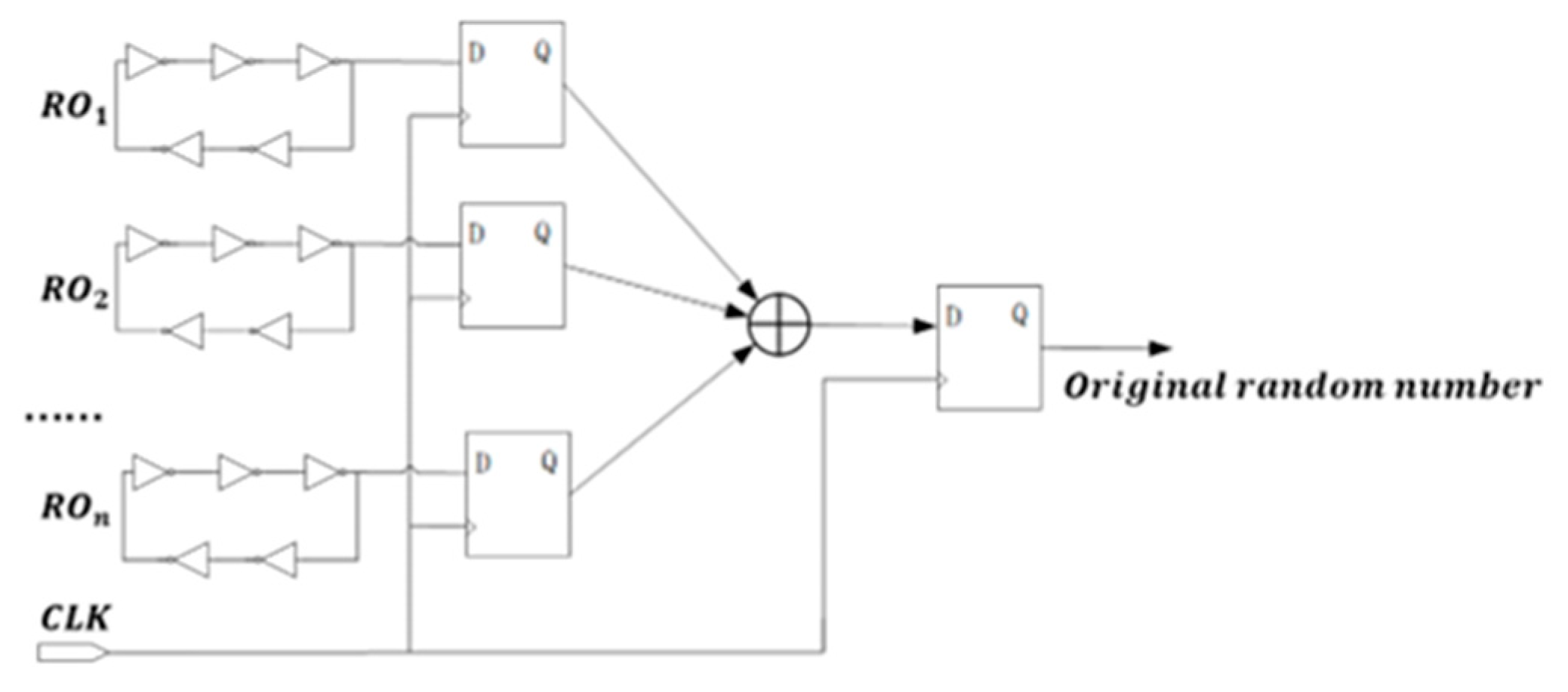
As previously discussed, the randomness of the numbers is closely related to the number of rings and period size: larger numbers of rings and longer periods generally correlate with greater randomness. Time-domain plots reveal that some random number sequences exhibit clear periodic patterns, except for those with notably low entropy. In contrast, sequences with higher randomness show no discernible structure, with the 0 s and 1 s appearing uniformly and randomly distributed.
In the frequency domain, ideal random numbers should exhibit a flat PSD curve. The results demonstrate that data with poor randomness display substantial fluctuations in the PSD plot, whereas data with stronger randomness tend to produce flatter PSD curves. Consequently, in the development of correlation identification models, the focus should be placed on frequency-domain features.
3.1. Design of the Deep Learning Network Framework
Traditional Recurrent Neural Network (RNN) models often encounter the challenges of gradient vanishing or exploding when processing long sequence data, which limits their ability to learn long-term dependencies [
34]. In contrast, LSTM (Long Short-Term Memory network) effectively addresses these issues with its unique gating mechanisms, including forget gates, input gates, and output gates, enabling sustained data dependency and making it highly suitable for long-duration sequence prediction [
35]. Additionally, visualizing the power spectral density (PSD) of random numbers reveals rich features hidden within the frequency domain. The Fast Fourier Transform (FFT) efficiently converts time-domain features into frequency-domain features, while the Feedforward Neural Network (FNN), due to its simple structure and ease of training, excels in handling time series signals with pronounced nonlinear characteristics [
36].
The frequency-domain characteristics of random numbers provide insights into potential phase relationships and harmonic connections between signals, offering a distinct advantage over time-domain features in revealing periodicity and correlations. However, time-domain features complement this by capturing details that may be overlooked in frequency-domain analysis through direct examination of the time series. The integration of both time-domain and frequency-domain features allows for a more comprehensive exploration of the hidden, non-intuitive correlations between signals. This process is grounded in multimodal learning, where time-domain and frequency-domain modalities offer complementary information that enhances feature representation. By processing both domains through separate deep network branches, each can learn domain-specific features. Fusion of these features enables the network to leverage the unique strengths of both representations, resulting in a more robust and informative feature vector. This process also taps into the deep neural network’s ability to model complex relationships between the time-domain and frequency-domain signals. In tasks such as periodic signal prediction, anomaly detection, or classification, frequency-domain features enhance model performance by providing periodicity information while time-domain data unveil finer sequence variations. Therefore, the combination of these features increases the accuracy and robustness of models when addressing these tasks.
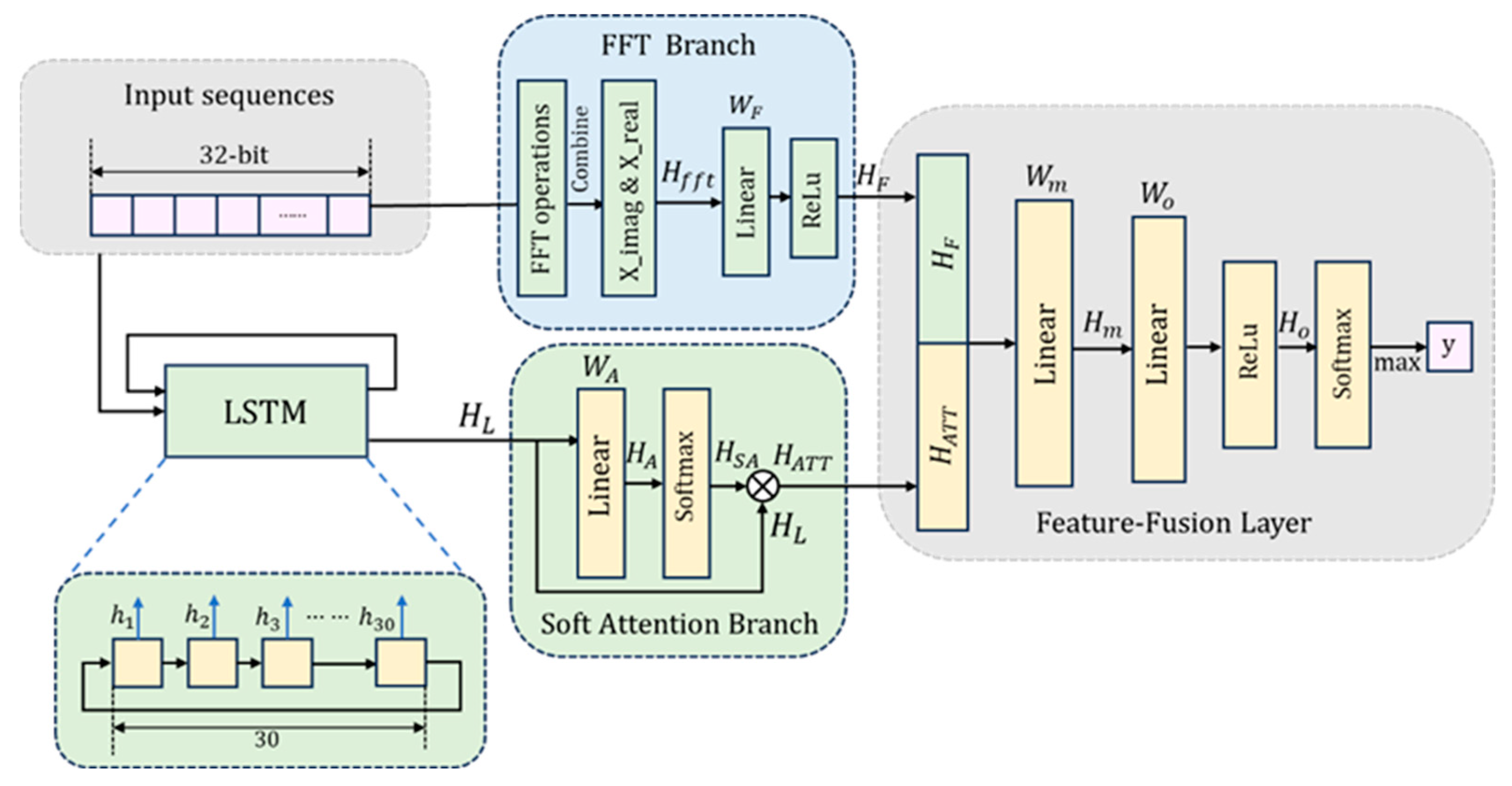
By merging time-domain and frequency-domain features, this study substantially improves the prediction accuracy and efficiency of random number sequences. LSTM processes the time-domain information, while FFT handles the frequency-domain components. The soft attention mechanism works in conjunction with fully connected layers to guide the model’s focus toward the most critical features, thereby optimizing overall prediction performance. The schematic representation is provided in
Figure 6.
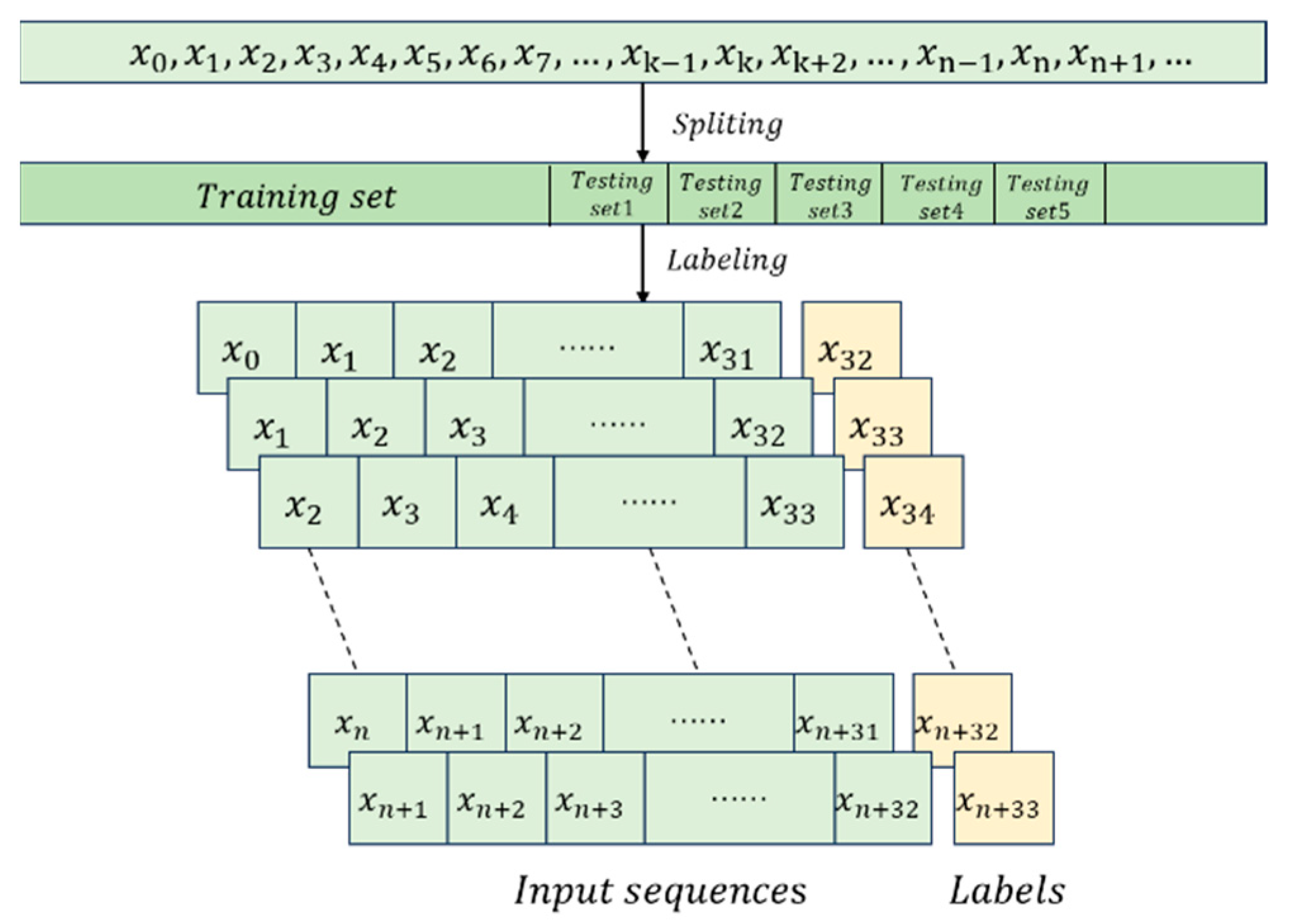
The input random number sequence is first divided into 32-bit blocks, denoted as . The time-domain branch processes these sequences through 30 LSTM units, with each unit outputting a hidden state at each corresponding time step. These hidden states are subsequently fed into the soft attention mechanism.
A simplified soft attention layer is employed to weight the input features, emphasizing the most salient information. This layer consists of a fully connected layer followed by a Softmax layer, which maps the input features to a consistent dimensionality. The attention mechanism calculates the weight of each feature, assigning higher weights to important features and lower weights to relatively less important ones. This allows the model to establish relationships between different parts of the input and perform weighted contributions from different features. Specifically, given the input tensor
, attention scores
are computed through a linear transformation:
Softmax is applied to normalize these scores along the feature dimension, yielding the relative importance of each feature for the current sample:
After normalization, the attention weights are element-wise multiplied with the original input features to generate the weighted feature representation:
The output tensor is reshaped to match the original input dimensions, preserving the structure. This mechanism enables the model to focus on the most relevant parts of the input.
The frequency-domain branch transforms the time-domain signal
into its frequency-domain representation using Fast Fourier Transform (FFT), yielding real and imaginary components. These features can reveal the periodicity and correlations within the sequence. By analyzing the frequency-domain signals, the model can identify the frequency components of the signal, effectively capturing the underlying patterns within the sequence. These components are then processed through a fully connected layer with 16 neurons and an ReLU activation to extract frequency-related features:
In the feature fusion stage, the outputs from the time-domain and frequency-domain branches are concatenated and passed through a fully connected layer with 30 neurons:
These fused features are further processed through a fully connected layer with 20 neurons and an ReLU activation:
Finally, the model outputs the predicted class through a Softmax layer:
This architecture significantly enhances the prediction accuracy of random number sequences by integrating both time-domain and frequency-domain features. LSTM processes the time-domain information, capturing the instantaneous changes within the sequence, while FFT handles the frequency-domain components, revealing the periodic elements of the sequence. The soft attention mechanism, combined with fully connected layers, ensures that the model focuses on the most critical features, thereby optimizing overall predictive performance. By fusing these two types of features, the model can identify non-intuitive correlations within the sequence.
3.2. System Evaluation
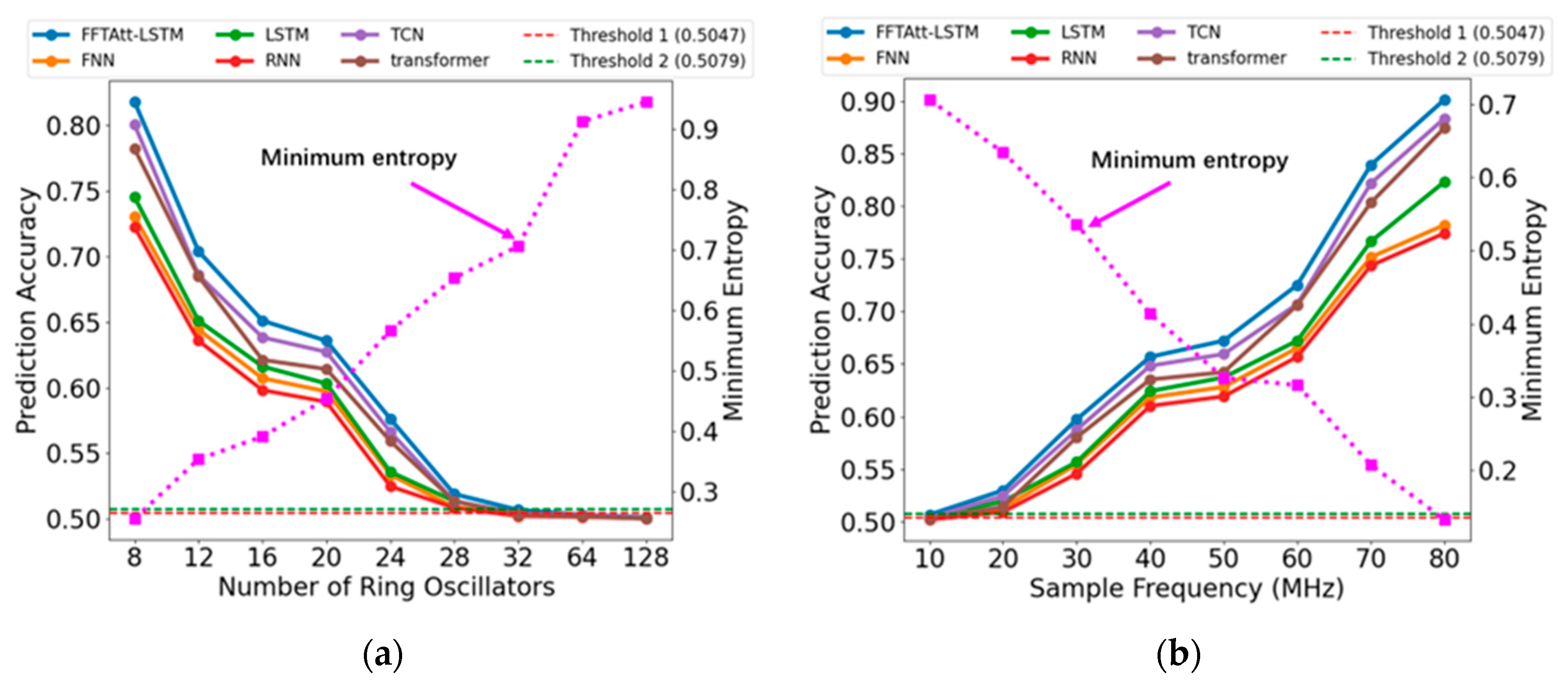
In this study, the neural network’s prediction accuracy is employed to evaluate the presence of correlation in random sequences. In an ideal and unpredictable random system, the probabilities of 0 and 1 are equal, with each occurring at a 50% rate. Consequently, a minimum entropy approaching 1 indicates a higher degree of randomness in the system. The neural network’s prediction accuracy is calculated as:
where
is the number of successful predictions for the next bit, and
is the number of failed predictions.
For an ideal random number sequence, the assumption of independence and identical distribution holds, indicating that each bit is independent and there is no correlation between them. According to the central limit theorem [
37], the prediction for the next bit follows a distribution
, where
is the number of predictions. In the experiments, the test set contains 100,000 sequences, which leads to
predictions and a standard deviation of
. Set 3σ and 5σ as the boundaries, corresponding to
and
, respectively. If the prediction probability is higher than
, it indicates that there is a 99.9% probability of identifying the correlation between sequences, which, at this time, means that there is an obvious correlation among the random numbers. If the prediction probability is lower than
, it indicates that the correlation among the random numbers is extremely small. When the prediction probability is between
and
, it indicates that there is a risk of weak correlation among the random numbers.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}