
Centralized Hierarchical Coded Caching Scheme for Two-Layer Network


Abstract
1. Introduction
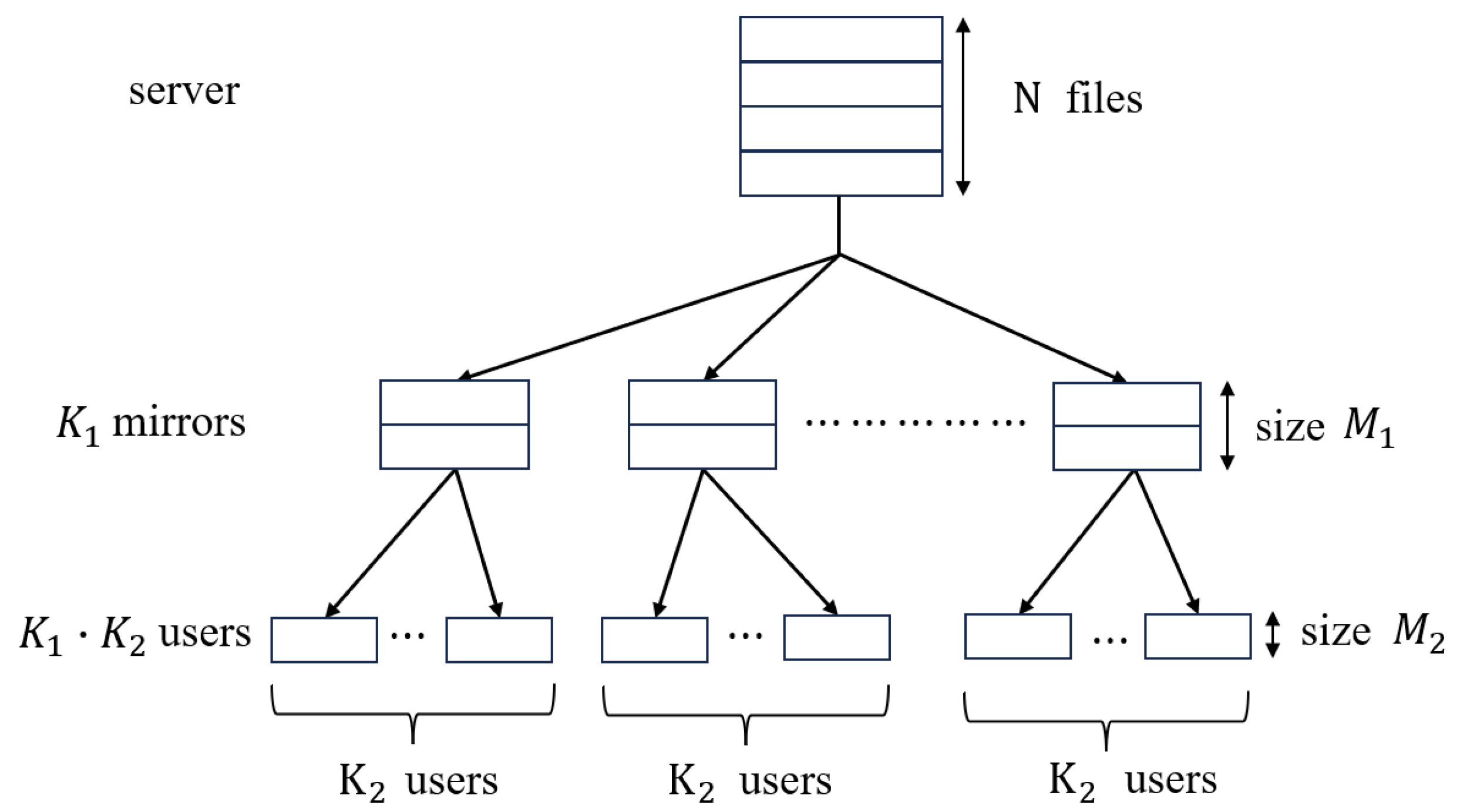
1.1. Two-Layer Hierarchical Network Model and Related Works
- Placement Phase: Each file is split into F packets with equal size, i.e., ; then, the mirrors and users cache some packets of each file. Denote the content cached by the i-th mirror and user by and , respectively. In this phase, the server has no knowledge of the users’ future requests.
- Delivery Phase: Each user randomly requests a file from the server, assuming that user requests the file , the request is denoted by . The server broadcasts coded messages of total size files to all mirrors, and each mirror broadcasts coded messages of total size files to all its attached users, such that each user can rebuild their desired file. is referred to as the transmission load from the server to the mirrors, and is called the transmission load from each mirror to its attached users.
1.2. Contribution and Organization
- For any integers a and b with , we define and .
- For any positive integers c, we define .
- For two integers , if , is the binomial coefficient defined as , and we let if or or .
- For any array , represents the element in the i-th row and j-th column of , where and .
2. Placement Delivery Array
- C1.
- The symbol “∗” appears Z times in each column;
- C2.
- Each integer occurs at least once in the array;
- C3.
- For any two distinct entries and , if , then and .
3. Main Results
- Placement Phase: Each file is split into F packets, i.e., . The j-th packet of each file is cached by the -th mirror if each element of the j-th row in the subarray is “∗”, i.e.,Since the number of rows in each consisting entirely of “∗”s is , the memory ratio of each mirror isThe cached content of user consists of two parts, i.e.,where is not cached by the -th mirror and is a subset of the content cached by the -th mirror. Specifically, the j-th packet of each file is cached by user if it is not cached by the -th mirror and the element at the j-th row and -th column of the subarray is “∗”, i.e.,Each packet cached by the -th mirror is further divided into subpackets, i.e., for any , we have . The subpacket is cached by user if the corresponding packet is cached by the -th mirror and the element at the h-th row and -th column of is “∗”, i.e.,Hence, the memory ratio of each user is
- Delivery Phase: Each user requests a file from the server, assuming that user requests the file . The transmission from the server to the mirrors is according to the PDA . Specifically, for any integer , the server sendsto the mirrors. Therefore, the transmission load from the server to the mirrors isThe transmission from each mirror to the attached users consists of two parts. First, each mirror cancels useless packets (if any) in the received useful messages using the cached content, then forwards them to the attached users. The number of messages forwarded by each mirror is . Second, each mirror transmits its cached contents to its attached users according to the PDA . Specifically, for any packet index j satisfying that the j-th packet of each file is cached by the -th mirror, i.e., where , for any integer , the -th mirror sendsto all its attached users. Hence, the transmission load from each mirror to its attached users is
4. An Illustrative Example for Theorem 1
- Placement Phase: Each file is split into packets, i.e., . The j-th packet of each file is cached by the -th mirror if each element of the j-th row in the subarray is “∗”. From (3) and (9), the cached content of each mirror is as follows:thus, the memory ratio of each mirror is .The cached content of user consists of two parts, i.e., , where the first part is not cached by the -th mirror, and the second part is a subset of the content cached by the -th mirror. From (5) and (10), the first part of the cached content of each user is as follows:Each packet cached by the -th mirror is further divided into subpackets, i.e., for any , we have . From (6), (10) and (11), the second part of the cached content of each user is as follows:Hence, the memory ratio of each user is .
- Delivery Phase: Each user requests a file from the server, assuming the request vector isi.e., user request respectively. The transmission from the server to the mirrors is according to the PDA in (9). Specifically, the server sendsto the mirrors from (7) and (9). Therefore, the transmission load from the server to the mirrors is .The transmission from each mirror to the attached users consists of two parts. First, each mirror cancels useless packets (if any) in the received useful messages by using the cached content, then forwards them to the attached users. Specifically, the first mirror cancels in to obtain , cancels in to obtain , then forwards to user and . The second mirror cancels in to obtain , cancels in to obtain , then forwards to user and . Second, each mirror transmits coded subpackets to the attached users according to the PDA in (10). Specifically, the first mirror sendsto its attached users, and the second mirror sendsto its attached users from (8), (10) and (11). Thus, the transmission load from each mirror to its attached users is .
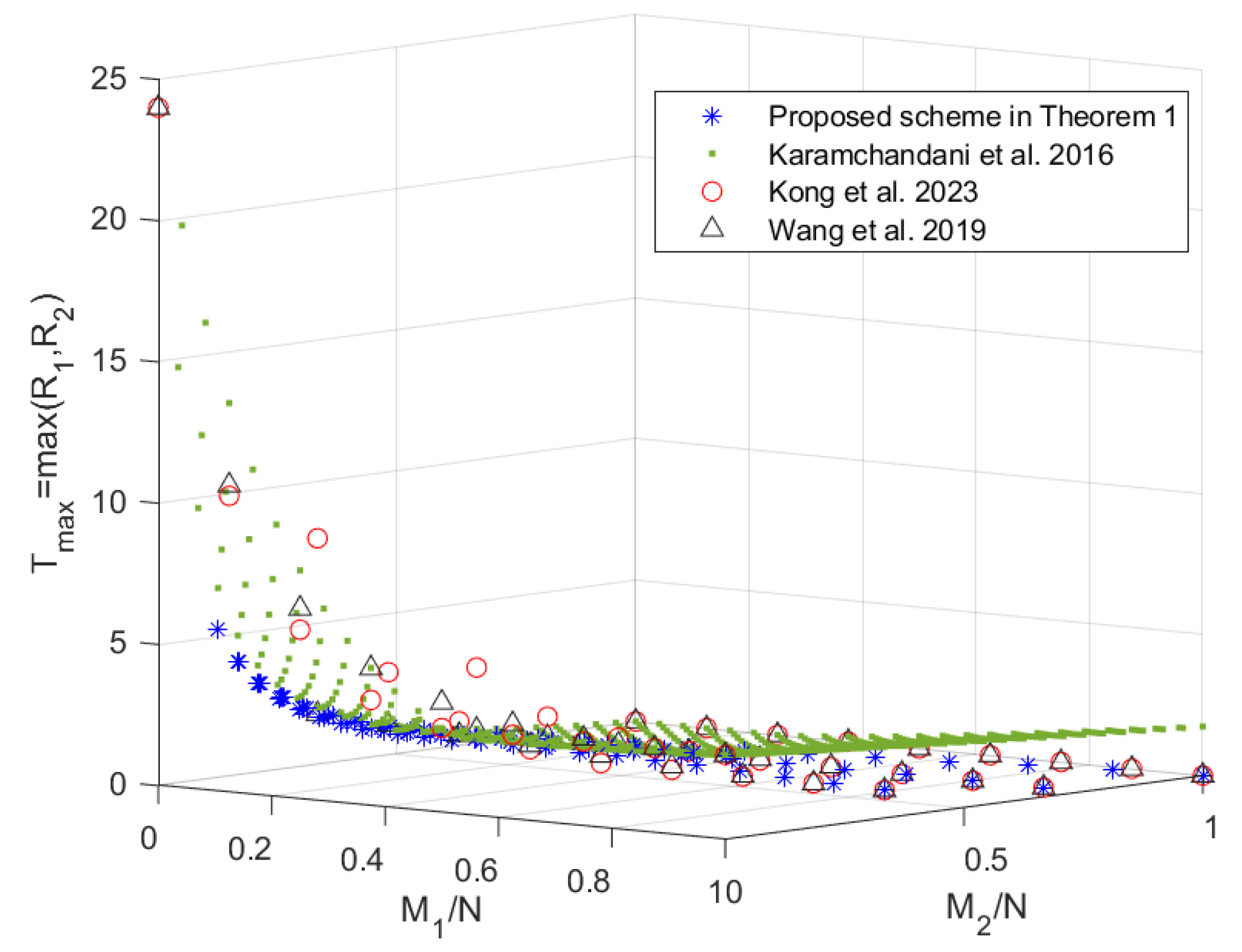
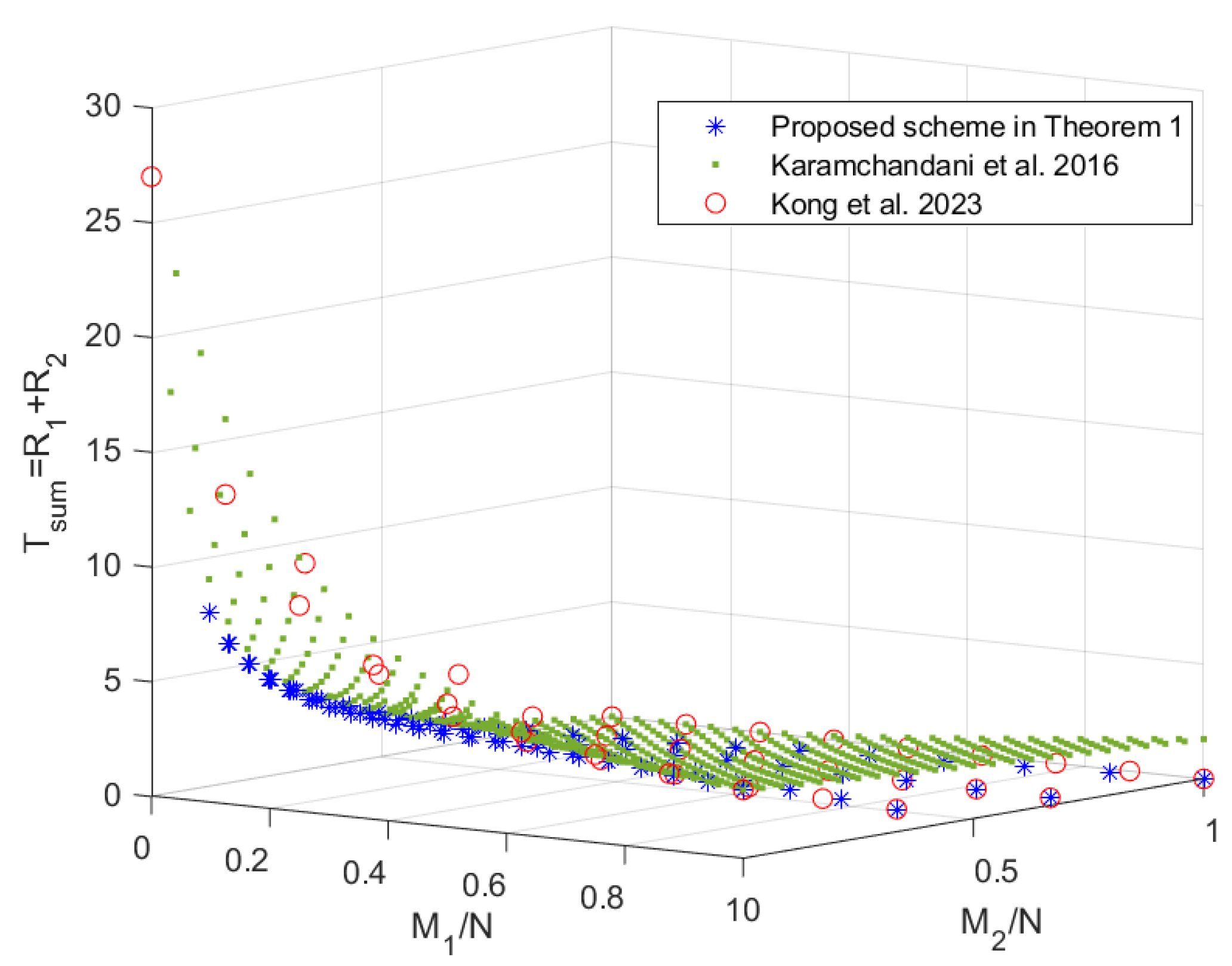
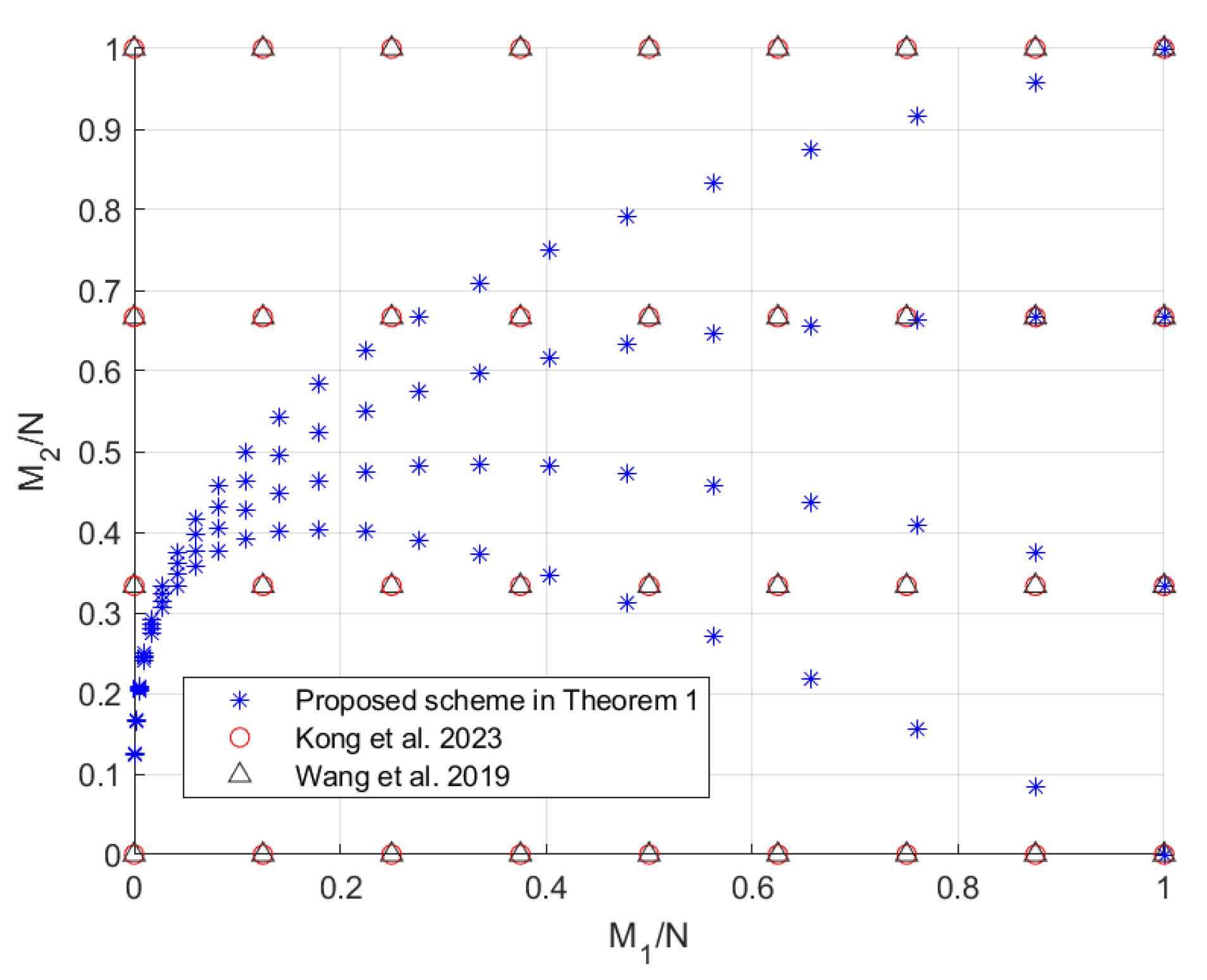
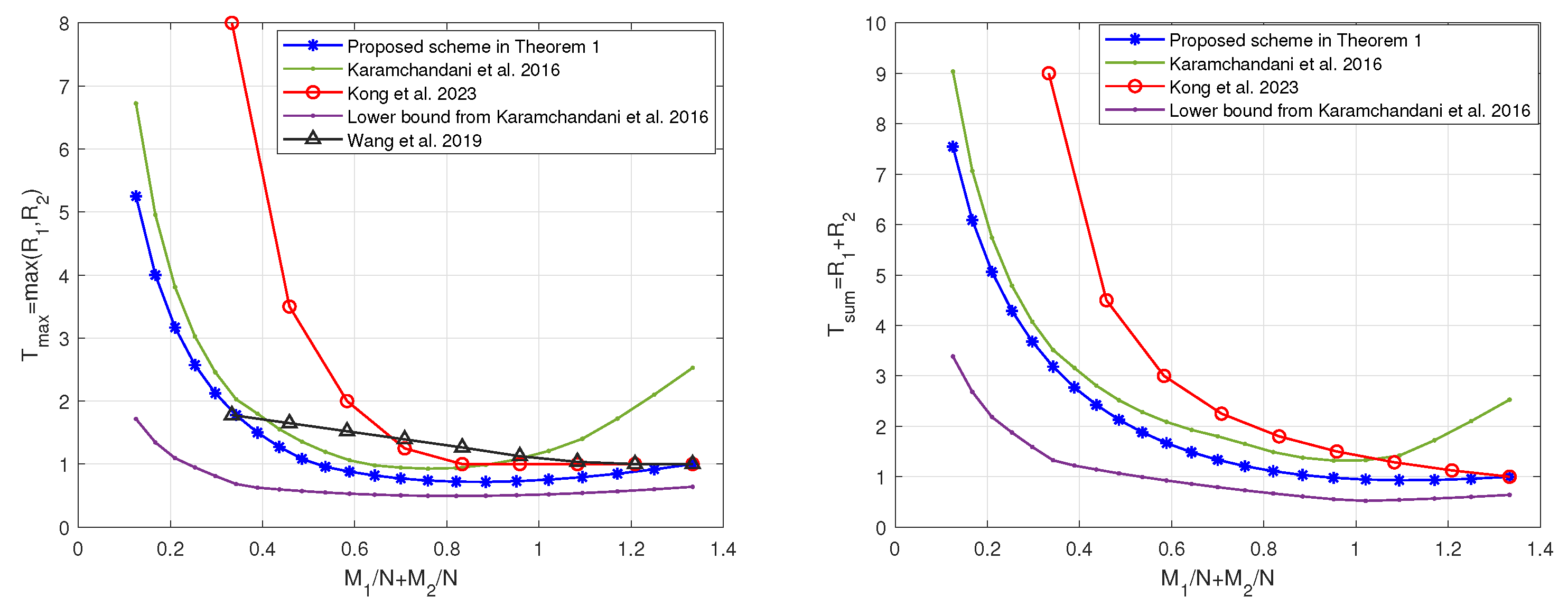
5. Performance Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Maddah-Ali, M.A.; Niesen, U. Fundamental Limits of Caching. IEEE Trans. Inf. Theory 2014, 60, 2856–2867. [Google Scholar] [CrossRef]
- Wan, K.; Tuninetti, D.; Piantanida, P. On the optimality of uncoded cache placement. In Proceedings of the 2016 IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 161–165. [Google Scholar] [CrossRef]
- Wan, K.; Tuninetti, D.; Piantanida, P. An Index Coding Approach to Caching with Uncoded Cache Placement. IEEE Trans. Inf. Theory 2020, 66, 1318–1332. [Google Scholar] [CrossRef]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. The Exact Rate-Memory Tradeoff for Caching with Uncoded Prefetching. IEEE Trans. Inf. Theory 2018, 64, 1281–1296. [Google Scholar] [CrossRef]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. Characterizing the Rate-Memory Tradeoff in Cache Networks Within a Factor of 2. IEEE Trans. Inf. Theory 2019, 65, 647–663. [Google Scholar] [CrossRef]
- Shanmugam, K.; Ji, M.; Tulino, A.M.; Llorca, J.; Dimakis, A.G. Finite-Length Analysis of Caching-Aided Coded Multicasting. IEEE Trans. Inf. Theory 2016, 62, 5524–5537. [Google Scholar] [CrossRef]
- Yan, Q.; Cheng, M.; Tang, X.; Chen, Q. On the Placement Delivery Array Design for Centralized Coded Caching Scheme. IEEE Trans. Inf. Theory 2017, 63, 5821–5833. [Google Scholar] [CrossRef]
- Yan, Q.; Tang, X.; Chen, Q.; Cheng, M. Placement Delivery Array Design Through Strong Edge Coloring of Bipartite Graphs. IEEE Commun. Lett. 2018, 22, 236–239. [Google Scholar] [CrossRef]
- Cheng, M.; Wang, J.; Zhong, X.; Wang, Q. A Framework of Constructing Placement Delivery Arrays for Centralized Coded Caching. IEEE Trans. Inf. Theory 2021, 67, 7121–7131. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, M.; Wan, K.; Caire, G. Placement Delivery Array Construction via Cartesian Product for Coded Caching. IEEE Trans. Inf. Theory 2023, 69, 7602–7626. [Google Scholar] [CrossRef]
- Aravind, V.R.; Sarvepalli, P.K.; Thangaraj, A. Lifting constructions of PDAs for coded caching with linear subpacketization. IEEE Trans. Commun. 2022, 70, 7817–7829. [Google Scholar] [CrossRef]
- Michel, J.; Wang, Q. Placement Delivery Arrays From Combinations of Strong Edge Colorings. IEEE Trans. Commun. 2020, 68, 5953–5964. [Google Scholar] [CrossRef]
- Tang, L.; Ramamoorthy, A. Coded Caching Schemes with Reduced Subpacketization from Linear Block Codes. IEEE Trans. Inf. Theory 2018, 64, 3099–3120. [Google Scholar] [CrossRef]
- Shangguan, C.; Zhang, Y.; Ge, G. Centralized Coded Caching Schemes: A Hypergraph Theoretical Approach. IEEE Trans. Inf. Theory 2018, 64, 5755–5766. [Google Scholar] [CrossRef]
- Shanmugam, K.; Tulino, A.M.; Dimakis, A.G. Coded caching with linear subpacketization is possible using Ruzsa-Szeméredi graphs. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1237–1241. [Google Scholar] [CrossRef]
- Chittoor, H.H.S.; Krishnan, P.; Sree, K.V.S.; Mamillapalli, B. Subexponential and Linear Subpacketization Coded Caching via Projective Geometry. IEEE Trans. Inf. Theory 2021, 67, 6193–6222. [Google Scholar] [CrossRef]
- Agrawal, S.; Sushena Sree, K.V.; Krishnan, P. Coded Caching based on Combinatorial Designs. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1227–1231. [Google Scholar] [CrossRef]
- Xu, M.; Xu, Z.; Ge, G.; Liu, M.Q. A Rainbow Framework for Coded Caching and Its Applications. IEEE Trans. Inf. Theory 2024, 70, 1738–1752. [Google Scholar] [CrossRef]
- Karamchandani, N.; Niesen, U.; Maddah-Ali, M.A.; Diggavi, S.N. Hierarchical Coded Caching. IEEE Trans. Inf. Theory 2016, 62, 3212–3229. [Google Scholar] [CrossRef]
- Wang, K.; Wu, Y.; Chen, J.; Yin, H. Reduce Transmission Delay for Caching-Aided Two-Layer Networks. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2019–2023. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Z.; Xiao, M.; Wu, G.; Li, S. Centralized caching in two-layer networks: Algorithms and limits. In Proceedings of the 2016 IEEE 12th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), New York, NY, USA, 17–19 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Kong, Y.; Wu, Y.; Cheng, M. Combinatorial Designs for Coded Caching on Hierarchical Networks. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, UK, 26–29 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, Y.; Song, X.; Wang, K.; Cao, S.; Chen, J.; Ma, S. Communication-Efficient Centralized and Decentralized Coded Caching for Hierarchical Cache-Aided Networks. IEEE Trans. Cogn. Commun. Netw. 2025. early access. [Google Scholar] [CrossRef]
- Rashid Ummer N, T.; Sundar Rajan, B. Optimal Placement Delivery Arrays from t-Designs with Application to Hierarchical Coded Caching. arXiv 2024, arXiv:2402.07188. [Google Scholar]
- Pandey, R.; Rajput, C.; Rajan, B.S. Coded Caching for Hierarchical Two-Layer Networks with Coded Placement. In Proceedings of the 2024 IEEE International Symposium on Information Theory (ISIT), Athens, Greece, 7–12 July 2024; pp. 2222–2227. [Google Scholar] [CrossRef]
- Xu, F.; Tao, M.; Liu, K. Fundamental Tradeoff Between Storage and Latency in Cache-Aided Wireless Interference Networks. IEEE Trans. Inf. Theory 2017, 63, 7464–7491. [Google Scholar] [CrossRef]
- Sengupta, A.; Tandon, R.; Simeone, O. Fog-Aided Wireless Networks for Content Delivery: Fundamental Latency Tradeoffs. IEEE Trans. Inf. Theory 2017, 63, 6650–6678. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations or Acronyms | Meaning |
|---|---|
| The number of mirrors | |
| The number of users connected to each mirror | |
| The total number of users | |
| N | The number of files |
| The cache size of each mirror | |
| The cache size of each user | |
| The communication load from the server to the mirrors | |
| The communication load from each mirror to the attached users | |
| The maximum coding delay | |
| The sum coding delay | |
| The i-th file | |
| The j-th packet of the i-th file | |
| The h-th subpacket of the packet | |
| The cached content of the -th mirror | |
| The -th user connected to the -th mirror | |
| The file requested by user | |
| The cached content of user | |
| The cached content of user which is not cached by the -th mirror | |
| The cached content of user which is cached by the -th mirror | |
| PDA | Placement delivery array |
| MN PDA | The PDA corresponding to the MN scheme in [1] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, K.; Wang, J.; Cheng, M. Centralized Hierarchical Coded Caching Scheme for Two-Layer Network. Entropy 2025, 27, 316. https://doi.org/10.3390/e27030316
Zhao K, Wang J, Cheng M. Centralized Hierarchical Coded Caching Scheme for Two-Layer Network. Entropy. 2025; 27(3):316. https://doi.org/10.3390/e27030316
Chicago/Turabian StyleZhao, Kun, Jinyu Wang, and Minquan Cheng. 2025. "Centralized Hierarchical Coded Caching Scheme for Two-Layer Network" Entropy 27, no. 3: 316. https://doi.org/10.3390/e27030316
APA StyleZhao, K., Wang, J., & Cheng, M. (2025). Centralized Hierarchical Coded Caching Scheme for Two-Layer Network. Entropy, 27(3), 316. https://doi.org/10.3390/e27030316