A Parameter Communication Optimization Strategy for Distributed Machine Learning in Sensors


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
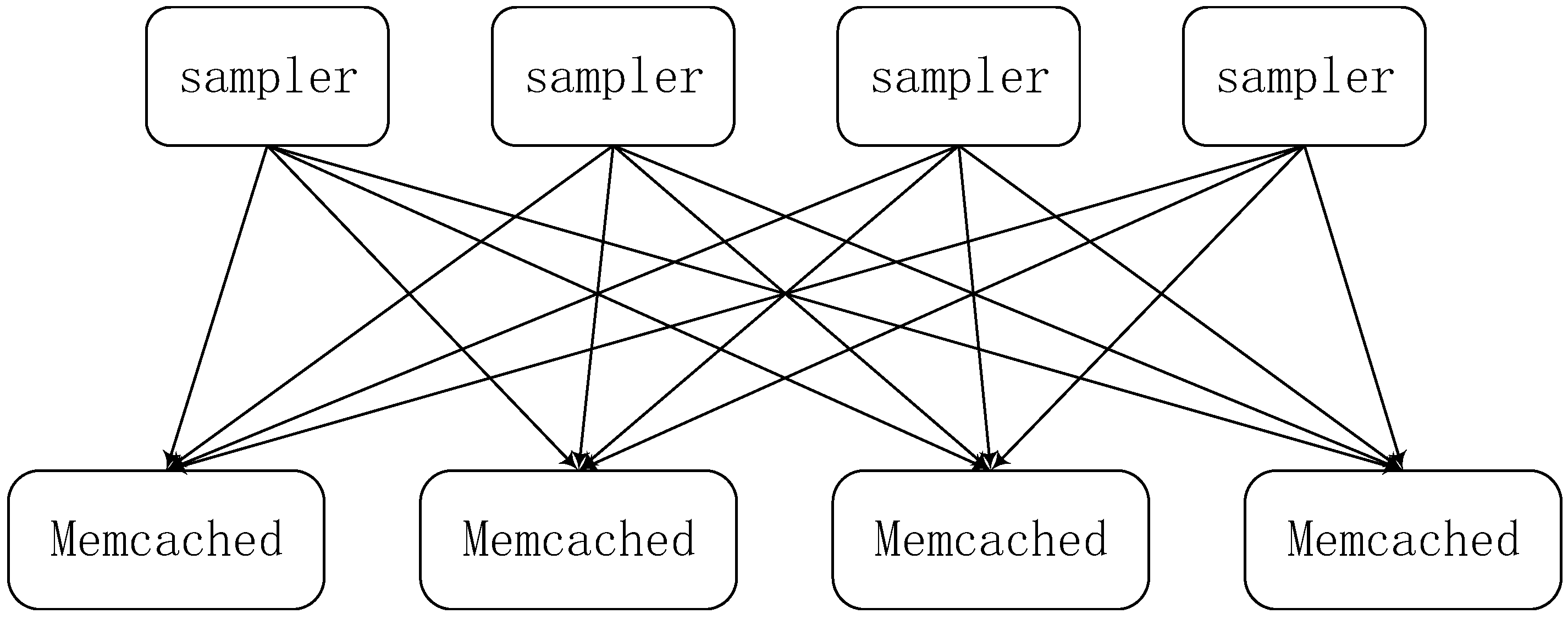
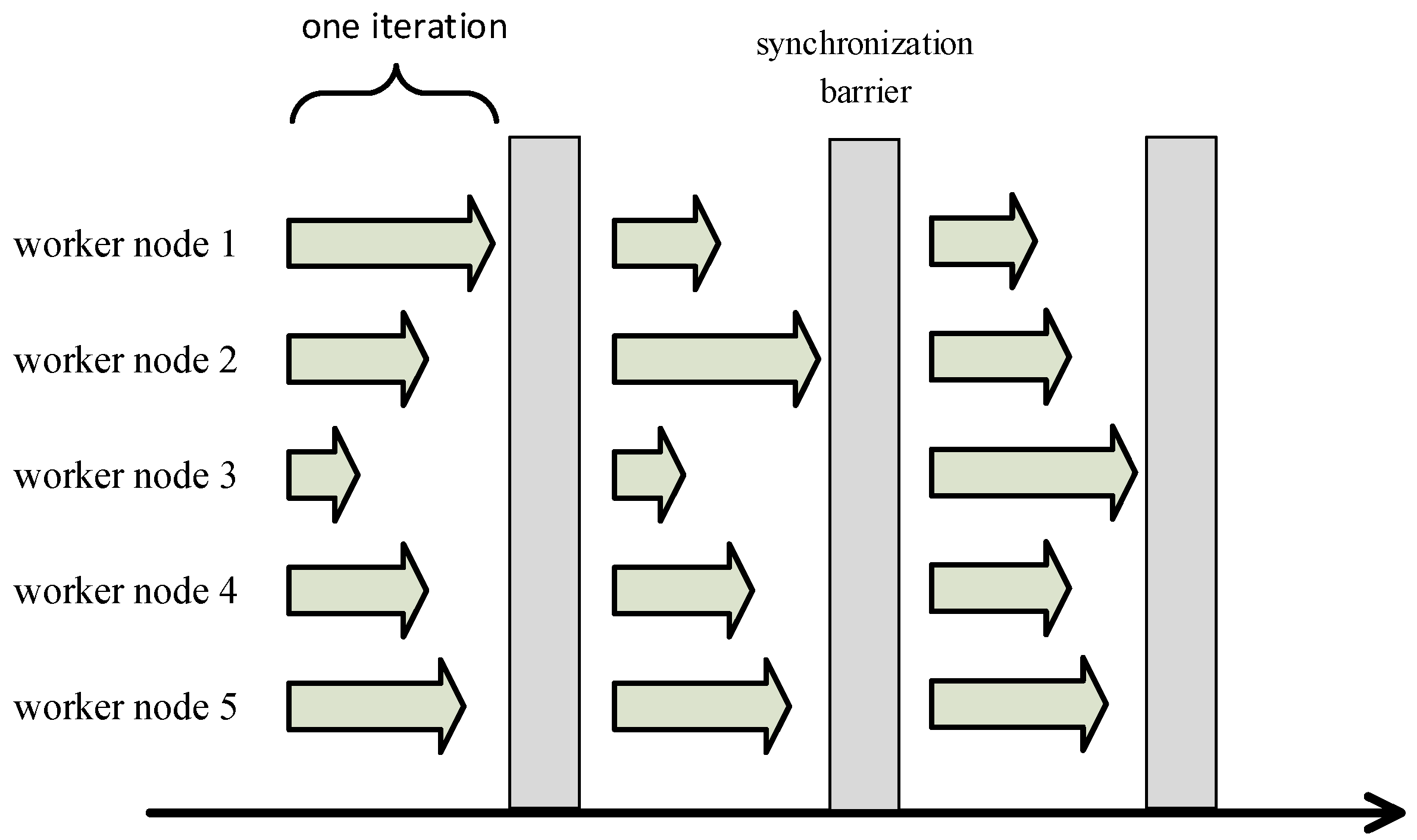
2.1. The Distributed Machine Learning System
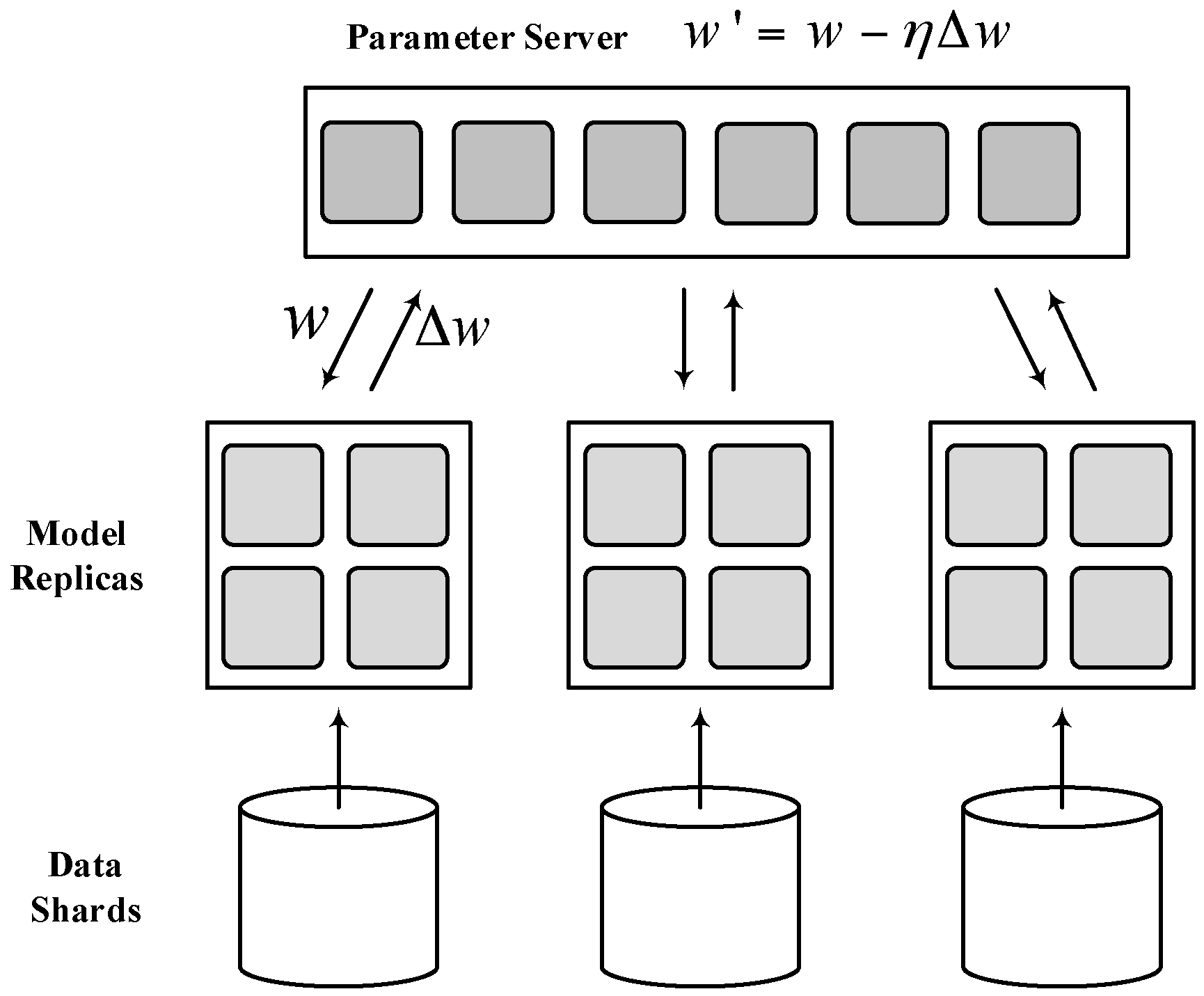
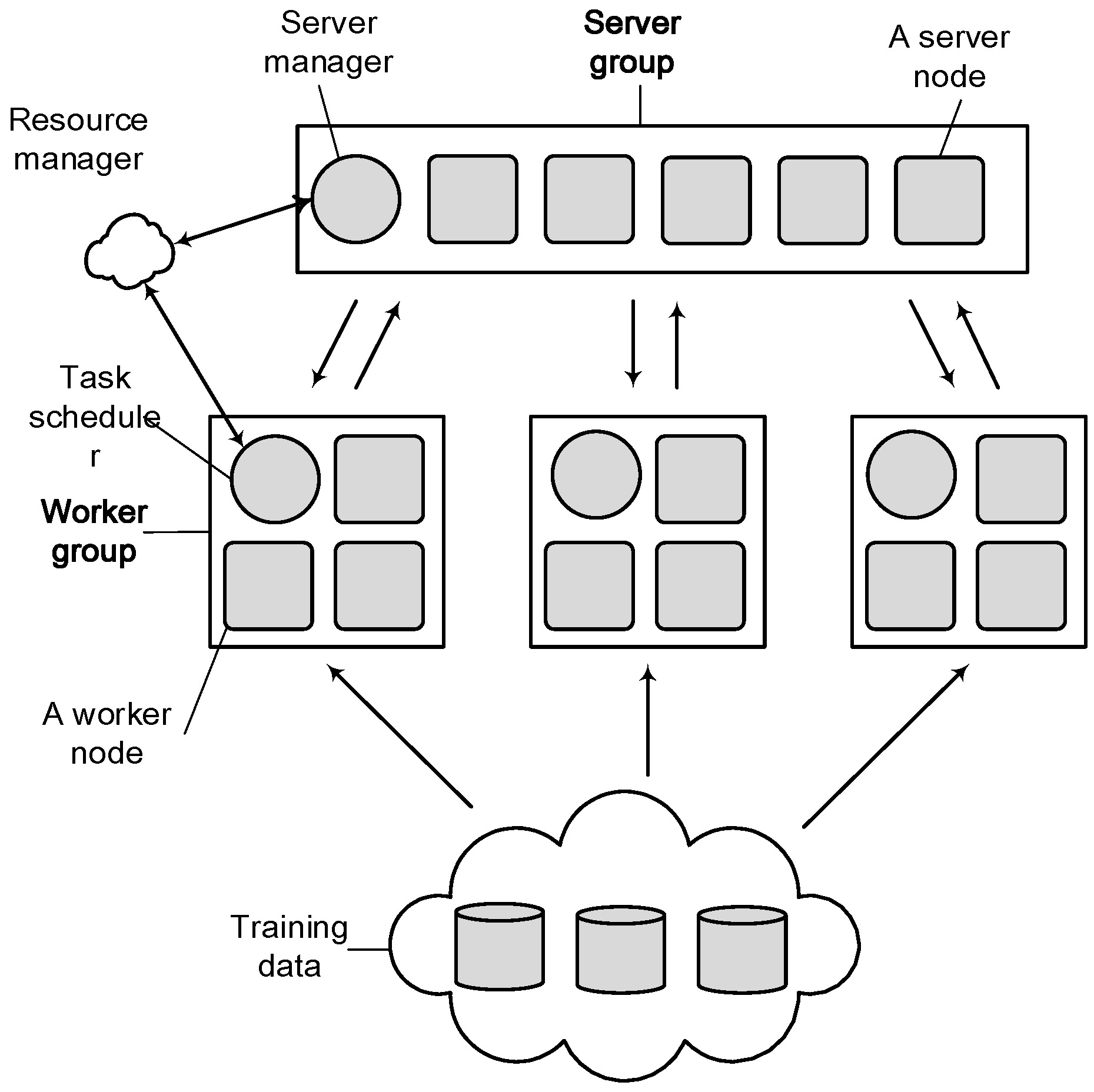
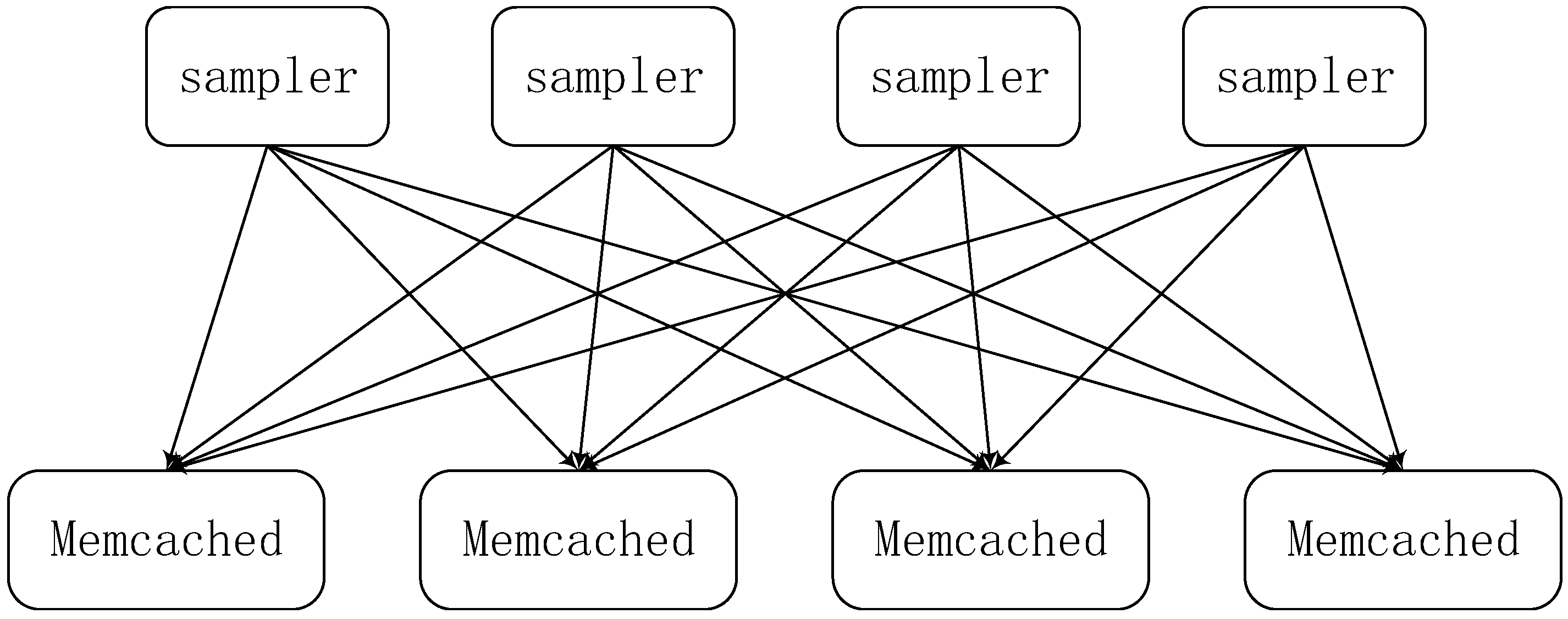
2.2. Parameter Server System
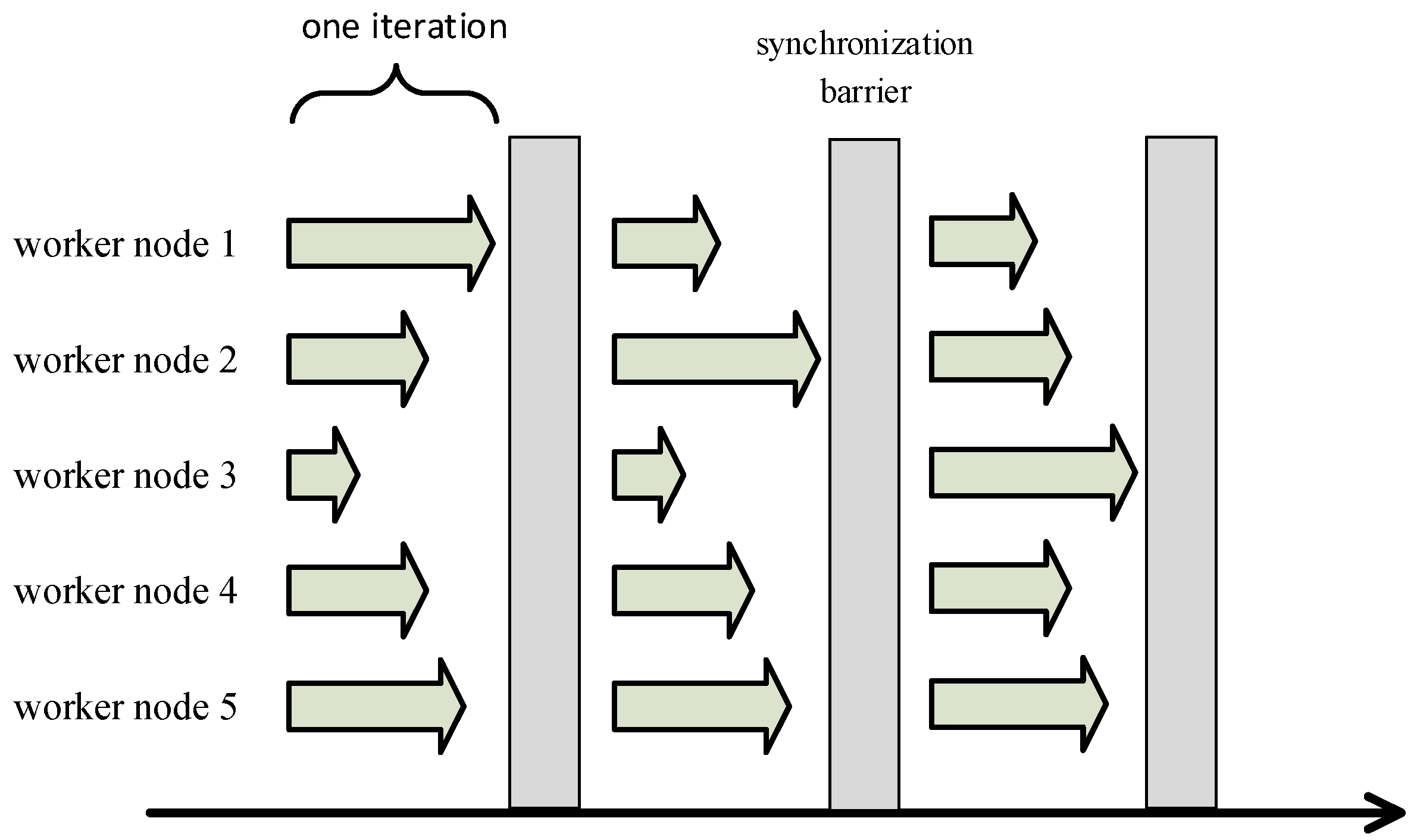
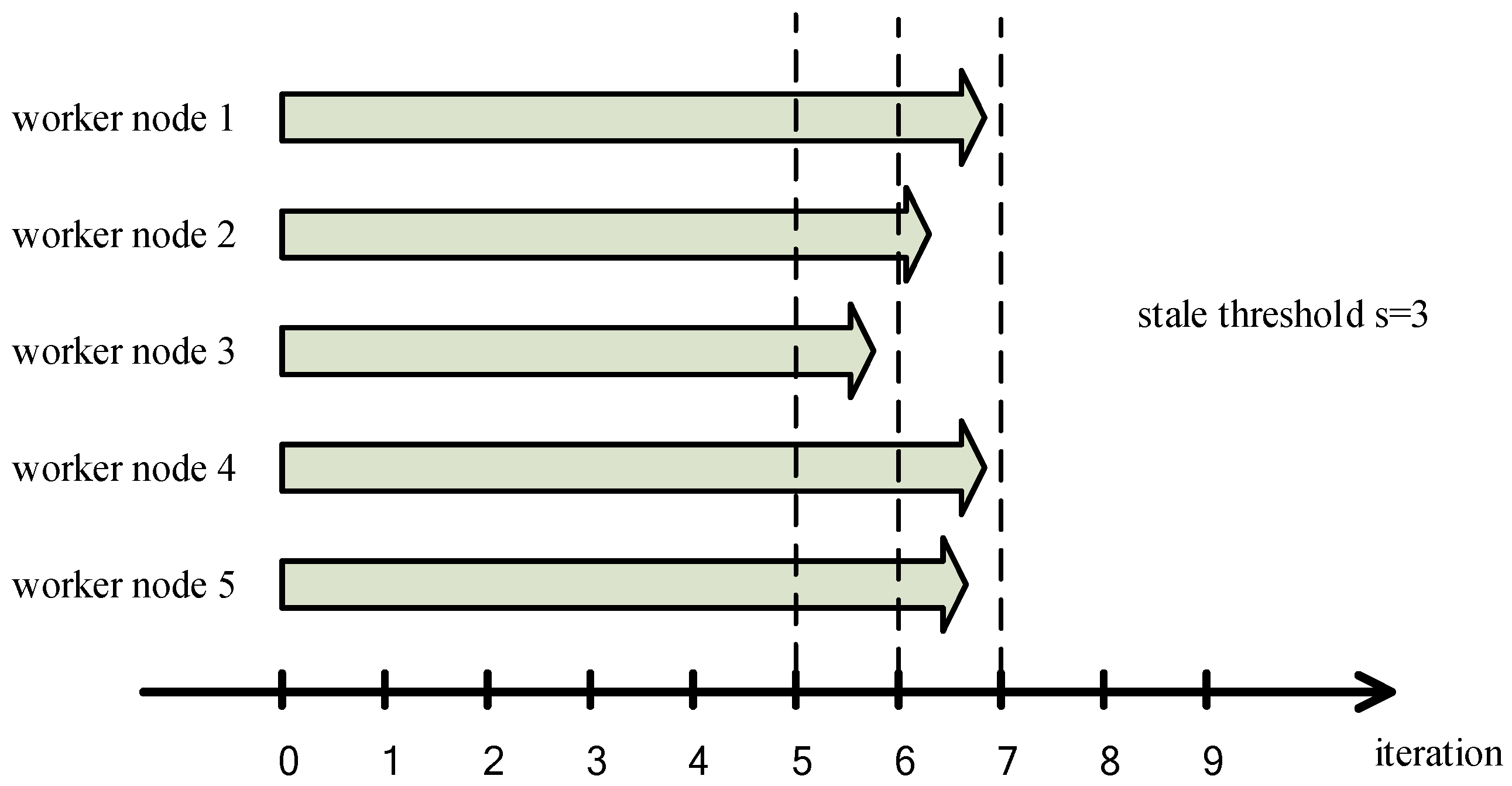
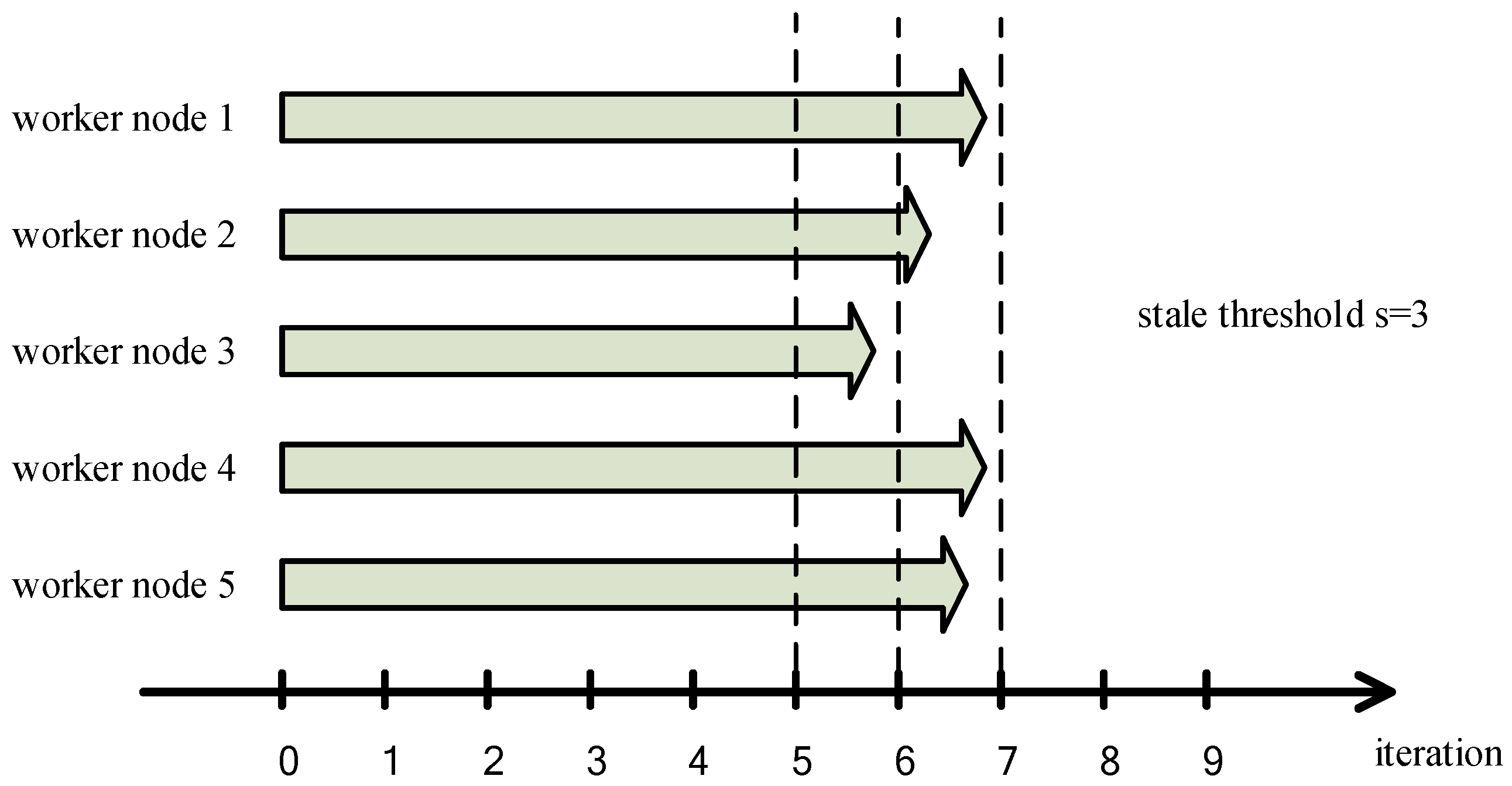
2.3. Stale Synchronous Parallel Strategy
2.4. Robust Optimization
3. Communication Optimization
3.1. Theoretical Analysis
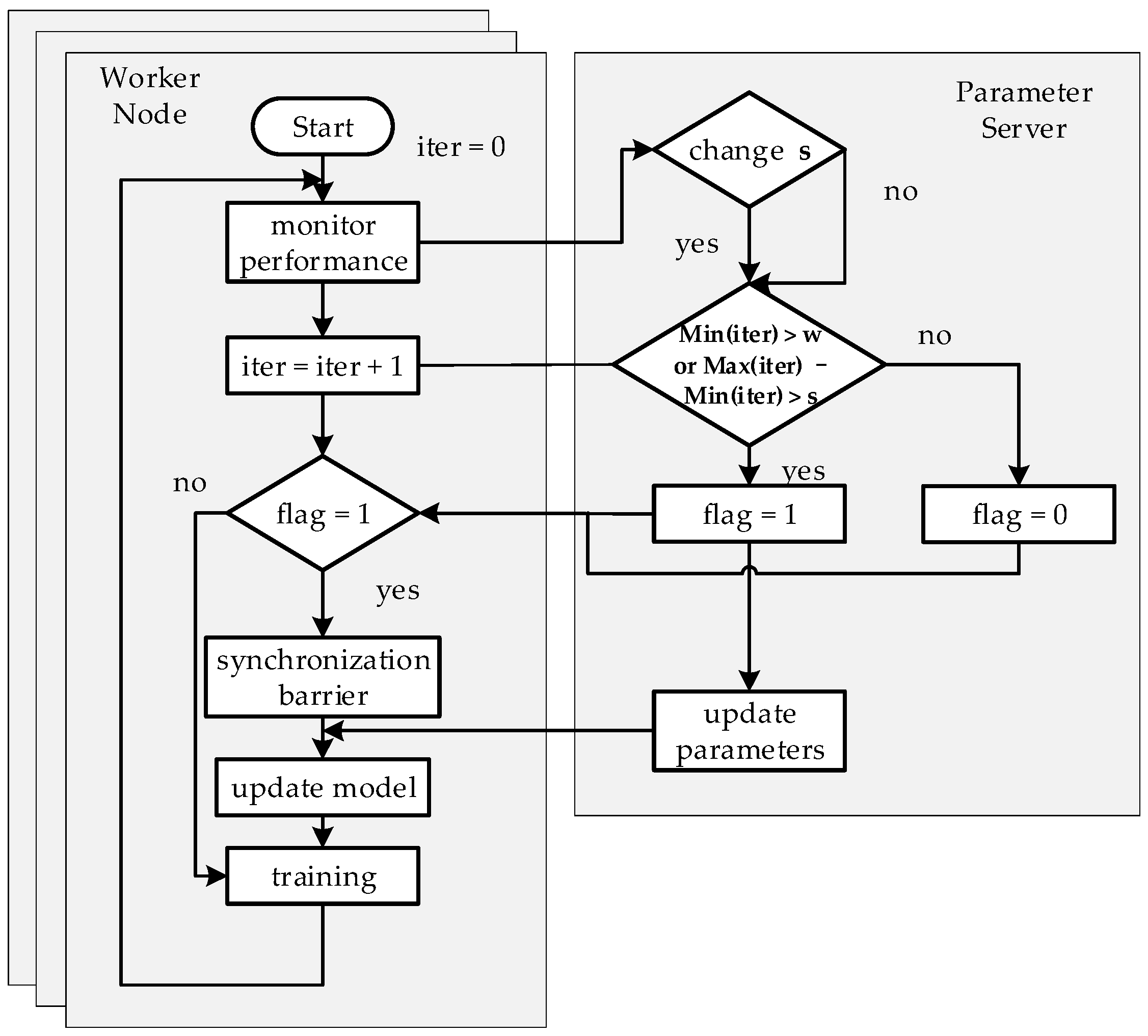
3.2. Dynamic Synchronous Parallel Strategy
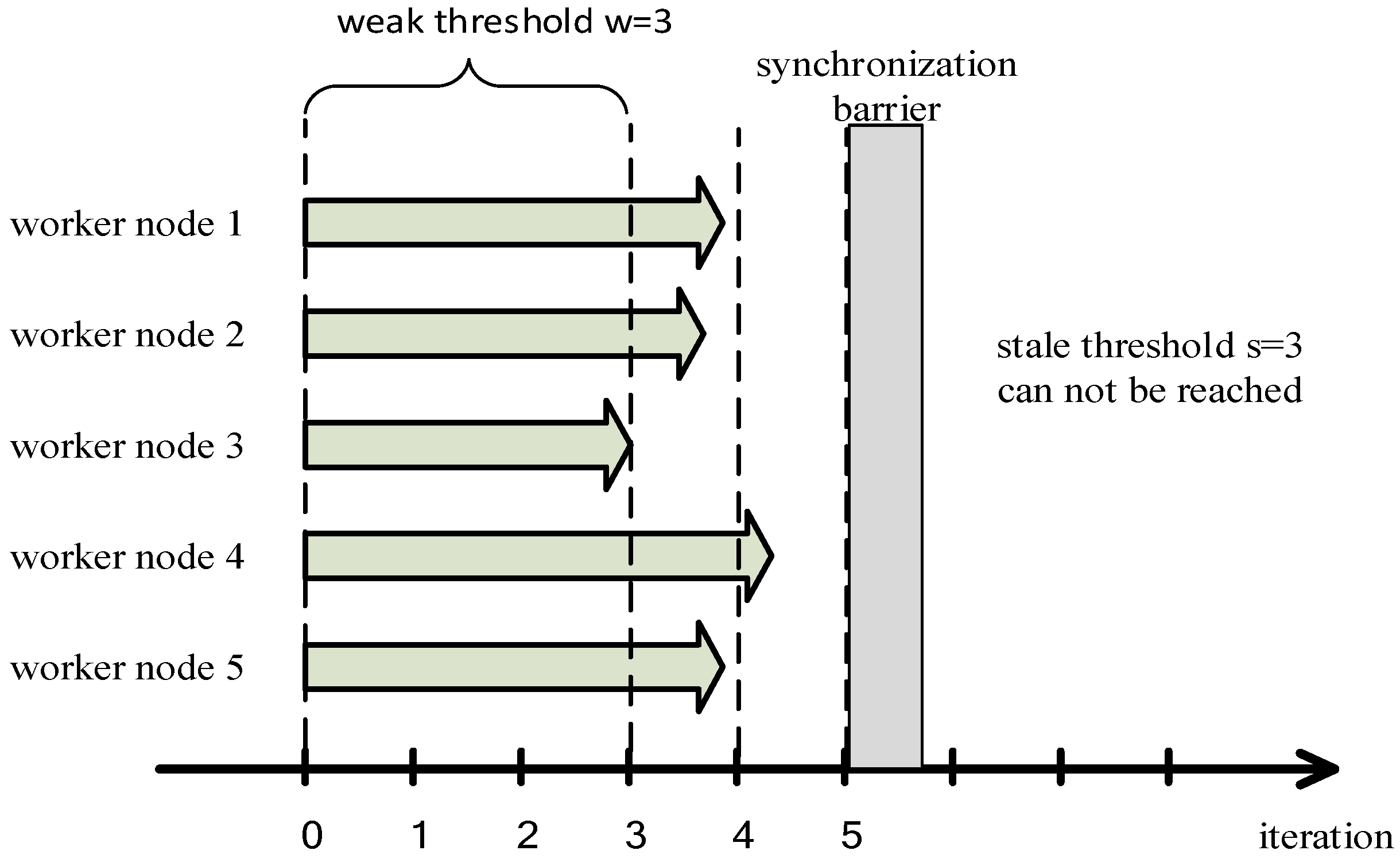
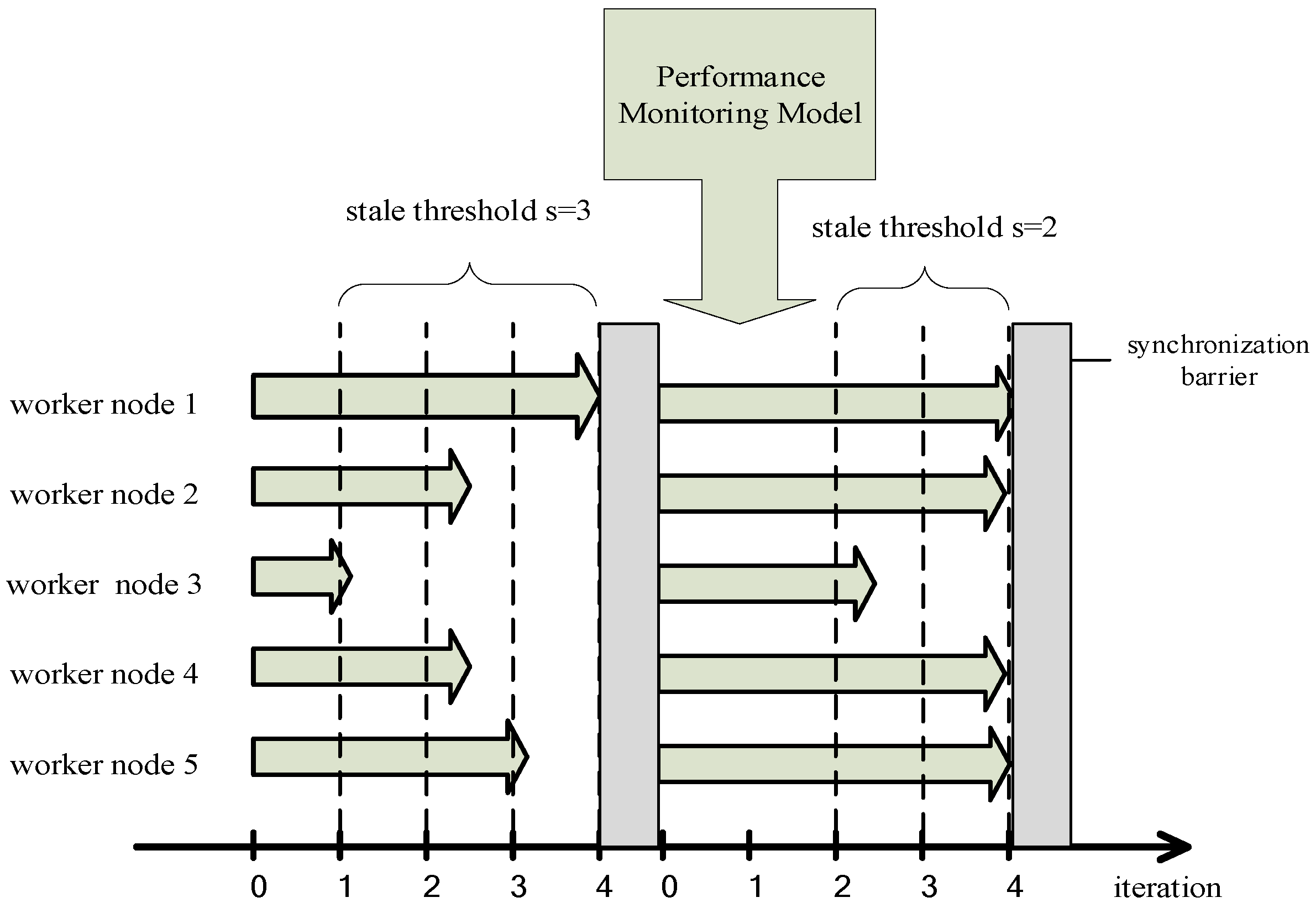
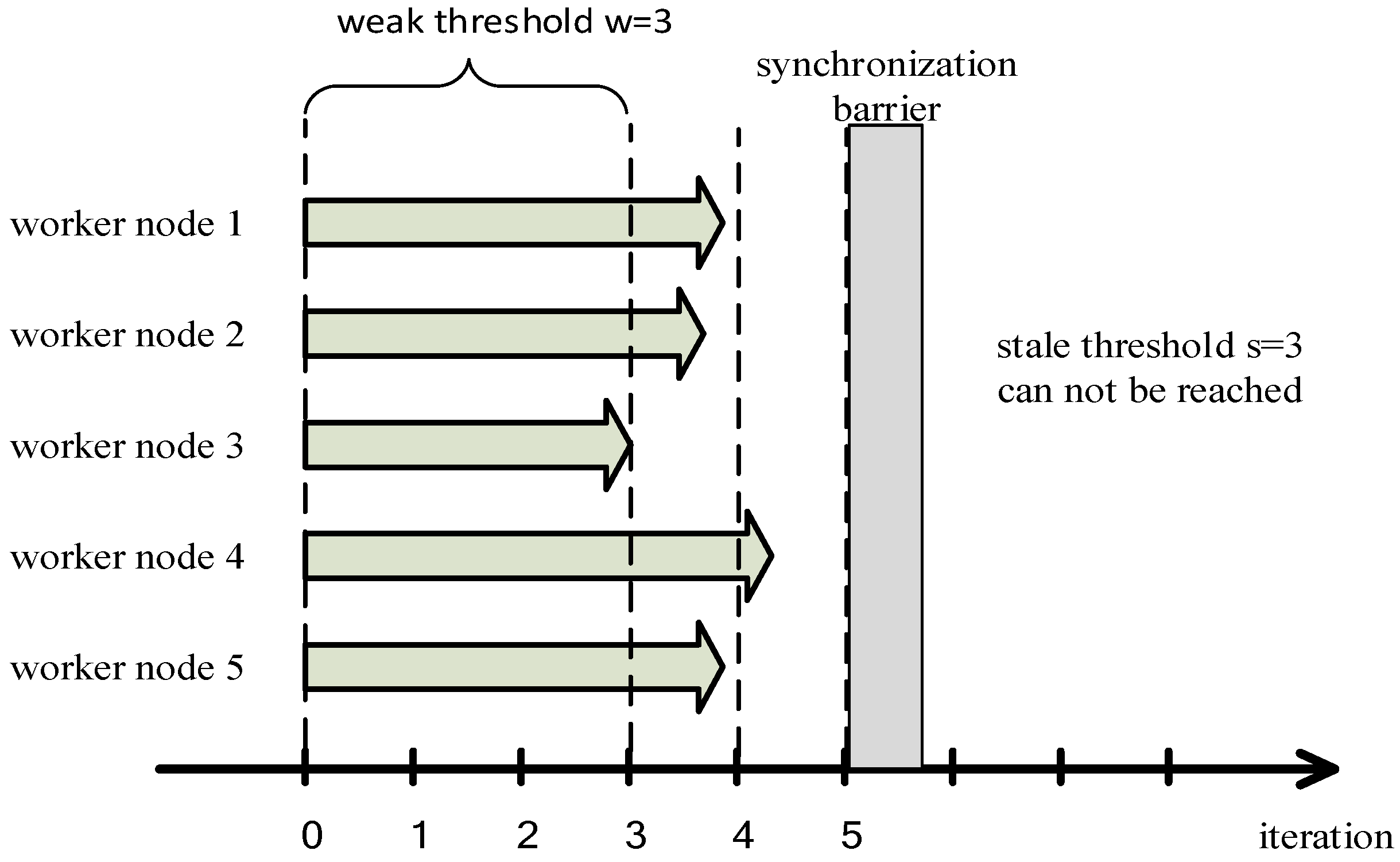
3.2.1. Problems of SSP
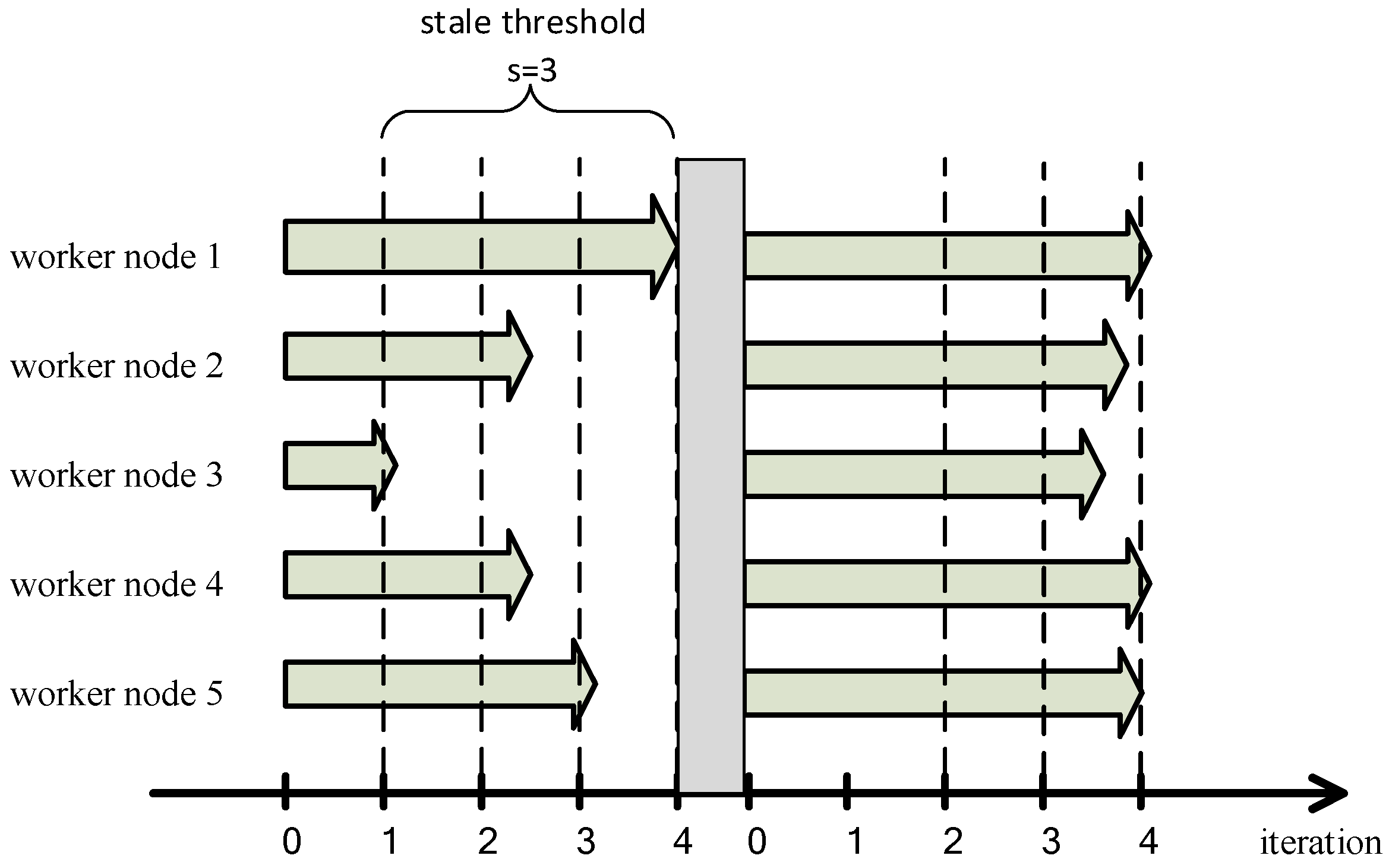
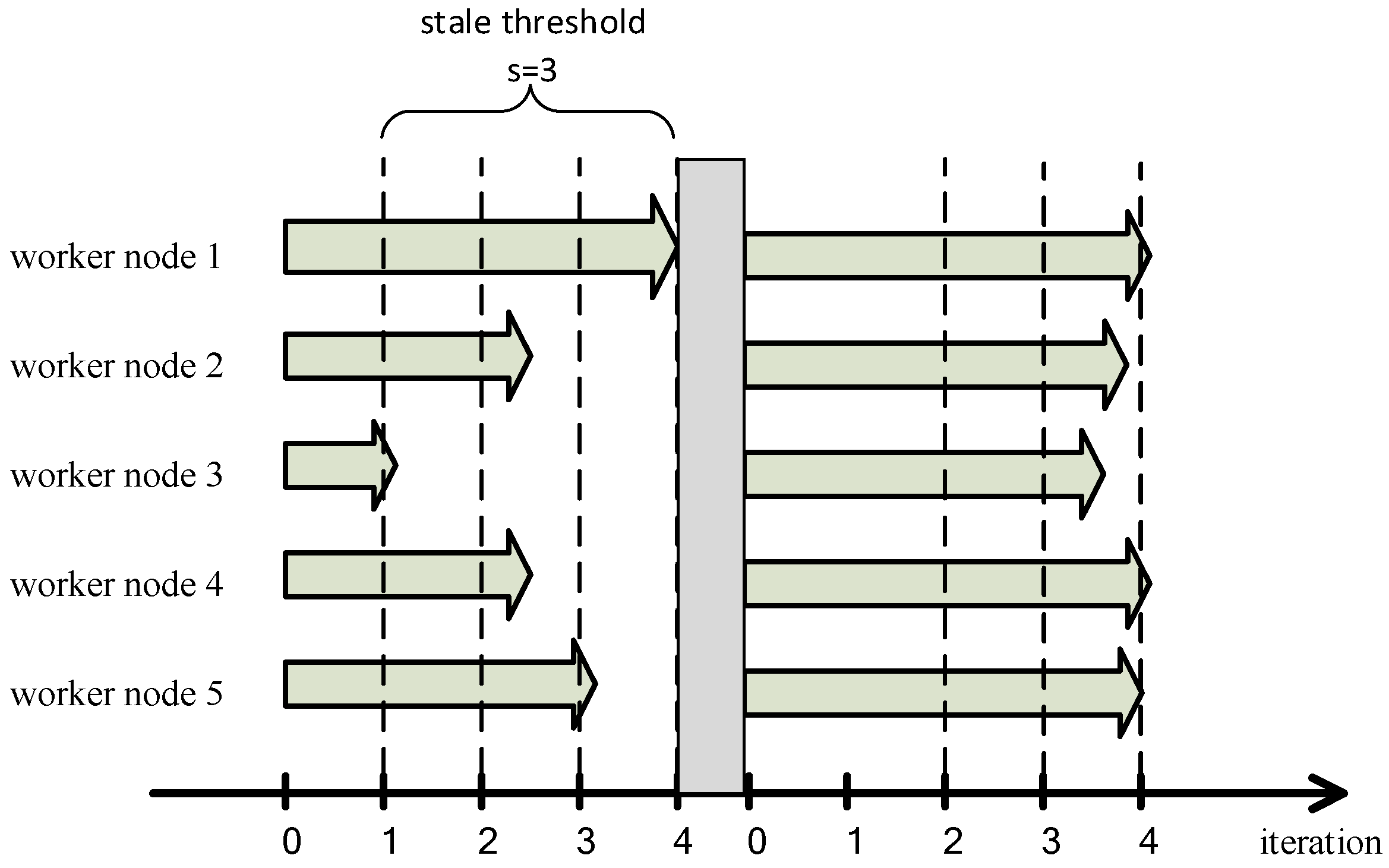
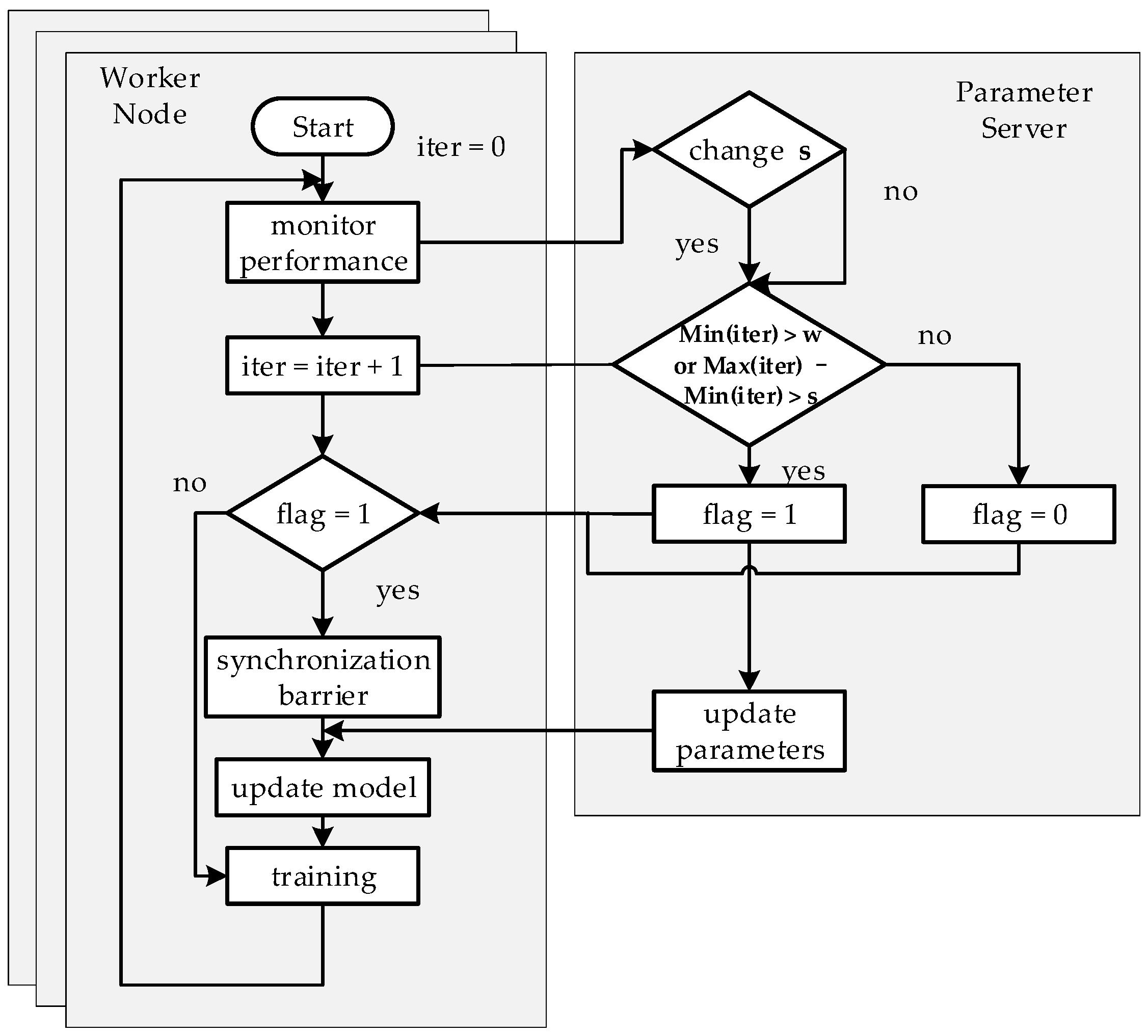
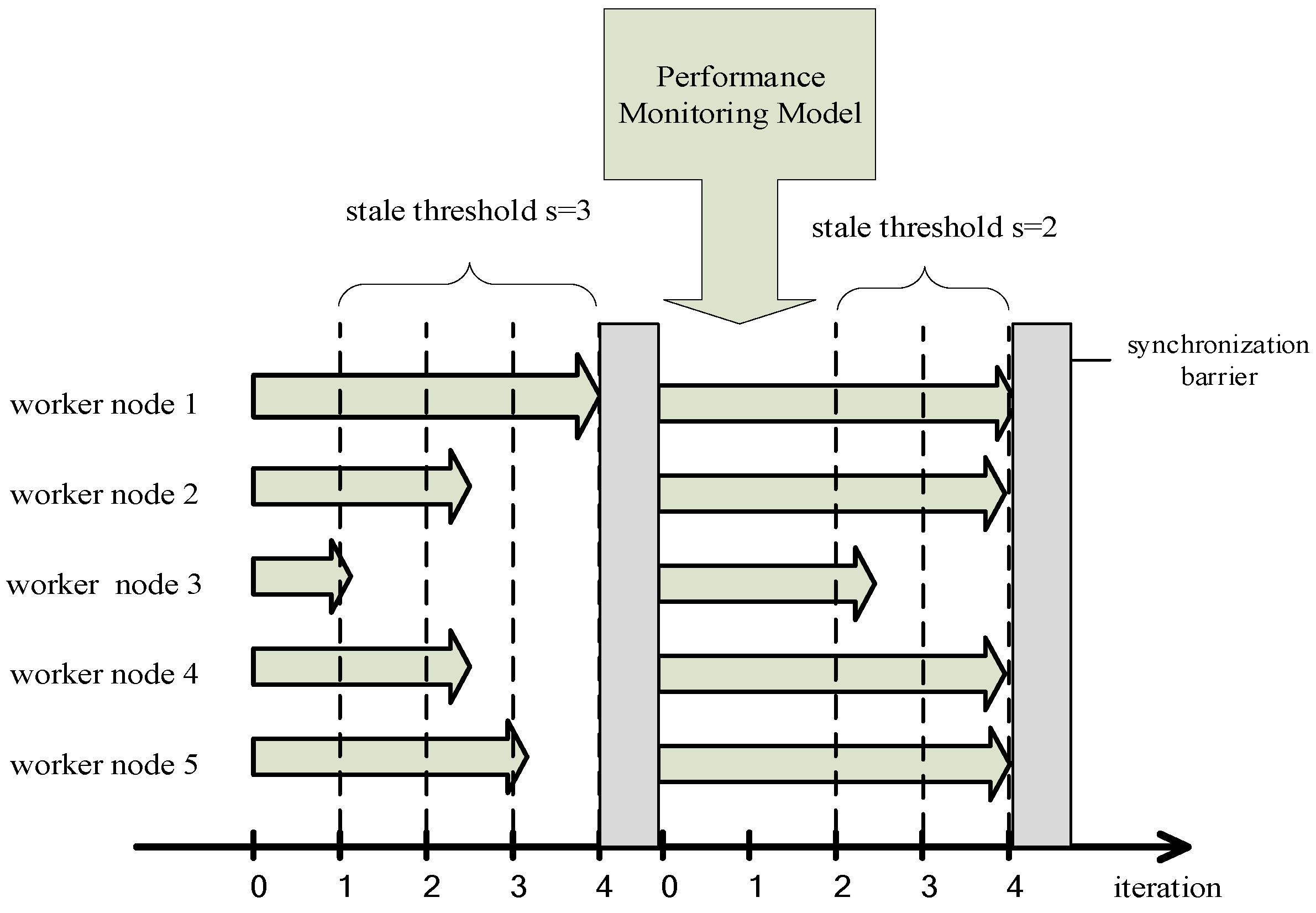
3.2.2. Improvements of SSP
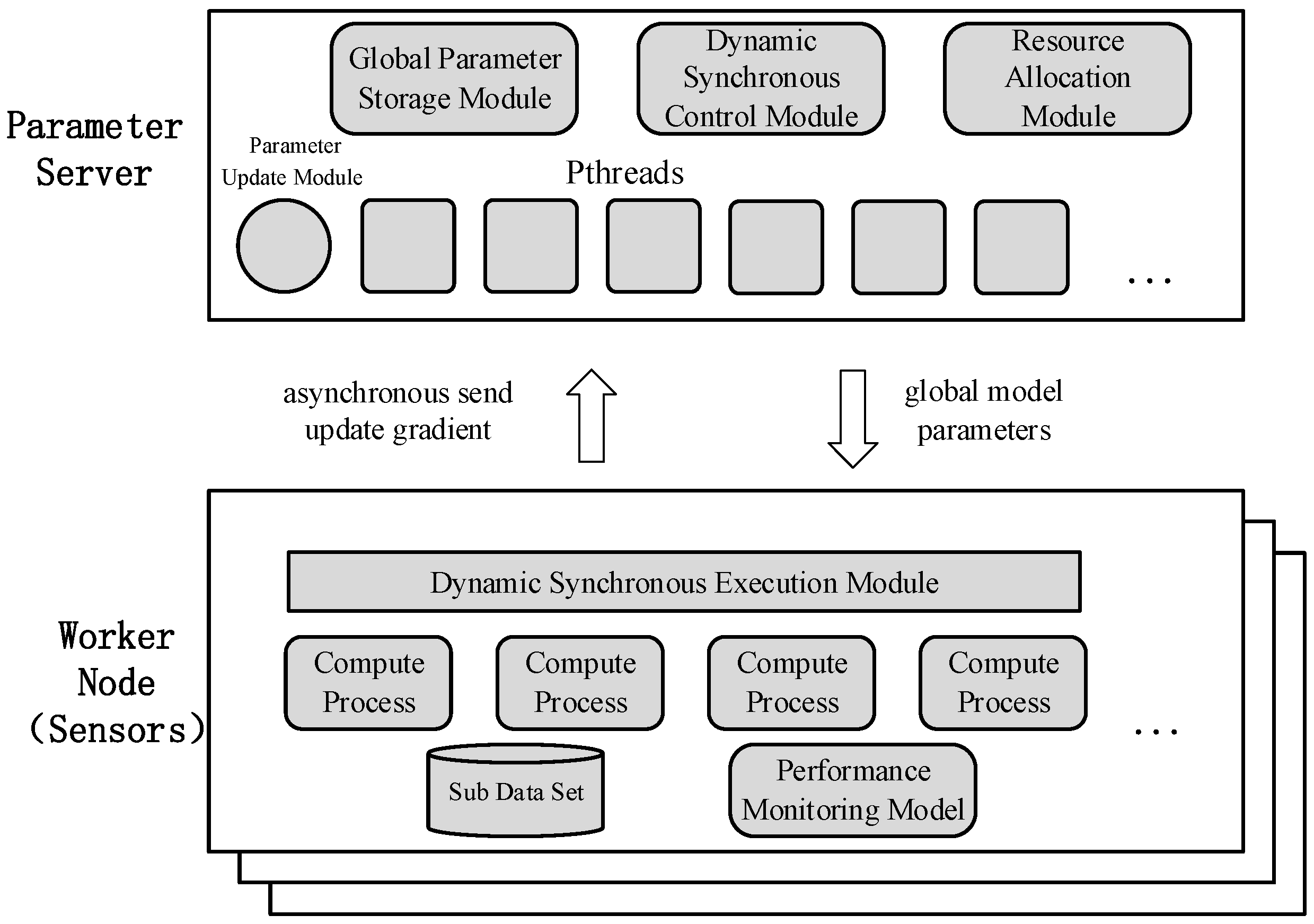
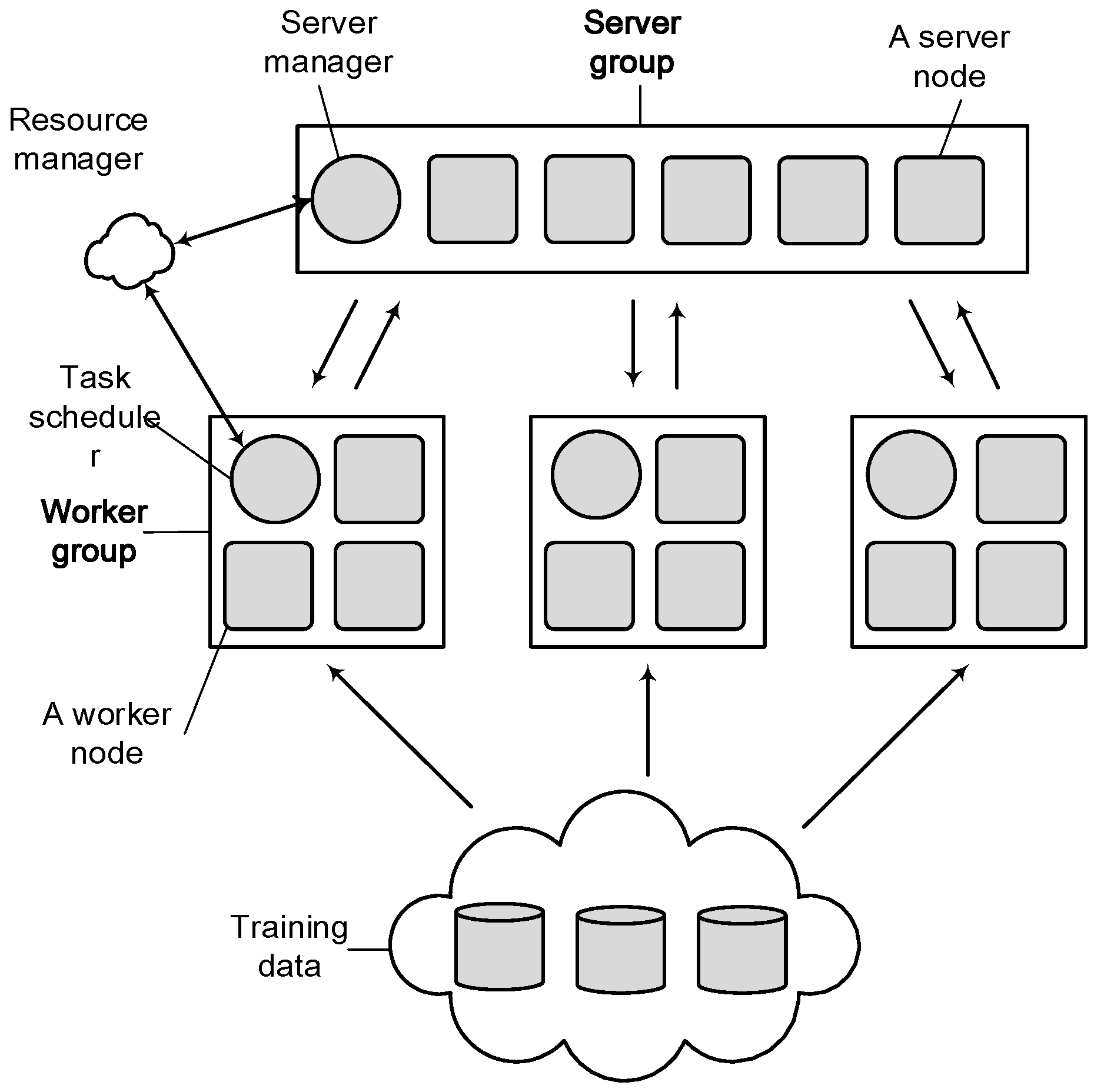
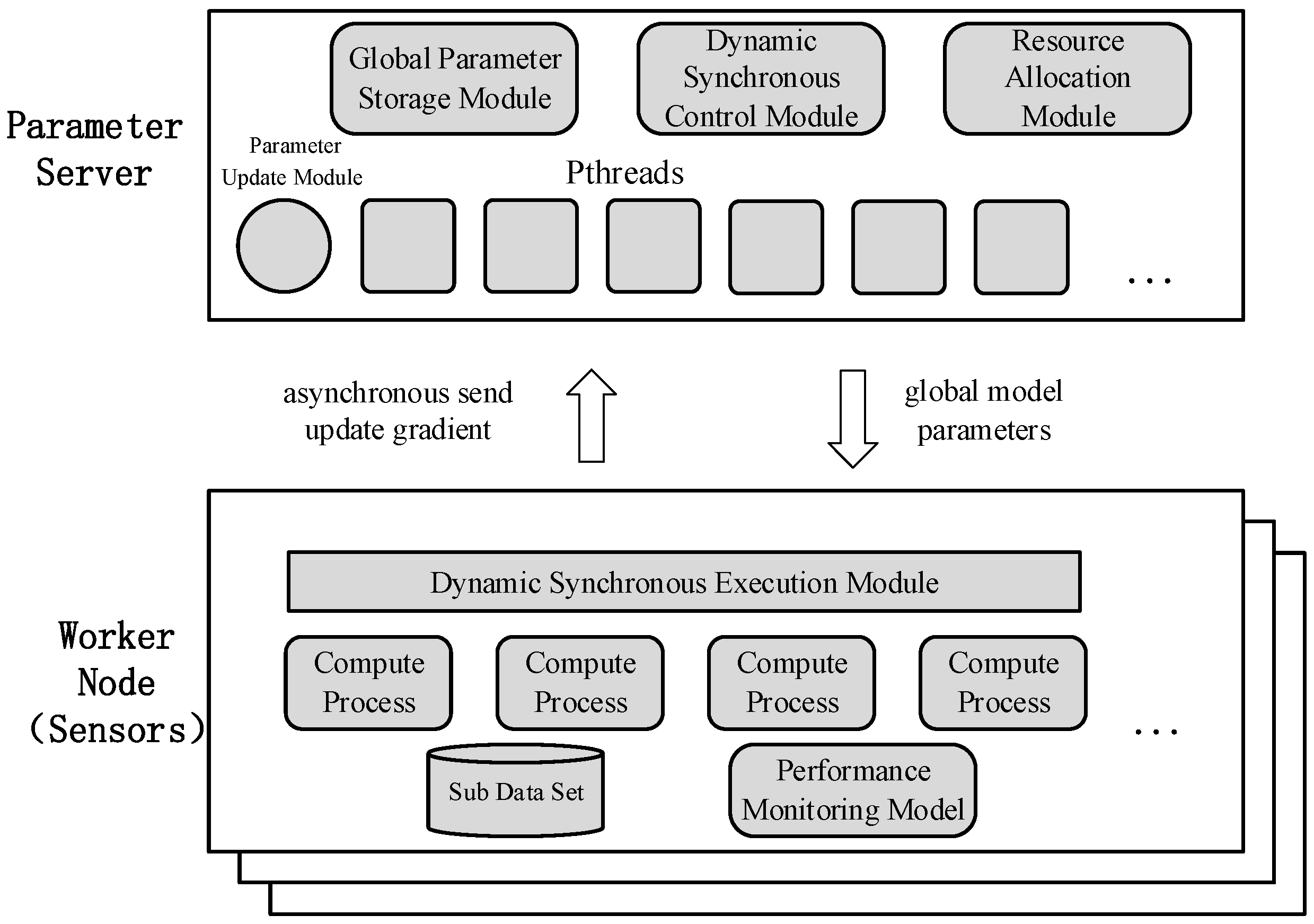
3.3. Distributed Machine Learning System in Sensors Based on Caffe
4. Experiments and Results
4.1. Experimental Environment
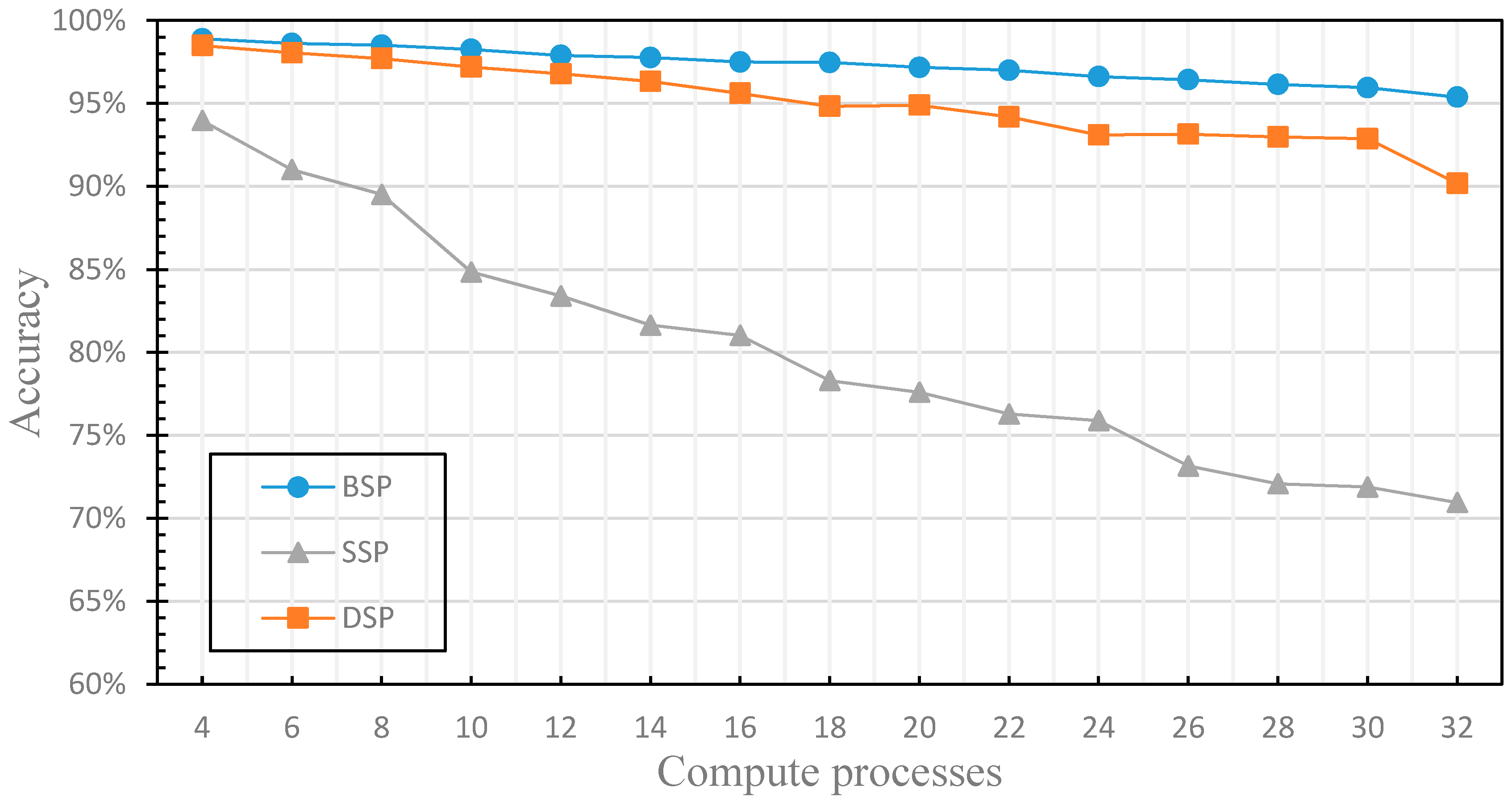
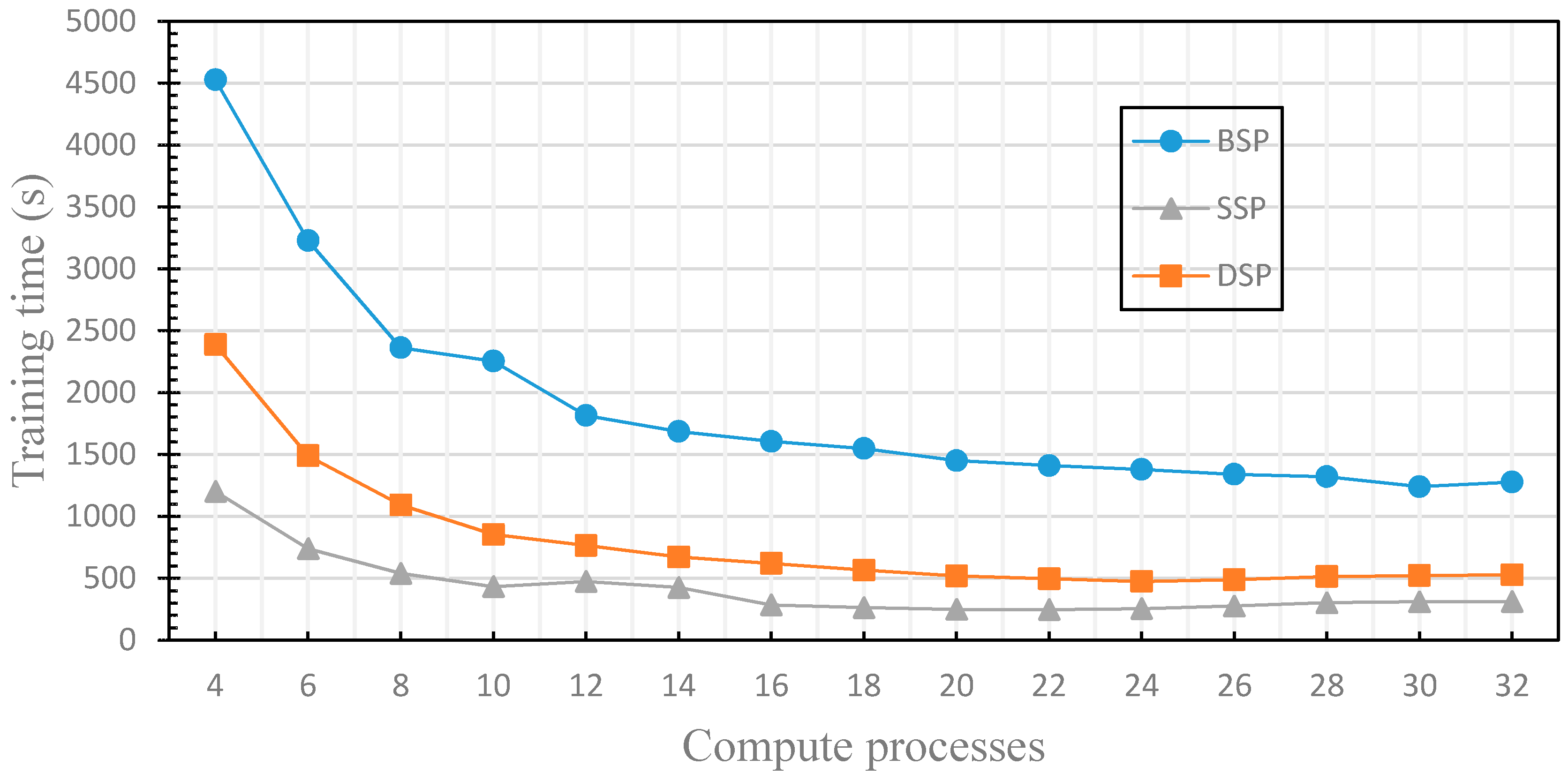
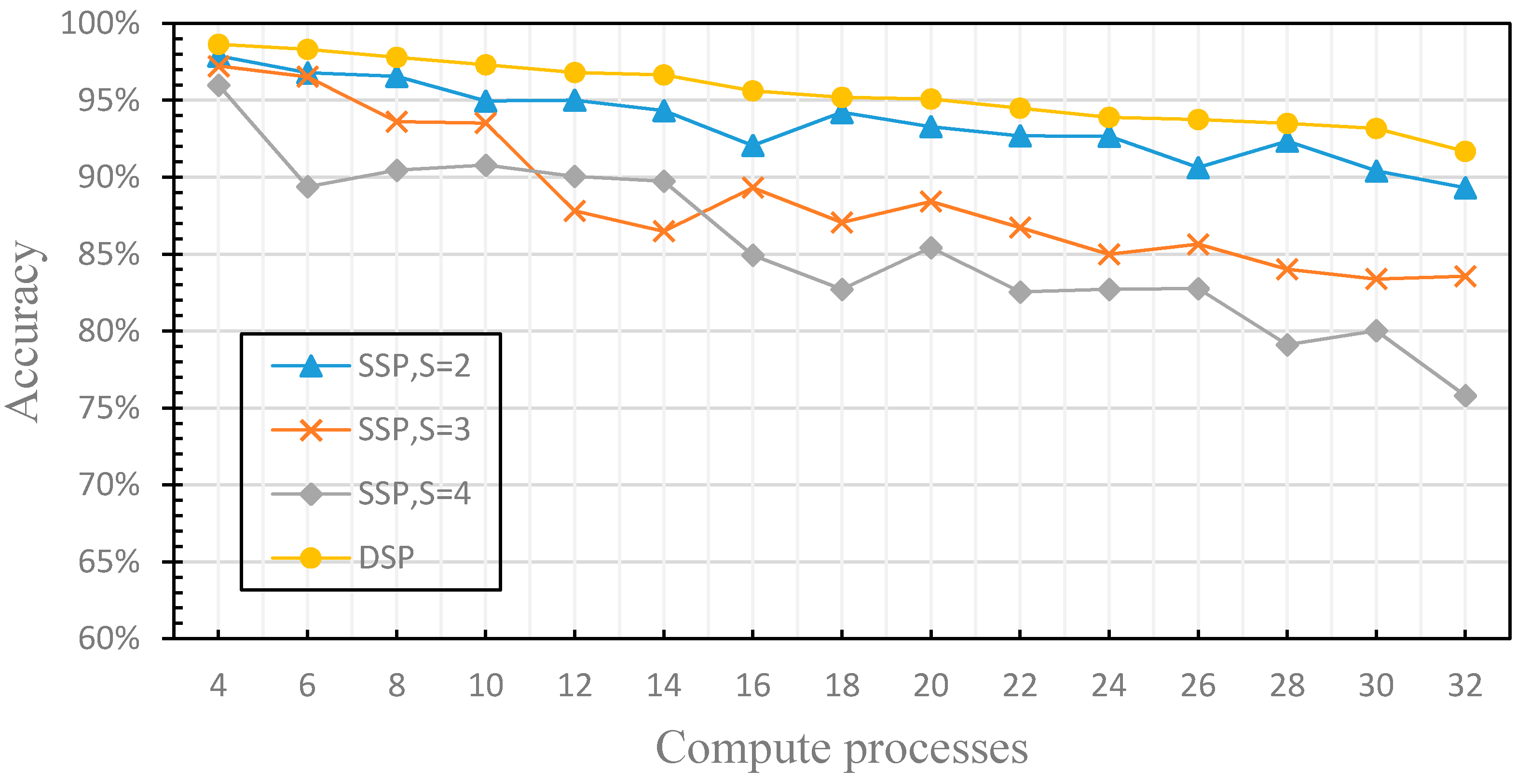
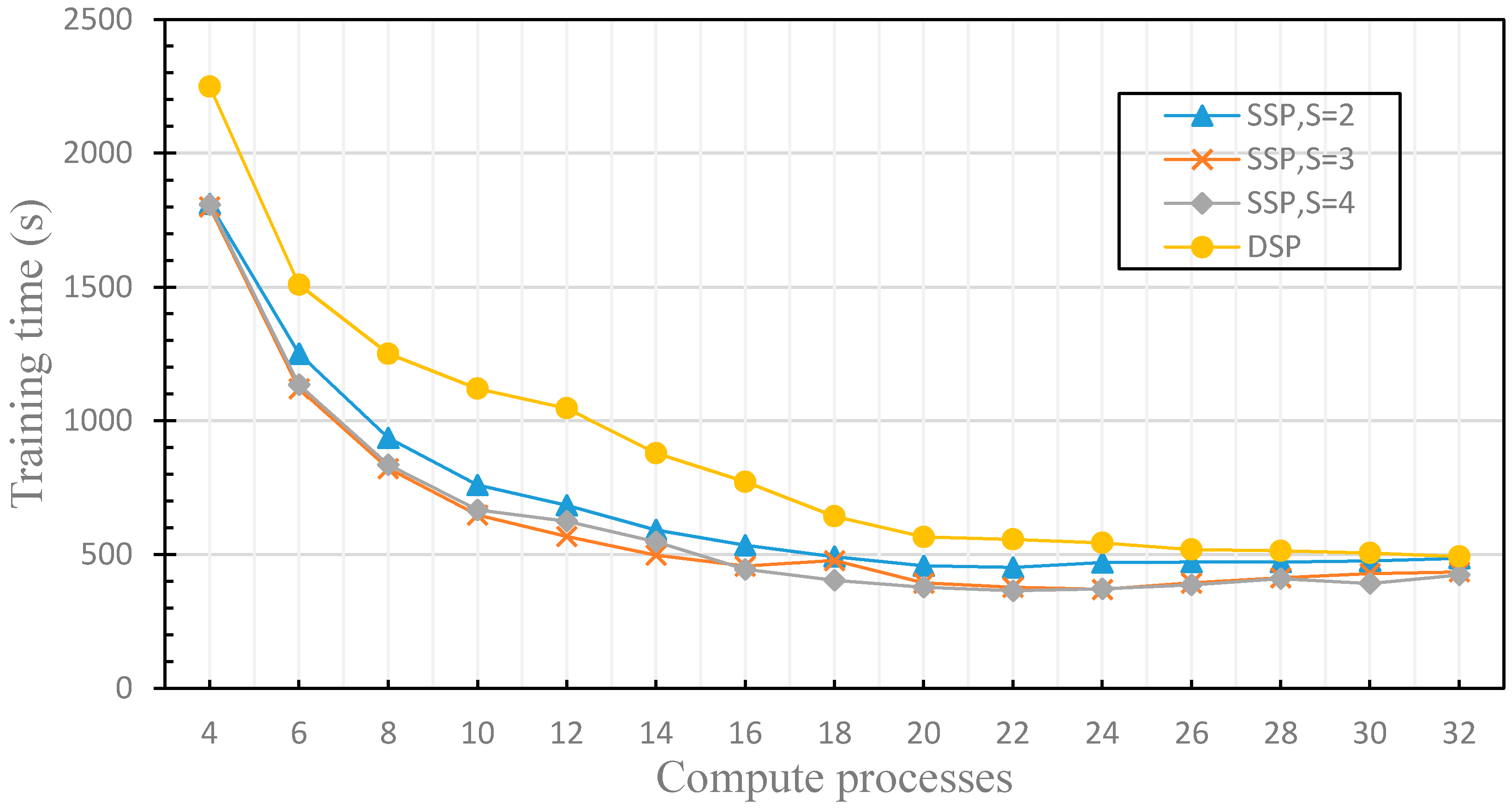
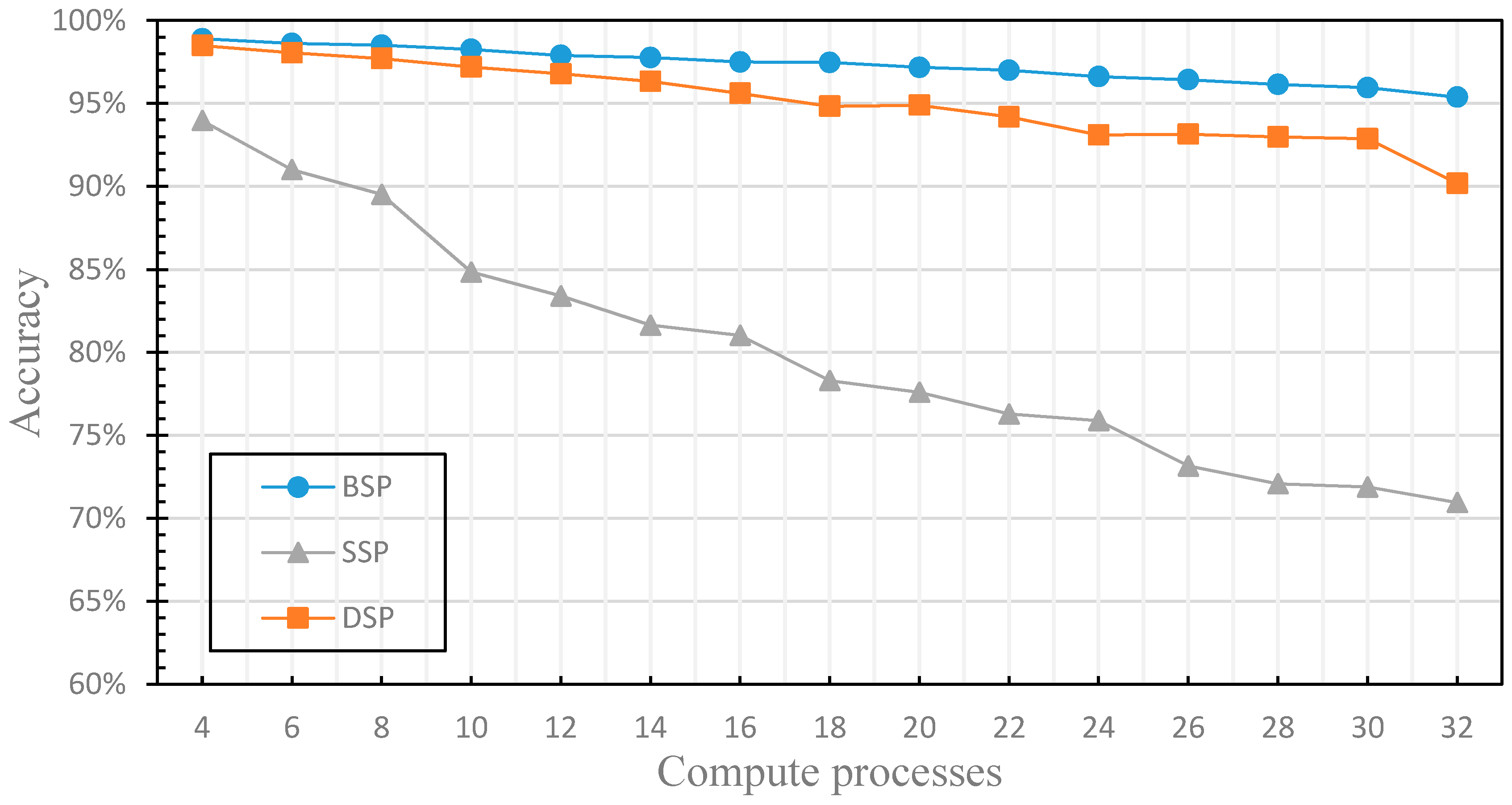
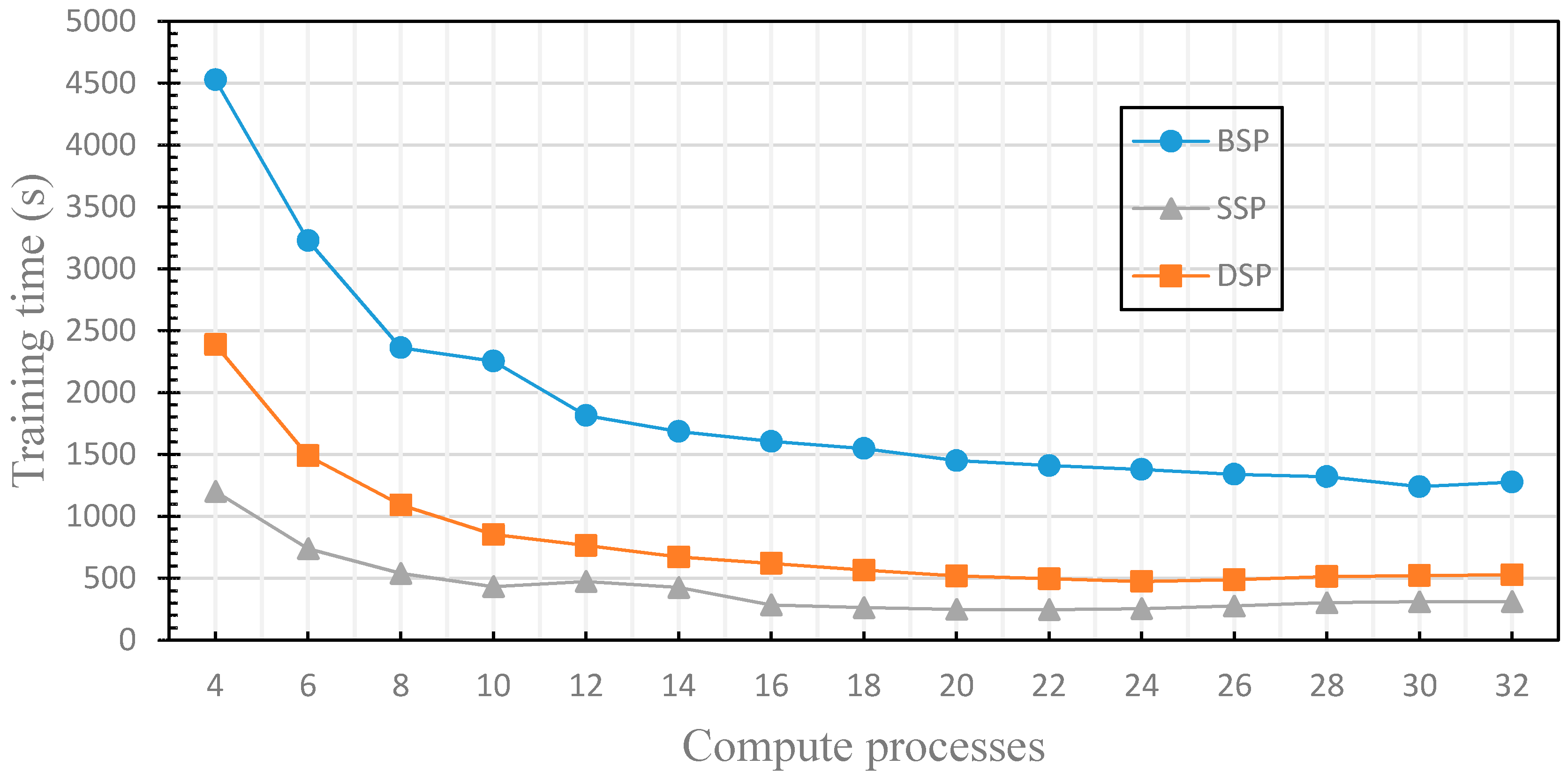
4.2. The Finite of the Fault Tolerance
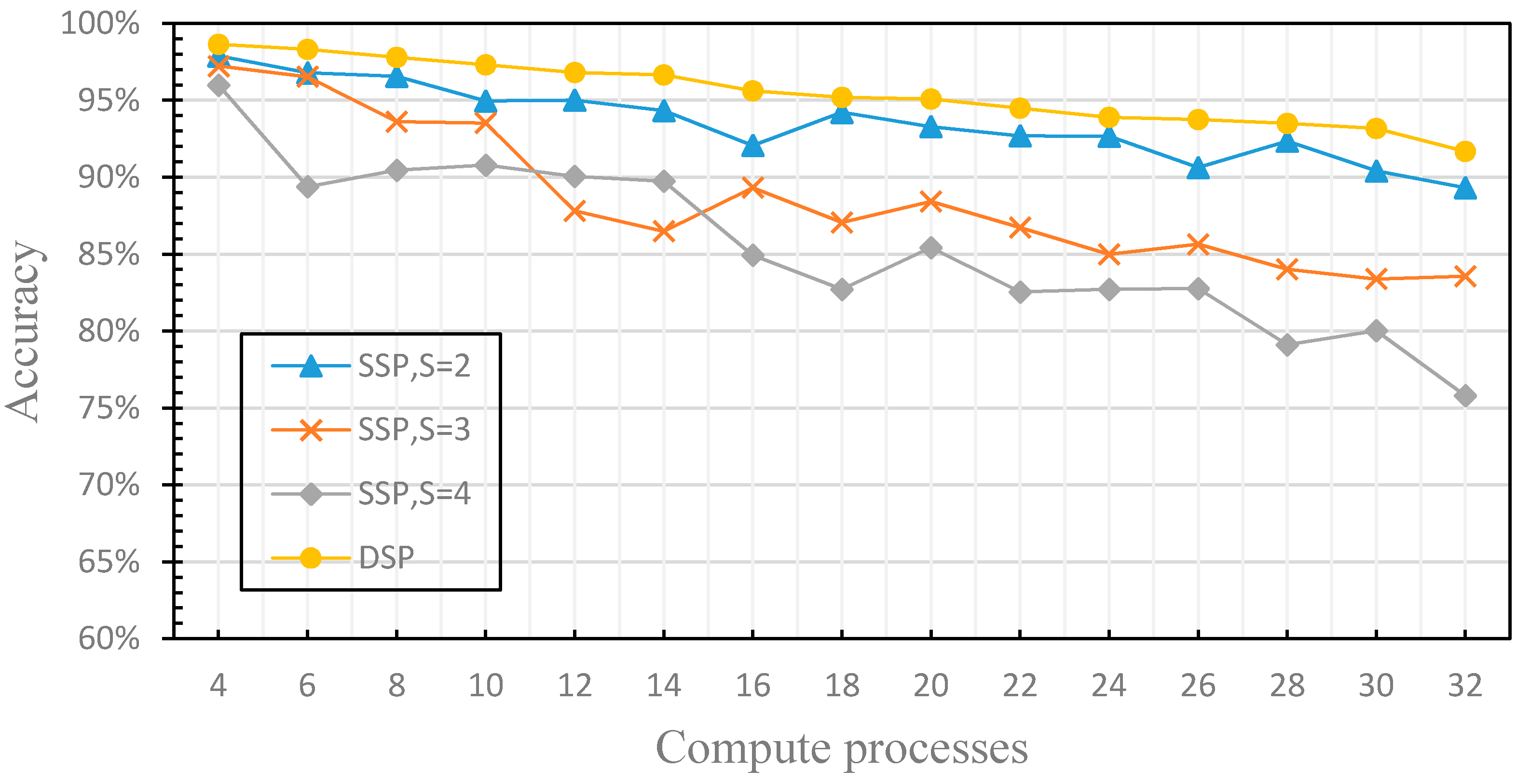
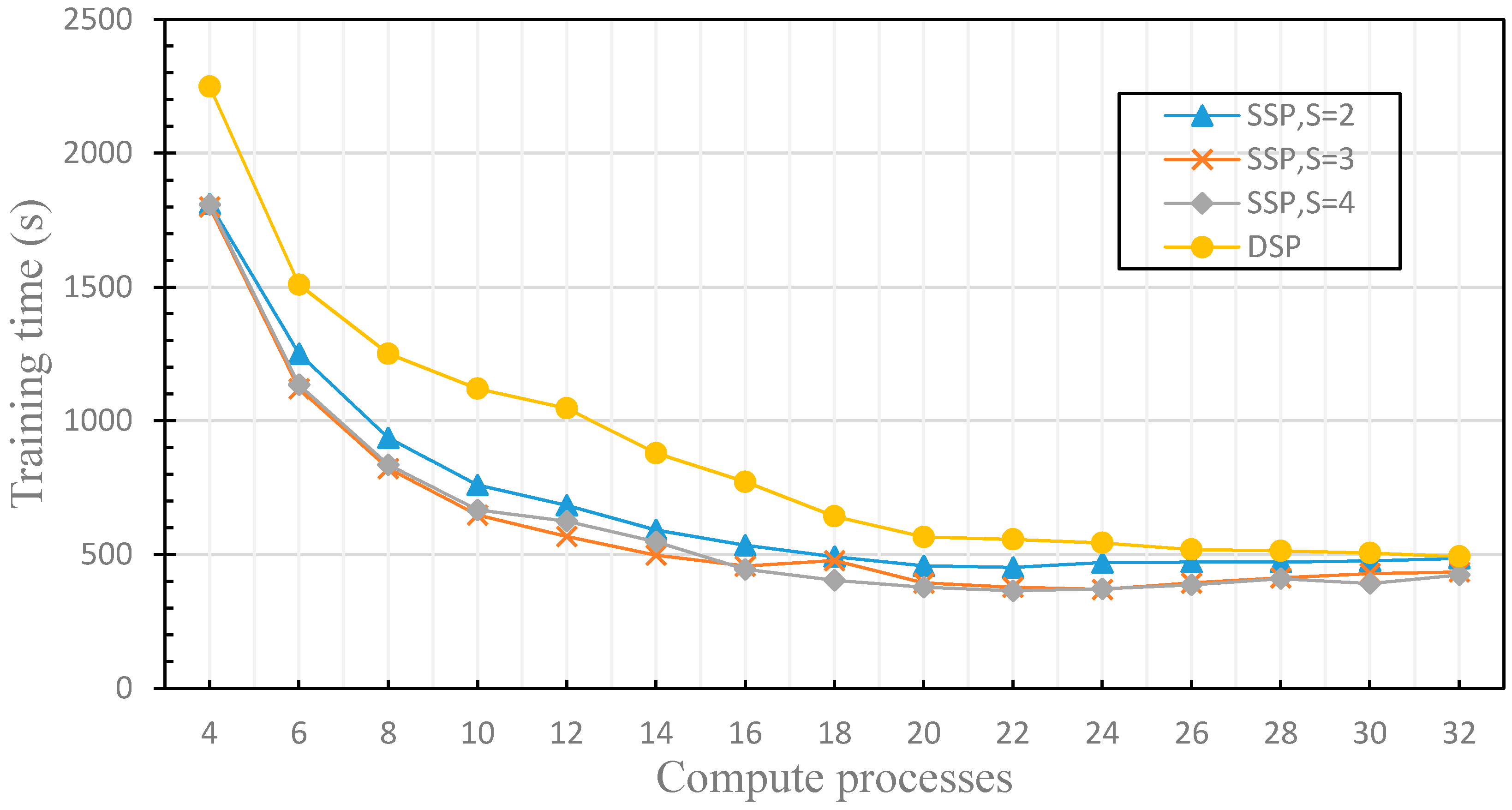
4.3. The Dynamics of the Fault Tolerance
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- D’Andreagiovanni, F.; Nardin, A. Towards the fast and robust optimal design of wireless body area networks. Appl. Soft Comput. 2015, 37, 971–982. [Google Scholar] [CrossRef]
- Tsouri, G.R.; Prieto, A.; Argade, N. On Increasing Network Lifetime in Body Area Networks Using Global Routing with Energy Consumption Balancing. Sensors 2012, 12, 13088. [Google Scholar] [CrossRef] [PubMed]
- Natalizio, E.; Loscri, V.; Viterbo, E. Optimal placement of wireless nodes for maximizing path lifetime. IEEE Commun. Lett. 2008, 12. [Google Scholar] [CrossRef]
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Pandana, C.; Liu, K.R. Near-optimal reinforcement learning framework for energy-aware sensor communications. IEEE J. Sel. Areas Commun. 2005, 23, 788–797. [Google Scholar] [CrossRef]
- Junejo, K.N.; Goh, J. Behaviour-Based Attack Detection and Classification in Cyber Physical Systems Using Machine Learning. In Proceedings of the ACM International Workshop on Cyber-Physical System Security, Xi’an, China, 30–30 May 2016; pp. 34–43. [Google Scholar]
- Van Norden, W.; de Jong, J.; Bolderheij, F.; Rothkrantz, L. Intelligent Task Scheduling in Sensor Networks. In Proceedings of the 2005 8th International Conference on Information Fusion, Philadelphia, PA, USA, 25–28 July 2005; IEEE: Philadelphia, PA, USA, 2005; p. 8. [Google Scholar]
- Yin, J.; Lu, X.; Zhao, X.; Chen, H.; Liu, X. BURSE: A bursty and self-similar workload generator for cloud computing. IEEE Trans. Parall Distrib. Syst. 2015, 26, 668–680. [Google Scholar] [CrossRef]
- Di, M.; Joo, E.M. A Survey of Machine Learning in Wireless Sensor Netoworks from Networking and Application Perspectives. In Proceedings of the 2007 6th International Conference on Information, Communications & Signal Processing, Singapore, 10–13 December 2007; IEEE: Singapore, 2007; pp. 1–5. [Google Scholar]
- McColl, W.F. Bulk synchronous parallel computing. In Abstract Machine Models for Highly Parallel Computers; Oxford University Press: Oxford, UK, 1995; pp. 41–63. [Google Scholar]
- Gerbessiotis, A.V.; Valiant, L.G. Direct bulk-synchronous parallel algorithms. J. Parallel Distrib. Commun. 1994, 22, 251–267. [Google Scholar] [CrossRef]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Senior, A.; Tucker, P.; Yang, K.; Le, Q.V. Large Scale Distributed Deep Networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Lake Tahoe, NV, USA, 2012; pp. 1223–1231. [Google Scholar]
- Ahmed, A.; Aly, M.; Gonzalez, J.; Narayanamurthy, S.; Smola, A. Scalable Inference in Latent Variable Models. In Proceedings of the International conference on Web search and data mining (WSDM), Seattle, DC, USA, 8–12 February 2012; pp. 1257–1264. [Google Scholar]
- Chilimbi, T.; Suzue, Y.; Apacible, J.; Kalyanaraman, K. Project Adam: Building an Efficient and Scalable Deep Learning Training System. In Proceedings of the Usenix Conference on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014; pp. 571–582. [Google Scholar]
- Cui, H.; Tumanov, A.; Wei, J.; Xu, L.; Dai, W.; Haber-Kucharsky, J.; Ho, Q.; Ganger, G.R.; Gibbons, P.B.; Gibson, G.A. Exploiting Iterative-Ness for Parallel ML Computations. In Proceedings of the ACM Symposium on Cloud Computing, Seattle, WA, USA, 3–5 November 2014; ACM: New York, NY, USA, 2014; pp. 1–14. [Google Scholar]
- Ho, Q.; Cipar, J.; Cui, H.; Lee, S.; Kim, J.K.; Gibbons, P.B.; Gibson, G.A.; Ganger, G.; Xing, E.P. More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server; Neural Information Processing Systems Foundation, Inc.: Lake Tahoe, NV, USA, 2013; pp. 1223–1231. [Google Scholar]
- Xing, E.P.; Ho, Q.; Xie, P.; Wei, D. Strategies and principles of distributed machine learning on big data. Engineering 2016, 2, 179–195. [Google Scholar] [CrossRef]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv, 2015; arXiv:1512.01274. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Coates, A.; Huval, B.; Wang, T.; Wu, D.J.; Ng, A.Y.; Catanzaro, B. Deep Learning with COTS HPC Systems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1337–1345. [Google Scholar]
- Sparks, E.R.; Talwalkar, A.; Smith, V.; Kottalam, J.; Pan, X.; Gonzalez, J.; Franklin, M.J.; Jordan, M.I.; Kraska, T. MLI: An API for Distributed Machine Learning. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining (ICDM), Dallas, TX, USA, 7–10 December 2013; pp. 1187–1192. [Google Scholar]
- Yin, J.; Lo, W.; Deng, S.; Li, Y.; Wu, Z.; Xiong, N. Colbar: A collaborative location-based regularization framework for QoS prediction. Inf. Sci. 2014, 265, 68–84. [Google Scholar] [CrossRef]
- Yu, K. Large-Scale Deep Learning at Baidu. In Proceedings of the ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 November–1 October 2013; pp. 2211–2212. [Google Scholar]
- Zou, Y.; Jin, X.; Li, Y.; Guo, Z.; Wang, E.; Xiao, B. Mariana: Tencent deep learning platform and its applications. Proc. VLDB Endow. 2014, 7, 1772–1777. [Google Scholar] [CrossRef]
- Le, Q.V. Building High-Level Features Using Large Scale Unsupervised Learning. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; IEEE: Vancouver, BC, Canada, 2013; pp. 8595–8598. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Smola, A.; Narayanamurthy, S. An architecture for parallel topic models. Proc. VLDB Endow. 2010, 3, 703–710. [Google Scholar] [CrossRef]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Long, J.; Shekita, E.J.; Su, B.Y. Scaling Distributed Machine Learning with the Parameter Server. In Proceedings of the Usenix Conference on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014; pp. 583–598. [Google Scholar]
- Li, M.; Andersen, D.G.; Smola, A.; Yu, K. Communication Efficient Distributed Machine Learning with the Parameter Server. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 19–27. [Google Scholar]
- Wei, J.; Dai, W.; Qiao, A.; Ho, Q.; Cui, H.; Ganger, G.R.; Gibbons, P.B.; Gibson, G.A.; Xing, E.P. Managed Communication and Consistency for Fast Data-Parallel Iterative Analytics. In Proceedings of the Proceedings of the Sixth ACM Symposium on Cloud Computing, Kohala Coast, HI, USA, 27–29 August 2015; ACM: New York, NY, USA, 2015; pp. 381–394. [Google Scholar]
- Sra, S.; Nowozin, S.; Wright, S.J. Optimization for Machine Learning; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Bertsimas, D.; Sim, M. The price of robustness. Oper. Res. 2004, 52, 35–53. [Google Scholar] [CrossRef]
- Büsing, C.; D’Andreagiovanni, F. New Results about Multi-Band Uncertainty in Robust Optimization. In Experimental Algorithms, Proceedings of the 11th International Symposium, SEA 2012, Bordeaux, France, 7–9 June 2012; Lecture Notes in Computer Science; Springer: Bordeaux, France, 2012; Volume 7276, pp. 63–74. [Google Scholar]
- Bauschert, T.; Busing, C.; D’Andreagiovanni, F.; Koster, A.C.; Kutschka, M.; Steglich, U. Network planning under demand uncertainty with robust optimization. IEEE Commun. Mag. 2014, 52, 178–185. [Google Scholar] [CrossRef]
- Gemulla, R.; Nijkamp, E.; Haas, P.J.; Sismanis, Y. Large-Scale Matrix Factorization with Distributed Stochastic Gradient Descent. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; ACM: New York, NY, USA, 2011; pp. 69–77. [Google Scholar]
- Dai, W.; Kumar, A.; Wei, J.; Ho, Q.; Gibson, G.; Xing, E.P. High-Performance Distributed ML at Scale through Parameter Server Consistency Models. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Li, M.; Zhou, L.; Yang, Z.; Li, A.; Xia, F.; Andersen, D.G.; Smola, A. Parameter Server for Distributed Machine Learning. In Proceedings of the Big Learning NIPS Workshop, Lake Tahoe, NV, USA, 9 December 2013; p. 2. [Google Scholar]
- Cun, Y.L.; Boser, B.; Denker, J.S.; Howard, R.E.; Habbard, W.; Jackel, L.D.; Henderson, D. Handwritten Digit Recognition with a Back-Propagation Network. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Denver, CO, USA, 1990; pp. 396–404. [Google Scholar]

© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Tu, H.; Ren, Y.; Wan, J.; Zhou, L.; Li, M.; Wang, J.; Yu, L.; Zhao, C.; Zhang, L. A Parameter Communication Optimization Strategy for Distributed Machine Learning in Sensors. Sensors 2017, 17, 2172. https://doi.org/10.3390/s17102172
Zhang J, Tu H, Ren Y, Wan J, Zhou L, Li M, Wang J, Yu L, Zhao C, Zhang L. A Parameter Communication Optimization Strategy for Distributed Machine Learning in Sensors. Sensors. 2017; 17(10):2172. https://doi.org/10.3390/s17102172
Chicago/Turabian StyleZhang, Jilin, Hangdi Tu, Yongjian Ren, Jian Wan, Li Zhou, Mingwei Li, Jue Wang, Lifeng Yu, Chang Zhao, and Lei Zhang. 2017. "A Parameter Communication Optimization Strategy for Distributed Machine Learning in Sensors" Sensors 17, no. 10: 2172. https://doi.org/10.3390/s17102172
APA StyleZhang, J., Tu, H., Ren, Y., Wan, J., Zhou, L., Li, M., Wang, J., Yu, L., Zhao, C., & Zhang, L. (2017). A Parameter Communication Optimization Strategy for Distributed Machine Learning in Sensors. Sensors, 17(10), 2172. https://doi.org/10.3390/s17102172