
Investigating the Performance of Oxford Nanopore Long-Read Sequencing with Respect to Illumina Microarrays and Short-Read Sequencing

 , , , , ,
, , , , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
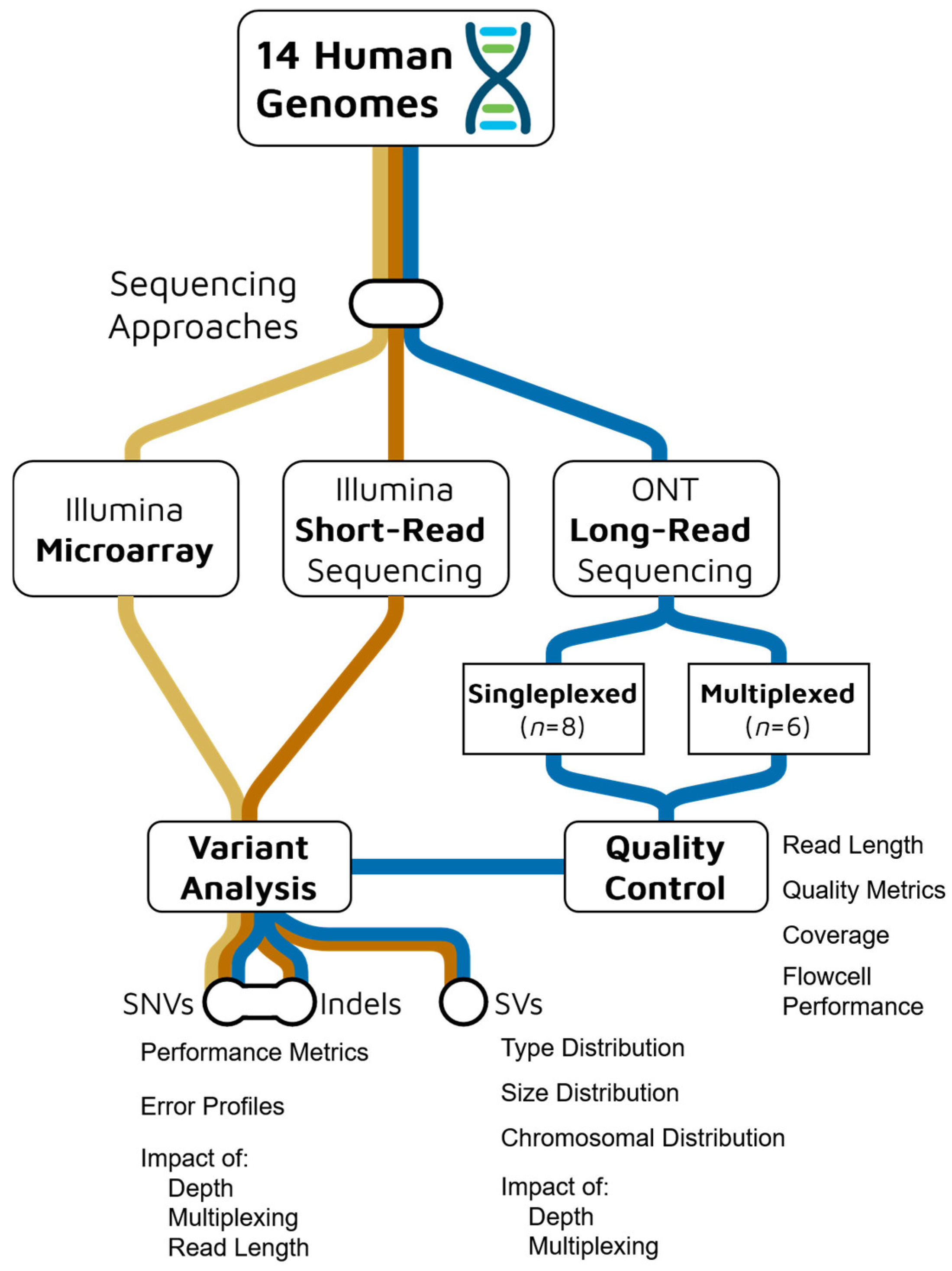
2. Results
2.1. Sequencing Quality Control
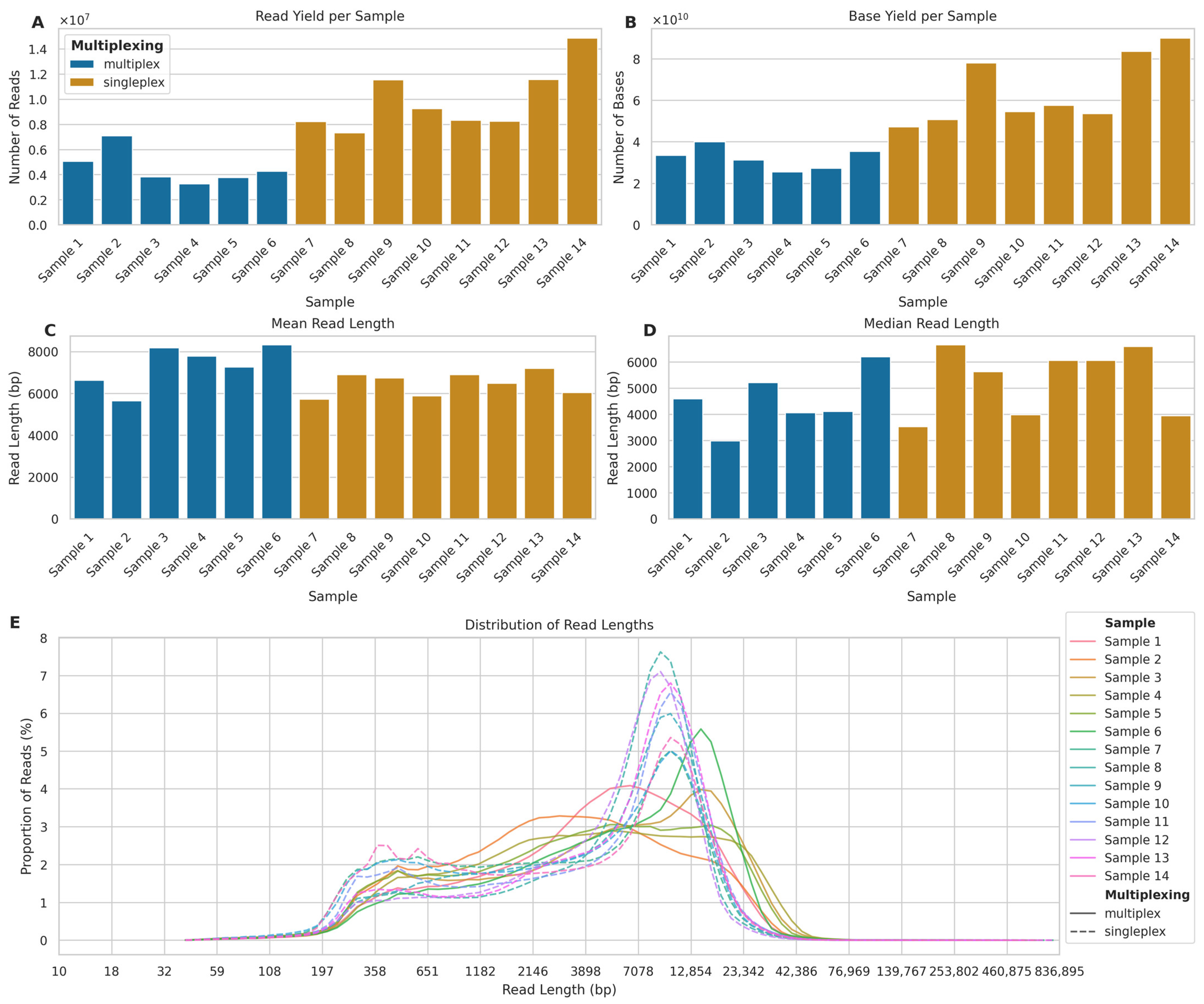
2.1.1. Sequencing Yields
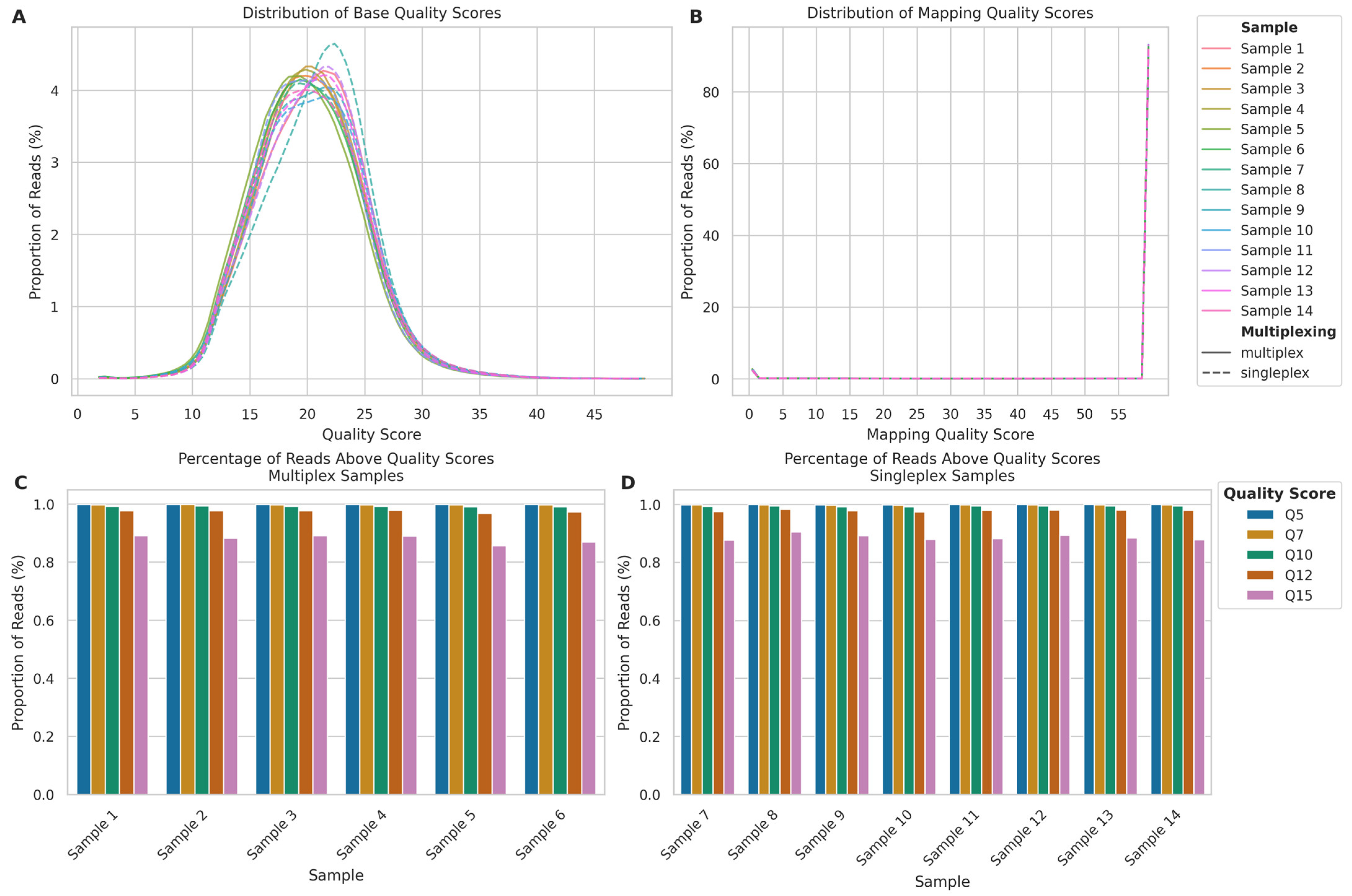
2.1.2. Read and Alignment Quality
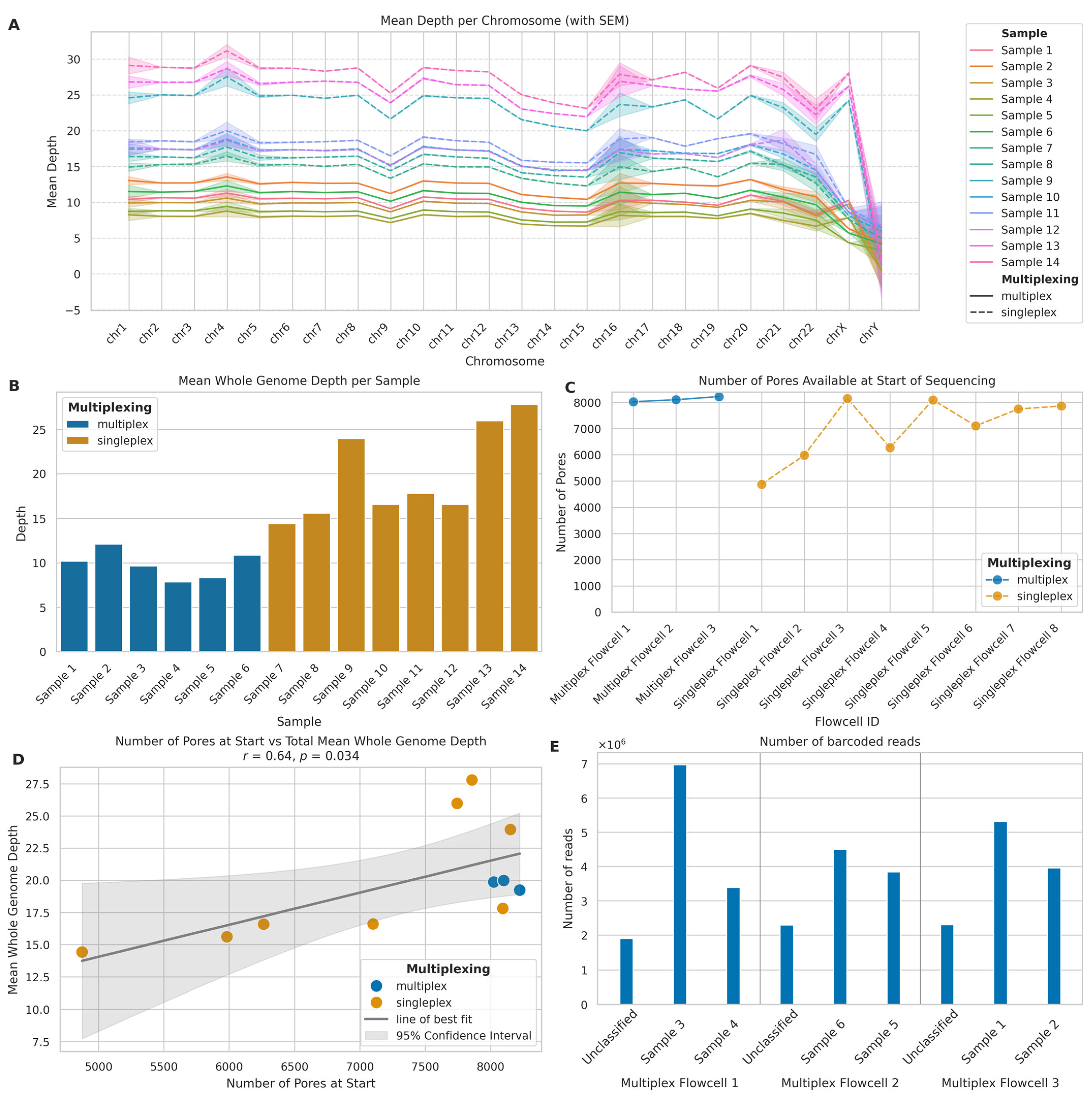
2.1.3. Depth of Coverage
2.1.4. Flowcell and Barcoding Quality
2.2. Single Nucleotide Variants Benchmark
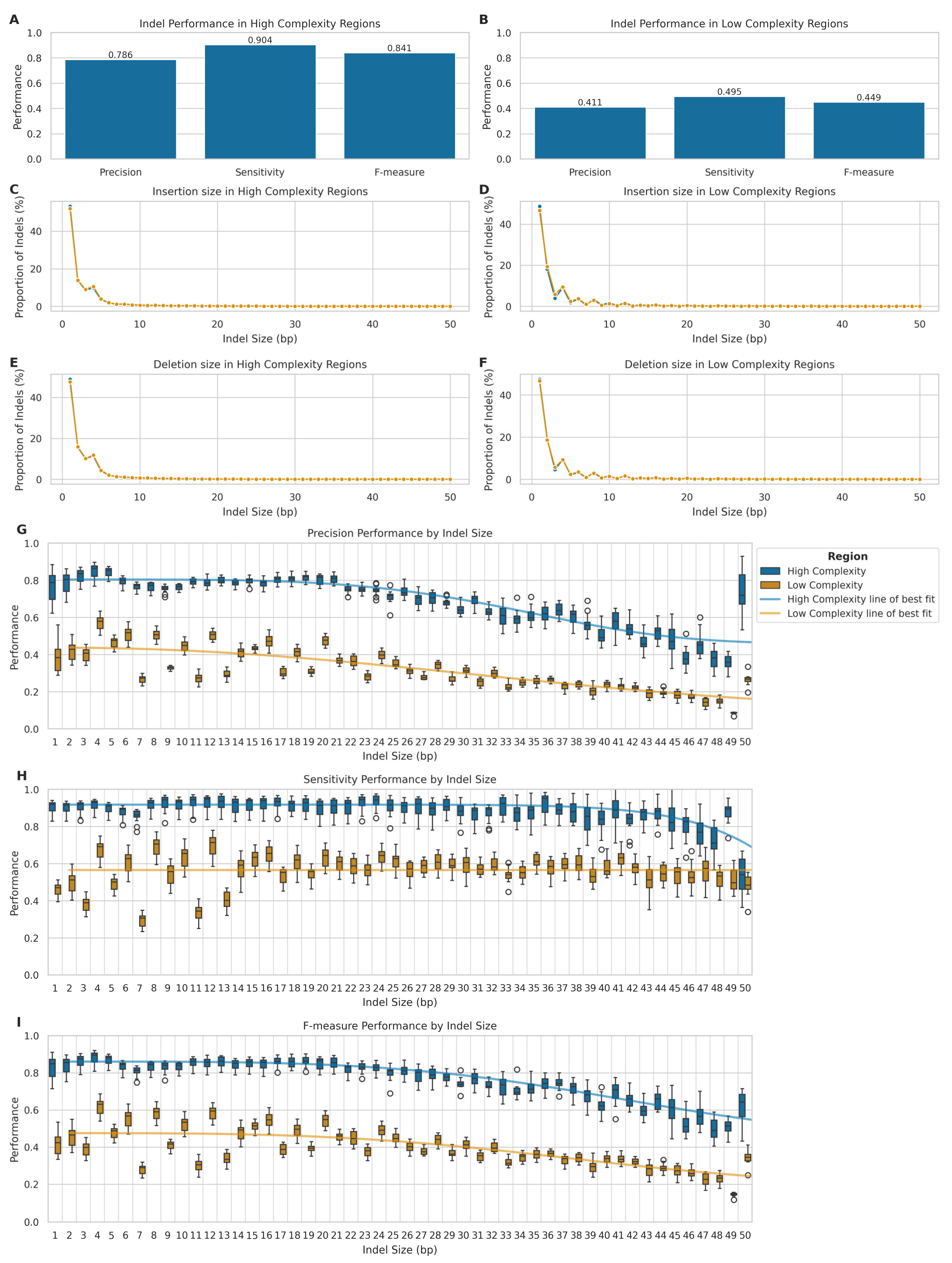
2.3. Indels Benchmark
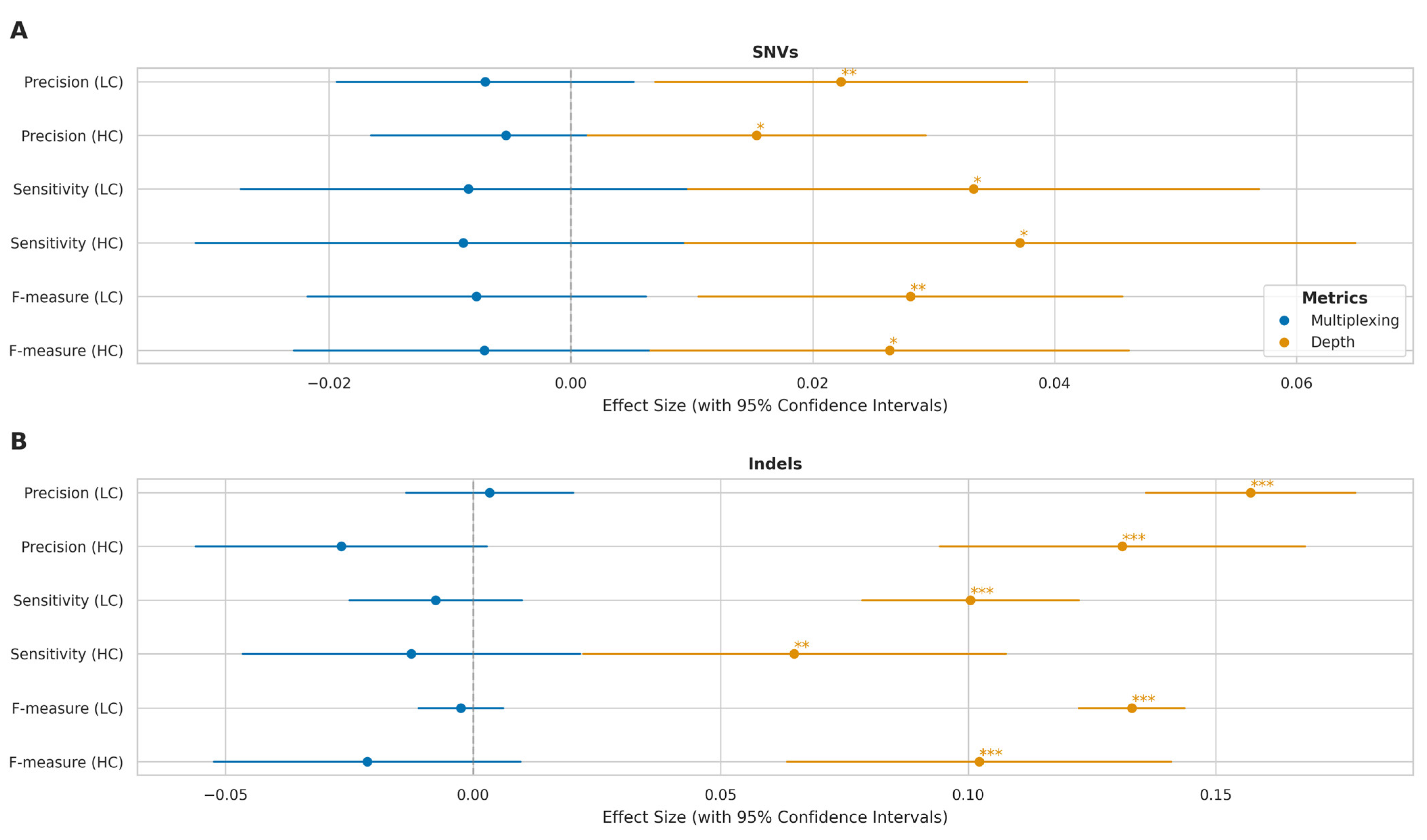
2.4. Impact of Multiplexing on Variant Calling
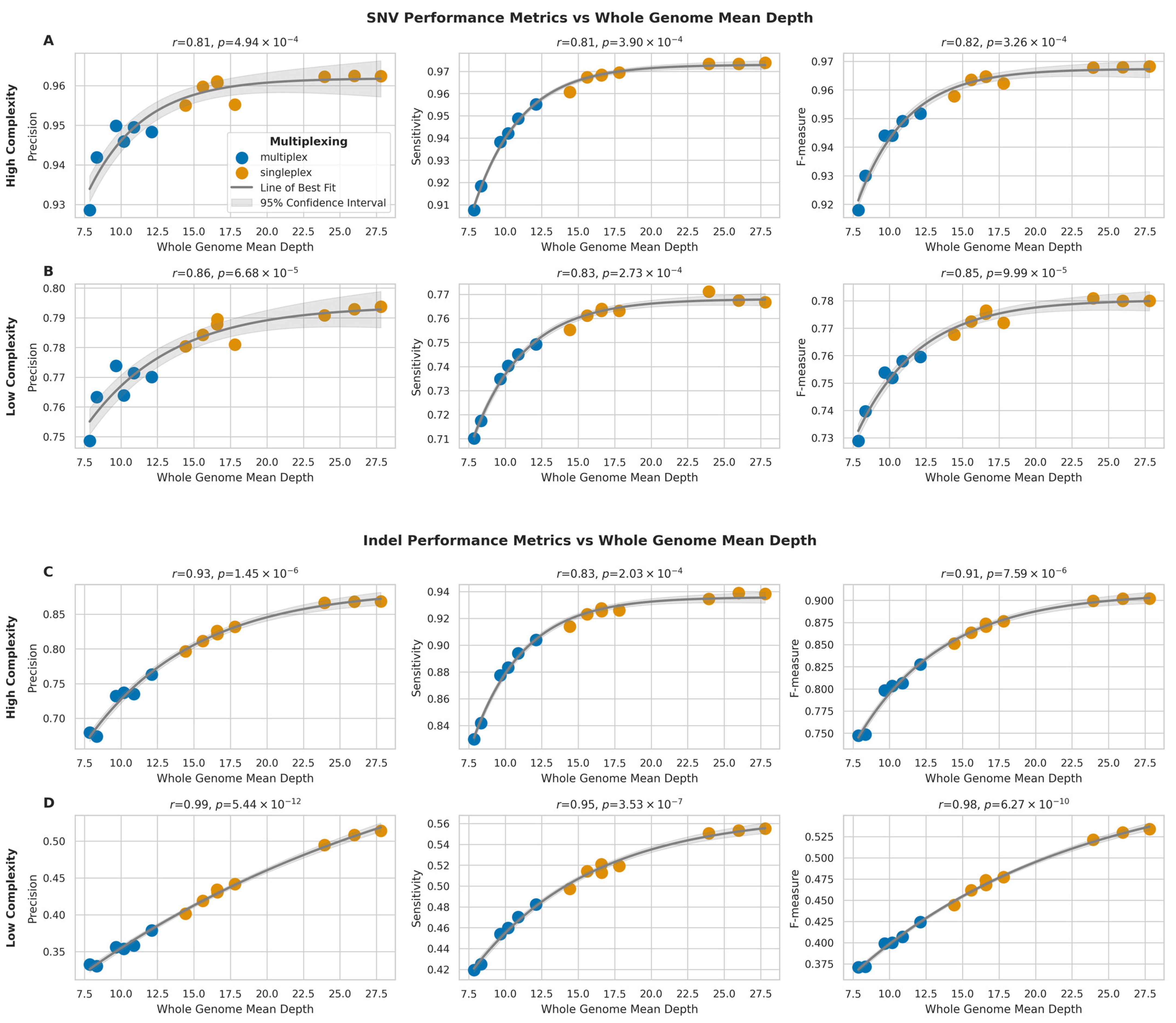
2.5. Impact of Sequencing Depth on Variant Calling
2.6. Impact of Read Length on Variant Calling
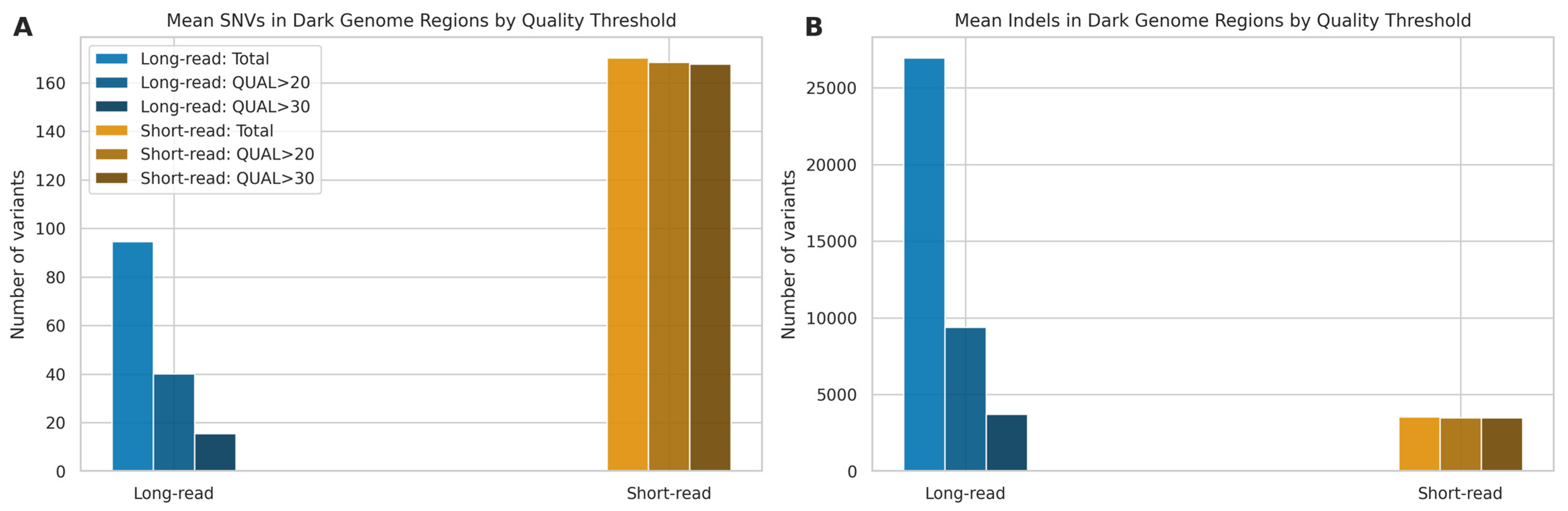
2.7. Dark Genome Analysis
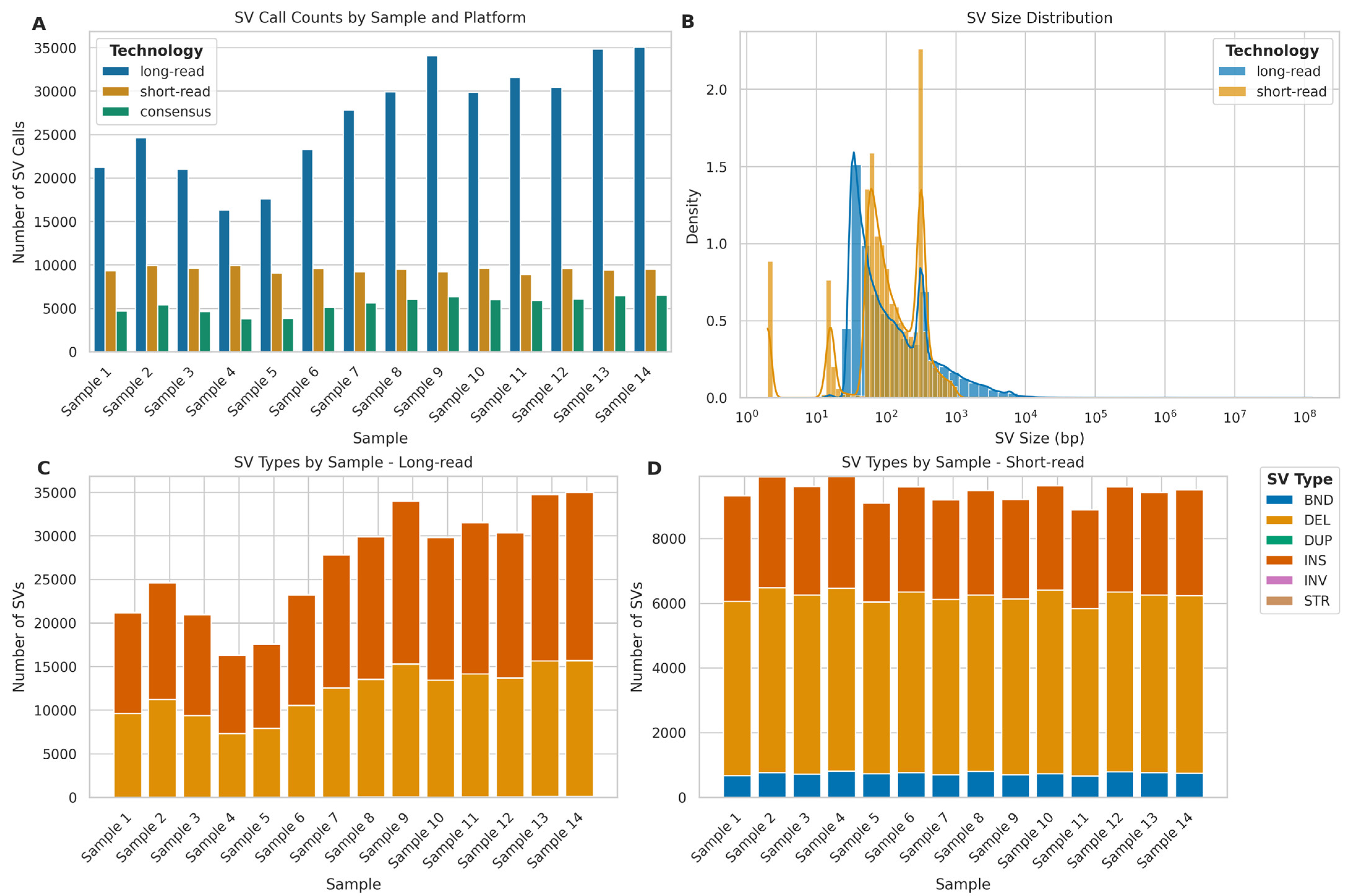
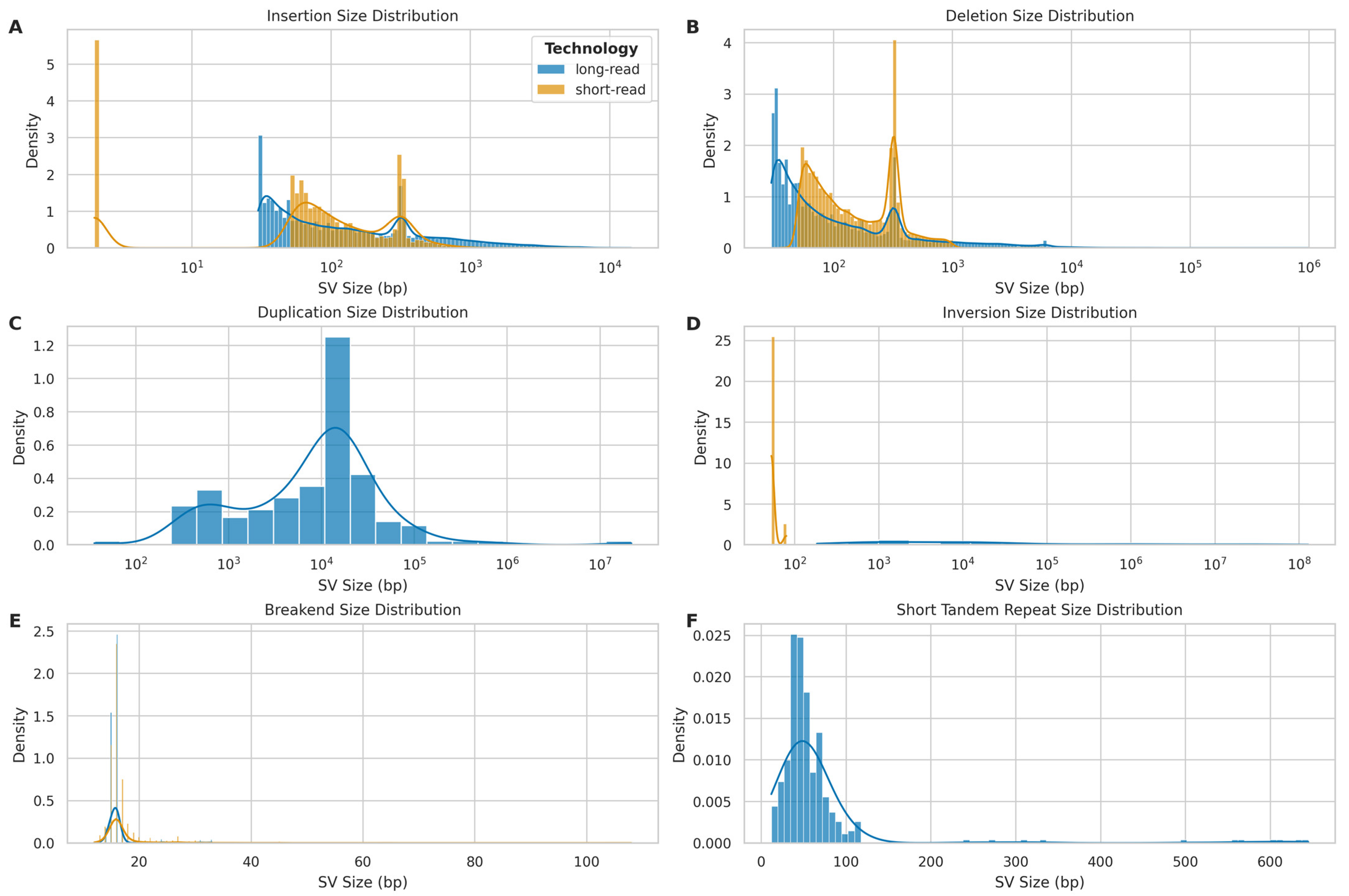
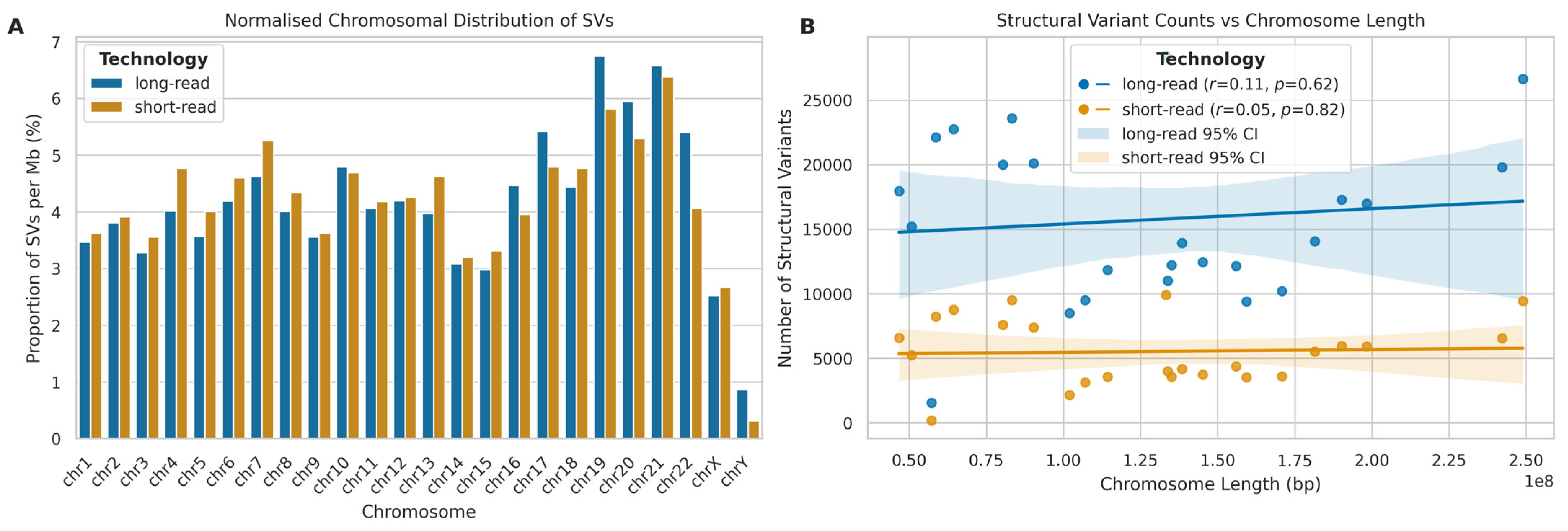
2.8. Structural Variant Calling Evaluation
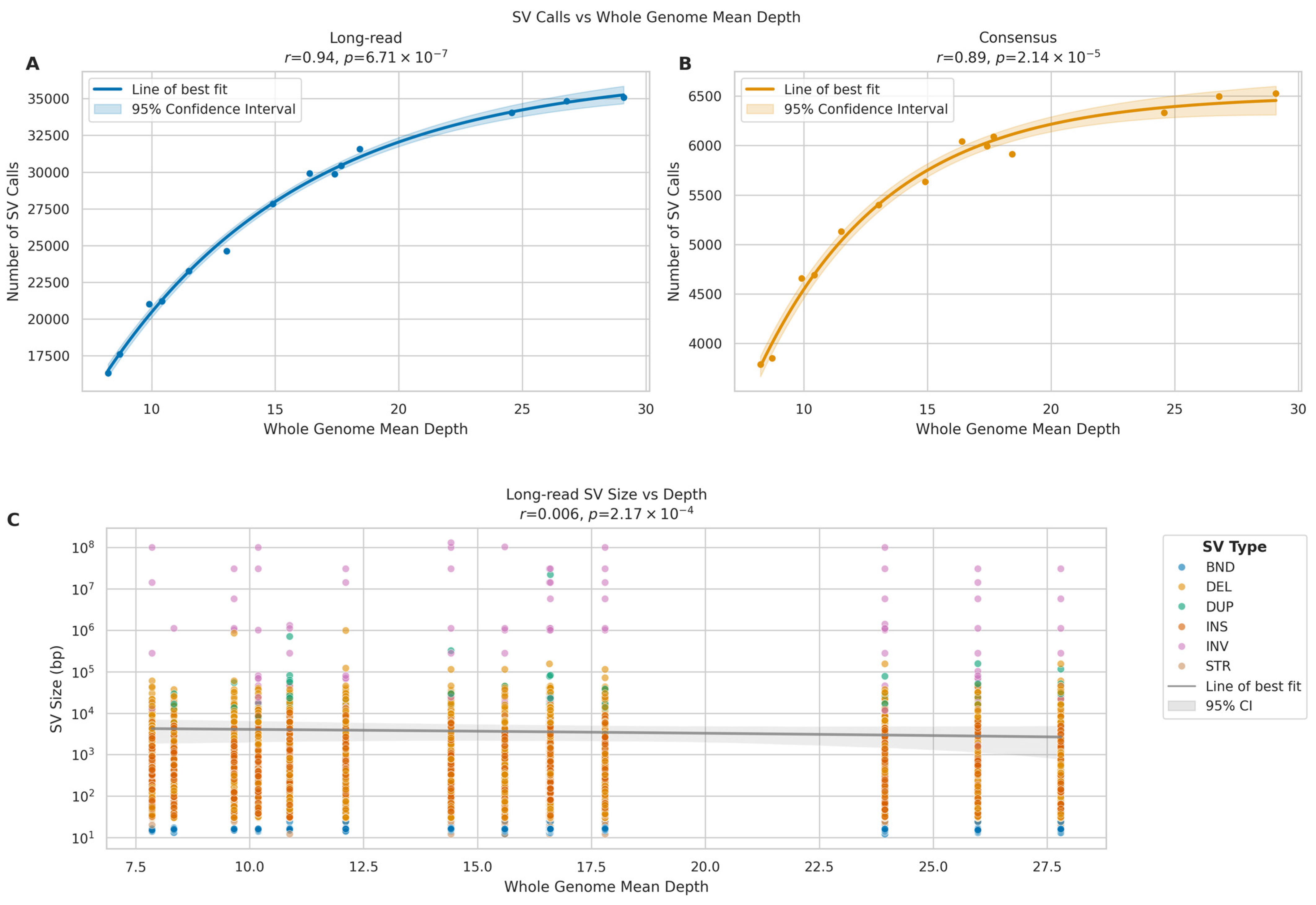
2.9. Impact of Sequencing Depth on Calling Structural Variants
3. Discussion
3.1. Sequencing Quality and Yields
3.2. Single Nucleotide Variants Detection
3.3. Indel Detection
3.4. Dark Genome Variant Calling Performance
3.5. Impact of Experimental Factors on Variant Calling
3.6. Structural Variants Detection
3.7. Limitations and Future Directions
4. Materials and Methods
4.1. Sample Selection and Preparation
4.2. Microarray Genotyping
4.3. Illumina Short-Read Sequencing
4.4. Oxford Nanopore Long-Read Sequencing
4.5. Variant Comparison and Benchmarking
4.5.1. Single Nucleotide Variants and Indels
4.5.2. Dark Genome Variants
4.5.3. Structural Variants
4.6. Statistical Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ONT | Oxford Nanopore Technologies |
| LRS | Long-read sequencing |
| SNV | Single nucleotide variant |
| DNA | Deoxyribonucleic acid |
| SNP | Single nucleotide polymorphism (syn. SNV) |
| GWAS | Genome-wide association study |
| TE | Transposable element |
| STR | Short tandem repeat |
| GIAB | Genome in a Bottle |
| SV | Structural variant |
| SD | Standard deviation |
| CV | Coefficient of variation |
| RTG | Real Time Genomics |
| VCF | Variant call format |
| KS | Kolmogorov–Smirnov test |
| ANCOVA | Analysis of covariance |
| HC | High complexity |
| LC | Low complexity |
| ALS | Amyotrophic lateral sclerosis |
| GATK | Genome Analysis Toolkit |
| PCR | Polymerase chain reaction |
| BAM | Binary Alignment Map |
References
- Lander, E.S.; Linton, L.M.; Birren, B.; Nusbaum, C.; Zody, M.C.; Baldwin, J.; Devon, K.; Dewar, K.; Doyle, M.; FitzHugh, W.; et al. Initial sequencing and analysis of the human genome. Nature 2001, 409, 860–921. [Google Scholar] [PubMed]
- Venter, J.C.; Adams, M.D.; Myers, E.W.; Li, P.W.; Mural, R.J.; Sutton, G.G.; Smith, H.O.; Yandell, M.; Evans, C.A.; Holt, R.A.; et al. The sequence of the human genome. Science 2001, 291, 1304–1351. [Google Scholar] [CrossRef] [PubMed]
- International Human Genome Sequencing Consortium. Finishing the euchromatic sequence of the human genome. Nature 2004, 431, 931–945. [Google Scholar] [CrossRef]
- Richards, S.; Aziz, N.; Bale, S.; Bick, D.; Das, S.; Gastier-Foster, J.; Grody, W.W.; Hegde, M.; Lyon, E.; Spector, E.; et al. Standards and guidelines for the interpretation of sequence variants: A joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet. Med. 2015, 17, 405–424. [Google Scholar] [CrossRef] [PubMed]
- Balague-Dobon, L.; Caceres, A.; Gonzalez, J.R. Fully exploiting SNP arrays: A systematic review on the tools to extract underlying genomic structure. Brief. Bioinform. 2022, 23, bbac043. [Google Scholar] [CrossRef] [PubMed]
- Cooley, L.D.; Lebo, M.; Li, M.M.; Slovak, M.L.; Wolff, D.J.; A Working Group of the American College of Medical Genetics and Genomics (ACMG) Laboratory Quality Assurance Committee. American College of Medical Genetics and Genomics technical standards and guidelines: Microarray analysis for chromosome abnormalities in neoplastic disorders. Genet. Med. 2013, 15, 484–494. [Google Scholar] [CrossRef]
- Edwards, S.L.; Beesley, J.; French, J.D.; Dunning, A.M. Beyond GWASs: Illuminating the dark road from association to function. Am. J. Hum. Genet. 2013, 93, 779–797. [Google Scholar] [CrossRef]
- Stoler, N.; Nekrutenko, A. Sequencing error profiles of Illumina sequencing instruments. NAR Genom. Bioinform. 2021, 3, lqab019. [Google Scholar] [CrossRef]
- Hu, T.; Chitnis, N.; Monos, D.; Dinh, A. Next-generation sequencing technologies: An overview. Hum. Immunol. 2021, 82, 801–811. [Google Scholar] [CrossRef]
- Iacoangeli, A.; Al Khleifat, A.; Sproviero, W.; Shatunov, A.; Jones, A.R.; Morgan, S.L.; Pittman, A.; Dobson, R.J.; Newhouse, S.J.; Al-Chalabi, A. DNAscan: Personal computer compatible NGS analysis, annotation and visualisation. BMC Bioinform. 2019, 20, 213. [Google Scholar] [CrossRef]
- Marriott, H.; Kabiljo, R.; Al Khleifat, A.; Dobson, R.J.; Al-Chalabi, A.; Iacoangeli, A. DNAscan2: A versatile, scalable, and user-friendly analysis pipeline for human next-generation sequencing data. Bioinformatics 2023, 39, btad152. [Google Scholar] [CrossRef] [PubMed]
- Garcia, M.; Juhos, S.; Larsson, M.; Olason, P.I.; Martin, M.; Eisfeldt, J.; DiLorenzo, S.; Sandgren, J.; Diaz De Stahl, T.; Ewels, P.; et al. Sarek: A portable workflow for whole-genome sequencing analysis of germline and somatic variants. F1000Research 2020, 9, 63. [Google Scholar] [CrossRef] [PubMed]
- Genomes Project, C.; Auton, A.; Brooks, L.D.; Durbin, R.M.; Garrison, E.P.; Kang, H.M.; Korbel, J.O.; Marchini, J.L.; McCarthy, S.; McVean, G.A.; et al. A global reference for human genetic variation. Nature 2015, 526, 68–74. [Google Scholar]
- Karczewski, K.J.; Francioli, L.C.; Tiao, G.; Cummings, B.B.; Alfoldi, J.; Wang, Q.; Collins, R.L.; Laricchia, K.M.; Ganna, A.; Birnbaum, D.P.; et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 2020, 581, 434–443. [Google Scholar] [CrossRef]
- Iacoangeli, A.; Al Khleifat, A.; Sproviero, W.; Shatunov, A.; Jones, A.R.; Opie-Martin, S.; Naselli, E.; Topp, S.D.; Fogh, I.; Hodges, A.; et al. ALSgeneScanner: A pipeline for the analysis and interpretation of DNA sequencing data of ALS patients. Amyotroph. Lateral Scler. Front. Degener. 2019, 20, 207–215. [Google Scholar] [CrossRef]
- Investigators, G.P.P.; Smedley, D.; Smith, K.R.; Martin, A.; Thomas, E.A.; McDonagh, E.M.; Cipriani, V.; Ellingford, J.M.; Arno, G.; Tucci, A.; et al. 100,000 Genomes Pilot on Rare-Disease Diagnosis in Health Care—Preliminary Report. N. Engl. J. Med. 2021, 385, 1868–1880. [Google Scholar]
- Vollger, M.R.; Guitart, X.; Dishuck, P.C.; Mercuri, L.; Harvey, W.T.; Gershman, A.; Diekhans, M.; Sulovari, A.; Munson, K.M.; Lewis, A.P.; et al. Segmental duplications and their variation in a complete human genome. Science 2022, 376, eabj6965. [Google Scholar] [CrossRef]
- Bowles, H.; Kabiljo, R.; Al Khleifat, A.; Jones, A.; Quinn, J.P.; Dobson, R.J.B.; Swanson, C.M.; Al-Chalabi, A.; Iacoangeli, A. An assessment of bioinformatics tools for the detection of human endogenous retroviral insertions in short-read genome sequencing data. Front. Bioinform. 2022, 2, 1062328. [Google Scholar] [CrossRef]
- Halman, A.; Oshlack, A. Accuracy of short tandem repeats genotyping tools in whole exome sequencing data. F1000Research 2020, 9, 200. [Google Scholar] [CrossRef]
- Pfeiffer, F.; Grober, C.; Blank, M.; Handler, K.; Beyer, M.; Schultze, J.L.; Mayer, G. Systematic evaluation of error rates and causes in short samples in next-generation sequencing. Sci. Rep. 2018, 8, 10950. [Google Scholar] [CrossRef]
- Olson, N.D.; Wagner, J.; McDaniel, J.; Stephens, S.H.; Westreich, S.T.; Prasanna, A.G.; Johanson, E.; Boja, E.; Maier, E.J.; Serang, O.; et al. PrecisionFDA Truth Challenge V2: Calling variants from short and long reads in difficult-to-map regions. Cell Genom. 2022, 2, 100129. [Google Scholar] [CrossRef] [PubMed]
- Olson, N.D.; Wagner, J.; Dwarshuis, N.; Miga, K.H.; Sedlazeck, F.J.; Salit, M.; Zook, J.M. Variant calling and benchmarking in an era of complete human genome sequences. Nat. Rev. Genet. 2023, 24, 464–483. [Google Scholar] [CrossRef] [PubMed]
- Ebbert, M.T.W.; Jensen, T.D.; Jansen-West, K.; Sens, J.P.; Reddy, J.S.; Ridge, P.G.; Kauwe, J.S.K.; Belzil, V.; Pregent, L.; Carrasquillo, M.M.; et al. Systematic analysis of dark and camouflaged genes reveals disease-relevant genes hiding in plain sight. Genome Biol. 2019, 20, 97. [Google Scholar] [CrossRef]
- Jain, M.; Olsen, H.E.; Paten, B.; Akeson, M. The Oxford Nanopore MinION: Delivery of nanopore sequencing to the genomics community. Genome Biol. 2016, 17, 239. [Google Scholar]
- Wang, Y.; Zhao, Y.; Bollas, A.; Wang, Y.; Au, K.F. Nanopore sequencing technology, bioinformatics and applications. Nat. Biotechnol. 2021, 39, 1348–1365. [Google Scholar] [CrossRef]
- Logsdon, G.A.; Vollger, M.R.; Eichler, E.E. Long-read human genome sequencing and its applications. Nat. Rev. Genet. 2020, 21, 597–614. [Google Scholar] [CrossRef]
- Payne, A.; Holmes, N.; Rakyan, V.; Loose, M. BulkVis: A graphical viewer for Oxford nanopore bulk FAST5 files. Bioinformatics 2019, 35, 2193–2198. [Google Scholar] [CrossRef]
- Ahsan, M.U.; Gouru, A.; Chan, J.; Zhou, W.; Wang, K. A signal processing and deep learning framework for methylation detection using Oxford Nanopore sequencing. Nat. Commun. 2024, 15, 1448. [Google Scholar] [CrossRef]
- Laver, T.; Harrison, J.; O’Neill, P.A.; Moore, K.; Farbos, A.; Paszkiewicz, K.; Studholme, D.J. Assessing the performance of the Oxford Nanopore Technologies MinION. Biomol. Detect. Quantif. 2015, 3, 1–8. [Google Scholar] [CrossRef]
- Sereika, M.; Kirkegaard, R.H.; Karst, S.M.; Michaelsen, T.Y.; Sorensen, E.A.; Wollenberg, R.D.; Albertsen, M. Oxford Nanopore R10.4 long-read sequencing enables the generation of near-finished bacterial genomes from pure cultures and metagenomes without short-read or reference polishing. Nat. Methods 2022, 19, 823–826. [Google Scholar] [CrossRef]
- Ni, Y.; Liu, X.; Simeneh, Z.M.; Yang, M.; Li, R. Benchmarking of Nanopore R10.4 and R9.4.1 flow cells in single-cell whole-genome amplification and whole-genome shotgun sequencing. Comput. Struct. Biotechnol. J. 2023, 21, 2352–2364. [Google Scholar] [CrossRef] [PubMed]
- Stoeck, T.; Katzenmeier, S.N.; Breiner, H.-W.; Rubel, V. Nanopore duplex sequencing as an alternative to Illumina MiSeq sequencing for eDNA-based biomonitoring of coastal aquaculture impacts. Metabarcoding Metagenom. 2024, 8, e121817. [Google Scholar] [CrossRef]
- Nyaga, D.M.; Tsai, P.; Gebbie, C.; Phua, H.H.; Yap, P.; Le Quesne Stabej, P.; Farrow, S.; Rong, J.; Toldi, G.; Thorstensen, E.; et al. Benchmarking nanopore sequencing and rapid genomics feasibility: Validation at a quaternary hospital in New Zealand. NPJ Genom. Med. 2024, 9, 57. [Google Scholar] [CrossRef] [PubMed]
- Krusche, P.; Trigg, L.; Boutros, P.C.; Mason, C.E.; De La Vega, F.M.; Moore, B.L.; Gonzalez-Porta, M.; Eberle, M.A.; Tezak, Z.; Lababidi, S.; et al. Best practices for benchmarking germline small-variant calls in human genomes. Nat. Biotechnol. 2019, 37, 555–560. [Google Scholar] [CrossRef]
- Møller, P.L.; Holley, G.; Beyter, D.; Nyegaard, M.; Halldórsson, B.V. Benchmarking small variant detection with ONT reveals high performance in challenging regions. bioRxiv 2020. [Google Scholar] [CrossRef]
- Pei, S.; Liu, T.; Ren, X.; Li, W.; Chen, C.; Xie, Z. Benchmarking variant callers in next-generation and third-generation sequencing analysis. Brief. Bioinform. 2021, 22, bbaa148. [Google Scholar] [CrossRef]
- Ahsan, M.U.; Liu, Q.; Fang, L.; Wang, K. NanoCaller for accurate detection of SNPs and indels in difficult-to-map regions from long-read sequencing by haplotype-aware deep neural networks. Genome Biol. 2021, 22, 261. [Google Scholar] [CrossRef]
- Cleary, J.G.; Braithwaite, R.; Gaastra, K.; Hilbush, B.S.; Inglis, S.; Irvine, S.A.; Jackson, A.; Littin, R.; Nohzadeh-Malakshah, S.; Rathod, M.; et al. Joint variant and de novo mutation identification on pedigrees from high-throughput sequencing data. J. Comput. Biol. 2014, 21, 405–419. [Google Scholar] [CrossRef]
- Cleary, J.G.; Braithwaite, R.; Gaastra, K.; Hilbush, B.S.; Inglis, S.; Irvine, S.A.; Jackson, A.; Littin, R.; Rathod, M.; Ware, D.; et al. Comparing Variant Call Files for Performance Benchmarking of Next-Generation Sequencing Variant Calling Pipelines. bioRxiv 2015. [Google Scholar] [CrossRef]
- Barbitoff, Y.A.; Abasov, R.; Tvorogova, V.E.; Glotov, A.S.; Predeus, A.V. Systematic benchmark of state-of-the-art variant calling pipelines identifies major factors affecting accuracy of coding sequence variant discovery. BMC Genom. 2022, 23, 155. [Google Scholar] [CrossRef]
- Gresham, D.; Dunham, M.J.; Botstein, D. Comparing whole genomes using DNA microarrays. Nat. Rev. Genet. 2008, 9, 291–302. [Google Scholar] [CrossRef] [PubMed]
- Jeffares, D.C.; Jolly, C.; Hoti, M.; Speed, D.; Shaw, L.; Rallis, C.; Balloux, F.; Dessimoz, C.; Bahler, J.; Sedlazeck, F.J. Transient structural variations have strong effects on quantitative traits and reproductive isolation in fission yeast. Nat. Commun. 2017, 8, 14061. [Google Scholar] [CrossRef] [PubMed]
- Liao, X.; Zhu, W.; Zhou, J.; Li, H.; Xu, X.; Zhang, B.; Gao, X. Repetitive DNA sequence detection and its role in the human genome. Commun. Biol. 2023, 6, 954. [Google Scholar] [CrossRef]
- Grimwood, J.; Gordon, L.A.; Olsen, A.; Terry, A.; Schmutz, J.; Lamerdin, J.; Hellsten, U.; Goodstein, D.; Couronne, O.; Tran-Gyamfi, M.; et al. The DNA sequence and biology of human chromosome 19. Nature 2004, 428, 529–535. [Google Scholar] [CrossRef]
- Ryan, N.M.; Corvin, A. Investigating the dark-side of the genome: A barrier to human disease variant discovery? Biol. Res. 2023, 56, 42. [Google Scholar] [CrossRef]
- Nurk, S.; Koren, S.; Rhie, A.; Rautiainen, M.; Bzikadze, A.V.; Mikheenko, A.; Vollger, M.R.; Altemose, N.; Uralsky, L.; Gershman, A.; et al. The complete sequence of a human genome. Science 2022, 376, 44–53. [Google Scholar] [CrossRef]
- Kosugi, S.; Terao, C. Comparative evaluation of SNVs, indels, and structural variations detected with short- and long-read sequencing data. Hum. Genome Var. 2024, 11, 18. [Google Scholar] [CrossRef]
- Spargo, T.P.; Iacoangeli, A.; Ryten, M.; Forzano, F.; Pearce, N.; Al-Chalabi, A. Modelling Population Genetic Screening in Rare Neurodegenerative Diseases. Biomedicines 2025, 13, 1018. [Google Scholar] [CrossRef]
- Project MinE ALS Sequencing Consortium. Project MinE: Study design and pilot analyses of a large-scale whole-genome sequencing study in amyotrophic lateral sclerosis. Eur. J. Hum. Genet. 2018, 26, 1537–1546. [Google Scholar] [CrossRef]
- McKenna, A.; Hanna, M.; Banks, E.; Sivachenko, A.; Cibulskis, K.; Kernytsky, A.; Garimella, K.; Altshuler, D.; Gabriel, S.; Daly, M.; et al. The Genome Analysis Toolkit: A MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010, 20, 1297–1303. [Google Scholar] [CrossRef]
- Raczy, C.; Petrovski, R.; Saunders, C.T.; Chorny, I.; Kruglyak, S.; Margulies, E.H.; Chuang, H.Y.; Kallberg, M.; Kumar, S.A.; Liao, A.; et al. Isaac: Ultra-fast whole-genome secondary analysis on Illumina sequencing platforms. Bioinformatics 2013, 29, 2041–2043. [Google Scholar] [CrossRef] [PubMed]
- Labs, E.M. Basecalling Workflow. Available online: https://github.com/epi2me-labs/wf-basecalling (accessed on 17 September 2024).
- De Coster, W.; Rademakers, R. NanoPack2: Population-scale evaluation of long-read sequencing data. Bioinformatics 2023, 39, btad311. [Google Scholar] [CrossRef]
- Labs, E.M. Human Variation Workflow. Available online: https://github.com/epi2me-labs/wf-human-variation (accessed on 17 September 2024).
- Li, H. Minimap2: Pairwise alignment for nucleotide sequences. Bioinformatics 2018, 34, 3094–3100. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, B.S.; Quinlan, A.R. Mosdepth: Quick coverage calculation for genomes and exomes. Bioinformatics 2018, 34, 867–868. [Google Scholar] [CrossRef] [PubMed]
- Su, J.; Zheng, Z.; Ahmed, S.S.; Lam, T.W.; Luo, R. Clair3-trio: High-performance Nanopore long-read variant calling in family trios with trio-to-trio deep neural networks. Brief. Bioinform. 2022, 23, bbac301. [Google Scholar] [CrossRef]
- Smolka, M.; Paulin, L.F.; Grochowski, C.M.; Horner, D.W.; Mahmoud, M.; Behera, S.; Kalef-Ezra, E.; Gandhi, M.; Hong, K.; Pehlivan, D.; et al. Detection of mosaic and population-level structural variants with Sniffles2. Nat. Biotechnol. 2024, 42, 1571–1580. [Google Scholar] [CrossRef]
- Bonfield, J.K.; Marshall, J.; Danecek, P.; Li, H.; Ohan, V.; Whitwham, A.; Keane, T.; Davies, R.M. HTSlib: C library for reading/writing high-throughput sequencing data. Gigascience 2021, 10, giab007. [Google Scholar] [CrossRef]
- Danecek, P.; Bonfield, J.K.; Liddle, J.; Marshall, J.; Ohan, V.; Pollard, M.O.; Whitwham, A.; Keane, T.; McCarthy, S.A.; Davies, R.M.; et al. Twelve years of SAMtools and BCFtools. Gigascience 2021, 10, giab008. [Google Scholar] [CrossRef]
- English, A.C.; Menon, V.K.; Gibbs, R.A.; Metcalf, G.A.; Sedlazeck, F.J. Truvari: Refined structural variant comparison preserves allelic diversity. Genome Biol. 2022, 23, 271. [Google Scholar] [CrossRef]
- Chiu, R.; Rajan-Babu, I.S.; Friedman, J.M.; Birol, I. Straglr: Discovering and genotyping tandem repeat expansions using whole genome long-read sequences. Genome Biol. 2021, 22, 224. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Introduction to Python 3: Python Documentation Manual Part 1; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F. Scikit-learn: Machine learning in Python Fabian. J. Mach. Learn. Res. 2011, 12, 2825. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with Python. SciPy 2010, 7, 92–96. [Google Scholar]
- King’s College London e-Research. King’s Computational Research, Engineering and Technology Environment (CREATE). Available online: https://docs.er.kcl.ac.uk/ (accessed on 23 October 2024). [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, R.; Lee, H.; Williams, A.; Baffour-Kyei, A.; Lee, S.-H.; Troakes, C.; Al-Chalabi, A.; Breen, G.; Iacoangeli, A. Investigating the Performance of Oxford Nanopore Long-Read Sequencing with Respect to Illumina Microarrays and Short-Read Sequencing. Int. J. Mol. Sci. 2025, 26, 4492. https://doi.org/10.3390/ijms26104492
Santos R, Lee H, Williams A, Baffour-Kyei A, Lee S-H, Troakes C, Al-Chalabi A, Breen G, Iacoangeli A. Investigating the Performance of Oxford Nanopore Long-Read Sequencing with Respect to Illumina Microarrays and Short-Read Sequencing. International Journal of Molecular Sciences. 2025; 26(10):4492. https://doi.org/10.3390/ijms26104492
Chicago/Turabian StyleSantos, Renato, Hyunah Lee, Alexander Williams, Anastasia Baffour-Kyei, Sang-Hyuck Lee, Claire Troakes, Ammar Al-Chalabi, Gerome Breen, and Alfredo Iacoangeli. 2025. "Investigating the Performance of Oxford Nanopore Long-Read Sequencing with Respect to Illumina Microarrays and Short-Read Sequencing" International Journal of Molecular Sciences 26, no. 10: 4492. https://doi.org/10.3390/ijms26104492
APA StyleSantos, R., Lee, H., Williams, A., Baffour-Kyei, A., Lee, S.-H., Troakes, C., Al-Chalabi, A., Breen, G., & Iacoangeli, A. (2025). Investigating the Performance of Oxford Nanopore Long-Read Sequencing with Respect to Illumina Microarrays and Short-Read Sequencing. International Journal of Molecular Sciences, 26(10), 4492. https://doi.org/10.3390/ijms26104492