Current state-of-the-art RGB-T object detection models predominantly adopt end-to-end architectures to streamline both training and inference procedures. While this design paradigm offers operational convenience, it exhibits strong dependence on large-scale training datasets with precise manual annotations. Such heavy reliance on annotated data imposes significant constraints on further advancements in this field. Particularly in RGB-T multimodal fusion scenarios, the inherent data scarcity exacerbates these challenges. Theoretically, transfer learning could alleviate this data insufficiency by introducing relevant prior knowledge through pretraining on datasets from related tasks. However, the application of transfer learning in RGB-T object detection remains relatively unexplored, primarily due to the absence of large-scale annotated thermal infrared datasets. Moreover, establishing effective cross-modal prior knowledge constitutes a critical research challenge that demands immediate attention.
3.1. Cross-Modal Representation Network
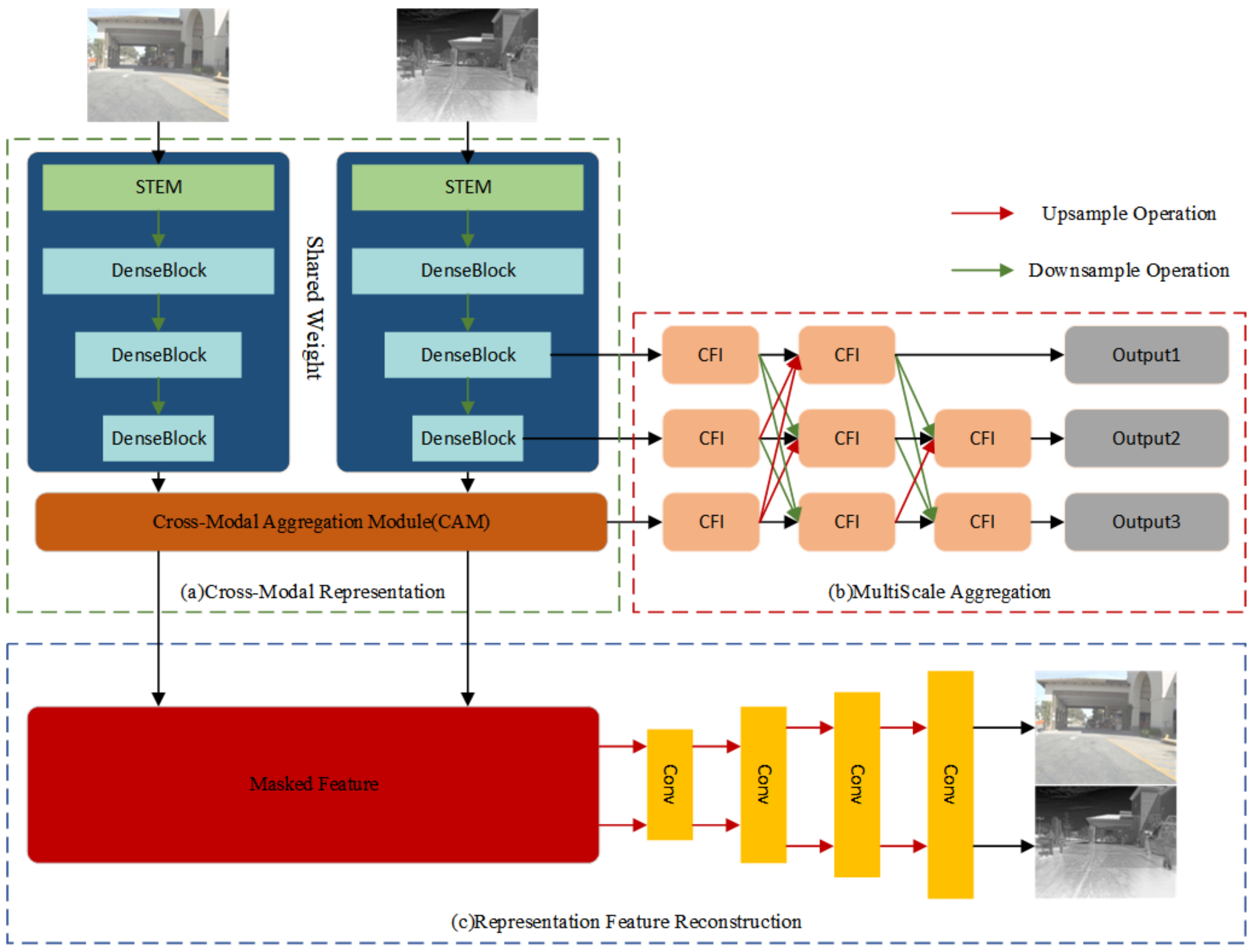
As depicted in
Figure 1a, the Cross-Modal Representation Network (CRN) consists of two principal elements: a feature extractor and the Cross-Modal Attention Module (CAM). The feature extractor is designed to derive high-level features from individual modalities, while CAM facilitates inter-modal information transfer and fusion. Although Transformer architectures demonstrate superior performance, they typically require extensive training data to effectively capture local image characteristics—a requirement impractical for RGB-T applications given dataset limitations. To address this, we implement a hybrid architecture combining CNNs and Transformers in the feature extractor and CAM, respectively, ensuring adequate contextual relationship modeling while preserving local inductive biases.
The CRN processes RGB images
and thermal infrared images
, where the single-channel thermal input is replicated across three channels to maintain architectural consistency. Feature extraction initiates with an STEM module that projects input images into a high-dimensional latent space, generating shallow features
and
through the transformation:
where the parameter-shared
operator performs simultaneous preliminary feature extraction and spatial downsampling for both modalities.
Following the design of most backbone networks, the entire network is divided into three stages, each processing RGB-T image features at different scales. To improve feature utilization and enhance representational capacity, we incorporate dense residual modules at each stage. Given the high dimensionality of infrared and visible light image data, which can lead to substantial computational and memory overhead, we integrate downsampling layers at multiple stages. These layers reduce the data dimensionality while enlarging the receptive field, enabling the model to output features at varying scales and depths. The features produced at each stage of the two branches are denoted as
and
(where
), with feature resolutions progressively reduced to 1/4, 1/8, and 1/16 of the original image size. Concurrently, the channel dimensions increase to 128, 256, 512, and 1024, ensuring sufficient information density in the extracted features. This operation can be represented as follows:
where parameter-shared
represents the function of the dense residual block at the
i-th stage. At the final stage of the network, the RGB and thermal infrared features
and
are embedded and transformed into feature vector sets
and
. These feature vectors are subsequently processed through the CAM for feature refinement. By normalizing and integrating the cross-modal information, the transformed feature vector sets
and
are derived. For downstream processing, we restructure these feature vector collections back into feature maps, yielding
and
. The inference and training phases employ distinct processing pipelines, with detailed procedures discussed in subsequent sections.
3.2. Cross-Modal Aggregation Module
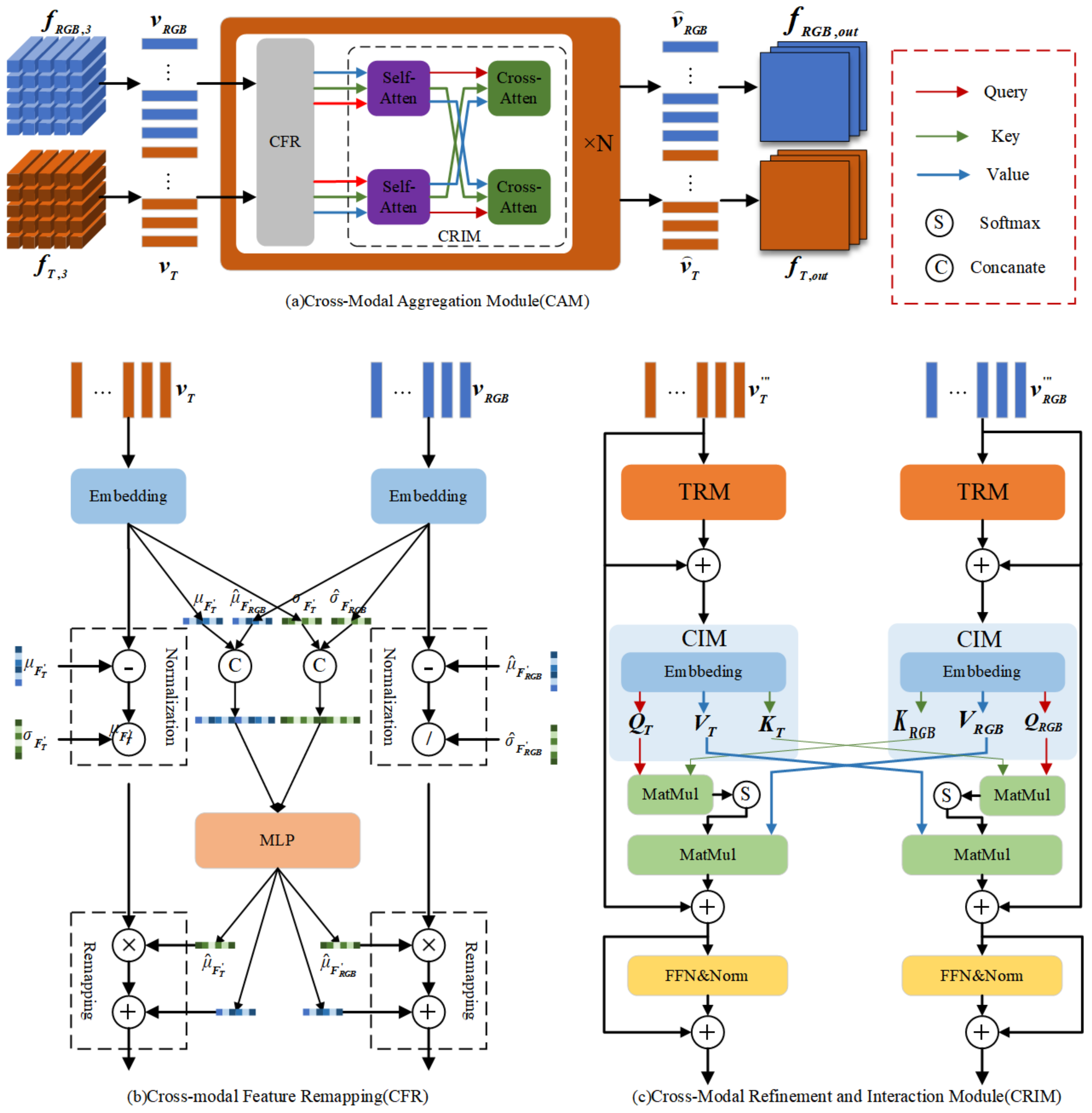
In existing RGB-T object detection models, information interaction between different modality features is typically achieved through feature addition or concatenation, followed by refinement using learnable layers. While this approach is simple and effective, it struggles when processing non-registered RGB-T images, and lacks a standardized methodology. To address these limitations, we propose the Cross-Modal Aggregation Module within the CRN, which aims to overcome these shortcomings. As illustrated in
Figure 2, the CAM comprises a series of stacked components, with the primary function of mitigating modality discrepancies and enhancing RGB-T feature fusion. The main functional components of the CAM include two parts: cross-modal feature remapping and information aggregation.
Cross-Modal Feature Remapping (CFR). In the CRN, we employ feature extractors with shared parameters to process RGB-T images, effectively reducing the network’s spatial complexity. However, due to the inherent differences in the imaging mechanisms of RGB and thermal infrared modalities, models without adaptive capabilities are susceptible to distributional discrepancies between these modalities during feature extraction, potentially degrading model performance significantly. To address this issue, we propose a Cross-Modal Feature Remapping Module, which adaptively recalibrates RGB-T features based on their statistical distributions. This remapping process helps mitigate modality discrepancies, ensuring more consistent feature representations for subsequent cross-modal information fusion.
The detailed architecture of the CFR module is depicted in Figure 4. Initially, after passing through an embedding layer, the extracted RGB and thermal infrared features are obtained, which can be mathematically represented as follows:
where
W represents the weight parameters of the embedding layer, and
b is the bias term. Inspired by prior research, modality differences are predominantly manifested in the statistical distribution properties of feature vectors, with mean and variance being the most characteristic parameters. To mitigate such modality discrepancies, we apply an initial normalization process to the extracted features, ensuring that feature vectors from both modalities conform to a standard normal distribution with zero mean and unit variance. This operation can be represented as follows:
where
and
represent the mean and variance of the feature vectors
and
, respectively. The aforementioned normalization method processes each feature vector independently. However, in practical applications, target objects are typically represented by multiple feature vectors. Therefore, we preserve the mean and variance information of the RGB and thermal infrared feature vectors across different channels and concatenate these statistics into a composite feature vector. Subsequently, through a two-layer multilayer perceptron (MLP), we correlate these key statistics and adaptively generate correction parameters
and
based on the global cross-modal information. This operation can be represented as follows:
where
represents the equivalent function of the MLP. Finally, we perform the remapping operation on the normalized features using the correction parameters to obtain the output dual-band features
and
. This operation can be expressed as follows:
Cross-Modal Refinement and Interaction Module(CRIM). After completing the RGB-T feature remapping, a critical challenge emerges: determining how to effectively process and fuse these cross-modal features. To address this, we propose the Cross-Modal Refinement and Interaction Module (CRIM), whose detailed architecture is illustrated in
Figure 2c. CRIM comprises three core components: the Trinity Refinement Module (TRM), the Cross-Attention Interaction Module (CIM), and the Feed-Forward Network (FFN).
For both modalities, we first employ a shared-parameter encoder for preliminary feature processing. To further enhance intra-modal and inter-modal information extraction, we designed the Trinity Refinement Module, which refines feature granularity while strengthening both contextual information and inter-channel relationships. The architecture of TRM is detailed in
Figure 3.
The vector is reshaped into an input feature map , which undergoes dimensional compression to capture global contextual information. Through two matrix multiplication operations, the information extracted from three dimensions is aggregated to obtain a robust global feature representation. This process effectively captures long-range dependencies, significantly enhancing the modal features’ expressive power. The integrated global information serves as pixel-level attention weights, applied to input features via element-wise multiplication for key information extraction.
To mitigate information loss and gradient vanishing, we incorporate local skip connections. The final output feature map
is converted back to vector form
for subsequent processing. These operations are formulated as follows:
where
denotes the dimension-wise compression operation employing adaptive average pooling across height, width, and channel dimensions. While maintaining robust detection performance for unaligned RGB-T images remains our objective, the aforementioned operations alone prove insufficient for facilitating effective cross-modal interaction between RGB and thermal modalities.
Existing approaches predominantly focus on aligned RGB-T image pairs, lacking the capability for feature matching under spatial misalignment. To address this limitation, we propose a Cross-Modal Self-Attention Mechanism that enables comprehensive feature matching and fusion between misaligned RGB-T modalities. The mechanism operates as follows:
where
and
represent the input feature vectors from the RGB and T modalities, respectively;
,
, and
represent the query, key, and value vectors derived from
;
,
, and
are learnable linear transformation matrices. Similarly,
,
, and
denote the query, key, and value vectors obtained from
.
represents the feature dimension for each attention head, and
serves as a scaling factor to prevent excessively large values in the dot product. The cross-modal attention computes similarity scores between the RGB key
and the TIR query
via dot product, followed by normalization with factor
to obtain attention weights. These weights are then applied to perform a weighted summation of the RGB value
to update the TIR features, denoted as
. Similarly, RGB features are updated via the TIR key and value to obtain
.
and
represent residual connections that preserve original feature information.
In the RGB-T cross-attention mechanism, the query vector from the TIR modality interacts with the key vector from the RGB modality to compute similarity scores through dot product operations. These scores are subsequently normalized using a softmax function to generate attention weights. The weighted summation of RGB value vectors is then computed to update the TIR features. Conversely, the query vector interacts with the TIR key , and the weighted summation of updates the RGB features. This bidirectional cross-modal attention facilitates effective feature matching and fusion between RGB and TIR modalities, ensuring robust feature alignment even under conditions of spatial misalignment.
To further enhance the representational capacity of the model, we incorporate an FFN at the end of the CRIM module. By introducing additional non-linear transformations, the FFN significantly improves the model’s performance. This operation can be mathematically expressed as follows:
where
denotes the layer normalization function, and
represents the function implemented by the Feed-Forward Neural Network (FFN).
3.3. Cross-Modal Representation PreTraining
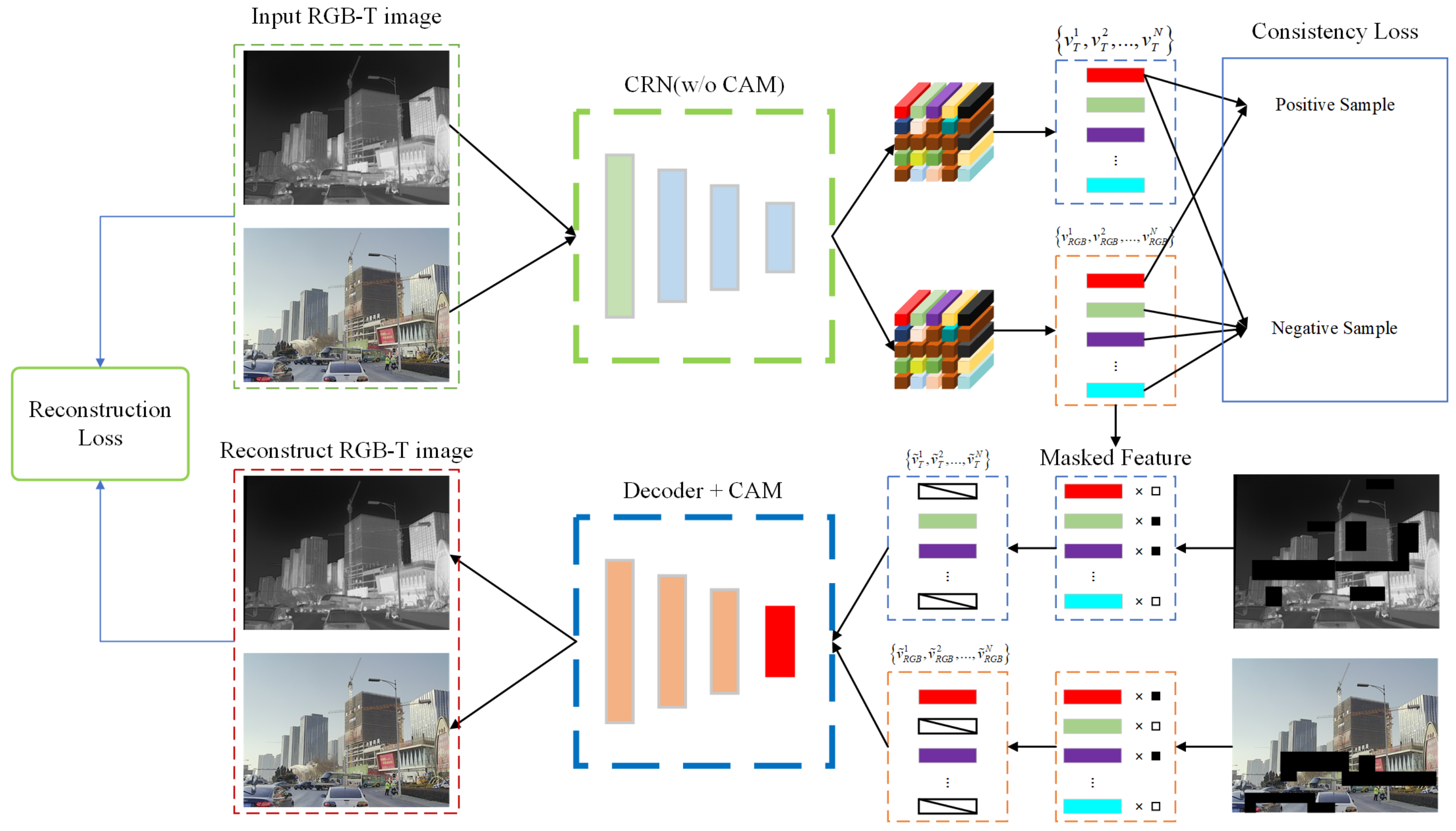
Although the CRN we designed exhibits strong potential for information complementarity, its performance heavily depends on the implementation of appropriate training methodologies. In existing RGB-T datasets, the quantity of registered and annotated samples is substantially smaller than that of unaligned and unannotated ones. To address this imbalance, we aim to develop an effective approach that can extract useful prior knowledge from a broader spectrum of datasets. Our proposed pretraining method, as illustrated in
Figure 4, comprises two primary steps, in addition to training the CRN on the conventional ImageNet and COCO datasets to provide it with foundational capabilities.
Inspired by Masked Autoencoders (MAEs) [
38,
39], we propose a cross-modal masked reconstruction method. This approach facilitates collaborative learning of cross-modal features by strategically applying partial masking to the encoded features of both modalities. Regarding mask generation, unlike traditional MAEs, we introduce additional constraints during the generation process to ensure that critical information required for reconstruction must simultaneously originate from both the source modality and the reference modality. This significantly enhances the model’s feature extraction capabilities and the complementary information between modalities. To achieve this, we impose constraints on the minimum and maximum overlap rates during mask generation. This unique design ensures a balanced information sharing between source and reference modalities: on one hand, it effectively prevents the model from over-relying on information from a single modality, encouraging full exploration and leveraging of each modality’s unique advantages; on the other hand, it significantly enhances the model’s sensitivity and adaptability to cross-modal information, thereby establishing a more robust foundation for subsequent downstream tasks.
During the pretraining stage, we refined and optimized the CRN structure to more efficiently extract and integrate multimodal information. Specifically, in the encoding component of the CRN, we removed certain elements of the CAM that focus exclusively on image feature encoding, and applied masking to the features. After feature encoding is completed, the masked encoded features are transmitted to the decoder, which incorporates the CAM, for reconstruction. The CAM serves a pivotal function in this process: it dynamically captures semantic correlations between source and reference modalities, excavates and leverages the complementary characteristics of both modalities, and achieves efficient cross-modal information fusion. This architecture requires the decoder not only to restore masked image information but also to fully utilize cross-modal synergy for precise comprehensive modeling of the overall content. This integration of modality interaction with preservation of image self-information enables the model to demonstrate enhanced cross-modal understanding capabilities in the reconstruction task while improving self-supervised learning effectiveness.
We employ the root mean square error (RMSE) as the primary reconstruction loss:
where
and
represent the reconstructed RGB and thermal infrared images, and
and
denote the total number of pixels in the RGB and infrared images. However, due to the limited scale of collected RGB-T samples, which represent only a restricted subset of real-world scenarios, relying solely on MSE may neglect semantic information and complex patterns in the data. Therefore, we incorporate Generative Adversarial Learning (GAN) [
40,
41] to learn the implicit data distribution and capture richer patterns, which is validated in subsequent experiments. Beyond adversarial loss, we also introduce perceptual loss to ensure semantic consistency between reconstructed and real images. The expression for perceptual loss is as follows:
where
denotes the CRN functioning as the generator,
represents the discriminator model, and
indicates the features extracted from the
j-th layer of the VGG network. Although unaligned samples significantly outnumber registered samples, the registered samples spatially align the semantic and texture information of RGB-T modalities, thereby providing more robust supervisory signals.
To ensure semantic consistency during the reconstruction process of registered RGB-T images, we incorporate a contrastive loss [
42,
43] to aggregate semantic information from corresponding regions across the two modalities. Specifically, we select N sets of feature vectors from different spatial locations, designating feature vectors from identical locations as positive samples and optimizing them to be maximally proximate in the feature space during training. Conversely, feature vectors from different locations are designated as negative samples and are optimized to be maximally distant in the feature space. The expression for this contrastive loss function is as follows:
where
denotes the similarity measurement function, and the cosine similarity
is employed in this work. Ultimately, we formulate a hybrid loss function that integrates the aforementioned losses to govern the CRN training process. The expression for this comprehensive loss is as follows:
where
represents the indicator function that outputs 0 for unaligned samples and 1 for aligned samples. Through this methodology, we can effectively extract latent information from a substantial volume of unaligned RGB-T images while simultaneously leveraging the semantic and texture information embedded in registered samples for effective supervision.
3.4. Object Detection
After extracting the requisite features through the CRN, the subsequent task involves decoding these abstract representations into precise target localization and dimensional information. This decoding process is implemented via a meticulously designed decoder architecture, which is elaborated in the following sections.
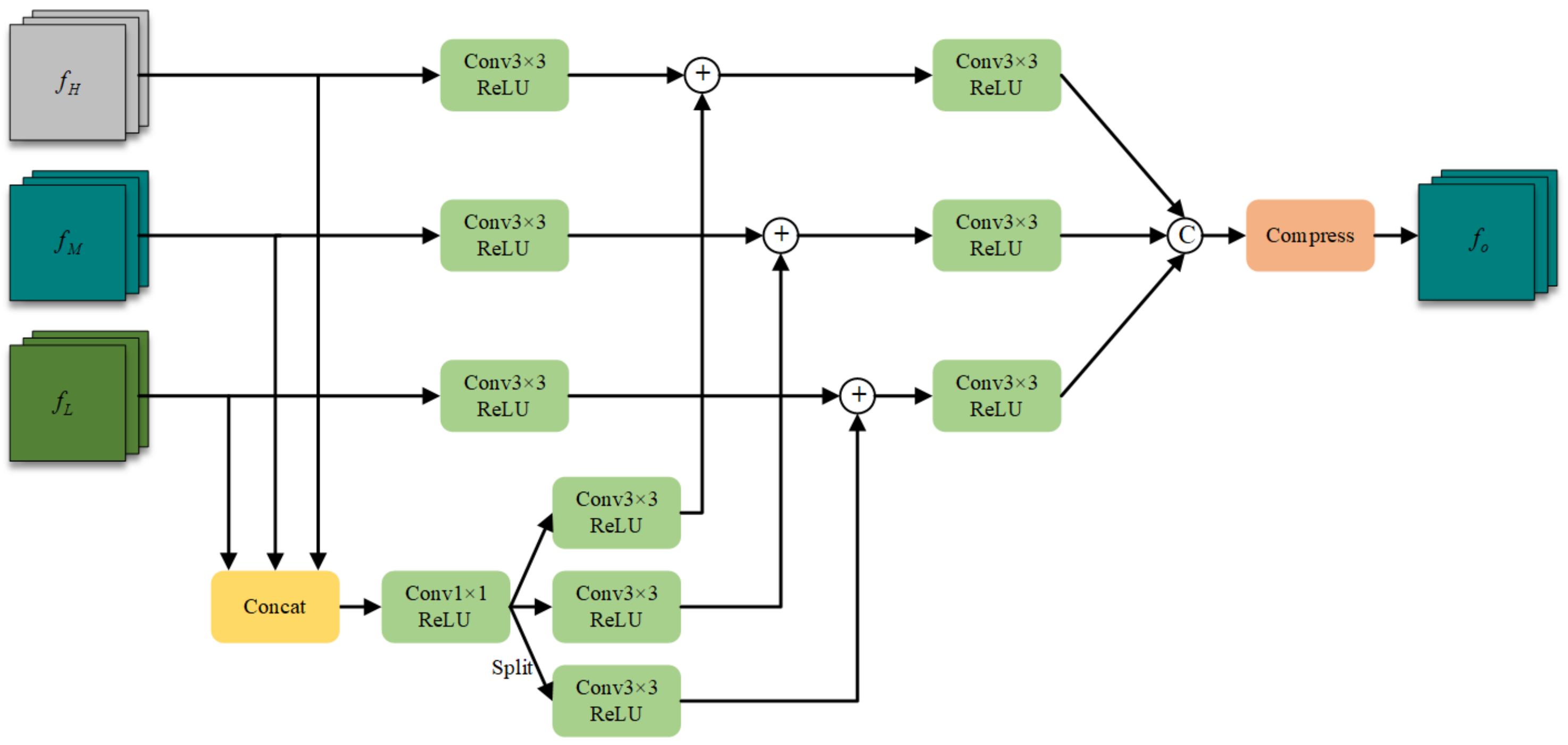
Cross-Scale Feature Integration. Numerous research efforts have demonstrated that enhancing the processing and aggregation of multiscale features constitutes a pivotal strategy for addressing the challenge of target scale variation. Building upon this established approach, we introduce the Cross-Scale Feature Integration Module (CFI), which performs dense fusion of features across various scales and generates three feature maps at different resolutions. The architectural framework of the CFI is illustrated in
Figure 5.
The feature maps processed by the output head ultimately encode the positional coordinates, dimensional parameters, and categorical attributes of targets at multiple scales. Through this architectural design, we ensure comprehensive information exchange across different scales, substantially enhancing the model’s capacity to detect targets of varying dimensions and improving overall detection accuracy and robustness across diverse operational scenarios.
Loss Function. In object detection tasks, precise localization loss is indispensable. Therefore, we adopt the loss function from the YOLOv8 model [
33], which has demonstrated excellent performance. The total loss function is defined as follows:
where
represents the classification loss and
constitute the regression loss. The expressions for these components are
where
N denotes the total number of samples,
represents the ground truth label of sample
i (1 for positive samples and 0 for negative samples), and
indicates the predicted probability of sample
i. In the CIoU loss,
measures the intersection over union between the predicted bounding box and the ground truth box,
quantifies the normalized Euclidean distance between the centers of the predicted box
b and ground truth box
,
c represents the diagonal length of the smallest enclosing box covering both boxes,
v measures the consistency of aspect ratios between the two boxes, and
serves as a weighting coefficient.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}