
Genome-Wide Identification and Characterization of the Cystatin Gene Family in Bread Wheat (Triticum aestivum L.)


 ,
,  and
and
Abstract
:1. Introduction
2. Results
2.1. Genome-Wide Identification of the TaCystatin Family
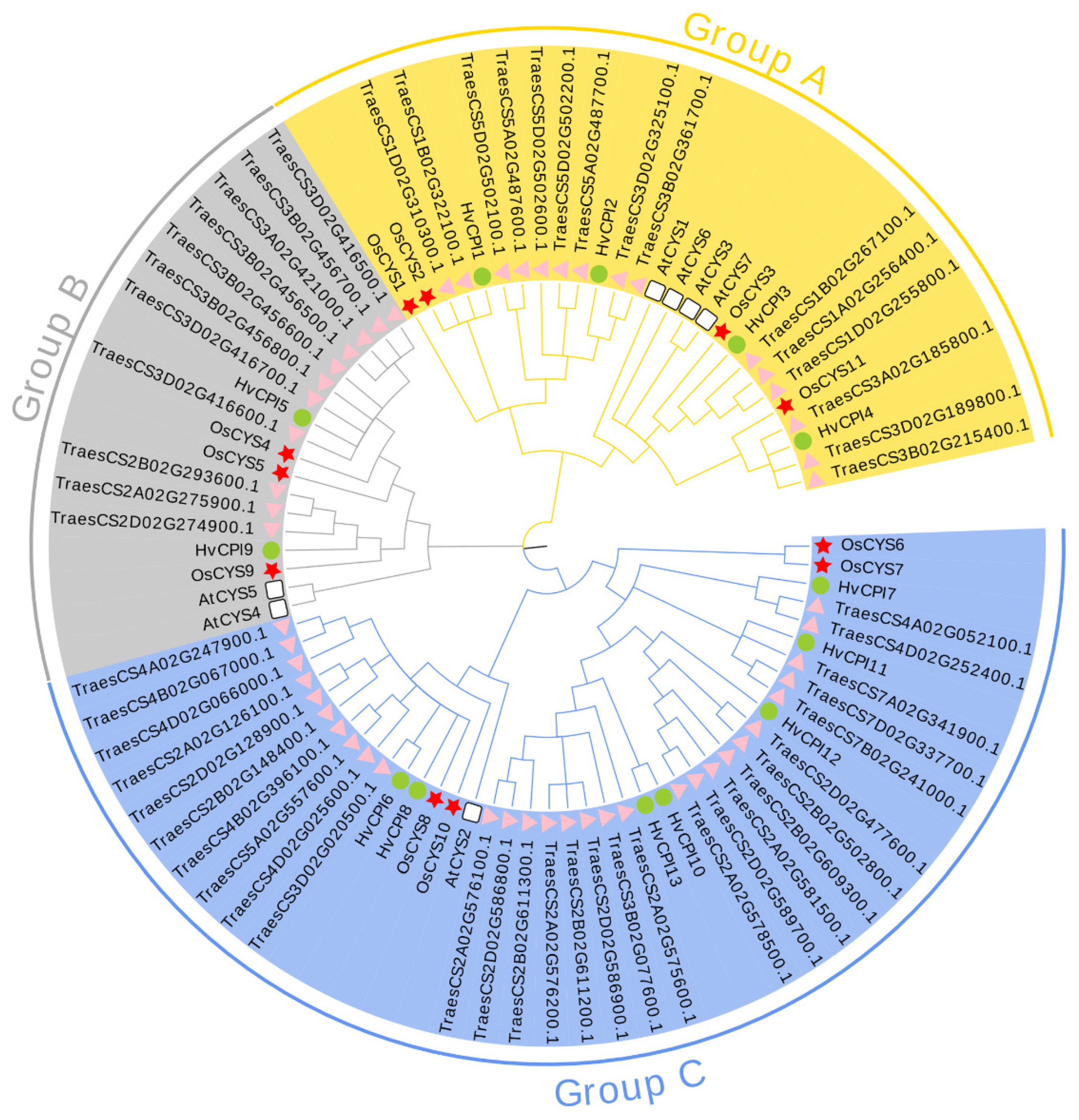
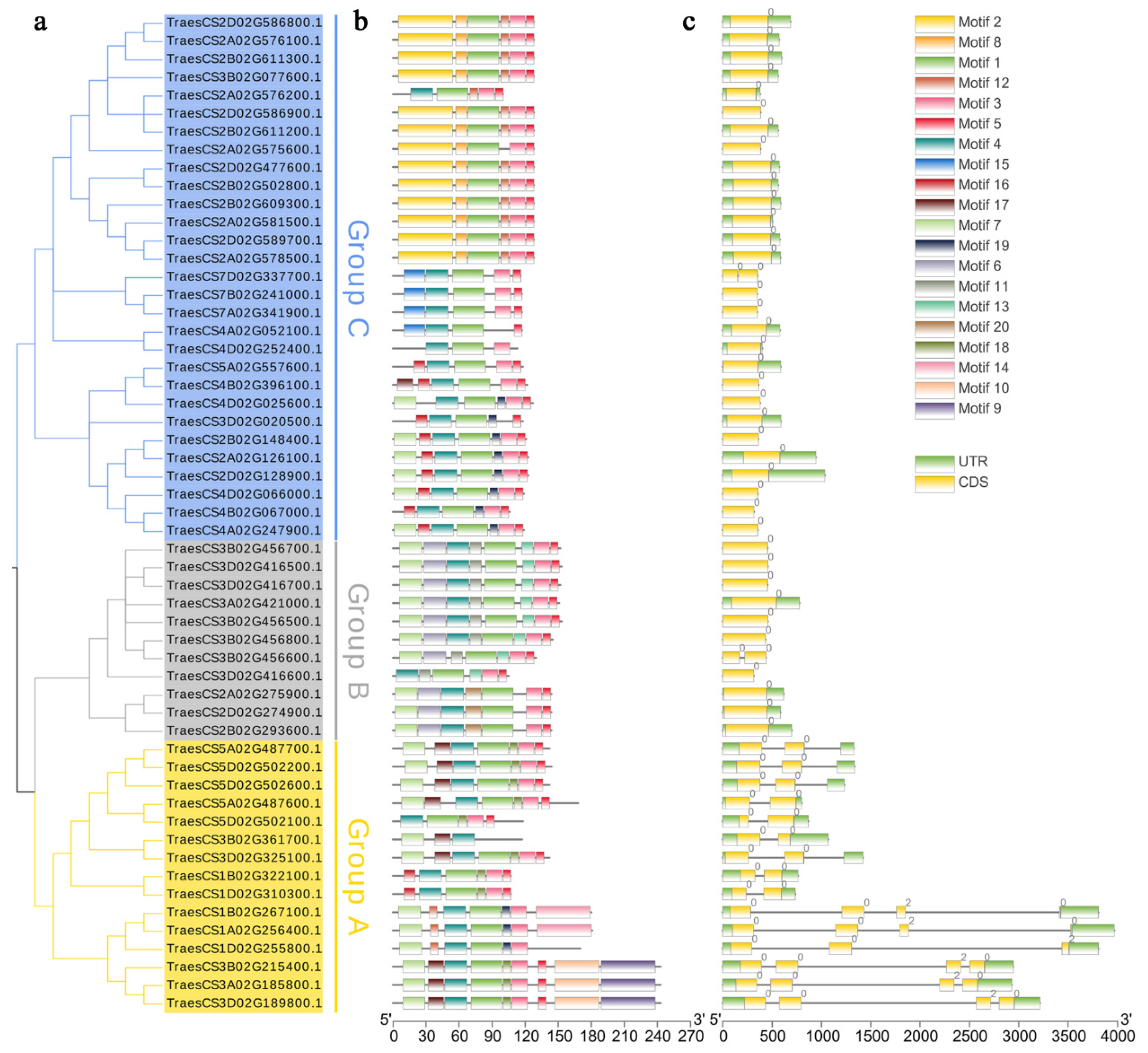
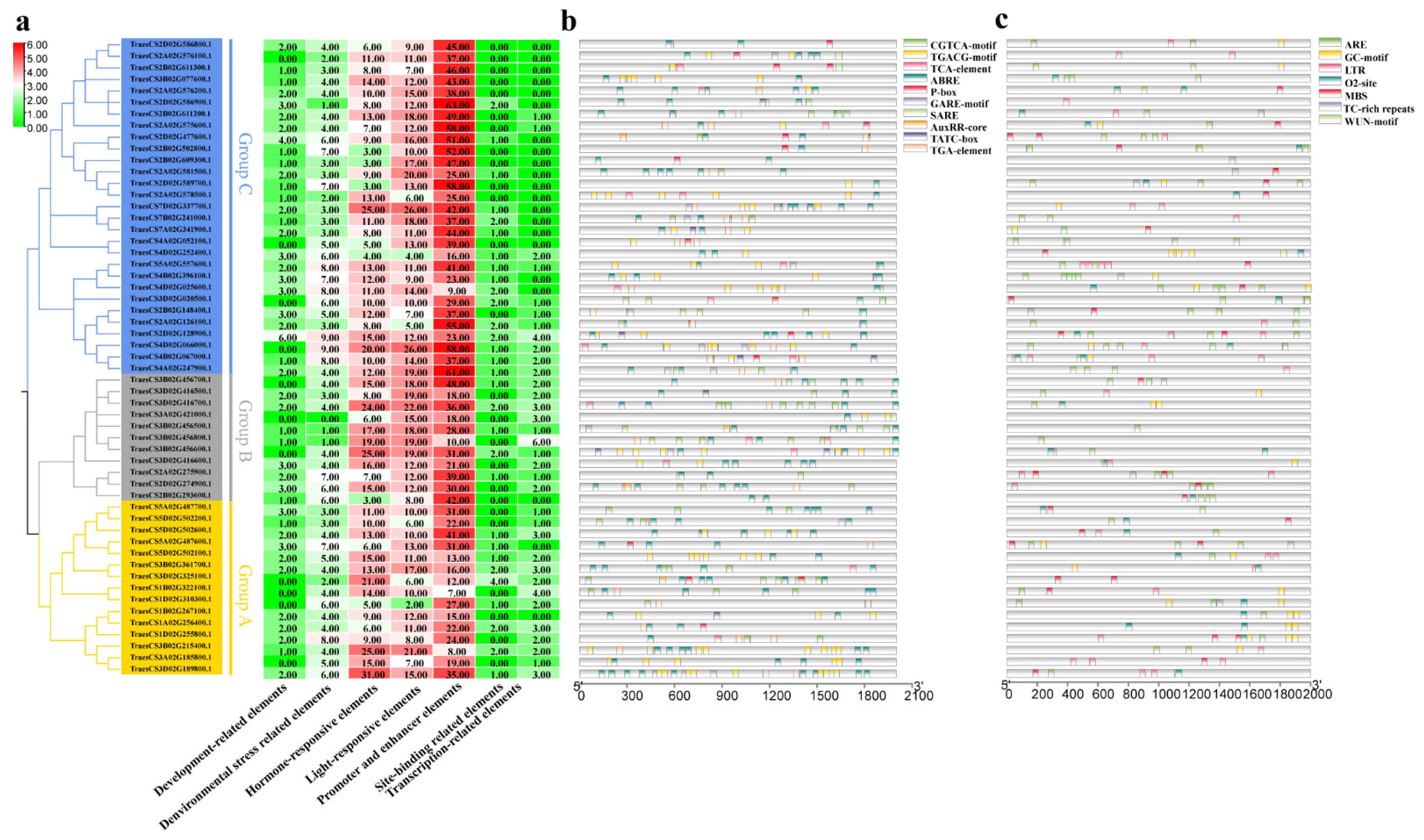
2.2. Phylogenetic and Classification Analysis of Cystatins
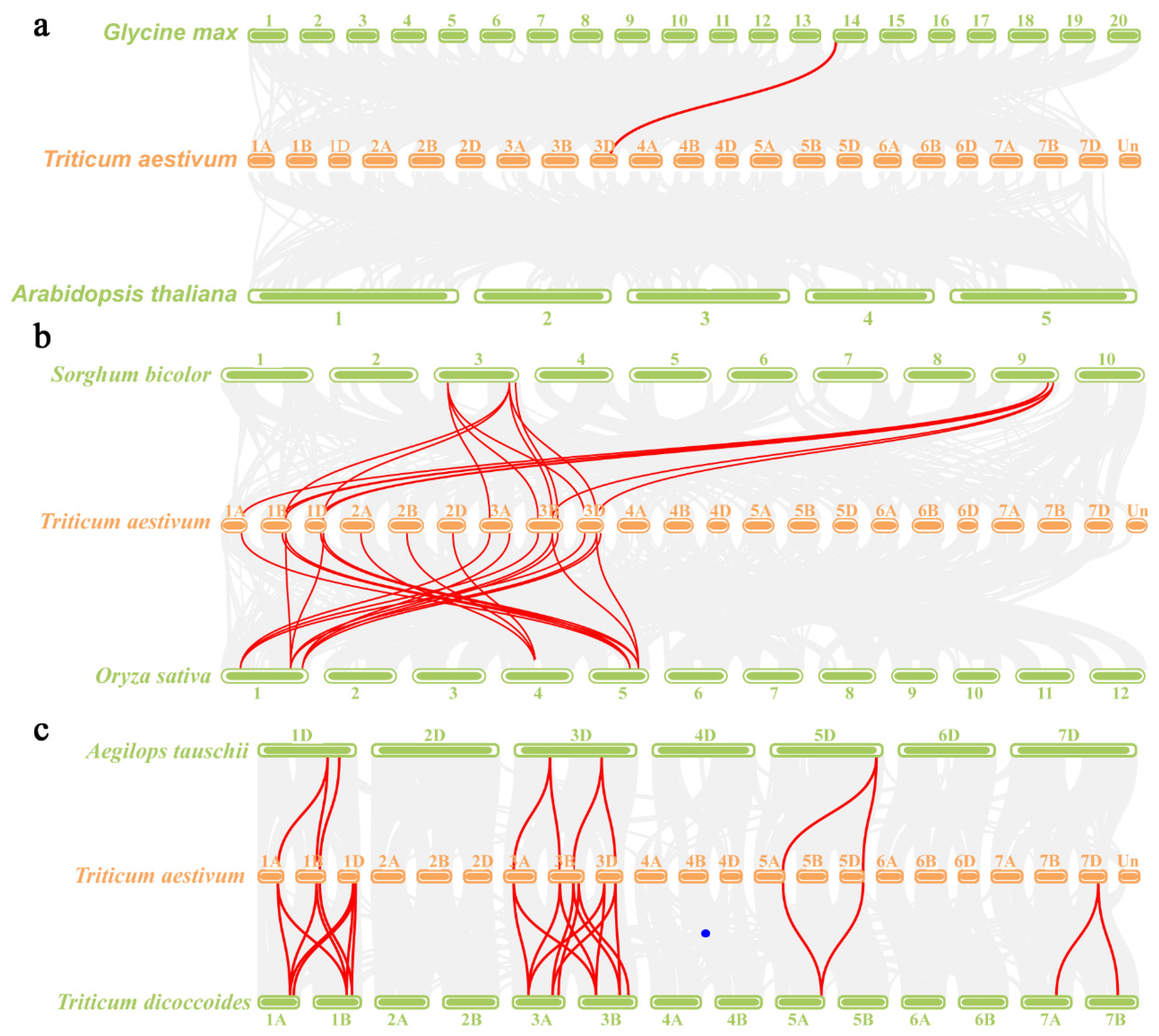
2.3. Duplication Events Analysis of the TaCystatin Family
2.4. Analysis of Cystatin Paralogs and Orthologs
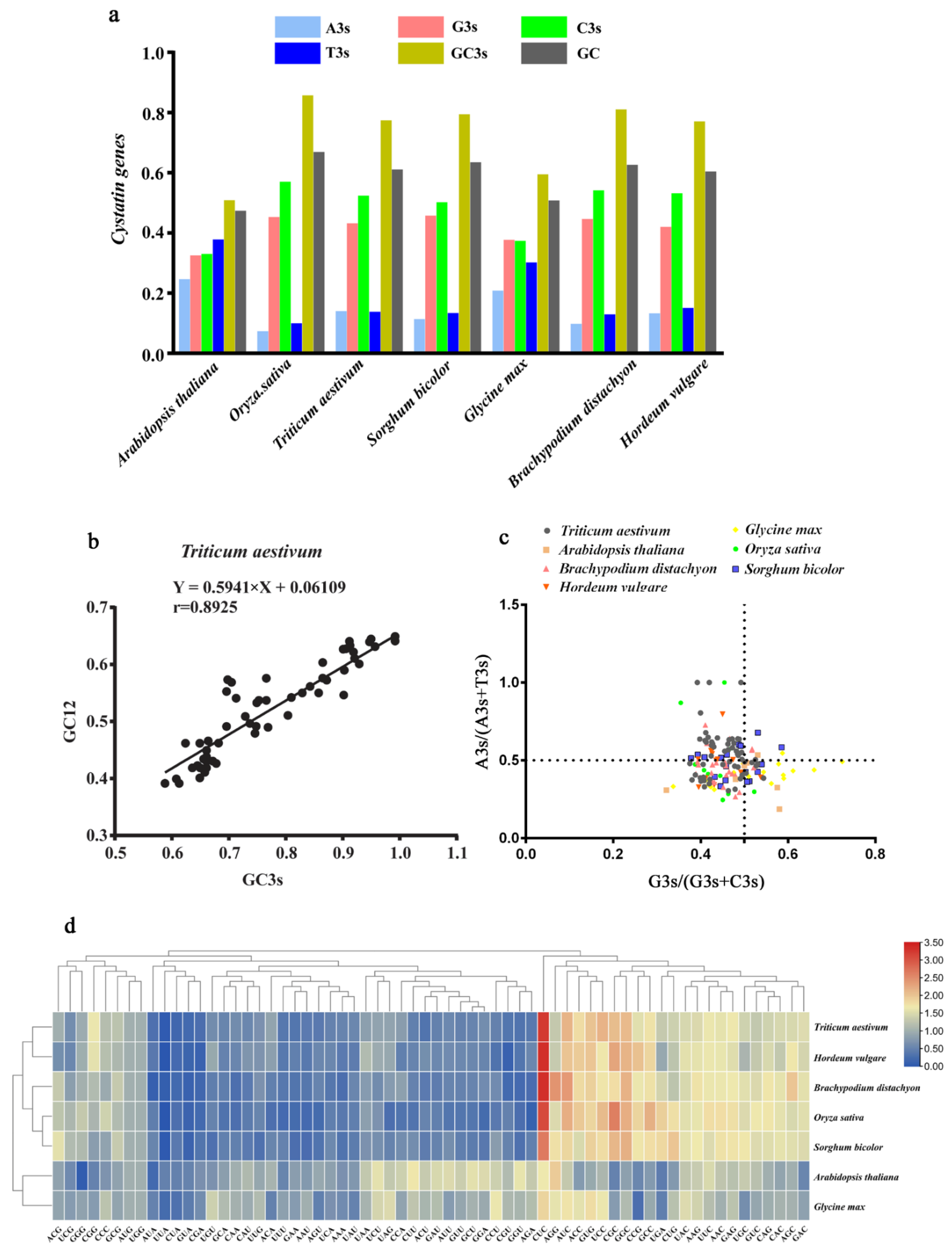
2.5. Codon Usage Pattern Analysis of Cystatin Genes in Plants
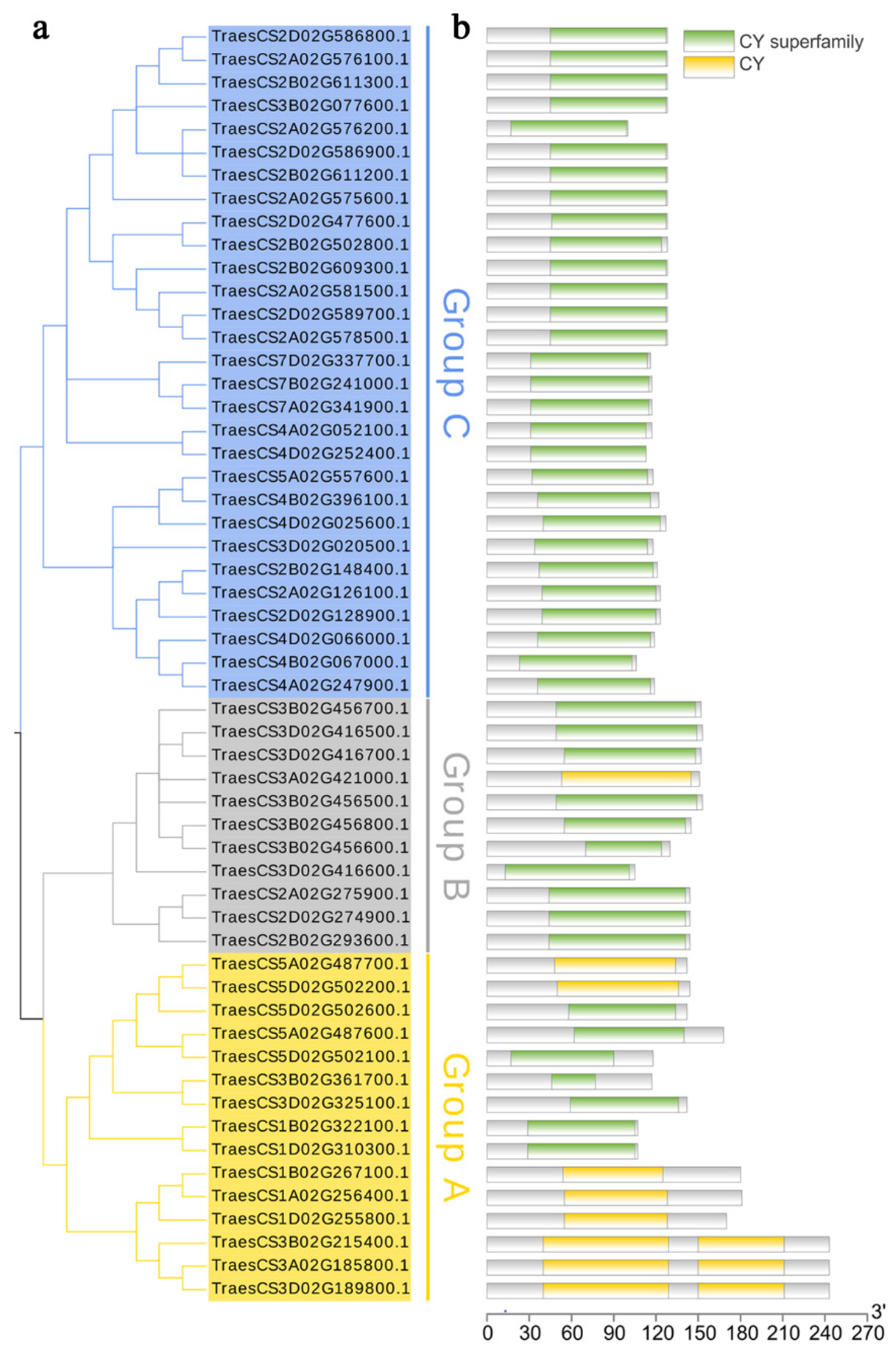
2.6. Conserved Motifs and Gene Structure Analysis of TaCystatin
2.7. Prediction of Cis-Acting Regulatory Elements in Promoter Regions of TaCystatins
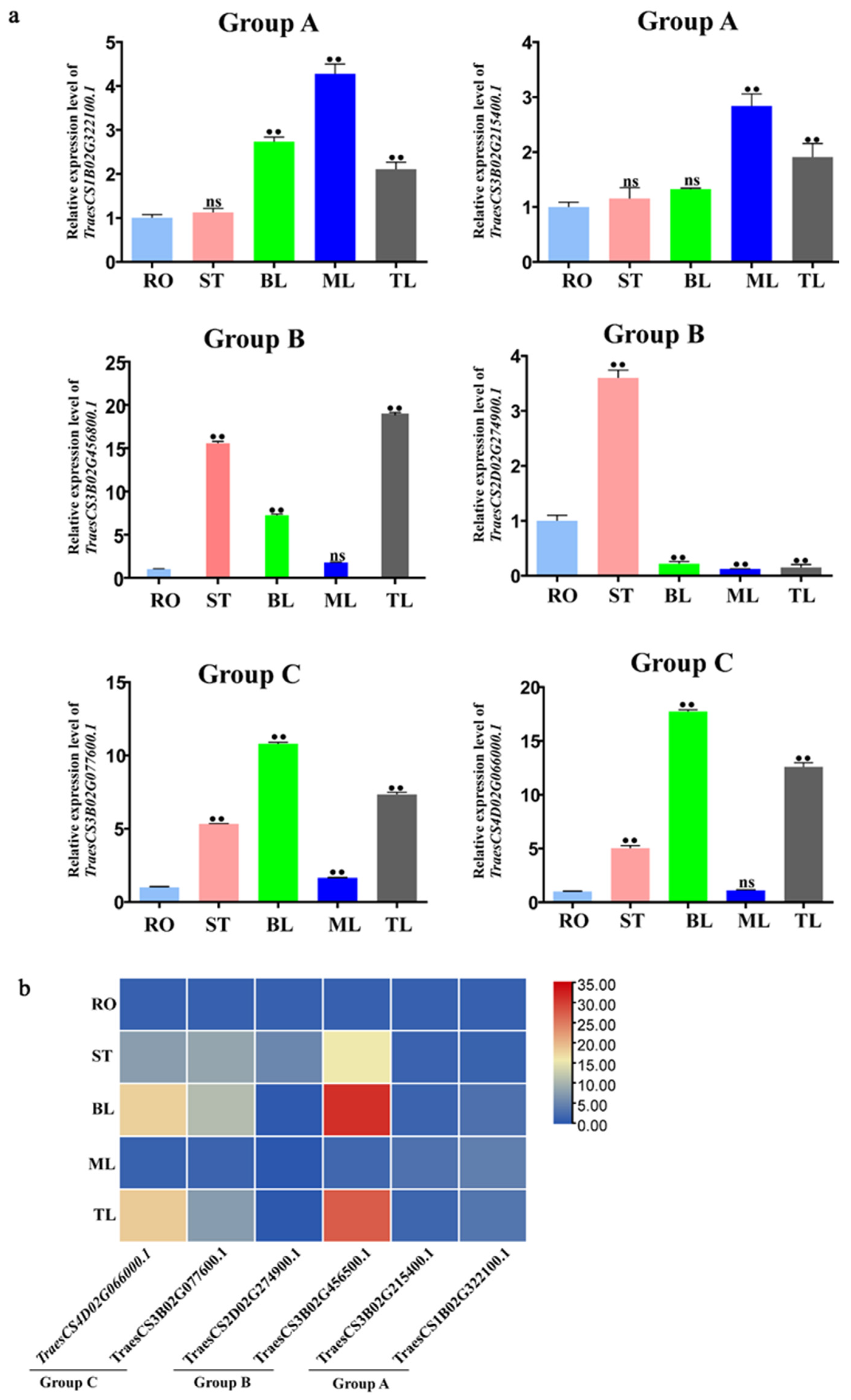
2.8. Tissue-Specific Expression Analysis of TaCystatins
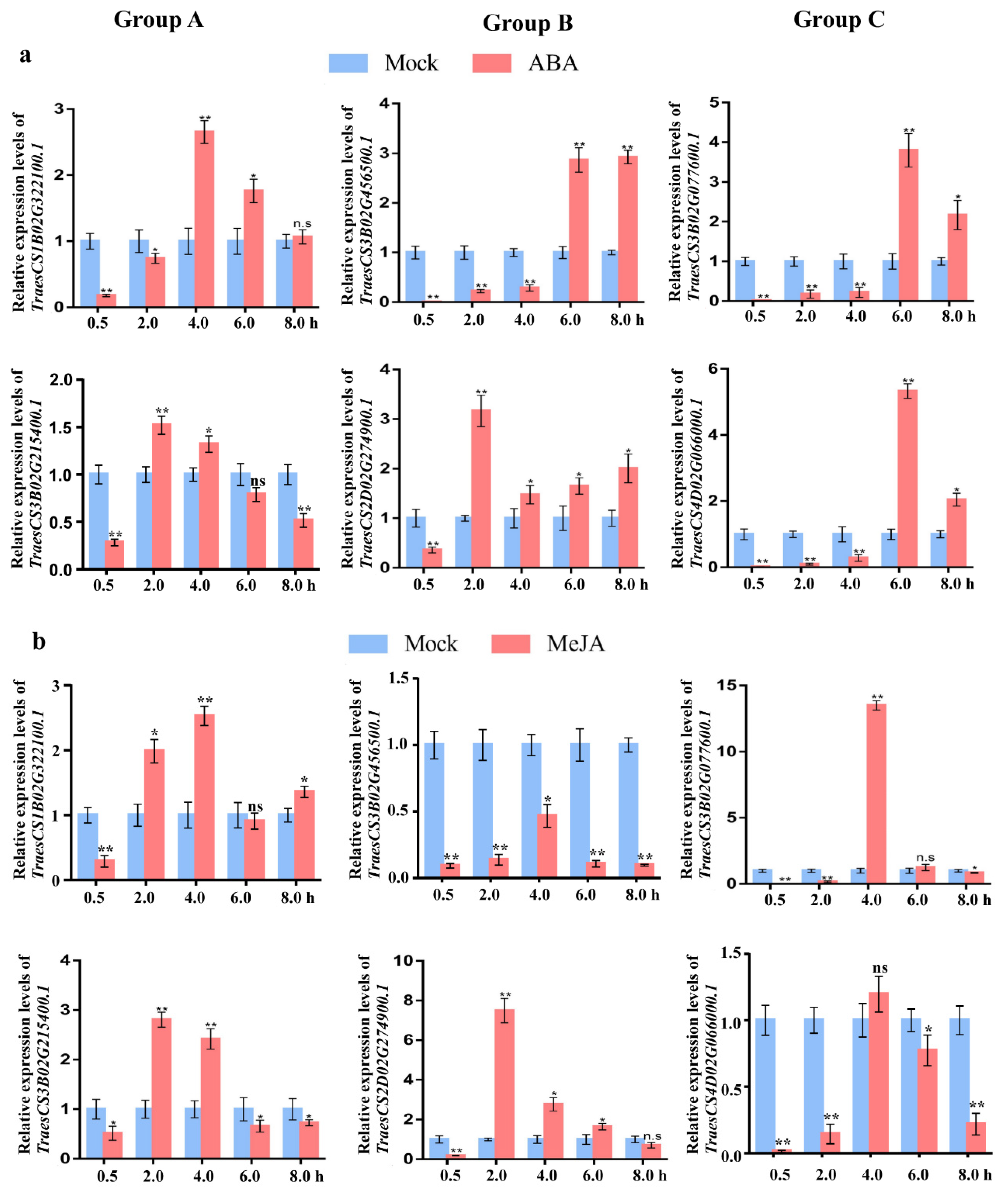
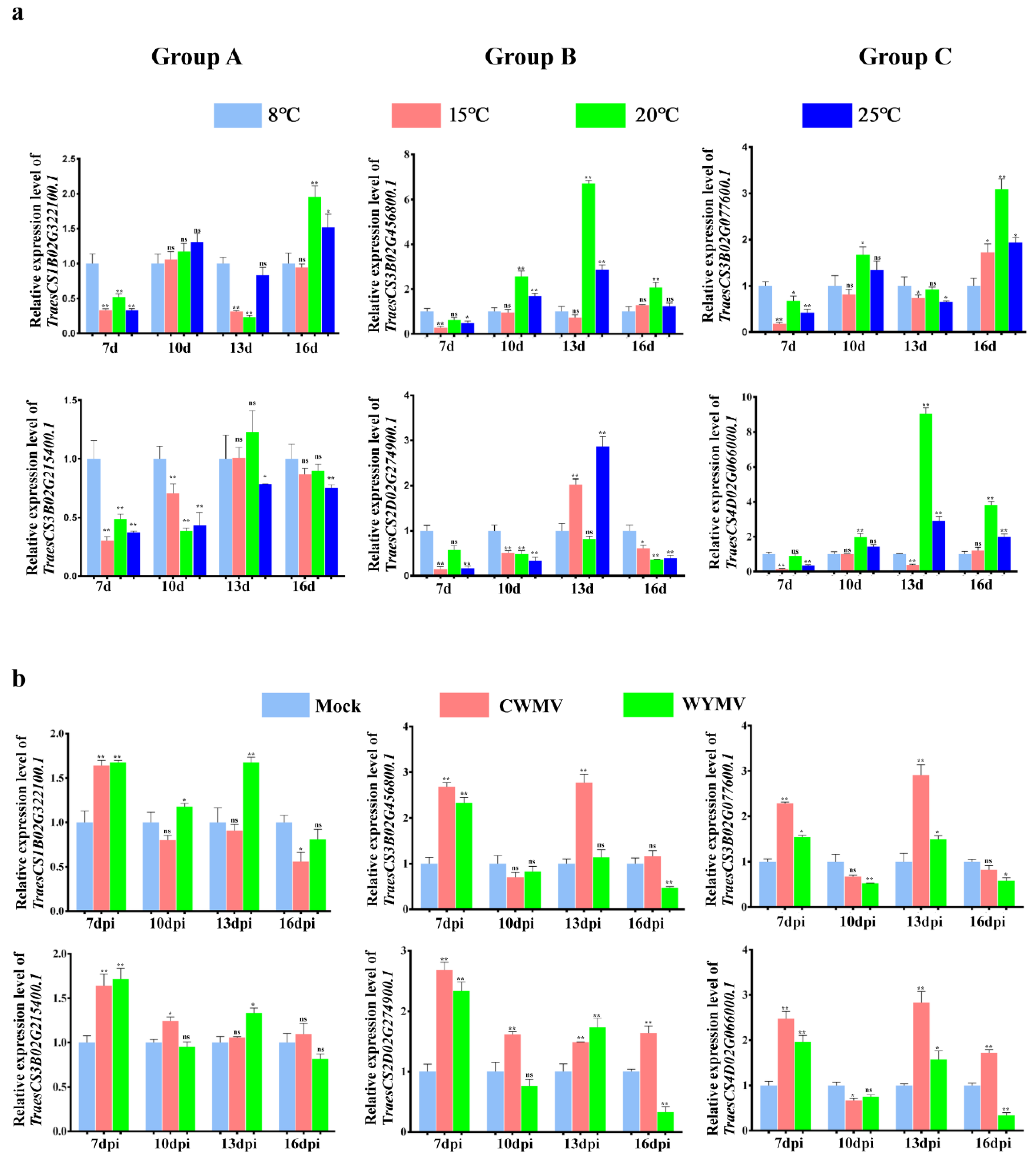
2.9. Expression Analysis of TaCystatins under Abiotic and Biotic Stress
3. Discussion
4. Materials and Methods
4.1. Identification of Cystatin Family in Wheat
4.2. Multiple Sequence Alignment and Phylogenetic Analysis
4.3. Gene Duplication Analysis of TaCystatins
4.4. Codon Usage Pattern Analysis
4.5. Gene Structure and Motif Analysis
4.6. Promoter Analysis
4.7. Plant Cultivation and Viral Inoculation
4.8. RNA Isolation and Real-Time Quantitative Polymerase Chain Reaction (RT-qPCR)
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van der Hoorn, R.A.; Klemenčič, M. Plant proteases: From molecular mechanisms to functions in development and immunity. J. Exp. Bot. 2021, 72, 3337–3339. [Google Scholar] [CrossRef]
- Nduwimana, J.; Guenet, L.; Dorval, I.; Blayau, M.; Le Gall, J.Y.; Le Treut, A. Proteases. Ann. Biol. Clin-Paris. 1995, 53, 251–264. [Google Scholar]
- Rawlings, N.D. Peptidase inhibitors in the MEROPS database. Biochimie 2010, 92, 1463–1483. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A.J. Classification of peptidases. Methods Enzymol. 1994, 244, 1. [Google Scholar]
- Misas-Villamil, J.C.; Van der Hoorn, R.A.; Doehlemann, G. Papain-like cysteine proteases as hubs in plant immunity. New Phytol. 2016, 212, 902–907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinez, M.; Cambra, I.; Carrillo, L.; Diaz-Mendoza, M.; Diaz, I. Characterization of the entire cystatin gene family in barley and their target cathepsin L-like cysteine-proteases, partners in the hordein mobilization during seed germination. Plant. Physiol. 2009, 151, 1531–1545. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Zhang, D.-S.; Liu, H.-S.; Yin, C.-S.; Li, X.-X.; Liang, W.-Q.; Yuan, Z.; Xu, B.; Chu, H.-W.; Wang, J.; et al. The rice tapetum degeneration retardation gene is required for tapetum degradation and anther development. Plant. Cell 2006, 18, 2999–3014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arai, S.; Watanabe, H.; Kondo, H.; Emori, Y.; Abe, K. Papain-inhibitory activity of oryzacystatin, a rice seed cysteine proteinase inhibitor, depends on the central Gln-Val-Val-Ala-Gly region conserved among cystatin superfamily members. J. Biochem. 1991, 109, 294–298. [Google Scholar]
- Brown, W.M.; Dziegielewska, K.M. Friends and relations of the cystatin superfamily—New members and their evolution. Protein Sci. 1997, 6, 5–12. [Google Scholar] [CrossRef] [Green Version]
- Martínez, M.; Abraham, Z.; Carbonero, P.; Díaz, I. Comparative phylogenetic analysis of cystatin gene families from Arabidopsis, rice and barley. Mol. Genet. Genom. 2005, 273, 423–432. [Google Scholar] [CrossRef]
- Tan, Y.; Wang, S.; Liang, D.; Li, M.; Ma, F. Genome-wide identification and expression profiling of the cystatin gene family in apple (Malusx domestica Borkh.). Plant. Physiol Biochem. 2014, 79, 88–97. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, X.; Wang, Q.; Sun, J.; He, D. Genome-wide identification and analysis of cystatin family genes in Sorghum (Sorghum bicolor L. Moench). PeerJ 2021, 9, e10617. [Google Scholar] [CrossRef]
- Stubbs, M.T.; Laber, B.; Bode, W.; Huber, R.; Jerala, R.; Lenarcic, B.; Turk, V. The refined 2.4 A X-ray crystal structure of recombinant human stefin B in complex with the cysteine proteinase papain: A novel type of proteinase inhibitor interaction. EMBO J. 1990, 9, 1939–1947. [Google Scholar] [CrossRef] [PubMed]
- Benchabane, M.; Schlueter, U.; Vorster, J.; Goulet, M.C.; Biochimie, D.M.J. Plant cystatins. Biochimie 2010, 92, 1657–1666. [Google Scholar] [CrossRef]
- Martinez, M.; Diaz, I. The origin and evolution of plant cystatins and their target cysteine proteinases indicate a complex functional relationship. BMC Evol. Biol. 2008, 8, 198–206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Misaka, T.; Kuroda, M.; Iwabuchi, K.; Abe, K.; Arai, S. Soyacystatin, a novel cysteine proteinase inhibitor in soybean, is distinct in protein structure and gene organization from other cystatins of animal and plant origin. Eur. J. Biochem. 1996, 240, 609–614. [Google Scholar] [CrossRef]
- Martinez, M.; Diaz-Mendoza, M.; Carrillo, L.; Diaz, I. Carboxy terminal extended phytocystatins are bifunctional inhibitors of papain and legumain cysteine proteinases. FEBS Lett. 2007, 581, 2914–2918. [Google Scholar] [CrossRef] [Green Version]
- Solomon, M.; Belenghi, B.; Delledonne, M.; Menachem, E.; Levine, A. The involvement of cysteine proteases and protease inhibitor genes in the regulation of programmed cell death in plants. Plant. Cell 1999, 11, 431–444. [Google Scholar] [CrossRef]
- Kiyosaki, T.; Matsumoto, I.; Asakura, T.; Funaki, J.; Kuroda, M.; Misaka, T.; Arai, S.; Abe, K. Gliadain, a gibberellin-inducible cysteine proteinase occurring in germinating seeds of wheat, Triticum aestivum L., specifically digests gliadin and is regulated by intrinsic cystatins. FEBS J. 2007, 274, 1908–1917. [Google Scholar] [CrossRef]
- Díaz-Mendoza, M.; Velasco-Arroyo, B.; González-Melendi, P.; Martínez, M.; Díaz, I. C1A cysteine protease-cystatin interactions in leaf senescence. J. Exp. Bot. 2014, 65, 3825–3833. [Google Scholar] [CrossRef] [Green Version]
- Zhao, P.; Zhou, X.M.; Zou, J.; Wang, W.; Wang, L.; Peng, X.B.; Sun, M.X. Comprehensive analysis of cystatin family genes suggests their putative functions in sexual reproduction, embryogenesis, and seed formation. J. Exp. Bot. 2014, 65, 5093–5107. [Google Scholar] [CrossRef] [Green Version]
- Van der Linde, K.; Hemetsberger, C.; Kastner, C.; Kaschani, F.; Van der Hoorn, R.A.; Kumlehn, J.; Doehlemann, G. A maize cystatin suppresses host immunity by inhibiting apoplastic cysteine proteases. Plant. Cell 2012, 24, 1285–1300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carrillo, L.; Martinez, M.; Alvarez-Alfageme, F.; Castañera, P.; Smagghe, G.; Diaz, I.; Ortego, F. A barley cysteine-proteinase inhibitor reduces the performance of two aphid species in artificial diets and transgenic Arabidopsis plants. Transgenic Res. 2011, 20, 305–319. [Google Scholar] [CrossRef]
- Martínez, M.; López-Solanilla, E.; Rodríguez-Palenzuela, P.; Carbonero, P.; Díaz, I. Inhibition of plant-pathogenic fungi by the barley cystatin Hv-CPI is not associated with its cysteine-proteinase inhibitory properties. Mol. Plant. Microbe 2003, 16, 876–883. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dutt, S.; Pandey, D.; Kumar, A. Jasmonate signal induced expression of cystatin genes for providing resistance against Karnal bunt in wheat. Plant. Signal. Behav. 2011, 6, 821–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, C.; Kim, T.; Chung, W.S.; Lim, C.O. The Arabidopsis phytocystatin AtCYS5 enhances seed germination and seedling growth under heat stress conditions. Mol. Cells 2017, 40, 577–586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, Y.; Li, M.; Ma, F.J.P.C.T.; Culture, O. Overexpression of MpCYS2, a phytocystatin gene from Malus prunifolia (Willd.) Borkh., confers drought tolerance and protects against oxidative stress in Arabidopsis. Plant. Cell Tiss. Org. 2015, 123, 15–27. [Google Scholar] [CrossRef]
- Pfeifer, M.; Kugler, K.G.; Sandve, S.R.; Zhan, B.; Rudi, H.; Hvidsten, T.R.; Mayer, K.F.; Olsen, O.A. Genome interplay in the grain transcriptome of hexaploid bread wheat. Science 2014, 345, 1250091. [Google Scholar] [CrossRef] [Green Version]
- Ray, D.K.; Mueller, N.D.; West, P.C.; Foley, J.A. Yield trends are insufficient to double global crop production by 2050. PLoS ONE 2013, 8, e66428. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhao, P.; Zhou, X.M.; Xiong, H.X.; Sun, M.X. Genome-wide identification and characterization of cystatin family genes in rice (Oryza sativa L.). Plant. Cell Rep. 2015, 34, 1579–1592. [Google Scholar] [CrossRef] [PubMed]
- Yuan, S.; Li, R.; Wang, L.; Chen, H.; Zhang, C.; Chen, L.; Hao, Q.; Shan, Z.; Zhang, X.; Chen, S.; et al. Search for nodulation and nodule development-related cystatin genes in the genome of soybean (Glycine max). Front. Plant. Sci. 2016, 7, 1595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Subburaj, S.; Zhu, D.; Li, X.; Hu, Y.; Yan, Y. Molecular Characterization and Expression Profiling of Brachypodium distachyon L. Cystatin genes reveal high evolutionary conservation and functional divergence in response to abiotic stress. Front. Plant. Sci. 2017, 8, 743–751. [Google Scholar] [PubMed]
- Abraham, Z.; Martinez, M.; Carbonero, P.; Diaz, I. Structural and functional diversity within the cystatin gene family of Hordeum vulgare. J. Exp. Bot. 2006, 57, 4245–4255. [Google Scholar] [CrossRef] [PubMed]
- Borrill, P.; Adamski, N.; Uauy, C. Genomics as the key to unlocking the polyploid potential of wheat. New Phytol. 2015, 208, 1008–1022. [Google Scholar] [CrossRef] [PubMed]
- International Wheat Genome Sequencing (IWGSC). Shifting the limits in wheat research and breeding using a fully annotated reference genome. Science 2018, 361, 7191. [Google Scholar] [CrossRef] [Green Version]
- Schilling, S.; Kennedy, A.; Pan, S.; Jermiin, L.S.; Melzer, R. Genome-wide analysis of MIKC-type MADS-box genes in wheat: Pervasive duplications, functional conservation and putative neofunctionalization. New Phytol 2020, 225, 511–529. [Google Scholar] [CrossRef] [Green Version]
- Cannon, S.B.; Mitra, A.; Baumgarten, A.; Young, N.D.; May, G. The roles of segmental and tandem gene duplication in the evolution of large gene families in Arabidopsis thaliana. BMC Plant. Biol. 2004, 4, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Hurst, L.D. The Ka/Ks ratio: Diagnosing the form of sequence evolution. Trends Genet. 2002, 18, 486. [Google Scholar] [CrossRef]
- Brenchley, R.; Spannagl, M.; Pfeifer, M.; Barker, G.L.; D’Amore, R.; Allen, A.M.; McKenzie, N.; Kramer, M.; Kerhornou, A.; Bolser, D.; et al. Analysis of the bread wheat genome using whole-genome shotgun sequencing. Nature 2012, 491, 705–710. [Google Scholar] [CrossRef] [Green Version]
- Hershberg, R.; Petrov, D.A. Selection on codon bias. Annu. Rev. Genet. 2008, 42, 287–299. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Li, Y.; Ji, K.K.; Zhu, J.; Ling, P.; Zhou, T.; Fan, L.Y.; Xie, S.Q. Genome-wide codon usage pattern analysis reveals the correlation between codon usage bias and gene expression in Cuscuta australis. Genomics 2020, 112, 2695–2702. [Google Scholar] [CrossRef]
- Roberts, R.J. Restriction and modification enzymes and their recognition sequences. Nucleic Acids Res. 1982, 10, 117–144. [Google Scholar] [CrossRef] [Green Version]
- Angellotti, M.C.; Bhuiyan, S.B.; Chen, G.; Wan, X.F. Codon usage bias analysis within and across genomes. Nucleic Acids Res. 2007, 35, 132–136. [Google Scholar] [CrossRef] [PubMed]
- LaBella, A.L.; Opulente, D.A.; Steenwyk, J.L.; Hittinger, C.T.; Rokas, A. Variation and selection on codon usage bias across an entire subphylum. PLoS Genet. 2019, 15, e1008304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mazumdar, P.; Binti Othman, R.; Mebus, K.; Ramakrishnan, N.; Ann Harikrishna, J. Codon usage and codon pair patterns in non-grass monocot genomes. Ann. Bot. 2017, 120, 893–909. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brown, C.M.; Stockwell, P.A.; Trotman, C.N.; Tate, W.P. Sequence analysis suggests that tetra-nucleotides signal the termination of protein synthesis in eukaryotes. Nucleic Acids Res. 1990, 18, 6339–6345. [Google Scholar] [CrossRef]
- Kawabe, A.; Miyashita, N.T. Patterns of codon usage bias in three dicot and four monocot plant species. Genes Genet. Syst. 2003, 78, 343–352. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, G.; Pan, Z.; Gao, S.; He, Y.; Xia, Q.; Jin, Y.; Yao, H. Analysis of synonymous codon usage of chloroplast genome in Porphyra umbilicalis. Genes Genom. 2019, 41, 1173–1181. [Google Scholar] [CrossRef]
- Tao, L.; Zhihua, N.; Mingshan, S.; Liang, C.J. High-frequency codon analysis and its application in codon analysis of tobacco. PLoS ONE 2002, 41, 551–554. [Google Scholar]
- Chen, C.; Chen, H.; Zhang, Y.; Thomas, H.R.; Frank, M.H.; He, Y.; Xia, R. TBtools: An integrative toolkit developed for interactive analyses of big biological data. Mol. Plant. 2020, 13, 1194–1202. [Google Scholar] [CrossRef]
- Wang, X.; Yan, X.; Li, S.; Jing, Y.; Gu, L.; Zou, S.; Zhang, J.; Liu, B. Genome-wide identification, evolution and expression analysis of the aspartic protease gene family during rapid growth of moso bamboo shoots. BMC Genom. 2021, 22, 45. [Google Scholar]
- Hernandez-Garcia, C.M.; Finer, J.J. Identification and validation of promoters and cis-acting regulatory elements. Plant. Sci. 2014, 19, 217–218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamaguchi-Shinozaki, K.; Shinozaki, K. Organization of cis-acting regulatory elements in osmotic and cold-stress-responsive promoters. Trends Plant. Sci. 2005, 10, 88–94. [Google Scholar] [CrossRef]
- Kaur, A.; Pati, P.K.; Pati, A.M.; Nagpal, A.K. In-silico analysis of cis-acting regulatory elements of pathogenesis-related proteins of Arabidopsis thaliana and Oryza sativa. PLoS ONE 2017, 12, e0184523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wanapu, C.; Shinmyo, A. Cis-regulatory elements of the peroxidase gene in Arabidopsis thaliana involved in root-specific expression and responsiveness to high-salt stress. Ann. N. Y. Acad. Sci. 1996, 782, 107–114. [Google Scholar] [CrossRef]
- Vishwakarma, K.; Upadhyay, N.; Kumar, N.; Yadav, G.; Singh, J.; Mishra, R.K.; Kumar, V.; Verma, R.; Pandey, M.; Sharma, S. Abscisic acid signaling and abiotic Stress tolerance in plants. Front. Plant. Sci. 2017, 8, 161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lescot, M.; Déhais, P.; Thijs, G.; Marchal, K.; Moreau, Y.; Van de Peer, Y.; Rouzé, P.; Rombauts, S. PlantCARE, a database of plant cis-acting regulatory elements and a portal to tools for in silico analysis of promoter sequences. Nucleic Acids Res. 2002, 30, 325–327. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.C.; Luan, S. ABA signal transduction at the crossroad of biotic and abiotic stress responses. Plant. Cell Environ. 2012, 35, 53–60. [Google Scholar] [CrossRef]
- Alazem, M.; Lin, N.S. Antiviral roles of abscisic acid in plants. Front. Plant. Sci. 2017, 8, 1760. [Google Scholar] [CrossRef] [Green Version]
- Santner, A.; Estelle, M. Recent advances and emerging trends in plant hormone signalling. Nature 2009, 459, 1071–1078. [Google Scholar] [CrossRef]
- He, L.; Chen, X.; Yang, J.; Zhang, T.; Li, J.; Zhang, S.; Zhong, K.; Zhang, H.; Chen, J.; Yang, J. Rice black-streaked dwarf virus-encoded P5-1 regulates the ubiquitination activity of SCF E3 ligases and inhibits jasmonate signaling to benefit its infection in rice. New Phytol. 2020, 225, 896–912. [Google Scholar] [CrossRef] [Green Version]
- Belenghi, B.; Acconcia, F.; Trovato, M.; Perazzolli, M.; Bocedi, A.; Polticelli, F.; Ascenzi, P.; Delledonne, M. AtCYS1, a cystatin from Arabidopsis thaliana, suppresses hypersensitive cell death. Eur. J. Biochem. 2003, 270, 2593–2604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hwang, J.E.; Hong, J.K.; Lim, C.J.; Chen, H.; Je, J.; Yang, K.A.; Kim, D.Y.; Choi, Y.J.; Lee, S.Y.; Lim, C.O. Distinct expression patterns of two Arabidopsis phytocystatin genes, AtCYS1 and AtCYS2, during development and abiotic stresses. Plant. Cell Rep. 2010, 29, 905–915. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.J.; Senthilkumar, R.; Jane, W.N.; He, Y.; Tian, Z.; Yeh, K.W. Transplastomic Nicotiana benthamiana plants expressing multiple defence genes encoding protease inhibitors and chitinase display broad-spectrum resistance against insects, pathogens and abiotic stresses. Plant. Biotechnol. J. 2014, 12, 503–515. [Google Scholar] [CrossRef] [PubMed]
- Rezaei, E.E.; Siebert, S.; Hüging, H.; Ewert, F. Climate change effect on wheat phenology depends on cultivar change. Sci. Rep. 2018, 8, 4891. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Zhang, T.Y.; Liao, Q.S.; He, L.; Li, J.; Zhang, H.M.; Chen, X.; Li, J.; Yang, J.; Li, J.B.; et al. Chinese wheat mosaic virus-induced gene slencing in monocots and dicots at Low temperature. Front. Plant. Sci. 2018, 9, 1627. [Google Scholar] [CrossRef] [PubMed]
- Martinez, M.; Santamaria, M.E.; Diaz-Mendoza, M.; Arnaiz, A.; Carrillo, L.; Ortego, F.; Diaz, I. Phytocystatins: Defense proteins against phytophagous insects and acari. Int. J. Mol. Sci. 2016, 17, 1747. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhan, Y.; Wu, C.; Gong, S.; Zhu, N.; Chen, S.; Li, H. Cloning of a cystatin gene from sugar beet M14 that can enhance plant salt tolerance. Plant. Sci. 2012, 191, 93–99. [Google Scholar] [CrossRef]
- Haq, S.K.; Atif, S.M.; Khan, R.H. Protein proteinase inhibitor genes in combat against insects, pests, and pathogens: Natural and engineered phytoprotection. Arch. Biochem. Biophys. 2004, 431, 145–159. [Google Scholar] [CrossRef]
- Shindo, T.; Van der Hoorn, R.A. Papain-like cysteine proteases: Key players at molecular battlefields employed by both plants and their invaders. Mol. Plant. Pathol. 2008, 9, 119–125. [Google Scholar] [CrossRef]
- Dubcovsky, J.; Dvorak, J. Genome plasticity a key factor in the success of polyploid wheat under domestication. Science 2007, 316, 1862–1866. [Google Scholar] [CrossRef] [Green Version]
- Brule, C.E.; Grayhack, E.J. Synonymous codons: Choose wisely for expression. Trends Genet. 2017, 33, 283–297. [Google Scholar] [CrossRef] [Green Version]
- Qian, W.; Yang, J.R.; Pearson, N.M.; Maclean, C.; Zhang, J. Balanced codon usage optimizes eukaryotic translational efficiency. PLoS Genet. 2012, 8, e1002603. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, S.; Takano, T. Two cysteine proteinase inhibitors from Arabidopsis thaliana, AtCYSa and AtCYSb, increasing the salt, drought, oxidation and cold tolerance. Plant. Mol. Biol. 2008, 68, 131–143. [Google Scholar] [CrossRef]
- Mistry, J.; Finn, R.D.; Eddy, S.R.; Bateman, A.; Punta, M. Challenges in homology search: HMMER3 and convergent evolution of coiled-coil regions. Nucleic Acids Res. 2013, 41, e121. [Google Scholar] [CrossRef] [Green Version]
- Wilkins, M.R.; Gasteiger, E.; Bairoch, A.; Sanchez, J.C.; Williams, K.L.; Appel, R.D.; Hochstrasser, D.F. Protein identification and analysis tools in the ExPASy server. Methods Mol. Biol. 1999, 112, 531–552. [Google Scholar] [PubMed]
- Chou, K.C.; Shen, H.B. Plant-mPLoc: A top-down strategy to augment the power for predicting plant protein subcellular localization. PLoS ONE 2010, 5, e11335. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Tang, H.; Debarry, J.D.; Tan, X.; Li, J.; Wang, X.; Lee, T.H.; Jin, H.; Marler, B.; Guo, H.; et al. MCScanX: A toolkit for detection and evolutionary analysis of gene synteny and collinearity. Nucleic Acids Res. 2012, 40, e49. [Google Scholar] [CrossRef] [Green Version]
- Peden, J.F. Analysis of codon usage. PeerJ 2000, 90, 73–74. [Google Scholar]
- Bolser, D.M.; Kerhornou, A.; Walts, B.; Kersey, P. Triticeae resources in Ensembl plants. Plant. Cell Physiol. 2015, 56, e3. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.L.; Boden, M.; Buske, F.A.; Frith, M.; Grant, C.E.; Clementi, L.; Ren, J.; Li, W.W.; Noble, W.S. MEME SUITE: Tools for motif discovery and searching. Nucleic Acids Res. 2009, 37, 202–208. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, S.; Zhang, T.; Ye, Z.; Han, X.; Zhong, K.; Yang, J.; Chen, J.; Liu, P. Construction and biological characterization of an infectious full-length cDNA clone of a Chinese isolate of Wheat yellow mosaic virus. Virology 2021, 556, 101–109. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, F.; Xie, L.; Song, X.J.; Li, J.; Chen, J.P.; Zhang, H.M. Functional identification of two minor capsid proteins from Chinese wheat mosaic virus using its infectious full-length cDNA clones. J. Gen. Virol. 2016, 97, 2441–2450. [Google Scholar] [CrossRef]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the 2−ΔΔCT Method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence ID | Gene Location | ORF Length (bp) | Size (aa) | MW (KDa) | pI | GRAVY | Splice Variants | Subcellular Location | |
|---|---|---|---|---|---|---|---|---|---|
| TraesCS2A02G576200.1 | 770342688 | 770343067 | 303 | 100 | 11.51618 | 9.07 | −0.551 | 1 | Cytoplasmic |
| TraesCS3D02G416600.1 | 528084470 | 528084787 | 318 | 105 | 11.42406 | 8.57 | −0.016 | 1 | Cytoplasmic |
| TraesCS4B02G067000.1 | 59866358 | 59866678 | 321 | 106 | 11.71911 | 6.83 | −0.444 | 1 | Mitochondrial |
| TraesCS1D02G310300.1 | 406552140 | 406552876 | 324 | 107 | 11.78746 | 6.74 | −0.361 | 1 | Cytoplasmic |
| TraesCS1B02G322100.1 | 546534514 | 546535277 | 324 | 107 | 11.77056 | 9.13 | −0.293 | 1 | Mitochondrial |
| TraesCS4D02G252400.1 | 421220747 | 421221148 | 342 | 113 | 12.32008 | 5.21 | 0.044 | 1 | Extracellular |
| TraesCS7D02G337700.1 | 431120375 | 431120733 | 351 | 116 | 12.60957 | 9.4 | 0.039 | 1 | Extracellular |
| TraesCS3B02G361700.1 | 573403587 | 573404657 | 354 | 117 | 12.74076 | 9.18 | 0.113 | 1 | Extracellular |
| TraesCS7A02G341900.1 | 501921436 | 501921789 | 354 | 117 | 12.93808 | 9.3 | 0.126 | 1 | Extracellular |
| TraesCS7B02G241000.1 | 448639521 | 448639874 | 354 | 117 | 12.83683 | 9.4 | 0.014 | 1 | Extracellular |
| TraesCS4A02G052100.1 | 43031303 | 43031882 | 354 | 117 | 13.18154 | 10.11 | −0.112 | 1 | Mitochondrial |
| TraesCS5D02G502100.1 | 529800899 | 529801767 | 357 | 118 | 13.52646 | 5.01 | −0.419 | 1 | Cytoplasmic |
| TraesCS5A02G557600.1 | 708451918 | 708452506 | 357 | 118 | 12.96505 | 9.61 | −0.057 | 1 | Mitochondrial |
| TraesCS3D02G020500.1 | 6949696 | 6950286 | 357 | 118 | 12.49836 | 9.98 | 0.117 | 1 | Extracellular |
| TraesCS4D02G066000.1 | 40824447 | 40824806 | 360 | 119 | 13.14997 | 9.15 | −0.267 | 1 | Extracellular |
| TraesCS4A02G247900.1 | 558676008 | 558676367 | 360 | 119 | 13.21215 | 9.15 | −0.21 | 1 | Mitochondrial |
| TraesCS2B02G148400.1 | 114430719 | 114431084 | 366 | 121 | 12.93972 | 9.59 | −0.06 | 1 | Mitochondrial |
| TraesCS4B02G396100.1 | 670456115 | 670456483 | 369 | 122 | 13.43764 | 9.76 | 1 | Mitochondrial | |
| TraesCS2A02G126100.1 | 74561376 | 74562320 | 372 | 123 | 13.01076 | 9.5 | 0.027 | 1 | Extracellular |
| TraesCS2D02G128900.1 | 74985591 | 74986626 | 372 | 123 | 13.08292 | 10.12 | −0.059 | 1 | Extracellular |
| TraesCS3B02G077600.1 | 48667966 | 48668528 | 387 | 128 | 14.54467 | 5.88 | −0.203 | 1 | Cytoplasmic |
| TraesCS2D02G589700.1 | 645958642 | 645959221 | 387 | 128 | 14.58468 | 6.04 | −0.241 | 1 | Cytoplasmic |
| TraesCS2A02G578500.1 | 771772538 | 771773124 | 387 | 128 | 14.5586 | 6.04 | −0.282 | 1 | Cytoplasmic |
| TraesCS2B02G609300.1 | 789563953 | 789564540 | 387 | 128 | 14.47153 | 6.06 | −0.178 | 1 | Cytoplasmic |
| TraesCS2A02G581500.1 | 773562880 | 773563385 | 387 | 128 | 14.59085 | 6.4 | −0.054 | 1 | Extracellular |
| TraesCS2B02G611300.1 | 790623664 | 790624261 | 387 | 128 | 14.48565 | 6.83 | −0.135 | 1 | Chloroplast |
| TraesCS2D02G586800.1 | 644923731 | 644924419 | 387 | 128 | 14.48569 | 7.78 | −0.141 | 1 | Extracellular |
| TraesCS2B02G502800.1 | 697398239 | 697398802 | 387 | 128 | 14.58693 | 7.8 | −0.163 | 1 | Cytoplasmic |
| TraesCS2B02G611200.1 | 790612843 | 790613405 | 387 | 128 | 14.4467 | 8.93 | −0.16 | 1 | Extracellular |
| TraesCS2A02G576100.1 | 770290351 | 770290922 | 387 | 128 | 14.45468 | 8.95 | −0.169 | 1 | Extracellular |
| TraesCS2D02G586900.1 | 644975269 | 644975655 | 387 | 128 | 14.51576 | 9.14 | −0.212 | 1 | Extracellular |
| TraesCS2A02G575600.1 | 770023125 | 770023511 | 387 | 128 | 14.39963 | 9.26 | 0.005 | 1 | Extracellular |
| TraesCS2D02G477600.1 | 579510589 | 579511163 | 387 | 128 | 14.55305 | 9.33 | −0.109 | 1 | Cytoplasmic |
| TraesCS3B02G456600.1 | 698000195 | 698000638 | 393 | 130 | 13.82574 | 7.67 | 0.068 | 1 | Chloroplast |
| TraesCS3D02G325100.1 | 437966538 | 437967959 | 429 | 142 | 15.71427 | 6.14 | −0.056 | 1 | Cytoplasmic |
| TraesCS5D02G502600.1 | 529845043 | 529846275 | 429 | 142 | 15.68523 | 8.8 | −0.136 | 1 | Extracellular |
| TraesCS5A02G487700.1 | 657756833 | 657758161 | 429 | 142 | 16.08189 | 9.69 | −0.142 | 1 | Mitochondrial |
| TraesCS5D02G502200.1 | 529815663 | 529817000 | 435 | 144 | 16.3071 | 7.95 | −0.092 | 1 | Extracellular |
| TraesCS2A02G275900.1 | 455481094 | 455481712 | 435 | 144 | 15.05153 | 10.01 | 0.183 | 1 | Chloroplast |
| TraesCS2B02G293600.1 | 409400473 | 409401171 | 435 | 144 | 14.78817 | 10.16 | 0.202 | 1 | Chloroplast |
| TraesCS2D02G274900.1 | 344303051 | 344303637 | 435 | 144 | 14.93736 | 10.23 | 0.166 | 1 | Chloroplast |
| TraesCS3B02G456800.1 | 698194875 | 698195312 | 438 | 145 | 15.55955 | 8.55 | −0.24 | 1 | Extracellular |
| TraesCS3A02G421000.1 | 662520087 | 662520865 | 456 | 151 | 16.17131 | 7.66 | −0.164 | 1 | Extracellular |
| TraesCS4D02G025600.1 | 10999710 | 11000093 | 384 | 127 | 13.30729 | 9.17 | 0.227 | 1 | Extracellular |
| TraesCS3B02G456700.1 | 698122257 | 698122715 | 459 | 152 | 16.27537 | 7.66 | −0.199 | 1 | Extracellular |
| TraesCS3D02G416700.1 | 528094859 | 528095317 | 459 | 152 | 16.10226 | 7.66 | −0.114 | 1 | Extracellular |
| TraesCS3D02G416500.1 | 527735678 | 527736139 | 462 | 153 | 16.20031 | 8.43 | −0.15 | 1 | Extracellular |
| TraesCS3B02G456500.1 | 697983253 | 697983714 | 462 | 153 | 16.19928 | 8.45 | −0.112 | 1 | Extracellular |
| TraesCS5A02G487600.1 | 657725166 | 657725966 | 507 | 168 | 19.1852 | 6.16 | −0.283 | 1 | Extracellular |
| TraesCS1D02G255800.1 | 348063436 | 348067242 | 513 | 170 | 18.15371 | 9.42 | −0.115 | 1 | Extracellular |
| TraesCS1B02G267100.1 | 469999341 | 470003147 | 543 | 180 | 19.01667 | 7.79 | −0.018 | 1 | Extracellular |
| TraesCS1A02G256400.1 | 448926775 | 448930744 | 546 | 181 | 19.11479 | 8.62 | −0.044 | 2 | Chloroplast |
| TraesCS3D02G189800.1 | 177482785 | 177486000 | 732 | 243 | 26.60537 | 6.37 | −0.249 | 1 | Extracellular |
| TraesCS3A02G185800.1 | 218117459 | 218120388 | 732 | 243 | 26.60537 | 6.37 | −0.249 | 1 | Extracellular |
| TraesCS3B02G215400.1 | 256357151 | 256360095 | 732 | 243 | 26.74851 | 6.38 | −0.288 | 1 | Extracellular |
| TraesCS3B02G215400.1 | 256357151 | 256360095 | 732 | 243 | 26.74851 | 6.38 | −0.288 | 1 | Extracellular |
| Lineage | Organism | Genome Size | Total Number of Cystatin Proteins |
|---|---|---|---|
| Dicots | Arabidopsis thaliana (2n) | 135 Mb | 7 |
| Glycine max (2n) | 1.15 Gb | 20 | |
| Monocots | Oryza sativa (2n) | 500 Mb | 11 |
| Sorghum bicolor (2n) | 700 Mb | 22 | |
| Hordeum vulgare (6n) | 1.35 Gb | 13 | |
| Brachypodium distachyon (2n) | 300 Mb | 23 | |
| Triticum aestivum (6n) | 15.8 Gb | 55 |
| Homoeologous (A:B:D) | All Wheat Genes 1 | Classes 2 | Number of Groups | Number of Genes | % of Total TaCystatins | ||
|---|---|---|---|---|---|---|---|
| A | B | C | |||||
| 1:1:1 | 35.8% | 2 | 1 | 5 | 8 | 24 | 43.65% |
| n: 1:1, 1: n:1, or 1:1: n & | 5.7% | 1 | 1 | 2 | 8 | 14.55% | |
| 1:1:0, 1:0:1, or 0:1:1 | 13.2% | 2 | 2 | 4 | 8 | 14.55% | |
| Orphans | 37.1% | 1 | 1 | 1 | 1.81% | ||
| Other ratios | 8% | 1 | 1 | 2 | 4 | 14 | 25.45% |
| Species Name | CBI | Fop | ENC | GC3s | GC Content |
|---|---|---|---|---|---|
| Triticum aestivum | 0.093 | 0.470 | 42.185 | 0.774 | 0.611 |
| Arabidopsis thaliana | 0.010 | 0.423 | 52.233 | 0.509 | 0.473 |
| Brachypodium distachyon | 0.109 | 0.479 | 40.929 | 0.810 | 0.626 |
| Hordeum vulgare | 0.096 | 0.474 | 41.722 | 0.770 | 0.604 |
| Glycine max | 0.028 | 0.433 | 50.735 | 0.595 | 0.508 |
| Oryza sativa | 0.106 | 0.477 | 38.076 | 0.857 | 0.669 |
| Sorghum bicolor | 0.094 | 0.468 | 42.536 | 0.794 | 0.634 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Chen, X.; Xu, M.; Liu, T.; Zhang, T.; Li, J.; Yang, J.; Chen, J.; Zhong, K. Genome-Wide Identification and Characterization of the Cystatin Gene Family in Bread Wheat (Triticum aestivum L.). Int. J. Mol. Sci. 2021, 22, 10264. https://doi.org/10.3390/ijms221910264
He L, Chen X, Xu M, Liu T, Zhang T, Li J, Yang J, Chen J, Zhong K. Genome-Wide Identification and Characterization of the Cystatin Gene Family in Bread Wheat (Triticum aestivum L.). International Journal of Molecular Sciences. 2021; 22(19):10264. https://doi.org/10.3390/ijms221910264
Chicago/Turabian StyleHe, Long, Xuan Chen, Miaoze Xu, Tingting Liu, Tianye Zhang, Juan Li, Jian Yang, Jianping Chen, and Kaili Zhong. 2021. "Genome-Wide Identification and Characterization of the Cystatin Gene Family in Bread Wheat (Triticum aestivum L.)" International Journal of Molecular Sciences 22, no. 19: 10264. https://doi.org/10.3390/ijms221910264
APA StyleHe, L., Chen, X., Xu, M., Liu, T., Zhang, T., Li, J., Yang, J., Chen, J., & Zhong, K. (2021). Genome-Wide Identification and Characterization of the Cystatin Gene Family in Bread Wheat (Triticum aestivum L.). International Journal of Molecular Sciences, 22(19), 10264. https://doi.org/10.3390/ijms221910264