1. Introduction
Hate speech on social media can have adverse effects on users. Surveys indicate that online hate speech contributes to suicide attempts and suicidal ideation, as well as mental health issues [
1]. On a macro level, online hate speech can exacerbate social polarization and undermine social stability [
2]. As social media continues to evolve and its content expands, the proliferation of hate speech also increases [
3], making automatic detection of hate speech a crucial element in combating it. Globally, a range of laws and policies have been introduced to maintain a clear online legal environment for citizens. These regulations not only standardize the content of online speech content, but also set higher standards for online platform operators. The severity of the situation has prompted social media platforms and academic researchers to propose traditional machine learning and deep learning solutions for automatic detection [
4] and early detection [
5] of online hate speech. Among these solutions, large pretrained language models (LLMs) have demonstrated their superiority in many natural language processing (NLP) tasks [
6] and have also shown excellent performance in hate speech detection [
7].
However, existing research has primarily focused on detecting hate speech in English and Western cultural contexts, neglecting a significant amount of online hate speech from other languages and cultures. This limits the global identification and control of aggressive language. There has been very little research on multilingual hate speech detection. One feasible method is to fine-tune pretrained language models [
8,
9]. At the same time, deep neural networks used in hate speech detection often have considerable depth or breadth, and typically contain numerous parameters. This results in high computational requirements, restricting the application of these models on personal computers.
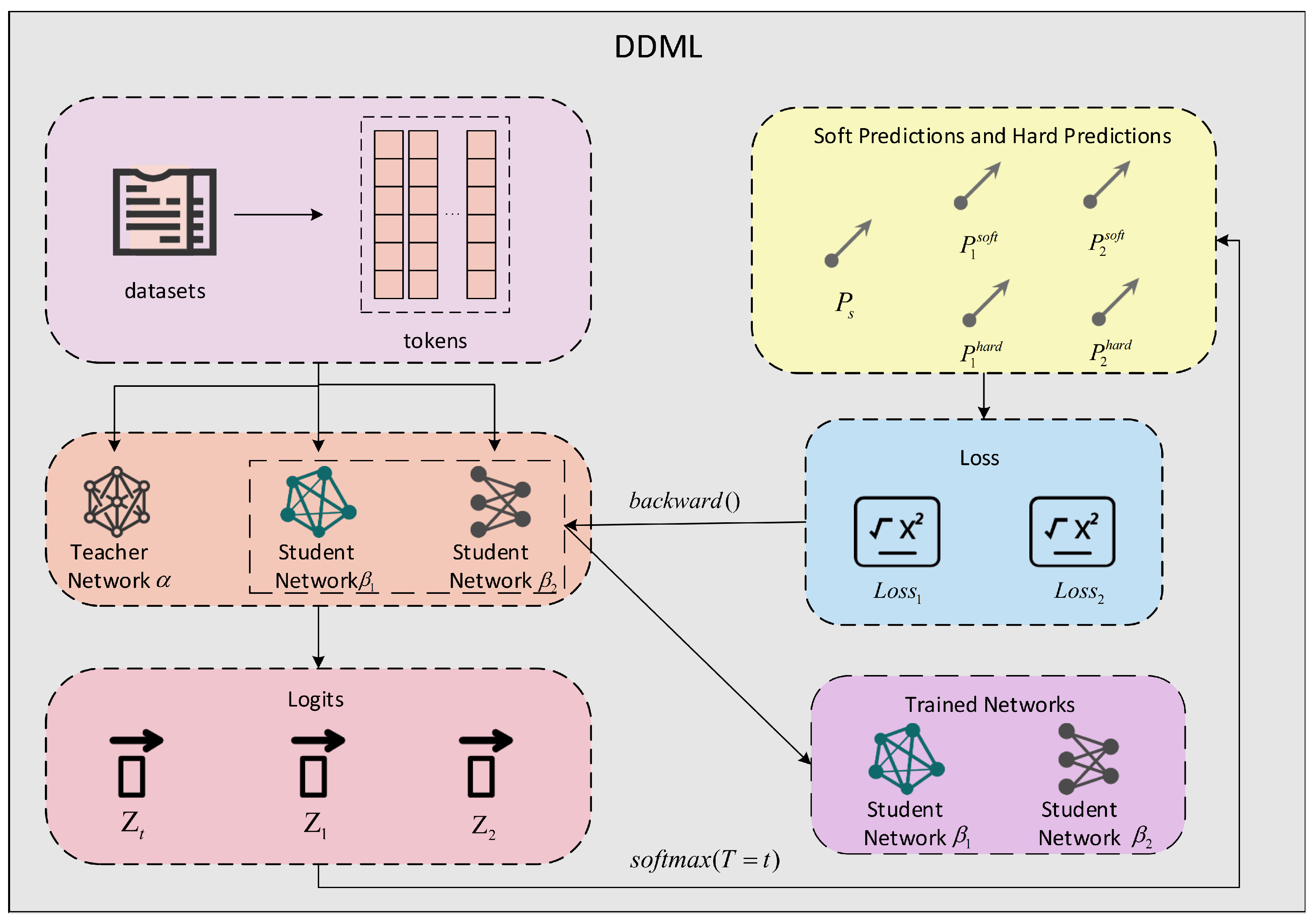
Knowledge distillation is a model compression technique that enhances the performance of a smaller model (the student) by transferring knowledge from a larger, high-performing model (the teacher). This method allows the student model to learn and mimic the teacher model’s behavior while maintaining a smaller model size and lower computational cost. Knowledge distillation is an excellent solution for addressing the deployment challenges of large models.
In real-life scenarios, students in a class learn not only from the teacher but also from their peers, which reinforces the knowledge gained from the teacher. Similarly, we believe that the student network can obtain knowledge not only from the teacher network but also from other student networks. In this paper, we aim to address the issues mentioned above by using a deep neural network with fewer parameters. To achieve excellent detection accuracy with a smaller deep neural network, we propose a method similar to model distillation [
10], which we call Deep Distill–Mutual Learning (DDML).
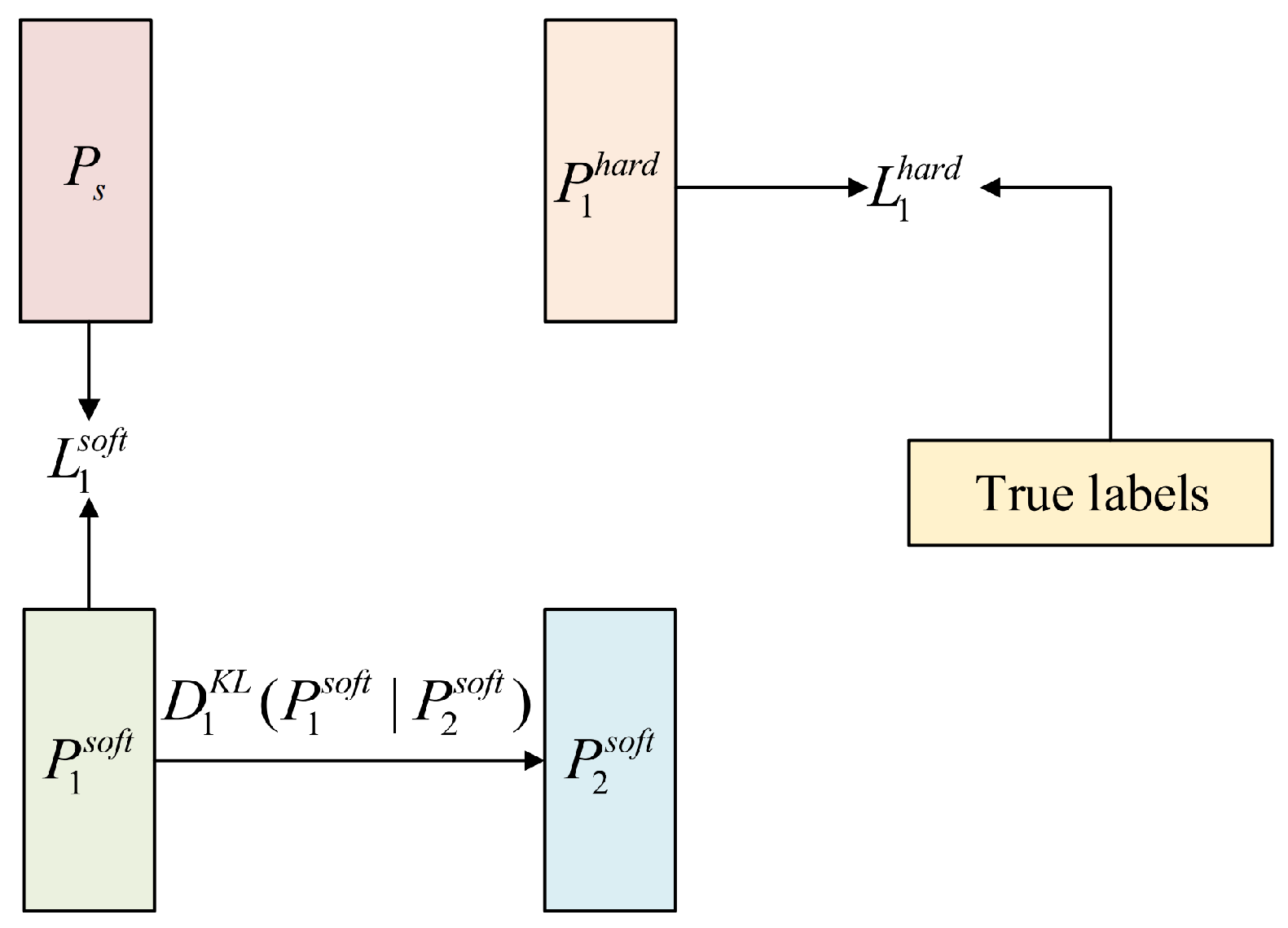
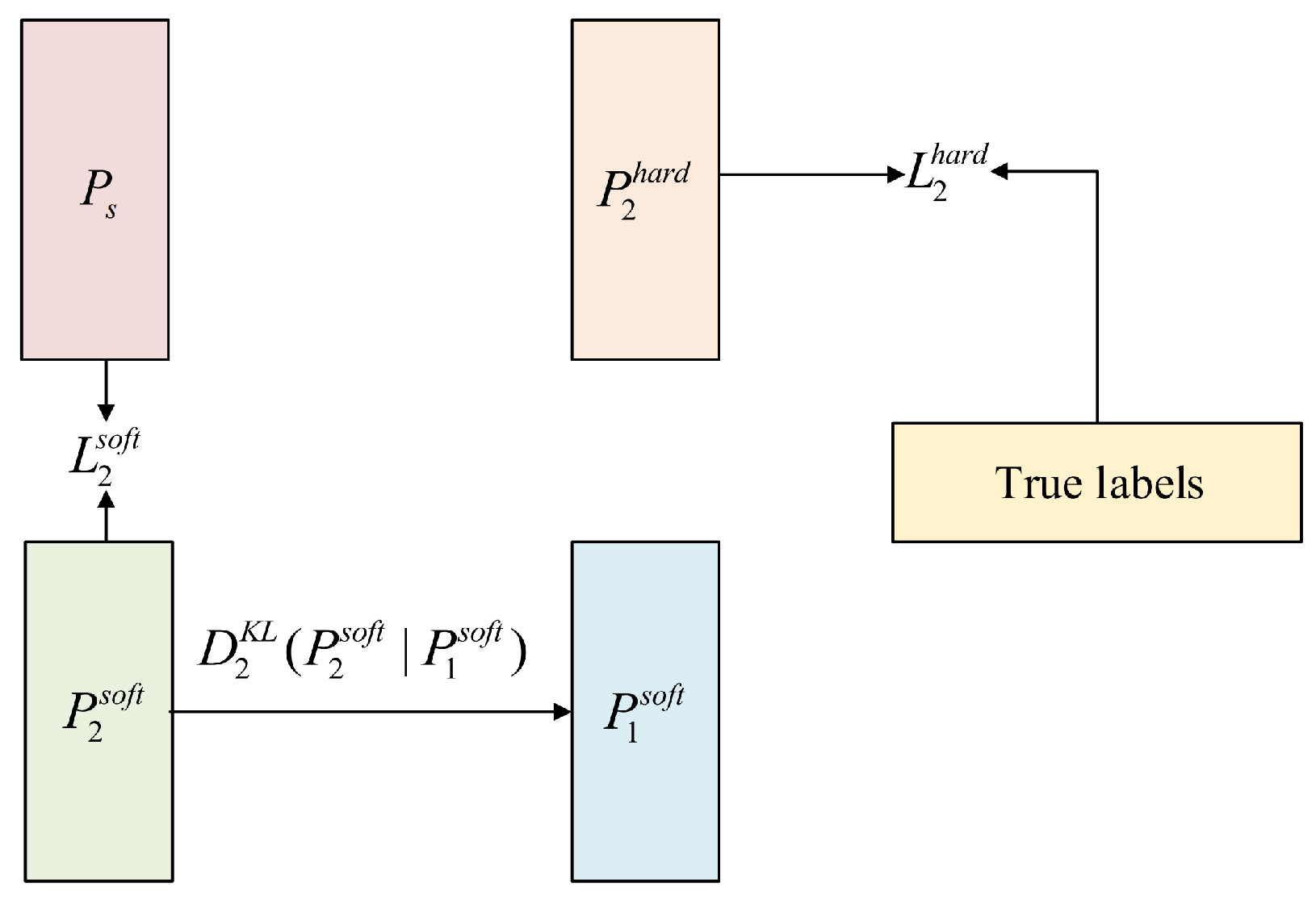
Model distillation typically starts with a larger and more powerful pretrained teacher network which transfers knowledge to a smaller untrained student network. Our proposed DDML requires a powerful teacher network along with two or more student networks. While the teacher network transfers knowledge to the student networks in one direction, the student networks also learn from each other to solve the problem. Specifically, each student network uses three types of loss: the traditional supervised learning loss, the loss of the teacher network’s output, and the imitation loss, which mimics other students. Our experiments show that the performance of student networks trained in this way surpasses that of student networks trained using the traditional model distillation method.
It may not be immediately clear why the proposed DDML learning strategy outperforms the traditional distillation method. In this regard, intuition can be gained from the following. Each student network is trained using both the true labels and the outputs of the powerful teacher model, which generally improves the performance of the student networks. However, because each student network has a different architecture and initial conditions, they learn different representations, leading to varying predictions. These differences provide additional knowledge during the training process, helping the student networks to achieve better performance.
The main contributions of this paper are as follows:
1. First, we develop a knowledge distillation-based deep neural network training method called DDML for online hate speech detection. This method facilitates the construction of a lightweight hate speech detection model, making it well suited for deployment on resource-constrained devices.
2. Second, we leverage various deep neural networks, including BERT [
11] and XLM-R [
12], and train them using the proposed DDML method. On the one hand, this approach ensures high detection accuracy across different architectures, while on the other it enables robust performance in monolingual, multilingual, and machine translation-based hate speech detection tasks.
3. Third, we conduct extensive experiments across ten languages and nine datasets to validate the effectiveness of the proposed method. The results demonstrate that our approach achieves an average F1 score improvement of 4.87% over the baseline, highlighting its superior performance in diverse linguistic settings.
4. Experiment
In the following, we describe the use of the design from Part III to conduct experiments. First, we introduce the datasets, baseline, transformer-based models, and implementation details, then the use of the acquired data to conduct experiments and collect results.
We implemented all networks and training procedures in PyTorch (version 2.0.1+cu117) and conducted all experiments on an NVIDIA RTX A6000 GPU (made by NVIDIA, in Santa Clara, CA, USA). For the transformer-based models, we used the HuggingFace transformer library and initialized the selected pretrained models with weights provided by this library.
4.1. Datasets
To detect multilingual hate speech, we conducted experiments on the following nine datasets:
SemEval2020 [
15], which contains four low-resource languages: Arabic, Danish, Swiss, and Turkish.
HASOC2020 [
34], which contains three languages: English, German, and Hindi.
GermEval 2018 [
35]: Haspeede2 [
36], HaterNET [
37], OLID [
38], and COLD [
39] are single-language datasets respectively consisting of German, Italian, Spanish, English, and Chinese.
OffComBr-2 [
40] is a dataset of hate speech comments in Portuguese from the Brazilian news website (accessed on 19 November 2024)
https://g1.globo.com/.
Twitter Racism [
22], the zero-shot learning dataset proposed by Nozza, is insufficient for detection of hate speech against women. Thus, to verify the performance of the network trained by DDML in the detection of such hate speech, we selected the Twitter Racism Dataset from HuggingFace, which is an English dataset of hate speech against women.
To verify the performance of the network trained by DDML on other types of hate speech, we also selected the public dataset SexismDetection from HuggingFace, which is an English hate speech dataset focusing on sexism.
Table 1 provides the basic statistics of these monolingual datasets after merging the training and the test sets.
To verify the performance of the student networks on a large multilingual dataset, we combined the eight datasets used by Awal et al. [
41] in their HateMAML study: English (OLID), Arabic (SemEval), Danish (SemEval), Turkish (SemEval), Greek (SemEval), German (HASOC), Italian-news (Haspeede), and Italian-tweets (Haspeede). The result was a new large-scale dataset named UniHate.
To create a larger dataset while maintaining consistency with the work of Firmino et al. [
42], we combined the Haspeede [
36], OffCombr-2 [
40], and HaterNet [
37] datasets, shuffled their order, and synthesized a new multilingual dataset named Multilingual. This multilingual dataset was then translated into English using Google Translator and DeepL Translator. Both the merged multilingual dataset and the translated dataset were used in our experiments (see
Table 2).
4.2. Baseline
DDML is a network training method for hate speech detection. Therefore, we used the following methods as baselines for the experiment.
HateMAML [
41]: Awal et al. proposed the HateMAML method for hate speech detection in 2024. They conducted experiments on OLID [
38] (HatEval2019), SemEval2020 [
15], HaSpeedDe [
36], and HASOC2020 [
34] datasets, achieving good results. Therefore, we used HateMAML as one of the baselines for these datasets.
Cross-Lingual Learning for Hate Speech Detection (CLHSD) [
42]: Firmino et al. conducted experiments on datasets consisting of Italian (Haspeede [
36]) and Portuguese (OffComBr-2 [
40]) using various training strategies, including zero-shot transfer (ZST) learning, joint learning (JL), and cascade learning (CL), demonstrating the effectiveness of cross-lingual learning in hate speech detection.
Transfer Learning For Hate Speech Detection (TLHSD) [
43]: Fillies et al. used transfer learning methods to classify hate speech in German, Italian, and Spanish on the GermEval 2018 [
35], Haspeede [
36], and HaterNET [
37] datasets in 2023, achieving good results. Therefore, we used the transfer learning method as one of the baselines for the above three datasets.
4.3. Transformer-Based Models
This experiment utilized different versions of the BERT [
11] network and various versions of the XLM-R [
12] network. The different BERT versions included mBERT (bert-base-multilingual-uncased) [
11], distillBERT (distillbert-base-uncased) [
44], GermanBERT (bert-base-german-cased), ItalianBERT (bert-base-italiana-cased), BETO (bert-base-spanish-wwm-cased) [
45], and BERTimbau (bert-base-portuguese-cased). The different XLM-R versions included XLM-R (xlm-roberta-large) [
12] and XLM-R (xlm-roberta-base) [
12]. For training neural networks based on DDML, XLM-R (xlm-roberta-large) [
12] was uniformly selected as the teacher network. The specific networks and their parameter sizes are shown in
Table 3.
The different versions of the BERT network are all based on the transformer encoder model, which focuses on understanding the context of text data. These networks use a multilayer stacked transformer encoder architecture in which all layers process the input in parallel while leveraging bidirectional context to learn semantic representations. At the same time, all versions of the BERT network are bidirectional encoders that are pretrained through two tasks, namely, masked language model (MLM) and next-sentence prediction (NSP).
As with BERT, The XLM-R series of models is also based on the transformer encoder architecture. XLM-R is a multilingual version of BERT designed to achieve cross-lingual transfer learning via pretraining on multiple languages. The pretraining approach of XLM-R is similar to that of BERT, using the masked language model (MLM) for training; the difference lies in its use of a large amount of multilingual data (such as datasets from 100 languages). XLM-R achieves cross-lingual generalization by training on these languages in a unified manner.
For the transformer-based models, we used the HuggingFace transformers library and initialized the selected pretrained models with the weights provided by this library.
5. Results and Analysis
We utilized four evaluation metrics: accuracy, precision, recall, and F1 Score (macro). The following descriptions use the abbreviations TP (true positive), TN (true negative), FP (false positive), and FN (false negative). Accuracy is the ratio of the number of samples predicted correctly by the model to the total number of samples:
Precision refers to the proportion of true positive samples among all samples predicted as positive by the model:
Recall refers to the proportion of true positive samples that are successfully identified by the model out of all actual positive samples:
Finally, the F1 score is particularly useful in cases where the dataset is imbalanced, i.e., when the number of positive and negative samples differs greatly:
Precision and recall often constrain each other; increasing precision (i.e., reducing false positives) may lead to a decrease in recall (more false negatives), while increasing recall (reducing false negatives) may cause the precision to drop (more false positives). The F1 score is the harmonic mean of the precision and recall, and as such can be used as a comprehensive metric to evaluate a model.
Our experiment was conducted five times fir each group. Therefore, in the tables in this section, specifically
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8, each
represents
x as the average value of the F1 score or accuracy, with
y as the standard deviation.
5.1. Comparison Experiment Between DDML and HateMAML
HateMAML was proposed by Awal et al. [
41], who conducted experiments on the OLID, SemEval, HASOC, and Haspeede datasets using mBERT and XLM-R (xlm-roberta-base) networks. Therefore, our experimental design for these datasets used the same two networks as student networks. Furthermore, we incorporated the large multilingual UniHate dataset alongside these datasets for comparison.
Table 4 presents the accuracy, precision, recall, and F1 score results of the XLM-R and mBERT student networks trained using DDML on the OLID, SemEval2020, HaSpeedDe, and HASOC2020 datasets in comparison with those of HateMAML.
From the overall experimental data, it is evident that our DDML method not only outperforms HateMAML in terms of accuracy but also achieves generally better results in precision, recall, and F1 score. This advantage is validated across different models (mBERT and XLM-R) and multiple language datasets, demonstrating that DDML has stronger generalization ability and robustness compared to HateMAML.
The experimental data show that DDML demonstrates significant improvements across multiple language datasets, proving its applicability to languages beyond English such as Arabic, Danish, Turkish, and Italian. Even for high-resource languages such as English and German, DDML still outperforms HateMAML, suggesting that it can further optimize models and enhance classification performance even when large amounts of data are available. For example, on the German (HASOC) dataset, the F1 score of mBERT trained with DDML reached 0.8125, whereas HateMAML achieved only 0.7772, demonstrating that DDML consistently provides performance gains. For low-resource languages such as Arabic and Turkish, the improvements with DDML are even more pronounced, with the largest performance boost observed on the Arabic dataset. Specifically, the F1 score of XLM-R trained with DDML was 33% higher than that of HateMAML. At the same time, the network trained with DDML shows a relatively balanced performance in both precision and recall on most datasets, indicating that the network handles positive and negative samples in a balanced manner without a significant bias toward any particular class. This suggests that DDML is particularly well suited for tasks with limited data and complex distributions, as it can make more effective use of the available samples to enhance model generalization. Notably, DDML performed well on the large-scale multilingual UniHate dataset, surpassing HateMAML in all four evaluation metrics. This further demonstrates that networks trained with DDML have stronger generalization capabilities on large datasets and a better understanding of multiple languages.
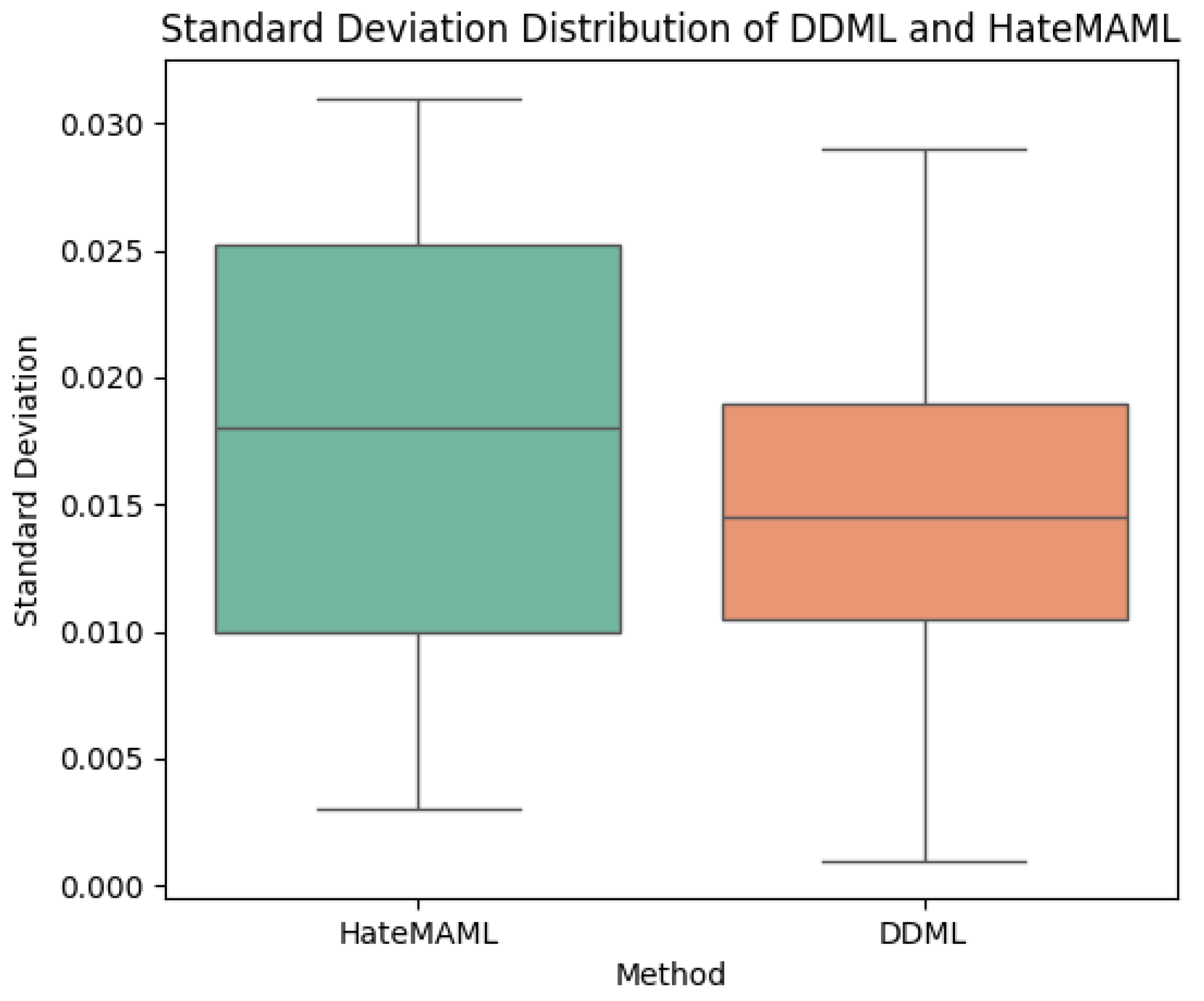
From the perspective of standard deviation, deep neural networks trained with DDML generally exhibit lower standard deviations, indicating that DDML has stronger stability and less fluctuation. Compared to HateMAML, DDML demonstrates better stability, as the F1 score and accuracy of HateMAML both tend to fluctuate more, suggesting that it may be more sensitive to the training data or hyperparameters. The box plots of the standard deviation distributions for both training methods is shown in
Figure 4.
5.2. Comparison Experiment Between DDML and CLHSD
In order to replicate the CLHSD experiment by Firmino et al. [
42] and compare it with DDML, this experiment adopted the same methodology as the original paper, using the Haspeede dataset as the source language and the OffComBr-2 dataset as the target language. Additionally, we replicated the four experimental strategies used in the original paper: joint learning (JL), cascaded learning (CL), combined CL/JL (combining 70% of the source dataset with 30% of the target dataset), and CL/JL+ (initial training cycle using the same data split as CL/JL, followed by subsequent training cycles in which the remaining language corpus is split based on the number of training cycles using k-fold cross-validation).
Joint learning is a machine learning paradigm in which the core idea is to simultaneously optimize multiple related tasks or objectives within the same training process, thereby enabling models to leverage information from different tasks to enhance overall performance. Joint learning has widespread applications in multitask learning, cross-domain learning, knowledge distillation, and other related fields. Cascaded learning is another machine learning paradigm; in CL, the core idea is to decompose the learning task into multiple stages, with the model for each stage relying on the output of the previous stage to gradually optimize the final prediction result. This method can improve the efficiency and accuracy of the model while reducing the computational complexity. It is widely used in computer vision, natural language processing, reinforcement learning, and other fields.
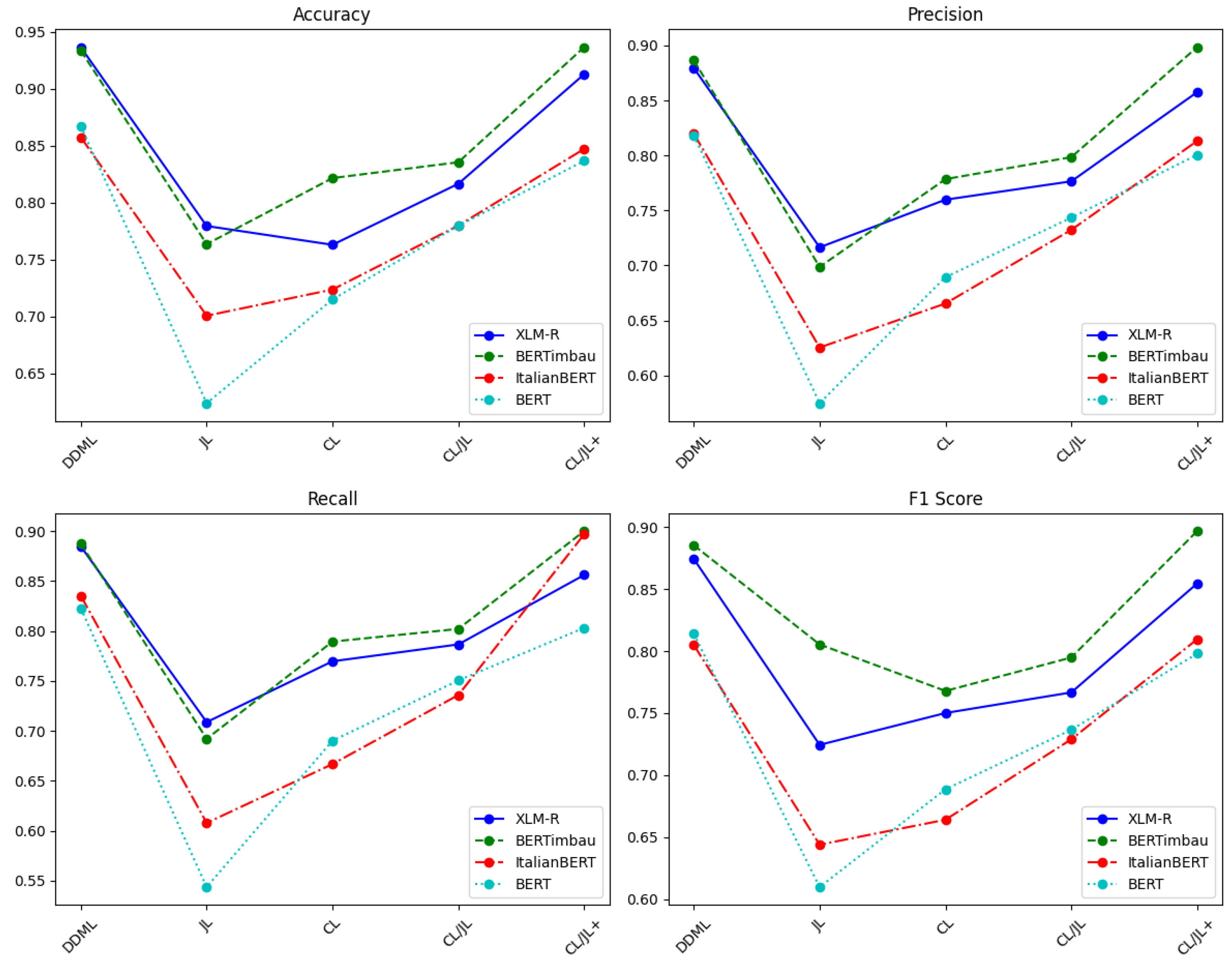
The comparison between DDML and CLHSD on the OffComBr-2 dataset is shown in
Table 5 and
Table 6 and
Figure 5. From the table data, it is evident that DDML performs significantly better than CLHSD with each of the JL, CL, CL/JL, and CL/JL+ strategies. On four different deep neural networks (XLM-R, BERTimbau, ItalianBERT, and BERT), the DDML training method exhibits the best performance in both accuracy and F1 score or at least matches the CL/JL+ method. On all models, the F1 score under DDML is either the highest or comparable to the CL/JL+ method, indicating that DDML not only improves classification accuracy but also ensures the robustness of the model, allowing it to maintain strong performance across different test sets. By observing the precision and recall results, it can be seen that the network trained with DDML achieves balanced performance between the two metrics, with both results being close to the F1 score. This indicates that the DDML model does not favor optimizing precision at the cost of recall, nor does it prioritize recall at the expense of precision.; in other words, the model reaches a good compromise between the two metrics, resulting in a relatively ideal outcome.
In conclusion, DDML outperforms CLHSD on the OffComBr-2 dataset. DDML shows stronger advantages in both accuracy and F1 score, effectively enhancing the performance of hate speech detection tasks while also demonstrating greater generalization ability and stability.
5.3. Comparison Experiment Between DDML and TLHSD
In their research based on TLHSD, Fillies et al. [
43] used GermanBERT, ItalianBERT, and BETO on the GermEval 2018, Haspeede, and HaterNET datasets. For the experiments reported in this subsection, we used the corresponding networks on the same three datasets. Additionally, as a comparison, we used XLM-R (xlm-roberta-base) as the student network. For comparison with the study by Fillies et al. [
43], our student network used distillBERT on the Multilingual, GoogleMultilingual, and DeeplMultilingual datasets, as was the case in their research.
The results of our experiment comparing DDML and TLHSD are shown in
Table 7 and
Table 8 and in
Figure 6. From the results in
Table 7, it can be seen that DDML outperforms TLHSD on all three datasets. In terms of accuracy, DDML demonstrates higher accuracy on the three different language datasets, indicating its better ability to adapt to different language environments and improve the model’s overall classification ability. Regarding the F1 score, DDML achieves a higher F1 score on all datasets compared to TLHSD, demonstrating that the neural networks trained with DDML exhibit more balanced performance across different datasets.
The experimental results in
Table 8 show that DDML outperforms TLHSD across all datasets and evaluation metrics in terms of both accuracy and F1 score. DDML performs exceptionally well with the XLM-R model, achieving an accuracy of over 0.75 on multiple datasets, which is significantly higher than the results for TLHSD. This indicates that DDML can effectively learn cross-lingual hate speech detection features on large and complex datasets, resulting in improved detection performance.
In summary, the experimental results of DDML on all monolingual and multilingual datasets demonstrate that it outperforms TLHSD in both accuracy and F1 score. Notably, DDML shows significant improvement on the Italian and Spanish datasets, suggesting that our proposed method exhibits better feature learning capabilities, stronger generalization, and greater stability in multilingual hate speech detection tasks.
5.4. Experiments Applying DDML to Racism and Sexism Datasets
The experiments described in this subsection tested the performance of DDML on different racism and sexism datasets. Because Awal et al. [
41] did not use the Hindi (HASOC) and English (HASOC) datasets in their study on HateMAML, and as the previous sections did not include any experiments on Chinese-language datasets, we included the Hindi (HASOC) and Chinese (COLD) datasets for the experiments in this section. To validate the effectiveness of DDML, we used CLHSD (CL/JL+), which performed the best in the previous experiments, as a comparison, and trained the model using Italian (Haspeede) as the source language. The experimental results are shown in
Table 9 and
Figure 7.
DDML achieved better results across the different datasets, particularly in terms of the key F1 score evaluation metric, where it consistently outperformed CLHSD (CL/JL+) in all experiments. This indicates that our proposed training approach can effectively enhance the overall predictive capability of the resulting model.
In classification tasks, there is usually a tradeoff between precision and recall, with methods tending to either improve precision at the cost of recall or vice versa. Our proposed DDML achieves a good balance between precision and recall, allowing the model to achieve improved prediction accuracy without significantly sacrificing recall.
Across different models, DDML not only performs well on mBERT but also demonstrates stable performance improvements on XLM-R, a more powerful multilingual model.
Due to the limited availability of training data, it is generally more challenging to train models for low-resource languages such as Hindi and Chinese in comparison to high-resource languages such as English. This makes it difficult for the resulting models to learn sufficient semantic and syntactic patterns. Despite this, DDML still achieves strong performance on the Hindi dataset.
In summary, DDML outperforms CLHSD (CL/JL+) across multiple dimensions, including overall performance, precision–recall balance, generalization capability, and adaptability to low-resource languages, demonstrating its superior training strategy.
5.5. DDML Error Analysis
Models from both the BERT series and the XLM-R series outperform the baseline when trained with DDML. Performance is improved in terms of both overall accuracy and F1 score, while achieving a better balance between precision and recall. However, the mBERT model trained with DDML is insufficiently competitive on two datasets, namely, the Greek and Turkish HASOC datasets.
Our analysis indicates that the main reasons for this are as follows:
1. Insufficient coverage of pretraining data for the language model: mBERT may not have adequately covered the specific domains or corpora of the Greek and Turkish languages during pretraining. This could have resulted in mBERT acquiring a weaker understanding of these two languages, affecting the performance of DDML on these datasets.
2. Imbalanced sample distribution in the datasets: In the case of imbalanced samples in these two datasets, the model may have predicted the more frequent category (i.e., negative samples), leading to weaker prediction performance for positive samples. This can be corroborated by the lower recall results.
6. Conclusions
This paper is the first to propose the use of knowledge distillation for offensive language identification, introducing a novel distillation framework named DDML. We conducted classification experiments using data from nine datasets and six pretrained models from HuggingFace spanning a total of ten languages. The results show that our proposed DDML significantly outperforms baseline methods. Our experiments also reveal that models trained with DDML consistently achieve better average performance with XLM-R compared to BERT-based networks across both monolingual and multilingual datasets. Thus, XLM-R models should be prioritized when developing hate speech detectors. Moreover, we believe that DDML has broader applicability beyond hate speech detection, and could be used effectively in any domain where network-based problem solving is required.
However, the proposed DDML still has several aspects worth discussing and exploring further in future work:
1. Model efficiency tradeoffs: DDML uses a powerful teacher network and two or more smaller student networks. Even though the teacher network does not participate in backpropagation or parameter updates during training, the process still requires a significant amount of computational resources. Therefore, future work could introduce tradeoffs between training complexity and model performance with the aim of reducing the computational resources required for training while maintaining model performance as much as possible. We believe that there are two approaches worth considering in this regard. The first is to reduce the number of parameters in the student network by using RNN and LSTM networks, which also have strong sequence modeling capabilities. This can reduce the student network’s parameter size from 100 M–200 M to below 10 M. The second approach involves reducing the number of parameters in the teacher network. Similar to XLM-RoBERTa-Large, which we used in this paper, Google’s T5 series models [
46] are large-scale pretrained language models; however, T5 models have only around 200 M parameters, which would significantly reduce the computational burden compared to the 561 M parameters of xlm-roBERTa-large.
2. The performance of mBERT on the Turkish and Greek datasets is insufficiently competitive: The mBERT model trained with DDML did not perform competitively on Turkish and Greek datasets. We believe that future research could address this issue by applying data augmentation to these two datasets and conducting more pretraining of the student networks for these languages.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}