
Neighbor-Enhanced Link Prediction in Bipartite Networks



Abstract
1. Introduction
- Model: The NeiBLP framework introduces a novel, parameter-free similarity approach to tackle degree heterogeneity in bipartite networks. By normalizing the contributions derived from the -Quadrangle Graph, the framework effectively mitigates the inherent degree bias commonly observed in such networks.
- Node contribution differentiation: NeiBLP proposes two novel indices, and , to distinguish the contributions of cross-type and same-type nodes. This differentiation effectively accounts for degree effects while simultaneously integrating shared neighbor information.
- Performance: We conducted experiments on ten real-world bipartite networks and compared NeiBLP to nineteen baseline algorithms. Our results demonstrate that NeiBLP outperforms the state-of-the-art bipartite link prediction algorithms and consistently achieves high AUC and Precision scores across diverse bipartite networks.
2. Related Work
2.1. Similarity-Based Methods
2.2. Projection-Based Methods
2.3. Dimensionality Reduction-Based Methods
2.4. Other Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Subcategory | Advantages | Disadvantages | Methods |
|---|---|---|---|---|
| Similarity-based | Local | Simple and efficient, low computational complexity | Capture limited structure information | CN [26], PA [49], L3 [5], CAR [50] |
| Global | Capture global structure information | High computational complexity | LPOP [27], Katz [51] | |
| Quasi-local | Low time complexity | Limited information, network-dependent | LP35 [27], CNDP [52] | |
| Projection-based | Weighted projection | Advanced unipartite link prediction methods can be used | Loss of bipartite structure information | PLP [15], NBI [14], NARM [30] |
| Unweighted mapping | Simple and intuitive | Association strength between nodes of the same type is missing | Refs. [28,29] | |
| Dimensionality reduction-based | Matrix factorization-based | Capture global and local structure | Hyperparameter tunning | DNMF [53], LO [54], BNLP-IEI [32], SRNMF [55] |
| Network embedding | Could utilize attribute information for prediction | Hyperparameter tunning, limited interpretability | STERLING [39], BiANE [38] | |
| Other methods | Structural perturbation theory | Efficient and robust | High time complexity | SPM [40], SPRDA [43], SESP [42] |
| Information-theoretic | Highly interpretable | High time complexity | PMIL [56], MapSim [46] | |
| Deep learning | Capture non-linear structure information | Limited interpretability | ICTC [45], LGAE [44] | |
| GNN-based | Capture complex non-linear structural information | Limited interpretability | SRGL [17], IGMC [48] |
3. Methodology
3.1. Problem Description
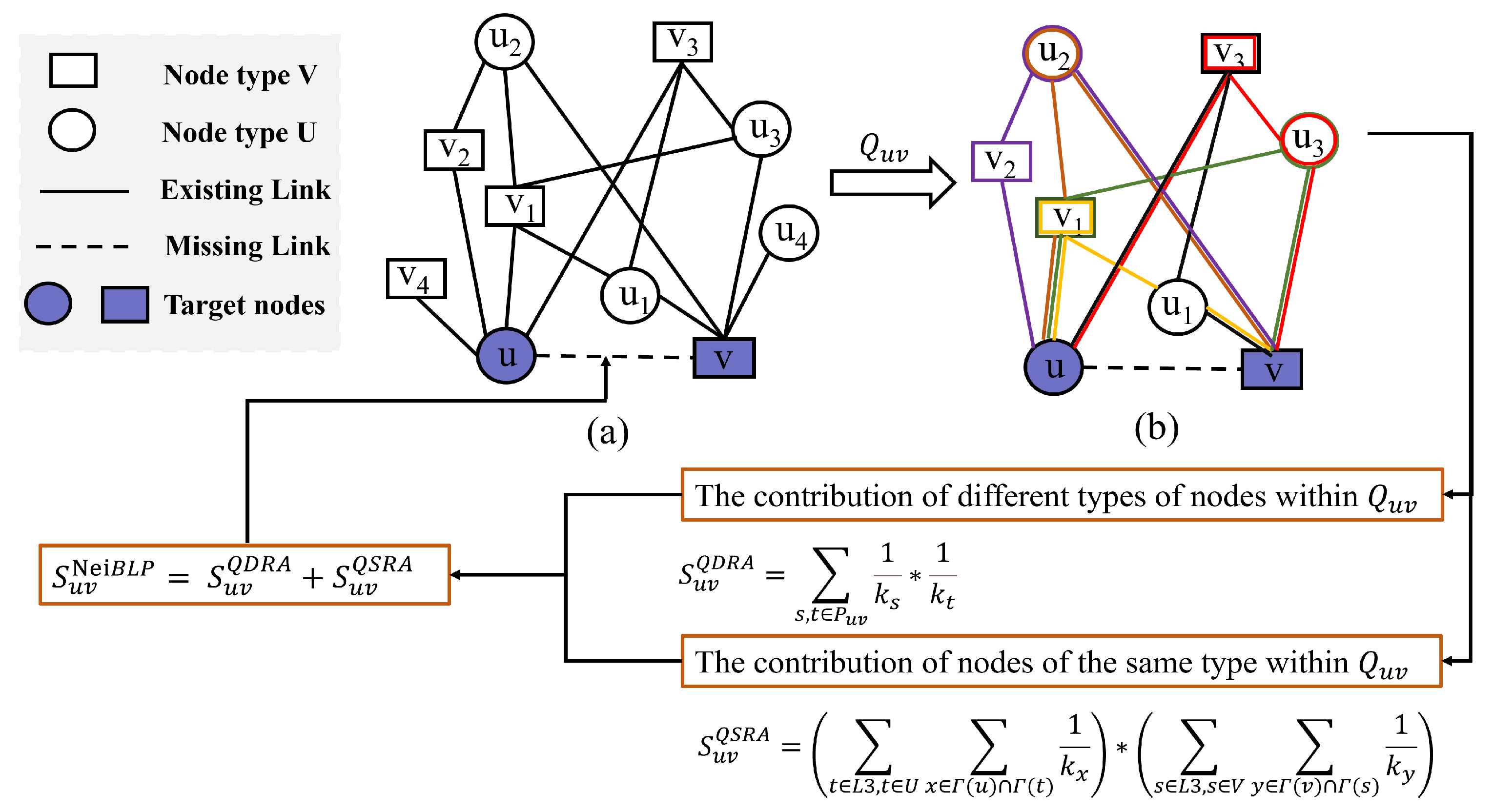
3.2. From Structural Indistinguishability to a New Index
3.3. NeiBLP: The Proposed Framework
3.4. Algorithm Description
| Algorithm 1 The calculation process of NeiBLP framework |
| Input: Bipartite network . Output: Predicted similarity matrix . |
3.5. Complexity Analysis
4. Experimental Results
4.1. Datasets
4.2. Division of Datasets
4.3. Baseline Algorithms
4.4. Evaluation Metrics
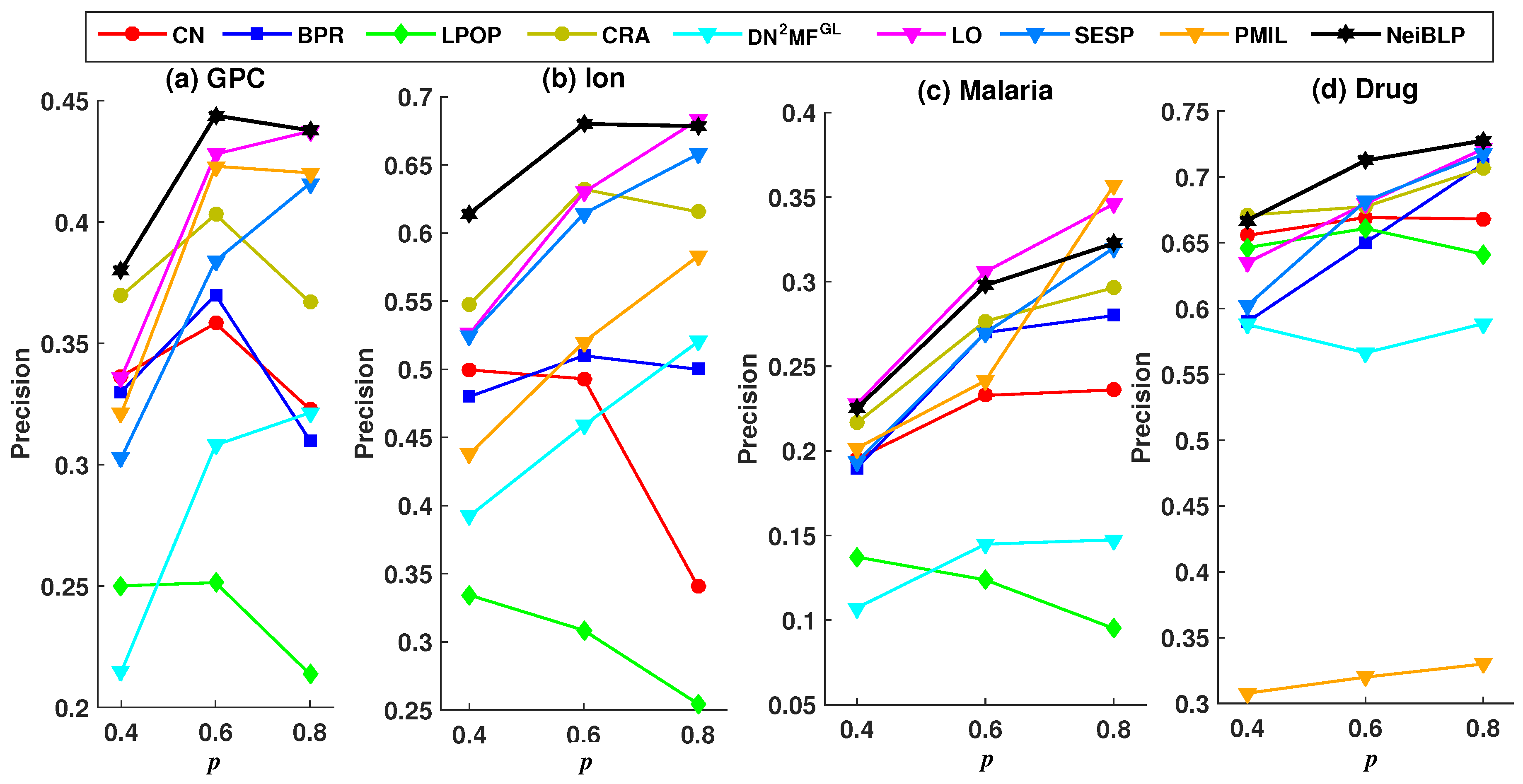
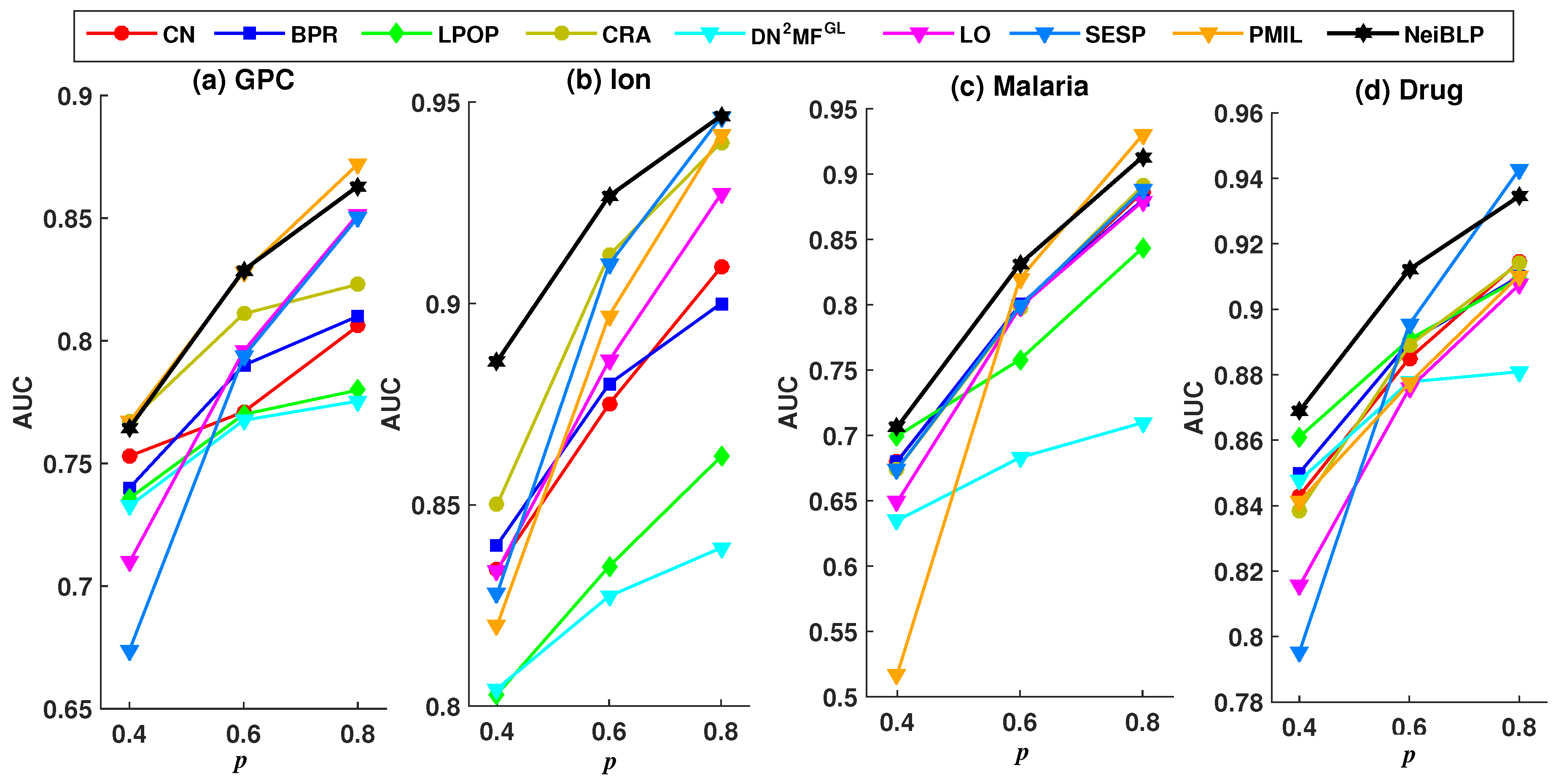
4.5. Experiment Analysis
4.5.1. Comparison with Baselines
4.5.2. Robustness Analysis
4.5.3. Ablation Study
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. A Stat. Mech. Its Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Arrar, D.; Kamel, N.; Lakhfif, A. A comprehensive survey of link prediction methods. J. Supercomput. 2024, 80, 3902–3942. [Google Scholar] [CrossRef]
- Assouli, N.; Benahmed, K.; Gasbaoui, B. How to predict crime—Informatics-inspired approach from link prediction. Phys. A Stat. Mech. Its Appl. 2021, 570, 125795. [Google Scholar] [CrossRef]
- Rai, A.K.; Tripathi, S.P.; Yadav, R.K. A novel similarity-based parameterized method for link prediction. Chaos Solitons Fractals 2023, 175, 114046. [Google Scholar] [CrossRef]
- Kovács, I.A.; Luck, K.; Spirohn, K.; Wang, Y.; Pollis, C.; Schlabach, S.; Bian, W.; Kim, D.-K.; Kishore, N.; Hao, T.; et al. Network-based prediction of protein interactions. Nat. Commun. 2019, 10, 1240. [Google Scholar] [CrossRef]
- Wong, L.; Wang, L.; You, Z.-H.; Yuan, C.-A.; Huang, Y.-A.; Cao, M.-Y. Gklomli: A link prediction model for inferring mirna–lncrna interactions by using gaussian kernel-based method on network profile and linear optimization algorithm. BMC Bioinform. 2023, 24, 188. [Google Scholar] [CrossRef]
- Dhelim, S.; Ning, H.; Aung, N.; Huang, R.; Ma, J. Personality-aware product recommendation system based on user interests mining and metapath discovery. IEEE Trans. Comput. Soc. Syst. 2020, 8, 86–98. [Google Scholar] [CrossRef]
- Yu, X.; Tu, L.; Chai, L.; Wang, X.; Chen, J. Construction of implicit social network and recommendation between users and items via the isr-rrm algorithm. Expert Syst. Appl. 2024, 235, 121229. [Google Scholar] [CrossRef]
- Cannistraci, C.V.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1613. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M.E. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar] [CrossRef]
- Chen, G.; Wang, H.; Fang, Y.; Jiang, L. Link prediction by deep non-negative matrix factorization. Expert Syst. Appl. 2022, 188, 115991. [Google Scholar] [CrossRef]
- Cui, P.; Wang, X.; Pei, J.; Zhu, W. A survey on network embedding. IEEE Trans. Knowl. Data Eng. 2018, 31, 833–852. [Google Scholar] [CrossRef]
- Vural, H.; Kaya, M. Prediction of new potential associations between lncrnas and environmental factors based on katz measure. Comput. Biol. Med. 2018, 102, 120–125. [Google Scholar] [CrossRef]
- Zhou, T.; Ren, J.; Medo, M.; Zhang, Y.-C. Bipartite network projection and personal recommendation. Phys. Rev. E 2007, 76, 046115. [Google Scholar] [CrossRef]
- Gao, M.; Chen, L.; Li, B.; Li, Y.; Liu, W.; Xu, Y.-C. Projection-based link prediction in a bipartite network. Inf. Sci. 2017, 376, 158–171. [Google Scholar] [CrossRef]
- Zhang, Z.-C.; Zhang, X.-F.; Wu, M.; Ou-Yang, L.; Zhao, X.-M.; Li, X.-L. A graph regularized generalized matrix factorization model for predicting links in biomedical bipartite networks. Bioinformatics 2020, 36, 3474–3481. [Google Scholar] [CrossRef]
- Jin, X.; Kong, D.; Xie, M.; Huang, Y.; Liu, M.; Yang, W.; Shi, H.; Liu, Y. Self-supervised reconstructed graph learning for link prediction in bipartite graphs. Neurocomputing 2024, 602, 128250. [Google Scholar] [CrossRef]
- Larremore, D.B.; Clauset, A.; Jacobs, A.Z. Efficiently inferring community structure in bipartite networks. Phys. Rev. E 2014, 90, 012805. [Google Scholar] [CrossRef] [PubMed]
- Estrada, E. Degree heterogeneity of graphs and networks. i. interpretation and the “heterogeneity paradox”. J. Interdiscip. Math. 2019, 22, 503–529. [Google Scholar] [CrossRef]
- Newman, M.E. Clustering and preferential attachment in growing networks. Phys. Rev. E 2001, 64, 025102. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Liu, S.; Ji, X.; Liu, C.; Bai, Y. Extended resource allocation index for link prediction of complex network. Phys. A Stat. Mech. Its Appl. 2017, 479, 174–183. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Aziz, F.; Gul, H.; Muhammad, I.; Uddin, I. Link prediction using node information on local paths. Phys. A Stat. Mech. Its Appl. 2020, 557, 124980. [Google Scholar] [CrossRef]
- Song, A.; Liu, Y.; Wu, Z.; Zhai, M.; Luo, J. A local random walk model for complex networks based on discriminative feature combinations. Expert Syst. Appl. 2019, 118, 329–339. [Google Scholar] [CrossRef]
- Daminelli, S.; Thomas, J.M.; Durán, C.; Cannistraci, C.V. Common neighbours and the local-community-paradigm for topological link prediction in bipartite networks. New J. Phys. 2015, 17, 113037. [Google Scholar] [CrossRef]
- Zhao, Z.; Wu, S.; Luo, G.; Zhang, N.; Hu, A.; Liu, J. Mining odd-length paths for link prediction in bipartite networks. Phys. A Stat. Mech. Its Appl. 2024, 646, 129853. [Google Scholar] [CrossRef]
- Newman, M.E. The structure of scientific collaboration networks. Proc. Natl. Acad. Sci. USA 2001, 98, 404–409. [Google Scholar] [CrossRef]
- Newman, M.E. Scientific collaboration networks. i. network construction and fundamental results. Phys. Rev. E 2001, 64, 016131. [Google Scholar] [CrossRef]
- Aslan, S.; Kaya, B. Time-aware link prediction based on strengthened projection in bipartite networks. Inf. Sci. 2020, 506, 217–233. [Google Scholar] [CrossRef]
- Pech, R.; Hao, D.; Pan, L.; Cheng, H.; Zhou, T. Link prediction via matrix completion. Europhys. Lett. 2017, 117, 38002. [Google Scholar] [CrossRef]
- Chen, X.; Liu, C.; Li, X.; Sun, Y.; Yu, W.; Jiao, P. Link prediction in bipartite networks via effective integration of explicit and implicit relations. Neurocomputing 2024, 566, 127016. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Biswas, B.; Tiwari, P.; Lehmann, J.; Vahdati, S. Deep nonnegative matrix factorization with joint global and local structure preservation. Expert Syst. Appl. 2024, 249, 123645. [Google Scholar] [CrossRef]
- Giamphy, E.; Guillaume, J.-L.; Doucet, A.; Sanchis, K. A survey on bipartite graphs embedding. Soc. Netw. Anal. Min. 2023, 13, 54. [Google Scholar] [CrossRef]
- Li, B.; Chen, Z.; Lu, L.; Qi, P.; Zhang, L.; Ma, Q.; Hu, H.; Zhai, J.; Li, X. Cascaded frameworks in underwater optical image restoration. Inf. Fusion 2025, 117, 102809. [Google Scholar] [CrossRef]
- Ahmad, H.K.; Qi, C.; Wu, Z.; Muhammad, B.A. Abine-crs: Course recommender system in online education using attributed bipartite network embedding. Appl. Intell. 2023, 53, 4665–4684. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Huang, W.; Li, Y.; Fang, Y.; Fan, J.; Yang, H. Biane: Bipartite attributed network embedding. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 149–158. [Google Scholar]
- Jing, B.; Yan, Y.; Ding, K.; Park, C.; Zhu, Y.; Liu, H.; Tong, H. Sterling: Synergistic representation learning on bipartite graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, QC, Canada, 20–24 February 2024; Volume 38, pp. 12976–12984. [Google Scholar]
- Lü, L.; Pan, L.; Zhou, T.; Zhang, Y.-C.; Stanley, H.E. Toward link predictability of complex networks. Proc. Natl. Acad. Sci. USA 2015, 112, 2325–2330. [Google Scholar] [CrossRef]
- Muscoloni, A.; Cannistraci, C.V. Short note on comparing stacking modelling versus cannistraci-hebb adaptive network automata for link prediction in complex networks. Preprints 2021. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, P.; Yu, Y.; Li, X.; Tang, M. Toward link predictability of bipartite networks based on structural enhancement and structural perturbation. Phys. A Stat. Mech. Its Appl. 2019, 527, 121072. [Google Scholar] [CrossRef]
- Zheng, K.; Zhang, X.-L.; Wang, L.; You, Z.-H.; Ji, B.-Y.; Liang, X.; Li, Z.-W. Sprda: A link prediction approach based on the structural perturbation to infer disease-associated piwi-interacting rnas. Briefings Bioinform. 2023, 24, bbac498. [Google Scholar] [CrossRef]
- Salha, G.; Hennequin, R.; Vazirgiannis, M. Keep it simple: Graph autoencoders without graph convolutional networks. arXiv 2019, arXiv:1910.00942. [Google Scholar]
- Shin, J.; Gim, M.; Park, D.; Kim, S.; Kang, J. Bipartite link prediction by intra-class connection based triadic closure. IEEE Access 2020, 8, 140194–140204. [Google Scholar] [CrossRef]
- Blöcker, C.; Smiljanić, J.; Scholtes, I.; Rosvall, M. Similarity-based link prediction from modular compression of network flows. In Proceedings of the Learning on Graphs Conference, PMLR, Virtual Event, 9–12 December 2022; pp. 1–18. [Google Scholar]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2018; Volume 31. [Google Scholar]
- Zhang, M.; Chen, Y. Inductive matrix completion based on graph neural networks. arXiv 2019, arXiv:1904.12058. [Google Scholar]
- Barabâsi, A.-L.; Jeong, H.; Néda, Z.; Ravasz, E.; Schubert, A.; Vicsek, T. Evolution of the social network of scientific collaborations. Phys. A Stat. Mech. Its Appl. 2002, 311, 590–614. [Google Scholar] [CrossRef]
- Durán, C.; Daminelli, S.; Thomas, J.M.; Haupt, V.J.; Schroeder, M.; Cannistraci, C.V. Pioneering topological methods for network-based drug–target prediction by exploiting a brain-network self-organization theory. Briefings Bioinform. 2018, 19, 1183–1202. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Huang, Y.-A.; You, Z.-H.; Yan, G.-Y.; Wang, X.-S. A novel approach based on katz measure to predict associations of human microbiota with non-infectious diseases. Bioinformatics 2017, 33, 733–739. [Google Scholar] [CrossRef]
- Rafiee, S.; Salavati, C.; Abdollahpouri, A. Cndp: Link prediction based on common neighbors degree penalization. Phys. A Stat. Mech. Its Appl. 2020, 539, 122950. [Google Scholar] [CrossRef]
- Yao, Y.; He, Y.; Huang, Z.; Xu, Z.; Yang, F.; Tang, J.; Gao, K. Deep non-negative matrix factorization with edge generator for link prediction in complex networks. Appl. Intell. 2024, 54, 592–613. [Google Scholar] [CrossRef]
- Pech, R.; Hao, D.; Lee, Y.-L.; Yuan, Y.; Zhou, T. Link prediction via linear optimization. Phys. A Stat. Mech. Its Appl. 2019, 528, 121319. [Google Scholar] [CrossRef]
- Wang, W.; Chen, X.; Jiao, P.; Jin, D. Similarity-based regularized latent feature model for link prediction in bipartite networks. Sci. Rep. 2017, 7, 16996. [Google Scholar] [CrossRef]
- Kumar, P.; Sharma, D. A potential energy and mutual information based link prediction approach for bipartite networks. Sci. Rep. 2020, 10, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Yamanishi, Y.; Araki, M.; Gutteridge, A.; Honda, W.; Kanehisa, M. Prediction of drug–target interaction networks from the integration of chemical and genomic spaces. Bioinformatics 2008, 24, i232–i240. [Google Scholar] [CrossRef] [PubMed]
- Larremore, D.B.; Clauset, A.; Buckee, C.O. A network approach to analyzing highly recombinant malaria parasite genes. PLoS Comput. Biol. 2013, 9, e1003268. [Google Scholar] [CrossRef] [PubMed]
- Yamanishi, Y.; Kotera, M.; Moriya, Y.; Sawada, R.; Kanehisa, M.; Goto, S. Dinies: Drug–target interaction network inference engine based on supervised analysis. Nucleic Acids Res. 2014, 42, W39–W45. [Google Scholar] [CrossRef]
- Newman, M.E. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Coscia, M.; Hausmann, R.; Hidalgo, C.A. The structure and dynamics of international development assistance. J. Glob. Dev. 2013, 3, 1–42. [Google Scholar] [CrossRef]
- Guimera, R.; Mossa, S.; Turtschi, A.; Amaral, L.N. The worldwide air transportation network: Anomalous centrality, community structure, and cities’ global roles. Proc. Natl. Acad. Sci. USA 2005, 102, 7794–7799. [Google Scholar] [CrossRef]
- Yildirim, M.A.; Coscia, M. Using random walks to generate associations between objects. PloS ONE 2014, 9, e104813. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 1983, 148, 839–843. [Google Scholar] [CrossRef]




| Network | Sparsity (%) | |||||
|---|---|---|---|---|---|---|
| GPC | 95 | 223 | 635 | 6.68 | 2.85 | 97.00 |
| Enzymes | 664 | 445 | 2926 | 4.41 | 6.58 | 99.01 |
| Ion | 210 | 204 | 1476 | 7.03 | 7.24 | 96.55 |
| Malaria | 297 | 806 | 2965 | 9.98 | 3.68 | 98.76 |
| Drug | 200 | 150 | 454 | 2.27 | 3.03 | 98.49 |
| SW | 18 | 14 | 89 | 4.94 | 6.36 | 64.68 |
| C2O | 144 | 151 | 12,170 | 84.51 | 80.60 | 44.03 |
| Na-net | 940 | 940 | 6892 | 12.95 | 12.95 | 99.22 |
| ML100K | 1574 | 943 | 82,520 | 52.43 | 87.51 | 94.42 |
| DBLP | 6001 | 1308 | 29,256 | 4.88 | 22.37 | 99.63 |
| Method | Formula | Parameter Description |
|---|---|---|
| CN [26] | represents the set of neighbors of u | |
| JC [26] | ||
| AA [26] | ||
| LP3 [27] | B denotes the adjacency matrix, denotes third-order paths | |
| LP35 [27] | is a hyperparameter used to control the contribution of the third-order paths, denotes fifth-order paths | |
| L3 [5] | denotes whether there is an interaction between nodes u and s. If such interaction exists, then , otherwise | |
| LPOP [27] | is a hyperparameter that controls the weight of different odd-length paths | |
| CAR [50] | ||
| CAA [50] | ||
| CRA [50] | ||
| NBI [14] | ||
| BPR [63] | ||
| SESP [42] | and correspond to the k-th eigenvalue and eigenvector | |
| SRNMF [55] | and are the balance parameters, denotes the similarity between nodes i and j | |
| RPCA [31] | the weight parameter | |
| D [33] | a deep non-negative matrix factorization method with joint global and local structure preservation | the number of layers, the size of each layer, the balancing parameters |
| LO [54] | is a free parameter that balances the two requirements | |
| ICTC [45] | ICTC leverages a linear graph autoencoder (LGAE) to capture intra-class relationships | learning rate, hidden dimension, and epoch |
| PMIL [56] | is the weight of pattern |
| Drug | Malaria | Ion | Na-Net | C2O | GPC | ML100K | SW | Enzymes | DBLP | |
|---|---|---|---|---|---|---|---|---|---|---|
| CN | ||||||||||
| AA | ||||||||||
| RA | ||||||||||
| CAR | ||||||||||
| CAA | ||||||||||
| CRA | ||||||||||
| L3 | ||||||||||
| LP3 | ||||||||||
| LP35 | ||||||||||
| LPOP | ||||||||||
| SESP | ||||||||||
| NBI | ||||||||||
| BPR | ||||||||||
| SRNMF | ||||||||||
| D | ||||||||||
| LO | ||||||||||
| RPCA | ||||||||||
| ICTC | − | |||||||||
| PMIL | − | − | ||||||||
| NeiBLP |
| Drug | Malaria | Ion | Na-Net | C2O | GPC | ML100K | SW | Enzymes | DBLP | |
|---|---|---|---|---|---|---|---|---|---|---|
| CN | ||||||||||
| AA | ||||||||||
| RA | ||||||||||
| CAR | ||||||||||
| CAA | ||||||||||
| CRA | ||||||||||
| L3 | ||||||||||
| LP3 | ||||||||||
| LP35 | ||||||||||
| LPOP | ||||||||||
| SESP | ||||||||||
| NBI | ||||||||||
| BPR | ||||||||||
| SRNMF | ||||||||||
| D | ||||||||||
| LO | ||||||||||
| RPCA | ||||||||||
| ICTC | − | |||||||||
| PMIL | − | − | ||||||||
| NeiBLP |
| Methods | Parameters | All Datasets |
|---|---|---|
| SRNMF | regularization parameter | 2 |
| balance parameter | 0.5 | |
| cumulative contribution rate | 0.95 | |
| D | latent space | 80–10 |
| balancing parameter | 1 | |
| balancing parameter | 1 | |
| balancing parameter | 1 | |
| ICTC | learning rate | 0.1 |
| hidden dimension | 32 | |
| epoch | 200 | |
| SESP | perturbation rate | 0.9 |
| LP35 | weight of fifth-order path | 0.1 |
| LPOP | weight of odd-length path | |
| RPCA | weighting parameter | 0.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, G.; Liu, C.; Wei, C.; Li, Y.; Chen, X.; Li, X. Neighbor-Enhanced Link Prediction in Bipartite Networks. Entropy 2025, 27, 556. https://doi.org/10.3390/e27060556
Cheng G, Liu C, Wei C, Li Y, Chen X, Li X. Neighbor-Enhanced Link Prediction in Bipartite Networks. Entropy. 2025; 27(6):556. https://doi.org/10.3390/e27060556
Chicago/Turabian StyleCheng, Guangtao, Chaochao Liu, Chuting Wei, Yueyue Li, Xue Chen, and Xiaobo Li. 2025. "Neighbor-Enhanced Link Prediction in Bipartite Networks" Entropy 27, no. 6: 556. https://doi.org/10.3390/e27060556
APA StyleCheng, G., Liu, C., Wei, C., Li, Y., Chen, X., & Li, X. (2025). Neighbor-Enhanced Link Prediction in Bipartite Networks. Entropy, 27(6), 556. https://doi.org/10.3390/e27060556