Abstract
Recent studies have shown that hate speech on social media negatively impacts users’ mental health and is a contributing factor to suicide attempts. On a broader scale, online hate speech can undermine social stability. With the continuous growth of the internet, the prevalence of online hate speech is rising, making its detection an urgent issue. Recent advances in natural language processing, particularly with transformer-based models, have shown significant promise in hate speech detection. However, these models come with a large number of parameters, leading to high computational requirements and making them difficult to deploy on personal computers. To address these challenges, knowledge distillation offers a solution by training smaller student networks using larger teacher networks. Recognizing that learning also occurs through peer interactions, we propose a knowledge distillation method called Deep Distill–Mutual Learning (DDML). DDML employs one teacher network and two or more student networks. While the student networks benefit from the teacher’s knowledge, they also engage in mutual learning with each other. We trained numerous deep neural networks for hate speech detection based on DDML and demonstrated that these networks perform well across various datasets. We tested our method across ten languages and nine datasets. The results demonstrate that DDML enhances the performance of deep neural networks, achieving an average F1 score increase of 4.87% over the baseline.
1. Introduction
Hate speech on social media can have adverse effects on users. Surveys indicate that online hate speech contributes to suicide attempts and suicidal ideation, as well as mental health issues [1]. On a macro level, online hate speech can exacerbate social polarization and undermine social stability [2]. As social media continues to evolve and its content expands, the proliferation of hate speech also increases [3], making automatic detection of hate speech a crucial element in combating it. Globally, a range of laws and policies have been introduced to maintain a clear online legal environment for citizens. These regulations not only standardize the content of online speech content, but also set higher standards for online platform operators. The severity of the situation has prompted social media platforms and academic researchers to propose traditional machine learning and deep learning solutions for automatic detection [4] and early detection [5] of online hate speech. Among these solutions, large pretrained language models (LLMs) have demonstrated their superiority in many natural language processing (NLP) tasks [6] and have also shown excellent performance in hate speech detection [7].
However, existing research has primarily focused on detecting hate speech in English and Western cultural contexts, neglecting a significant amount of online hate speech from other languages and cultures. This limits the global identification and control of aggressive language. There has been very little research on multilingual hate speech detection. One feasible method is to fine-tune pretrained language models [8,9]. At the same time, deep neural networks used in hate speech detection often have considerable depth or breadth, and typically contain numerous parameters. This results in high computational requirements, restricting the application of these models on personal computers.
Knowledge distillation is a model compression technique that enhances the performance of a smaller model (the student) by transferring knowledge from a larger, high-performing model (the teacher). This method allows the student model to learn and mimic the teacher model’s behavior while maintaining a smaller model size and lower computational cost. Knowledge distillation is an excellent solution for addressing the deployment challenges of large models.
In real-life scenarios, students in a class learn not only from the teacher but also from their peers, which reinforces the knowledge gained from the teacher. Similarly, we believe that the student network can obtain knowledge not only from the teacher network but also from other student networks. In this paper, we aim to address the issues mentioned above by using a deep neural network with fewer parameters. To achieve excellent detection accuracy with a smaller deep neural network, we propose a method similar to model distillation [10], which we call Deep Distill–Mutual Learning (DDML).
Model distillation typically starts with a larger and more powerful pretrained teacher network which transfers knowledge to a smaller untrained student network. Our proposed DDML requires a powerful teacher network along with two or more student networks. While the teacher network transfers knowledge to the student networks in one direction, the student networks also learn from each other to solve the problem. Specifically, each student network uses three types of loss: the traditional supervised learning loss, the loss of the teacher network’s output, and the imitation loss, which mimics other students. Our experiments show that the performance of student networks trained in this way surpasses that of student networks trained using the traditional model distillation method.
It may not be immediately clear why the proposed DDML learning strategy outperforms the traditional distillation method. In this regard, intuition can be gained from the following. Each student network is trained using both the true labels and the outputs of the powerful teacher model, which generally improves the performance of the student networks. However, because each student network has a different architecture and initial conditions, they learn different representations, leading to varying predictions. These differences provide additional knowledge during the training process, helping the student networks to achieve better performance.
The main contributions of this paper are as follows:
1. First, we develop a knowledge distillation-based deep neural network training method called DDML for online hate speech detection. This method facilitates the construction of a lightweight hate speech detection model, making it well suited for deployment on resource-constrained devices.
2. Second, we leverage various deep neural networks, including BERT [11] and XLM-R [12], and train them using the proposed DDML method. On the one hand, this approach ensures high detection accuracy across different architectures, while on the other it enables robust performance in monolingual, multilingual, and machine translation-based hate speech detection tasks.
3. Third, we conduct extensive experiments across ten languages and nine datasets to validate the effectiveness of the proposed method. The results demonstrate that our approach achieves an average F1 score improvement of 4.87% over the baseline, highlighting its superior performance in diverse linguistic settings.
2. Related Works
In this section, we introduce previous work related to hate speech detection and knowledge distillation.
2.1. Hate-Speech Detection
In recent years, hate speech detection has gained significant attention. Historically, research has predominantly focused on English due to the scarcity of datasets, with some studies extending to monolingual hate detection in other languages such as German [13], Greek [14], and others. However, hate speech is a global issue and is not confined to a single language. The availability of more diverse resources is crucial for advancing automatic detection tools. Significant strides have been made in providing multilingual resources; for instance, SemEval offers a series of high-quality multilingual labeled datasets [15], while EVALITA provides a shared framework for consistently evaluating various systems and methods [16]. Additionally, Facebook’s transformer-based XLM-R model supports over one hundred languages through pretraining [12]. Prior studies on multilingual hate speech detection have explored several approaches, including both transfer learning, which leverages large pretrained models and shared word embeddings across multiple languages to enhance detection capabilities, and zero-shot learning, which aims to detect hate speech in languages for which no labeled data are available.
2.1.1. Transfer Learning for Hate Speech Detection
The core idea of transfer learning involves initially training a network extensively on a high-resource language such as English in order to learn general features. This network is then used as a starting point and fine-tuned with a small amount of data in a new language. Ranasinghe et al. [7] were the first to apply cross-lingual contextual word embeddings in offensive language identification, projecting predictions from English to other languages using benchmarked datasets from shared tasks on Bengali, Hindi, and Spanish. Aluru et al. [8] conducted the first extensive evaluation of multilingual hate speech detection using a dataset covering nine languages from sixteen different sources. They found that LASER [17] embeddings with logistic regression performed the best in low-resource scenarios, while in high-resource scenarios BERT-based models [11] significantly outperformed other methods. Previous research has also explored translation-based solutions to address the shortage of hate speech data in low-resource languages. These approaches depend heavily on the quality of translation APIs, and as such can incur significant overhead due to the large number of translation requirements. Additionally, during the fine-tuning process in transfer learning, models may experience “catastrophic forgetting” of knowledge acquired during pretraining, particularly when the target tasks differ significantly from the source tasks [18].
2.1.2. Zero-Shot Learning for Hate Speech Detection
Zero-shot learning involves training models to recognize unseen classes by learning intermediate attribute classifiers or a mixture of seen class proportions. This approach enables the network to generalize to new languages without additional training data. Endang et al. [19] explored hate speech detection in low-resource languages by first transferring knowledge from English in a zero-shot learning manner. They proposed two joint learning models, and achieved state-of-the-art performance in most languages. Jiang et al. [20] developed a tailored architecture based on frozen pretrained transformers for cross-lingual zero-shot and few-shot learning using the HatEval dataset. Their approach achieved competitive results on the English and Spanish subsets. Despite these advancements, zero-shot learning for hate speech detection has notable limitations. Sahin et al. [21] assessed the zero-shot performance of various models trained on different hate speech datasets. Their results indicated that transformer-based language models outperformed traditional models, with few-shot methods surpassing zero-shot methods. However, Nozza et al. [22] found that zero-shot learning methods performed poorly in detecting hate speech against women. In their research, they argued that hate speech detection is language-specific that and natural language processing methods must account for this specificity in order to be effective. Similarly, Montariol et al. [23] highlighted the limitations of hate speech models in rigorous experimental settings across various domains and languages.
2.2. Knowledge Distillation
In recent years, deep neural networks have achieved remarkable success in both industry and academia [24]. This success is largely due to deep learning’s ability to scale with large datasets and manage billions of model parameters. However, deploying these large models on resource-constrained devices such as embedded systems presents significant challenges. These challenges arise not only from these models’ high computational complexity but also from their substantial storage requirements. To address these challenges, various model compression and acceleration techniques have been developed. Among these techniques, knowledge distillation has garnered significant attention for its effectiveness in training smaller student models from larger teacher models. In knowledge distillation, the type of knowledge being transferred plays a crucial role in the student models’ performance. This knowledge is generally categorized into three types: (1) response-based knowledge, (2) feature-based knowledge, and (3) relationship-based knowledge.
2.2.1. Feature-Based Knowledge
Feature-based knowledge distillation leverages intermediate-layer feature activations from the teacher model, which are then used to train the student model. The goal is for the student model to learn similar feature representations as the teacher model. Romero et al. [25] extended knowledge distillation by allowing the training of student models that are deeper than the teacher model. They used intermediate representations learned by the teacher as hints to enhance the student model’s training process and final performance. Ding et al. [26] demonstrated that the performance of student convolutional neural networks (CNNs) can be significantly improved by accurately defining CNN attention and by having the student CNN mimic the attention map of the more powerful teacher network. Chen et al. [27] introduced Semantic Calibration for Cross-Layer Knowledge Distillation (SemCKD), which uses an attention mechanism to automatically assign the appropriate target layer of the teacher model to each layer of the student model. However, knowledge-based distillation might not fully capture global structural information, which can result in the student model failing to learn all the useful features of the teacher model [28].
2.2.2. Relation-Based Knowledge
Relation-based knowledge distillation focuses on capturing and transferring the relationships between feature maps in a neural network, such as correlations, graph representations, and similarity matrices. This approach aims to convey these structural relationships from the teacher model to the student model. Park et al. [29] introduced Relational Knowledge Distillation (RKD), which transfers mutual relationships between data examples. They proposed using distance and angle distillation losses to penalize structural differences in these relationships. Experiments across various tasks demonstrated that RKD significantly improves the performance of the student model. To leverage knowledge from multiple teacher models, Zhang and Peng [30] created two graphs, one of which uses the logits of each teacher model as nodes while the other uses the features. Through these graphs, their approach models the importance and relationships of different teachers prior to transferring knowledge. Lee et al. [31] developed a method for distilling dataset-based knowledge from a teacher model using an attention network. Their approach involves embedding the teacher model’s knowledge into a graph via multi-head attention (MHA) and performing multitask learning to provide the student model with a relational inductive bias. However, relation-based distillation can be complex and computationally intensive, as it requires capturing and utilizing structured relationships between the outputs of the teacher model [32].
2.2.3. Response-Based Knowledge
Our proposed DDML proposed incorporates response-based distillation as its initial step. Response-based knowledge distillation focuses on the final output layer of the teacher model, aiming to train the student model to replicate the teacher model’s prediction results. This is typically achieved by minimizing the difference between the logits of the student and teacher models, using soft targets as the source of knowledge. Hinton et al. [10] introduced a distillation method based on soft targets, where the soft targets represent the predicted probability distribution of the teacher model for each class. This approach allows the student model to learn the teacher model’s probability distribution, thereby enhancing the student model’s generalization ability. Additionally, Kim et al. [33] proposed a class distance loss that helps the teacher network to create a densely clustered vector space. This facilitates easier learning for the student network by making the structure of the teacher’s feature space more accessible.
3. Methodology
In this section, we illustrate the overall system architecture of DDML using two student networks as examples, discuss the calculation of the DDML loss function, describe the optimization process of DDML, and finally extend DDML to more than two student networks.
3.1. System Overview
In Section 3.1 and Section 3.2, we illustrate the use of two student networks as an example. The overall framework of DDML with two student networks is depicted in Figure 1.
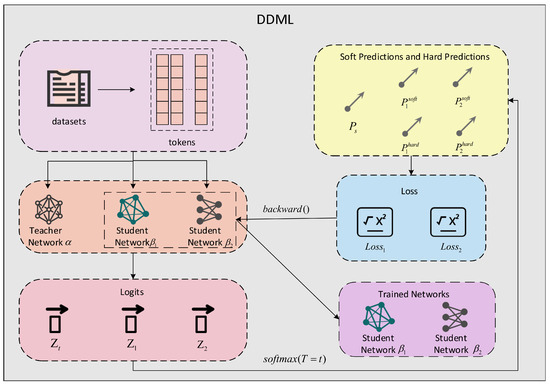
Figure 1.
DDML schematic with two student networks. In DDML, the teacher network does not perform backpropagation, which means that the parameters of the teacher network are not updated, while for the student network the opposite holds. It should be noted that the two student networks need to either use different types of models or use models with different pretraining levels.
Given a sentences containing N words from M classes, we denote the corresponding label set as with . We first segment the sentence X to obtain its corresponding tokens , then input the tokens into the teacher network , student network , and student network and obtain the output logits Z of the three networks:
Here, , , and ; , , and are the logits output by networks , , and respectively; and , , and represent the operation process of networks , m and , respectively. The probabilities of class m for sentence X are computed as follows:
where , , the parameter T is the distillation temperature, is the probability of the teacher network classifying sentence X and finding that it belongs to category m, and is the probability of the student network classifying sentence X and finding that it belongs to category m. Soft labels and hard labels are obtained by the following formula:
where and . When , the hard predictions , of the student network , can be obtained by Formula (5), while when and , the same formula can be used to obtain the soft predictions , of the student network , , where represents the soft predictions obtained by teacher network .
3.2. Loss Function of DDML
For the loss function, we choose the cross-entropy loss. In order to calculate the difference between the prediction vectors , of the two student networks, we also calculate the Kullback–Leibler divergence (KL divergence) between and . The method for calculating the loss function of the two student networks and is shown in Figure 2 and Figure 3.
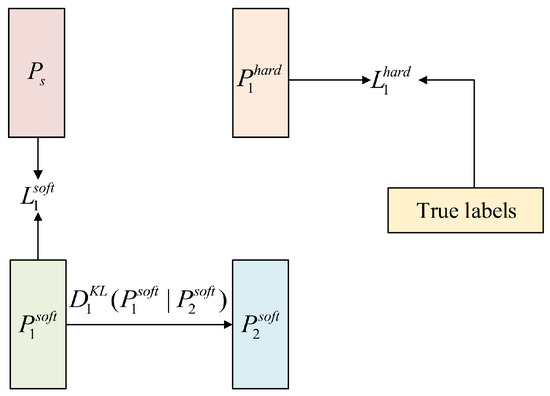
Figure 2.
The loss of the student network consists of three parts: , , and .
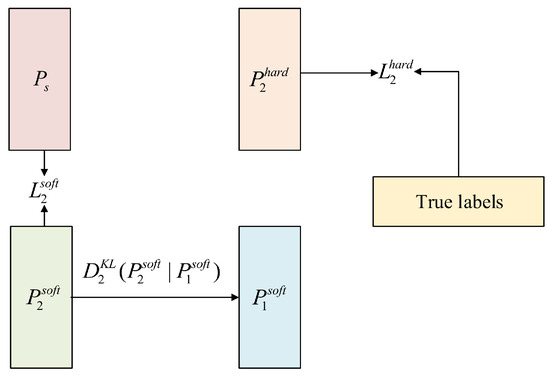
Figure 3.
The loss of the student network consists of three parts: , , and .
For student network , three losses are used in its loss function: , , and . The calculation of these three losses is as follows:
where
The method for calculating the final loss of student network is as follows:
3.3. Optimization of DDML
The key difference between traditional model distillation and DDML is the latter’s incorporation of a mutual learning strategy. In DDML, multiple student networks are optimized simultaneously, and learn not only from the teacher network but also from each other. This mutual learning approach is embedded throughout the entire training process. For instance, with two student networks, the predictions of each network are computed, then the Kullback–Leibler (KL) divergence between the predictions of one network and those of the other is incorporated into the loss function.
3.4. Extension to Multiple Student Networks
Assuming that there are K student networks, the loss function calculation of the student network i becomes
Equation (11) shows that in the case of K networks, each student takes the teacher network and the other student networks in DDML as its teacher, that is, its imitation target. It is worth noting that Equation (10) is a special case of Equation (11) in which . It should be noted that we have added the coefficient to ensure that the training is mainly directed by supervised learning of the true labels and teacher network’s soft predictions. The algorithm is summarized in Algorithm 1.
| Algorithm 1 Deep Distill–Mutual Learning |
|
4. Experiment
In the following, we describe the use of the design from Part III to conduct experiments. First, we introduce the datasets, baseline, transformer-based models, and implementation details, then the use of the acquired data to conduct experiments and collect results.
We implemented all networks and training procedures in PyTorch (version 2.0.1+cu117) and conducted all experiments on an NVIDIA RTX A6000 GPU (made by NVIDIA, in Santa Clara, CA, USA). For the transformer-based models, we used the HuggingFace transformer library and initialized the selected pretrained models with weights provided by this library.
4.1. Datasets
To detect multilingual hate speech, we conducted experiments on the following nine datasets:
SemEval2020 [15], which contains four low-resource languages: Arabic, Danish, Swiss, and Turkish.
HASOC2020 [34], which contains three languages: English, German, and Hindi.
GermEval 2018 [35]: Haspeede2 [36], HaterNET [37], OLID [38], and COLD [39] are single-language datasets respectively consisting of German, Italian, Spanish, English, and Chinese.
OffComBr-2 [40] is a dataset of hate speech comments in Portuguese from the Brazilian news website (accessed on 19 November 2024) https://g1.globo.com/.
Twitter Racism [22], the zero-shot learning dataset proposed by Nozza, is insufficient for detection of hate speech against women. Thus, to verify the performance of the network trained by DDML in the detection of such hate speech, we selected the Twitter Racism Dataset from HuggingFace, which is an English dataset of hate speech against women.
To verify the performance of the network trained by DDML on other types of hate speech, we also selected the public dataset SexismDetection from HuggingFace, which is an English hate speech dataset focusing on sexism. Table 1 provides the basic statistics of these monolingual datasets after merging the training and the test sets.

Table 1.
Statistics for the monolingual datasets.
To verify the performance of the student networks on a large multilingual dataset, we combined the eight datasets used by Awal et al. [41] in their HateMAML study: English (OLID), Arabic (SemEval), Danish (SemEval), Turkish (SemEval), Greek (SemEval), German (HASOC), Italian-news (Haspeede), and Italian-tweets (Haspeede). The result was a new large-scale dataset named UniHate.
To create a larger dataset while maintaining consistency with the work of Firmino et al. [42], we combined the Haspeede [36], OffCombr-2 [40], and HaterNet [37] datasets, shuffled their order, and synthesized a new multilingual dataset named Multilingual. This multilingual dataset was then translated into English using Google Translator and DeepL Translator. Both the merged multilingual dataset and the translated dataset were used in our experiments (see Table 2).
Table 2.
Statistics for the multilingual datasets.
4.2. Baseline
DDML is a network training method for hate speech detection. Therefore, we used the following methods as baselines for the experiment.
HateMAML [41]: Awal et al. proposed the HateMAML method for hate speech detection in 2024. They conducted experiments on OLID [38] (HatEval2019), SemEval2020 [15], HaSpeedDe [36], and HASOC2020 [34] datasets, achieving good results. Therefore, we used HateMAML as one of the baselines for these datasets.
Cross-Lingual Learning for Hate Speech Detection (CLHSD) [42]: Firmino et al. conducted experiments on datasets consisting of Italian (Haspeede [36]) and Portuguese (OffComBr-2 [40]) using various training strategies, including zero-shot transfer (ZST) learning, joint learning (JL), and cascade learning (CL), demonstrating the effectiveness of cross-lingual learning in hate speech detection.
Transfer Learning For Hate Speech Detection (TLHSD) [43]: Fillies et al. used transfer learning methods to classify hate speech in German, Italian, and Spanish on the GermEval 2018 [35], Haspeede [36], and HaterNET [37] datasets in 2023, achieving good results. Therefore, we used the transfer learning method as one of the baselines for the above three datasets.
4.3. Transformer-Based Models
This experiment utilized different versions of the BERT [11] network and various versions of the XLM-R [12] network. The different BERT versions included mBERT (bert-base-multilingual-uncased) [11], distillBERT (distillbert-base-uncased) [44], GermanBERT (bert-base-german-cased), ItalianBERT (bert-base-italiana-cased), BETO (bert-base-spanish-wwm-cased) [45], and BERTimbau (bert-base-portuguese-cased). The different XLM-R versions included XLM-R (xlm-roberta-large) [12] and XLM-R (xlm-roberta-base) [12]. For training neural networks based on DDML, XLM-R (xlm-roberta-large) [12] was uniformly selected as the teacher network. The specific networks and their parameter sizes are shown in Table 3.
Table 3.
Transformer-based model parameters.
The different versions of the BERT network are all based on the transformer encoder model, which focuses on understanding the context of text data. These networks use a multilayer stacked transformer encoder architecture in which all layers process the input in parallel while leveraging bidirectional context to learn semantic representations. At the same time, all versions of the BERT network are bidirectional encoders that are pretrained through two tasks, namely, masked language model (MLM) and next-sentence prediction (NSP).
As with BERT, The XLM-R series of models is also based on the transformer encoder architecture. XLM-R is a multilingual version of BERT designed to achieve cross-lingual transfer learning via pretraining on multiple languages. The pretraining approach of XLM-R is similar to that of BERT, using the masked language model (MLM) for training; the difference lies in its use of a large amount of multilingual data (such as datasets from 100 languages). XLM-R achieves cross-lingual generalization by training on these languages in a unified manner.
For the transformer-based models, we used the HuggingFace transformers library and initialized the selected pretrained models with the weights provided by this library.
5. Results and Analysis
We utilized four evaluation metrics: accuracy, precision, recall, and F1 Score (macro). The following descriptions use the abbreviations TP (true positive), TN (true negative), FP (false positive), and FN (false negative). Accuracy is the ratio of the number of samples predicted correctly by the model to the total number of samples:
Precision refers to the proportion of true positive samples among all samples predicted as positive by the model:
Recall refers to the proportion of true positive samples that are successfully identified by the model out of all actual positive samples:
Finally, the F1 score is particularly useful in cases where the dataset is imbalanced, i.e., when the number of positive and negative samples differs greatly:
Precision and recall often constrain each other; increasing precision (i.e., reducing false positives) may lead to a decrease in recall (more false negatives), while increasing recall (reducing false negatives) may cause the precision to drop (more false positives). The F1 score is the harmonic mean of the precision and recall, and as such can be used as a comprehensive metric to evaluate a model.
Our experiment was conducted five times fir each group. Therefore, in the tables in this section, specifically Table 4, Table 5, Table 6, Table 7 and Table 8, each represents x as the average value of the F1 score or accuracy, with y as the standard deviation.
Table 4.
Comparison of experimental results for DDML and HateMAML on the OLID, SemEval2020, HaSpeedDe, and HASOC2020 datasets. In this table, the bolded parts are the well-performing ones in this set of experiments, results marked with ▴ represent the DDML results and those marked with • represent the HateMAML results.
Table 5.
Comparison of experimental results (accuracy and F1 score) between DDML and CLHSD on the OffComBr-2 dataset. In this table, the bolded parts are the well-performing ones in this set of experiments.
Table 6.
Comparison of experimental results (precision and recall) between DDML and CLHSD on the OffComBr-2 dataset. In this table, the bolded parts are the well-performing ones in this set of experiments.
Table 7.
Experimental results comparing DDML and TLHSD on the GermEval, Haspeede, and HaterNet datasets. In this table, the bolded parts are the well-performing ones in this set of experiments.
Table 8.
Comparison of experimental results between DDML and TLHSD on the Multilingual, GoogleMultilingual, and DeepLMultilingual datasets. In this table, the bolded parts are the well-performing ones in this set of experiments.
5.1. Comparison Experiment Between DDML and HateMAML
HateMAML was proposed by Awal et al. [41], who conducted experiments on the OLID, SemEval, HASOC, and Haspeede datasets using mBERT and XLM-R (xlm-roberta-base) networks. Therefore, our experimental design for these datasets used the same two networks as student networks. Furthermore, we incorporated the large multilingual UniHate dataset alongside these datasets for comparison.
Table 4 presents the accuracy, precision, recall, and F1 score results of the XLM-R and mBERT student networks trained using DDML on the OLID, SemEval2020, HaSpeedDe, and HASOC2020 datasets in comparison with those of HateMAML.
From the overall experimental data, it is evident that our DDML method not only outperforms HateMAML in terms of accuracy but also achieves generally better results in precision, recall, and F1 score. This advantage is validated across different models (mBERT and XLM-R) and multiple language datasets, demonstrating that DDML has stronger generalization ability and robustness compared to HateMAML.
The experimental data show that DDML demonstrates significant improvements across multiple language datasets, proving its applicability to languages beyond English such as Arabic, Danish, Turkish, and Italian. Even for high-resource languages such as English and German, DDML still outperforms HateMAML, suggesting that it can further optimize models and enhance classification performance even when large amounts of data are available. For example, on the German (HASOC) dataset, the F1 score of mBERT trained with DDML reached 0.8125, whereas HateMAML achieved only 0.7772, demonstrating that DDML consistently provides performance gains. For low-resource languages such as Arabic and Turkish, the improvements with DDML are even more pronounced, with the largest performance boost observed on the Arabic dataset. Specifically, the F1 score of XLM-R trained with DDML was 33% higher than that of HateMAML. At the same time, the network trained with DDML shows a relatively balanced performance in both precision and recall on most datasets, indicating that the network handles positive and negative samples in a balanced manner without a significant bias toward any particular class. This suggests that DDML is particularly well suited for tasks with limited data and complex distributions, as it can make more effective use of the available samples to enhance model generalization. Notably, DDML performed well on the large-scale multilingual UniHate dataset, surpassing HateMAML in all four evaluation metrics. This further demonstrates that networks trained with DDML have stronger generalization capabilities on large datasets and a better understanding of multiple languages.
From the perspective of standard deviation, deep neural networks trained with DDML generally exhibit lower standard deviations, indicating that DDML has stronger stability and less fluctuation. Compared to HateMAML, DDML demonstrates better stability, as the F1 score and accuracy of HateMAML both tend to fluctuate more, suggesting that it may be more sensitive to the training data or hyperparameters. The box plots of the standard deviation distributions for both training methods is shown in Figure 4.
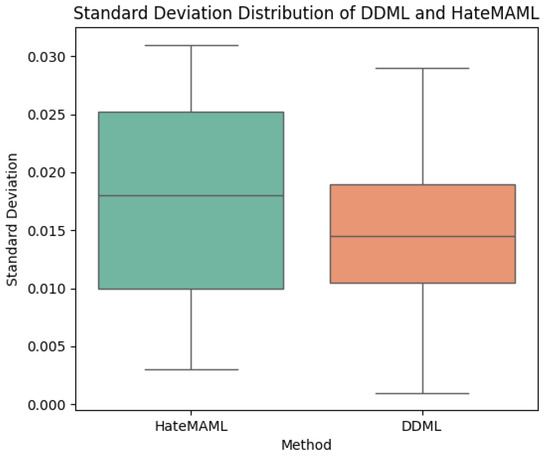
Figure 4.
Standard deviation distributions of DDML and HateMAML.
5.2. Comparison Experiment Between DDML and CLHSD
In order to replicate the CLHSD experiment by Firmino et al. [42] and compare it with DDML, this experiment adopted the same methodology as the original paper, using the Haspeede dataset as the source language and the OffComBr-2 dataset as the target language. Additionally, we replicated the four experimental strategies used in the original paper: joint learning (JL), cascaded learning (CL), combined CL/JL (combining 70% of the source dataset with 30% of the target dataset), and CL/JL+ (initial training cycle using the same data split as CL/JL, followed by subsequent training cycles in which the remaining language corpus is split based on the number of training cycles using k-fold cross-validation).
Joint learning is a machine learning paradigm in which the core idea is to simultaneously optimize multiple related tasks or objectives within the same training process, thereby enabling models to leverage information from different tasks to enhance overall performance. Joint learning has widespread applications in multitask learning, cross-domain learning, knowledge distillation, and other related fields. Cascaded learning is another machine learning paradigm; in CL, the core idea is to decompose the learning task into multiple stages, with the model for each stage relying on the output of the previous stage to gradually optimize the final prediction result. This method can improve the efficiency and accuracy of the model while reducing the computational complexity. It is widely used in computer vision, natural language processing, reinforcement learning, and other fields.
The comparison between DDML and CLHSD on the OffComBr-2 dataset is shown in Table 5 and Table 6 and Figure 5. From the table data, it is evident that DDML performs significantly better than CLHSD with each of the JL, CL, CL/JL, and CL/JL+ strategies. On four different deep neural networks (XLM-R, BERTimbau, ItalianBERT, and BERT), the DDML training method exhibits the best performance in both accuracy and F1 score or at least matches the CL/JL+ method. On all models, the F1 score under DDML is either the highest or comparable to the CL/JL+ method, indicating that DDML not only improves classification accuracy but also ensures the robustness of the model, allowing it to maintain strong performance across different test sets. By observing the precision and recall results, it can be seen that the network trained with DDML achieves balanced performance between the two metrics, with both results being close to the F1 score. This indicates that the DDML model does not favor optimizing precision at the cost of recall, nor does it prioritize recall at the expense of precision.; in other words, the model reaches a good compromise between the two metrics, resulting in a relatively ideal outcome.
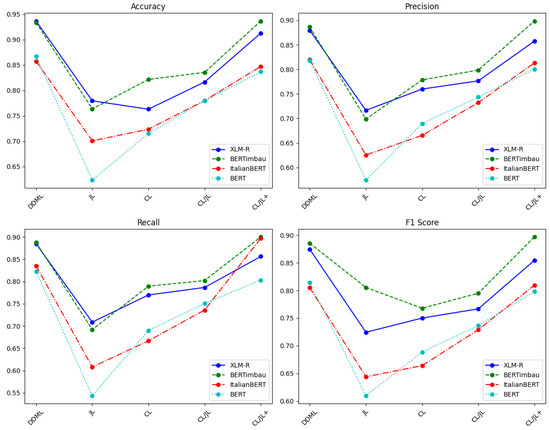
Figure 5.
Comparison of experimental results between DDML and CLHSD on the OffComBr-2 dataset.
In conclusion, DDML outperforms CLHSD on the OffComBr-2 dataset. DDML shows stronger advantages in both accuracy and F1 score, effectively enhancing the performance of hate speech detection tasks while also demonstrating greater generalization ability and stability.
5.3. Comparison Experiment Between DDML and TLHSD
In their research based on TLHSD, Fillies et al. [43] used GermanBERT, ItalianBERT, and BETO on the GermEval 2018, Haspeede, and HaterNET datasets. For the experiments reported in this subsection, we used the corresponding networks on the same three datasets. Additionally, as a comparison, we used XLM-R (xlm-roberta-base) as the student network. For comparison with the study by Fillies et al. [43], our student network used distillBERT on the Multilingual, GoogleMultilingual, and DeeplMultilingual datasets, as was the case in their research.
The results of our experiment comparing DDML and TLHSD are shown in Table 7 and Table 8 and in Figure 6. From the results in Table 7, it can be seen that DDML outperforms TLHSD on all three datasets. In terms of accuracy, DDML demonstrates higher accuracy on the three different language datasets, indicating its better ability to adapt to different language environments and improve the model’s overall classification ability. Regarding the F1 score, DDML achieves a higher F1 score on all datasets compared to TLHSD, demonstrating that the neural networks trained with DDML exhibit more balanced performance across different datasets.
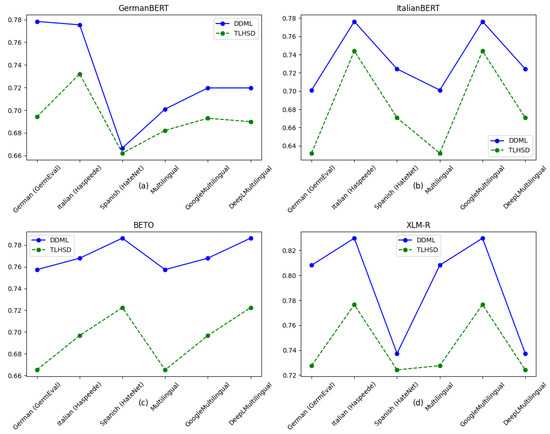
Figure 6.
Comparison of F1 score results between DDML and TLHSD on the GermEval, Haspeede, and HaterNet datasets. In this figure, subfigures (a–d) represent the F1 Score performance of GermanBERT, ItalianBERT, BETO, and XLM-R on six datasets: German (GermEval), Italian (Haspeede), Spanish (HaterNet), Multilingual, GoogleMultilingual, and DeepLMultilingual, respectively. The blue line represents the F1 Score of the model trained with DDML, while the green line represents the F1 Score of the model trained with TLHSD.
The experimental results in Table 8 show that DDML outperforms TLHSD across all datasets and evaluation metrics in terms of both accuracy and F1 score. DDML performs exceptionally well with the XLM-R model, achieving an accuracy of over 0.75 on multiple datasets, which is significantly higher than the results for TLHSD. This indicates that DDML can effectively learn cross-lingual hate speech detection features on large and complex datasets, resulting in improved detection performance.
In summary, the experimental results of DDML on all monolingual and multilingual datasets demonstrate that it outperforms TLHSD in both accuracy and F1 score. Notably, DDML shows significant improvement on the Italian and Spanish datasets, suggesting that our proposed method exhibits better feature learning capabilities, stronger generalization, and greater stability in multilingual hate speech detection tasks.
5.4. Experiments Applying DDML to Racism and Sexism Datasets
The experiments described in this subsection tested the performance of DDML on different racism and sexism datasets. Because Awal et al. [41] did not use the Hindi (HASOC) and English (HASOC) datasets in their study on HateMAML, and as the previous sections did not include any experiments on Chinese-language datasets, we included the Hindi (HASOC) and Chinese (COLD) datasets for the experiments in this section. To validate the effectiveness of DDML, we used CLHSD (CL/JL+), which performed the best in the previous experiments, as a comparison, and trained the model using Italian (Haspeede) as the source language. The experimental results are shown in Table 9 and Figure 7.
Table 9.
Comparison of experimental results between DDML and CLHSD (CL/JL+) on the Twitter Racism, SexismDetection, English (HASOC), Chinese (COLD), and Hindi (HASOC) datasets. In this table, the bolded parts are the well-performing ones in this set of experiments, results marked with ▴ represent the DDML results, while results marked with • represent the CLHSD (CL/JL+) results.
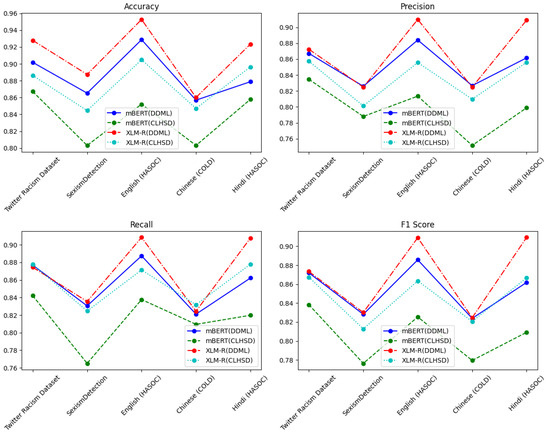
Figure 7.
Comparison of experimental results between DDML and TLHSD (CL/JL+) on the Twitter Racism, SexismDetection, English (HASOC), Chinese (COLD), and Hindi (HASOC) datasets.
DDML achieved better results across the different datasets, particularly in terms of the key F1 score evaluation metric, where it consistently outperformed CLHSD (CL/JL+) in all experiments. This indicates that our proposed training approach can effectively enhance the overall predictive capability of the resulting model.
In classification tasks, there is usually a tradeoff between precision and recall, with methods tending to either improve precision at the cost of recall or vice versa. Our proposed DDML achieves a good balance between precision and recall, allowing the model to achieve improved prediction accuracy without significantly sacrificing recall.
Across different models, DDML not only performs well on mBERT but also demonstrates stable performance improvements on XLM-R, a more powerful multilingual model.
Due to the limited availability of training data, it is generally more challenging to train models for low-resource languages such as Hindi and Chinese in comparison to high-resource languages such as English. This makes it difficult for the resulting models to learn sufficient semantic and syntactic patterns. Despite this, DDML still achieves strong performance on the Hindi dataset.
In summary, DDML outperforms CLHSD (CL/JL+) across multiple dimensions, including overall performance, precision–recall balance, generalization capability, and adaptability to low-resource languages, demonstrating its superior training strategy.
5.5. DDML Error Analysis
Models from both the BERT series and the XLM-R series outperform the baseline when trained with DDML. Performance is improved in terms of both overall accuracy and F1 score, while achieving a better balance between precision and recall. However, the mBERT model trained with DDML is insufficiently competitive on two datasets, namely, the Greek and Turkish HASOC datasets.
Our analysis indicates that the main reasons for this are as follows:
1. Insufficient coverage of pretraining data for the language model: mBERT may not have adequately covered the specific domains or corpora of the Greek and Turkish languages during pretraining. This could have resulted in mBERT acquiring a weaker understanding of these two languages, affecting the performance of DDML on these datasets.
2. Imbalanced sample distribution in the datasets: In the case of imbalanced samples in these two datasets, the model may have predicted the more frequent category (i.e., negative samples), leading to weaker prediction performance for positive samples. This can be corroborated by the lower recall results.
6. Conclusions
This paper is the first to propose the use of knowledge distillation for offensive language identification, introducing a novel distillation framework named DDML. We conducted classification experiments using data from nine datasets and six pretrained models from HuggingFace spanning a total of ten languages. The results show that our proposed DDML significantly outperforms baseline methods. Our experiments also reveal that models trained with DDML consistently achieve better average performance with XLM-R compared to BERT-based networks across both monolingual and multilingual datasets. Thus, XLM-R models should be prioritized when developing hate speech detectors. Moreover, we believe that DDML has broader applicability beyond hate speech detection, and could be used effectively in any domain where network-based problem solving is required.
However, the proposed DDML still has several aspects worth discussing and exploring further in future work:
1. Model efficiency tradeoffs: DDML uses a powerful teacher network and two or more smaller student networks. Even though the teacher network does not participate in backpropagation or parameter updates during training, the process still requires a significant amount of computational resources. Therefore, future work could introduce tradeoffs between training complexity and model performance with the aim of reducing the computational resources required for training while maintaining model performance as much as possible. We believe that there are two approaches worth considering in this regard. The first is to reduce the number of parameters in the student network by using RNN and LSTM networks, which also have strong sequence modeling capabilities. This can reduce the student network’s parameter size from 100 M–200 M to below 10 M. The second approach involves reducing the number of parameters in the teacher network. Similar to XLM-RoBERTa-Large, which we used in this paper, Google’s T5 series models [46] are large-scale pretrained language models; however, T5 models have only around 200 M parameters, which would significantly reduce the computational burden compared to the 561 M parameters of xlm-roBERTa-large.
2. The performance of mBERT on the Turkish and Greek datasets is insufficiently competitive: The mBERT model trained with DDML did not perform competitively on Turkish and Greek datasets. We believe that future research could address this issue by applying data augmentation to these two datasets and conducting more pretraining of the student networks for these languages.
Author Contributions
Z.L. proposed the idea for the article, designed and conducted the experiments, and wrote the article. Z.S. provided essential technical guidance during the experimental phase, while B.L. offered critical support by supplying experimental equipment, shaping the conceptual framework of the paper, and conducting the final proofreading. H.W. contributed significantly to language refinement and dataset sourcing, which were crucial to this research. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ouaddah, A.; Elkalam, A.A.; Ouahman, A.A. Towards a novel privacy-preserving access control model based on blockchain technology in IoT. In Europe and MENA Cooperation Advances in Information and Communication Technologies; Springer: Berlin/Heidelberg, Germany, 2017; pp. 523–533. [Google Scholar]
- Schäfer, S.; Sülflow, M.; Reiners, L. Hate Speech as an Indicator for the State of the Society. J. Media Psychol. 2021, 34, 3–15. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef] [PubMed]
- Shawkat, N.; Saquer, J.; Shatnawi, H. Evaluation of Different Machine Learning and Deep Learning Techniques for Hate Speech Detection. In Proceedings of the the 2024 ACM Southeast Conference, Marietta, GA, USA, 18–20 April 2024; pp. 253–258. [Google Scholar]
- Castaño-Pulgarín, S.A.; Suárez-Betancur, N.; Vega, L.M.T.; López, H.M.H. Internet, social media and online hate speech. Systematic review. Aggress. Violent Behav. 2021, 58, 101608. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Ranasinghe, T.; Zampieri, M. Multilingual offensive language identification with cross-lingual embeddings. arXiv 2020, arXiv:2010.05324. [Google Scholar]
- Aluru, S.S.; Mathew, B.; Saha, P.; Mukherjee, A. A deep dive into multilingual hate speech classification. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Applied Data Science and Demo Track: European Conference, Ghent, Belgium, 14–18 September 2020; pp. 423–439. [Google Scholar]
- Pamungkas, E.W.; Patti, V. Cross-domain and cross-lingual abusive language detection: A hybrid approach with deep learning and a multilingual lexicon. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 29–31 July 2019; pp. 363–370. [Google Scholar]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Conneau, A. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Khan, S.; Shahid, M.; Singh, N. White-box attacks on hate-speech BERT classifiers in german with explicit and implicit character level defense. arXiv 2022, arXiv:2202.05778. [Google Scholar] [CrossRef]
- Perifanos, K.; Goutsos, D. Multimodal Hate Speech Detection in Greek Social Media. Multimodal Technol. Interact. 2021, 5, 34. [Google Scholar] [CrossRef]
- Zampieri, M.; Nakov, P.; Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Mubarak, H.; Derczynski, L.; Pitenis, Z.; Çöltekin, Ç. SemEval-2020 task 12: Multilingual offensive language identification in social media (OffensEval 2020). arXiv 2020, arXiv:2006.07235. [Google Scholar]
- Basile, V.; Di Maro, M.; Croce, D.; Passaro, L. Evalita 2020: Overview of the 7th evaluation campaign of natural language processing and speech tools for italian. In Proceedings of the Ceur Workshop Proceedings, Virtual Event, 17 December 2020; Volume 2765. [Google Scholar]
- Artetxe, M.; Schwenk, H. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond. Trans. Assoc. Comput. Linguist. 2019, 7, 597–610. [Google Scholar] [CrossRef]
- Ruiz-Garcia, M. Model architecture can transform catastrophic forgetting into positive transfer. Sci. Rep. 2022, 12, 10736. [Google Scholar] [CrossRef] [PubMed]
- Pamungkas, E.W.; Basile, V.; Patti, V. A joint learning approach with knowledge injection for zero-shot cross-lingual hate speech detection. Inf. Process. Manag. 2021, 58, 102544. [Google Scholar] [CrossRef]
- Jiang, A.; Zubiaga, A. Cross-lingual capsule network for hate speech detection in social media. In Proceedings of the 32nd ACM Conference on Hypertext and Social Media, Virtual Event, 30 August–2 September 2021; pp. 217–223. [Google Scholar]
- Sahin, U.; Kucukkaya, I.E.; Ozcelik, O.; Toraman, C. Zero and Few-Shot Hate Speech Detection in Social Media Messages Related to Earthquake Disaster. In Proceedings of the 2023 31st Signal Processing and Communications Applications Conference, Istanbul, Turkiye, 5–8 July 2023; pp. 1–4. [Google Scholar]
- Nozza, D. Exposing the limits of zero-shot cross-lingual hate speech detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 2–5 August 2021; pp. 907–914. [Google Scholar]
- Montariol, S.; Riabi, A.; Seddah, D. Multilingual auxiliary tasks training: Bridging the gap between languages for zero-shot transfer of hate speech detection models. arXiv 2022, arXiv:2210.13029. [Google Scholar]
- Li, B.; Shi, Y.; Guo, Y.; Kong, Q.; Jiang, Y. Incentive and knowledge distillation based federated learning for cross-silo applications. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops, Virtual Event, 2–5 May 2022; pp. 1–6. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Ding, Q.; Wu, S.; Sun, H.; Guo, J.; Xia, S.T. Adaptive regularization of labels. arXiv 2019, arXiv:1908.05474. [Google Scholar]
- Chen, D.; Mei, J.P.; Zhang, Y.; Wang, C.; Wang, Z.; Feng, Y.; Chen, C. Cross-layer distillation with semantic calibration. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 7028–7036. [Google Scholar]
- Yang, Z.; Li, Z.; Zeng, A.; Li, Z.; Yuan, C.; Li, Y. ViTKD: Feature-based Knowledge Distillation for Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 1379–1388. [Google Scholar]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Zhang, C.; Peng, Y. Better and faster: Knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classification. arXiv 2018, arXiv:1804.10069. [Google Scholar]
- Lee, S.; Song, B.C. Graph-based knowledge distillation by multi-head attention network. arXiv 2019, arXiv:1907.02226. [Google Scholar]
- Zhang, R.; Shen, J.; Liu, T.; Liu, J.; Bendersky, M.; Najork, M.; Zhang, C. Knowledge Distillation with Perturbed Loss: From a Vanilla Teacher to a Proxy Teacher. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 4278–4289. [Google Scholar]
- Kim, S.W.; Kim, H.E. Transferring knowledge to smaller network with class-distance loss. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Mandl, T.; Modha, S.; Majumder, P.; Patel, D.; Dave, M.; Mandlia, C.; Patel, A. Overview of the hasoc track at fire 2019: Hate speech and offensive content identification in indo-european languages. In Proceedings of the 11th Annual Meeting of the Forum for Information Retrieval Evaluation, New York, NY, USA, 12 December 2019; pp. 14–17. [Google Scholar]
- Wiegand, M.; Siegel, M.; Ruppenhofer, J. Overview of the germeval 2018 shared task on the identification of offensive language. In Proceedings of the GermEval 2018 Workshop, Vienna, Austria, 21 September 2018. [Google Scholar]
- Sanguinetti, M.; Comandini, G.; Di Nuovo, E.; Frenda, S.; Stranisci, M.; Bosco, C.; Caselli, T.; Patti, V.; Russo, I. Haspeede 2@ evalita2020: Overview of the evalita 2020 hate speech detection task. In Proceedings of the Evaluation Campaign of Natural Language Processing and Speech Tools for Italian, Online, 17 December 2020. [Google Scholar]
- Fersini, E.; Rosso, P.; Anzovino, M. Overview of the task on automatic misogyny identification at IberEval 2018. Ibereval@sepln 2018, 2150, 214–228. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the type and target of offensive posts in social media. arXiv 2019, arXiv:1902.09666. [Google Scholar]
- Deng, J.; Zhou, J.; Sun, H.; Zheng, C.; Mi, F.; Meng, H.; Huang, M. COLD: A benchmark for Chinese offensive language detection. arXiv 2022, arXiv:2201.06025. [Google Scholar]
- De Pelle, R.P.; Moreira, V.P. Offensive comments in the brazilian web: A dataset and baseline results. In Proceedings of the Anais do VI Brazilian Workshop on Social Network Analysis and Mining, Brasilia, Brazil, 21–25 July 2017. [Google Scholar]
- Awal, M.R.; Lee, R.K.W.; Tanwar, E.; Garg, T.; Chakraborty, T. Model-agnostic meta-learning for multilingual hate speech detection. IEEE Trans. Comput. Soc. Syst. 2023, 11, 1086–1095. [Google Scholar] [CrossRef]
- Firmino, A.A.; de Souza Baptista, C.; de Paiva, A.C. Improving hate speech detection using cross-lingual learning. Expert Syst. Appl. 2024, 235, 121115. [Google Scholar] [CrossRef]
- Fillies, J.; Hoffmann, M.P.; Paschke, A. Multilingual Hate Speech Detection: Comparison of Transfer Learning Methods to Classify German, Italian, and Spanish Posts. In Proceedings of the 2023 IEEE International Conference on Big Data, Sorrento, Italy, 15–18 December 2023; pp. 5503–5511. [Google Scholar]
- Sanh, V. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Cañete, J.; Chaperon, G.; Fuentes, R.; Ho, J.H.; Kang, H.; Pérez, J. Spanish pre-trained bert model and evaluation data. arXiv 2023, arXiv:2308.02976. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).