Abstract
In this paper, we explore the storage capacity and maximal information content of a random recurrent neural network characterized by a very low connectivity. A specific set of patterns is embedded into the network according to the Hebb prescription, a fundamental principle in neural learning. We thoroughly examine how various properties of the network, such as its connectivity and the level of synaptic noise, influence its performance and information retention capabilities, which is evaluated through an entropy measure. Our theoretical analyses are complemented by extensive simulations, and the results are validated through comparisons with the retrieval of real biometric patterns, including retinal vessel maps and fingerprints. This comprehensive approach provides deeper insights into the functionality and limitations of finite-connectivity neural networks and their applicability to the retrieval of complex, structured patterns.
PACS:
87.18.Sn; 05.20.y; 75.10.Nr; 64.60.Cn
1. Introduction
Since the seminal work of Hopfield [1], Attractor Neural Network (ANN) remains as a permanent subject of investigation. With the recent development in the broad field of Artificial Intelligence and the plethora of its applications in modern life, this subject deserves renewed interest.
The Finite Connectivity Attractor Neural Network (FCANN) is an ANN where the neuron’s average connectivity is finite, which allows for a more realistic description of biological neural networks than the classical mean-field one [2]. The number of neurons and connectivities in biological systems are spread over a wide range. As extreme examples, C. elegans have around 300 neurons with average connectivity of around 10 [3,4], while in the human brain these numbers are in the order of and , respectively. The FCANN model was introduced in [5], where an improved replica method was employed to investigate the thermodynamic properties of a network in which the patterns are stored according to a generalized Hebbian rule. In the present work we extend the formalism of [5] and develop the equations to explicitly evaluate the main observables.
Beyond the storage capacity, key properties of an ANN are the information content capacity and the ability to retrieve the information in different scenarios. The information capacity can be evaluated theoretically through entropy measurements [6]. The retrieval ability can be investigated through computer simulations or by applying to real problems. As a proof of concept the FCANN is used for retinal images retrieval. Digital Retinal Images for Vessel Extraction and Recognition is a research field within ophthalmology, which allows the early diagnosis of eye diseases such as diabetic retinopathy, glaucoma, and macular degeneration. Also, retina recognition is a biometric modality and technology that utilizes the unique patterns of blood vessels in the retina to identify individuals. This method is highly reliable due to the distinct and unchangeable nature of retinal patterns, which remain stable throughout the individual’s life [7].
Some main applications of retina recognition are the following ones:
- (a)
- Security and Access Control: Retina images are used in high-security environments, such as military and government environments, to control access. Retina scanners are employed to secure restricted areas and ensure that only authorized personnel can enter.
- (b)
- Healthcare: Medical identification systems use retina recognition to accurately match patients with their medical records. Retinal scans are also utilized in diagnosing and monitoring diseases like diabetes and hypertension, which affect retinal blood vessels.
- (c)
- Banking systems: Financial institutions use retina recognition for secure authentication of transactions, ATMs, and online banking services to increase security and reduce fraud.
In recent years, the use of neural networks has emerged to automate and improve the accuracy of retina recognition [8]. Convolutional Neural Networks (CNNs) are particularly suitable for retina recognition due to their ability to extract relevant features from images through convolutional and pooling layers. It has been used for health monitoring and even inspired a particular CNN architecture [9]. Also other types of neural networks, such as multilayer feedforward perceptron, were considered to identify the individual to which a retina belongs. It is more precise than a human observer, automatic, efficient, and fast. However it cannot be used to reconstruct a complete noisy image [10]. In the present paper we propose to apply an extremely diluted Attractor Neural Network to recognize and retrieve a retinal structure from a noisy sample in a dataset.
The aim of this paper is to offer a deeper understanding of the FCANN, exploring features of its thermodynamics properties and its capabilities as an information storage device. It is organized as follows. Section 2 summarizes key findings and methods of related works. Section 3 offers a brief review of the replica method for finite connectivity networks, following the steps of [5]. In Section 4, a brief description of the calculation of information content is presented. In Section 5, we present an evaluation of the RS solution. Numerical simulations and retrieval of real retina patterns are described in Section 6. In Section 7 the results are presented. Some further remarks and conclusions are addressed in Section 8.
2. Related Works
The topology of the FCANN is that of the Erdös–Renyi network [11], consisting of N nodes, interacting with a finite neighborhood of nodes, randomly chosen, with average c. Finite connectivity disordered systems can be theoretically approached through different ways. One of them requires a large number (essentially infinite) of order parameters, like in [12]. The one that is adopted in the present work access the system’s properties by constructing the distribution of local fields acting on each site. See, e.g., ref. [13]. In the context of neural networks, it is used in ref. [5]. The technique has been successfully applied to disordered magnetic materials [14].
In previous works, the evaluation of information content has been crucial for understanding the dynamics of neural networks and spin models. Specifically, the information content of a fully connected three-state artificial neural network (ANN) was analyzed by ref. [15]. The study focuses on a three-state ANN, proposing a self-control model to explain low-activity patterns and examining an extremely diluted network. Furthermore, studies on threshold binary ANNs have demonstrated that these networks, when learning biased patterns, exhibit similar behaviors, with mutual information serving as a key measure of the network’s capacity as associative memory [16], where the authors explore the role of information measures in optimizing learning algorithms, contributing further to the understanding of neural network behavior. Finally, in ref. [6], it was shown that the mutual information expression as a function of macroscopic measures, such as the overlaps between patterns and neurons, can be used to derive new learning rules and even a complete original quartic (or biquadratic) ANN. This approach underscores the absolute relevance of using entropy information for ANNs, as it provides both a theoretical and practical framework for improving network performance.
Previous studies have also investigated extensions of Attractor Neural Networks to improve retrieval performance and storage capacity for both random and structured patterns. In ref. [17], a constructive heuristic and a genetic algorithm were proposed to optimize the assignment of retinal vessels and fingerprint patterns to ensembles of diluted attractor networks. By minimizing the similarity between pattern subsets using cosine, Jaccard, and Hamming metrics, the authors reduced cross–talk noise and increased the ensemble’s storage capacity, with validation on random, fingerprint, and retinal image datasets. The retrieval of structured patterns, specifically fingerprints, was also addressed in ref. [18], where a metric attractor network (MANN) was employed to exploit spatial correlations in the data. A theoretical framework linking retrieval performance to load ratio, connectivity, density, randomness, and a spatial correlation parameter was introduced, with good agreement between theory and experiments.
While the above approaches are rooted in statistical physics and theoretical neuroscience, recent trends in machine learning have shifted toward high-capacity architectures trained on large-scale image and biometric datasets. For instance, ref. [10] developed a retina-based identification system using feedforward neural networks trained via backpropagation, applying preprocessing, feature extraction, and classification stages. Their system, which used grayscale vascular segmentation from the DRIVE database, demonstrated the feasibility of automated personal identification using the retina as a biometric trait. More recent developments have focused on multimodal biometric systems that integrate multiple physiological characteristics. A representative example is the hybrid identification framework proposed by ref. [19], which combines convolutional neural networks (CNNs), Softmax, and Random Forest (RF) classifiers for the joint recognition of fingerprint, finger-vein, and face images. Their architecture applies K-means and DBSCAN algorithms for segmentation, exposure fusion for contrast enhancement, and CNNs as feature extractors, followed by classification through Softmax and RF layers. This line of research highlights the strong trend toward data-driven models for high-dimensional feature learning.
Complementary to CNN-based approaches, recurrent neural networks (RNNs) have also been explored for biometric and anomaly detection tasks. In ref. [20], the authors reviewed RNN applications in biometric authentication, expression recognition, and anomaly detection, emphasizing architectures such as Long Short-Term Memory (LSTM) and deep residual RNNs. These networks capture temporal dependencies in sequential biometric data such as gait, keystroke dynamics, or handwriting, achieving high recognition performance without requiring explicit spatial feature design. The review also underlines the versatility of RNNs for behavioral authentication and continuous monitoring applications.
In contrast to these modern machine learning approaches, characterized by dense connectivity, large parameter spaces, and supervised training on extensive datasets, the FCANN model developed in this work remains grounded in the information and statistical mechanics formulation of attractor networks. Our approach focuses on how information is represented, stored, and retrieved within a sparsely connected system, using entropy and mutual information as evaluation measures. In the present paper, we extend this analysis to an ANN with binary uniform patterns and very low connectivity. Despite the reduced connectivity, we find that entropy information remains essential for optimizing the system’s hyperparameters, namely, the temperature (external noise) and the learning ratio (internal noise). The search for an expression for entropy and the calculation of optimal parameters, aimed at maximizing the mutual information between neurons and the data, proves central to enhancing the overall efficiency of neural networks.
3. Methodology
Figure 1 presents a schematic overview of the Finite Connectivity Attractor Neural Network (FCANN) framework employed in this work. The network is represented as a set of neurons connected through an Erdös–Rényi topology with finite average connectivity , emphasizing the sparse nature of the architecture compared to fully connected models. Patterns are embedded into the synaptic couplings following the Hebbian learning rule, with two distinct types of stored inputs: (i) random binary patterns, used for theoretical analysis and numerical simulations, and (ii) biometric patterns, specifically fingerprint images and retinal vessel maps, used to evaluate retrieval performance on real data. The diagram also illustrates the retrieval phase, in which the network reconstructs an original pattern from a noisy or partially degraded version, allowing the evaluation of the retrieval overlap m and the information content i. The retrieval basin of the system is illustrated in the figure for and , serving as a representative example of retrieval performance for a specific pattern load, and linking the conceptual schematic to the quantitative results presented in later sections.
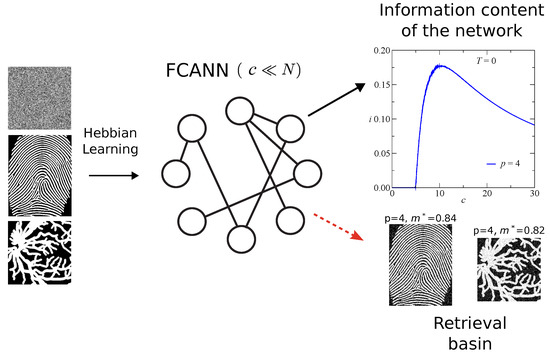
Figure 1.
Finite Connectivity Attractor Neural Network (FCANN) schematic. Hebbian learning of random and biometric patterns (fingerprints and retinal vessels).
Model and Theoretical Development
The thermodynamics properties are accessed through the calculation of the partition function.
Definition 1.
The system is composed by a set of formal neurons, represented by Ising variables , . A set of patterns , , where α is a finite load parameter, is embedded in the couplings through the Hebb’s rule
where is the probability that neurons i and j are connected. The and are independent, identically distributed random variables satisfying, respectively, the distributions
and
where c is the average connectivity.
Definition 2.
The system’s Hamiltonian is given by
As usual, the thermodynamic properties are derived from the free-energy density
where
is the partition function.
- Statement 1.
- The free-energy density can be written as
Proof.
To deal with the averages in Equation (5), the replica method is applied,
where n is an integer. The replicated partition function reads
where is a vector that represents the state of replica . Averaging over , we have
For , this can be written as
To sum over the site variables, it is convenient to withdraw them from the inner exponential. To do this, we follow [5] and use the concept of sub-lattices. Sub-lattice is the set of sites i that . Let us define , where is the number of sites belonging to . With the sub-lattices, Equation (11) can be expressed as
An explanation of the meaning of the vectors appearing in the above equation is needed. The replica labeled vectors are n N-component vectors, meaning the whole spin state on each replica. The site labeled vector is an n-component vector which means the whole replica state in site i. Non-labeled vector is a n-component vector which means the whole replica state of the one-site problem.
Contrary to the fully connected problem where, in the case of the replica symmetric solution, only the magnetization and the correlation between two replicas are the relevant order parameters, in finite connectivity problems higher-order correlations between replicas need to be taken in account [12]. This way, it is convenient to use the sub-lattice distribution of spin states,
that is introduced in Equation (12) with the conjugated variables :
Summing over the site variables and changing variables , we have
In the limit , the integral can be evaluated by the saddle-point method. The saddle point method, or steepest descent, is an asymptotic technique used to approximate integrals, especially those with a large parameter, like N in the equation above. The free-energy density, Equation (8), becomes
where means that we take the extremum of the expression between braces relative to and , i.e., the variables need to satisfy the saddle-point equations
and
Eliminating , the remaining equation reads
where is a normalization factor. Introducing Equation (19) in Equation (16), Equation (7) is obtained. □
As it will be explained below, all the thermodynamic observables can be obtained from the sub-lattices distributions of local fields , where
is the field acting on neuron i belonging to sub-lattice due to the interaction with neighbor neurons.
- Statement 2.
- The distribution of the local fields in RS hypothesis is
Proof.
To solve Equation (19) we proceed with the RS Ansatz that assumes the invariance of under permutation of replicas:
where is the distribution of local field and is the main tool to evaluate all the relevant observables. Introducing the Ansatz in Equation (19) and expanding the exponential we have, unless it is for the normalization factor,
where . Summing over the site variables in the right-hand side and rearranging terms, this becomes, in the limit ,
Solving for , we obtain
□
4. Network Performance: Entropy and Order Parameters
Knowing the distribution of local fields for all sub-lattices, we can evaluate the observables that allow to evaluate the performance of the network in handling information. The retrieval of a given pattern is signaled by a non-zero pattern overlap, in the limit
where and mean thermal and disorder averages, respectively. This becomes, after applying the replica theory,
The spin glass order parameter
becomes, in the replica symmetric solution,
The first quantity upon which we may characterize the network performance is the storage capacity . It is defined as , where is the maximum number of patterns that still allow for a finite overlap m.
Beyond the storage capacity, the information content i is also a key quantity.
- Statement 3.
- The information content is given by
Proof.
According to the Shannon’s information theory [21], these entropies are given by
and
where is the probability that a given neuron assumes the state S, and is the conditional probability that a given neuron assumes the state S given the pattern . Averaging over disorder, we have
Since our network is unbiased, . Then, Equation (31) becomes simply . To evaluate the conditional entropy, Equation (32) and still considering that the patterns are unbiased, we just need for the conditional probabilities the quantities and , i.e., the probabilities that the neurons are parallel or anti-parallel to the patterns. According to Equation (26), and using that , we have
and
From Equation (33),
Replacing Equations (34) and (35) in Equation (36), we arrive at the expression in Equation (30), which depends only on m for any temperature because the patterns are unbiased. □
5. Stability of the RS Solution
In finite connectivity and disordered systems, the stability of the RS solution can be evaluated through the two-replica method [22,23], consisting of solving the saddle-point equations for two independent systems with the Hamiltonian
The two systems share the same choice of random variables . The joint distribution of local fields obeys the self-consistent equation
The overlap , between two replicas, is given by
The RS solution is stable if is diagonal, i.e.,
which results in and is unstable otherwise.
6. Numerical Simulations
Simulations were realized to compare the model’s theory and experiment. A random network of N neurons with average connectivity c was created, with p embedded patterns according to Equation (1). To simulate a heat bath dynamics, each neuron was asynchronously updated according to
where returns the signal of x. The local field is given by
with the j summation running over all i neighbors and
is Gaussian noise with being an uniform random variable.
Beyond simulations with random input patterns, the algorithm above was applied to real input patterns consisting of retina images with pixels.
7. Results
The main purpose in this paper is to resume the discussion of the FCANN model addressing some relevant questions not addressed before, like information capacity and RS stability.
All the observable are accessed through the calculation of and by using a population dynamic algorithm. There are sub-networks and, in principle, one local field distribution for each sub-network. Nevertheless, due to the reduction to a single neuron problem, there are only two distinct local fields distributions, one for the single neuron assuming the state +1, for a given pattern and other for the single neuron assuming the state −1, for a given pattern. Furthermore, if the patterns are not biased, like presently, the two distributions are mirrored. The population dynamic algorithm runs as follows, for each distribution: a population of fields is randomly created. We found that populations of fields and populations of produce similar results and we adopted throughout the paper. Then, for each iteration, (1) an integer k is chosen according to a Poisson distribution with average c; (2) k fields are randomly chosen from the population; (3) the summation in the Dirac’s -function in Equation (25) is calculated; and (4) a further local field is chosen and the result of the previous step is assigned to it. The procedure is repeated until convergence. The joint distribution Equation (38) is calculated similarly, except that two independently generated populations evolve with the same choice of randomness.
In the RS solution, the thermodynamic behavior of the neural network is characterized by the retrieval overlap m, the spin glass parameter q and the overlap between replicas . As an example of the outcome, plots of these parameters versus the temperature are presented in Figure 2, for representative connectivity values and . The main distinction between them is that there is a re-entrant SG phase at low temperature for , contrary to . For , there are two regimes: (i) , there is a stable retrieval solution (R) with and for and a stable paramagnetic (PM) solution with for , where is the critical temperature; (ii) and , it appears an unstable retrieval solution (R’) with and for . For , , and are representative of three regimes, depending on and the temperature, namely: (i) , where there is a R solution for and a PM solution for ; (ii) , where there is an unstable R solution for , a stable R solution for and a PM solution for ; (iii) , where there is a spin glass (SG) solution with and for , an unstable RS solution for , a stable R solution for and a PM solution for . For comparison, the overlaps obtained from simulations on random networks with neurons, with average connectivity values and , are also shown in Figure 2. The results show that, in the retrieval region, m is weakly dependent on T, decreasing abruptly to zero at . Furthermore, it is worthy to remark that the simulated overlap decreases faster with the increase of p, as compared with the theoretical overlap. For example, for and , the theoretical overlap is greater than 0.5 over a large range in temperature, while the simulated one is around 0.1. Contrary to the absolute value of the order parameters, theoretical and simulation results show a good agreement in which concerns the critical temperature for retrieval, with the agreement increasing with c.
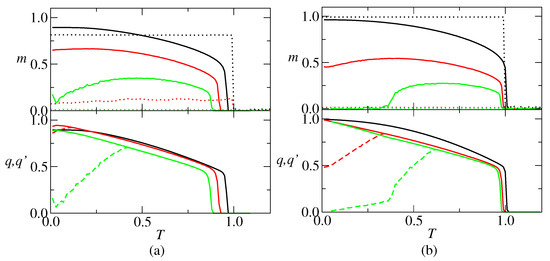
Figure 2.
Retrieval overlap m, spin-glass parameter q (solid lines) and overlap between replicas (dashed lines) versus temperature T. (a) , (black), (red) and (green); (b) , (black), (red) and (green). The RS solution becomes unstable at , pointed out by the bifurcation between q and . Dotted lines in the upper graphics represent simulation results for a network with neurons. In the lower graphics, the dashed lines represent the .
An overall picture of the model’s behavior can be achieved by drawing T versus phase diagrams, which are presented, for , and , in Figure 3. For comparison, results for the extremely diluted network [24] are also shown. The critical temperature signals the transition R-PM. As c increases, it approaches , which is the result. The AT line (from de Almeida-Thouless [25]) that signals the R-R’ transition displaces to the right, which means that the RS stable region increases as c decreases. In particular the finite c RS solution is stable at , for a c dependent low . This is in contrast to , where the RS solution is unstable for . The freezing temperature that signals the SG-PM transition increases as c increases, approaching the limit for . The R’-SG transition deserves further attention. It is re-entrant, which may be credited to the RS solution instability. According to the full RSB Parisi’s scheme [26,27], the R (a ferromagnetic phase) to SG transition is a vertical line at . We believe that, although difficult to calculate, this still applies to finite connectivity neural networks. It is worthy to remark that the re-entrance becomes less pronounced as c decreases and that it does not exist at all for . Furthermore, the theoretical R’-SG transition for is close to , which is the full RSB value. This suggests that low connectivity is capable of curing some of the pathologies associated with the RS solution.
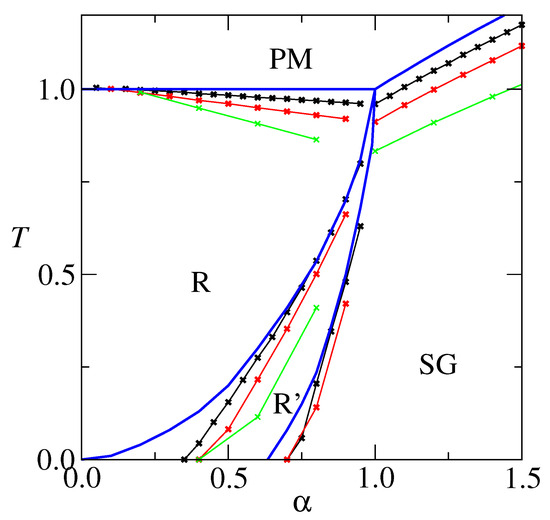
Figure 3.
Phase diagram T versus for (black) and (red) and (green). Symbols indicate the outcome of calculations, and lines are only to guide the eyes. For comparison, results for the extremely diluted are also shown (blue), from ref. [24].
Since neural networks deal with information storage and retrieval, it is useful to investigate the relationship between the amount of information, the average connectivity, and the number of stored patterns. From a practical point of view, what is most promising: to built one dense network with a large c to store a large p or several less dense networks with a small c to store a small p in each one? A tentative answer is addressed in Figure 4, with the information content plotted as a function of the connectivity for p varying from 1 to 9, at zero temperature. The results show that i is a non-monotonic function of c and, consequently, for each p there is a c that maximizes i. The absolute maximum is , obtained for both and and then slowly decreases for larger p. Curves for the information content versus connectivity were also evaluated through numerical simulations on a network with 100,000 units. The result, shown in Figure 4, shows a good agreement with the RS results, except that the theoretical results overestimate the simulation ones. We could enumerate five reasons for deviations from theoretical to simulations: (1) finite N, error around ; (2) discrete c in simulations versus continuous c in theory; (3) correlations between patterns for small c; (4) numerical errors in the evaluation of ; and (5) RS hypothesis. All these errors combined can explain the discrepancies in Figure 2 and why the dots in Figure 4 are under the continuous curves.
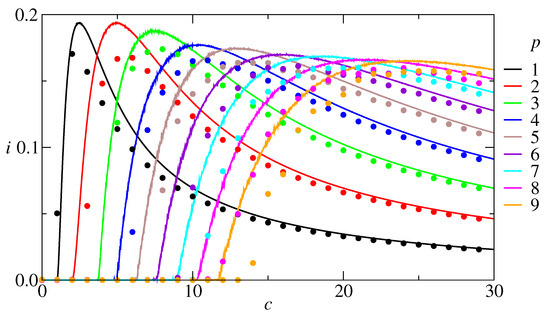
Figure 4.
Information content as a function of the connectivity, at , for several values of p, RS results. Dots: corresponding simulation results for a network with 100,000 neurons. The results show that for each number of patterns there is a connectivity that maximizes the information content. Furthermore, the maximal information content is obtained with a low number of patterns. This should be a valuable information for designers of artificial neural networks.
To clarify the tendency, Figure 5a shows as a function of p. Initially, decreases for , but then it stabilizes for large p. The picture is qualitatively similar for larger temperatures. The figure also shows that is not a monotonic decreasing function of the temperature. Instead, it slightly increases till before decreasing. This may be explained by the general argument that a low level of noise allows to avoid many spurious local minima. The load value , corresponding to , is shown in Figure 5b. This value is close to at low p, and then slowly decreases. It is worthy to remark that increases with T at low temperature which means that, for a given p, appears at a lower c.
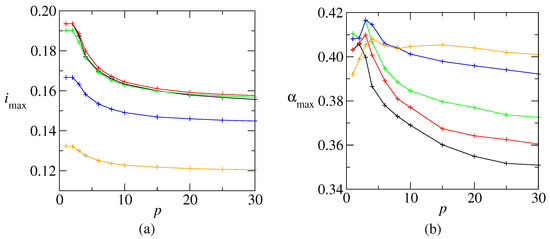
Figure 5.
(a) Maximum information content as a function of p, at (black), (red) (green), (blue) and (orange). (b) The corresponding , where is the connectivity value that maximizes the information content, for each p value. The same color scheme as in (a). The lines are only to guide the eyes.
The simulation results presented so far refer to random input patterns. We may ask whether the theoretical predictions also hold for real-world visual data. To explore this, we employed binarized digital retina patterns derived from the DRIVE dataset [28], which contains high-resolution fundus images of human retinas. Each image was cropped to remove peripheral borders lacking structural information and then binarized to represent the main vascular structures as black–white patterns. The resulting images have a resolution of pixels, corresponding to a total of 99,856 binary units per pattern.
The original mean activity of these binary retina patterns, measured as the proportion of white (active) pixels, was approximately , indicating a strong bias toward sparsity. To produce input patterns more comparable to the random binary patterns used in the previous simulations, each image was morphologically dilated to increase the active proportion to approximately . This preprocessing step balances the input activity and facilitates a fair comparison between theoretical and empirical results.
The modified retina images were then used as real input patterns to evaluate the network’s retrieval ability at (noiseless retrieval), with a connectivity fixed at . The results, presented in Figure 6, show that the fixed-point overlap decreases with the number of stored patterns, in agreement with Figure 2. Moreover, the overlap is only weakly affected by the level of initial noise, indicating that the retrieval state exhibits a large basin of attraction, demonstrating robustness for biometric structured input patterns.

Figure 6.
Retinal vessel patterns retrieval at . The patterns are binarized images of retinas, consisting of 99,856 pixels and .
A similar analysis was performed using binarized fingerprint images derived from the FVC2004: Third Fingerprint Verification Competition dataset [29] as real input patterns. The original images are in grayscale and were first gray-threshold binarized to emphasize ridge structures. The initial mean activity, measured as the proportion of white (active) pixels, was approximately 0.23, reflecting the intrinsic sparsity of fingerprint ridge patterns. To reduce bias and improve comparability with the random and retina-based patterns, the binarized images were morphologically dilated, yielding more balanced activity distributions while preserving the overall ridge topology.
The images were then cropped to retain the regions containing the most relevant fingerprint information, resulting in a final resolution of pixels, corresponding to 89,420 binary units per pattern. As in the retina case, the network connectivity was set to , and retrieval performance was evaluated at (noiseless retrieval).
The results, shown in Figure 7, exhibit the same qualitative behavior observed with the retinal patterns: the fixed-point overlap decreases as the number of stored patterns p increases, while remaining relatively robust to variations in the initial noise level. These findings confirm that the FCANN model can successfully retrieve complex biometric patterns beyond retinal structures, further supporting the generality and robustness of the theoretical predictions when applied to structured, real-world data.

Figure 7.
Fingerprint patterns retrieval at . The patterns are binarized images of fingerprints, consisting of 89,420 pixels and .
8. Discussion and Conclusions
Biological neural networks are extremely diluted, in the sense that each neuron interacts directly to a few fractions of the neuron population. Even then, the average connectivity amounts to several thousands of connections. Although there is no formal limit to the finite connectivity theory, in practice it is difficult to attain the biologic regime due to limitations in computation requirements: the computer time consumption is roughly proportional to the average connectivity. Nevertheless, the results presented in this paper may be significant to biological NN and, more than this, they may be relevant to applications in artificial neural networks, where the connectivity hardly compares to the biological realm.
Related to the previous work [5], we present the equations in an alternative form that allows to apply population dynamics and evaluate explicitly the order parameters as a function of the connectivity, learned patterns, and temperature. Also the information entropy was calculated, and we searched for the optimal information capacity as a function of the connectivity. Theoretical results were compared to simulations and biometric data.
A special attention was dedicated to the T versus phase diagram. Using the two-replica method, the AT line for three representative c values was investigated. It was observed that for a connectivity as low as , replica symmetry breaking effects, like the re-entrant behavior, are absent. This suggests that finite connectivity calculations is indeed an improvement, compared to the classical fully connected model. The RS transition from the unstable R to SG was also presented.
Numerical simulations with random and real input patterns were compared to the theory, showing a good agreement in predicting the R-PM transition, as well as in the information content. Nevertheless, there is a partial agreement in the prediction of the R’-SG transition. This subject deserves further investigation.
We keep thinking about biological and artificial neural networks. The results of this work also offer ideas about efficient information storage strategies. The energetic cost associated to the storage must be related both to the network unities (the neurons) as well as to the wiring (couplings). The results show that the maximal information “per coupling” is obtained for and 2, with low connectivity. If the wiring is most expensive than the unities themselves, this implies that low connectivity networks are more efficient to store information than densely connected networks. Meanwhile, the results also show that the maximal information decreases slowly with increasing p. This means that, if the relative wiring to unities cost is not too large, densely connected network could be an efficient strategy. Independently of the relative wiring and unities energy costs, an efficient neural network should operate in the range . It is worthy to remark that this range lies into the region where the RS solution is stable, and then it is a significant result.
Effects of thermal noise on information storage capacity were also investigated. The results show that a low level of noise (low T) are not harmful, and may even be beneficial, which means that sparse networks are robust against thermal noise.
Author Contributions
Conceptualization, D.D.-C.; Methodology, R.E.J.; Software, M.G.-R.; Validation, M.G.-R.; Formal analysis, R.E.J.; Resources, M.G.-R.; Data curation, M.G.-R.; Writing—original draft, A.S.; Writing—review & editing, R.E.J.; Visualization, F.B.R.; Supervision, D.D.-C.; Project administration, D.D.-C.; Funding acquisition, F.B.R. All authors have read and agreed to the published version of the manuscript.
Funding
R.E. thanks to Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES, Brazil) for the support within the scope of the PRINT program. R.E. thanks the staff at UAM, where part of the work was carried out. F.R. was supported by grant PID2023-149669NBI00 (MCIN/AEI and ERDF—“A way of making Europe”). M.G. thanks UDLA 488.A.XIV.24.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554. [Google Scholar] [CrossRef]
- Amit, D.J.; Gutfreund, H.; Sompolinsky, H. Statistical mechanics of neural networks near saturation. Ann. Phys. 1987, 173, 30–67. [Google Scholar] [CrossRef]
- White, J.G.; Southgate, E.; Thomson, J.N.; Brenner, S. The structure of the nervous system of the nematode Caenorhabditis elegans: The mind of a worm. Phil. Trans. R. Soc. Lond. 1986, B314, 1–340. [Google Scholar]
- Laasch, N.; Braun, W.; Knoff, L.; Bielecki, J.; Hilgetag, C.C. Comparison of derivative-based and correlation-based methods to estimate effective connectivity in neural networks. Sci. Rep. 2025, 15, 5357. [Google Scholar] [CrossRef]
- Wemmenhove, B.; Coolen, A.C.C. Finite connectivity attractor neural networks. J. Phys. A Math. Gen. 2003, 36, 9617–9633. [Google Scholar] [CrossRef]
- Dominguez, D.; Korutcheva, E. Three-state neural network: From mutual information to the Hamiltonian. Phys. Rev. E 2000, 62, 7132. [Google Scholar] [CrossRef][Green Version]
- Mittal, K.; Rajam, V.M.A. Computerized retinal image analysis-a survey. Multimed. Tools Appl. 2020, 79, 22389–22421. [Google Scholar] [CrossRef]
- García, M.; Sánchez, C.I.; López, M.I.; Abásolo, D.; Hornero, R. Neural network based detection of hard exudates in retinal images. Comput. Methods Programs Biomed. 2009, 93, 9–19. [Google Scholar] [CrossRef]
- Kim, J.; Sangjun, O.; Kim, Y.; Lee, M. Convolutional neural network with biologically inspired retinal structure. Procedia Comput. Sci. 2016, 88, 145–154. [Google Scholar] [CrossRef]
- Sadikoglu, F.; Uzelaltinbulat, S. Biometric retina identification based on neural network. Procedia Comput. Sci. 2016, 102, 26–33. [Google Scholar] [CrossRef]
- Erdös, P.; Rényi, A. On Random Graphs I. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar] [CrossRef]
- Viana, L.; Bray, A.J. Phase diagrams for dilute spin glasses. J. Phys. C Solid State Phys. 1985, 18, 3037. [Google Scholar] [CrossRef]
- Monasson, R. Optimization problems and replica symmetry breaking in finite connectivity spin glasses. J. Phys. Math. Gen. 1998, 31, 513–529. [Google Scholar] [CrossRef]
- Erichsen, R., Jr.; Silveira, A.; Magalhaes, S.G. Ising spin glass in a random network with a Gaussian random field. Phys. Rev. E 2021, 103, 022133. [Google Scholar] [CrossRef]
- Bolle, D.; Dominguez, D.R.C.; Amari, S. Mutual information of sparsely coded associative memory with self-control and ternary neurons. Neural Netw. 2000, 13, 455–462. [Google Scholar] [CrossRef]
- Dominguez, D.R.C.; Bollé, D. Self-Control in Sparsely Coded Networks. Phys. Rev. Lett. 1998, 80, 2961–2964. [Google Scholar] [CrossRef]
- González-Rodríguez, M.; Sánchez, Á.; Dominguez, D.; Rodríguez, F.B. A constructive heuristic for pattern assignment in an ensemble of attractor neural networks to increase storage capacity. Expert Syst. Appl. 2025, 279, 127351. [Google Scholar] [CrossRef]
- Doria, F.; Erichsen Jr, R.; González, M.; Rodríguez, F.B.; Sánchez, Á.; Dominguez, D. Structured patterns retrieval using a metric attractor network: Application to fingerprint recognition. Phys. A Stat. Mech. Its Appl. 2016, 457, 424–436. [Google Scholar] [CrossRef]
- mehdi Cherrat, E.; Alaoui, R.; Bouzahir, H. Convolutional neural networks approach for multimodal biometric identification system using the fusion of fingerprint, finger-vein and face images. PeerJ Comput. Sci. 2020, 6, e248. [Google Scholar] [CrossRef]
- Ackerson, J.M.; Dave, R.; Seliya, N. Applications of recurrent neural network for biometric authentication & anomaly detection. Information 2021, 12, 272. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kwon, C.; Thouless, D.J. Spin glass with two replicas on a Bethe lattice. Phys. Rev. B 1991, 43, 8379–8390. [Google Scholar] [CrossRef]
- Silveira, A.; Erichsen, R.; Magalhaes, S.G. Geometrical frustration and cluster spin glass with random graphs. Phys. Rev. E 2021, 103, 051104. [Google Scholar] [CrossRef]
- Watkin, T.L.H.; Sherrington, D. A neural network with low symmetric connectivity. Europhys. Lett. 1991, 14, 791. [Google Scholar] [CrossRef]
- de Almeida, J.R.L.; Thouless, D.J. Stability of the Sherrington-Kirkpatrick solution of a spin glass model. J. Phys. A Math. Gen. 1978, 11, 983. [Google Scholar] [CrossRef]
- Parisi, G. Infinite number of order parameters for spin-glasses. Phys. Rev. Lett. 1979, 43, 1754. [Google Scholar] [CrossRef]
- Binder, K.; Young, A.P. Spin glasses: Experimental facts, theoretical concepts, and open questions. Rev. Mod. Phys. 1986, 58, 801. [Google Scholar] [CrossRef]
- Staal, J.; Abramoff, M.; Niemeijer, M.; Viergever, M.; Van Ginneken, B. Digital Retinal Image for Vessel Extraction (DRIVE) Database; Image Sciences Institute, University Medical Center Utrecht: Utrecht, The Netherlands, 2004. [Google Scholar]
- Maio, D.; Maltoni, D.; Cappelli, R.; Wayman, J.L.; Jain, A.K. FVC2004: Third fingerprint verification competition. In Biometric Authentication; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–7. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).