
Vector Flows That Compute the Capacity of Discrete Memoryless Channels †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Notations
3. Optimizing Continuous-Time Dynamics
3.1. Preliminaries
3.2. Optimizing Differential Equation on the Standard Simplex
- (i)
- There exists and is a stationary point for (3);
- (ii)
- If , then is a KKT point for (2);
- (iii)
- If and f is concave and continuous on , then is a global solution of (2).
for every , with equality for every .
4. Problem Formulation
4.1. Discrete Memoryless Channel and Capacity
In other words, we are assuming that represents the minimal output alphabet required for a description of the DMC. In fact, this assumption ensures that for any selected symbol there exists a corresponding input distribution for which y occurs as output with positive probability.For every , there exists at least one such that .
4.2. Optimization Program for the Capacity
5. Vector Flow for Capacity Computation
5.1. Flow Definition and Its Properties
- (a)
- ;
- (b)
- ;
- (c)
- .
- If , then ;
- If , then if and only if , where the set is defined by .
- The vector ;
- The function given by
- The real number as a positive solution to the system of inequalitieswhere and C are defined as in (4), (6) (note that such an exists, since as and for ).
- for every ;
- ;
- for every .
- (a)
- for every ;
- (b)
- ;
- (c)
- For every , if then .
- (a)
- The equality holds for every ;
- (b)
- Either is a stationary point for (7) or is strictly increasing;
- (c)
- There exists , and is a stationary point for (7);
- (d)
- The restriction of to the set attains its maximum in :
5.2. Connection with Blahut–Arimoto Algorithm
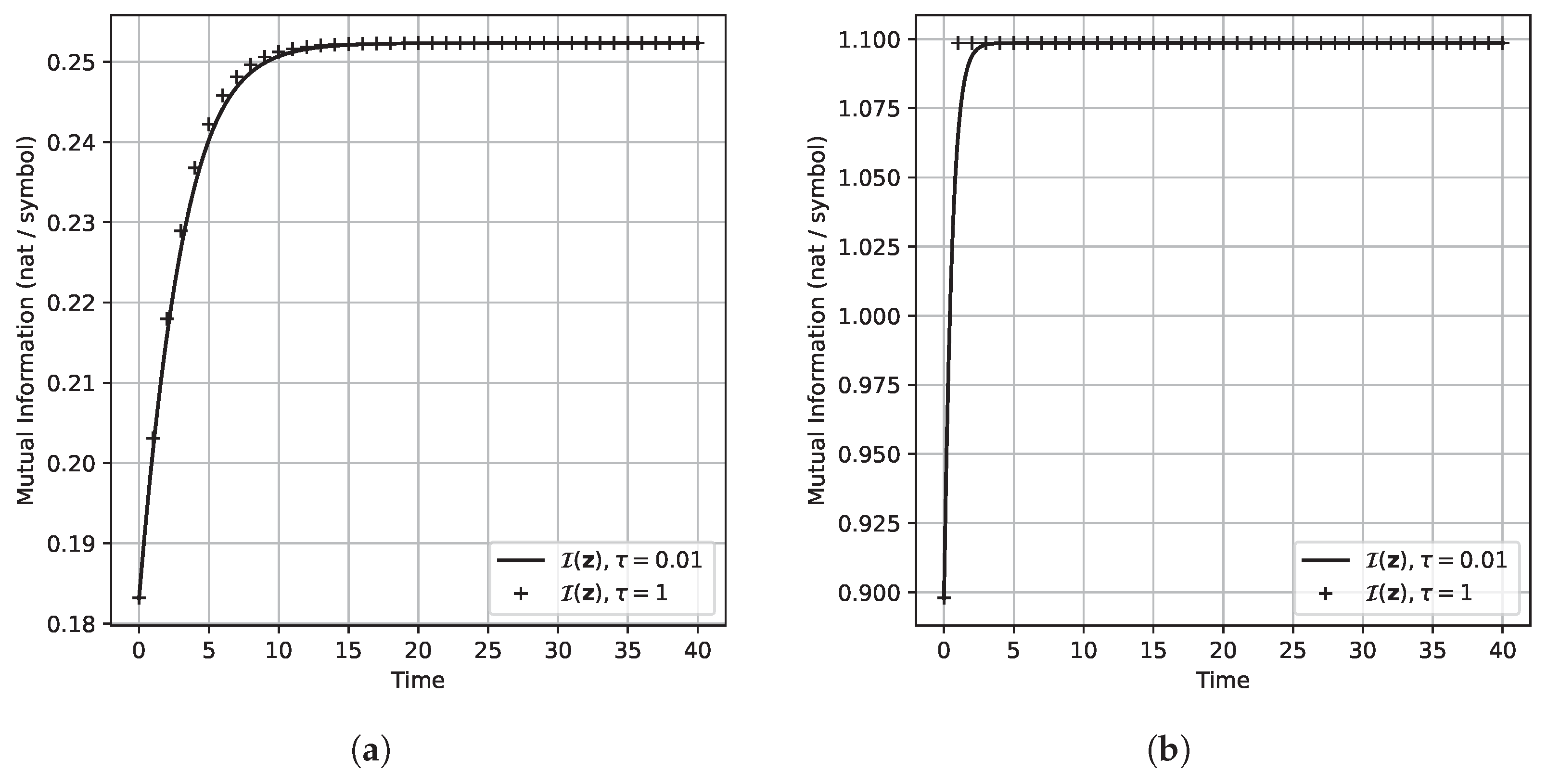
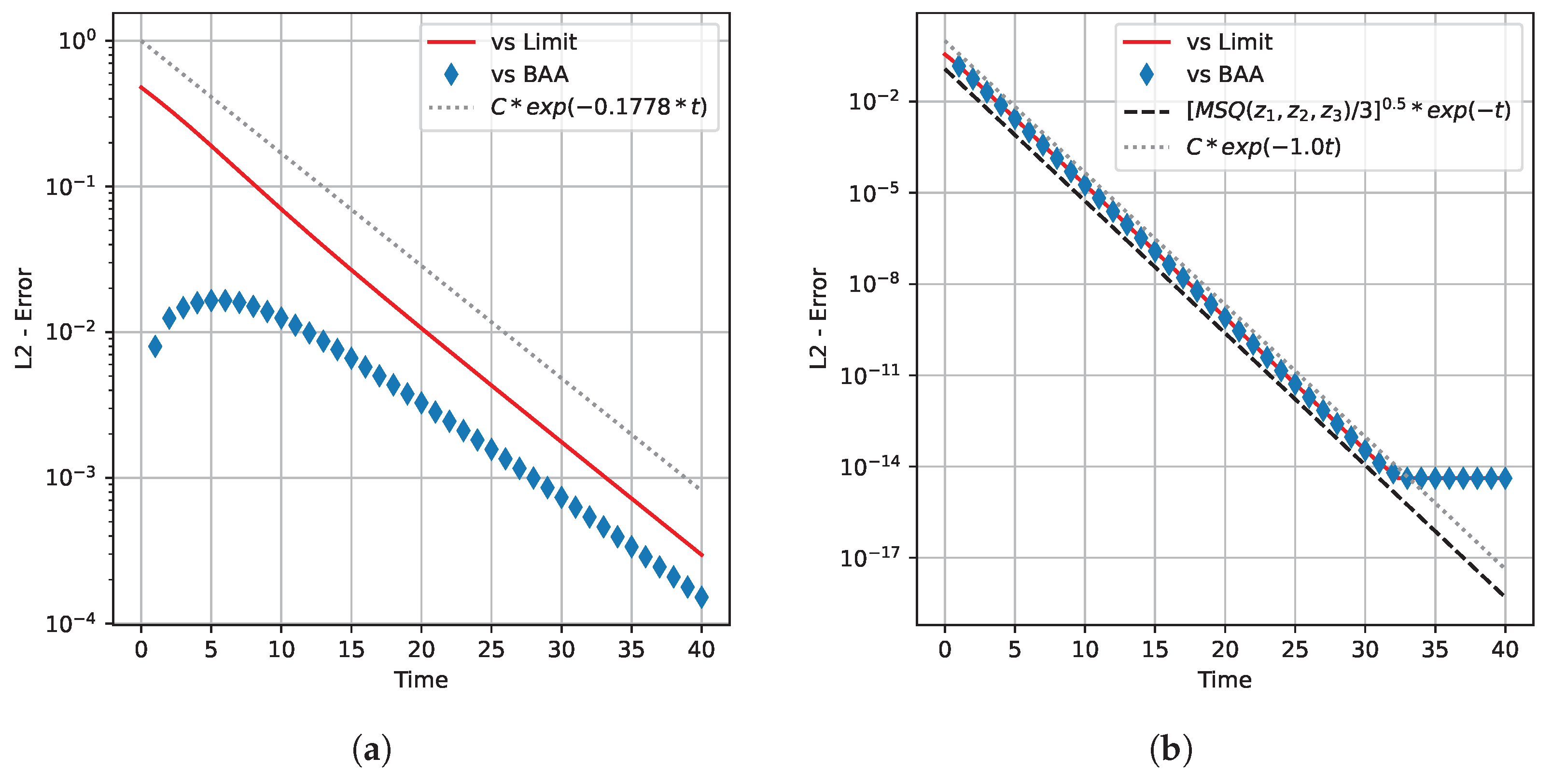
6. Convergence Rate
6.1. Conditions for Exponential Convergence
- type if and ;
- type if and ;
- type if and .
- (N1)
- For some positive , the indices , …, are of type and the remaining indices are of type .
- (N2)
- The first rows of the transition matrix are independent.
6.2. Noiseless Symmetric Channels
- Deterministic if the output Y is a deterministic function of the input X.
- Lossless if the input X is completely determined by the output Y.
- Noiseless if it is both deterministic and lossless.
- Symmetric if in the transition matrix every row is a permutation of every other row, and every column is a permutation of every other column.
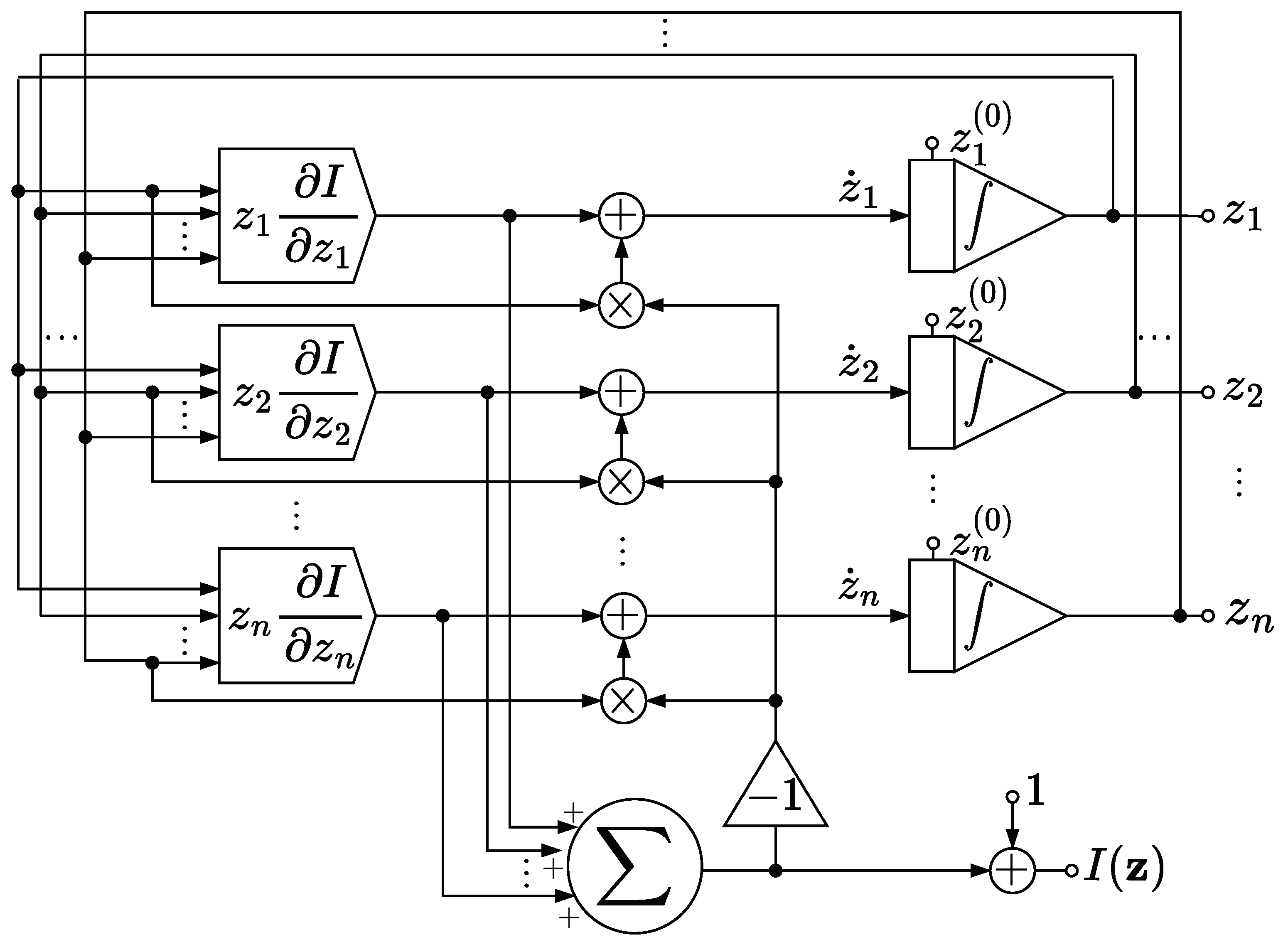
7. Analog Implementation
8. Some Illustrative Examples
| Algorithm 1 Discretizing the CC-ODE to compute the capacity [29]. | |
| Input: , stepsize; Niter, maximum number of iterations; , tolerance; , initialization point. | |
| Output: , estimated channel capacity; , estimated optimal input distribution; k, number of integration steps performed. | |
| 1: | |
| 2: | ▹ Initializing . |
| 3: | |
| 4: while do | |
| 5: | |
| 6: | ▹ Note: is the -norm of . |
| 7: | ▹ Updating . |
| 8: | |
| 9: end while | |
| 10: | |
| 11: | |
| 12: return , , k | |
9. Discussion
- In formulating Lemma 1, we tried to require only the essential hypotheses we used in its proof. Consequently, even though we apply Lemma 1 only in Proposition 2, it is applicable also in other, more general settings.
- As far as the proposed circuits are concerned, note that could be produced by considering a module that outputs and whose output is then multiplied by . However, note that is a bounded function of the input by Proposition 4, which in general is not true for .
- We also remark on the following feature of the circuit presented in Figure 1. Assume that, for whatever reason, there are u input symbols , , …, that become unavailable, in the sense that any input distribution is now constrained to assign null probability to , , …, . Indeed, this constraint on the channel corresponds to replacing it with , where and is obtained from by removing the rows , , …, . In case every symbol of the output alphabet can still be obtained with positive probability, then the capacity of may be computed without altering the circuit design displayed for , but by simply modifying the initialization rules on . Specifically, by Proposition 2.(d), it is sufficient to initialize so that if and only if , , …, , and the dynamics evolves so as to maximize under this constraint;
- Note that noise could negatively affect the capacity computation, despite the normalization module of Figure 2. Indeed, suppose that a perturbation causes to change its support at time , and that for , no additional perturbations affect the dynamics. Then it is possible that converges towards an input distribution that is still optimal, but for the wrong channel, as in the case discussed in the previous remark. To check if this has occurred, a good idea could be to consider some “perturb and restart” strategies. For instance, when the capacity of is sought in the presence of noise, assume that a trajectory initialized in some converges to some . We may then restart the dynamics in some that is obtained by perturbing slightly , and then check whether converges once again to , or if converges to in case we know in advance that there exists a unique optimal input distribution.
- By Proposition 4 and Peano’s theorem, the ODE (7) extended by continuity admits a solution for any initialization , regardless of whether lies in or not. Indeed, a solution for (7) can always be found by considering the “subchannel” of induced by the support of , similarly to the approach discussed before in Proposition 2.(d). However, in case , note that the Picard–Lindelöf theorem cannot be applied, and we did not manage to prove that such a solution is unique. Despite this, for symmetric noiseless channels, note that the general integral (31) can be extended by continuity also for , and arguing by induction it is not hard to see that, for these trivial channels, solutions for the extended ODE are unique.
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. ODEs on Compact Convex Sets
Appendix B. Support Invariance and Lyapunov Function
- (i)
- We have for ;
- (ii)
- The support of is invariant for ;
- (iii)
- Either is a constant function or is strictly increasing.
- The function has non-negative derivative, and is thereby non-decreasing.
- If for some the equality holds, then for every , and it is easy to check that in this case —thus, by the Picard-Lindelöf theorem.
Appendix C. An Example
Appendix D. Proof of Claim 1
- , with equality only for .
- if and only if .
- We have , and by definition of ,
- The proof is concluded if we also show that
Appendix E. Proof of Claim 2
Appendix F. Proof of Proposition 1
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Csiszár, I.; Tusnády, G. Information geometry and alternating minimization procedures. Stat. Decis. 1984, 1, 205–237. [Google Scholar]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef]
- Yu, Y. Squeezing the Arimoto-Blahut algorithm for faster convergence. IEEE Trans. Inf. Theory 2010, 56, 3149–3157. [Google Scholar] [CrossRef]
- Matz, G.; Duhamel, P. Information geometric formulation and interpretation of accelerated Blahut-Arimoto-type algorithms. In 2004 IEEE Information Theory Workshop; IEEE Press: Piscataway, NJ, USA, 2004; pp. 66–70. [Google Scholar] [CrossRef]
- Nakagawa, K.; Takei, Y.; Hara, S.I.; Watabe, K. Analysis of the convergence speed of the Arimoto-Blahut algorithm by the second-order recurrence formula. IEEE Trans. Inf. Theory 2021, 67, 6810–6831. [Google Scholar] [CrossRef]
- Boche, H.; Schaefer, R.F.; Poor, H.V. Algorithmic computability and approximability of capacity-achieving input distributions. IEEE Trans. Inf. Theory 2023, 69, 5449–5462. [Google Scholar] [CrossRef]
- Helmke, U.; Moore, J.B. Optimization and Dynamical Systems; Springer: London, UK, 1994. [Google Scholar]
- Brockett, R.W. Dynamical systems that sort lists, diagonalize matrices, and solve linear programming problems. Linear Algebra Its Appl. 1991, 146, 79–91. [Google Scholar] [CrossRef]
- Arora, S.; Hazan, E.; Kale, S. The multiplicative weights update method. Theory Comput. 2012, 8, 121–164. [Google Scholar] [CrossRef]
- Naja, Z.; Alberge, F.; Duhamel, P. Geometrical interpretation and improvements of the Blahut-Arimoto’s algorithm. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech, and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 2505–2508. [Google Scholar] [CrossRef]
- Weibull, J. Evolutionary Game Theory; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Sandholm, W.H. Population Games and Evolutionary Dynamics; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Khalil, H.K. Nonlinear Systems, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Roman, S. Coding and Information Theory; Graduate texts in mathematics; Springer: New York, NY, USA, 1992; Volume 134. [Google Scholar]
- MacLennan, B.J. Analog Computation. In Encyclopedia of Complexity and Systems Science; Meyers, R.A., Ed.; Springer: New York, NY, USA, 2009; pp. 271–294. [Google Scholar] [CrossRef]
- Taherkhani, A.; Belatreche, A.; Li, Y.; Cosma, G.; Maguire, L.P.; McGinnity, T.M. A review of learning in biologically plausible spiking neural networks. Neural Netw. 2020, 122, 253–272. [Google Scholar] [CrossRef]
- Wang, Q.; Meng, C.; Wang, C. Analog continuous-time filter designing for Morlet wavelet transform using constrained L2-norm approximation. IEEE Access 2020, 8, 121955–121968. [Google Scholar] [CrossRef]
- Schuman, C.D.; Kulkarni, S.R.; Parsa, M.; Mitchell, J.P.; Date, P.; Kay, B. Opportunities for neuromorphic computing algorithms and applications. Nat. Comput. Sci. 2022, 2, 10–19. [Google Scholar] [CrossRef] [PubMed]
- Edwards, J.; Parker, L.; Cardwell, S.G.; Chance, F.S.; Koziol, S. Neural-inspired dendritic multiplication using a reconfigurable analog integrated circuit. In Proceedings of the 2024 IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 19–22 May 2024. [Google Scholar] [CrossRef]
- Hasler, J. Energy-efficient programable analog computing. IEEE Solid-State Circuits Mag. 2024, 16, 32–40. [Google Scholar] [CrossRef]
- Hasler, J.; Hao, C. Programmable analog system benchmarks leading to efficient analog computation synthesis. ACM Trans. Reconfig. Technol. Syst. 2024, 17, 1–25. [Google Scholar] [CrossRef]
- Parker, L.; Cardwell, S.G.; Chance, F.S.; Koziol, S. Bio-inspired active silicon dendrite for direction selectivity. In Proceedings of the 2024 International Conference on Neuromorphic Systems (ICONS), Arlington, VA, USA, 30 July–2 August 2024; pp. 343–349. [Google Scholar] [CrossRef]
- Ulmann, B. Beyond zeros and ones—analog computing in the twenty-first century. Int. J. Parallel Emergent Distrib. Syst. 2024, 39, 139–151. [Google Scholar] [CrossRef]
- Torsello, A.; Pelillo, M. Continuous-time relaxation labeling processes. Pattern Recognit. 2000, 33, 1897–1908. [Google Scholar] [CrossRef]
- Beretta, G.; Chiarot, G.; Cinà, A.E.; Pelillo, M. Computing the capacity of discrete channels using vector flows. In Dynamics of Information Systems: 7th International Conference, DIS 2024, Kalamata, Greece, 2–7 June 2024, Revised Selected Papers; Moosaei, H., Kotsireas, I., Pardalos, P.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2025; Volume 14661, pp. 119–128. [Google Scholar] [CrossRef]
- Faybusovich, L. Dynamical systems which solve optimization problems with linear constraints. IMA J. Math. Control Inf. 1991, 8, 135–149. [Google Scholar] [CrossRef]
- Alvarez, F.; Bolte, J.; Brahic, O. Hessian Riemannian gradient flows in convex programming. SIAM J. Control Optim. 2004, 43, 477–501. [Google Scholar] [CrossRef]
- Hofbauer, J.; Sigmund, K. Evolutionary Games and Population Dynamics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Birkhoff, G.; Rota, G.C. Ordinary Differential Equations; Wiley: Hoboken, NJ, USA, 1989. [Google Scholar]
- Teschl, G. Ordinary Differential Equations and Dynamical Systems; American Mathematical Society: Providence, RI, USA, 2024. [Google Scholar]
- Hirsch, M.W.; Smale, S.; Devaney, R.L. Differential Equations, Dynamical Systems, and an Introduction to Chaos, 3rd ed.; Academic Press: Waltham, MA, USA, 2013. [Google Scholar]
- Mertikopoulos, P.; Sandholm, W.H. Riemannian game dynamics. J. Econ. Theory 2018, 177, 315–364. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Boyd, S.P.; El Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear Matrix Inequalities in System and Control Theory; SIAM Studies in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1994; Volume 15. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neurons with graded response have collective computational properties like those of two-state neurons. Proc. Natl. Acad. Sci. USA 1984, 81, 3088–3092. [Google Scholar] [CrossRef]
- Cichocki, A.; Unbehauen, R. Neural Networks for Optimization and Signal Processing; Wiley: Hoboken, NJ, USA, 1993. [Google Scholar]
- He, K.; Saunderson, J.; Fawzi, H. A Bregman proximal perspective on classical and quantum Blahut-Arimoto algorithms. IEEE Trans. Inf. Theory 2024, 70, 5710–5730. [Google Scholar] [CrossRef]
- Chu, M.T. On the continuous realization of iterative processes. SIAM Rev. 1988, 30, 375–387. [Google Scholar] [CrossRef]
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming; Springer: Cham, Switzerland, 2016. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beretta, G.; Pelillo, M. Vector Flows That Compute the Capacity of Discrete Memoryless Channels. Entropy 2025, 27, 362. https://doi.org/10.3390/e27040362
Beretta G, Pelillo M. Vector Flows That Compute the Capacity of Discrete Memoryless Channels. Entropy. 2025; 27(4):362. https://doi.org/10.3390/e27040362
Chicago/Turabian StyleBeretta, Guglielmo, and Marcello Pelillo. 2025. "Vector Flows That Compute the Capacity of Discrete Memoryless Channels" Entropy 27, no. 4: 362. https://doi.org/10.3390/e27040362
APA StyleBeretta, G., & Pelillo, M. (2025). Vector Flows That Compute the Capacity of Discrete Memoryless Channels. Entropy, 27(4), 362. https://doi.org/10.3390/e27040362