1. Introduction
In refs. [
1,
2], studies of permutation arrays under the Chebyshev metric were presented. This complemented many studies of permutation arrays under other metrics, such as the Hamming metric [
3,
4,
5], Kendall
metric [
6,
7], and several others [
8]. The use of the Chebyshev metric was motivated by applications of error correcting codes and recharging in flash memories [
6].
The flash memory application is based on a rank-modulation scheme [
9], which eliminates the need to use absolute values of cell levels in storing information. Instead, relative ranks are used. The data are coded by permutations of a finite number of ranks.
Let and be two permutations on the symbols in . The Chebyshev distance between and , denoted by , is . For an array (set) of permutations, say, A, the Chebyshev distance of A, denoted by , is . An array A of permutations on with will be called an -PA. Let denote the maximum size of any -PA. We shall also define analogously the Chebyshev distance between two strings and the Chebyshev distance of an array of strings. The context will make clear whether the objects are strings or permutations.
Previous work on permutation arrays under the Chebyshev metric gave upper bounds based on a Gilbert–Varshamov inequality [
10,
11] (see our Theorem 2, or, for a recursive inequality, see our Theorem 3). In [
2], it was also shown for fixed
that there exist constants
and
such that
for
(see our Theorem 1). Upper bounds on
and
were given in [
2]. We give substantial improvements on these upper bounds.
We consider strings over the alphabet
. A set
A of such strings of length
n is
separable if for any two strings in
A, there is a position
such that the
symbol in one string is 0 and the
symbol in the other is a 2. We will often view such a set
A as a matrix in which the rows are the strings in
A (ordered arbitrarily) and the columns are the coordinate positions
of entries in these strings. So, the
’th entry of
A in this view is the entry (
or 2 ) in the
j’th position of string
i of
A. If every string in a separable array
A has length
n and has
a occurrences of the symbol 0 and
b occurrences of the symbol 2, then we call
A an
-array. The maximum number of strings in an
-array is denoted by
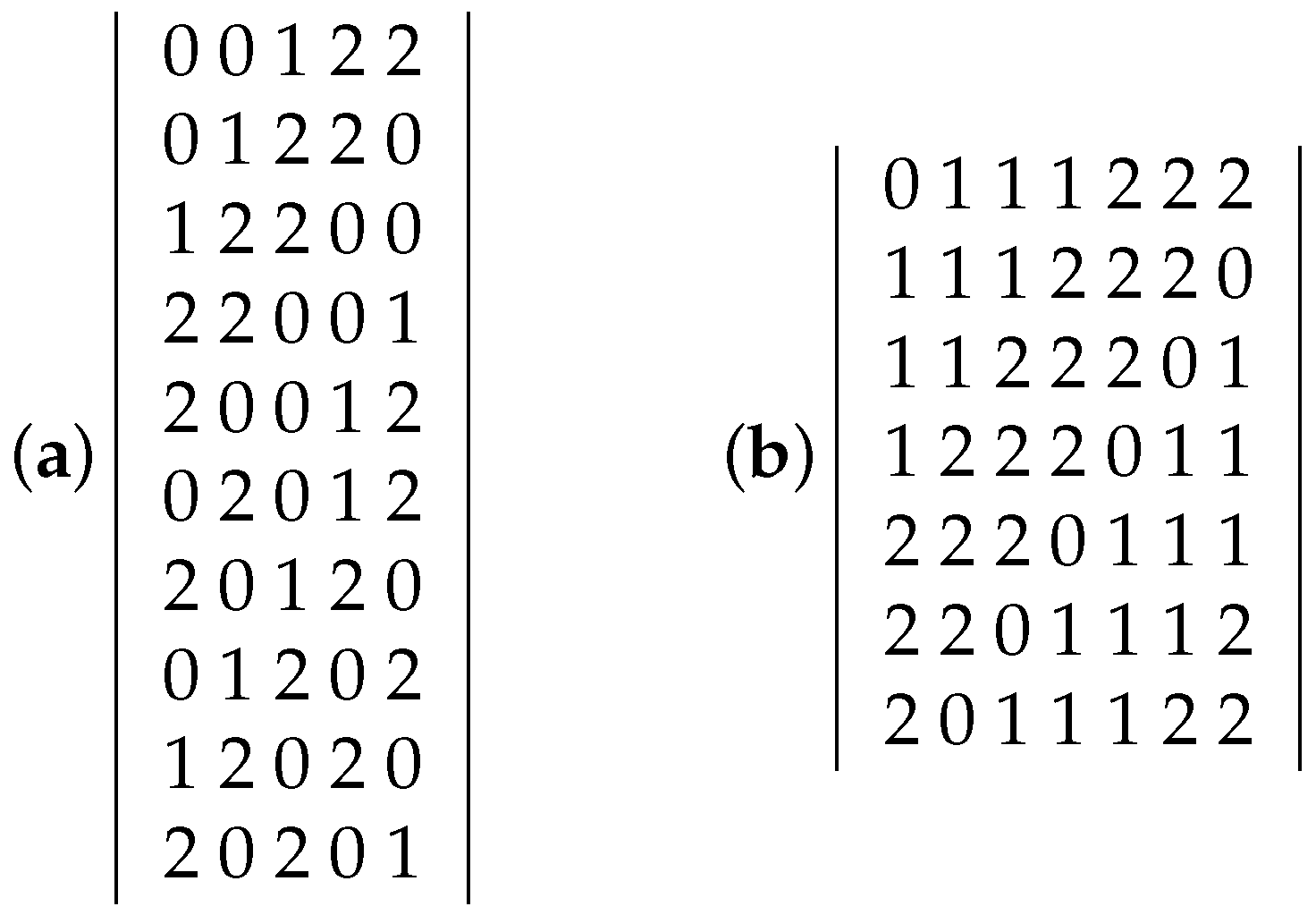
. Examples of a
array and a
array are shown in
Figure 1.
Such matrices, consisting of the three symbols 0, 1, and 2, are reminiscent of weighing matrices. A
W of weight
w is a square matrix of rank
n containing symbols −1, 0, and 1 such that
[
12]. A weighing matrix is an extension of Hadamard matrices [
13] by adding the symbol 0 (see [
14]). A
is a weighing matrix in which each row is a circular shift of the first row [
14]. There are examples of
weighing matrices that can be transformed to an
-array, for appropriate
a and
b, by transforming the three symbols (−1, 0, 1) to (0, 1, 2), respectively. For example, the circulant weighing matrix with first row (−1 1 0 1 1 0) is transformed into a circulant (6, 1, 3)-array with first row (0 2 1 2 2 1) by the indicated replacement of symbols.
The motivation for our study begins with Lemma 1, given in the next section, showing that any upper bound for also serves as an upper bound for the Chebyshev function . The resulting upper bounds we obtain on the Chebyshev function give improvements over what was previously known in the literature.
Our results are the following.
By means of a transformation, we adapt a result of Bollobás from the theory of extremal sets to show that . From this, we derive (as r grows). This improves on the previously known upper bound for for large r.
We develop recursive methods for upper bounding . For small r, these yield upper bounds for , which improve on both the previously known upper bounds for and on the bound obtained through the transformation of the Bollobás result stated above.
We will need the following notation and terms. For an array A, we let be the number of rows in A. For any row r in an array A, we let be the entry of r in column i (which we also call position i) of A. Given a set S of rows in A, we say that S is separated in a set of columns C if for any two rows there is a column such that one of is 0 while the other is 2. Given two sets of rows in A, we refer to internal separations of and as that set of columns at which either is separated or is separated. We refer to cross separations of and as that set of columns C such that for any two rows and , there is a column at which are separated.
2. Background and Preliminary Results
We begin with a theorem by Klove et al. [
2], preceded by a definition.
Definition 1. If A is a -PA, then the integers and are called potent symbols. Moreover, the integers are called low potent symbols and the integers are called high potent symbols.
Their proof of the following upper bound, here omitted, uses the idea of potent symbols.
Theorem 1 (Klove et al. [
2])
. For fixed , there exist constants and such that for . Moreover,and Exact values are known for
and
, namely,
,
[
2],
, and
[
1]. The upper bounds for
and
given in (1) and (2) turn out to be quite generous. For example, inequality (1) gives the bound
, but we know that
. We will see additional improvements on
as given in Equation (
1) later in this paper.
The role of potent symbols motivates the idea behind the following lemma, which establishes the connection between the Chebyshev function and . Consider an -PA, which we call A, and any row of A. The idea is to put the symbols of into three groups. Those that are high (resp. low) potent symbols, namely, (resp. ), are relabeled 2 (resp. 0), while all other symbols are relabeled 1. Repeating this replacement over all rows of A, independently in any two rows, will yield an -array, as we will see below. On the other hand, given an array B, we perform the inverse replacement independently in each row of B to obtain an )-PA. We obtain bounds linking the R function with the Chebyshev function in the lemma following.
Lemma 1. when .
Proof. We begin with the first inequality. Let
A be an
-PA, where
. Create an
-array
as follows. For each row
, create a row
by
Then, is an array over the symbols , having k many 0’s and k many 2’s in each row. Since , then for any two rows and of A, there is a position i such that . So, one of or is and the other must be . Consequently, one of or is transformed into a 2 and the other into a 0. So the rows and are separated in . Furthermore, as any two rows of are separated, any two such rows must be distinct. Therefore is an -array and , so the inequality follows.
Consider now the second inequality. Let B be an -array with the maximum possible number of rows. Let be the permutation array obtained from B by arbitrarily replacing, in any row of B, the k many 2’s by the high potent symbols , the k many 0’s by the low potent symbols , and the 1 symbols by the symbols . (It is, of course, required that the replacements create a permutation). The replacements performed on any two rows of B are performed independently of each other. Since B is separable, given any two rows r and s of , there is a column c in for which one of is a high potent symbol while the other is a low potent symbol. So, we have . Since rows r and s were arbitrary, this shows that . So, by monotonicity in d of , we obtain . □
The following Corollary of Lemma 1 shows that reaches a maximum that depends only on k.
Corollary 1. There are constants and (depending only on k) such that for all , we have . Moreover, we can take and . Here, and are the constants from Theorem 1.
Proof. By the second inequality of Lemma 1, we have
. So, by Theorem 1, for ; that is, for . □
We note that a transformation of an -array with N rows into an -PA with N rows is not known to be always possible.
We will see later that the existence of the constants and follows from one of our theorems (Theorem 6), together with an improvement on the bounds given in Theorem 1 for the constants and . Still, we mention Corollary 1 here to show that the existence of and is already implied by Theorem 1 combined with the argument in that Corollary.
There are a few other theorems in the literature that give upper bounds on the Chebyshev function. Let be the number of permutations on within Chebyshev distance d of the identity permutation.
Theorem 2 (Theorem 11 [
2])
. For even d and , . Theorem 3 (Theorem 12 [
1])
. For , Corollary 2. For and , Proof. Consider any -array A, which we can take to be of maximum possible size . Create subsets of the rows of A, determined by the positions of their k many 0’s. That is, two rows are in the same subset if they both have k many 0’s occurring in the same k positions. There are such sets. Any two rows in such a set must be separated somewhere in the remaining positions, using many 0’s and t many 2’s in those positions. Hence, any such set of rows must have the size at most . It follows that . □
Corollary 3. For all .
Proof. Setting in Corollary 2, we have since for all m. □
We will see later (Theorem 9) a bound on that depends only on t once n is big enough. But, the bound in Corollary 3 is still the best for n that is small enough relative to t, as we will see.
Some of the best previous upper bounds for small n were given using Theorem 3. For example, from Theorem 3, , choosing , respectively. To see this, consider the following. Since for any r, taking , we obtain . As mentioned previously after Theorem 1, , so, taking , we obtain . Again, recalling , we take to obtain . Since for all , Theorem 3 gives the upper bound . In an application of our recursive upper bounds, we will see later in Corollary 7 that , yielded by Lemma 1. . Thus, Theorem 3 gave the best upper bound for for , while our new recursive results give an improved bound for when .
Similarly, from Theorem 3, , where , choosing , respectively. The previous paragraph shows that for all . Calculating, for and for all . In Corollary 8, which we will see later, we obtain . Calculating, one observes that for all . So, we obtain the improved upper bound: for all .
We observe that
is symmetric and monotone; that is,
Later in this paper, it will be useful to consider separable arrays on in which the number of 0’s and 2’s in each row is not constant for all rows. The following definition and the lemma which follows treat this case.
Definition 2. For , an -array is a separable array of length n strings over such that each string in A has at most a many 0’s and at most b many 2’s. Let be the maximum size of any -array.
Lemma 2. If and , then Proof. Let A be an -array with entries from , realizing . Consider any string in A having many 0’s and many 2’s. Since , we have , so A must have at least many 1’s in its row corresponding to . We transform into a string with s many 0’s and t many 2’s as follows. We convert any of the 1’s in to 0’s and any of the remaining 1’s to 2’s and let be the resulting string. Let be the array obtained from A by replacing each by .
It suffices to show that is separable. It would then follow that no two strings are the same, since they would not be separated, and since the number of rows in is at most , then, also, . So, let be two arbitrary strings of A and let be the respective transformed strings in . There is a column c of A where (in either order). Since the transformation affects no symbols in or that are either 0 or 2, it follows that and and, hence, and are separated. Thus, is separable. □
The following theorem will lead to the exact value for .
Theorem 4. Suppose that such that Then, for all .
Proof. Suppose to the contrary that for some . Let n be the smallest such number. Let be an -array. Let denote the number of 0 and 2 symbols in position i, taken over all rows of A. Let , so that . We show that for all i. Suppose, by symmetry of argument, that and (by rearranging the order) only , have 0 or 2 symbols in the first position. By our assumption, all of the first rows, and only the first rows, have a 0 or 2 symbol in position 1. So, if there are rows, each adding 0 or 2 symbols to some position , the total number of 0 or 2 symbols (other than the one in position 1) is . Since the number of positions, namely, , is greater than , by the pigeonhole principle, there is a position where no do not has any 0 or 2 symbols. Now, do the following:
For each row , , exchange the 0 or 2 symbol in position 1 with the symbol in position j.
Delete the symbol in position 1 in all rows.
The result is a separable array of rows, where each row is a string of length . This contradicts our choice of n being the smallest. So, we have for all i.
Note that the total number of 0 and 2 symbols in the
-array
A is
. As
, for all i, we have
, which contradicts inequality (
6). So, the
-array
A with
rows does not exist. □
Theorem 15 was used in [
1] to prove that
for all
. A similar proof shows that
for all
.
Corollary 4. For all , R(n;2,2) = 10.
Proof. for all , by computation. In Theorem 4, set , and . Then, and . So, for all , following Theorem 4.
Therefore, for all . □
An example of a
-array with 10 rows realizing
is given in
Figure 1a.
3. Applying a Result of Bollobás
We begin with the following result of Bollobás from the theory of extremal sets. It is actually a reformulation, given in [
15], of a theorem on saturated hypergraphs originally appearing in [
16]. The proof can be found in [
15].
Theorem 5. For two nonnegative integers a and b, write . Let be a finite collection of finite sets such that if . For , set , . Then, with equality if there is a set Y and integers such that , and is the collection of all ordered pairs of subsets of Y with and .
In particular, if and for all , then .
We obtain an upper bound for by reducing to the above theorem.
Theorem 6. .
Proof. Let M be a an -array realizing , and set . For any , let be the set of column indices at which row i of M has 0 entries and the set of column indices at which row i of M has 2 entries.
Now, construct a array Q whose first n columns are the same as in M and whose subarray consisting of the last n columns is obtained by interchanging 0 and 2 entries in M, leaving the 1 entries unchanged. That is, is obtained from M by flipping each 2 entry of M to a 0 entry in , flipping each 0 entry in M to a 2 entry in and leaving each 1 in M unchanged as a 1 entry in . Let (resp. ) be the column indices in corresponding to the column indices of (resp. ) by a translation of n. That is, we have and . Now, for each i, , define two sets of column indices, and , of Q by and . Observe that (resp. ) is the set of column indices at which row i of Q has 0 (resp. 2) entries.
We now show that for , the sets , can play the roles of and (respectively) in the statement of Theorem 5 with . Trivially, we have for each i since . Now, take , . We must show that and . Since M is separable, we have or , so assume by symmetry that . Then, immediately, we have since and . Also, it follows from and the interchange of 0’s and 2’s that . Therefore, since and . Thus, the conditions of Theorem 5 are satisfied. Since for all i, we obtain . □
The preceding theorem implies Corollary 1 with the considerably improved value over that obtained by combining that corollary and Theorem 1.
Corollary 5. (as r grows).
Proof. By Lemma 1 and Theorem 6, we have . The final equality follows from the Stirling approximation applied to . □
We note that the preceding corollary implies that , where is the constant in Theorem 1. This is an improvement on the upper bound for given in that theorem.
4. Recursive Techniques
4.1. The Positions Method
In this subsection, we introduce a technique, called positions, to recursively obtain an upper bound for . The strategy involves considering a fixed row of a -array A, with a occurrences of the symbol 0 in positions and b occurrences of the symbol 2 in positions . By separability, every row in A other than must either have a symbol 2 in at least one of the positions or a symbol 0 in at least one of the positions . Let (respectively, ) be the set of rows in A with the symbol 2 (respectively, symbol 0) in position (resp., ). Each (resp. ) must be a separable subarray of A, with separations occurring at positions other than (respectively, ). As one 2 (one 0) is used in position (resp., ), there are at most a many 0’s and at most many 2’s (resp., many 0’s and b many 2’s) that can be used to separate (resp. ). This method gives the following recursive bound on .
Theorem 7. For all and , .
Proof. Let A be an -array of size . Let be a permutation in A. Suppose that in , the 0’s are at positions and the 2’s are at positions . Every permutation has a symbol 2 in at least one of the positions or a symbol 0 in at least one of the positions . For every position , there are at most strings with and, hence, a total of at most such strings over all . For every position , there are at most strings in with and, hence, a total of at most such strings over all . The bound follows. □
We can obtain an exact formula for in the next lemma and the theorem that follows.
Lemma 3. For all and ,
Proof. Suppose
. Let
be the permutation
Consider permutations defined by , that is, is obtained from by shifting elements rightward by i with wraparound.
First, we observe that the array A with rows , appearing in A in order of their index, is separated. It suffices to show that row is separated from any row , . The 0 in position 1 of separates from the 2 in column 1 of for . The 2’s in columns through n of each separate from the 0 in the same columns for , . Therefore, the permutations are pairwise separable and .
If
, then
, the first inequality by monotonicity of
for a fixed
k (see Equation (
4)) and the second by the same circular shift construction just given. □
Theorem 8. - (a)
For all and ,
- (b)
Suppose a separated array A has at most one 0 and at most k many 2’s in each row. If A has rows, then A must have exactly one zero and k many 2’s in each row.
- (c)
Suppose A is an -array. If A has rows, then A is a array also with one 0 and k many 2’s in each column.
Proof. Consider first (a). In view of the lower bound in Lemma 3, it remains only to prove the corresponding upper bounds.
The upper bound follows from the fact that any two rows do not have 0 in the same position. Suppose .
Take an -array with p rows. There are pairs of rows that have to be separated. Let Q be the total number of unordered pairs with both the 0 and the 2 lying in the same column of A. Then, .
But, Q ≤ {the number of 2’s that are members of such a pair (since there is only one 0 per column)} ≤ {the total number of 2’s in the array} .
So, we obtain . Solving for p, we obtain .
Consider now (b). Recall that no two 0’s of A can be in the same column, since, otherwise, the two rows containing those 0’s cannot be separated. For any column i containing a 0, let be the number of of 2’s in column i. Since A is separated, the number of pairwise row separations in A is at least . Since there is at most one 0 in each column, we have .
Assume to the contrary that claim is false, so that either some row contains no 0 or some row has fewer than k many 0’s. Suppose first that some row contains no 0. Then, since it has at most k many 2’s, this row can be separated from most k other rows since its separation from other rows can only occur at columns containing its 2’s, and each column has at most one 0. This contradicts A being separated, which requires each row to be separated from other rows.
So we may suppose that A has many 0’s, but that some row has at most many 2’s. Then, by the assumption in b), the total number of 2’s in A is less than but is also equal to . Then, we have , a contradiction.
Consider now (c). Since no two 0’s of A can be in the same column, it follows that each column has exactly one 0. It also follows that A must be a array.
Suppose to the contrary that some column c of A has at most many 2’s. Consider the row r passing through the 0 in column c. Row r must be separated from each of the other rows of A. There are separation pairs involving row r that use the 0 in column c. The remaining separation pairs involving row r must use the k many 2’s in row r. But each such 2 participates in only a single separation, that being with the unique 0 in its column. Hence, we cannot find separations involving these 2’s, a contradiction. □
An example of a
-array realizing
is given in
Figure 1b.
In the next lemma and theorem that follow, we use the positions technique to obtain an upper bound on .
As a notation, for any subarray B of an array A, let (resp, ) be the set of columns (resp. rows) of B. Further, let (resp. ) be the set of rows (resp. columns) of A containing entries of B. For a particular column c, , in some array A of n columns, we refer to it just by its index c. For example, for a subarray B of A, we write or for or , respectively.
Now, let A be an -array and let c be some column of A. Let B be the subarray consisting of all rows of A with a 0 in column c. Then, has one 0 and k many 2’s in each row. Assume now that B has exactly rows. We then let be that -array in B (guaranteed to exist by Theorem 8), which has dimensions .
Lemma 4. Let A be an -array and let be two distinct columns of A. Let (resp. ) be the subarray of A whose rows have a 0 entry in column (resp. ). If , then .
Proof. Since each row of and has one 0 and k many 2’s, we have by Theorem 8. By our assumption and the same theorem, we then see that , , is a -array with dimensions and one 0 and k many 2’s in each row and in each column. Note also that if , then any two rows in this intersection have both 0’s in the same two coordinates and and, hence, cannot be separated, a contradiction to A being separated.
We are thus reduced to showing that leads to a contradiction. Slightly abusing previous notation, in what follows, we use the term potent symbol to refer to either a 0 symbol or a 2 symbol in A.
Assume that . It follows that every entry in is nonzero. So, since every column of has a 0. Since each row of contains one 0 and k many 2’s, and since every entry of is 0 by definition, it follows that every potent symbol in lies in . So, there remain no potent symbols of that can appear in . So, every entry in is 1. By a symmetric argument, we also have that every potent symbol in lies in and that every entry of is 1. It follows that all cross separations must occur in the columns contained in .
The number of cross separations must be at least , since every row of must be separated from every row of . Now, in each column , there are many cross separations, obtained by pairing the 0 in with each of the k many 2’s in , and the same with and interchanged. Since , the total number of cross separations is at most , a contradiction. □
In the theorem that follows, we abbreviate the symbols , , and so on by or ; that is, we drop the first coordinate in the R function. We take n large enough so that depends only on k (see Corollary 1). By monotonicity, the upper bound we then obtain for holds also for , where .
Theorem 9. .
Proof. Let A be be an array achieving the maximum possible number of rows for such arrays. Let be a fixed row of A, with its two 0’s in columns and and its k many 2’s in columns . Every row of , being separable from , must have a 2 in at least one of the columns and or a 0 in at least one of the columns .
Let (resp. ) be the subarray of consisting of the rows of A with a 2 in column (resp. ). Note that any row of has at most many 2’s outside the columns
First, we give an upper bound for as follows. Let be the set of rows in with no 0 entry in columns . Then, by Lemma 2. Let be the set of rows in with exactly one 0 in one of the columns or . Then, by Lemma 4 and Theorem 8, we have . Finally, no row of can have both its 0’s in columns since such a row would not be separated from . Therefore, we have .
Let , be the subarray of A consisting of the rows of A with a 0 in column . Note that .
We now give an upper bound for
. First note that for any triple of indices
, we have
, since any row of
A contained in this triple intersection has three 0 entries, contradicting
A being an
-array. Applying inclusion–exclusion, we thus obtain
Also note that or 1 since any two rows of A contained in have both of their 0 entries in the same two columns and, hence, cannot be separated.
We now maximize the right side of (
7) over all possible collections of subarrays
of
A as defined above. Let
for
, while
for
. By Lemma 4, we have
for
. Therefore, we obtain
To maximize on the domain , we differentiate to obtain , so is the only critical point, and, also, , while . So, the maximum of at integer values is max So, we have .
Finally, for , we obtain the following recurrence, where the first summand “1” accounts for the fixed permutation .
.
We can unravel this recurrence to obtain
□
We note that the upper bound on from Theorem 9, being independent of n once n is big enough, is better than the bound from Corollary 3 for n that is large relative to k, but the latter bound is stronger when for a suitable constant C. Also, the bound from Theorem 9 is stronger than the bound from Theorem 6 for all but small k.
As examples to be used later, we mention the following.
Corollary 6. and .
4.2. The Partition Method
In this subsection, we develop a recursive method, which we call the partition method, which, in some sense, generalizes the positions method of the previous subsection. In the partition method, we consider subarrays of a separable array A over defined by restrictions of rows of A to a certain set of coordinates in A. In the preceding positions method, the subarrays were defined by their restriction to a single coordinate.
Let A be an -array with, say, . Choose a row with s occurrences of the symbol 0 in positions and t occurrences of the symbol 2 in positions . For separation, all rows in A other than must have either a symbol 2 in one of the positions or a symbol 0 in one of the positions . Let S be the set of strings in A with at least one 2 in the positions and let T be the set of strings in A with at least one 0 in the positions . Since every string in A is separated from , we have , so . In this section, we upper bound (and similarly ) by partitioning S into certain collections of strings, and then upper bound the sizes of each of these collections. The collections come in two types as follows. For any string , let be the length s restriction of to the positions ; that is, . Also, let be the set of positions among at which has a 2 symbol. The two types of collections are the following.
- (1)
has no 0 symbols}.
- (2)
For each nonempty subset satisfying , let contain at least one 0 and .
Clearly, is a partition of S, so . We upper bound the sizes of these sets of rows in the following lemma.
Lemma 5. The sets , satisfy the following.
- (a)
No two strings in and no two string in are separable in any of the coordinates . So, all internal separations in and in occur outside the coordinates .
- (b)
.
- (c)
.
Proof. For (a), no two strings in
are separable in one of the coordinates
, since neither has a 0 in those coordinates. Similarly, no two strings
,
in any
are separable in a coordinate
since we have
if and only if
. Thus, all internal separations in
or in any
occur in columns outside
. We then define the subarrays
and
of
A by
So, (resp. ) is the set of length strings obtained by deleting the substring from each string (resp. ). Note that since for any two strings , we have because, for some coordinate c outside , we must have and . This is because all internal separation in occurs outside the coordinates, as observed above. Similarly, for any nonempty subset .
Consider now part (b). Since any has no 0’s in positions , then is a length string containing s many 0’s and at most many 2’s. Hence, . The second inequality then follows Lemma 2.
For part (c), note that by definition for any , contains at least one 0 and many 2’s. So, is a length string that has at most many 0’s and at most many 2’s. So, we obtain . Again, the second inequality follows Lemma 2. □
We mention the analogue of Lemma 5 for subsets of T that correspond to and the sets . For any string , let be the length t restriction of to the positions ; that is, . Also, let be the set of positions among at which has a 0 symbol. In a similar way, one can define sets of rows and within T as follows.
- (1)
has no 2 symbols}.
- (2)
For each nonempty subset , , let contain at least one 2 and . The restriction is necessary since each row in A has at most s many 0’s.
Again, we have as a partition of T, so . The corresponding upper bounds for and are given in the following lemma. We omit the proof as it is entirely analogous to the proof of Lemma 5.
Lemma 6. The sets and satisfy the following.
- (a)
No two strings in and no two strings in are separable in the coordinates . So, all internal separations in and in occur outside the coordinates .
- (b)
- (c)
.
We illustrate the use of the partition method for upper bounding in the following corollary.
Corollary 7. .
Proof. Consider an array A achieving . We find the sets , (with a symmetric procedure for finding the sets ). Then, we use Lemma 5 and other theorems to upper bound and for each , . From this, we obtain a bound for S and, using Lemma 6, a symmetric bound on T. Finally, using , we obtain our bound for .
Again, we take to a row of an array A, with its three 0’s in coordinates and its three 2’s in coordinates . We describe the sets of rows in or by specifying for each row in such a set its length 3 restriction to . Then, we upper bound and using the preceding lemmas and additional results already given. The justification for these bounds are given after the list of sets and .
, .
, , .
, , .
, , .
, , .
, , .
, , .
The bound for in item 1 comes from Theorem 9, for in items 2–4 from Theorem 8, and in items 5–7 from Corollary 4. We obtain by symmetry using sets and , as in Lemma 6. Finally, we have . □
Note that from Lemma 1, we then have , an improvement over the previous bound , cited in Theorem 1. This bound is also an improvement on the bound in Corollary 5 derived from the theorem of Bollobás.
The partition technique shown in the above example is generalized in the next two theorems.
Theorem 10. For all , .
Proof. Let A be an array realizing and let be a row of A. As usual, we take to have 0’s in positions and 2’s in positions . We continue with the notation from the two lemmas preceding this theorem and we take in those lemmas. In particular, we have , and we now proceed to estimate , the estimate for being identical by symmetry.
By Lemma 5, we have .
For each subset
, we have by Lemma 5 that
. If
, there are
such
D’s. Since
, we obtain
We have the same bound for
T based on Lemma 6 and
. Since
, we then obtain
By Lemma 2 and Equation (
4), the theorem follows. □
Theorem 11. For all ,
Proof. We continue with the notation of Theorem 10 and the Lemmas that precede it.
Using exactly the same reasoning as in Theorem 10, we obtain
The estimate for T is very similar, except for a restriction on the sizes of sets E defining the sets .
By Lemma 6, we have
. By the same lemma, we have that for any
with the size restriction
, we have
. Since there are
,
choices for the set
E, we obtain
Finally, the theorem follows from Equations (
11) and the preceding bound for
. □
We now calculate some values from the above recurrences.
Corollary 8. , and .
Proof. We denote
by
for short (using monotonicity of
in
n). Then, the bounds in Theorems 10 and 11 can be written as
For starting values in these recurrences, we use Theorem 9 for and , Corollary 7 for , Theorem 8 for , Corollary 4 for , and for all k. Now, applying the recurrences, we obtain the following values.
.
= 3087.
= 1669.
= 12,327.
= 69,435.
□
By Lemma 1, we have 3087, so in the notation of Theorem 1, we have . This is an improvement over that given in inequality (1), namely, . It is also an improvement on the bound derived from Corollary 5 based on the reduction from the theorem of Bollobás. The latter bound is still best though for large r.
Similarly, from the bound 69,435, we obtain 69,435. This improves considerably the bound , which is roughly .
A rough upper bound for
obtained by applying the positions technique is
. Since
(for
n large enough), this is also a considerable improvement on the bound for
from inequality (
1). The positions and partition techniques give good bounds for
(and, hence,
) for moderately large
k, but, still, the best such bounds so far for large
k come from Corollary 5.



{kind=link}