1. Introduction
LDPC codes was determined as the 5G NR data channel coding scheme at the 2016 3GPP Conference [
1]. After that, the research on implementation of 5G LDPC codes is gradually increasing. In [
2], the base matrix of the initial code rate is split, and the smaller sub-base matrix is used to replace the whole base matrix, which improves the efficiency and throughput of encoding and decoding. In [
3,
4,
5], the optimization method of LDPC codes in 5G three scenarios was proposed.
Low latency implementation of LDPC encoding has always been a focus of LDPC application research. For the implementation of the encoder, if the algorithm of multiplying the generator matrix
G is directly used, the data storage and computational complexity is quadratic in the code length. To address this issue, a simplified algorithm (RU method) is proposed in [
6] by transforming the sparse parity check matrix
H into an approximate lower triangular form to quickly calculate the parity bits. In [
7], two encoders based on the RU method have been implemented, but the amount of storage and calculations required increased significantly. After that, through the structural design of the LDPC codes, a quasi-cyclic structure was proposed to greatly reduce the complexity of encoding and the utilization of storage resources.
Some recent studies have focused on the hardware implementation of QC-LDPC codes encoding. Owing to the fact that the encoding complexity of the RU method is lower than that of the direct encoding algorithm, many encoder designs are based on the RU method for structural optimization. The most significant innovation is the parallelized encoding architecture. In [
8], an area efficient parallel LDPC encoding scheme is proposed for QC-LDPC codes. This architecture uses multiple parallel cyclic shift network and bit selection algorithm to reduce the hardware complexity. In [
9], a multigigabit QC-LDPC encoding architecture is proposed; this architecture leverages the inherent parallelism of QC structural by simultaneously processing multiple bits according to optimal scheduling. In [
10], a high-efficiency multi-rate encoder for IEEE 802.16e QC-LDPC codes is proposed; this design uses the double diagonal structure in the parity matrix to avoid the inverse matrix operation that requires a lot of calculations. Meanwhile, a parallel matrix vector multiplication structure and storage compression are used to increase the encoding speed and significantly reduce the number of storage bits required. In [
11], a fully parallel QC-LDPC encoder based on a reduced complexity XOR tree designed specifically for the IEEE 802.11n standard was proposed. In [
12], a pipeline architecture for QC-LDPC encoder was proposed. The design can be easily reconstructed to support variable code rates and code lengths through parameter configuration. In [
13], the encoder stores the matrix vector in random access memory (RAM). The row index of the non-zero entry in each column of the sparse check matrix is used as the write address of the RAM, which reduces the complexity of storage and calculation.
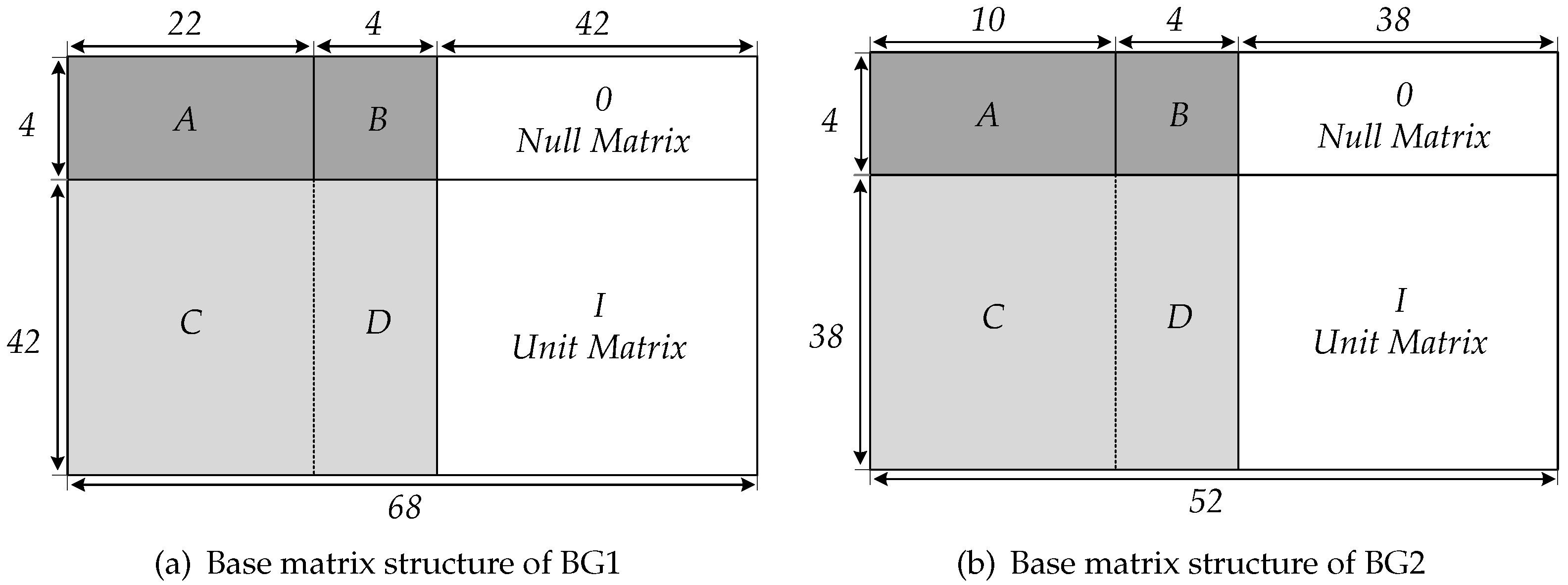
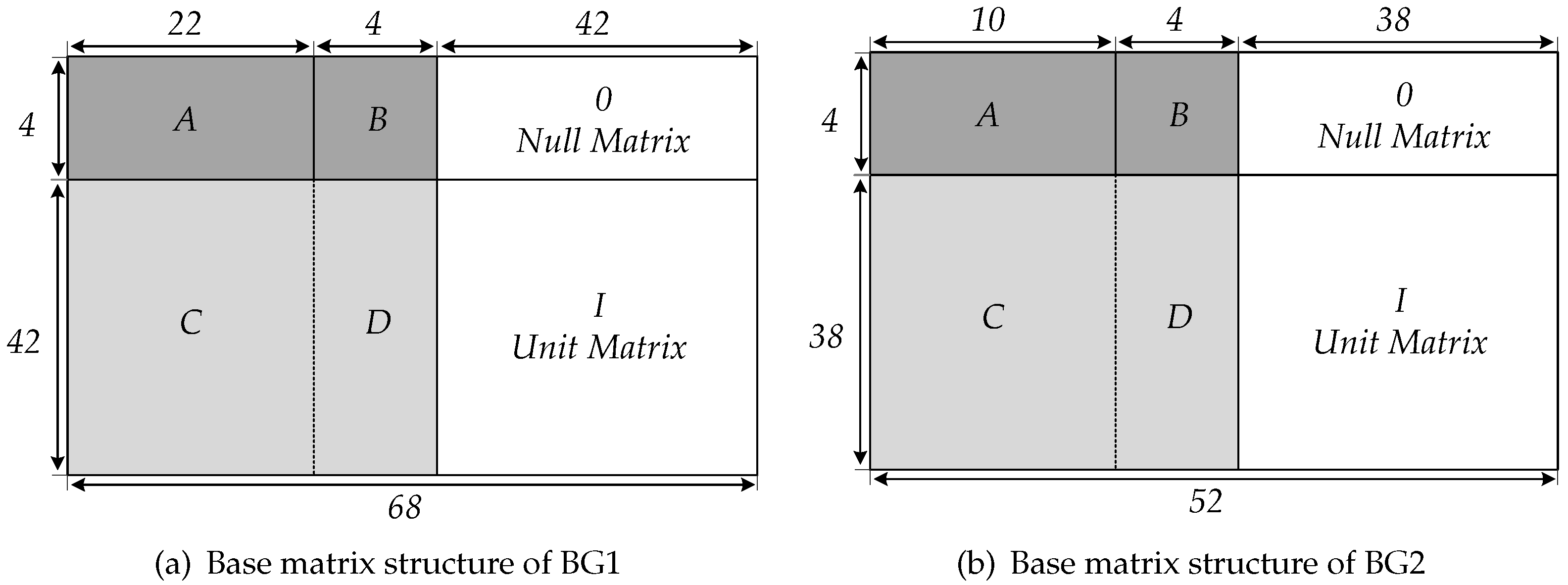
In 5G NR, the channel coding scheme also adopts QC-LDPC codes. For the compatibility of multiple scenarios, the 5G standard has developed two different base graphs, BG1 and BG2, which correspond to two different base matrices,
and
. According to the lifting sizes of 5G QC-LDPC codes, the
matrix corresponds to a total of 16 parity check matrices (PCM) which defines the 5G LDPC coding schemes [
14]. Therefore, the hardware that supports 5G NR codes must provide a high level of flexibility to satisfy different PCMs.
5G NR has three scenarios, enhance Moblie BroadBoand (eMBB), Ultra Reliable Low Latency Communication (URLLC), and massive Machnice Type Communication (mMTC). Specifically, it requires a peak throughput of 10 Gbps for the uplink, 20 Gbps for the downlink, and a user-plane delay of 4 ms for eMBB and 1 ms for URLLC. After evaluation by 3GPP, it is confirmed that the LDPC encoding scheme under BG2 designed for eMBB scenarios is used in URLLC scenarios (mainly low latency) [
15]. In [
16], a prototype of 5G physical downlink shared channel (PDSCH) transmitter was carried out on software defined radio (SDR), with channel coding experiments including complete processing flow of data transmission in TS38.212, and the system performance of 5G NR was evaluated. In some studies, 5G LDPC encoder is designed according to the complete encoding chain of uplink and downlink channels [
17,
18], including cyclic redundancy check (CRC) encoding, code block segmentation, LDPC encoding, rate matching, and bit interleaving. By assembling all the processes in the encoding chain, fully functional encoding hardware products can be delivered. At the base station transmitter, channel coding is the crucial operation that affects the bit processing time in physical layer. Therefore, it is necessary to propose a higher parallel encoding algorithm and hardware architecture for 5G QC-LDPC.
There are some references regarding the hardware implementation of 5G LDPC encoder. In [
19], an efficient LPDC encoding algorithm was proposed, and a high throughput and low latency encoding architecture is implemented. Synthesis results on TSMC 65-nm CMOS technology with different submatrix sizes were carried out. In [
20], a flexible and high-throughput 5G LDPC encoder was implemented on the compute unified device architecture (CUDA) platform through the scheme proposed in [
19], and the throughput of 38–62 Gbps from 1/2 to 8/9 rate was achieved on a single GPU. In [
21], an encoder with the advantages of parallel encoding and pipeline operation is proposed; it was synthesized in a 65 nm CMOS technology and the parallelism of this scheme is higher compared with [
19]. In [
22], a serial-optimized QC-LDPC encoder is proposed, which uses genetic algorithm to optimize the encoding. In the case of short codes, multiple check matrix sub-blocks can be partially processed in parallel. The same degree of parallelism as the long code is achieved.
This paper focuses on low latency LDPC encoding specified in 3GPP. One purpose is achieving low power budget in a 5G NR baseband. If we design a LDPC encoder with lower latency, we can give extra computing time in a TTI to other algorithms with heavy power consumption. Thus the degree of parallelization can be relaxed for heavy power algorithms such as channel equalization and detection in uplink [
23]. The total power consumption in a base station can therefore be reduced. In order to resolve the issues in the existing schemes, the main contributions of our work are as follows:
(1) The proposed encoder is optimized according to the structure of the parity matrix in 5G standard, which can achieve lower latency and higher throughput than the existing work. Compared with the clock consumption in [
19], our design reduces the encoding latency by 56%.
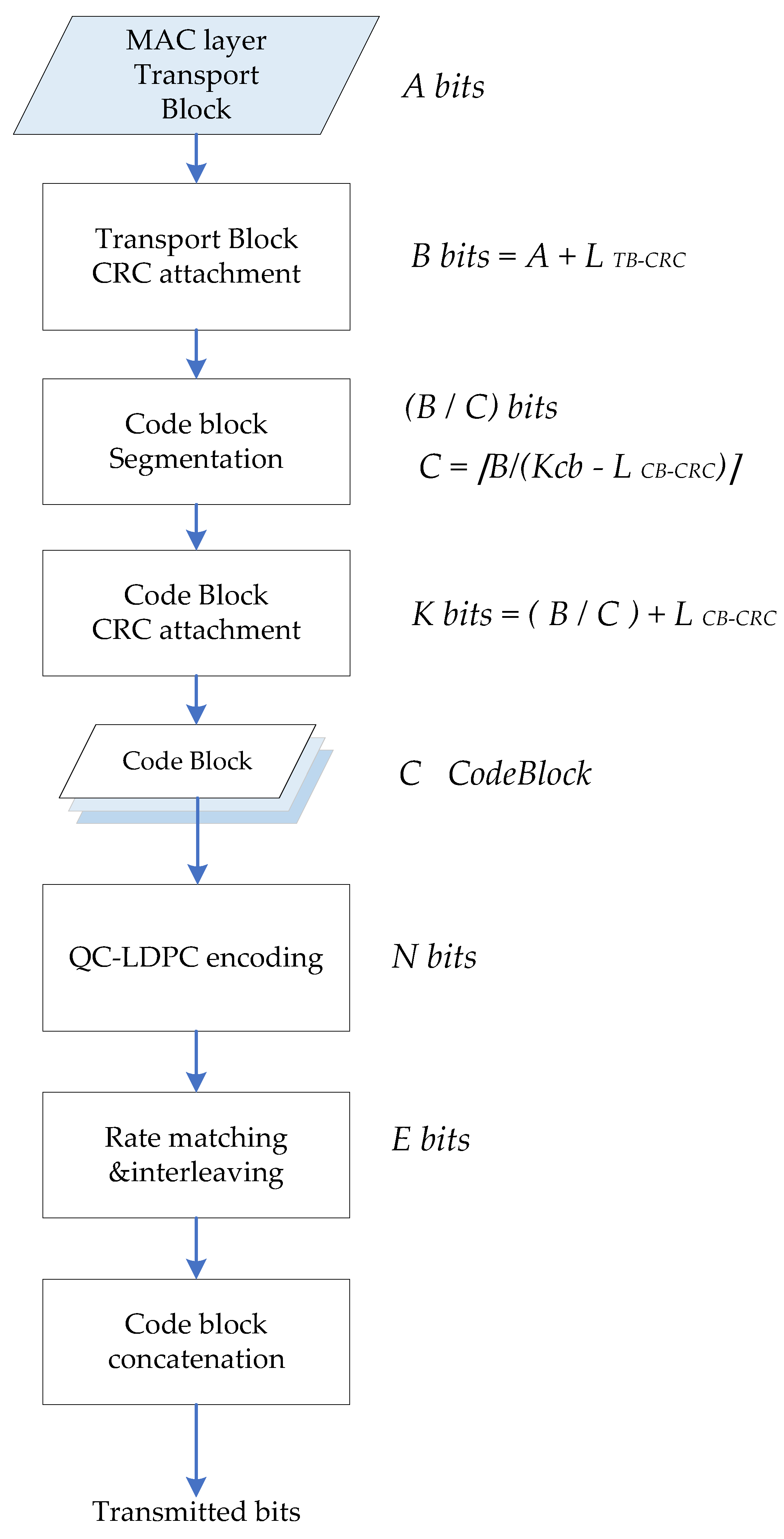
(2) A parallel CRC is seamlessly integrated into the design enabling LDPC encoding from transport block (TB) level, which means that LDPC encoding can be started from TB input. Thus, the complete encoding calculation of PDSCH is implemented.
(3) The encoder is designed to be fully compatible with 5G NR standard and with flexibility and extendibility. Our design uses the largest lifting size as the hardware scale in the shift networks (CNs) of the encoding calculation. Meanwhile, a configurable circuit module is added to CNs to deal with different encoding scenarios. The parameter adaptation module schedules the configurable circuit to change the input and output of the CNs. Hence, the ASIC synthesis of the encoder can support full-size PCM, including all code lengths and code rates encoding for transport blocks (TBs).
Our design is verified and proven by synthesized register transfer level (RTL) design and silicon layout. The IC layout is based on CMOS technology of SMIC 28nm. The results show that at 800 MHz, the encoding time of maximum code length in BG1 is only 33.75 ns (27 clocks), which sufficiently meets the throughput requirement and offers a lower latency for the 5G NR standard.
The rest of this paper is organized as follows.
Section 2 describes the coding process of 5G LDPC codes and the structure of the parity check matrix. In
Section 3, a high parallel encoding method and the corresponding encoder structure are proposed. The design details and flexible configuration are discussed in
Section 4. The silicon verification and comparison results are given in
Section 5.
Section 6 concludes our paper.
3. Design of 5G QC-LDPC Encoder
3.1. QC-LDPC High-Parallel Encoding Algorithm
In [
19], an LDPC encoding algorithm for 5G has been proposed. Based on it, this paper optimizes the calculation flow of the parity codeword and arranges the operations in parallel to improve the parallelism of the overall encoding and reduce the latency of the encoder. According to the 3GPP standard, the code block
C is divided into information code blocks
S, the first group of parity
, and the second group of parity
, whose lengths are
,
,
corresponding to
of
H matrix respectively.
is the number of columns of the kernel matrix and
is the number of rows of the
H matrix, so that
can be expressed as
According to the structure of the parity matrix
H shown in
Figure 3, the check equation for encoding is represented as
The expansion of (2) denoted as
Simplify and obtain
and
denoted as
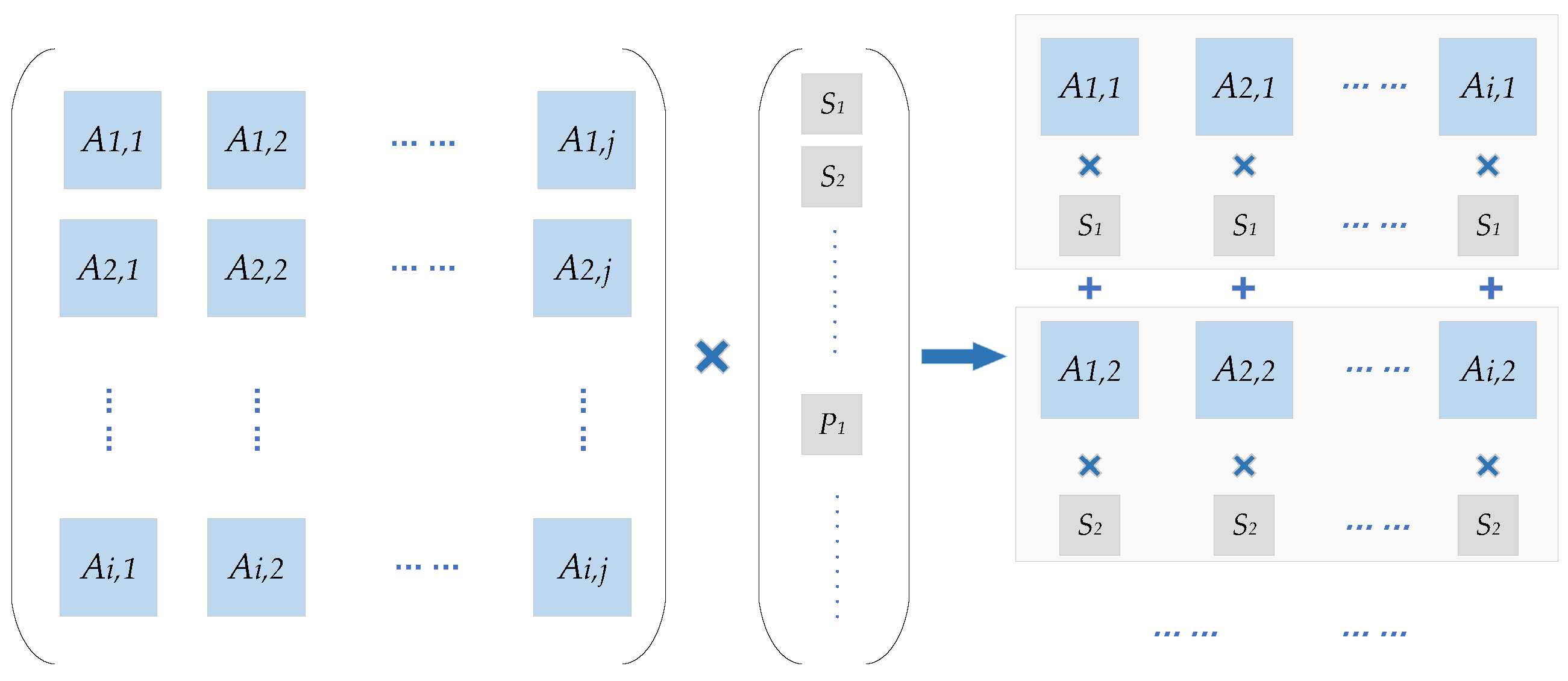
Divide
into four vectors
,
,
, and
with length
Z and assign the result
as
, where
is the element of each row of
A matrix.
is the code word of each segment
Z in the information
S. This calculation is actually to cyclic shift the Z-length code block corresponding to each element of the PCM, and the number of shifts is the value of the element, that is, the cyclic shift coefficient.
The encoding operation can thus be divided into two stages: obtaining
and
. In this paper, the calculation of
and
is parallelized, and the maximum parallel structures are designed according to the number of columns of
A matrix and the number of rows of
C matrix respectively. In the process of obtaining
, in order to avoid the complexity of matrix inversion, traversing each two
B submatrices of
and
, (8–11) shows the four structures of the B matrix, where −1 represents the 0 matrix of
, 1 and 105 represent the
unit matrix that is right cyclic shift once and 105 times, and 0 represents the
unit matrix. Under the principle of GF(2) operations, the process of solving (5) can be converted to (12–15),
means the right barrel shift of
bits.
When
is obtained, the
offers hardware reuse possibility to complete the
operation, and the second group of parity
is calculated according to (16), where
is the element of each row of
C matrix,
is the element of each row of
D matrix, and
is the code word of each segment
Z in the information
S.
3.2. QC-LDPC Encoder Architecture
The encoding algorithm discussed earlier is based on the structural characteristics of the 5G QC-LDPC code; it has the same linear complexity with the RU method. Herein, this paper uses the proposed algorithm for hardware implementation, not only mapping the algorithm to the circuit architecture but also considering the selection and optimization of the circuit architecture in the mapping process and approaching the limit of the LDPC encoding latency.
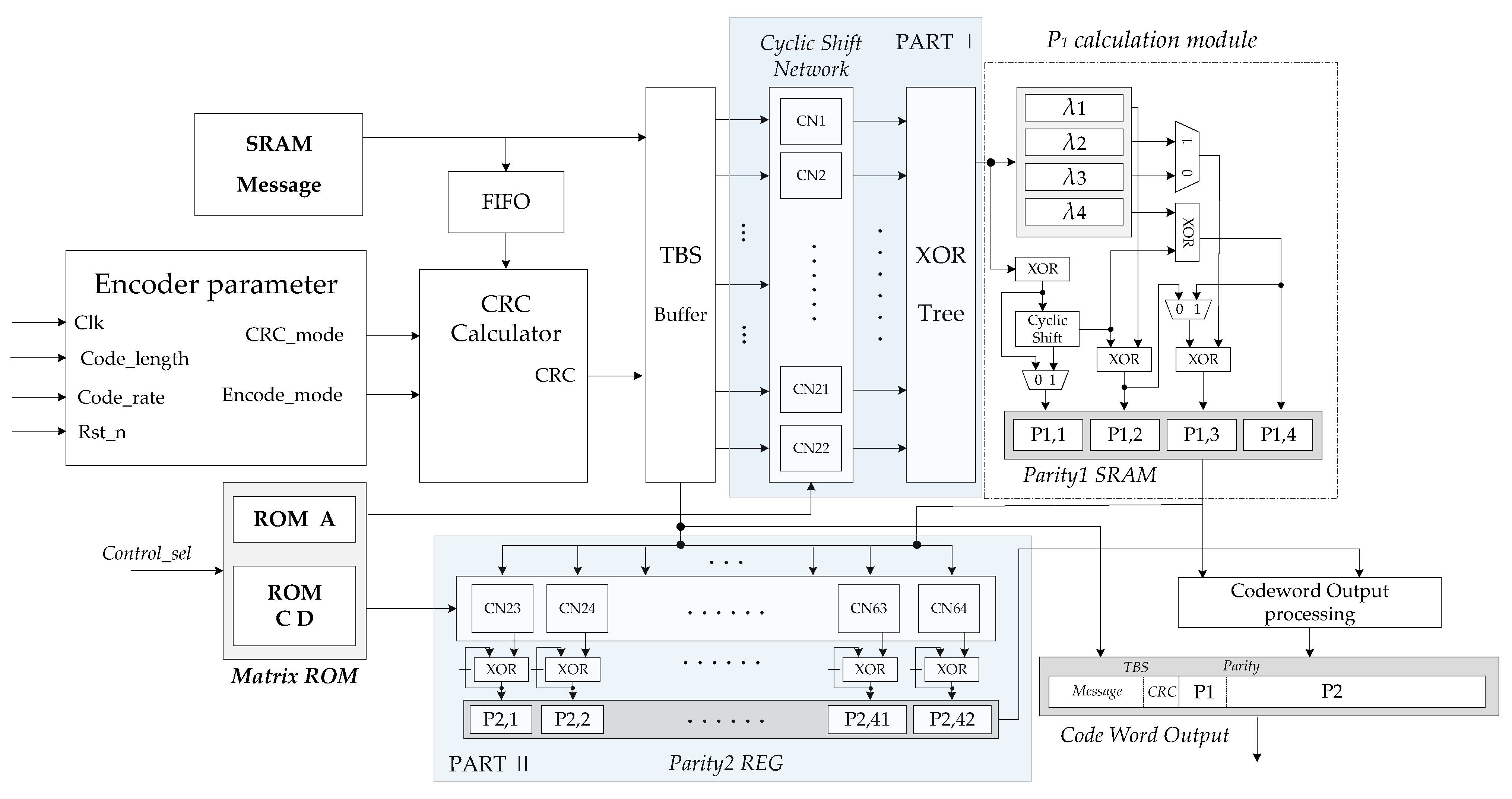
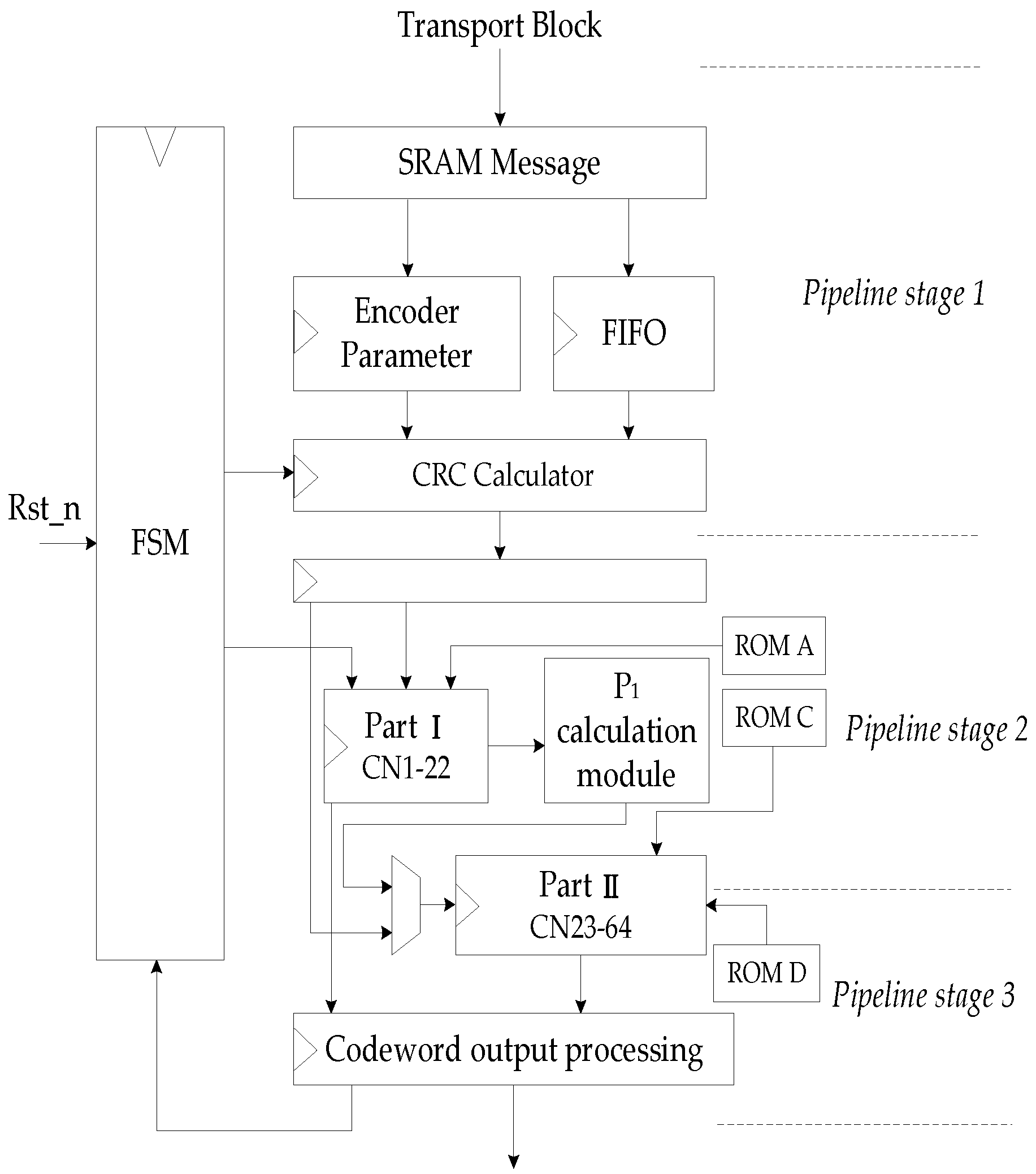
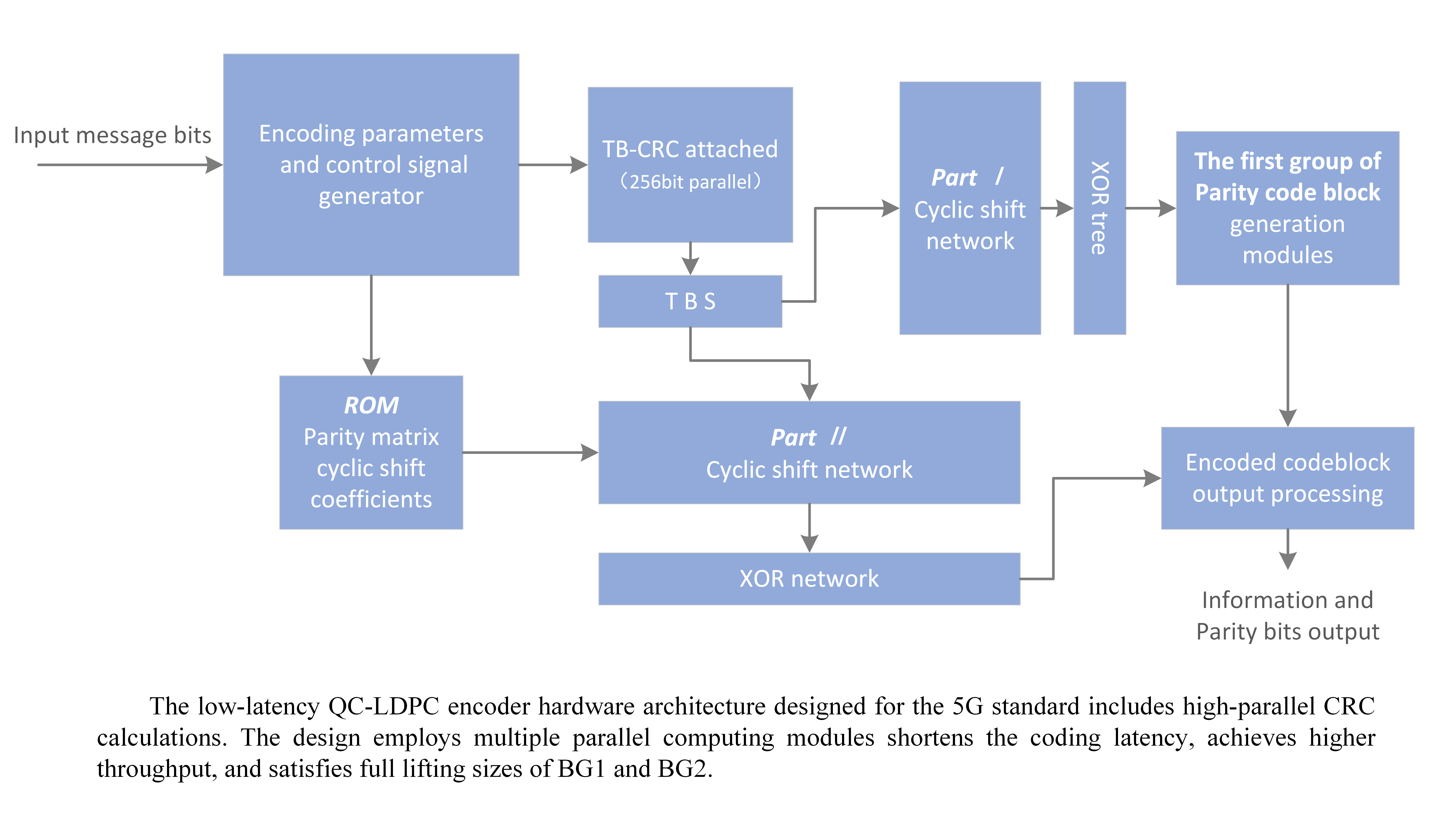
The overall hardware structure of the encoder is shown in
Figure 5. In this encoder, the memory and functional modules are considered as the major influencing factors of the overall area, latency, and power performance of the hardware design. The encoding algorithm used and the operating frequency of the hardware determine the throughput of the overall architecture.
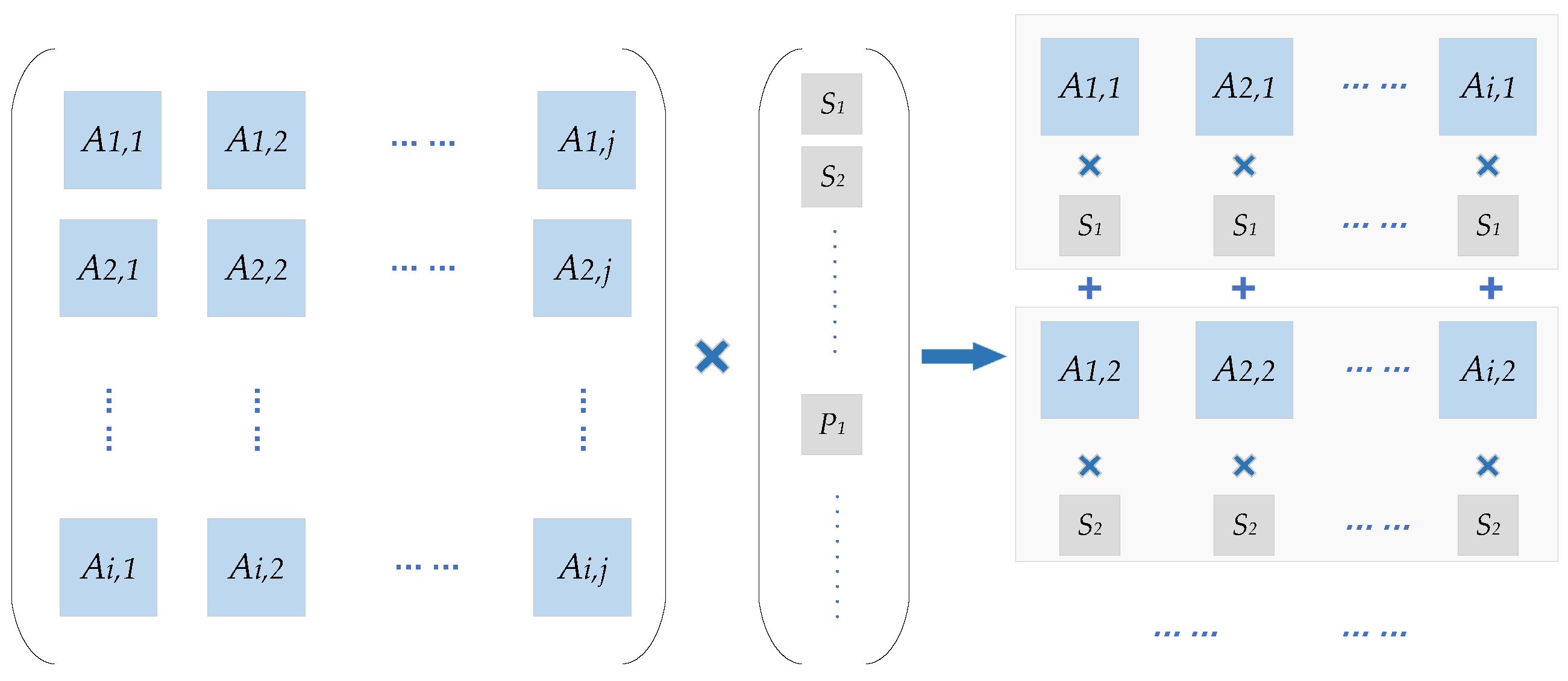
According to the aforementioned high parallel encoding algorithm, the encoding calculation is actually to complete the multiplication of the PCM and the information vector. PCM is composed of
zero matrix and unit cyclic shift matrix; the multiplication of these submatrices and the information vector is actually a bit-level cyclic shift. Thus, the encoder designed in this paper is implemented by cyclic shift network and combinational logic circuits. The encoding calculation is mainly composed of two parts in parallel, Part I calculates
in Equation (
5), and Part II calculates
and
in Equation (
6). In order to realize low latency encoding, 64
cyclic shift network (CN) modules are used, which are barrel shift logic. The encoder mainly consists of the following functional modules:
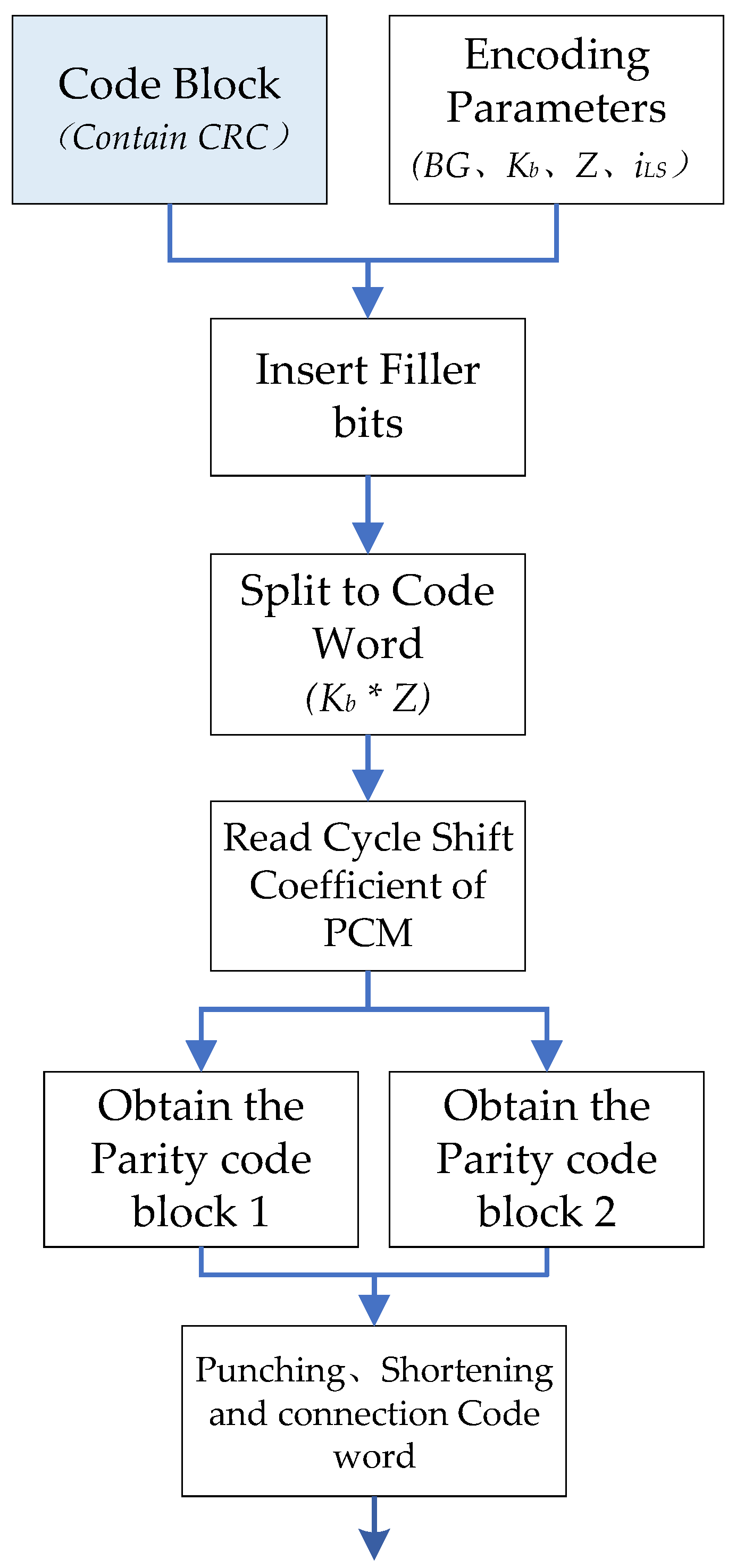
(1) Message buffer SRAM: The transmission information of the media access control (MAC) layer is stored in this module; the information is converted through first input first output (FIFO) to perform multi-byte fast CRC check calculation. Then, the information and its generated CRC bits are transferred to the TBS buffer.
(2) Memory blocks: In
Figure 5, the matrix ROM stores the cyclic shift coefficient values of the PCM corresponding to the
A,
C, and
D submatrices.
(3) Encoder parameter calculation module: calculating some parameters required by the encoder according to the code length and the original code rate. Meanwhile, the selected encoding parameters will affect the control signal and state machine of the encoder.
(4) CRC calculator module: executing the CRC calculation of the transmission block with high parallelism.
(5) Transport blocks size buffer: combining information bits and CRC into block code words, each code word length is Z.
(6) Cyclic shift network Part I and Part II: cyclic shift network is used to implement the cyclic shift of Z length code words, according to the cyclic shift coefficient provided by the control signal. CNs is a configurable barrel shift register; corresponding to the Z value that does not meet the hardware scale, the input and output of the cyclic shift will be adapted.
(7) calculation module: this module consists of combinational logic circuit and memory and configurable circular shift registers. Each has two kinds of B submatrices, so this module can flexibly implement different computation processes of different B submatrices. Herein, the calculation of Equations (8)–(11) is also parallelized to speed up the process of obtaining .
(8) Codeword output processing module: punching and shortening the parity code blocks. Connecting the information code block and the parity check code block and output according to the code rate.
According to the column number of matrix A, Part I is designed using 22 CN for code blocks, which are inputs into each CN sub-module. Meanwhile, one row elements in operations have the current value of CN, equaling to a binary addition operation. The execution in 22 parallel CN sub-modules use four clock cycles to get the intermediate variables and to store in memory.
In order to speed up the calculation of (6), Part II may use more CN sub-modules. In each calculation cycle, the same as the execution in each code block of , a codeword is delivered to CN, and a column elements of C matrix is read as the cyclic shift coefficient inputs each CN. When the cyclic shift is completed, the results are kept in registers.
After 22 calculation cycles, 22 column of C matrix is used by 42 CN sub-modules. The 42 CN process the cyclic shift of the information code block in parallel. Finally, the outputs of 42 XOR blocks give the last result. After the calculation is completed, the 4 column elements of D matrix in ROM are sent into 42 CN in turn, and 4 sets of vectors are also delivered to CN in parallel; a group of results of are obtained in each cycle. After four times of cyclic shifts and XOR operations, the execution of (12) is completed, and the second group parity is obtained. When two groups of parities are obtained, the filler invalid bits are removed by the codeword output processing module. Meanwhile, the first two columns of the information code blocks with Z-length are punched out, and the parity codes are punched according to the code rate, then the encoded blocks give output towards the rate matching section.
3.3. Execution Pipeline Scheduling
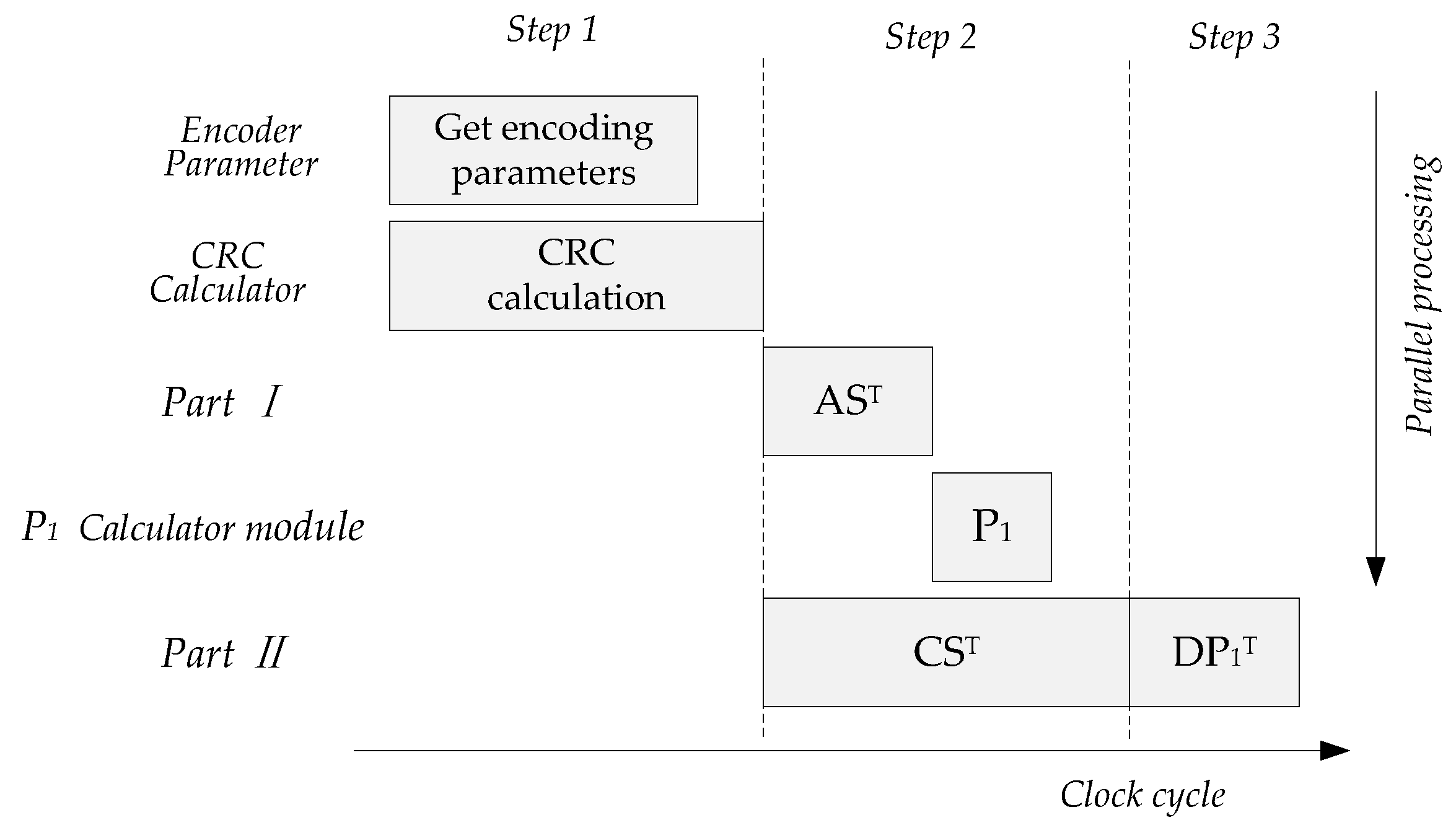
When the maximum code length is not over the length defined by base graph, the parallel operation process of the encoder is shown in
Figure 6, which can be divided into five calculation parts and three steps. The first clock pipeline is for the generation of coding parameters and CRC calculation of TB, the second pipeline is the parallel calculation of
,
and
, and the third pipeline is the calculation of
. The latency of the whole encoding process includes CRC calculation and Part II calculation, and the clock cost of LDPC encoding is determined by Part II.
Figure 7 is the flow chart of 8424 bits data encoding operation under BG1. Firstly, the parameters required for encoding are obtained from the transport block data in the encoding parameter module of the encoder. The bit stream is transmitted to the CRC calculation module through the FIFO module, and the CRC is attached to the TB to form the TBS. Then, the elements of the matrix
A and matrix
C,
D are read to complete the encoding calculation in Part I and Part II respectively. After obtaining two groups of parity code blocks, the filler bits of codeword are processed in the codeword output processing module of the encoder; the invalid bits will be removed and the first two columns of information bits and parity bits are punctured. Finally, the information code blocks and the parity check code blocks are connected as the encoder output.
The control circuit of the encoder issues the overall control of the operation of the encoder, so that each calculation module can orderly perform their own tasks. In this design, the state machine and control signal are used to control the operation of the encoder. It mainly realizes the control signal in sequence to all modules.
Figure 8 is the pipeline diagram of the hardware structure of the encoder.
After the parameters are calculated and information bits are stored in SRAM, finite state machine (FSM) issues CRC calculate enable signal. When CRC calculation is completed, the encoder is enabled, the parity check matrix is read in, and the information encoding is carried out. After completing the Part I operation, the calculation of starts. After obtaining the first set of parity codes, the hardware waits for the completion of the first round running of Part II, and the input information is switched to to calculate the second set of parity codes. When all parity codes are obtained, the encoding end signal is enabled to reset the FSM. The encoder returns to the initial state to perform the encoding of the next frame of information data.
4. Encoder Design Details
According to the encoding algorithm and the structure characteristics of the 5G QC-LDPC code, the cyclic shift of encoder and XOR operation in GF(2) is purely logic operations. The hardware complexity of the encoder will increase with the increase of the code length. Especially for CRC calculation, the complexity of encoding hardware will increase linearly with code length. The design of this paper is based on the requirements of 5G NR. In the eMBB scenario, NR requires large-scale data transmission. In the URLLC scenario, NR requires ultra-low latency and high reliability. Hence we need to design an encoder whose performance is close to the latency limit. The solution is to maximize the parallelism of encoding calculations; at the same time, the hardware must be configurable and have reasonable resource utilization. Therefore, this paper optimizes the parallelism of CRC and QC-LDPC encoding and selects a suitable architecture for the flexible configuration.
4.1. CRC Implementation in Parallel
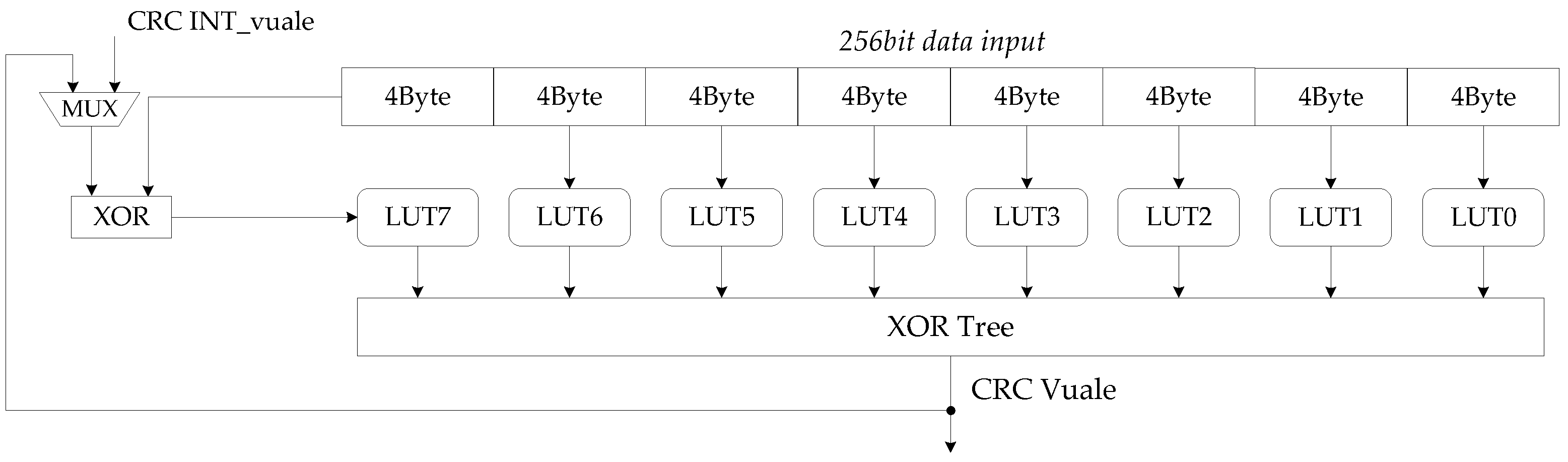
The conventional CRC calculation uses LFSR serial calculation method to calculate bit by bit. The processing in serial has low processing efficiency; it is thus almost impossible to complete CRC calculation for large transmission blocks in 5G communication. In this paper, a high-parallel hardware architecture based on look-up table method is designed for CRC calculation.
The CRC calculation module in the encoder was mainly composed of look up table (LUT) structure and XOR gate circuit. LUT is actually composed of SRAM, the CRC value of each byte of data is stored in it. LUT using bytes as the input to avoid the excessive memory resource occupation caused by the increase in the number of input bits. Therefore, the CRC calculation module is designed to decompose the number of bytes of the input bit stream into the number of LUTs.
The look-up table algorithm pre-calculates the specified CRC value for each data byte and stores it in SRAM; through the LUT structure, fast CRC calculation can be performed for long bit stream data [
24]. The CRC calculation module divides the input long bit stream into short bits in bytes and uses the LUT to calculate the CRC value of these bytes. Finally, a multi-byte CRC XOR is used to obtain the CRC value of the long bit stream. There are
situations for bits byte, so that 256 CRC values are stored in LUT; the input of the LUT structure is 8-bits CRC data as the address to obtain the corresponding stored CRC value in the LUT.
The maximum code length supported by BG1 is 8448 bits. In URLLC scenarios, BG2 is mainly for short code length encoding. As the communication scenario changes, the amount of data transmitted by the data channel also changes. The length of the TB handed over to the CRC calculation module is less than 8424 on the premise of LDPC encoding. Therefore, this paper designs hardware architecture for processing 256 bits data CRC calculation in one clock, as shown in
Figure 9. By implementing low latency CRC computing while maintaining low hardware resource overhead, the overall coding time can be further reduced.
The design of LUTs is in bytes and decomposition of 256 bits is into 32 bytes. A total of 32 LUT units are thus required. To simplify the number of modules in the architecture, we designed a LUT as a module that can look up CRC values for 4 bytes. Therefore, LUT0-LUT7 can perform CRC calculation for 256 bit data. In the process of calculation, there are two problems worthy of attention: when the input data is less than 256 bits, 0 shall be filled in the high significant bits before the CRC calculation; when the input data is larger than 256 bits and cannot be divided by 256, the calculation module will be based on the information of TB length, 0 filled in the high significant bits. Because the CRC value of 0 is also 0, zero-filling will not change the result. The calculation of long bit stream information also starts from the high significant bit.
In each clock, the architecture uses 32 bytes of 256bits data as the index of each LUT look-up table and obtains 32 values. After XOR logic operation, the CRC value (partial remainder) of the 256 bits input data is obtained. The MSB byte of the next 256bits data is XOR with the partial remainder; the result continues to be calculated until all data calculations are completed and the partial remainder becomes the final remainder. The computing latency of 8428 bits inputs is only 33 clocks.The results demonstrate that the CRC calculation module is a suitable design for the overall encoder, and its high parallelism satisfies the fast CRC calculation and maintains a low hardware complexity.
4.2. Design for Flexible Configuration
To adapt to variable code length and the eight code rates in the standard, we design a configurable circuit. Code length and code rate as dynamic parameters input into module, configuring static parameters for the following encoding calculations. The encoder parameter module performs parameter calculation via selection and output to the remaining modules after receiving code length and code rate information. The parameters are the base graph BG, the number of kernel matrix columns , the lifting size Z, and the corresponding sets of Z. BG and determine the number of iterations for CN. The lifting size reads the memory module for parity check matrix information used in this encoding based on the group to which Z belongs. The codeword output processing module punches and shortens the information bits according to the code rate and , as well as the parity bits.
The encoder hardware scale is designed according to the maximum parity check matrix under BG1, the matrix H is constructed by size submatrix, and each submatrix is multiplied by the corresponding Z length information vector or vector. Therefore, the number of CN is set according to the maximum matrix dimension and the fixed length of the barrel shift is set to . is used as the CN hardware length to adapt to multiple size submatrix. A Z-bits as the information or parity is input into CN, if Z is less than , the LSB vacant bits will be filled with 0 bits, only Z significant bits are shifted during cyclic shift, and only Z significant bits of each code word are as the output at the end of encoding. Meanwhile, the parity codeword can be achieved according to Z as a group. It can also meet the redundancy version requirement of QC-LDPC IR-HARQ transmission.
The encoder hardware shall adapt to changes of code rates. When the code rates are less than 2/5,
C,
D matrix has more rows than columns. In order to design a more parallel
hardware, the multiplication operation between the
H matrix and the vector is converted as shown in
Figure 10. For high code rate, the encoder uses the code word output processing module to punch the corresponding number of
Z-bits parity codes. With
[C D] matrix row number as the degree of parallelism, the number of Part II calculation modules is configured. The increase of the CN parallelization degree reduces the encoding delay and improves the throughput.
Therefore, the encoder can achieve code rate compatibility, but the encoding latency of different code rate under different BG depends on the encoding time at the lowest code rate. The proposed encoder needs + 4 clock cycles to generate parity sequences under BG1 ( = 22) and BG2 ( = 10); it also needs one clock to output the encoded codeword. Therefore, the proposed encoder needs a total of and 5 clock cycles to complete the encoding of an information sequence.
The configurable barrel shift register design allows the encoder to be code length configurable. It avoids the waste caused by changing the hardware scale of the encoder for different lifting size. More CN numbers further shorten the encoding latency. The design of the configurable circuit makes the encoder fully meet the requirements of 5G NR flexibility. Although these schemes increase the hardware complexity of the encoder, they have achieved greater improvements in the performance of the encoder such as latency and throughput. Thus it achieves a balance between hardware complexity and encoder performance. We are constantly approaching the limit of the performance of the encoder within the complexity limit that the IC can achieve.
Based on encoding algorithms, we have studied the dynamic configurable scheme of the encoder in this section. We designed a parameterized encoder module; static parameters are available during power on process, and dynamic parameters are changed by L2/L3 setting via MAC-PHY (Port Physical Layer) API (Application Programming Interface). Then, the encoder schedules the hardware to perform encoding operations. The encoder can thus handle variable code length and rate for LDPC encoding through a fixed hardware architecture, which makes the encoder compatible with all configurations following 5G standard.
6. Conclusions
In this paper, a 5G QC-LDPC encoder including CRC calculation is proposed. The designed hardware architecture has high parallelism and flexibility. Through parameter configuration, LDPC codes of various code lengths and code rates in the 5G standard can be encoded. This is achieved by improving the cyclic shift structure, the encoder uses the maximum lifting sizes of the 5G standard as the hardware scale and uses encoding parameters to constrain the hardware to achieve effective compatibility of the encoder.
In addition to architecture innovation, the encoder includes the parallelization of CRC calculations and designed a 256-bit parallel CRC calculation architecture based on look-up tables. Therefore, the encoder can perform the complete process of 5G LDPC encoding, which is an innovation compared to existing work.
The hardware implementation of the encoder is based on SIMC 28 nm CMOS technology. Compared with existing similar LDPC encoders, the proposed encoder achieves higher throughput, lower encoding latency, and the equivalent bit operation of each clock is also improved. Hence, our design achieves a better balance among flexibility, coding efficiency, and hardware power consumption and is suitable for 5G eMBB and URLLC scenarios.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}