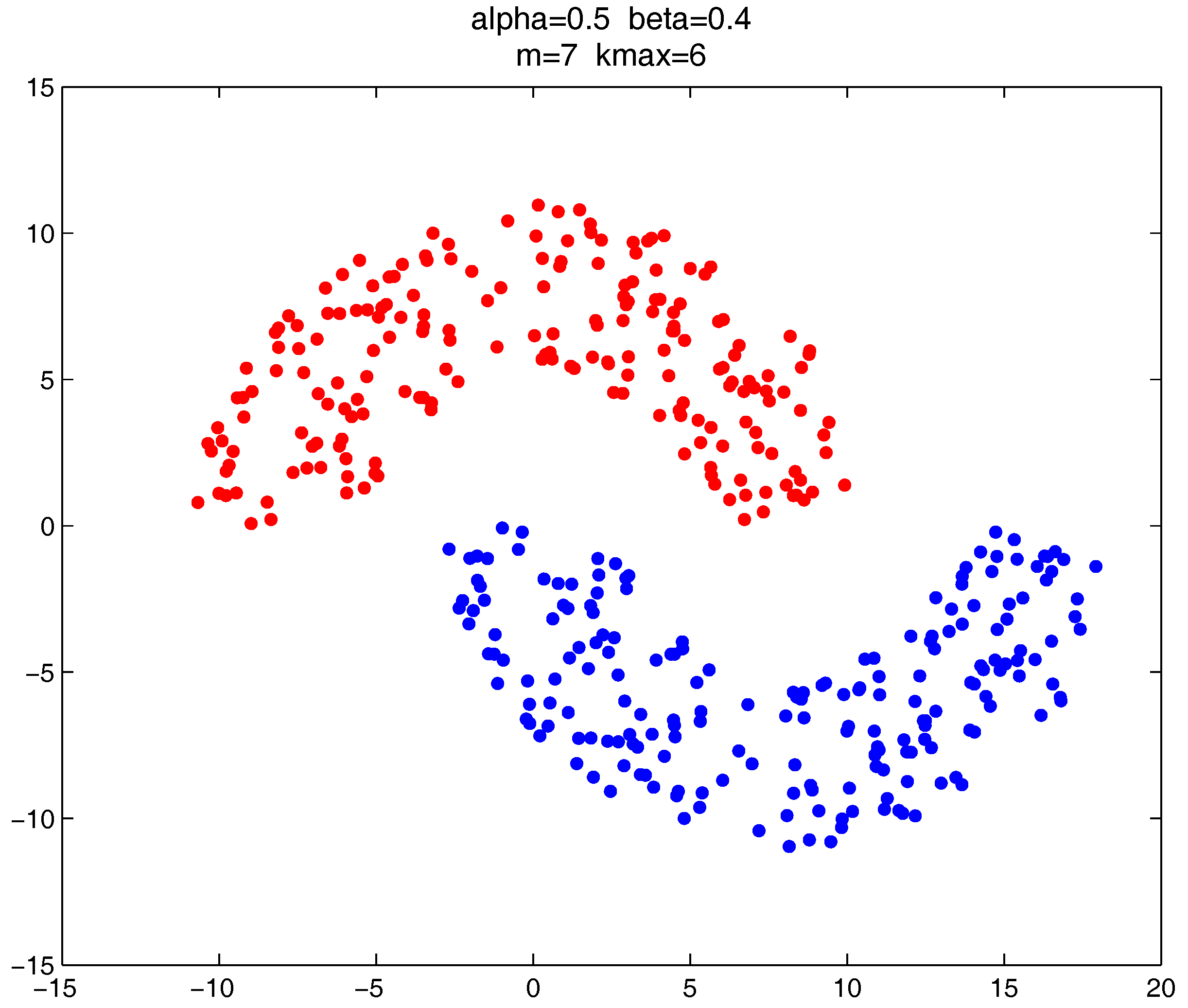
In this section, we give the clustering results of the proposed clustering ensemble framework on some 2D datasets. The corresponding parameter settings are provided for each case.
As shown in
Figure 20,
Figure 21 and
Figure 22, all the tested datasets have non-spherically-shaped clusters. These datasets usually cannot be correctly clustered with the simple centroid-based clustering methods, or the clustering ensemble methods based on them. However, by applying the
metric to part of the data points in the datasets, our proposed clustering ensemble framework can generate very good results on these datasets.
4.4.3. Time Complexity of the Proposed Framework
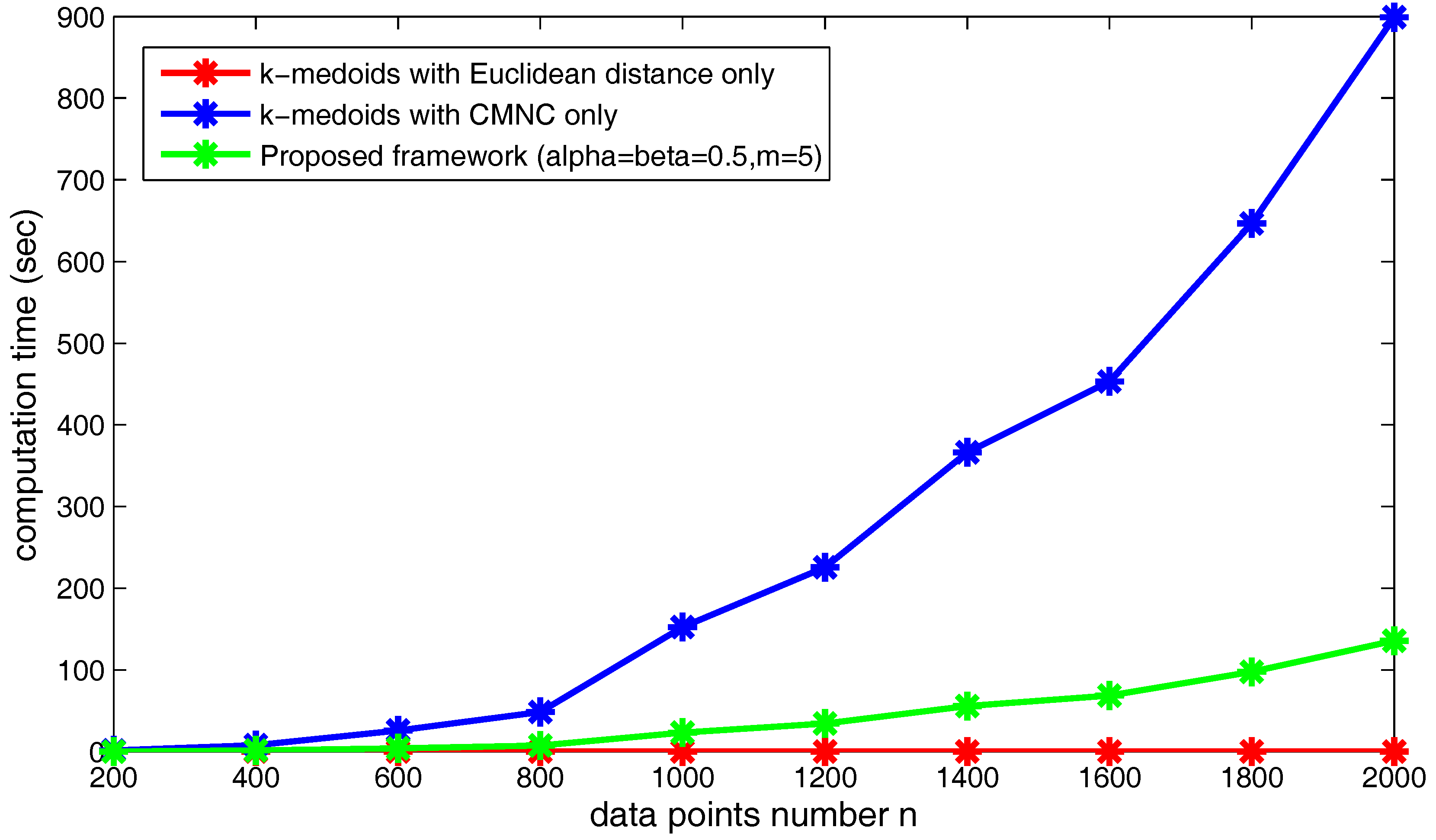
Although using for the “bad data points” in our proposed framework will promote the accuracy of the clustering results, it is to some degree at the price of increasing the time complexity. Here, we will make a comparison of the execution time between the proposed framework combining different closeness measures and the traditional framework using only the Euclidean distance. The execution time of the method that directly uses to substitute the Euclidean distance in the traditional framework (i.e., the method without the “bad data points” identification) is also given for comparison. Meanwhile, we will also compare the execution time of the new framework under different parameter settings. All of the following tests are implemented in MATLAB R2009b, Microsoft Windows 10 operation system and based on Intel core i7 3.6-GHz CPU (quad core), 8 G DDR3 RAM.
The factors that influence the computation time of the proposed framework include the total data points number
n, the clusterers number
m and the number of the found “bad data points” determined by
and
. First, we will examine the change of the computation time on the synthetic dataset “double-moon” when
n increases. The dataset with different numbers of data points
n is shown in
Figure 23.
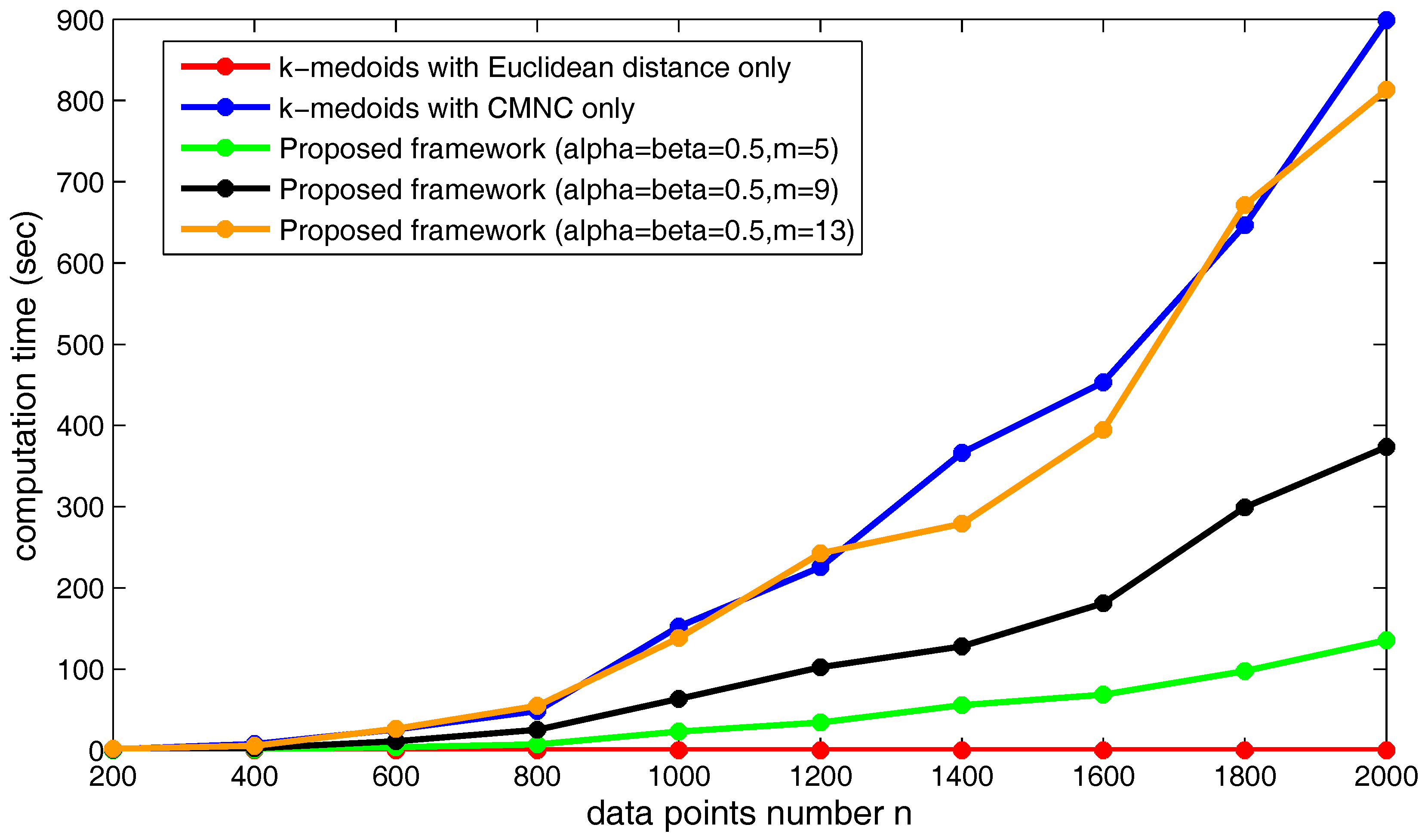
Figure 24 shows the increasing of the execution time of the three kinds of methods when the data point’s number
n increases. Obviously, under the shown parameter settings, the proposed framework saves much time compared to using
only in the clustering method.
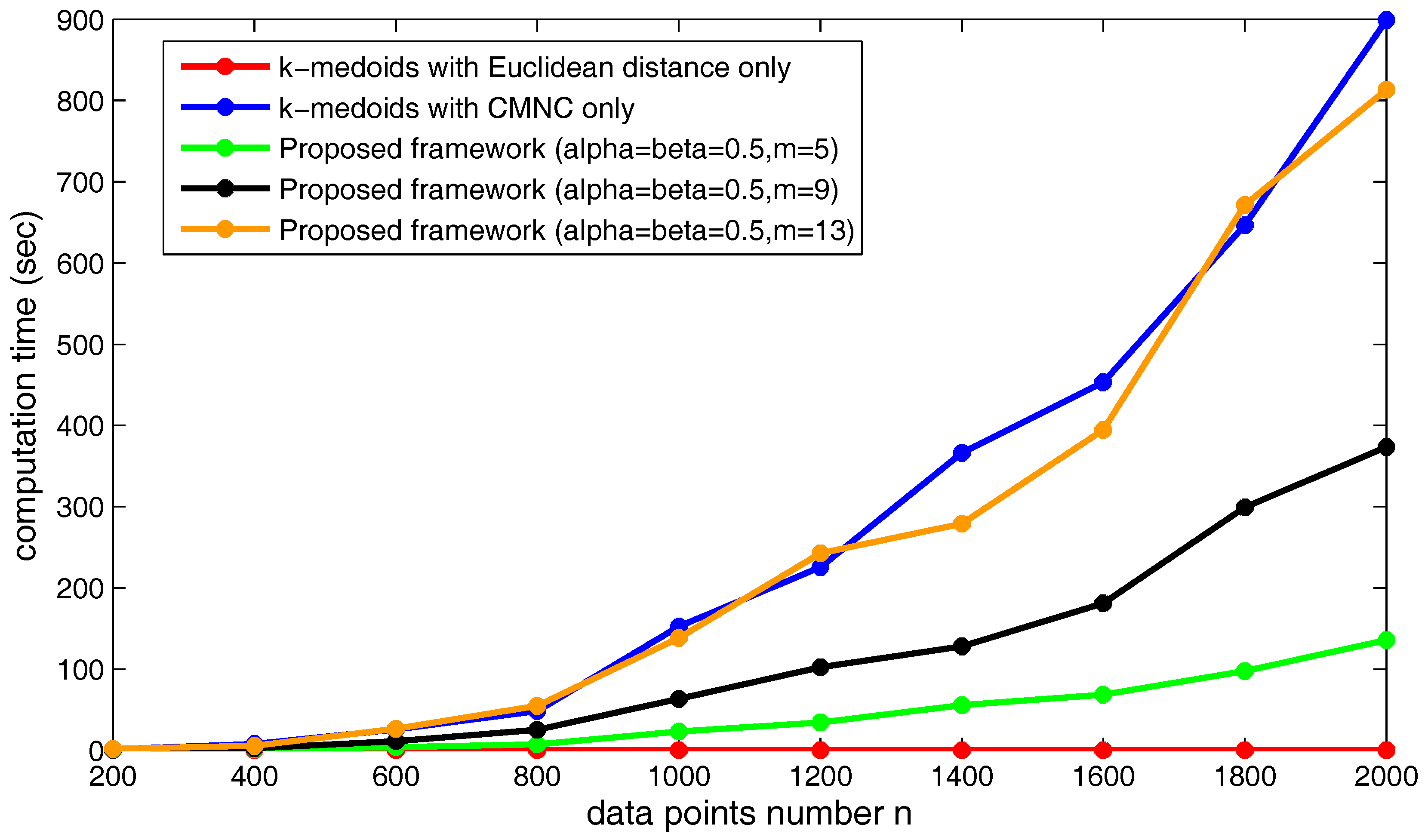
Next, we will examine the change of the computation time when the clusterer’s number
m changes. In
Figure 25, the computation time of the proposed framework using different numbers of sub-clusterers (
m) is illustrated. As shown in the figure, the computation time increases along with the increasing of
m. Under the shown parameter settings, if
m continues to grow, the computation time of the proposed framework will exceed the time cost by the clustering method using
only. In practice,
m could be assigned a relatively small value in order not to produce too much computational cost.
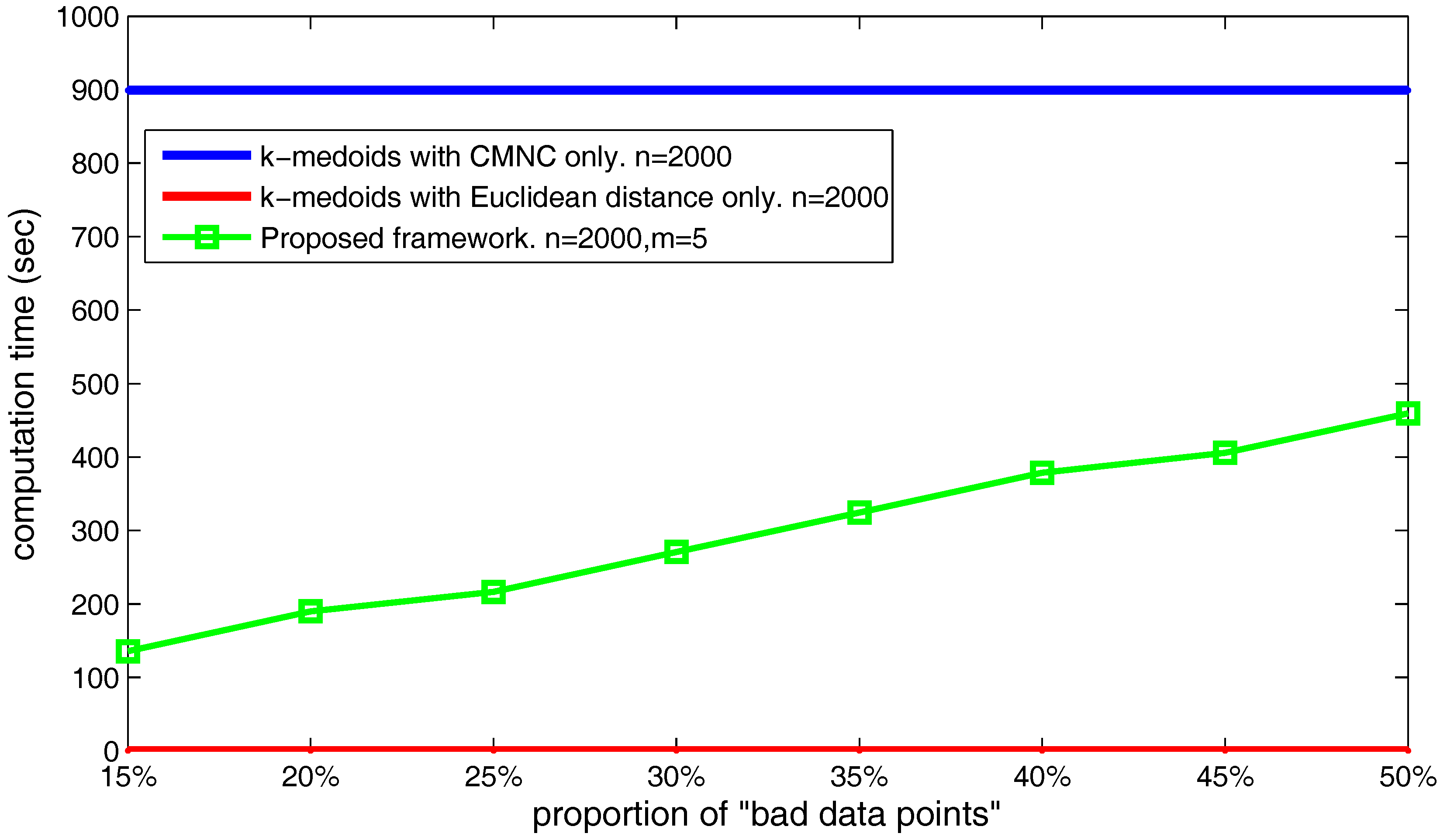
The number of the found “bad data points” can also influence the computation time of the proposed framework. As shown in
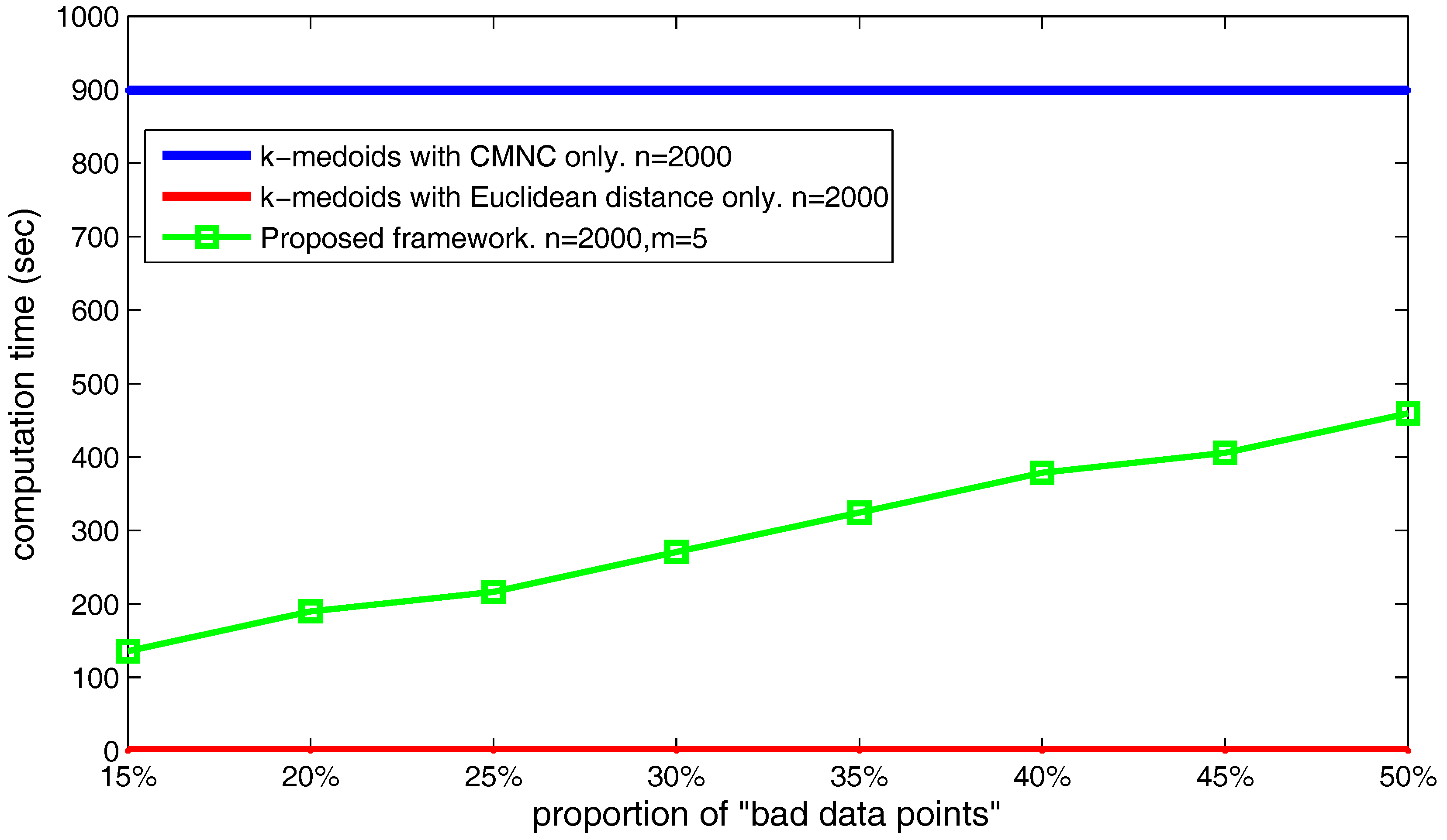
Figure 26, we set the data point’s number
and
, and choose different
,
values making the number of the found “bad data points” occupy from 20–50% of the total data point’s number. The figure shows that the time cost basically increases linearly with the increasing of the found “bad data points” number.
Generally speaking, the proposed framework can generate correct clustering results on the tasks with which the traditional ones cannot deal. By using the Euclidean distance and the measure together, the actual usage frequency of can be greatly lowered. Therefore, the framework is also much more time efficient than the method using only.
5. Conclusions
This paper proposes a novel closeness measure between data points based on the neighborhood chain called . Instead of using geometric distances alone, measures the closeness between data points by quantifying the difficulty to establish a neighborhood chain between the two points. As shown in the experimental results, by substituting the closeness measure in traditional clustering methods, the -based methods can achieve much better clustering results, especially in clustering tasks with arbitrary cluster shapes and different cluster scales.
Based on , we also propose a multi-layer clustering ensemble framework that combines two closeness measures: the Euclidean distance and the metric. A “bad data points” (data points that cannot be easily grouped into the correct cluster, e.g., the data points in the overlapping regions of the two non-spherically-shaped clusters) identification algorithm is proposed to find those data points whose closeness to the clusters’ centroids need to be computed with the metric. By incorporating the two closeness measures, the proposed framework can counter-act the drawbacks of the traditional clustering methods using the Euclidean distance alone. Meanwhile, it is more time efficient than the clustering method using the metric alone.
The major focus of our future work is to further reduce the computational complexity of the proposed framework. In our work, the execution time can be reduced by limiting the number of data points that use metric. However, we find that in some complicated cases, in order to ensure a tolerable clustering accuracy, a large proportion of data points will be identified to be the “bad data points”. This might lead to a significant decline in the time efficiency of the framework. To resolve the problem, more work should be done to optimize the nearest neighbors’ searching process (which produces the most computational cost in ) and to further refine the “bad data points” identification algorithm. One possible improvement on which we will do further research is to find some key data points that can represent part or even the whole group of the “bad data points”. Applying on the representative data points might reduce the actual computation involving .






{kind=link}
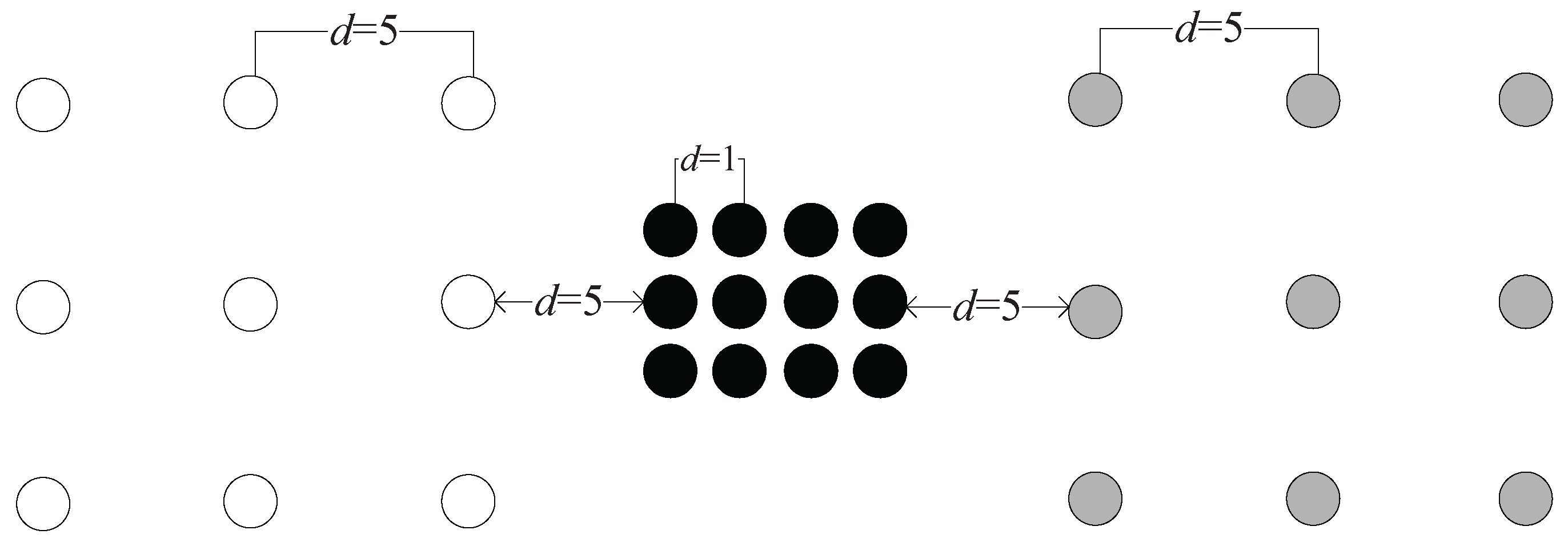{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}