
Identification and Structural Aspects of G-Quadruplex-Forming Sequences from the Influenza A Virus Genome


Abstract
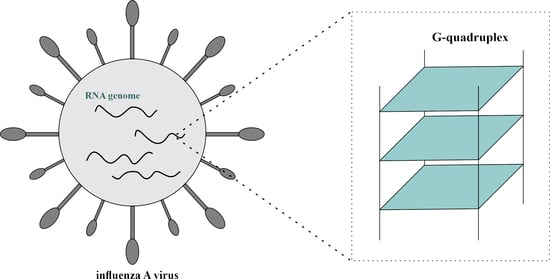
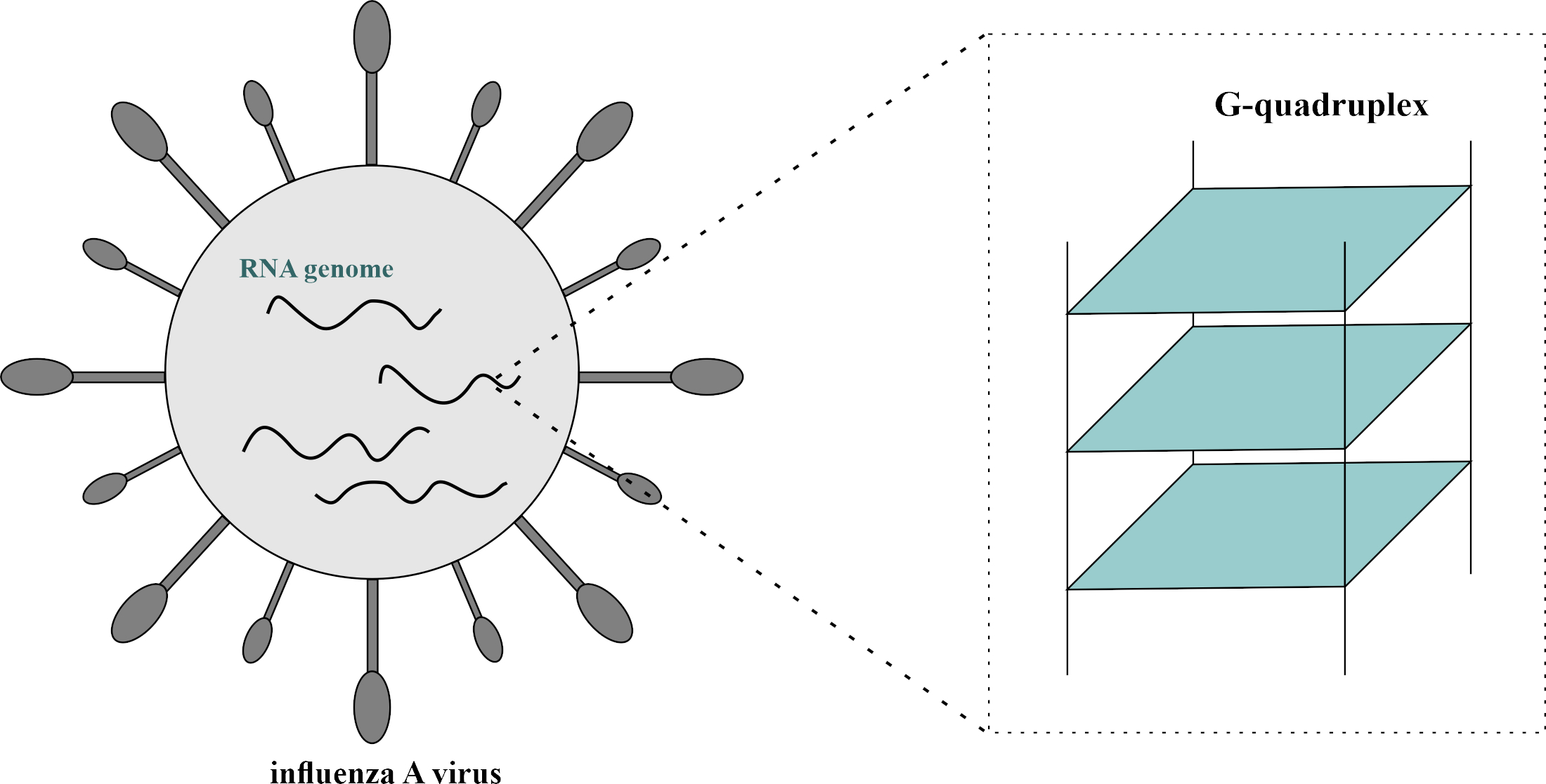
1. Introduction
2. Results
2.1. Identification of Potential Quadruplex-Forming Sequences (PQS) Motifs in the Influenza A Virus (IAV) Genome
2.2. Identification of Nucleotide Residues Frequency in PQS Motifs
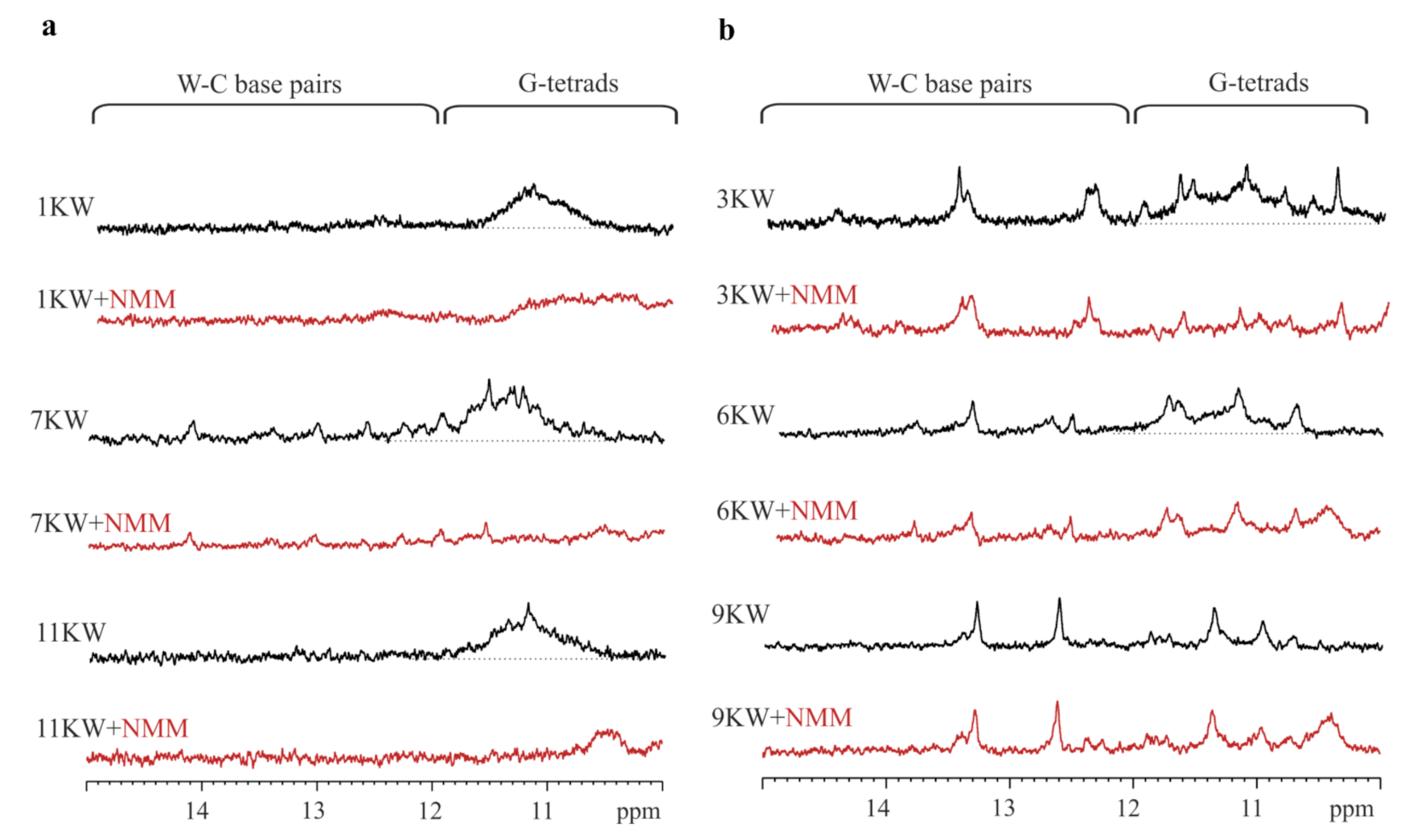
2.3. Characterization of PQS Motifs by Nuclear Magnetic Resonance (1H NMR)
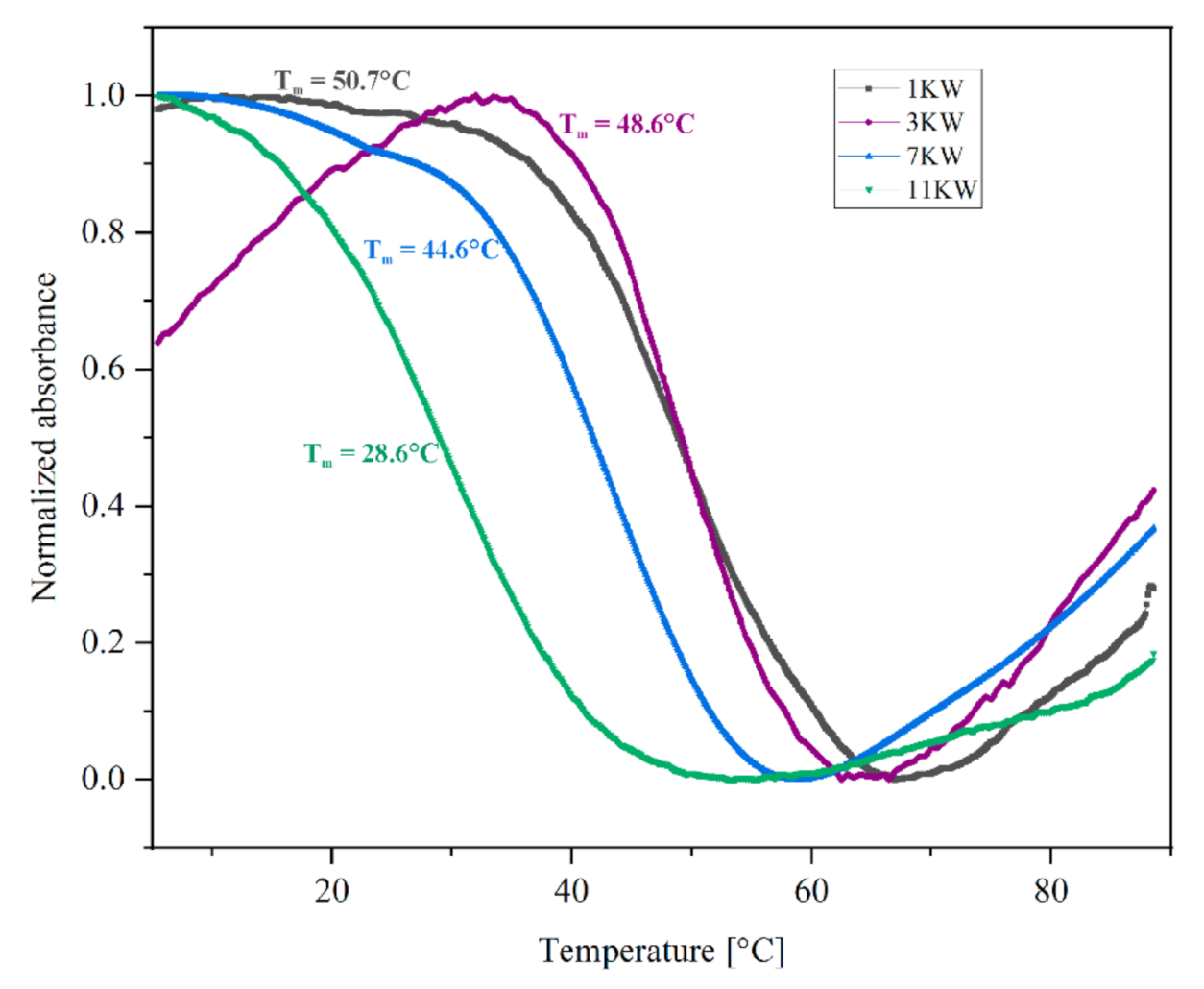
2.4. Determination of Thermal Melting Profiles of PQS Motifs
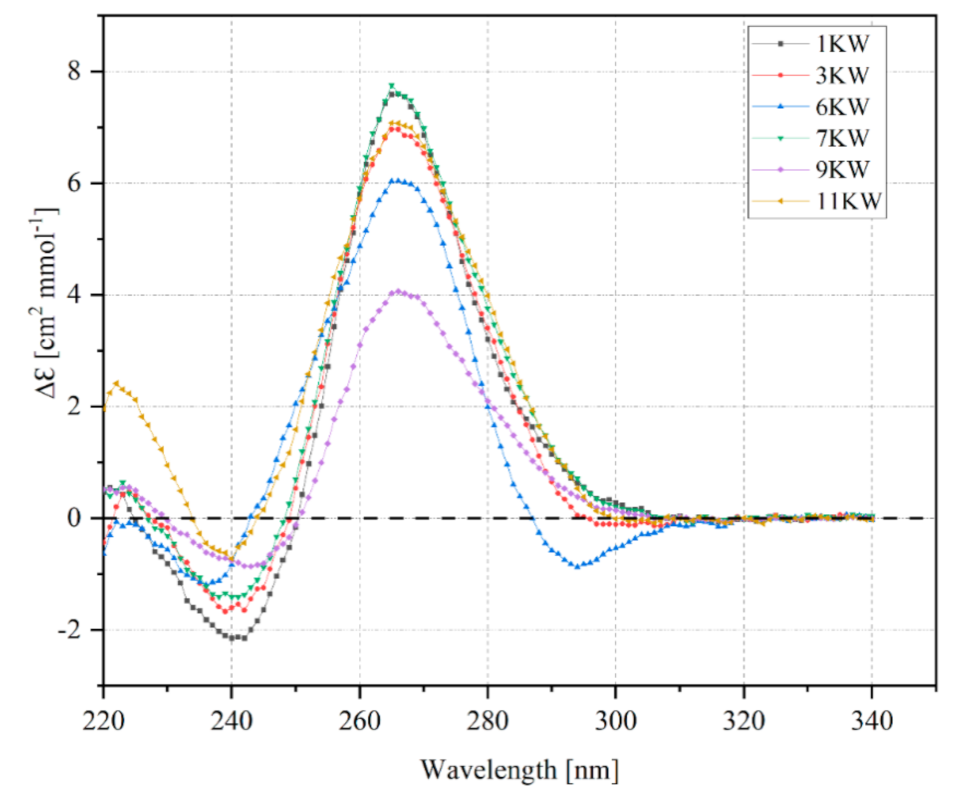
2.5. Circular Dichroism Spectra of PQS Oligomers
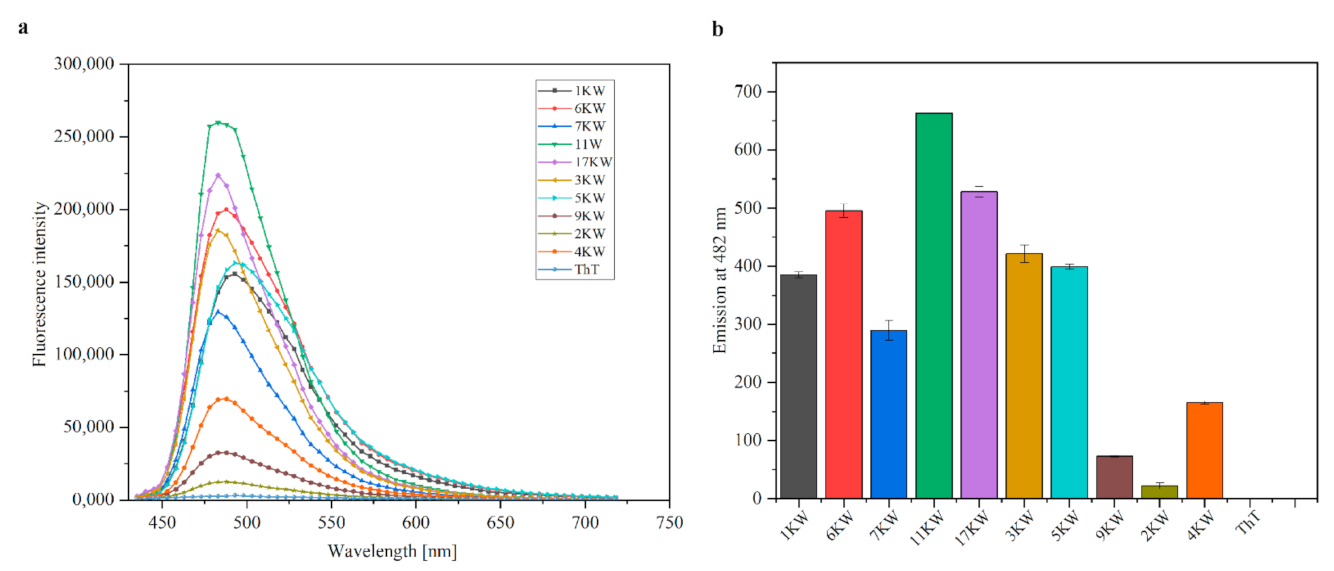
2.6. Thioflavin T Fluorescence Intensity Measurements
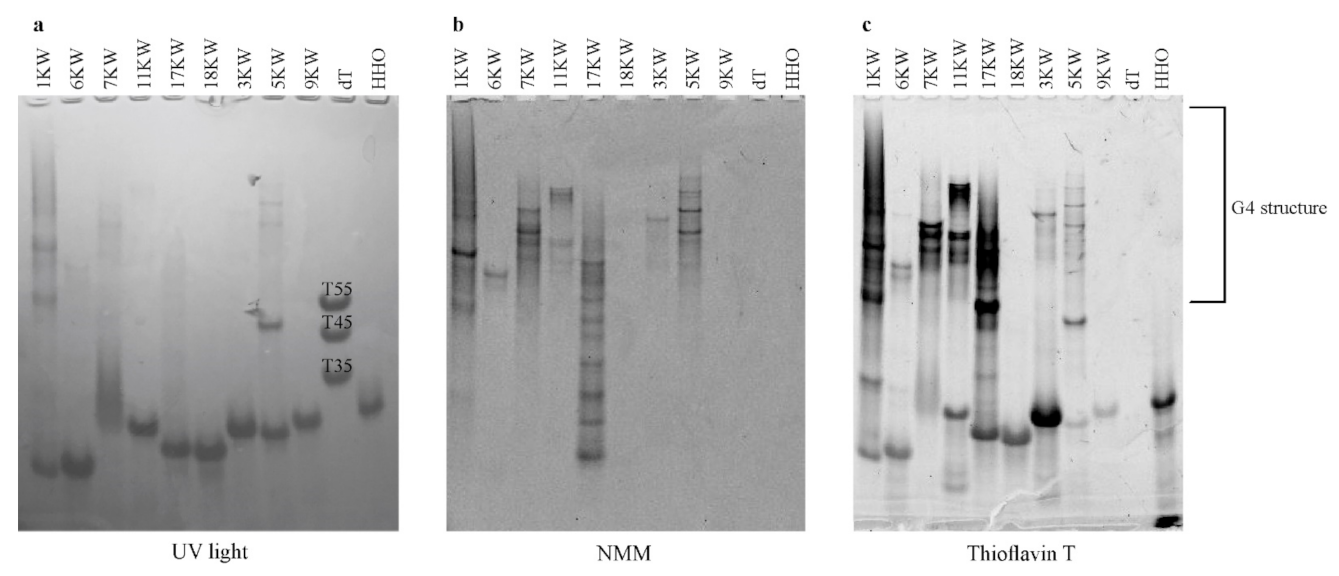
2.7. Native Gel Electrophoresis
3. Discussion
4. Materials and Methods
4.1. Identification of PQS Motifs in the IAV Genome
4.2. Sequence Alignment and Frequency of Nucleotide Residues Analysis
4.3. Synthesis and Purification of Oligonucleotides
4.4. NMR Spectroscopy
4.5. Ultraviolet (UV) Melting Measurements
4.6. Circular Dichroism Spectroscopy
4.7. Fluorescence Intensity Measurements
4.8. Native Polyacrylamide Electrophoresis
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Takemoto, Y. Therapeutic approach for seasonal influenza and pandemic. In Influenza-Therapeutics and Challenges; Saxena, S.K., Ed.; IntechOpen: London, UK, 2018; Volume 1, pp. 133–150. [Google Scholar]
- Mostafa, A.; Abdelwhab, E.M.; Mettenleiter, T.C.; Pleschka, S. Zoonotic potential of influenza A viruses: A comprehensive overview. Viruses 2018, 10, 497. [Google Scholar] [CrossRef]
- Blümel, J.; Burger, R.; Drosten, C.; Gröner, A.; Gürtler, L.; Heiden, M.; Hildebrandt, M.; Jansen, B.; Klamm, H.; Montag-Lessing, T.; et al. Influenza Virus. Transfus. Med. Hemother. 2009, 36, 32–39. [Google Scholar]
- Shao, W.; Li, X.; Goraya, M.U.; Wang, S.; Chen, J.L. Evolution of influenza A virus by mutation and re-assortment. Int. J. Mol. Sci. 2017, 18, 1650. [Google Scholar] [CrossRef]
- Samji, T. Influenza A: Understanding the viral life cycle. Yale J. Biol. Med. 2009, 82, 153–159. [Google Scholar]
- Noda, T.; Kawaoka, Y. Structure of influenza virus ribonucleoprotein complexes and their packaging into virions. Rev. Med. Virol. 2010, 20, 380–391. [Google Scholar] [CrossRef]
- Ferhadian, D.; Contrant, M.; Printz-Schweigert, A.; Smyth, R.P.; Paillart, J.C.; Marquet, R. Structural and functional motifs in influenza virus RNAs. Front. Microbiol. 2018, 9, 1–11. [Google Scholar] [CrossRef]
- Zheng, W.; Tao, Y.J. Structure and assembly of the influenza A virus ribonucleoprotein complex. FEBS Lett. 2013, 587, 1206–1214. [Google Scholar] [CrossRef]
- Lee, N.; Le Sage, V.; Nanni, A.V.; Snyder, D.J.; Cooper, V.S.; Lakdawala, S.S. Genome-wide analysis of influenza viral RNA and nucleoprotein association. Nucleic Acids Res. 2017, 45, 8968–8977. [Google Scholar] [CrossRef]
- Simon, L.M.; Morandi, E.; Luganini, A.; Gribaudo, G.; Martinez-Sobrido, L.; Turner, D.H.; Oliviero, S.; Incarnato, D. In vivo analysis of influenza A mRNA secondary structures identifies critical regulatory motifs. Sour. Nucleic Acids Res. 2019, 47, 7003–7017. [Google Scholar] [CrossRef]
- Szabat, M.; Lorent, D.; Czapik, T.; Tomaszewska, M.; Kierzek, E.; Kierzek, R. RNA secondary structure as a first step for rational design of the oligonucleotides towards inhibition of influenza a virus replication. Pathogens 2020, 9, 925. [Google Scholar] [CrossRef]
- Kao, S.Y.; Calman, A.F.; Luciw, P.A.; Peterlin, B.M. Anti-termination of transcription within the long terminal repeat of HIV-1 by tat gene product. Nature 1987, 330, 489–493. [Google Scholar] [CrossRef] [PubMed]
- Cammas, A.; Millevoi, S. RNA G-quadruplexes: Emerging mechanisms in disease. Nucleic Acids Res. 2017, 45, 1584–1595. [Google Scholar] [CrossRef]
- Xi, H.; Juhas, M.; Zhang, Y. G-quadruplex based biosensor: A potential tool for SARS-CoV-2 detection. Biosens. Bioelectron. 2020, 167, 112494. [Google Scholar] [CrossRef] [PubMed]
- Małgowska, M.; Gudanis, D.; Teubert, A.; Dominiak, G.; Gdaniec, Z. How to study G-quadruplex structures. Biotechnologia 2012, 93, 381–390. [Google Scholar] [CrossRef]
- Kharel, P.; Becker, G.; Tsvetkov, V.; Ivanov, P. Properties and biological impact of RNA G-quadruplexes: From order to turmoil and back. Nucleic Acids Res. 2020, 48, 12534–12555. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.R.; Zhang, Q.Y.; Wang, J.Q.; Ge, X.Y.; Song, Y.Y.; Wang, Y.F.; Li, X.D.; Fu, B.S.; Xu, G.H.; Shu, B.; et al. Chemical targeting of a G-quadruplex RNA in the Ebola virus L gene. Cell Chem. Biol. 2016, 23, 1113–1122. [Google Scholar] [CrossRef]
- Fleming, A.M.; Ding, Y.; Alenko, A.; Burrows, C.J. Zika virus genomic RNA possesses conserved G-quadruplexes characteristic of the Flaviviridae family. ACS Infect. Dis. 2016, 2, 674–681. [Google Scholar] [CrossRef] [PubMed]
- Ji, D.; Juhas, M.; Tsang, C.M.; Kwok, C.K.; Li, Y.; Zhang, Y. Discovery of G-quadruplex-forming sequences in SARS-CoV-2. Brief. Bioinform. 2020, 22, 1150–1160. [Google Scholar] [CrossRef] [PubMed]
- Brázda, V.; Porubiaková, O.; Cantara, A.; Bohálová, N.; Coufal, J.; Bartas, M.; Fojta, M.; Mergny, J.L. G-quadruplexes in H1N1 influenza genomes. BMC Genom. 2021, 22, 77. [Google Scholar] [CrossRef] [PubMed]
- Puig Lombardi, E.; Londoño-Vallejo, A. A guide to computational methods for G-quadruplex prediction. Nucleic Acids Res. 2020, 48, 1–15. [Google Scholar] [CrossRef]
- Stephens, R.M.; Schneider, T.D. Sequence logos: A new way to display consensus sequences. Nucleic Acids Res. 1990, 18, 6097–6100. [Google Scholar]
- Crooks, G.; Hon, G.; Chandonia, J.; Brenner, S. WebLogo: A sequence logo generator. Genome Res. 2004, 14, 1188–1190. [Google Scholar] [CrossRef]
- Barnwal, R.P.; Yang, F.; Varani, G. Applications of NMR to structure determination of RNAs large and small. Arch. Biochem. Biophys. 2017, 628, 42–56. [Google Scholar] [CrossRef]
- da Silva, M.W. NMR methods for studying quadruplex nucleic acids. Methods 2007, 43, 264–277. [Google Scholar] [CrossRef] [PubMed]
- Rachwal, P.A.; Fox, K.R. Quadruplex melting. Methods 2007, 43, 291–301. [Google Scholar] [CrossRef] [PubMed]
- Mergny, J.L.; Lacroix, L. UV melting of G-quadruplexes. Curr. Protoc. Nucleic Acid Chem. 2009, 37, 1–15. [Google Scholar] [CrossRef]
- Kypr, J.; Kejnovská, I.; Bednářová, K.; Vorlíčková, M. Circular dichroism spectroscopy of nucleic acids. Compr. Chiroptical Spectrosc. 2012, 2, 575–586. [Google Scholar]
- del Villar-Guerra, R.; Trent, J.O.; Chaires, J.B. G-quadruplex secondary structure from circular dichroism spectroscopy. Angew. Chem. 2018, 57, 7171–7175. [Google Scholar] [CrossRef]
- Bao, H.L.; Xu, Y. Investigation of higher-order RNA G-quadruplex structures in vitro and in living cells by 19 F NMR spectroscopy. Nat. Protoc. 2018, 13, 652–665. [Google Scholar] [CrossRef]
- Mohanty, J.; Barooah, N.; Dhamodharan, V.; Harikrishna, S.; Pradeepkumar, P.I.; Bhasikuttan, A.C. Thioflavin T as an efficient inducer and selective fluorescent sensor for the human telomeric G-quadruplex DNA. J. Am. Chem. Soc. 2013, 135, 367–376. [Google Scholar] [CrossRef]
- Xu, S.; Li, Q.; Xiang, J.; Yang, Q.; Sun, H.; Guan, A.; Wang, L.; Liu, Y.; Yu, L.; Shi, Y.; et al. Thioflavin T as an efficient fluorescence sensor for selective recognition of RNA G-quadruplexes. Sci. Rep. 2016, 6, 24793. [Google Scholar] [CrossRef]
- Jing, S.; Liu, Q.; Jin, Y.; Li, B. Dimeric G-quadruplex: An effective nucleic acid scaffold for lighting up thioflavin T. Anal. Chem. 2021, 93, 1333–1341. [Google Scholar] [CrossRef]
- De La Faverie, A.R.; Guédin, A.; Bedrat, A.; Yatsunyk, L.A.; Mergny, J.L. Thioflavin T as a fluorescence light-up probe for G4 formation. Nucleic Acids Res. 2014, 42, e65. [Google Scholar] [CrossRef]
- Smith, J.S.; Johnson, F.B. Isolation of G-quadruplex DNA using NMM-sepharose affinity chromatography. Methods Mol. Biol. 2010, 608, 207–221. [Google Scholar]
- Liu, S.; Peng, P.; Wang, H.; Shi, L.; Li, T. Thioflavin T binds dimeric parallel-stranded GA-containing non-G-quadruplex DNAs: A general approach to lighting up double-stranded scaffolds. Nucleic Acids Res. 2017, 45, 12080–12089. [Google Scholar] [CrossRef]
- Paules, C.I.; Fauci, A.S. Influenza vaccines: Good, but we can do better. J. Infect. Dis. 2019, 219, S1–S4. [Google Scholar] [CrossRef] [PubMed]
- Gilbertson, B.; Zheng, T.; Gerber, M.; Printz-Schweigert, A.; Ong, C.; Marquet, R.; Isel, C.; Rockman, S.; Brown, L. Influenza NA and PB1 gene segments interact during the formation of viral progeny: Localization of the binding region within the PB1 gene. Viruses 2016, 8, 238. [Google Scholar] [CrossRef] [PubMed]
- Gultyaev, A.P.; Fouchier, R.A.M.; Olsthoorn, R.C.L. Influenza virus RNA structure: Unique and common features. Int. Rev. Immunol. 2010, 29, 533–556. [Google Scholar] [CrossRef]
- Arranz, R.; Coloma, R.; Chichón, F.J.; Conesa, J.J.; Carrascosa, J.L.; Valpuesta, J.; Ortín, J.; Martín-Benito, J. The Structure of Native Influenza Virion Ribonucleoproteins. Science 2012, 338, 1634–1638. [Google Scholar] [CrossRef]
- Williams, G.D.; Townsend, D.; Wylie, K.M.; Kim, P.J.; Amarasinghe, G.K.; Kutluay, S.B.; Boon, A.C.M. Nucleotide resolution mapping of influenza A virus nucleoprotein-RNA interactions reveals RNA features required for replication. Nat. Commun. 2018, 9, 465. [Google Scholar] [CrossRef] [PubMed]
- Le Sage, V.; Kanarek, J.P.; Snyder, D.J.; Cooper, V.S.; Lakdawala, S.S.; Lee, N. Mapping of Influenza Virus RNA-RNA Interactions Reveals a Flexible Network. Cell Rep. 2020, 31, 107823. [Google Scholar] [CrossRef] [PubMed]
- Jaubert, C.; Bedrat, A.; Bartolucci, L.; Di Primo, C.; Ventura, M.; Mergny, J.L.; Amrane, S.; Andreola, M.L. RNA synthesis is modulated by G-quadruplex formation in Hepatitis C virus negative RNA strand. Sci. Rep. 2018, 8, 8120. [Google Scholar] [CrossRef] [PubMed]
- Lombardi, E.P.; Londoño-Vallejo, A.; Nicolas, A. Relationship between G-quadruplex sequence composition in viruses and their hosts. Molecules 2019, 24, 1942. [Google Scholar] [CrossRef] [PubMed]
- Garant, J.M.; Perreault, J.P.; Scott, M.S. Motif independent identification of potential RNA G-quadruplexes by G4RNA screener. Bioinformatics 2017, 33, 3532–3537. [Google Scholar] [CrossRef]
- Kikin, O.; D’Antonio, L.; Bagga, P.S. QGRS Mapper: A web-based server for predicting G-quadruplexes in nucleotide sequences. Nucleic Acids Res. 2006, 34, 676–682. [Google Scholar] [CrossRef]
- Kocman, V.; Plavec, J. Tetrahelical structural family adopted by AGCGA-rich regulatory DNA regions. Nat. Commun. 2017, 8, 15355. [Google Scholar] [CrossRef]
- Guédin, A.; Gros, J.; Alberti, P.; Mergny, J.L. How long is too long? Effects of loop size on G-quadruplex stability. Nucleic Acids Res. 2010, 38, 7858–7868. [Google Scholar] [CrossRef]
- Lavezzo, E.; Berselli, M.; Frasson, I.; Perrone, R.; Palù, G.; Brazzale, A.R.; Richter, S.N.; Toppo, S. G-quadruplex forming sequences in the genome of all known human viruses: A comprehensive guide. PLoS Comput. Biol. 2018, 14, e1006675. [Google Scholar] [CrossRef] [PubMed]
- Bartas, M.; Brázda, V.; Bohálová, N.; Cantara, A.; Volná, A.; Stachurová, T.; Malachová, K.; Jagelská, E.B.; Porubiaková, O.; Červeň, J.; et al. In-Depth Bioinformatic Analyses of Nidovirales Including Human SARS-CoV-2, SARS-CoV, MERS-CoV Viruses Suggest Important Roles of Non-canonical Nucleic Acid Structures in Their Lifecycles. Front. Microbiol. 2020, 11, 1–16. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, L. G-quadruplexes are present in human coronaviruses including SARS-CoV-2. Front. Microbiol. 2020, 11, 1–8. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Zhu, Y.; Diao, L. A fluorescence method for homogeneous detection of influenza A DNA sequence based on guanine-quadruplex-N-methylmesoporphyrin IX complex and assistance-DNA inhibition. J. Med. Virol. 2019, 91, 979–985. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Qin, G.; Niu, J.; Wang, Z.; Wang, C.; Ren, J.; Qu, X. Targeting RNA G-quadruplex in SARS-CoV-2: A promising therapeutic target for COVID-19? Angew. Chem. Int. Ed. 2021, 60, 432–438. [Google Scholar] [CrossRef] [PubMed]
- Kierzek, E.; Kierzek, R. The thermodynamic stability of RNA duplexes and hairpins containing N6-alkyladenosines and 2-methylthio-N6-alkyladenosines. Nucleic Acids Res. 2003, 31, 4472–4480. [Google Scholar] [CrossRef] [PubMed]
- Xia, T.; SantaLucia, J.; Burkard, M.E.; Kierzek, R.; Schroeder, S.J.; Jiao, X.; Cox, C.; Turner, D.H. Thermodynamic parameters for an expanded nearest-neighbor model for formation of RNA duplexes with Watson-Crick base pairs. Biochemistry 1998, 37, 14719–14735. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segment (Protein) | Segment Length (nt) | PQS Name | PQS Location within Segment | Sequence (5′-3′) |
|---|---|---|---|---|
| 1 (PB2) | 2341 | 1KW | 436–460 | CUGGUGGGGCAGCAGCAAAGGGGAG |
| 6KW | 1018–1040 | GGUGCAUGGGGUUCAGUCGCUGG | ||
| 2 (PB1) | 2341 | 2KW | 360–381 | UUGGCUGGACCAUGGGCUGGCA |
| 7KW | 2097–2128 | GGUAGUGGUCCAUCAAUCGGGUUGAGCUGGGG | ||
| 8KW | 2224–2259 | GGCUGUAUGGAGGAUCUCCAGUAUAAGGGAAUGUGG | ||
| 3 (PA) | 2233 | 9KW | 495–526 | UUGGAGGUUCCAUUGGUUCUCACAUAUAGGAA |
| 10KW | 1381–1412 | GGCAAAGAGGCCCAUCAGGCAAUCUGAGGGG | ||
| 3KW | 1532–1564 | AAGGCUGGGGAAGUUCGGUGGGAGACUUUGGUC | ||
| 4 (HA) | 1779 | 11KW | 807–834 | GGAUGUAUAUUCUGAAAUGGGAGGCUGG |
| 4KW | 1133–1157 | UUGGUCAGCACUAGUAGGUGGAUGG | ||
| 7 (M1) (M2) | 1027 | 12KW | 935–959 | UCGGCUUUGAGGGGGCCUGACGGGA |
| 8 (NS1) (NS2) | 890 | 5KW | 751–778 | UCGGCGGAGCCGAUCAAGGAAUGGGGCA |
| G—G-rich sites which can be involved in RNA G-quadruplex formation. | ||||
| PQS Name | Influenza Type A | H1N1 Subtype | ||
|---|---|---|---|---|
| Number of Sequences | Similarity [%] | Number of Sequences | Similarity [%] | |
| 1KW | 20,593 | 86.1 | 8793 | 93.0 |
| 2KW | 20,430 | 96.0 | 8597 | 96.4 |
| 3KW | 20,069 | 93.3 | 8743 | 93.0 |
| 4KW | 20,534 | 71.0 | 9081 | 86.0 |
| 5KW | 12,902 | 95.1 | 5569 | 96.7 |
| 6KW | 20,593 | 86.8 | 8793 | 92.4 |
| 7KW | 20,430 | 96.1 | 8597 | 93.4 |
| 8KW | 20,430 | 97.5 | 8597 | 97.8 |
| 9KW | 20,069 | 86.9 | 8743 | 97.4 |
| 10KW | 20,069 | 80.0 | 8743 | 92.3 |
| 11KW | 20,534 | 84.1 | 9081 | 95.0 |
| 12KW | 11,392 | 95.4 | 4767 | 99.6 |
| Number of sequences deposited in the Influenza Research Database (December 2020). | ||||
| PQS Name | LOGO Sequence | PQS Length (nt) | Conserved Nucleotides | Conservation (%) | Variable Nucleotides | Variability (%) |
|---|---|---|---|---|---|---|
| 1KW |  | 25 | 20 | 80.0 | 5 | 20.0 |
| 2KW |  | 22 | 18 | 81.8 | 4 | 18.2 |
| 3KW |  | 33 | 26 | 78.8 | 7 | 21.2 |
| 4KW |  | 25 | 11 | 44.0 | 14 | 56.0 |
| 5KW |  | 28 | 21 | 75.0 | 7 | 25.0 |
| 6KW |  | 23 | 16 | 69.6 | 7 | 30.4 |
| 7KW |  | 32 | 24 | 75.0 | 8 | 25.0 |
| 8KW |  | 36 | 30 | 83.4 | 6 | 16.6 |
| 9KW |  | 32 | 26 | 81.3 | 6 | 18.7 |
| 10KW |  | 31 | 20 | 64.5 | 11 | 35.5 |
| 11KW |  | 28 | 18 | 64.3 | 10 | 35.7 |
| 12KW |  | 25 | 23 | 92.0 | 2 | 8.0 |
| PQS Name | 1H NMR Spectra | UV Melting Profile at 295nm | CD Spectra | Thioflavin T Fluorescence Enhancement | Native Polyacrylamide Gel Electrophoresis | G4 Structure Folding |
|---|---|---|---|---|---|---|
| 1KW | ✓ | ✓ | ✓ | ✓ | ✓ | yes |
| 7KW | ✓ | ✓ | ✓ | ✓ | ✓ | yes |
| 11KW | ✓ | ✓ | ✓ | ✓ | ✓ | yes |
| 3KW | ✓ - | ✓ - | ✓ | ✓ | ✓ | probably |
| 6KW | ✓ - | ✓ - | ✓ - | ✓ | ✓ | probably |
| 9KW | ✓ - | ✓ - | ✓ | ✓ - | ✓ - | no |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomaszewska, M.; Szabat, M.; Zielińska, K.; Kierzek, R. Identification and Structural Aspects of G-Quadruplex-Forming Sequences from the Influenza A Virus Genome. Int. J. Mol. Sci. 2021, 22, 6031. https://doi.org/10.3390/ijms22116031
Tomaszewska M, Szabat M, Zielińska K, Kierzek R. Identification and Structural Aspects of G-Quadruplex-Forming Sequences from the Influenza A Virus Genome. International Journal of Molecular Sciences. 2021; 22(11):6031. https://doi.org/10.3390/ijms22116031
Chicago/Turabian StyleTomaszewska, Maria, Marta Szabat, Karolina Zielińska, and Ryszard Kierzek. 2021. "Identification and Structural Aspects of G-Quadruplex-Forming Sequences from the Influenza A Virus Genome" International Journal of Molecular Sciences 22, no. 11: 6031. https://doi.org/10.3390/ijms22116031
APA StyleTomaszewska, M., Szabat, M., Zielińska, K., & Kierzek, R. (2021). Identification and Structural Aspects of G-Quadruplex-Forming Sequences from the Influenza A Virus Genome. International Journal of Molecular Sciences, 22(11), 6031. https://doi.org/10.3390/ijms22116031