Gaussian Multiscale Aggregation Applied to Segmentation in Hand Biometrics

Abstract
: This paper presents an image segmentation algorithm based on Gaussian multiscale aggregation oriented to hand biometric applications. The method is able to isolate the hand from a wide variety of background textures such as carpets, fabric, glass, grass, soil or stones. The evaluation was carried out by using a publicly available synthetic database with 408,000 hand images in different backgrounds, comparing the performance in terms of accuracy and computational cost to two competitive segmentation methods existing in literature, namely Lossy Data Compression (LDC) and Normalized Cuts (NCuts). The results highlight that the proposed method outperforms current competitive segmentation methods with regard to computational cost, time performance, accuracy and memory usage.1. Introduction
Hand biometrics is receiving an increasing attention at present because of their huge applicability in daily scenarios and the relation between user acceptance and identification/verification rates [1,2].
The characteristics of this biometric technique in terms of non-invasiveness and acceptability highlight the fact that hand biometrics could be a proper and adequate biometric method for verification and identification in devices like PC or mobile phones, since hand biometrics system requirements are easily met with a standard camera and hardware processor.
However, as applications requiring hand biometrics tends to contact-less, platform-free scenarios (e.g., smartphones [3]), hand acquisition (capturing and segmentation) is being increased in difficulty. In other words, hand biometrics is evolving from constrained and contact-based scenarios [4,5] to opposite approaches where less collaboration is required from individuals [3,6], providing non-invasive characteristics to this biometric technique, and thus, improving its acceptability.
Consequently, image pre-processing becomes compulsory to tackle with this problem, by providing an accurate segmentation algorithm to isolate hand from background, whatever its nature, and independent from environment and illumination conditions.
Thus, a segmentation method is proposed able to isolate hand from different background, regardless the environmental and illumination conditions.
The proposed approach is based on multiscale aggregation, gathering pixels along scales according to a given similarity Gaussian function. This method produces an iterative clustering aggregation, providing a solution for hand image segmentation with a quasi-linear computational cost and an adequate accuracy for biometric applications.
The method has been tested with a synthetic image database, with around 408,000 images considering different backgrounds (e.g., soil, skins/fur, carpets, walls or grass) and illumination environments, and compared to two competitive approaches in literature in terms of image segmentation. These approaches are named Lossy Data Compression (LDC) [7] and Normalized Cuts (NCut) [8].
Finally, the layout of the paper remains as follows: Section 2 provides and overview on the current literature, describing the proposed method under Section 3. The database involved in evaluation is presented in Section 4, together with the results, presented in Section 5, providing conclusions and future work in Section 6.
2. Literature Review
Segmentation is an important research field in image processing [9], essential in biometric techniques involving image-based data acquisition like hand geometry [10], palmprint [11], hand vein [12], face [13], iris [14], ear [15], gait [16] or handwriting [17].
In fact, the overall performance in terms of identification accuracy relies strongly on the result provided by the segmentation and pre-processing procedure.
Concerning hand-based biometrics, segmentation has received little attention in early works, provided that initial approaches carry out the acquisition procedure in a constrained and homogeneous background [4,18]. This background was selected so that hand segmentation is a trivial task by simple thresholding.
However, as hand biometrics is evolving from contact and peg-based approaches to completely contact-less, peg-free and platform independent scenarios, hand segmentation is increasing its difficulty and complication [6,19,20].
Several approaches in literature tackle with this problem by providing non-contact, platform-free scenarios but with constrained background, usually employing a monochromatic color, easily distinctive from hand texture by means of simple image thresholding [21–23]. More realistic environments propose a color-based segmentation, detecting hand-like pixels either based on probabilistic [24], clustering methods [25] or edge detection [4,5,20].
A possible solution for unconstrained and non-homogeneous backgrounds is a segmentation method based on multiscale aggregation [26–30], inspired on the well-known Normalized Cuts approach [8].
The most common applications of this approach consider image segmentation and boundary detection based on texture [29,31], providing accurate results when compared to human segmentation and other competitive approaches in literature [32].
The results obtained by multiscale aggregation in the fields of unsupervised image segmentation are certainly promising [32], and the application of this method for hand segmentation has been recently proposed [3].
Nonetheless, several aspects must be improved in terms of computational cost and memory usage efficiency [3,30,32]. In fact, these methods are strongly dependent on the number of pixels in an image, and only small images are supported. This limitation was partially solved [3,30], providing a quasi-linear segmentation method, described in detail in the following section.
3. Gaussian Multiscale Aggregation
The proposed approach attempts to provide an accurate segmentation of a colour hand image. The algorithm strategy consists of aggregating similar nodes according to a specific criteria along different scales until a given goal is met, ensuring that aggregated nodes within segments verify certain properties.
First step of the algorithm consists of providing a particular structure to the amount of elements within the image. Likewise to other methods [30], the proposed algorithms assumes that a given image I can be represented by a graph = (, ) where nodes in represent pixels in the image and edges in stands for the structure provided to the set of nodes.
In this approach, the structure on the first scale is assumed to be a 4-neighbourhood strategy, while for subsequent scales, structure is provided by means of Delaunay triangulation [33].
In addition, each node is represented by a similarity function denoted by , where vi ∈ designates a node in graph and s indicates the scale the element vi belongs to. This similarity function is described in terms of relative measures with respect to intensity average and standard deviation.
More in detail, is represented by a gaussian distribution (μ, σ) where μ and σ specify the average and standard deviation neighbour intensity, provided the 4-neighbourhood structure.
Thus, similarity functions leads to the concept of likelihood between nodes in connecting edges, providing a definition of weights within graph .
Given a graph = (, ), the similarity among pair of nodes is provided by means of weights , which are defined for each scale s as:
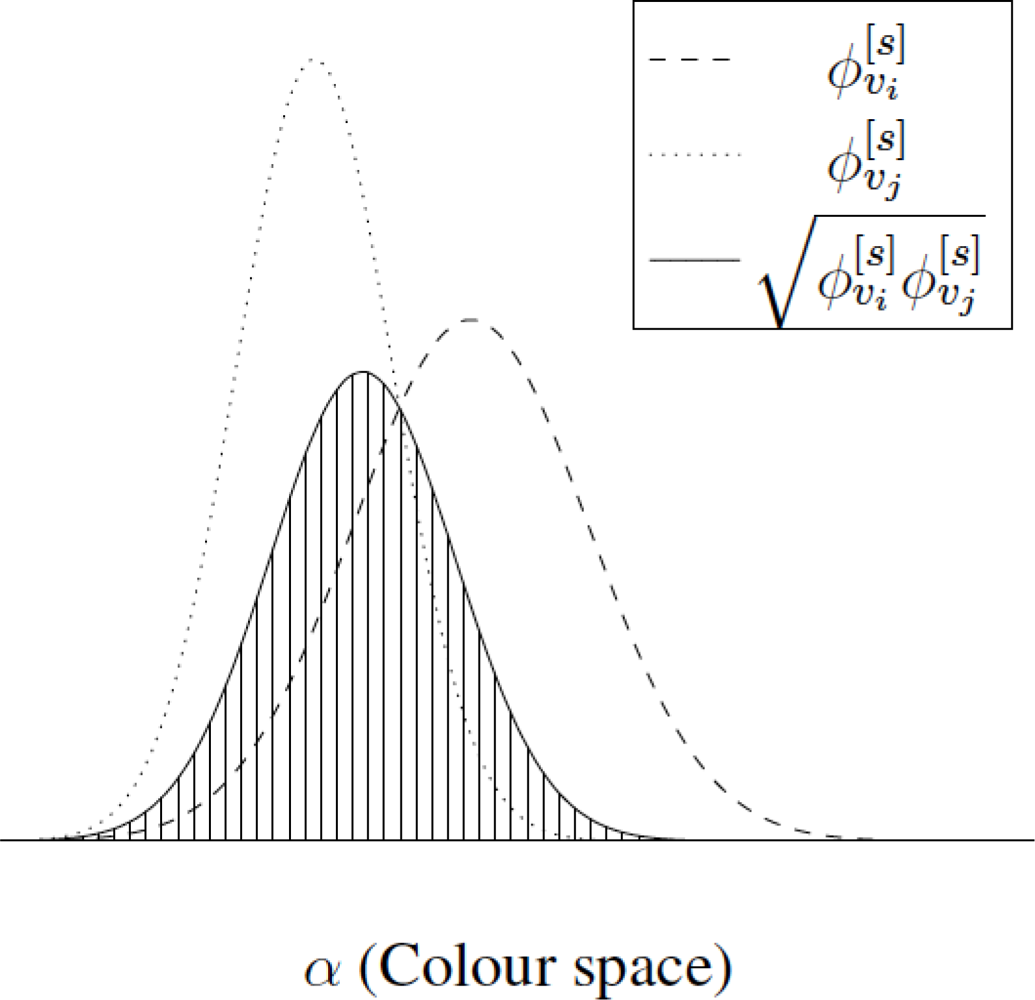
Figure 1 represents two functions φ[s] associated to a pair of nodes vi and vj, showing the weight associated to their similarity (striped region). The higher the similarity between both nodes, the bigger the striped region.
Therefore, graph = (, , ) contains not only structural information on a given scale s but also relational details about the similarity of each node neighbourhood.
Furthermore, i,j can be regarded as the weight associated to edge ei,j, so that i,j = (ei,j). Notice that weights are not defined for each pair of nodes in , but only for those pairs of nodes with correspondence in edge set .
Some properties can be extracted from the definition of i,j ∈ as the similarity between two nodes vi and vj, then i,j satisfies ∀i, j:
i,j ≥ 0
i,j = j,i
i,j = 1 ↔ φi = φj
Property (1) results from the definition given by Equation (1), since the integration of two non-negative functions provides a non-negative result. Similarly, property (2) is derived from the commutative product of a function product. Property (3) indicates that maximum value of weight is obtained if and only if nodes vi and vj have the same similarity distribution.
These former properties stand for each scale s, although for the sake of simplicity this index was not included on previous notation.
Furthermore, each node vi ∈ contains also information on the location within the image in terms of positions, which will be useful in posterior scale aggregation steps.
On the other hand, the essence of this algorithm relies on aggregation, which consists of grouping and clustering those similar nodes/segments in subgraphs, according to some criteria along scales.
The proposed method bases the aggregation procedure on the weights in , given the fact that, those pairs of nodes/subgraphs with higher weights are more similar than those with lower weights, and therefore, those former pairs deserve to be aggregated under a same segment/subgraph. Thus, a function must be defined to provide some order in set , so that posterior subgraphs in subsequent scales contain nodes with high weights and, therefore, high similarity.
Let Ω be an ordering function, which orders edges in according to , as follows:
In other words, let e = {e1, . . ., em} be a set of edges. If Ω is applied to previous set e, then it is satisfied that Ω(e)i ≥ Ω(e)j, with i ≤ j, ∀ i, j, being Ω(e)i the ith element in the ordered set Ω(e). Concretely, Ω represent the weight set after Ω is applied.
Once the concept of ordering function is introduced, the algorithm aggregates pair of nodes based on this former weight ordering, ensuring that the dispersion of each segment remains bounded. This aggregation criteria is represented by the Equation (3):
Once pairs of nodes have been ordered and an aggregation criteria have been stated, the Gaussian Multiscale Algorithm aggregates pair of nodes with previous criteria Equation (4), considering the fact that represents the n-th graph in scale s, so that .
In addition, the number of assigned graphs in scale s is given by p, whose description is provided in Equation (5), which depends on δ̄i,j = 1 − δi,j as follows:
Gaussian Multiscale Aggregation assures that every node in scale s − 1 is assigned a segment/subgraph in scale s.
After aggregation, nodes in scale s are gathered into p subgraphs, with p < N[s], being N[s] the number of nodes in scale s. Each subgraph contains a set of nodes, whose number is unknown a priori. These subgraphs must be compared in subsequent scales, and thus the similarity function in subgraphs is defined in Equation (7).
Consequently, let be the nth aggregated graph in scale s + 1, which gathers a set of m subgraphs { , . . ., } in scale s. Then the similarity function for graph , namely is defined as
Therefore, similarity functions can be completely defined as in Equation (8)
Concerning location, the position of subgraphs is obtained by averaging the position of the nodes contained on each subgraph. This is essential in order to provide a neighbourhood structure, since after aggregation every scale s collects a scatter set of subgraphs. This structure is given by means of Delaunay triangulation.
A Delaunay graph for a set S = {p1, . . ., pn} of points in the plane has the set S as its vertices. Two vertices pi and pj are joined by a straight-line (representing an edge) if and only if the Voronoi regions V (pi) and V (pj) share an edge. In addition, for a set of points in 2, knowing the locations of the endpoints permits a solution in O(nlogn) time. Therefore, Delaunay triangulation is a suitable method to provide a neighbourhood structure to previous aggregated subgraphs.
This operation represents the final step in the loop, since at this moment, there exist a new subgraph at scale s + 1 where each represents a node, and edges [s+1] are provided by Delaunay triangulation, and weights [s+1] are obtained based on Equations (1) and (8).
The whole loop is repeated until only two subgraphs remain, as stated at the beginning of this section. However, due to the constraints provided to aggregate (Equation (9)), the method could not aggregate more segments, without achieving the goal of dividing image into two subgraphs. Therefore, Equation (3) is in practice relaxed and stated as follows in Equation (9):
The computational cost of this algorithm is quasi-linear with the number of pixels, since each scale gathers nodes in the sense that nodes in subsequent scales are reduced by (in practice) a three times factor (Figure 4). Therefore, time to process the first scale (which contains the highest number of nodes) is greater than the rest of times to process subsequent scales, and the total time is approximately comparable to two times the processing time to aggregate first scale. This statement will be supported within the results of Section 5.
4. Database
After presenting the algorithm, next section describes the creation of the database involved in evaluation.
This section describes the creation of a synthetic database containing a total of 408,000 images of hands with a wide range of possible backgrounds like carpets, fabric, glass, grass, mud, different objects, paper, parquet, pavement, plastic, skin and fur, sky, soil, stones, tiles, tree, wall and wood.
The main aim of this database is twofold:
First, the main purpose is to provide a comparative evaluation frame for segmentation algorithm, where existing approaches in literature could be compared. In other words, this database makes it possible to assess to what extent the segmentation algorithm can satisfactory perform a hand isolation from background on real scenarios.
In addition, this database contains the ground-truth result for each image, providing a possible supervised evaluation criteria. These ground-truth images were obtained, given that hands were taken with a blue-coloured background, so that hand can be easily extracted by simple thresholding [22].
The creation of the synthetic database (named GB2S Database) considers the hands extracted in former database and the set of the aforementioned different textures, which were obtained from the website http://mayang.com/textures/.
First of all, a straightforward segmentation was carried out with a threshold-based segmentation [22], obtaining two binary masks: Mh, corresponding to those pixels representing hand, and Mb with pixels corresponding to background.
Afterwards, both masks are laid one over each other, with Mb containing pixels associated to a specific texture, resulting in an image with the hand over a desired background (grass, water, wood and so forth).
In order to ensure there is no considerable difference in illumination between hand and background, each image is converted from RGB to YCbCr color space [9] carrying out a histogram equalization in terms of illumination (Y), performing afterwards the inverse transform from YCbCr to RGB color space. Finally, a morphological operation consisting on an opening operator with a structural element of a disk of small size (5 pixels radio) is considered to fade the boundary between hand and background, so that hand is integrated within background.
All these former operations attempt to ensure a fair scenario, simulating the conditions provided in real situations.
For each hand image, a total of 5 × 17 (five images and 17 textures) synthetic images are created, collecting a total of 120 × 2 × 20 × 5 × 17 = 408,000 images (120 individuals, two hands, 20 acquisitions per hand, five images and 17 textures) to properly evaluate segmentation on real scenarios. Some visual examples of this database are provided in Figure 2.
This presented database is publicly available at http://www.gb2s.es/.
Once the database has been presented, the following section comes out with the evaluation of the algorithm and the obtained results.
5. Results and Discussion
This section contains the results of the comparative evaluation of the proposed approach to LDC [7] and NCut [8]. First, the evaluation criteria is stated in order to provide a comparative frame, providing afterwards the results obtained in the evaluation.
5.1. Evaluation Criteria
Although there exist some unsupervised evaluation methods for image segmentation [32,34,35], we have preferred a supervised segmentation, since the synthetic database GB2S contains the corresponding ground-truth associated to each image. Segmentation results will be compared to this ground-truth image.
The proposed evaluation method is based on F-measure, [36], defined as follows:
Aiming a fair comparison, the propose algorithm is compared to two competitive segmentation methods existing in the literature, namely Lossy Data Compression (LDC) [7] and Normalized Cuts (NCut) [8].
5.2. Gaussian Multiscale Aggregation Evaluation
The evaluation of a segmentation method involves different aspects concerning accuracy, computational cost and parameters dependency.
First aspect is related to what extent the algorithm is able to properly detect or isolate a specific object within an image. Concretely in this paper, accuracy is understood as the capability of the proposed algorithm to properly isolate hand from background.
Table 1 shows the results in terms of F-measure of the proposed methods in comparison to LDC approach and Normalized Cuts. Although the results obtained by the proposed method (first column) can be improved, they overcome the other two schemes. Reader may notice that scenarios with textures similar to hand (e.g., soil) decrease the performance of the segmentation algorithms, but the proposed method still provides F-measure rates of more than 88%.
In addition, accuracy can be also visually evaluated. Figure 3 presents a comparative frame for segmentation evaluation, comparing the results obtained for the LDC method, Normalized Cuts and the proposed method. Reader can compare the obtained results (columns 4–6) to the ground-truth (column 2). The results obtained by the proposed approach conserve more precisely the shape of the hand even in scenarios with similar textures like parquet (row 5) or wood (last row).
Secondly, concerning computational cost, Table 2 presents the segmentation time in relation to the number of pixels of the images. This temporal evaluation was carried out in a PC computer @2.4 GHz Intel Core 2 Duo with 4 GB 1,067 MHz DDR3 of memory, considering that the proposed method was completely implemented in MATLAB.
The results provided in Table 2 shows that the proposed algorithm is faster than the compared approaches. In addition, the proposed method can segment images of higher sizes, but LDC and NCut cannot handle higher sizes images without running out of memory.
Finally, this section will study the dependency of two parameters strongly related to algorithm performance, namely k factor and aggregation linearity (Equations (9) and (10)).
Factor k controls the aggregation capability of the overall method. Within these experiments, factor k was experimentally fixed to k = 0.01, ensuring that the number of segments in the last scale is two: hand and background. However, extending the proposed approach to other applications in image processing would imply to provide a dynamic factor k, depending whether the algorithm standstills in a certain scale. The proposal of a dynamic factor k remains as future work.
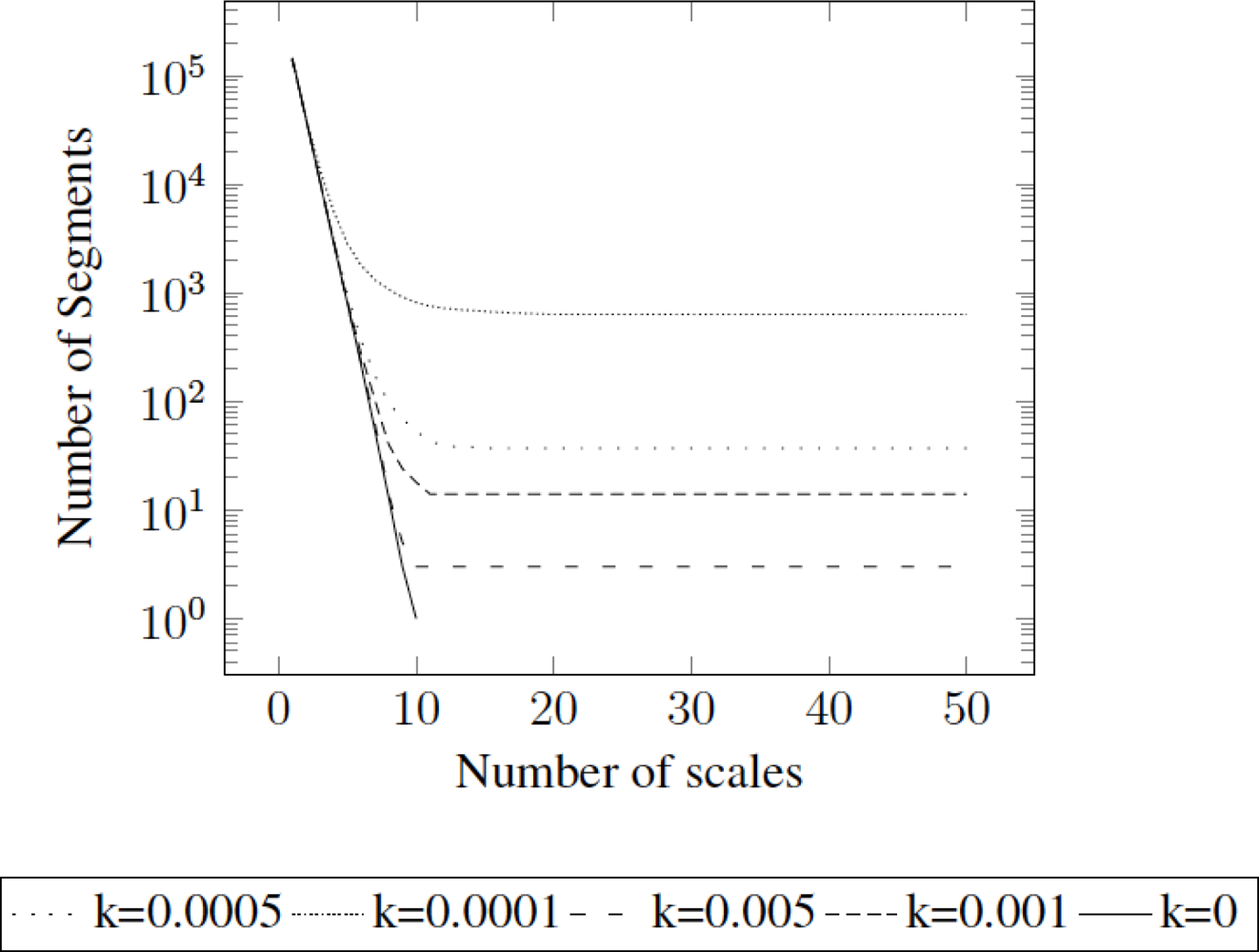
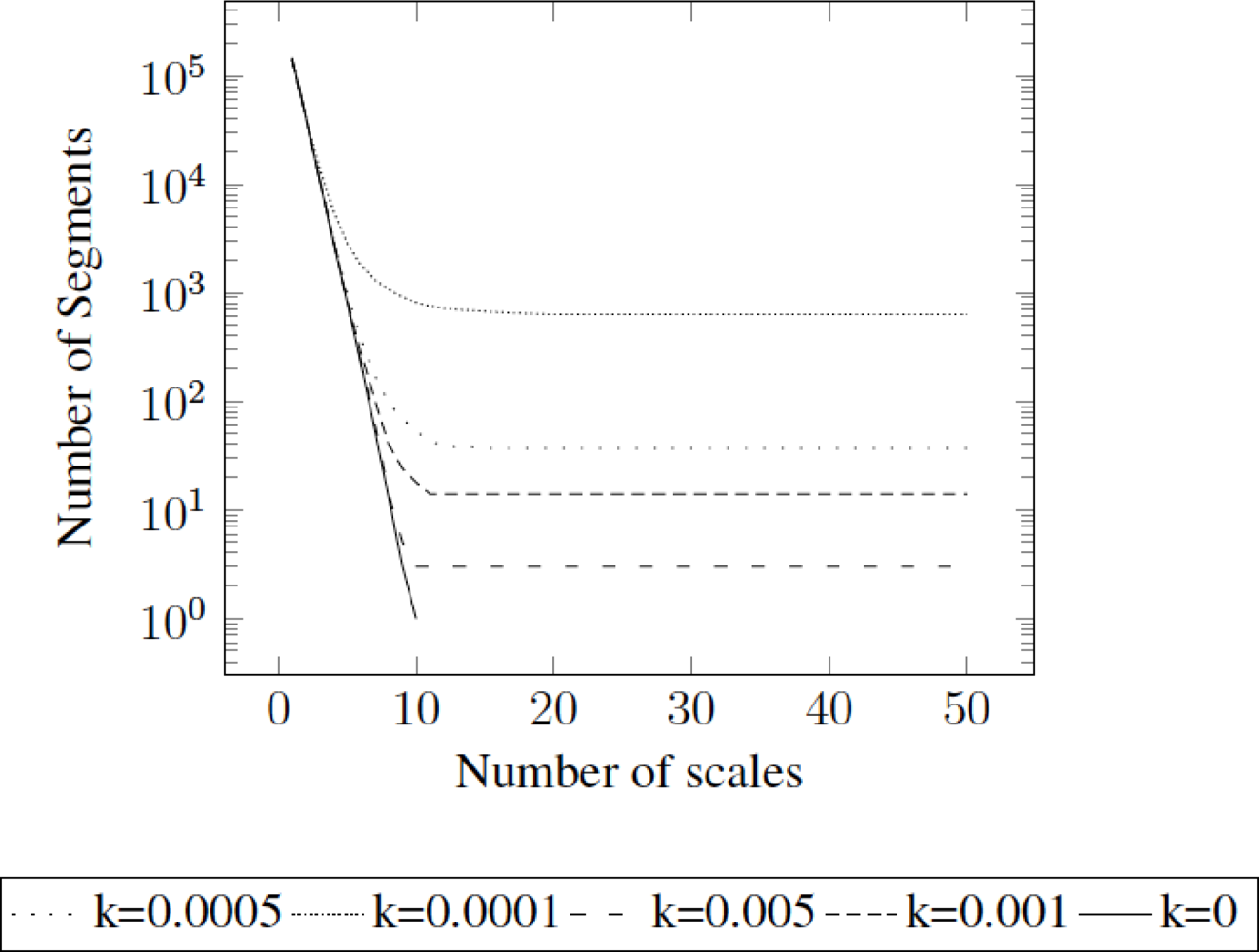
Figure 4 presents the relation between number of segments along scales using different values of k. Notice that k = 0 implies no stopping criteria, and therefore aggregates scales until only one segment is obtained.
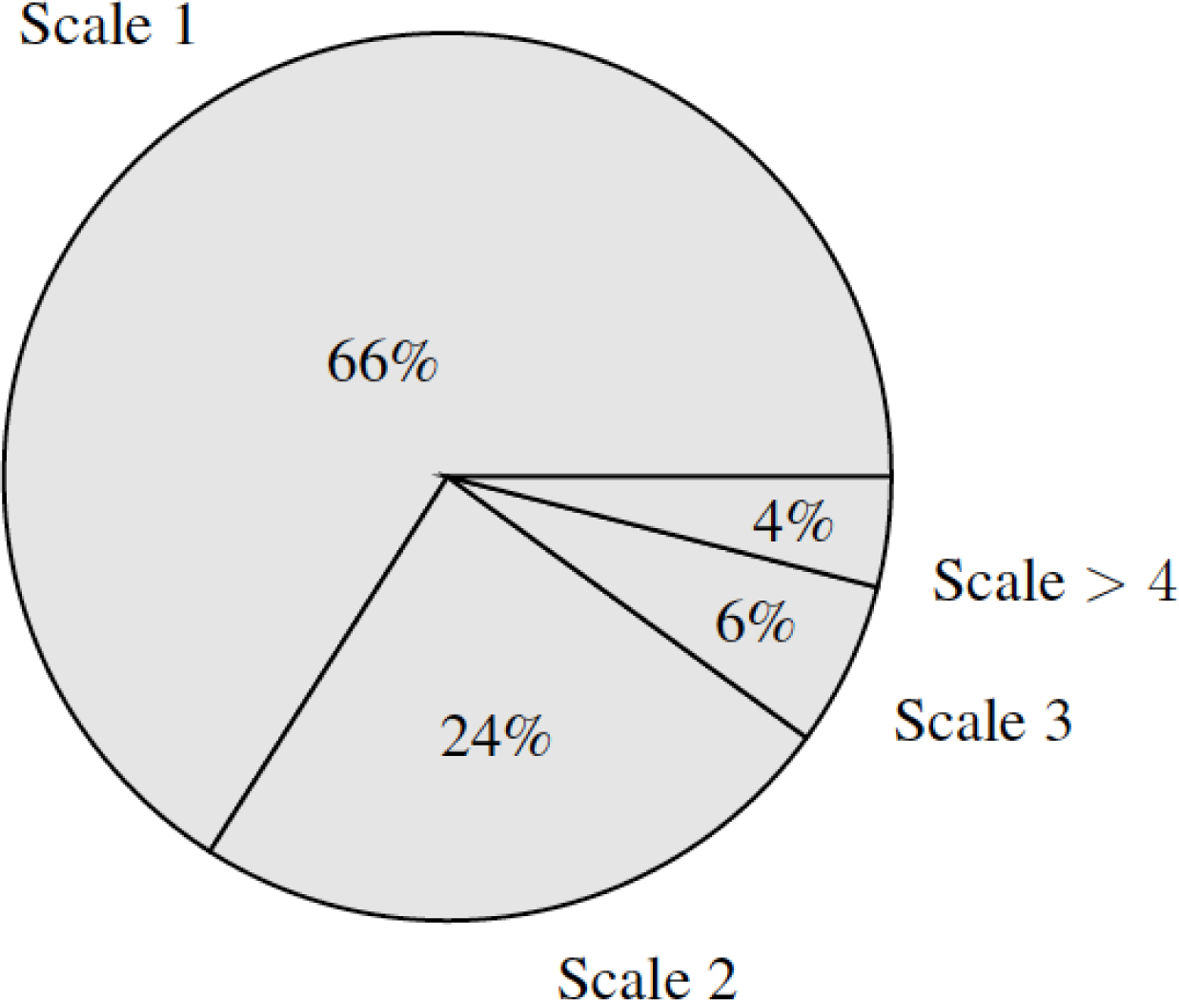
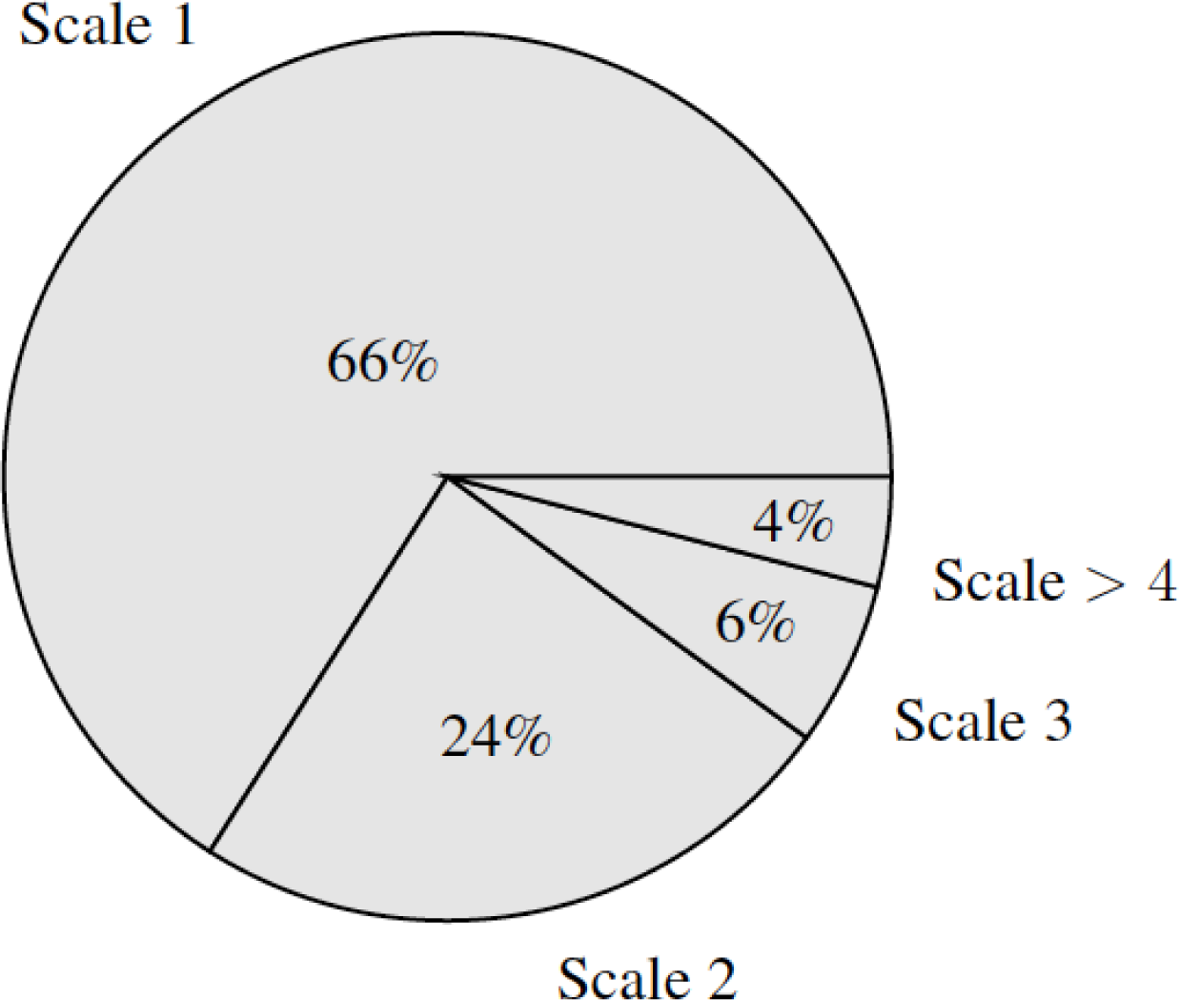
During the explanation of the method, the algorithm is said to be quasi-linear with the number of pixels. This statement is supported by Table 2, but for clarity sake, we provide a chart (Figure 5) indicating which proportion of time is required for each scale. The most demanding scale is the first one, whose proportion is higher than the other parts, concluding that the algorithm has indeed a quasi-linear behaviour in relation to the number of pixels.
6. Conclusions and Future Work
The application of hand biometrics to unconstrained and contact-less, platform-free environments implies an increase in difficulty in the pre-processing and segmentation procedure in hand acquisition. Therefore, an unsupervised segmentation algorithm has been proposed based on Gaussian multiscale aggregation. This method gathers iteratively those pixels similar in texture and color under segments, until a certain number of clusters/segments is provided as a result.
This method is able to isolate hand from a wide range of backgrounds (carpets, fabric, glass, grass, mud, different objects, paper, parquet, pavement, plastic, skin and fur, sky, soil, stones, tiles, tree, wall and wood), simulating real situations and unconstrained background scenarios.
Besides, the evaluation of the proposed approach has been carried out based on a publicly available synthetic database, containing 408,000 hand image acquisitions with different background textures. The evaluation consisted of a comparison of the performance in terms of accuracy and computational cost to two competitive segmentation methods existing in literature, namely Lossy Data Compression (LDC) [7] and Normalized Cuts (NCuts) [8].
The results obtained point out that the performance of the proposed algorithm outcomes existing segmentation algorithms in literature, regarding not only accuracy and computational cost, but also memory usage, since the proposed algorithm is quasi-linear in relation to the number of pixels.
As future work, we consider to implement the method with a dynamic k parameter, so that the algorithm can be adapted to any image, providing segmentations of more complex images. In addition, we aim a faster implementation of the method considering both software and hardware optimized implementation, together with a more complete evaluation with other publicly available databases.
Acknowledgments
This research has been supported by the Ministry of Industry, Tourism and Trade of Spain, in the framework of the project CENIT-Segur@, reference CENIT-2007 2004.
References
- Kukula, E.; Elliott, S. Implementation of Hand Geometry at Purdue University’s Recreational Center: An Analysis of User Perspectives and System Performance. Proceedings of CCST ’05: 39th Annual International Carnahan Conference on Security Technology, Albuquerque, NM, USA, 11–14 October 2005; pp. 83–88.
- Kukula, E.; Elliott, S. Implementation of hand geometry: An analysis of user perspectives and system performance. IEEE Aero. Electron. Syst. Mag 2006, 21, 3–9. [Google Scholar]
- Muñoz, A.G.C.; Ávila, C.S.; de Santos Sierra, A; Casanova, J.G. A mobile-oriented hand segmentation algorithm based on fuzzy multiscale aggregation. In ISVC’10 Proceedings of the 6th International Conference on Advances in Visual Computing—Volume Part I; Springer-Verlag: Berlin, Heidelberg, Germany, 2010; pp. 479–488. [Google Scholar]
- Sanchez-Reillo, R.; Sanchez-Avila, C.; Gonzalez-Marcos, A. Biometric identification through hand geometry measurements. IEEE Trans. Patt. Anal. Mach. Intell 2000, 22, 1168–1171. [Google Scholar]
- Jain, A.; Ross, A.; Pankanti, S. A Prototype Hand Geometry-Based Verification System. Proceedings of Second International Conference on Audio- and Video-Based Biometric Person Authentication, Washington, DC, USA, 22–23 March 1999; Volume 1. pp. 166–171.
- Morales, A.; Ferrer, M.A.; Daz, F.; Alonso, J.B.; Travieso, C.M. Contact-Free Hand Biometric System for Real Environments. Proceedings of European Conference on Signal Processing 2008, Lausanne, Switzerland, 25–29 August 2008.
- Ma, Y.; Derksen, H.; Hong, W.; Wright, J. Segmentation of multivariate mixed data via lossy data coding and compression. IEEE Trans. Patt. Anal. Mach. Intell 2007, 29, 1546–1562. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Patt. Anal. Mach. Intell 2000, 22, 888–905. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed; Prentice-Hall, Inc: Upper Saddle River, NJ, USA, 2006. [Google Scholar]
- Morales, A.; Ferrer, M.; Alonso, J.; Travieso, C. Comparing Infrared and Visible Illumination for Contactless Hand Based Biometric Scheme. Proceedings of ICCST 2008: 42nd Annual IEEE International Carnahan Conference on Security Technology, Prague, Czech Republic, 13–16 October 2008; pp. 191–197.
- Hennings-Yeomans, P.; Kumar, B.; Savvides, M. Palmprint Classification Using Multiple Advanced Correlation Filters and Palm-Specific Segmentation. IEEE Trans. Inform. Forensics Secur 2007, 2, 613–622. [Google Scholar]
- Wang, Y.; Wang, H. Gradient Based Image Segmentation for Vein Pattern. Proceedings of ICCIT ’09: Fourth International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea, 24–26 November 2009; pp. 1614–1618.
- Segundo, M.; Silva, L.; Bellon, O.; Queirolo, C. Automatic face segmentation and facial landmark detection in range images. IEEE Trans. Syst. Man Cyber. B Cyber 2010, 40, 1319–1330. [Google Scholar]
- He, Z.; Tan, T.; Sun, Z.; Qiu, X. Toward accurate and fast iris segmentation for iris biometrics. IEEE Trans. Patt. Anal. Mach. Intell 2009, 31, 1670–1684. [Google Scholar]
- Yan, P.; Bowyer, K. Biometric recognition using 3D ear shape. IEEE Trans. Patt. Anal. Mach. Intell 2007, 29, 1297–1308. [Google Scholar]
- Huang, L.; Xu, Z.; Hu, F. A Novel Gait Contours Segmentation Algorithm. Proceedings of 2010 International Conference on Computer, Mechatronics, Control and Electronic Engineering (CMCE), Changchun, China, 24–26 August 2010; Volume 6. pp. 410–413.
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Patt. Anal. Mach. Intell 2009, 31, 855–868. [Google Scholar]
- Lew, Y.; Ramli, A.; Koay, S.; Ali, R.; Prakash, V. A Hand Segmentation Scheme Using Clustering Technique in Homogeneous Background. Proceedings of SCOReD 2002: Student Conference on Research and Development, Shah Alam, Malaysia, 16–17 July 2002; pp. 305–308.
- Woodard, D.L.; Flynn, P.J. Finger surface as a biometric identifier. Comput. Vis. Image Underst 2005, 100, 357–384. [Google Scholar]
- Zheng, G.; Wang, C.J.; Boult, T. Application of projective invariants in hand geometry biometrics. IEEE Trans. Inform. Forensics Secur 2007, 2, 758–768. [Google Scholar]
- Kumar, A.; Zhang, D. Personal recognition using hand shape and texture. IEEE Trans. Image Process 2006, 15, 2454–2461. [Google Scholar]
- Amayeh, G.; Bebis, G.; Erol, A.; Nicolescu, M. Peg-Free Hand Shape Verification Using High Order Zernike Moments. Proceedings of CVPRW ’06: 2006 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 17–22 June 2006; p. 40.
- Kumar, A.; Wong, D.C.M.; Shen, H.C.; Jain, A.K. Personal Verification Using Palmprint and Hand Geometry Biometric. Proceeding of AVBPA’03: the 4th International Conference on Audio- and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; pp. 668–678.
- Doublet, J.; Lepetit, O.; Revenu, M. Contactless Hand Recognition Based on Distribution Estimation. Proceeding of Biometrics Symposium 2007, Baltimore MD, USA, 11–13 September 2007; pp. 1–6.
- de Santos Sierra, A.; Casanova, J.; Avila, C.; Vera, V. Silhouette-Based Hand Recognition on Mobile Devices. Proceeding of IEEE 43rd Annual International Carnahan Conference on Security Technology, Zürich, Switzerland, 5–8 October 2009; pp. 160–166.
- Galun, M.; Apartsin, A.; Basri, R. Multiscale Segmentation by Combining Motion and Intensity Cues. Proceeding of CVPR 2005: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1. pp. 256–263.
- Sharon, E.; Brandt, A.; Basri, R. Fast Multiscale Image Segmentation. Proceeding of IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 13–15 June 2000.
- Gauch, J. Image segmentation and analysis via multiscale gradient watershed hierarchies. IEEE Trans. Image Process 1999, 8, 69–79. [Google Scholar]
- Vanhamel, I.; Pratikakis, I.; Sahli, H. Multiscale gradient watersheds of color images. IEEE Trans. Image Process 2003, 12, 617–626. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vision 2004, 59, 167–181. [Google Scholar]
- Galun, M.; Sharon, E.; Basri, R.; Brandt, A. Texture Segmentation by Multiscale Aggregation of Filter Responses and Shape Elements. Proceeding of Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 716–723.
- Chen, S.; Cao, L.; Wang, Y.; Liu, J.; Tang, X. Image segmentation by MAP-ML estimations. IEEE Trans. Image Process 2010, 19, 2254–2264. [Google Scholar]
- Berg, M.; Cheong, O.; van Kreveld, M.; Overmars, M. Computational Geometry: Algorithms and Applications; Springer: Berlin, Heidelberg, Germany, 2008. [Google Scholar]
- Unnikrishnan, R.; Pantofaru, C.; Hebert, M. Toward objective evaluation of image segmentation algorithms. IEEE Trans. Patt. Anal. Mach. Intell 2007, 29, 929–944. [Google Scholar]
- Meilǎ, M. Comparing Clusterings: An Axiomatic View. Proceedings of ICML ’05: the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 577–584.
- Alpert, S.; Galun, M.; Basri, R.; Brandt, A. Image Segmentation by Probabilistic Bottom-Up Aggregation and Cue Integration. Proceedings of CVPR ’07: IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Texture | Proposed, F (%) | LDC, F (%) | NC, F (%) |
|---|---|---|---|
| Carpets | 92.1 ± 0.1 | 73.7 ± 0.3 | 65.1 ± 0.3 |
| Paper | 91.3 ± 0.1 | 83.2 ± 0.2 | 72.8 ± 0.4 |
| Stones | 91.2 ± 0.1 | 78.2 ± 0.4 | 71.5 ± 0.3 |
| Fabric | 88.4 ± 0.3 | 65.3 ± 0.1 | 60.1 ± 0.2 |
| Parquet | 88.3 ± 0.2 | 66.1 ± 0.2 | 62.3 ± 0.3 |
| Tiles | 90.1 ± 0.2 | 71.5 ± 0.3 | 68.7 ± 0.2 |
| Glass | 94.1 ± 0.1 | 75.8 ± 0.1 | 71.4 ± 0.1 |
| Pavement | 88.9 ± 0.2 | 67.8 ± 0.1 | 63.7 ± 0.2 |
| Tree | 96.0 ± 0.2 | 73.4 ± 0.2 | 67.2 ± 0.1 |
| Grass | 93.3 ± 0.2 | 70.1 ± 0.1 | 65.3 ± 0.2 |
| Skin and Fur | 95.3 ± 0.3 | 82.3 ± 0.2 | 71.8 ± 0.3 |
| Wall | 94.1 ± 0.1 | 70.9 ± 0.2 | 62.3 ± 0.2 |
| Mud | 89.5 ± 0.2 | 68.3 ± 0.1 | 60.1 ± 0.2 |
| Sky | 96.1 ± 0.1 | 77.2 ± 0.2 | 71.3 ± 0.1 |
| Wood | 93.5 ± 0.1 | 82.5 ± 0.2 | 73.5 ± 0.1 |
| Objects | 92.0 ± 0.1 | 70.1 ± 0.1 | 61.6 ± 0.3 |
| Soil | 89.0 ± 0.2 | 67.2 ± 0.3 | 59.7 ± 0.2 |
| Image Dimensions | Number of Pixels | Proposed (seconds) | LDC (seconds) | NCut (seconds) |
|---|---|---|---|---|
| 600 × 800 | 480,000 | 30.1 | 233.1 | 321.7 |
| 450 × 600 | 270,000 | 19.8 | 63.4 | 129.5 |
| 300 × 400 | 120,000 | 9.4 | 52.1 | 25.1 |
| 150 × 200 | 30,000 | 3.1 | 32.8 | 7.2 |
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Sierra, A.d.S.; Ávila, C.S.; Casanova, J.G.; Pozo, G.B.d. Gaussian Multiscale Aggregation Applied to Segmentation in Hand Biometrics. Sensors 2011, 11, 11141-11156. https://doi.org/10.3390/s111211141
Sierra AdS, Ávila CS, Casanova JG, Pozo GBd. Gaussian Multiscale Aggregation Applied to Segmentation in Hand Biometrics. Sensors. 2011; 11(12):11141-11156. https://doi.org/10.3390/s111211141
Chicago/Turabian StyleSierra, Alberto de Santos, Carmen Sánchez Ávila, Javier Guerra Casanova, and Gonzalo Bailador del Pozo. 2011. "Gaussian Multiscale Aggregation Applied to Segmentation in Hand Biometrics" Sensors 11, no. 12: 11141-11156. https://doi.org/10.3390/s111211141
APA StyleSierra, A. d. S., Ávila, C. S., Casanova, J. G., & Pozo, G. B. d. (2011). Gaussian Multiscale Aggregation Applied to Segmentation in Hand Biometrics. Sensors, 11(12), 11141-11156. https://doi.org/10.3390/s111211141