
Affinity Propagation Clustering of Measurements for Multiple Extended Target Tracking

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Statement and State-of-the-Art Methods
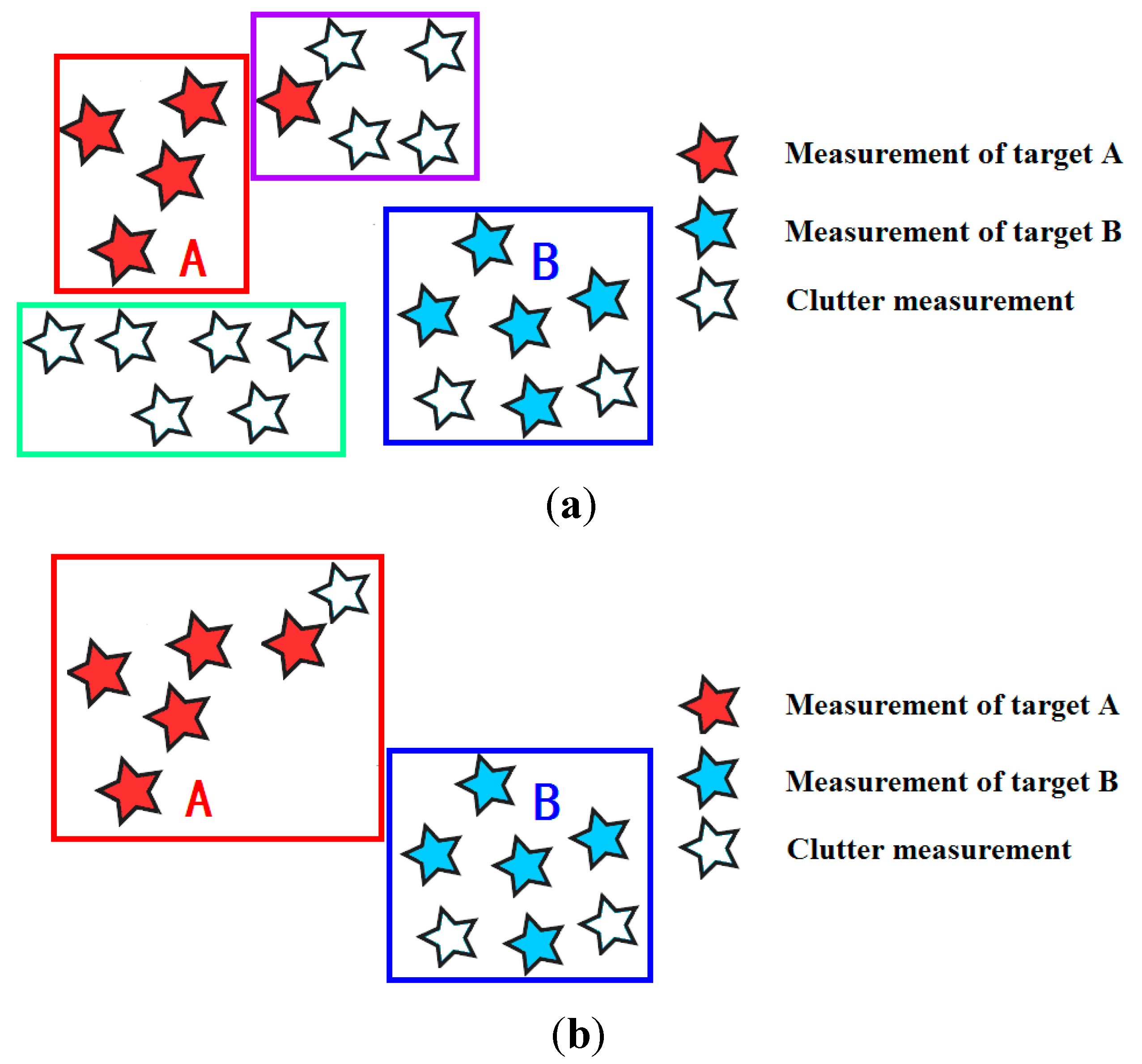
2.1. Measurement Partitioning
2.2. State-of-the-Art Methods of Partitioning
2.3. Existing Problems of State-of-the-Art Methods
3. ET-GM-PHD Filter
4. Affinity Propagation Clustering of Measurement Set
4.1. Clutter Removal
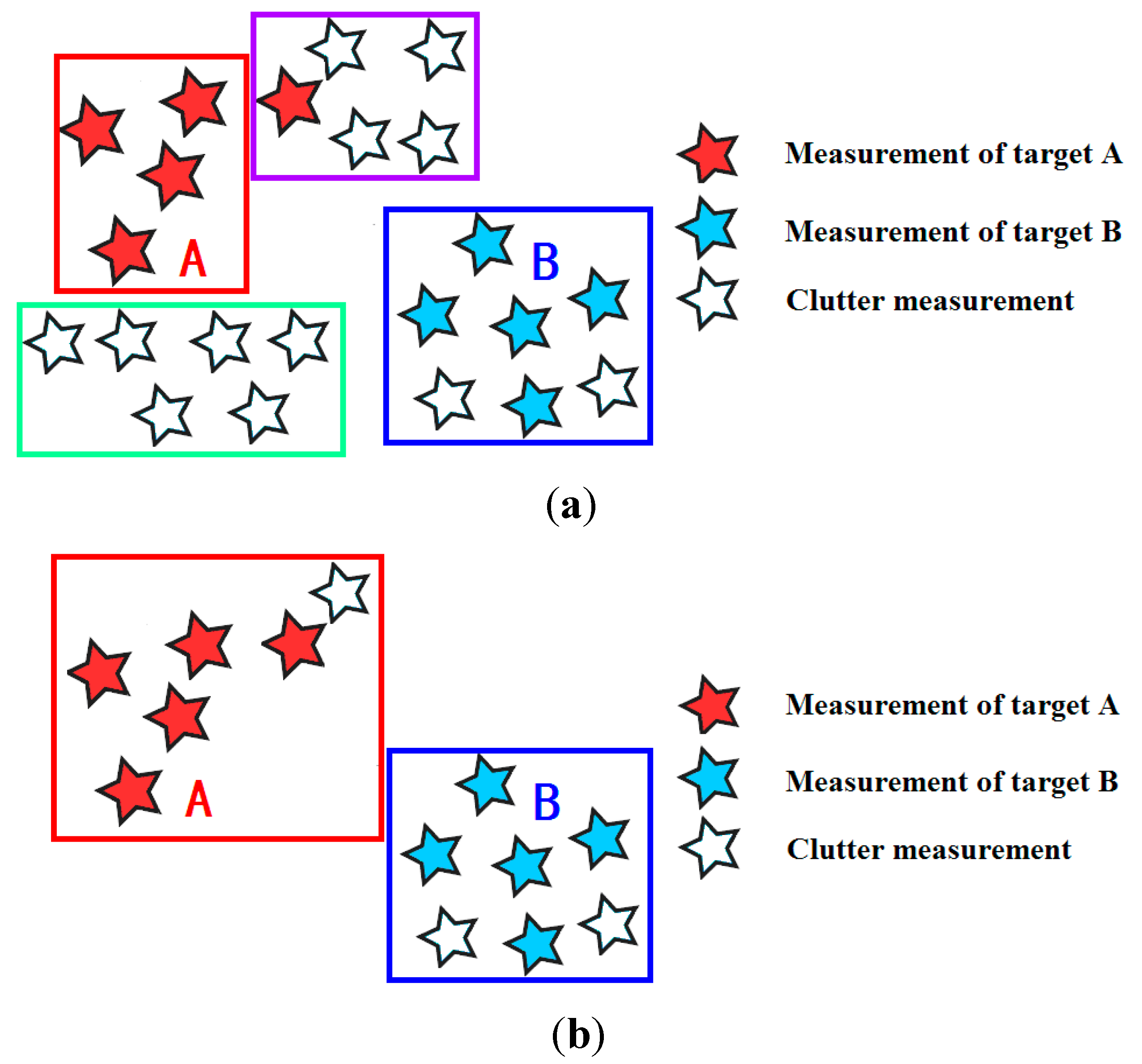
4.2. Affinity Propagation Clustering for Measurement Partitioning
- (1)
- Assuming that is the intensity in RFS form of extended targets at time step ;
- (2)
- The prediction of the extended target intensity is calculated by Equation (3);
- (3)
- Remove the clutter measurements:Given a threshold , an elliptical region is defined with linear Gaussian assumption as follows:where denotes the validation region at time step .The meaurements falling in the elliptical region can be obtained by:The measurements out of the validation region can be removed as the clutter measurements;
- (4)
- Measurements partitioning:Calculate the similarity matrix using the negative Euclidean distance between each pair of the measurements in ;All the target-generated measurements have the same opportunity to be chosen as an exemplar. In our study, the preferernce parameters are set to the mean value of the similarities, given by:All the resonsibilities and availabilities are set to 0 initially, and then the “responsibility” and “availability” are updated iteratively, until they reach a specified value using Equations (10)–(12). The affinity propagation clustering retrieves the number of partitions iteratively, and then the optimal measurement partition is obtained without setting the parameters of the number of clusters;
- (5)
- The predicted intensity can be updated to using the new measurement partition and Equations (3) and (4). Because partial clutter measurements are removed by the elliptical gating, the clutter intensity should be revised. The non-removed clutter in the validation region is also modeled as Poission distribution with , where is the volume of the validation region;
- (6)
- The Gaussian component merging and pruning process are similar to the GM-PHD filter for standard targets tracking described in [13], and the state estimation of the extended targets also involves the estimation of target number and the extracting of the Gaussian mixture components with the highest weights from the posterior intensity as the state estimates.
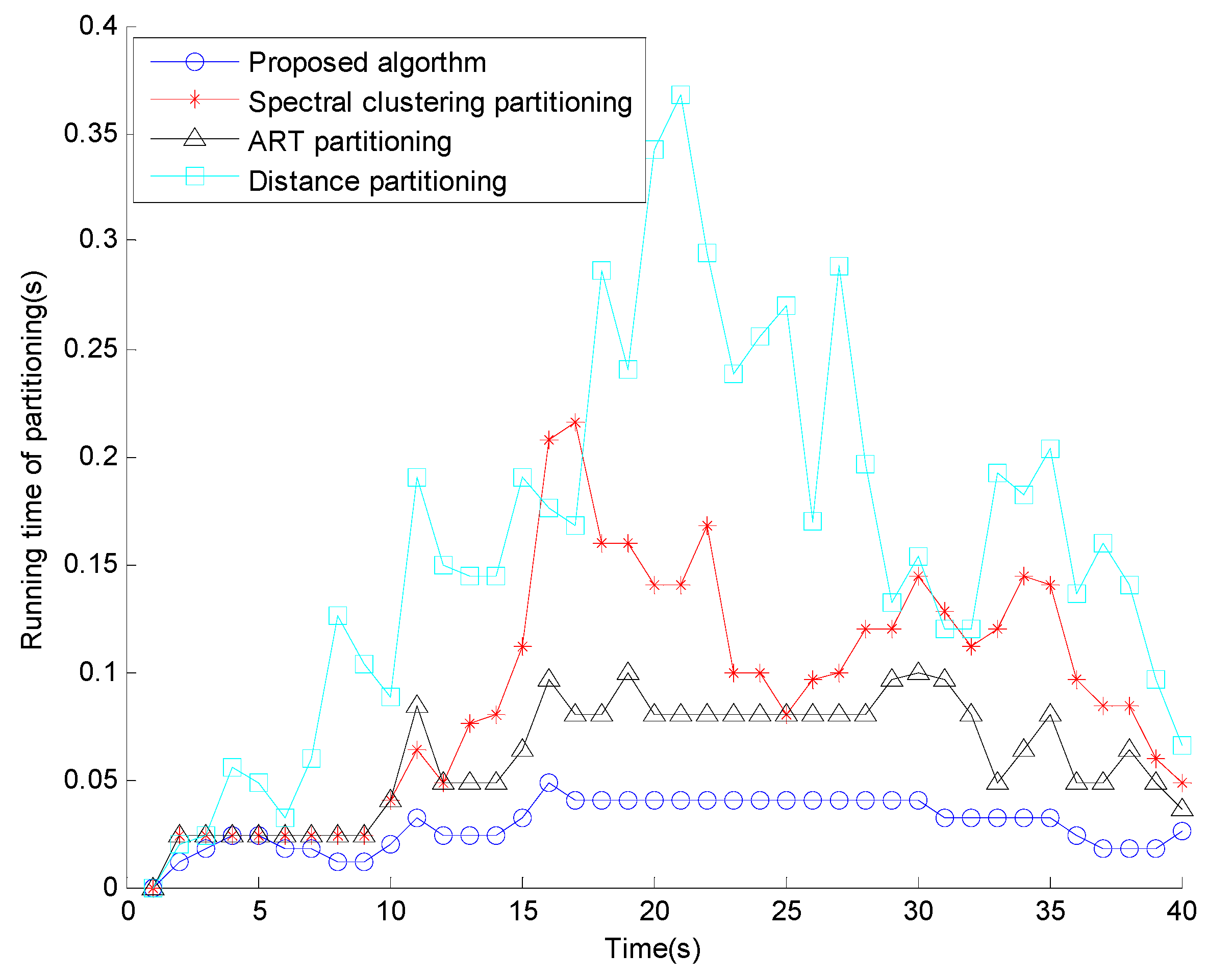
4.3. Computational Complexity Analyses
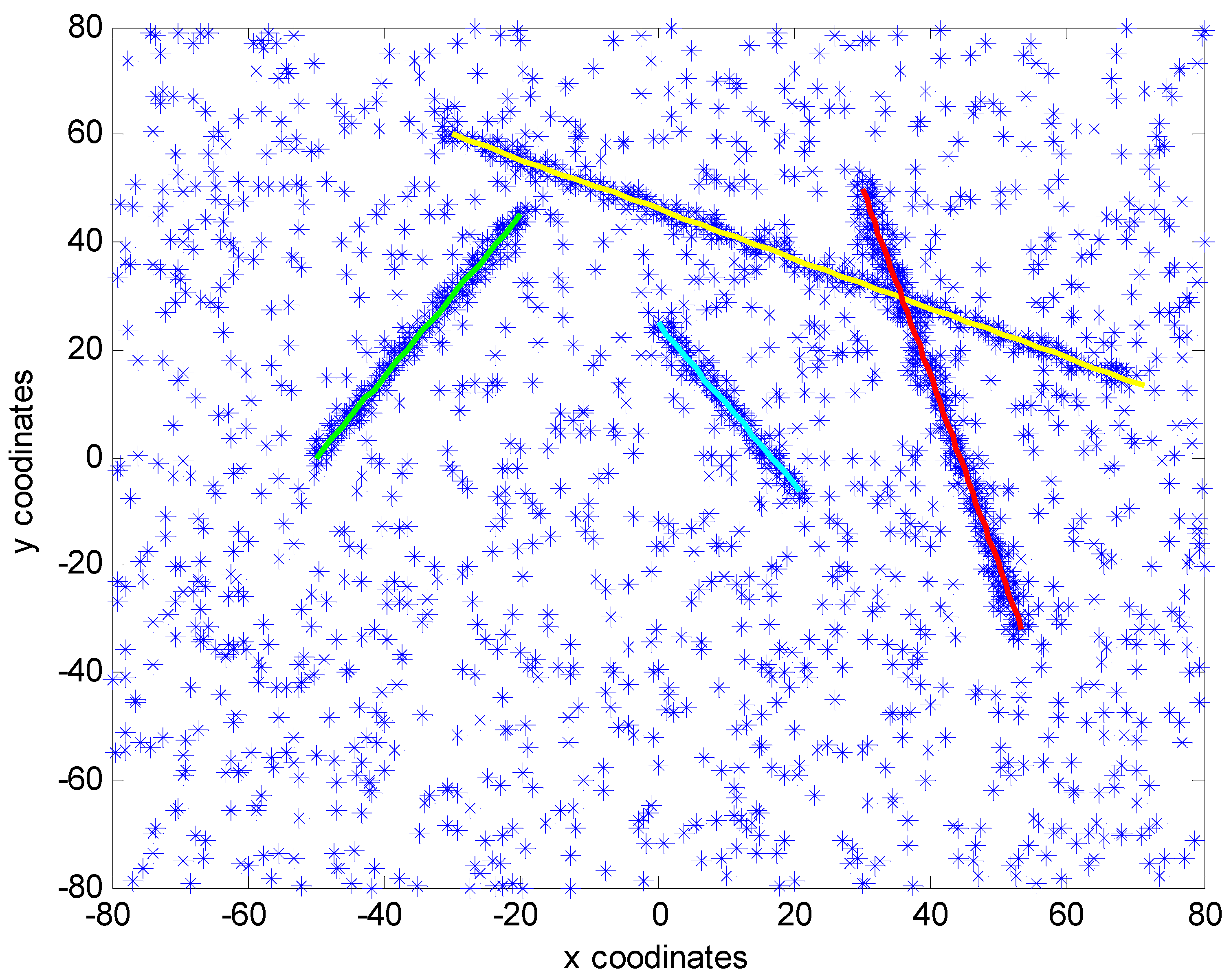
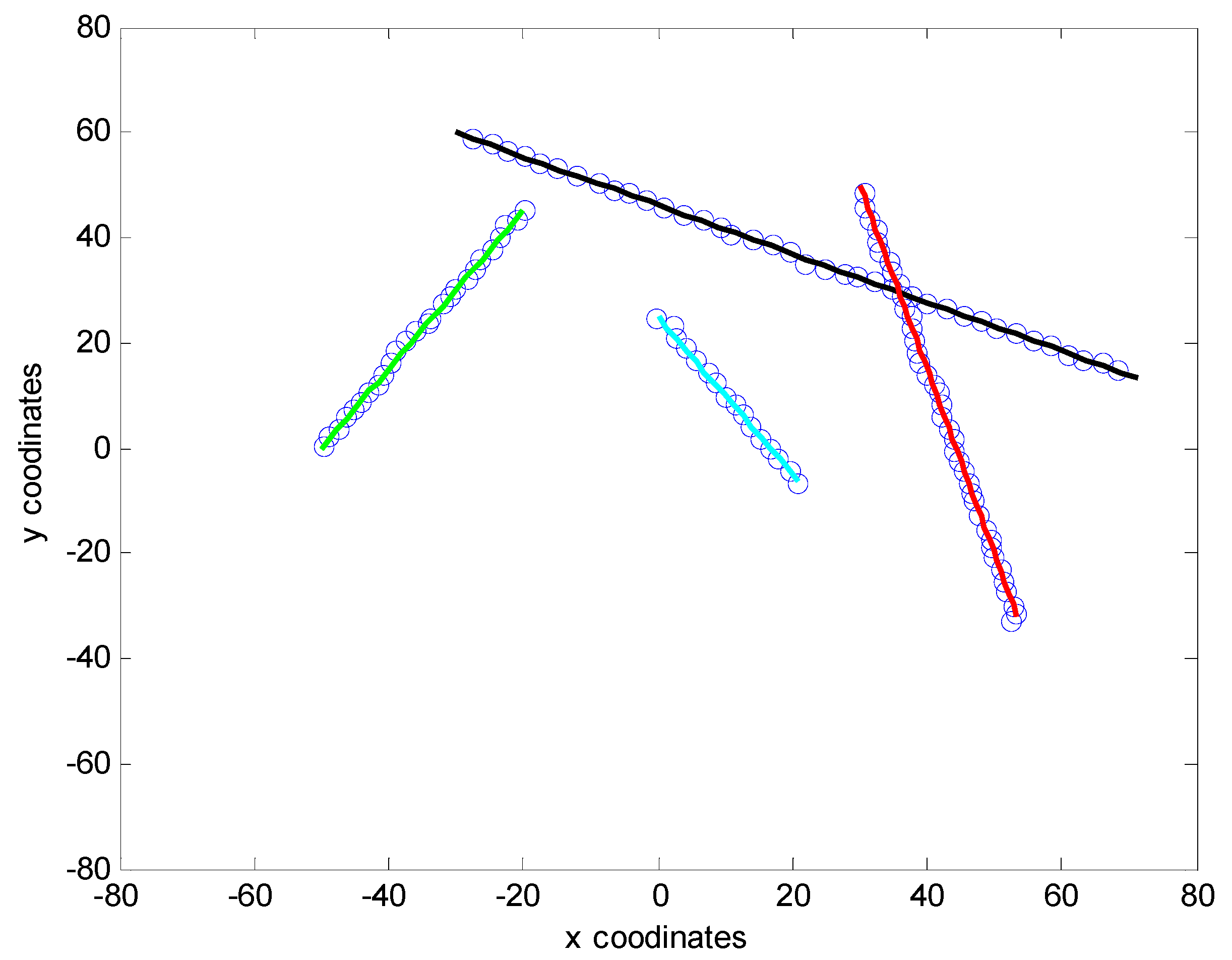
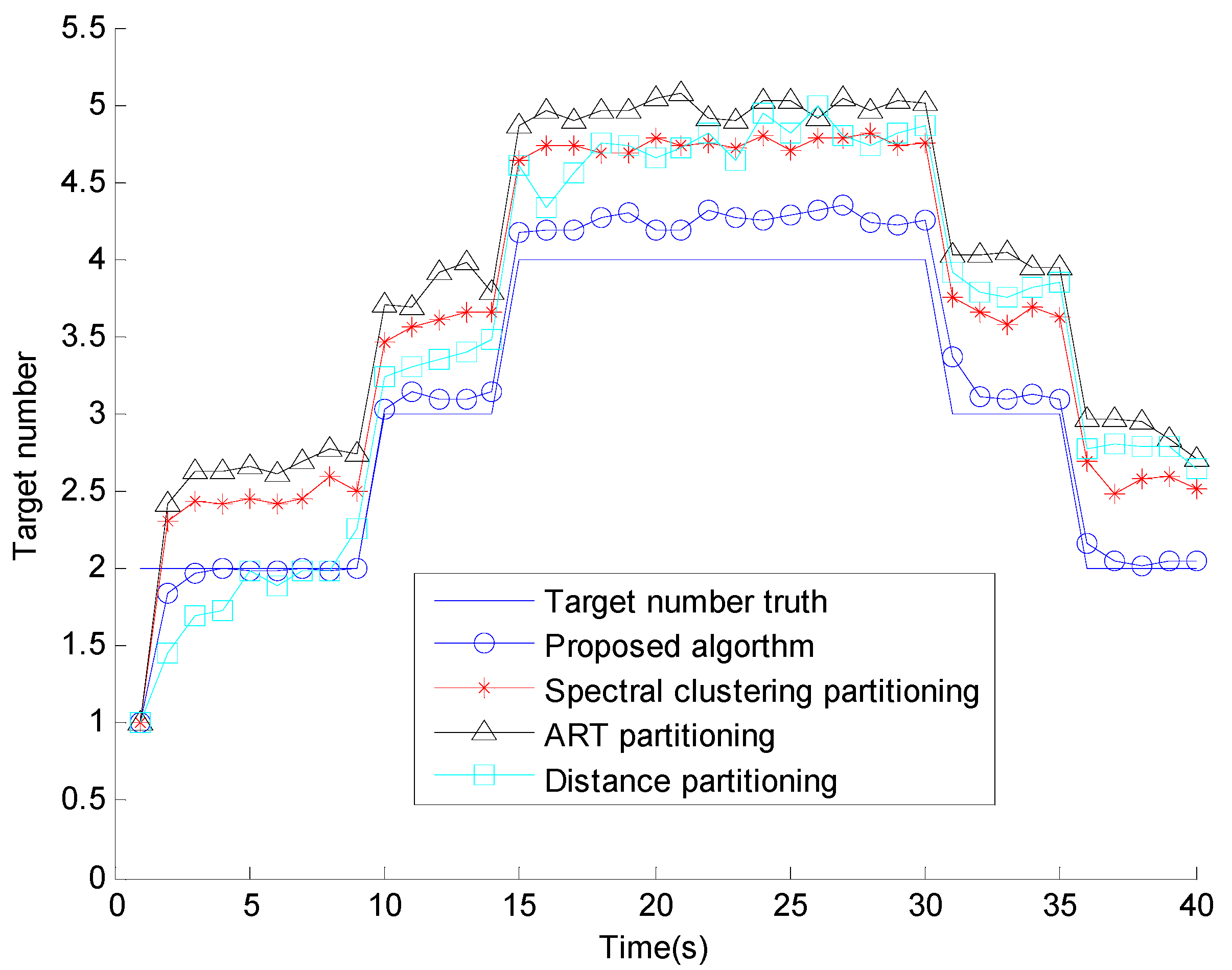
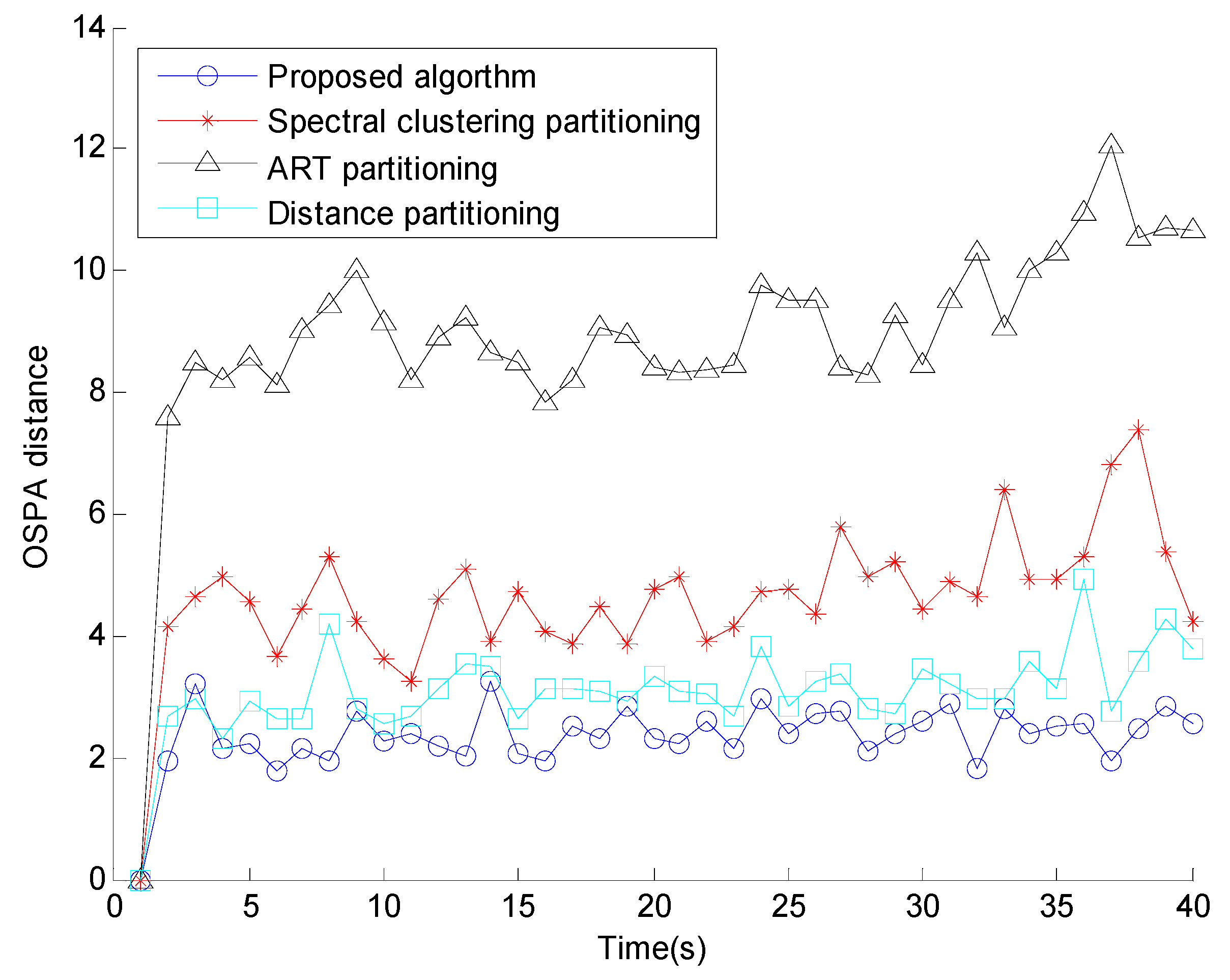
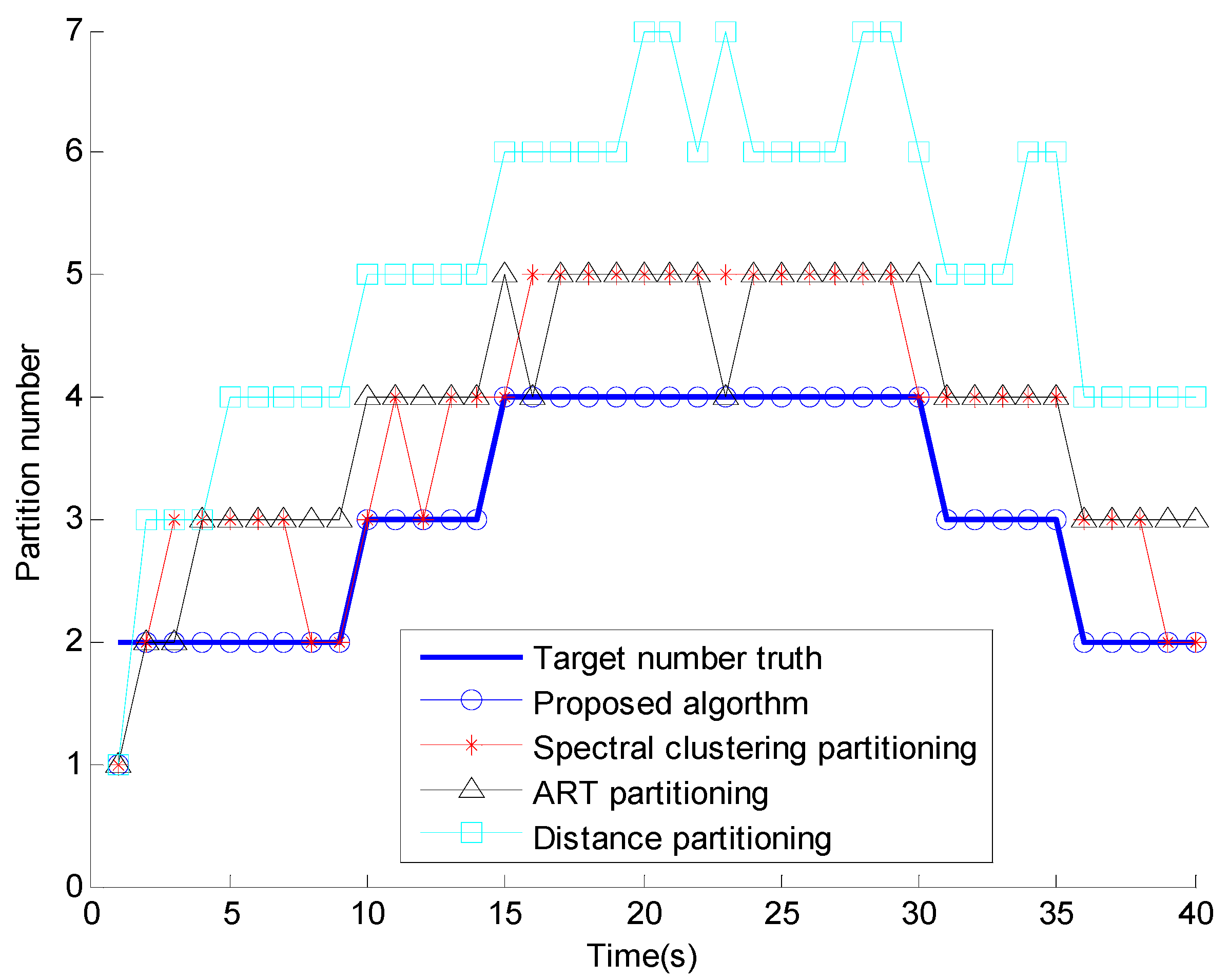
5. Numerical Simulations
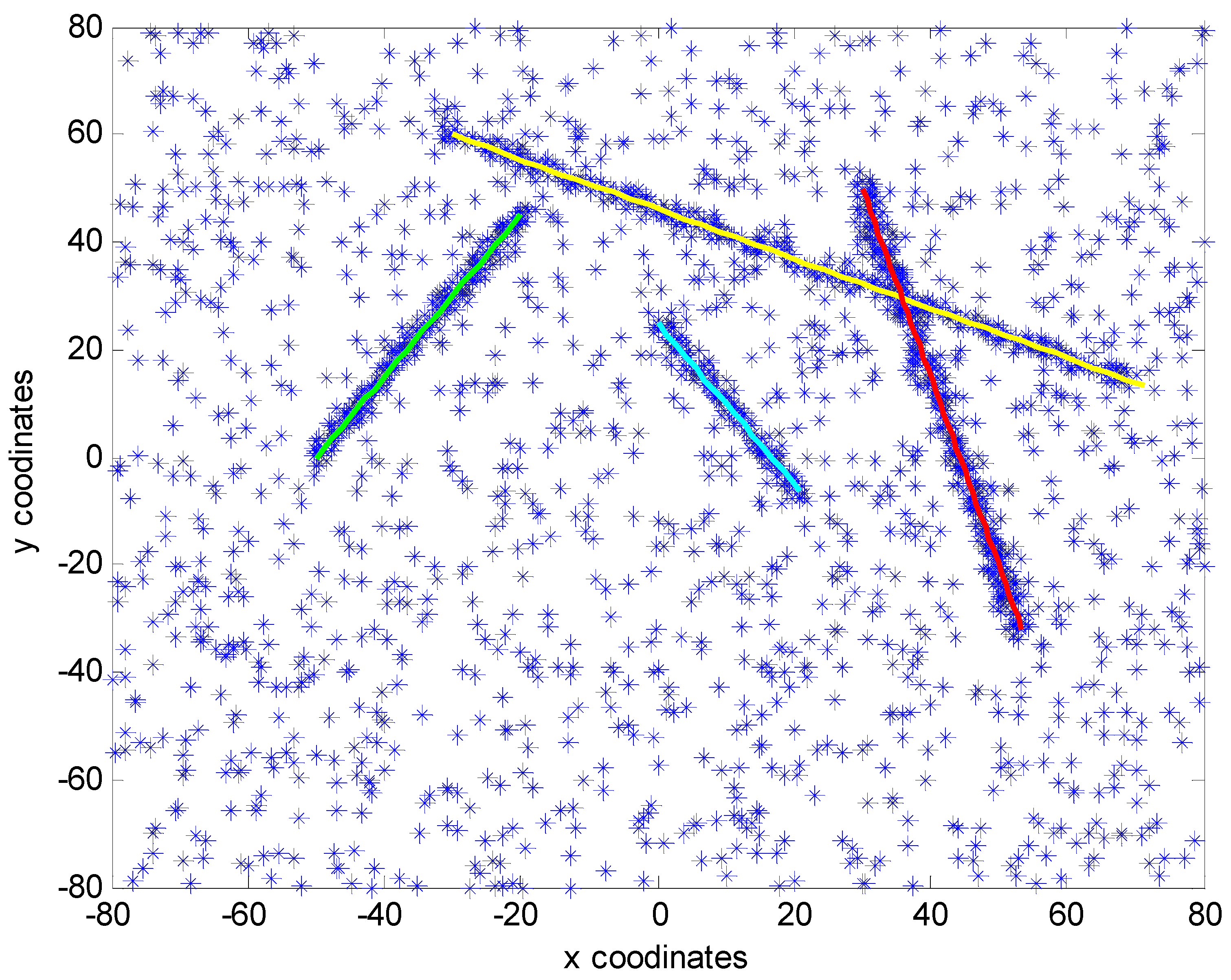
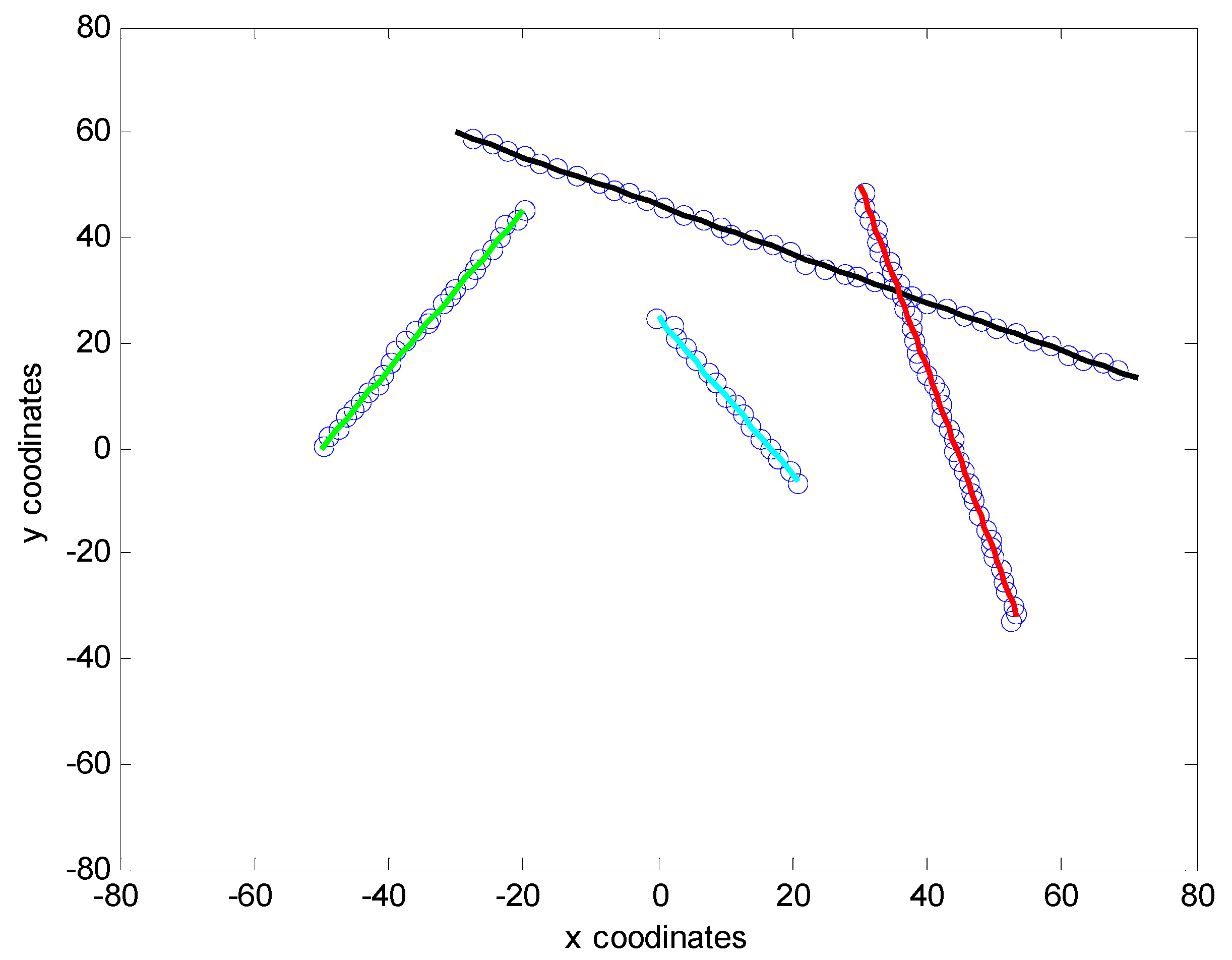
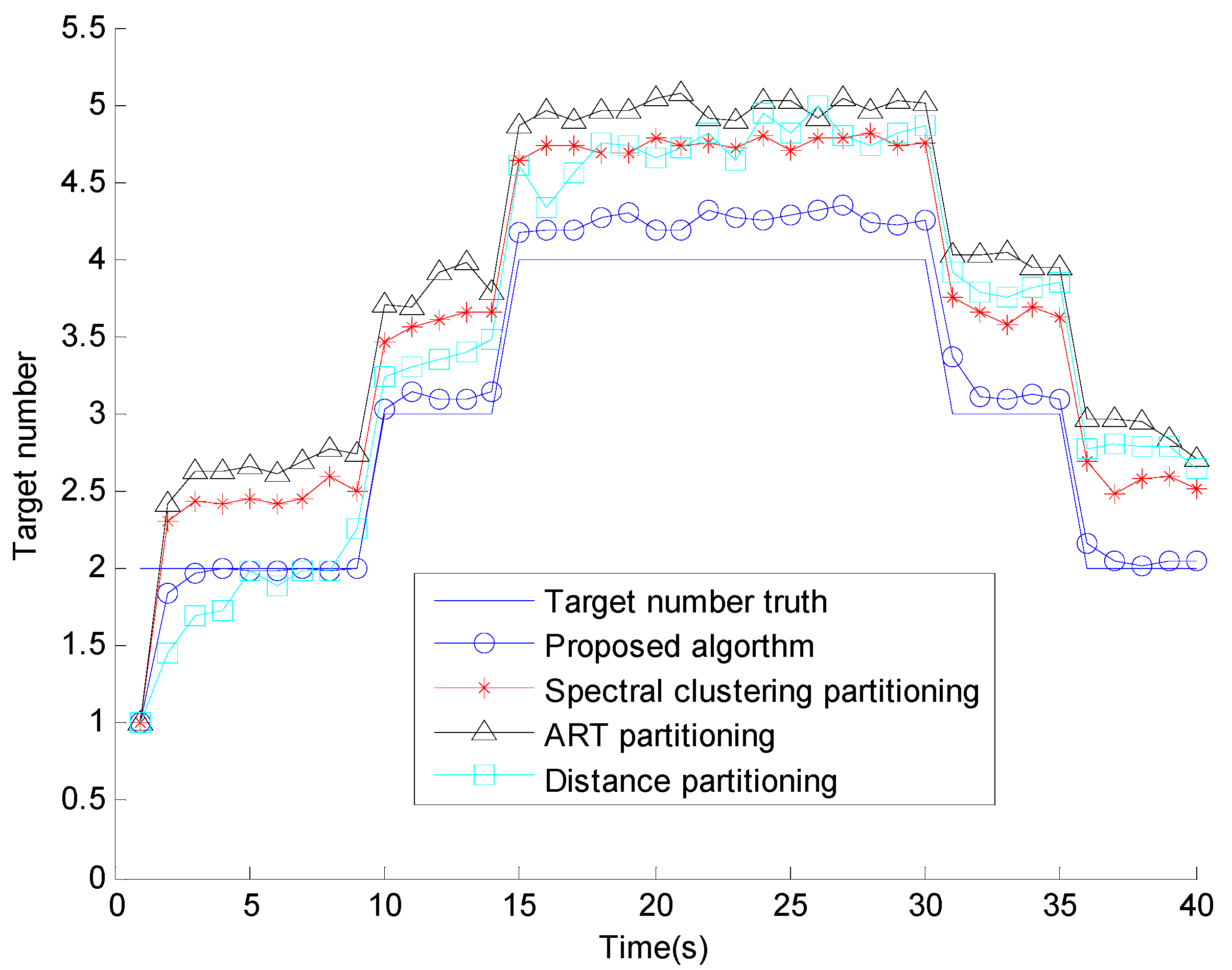
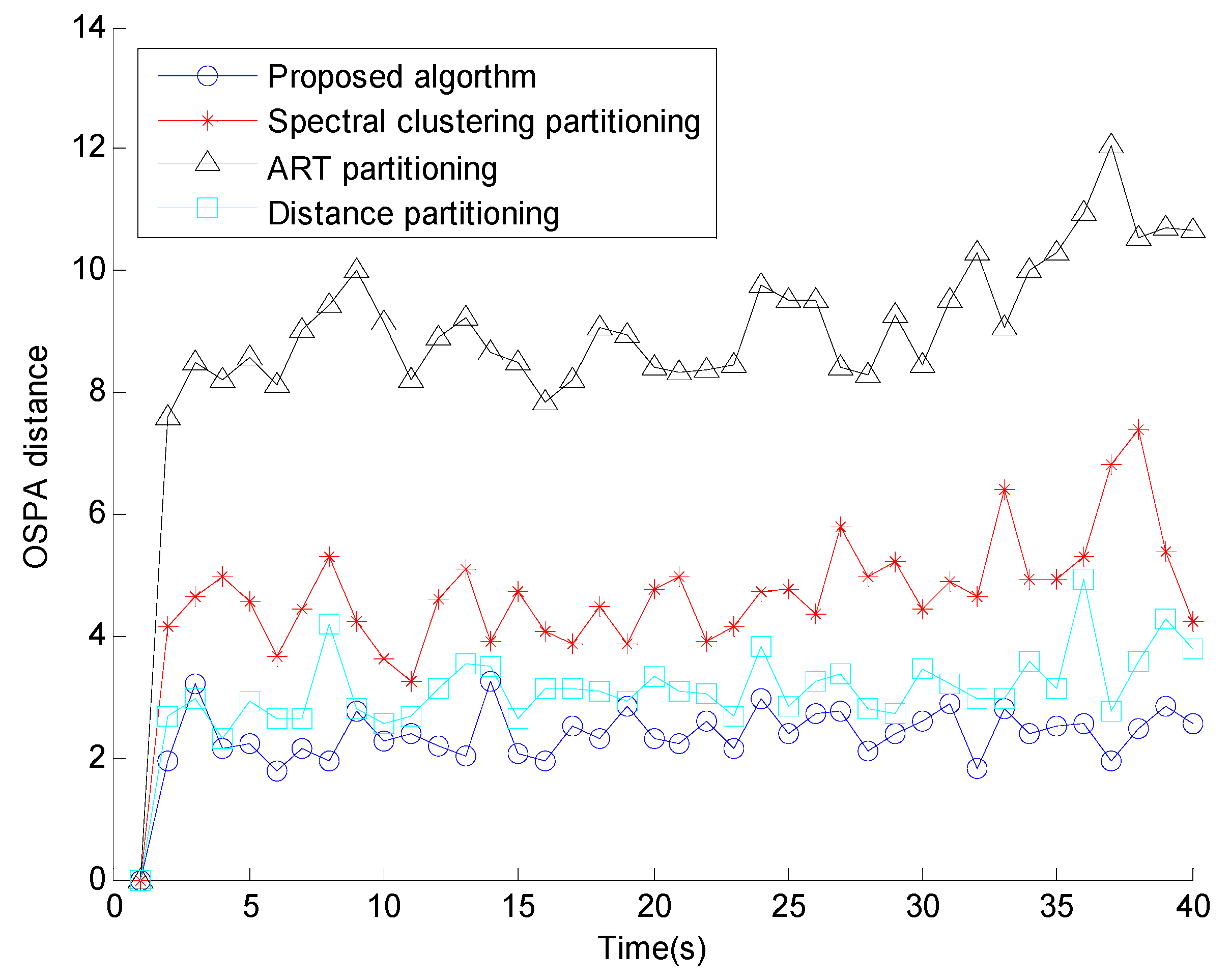
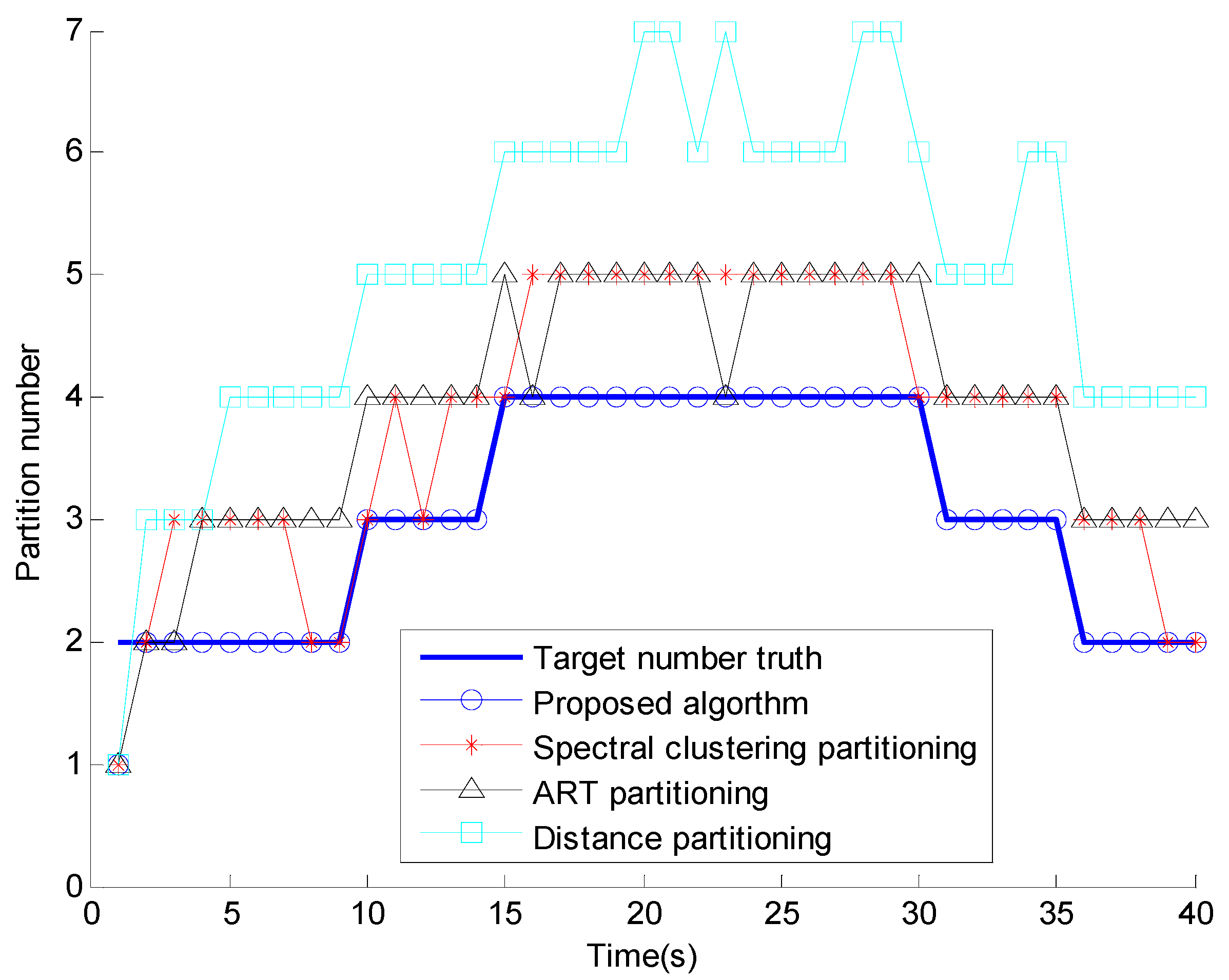
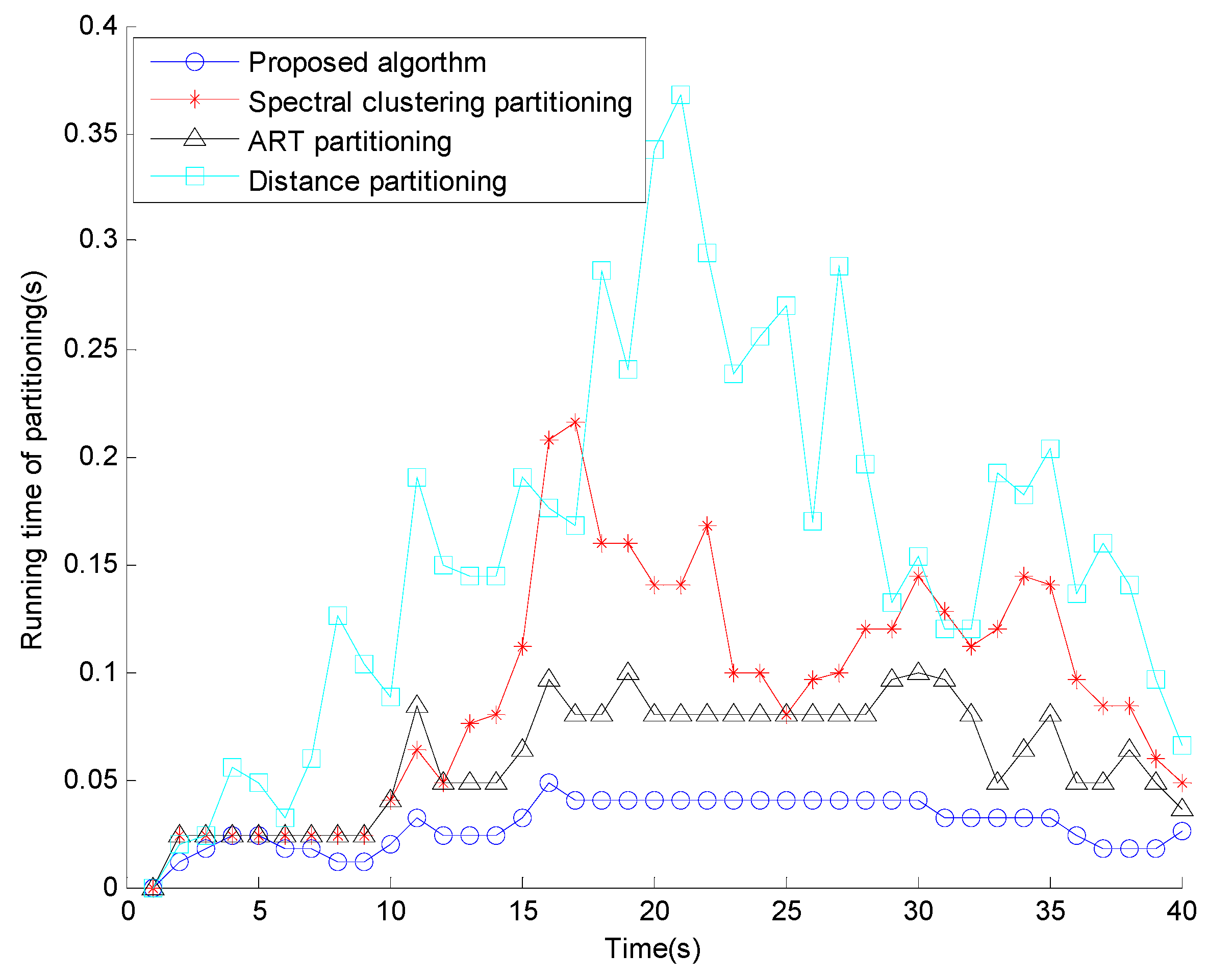
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bar-Shalom, Y.; Li, X.-R. Multitarget-Multisensor Tracking: Principles and Techniques; University of Connecticut: Storrs, CT, USA, 1995. [Google Scholar]
- Bar-Shalom, Y. Tracking and Data Association; Academic Press Professional, Inc.: Waltham, MA, USA, 1987. [Google Scholar]
- Mahler, R. Random sets: Unification and computation for information fusion—A retrospective assessment. In Proceedings of the Seventh International Conference on Information Fusion, Stockholm, Sweden, 28 June–1 July 2004; pp. 1–20.
- Mahler, R.P. Multitarget bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R. Phd filters for nonstandard targets, i: Extended targets. In Proceedings of the 12th International Conference on Information Fusion, 2009 (FUSION’09), Seattle, WA, USA, 6–9 July 2009; pp. 915–921.
- Granstrom, K.; Lundquist, C.; Orguner, U. A gaussian mixture phd filter for extended target tracking. In Proceedings of the 2010 13th Conference on Information Fusion (FUSION), Edinburgh, UK, 26–29 July 2010; pp. 1–8.
- Granstrom, K.; Lundquist, C.; Orguner, O. Extended target tracking using a gaussian-mixture phd filter. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3268–3286. [Google Scholar] [CrossRef]
- Granstrom, K.; Orguner, U. A phd filter for tracking multiple extended targets using random matrices. IEEE Trans. Signal Process. 2012, 60, 5657–5671. [Google Scholar] [CrossRef]
- Swain, A.; Clark, D. The phd filter for extended target tracking with estimable extent shape parameters of varying size. In Proceedings of the 2012 15th International Conference on Information Fusion (FUSION), Singapore, 9–12 July 2012; pp. 1111–1118.
- Zhang, Y.; Ji, H. A novel fast partitioning algorithm for extended target tracking using a Gaussian mixture phd filter. Signal Process. 2013, 93, 2975–2985. [Google Scholar] [CrossRef]
- Yang, J.; Liu, F.; Ge, H.; Yuan, Y. Multiple extended target tracking algorithm based on gm-phd filter and spectral clustering. EURASIP J. Adv. Signal Process. 2014. [Google Scholar] [CrossRef]
- Clark, D.; Ruiz, I.T.; Petillot, Y.; Bell, J. Particle phd filter multiple target tracking in sonar image. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 409–416. [Google Scholar] [CrossRef]
- Vo, B.-N.; Ma, W.-K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Pasha, S.A.; Vo, B.-N.; Tuan, H.D.; Ma, W.-K. A Gaussian mixture phd filter for jump markov system models. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 919–936. [Google Scholar] [CrossRef]
- Clark, D.; Vo, B.-T.; Vo, B.-N.; Godsill, S. Gaussian mixture implementations of probability hypothesis density filters for non-linear dynamical models. In Proceedings of the 2008 IET Seminar on Target Tracking and Data Fusion: Algorithms and Applications, Birmingham, UK, 15–16 April 2008.
- Gilholm, K.; Salmond, D. Spatial distribution model for tracking extended objects. IEE Proc. Radar Sonar Navig. 2005, 152, 364–371. [Google Scholar] [CrossRef]
- Blackrnan, S.; House, A. Design and Analysis of Modern Tracking Systems; Artech House: Boston, MA, USA, 1999. [Google Scholar]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Granström, K.; Orguner, U. Implementation of the Giw-Phd Filter; Report No LiTH-ISY-R-3046; Department of Electrical Engineering, Linköping University: Linköping, Sweden, 2012. [Google Scholar]
- Ristic, B.; Vo, B.-N.; Clark, D.; Vo, B.-T. A metric for performance evaluation of multi-target tracking algorithms. IEEE Trans. Signal Process. 2011, 59, 3452–3457. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Wu, R. Affinity Propagation Clustering of Measurements for Multiple Extended Target Tracking. Sensors 2015, 15, 22646-22659. https://doi.org/10.3390/s150922646
Zhang T, Wu R. Affinity Propagation Clustering of Measurements for Multiple Extended Target Tracking. Sensors. 2015; 15(9):22646-22659. https://doi.org/10.3390/s150922646
Chicago/Turabian StyleZhang, Tao, and Renbiao Wu. 2015. "Affinity Propagation Clustering of Measurements for Multiple Extended Target Tracking" Sensors 15, no. 9: 22646-22659. https://doi.org/10.3390/s150922646
APA StyleZhang, T., & Wu, R. (2015). Affinity Propagation Clustering of Measurements for Multiple Extended Target Tracking. Sensors, 15(9), 22646-22659. https://doi.org/10.3390/s150922646