Modified OMP Algorithm for Exponentially Decaying Signals


Abstract
: A group of signal reconstruction methods, referred to as compressed sensing (CS), has recently found a variety of applications in numerous branches of science and technology. However, the condition of the applicability of standard CS algorithms (e.g., orthogonal matching pursuit, OMP), i.e., the existence of the strictly sparse representation of a signal, is rarely met. Thus, dedicated algorithms for solving particular problems have to be developed. In this paper, we introduce a modification of OMP motivated by nuclear magnetic resonance (NMR) application of CS. The algorithm is based on the fact that the NMR spectrum consists of Lorentzian peaks and matches a single Lorentzian peak in each of its iterations. Thus, we propose the name Lorentzian peak matching pursuit (LPMP). We also consider certain modification of the algorithm by introducing the allowed positions of the Lorentzian peaks' centers. Our results show that the LPMP algorithm outperforms other CS algorithms when applied to exponentially decaying signals.1. Introduction
Compressed sensing (CS) theory provides the methods to solve an underdetermined linear equation y = Ax within a set of sparse vectors x ∈ ℂn. The unconstrained linear equation for an m × n matrix A of a maximum rank may have infinitely many solutions for m < n. However, the number of sparse solutions happens to be finite. Vectors in ℂn having at most l ∈ ℕ non-zero coordinates are referred to as the l-sparse vectors.
All l-sparse vectors fulfilling the equation y = Ax may be found by considering linear sub-problems of solving y = Ax with the constraint x ∈ ℂI, where ℂI ⊂ ℂn denotes the subspace of vectors supported by I ⊂ [1,n]. This provides all l-sparse solutions, but the overall problem was proven to be NP-hard. Remarkably, the sparsest vector x̂ solving y = Ax may be found as the solution of the l1-minimization problem:
A number of CS algorithms has been proposed, including: iterative soft thresholding (IST) [2], orthogonal matching pursuit (OMP) [3], compressive sampling matching (COSAMP) [4], stage-wise orthogonal matching pursuit (StOMP) [5] and iterative re-weighted least squares (IRLS) [6]. Inspired by the greedy CS algorithm, OMP, and motivated by a case of nuclear magnetic resonance (NMR) spectroscopy, we propose an approach that is designed specifically to recover a signal being a combination of exponentially decaying components. The spectrum of such a signal consists of Lorentzian peaks. The algorithm matches a single peak in each of its iterations, and thus, the name Lorentzian peak matching pursuit (LPMP) is proposed. The peaks' centers and heights are found as in the OMP algorithm, whereas the widths of the peaks are determined in a novel way.
2. NMR Spectroscopy and CS
The sources of the free induction decay (FID) signal measured in NMR spectroscopy are magnetic moments of atomic nuclei with non-zero spin, e.g., 1H,13C,15N,19F, that undergo coherent precession when excited by radio-frequency irradiation in the presence of a high static magnetic field [7]. The time dependence of an ideal FID signal f(t) is given by the following linear combination:
The precession frequencies (and thus, the frequencies of the emitted FID signal) are in the order of MHz, but their band is very narrow, typically a few kHz. In such a narrow range, tens or even hundreds of peaks are present. Often, the spectral resolution (peak width compared to the difference in resonance frequencies) is too low to resolve peaks and, thus, makes an analysis difficult. Fortunately, the peak dispersion can be improved by the acquisition of the multidimensional NMR signal [8] where additional (“indirect”) time dimensions are introduced. Peaks in the multidimensional NMR spectrum correspond to groups of nuclei coupled by some physical interaction. Using the above notation, the formula of the two-dimensional FID is:
The reason for the application of CS in multidimensional NMR spectroscopy is a time-consuming sampling of the indirect dimensions of the FID signal (t1 in Equation (2)). There are three reasons for the lengthy acquisition. Firstly, each measurement point in the indirect dimension takes a few seconds of “real” time. Secondly, the sampling density has to fulfil the Nyquist theorem [9]. Finally, the sampling has to reach far into the indirect time domain to provide sufficient spectral resolution [10]. The latter, together with the Nyquist condition for the sampling density, means that, often, many thousands of sampling points have to be acquired. This makes an experiment unacceptably long (days in the case of three or four dimensions) or completely impossible in the case of higher dimensionality (5D and more). Thus, there is a need for alternative sampling approaches that allow one to save expensive spectrometer time preserving the spectral information. Most of them use the non-uniform sampling, where the major part of the points is not measured, but reconstructed after the experiment based on certain assumptions [11,12]. The CS, where the assumption is spectral sparsity, has been successfully applied in NMR exploiting the algorithms based on convex l1-norm or non-convex lp-norm minimization [13,14]. The history of the application of the “greedy” algorithm, OMP, in NMR is long; in fact, the algorithm was transferred from radio astronomy, where it existed under the name, CLEAN [15]. Direct application of CLEAN in NMR is possible [16], but far from being perfect, because of the aforementioned approximate sparsity of the signal. Thus, various modifications of CLEAN have been proposed [17-19]. Importantly, none of these works refer to OMP formalism and do not explain the modifications by the sparsity criteria. We propose an approach that directly exploits the fact that the NMR spectrum consists of a low number of Lorentzian peaks. Thus, LPMP is based on the sparsity concept, which is more relevant in the case of NMR than classical CS methods.
3. OMP Algorithm
Let us fix the notation. For m,n ∈ ℤ and m < n, we write [m, n] = {m, m + 1,…, n}. Let m, n ∈ ℕ. For matrix A ∈ Mm×n(ℂ), its range and kernel are denoted ran A and ker A, respectively. The Hermitian conjugate of A is denoted by A*. The number of non-zero coordinates of x ∈ Cn is denoted by ‖x‖0, and supp x (the support of x) denotes the set of x non-zero coordinates. Note that ‖x‖0 = # supp x (the cardinality of a set I is denoted by # I). We define χn,l ⊂ ℂn:
OMP algorithm arose in the context of the sparse approximation problem; see [3]. In order to formulate the problem, let us fix a matrix A ⊂ Mm×n(ℂ) satisfying ran A = ℂm. The matrix A is in this context referred to as the dictionary matrix.
Definition 1
Adopting the above notation, we say that x ∈ χn,l is an optimal l-sparse approximate representation of a vector y ∈ ℂm if:
We say that y is l-representable, if there exists a vector x ∈ χn,l, such that y = Ax.
For a subset I ⊂ [1, n] of cardinality l, we define a vector subspace ℂI ⊂ ℂn:
The restriction of A to ℂI is denoted by AI : ℂI → ℂm.
Definition 2
We say that A ⊂ Mm×n(ℂ) is l-injective if ker AI = {0} for all I ⊂ [1, n], # I = l.
For an l-injective matrix A and I ⊂ [1, n], # I = l, we define:
Since xI is a vector satisfying AIxI = yI, where yI is an orthogonal projection of y onto ran AI, we may see the uniqueness of xI for l-injective A. Let us note that x ∈ χn,l is an optimal l-sparse approximate representation of y ∈ ℂm if:
Although l-injectivity of the matrix A does not exclude a vector x′ ∈ χn,l, x′ ≠ x, such that ‖y — Ax‖2 = ‖y — Ax′‖2, we shall usually choose an optimal l-sparse approximate and denote it by xl.
The OMP algorithm provides a certain approximation of xl ∈ ℂn, which we denote by Remarkably, is found on the basis of Denoting the support by , the index il ∈ [1, n] is given by:
The OMP vector is defined as ; see Equation (3) for the definition of . For the coherence, restricted isometry property (RIP) conditions that imply the equality , we refer to [3] and [20], respectively. For the recovery limits of the OMP, see [21]. The OMP algorithm (Algorithm 1) is schematically described below.
| Algorithm 1 Orthogonal matching pursuit. |
|
4. Free Induction Decay Signals in NMR
The free induction decay signal in NMR consists of the combination of exponentially decaying oscillations (see Equations (1) and (2)). The signal can be multidimensional, but for the sake of simplicity, we will limit ourselves to the one-dimensional indirect part of the two-dimensional signal, corresponding to f(t) from Equation (1). Given the damping factor γ ≥ 0 and the oscillation frequency ω ∈ (x0211D), a single decaying oscillation is given by:
Its Fourier transform:
The FID signal is sampled at the rate given by the Nyquist theorem for the range cut off ν ∈ [–Ω, Ω]. In order to perform the NMR signal processing, the frequency resolution ΔΩ is introduced, where and N ∈ ℕ. For any l ∈ [–N,N], we get the basic complex oscillation e2πιωlt, where . The NMR signals can be approximated by the finite combination of the basic complex oscillations:
The approximation being -periodic works only for . Assuming that the series evaluated at coincides with sampling points of f, i.e., f(tk) for k ∈ [0,2N], we get:
Introducing the time unit and the frequency unit , we may enumerate the time and frequency by the integers [0, 2N] and [–N, N], respectively. Then, the relation between the peak intensities a and the time samples f is given by a = Ff, where F is the Fourier transform matrix:
l ∈ [–N, N] and k ∈ [0, 2N]. In order to model the Lorentzian peaks within our framework, let us introduce the width peak unit Γ and a damping matrix C ∈ M(2N+1)×(2N+1)(ℂ):
Using the above notation, the FID signal is given by:
5. Lorentzian Peak Matching Pursuit
The spectrum f̂ corresponding to FID signal (Equation (5)) is given by:
We shall assume that j ∈ [0, J], which gives the maximal width JΓ and the width resolution Γ. Let K = {k1, k2,…, km} ⊂ [0, 2N] be the sampling scheme, y ∈ ℂm the measured signal yi = f(tki) and A = Fk the matrix consisting of rows of the Fourier matrix F enumerated by the elements of K.
The Lorentzian peak matching pursuit algorithm matches a Lorentzian peak in each of its iterations. In order to match a peak LPMP establishes first the peak's center l. The center l1 ∈ [–N, N] of the first peak is determined by:
In order to determine the width of the first peak j1 ∈ [0, J], we find bl1,j ∈ ℂ, such that:
Then, j1 ∈ [0, J] is a number satisfying:
In the second step of the algorithm, we determine the second peak's center l2 by:
In order to determine the second peak's width j2 ∈ [0, J], we find bl2,j, bl1,j1 ∈ ℂ minimizing:
We begin the third step of the algorithm by determining the third peak's center l3:
Then, j3 and l3 are found as in the previous steps.
Note that in the k-th step of the algorithm, the peak's width jkΓ is found and not changed afterwards. The blk,jk coordinate may, in turn, vary in the n-th step of the algorithm for n > k. The algorithm is performed until the accuracy threshold ‖y – Ax‖ < ε is achieved; for a different stopping criterion, see Section 5.1.
5.1. Stopping Criterion
If a number of Lorentzian peaks in the spectrum cannot be assumed a priori, then the stopping criterion for the LPMP becomes a crucial issue.
Notably, the dimension of a measurement vector y provides a mathematical bound for the number of iterations in LPMP. The implementation of the LPMP algorithm uses an inversion of a matrix, which ceases to be invertible when the number of peaks exceeds the number of measurements. In what follows, we shall introduce the stopping criteria that further restrict the number of iterations. One commonly used criterion is the threshold ε of accuracy used in Algorithm 2.
Let us denote the result of the k-th LPMP iteration by f̂k. The k + 1 iteration is performed if:
Alternatively, the noise amplitude σ can be used for a stopping criterion. In this case, LPMP stops on the k-th iteration if |f̂k(lk)| ≤ σ.
| Algorithm 2 Lorentzian peak matching pursuit. |
|
5.2. Mask
NMR experiments are often performed in series, with some or all peaks preserving their positions in at least some of the dimensions. This fact has been exploited to restrict the allowed peak frequencies and to improve the results of NUS (non-uniform sampling) reconstruction, e.g., in hyperdimensional spectroscopy [22], the SIFT method [23] or high-dimensional spectra [24]. It is easy to use this information in the LPMP algorithm by introducing the subset Mask ⊂ [−N, N] of admissible peak centers in the frequency domain. In what follows, we give a detailed description of the masked LPMP algorithm (Algorithm 3), taking into an account the stopping criterion described in Section 5.1.
| Algorithm 3 Lorentzian peak matching pursuit with a mask. |
|
6. Results and Discussion
In this section, we present the results of the LPMP performance tests. Extensive simulations on different levels of sampling sparsity provided a quantitative characterization of the method. As an example of an application, we have chosen the challenging NOESY (nuclear Overhauser effect spectroscopy) experiment [25] with a high dynamic range of peak intensities.
The parameters of the synthetic spectrum used in the simulations are given in Table 1. The spectral parameters were chosen to simulate various experimental scenarios, i.e., (I) peak widths differ from peak to peak, which corresponds to the differences in relaxation rates in the case of the NMR experiment; (II) the range of intensities is high; (III) two of the peaks overlap; and (IV) the peaks' centers and widths are off-grid.
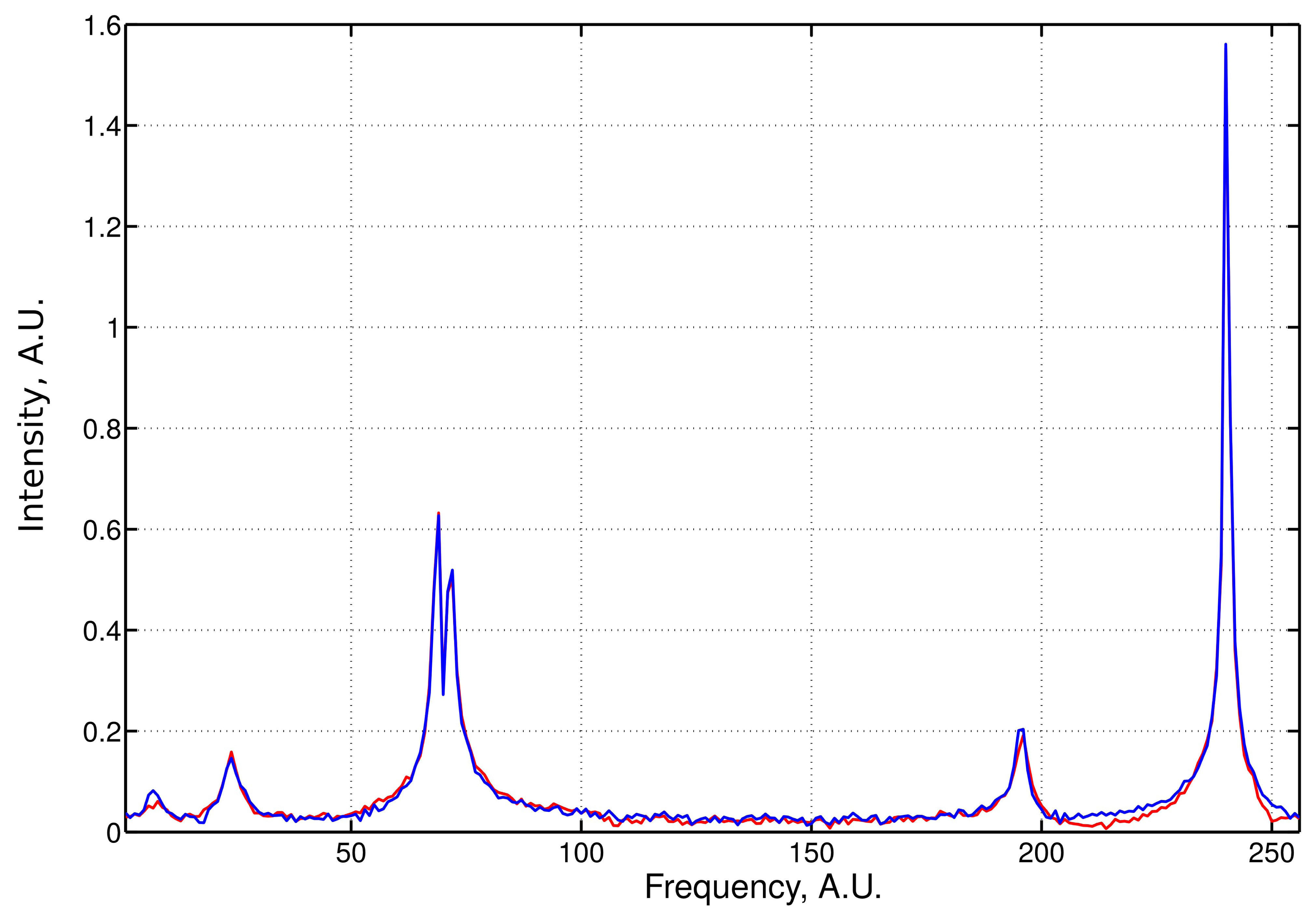
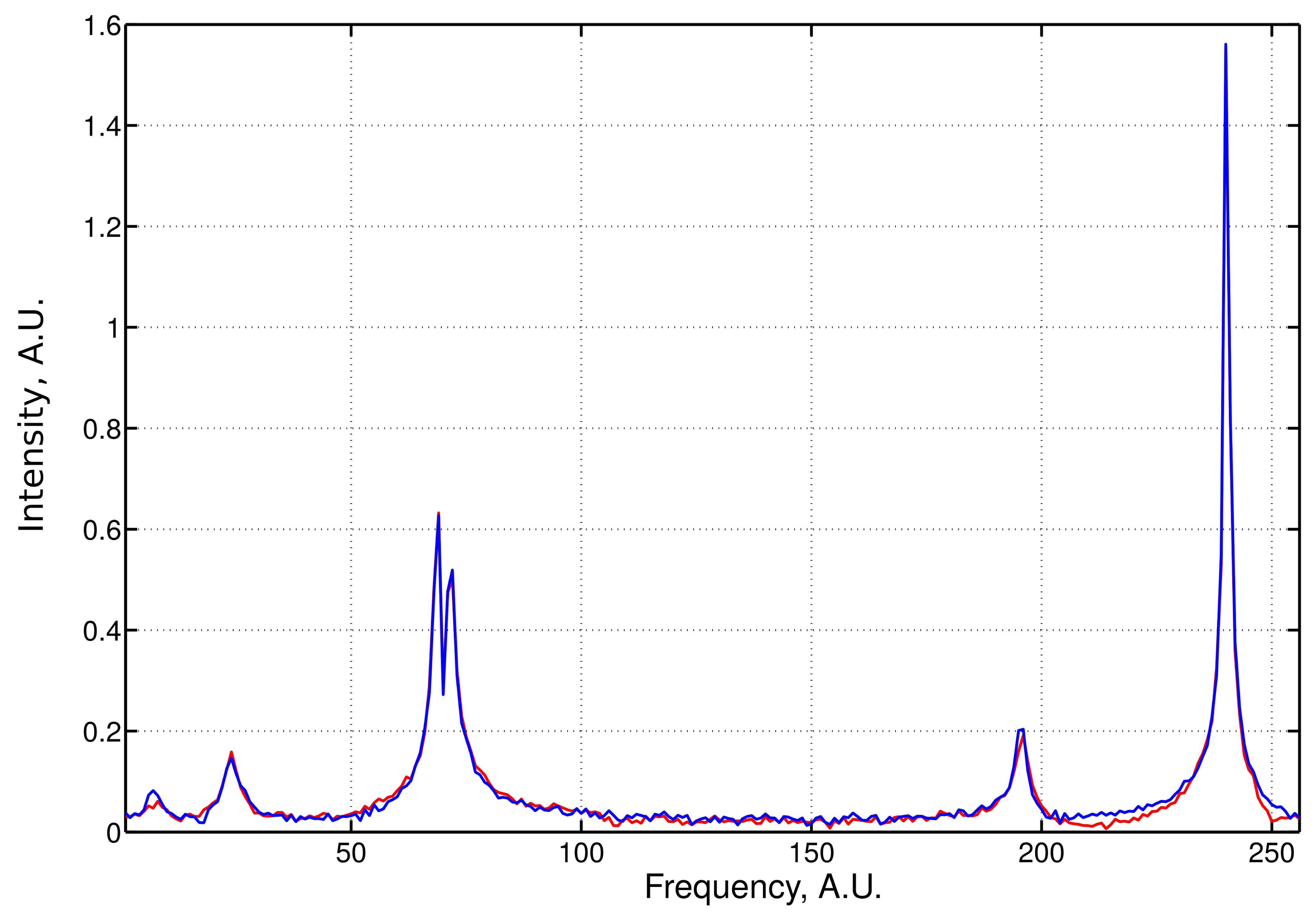
An example of the LPMP recovery of an NMR spectrum based on 120 sampling points drawn at random from a 256-point full grid is presented in Figure 1. The signal was contaminated with 5% of noise. We performed systemic simulations with a varying sampling level. For each level, 50 different sampling schedules were generated. Denoting the frequency spectrum vector obtained from the full sampling by f̂ and the LPMP recovery by f̂LPMP, we compute the recovery error ‖f̂–f̂LPMP‖, and then, we average it over 50 sampling distributions. The LPMP performance is depicted in Figure 2 (left), where it is also compared with other popular CS algorithms: IST, OMP, COSAMP and StOMP. For all sampling levels, LPMP is revealed to be superior to other CS algorithms.
In order to test the masked version of LPMP algorithm, we introduced the mask of ±5 frequency points around the peaks' centers. The simulation results are presented in Figure 2 (right). As expected, masking has a more pronounced effect on the low sampling levels.
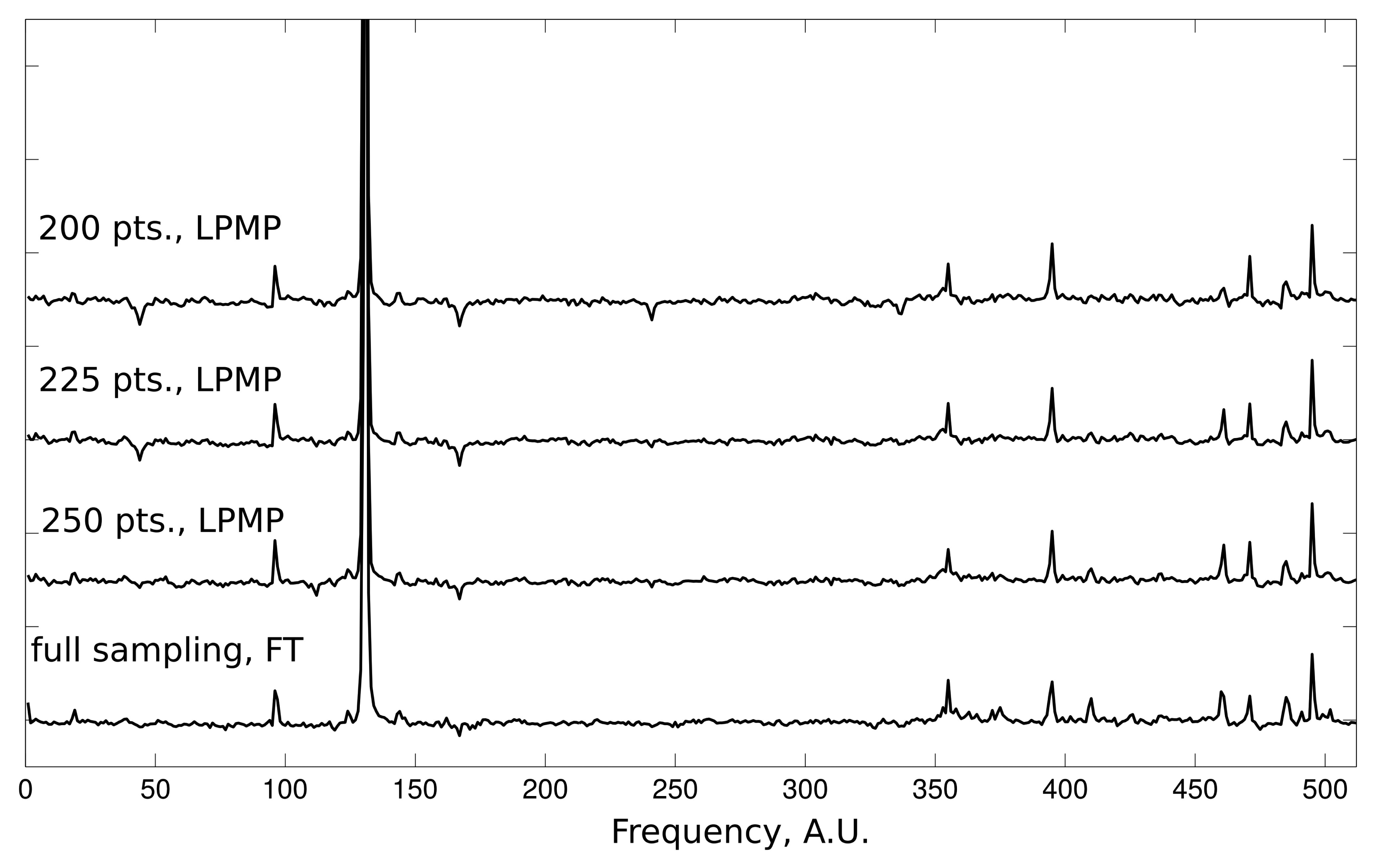
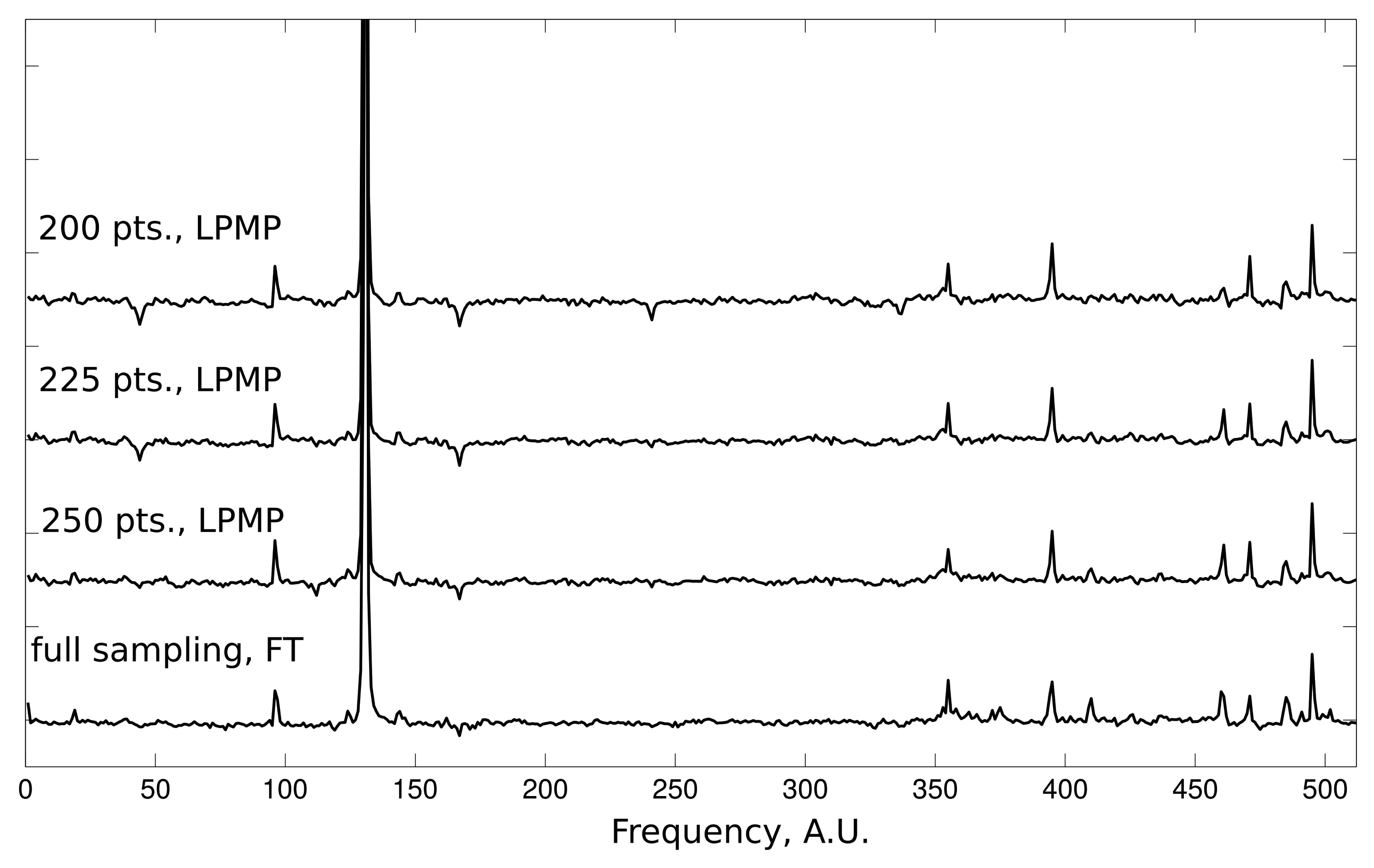
The qualitative aspects of LPMP reconstruction can be evaluated on the data from the 2D NOESY experiment. Each reconstructed 1D slice of the 2D NOESY spectrum contains one dominating peak accompanied by a group of smaller peaks. Such a case of large intensity range is very challenging for CS methods. In Figure 3, we present the results of the LPMP spectrum recovery obtained on the basis of 200, 225 and 250 random measurements of the corresponding FID signal of length 512. The 2D NOESY spectrum was recorded on a 600-MHz Varian UNITY Inova spectrometer at 25 °C using a sample of human ubiquitin protein (1 mM concentration).
In order to explain the effectiveness of LPMP algorithm in the NMR context, let us emphasize the key difference between the OMP and LPMP methods. OMP tries to obtain the frequency-domain representation having the minimal number of non-zeros, which cannot be exact, even for a single Lorentzian peak. LPMP improves OMP by replacing every determined spectral non-zero with the Lorentzian peak of the appropriate width. Roughly speaking, this corresponds to the concept of sparsity in the sense of a number of Lorentzian peaks.
7. Conclusions
Our results show that LPMP is superior to the generic CS methods when applied to exponentially decaying signals. Comparison with OMP, StOMP, IST and COSAMP revealed that the assumption of the Lorentzian spectral line shape improves the quality of the reconstruction with LPMP. Moreover, its performance can be further improved by limiting (“masking”) the support of a signal. We believe that this method will find applications in NMR spectroscopy. Other fields of possible application may include different kinds of spectroscopy, wireless communications, sonar and radar. In fact, reconstruction of any non-uniformly sampled exponentially-damped signal can benefit from the application of LPMP.
Acknowledgments
The authors thank the Polish Ministry of Science and Higher Education for support with Iuventus Plus Grant No. IP2011 023171 and the National Centre of Science for support with Sonata Bis 2 Grant No. DEC-2012/07/E/ST4/01386. Krzysztof Kazimierczuk thanks the Foundation for Polish Science for the support with the Team program.
Author Contributions
Paweł Kasprzak developed the core of the algorithm and described it. Krzysztof Kazimierczuk adapted it to NMR requirements and wrote the NMR part of the publication.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Candès, E.J.; Romberg, J.K.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar]
- Papoulis, A. A new algorithm in spectral analysis and band-limited extrapolation. IEEE T Circuits Syst. 1975, 22, 735–742. [Google Scholar]
- Tropp, J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory 2004, 50, 2231–2242. [Google Scholar]
- Needell, D.; Tropp, J. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmonic Anal. 2009, 26, 301–321. [Google Scholar]
- Donoho, D.L.; Tsaig, Y.; Drori, I.; Starck, J.L. Sparse solution of underdetermined linear equations by stage-wise orthogonal matching pursuit. IEEE Trans. Inf. Theory 2012, 58, 1094–1121. [Google Scholar]
- Candès, E.J.; Wakin, M.B.; Boyd, S.P. Enhancing Sparsity by Reweighted l1 Minimization. J. Fourier Anal. Appl. 2008, 14, 877–905. [Google Scholar]
- Keeler, J. Understanding NMR Spectroscopy, 2nd ed.; Wiley: Chichester, UK, 2010; p. 526. [Google Scholar]
- Jeener, J. AMPERE International Summer School; Basko Polje, Yugoslavia, 1971. [Google Scholar]
- Nyquist, H. Certain topics in telegraph transmission theory. Trans. Am. Inst. Electr. Eng. 1928, 47, 617–644. [Google Scholar]
- Szantay, C. NMR and the uncertainty principle: How to and how not to interpret homogeneous line broadening and pulse nonselectivity. IV. (Un?)certainty. Concept. Magn. Reson. A. 2008, 32A, 373–404. [Google Scholar]
- Kazimierczuk, K.; Stanek, J.; Zawadzka-Kazimierczuk, A.; Koźmiński, W. Random sampling in multidimensional NMR spectroscopy. Prog. Nucl. Magn. Reson. Spectrosc. 2010, 57, 420–434. [Google Scholar]
- Coggins, B.E.; Venters, R.A.; Zhou, P. Radial sampling for fast NMR: Concepts and practices over three decades. Prog. Nucl. Magn. Reson. Spectrosc. 2010, 57, 381–419. [Google Scholar]
- Kazimierczuk, K.; Orekhov, V.Y. Accelerated NMR spectroscopy by using compressed sensing. Angew. Chem. Int. Ed. Engl. 2011, 50, 5556–5559. [Google Scholar]
- Holland, D.J.; Bostock, M.J.; Gladden, L.F.; Nietlispach, D. Fast multidimensional NMR spectroscopy using compressed sensing. Angew. Chem. Int. Ed. Engl. 2011, 50, 6548–6551. [Google Scholar]
- Högbom, J.A. Aperture synthesis with a non-regular distribution of interferometer baselines. Astron. Astrophys. Suppl. 174. 15, 417–426.
- Coggins, B.E.; Zhou, P. High resolution 4-D spectroscopy with sparse concentric shell sampling and FFT-CLEAN. J. Biomol. NMR 2008, 42, 225–239. [Google Scholar]
- Stanek, J.; Kozmiński, W. Iterative algorithm of discrete Fourier transform for processing randomly sampled NMR data sets. J. Biomol. NMR 2010, 47, 65–77. [Google Scholar]
- Coggins, B.E.; Werner-Allen, J.W.; Yan, A.; Zhou, P. Rapid Protein Global Fold Determination Using Ultrasparse Sampling, High-Dynamic Range Artifact Suppression, and Time-Shared NOESY. J. Am. Chem. Soc. 2012, 134, 18619–18630. [Google Scholar]
- Kazimierczuk, K.; Zawadzka, A.; Kozmiński, W.; Zhukov, I. Lineshapes and Artifacts in Multidimensional Fourier Transform of Arbitrary Sampled NMR Data Sets. J. Magn. Reson. 2007, 188, 344–356. [Google Scholar]
- Zhang, T. Sparse recovery with orthogonal matching pursuit under RIP. IEEE Trans. Inf. Theory 2011, 57, 6215–6221. [Google Scholar]
- Wang, J.; Shim, B. On the Recovery Limit of Sparse Signals Using Orthogonal Matching Pursuit. IEEE Trans. Signal Process 2012, 60, 4973–4976. [Google Scholar]
- Jaravine, V.A.; Zhuravleva, A.V.; Permi, P.; Ibraghimov, I.; Orekhov, V.Y. Hyperdimensional NMR spectroscopy with nonlinear sampling. J. Am. Chem. Soc. 2008, 130, 3927–3936. [Google Scholar]
- Matsuki, Y.; Konuma, T.; Fujiwara, T.; Sugase, K. Boosting Protein Dynamics Studies Using Quantitative Nonuniform Sampling NMR Spectroscopy. J. Phys. Chem. B. 2011, 115, 13740–13745. [Google Scholar]
- Kazimierczuk, K.; Zawadzka-Kazimierczuk, A.; Koźmiński, W. Non-uniform frequency domain for optimal exploitation of non-uniform sampling. J. Magn. Reson. 2010, 205, 286–292. [Google Scholar]
- Kaiser, R. Use of the Nuclear Overhauser Effect in the Analysis of High-Resolution Nuclear Magnetic Resonance Spectra. J. Chem. Phys. 1963, 39, 2435–2442. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Center | 5.6 | 22.7 | 67.8 | 70.4 | 194.5 | 239.25 |
|---|---|---|---|---|---|---|
| width | 5.2 | 5.4 | 2.6 | 2.8 | 4 | 1.5 |
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kazimierczuk, K.; Kasprzak, P. Modified OMP Algorithm for Exponentially Decaying Signals. Sensors 2015, 15, 234-247. https://doi.org/10.3390/s150100234
Kazimierczuk K, Kasprzak P. Modified OMP Algorithm for Exponentially Decaying Signals. Sensors. 2015; 15(1):234-247. https://doi.org/10.3390/s150100234
Chicago/Turabian StyleKazimierczuk, Krzysztof, and Paweł Kasprzak. 2015. "Modified OMP Algorithm for Exponentially Decaying Signals" Sensors 15, no. 1: 234-247. https://doi.org/10.3390/s150100234
APA StyleKazimierczuk, K., & Kasprzak, P. (2015). Modified OMP Algorithm for Exponentially Decaying Signals. Sensors, 15(1), 234-247. https://doi.org/10.3390/s150100234