
Structural Damage Detection Using Supervised Nonlinear Support Vector Machine

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Theory of Nonlinear Support Vector Machine
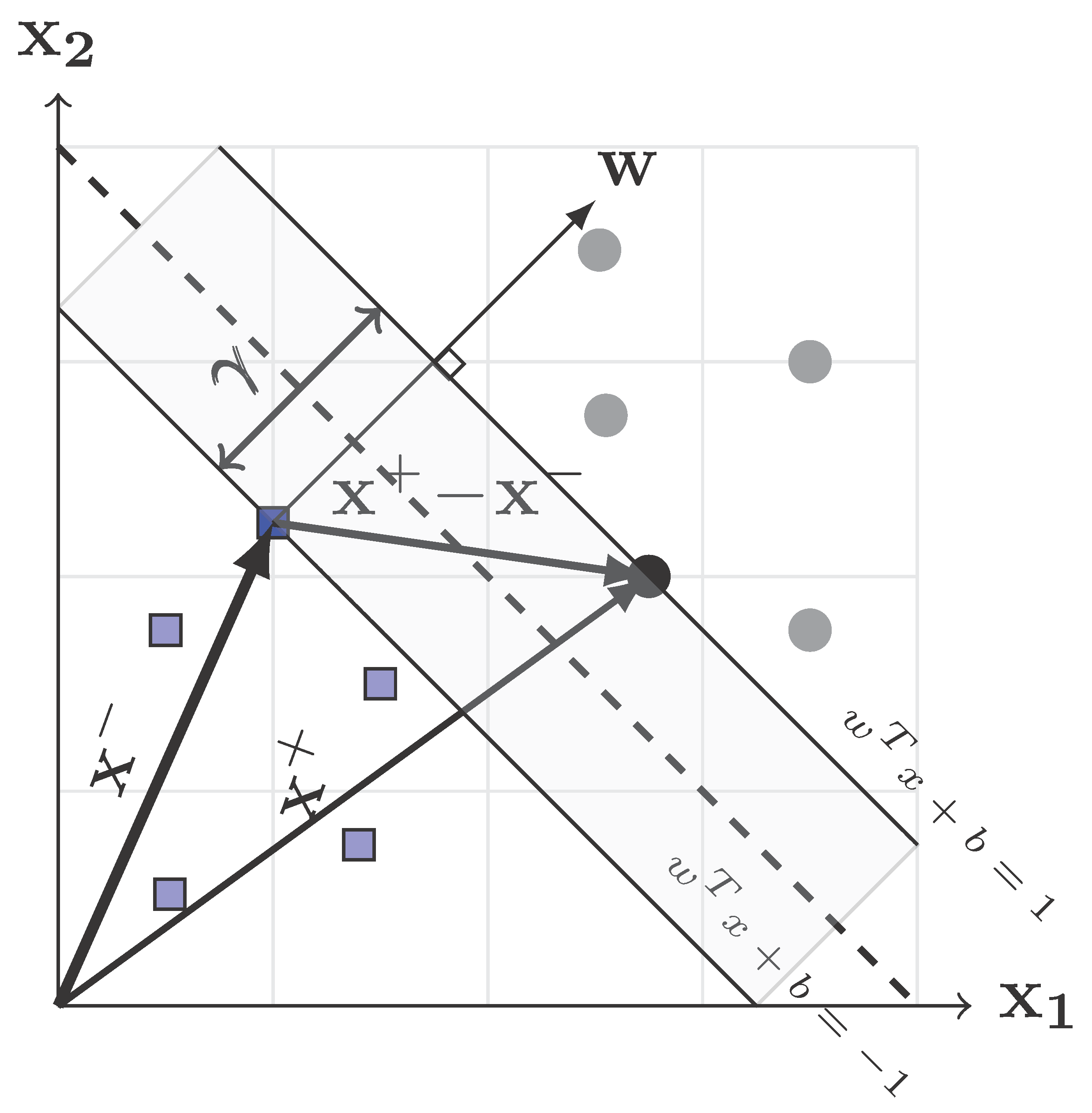
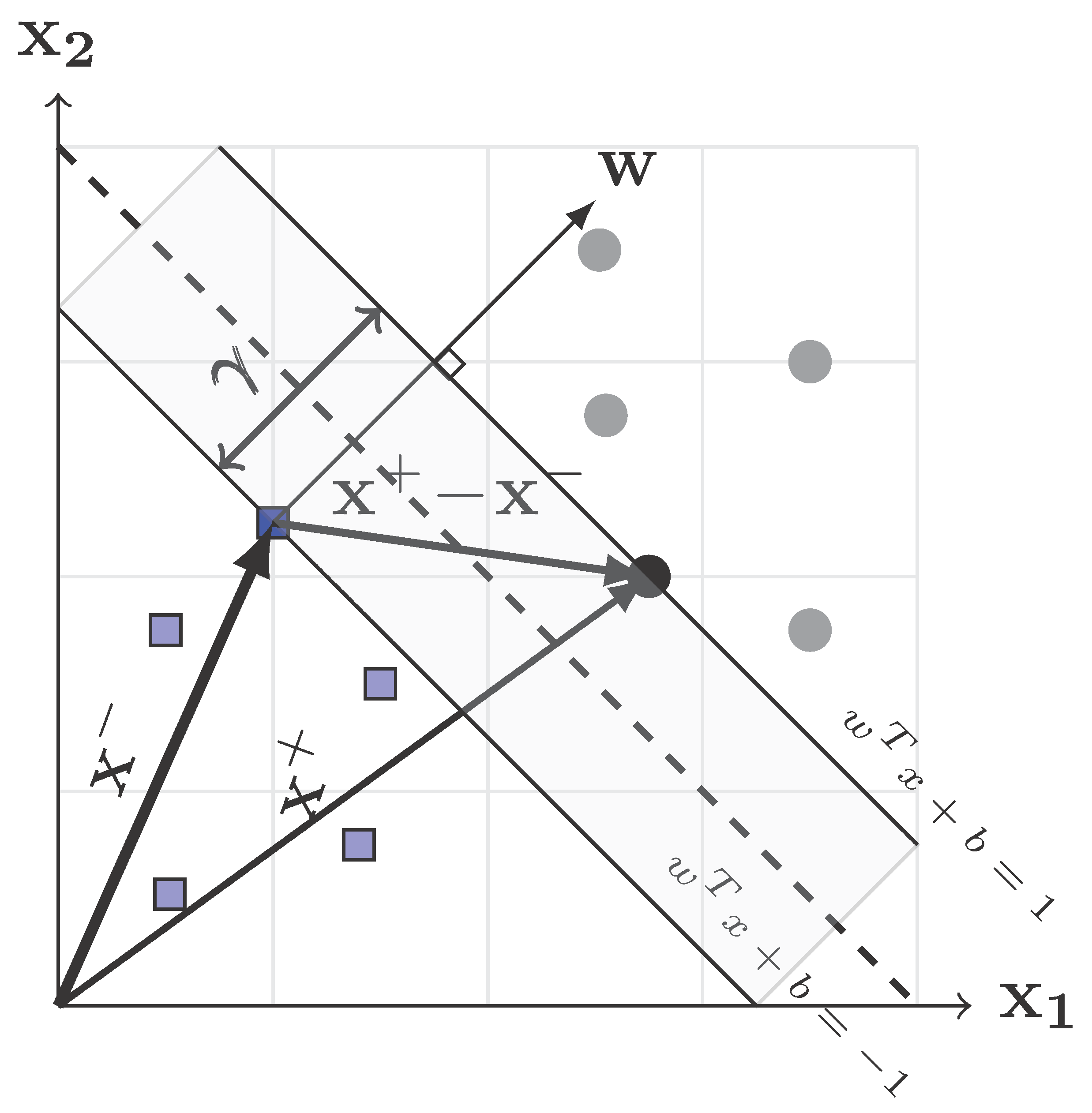
2.1. Linear SVM
2.2. Nonlinear SVM
Kernel Trick
2.3. Numerical Algorithm
| Algorithm 1: Numerical procedure for classification using nonlinear SVM. |
 |
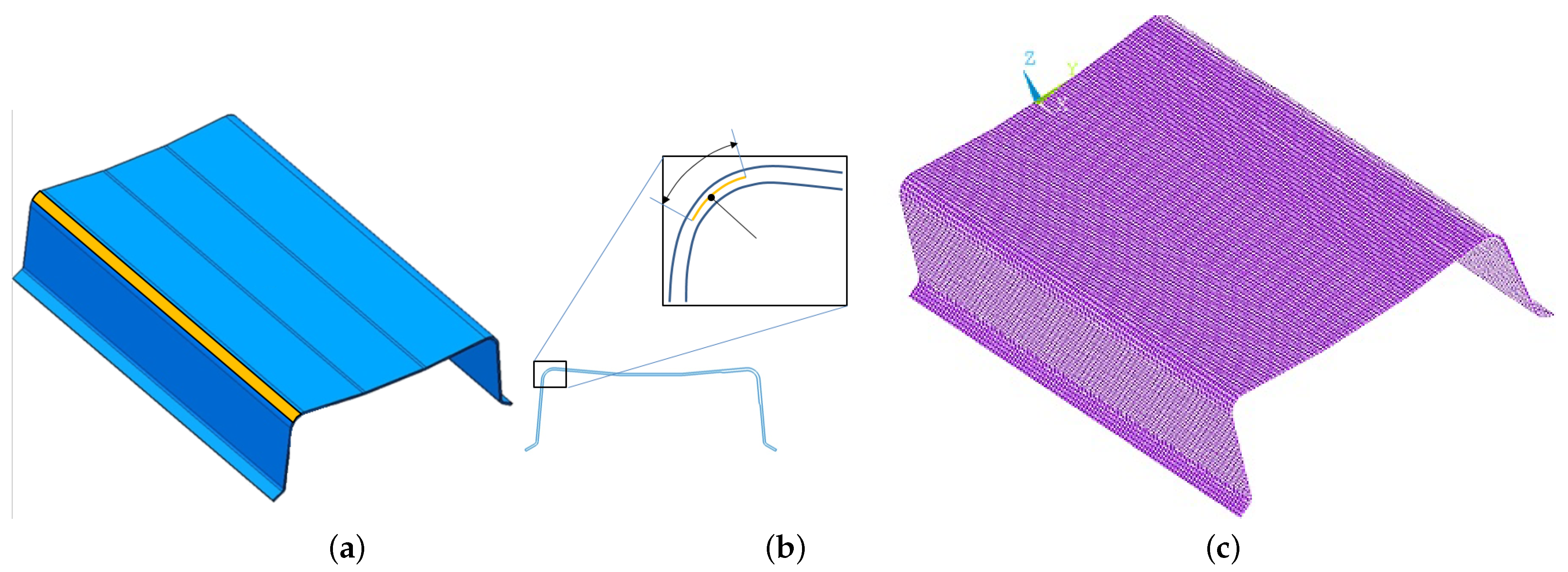
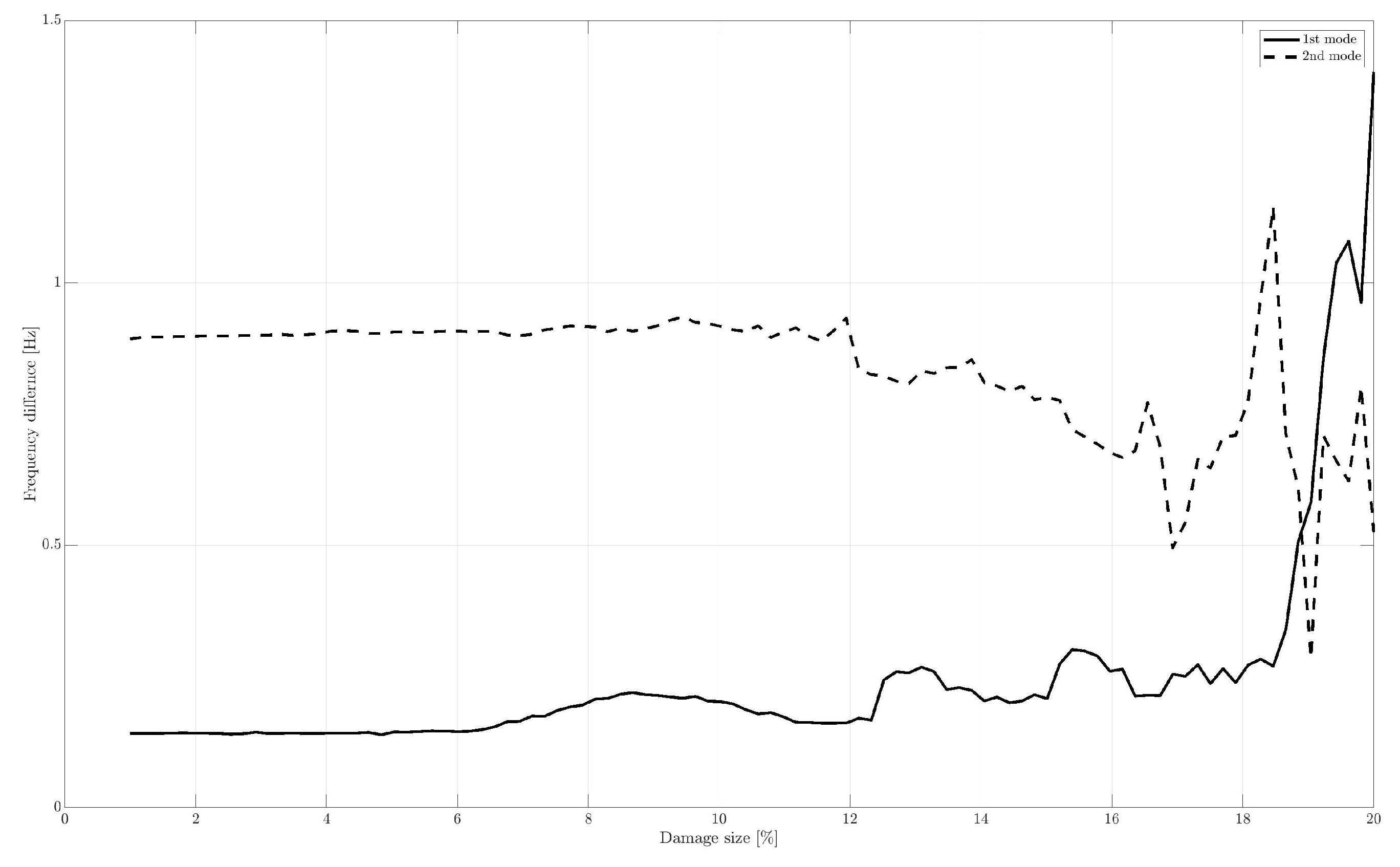
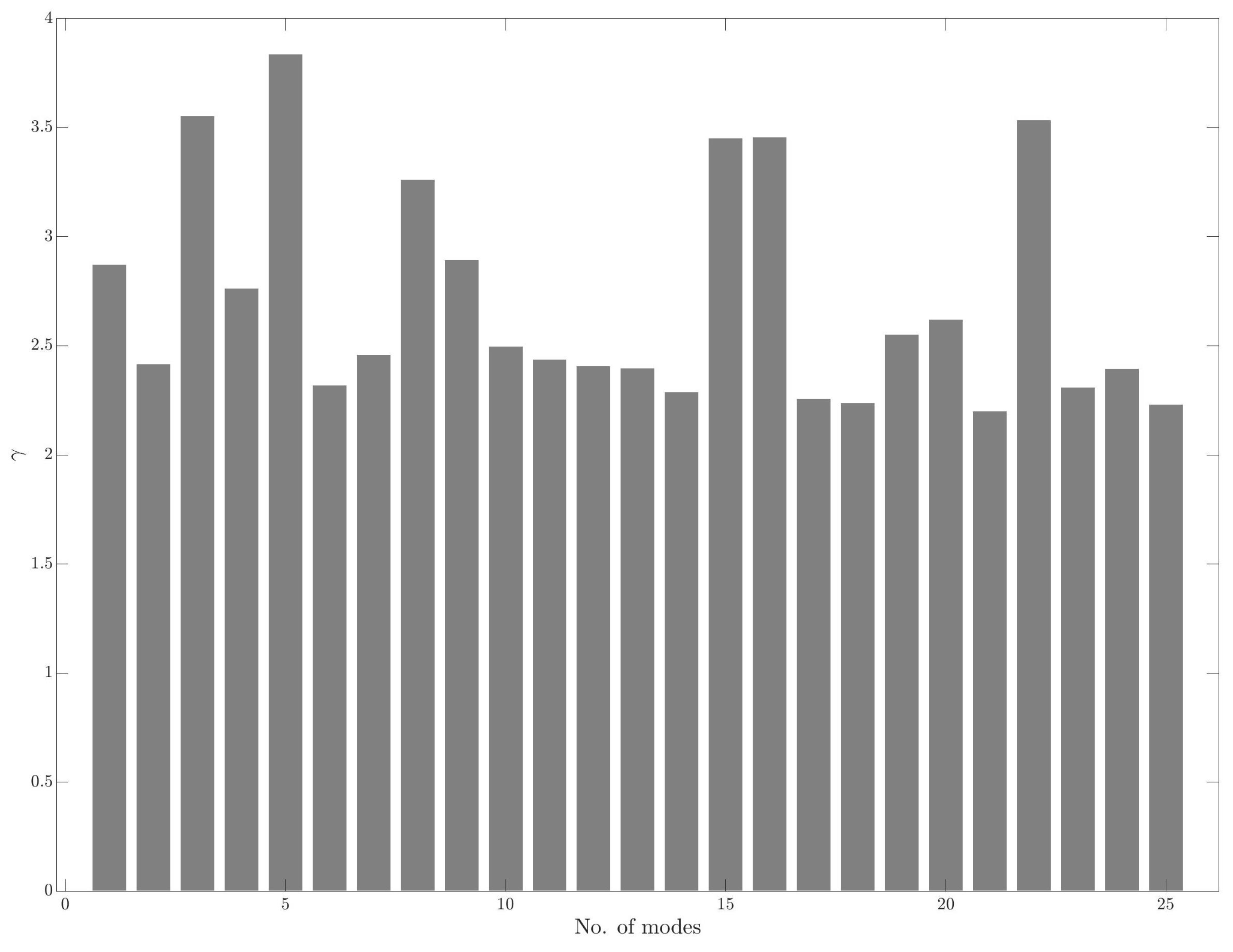
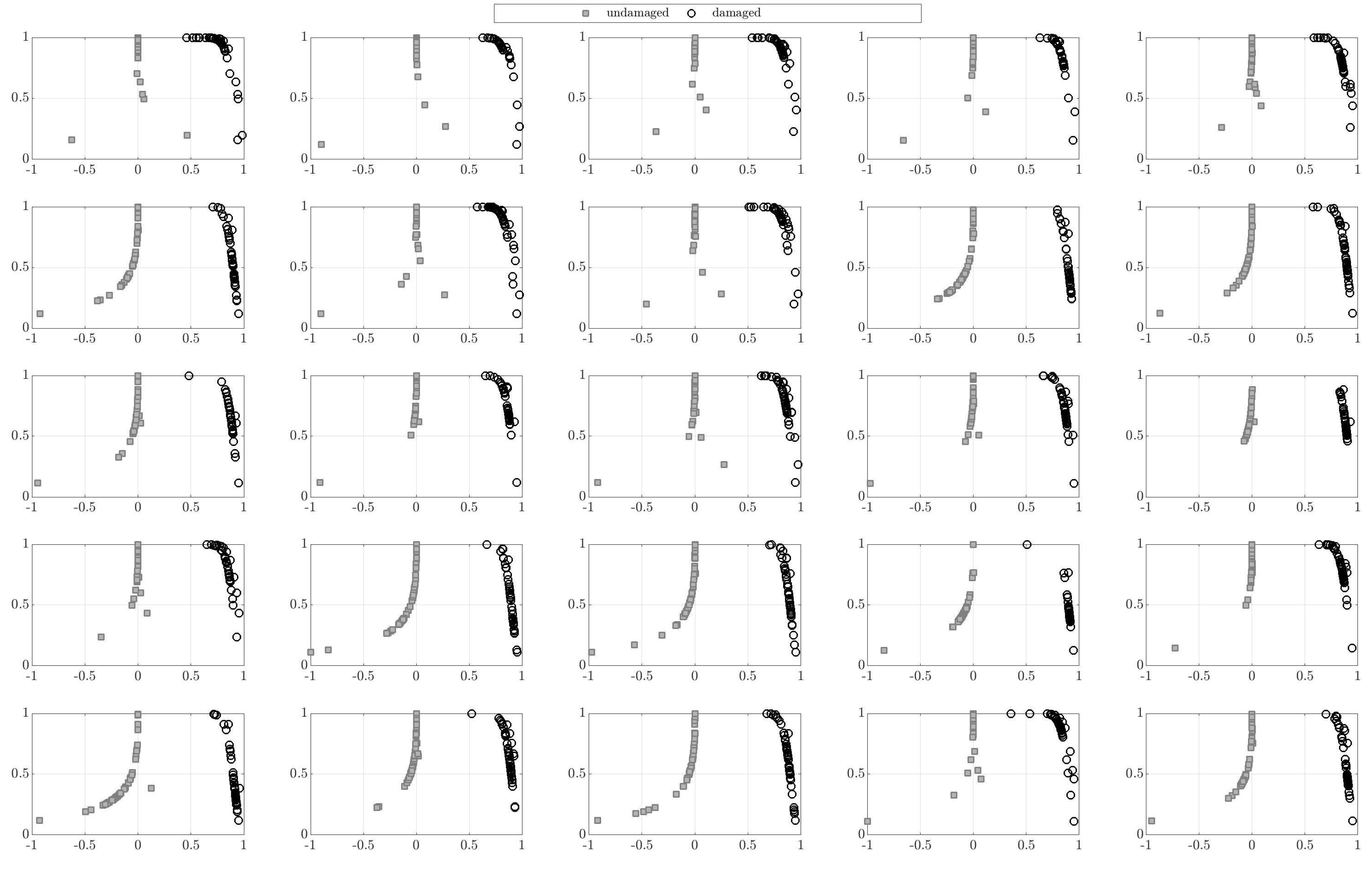
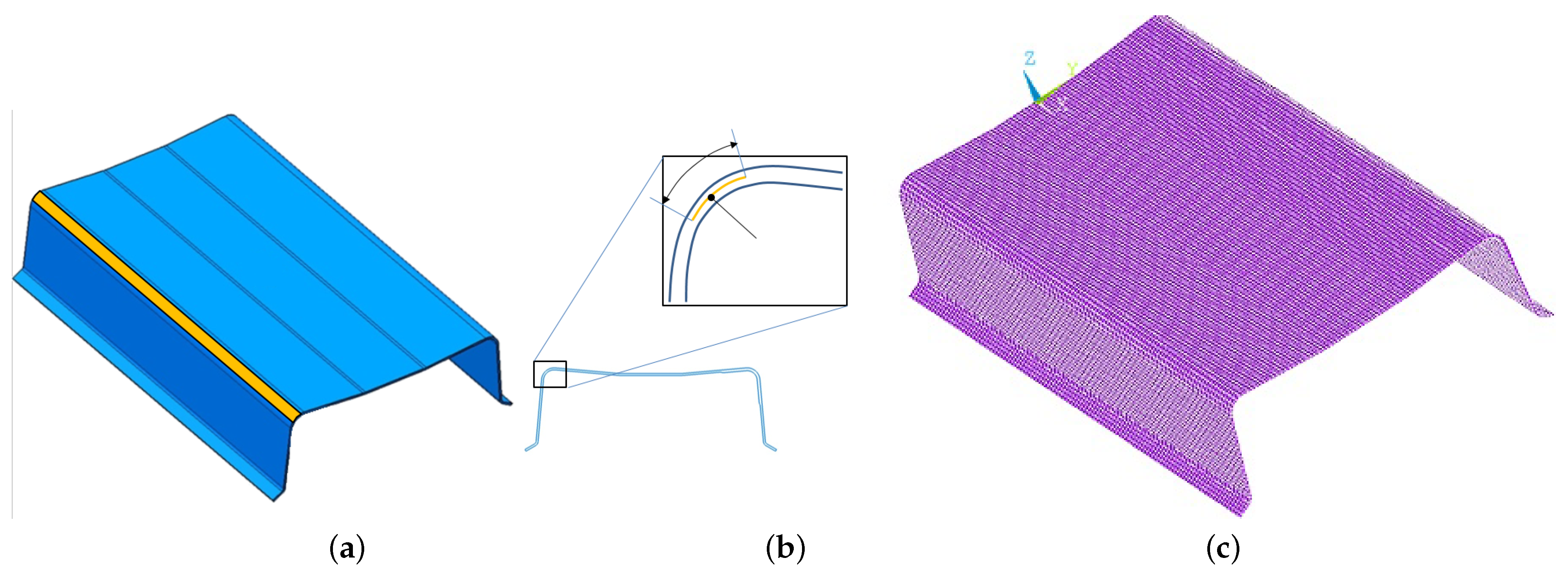
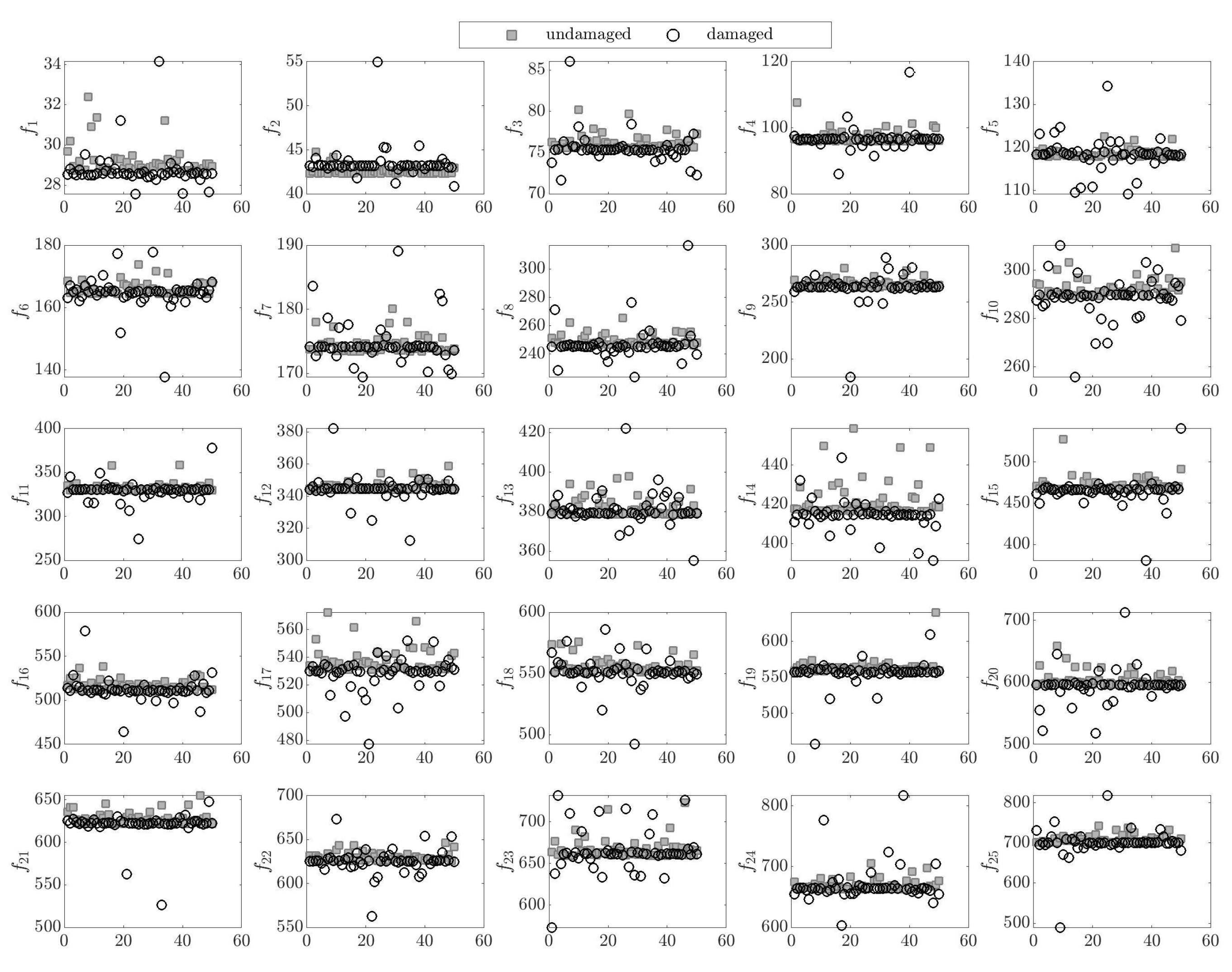
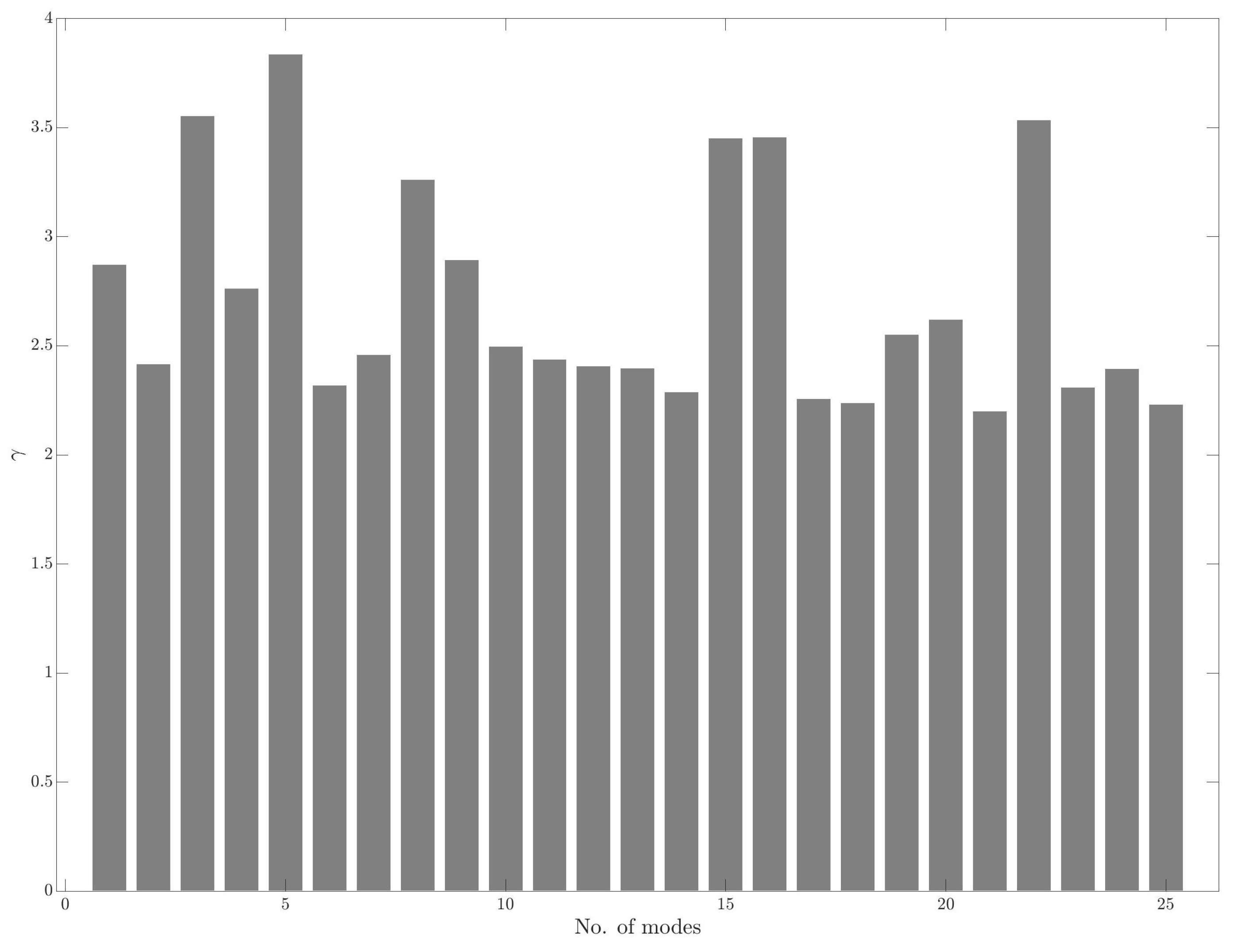
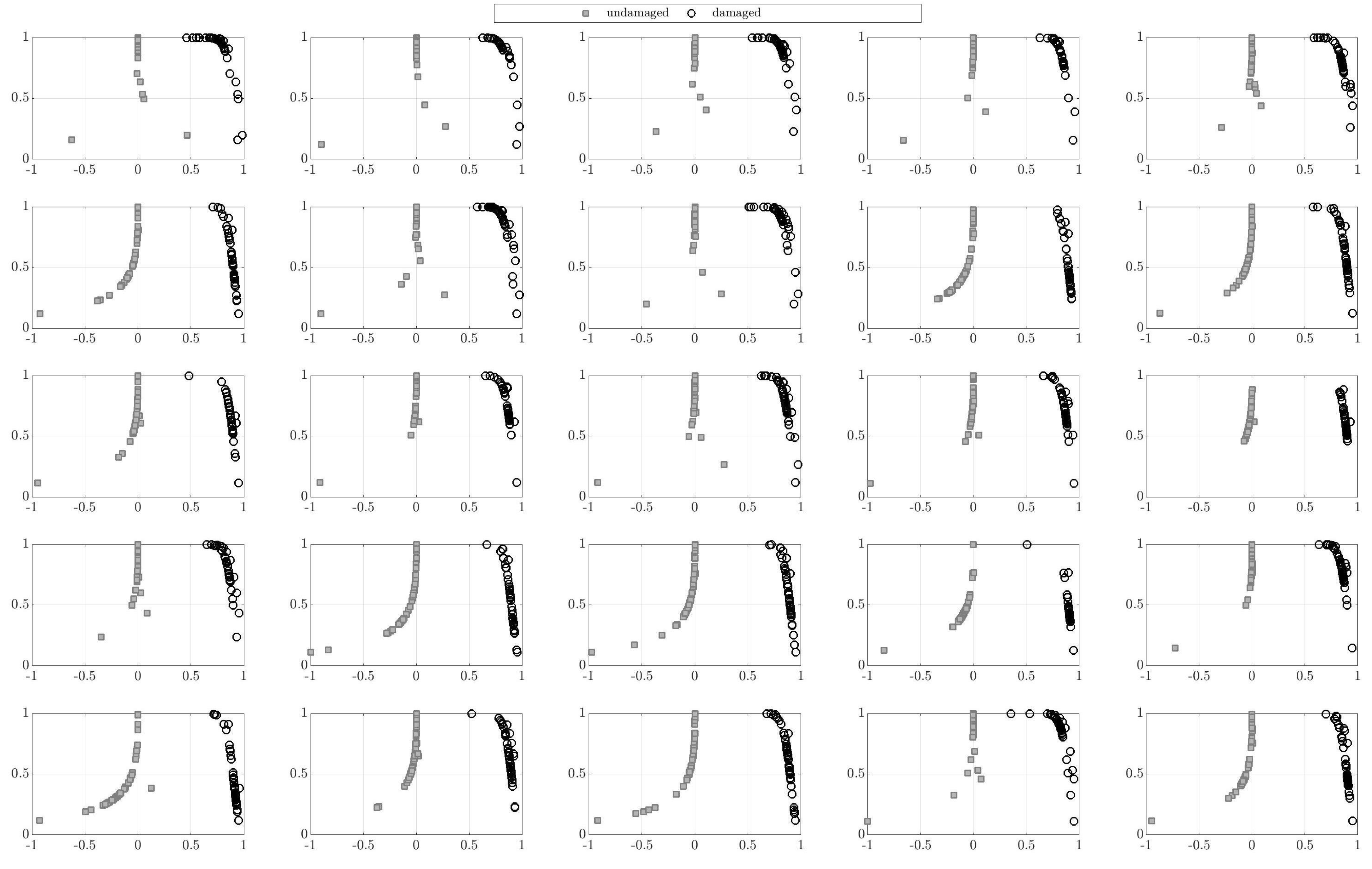
3. Numerical Results
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chen, X.; Yang, Z.; Tian, S.; Sun, Y.; Sun, R.; Zuo, H.; Xu, C. A Review of the Damage Detection and Health Monitoring for Composite Structures. J. Vib. Meas. Diagn. 2018, 38, 1–10. [Google Scholar]
- Doebling, S.W.; Farrar, C.R.; Prim, M.B.; Shevitz, D.W. Damage Identification and Health Monitoring of Structural and Mechanical Systems from Changes in Their Vibration Characteristics: A Literature Review; Technical Report 249299; Los Alamos National Laboratory: Los Alamos, NM, USA, 1996.
- Geweth, C.A.; Khosroshahi, F.S.; Sepahvand, K.; Kerkeling, C.; Marburg, S. Damage Detection of Fibre-Reinforced Composite Structures Using Experimental Modal Analysis. Procedia Eng. 2017, 199, 1900–1905. [Google Scholar] [CrossRef]
- Kessler, S.S.; Spearing, S.M.; Atalla, M.J.; Cesnik, C.E.; Soutis, C. Damage detection in composite materials using frequency response methods. Compos. Part Eng. 2002, 33, 87–95. [Google Scholar] [CrossRef]
- Doebling, S.W.; Farrar, C.R.; Prime, M.B. A summary review of vibration-based damage identification methods. Shock Vib. Dig. 1998, 30, 91–105. [Google Scholar] [CrossRef] [Green Version]
- Salawu, O. Detection of structural damage through changes in frequency: A review. Eng. Struct. 1997, 19, 718–723. [Google Scholar] [CrossRef]
- Wu, J.; Xu, X.; Liu, C.; Deng, C.; Shao, X. Lamb wave-based damage detection of composite structures using deep convolutional neural network and continuous wavelet transform. Compos. Struct. 2021, 276, 114590. [Google Scholar] [CrossRef]
- Ghiasi, R.; Torkzadeh, P.; Noori, M. A machine-learning approach for structural damage detection using least square support vector machine based on a new combinational kernel function. Struct. Health Monit. 2016, 15, 302–316. [Google Scholar] [CrossRef]
- Yang, B.S.; Hwang, W.W.; Kim, D.J.; Tan, A.C. Condition classification of small reciprocating compressor for refrigerators using artificial neural networks and support vector machines. Mech. Syst. Signal Process. 2005, 19, 371–390. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; Association for Computing Machinery: Melbourne, Australia, 1992; pp. 144–152. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–287. [Google Scholar] [CrossRef]
- Worden, K.; Lane, A.J. Damage identification using support vector machines. Smart Mater. Struct. 2001, 10, 540–547. [Google Scholar] [CrossRef]
- Liu, L.; Meng, G. Localization of Damage in Beam-like Structures by Using Support Vector Machine. In Proceedings of the International Conference on Neural Networks and Brain, Beijing, China, 13–15 October 2005; Volume 2, pp. 919–924. [Google Scholar]
- Matic, D.; Kulic, F.; Pineda-Sánchez, M.; Kamenko, I. Support vector machine classifier for diagnosis in electrical machines: Application to broken bar. Expert Syst. Appl. 2012, 39, 8681–8689. [Google Scholar] [CrossRef]
- HoThu, H.; Mita, A. Damage Detection Method Using Support Vector Machine and First Three Natural Frequencies for Shear Structures. Open J. Civ. Eng. 2013, 3, 104–112. [Google Scholar] [CrossRef] [Green Version]
- Finotti, R.P.; de Souza Barbosa, F.; Cury, A.A.; Gentile, C. A novel natural frequency-based technique to detect structural changes using computational intelligence. Procedia Eng. 2017, 199, 3314–3319. [Google Scholar] [CrossRef]
- Viitaniemi, V.; Sjöberg, M.; Koskela, M.; Ishikawa, S.; Laaksonen, J. Chapter 12—Advances in visual concept detection: Ten years of TRECVID. In Advances in Independent Component Analysis and Learning Machines; Bingham, E., Kaski, S., Laaksonen, J., Lampinen, J., Eds.; Academic Press: Cambridge, MA, USA, 2015; pp. 249–278. [Google Scholar]
- Crammer, K.; Singer, Y. On the Algorithmic Implementation of Multiclass Kernel-Based Vector Machines. J. Mach. Learn. Res. 2002, 2, 265–292. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sepahvand, K.K. Structural Damage Detection Using Supervised Nonlinear Support Vector Machine. J. Compos. Sci. 2021, 5, 303. https://doi.org/10.3390/jcs5110303
Sepahvand KK. Structural Damage Detection Using Supervised Nonlinear Support Vector Machine. Journal of Composites Science. 2021; 5(11):303. https://doi.org/10.3390/jcs5110303
Chicago/Turabian StyleSepahvand, Kian K. 2021. "Structural Damage Detection Using Supervised Nonlinear Support Vector Machine" Journal of Composites Science 5, no. 11: 303. https://doi.org/10.3390/jcs5110303
APA StyleSepahvand, K. K. (2021). Structural Damage Detection Using Supervised Nonlinear Support Vector Machine. Journal of Composites Science, 5(11), 303. https://doi.org/10.3390/jcs5110303