A Local Weighted Nearest Neighbor Algorithm and a Weighted and Constrained Least-Squared Method for Mixed Odor Analysis by Electronic Nose Systems


Abstract
: A great deal of work has been done to develop techniques for odor analysis by electronic nose systems. These analyses mostly focus on identifying a particular odor by comparing with a known odor dataset. However, in many situations, it would be more practical if each individual odorant could be determined directly. This paper proposes two methods for such odor components analysis for electronic nose systems. First, a K-nearest neighbor (KNN)-based local weighted nearest neighbor (LWNN) algorithm is proposed to determine the components of an odor. According to the component analysis, the odor training data is firstly categorized into several groups, each of which is represented by its centroid. The examined odor is then classified as the class of the nearest centroid. The distance between the examined odor and the centroid is calculated based on a weighting scheme, which captures the local structure of each predefined group. To further determine the concentration of each component, odor models are built by regressions. Then, a weighted and constrained least-squares (WCLS) method is proposed to estimate the component concentrations. Experiments were carried out to assess the effectiveness of the proposed methods. The LWNN algorithm is able to classify mixed odors with different mixing ratios, while the WCLS method can provide good estimates on component concentrations.1. Introduction
An electronic nose is a biomimetic olfactory system developed based on chemical sensor principles, electronic system design and data analysis techniques. In the biological olfactory system, there are about 350 different odorant receptors in humans and about 1,000 in mice. Different odors are recognized by different combinations of odorant receptors [1,2]. Learning from this mechanism, an array of different chemical sensors is used in the design of an electronic nose. An odor can be identified by classifying its response pattern generated by the sensor array in the electronic nose [3–5].
The state-of-the-art techniques for sensor array data analysis and the applicability of each technique have been discussed by Jurs [6]. One type of data analysis methods is classification, which aims to group an object into one of the predefined class. K-Nearest Neighbor classifier (KNN) is one of the widely applied classification method that classifies an item according to the majority voting of the K nearest items. Instead of setting a global value for K, Locally Adaptive Nearest Neighbor (Local KNN) computes a locally varying K value for each query point by using the information from the neighbors of the query point [7]. On the other hand, since features may not be equally effective for classification, Discriminant Adaptive Nearest Neighbor (DANN) uses a locally weighted distance measurement scheme to compute the distance between two points [8]. The accuracy of KNN and its two variants, Local KNN and DANN, were examined by Bicego [9]. These three KNN-based methods were comparable on the examined data sets regardless of the computational cost.
The methods of dimensionality reduction, such as Principal Component Analysis (PCA) and Linear Discrimination Analysis (LDA), seek to reduce the data size required for classification. PCA is an unsupervised method, which finds a set of orthogonal projection directions that capture the largest amount of variation in data without using the class information of the data. On the other hand, LDA makes use of the class labels to find a lower-dimensional vector space for best class separation. For example, a 100% classification rate was achieved by LDA for classification of different tomato maturity states and different qualities of green tea samples [10,11]. The study in [12] indicates that PCA could yield superior classification results when a small training set is used. However, traditional classification methods would require significant computational cost if the sensor number is large.
Regression analysis is a statistical data analysis approach which seeks a continuous fitting function of independent variables to model the dependent variables. The Least-Squares method can be used to find such fitting function by minimizing the sum of squared differences between each of the known data point and the fitting function. The NASA’s Jet Propulsion Laboratory (JPL) used a set of self-developed polymer composite sensors to quantify single and mixed contaminants [13,14]. A second order polynomial regression based on the assumption of additive linearity was used to model the relationship between the gas concentration vector and the sensor responses. Carmel et al. [15] took the same assumption and further considered the relative influence of each component on the total mixture response. The modified model provided a promising result when more than two components were present in the examined mixture.
Although the classification methods represent a promising technology for analyzing electronic nose data, its applications are mainly focused on discrimination between different odors. Moreover, odors containing the same components but with different mixing ratios are generally perceived as different smells. For this reason, a traditional classification method will not be applicable for differentiating the smells. A more practical solution is to partition the odor space into subspaces and classify an odor into one of the subspaces. This paper adopts a supervised strategy to categorize the mixed odor dataset into several groups according to the components. The nearest neighbor method is then used to classify the response pattern into one of the predefined groups. A weighting scheme is proposed to re-scale the distance between two data points and thus the classification accuracy could be improved. Another solution for analysis of odor mixture is to directly determine the concentration of each component present in the examined mixture by analyzing the response pattern. Regression methods are applied in this paper to build odor models. The component concentrations are estimated by solving a weighted and constrained least-squares problem, in which each of the squared error term is weighted to reflect the reliability of each estimated sensor response.
The rest of this paper is organized as follows: Firstly, the proposed methods for analyzing mixed odors will be described in Section 2. Then, the data collection methods and experimental results will be provided to evaluate and support the proposed methods in Section 3. Finally, Section 4 will conclude the contribution of this work.
2. The Proposed Analysis Methods
Traditionally, an electronic nose is not designed to analyze mixed odors but merely to differentiate between different smells. This paper proposes to determine the components that are most significant in a mixture by analyzing the sensor response pattern of the odor mixture. This work is based on the following two assumptions [13–15]:
♦ Homogeneity: The sensor response to an odor is proportional to the odor concentration.
♦ Linear Additive: The sensor response to a mixture is equal to the linear summation of the sensor response to each of its components.
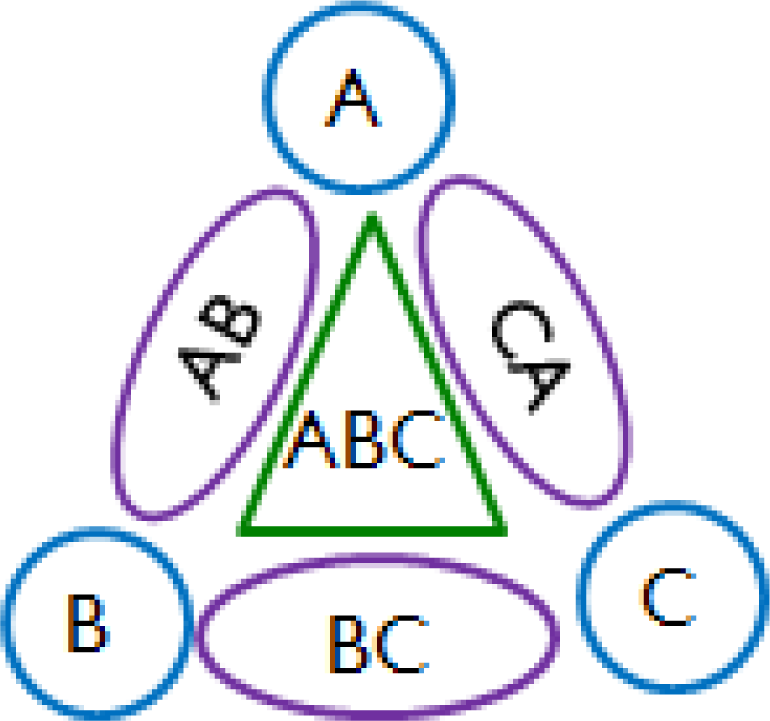
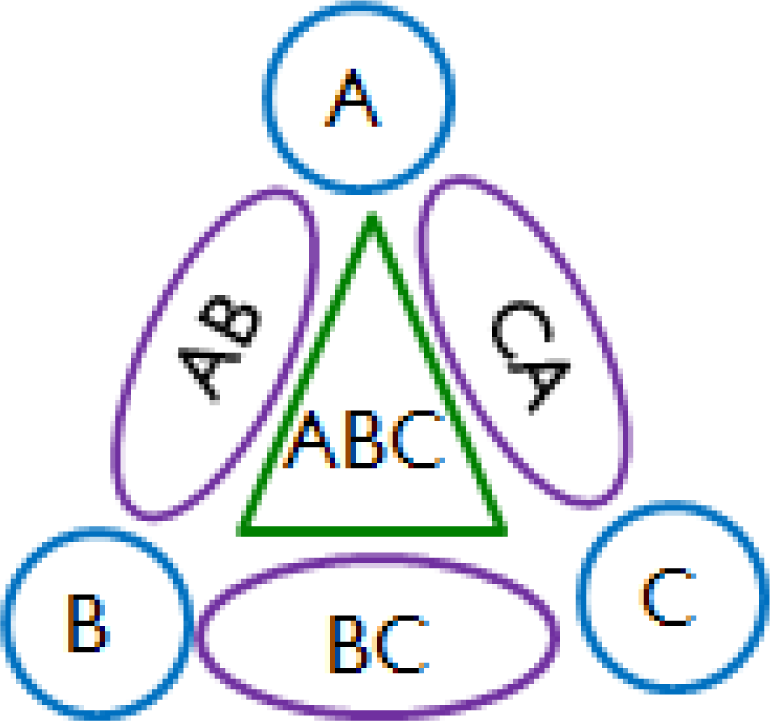
Based on the assumption of homogeneity, the normalized mixed odor dataset could be categorized according to the contained components without considering the concentration of each component. For example, the categorization results for odors of three components would be like the one shown in Figure 1. The response pattern of the examined odor would then be classified to one of the predefined classes by using a classification method. However, the sensors may not provide enough useful information sufficient enough to classify an odor. A method of dimensionality reduction, such as PCA and LDA, can then be applied to select the significant features to achieve a better result of data partition. However, both PCA and LDA require solving a complex matrix eigenvalue problem in order to find the projection directions. In this paper, a simple local weighting scheme is proposed to properly weight each feature for a class.
2.1. Locally Weighted Nearest Neighbor (LWNN)
Assume that there are N predefined classes. In the nearest neighbor classification method, which is actually a KNN method with K = 1, a predefined class Classi is represented by its centroid o⃑i, where 1 ≤ i ≤ N and m is the number of sensors. Here, we define the class centroid as the mean point of class:
Note that Equation (4) indicates that is the points belonging to the same class exhibit a string correlation in jth feature, a large weight would be assigned to this feature for the class. Aside from these observations, the optimal weighting vectors can be computed without too much effort since the computation of each weighting term is expressed in a closed-form.
As aforementioned, the proposed Locally Weighted Nearest Neighbor algorithm (LWNN) uses the weighting scheme to re-scale the Euclidean distance between two data points when finding the nearest neighbor. Unlike the original KNN algorithm, the proposed LWNN algorithm has a training stage, which computes both the centroid and the associated independent weighting vector of each predefined class (Table 1). Then, as shown in Table 2, LWNN classifies a testing data point as the class of the centroid that has the minimum weighted distance to the examined point. Note that it is unnecessary to take any additional step to determine the best K value so as to increase the classification accuracy. In practice, as it will be shown later in Section 3, the experimental results of determining the component set demonstrates that the accuracy of the proposed LWNN classifier is comparable to that of those commonly used KNN-based methodologies.
2.2. Odor Concentration Estimation by Weighted Least-Squares Method
Although the proposed LWNN method can be used to efficiently determine the set of components present in an odor mixture, the concentration of each component is still unknown. Nevertheless, a regression method could be used to estimate the component concentration. According to the assumption of homogeneity, the sensor generated by the ith sensor to the jth odor component at a concentration cj can be formulized as:
Based on the linear additive assumption, the response of the ith sensor when exposed to an odor mixture consists of n components with concentrations c1, c2,..., cn, respectively, can be formulized as:
Note that the response of each component is weighted with a weighting term βi,j and an offset term βi,offest is introduced in Equation (6) to get a better fit for the sensor responses. According to [15], this weighting scheme on the response of each component can be seen as a reflection of the relative influence of each component on the total response.
The parameters in Equation (6) could be obtained by applying a method for linear least-squares problems. Then, the concentration of each mixture component can be estimated by solving the following least-squares formulation:
In order to get a close form expression for each of the weighting terms, the product of the weighting terms is set to one:
According to Equation (4), the weighting term of the ith sensor is defined as:
The proposed methodology that uses a weighted and constrained least-squares method (WCLS) to estimate the component concentrations of a mixed odor is presented in Table 3 and Table 4. In the training stage, a set of odor models for both pure and mixed odors are built by using the least-squares method. Moreover, a set f weighting terms are computed and then used in the testing stage to estimate the concentration of each component present in an odor mixture.
Although mixing of odors can yield linear additive trend, it is not necessarily common. The effect of mixing can often lead to (1) masking or dominance by a stronger component [16], (2) hypoadditivity (lower than the sum or average) [17,18], and (3) synergistic effects [19,20].
3. Experimental Results and Discussion
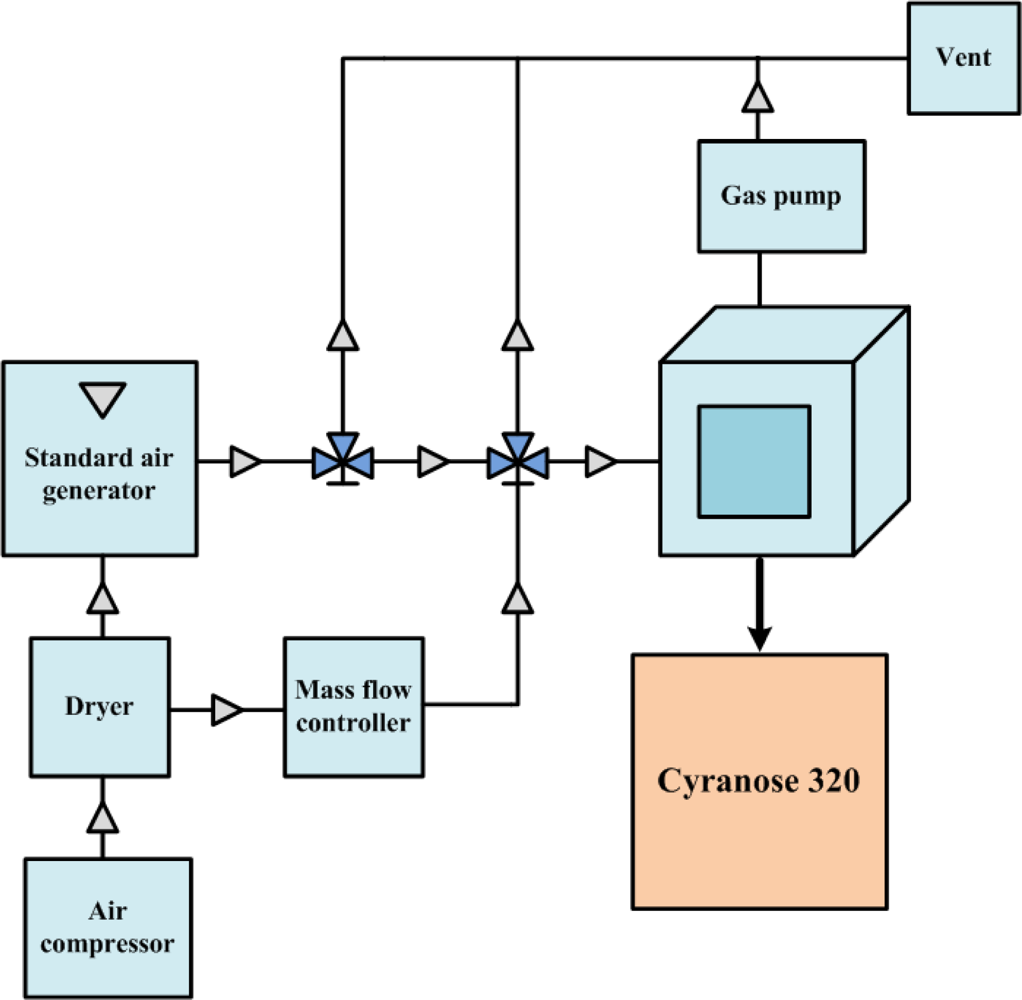
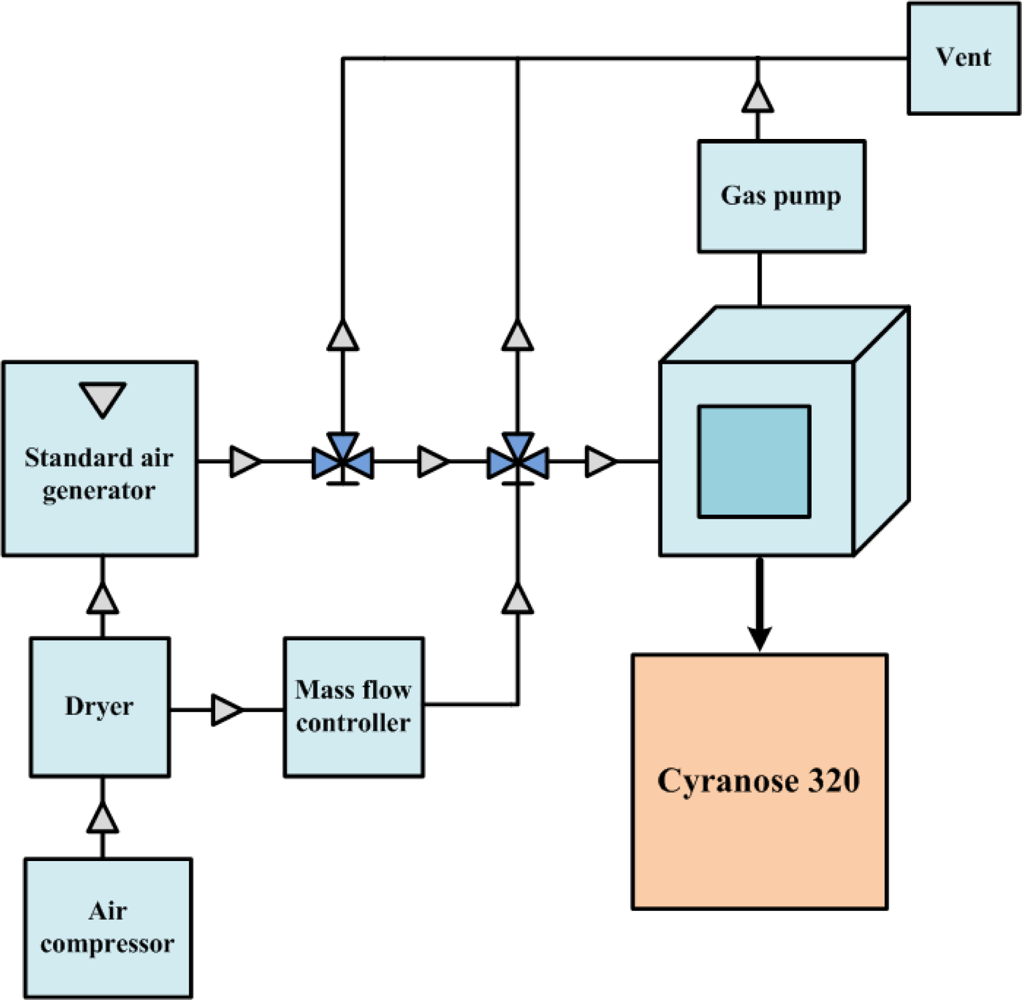
Figure 2 shows the experimental setup used to collect the volatile organic compound (VOC) for analysis. The target gas for the test was produced by a standard air generator (AID360). The solvent of the testing gas sat inside the diffusion tube of the standard air generator under room temperature. A constant heater was used to increase the temperature in the tube to cause the organic solvent to evaporate. By the time the whole system reached steady temperature and flow rate for the whole system, a testing gas with stable concentration was achieved. Diffusion rate can be theoretically controlled by the temperature setting, and air concentration can be accurately calculated by measuring the weight loss of the organic solvent. The testing gas was carried out by steady air coming from the air compressor. The gas flow rate was controlled by the mass flow controller (MFC). The testing air was then infused into the glass chamber, which connects to a commercial Cyranose 320 electronic nose, which consists of 32 carbon black composite sensors. After completing the experiment, the testing air was pumped out to a Fourier transform infrared spectrophotometer (FTIR) with built-in database for cross-validation, and dry air was again used to purge the chamber. A collection of 133 mixed odor data collected by Cyranose 320 was uploaded to a personal computer after the experiment for further analysis. Three highly volatile solvents: methanol, ethanol and acetone, were mixed with different mixing ratios by using multiple air generators and mass flow controllers. The collected data are randomly divided into two sets, called the training set and the testing set, each of which contains 67 and 66 odor data, respectively. Since there are eight different types of sensors in the Cyranose 320, eight response features are derived by averaging the responses generated by four sensors of the same type in order to get a more stable sensor response. That is to say, an odor is represented by the odor pattern formed from eight averaged sensor responses.
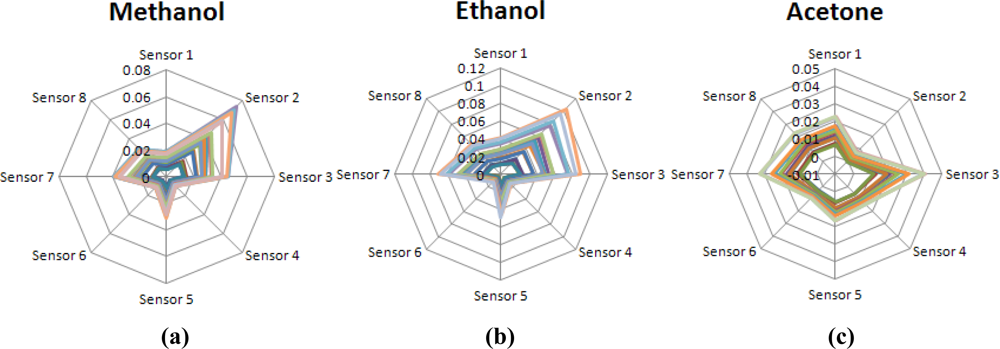
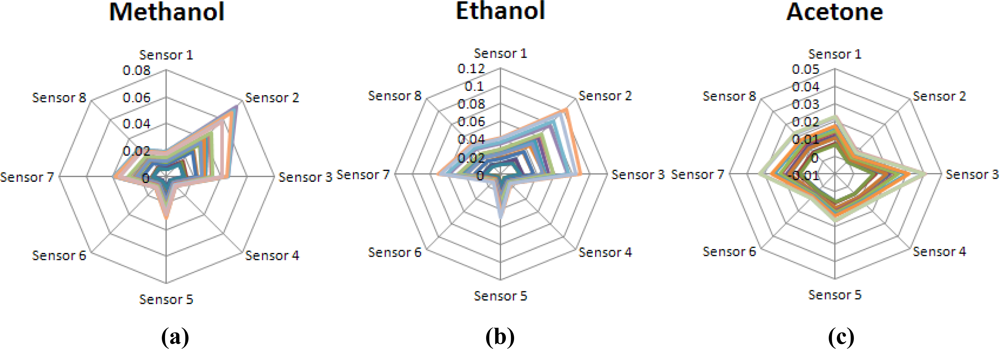
Figure 3 shows the normalized odor patterns of the examined components: methanol, ethanol and acetone, with different concentrations. As shown, the normalized odor pattern of acetone is quite different to those of the others. However, both methanol and ethanol have almost the same normalized odor pattern because these two compounds are very similar in chemical structures and intermolecular forces.
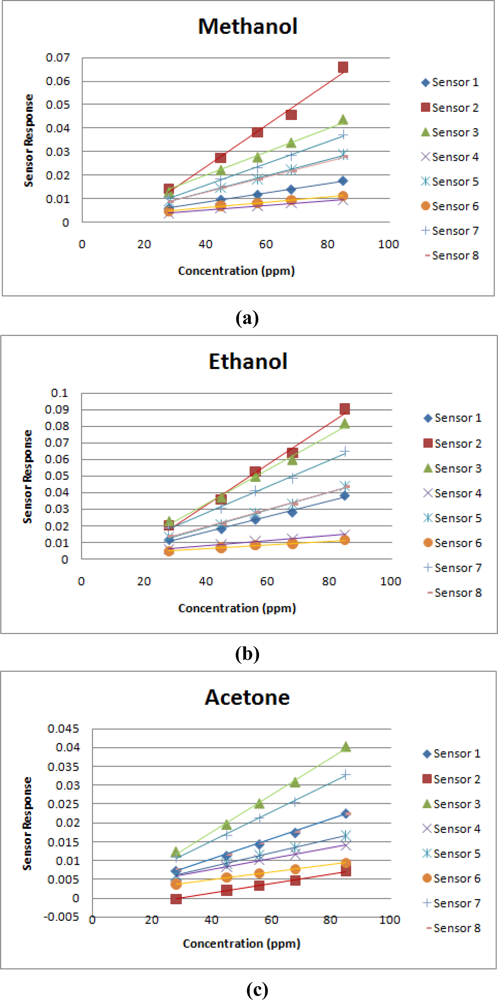
Figure 4 shows the relationship between the sensor responses and the concentrations of the examined components and the regression line. As expected, the sensor responses are proportional to the odor concentrations. Consequently, both of the proposed LWNN method (Section 2.1) and the odor model of single compound (Section 2.2) are supported by the confirmation of the homogeneity assumption.
3.1. Odor Component Determination Results
This section presents the performance of the KNN-based methodologies, which are listed below:
KNN: KNN using the default Euclidean distance metric.
PCA+KNN: KNN over the reduced space generated by Principal Component Analysis (PCA).
LDA+KNN: KNN over the reduced space generated by Linear Discrimination Analysis (LDA).
WNN: The proposed Locally Weighted Nearest Neighbor method.
For each method, except for LWNN, in which the K value is fixed to one, the value of K varies from one to five. The performances of the four KNN-based methods were evaluated by using the collected odor data. The training dataset were partitioned into seven component sets according to the components:
♦ M: methanol.
♦ E: ethanol.
♦ A: acetone.
♦ ME: mixture of methanol and ethanol.
♦ EA: mixture of ethanol and acetone.
♦ AM: mixture of acetone and methanol.
♦ MEA: mixture of methanol, ethanol and acetone.
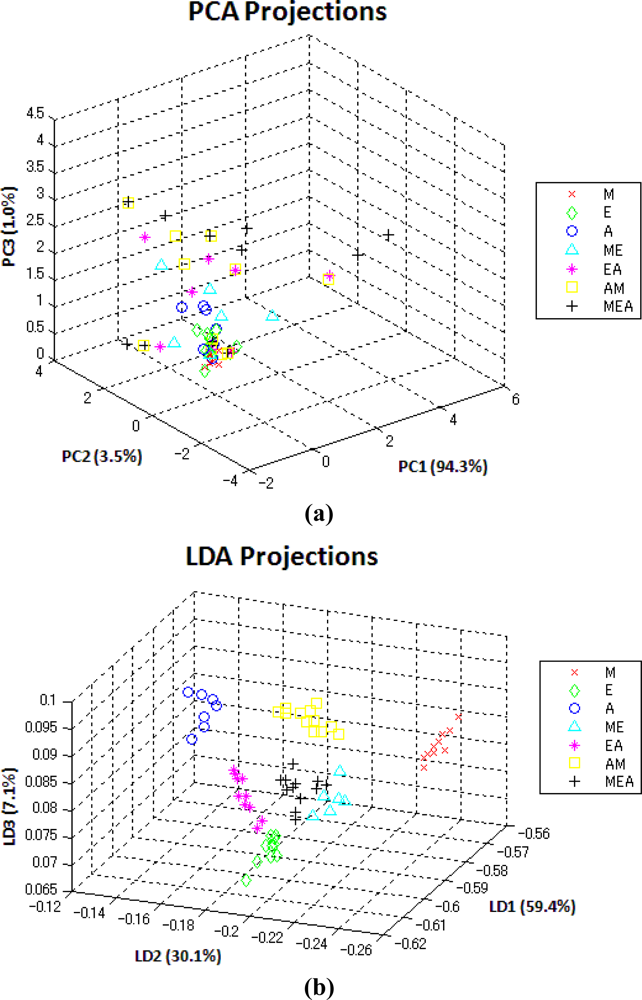
The results are summarized in Table 5. For each method, the K value that provided the best performance on the testing set is marked. As shown, the LDA + KNN strategy outperforms the other methods over the collected odor data set; while PCA has the worst performance.
The reason is that PCA seeks to separate all the data points as widely as possible. However, the local correlation structure of each component set may be distorted. As shown in Figure 5, the method of PCA widely distributes all the data points while they are mixed together. In contrast, LDA can discriminate between different classes and keep the data points of the same class as compact as possible. Note that the projections of LDA over the testing dataset in Figure 5 match up the seven partitions in Figure 1.
Although the method of KNN applied with LDA outperforms the proposed LWNN method; LWNN is the most efficient way among the examined KNN-based methods since there is no additional computation to determine the best K value. Moreover, LWNN does not require solving any costly eigenvalue problem, which is necessary for both PCA and LDA. Nevertheless, the proposed LWNN method yields an acceptable accuracy to classify and identify the component set.
3.2. Estimation Results for Mixed Odors
This section reports the performance of the proposed methodology that uses a weighted and constrained least-squares method to estimate the concentration of each component present in an odor mixture. The randomly assigned training dataset are used to build odor models:
PM: the odor model for methanol.
PE: the odor model for ethanol.
PA: the odor model for acetone.
M: the odor model for mixtures of methanol, ethanol and acetone.
Two methodologies for estimating component concentrations are tested and compared in this section:
CLS: the constrained least-squares method.
WCLS: the proposed weighted and constrained least-squares method.
The metric of Root Mean Squared Error (RMSE) is adopted to evaluate the error between the estimated component concentration (cE1, cE2, ... cEn) and the real component concentrations (cR1, cR2, ... cRn), i.e.,
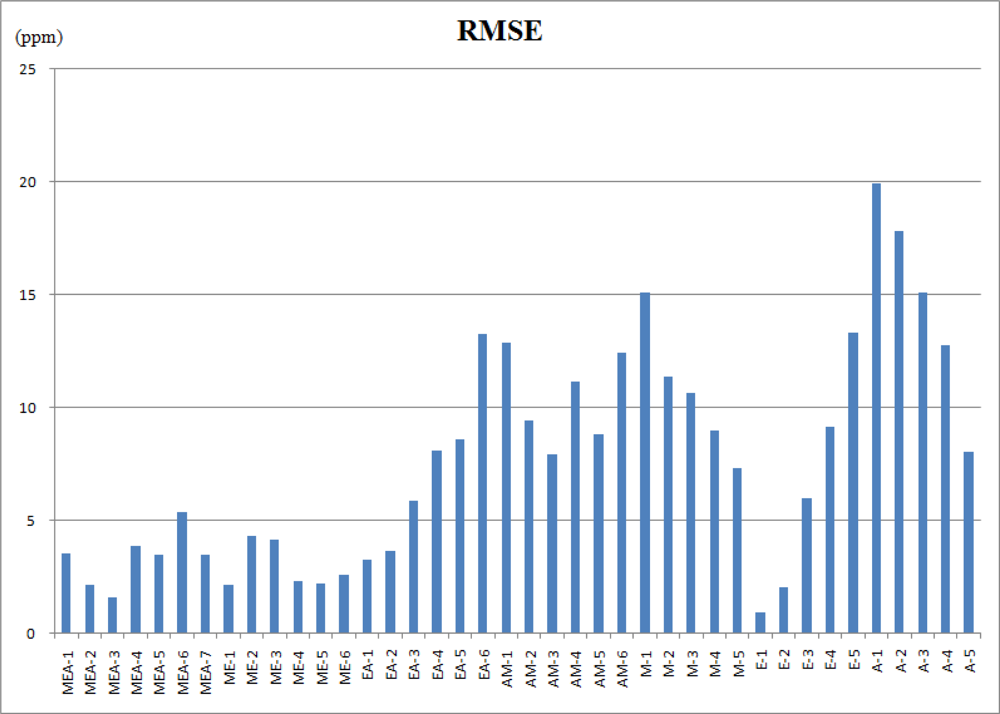
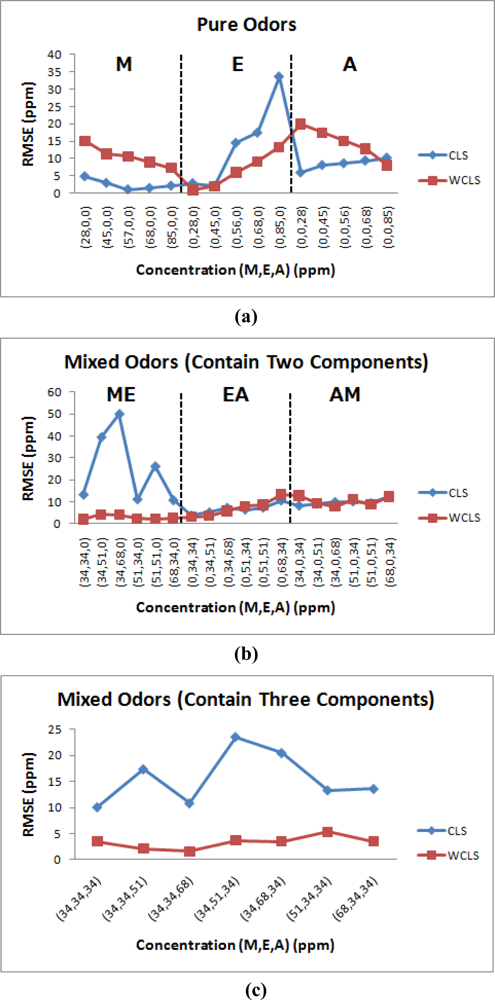
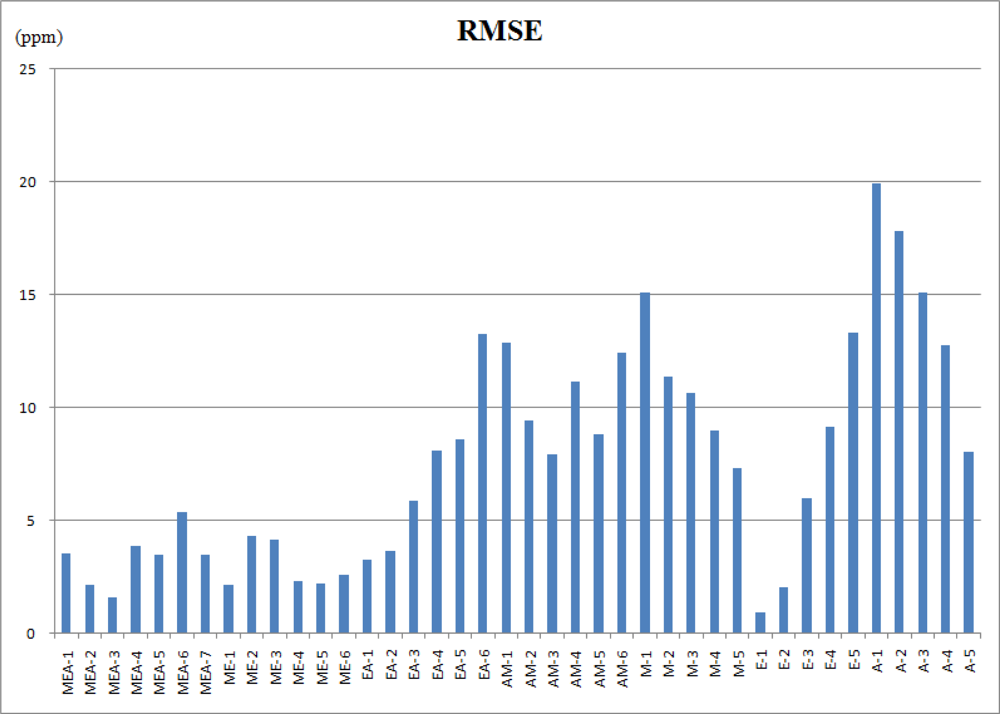
Figure 6 shows the estimated errors of the regular constrained least-squares method (CLS) and the proposed weighted and constrained least-squares method (WCLS) over the testing odor dataset. The error presented is the averaged error for each concentration combination. As shown, the proposed WCLS methodology generally produces much better estimates compared to the other method: the error curves of WCLS are almost always lower than those of CLS especially for mixed odors. As presented in Table 6, the maximum error for estimate of mixtures containing all the three components is no more than 6 ppm. However, when the number of components decreases, the estimate result becomes worse (Table 7 and Table 8). Figure 7 shows the root mean squared error (RMSE) of all the estimated results in tables 6–8. The reason is attributed to the proposed weighting scheme which assigns a larger weight to the responses of sensors 1, 3 and 8, where the responses of methanol and acetone are similar to those of ethanol. Consequently, for the component set of A, the proposed WCLS methodology could not differentiate between ethanol and acetone when the concentration of acetone is low. Moreover, since the patterns of both ethanol and methanol are quite similar as we have seen in Figure 3, the proposed methodology would be confused. Therefore, for the four component sets: M, E, EA and AM the estimate would report a high concentration of methanol accompanied with a low concentration of ethanol, and vice versa. Nevertheless, when both methanol and ethanol are present in the examined odor, the proposed WCLS could provide a good concentration estimate.
4. Conclusion
This study aimed to determine the mixture components and estimate the concentration of each of the contained component, assuming homogeneity and linear additive. A KNN-based method, LWNN, is proposed to determine the components present in a mixed odor by classifying its sensor responses to the closest previously partitioned component sets. Furthermore, a local weighting scheme, which associates each component set with an independent weighting vector, is proposed to re-scale the distance between a testing data point and the centroid of a component set. For each component set, a higher weight is assigned to the sensor response when the sensor yields a very consistent response to that class.
To further estimate the component concentrations, odor models have been built by regressions. Based on these odor models, a weighted and constrained least-squares problem is solved to estimate the concentration of each of the component present in the examined mixture. A weighting scheme is adopted to reflect the reliability of each estimated sensor response. If the estimated response value of a sensor is close to the observed response, a large weight would be assigned to the squared error between the estimated and observed sensor response.
To evaluate the effectiveness of the proposed methods, a set of odor data has been collected by mixing three highly volatile solvents with different mixing ratios. LDA has been noted for its ability to discriminate between different component sets regardless of its high computational cost. Furthermore, the proposed LWNN method is shown to be comparable to the commonly applied KNN-based methodology but with lower computational cost since there is no additional computation to determine the best K value for better classification performance. However, LWNN is not suitable for estimation of component concentrations and becomes complex when the number of component increases. The proposed methodology that uses a weighted and constrained least-squares method (WCLS) also demonstrates to provide a good estimate for component concentrations especially for odor mixtures, yet WCLS may provide erroneous concentration estimates for pure odors.
Acknowledgments
The authors would like to acknowledge the support of the National Science Council of Taiwan, under Contract No. NSC 97-2220-E-007-036 and NSC 98-2220-E-007-017. We also acknowledge the support of the Chung-Shan Institute of Science and Technology, under Contract No. CSIST-808-V207. The authors would like to thank National Chip Implementation Center (CIC) for technical support.
References and Notes:
- Buck, LB. Unraveling the sense of smell. In the Nobel Lecture, Sal Adam, Berzeliuslaboratoriet, Karolinska Institutet, Stockholm, Sweden, 8 December 2004..
- Buck, LB. Olfactory receptors and odor coding in mammals. Nutr. Rev 2008, 62, S184–S188. [Google Scholar]
- Muñoz, BC; Steinthal, G; Sunshine, S. Conductive polymer-carbon black composites-based sensor arrays for use in an electronic nose. Sens. Rev 1999, 19, 300–305. [Google Scholar]
- James, D; Scott, SM; Ali, Z; O’Hare, WT. Chemical sensors for electronic nose systems. Microchim. Acta 2005, 149, 1–17. [Google Scholar]
- Lonergan, MC; Severin, EJ; Doleman, BJ; Beaber, SA; Grubbs, RH; Lewis, NS. Array-based vapor sensing using chemically sensitive, carbon black-polymer resistors. Chem. Mater 1996, 8, 2298–2312. [Google Scholar]
- Jurs, PC; Bakken, GA; McClelland, HE. Computational methods for the analysis of chemical sensor array data from volatile analytes. Chem. Rev 2000, 100, 2649–2678. [Google Scholar]
- Wettschereck, D; Dietterich, T. Locally adaptive nearest neighbor algorithms. In Advances in Neural Information Processing Systems 6 (NIPS 1993); Cowan, JD, Tesauro, G, Alspector, J, Eds.; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1994; pp. 184–191. [Google Scholar]
- Hastie, T; Tibshirani, R. Discriminant adaptive nearest neighbor classification. IEEE Trans. Patt. Anal. Mach. Int 1996, 18, 607–616. [Google Scholar]
- Bicego, M; Tessari, G; Tecchiolli, G; Bettinelli, M. A comparative analysis of basic pattern recognition techniques for the development of small size electronic nose. Sens. Actuat.—B: Chem 2002, 85, 137–144. [Google Scholar]
- Gmez, AH; Hu, G; Wang, J; Pereira, AG. Evaluation of tomato maturity by electronic nose. Comput. Electron. Agric 2006, 54, 44–52. [Google Scholar]
- Yu, H; Wang, J; Zhang, H; Yu, Y; Yao, C. Identification of green tea grade using different feature of response signal from e-nose sensors. Sens. Actuat.—B: Chem 2008, 128, 455–461. [Google Scholar]
- Martínez, AM; Kak, AC. PCA versus LDA. IEEE Trans. Patt. Anal. Mach. Int 2001, 23, 228–233. [Google Scholar]
- Shevade, AV; Zhou, H; Homer, ML; Ryan, MA. Nonlinear least-squares based method for identifying and quantifying single and mixed contaminants in air with an electronic nose. Sensors 2006, 6, 1–18. [Google Scholar]
- Ryan, MA; Zhou, H; Buehler, MG; Manatt, KS; Mowrey, VS; Jackson, SP; Kisor, AK; Shevade, AV; Homer, ML. Monitoring space shuttle air quality using the jet propulsion laboratory electronic nose. IEEE Sens. J 2004, 4, 337–347. [Google Scholar]
- Carmel, L; Sever, N; Harel, D. On predicting responses to mixtures in quartz microbalance sensors. Sens. Actuat.—B: Chem 2005, 106, 128–135. [Google Scholar]
- Kim, K-H. Experimental demonstration of masking phenomenon between competing odorants via an air dilution sensory test. Sensors 2010, 10, 7287–7302. [Google Scholar]
- Laing, DG; Panhuber, H; Slotnick, BM. Odor masking in the rat. Physiol. Behav 1989, 45, 689–694. [Google Scholar]
- Comett-Muniz, JE; Cain, WS; Abraham, M. H. Dose-addition of individual odorants in the odor detection of binary mixtures. Behav. Brain Res 2003, 138, 95–105. [Google Scholar]
- Laska, M; Hudson, R. A comparison of the detection thresholds of odour mixtures and their components. Chem. Senses 1991, 16, 651–662. [Google Scholar]
- Miyazawa, T; Gallagher, M; Preti, G; Wise, PM. Synergistic mixture interactions in detection of perithreshold odors by humans. Chem. Senses 2008, 33, 363–369. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: the training dataset. |
| Procedure: |
| (1) Start with a set of predefined classes, Class1, Class2,…, ClassN. For each class, Classi, |
| (2) Compute its centroid and its associated weighting vector by Equation (1) and (4). |
| Input: the testing dataset. |
| Procedure: |
| For each data point x⃗, |
| (1) Compute the weighted distances between x⃗ and each of the class centroid by Equation (2). |
| (2) Classify x⃗ as the class whose centroid has the minimum weighted distance to x⃗. |
| Input: the training odor dataset. |
| Procedure: |
| For each pure odor, |
| (1) Build the pure odor model according to Equation (5). |
| (2) Build the mixed odor model according to Equation (6). |
| Compare each of the weighting terms by Equation (9). |
| Input: the testing odor dataset. |
| Procedure: |
| For each testing odor data, |
| (1) Estimate the component concentration by solving a weighted least-squares problem as Equation (8). |
| Accuracy (%) | K = 1 | K = 2 | K = 3 | K = 4 | K = 5 |
|---|---|---|---|---|---|
| KNN | 93.94 | 93.94 | *95.45 | 93.94 | 93.94 |
| LDA + KNN | 96.97 | *100.00 | 98.48 | 98.48 | 96.97 |
| PCA + KNN | *48.48 | 39.39 | 39.39 | 40.91 | 25.76 |
| LWNN | *95.45 | — | — | — | — |
| Real Concentrations | Estimated | ||||||
|---|---|---|---|---|---|---|---|
| Component Set | M (ppm) | E (ppm) | A (ppm) | M (ppm) | E (ppm) | A (ppm) | RMSE (ppm) |
| MEA-1 | 34 | 34 | 34 | 33.32 | 30.12 | 38.61 | 3.50 |
| MEA-2 | 34 | 34 | 51 | 37.29 | 33.34 | 49.54 | 2.11 |
| MEA-3 | 34 | 34 | 68 | 34.69 | 31.50 | 68.82 | 1.57 |
| MEA-4 | 34 | 51 | 34 | 38.85 | 49.33 | 29.74 | 3.85 |
| MEA-5 | 34 | 68 | 34 | 35.82 | 64.28 | 38.30 | 3.45 |
| MEA-6 | 51 | 34 | 34 | 56.11 | 36.80 | 26.81 | 5.34 |
| MEA-7 | 68 | 34 | 34 | 66.88 | 29.93 | 38.24 | 3.45 |
| Real Concentrations | Estimated | ||||||
|---|---|---|---|---|---|---|---|
| Component Set | M (ppm) | E (ppm) | A (ppm) | M (ppm) | E (ppm) | A (ppm) | RMSE (ppm) |
| ME-1 | 34 | 34 | 0 | 31.70 | 31.19 | 0.46 | 2.11 |
| ME-2 | 34 | 51 | 0 | 37.79 | 45.23 | 2.84 | 4.31 |
| ME-3 | 34 | 68 | 0 | 39.66 | 64.52 | 2.67 | 4.13 |
| ME-4 | 51 | 34 | 0 | 47.44 | 32.20 | 0.00 | 2.30 |
| ME-5 | 51 | 51 | 0 | 52.46 | 47.45 | 0.00 | 2.22 |
| ME-6 | 68 | 34 | 0 | 64.05 | 31.94 | 0.00 | 2.57 |
| EA-1 | 0 | 34 | 34 | 0.48 | 32.50 | 28.64 | 3.23 |
| EA-2 | 0 | 34 | 51 | 2.82 | 28.63 | 49.35 | 3.63 |
| EA-3 | 0 | 34 | 68 | 2.93 | 24.32 | 68.49 | 5.85 |
| EA-4 | 0 | 51 | 34 | 5.77 | 39.01 | 38.21 | 8.06 |
| EA-5 | 0 | 51 | 51 | 5.39 | 37.60 | 54.68 | 8.61 |
| EA-6 | 0 | 68 | 34 | 9.61 | 48.33 | 40.86 | 13.25 |
| AM-1 | 34 | 0 | 34 | 19.27 | 13.62 | 24.29 | 12.87 |
| AM-2 | 34 | 0 | 51 | 20.29 | 7.45 | 46.22 | 9.42 |
| AM-3 | 34 | 0 | 68 | 20.92 | 2.77 | 65.17 | 7.89 |
| AM-4 | 51 | 0 | 34 | 33.37 | 7.59 | 32.14 | 11.13 |
| AM-5 | 51 | 0 | 51 | 36.08 | 3.06 | 51.03 | 8.79 |
| AM-6 | 68 | 0 | 34 | 51.07 | 1.96 | 47.15 | 12.43 |
| Real Concentrations | Estimated | ||||||
|---|---|---|---|---|---|---|---|
| Component Set | M (ppm) | E (ppm) | A (ppm) | M (ppm) | E (ppm) | A (ppm) | RMSE (ppm) |
| M-1 | 28 | 0 | 0 | 7.55 | 16.20 | 0.00 | 15.06 |
| M-2 | 45 | 0 | 0 | 28.94 | 11.38 | 0.00 | 11.36 |
| M-3 | 57 | 0 | 0 | 40.94 | 9.07 | 0.00 | 10.65 |
| M-4 | 68 | 0 | 0 | 53.96 | 6.57 | 0.00 | 8.95 |
| M-5 | 85 | 0 | 0 | 73.01 | 3.92 | 0.00 | 7.28 |
| E-1 | 0 | 28 | 0 | 0.02 | 29.57 | 0.00 | 0.91 |
| E-2 | 0 | 45 | 0 | 1.32 | 41.71 | 0.00 | 2.05 |
| E-3 | 0 | 56 | 0 | 6.52 | 48.33 | 2.49 | 5.99 |
| E-4 | 0 | 68 | 0 | 8.00 | 54.99 | 4.30 | 9.16 |
| E-5 | 0 | 85 | 0 | 6.12 | 68.56 | 15.00 | 13.33 |
| A-1 | 0 | 0 | 28 | 0.00 | 20.17 | 0.00 | 19.92 |
| A-2 | 0 | 0 | 45 | 0.00 | 15.19 | 18.17 | 17.80 |
| A-3 | 0 | 0 | 56 | 0.00 | 11.64 | 32.61 | 15.08 |
| A-4 | 0 | 0 | 68 | 0.00 | 7.54 | 47.22 | 12.76 |
| A-5 | 0 | 0 | 85 | 0.00 | 0.97 | 71.11 | 8.04 |
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/.)
Share and Cite
Tang, K.-T.; Lin, Y.-S.; Shyu, J.-M. A Local Weighted Nearest Neighbor Algorithm and a Weighted and Constrained Least-Squared Method for Mixed Odor Analysis by Electronic Nose Systems. Sensors 2010, 10, 10467-10483. https://doi.org/10.3390/s101110467
Tang K-T, Lin Y-S, Shyu J-M. A Local Weighted Nearest Neighbor Algorithm and a Weighted and Constrained Least-Squared Method for Mixed Odor Analysis by Electronic Nose Systems. Sensors. 2010; 10(11):10467-10483. https://doi.org/10.3390/s101110467
Chicago/Turabian StyleTang, Kea-Tiong, Yi-Shan Lin, and Jyuo-Min Shyu. 2010. "A Local Weighted Nearest Neighbor Algorithm and a Weighted and Constrained Least-Squared Method for Mixed Odor Analysis by Electronic Nose Systems" Sensors 10, no. 11: 10467-10483. https://doi.org/10.3390/s101110467
APA StyleTang, K.-T., Lin, Y.-S., & Shyu, J.-M. (2010). A Local Weighted Nearest Neighbor Algorithm and a Weighted and Constrained Least-Squared Method for Mixed Odor Analysis by Electronic Nose Systems. Sensors, 10(11), 10467-10483. https://doi.org/10.3390/s101110467