
Multi-Branch Network with Multi-Feature Enhancement for Improving the Generalization of Facial Forgery Detection

Abstract
1. Introduction
- (1)
- A multi-branch network is constructed to extract various features through its three parallel branches, delving deeply into the subtle traces of forgery present in facial images, thereby improving the generalization of facial forgery detection.
- (2)
- The adaptive feature concatenation mechanism is proposed to integrate diverse features extracted from the three parallel branches, which dynamically adjusts the weights of each feature channel, allowing the model to focus on the most relevant features.
- (3)
- Spatial pyramid pooling is introduced into the classifier to enhance the expressive power of fused features, enabling the model to better capture the spatial hierarchies and variations within the input features, which is crucial for effective deepfake detection.
- (4)
- The independent loss functions are designed for each branch, aimed at ensuring that each branch effectively learns its specific features, while the combination of these functions through the overall loss function promotes collaborative optimization of the model.
- (5)
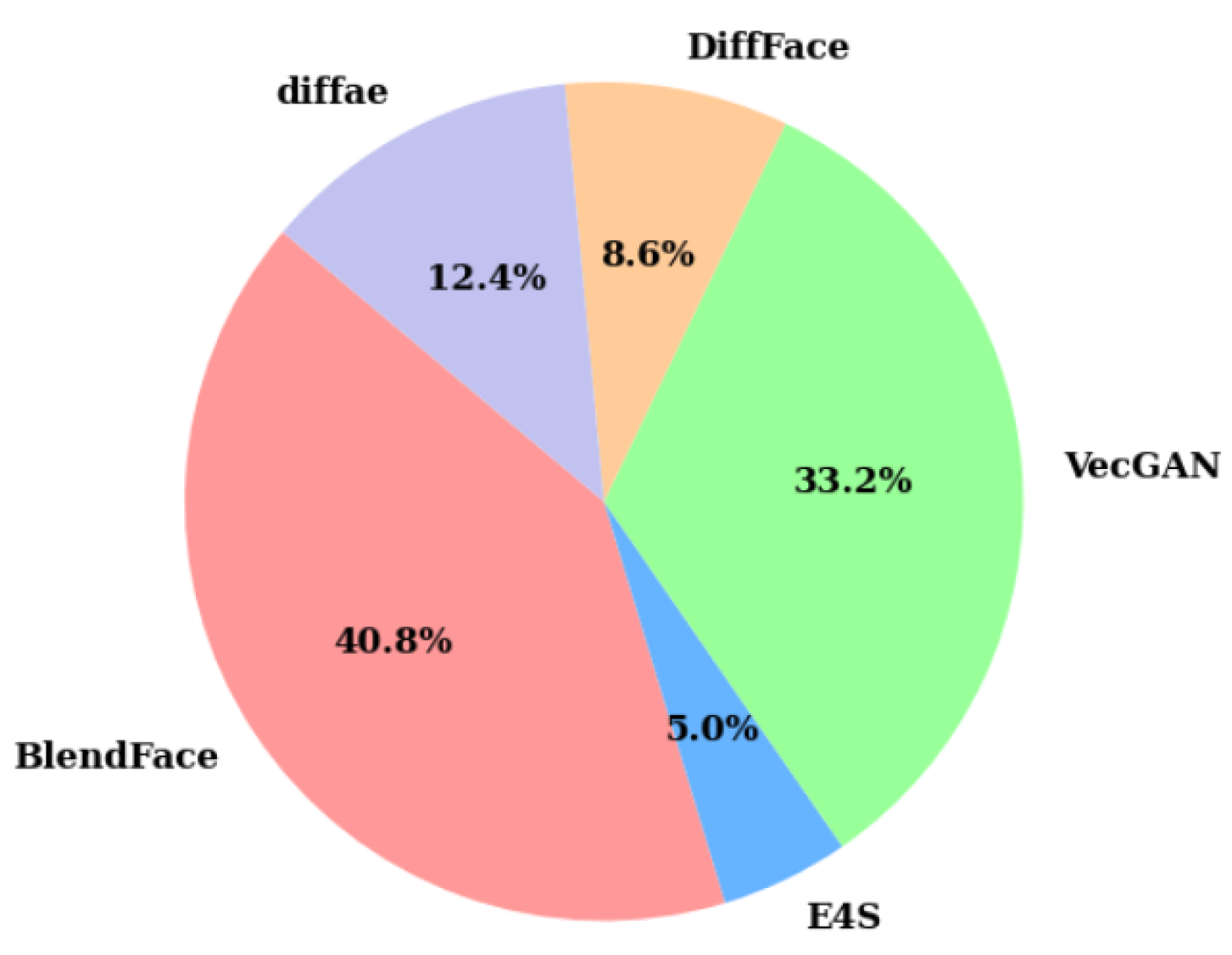
- A large-scale dataset, HybridGenFace, is built, which including over two million synthetic facial images generated by GANs and DMs, addressing the gap in existing datasets that predominantly focus on a single generation type, thereby providing a comprehensive dataset for training and evaluating facial forgery detection methods.
2. Related Work
2.1. Deepfake Face Generation
2.2. Existing Deepfake Facial Datasets
2.3. Facial Forgery Detection
3. Method
3.1. Multi-Branch Network with Multi-Feature Extraction
3.1.1. Texture Feature Extraction Branch
3.1.2. Fine-Grained Feature Extraction Branch
3.1.3. Multi-Scale Feature Extraction Branch
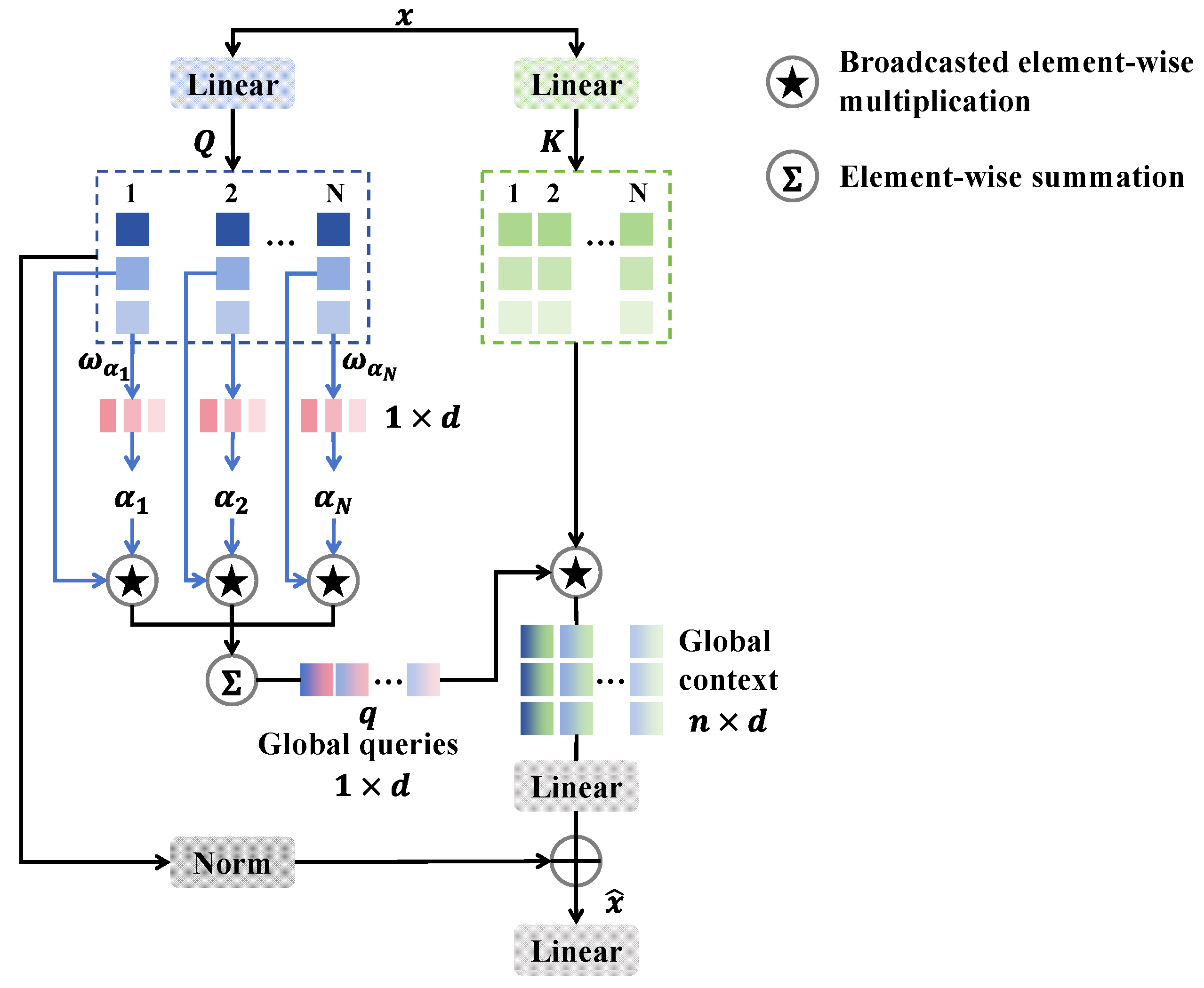
3.2. Adaptive Feature Concatenation Mechanism
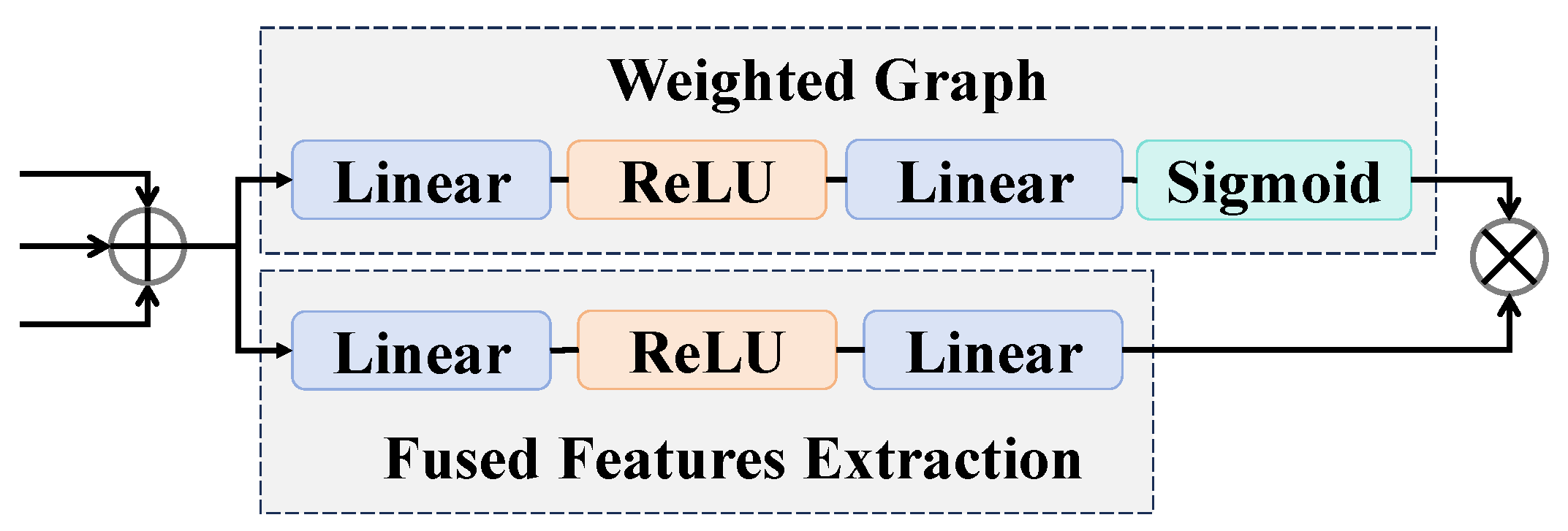
3.3. Classifier Based on Spatial Pyramid Pooling
3.4. Loss Functions
4. HybridGenFace Dataset
4.1. Data Collection and Processing
4.2. Generation and Postprocessing
4.3. Comparison with Existing Deepfake Facial Datasets
4.3.1. Statistical Analysis
4.3.2. Feature Space Distribution
4.3.3. Detection Comparison
5. Experiments
5.1. Experimental Settings
5.1.1. Datasets
5.1.2. Implementation Details
5.1.3. Evaluation Metrics
5.2. In-Domain Evaluation
5.3. Cross-Domain Evaluation
5.3.1. Evaluation Experiments on CelebDF-V2, CelebDF-V1 and DFDC
5.3.2. Evaluation Experiments on GID-DF and GID-FF
5.3.3. Evaluation Experiments on UADFV, WildDeepfake, Diff, and HybridGenFace
5.4. Visualization Experiments
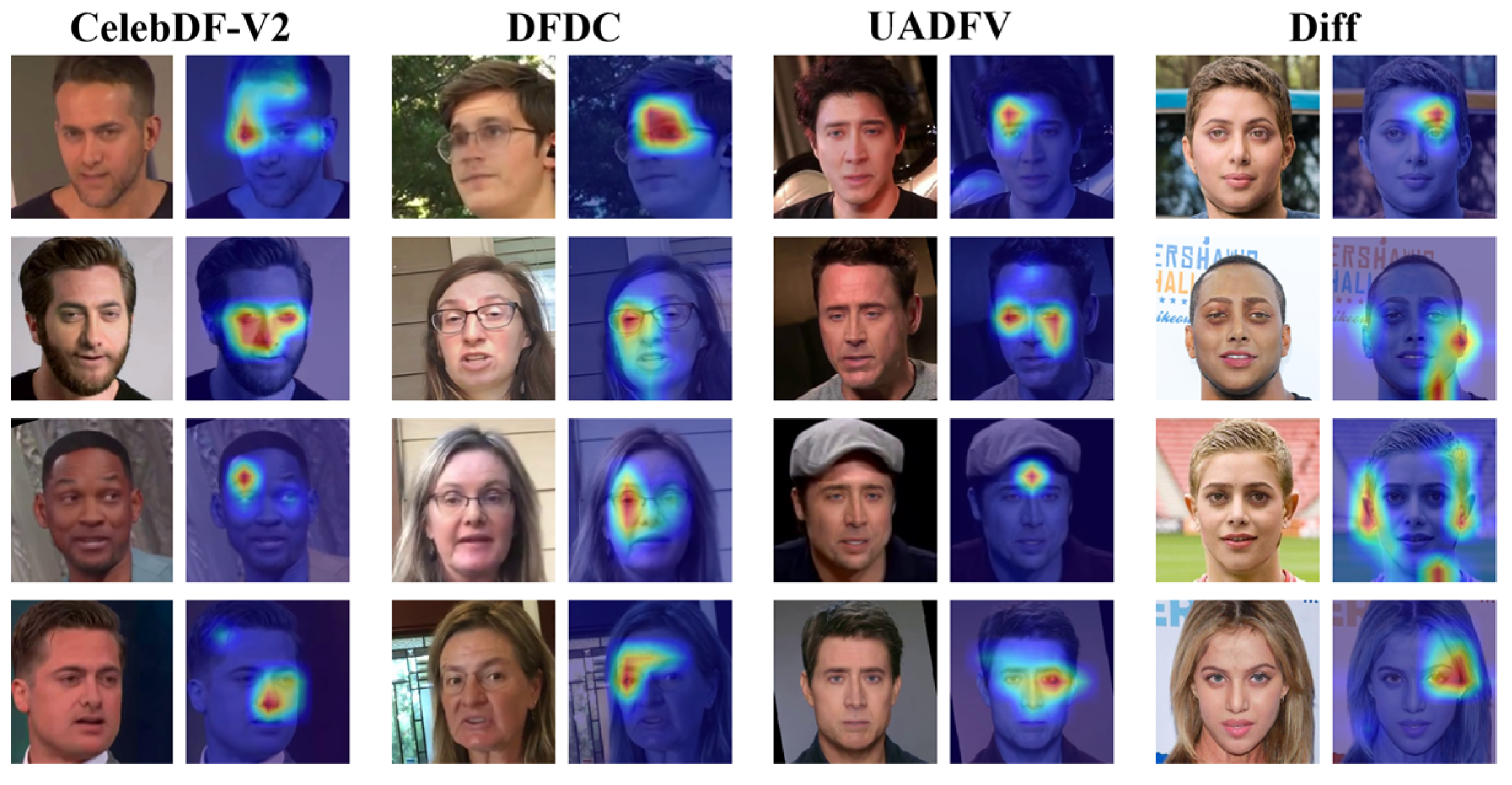
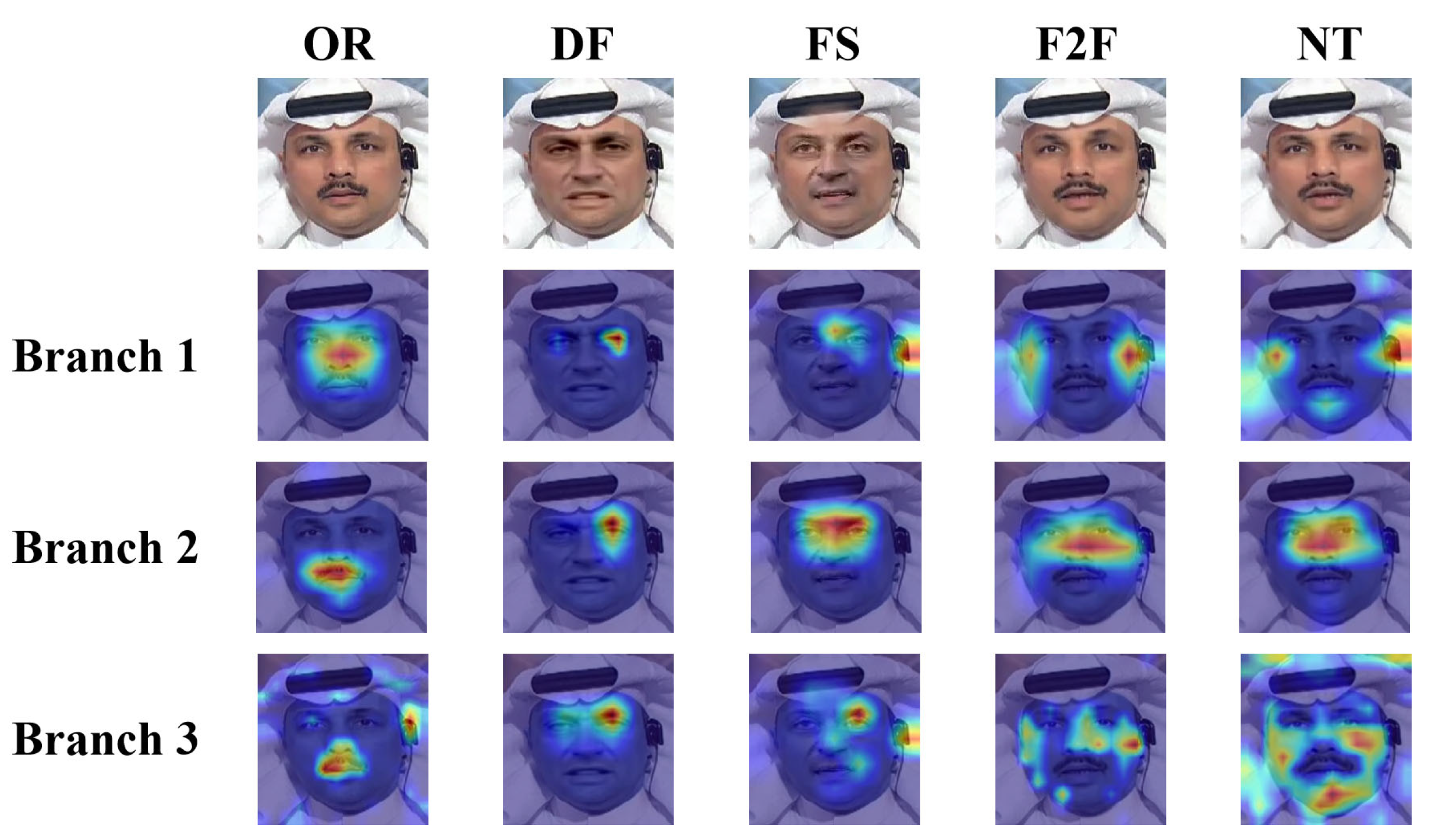
5.4.1. Visualization of Interpretable Decisions
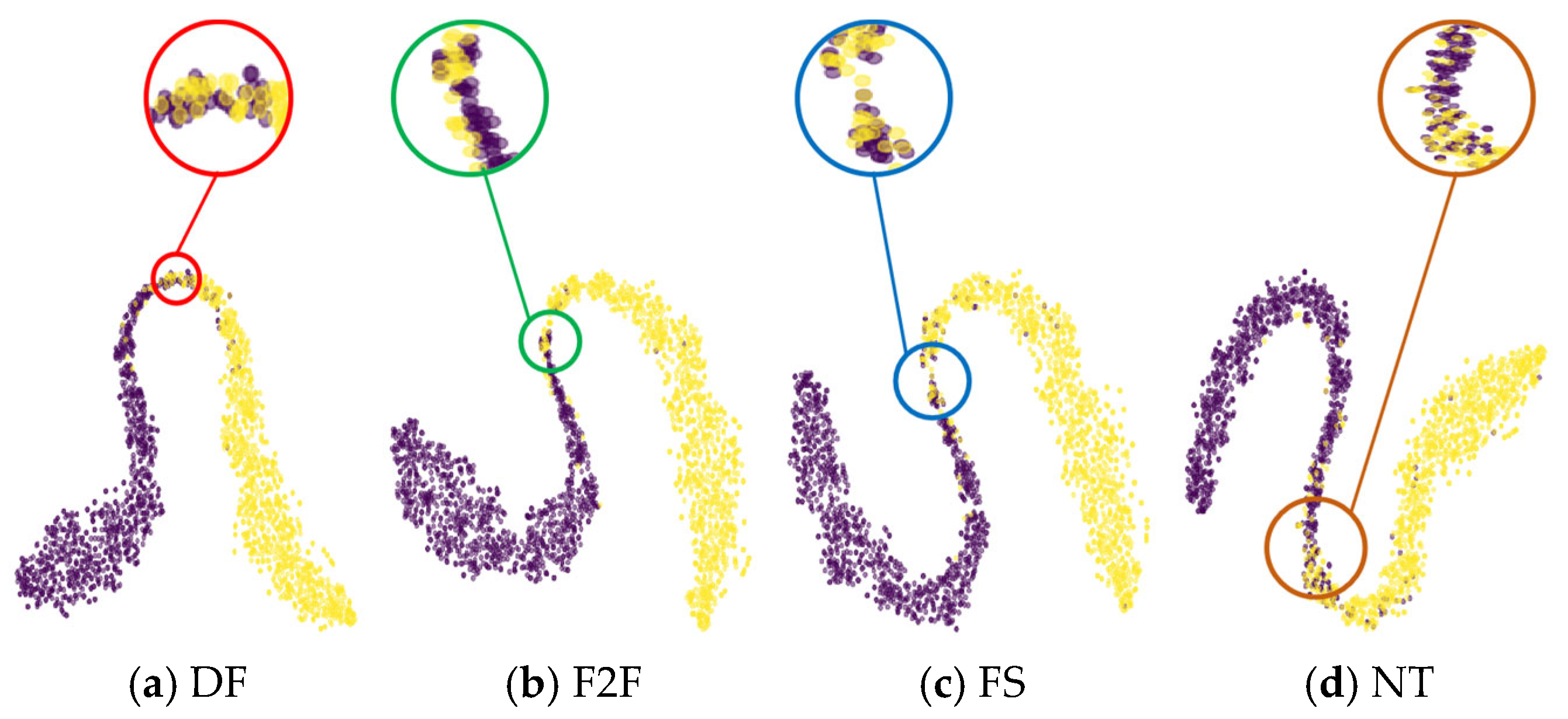
5.4.2. Visualization of the Feature Distribution
5.5. Ablation Experiments
5.5.1. Effectiveness of Different Modules
5.5.2. Effectiveness of the Number of Blocks of Each Branch
5.5.3. Effectiveness of the Hidden Dimension of the Adaptive Feature Concatenation Mechanism
5.5.4. Effectiveness of Different Weight Coefficients for the Branch Loss
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Niessner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for Deepfake forensics. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3204–3213. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar] [CrossRef]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? Assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar] [CrossRef]
- Dufour, N.; Gully, A.; Karlsson, P.; Vorbyov, A.V.; Leung, T.; Childs, J.; Bregler, C. Deepfake Detection Dataset. 2019. Available online: https://research.google/blog/contributing-data-to-deepfake-detection-research (accessed on 15 January 2025).
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Canton-Ferrer, C. The Deepfake detection challenge (DFDC) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar] [CrossRef]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. WildDeepfake: A challenging real-world dataset for Deepfake detection. In Proceedings of the 28th ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar] [CrossRef]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. Forgerynet: A versatile benchmark for comprehensive forgery analysis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4358–4367. [Google Scholar] [CrossRef]
- Borji, A. Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and dall-e 2. arXiv 2023, arXiv:2210.00586. [Google Scholar] [CrossRef]
- Cheng, H.; Guo, Y.; Wang, T.; Nie, L.; Kankanhalli, M. Diffusion facial forgery detection. In Proceedings of the 32nd ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA, 28 October–1 November 2024; pp. 5939–5948. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver BC Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar] [CrossRef]
- Kim, K.; Kim, Y.; Cho, S.; Seo, J.; Nam, J.; Lee, K.; Kim, S.; Lee, K. Diffface: Diffusion-based face swapping with facial guidance. arXiv 2022, arXiv:2212.13344. [Google Scholar] [CrossRef]
- Kim, M.; Liu, F.; Jain, A.; Liu, X. Dcface: Synthetic face generation with dual condition diffusion model. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12715–12725. [Google Scholar] [CrossRef]
- Huang, Z.; Chan, K.C.; Jiang, Y.; Liu, Z. Collaborative diffusion for multi-modal face generation and editing. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6080–6090. [Google Scholar] [CrossRef]
- Huang, Z.C.; Ye, F.; Huang, T.Q. Detection and analysis of synthetic faces based on diffusion models. J. Fujian Norm. Univ. 2024, 40, 14–22. [Google Scholar] [CrossRef]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Dagar, D.; Vishwakarma, D.K. A noise and edge extraction-based dual-branch method for shallowfake and deepfake localization. Signal Image Video Process. 2025, 19, 198. [Google Scholar] [CrossRef]
- Guo, Z.; Jia, Z.; Wang, L.; Wang, D.; Yang, G.; Kasabov, N. Constructing New Backbone Networks via Space-Frequency Interactive Convolution for Deepfake Detection. IEEE Trans. Inf. Forensics Secur. 2024, 19, 401–413. [Google Scholar] [CrossRef]
- Khormali, A.; Yuan, J.-S. DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer. Appl. Sci. 2022, 12, 2953. [Google Scholar] [CrossRef]
- Tian, X.I.; Lingyun, Y.U.; Changwei, L.U.; Hongtao, X.I.; Zhang, Y. Survey of deep face manipulation and fake detection. J. Tsinghua Univ. 2023, 63, 1350–1365. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4396–4405. [Google Scholar] [CrossRef]
- Kumar, L.; Singh, D.K. Diversified realistic face image generation GAN for human subjects in multimedia content creation. Comput. Animat. Virtual Worlds 2024, 35, e2232. [Google Scholar] [CrossRef]
- Zhao, N.; Dang, S.; Lin, H.; Shi, Y.; Cao, N. Bring clipart to life. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 23284–23293. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Cao, G.; Wang, H.; Cao, W. Hypereditor: Achieving both authenticity and cross-domain capability in image editing via hypernetworks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 7051–7059. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject driven generation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22500–22510. [Google Scholar] [CrossRef]
- Wodajo, D.; Atnafu, S. Deepfake video detection using convolutional vision transformer. arXiv 2021, arXiv:2102.11126. [Google Scholar] [CrossRef]
- Zhao, H.; Wei, T.; Zhou, W.; Zhang, W.; Chen, D.; Yu, N. Multi-attentional Deepfake detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16312–16321. [Google Scholar] [CrossRef]
- Miao, C.; Tan, Z.; Chu, Q.; Yu, N.; Guo, G. Hierarchical frequency-assisted interactive networks for face manipulation detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3008–3021. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 17379–17390. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the 40th International Conference on Machine Learning (ICML′23), Honolulu, HI, USA, 23–29 July 2023; Volume 202, pp. 23803–23828. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Shiohara, K.; Yang, X.; Taketomi, T. Blendface: Re-designing identity encoders for face-swapping. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 7600–7610. [Google Scholar] [CrossRef]
- Li, M.; Yuan, G.; Wang, C.; Liu, Z.; Zhang, Y.; Nie, Y.; Wang, J.; Xu, D. E4s: Fine-grained face swapping via editing with regional gan inversion. arXiv 2023, arXiv:2310.15081. [Google Scholar] [CrossRef]
- Dalva, Y.; Altındiş, S.F.; Dundar, A. Vecgan: Image-to-image translation with interpretable latent directions. In Proceedings of the Computer Vision-ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin, Heidelberg, 2022; pp. 153–169. [Google Scholar] [CrossRef]
- Preechakul, K.; Chatthee, N.; Wizadwongsa, S.; Suwajanakorn, S. Diffusion autoencoders: Toward a meaningful and decodable representation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10609–10619. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a capsule network to detect fake images and videos. arXiv 2019, arXiv:1910.12467. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5202–5211. [Google Scholar] [CrossRef]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 772–781. [Google Scholar] [CrossRef]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the Computer Vision-ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 86–103. [Google Scholar]
- Miao, C.; Tan, Z.; Chu, Q.; Liu, H.; Hu, H.; Yu, N. F2trans: High-frequency fine-grained transformer for face forgery detection. IEEE Trans. Inf. Forensics Secur. 2022, 18, 1039–1051. [Google Scholar] [CrossRef]
- Gu, Q.; Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Yi, R. Exploiting fine-grained face forgery clues via progressive enhancement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; AAAI Press: Washington, DC, USA, 2022; pp. 735–743. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Ouyang, W.; Han, X.; Chen, J.; Jiang, Y.G.; Li, S.N. M2tr: Multi-modal multi-scale transformers for Deepfake detection. In Proceedings of the 2022 International Conference on Multimedia Retrieval, Association for Computing Machinery, Newark, NJ, USA, 27–30 June 2022; pp. 615–623. [Google Scholar] [CrossRef]
- Wang, J.; Sun, Y.; Tang, J. Lisiam: Localization invariance Siamese network for Deepfake detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2425–2436. [Google Scholar] [CrossRef]
- Khormali, A.; Yuan, J.-S. Self-supervised graph transformer for deepfake detection. IEEE Access 2024, 12, 58114–58127. [Google Scholar] [CrossRef]
- Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Li, J.; Ji, R. Local relation learning for face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; AAAI Press: Washington, DC, USA, 2022; pp. 1081–1088. [Google Scholar] [CrossRef]
- Jia, G.; Zheng, M.; Hu, C.; Ma, X.; Xu, Y.; Liu, L.; Deng, Y.; He, R. Inconsistency-aware wavelet dual-branch network for face forgery detection. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 308–319. [Google Scholar] [CrossRef]
- Zhou, K.; Sun, G.; Wang, J.; Yu, L.; Li, T. MH-FFNet: Leveraging mid-high frequency information for robust fine-grained face forgery detection. Expert Syst. Appl. 2025, 276, 127108. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face x-ray for more general face forgery detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5000–5009. [Google Scholar] [CrossRef]
- Yang, J.; Li, A.; Xiao, S.; Lu, W.; Gao, X. Mtd-net: Learning to detect Deepfakes images by multi-scale texture difference. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4234–4245. [Google Scholar] [CrossRef]
- Tan, Z.; Yang, Z.; Miao, C.; Guo, G. Transformer-based feature compensation and aggregation for Deepfake detection. IEEE Signal Process. Lett. 2022, 29, 2183–2187. [Google Scholar] [CrossRef]
- Guo, Z.; Yang, G.; Zhang, D.; Xia, M. Rethinking gradient operator for exposing ai-enabled face forgeries. Expert Syst. Appl. 2023, 215, 119361. [Google Scholar] [CrossRef]
- Gao, J.; Xia, Z.; Marcialis, G.L.; Dang, C.; Dai, J.; Feng, X. Deepfake detection based on high-frequency enhancement network for highly compressed content. Expert Syst. Appl. 2024, 249, 123732. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar] [CrossRef]
- Cozzolino, D.; Thies, J.; Rössler, A.; Riess, C.; Nießner, M.; Verdoliva, L. Forensictransfer: Weakly-supervised domain adaptation for forgery detection. arXiv 2018, arXiv:1812.02510. [Google Scholar] [CrossRef]
- Li, D.; Yang, Y.; Song, Y.Z.; Hospedales, T. Learning to generalize: Meta-learning for domain generalization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; AAAI Press: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Sun, K.; Liu, H.; Ye, Q.; Gao, Y.; Liu, J.; Shao, L.; Ji, R. Domain general face forgery detection by learning to weight. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; AAAI Press: Washington, DC, USA, 2021; pp. 2638–2646. [Google Scholar] [CrossRef]
- Sun, K.; Yao, T.; Chen, S.; Ding, S.; Li, J.; Ji, R. Dual contrastive learning for general face forgery detection. arXiv 2021, arXiv:2112.13522. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images Are Surprisingly Easy to Spot… for Now. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8692–8701. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Images |
|---|---|---|
| GANs | BlendFace | 876,261 |
| E4S | 106,482 | |
| VecGAN | 714,000 | |
| DMs | DiffFace | 185,385 |
| DiffAE | 266,322 | |
| Total | 2,148,450 | |
| Dataset | Methods | Real | Fake |
|---|---|---|---|
| UADFV | 1 | 17.3 K | 17.3 K |
| Deepfake-TIMIT | 2 | 34.0 K | 34.0 K |
| FaceForensics++ | 4 | 509.9 K | 1830.1 K |
| DFD | 5 | 315.4 K | 2242.7 K |
| DFDC | 2 | 488.4 K | 1783.3 K |
| WildDeepfake | - | 440.5 K | 739.6 K |
| Celeb-DF | 1 | 225.4 K | 2116.8 K |
| ForgeryNet | 15 | 1438.2 K | 1457.9 K |
| GFW | 3 | 30 K | 15.0 K |
| Diff | 13 | 30 K | 500 K |
| HybridGenFace (HGF) | 5 | 716.16 K | 2148.45 K |
| Dataset | UADFV | FF++ | DFDC | Celeb-DF | GFW | HGF |
|---|---|---|---|---|---|---|
| Mask-SSIM↑ | 0.82 | 0.81 | 0.84 | 0.92 | 0.49 | 0.93 |
| Perceptual Loss↓ | 0.73 | 0.67 | 0.63 | 0.59 | 0.98 | 0.53 |
| PSNR↑ | 17.05 | 18.47 | 17.12 | 18.70 | 15.86 | 18.86 |
| Method | Training Datasets | Testing Datasets | ||||
|---|---|---|---|---|---|---|
| FF++ | HGF | Celeb-DF | WildDeepfake | Diff | ||
| Capsule | FF++ | 86.76 | 47.51 | 67.42 | 68.46 | 46.78 |
| HGF | 87.50 | 70.62 | 67.95 | 70.03 | 50.09 | |
| Methods | Input Size | AUC | ACC |
|---|---|---|---|
| Xception [3] | 299 | 94.86 | 92.39 |
| SPSL [50] | 299 | 95.32 | 91.50 |
| F3-Net [51] | 299 | 98.10 | 97.52 |
| HFI-Net [35] | 384 | 98.66 | 95.12 |
| LiSiam [55] | 299 | 99.13 | 96.51 |
| F2Trans-S [52] | 224 | 99.18 | 96.09 |
| F2Trans-B [52] | 224 | 99.24 | 96.60 |
| MaDD [33] | 380 | 99.29 | 97.60 |
| PEL [53] | 320 | 99.32 | 97.63 |
| MH-FFNet [59] | 224 | 99.44 | 97.37 |
| SGF [56] | 320 | 99.34 | 98.41 |
| Local-Relation [57] | 229 | 99.46 | 97.59 |
| M2TR [54] | 320 | 99.51 | 97.93 |
| HRNet-18 [58] | 224 | 99.60 | 96.95 |
| M2EH-T (Ours) | 224 | 99.75 | 97.09 |
| M2EH-S (Ours) | 224 | 99.80 | 97.59 |
| Methods | Testing Dataset (AUC) | ||
|---|---|---|---|
| CelebDF-V2 | CelebDF-V1 | DFDC | |
| M2TR [54] | 65.17 | 68.57 | 69.94 |
| Xception [3] | 65.30 | - | 72.20 |
| GocNet [63] | 65.56 | - | 66.73 |
| MaDD [33] | 67.44 | - | - |
| HIFE [64] | 68.41 | - | 65.46 |
| F3-Net [51] | 68.69 | 63.57 | 67.45 |
| MTD-Net [61] | 70.12 | - | - |
| HRNet-18 [58] | - | 72.30 | - |
| Face X-ray [60] | - | 74.20 | 70.00 |
| GFFD [34] | - | 79.40 | 79.70 |
| Trans-FCA [62] | 78.57 | - | - |
| M2EH-T (Ours) | 79.54 | 77.46 | 88.92 |
| M2EH-S (Ours) | 80.10 | 76.89 | 88.78 |
| Methods | GID-DF | GID-FF | ||
|---|---|---|---|---|
| AUC | ACC | AUC | ACC | |
| EfficientNet [65] | 91.11 | 82.40 | 80.1 | 63.32 |
| ForensicTransfer [66] | - | 72.01 | - | 64.50 |
| Multi-task [20] | - | 70.30 | - | 58.74 |
| MLDG [67] | 91.82 | 84.21 | 77.10 | 63.46 |
| LTW [68] | 92.70 | 85.60 | 80.20 | 65.60 |
| DCL [69] | 94.90 | 87.70 | 82.93 | 68.40 |
| M2TR [54] | 94.91 | 81.07 | 76.99 | 55.71 |
| F3-Net [51] | 94.95 | 83.57 | 81.20 | 61.07 |
| M2EH-T (Ours) | 95.15 | 85.86 | 84.92 | 70.89 |
| M2EH-S (Ours) | 95.23 | 86.50 | 86.66 | 70.91 |
| Methods | Testing Dataset (AUC) | |||
|---|---|---|---|---|
| UADFV | WildDeepfake | Diff | HGF | |
| Multi-task [20] | 61.11 | 57.62 | 41.73 | 40.80 |
| Capsule [48] | 81.01 | 68.46 | 57.68 | 52.50 |
| DCVit [32] | 63.59 | 70.33 | 50.88 | 54.80 |
| CNNDetection [70] | 63.99 | 57.38 | 58.97 | 57.78 |
| M2TR [54] | 82.70 | 76.30 | 70.90 | 56.80 |
| M2EH-S (Ours) | 87.77 | 87.35 | 63.96 | 56.62 |
| M2EH-T (Ours) | 90.75 | 77.09 | 72.58 | 59.42 |
| Avg | 75.85 | 70.65 | 59.53 | 54.10 |
| Branch 1 | Branch 2 | Branch3 | Fuse | SPP | Branch Loss | FF++ | CelebDF-V2 | DFDC |
|---|---|---|---|---|---|---|---|---|
| √ | √ | 95.60 | 50.00 | 49.42 | ||||
| √ | √ | 57.42 | 50.56 | 52.33 | ||||
| √ | √ | 81.35 | 59.69 | 59.23 | ||||
| √ | √ | √ | 99.57 | 78.82 | 87.31 | |||
| √ | √ | √ | √ | 99.68 | 79.47 | 88.85 | ||
| √ | √ | √ | √ | 99.70 | 79.44 | 88.89 | ||
| √ | √ | √ | √ | 99.63 | 79.08 | 87.98 | ||
| √ | √ | √ | √ | √ | √ | 99.75 | 79.54 | 88.92 |
| Swin Transformer Block | ConvNeXt Block | ConvBlock | FF++ | CelebDF-V2 | DFDC |
|---|---|---|---|---|---|
| {2, 2, 6, 2} | {3, 3, 9, 3} | {4, 4, 12, 6} | 99.75 | 79.54 | 88.92 |
| {2, 2, 6, 2} | {3, 3, 27, 3} | {4, 4, 36, 6} | 98.86 | 77.03 | 87.35 |
| {2, 2, 18, 2} | {3, 3, 9, 3} | {4, 4, 12, 6} | 98.66 | 78.17 | 86.22 |
| {2, 2, 18, 2} | {3, 3, 27, 3} | {4, 4, 36, 6} | 99.80 | 80.10 | 88.78 |
| Hidden Dimension | Parameter | FF++ | CelebDF-V2 | DFDC |
|---|---|---|---|---|
| 1000 | 125,619,785 | 99.75 | 79.54 | 88.92 |
| 3000 | 149,623,785 | 99.78 | 78.37 | 88.01 |
| Branch Loss 1 | Branch Loss 2 | Branch Loss 3 | FF++ | CelebDF-V2 | DFDC |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 99.71 | 79.37 | 88.03 |
| 0.1 | 0.1 | 0.1 | 99.61 | 78.72 | 87.91 |
| 0.001 | 0.001 | 0.001 | 99.75 | 79.54 | 88.92 |
| 0.00001 | 0.0001 | 0.0001 | 99.70 | 79.39 | 88.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, S.; Tan, Q.; Zhou, Q.; Wang, R. Multi-Branch Network with Multi-Feature Enhancement for Improving the Generalization of Facial Forgery Detection. Entropy 2025, 27, 545. https://doi.org/10.3390/e27050545
Meng S, Tan Q, Zhou Q, Wang R. Multi-Branch Network with Multi-Feature Enhancement for Improving the Generalization of Facial Forgery Detection. Entropy. 2025; 27(5):545. https://doi.org/10.3390/e27050545
Chicago/Turabian StyleMeng, Siyu, Quange Tan, Qianli Zhou, and Rong Wang. 2025. "Multi-Branch Network with Multi-Feature Enhancement for Improving the Generalization of Facial Forgery Detection" Entropy 27, no. 5: 545. https://doi.org/10.3390/e27050545
APA StyleMeng, S., Tan, Q., Zhou, Q., & Wang, R. (2025). Multi-Branch Network with Multi-Feature Enhancement for Improving the Generalization of Facial Forgery Detection. Entropy, 27(5), 545. https://doi.org/10.3390/e27050545